
Методы кодирования данных
Содержание:

Введение
Кодирование информации – это процесс формирования определенного представления информации. При кодировании информация представляется в виде дискретных данных. Декодирование является обратным к кодированию процессом. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (например, звуки, изображения, показания приборов и так далее) для обработки на компьютере должна быть преобразована в числовую форму. С помощью программ для компьютера можно выполнить обратные преобразования полученной информации.
При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Знаки или символы любой природы, из которых конструируются информационные сообщения, называют кодами. Полный набор кодов составляет алфавит кодирования. Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми. Ввод чисел в компьютер и вывод их для чтения человеком может осуществляться в привычной десятичной форме, а все необходимые преобразования выполняют программы, работающие на компьютере.
Первичная задача программиста заключается в применении решения о форме представления данных и выборе алгоритмов, применяемых к этим данным. И лишь затем выбранная структура программы и данных реализуется на конкретном языке программирования. В связи с этим знание классических методов и приемов обработки данных позволяет избежать ошибок, которые могут возникать при чисто интуитивной разработке программ.
Данная курсовая работа посвящена различным методам кодирования информации. Некоторые рассмотренные методы проиллюстрированы наглядными примерами. Для некоторых методов приведен конкретный алгоритм, позволяющий легко программировать данный метод.
1. НЕОБХОДИМЫЕ ПОНЯТИЯ И ОПРЕДЕЛЕНИЯ
Теория кодирования и теория информации возникли в начале XX века. Начало развитию этих теорий как научных дисциплин положило появление в 1948 г. статей К.Шеннона, которые заложили фундамент для дальнейших исследований в этой области.
Кодирование – способ представления информации в удобном для хранения и передачи виде. В связи с развитием информационных технологий кодирование является центральным вопросом при решении самых разных задач программирования, таких как:
1. представление данных произвольной структуры (числа, текст, графика) в памяти компьютера;
2. обеспечение помехоустойчивости при передаче данных по каналам связи;
3. сжатие информации в базах данных.
Основной моделью, которую изучает теория информации, является модель системы передачи сигналов:
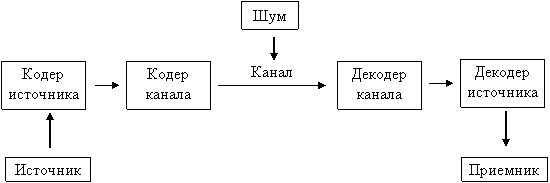
Рисунок 1. Модель системы передачи сигналов
Начальным звеном в приведенной выше модели является источник информации. Здесь рассматриваются дискретные источники без памяти, в которых выходом является последовательность символов некоторого фиксированного алфавита. Множество всех различных символов, порождаемых некоторым источником, называется алфавитом источника, а количество символов в этом множестве – размером алфавита источника. Например, можно считать, что текст на русском языке порождается источником с алфавитом из 33 русских букв, пробела и знаков препинания[1].
Кодирование дискретного источника заключается в сопоставлении символов алфавита А источника символам некоторого другого алфавита В. Причем обычно символу исходного алфавита А ставится в соответствие не один, а группа символов алфавита В, которая называется кодовым словом. Кодовый алфавит – множество различных символов, используемых для записи кодовых слов. Кодом называется совокупность всех кодовых слов, применяемых для представления порождаемых источником символов.
Пример.
Азбука Морзе является общеизвестным кодом из символов телеграфного алфавита, в котором буквам русского языка соответствуют кодовые слова (последовательности) из «точек» и «тире».
Далее будем рассматривать двоичное кодирование, то есть размер кодового алфавита равен 2. Конечную последовательность битов (0 или 1) назовем кодовым словом, а количество битов в этой последовательности – длиной кодового слова.
Пример.
Код ASCII (американский стандартный код для обмена информацией) каждому символу ставит в однозначное соответствие кодовое слово длиной 8 бит. Дадим строгое определение кодирования. Пусть даны алфавит источника А={а1, а2, …аn} кодовый алфавит В={b1, b2, …bn}. Обозначим множество А*(В*) множество всевозможных последовательностей в алфавите А(В). Множество всех сообщений в алфавите А обозначим S. Тогда отображение F:S→ В*, которое преобразует множество сообщений в кодовые слова в алфавите В, называется кодированием. Если αєS, то F(α)=βє В* – кодовое слово. Обратное отображение F-1 (если оно существует) называется декодированием.
Задача кодирования сообщения ставится следующим образом. Требуется при заданных алфавитах А и В и множестве сообщений S найти такое кодирование F, которое обладает определенными свойствами и оптимально в некотором смысле. Свойства, которые требуются от кодирования, могут быть различными. Приведем некоторые из них:
1. существование декодирования;
2. помехоустойчивость или исправление ошибок при кодировании: декодирование обладает свойством F-1(β)= F-1(βا), β~β¢ (эквивалентно β¢ с ошибкой);
3. обладает заданной трудоемкостью (время, объем памяти).
Известны два класса методов кодирования дискретного источника информации: равномерное и неравномерное кодирование[2]. Под равномерным кодированием понимается использование кодов со словами постоянной длины. Для того чтобы декодирование равномерного кода было возможным, разным символам алфавита источника должны соответствовать разные кодовые слова. При этом длина кодового слова должна быть не меньше [lognm] символов, где m – размер исходного алфавита, n – размер кодового алфавита.
Пример.
Для кодирования источника, порождающего 26 букв латинского алфавита, равномерным двоичным кодом требуется построить кодовые слова длиной не меньше [log226]=5 бит.
При неравномерном кодировании источника используются кодовые слова разной длины. Причем кодовые слова обычно строятся так, что часто встречающиеся символы кодируются более короткими кодовыми словами, а редкие символы – более длинными (за счет этого и достигается «сжатие» данных)[3].
Под сжатием данных понимается компактное представление данных, достигаемое за счет избыточности информации, содержащейся в сообщениях. Большое значение для практического использования имеет неискажающее сжатие, позволяющее полностью восстановить исходное сообщение. При неискажающем сжатии происходит кодирование сообщения перед началом передачи или хранения, а после окончания процесса сообщение однозначно декодируется (это соответствует модели канала без шума (помех)).
Методы сжатия данных можно разделить на две группы: статические методы и адаптивные методы. Статические методы сжатия данных предназначены для кодирования конкретных источников информации с известной статистической структурой, порождающих определенное множество сообщений. Эти методы базируются на знании статистической структуры исходных данных. К наиболее известным статическим методам сжатия относятся коды Хаффмана, Шеннона, Фано, Гилберта-Мура, арифметический код и другие методы, которые используют известные сведения о вероятностях порождения источником различных символов или их сочетаний.
Если статистика источника информации неизвестна или изменяется с течением времени, то для кодирования сообщений такого источника применяются адаптивные методы сжатия. Вадаптивных методах при кодировании очередного символа текста используются сведения о ранее закодированной части сообщения для оценки вероятности появления очередного символа[4]. В процессе кодирования адаптивные методы «настраиваются» на статистическую структуру кодируемых сообщений, то есть коды символов меняются в зависимости от накопленной статистики данных. Это позволяет адаптивным методам эффективно и быстро кодировать сообщение за один просмотр.
Существует множество различных адаптивных методов сжатия данных. Наиболее известные из них – адаптивный код Хаффмана, код «стопка книг», интервальный и частотный коды, а также методы из класса Лемпела-Зива.
2. КОДИРОВАНИЕ ЦЕЛЫХ ЧИСЕЛ
Рассмотрим семейство методов кодирования, не учитывающих вероятности появления символов источника. Поскольку все символы алфавита источника можно пронумеровать, то будем считать, что алфавит источника состоит из целых чисел. Каждому целому числу из определенного диапазона ставится в соответствие свое кодовое слово, поэтому эту группу методов также называют представлением целых чисел (representation of integers).
Основная идея кодирования состоит в том, чтобы отдельно кодировать порядок значения элемента xi («экспоненту» Ei) и отдельно – значащие цифры значения xi («мантиссу» Miا). Значащие цифры мантиссы начинаются со старшей ненулевой цифры, а порядок числа определяется позицией старшей ненулевой цифры в двоичной записи числа. Как и при десятичной записи, порядок равен числу цифр в записи числа без предшествующих незначащих нулей.
Пример.
Порядок двоичного числа равен 4, а мантисса – 1101.
Fixed + Variable (фиксированная длина экспоненты + переменная длина мантиссы).
Variable + Variable (переменная длина экспоненты + переменная длина мантиссы).
2.1. Коды класса Fixed + Variable
В кодах класса Fixed + Variable под запись значения порядка числа отводится фиксированное количество бит, а значение порядка числа определяет, сколько бит потребуется под запись мантиссы. Для кодирования целого числа необходимо произвести с числом две операции: определение порядка числа и выделение бит мантиссы (можно хранить в памяти готовую таблицу кодовых слов). Рассмотрим процесс построения кода данного класса на примере.
Пример.
Пусть R=15 – количество бит исходного числа. Отведем E=4бита под экспоненту (порядок), так как R≤24. При записи мантиссы можно сэкономить 1бит: не писать первую единицу, так как это всегда будет только единица. Таким образом, количество бит мантиссы меньше на один бит, чем количество бит для порядка.
Таблица 1. Код класса Fixed + Variable
|
Число |
Двоичное представление |
Кодовое слово |
Длина кодового слова |
|
0 1 |
0000 0001 |
4 4 |
|
|
2 3 |
0010 0 0010 1 |
5 5 |
|
|
4 5 6 7 |
0011 00 0011 01 0011 10 0011 11 |
6 6 6 6 |
|
|
8 9 10 … 15 |
… |
0 0 0 … 0 |
7 7 7 .. 7 |
|
16 17 … |
… |
0 0 … |
8 8 .. |
2.2. Коды класса Variable + Variable
В качестве кода числа берется двоичная последовательность, построенная следующим образом: несколько нулей (количество нулей равно значению порядка числа), затем единица как признак окончания экспоненты переменной длины, затем мантисса переменной длины (как в кодах Fixed + Variable).
Таблица 2. Код класса Variable + Variable
|
Число |
Двоичное представление |
Кодовое слово |
Длина кодового слова |
|
0 1 |
1 0 1 |
1 2 |
|
|
2 3 |
00 1 0 00 1 1 |
4 4 |
|
|
4 5 6 7 |
6 6 6 6 |
||
|
8 9 10 … |
… |
0000 1 000 0000 1 001 0000 1 010 … |
8 8 8 |
Если в рассмотренном выше коде исключить кодовое слово для нуля, то можно уменьшить длины кодовых слов на 1 бит, убрав первый нуль. Таким образом строится гамма-код Элиаса (γ-код Элиаса).
Таблица 3. Гамма-код Элиаса
|
Число |
Кодовое слово |
Длина кодового слова |
|
1 |
1 |
1 |
|
2 3 |
01 0 01 1 |
3 3 |
|
4 5 6 7 |
00 1 00 00 1 01 00 1 10 00 1 11 |
5 5 5 5 |
|
8 9 10 … |
000 1 000 000 1 001 000 1 010 … |
7 7 7 |
Другим примером кода класса Variable + Variable является омега-код Элиаса (ω-код Элиаса). В нем первое значение (кодовое слово для единицы) задается отдельно. Другие кодовые слова состоят из последовательности групп длиной L1,L2.,…,Lm, начинающихся с единицы. Конец всей последовательности задается нулевым битом. Длина первой группы составляет 2 бита, длина каждой следующей группы равна двоичному значению битов предыдущей группы плюс 1. Значение битов последней группы является итоговым значением всей последовательности групп, то есть первые m-1 групп служат лишь для указания длины последней группы.
Таблица 4. Омега-код Элиаса
|
Число |
Кодовое слово |
Длина кодового слова |
|
1 2 3 |
0 10 0 11 0 |
1 3 3 |
|
4 5 6 7 |
10 100 0 10 101 0 10 110 0 10 111 0 |
6 6 6 6 |
|
8 9 .. 15 |
11 1000 0 11 1001 0 … 11 1111 0 |
7 7 .. 7 |
|
16 17 .. 31 |
10 10 … 10 |
11 11 .. 11 |
|
32 |
10 |
12 |
При кодировании формируется сначала последняя группа, затем предпоследняя и так далее, пока процесс не будет завершен. При декодировании, наоборот, сначала считывается первая группа, по значению ее битов определяется длина следующей группы, или итоговое значение кода, если следующая группа – 0.
Рассмотренные типы кодов могут быть эффективны в следующих случаях
1. Вероятности чисел убывают с ростом значений элементов и их распределение близко к такому: Р(х)≥ Р(х+1), при любом x, то есть маленькие числа встречаются чаще, чем большие[5].
2. Диапазон значений входных элементов не ограничен или неизвестен. Например, при кодировании 32-битовых чисел реально большинство чисел маленькие, но могут быть и большие.
3. При использовании в составе других схем кодирования, например, кодировании длин серий.
2.3. Кодирование длин серий
Метод кодирования информации, известный как метод кодирования длин серий и предложенный П.Элиасом, при построении использует коды целых чисел. Входной поток для кодирования рассматривается как последовательность из нулей и единиц[6]. Идея кодирования заключается в том, чтобы кодировать последовательности одинаковых элементов (например, нулей) как целые числа, указывающие количество элементов в этой последовательности. Последовательность одинаковых элементов называется серией, количество элементов в ней – длиной серии.
Пример. Входную последовательность (общая длина 31 бит) можно разбить на серии, а затем закодировать их длины.
00000 1
Используем, например, γ-код Элиаса. Поскольку в коде нет кодового слова для нуля, то будем кодировать длину серии +1, то есть последовательность: Þ 00
Длина полученной кодовой последовательности равна 25 бит.
Метод длин серий актуален для кодирования данных, в которых есть длинные последовательности одинаковых бит. В нашем примере, если Р(0)>>Р(1).
3. НЕКОТОРЫЕ ТЕОРЕМЫ ПОБУКВЕННОГО КОДИРОВАНИЯ
Пусть даны алфавит источника А={а1, а2, …аn}, кодовый алфавит В={b1, b2, …bn}. Обозначим А*(В*) множество всевозможных последовательностей в алфавите А(В). Множество всех сообщений в алфавите А обозначим S. Кодирование F:S→ В* может сопоставлять код всему сообщению из множества S как единому целому или строить код сообщения из кодов его частей (побуквенное кодирование).
Пример.
А={a1,a2,a3}, B={0,1}. Побуквенное кодирование символов источника a1 ®1001 a2 ®0 a3®010 позволяет следующим образом закодировать сообщение a2a1a2a3 ®
Пример.
Азбука Морзе. Входной алфавит – английский. Наиболее часто встречающиеся буквы кодируются более короткими словами:
А ® 01, В ® 1000, С ® 1010, D ® 100, E ® 0, …
Побуквенное кодирование задается таблицей кодовых слов: αiєA, βiєВ*. Множество кодовых слов V={βi} называется множеством элементарных кодов. Используя побуквенное кодирование, можно закодировать любое сообщение α= αil…αikєS следующим образом F(α)=F(αil)…F(αik)=βil…βik, то есть общий код сообщения складывается из элементарных кодов символов входного алфавита.
Количество букв в слове α=α1…αk называется длиной слова. (Обозначение |αا|=k) Пустое слово, то есть слово, не содержащее ни одного символа обозначается Λ. Если α=α1α2, то α1 – начало (префикс) слова α, α2 – окончание (постфикс) слова α.
4. ОПТИМАЛЬНОЕ ПОБУКВЕННОЕ КОДИРОВАНИЕ. КОД ХАФФМАНА
Предложенный Хаффманом алгоритм построения оптимальных неравномерных кодов – одно из самых важных достижений теории информации как с теоретической, так и с прикладной точек зрения. Трудно поверить, но этот алгоритм был придуман в 1952 г. студентом Дэвидом Хаффманом в процессе выполнения домашнего задания.
Рассмотрим ансамбль сообщений X={1,…,N} с вероятностями сообщений {P1,…,PN}. Без потери общности мы считаем сообщения упорядоченными по убыванию вероятностей, то есть P1≤P2≤ …≤PN. Наша задача состоит в построении оптимального кода, то есть кода с наименьшей возможной средней длиной кодовых слов[7]. Понятно, что при заданных вероятностях такой код может не быть единственным, возможно существование семейства оптимальных кодов. Мы установим некоторые свойства всех кодов этого семейства. Эти свойства подскажут нам простой путь к нахождению одного из оптимальных кодов.
Пусть двоичный код С={ć1,Кćn} с длинами кодовых слов {m1,…,mN} оптимален для рассматриваемого ансамбля сообщений.
Свойство 1. Если Pi<Pj, то mi>mj.
Свойство 2. Не менее двух кодовых слов имеют одинаковую длину mmax=maxk mk.
Свойство 3. Среди кодовых слов длины mmax = maxk mk найдутся 2 слова, отличающиеся только в одном последнем символе.
Прежде, чем сформулировать следующее свойство, введем дополнительные обозначения[8]. Для рассматриваемого ансамбля X={1,…,N} и некоторого кода C, удовлетворяющего свойствам 1–3, введем вспомогательный ансамбль X’={1,…,N-1}, сообщениям которого сопоставим вероятности {P’1,…,P’N} следующим образом P1¢=P1K, PN¢2=PN-2, PN¢1=PN-1+PN
Из кода C построим код C' для ансамбля X', приписав сообщениям {х1¢К, хN-2¢} те же кодовые слова, что и в коде C, а сообщению хN-2¢ – слово ćN-1, представляющее собой общую часть слов ćN-1 и ćN (согласно свойству 3 эти два кодовых слова отличаются только в одном последнем символе).
Свойство 4. Если код C' для X' оптимален, то код C оптимален для X.
Итак, сформулированные свойства оптимальных префиксных кодов сводят задачу построения кода объема N к задаче построения кодов объема N'=N-1. Это означает, что мы получили рекуррентное правило построения кодового дерева оптимального неравномерного кода.
5. ПОЧТИ ОПТИМАЛЬНОЕ КОДИРОВАНИЕ
5.1. Код Шеннона
Код Шеннона позволяет построить почти оптимальный код с длинами кодовых слов Li<-log pi+1. Тогда по теореме Шеннона Lcp<H(p1,..., pn)+1.
Код Шеннона, удовлетворяющий этому соотношению, строится следующим образом:
- Упорядочим символы исходного алфавита А={a1,a2,…,an} по убыванию их вероятностей: p1≥p2≥p3≥…≥pn.
- Вычислим величины Qi, которые называются кумулятивные вероятности Q0=0, Q1=p1, Q2=p1+p2, Q3=p1+p2+p3, … , Qn=1.
- Представим Qi в двоичной системе счисления и возьмем в качестве кодового слова первые /-log pi / знаков после запятой[9].
Для вероятностей, представленных в виде десятичных дробей, удобно определить длину кодового слова Li из соотношения 1/2Li ≤ pi<1/2Li-1, i=1,…n
Пример.
Пусть дан алфавит A={a1,a2,a3,a4,a5,a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице 5.
Таблица 5. Код Шеннона
|
ai |
Pi |
Qi |
Li |
Кодовое слово |
|
a1 a2 a3 a4 a5 a6 |
1/22≤0.36<1/2 1/23≤0.18<1/22 1/23≤0.18<1/22 1/24≤0.12<1/23 1/24≤0.09<1/23 1/24≤0.07<1/23 |
0 0.36 0.54 0.72 0.84 0.93 |
2 3 3 4 4 4 |
00 010 100 1011 1101 1110 |
Построенный код является префиксным. Вычислим среднюю длину кодового слова и сравним ее с энтропией. Значение энтропии вычислено при построении кода Хаффмана (H=2.37), сравним его со значением средней длины кодового слова кода Шеннона
Lср= 0.36.2+(0.18+0.18).3+(0.12+0.09+0.07).4=2.92< 2.37+1,
что полностью соответствует утверждению теоремы Шеннона.
5.2. Код Фано
Метод Фано построения префиксного почти оптимального кода, для которого Lcp<H(p1,..., pn)+1, заключается в следующем. Упорядоченный по убыванию вероятностей список букв алфавита источника делится на две части так, чтобы суммы вероятностей букв, входящих в эти части, как можно меньше отличались друг от друга[10]. Буквам первой части приписывается 0, а буквам из второй части – 1. Далее также поступают с каждой из полученных частей. Процесс продолжается до тех пор, пока весь список не разобьется на части, содержащие по одной букве.
Пример.
Пусть дан алфавит A={a1, a2, a3, a4, a5, a6} с вероятностями p1=0.36, p2=0.18, p3=0.18, p4=0.12, p5=0.09, p6=0.07. Построенный код приведен в таблице 6 и на рисунке 2.
Таблица 6. Код Фано
|
ai |
Pi |
Кодовое слово |
Li |
|||
|
a1 |
0.36 |
0 |
0 |
2 |
||
|
a2 |
0.18 |
0 |
1 |
2 |
||
|
a3 |
0.18 |
1 |
0 |
2 |
||
|
a4 |
0.12 |
1 |
1 |
0 |
3 |
|
|
a5 |
0.09 |
1 |
1 |
1 |
0 |
3 |
|
a6 |
0.07 |
1 |
1 |
1 |
1 |
4 |
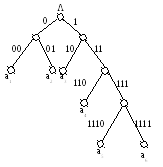
Рисунок 2. Кодовое дерево для кода Фано
Полученный код является префиксным и почти оптимальным со средней длиной кодового слова Lср=0.36.2+0.18.2+0.18.2+0.12.3+0.09.4+0.07.4=2.44
6. АРИФМЕТИЧЕСКОЕ КОДИРОВАНИЕ
Арифметическое кодирование – один из алгоритмов энтропийного сжатия.
В отличие от алгоритма Хаффмана, не имеет жесткого постоянного соответствия входных символов группам бит выходного потока. Это даёт алгоритму большую гибкость в представлении дробных частот встречаемости символов[11].
Как правило, превосходит алгоритм Хаффмана по эффективности сжатия, позволяет сжимать данные с энтропией, меньшей 1 бита на кодируемый символ, но некоторые версии имеют патентные ограничения от компании IBM
Пусть имеется некий алфавит, а также данные о частотности использования символов (опционально). Тогда рассмотрим на координатной прямой отрезок от 0 до 1.
Назовём этот отрезок рабочим. Расположим на нём точки таким образом, что длины образованных отрезков будут равны частоте использования символа, и каждый такой отрезок будет соответствовать одному символу[12].
Теперь возьмём символ из потока и найдём для него отрезок среди только что сформированных, теперь отрезок для этого символа стал рабочим. Разобьём его таким же образом, как разбили отрезок от 0 до 1. Выполним эту операцию для некоторого числа последовательных символов. Затем выберем любое число из рабочего отрезка. Биты этого числа вместе с длиной его битовой записи и есть результат арифметического кодирования использованных символов потока.
Возьмём для примера следующую последовательность:
NEUTRAL POSITIVE NEGATIVE END-OF-DATA
Сначала разобьём отрезок от 0 до 1 согласно частотам сигналов. Разбивать отрезок будем в порядке, указанном выше: NEUTRAL – от 0 до 0,6; POSITIVE – от 0,6 до 0,8; NEGATIVE – от 0,8 до 0,9; END-OF-DATA – от 0,9 до 1.
Теперь начнём кодировать с первого символа. Первому символу – NEUTRAL соответствует отрезок от 0 до 0,6. Разобьём этот отрезок аналогично отрезку от 0 до 1.
Закодируем второй символ – NEGATIVE. На отрезке от 0 до 0,6 ему соответствует отрезок от 0,48 до 0,54. Разобьём этот отрезок аналогично отрезку от 0 до 1.
Закодируем третий символ – END-OF-DATA. На отрезке от 0,48 до 0,54 ему соответствует отрезок от 0,534 до 0,54.
Так как это был последний символ, то кодирование завершено. Закодированное сообщение – отрезок от 0,534 до 0,54 или любое число из него, например, 0,538.
7. АДАПТИВНЫЕ МЕТОДЫ КОДИРОВАНИЯ
Эффективность метода ДИКМ может быть повышена путем перехода к адаптивной дифференциальной импульсно-кодовой модуляции (АДИКМ). При этом производится автоматическое регулирование величины шага квантования сигнала ошибки предсказания, а также автоматическая подстройка коэффициентов ci трансверсального фильтра устройства предсказания (рис. 3) в соответствии с изменением текущего спектра сообщения.
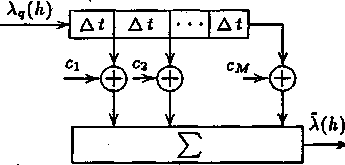
Рис. 3. Структурная схема трансверсального фильтра устройства предсказания
Для этого как в передающее, так и в приемное устройства вводятся дополнительные цепи автоматической регулировки усиления и подстройки параметров предсказателя на основе статистического оценивания параметров передаваемого сообщения[13].
Амплитуда речевого сигнала (РС) может изменяться в широких пределах в зависимости от диктора, условий передачи, а также внутри фразы при переходе от вокализованного к невокализованному сегменту. Один из методов учета этих флуктуаций состоит в адаптации свойств квантователя к уровню входного сигнала. Учесть нестационарный характер РС, в частности медленное изменение его мощности (дисперсии), позволяет адаптивный квантователь.
Основная идея адаптивного квантования состоит в том, что шаг квантования изменяется таким образом, чтобы соответствовать изменяющейся дисперсии кодируемого сигнала. В результате размеры шкалы квантования подстраивают в соответствии с энергией речи так, чтобы слабые сигналы квантовались малыми ступенями квантования, а сильные сигналы – большими. Благодаря непрерывной подстройке шага квантования к текущей мощности речи, разрядность шкалы квантования при АДИКМ удалось снизить до четырех бит.
Адаптивная дифференциальная ИКМ была стандартизирована в 1984 г. (Рек. ITU-T G.721) для скорости передачи речи 32 кбит/с, и включает в себя два метода обработки сигнала: дифференциальное кодирование с предсказанием и адаптивное квантование (рис. 4).
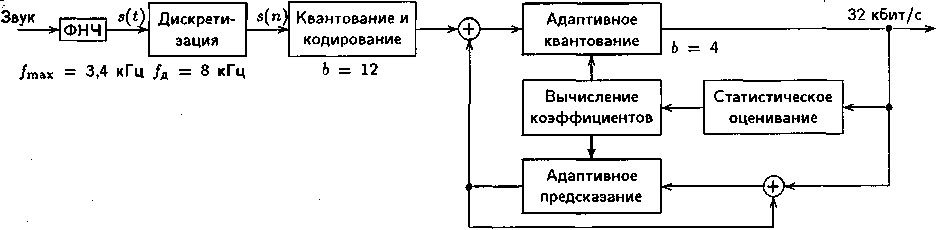
Рис. 4. Схема кодирования речи по Рек. ITU-T G.721
Аналоговый сигнал дискретизируется и линейно обрабатывается в 12-битном (b=12) квантователе. На следующем этапе вычисляется ошибка предсказания как разность между реальным и предсказанным значениями сигнала. Представленный 12-битным словом разностный сигнал обрабатывается в квантователе, имеющим логарифмическую (по основанию 2) характеристику и 16 порогов квантования (b=4). В результате формируется 4-битовое представление ошибки отсчета, что при частоте дискретизации 8 кГц обеспечивает скорость цифрового потока на выходе кодера АДИКМ равной 32 кбит/с. 4-битовый разностный сигнал на основе статистического оценивания его параметров позволяет определить коэффициенты предсказания, используемые как в адаптивном квантователе, так и в схеме адаптивного предсказания.
8. СЛОВАРНЫЕ КОДЫ КЛАССА LZ
Словарные коды класса LZ широко используются в практических задачах. На их основе реализовано множество программ-архиваторов. Эти методы также используются при сжатии изображений в модемах и других цифровых устройствах передачи и хранения информации.
Словарные методы сжатия данных позволяют эффективно кодировать источники с неизвестной или меняющейся статистикой. Важными свойствами этих методов являются высокая скорость кодирования и декодирования, а также относительно небольшая сложность реализации. Кроме того, LZ-методы обладают способностью быстро адаптироваться к изменению статистической структуры сообщений.
Словарные коды интенсивно исследуются и конструируются, начиная с 1977 года, когда появилось описание первого алгоритма, предложенного А.Лемпелом и Я.Зивом. В настоящее время существует множество методов, объединенных в класс LZ-кодов, которые представляют собой различные модификации метода Лемпела-Зива.
Общая схема кодирования, используемая в LZ-методах, заключается в следующем. При кодировании сообщение разбивается на слова переменной длины. При обработке очередного слова ведется поиск ему подобного в ранее закодированной части сообщения. Если слово найдено, то передается соответствующий ему код. Если слово не найдено, то передается специальный символ, обозначающий его отсутствие, и новое обозначение этого слова. Каждое новое слово, не встречавшееся ранее, запоминается, и ему присваивается индивидуальный код[14].
При декодировании по принятому коду определяется закодированное слово. В случае получения специального символа, сигнализирующего о передаче нового слова, принятое слово запоминается, и ему присваивается такой же, как и при кодировании, код. Таким образом, декодирование является однозначным, так как каждому слову соответствует свой собственный код.
По способу организации хранения и поиска слов словарные методы можно разделить на две большие группы:
- алгоритмы, осуществляющие поиск слов в какой-либо части ранее закодированного текста, называемой окном;
- алгоритмы, использующие адаптивный словарь, который включает ранее встретившиеся слова. Если словарь заполняется до окончания процесса кодирования, то в некоторых методах он обновляется (на место ранее встретившихся слов записываются новые), а в некоторых кодирование продолжается без обновления словаря.
Алгоритмы класса LZ отличаются размерами окна, способами кодирования слов, алгоритмами обновления словаря и тому подобное. Все указанные факторы влияют и на характеристики этих методов: скорость кодирования, объем требуемой памяти и степень сжатия данных, различные для разных алгоритмов. Однако в целом методы из класса LZ представляют значительный практический интерес и позволяют достаточно эффективно сжимать данные с неизвестной статистикой.
8.1. Кодирование с использованием скользящего окна
Рассмотрим основные этапы кодирования сообщения Х=х1х2х3х4…, которое порождается некоторым источником информации с алфавитом А. Пусть используется окно длины W, то есть при кодировании символа xi исходной последовательности учитываются W предыдущих символов[15].
Сначала осуществляется поиск в окне символа х1. Если символ не найден, то в качестве кода передается 0 как признак того, что этого символа нет в окне и двоичное представление х1.
Если символ х1 найден, то осуществляется поиск в окне слова х1х2, начинающегося с этого символа. Если слово х1х2 есть в окне, то производится поиск слова х1х2х3 , затем х1х2х3х4 и так далее, пока не будет найдено слово, состоящее из наибольшего количества входных символов в порядке их поступления[16]. В этом случае в качестве кода передается 1 и пара чисел (i, j), указывающая положение найденного слова в окне (i – номер позиции окна, с которой начинается это слово, j – длина этого слова, позиции в окне нумеруются справа налево). Затем окно сдвигается на j символов вправо по тексту и кодирование продолжается.
Для кодирования чисел (i, j) могут быть использованы рассмотренные ранее коды целых чисел.
Пример.
Пусть алфавит источника А={а, b, с}, длина окна W=6. Необходимо закодировать исходное сообщение bababaabacabac (рис. 5).

Рисунок 5. Кодирование последовательности bababaabacabac
Заключение
После кодирования первых шести букв окно будет иметь вид bababa.
- Далее проверяем наличие в окне буквы а. Она найдена, добавляем к ней b, ищем в окне ab. Эта пара есть в окне, добавляем букву а, ищем aba. Это слово есть в окне, добавляем букву с, ищем abac. Этого слова нет в окне, тогда кодируем aba кодовой комбинацией (1,3,3), где 1– признак того, что слово есть в «окне», 3 – номер позиции в окне, с которой начинается это слово, 3 – длина этого слова.
- Далее окно сдвигаем на 3 символа вправо и ищем в окне букву с. Ее нет в окне, поэтому кодируем комбинацией (0, «с»), где 0 – признак того, что буквы нет в окне, «с» – двоичное представление буквы. Окно сдвигаем на 1 символ вправо.
- Ищем в окне букву а, она найдена, добавляем к ней b, ищем в окне ab. Эта пара есть в окне, добавляем букву а, ищем aba. Это слово есть в окне, добавляем букву с, ищем abac. Это слово есть в окне, тогда кодируем abaс кодовой комбинацией (1,4,4), где 1 – признак того, что слово есть в окне, 4 – номер позиции в окне, с которой начинается это слово, 4 – длина этого слова.
СПИСОК ЛИТЕРАТУРЫ
- Белоногов, Г.Г. Автоматизация процессов накопления, поиска и обобщения информации / Г.Г. Белоногов, А.П. Новоселов. - М.: Наука, 2017. - 256 c.
- Берлекэмп, Э. Теория кодирования / Э. Берлекэмп. - М.: [не указано], 2017. – 575 c.
- Верещагин, Н. К. Информация, кодирование и предсказание / Н.К. Верещагин, Е.В. Щепин. - М.: ФМОП, МЦНМО, 2016. - 240 c.
- Кловский Д.Д. Теория передачи сигналов. -М.: Связь, 2004.
- Кудряшов Б.Д. Теория информации. Учебник для вузов Изд-во ПИТЕР, 2014. - 320с.
- Рябко Б.Я., Фионов А.Н. Эффективный метод адаптивного арифметического кодирования для источников с большими алфавитами // Проблемы передачи информации. - 2014. - Т.35, Вып. - С.95 - 108.
- Семенюк В.В. Экономное кодирование дискретной информации. - СПб.: СПбГИТМО (ТУ), 2011
- Быков С.Ф., Журавлев В.И., Шалимов И.А. Цифровая телефония: Учеб. пособие для вузов. – М.: Радио и связь, 2013. -144 с.
- Назаров М.В., Прохоров Ю.Н. Методы цифровой обработки и передачи речевых сигналов. - М.: Радио и связь, 2012. - 176 с.
- Грошев А.С., Закляков П. В, Информатика: учеб. для вузов — 3-е изд., перераб. и доп. — М.: ДМК Пресс, 2015 — 588 с.
- Шелухин О.И., Лукьянцев Н.Ф. Цифровая обработка и передача речи. – М.: Радио и связь, 2014. – 456 с.
- https://studfiles.net/preview/2919113/page:7/
- https://ru.wikipedia.org/wiki/Арифметическое_кодирование
- https://studfiles.net/preview/6389276/page:5/
- https://studfiles.net/preview/2919113/page:14/
-
Белоногов, Г.Г. Автоматизация процессов накопления, поиска и обобщения информации / Г.Г. Белоногов, А.П. Новоселов. - М.: Наука, 2017. - 256 c. ↑
-
Берлекэмп, Э. Теория кодирования / Э. Берлекэмп. - М.: [не указано], 2017. – 575 c. ↑
-
Верещагин, Н. К. Информация, кодирование и предсказание / Н.К. Верещагин, Е.В. Щепин. - М.: ФМОП, МЦНМО, 2016. - 240 c. ↑
-
Кловский Д.Д. Теория передачи сигналов. -М.: Связь, 2004. ↑
-
Кудряшов Б.Д. Теория информации. Учебник для вузов Изд-во ПИТЕР, 2008. - 320с. ↑
-
Рябко Б.Я., Фионов А.Н. Эффективный метод адаптивного арифметического кодирования для источников с большими алфавитами // Проблемы передачи информации. - 2009. - Т.35, Вып. - С.95 - 108. ↑
-
Семенюк В.В. Экономное кодирование дискретной информации. - СПб.: СПбГИТМО (ТУ), 2001 ↑
-
Быков С.Ф., Журавлев В.И., Шалимов И.А. Цифровая телефония: Учеб. пособие для вузов. – М.: Радио и связь, 2003. -144 с. ↑
-
Назаров М.В., Прохоров Ю.Н. Методы цифровой обработки и передачи речевых сигналов. - М.: Радио и связь, 1985. - 176 с. ↑
-
https://studfiles.net/preview/2919113/page:7/ ↑
-
https://ru.wikipedia.org/wiki/Арифметическое_кодирование ↑
-
Шелухин О.И., Лукьянцев Н.Ф. Цифровая обработка и передача речи. – М.: Радио и связь, 2000. – 456 ↑
-
https://studfiles.net/preview/6389276/page:5/ ↑
-
https://studfiles.net/preview/2919113/page:14/ ↑
-
https://studfiles.net/preview/2919113/page:14/ ↑
-
https://studfiles.net/preview/2919113/page:14/ ↑

- Выставочная-ярмарочная деятельность как инструмент маркетинга
- Интернет-маркетинговые решения для салона красоты(Тенденции развития рынка салонов красоты в России)
- Дидактическая игра как метод обучения
- Субъекты малого предпринимательства
- Современная законодательно-нормативная база защиты государственной тайны
- Понятие и виды наследования
- Добровольный отказ от совершения преступления и его уголовно-правовое значение
- Ответственность за вред причиненный источником повышенной опасности
- Роль рекламы в современном маркетинге ООО ПКФ «ВЕРСИЯ»
- Интернет-маркетинговые решения для мебельной фабрики (Общая характеристика АО «АНГСТРЕМ»)
- Кадровая стратегия в системе управления организацией.
- Кадровая стратегия в системе стратегического управления организацией (ЗАО «СТС Текновуд»)