
Операции, производимые с данными (Блок-схема шифра гласных букв)
Содержание:

Введение
Процедура доступа к данным может быть инициирована как самим компьютером (для решения каких-либо своих технических задач), так и конечным пользователем. В последнем случае пользователь формирует запрос, куда включает, в частности, обозначение требуемого вида доступа или действия и указание на то, над какими данными это действие надо выполнить. Как отмечалось ранее, идентификация данных осуществляется с помощью ключей. В качестве же требуемого действия может производиться одно из следующих: добавление, удаление, изменение, просмотр элемента или обработка данных из элемента.
При добавлении элемента информационный массив пополняется новыми данными в виде записи файла или файла в целом, соответственно, для структурированных и неструктурированных данных. В запросе в этом случае, помимо указанной выше информации, приводится и сам новый элемент. При этом объем информационного массива увеличивается.
Удаление, наоборот, является обратным действием, вызывающим исключение упомянутых данных. Это действие приводит к уменьшению объема информационного массива.
Изменение относится не к элементу, а к его составляющим – полям записи файла или тексту, хранящемуся в файле, и означает, в свою очередь, удаление прежних значений полей или строк текста и/или добавление новых. В запрос включается дополнительная информация, указывающая на требуемые составляющие изменяемого элемента, а также сами новые значения этих составляющих. Объем информационного массива при этом не меняется для структурированных данных и, возможно, меняется для неструктурированных;
Просмотр связан с предоставлением данных пользователю на устройстве вывода компьютера, как правило, на дисплее. В запросе в этом случае дополнительно указывается, какие составляющие элемента требуется просмотреть (по умолчанию просматривается весь элемент).
Обработка предусматривает выполнение некоторых арифметических операций над данными элемента, например, накопление суммы и т.д., и относится только к структурированным данным, а потому далее не рассматривается.
Стоить заметить, что концепция распределенных вычислений сложнее для восприятия. При этом, на данный момент есть не так много проектов, где предпринимаются попытки визуализировать алгоритм в действии. Одним из самых известных является реализация raft.io[1], которая на основном информационном сайте алгоритма Raft[2] показывает принцип его работы с помощью анимации. Визуализация дает базовое понимание о работе алгоритмаRaft, но она реализована для одного конкретного алгоритма и для одного конкретного тестового случая.
По причине отсутствия обширности визуализационной базы, когда студенты сталкиваются с темой распределенных вычислений впервые, уходит достаточно много времени на прорисовку «от руки» того, как меняются состояния узлов при взаимодействии, какой процесс отправил сообщение другому процессу и т.д. Это занимает достаточно много времени на лекциях и семинарах. Процесс обучения мог бы стать проще, если бы была возможность демонстрации работы данных в действии, с применением минимальных усилий.
Для этой цели разрабатывается проект “Parallel and Conquer” (PAC). Проект состоит из backend и frontend частей, взаимодействующих между собой. Frontend-часть отвечает за визуализацию данных для демонстрации, тестирования и дебага. Backend-часть реализует алгоритмы и тестовые сценарии для некоторых из них (на данный момент это Алгоритм пекарни Лэмпорта (LamportMutex)[3], Paxos[4], Raft). В данной работе будет описана frontend-часть проекта.
При создании инструментов, которые будут использоваться в образовательных целях, важно учитывать универсальность. Так как студенты используют разное программное обеспечение, выбор был сделан в сторону Web-приложения, как универсального решения для всех платформ.
PAC также должен был учитывать проблемы уже существующих решений и избегать их. Перед проектом ставились следующие требования:
- Простота использования
- Отсутствие зависимости от платформы
- Возможность отобразить основные алгоритмы, изучаемые в университетах, показав их особенности
- Возможность визуализации данных пользователя, вне зависимости от того, какие языки программирования ему известны
Далее будет сделан краткий обзор существующих решений в данной области, а затем будут описаны все детали использования интерфейса PAC, его техническая реализация и особенности.
Глава 1. Обзор существующих решений операций, производимые с данными
1.1. Понятие и сущность данных
Есть несколько инструментов для визуализации и тестирования, помогающих в изучении распределенных данных. Ниже приведен краткий обзор некоторых из них:
Xtango[5]— это система анимации данных общего назначения, которая помогает программистам реализовывать анимированное отображение своих собственных данных. Недостатки этой системы:
- необходимость написания программы на языке C или создание файла трассировки, который читаем драйвером C
- невозможность отображения дополнительной информации о состояниях процессов для тестирования и отладки
Polka[6]— это система анимирования, которая подходит для визуализации однопоточных и параллельных программ. Основным недостатком этой реализации является то, что она требует Motifили Xaw (набор виджетов Athena), поэтому пользователь должен приложить дополнительные усилия для использования этой системы.
“A tool for interactive visualization of distributed algorithms”[7](название проекта не указано) — это инструмент для визуализации распределенных вычислений. Он имеет ограниченный список данных, написанных на Java, но пользователь может реализовать свой собственный алгоритм, вызывая определенные методы из своего Java- кода. Требование знать определенный язык программирования может помешать некоторым студентам использовать этот инструмент визуализации, и в этом заключается недостаток данного решения.
У проекта Lydian[8]есть инструмент, разработанный, по словам авторов, для образовательных целей, который помогает в изучении распределенных данных. В проекте используется библиотека Polka для визуализации, обзор которой приведен выше. Анимация позволяет наблюдать за взаимодействием процессов, причинно-следственными связями и логическими временами. Тем не менее, в окошке приложения может быть отражена только одна компонента из всего приложения, из-за чего у пользователя нет возможности сравнивать и проводить связи между процессами, журналами, уникальным состоянием процесса и тем, как они влияют друг на друга.
Проект ViSiDiA[9]— это самый современный из перечисленных инструмент для визуализации с настраиваемым интерфейсом. Недостатки этого проекта заключаются в следующем:
- пользователь должен знать и использовать язык программирования Java
- для визуализации пользовательского проекта в код должны быть встроены методы библиотеки ViSiDiA
- загрузка проекта с официального сайта является сложной задачей из-за необходимости прямого контакта с разработчиками
Таким образом, существующие на данный момент решения имеют недостатки, которые могут быть существенны при выборе инструмента для визуализации и тестирования. “Parallel and Conquer” старается учесть проблемы описанных выше реализаций и создать простое в использовании приложение, которое будет понятно пользователю.
В отличие от операций с атрибутами, операции с данными по определению имеют размер 8 Кбайт. (Это размер блока данных, определенный NFS. Сравнительно недавно анонсированная версия протокола NFS+ допускает блоки данных размером до 4 Гбайт. Однако это существенно не меняет саму природу операций с данными). Кроме того, в то время как для каждого файла имеется только один набор атрибутов, количество блоков данных размером по 8 Кбайт в одном файле может быть большим (потенциально может достигать несколько миллионов). Для большинства типов NFS-серверов блоки данных обычно не кэшируются и, таким образом, обслуживание соответствующих запросов связано с существенным потреблением ресурсов системы. В частности, для выполнения операций с данными требуется значительно большая полоса пропускания сети: каждая операция с данными включает пересылку шести больших пакетов по Ethernet (двух по FDDI). В результате вероятность перегрузки сети представляет собой гораздо более важный фактор при рассмотрении операций с данными.
Как это ни удивительно, но в большинстве существующих систем доминируют операции с атрибутами, а не операции с данными. Если клиентская система NFS хочет использовать файл, хранящийся на удаленном файл-сервере, она выдает последовательность операций поиска (lookup) для определения размещения файла в удаленной иерархии каталогов, за которой следует операция getattr для получения маски прав доступа и других атрибутов файла; наконец, операция чтения извлекает первые 8 Кбайт данных. Для типичного файла, который находится на глубине четырех или пяти уровней подкаталогов удаленной иерархии, простое открывание файла требует пяти-шести операций NFS. Поскольку большинство файлов достаточно короткие (в среднем для большинства систем менее 16 Кбайт) для чтения всего файла требуется меньше операций, чем для его поиска и открывания. Последние исследования компании Sun обнаружили, что со времен операционной системы BSD 4.1 средний размер файла существенно увеличился от примерно 1 Кбайт до немногим более 8 Кбайт.
Для определения корректной конфигурации сервера NFS прежде всего необходимо отнести систему к одному из двух классов в соответствии с доминирующей рабочей нагрузкой для предполагаемых сервисов NFS: с интенсивными операциями над атрибутами или с интенсивными операциями над данными.
1.2. Data Warehouse (хранилище данных) и OLAP
Хранилище данных - это база данных, в которой хранится информация для поддержки принятия решений, управляемая отдельно от оперативной базы данных компании. Хранилище данных поддерживает обработку организационной информации, предлагая стабильную платформу консолидированных, транзакционных, организованных данных. С другой стороны, OLAP обозначает онлайн-аналитическую обработку, а куб - это еще одно слово для многомерного набора данных, поэтому куб OLAP - это промежуточное пространство для анализа информации. По сути, куб - это механизм, используемый для запроса данных в организованных, размерных структурах для анализа. Эти два варианта имеют разные требования к ИТ.
Хранилища данных исторически были проектом разработки, который может быть довольно дорогостоящим просто для постройки. Тем не менее, хранилища данных теперь также предлагаются в виде продукта - полностью построенного, конфигурируемого и способного вместить несколько типов данных. Некоторые решения для хранилищ данных могут управляться бизнес-пользователями. Куб OLAP не является открытым хранилищем данных SQL-сервера, поэтому для управления сервером требуется кто-то с техническими навыками и опытом работы с OLAP. Это соответствует конкретным требованиям к персоналу, но поскольку кубы OLAP используются во всем бизнес-секторе, в рабочей силе достаточно людей с навыками, необходимыми для управления кубом, - если бюджет учитывает расходы на эту должность. Хотя стоимость является важным фактором для рассмотрения, есть несколько характеристик, которые следует учитывать.
Лучшее понимание хранилищ данных и кубов OLAP чрезвычайно полезно для выбора вариантов реализации инструментов BI. Для некоторых, поскольку данные компании необходимы для такого регулярного анализа, хранение данных может очень хорошо определить путь, по которому организация пойдет для приобретения решений BI. Для других инвестиции в хранилище транзакционных данных могут быть вторичной покупкой в ответ на потребности обработки BI. В любом случае, различия важны при принятии решения о хранении данных.
Хранилище данных организовано с доступом бизнес-пользователей в центре дизайна. Это предметно-структурированный, что означает, что он организован вокруг таких тем, как продукт, продажи и клиент. Поскольку данные должны реплицироваться из планирования ресурсов предприятия (ERP), управления взаимоотношениями с клиентами (CRM) или любой другой системы организации данных, хранилища данных не используются для оперативного анализа. Вместо этого информация, хранящаяся в хранилищах данных, может использоваться для периодической отчетности; планирование, прогнозирование и моделирование; и в информационных панелях или графических оценочных карточках, где тренды и траектории данных компании могут быть визуально проанализированы. Кроме того, в хранилище могут храниться самые разные типы данных.
Хранилище данных создается таким образом, что оно может интегрировать несколько различных источников данных для создания консолидированной базы данных. Это делается с помощью методов очистки и интеграции данных, которые являются «умными» процессами, встроенными в хранилище данных. Следовательно, компания может хранить данные о персонале, финансовые операции и любую другую организационную информацию в одном месте - выходя за рамки цифр и денежных потоков. Это очень доступное хранилище, где данные реплицируются и преобразуются из операционной среды. Хранилища данных настолько эффективны с точки зрения доступности бизнес-пользователей благодаря своей структуре SQL-сервера. Однако их можно купить непосредственно уже построенными, или цена, связанная с разработкой собственного хранилища данных с течением времени программистами или другими ИТ-специалистами, может быть чрезмерной. Ценообразование хранилищ данных и проектов OLAP может стать основанием для отдельной статьи в блоге.
OLAP Cube в основном берет электронную таблицу и трехмерно анализирует опыт анализа. Разбивая его, OLAP означает аналитические данные, а не транзакционные, а кубическая часть номенклатуры относится к аспекту хранения. Кубы OLAP - это в основном многомерные базы данных. Они хранят данные для анализа, Многие продукты BI используют кубы OLAP для доступа к информации компании для отчетов, бюджетов или панелей мониторинга. Например, финансовый директор может захотеть отчитываться о финансовых данных компании по местоположению, по месяцам или по продуктам - эти элементы будут составлять измерения этого куба. Однако кубы OLAP не являются реляционными базами данных SQL-сервера, как хранилища данных.
Кубы OLAP не являются открытым хранилищем данных сервера SQL, поэтому для их обслуживания требуется кто-то, обладающий знаниями и опытом, в то время как хранилище данных сервера SQL может поддерживаться большинством ИТ-специалистов, которые регулярно проходят обучение работе с базами данных. К этому аспекту соответственно прикреплен ценник. Независимо от того, выделяете ли вы время и энергию от текущего сотрудника, чтобы сосредоточиться на управлении кубом OLAP, или ищете нового, возможно, штатного сотрудника, чтобы присоединиться к платежной ведомости для этой роли. Кроме того, OLAP-кубы имеют тенденцию быть более жесткими и ограниченными, когда речь заходит о разработке отчетов, из-за их табличных функций. Эстетика и возможности могут и, возможно, должны быть важны для компании, которая создает свой портфель решений для бизнес-аналитики.
Глава 2. Описание работы с данными
2.1 Описание работы программного приложения
Был проведен предварительный анализ большого количества классических шифров [1], из которых для модификации мы отобрали и исследовали на криптостойкость с последующей оценкой три классических алгоритма шифрования:
1. Простой числовой шифр
2. Шифр гласных букв
3. Календарный шифр
Для выполнения поставленных задач на языке программирования C# было разработано программное приложение с использованием среды программирования Visual Studio v.17 [3], общий вид которой представлен на рис. 1.
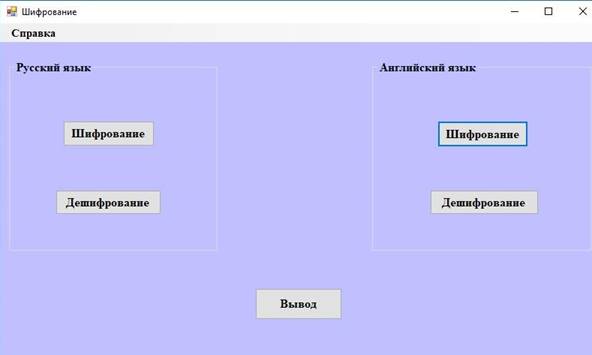
Рисунок 1. Общий вид разработанного программного приложения
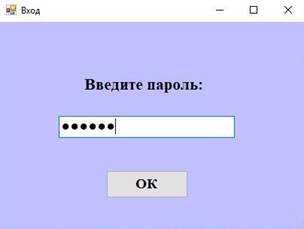
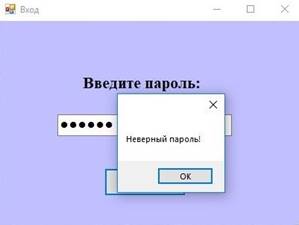
При запуске приложения возникает приветственное сообщение и пароль для ввода (Рис 2а). В случае неверно введенного пароля появляется соответствующее сообщение (Рис. 2б).
|
|
|
|
Рисунок 2а. Ввод пароля |
Рисунок 2б. Неверный пароль |
В Справке к приложению показывается сообщение о версии и функциях шифров (Рис. 3).

Рисунок 3. Информация о программе
Шифрование текстовых сообщений может осуществляться в 2-х вариантах: русском и английском.
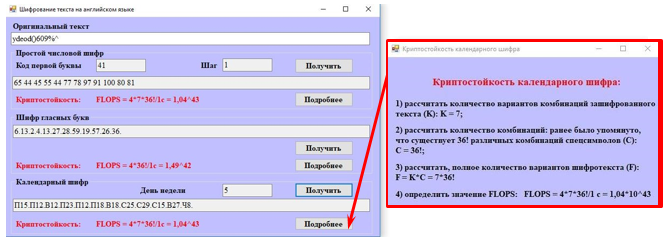
Рисунок 4а. Пример шифрования сообщения на английском языке и оценки криптостойкости
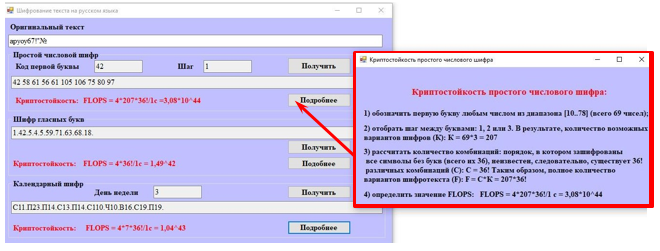
Рисунок 4б. Пример шифрования сообщения на русском языке и оценки криптостойкости
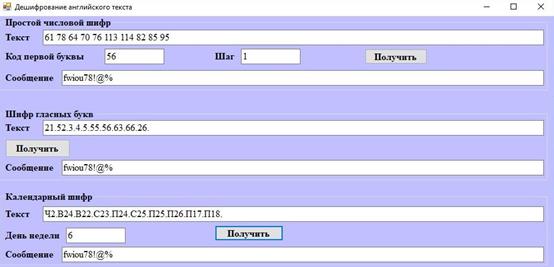
Рисунок 5а. Пример дешифрования сообщения на английском языке
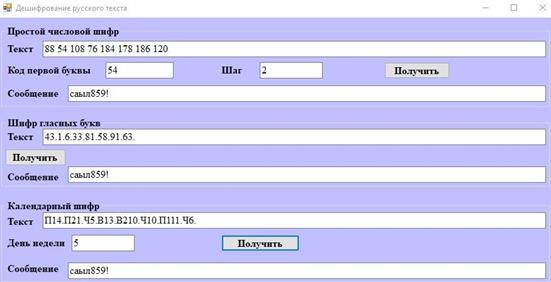
Рисунок 5б. Пример дешифрования сообщения на русском языке
Программа показывает криптостойкость шифров, сравнивая их по времени (Рис. 6).
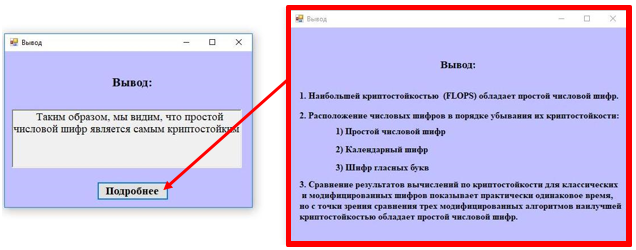
Рисунок 6. Результаты сравнения криптостойкости по показателю времени
Рассмотрим инструментарий, необходимый для демонстрации регистрации нового пользователя. Во-первых, на сайте необходимо создать соответствующую минимальному функционалу форму. Это будет обеспечено благодаря HTML. «HTML (от англ. HyperText Markup Language — «язык разметки гипертекста») — стандартный язык разметки документов во Всемирной паутине» [3]. Во-вторых, сайт следует разместить на сервере. И для этих нужд будет применена программа Denwer. Denwer — набор дистрибутивов (локальный сервер WAMP) и программная оболочка, предназначенные для создания и отладки сайтов на локальном ПК (без необходимости подключения к сети Интернет). В-третьих, для хранения информации о новых пользователях требуется наличие базы данных (БД). Так, система управления базами данных (СУБД) MySQL, администрирование которой будет обеспечено веб-приложением PhpMyAdmin, позволит структурированно хранить данные. PhpMyAdmin, в свою очередь, входит в упомянутый ранее Denwer. И, наконец, в качестве языка программирования выбран PHP — серверный скриптовый язык программирования.
Затем представим рассматриваемую в данной работе задачу регистрации нового пользователя на сайте. Отвечающий минимуму требований интерфейс содержит следующие элементы:
- поле для ввода логина;
- поле для ввода пароля;
- поле для повторного ввода пароля;
- кнопку для регистрации;
- сопроводительные уточняющие надписи (рисунок 7).
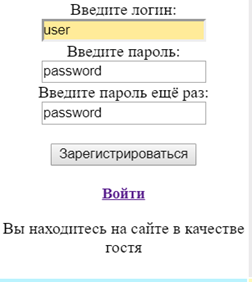
Рисунок 7. Входные данные для проведения запроса на добавление в БД
Обмен данными с сервером произойдёт благодаря коду на языке PHP, хранящемся в соответствующем документе, что запустит процесс отправки данных после нажатия на кнопку “Зарегистрироваться” (рисунок 8).
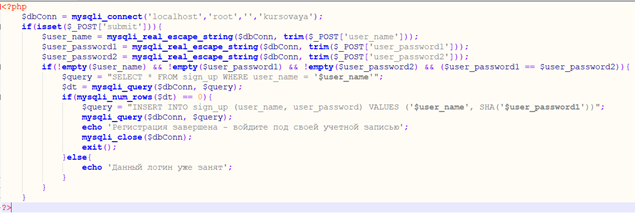
Рисунок 8. Php-фрагмент для проведения запроса на добавление в БД
Предыдущее действие даст результат проведённого запроса, показанный в программе phpMyAdmin (рисунок 9).
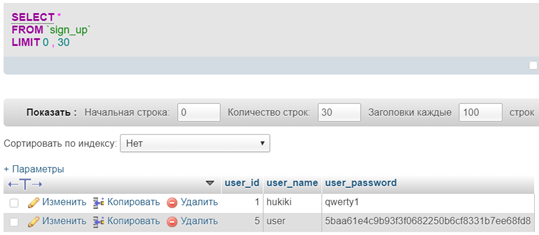
Рисунок 9. Php-фрагмент для проведения запроса на добавление в БД
Необходимо обратить внимание на различие между паролем, введённым в поле формы, и паролем, хранящимся в БД. Это вызвано тем, что любой текст, вводимый в поле ввода пароля, обрабатывается функцией SHA, являющейся в языке SQL алгоритмом хеширования. Уточним, что хеширование — процесс, в результате которого к некоторым данным генерируется новое значение, по которому невозможно «восстановить» исходные данные и которое с большой вероятностью является уникальным. В данном случае, цель применения хеширования состоит в обеспечении безопасности хранимых данных.
Как итог, на самом сайте регистрация сопровождается изменениями интерфейса, вызванными входом пользователя в свой новый аккаунт, — происходит переход к форме авторизации (рисунок 10).
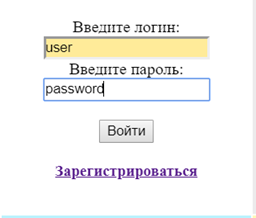
Рисунок 10. Авторизация
Таким образом, созданная с помощью PHP и MySQL система регистрации показала высокий уровень обеспечения безопасности авторизации и регистрации, что немаловажно при создании нового сайта.
2.2 Алгоритмы модификации классических числовых шифров
Модификация каждого из отобранных классических шифров заключается в расширении изначального алфавита, включающего в себя строчные и прописные буквы, некоторыми спецсимволами в кодировке ASCII.
1. Простой числовой шифр. Первую букву алфавита необходимо обозначить произвольным числом, а каждой последующей букве надо присвоить число, большее, чем предыдущее, на 1,2 или 3. Те же действия производятся и над остальными символами алфавита. Блок-схема представлена на рис.7.
2. Шифр гласных букв. При использовании такого шифра гласные буквы в алфавите нумеруются цифрами от 1 до 9. При этом, например, в русском алфавите буква А обозначается цифрой 1, буква Е – цифрой 2, буква И – цифрой 3 и так далее. Затем каждой согласной букве присваивается свой номер, который определяется ее положением относительно ближайшей к ней с левой стороны в алфавите гласной буквы. Так, например, буква Б – первая согласная буква, расположенная справа от буквы А имеющей номер 1. Поэтому букве Б присваивается число 11. Буква Д – четвертая справа от буквы А, ее обозначают числом 14. Буква Н – пятая справа от гласной буквы И, обозначенной числом 3. Поэтому букве Н должно соответствовать число 35. В соответствии с этим правилом выбираются числа, которыми будут заменены остальные буквы алфавита. Те же действия производятся и над остальными символами алфавита. Теперь достаточно в открытом тексте заменить символы соответствующими числами, записываемые через точку.
3. Календарный шифр. В этом шифре на первом шаге все символы заменяются на их порядковые номера в алфавите. Дни недели переводятся в числа месяца, а затем – в буквы открытого текста. Для расшифровки необходимо знать только месяц и год, используемые в шифре.
Далее необходимо обозначить название каждого дня недели буквой, с которой оно начинается. Понедельник – П, вторник – В, среда – С, четверг – Ч, пятница – П, суббота – С, воскресенье – В. Так как названия некоторых дней недели начинаются с одинаковых букв, для их различия можно применить цифры. Понедельник – П1, вторник – В1, среда – С1, четверг – Ч, пятница – П2, суббота – С2, воскресенье – В2 [1].
2.3. Блок-схема шифра гласных букв
На рис. 11 приведен пример блок-схемы шифра гласных букв, лежащий в основе двух других блок-схем.
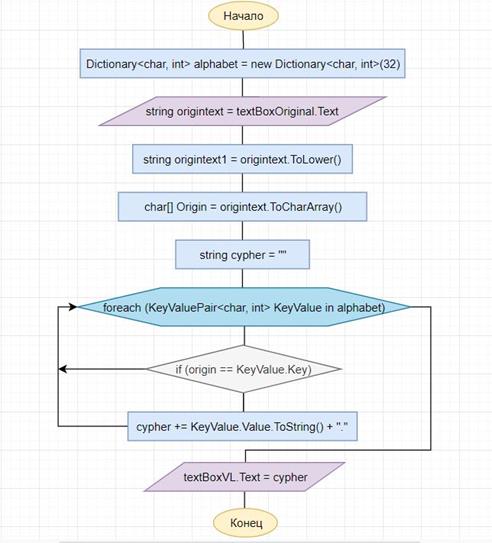
Рисунок 11. Блок-схема шифра гласных букв
2.4. Расчет криптостойкости модифицированных числовых шифров
Одним из вариантов оценки производительности выполнения алгоритма программы является определение значения FLOPS [4].
FLOPS – это количество вычислительных операций или инструкций, выполняемых над операндами с плавающей точкой в секунду. Его можно вычислить с помощью теоретически/эмпирически известного количества операций, необходимых для выполнения алгоритма, и измеренному времени:
FLOPS =4*N/t,
где: N – количество операций, необходимых для выполнения алгоритма,
t – время выполнения теста,
4 – операции с данными двойной точности выполняются одновременно над четырьмя 64-битными DP операндами в 256-битном регистре, поэтому умножаем на коэффициент 4.
Алгоритм расчета криптостойкости модифицированных числовых шифров осуществлялся согласно следующей последовательности действий.
1. Простой числовой шифр
1) обозначить первую букву любым числом из диапазона [10…78] (всего 69 чисел);
2) отобрать шаг между буквами: 1, 2 или 3. В результате, количество возможных вариантов шифров (К): К = 69*3 = 207
3) рассчитать количество комбинаций: порядок, в котором зашифрованы все символы без букв (всего их 36), неизвестен, следовательно, существует 36! различных комбинаций (C): С = 36! Таким образом, полное количество вариантов шифротекста (F): F = С*К = 207*36!
4) определить значение FLOPS: FLOPS = 4*207*36!/1 с = 3,08*10^44.
2. Шифр гласных букв
1) рассчитать количество комбинаций: для того, кто знает, как был зашифрован текст, расшифровать его не составит труда, но только его буквенную часть; поэтому порядок, в котором зашифрованы спецсимволы (всего их 36), неизвестен. Следовательно, существует 36! различных комбинаций (C): С = 36!
2) рассчитать полное количество вариантов шифротекста (F): F = С = 36!
3) определить значение FLOPS: FLOPS = 4*36!/1 с = 1,49*10^42.
3. Календарный шифр
1) рассчитать количество вариантов комбинаций зашифрованного текста (K): K = 7;
2) рассчитать количество комбинаций: ранее было упомянуто, что существует 36! различных комбинаций спецсимволов (С): С = 36!;
3) рассчитать, полное количество вариантов шифротекста (F): F = K*C = 7*36!
4) определить значение FLOPS: FLOPS = 4*7*36!/1 с = 1,04*10^43
2.5. Анализ полученных результатов
Сравнение криптостойкости классических шифров представлено в таблице 1.
Таблица 1.
Криптостойкость классических шифров
|
Шифр |
Вычисление криптостойкости |
Результат (FLOPS) |
|
1. Простой числовой шифр |
F = С*К F = 207 FLOPS = 4*207/1 с |
828 |
|
2. Шифр гласных букв |
F = С F=1 FLOPS = 4*1/1 с |
4 |
|
3. Календарный шифр |
F = С*К F = 7 FLOPS = 4*7/1 с |
28 |
Сравнение криптостойкости модифицированных числовых шифров представлено в таблице 2.
Таблица 2
Криптостойкость модифицированных шифров
|
Шифр |
Вычисление криптостойкости |
Результат (FLOPS) |
|
1. Простой числовой шифр |
F = С*К F = 207*36! FLOPS = 4*207*36!/1 с |
3,08*10^44 |
|
2. Шифр гласных букв |
F = С F=36! FLOPS = 4*36!/1 с |
1,49*10^42 |
|
3. Календарный шифр |
F = С*К F = 7*36! FLOPS = 4*7*36!/1 с |
1,04*10^43 |
При всём многообразии типов часто возникают ситуации, когда данные одного типа нужно преобразовать к другому типу.
Некоторые преобразования происходят неявно. Рассмотрим такой пример:
double a =3;
System.out.println(a);// в консоле будет отображено 3.0
Переменная типа double предусматривает хранение не только целой, но и десятичной части числа, т.е. фактически в переменную запишется значение 3.0 (три целых и ноль десятых), которое потом и выведется на экран с помощью следующей команды.
Java преобразовала целочисленное значение 3 в вещественное 3.0 самостоятельно, без явного участия разработчика. Такое преобразование (называемое также «приведение») типа данных называется неявным или автоматическим.
Оно происходит всякий раз, когда в процессе преобразования не могут потеряться какие-либо данные (т.е. когда преобразования производится к более универсальному типу: от коротких целых short к длинным целым long, от целых int к вещественным double и т.п.).
Потеря точности может происходить, когда будет предпринята попытка из вещественного числа получить целое. Это можно сделать, округлив число или взяв только его целую часть. Но дробную часть при этом придётся забыть, и, если она не была нулевой, то какие-то полезные данные могут потеряться.
Например, если мы произведём следующее присваивание, то при попытке откомпилировать программу получим ошибку «возможна потеря точности»:
int a =3.14;// ошибка possible loss of precision
Но даже если десятичная часть была бы нулевой (справа стояло бы значение 3.0), то мы получили бы ту же ошибку. То есть Java не занимается анализом самого значения, а обращает внимание только на его тип.
Явное преобразование
Тем не менее, преобразовать вещественное значение к целому можно, явно сообщив в программе о своём намерении. Для этого слева от исходного элемента надо в круглых скобках указать название типа, к которому его нужно привести.
int a =(int)3.14;// приведение типа
System.out.println(a);// выведет в консоль 3
Такое преобразование с указанием целевого типа называется явным. Явное преобразование вещественного значения к целому типу происходит за счёт отбрасывания десятичной части (берётся только целая часть).
double b =2.6;
int c =(int)(0.5+ b);// можно применять
// к целым выражениям
System.out.println(c);// выведет 3
System.out.println((int)9.69);// выведет 9
System.out.println((int)'A');// выведет 65 — кодсимвола«A»
System.out.println((double)3);// выведет 3.0
Явное преобразование может потребоваться также в тех случаях, когда значение типа, позволяющего хранить большее количество знаков надо привести к типу, способному хранить меньшее количество знаков числа. Например, когда long надо преобразовать к short. О том, как происходят такие преобразования, будет рассказано далее при обсуждении принципов хранения данных в памяти компьютера.
Заключение
В ходе информационного процесса данные преобразуются из одного вида в другой с помощью различных методов. Обработка данных включает в себя множество операций. По мере развития научно-технического прогресса и общего усложнения связей в человеческом обществе возрастают неуклонно трудозатраты на обработку данных. Прежде всего, это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общее увеличение объемов, обрабатываемых данных, связан с научно-техническим прогрессом, а именно с быстрыми темпами появления и внедрения новых носителей данных, средств их хранения и доставки.
В структуре возможных операций с данными можно выделить следующие:
• сбор - накопление информации с целью обеспечения достаточной полноты для принятия решений;
• формализация - приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сопоставимыми между собой, то есть повысить их уровень доступности;
• фильтрация - отсеивание «лишних» данных, в которых нет необходимости для принятия решений; при этом должен уменьшаться уровень «шума», а достоверность и адекватность данных должны возрастать;
• сортировка - упорядочение данных по заданному признаку с целью удобства использования; эта процедура повышает доступность информации;
• архивация - организация хранения данных в удобной и легкодоступной форме; служит для снижения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
• защита - комплекс мер, направленных на предотвращение утраты, воспроизведения и модификации данных;
• транспортировка - прием и передача (доставка и поставка) данных между удаленными участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя - клиентом;
• преобразование данных - перевод данных из одной формы в другую или из одной структуры в другую. Преобразование данных часто связано с изменением типа носителя, например, книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку. Необходимость в многократном преобразовании данных возникает также при их транспортировке, особенно если она осуществляется средствами, не предназначенными для транспортировки данного вида данных. В качестве примера можно упомянуть, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые изначально были ориентированы только на передачу аналоговых сигналов в узком диапазоне частот) необходимо преобразование цифровых данных в некое подобие звуковых сигналов, чем и занимаются специальные устройства - телефонные модемы.
Список использованной литературы
x
- x
- Когаловский М.Р. Глоссарий по стандартам платформы XML. Версия 7 (17-12-2006). // Электронные библиотеки. – М.: ИРИО, 2006.
- The World Wide Web Consortium (W3C). XQuery 1.0: An XML Query Language : W3C Recommendation / Boag S. et al. (eds.). – 2007, 23 Jan.
- The World Wide Web Consortium (W3C). XQuery Update Facility 1.0 : W3C Working Draft / Chamberlin D. et al. (eds.). – 2007, 28 Aug.
- Лизоркин Д.А., Лисовский К.Ю. SXML: XML-документ как S-выражение // Электронные библиотеки. – М.: ИРИО, 2003. – Т. 6, вып. 2. – ISSN 1562-5419 = Russian digital libraries journal.
- The World Wide Web Consortium (W3C). XML Information Set : W3C recommendation / Cowan J., Tobin R. (eds.). – 2nd edition. – 2004, 4 Feb.
- Kiselyov O. SXML specification / Rev. 3.0. – ACM SIGPLAN Notices. – New York: ACM Press, 2002. – Vol. 37, N 6. – pp. 52-58. – ISSN 0362-1340.
- Kiselyov O. A better XML parser through functional programming : Proc. Practical Aspects of Declarative Languages: 4th int. symposium, PADL'2002, Portland, 19-20 Jan., 2002 // Lecture Notes in Computer Science / Krishnamurthi S., Ramakrishnan C.R. (eds.). – Springer-Verlag Heidelberg, 2002. – Vol. 2257. – pp. 209-224. – ISSN: 0302-9743.
- Лизоркин Д.А. Оптимизация вычисления обратных осей языка XML Path при его реализации функциональными методами // Сборник трудов Института системного программирования РАН / Под ред. чл.-корр. РАН Иванникова В.П. – М.: ИСП РАН, 2004. – Т. 8, ч. 2. – 214 c. – с. 93-119. – ISBN 5-89823-026-2.
- Abelson H., Sussman G.J., Sussman J. Structure and Interpretation of Computer Programs. – 2nd ed. – London; New York: The MIT Press; McGraw Hill, 1996. – 657 pp. – ISBN 0-262-01153-0.
- Boehm H.-J. Space efficient conservative garbage collection : Proc. conf. on Programming Language Design and Implementation (SIGPLAN'93), Albuquerque, NM, Jun. 1993 // ACM SIGPLAN Notices. – New York: ACM Press, 1993. – Vol. 28(6). – pp. 197-206; New York: ACM Press, 2004. – Vol. 39, issue 4. – pp. 490-501. – ISSN 0362-1340.
- Lehti P. Design and Implementation of a Data Manipulation Processor for a XML Query Language : Ph.D. thesis. – 2001, Aug.
- Консорциум W3C. Язык XML Path (XPath) версия 1.0 = XML Path Language (XPath) Version 1.0 : Рекомендация Консорциума W3C / Под ред. Clark J., DeRose S.; пер. с англ. Усманов Р. – 1999, 16 ноя.
- S. S. Chawathe, A. Rajaraman, H. Garcia-Molina and J. Widom. Change Detection in Hierarchically Structured Information. Technical report; detailed version of paper appearing in SIGMOD 1996.
- Igor Tatarinov, Zachary G. Ives, Alon Y. Halevy, Daniel S. Weld. Updating XML : Proc. ACM SIGMOD int. conf. on Management of Data (SIGMOD'01), Santa Barbara, California, 21-24 May, 2001 // SIGMOD Conference / Aref W.G. (ed.). – New York: ACM Press, 2001. – pp. 413-424. – ISBN 1-58113-332-4.
- Лизоркин Д.А., Лисовский К.Ю. Язык XML Path (XPath) и его функциональная реализация SXPath // Электронные библиотеки. – М.: ИРИО, 2003. – Т. 6, вып. 4. – ISSN 1562-5419 = Russian digital libraries journal.
- A. Laux, L. Martin. XUpdate update language : XML:DB Working Draft. – 14 Sep, 2000.
- Лизоркин Д.А., Лисовский К.Ю. Реализация XLink – языка ссылок XML – с помощью функциональных методов // Программирование. – М.: Наука, 2005. – N 1. – С. 52-72. – ISSN 0361-7688 = Programming and computer software.
- Лизоркин Д.А. Язык запросов к совокупности XML-документов, соединенных при помощи ссылок языка XLink // Сборник трудов Института системного программирования РАН / Под ред. чл.-корр. РАН Иванникова В.П. – М.: ИСП РАН, 2004. – Т. 8, ч. 2. – 214 c. – с. 121-153. – ISBN 5-89823-026-2; Программирование. – М.: Наука, 2005. – N 3. – ISSN 0361-7688 = Programming and computer software.
- The World Wide Web Consortium (W3C). Extensible Markup Language (XML) 1.0 (Fourth Edition) : W3C Recommendation / Bray T. et al. (eds.). – 2006, 16 Aug.
- Лизоркин Д.А., Лисовский К.Ю. Пространства имен в XML и SXML // Электронные библиотеки. – М.: ИРИО, 2003. – Т. 6, вып. 3. – ISSN 1562-5419 = Russian digital libraries journal.
- Лизоркин Д.А. Функциональные методы обработки XML-данных / Ph.D. thesis = Диссертация на соискание ученой степени кандидата физико-математических наук по специальности 05.13.11. – 2005, 11 ноя.
- Кузнецов С.Д. Современные технологии баз данных : Годовой курс для студентов 3-го курса. – Центр Информационных Технологий.
- Гарсиа-Молина Г., Ульман Дж.Д., Уидом Дж. Системы Баз Данных. Полный курс / Пер. с англ. Варакина С.А.; под ред. Слепцова А.В. – М,: Вильямс, 2003. – 1088 с.: ил. – ISBN 5-8459-0384-X (рус.)
- Гринев М., Кузнецов С.Д, Фомичев А. XML-СУБД Sedna: технические особенности и варианты использования // Открытые системы. – 2004, вып 8.

- Факторы, влияющие на эффективность управленческих решений (Особенности выработки оптимального управленческого решения)
- Формы государства и государственное устройство
- Функции, цели и задачи социального обеспечения
- История возникновения и развития коммерции и предпринимательства за рубежом и в России (Предпринимательство)
- Презумпции и фикции в праве (Функции и применение)
- Презумпции и фикции в праве (понятие и значение)
- Управление поведением в конфликтных ситуациях ( АО «Альфа-Банк»)
- Государственная социальная политика в сфере занятости – региональный гендерный аспект
- Психосемантика рекламы (психосемантический подход)
- Выбор стиля руководства в организации («Центр социальной поддержки населения г. Твери»)
- Исследование особенностей политики содействия конкуренции в регионе
- Роль корпоративной культуры в организации