
Состав и свойства вычислительных систем. Информационное и математическое обеспечение вычислительных систем (Процессор )
Содержание:

Введение
С древних веков человеку необходимо было устройство для упрощения вычисления. Сначала это были обычные счеты, но с развитием технологий вычислительные машины тоже совершенствовались и прошли длинный путь развития. На данный момент известно о четырех поколения ЭВМ. Они прошли путь от вычислительных ламповых машин до современных компьютеров.
Основным критерием развития было повышение скорости вычисления или быстродействия системы. Наибольший прорыв был сделан с появления параллельного вычисления.
Вычислительные системы создаются для повышение ускорения процессов обработки данных, надежности и достоверности вычислений, предоставление пользователям дополнительных возможностей, например сохранение результатов вычислений.
Целью данной работы является рассмотреть состав и свойства вычислительной системы, информационное и математическое обеспечение.
1. Состав и свойства вычислительной системы
Вычислительная система – это совокупность взаимосвязанных и взаимодействующих процессоров или ЭВМ, периферийного оборудования и программного обеспечения, предназначенную для подготовки и решения задач пользователей. Отличительной особенностью ВС по отношению к ЭВМ является наличие в них нескольких вычислителей, реализующих параллельную обработку[1, с. 40].
Термин вычислительная система появилась в начале 60х годов прошлого века. Это связано с переходом на новый элемент – интегральная схема. Что послужило причиной разработки новых технических решений: разделение процессов обработки информации и ее ввода–вывода, множественный доступ и коллективное использование вычислительных ресурсов в пространстве и во времени. Появились сложные режимы работы ЭВМ – многопользовательская и многопрограммная обработка. Объединив в себе все новшества, и появился термин «вычислительная система», т.е. возможность построения параллельных ветвей в вычислениях, что не предусматривалось классической структурой ЭВМ[4, с. 37].
Паралелльное выполнение операций существенно повышает быстродействие системы, а так же надежность, если, на пример, выйдет из строя один элемент системы, его обязанности на себя может взять другой, и достоверность.
Для современных вычислительных систем требования совсем другие, а именно информационное обслуживание, сервис и качество этого обслуживания[1, с. 41].
В настоящее время широкий спектр в разработке и использовании ВС самого разнообразного применения. Эти системы очень сильно отличаются друг от друга своими возможностями и характеристиками. Существует большое количество признаков, по которым классифицируют ВС:
– целевому назначению и выполняемым функциям,
– типам и числу ЭВМ или процессоров,
– архитектура системы,
– режима работы,
– методы управления элементами системы,
– степени территориальная удаленность элементов ВС.
По назначению вычислительные системы делятся на универсальные и специализированные. Универсальные системы предназначены для решения широкого класса задач[4, с. 38]. Они подразумевают гибкость, маштабируемость и программируемость системы исходя из потребностей. Что делает очень дорогостоящей такую систему, т.к. в нее закладывается больше трудозатрат. Однако на основе любой универсальной системы можно создать специализированную систему. Специализированные системы ориентированы на решение узкого класса задач. Этот признак определяется различными критериями:
– структура системы подразумевает обработку определенного вида информации: работа только с числами, только с файлами и т.д. Подобные вычислительные системы разрабатываются в основном для суперЭВМ;
– состав системы подразумевает использование специального оборудования и специальных пакетов обслуживания техники[4, с. 38].
По режиму работы ВС различают системы, работающие в оперативном(on-line) и неоперативном временных режимах(off-line). On-line системы используют режим реального масштаба времени. Что подразумевает оперативный обмен информацией, незамедлительный ответ на запрос. В off-line системах возможен режим «отложенного ответа». Запрос будет выполнен с некоторой задержкой или даже в следующий сеанс работы[1, с. 42].
В зависимости от способа управления, вычислительные системы делятся на системы с централизованным управлением, т.е. управление выполняет выделенная машина или процессор, и децентрализованным, когда все компоненты равноправны и могут брать управление на себя[1, с. 42].
По типу ВС различаются на многомашинные и многопроцессорные.
Многомашинные вычислительные системы включают себя несколько компьютеров, информационно взаимодействующих друг с другом. Классическим примером служит компьютерная сеть[1, с. 57].
Многопроцесорная система содержит несколько процессоров, которые в процессе работы организуют информационный обмен и имеют единое управление вычислительными процессами[1, с. 57].
1.1 Состав вычислительной системы
Компьютерные системы строятся из трех компонентов: процессоров, памяти и устройств ввода-вывода.
1.1.1 Процессор
Процессор предназачен для того чтобы вызывать из памяти команды,определять их тип,а затем исполнять их.
Сам, в свою очередь, состоит из нескольких частей. Блок управления отвечает за вызов команд и определение их типа. Арифмитически-логическое устройство выполняет арифмитические и логичские операции[5, с. 70].
Внутри процессора находится память для хранения промежуточных результатов и некоторых команд управления. Эта память состоит из нескольких регистров, каждый из которых выполняет определенные функции.
Тракт данных состоит из регистров, АЛУ и нескольких соединительных шин. Содержимое регистров поступает в АЛУ, оно выполняет сложение, вычитание и другие операции над входными данными и помещает результат в выходной регистр. Содержимое этого регистра может записываться либо в регистр, либо в память[5, с. 70].
Большинство команд можно разделить на две группы: регистр-память и регистр-регистр.
Регистр-память вызывают слова из памяти, помещает их в регистры, где х использует в качестве входных данных АЛУ, после выполнения их помещают обратно в память.
Регистр-регистр оба операнда берутся из регистра, помещаются во входные регистры АЛУ, выполняют над ними какую-либо операцию и помещают обратно в регистр.
Этот процесс называется циклом тракта данных. Чем он проходит быстрее, тем быстрее работает компьютер[5, с. 71].
1.1.2 Память
Память – это тот компонент компьютера, в котором хранятся программы и данные
Иерархическая структура памяти позволяет хранить большие объемы данных.
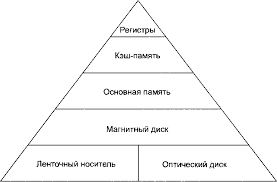
Рисунок 1 - Иерархия памяти
При движении по иерархии(рисунок 1) сверху вниз меняются три параметра: время доступа, объем и стоимость.
Регистры находятся непосредственно в процессоре, поэтому у них самый быстрый доступ и самый меленький объем.
Кэш-память небольшого объема с высокой скоростью работы. В ней находятся слова к которым чаще всего обращаются. Если процессору нужно какое-то слово, он сначала ищет в кэш, если не находит идет в основную память[5, с. 96].
Основная память используется для хранения программ, которые выполняются в данный момент. Она содержит два вида запоминающих устройств: постоянно запоминающие и оперативно запоминающее.
ПЗУ(ROM – READ ONLY MEMORY) предназначена для хранения постоянной, неизменной информации. Информация в ней доступна только для считывания[1, с. 149].
ОЗУ(RAM – Random Access Memory) предназначена для оперативного хранения, считывания и записи информации. Достоинство: адресное обращение и быстродействие. Недостатки: информация не сохраняется после выключения компьютера[1, с. 156].
К внешней памяти относится накопители на жестких, гибких и магнитных дисках. Их основное назначение: хранение больших объемов данных, запись выдача информации в ОЗУ.
1.1.3 Устройства ввода-вывода
Устройства ввода-вывода используются для передачи информации в компьютер и из компьютера. Они связаны с процессором и памятью одной или несколькими шинами. В качестве примера можно назвать: терминалы, мыши, принтеры, сканеры и модемы.
1.2 Параллельные компьютерные архитектуры
Скорость работы компьютеров становиться все выше, но требования к ним тоже растут. Повышение производительности компьютера просто за счет увеличения тактовой частоты, становиться труднее, так как необходимо отводить тепло. Поэтому разработчики стали применять параллелизм для ускорения вычислений[5, с. 597].
Когда несколько процессоров или обрабатывающих элементов находятся рядом и обмениваются большими объемами данными с небольшими задержками называются сильносвязными. И наоборот, когда находятся далеко друг от друга и обмениваются небольшими объемами данных с большими задержками называются слабосвязными[5, с. 598].
Параллелизм можно применить на разных уровнях. На самом низком реализован в самомом процессоре за счет конвейрезации и суперскалярной архитектуры. На следующем уровне можно благодаря установке нескольких процессоров на одной микросхеме. Чтобы увеличить мощность в разы, необходимо соединить несколько процессоров и обеспечить взаимодействие. Так получаются мульпроцессорные системы и кластерные компьютеры. И наконец, с помощью интернета можно объединить целые организации. В итоге получаются слабосвязанные распределенные вычислительные сети[5, с. 597].
Рассмотрим более подробно каждый уровень параллелизма.
1.2.1 Внутрипроцессорный параллелизм
Внутрипроцессорный параллелизм может быть на уровне команд, многопоточность и размещение на одной микросхеме несколько процессоров.
Параллелизм на уровне команд достигается за счет вызова нескольких команд за один тактовый цикл. Процессоры, в которых реализуется этот принцип делятся на два типа: суперскалярные и со сверхдлинным комнадным словом(VLIW) [5, с. 599].
Суперскалярные процессоры за один тактовый цикл вызывают несколько команд.
Один конвейер обрабатывает команду за несколько шагов, каждый из которых реализован своим аппаратным компонентом. На пример принцип работы конвейера из 5 блоков[5, с. 79].
Первым шагом команда вызывается из памяти и помещается в буфер, где храниться, пока не понадобиться. Вторым декодирует её и определяет тип и тип её операндов. Третий шаг определяет определяется их местонахождение и вызывается из памяти. Четвертым шагом выполняется команда, проходя через тракт данных. И пятым шагом записывается результат в нужный регистр[5, с. 80].
Суперскалярная архитектура представляет собой конвейер с большим числом функциональных блоков
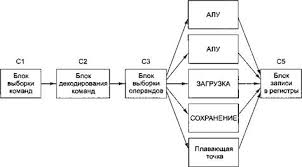
Рисунок 2 - Схема процессора с большим блоком команд
Другой вид параллелизма на уровне команд реализуется в процессорах со сверхдлинным командным словом. Изначально они действительно были длинными словами с командами, обращавшихся к нескольким функциональным блокам. Например конвейер на рисунке № 3 включается в себя пять функциональных блоков и способен выполнять одновременно две целочисленные операции, одну с плавающей точкой, одну команду загрузки и сохранения. Но возникли проблемы с тем что не все команды могли обращаться к соответствующим функциональным блокам, что привело к появлению пустых операций. Современные VLIW –системы предусмотрен механизм маркировки команд рисунок № 3 . Процессор может выбрать и запустить целиком связку. Компилятор отвечает за подготовку команд для совместного исполнения. По сути проблема совместимости команд переносится с периода исполнении на компиляцию. Что позволяет упростить и удешевить аппаратное обеспечение[1, с. 599].
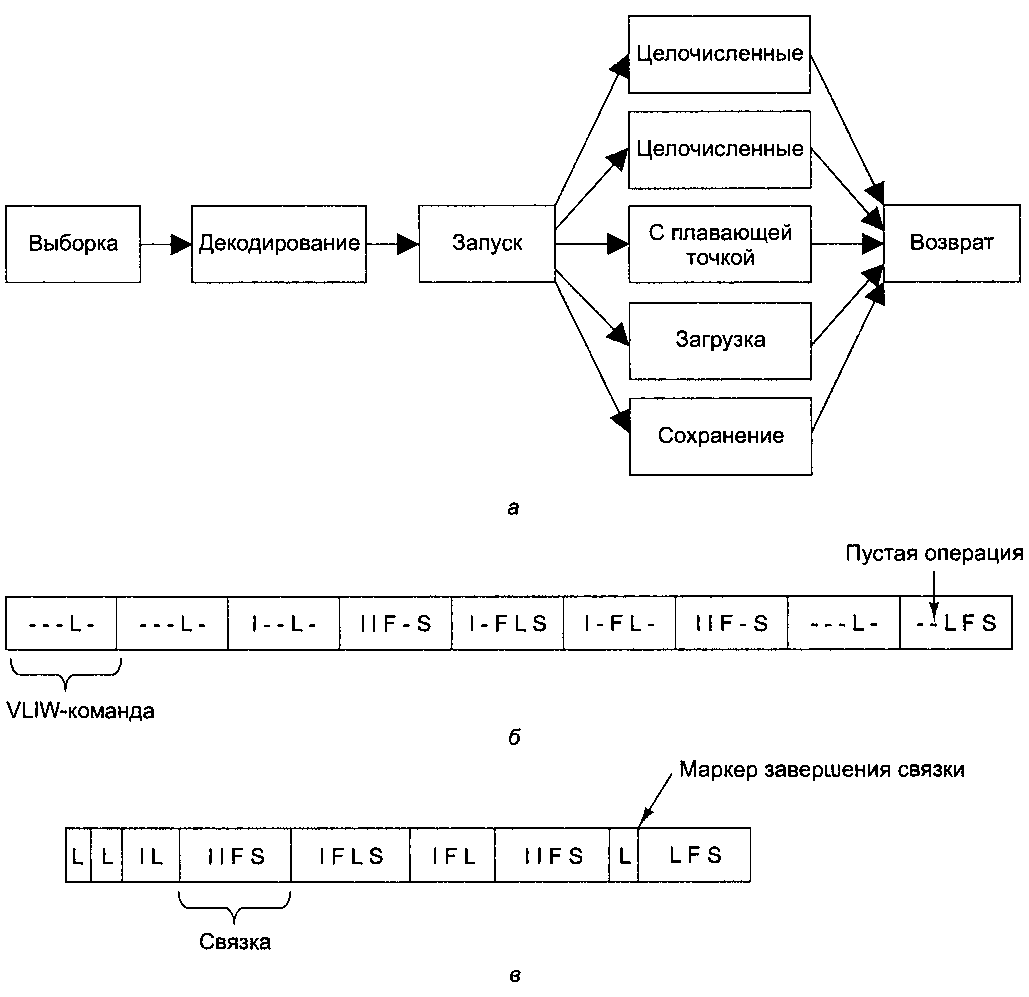
Рисунок 3 – Конвейер
1.2.2 Внутрипроцессорная многопоточность
У современных конвейеризованных процессоров есть одна проблема: при обращении к памяти слово не находиться ни в кэш первого уровни, ни второго. На загрузку такого слова уходит длительное время, а конвейере в это время простаивает.
Один вариантов решения проблемы внутрипроцессорная многопоточность(on-chip multithreading). Что позволяет процессору одновременно управлять несколькими программными потоками и маскировать простои. Принцип многопоточности можно представить так: если программный поток 1 блокируется, процессор может обеспечить полную загрузку аппаратуры, запустив программный поток 2[5, с. 607].
Это концепция имеет несколько вариантов реализации: мелкомодульная, крупномодульная и синхронная многопоточность.
Мелкомодульная многопоточность (fine-grained multithreading) можно представить так три программных потока (А, В, С), соответствующих 12 машинным циклам. В ходе первого цикла поток А выполняет команду А1. Поскольку эта команда завершается за один цикл, при наступлении второго цикла запускается команда А2. Ее обращение в кэш первого уровня оказывается неудачным, поэтому до извлечения нужного слова из кэша второго уровня проходит два цикла. Исполнение потока продолжается в цикле 5. Как показано на рисунке № 4, потоки В и С также регулярно простаивают. В рамках такого решения вызов последующей команды до завершения предыдущей не осуществляется[5, с. 608].
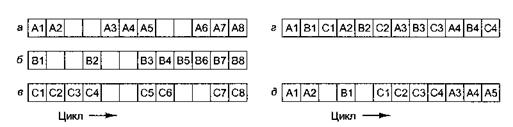
Рисунок 4 – Многопоточность
При мелкомодульной многопоточности в смежных циклах запускаются разные потоки, то есть происходит зацикливание потоков, что позволяет маскировать простой. Следовательно, при наличии трех программных потоков простаивающая операция все равно завершается вовремя. При простое в 4 цикла для беспрерывной работы понадобилось бы 4 программных потока, и т. д[5, с. 609].
Так как разные программные потоки ничего не знают друг о друге, им необходим свой набор регистров. Он должен быть указан для каждой вызываемой команды, и тогда аппаратное обеспечение будет знать, к какому набору регистров при необходимости нужно обращаться. Следовательно, максимальное число одновременно исполняемых программных потоков определяется в период разработки микросхемы.
Помимо обращения к памяти, причиной простоя может стать, то что следующей команде нужен результат предыдущей, а он еще не известен.
В остальных случаях команда вызвана быть не может, так как она следует за условным переходом, направление которого еще неизвестно.
Общее правило формулируется так: если в конвейере k ступеней, но по кругу можно запустить, по меньшей мере, k программных потоков, то в одном потоке в любой отдельно взятый момент не может выполняться более одной команды, поэтому конфликты между ними исключены. В такой ситуации процессор может работать на полной скорости, без простоя.
Не всегда число доступных потоков равно числу ступеней конвейера, поэтому некоторые разработчики предпочитают крупномодульную многопоточность (coarse-grained multithreading), которую иллюстрирует рисунок №.4. Программный поток А продолжает выполняться последовательно, вплоть до простоя. При этом теряется один цикл. Далее происходит переключение на первую команду программного потока В (В 1). Так как эта команда сразу переходит в состояние простоя, в цикле 6 выполняется уже команда С1[5, с. 607].
Исходя из представленного описания есть один недостаток при простое теряется один цикл. Однако, благодаря меньшему числу потоков сокращается расход ресурсов процессора.
Кроме переключения между потоками крупномодульная многопоточность позволяет немедленно переключиться с команд, которые способны вызвать простой, не выясняя намечается простой или нет. Эта стратегия позволяет избегать бесконечных циклов. Другими словами, исполнение продолжается до того момента, пока не обнаружится возможность возникновения проблемы, после чего следует переключение. Такие частые переключения роднят крупномодульную многопоточность с мелкомодульной[5, с. 608].
Для определения команды в потоке мелкомодульная многопточность использует индетефикатор потока.
Крупномодульная многопоточность предусматривает возможность очистки конвейера перед запуском каждого последующего потока. В таком случае четко определяется идентичность потока, исполняемого в данный момент. Естественно, данная методика эффективна только в том случае, если паузы между переключениями значительно больше времени, необходимого для очистки конвейера.
В суперскалярных процессорах есть еще синхронная многопоточность (simultaneous multithreading). Она представляет усовершенствованный вариант крупномодульной многопоточности, где каждый программный поток может запускать по две команды за такт, однако в случае простоя с целью обеспечения полной загрузки процессора запускаются команды следующего потока. При синхронной многопоточности полностью загружаются все функциональные блоки. В случае невозможности запуска команды из-за занятости функционального блока выбирается команда из другого потока[5, с. 609].
1.2.3 Однокристальные мультипроцессоры
Многопоточность повышает производительность,но есть системы где многопоточности недостаточно.
Для таких случаев существуют мультипроцессорные схемы. Микросхемы, на которых устанавливается два или более процессоров, применяются в основном в профессиональных серверах и бытовой электронике.
Мультипроцессорные схемы строятся на гомогенных и гетерогенных однокристальных мультипроцессорах.
Благодаря развитию технологии СБИС (сверхбольшая интегральная схема), в настоящее время на один кристалл можно установить два или более мощных процессоров. Поскольку такие процессоры всегда обращаются к одним и тем же модулям памяти (кэшу первого и второго уровней и основной памяти), они считаются единым мультипроцессором[5, с. 613].
Как правило, они устанавливаются в крупных фермах веб-серверов. При совместном размещении двух процессоров, разделении ресурсов памяти, дисковых и сетевых интерфейсов производительность сервера во многих случаях можно удвоить, причем расходы на это возрастут в значительно меньшей степени (так как даже если мультипроцессор будет стоить в два раза больше обычного процессора, его цена составляет лишь небольшую часть общей стоимости системы) [5, с. 613].
Для малых однокристальных мультипроцессоров имеются два типовых проектных решения. В первом из них присутствует одна микросхема и два конвейера: скорость исполнения команд теоретически удваивается. Во втором решении в микросхеме предусмотрено два независимых ядра, каждое из которых содержит полноценный процессор. Ядром называется большая микросхема (например, процессор, контроллер ввода-вывода или кэш-память), которая размещается на микросхеме в виде модуля, как правило, вместе с несколькими другими ядрами[5, с. 613].
Первое решение допускает совместное потребление ресурсов (таких как функциональные блоки) процессорами; иными словами, каждый процессор может обращаться к ресурсам, не затребованным другим процессором. Второе решение требует изменения конструкции микросхемы и не предусматривает более двух процессоров[5, с. 614].
1.2.4 Сопроцессоры
Быстродействие компьютера можно увеличить за счет введения дополнительного специализированного процессора. Такие системы называются сопроцессор. Он может либо выполнить команду или набор команд от процессора, либо действует самостоятельно и выполняет свои команды. Одной из областей применения таких систем является обработка графики или выполнение вычислений с плавающей точкой[5, с. 619].
Они могут быть выполнены в отдельном корпусе, виде подключаемой платы или установлены на основной микросхеме.
1.2.5 Сетевые сопроцессоры
Два компьютера называются связанными, если они могут обмениваться информацией. Очень часто происходит путаница между понятиями компьютерная сеть и распределенная система. Основное различие в том, что в распределенной системе наличие автономных компьютеров не заметно для пользователя. Для него это единая связанная система. Достигается за счет специализированного программного обеспечения над операционной системой. Такое программное обеспечение называется связующим. Самый большой пример такой системы – интернет, в котором для пользователя все выглядит как единый документ. В компьютерной сети пользователь имеет дело непосредственно с вычислительной системой, которая даже не пытается объединить все. То есть если компьютеры в сети имеют разное аппаратное и программное обеспечение пользователь это никак не сможет изменить. Следовательно, разница заключается в программном обеспечении, а не аппаратном. Не смотря, на это они имеют много общего. Обе эти системы занимаются перемещением файлов. Хотя есть разница в то, кто перемещает эти файлы, пользователь или сама система[5, с. 620].
Вычислительные сети бывают двух типов: локальные и глобальные.
Локальные сети соединяют компьютеры находящиеся в пределах зданий, а глобальные компьютеры находящиеся на значительном расстоянии.
Примером локальной сети может служить сеть любой организации. Допустим у организации, есть несколько этажей в здании с определенным количество компьютеров, принтеров. Чтобы у сотрудников была возможность печатать документы, не обязательно каждому ставить свой принтер. А вот благодаря сетевому соединению можно организовать доступ к ним. Еще одним ресурсом являются данные хранящиеся в базе данных, так же за чет сетевого соединения можно организовать доступ к ней, ее разместить на одном специально компьютере, который называется сервер. А такая архитектура называется клиент серверной.
Глобальная сеть географически более удаленная в плоть да разных стран. Строиться она из подсетей. Взаимодействие между которыми обеспечивается с помощью линей связи и маршрутизаторов. Линии связи непосредственно переносят данные от компьютера к компьютору. А марщрутизатор производит переключение между сетями, как он обычно соединяет разные подсети. Иногда в качестве такого соединения можно использовать интернет.
Как уже было сказано, в сеть могут входить различные устройства. А обмен между ними происходит пакетами. В зависимости от вида сети и пакета, он может требовать определенной обработки. Обработка может включать в себя принятие решения куда передать пакет, разбить его ан части или наоборот собрать из частей, защиту и т.д. Все это должно происходить очень быстро[5, с. 622].
Быструю обработку можно обеспечить с помощью специализированных интегральных схем, программируемых вентельных матриц и сетевых процессоров.
Специализированные интегральные схемы запрограммирована на строго определенные действия. Производство таких схем дорого, долго и их нельзя самостоятельно перепрограммировать[5, с. 623].
Программируемые вентельные матрицы, за счет вентелей организуются переходы. Их производство и сборок значительно быстрее и дешевле, чем специализированных интегральных схем и их можно перепрограммировать, но все равно долго и дорого[5, с. 623].
Сетевые процессоры способны обрабатывать входящие и исходящие пакеты со скоростью их передачи, в режиме реального времени. Обычно они реализуются в виде съемной платы, содержащей помимо кристалла сетевого процессора, память и вспомогательную логику. К плате подключается одна или несколько сетевых линий. Процессор получает из линии пакет, обрабатывает его и передает по другой линии, если это маршрутизатор, или отправляет в главную системную шину, если это оконечное устройство, например компьютер[5, с. 623].
1.2.6 Мультипроцессоры и мультикомпьютеры
Параллельный компьютер, в котором все процессоры совместно используют общую физическую память, называется мультипроцессором, или системой с общей памятью. Все процессы, работающие в мультипроцессоре совместно, могут иметь единое виртуальное адресное пространство, отображенное на общую память. Два процесса имеют возможность легко обмениваться информацией — для этого один из них просто записывает данные в общую память, а другой их считывает[5, с. 635].
Поскольку все процессоры в мультипроцессоре используют единое адресное пространство, функционирует только одна копия операционной системы. Соответственно, имеется только одна карта страниц памяти и одна таблица процессов. Когда процесс блокируется, его процессор сохраняет свое состояние в таблицах операционной системы, а затем просматривает эти таблицы в поисках другого процесса, который нужно запустить. Именно такая организация, в основе которой лежит единая система, и отличает мультипроцессор от мультикомпьютера[5, с. 636].
Мультипроцессор, как и все компьютеры, должен содержать устройства ввода- вывода (диски, сетевые адаптеры и т. п.). В одних мультипроцессорных системах только определенные процессоры получают доступ к устройствам ввода-вывода и, следовательно, обладают специальными средствами ввода-вывода. В других мультипроцессорных системах каждый процессор может получить доступ к любому устройству ввода-вывода. Если все процессоры имеют равный доступ ко всем модулям памяти и всем устройствам ввода-вывода, и между процессорами возможна полная взаимозаменяемость, такой мультипроцессор называется симметричным (Symmetric Multiprocessor, SMP) [5, с. 636].
Во втором варианте параллельной архитектуры каждый процессор имеет собственную память, доступную только этому процессору. Такая схема называется мультикомпьютером, или системой с распределенной памятью .
Ключевое отличие мультикомпьютера от мультипроцессора состоит в том, что каждый процессор в мультикомпьютере имеет собственную локальную память, к которой этот процессор может обращаться. Таким образом, мультипроцессоры имеют одно физическое адресное пространство, разделяемое всеми процессорами, а мультикомпьютеры содержат отдельные физические адресные пространства для каждого процессора[5, с. 636].
Поскольку процессоры в мультикомпьютере не могут взаимодействовать друг с другом простыми обращениями к общей памяти, процессоры обмениваются сообщениями через связывающую их коммуникационную сеть.
При отсутствии общей памяти, реализованной аппаратно, предполагается определенная программная структура. В мультикомпьютере невозможно иметь единое для всех процессоров виртуальное адресное пространство, позволяющее считывать и записывать информацию.
Программное обеспечение мультикомпьютера имеет более сложную структуру, чем программное обеспечение мультипроцессора. При этом основной проблемой становится правильное распределение данных и разумное их размещение. Это еще одно отличие мультикомпьютера от мультипроцессора, где размещение данных не влияет на правильность решения задачи, хотя может повлиять на производительность[5, с. 637].
Мультипроцессоры сложно разрабатывать, но легко программировать, а мультикомпьютеры легко строить, но трудно программировать. В результате постоянно предпринимаются попытки создания гибридных систем.
При разработке таких систем важно добиться масштабируемости, то есть она будет продолжать исправно работать при добавлении все новых и новых процессоров[5, с. 638].
Один из подходов основан на том, что современные компьютерные системы не монолитны, а имеют многоуровневую структуру. Это дает возможность реализовать общую память на любом из нескольких уровней.
Можно использовать использовать аппаратное обеспечение мультикомпыотера и операционную систему, которая будет моделировать общую память, предоставляя единое виртуальное адресное пространство, разбитое на страницы. При таком подходе получается распределенная общая память (Distributed Shared Memory, DSM), в которой каждая страница расположена в одном из модулей памяти, а каждая машина содержит собственную виртуальную память и собственные таблицы страниц. Если процессор выполняя команду обращается к странице, которой у него нет, происходит системное исключение. После этого операционная система находит нужную страницу и обращается к соответствующему процессору, чтобы тот выгрузил страницу из памяти и послал ее через внутреннюю коммуникационную сеть, по которой процессоры обмениваются сообщениями. Когда страница попадает процессу-получателю, она отображается на память, и выполнение прерванной команды возобновляется. Получается ,что операционная система просто получает недостающие страницы не с диска, а из памяти. При этом у пользователя создается впечатление, что машина имеет единую общую память[5, с. 638].
Можно реализовать общую память программно пользовательской системой реального времени. При таком подходе абстракцию общей памяти создает язык программирования, и эта абстракция реализуется компилятором (то есть модель общей памяти может зависеть от используемого языка программирования). Например, модель Linda основана на абстракции общего пространства кортежей (записей данных, содержащих наборы полей). Процессы любой машины могут взять кортеж из общего пространства или отправить его в общее пространство. Поскольку доступ к этому пространству полностью контролируется программно (системой реального времени Linda), никакой специальной аппаратной поддержки или особой операционной системы не требуется[5, с. 638].
1.3 Классификация параллельных компьютерных систем
Вычислительные системы появились как параллельные системы. За годы их разработки появились разные виды архитектуры. Поэтому необходима какая-то их классификации. Одна из них была предложена М. Флинном в 1966 году. В основе классификации лежат понятия потоков команд и потоков данных. Поток команд соответствует счетчику команд. Система с п процессорами имеет п счетчиков команд и, следовательно, п потоков команд. Поток данных состоит из набора операндов[5, с. 640].
Потоки команд и данных в какой-то степени независимы, поэтому существует 4 комбинации таких потоков .
SISD (Single Instruction stream Single Data stream — один поток команд с одним потоком данных) — это классическая последовательная компьютерная архитектура фон Неймана. Компьютер фон Неймана имеет один поток команд и один поток данных и в каждый момент времени может выполнять только одно действие[5, с. 640].
У машины, относящихся к категории SIMD (Single Instruction-stream Multiple Data-stream — один поток команд с несколькими потоками данных), имеется один блок управления, выдающий по одной команде, но при этом есть несколько АЛУ, которые могут обрабатывать несколько наборов данных одновременно. Прототип SIMD-машин — процессор ILLIAC IV (см. рис. 2.6). Хотя SIMD-машины не относятся к числу широко распространенных, в некоторых обычных компьютерах для обработки мультимедийных данных используются SIMD-команды. SSE-команды в процессорах Pentium относятся к категории SIMD-команд. В любом случае существует одна область, где идеи, почерпнутые из «мира SIMD», выходят на первый план, — это потоковые процессоры. Потоковые процессоры специально разработаны для обработки мультимедийных данных и в будущем они могут играть важную роль[5, с. 640].
MISD (Multiple Instruction-stream Single Data-stream — несколько потоков команд с одним потоком данных) —существуют ли реально такие машины не известно, хотя некоторые относят к категории MISD машины с конвейерами.
Последняя категория — MIMD (Multiple Instruction-stream Multiple Data- stream — несколько потоков команд с несколькими потоками данных). Здесь несколько независимых процессоров работают как часть большой системы. В эту категорию попадают большинство параллельных процессоров. И мультипроцессоры, и мультикомпьютеры — это MIMD-машины[5, с. 640].
В свете современных технологий классификацию Флинна можно расширить. SIMD-машины разделить на две подгруппы. В первую подгруппу попадают многочисленные суперкомпьютеры и другие машины, которые оперируют векторами, выполняя одну и ту же операцию над каждым элементом вектора. Во вторую подгруппу попадают машины типа ILLIAC IV, в которых главный блок управления посылает команды нескольким независимым АЛУ.
Категория MIMD на мультипроцессоры (машины с общей памятью) и мультикомпьютеры (машины с обменом сообщениями). Существует три типа мультипроцессоров. Они отличаются друг от друга механизмом доступа к общей памяти и называются UMA (Uniform Memory Access — однородный доступ к памяти), NUMA (NonUniform Memory Access — неоднородный доступ к памяти) и СОМА (Cache Only Memory Access — доступ только к кэш-памяти). В UMA-машинах каждый процессор имеет одно и то же время доступа к любому модулю памяти или каждое слово может быть считано из памяти с той же скоростью, что и любое другое слово. Если это технически невозможно, самые быстрые обращения замедляются, чтобы соответствовать самым медленным, поэтому программист не заметит никакой разницы, что позволяет создать однородный доступ. Такая однородность делает производительность предсказуемой, а этот фактор очень важен для создания эффективных программ[5, с. 641].
NUMA-машина, напротив, не обладает свойством однородности. Обычно у каждого процессора есть один из модулей памяти, который располагается к нему ближе, чем другие, поэтому доступ к этому модулю памяти происходит гораздо быстрее, чем к другим. В этом случае с точки зрения производительности очень важно, где окажутся программа и данные[5, с. 641].
Доступ к СОМА-машинам тоже оказывается неоднородным, но по другой причине. Подразумевается использования основной памяти каждого процессора в качестве кэш-памяти.
Во вторую основную категорию MIMD-машин попадают мультикомпьютеры, которые в отличие от мультипроцессоров не имеют общей памяти на архитектурном уровне. Другими словами, операционная система процессора, входящего в состав мультикомпьютера, не сможет получить доступ к памяти другого процессора. Процессору придется отправить сообщение и ждать ответа. Именно способность операционной системы считать слово из удаленного модуля памяти с помощью команды отличает мультипроцессоры от мультикомпьютеров. Так как мультикомпьютеры не имеют непосредственного доступа к удаленным модулям памяти, их иногда относят к категории NORMA (NO Remote Memory Access — отсутствие удаленного доступа к памяти) [5, с. 642].
Мультикомпьютеры тоже можно разделить на две дополнительные категории. К категории МРР (Massively Parallel Processor — процессор с массовым параллелизмом) относятся дорогостоящие суперкомпьютеры, которые состоят из большого количества процессоров, связанных высокоскоростной внутренней коммуникационной сетью. В качестве хорошо известного коммерческого примера можно назвать суперкомпьютер SP/3 компании IBM[5, с. 642].
Вторая категория мультикомпьютеров включает обычные персональные компьютеры или рабочие станции, которые связываются в соответствии с той или иной коммерческой коммуникационной технологией. Эти системы иногда называют сетями рабочих станций (Network Of Workstations, NOW), кластерами рабочих станций (Cluster Of Workstattions, COW), или просто кластерами (cluster) [5, с. 642].
1.3.1 UMA
Самые простые мультипроцессоры имеют всего одну шину. Два или более процессора и один или несколько модулей памяти используют эту шину для взаимодействия. Если процессору нужно считать слово из памяти, он сначала проверяет, свободна ли шина. Если шина свободна, процессор помещает адрес нужного слова на шину, устанавливает несколько управляющих сигналов и ждет, когда память поместит на шину запрошенное слово[5, с. 647].
Если шина занята, процессор просто ждет, когда она освободится. С этой схемой связана одна проблема. При наличии двух или трех процессоров доступ к шине регулировать не сложно, трудности возникают, когда процессоров 32 или 64. Производительность системы в этом случае полностью определяется пропускной способностью шины, и многим процессорам большую часть времени приходится простаивать[5, с. 647].
Чтобы разрешить проблему, нужно добавить к каждому процессору кэшпамять. Кэш-память может находиться внутри микросхемы процессора, рядом с микросхемой процессора, на плате процессора.
Допустимы любые комбинации этих вариантов. Поскольку в этом случае считывать многие слова можно будет из кэша, трафик на шине снизится, и система сможет обслуживать большее количество процессоров. Таким образом, кэширование дает в данном случае значительный эффект[5, с. 647].
В следующей схеме каждый процессор имеет не только кэш, но и собственную локальную память, к которой он получает доступ через выделенную локальную шину. Чтобы оптимально задействовать эту конфигурацию, компилятор должен поместить в локальные модули памяти весь программный код, строки, константы и другие данные, предназначенные только для чтения, а также стеки и локальные переменные. Общая память потребуется только для хранения совместно используемых переменных. В большинстве случаев такое разумное распределение значительно снижает интенсивность трафика на шине и не требует активного содействия со стороны компилятора[5, с. 648].
1.3.2 Numa
Количество процессоров в UMA-мультипроцессорах с одной шиной обычно ограничивается несколькими десятками, а для мультипроцессоров с перекрестной или многоступенчатой коммутацией требуется дорогое оборудование, к тому же количество процессоров в них не намного больше.
Чтобы объединить в одном мультипроцессоре более 100 процессоров, нужно какое-то иное решение. Ранее предполагалось, что все модули памяти имеют одинаковое время доступа. Если не замыкаться на этой концепции, можно прийти к мультипроцессорам с неоднородным доступом к памяти (NonUniform Memory Access, NUMA). Как и UMA- мультипроцессоры, они предоставляют единое адресное пространство для всех процессоров, но, в отличие от UMA-машин, доступ к локальным модулям памяти происходит быстрее, чем к удаленным. Следовательно, все UMA-программы смогут без изменений работать на NUMA-машинах, но производительность будет хуже, чем на UMA-машине с той же тактовой частотой[5, с. 656].
NUMA-машины имеют три ключевые характеристики, которые в совокупности отличают их от других мультипроцессоров:
- существует единое адресное пространство, видимое всеми процессорами;
- доступ к удаленной памяти производится командами LOAD и STORE;
- доступ к удаленной памяти выполняется медленнее, чем доступ к локальной[5, с. 656].
Если время доступа к удаленной памяти не замаскировано кэшированием (кэш отсутствует), такая система называется NC-NUMA (No Caching NUMA — NUMA без кэширования). Если присутствуют согласованные кэши, то система называется CC-NUMA (Coherent Cache NUMA — NUMA с согласованными кэшами). Программисты часто называют такую систему аппаратной распределенной общей памятью, поскольку она, по сути, аналогична распределенной общей памяти (DSM), реализованной программно, однако поддерживается аппаратно с использованием страниц маленького размера[5, с. 656].
Согласованность памяти в NC-NUMA-машине гарантирована, поскольку в ней отсутствует кэш-память. Каждое слово памяти может находиться только в одном месте, поэтому нет никакой опасности появления копии с устаревшими данными — здесь вообще нет копий. То, в каком именно модуле памяти находится та или иная страница, имеет большое значение, поскольку от этого зависит производительность. Для максимального увеличения производительности в NC-NUMA-машинах была реализована следующая сложная схема программной поддержки перемещения страниц[5, с. 657].
Обычно каждые несколько секунд запускался специальный «сторожевой» процесс (демон), называемый страничным сканером. Его задача — следить за статистикой использования страниц и перемещать их таким образом, чтобы росла производительность. Если страница оказывалась в «неправильном» месте, страничный сканер выгружал ее из памяти, поэтому следующее обращение к ней вызывало ошибку отсутствия страницы. Когда происходит ошибка отсутствия страницы, принимается решение о том, куда эту страницу поместить (возможно, не в тот модуль памяти, в котором она была раньше). Для предотвращения пробуксовки существовало правило, согласно которому страница после размещения должна оставаться на месте в течение времени АТ. Предлагалось множество других алгоритмов, но ни один из них так и не стал безусловно лучшим[5, с. 657].
1.3.3 Coma
NUMA- и CC-NUMA-машины обладают одним серьезным недостатком: обращения к удаленной памяти выполняются гораздо медленнее, чем к локальной. В CC-NUMA-машине эта разница в производительности в какой-то степени нивелируется за счет кэш-памяти[5, с. 664].
Однако если объем запрашиваемых удаленных данных значительно превышает вместимость кэш-памяти, постоянно будут происходить кэш-промахи, что негативно скажется на производительности.
Высокую производительность имеют UMA-машины, но число процессоров в них невелико, к тому же они довольно дороги. NC-NUMA-машины хорошо масштабируются, но в них требуется ручное или полуавтоматическое размещение страниц памяти, результаты которого часто плачевны. Дело в том, что очень непросто предсказать, где и какие страницы могут понадобиться, кроме того, страницы трудно перемещать из-за их больших размеров. CC-NUMA-машины, такие как мультипроцессор Sun Fire Е25К, начинают работать очень медленно, если большому числу процессоров требуются большие объемы удаленных данных. Так или иначе, каждая из этих схем имеет существенные недостатки[5, с. 665].
Однако существует мультипроцессор, в котором все эти проблемы решаются за счет использования основной памяти каждого процессора в качестве кэш-памяти. Такая система называется СОМА (Cache Only Memory Access — доступ только к кэш-памяти). В ней страницы не имеют собственных «домашних» машин, как в системах NUMA и CC-NUMA, фактически, страницы в этой системе вообще не имеют «прописки» [5, с. 665].
Вместо этого физическое адресное пространство делится на строки кэша, которые по запросу свободно перемещаются в системе. Блоки памяти не имеют собственных машин. Память, которая привлекает строки по мере необходимости, называется притягивающей. Использование основной памяти в качестве большого кэша увеличивает процент кэш-попаданий, а, следовательно, и производительность[5, с. 666].
К сожалению, ничего идеального не бывает. С системой СОМА связаны две новые проблемы:
- Как размещаются строки кэша?
- Что делать, когда удаляемая из памяти строка является последней копией?
Первая проблема связана со следующим фактом. Как известно, диспетчер памяти выполняет трансляцию виртуального адреса в физический. Если после трансляции оказывается, что строки нет в «настоящем» аппаратном кэше, очень трудно сказать, есть вообще искомая строка в основной памяти или ее там нет. Аппаратная поддержка механизма разбиения памяти на страницы здесь не поможет, поскольку каждая страница состоит из большого количества отдельных строк кэша, которые располагаются в системе независимо друг от друга. Даже если известно, что строки в основной памяти нет, как выяснить, где она есть? В данном случае нельзя спросить об этом «домашнюю» машину потерявшейся страницы, поскольку таковой машины в системе просто нет[5, с. 666].
Было предложено несколько решений этой проблемы. Чтобы знать, находится строка кэша в основной памяти или нет, для каждой строки кэша можно аппаратно поддерживать специальный тег. Тогда диспетчер памяти сможет сравнивать тег нужной строки с тегами всех строк кэша, пока не обнаружится совпадение.
Другое решение — отображать страницы целиком, но при этом не требовать наличия всех строк кэша. Тогда для каждой страницы потребуется аппаратно построить битовую карту, где каждой строке соответствует 1 бит, который и укажет на присутствие или отсутствие этой строки. В этой схеме, которая называется простой схемой СОМА, если строка присутствует, она должна находиться в правильной позиции на своей странице. Если она отсутствует, то любая попытка использовать ее должна вызывать исключение, которое позволит программно найти и задействовать нужную строку[5, с. 66].
Таким образом, система будет искать только те строки, которые действительно находятся в удаленной памяти. Еще одно решение — предоставить каждой странице «домашнюю» машину (домашнюю в том смысле, что в каталоге для нее выделяется запись, а не в том, что на этой машине хранятся данные). Тогда чтобы выяснить, где искать строку, можно отправить сообщение ее домашней машине. Другое решение — организовать память в виде древовидной структуры и искать, двигаясь вверх, пока строка не будет найдена.
Вторая проблема связана с удалением последней копии. Как и в CC-NUMA- машине, строка кэша может одновременно находиться в нескольких узлах. Если происходит кэш-промах, строку нужно прочитать, а это обычно означает ее удаление. А что произойдет, если выбранная строка окажется последней копией? В этом случае ее нельзя удалять[5, с. 666].
Одно из возможных решений — вернуться к каталогу и проверить, существуют ли другие копии. Если да, то строку можно смело удалять. Если нет, ее нужно где-то разместить. Другое решение — пометить одну из копий каждой строки кэша как главную и никогда ее не удалять. При таком подходе проверять каталог не потребуется. В любом случае СОМА-машина потенциально должна иметь более высокую производительность, чем CC-NUMA, но пока было создано всего несколько СОМА-машин, а для реализации всего их потенциала нужно накопить некоторый опыт[5, с. 666].
1.3.4 Мультикомпьютеры
В категорию MIMD входят два вида процессоров с параллельной архитектурой: мультипроцессоры и мультикомпьютеры. Мульти процессоры могут иметь общую память, доступ к которой выполняется обычными командами LOAD и STORE.
Для реализации такой памяти может использоваться множество схем, включая шины слежения, сети с перекрестной и многоступенчатой коммутацией, различные схемы на основе каталога. Во всех случаях программы, написанные для мультипроцессора, могут получать доступ к любому месту в памяти, не имея никакой информации о внутренней топологии или схеме реализации. Именно благодаря такой иллюзии мультипроцессоры весьма популярны у пользователей и программистов[5, с. 666].
Однако мультипроцессорам свойственны и некоторые недостатки, и это автоматически означает усиление роли мультикомпьютеров. В первую очередь, мультипроцессоры плохо масштабируются.
На их производительности может серьезно сказываться конкуренция за доступ к памяти. Если 100 процессоров постоянно пытаются считывать и записывать одни и те же переменные, конкуренция за ресурсы модулей памяти, шин и каталогов может сильно ударить по производительности[5, с. 666].
Вследствие этих и других факторов разработчики проявляют повышенный интерес к таким параллельным компьютерным архитектурам, в которых каждый процессор имеет собственную память, недоступную напрямую для других процессоров. Это — мультикомпьютеры. Поскольку программы на разных процессорах в мультикомпьютере не могут получить доступ к памяти других процессоров командами LOAD и STORE, они взаимодействуют друг с другом с помощью примитивов send и receive, которые используются для передачи сообщений. Это различие полностью меняет модель программирования[5, с. 666].
Каждый узел в мультикомпьютере состоит из одного или нескольких процессоров, ОЗУ (общего для процессоров только данного узла), дисковода и (или) других устройств ввода-вывода, а также коммуникационного процессора. Коммуникационные процессоры связаны между собой высокоскоростной коммуникационной сетью (см. далее подраздел «Коммуникационные сети»). Используется множество различных топологий, схем коммутации и алгоритмов выбора маршрута, однако у всех мультикомпьютеров есть общая черта: когда программа выполняет примитив send, коммуникационный процессор извещается об этом и передает блок данных в целевую машину (возможно, после предварительного запроса и получения разрешения) [5, с. 666].
2. Информационное и математическое обеспечение ВС
Кроме аппаратного обеспечения у любой вычислительной системы есть и программное. Оно представляет из себя комлекс программ осуществляющих как управление аппаратными устройствами, так и решение конкретных задач пользователя.
Все программное обеспечение можно разделить на системное и прикладное.
Системное программное обеспечение объединяет программные компоненты, обеспечивающие многоцелевое применение компьютера и мало зависящие от специфики вычислительных работ пользователей. Сюда входят программы, организующие вычислительный процесс в различных режимах работы машин, программы контроля работоспособности, диагностики и локализации неисправностей, программы контроля заданий пользователей, их проверки, отладки и т.д[1, с. 339].
Системное программное обеспечение включает в себя:
- операционную систему – обеспечивает эффективное функционирование компьютера в различных режимах, а так же работу программ и взаимодействие пользователя и устройств компьтера:
- сервисные программы – расширяют возможности операционной системы, предоставляя дополнительные услуги
- инструментальные программные средства – предназначены для разработки и отладки ПО
- системы технического обслуживания – диагностик, поиск неисправностей в компьютере[1, с. 340].
Прикладное программное обеспечение предназначено для решения одной конкретной задачи пользователя или комплекса задач.
Они объединяются в пакеты, чтобы наиболее полно обеспечить автоматизации труда каждого специалиста. Такой комплексный состав формирует многофункциональную обработку данных и объединение отдельных практических задач в ППП[4, с. 105].
Специализация пакета определяется характером решаемых задач (пакеты для разработки экономических документов, рекламных роликов, планирования и др.) или необходимостью управления специальной техникой (управление сложными технологическими процессами, управление бортовыми системами кораблей, самолетов и т.п.). Такие специальные пакеты программ могут иcпользовать отдельные подразделения, службы, отделы учреждений, предприятий, фирм для разработки различных планов, проектов, документов, исследований. В некоторых случаях прикладное программное обеспечение может иметь очень сложную структуру, включающую библиотеки, каталоги, программы-диспетчеры и другие обслуживающие компоненты. Программы прикладного программного обеспечения разрабатываются с учетом группы пользователей. Оно комплектуется в зависимости от места и роли автоматизированного рабочего места (АРМ) работника, использующего в своей деятельности компьютер. В ПО ПК обычно включают небольшое число пакетов программ (табличный процессор, текстовый редактор, система управления базами данных и др.), ориентированных на работу с документами[4, с. 105].
2.1 Операционная система
Для решения задачи компьютером необходимо две составляющие: программ, которые решают что будем выполнять, и аппаратных средств для непосредственного решения.
Операционная система управляет стандартными процедурами аппаратных средств, так как многое процессы управления являются подобными и мало зависит от программ.
Поэтому ОС взаимодействует с одной стороны с пользователями, предоставляя им более удобный интерфейс, программное окружение, где запускаются и исполняются другие программы, а с другой стороны ресурсами компьютера, процессами обработки информации[1, с. 341].
Управление ресурсами заключается в упрощении доступа к ним,а так же динамическое распределение их между конкурирующими за них процессами[1, с. 342].
Ресурсы бывают двух видов: аппаратные( процессор, дополнительный процессор, основная память, внешняя память, принтер и тд.) и программные( все доступные пользователю программы управления вычислительным процессом).
Управление процессами позволяет создавать эффективные режимы работы компьютера:
- однопользовательские и многопользовательские( сколько пользователей одновременно могут использовать этот компьютер)
- однопрограммный(однозадачный) и много программный( многозадачный). Многозадачный можно разделить на :
Пакетной обработки – пользователь не участвует, предварительно программа собирается в пакет для решения задачи
Разделения времени – каждый пользователь имеет доступ к системе в определенный промежуток времени
Реального времени – гарантированное обслуживание одновременно каждого запроса[1, с. 342].
2.2 Инструментальные программные средства
Инструментальные программные средства составляют языки программирования, языковые трансляторы, редакторы, средства отладки и другие вспомогательные программы.
Языки программирования служат средством передачи информации, средством записи текстов исходных программ.
В настоящее время известно несколько сотен языков программирования, которые используют пользователи при разработке своих заданий. Появление новых типов ЭВМ, например ПК, и новых областей их применения способствует появлению следующих поколений языковых средств, в большей степени отвечающих требованиям потребителей[4, с. 113].
Важнейшими характеристиками языка являются трудоемкость программирования и качество получаемого программного продукта. Качество программ определяется длиной программ (количеством машинных команд или емкостью памяти, необходимой для хранения программ), а также временем выполнения этих программ.
Машинные языки современных ЭВМ практически не используются даже программистами-профессионалами из-за чрезмерной трудоемкости процесса разработки про- грамм. В редких случаях их используют инженерно-технические работники вычисли- тельных центров для проверок работы устройств и блоков компьютера, для выяснения нестандартных, нештатных ситуаций, когда другими средствами не удается выявить причины их появления. Применение машинных языков требует знания специфики представления и преобразования информации в компьютере[4, с. 114].
Особое место имеют машинно-ориентированные языки (язык Ассемблера, или просто Ассемблер, автокоды, языки символического кодирования и др.). Несмотря на высокую трудоемкость, ими часто пользуются профессиональные системные программисты, на- пример, при разработке программ общего или специального ПО, особенно в тех случаях, когда эти программы должны быть максимально компактными и быстродействующими. Пользователям с недостаточной программистской подготовкой эти языки практически недоступны[4, с. 114].
Из процедурно-ориентированных языков широко известны Фортран, Алгол, Кобол, Basic, Pascal, Ада, Си и др. Спектр языков этой группы очень широк, и среди них существует определенная иерархия. Считается, что язык Basic предназначается для начинающих программистов, язык Pascal для студентов, это язык «правильного», классического программирования, язык СИ – для квалифицированных программистов и т.д. Существуют определенные соглашения в использовании языков программирования. Так, при создании программ для собственных работ пользователь может выбрать любой язык, да- же Basic. При разработке ПО для одного заказчика корректно использовать язык Pascal, при разработке программных средств для многих потребителей целесообразно использование языков Си и Ассемблер[4, с. 114].
С появлением ПК наиболее распространенными языками являются Basic и Pascal. Первоначально они разрабатывались для целей обучения. Их применение обеспечивает быстрый и удобный перенос программ, написанных на этих языках, с одного ПК на другой. Наиболее простым языком является Basic. Трансляторы для него имеются практически на всех ПК. Язык отличает простота и наличие средств интерактивной работы, что обеспечило ему популярность среди непрофессиональных программистов. Однако для построения сложных программ он в силу ограниченных возможностей (структурирова- ние программ и данных, идентификация переменных и т.д.) подходит плохо. Вместе с тем, следует отметить, что фирма Microsoft сделала этот достаточно простой язык осно- вой для обмена приложениями (Visual Basic for Application). Эта платформа перенесена и в следующее поколение операционных систем – Windows.net[4, с. 115].
Современный язык высокого уровня Pascal получил широкое распространение в силу ряда достоинств: простоты, ясности, сравнительно узкого набора возможных синтаксических конструкций наряду с семантическим их богатством. Общепризнано, что он является наилучшим средством для обмена программами между различными типами ПК. На основе разработки языка Pascal предложен ряд новых языков, например Модула- 2, в котором особое внимание уделяется построению программы как набора независимых модулей. На базе языка Pascal создан достаточно мощный язык Ада, который задумывался как универсальный и наиболее перспективный язык программирования. К нему было приковано внимание разработчиков всех новых типов ЭВМ. Однако широкого распространения он до сих пор не получил[4, с. 115].
Для разработки коммерческих программ больше используется язык Си, который удачно сочетает в себе средства языка высокого уровня и языка Ассемблера, что позволяет разрабатывать компактные, быстродействующие, высокоэффективные программные продукты. Объектно-ориентированный С++ в настоящее время является основным средством разработки критически важных приложений, требующих быстродействия и оптимизации работы с памятью[4, с. 115].
Все описанные выше языки программирования используют так называемые пошаговые описания алгоритмов. Именно в этом и заключается источник большой трудоемкости подготовки задач к решению. Несомненно, что для машин будущих поколений будут предложены более эффективные средства программирования. Так, например, все больше внимания уделяется разработке проблемно-ориентированных языков программирования (Симула, GPSS и др.). В этих языках имеется возможность описывать специфические алгоритмы обработки информации более крупными конструкциями. Это делает программы пользователей более наглядными, так как каждая используемая конструкция соответствует вполне определенному объекту, исследуемому пользователем[4, с. 115].
Другой интересной тенденцией является появление непроцедурных описательных языков. Их конструкции констатируют, какой результат желателен пользователю, не ука- зывая, каким образом это сделать. Примером такого языка служит язык ПРОЛОГ (ПРО- граммирование ЛОГики), который широко используется специалистами в области искус- ственного интеллекта. Конструкции языка несоответствуют математическим формулам, а определяют отношения между объектами и величинами. Язык состоит только из описаний и не имеет как таковых команд-инструкций[4, с. 115].
Развитие сетевых технологий привело к созданию языка Java, рожденного в недрах фирмы Sun и разрабатываемого в коалиции более чем 400 организаций. Он представляет собой интерпретационный язык высокого уровня; отличается простотой, независимостью от аппаратуры и отсутствием связей со сложными операционными системами. Это делает совместимыми компьютеры различных платформ, позволяет управлять ими с общих по- зиций. Именно язык Java способствовал внедрению анимации в Web-ресурсы сетей. По- этому многие фирмы приобрели лицензии на Java и обеспечивают его поддержку в своих разработках[4, с. 115].
Повышение роли структурного программирования привело к появлению языков Delphi (Object Pascal) фирмы Borland и Visual Basic фирмы Microsoft. Эти языки позволя- ют очень быстро разрабатывать приложения, однако по уровню гибкости оба языка силь- но уступают С++.
Необходимо отметить, что в компьютерах будущих поколений будут использоваться языки программирования, имеющие средства распараллеливания вычислительных работ для многомашинных и многопроцессорных вычислительных систем. Проблемы по- строения таких языков еще полностью не разрешены и находятся в стадии исследования[4, с. 115].
В состав САП включаются также языковые трансляторы для всех языков, которые используют пользователи при разработке своих программ. В зависимости от специфики вычислительного центра и контингента пользователей их состав формируется эмпири- чески. Обычно же он включает трансляторы процедурно-ориентированных языков высо- кого уровня (Pascal, Basic, Си) и машинно-ориентированных языков (Ассемблер).
Различают трансляторы двух типов: интерпретаторы и компиляторы.
Трансляторы-интерпретаторы предназначаются для последовательного пооператорного преобразования каждого предложения исходного модуля программы в блок машинных команд с одновременным их выполнением. Машинная программа в полном объеме при этом не создается, решение задач пользователей происходит замедленными темпами. Этот вид трансляции рекомендуется использовать при отладке новых программных продуктов[4, с. 115].
Трансляторы-компиляторы, напротив, предназначаются для формирования полного загрузочного модуля по исходным программам пользователя. Это позволяет отделить полученный программный продукт от среды его разработки и в последующем использовать его автономно[4, с. 115].
Из системных обслуживающих программ, широко используемых при подготовке вычислений, следует выделить редактор (редактор связей), загрузчик, библиотекарь, средства отладки и другие вспомогательные программы[4, с. 115].
Программы пользователей после обработки их транслятором (трансляторами) представляются в виде набора программных блоков, имеющих промежуточный формат, общий для всех трансляторов. Специфика исходных языков программирования при этом теряется. Объединение программных блоков в единую программу выполняет редактор. В зависимости от того, в какой стадии подготовки к решению находятся программы абонентов, они могут размещаться в различных библиотеках. Управляет размещением программ, последующей идентификацией и выборкой библиотекарь. Вызов готовых к решению программ в оперативную память, активизацию их с учетом их места размещения выполняет загрузчик[4, с. 116].
Средства отладки обеспечивают проверку заданий пользователей, поиск в них различного рода ошибок, вывод на печать запрашиваемой отладочной информации, распечатку содержимого зон оперативной памяти, выдачу различных управляющих блоков и таблиц и т.п. Вспомогательные программы (утилиты) служат для перемещения информации с одного носителя на другой, разметки накопителей, редактирования информации в наборах данных, сбора информации об ошибках[4, с. 116].
2.3 Пакеты прикладных программ
Информационное обеспечение это комплекс программ, предназначенных для решения определенного класса задач пользователей. Сначала к нему относили только готовые программы, которые регулярно использовал пользователь. Однако такие программы постоянно совершенствуется, дополняется, модифицируется. Поэтому все чаще включает в себя, наряду с комплексом готовых программ и программную среду, оболочку, в которой создаются пользовательские программы[4, с. 116].
К информационному обеспечению относится:
– системы обработки текстов (текстовые редакторы);
– системы обработки электронных таблиц;
– системы управления базами данных;
– системы деловой графики;
– коммуникационные системы;
– прикладные системы более узкой ориентации (организации вычислений, поддержки планирования, финансовых расчетов, автоматизации проектирования и др.).
Самые простые редакторы встраиваются в многие пакеты имеют достаточно скромные характеристики. Примерами подобных WP являются встроенный редактор командной строки DOS, программы Блокнот, Word Pad и др[4, с. 117].
Другие редакторы широкого назначения, обычно используются автономно. Они получили большую популярность и используются повсеместно при отработке документов различной сложности: от простейших справок до фундаментальных книг (Лексикон, Word и др.). Последние версии редакторов типа Word for Windows предоставляют пользователям возможности настольной издательской системы[4, с. 117].
Наиболее сложными редакторами являются WP мощных издательских систем, предназначенные для оформления и полной подготовки к типографскому изданию книг, журналов, буклетов (Aldus PageMaker, Ventura Publisher). Они позволяют включать в текст фотографии, иллюстрации, графики, диаграммы; использовать различные шрифты; менять параметры текста; осуществлять перемещение фрагментов; изменять оформление документа; автоматизировать его верстку[4, с. 117].
Системы обработки электронных таблиц или табличные процессоры, предназначены для работы с фактографическими документами. Этот вид документа представляет собой двумерную таблицу, как правило, заранее определенной формы, каждая клетка которой содержит значение некоторой характеристики объекта. Подобные документы являются наиболее распространенными в деятельности различных отделов, служб, предприятий и т.п. Примерами этих документов могут служить бухгалтерские ведомости, отчеты, планы, списки и прочее. Такие документы представлены в памяти ПК в виде электронных таблиц[4, с. 117].
Еще одной группой ППП являются системы управления базами данных (СУБД). Они появились, когда ЭВМ стали использоваться в контуре управления технологическими процессами и людскими коллективами. Разработка различных автоматизированных систем управления предполагает создание в памяти ПК информационных моделей объектов управления – больших информационных массивов, получивших название «базы данных» [4, с. 118].
База данных (БД) - это совокупность взаимосвязанных данных, хранящихся совместно в памяти компьютера.
Каждая БД состоит из записей. Запись образует подмножество данных, служащих для описания единичного объекта. Например, фамилия, имя, отчество, год рождения, адрес, место работы, номер телефона могут составлять одну запись и характеризовать одного человека. Информационный массив может содержать записи по отдельным цехам, службам, отделам всего предприятия. Назначением БД является удовлетворение информационных потребностей пользователей. СУБД автоматизирует работу пользователей с хранящимися данными. Количество информационных массивов в БД и их объем зависит от сложности создаваемой системы. Ядро БД составляет информация, наиболее часто используемая в процессах управления. Согласно принципу В. Парето (итальянский экономист XIX века), 20 % всей информации обеспечивают более 80 % всех задач управления. Эта часть в первую очередь и подлежит автоматизации[4, с. 118].
Достаточно мощные СУБД позволяют значительно автоматизировать процессы управления и удовлетворять до 90–95 % потребностей управленческого аппарата. Одним из основных назначений СУБД является автоматизация документооборота. На основе хранящейся информации можно автоматически формировать любые стандартные документы. Дополнительно к этому СУБД позволяет обращаться к данным и с нестандартными запросами для получения каких–либо справок, обобщений. СУБД поддерживает диалоговый режим работы пользователей, в которых запросы данных и реакция системы побуждают к формированию более точных запросов и исследованию данных[4, с. 118].
СУБД обеспечивает ввод, поиск, сортировку данных, составление отчетов. Они имеют возможность сопряжения с табличными процессорами для специфической обработки и графического представления данных. В настоящее время широко используются СУБД различных производителей. Все они в свою очередь состоят из языковых и программных средств. Различие между ними состоит в предлагаемом сервисе и удобствах работы[4, с. 118].
По мере накопления опыта разработки и применения ППП, пользователи стали переходить к эксплуатации интегрированных систем, объединяющих наиболее часто используемые прикладные системы и пакеты. Сочетание различных видов обработки в рамках единой операционной среды создает дополнительные удобства пользователям. Упрощение общения достигается путем разработки «дружественного» ПО путем подсказок, инструкций, предоставления вариантов действий и т.д. Фирмы–разработчики таких пакетов стараются сохранить в них единые принципы представления информации, управления и работы[4, с. 119].
Интегрированные пакеты программ можно рассматривать как дальнейшую надстройку ОС, так как в них аккумулируются средства, определяющие специфику работы конкретного пользователя. В этом они становятся похожи на ППос. Обычно ППос содержат средства более общего характера. ППос больших ЭВМ условно можно разделить на три группы[4, с. 119].
• пакеты, обеспечивающие специфические режимы работы под управлением ОС (работа в многомашинных и многопроцессорных системах, работа в сети ЭВМ, реализация определенных режимов и т.д.). К этой же группе относятся и пакеты программ для управления специальными техническими средствами;
• ПП общего назначения для научно–технических расчетов, задач математического программирования и т.п.;
• ПП, ориентированные на применение ЭВМ в АСУ. Данные пакеты включают программы обработки документов, программы формирования и обслуживания информационно–поисковых систем и т.п[4, с. 119].
Заключение
В эпоху развития информационных технологий. Информация стала самым дорогой величиной. Быстрота получения необходимы вычислений или формирование документов, координально меняет производства и структуры организаций. Позволяя как можно больше автоматизировать рутинных операций и облегчить жизнь специалистам. И если раньше они использовались только для трудоемких вычислений, то теперь они составляют целые автоматизированные рабочие места, собирают машины и т.д.
Технологии не стоят на месте, но развитие одного конкретного компьютера уже достигло своего предела. Будущее за системами, которые в дальнейшем возможно будут работать без участия человека.
И все это информационные (вычислительные системы) для работы которых теперь достаточно иметь выход в интернет меняют реальность человека и рабочее место. Сокращая до минимума необходимых элементов для выполнения работы.
В данной работе были рассмотрены состав, виды вычислительных систем, а так же их математическое и информационное обеспечение.
СПИСОК ЛИТЕРАТУРЫ
1. Бройдо, В.Л. Вычислительные системы, сети и телекоммуникации : учебное пособие / В. Л. Бройдо. – СПб. : Питер, 2004. – 703 с.
2. Галкин, В.А. Телекоммуникации и сети : учебное пособие / В.А. Галкин, Ю.А. Григорьев. – М. : МГТУ им. Н.Э. Баумана, 2003. – 608 с.
3. Мелехин, В.Ф. Вычислительные машины, системы и сети : учебник / В.Ф. Мелехин, Е.Г. Павловский. – М. : Академия, 2006. – 560с.
4. Пятибратов, А.П. Вычислительные системы, сети и телекоммуникации : учебник для вузов / А.П. Пятибратов, Л.П. Гудыно, А.А. Кириченко ; под ред. А.П. Пятибратова. – М. : Финансы и статистика, 2005. – 560 с.
5. Таненбаум, Э. Архитектура компьютера/ Э. Таненбаум. – СПб. : Питер, 2007. – 844 с.

- Расчет оптимального размера запасов
- Основы интегрированных коммуникаций ( рекламы и связей с общественностью )
- Определение рыночных возможностей предприятия (Выявление и оценка маркетинговых возможностей)
- «Профессиональный cтреcc в управленческой деятельности»
- Профессиональный cтреcc в управленческой деятельности
- Управление каналами сбыта в системе товародвижения реально существующей организации.(ТЕОРЕТИЧЕСКИЕ ОСНОВЫ УПРАВЛЕНИЯ СБЫТОМ ПРОДУКЦИИ ПРЕДПРИЯТИЙ)
- «Основные функции в системе менеджмента («Запсибкомбанк»)
- Совершенствование кадрового менеджмента в системе государственной гражданской службы: тенденции и приоритеты (Анализ кадровой работы)
- Презумпции и фикции (Значение фикций в законодательстве)
- Маркетинговые структуры предприятия (теоретические аспекты) (ООО «Керамос»)
- ОСНОВНЫЕ ФУНКЦИИ В СИСТЕМЕ МЕНЕДЖМЕНТА (Проектирование функций менеджмента)
- Понятие и виды ценных бумаг (Понятие «ценная бумага»)