
Мультипроцессоры
Содержание:

ВВЕДЕНИЕ
Для мультипроцессорных систем используют модульный принцип построения, позволяющий наращивать их структуру, решать проблемы надежности, а также снижать стоимость производства.
Под модулем понимают любое функциональное устройство вычислительной системы с собственным управлением, способное функционировать самостоятельно под воздействием команд процессора. Наличие однотипных модулей в вычислительных системах дает возможность переключать потоки информации при обнаружении неисправностей в модулях. В результате этого система изменяет параметры, но сохраняет работоспособность. Так модульность аппаратных средств повышает • живучесть» вычислительной системы.
Мультипроцессор — это подкласс многопроцессорных компьютерных систем, где есть несколько процессоров и одно адресное пространство, видимое для всех процессоров. В таксономии Флинна мультипроцессоры относятся к классу SM-MIMD-машин. Мультипроцессор запускает одну копию ОС с одним набором таблиц, в том числе тех, которые следят какие страницы памяти свободны. По ролям, которые играют процессоры в мультипроцессорной системе, различают: симметричные мультипроцессоры (SMP) - все процессоры играют одинаковую роль и имеют одинаковый доступ к памяти и периферии, и асимметричные мультипроцессоры (AMP) - процессоры играют разные роли или по-разному обращаются к периферийным устройствам. Технология AMP была лишь переходной в 60-х годах до того момента, когда была отработана технология SMP.
По способу адресации памяти различают несколько типов мультипроцессоров, среди которых: UMA (Uniform Memory Access), NUMA (Non Uniform Memory Access) и COMA (Cache Only Memory Access).
В связи с большой скоростью развития вычислительной техники и информационных систем в настоящее время, мультипроцессоры занимают одну из главных ролей в развитие сферы. Поэтому тема данной работы является актуальной в настоящее время.
Объект исследования – мультипроцессоры.
Предмет исследование – процесс использование мультипроцессоров в современном мире.
Цель данной работы – рассмотрение важности мультипроцессоров в современном мире.
Для достижения поставленной цели будут решены следующие задачи:
1)будет рассмотрена теоретическая сущность мультипроцессоров.
2) будут рассмотрены примеры использования мультипроцессоров в современном мире.
ГЛАВА 1. ТЕОРЕТИЧЕСКИЕ ОСНОВЫ МУЛЬТИПРОЦЕССОРОВ
1.1 Сущность и классификация мультипроцессоров
Вычислительная система (ВС) - это взаимосвязанная совокупность аппаратных средств вычислительной техники и программного обеспечения, предназначенная для обработки информации.
Иногда под ВС понимают совокупность технических средств ЭВМ, в которую входит не менее двух процессоров, связанных общностью управления и использования общесистемных ресурсов (память, периферийные устройства, программное обеспечение и т.п.).
Элементы массивно-параллельного процессора связаны между собой, поскольку их работу контролирует один блок управления. Система нескольких параллельных процессоров, разделяющих общую память, называется мультипроцессором. Поскольку каждый процессор может записывать или считывать информацию из любой части памяти, их работа должна согласовываться программным обеспечением, чтобы не допустить каких-либо пересечений.
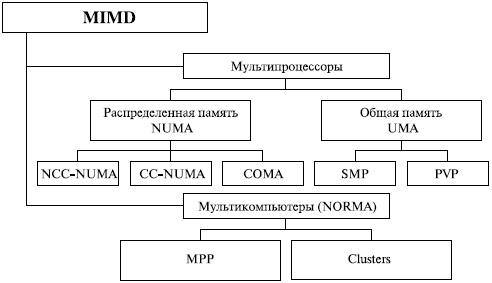
Рис. 2. Виды систем
Возможны разные способы воплощения этой идеи. Самый простой из них — наличие одной шины, соединяющей несколько процессоров и одну общую память. Схема такого мультипроцессора показана на рис. 1а. Такие системы производят многие компании.
Нетрудно понять, что при наличии большого числа быстро работающих процессоров, которые постоянно пытаются получить доступ к памяти через одну и ту же шину, будут возникать конфликты. Чтобы разрешить эту проблему и повысить производительность компьютера, были разработаны различные модели. Одна из них изображена на рис. 1б. В таком компьютере каждый процессор имеет свою собственную локальную память, которая недоступна для других процессоров. Эта память используется для программ и данных, которые не нужно разделять между несколькими процессорами. При доступе к локальной памяти главная шина не используется, и, таким образом, поток информации в этой шине снижается. Возможны и другие варианты решения проблемы (например, кэш-память).
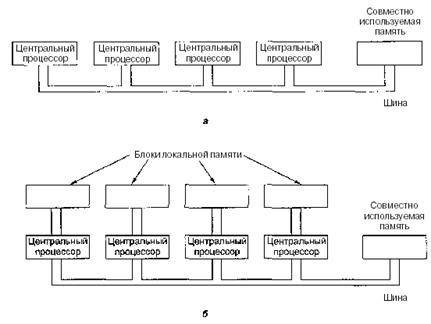
Рис. 1. Мультипроцессор с одной шиной и одной общей памятью (а); мультипроцессор,в котором для каждого процессора имеется собственная локальная память (б)
Мультипроцессоры имеют преимущество перед другими видами параллельных компьютеров, поскольку с единой разделенной памятью очень легко работать. Например, представим, что программа ищет раковые клетки на сделанном через микроскоп снимке ткани. Фотография в цифровом виде может храниться в общей памяти, при этом каждый процессор обследует какую-нибудь определенную область фотографии. Поскольку каждый процессор имеет доступ к общей памяти, обследование клетки, которая начинается в одной области и продолжается в другой, не представляет трудностей.
В мультипроцессорных системах используется несколько процессоров, каждый из которых работает под управлением своих собственных команд и которые обычно обмениваются информацией через общую память. Одним из способов классификации мультипроцессорных систем является проявляющаяся в них степень связности составных частей.
В мультипроцессорных системах, содержащих кэши данных, после чтения данных из общей памяти одним из процессоров эти данные могут быть скопированы в какой-либо из кэшей, и последующие обращения за ними могут происходить уже к кэшу, а не к общей основной памяти. Если затем другие процессоры изменяют эти данные в общей памяти, то копия, хранящаяся в кэше, становится некорректной. Этой проблемы не возникает, если кэш служит для размещения только команд, как в MC68020, но при этом теряются преимущества кэш-памяти, связанные с возможностью многократного чтения данных из буферов. Идентичность содержимого кэша и общей памяти в системе Z80000 обеспечивается за счет ограничений, накладываемых на общую память, и предотвращения считывания в кэш емкостью 1К байт каждая.
В мультипроцессорных системах часто требуется синхронизация центральных процессоров.
В настоящих мультипроцессорных системах (система HIS 645, мультипроцессорная система IBM 360 / M65) непосредственно взаимосвязанные процессоры обладают примерно одинаковой вычислительной мощностью. Ни один из них не является главным, ни один подчиненным. Некоторые устройства могут быть подсоединены к одному ЦП.
В мультипрограммных и мультипроцессорных системах управление вычислительным процессом реализуется уже сочетанием как аппаратурных, так и программных средств. Такую систему управления можно представить в виде некоторой иерархической структуры, на верхнем уровне которой располагаются программные средства управления, а на нижнем.
Как строятся мультипроцессорные системы с общей памятью.
Как строятся мультипроцессорные системы с индивидуальной памятью.
При использовании мультипроцессорных систем имеется возможность применять специальные методы повышения эффективности в тех случаях, когда лимитирующим звеном машины оказывается процессор. Когда несколько последовательностей команд выполняются параллельно, необходимы специальные средства управления, которые обеспечивали бы одновременность окончания работы во всех процессорах. Подобный метод еще мало изучен и, по-видимому, для его эффективного использования потребуется разработка новых символических языков.
Когда в мультипроцессорной системе имеется несколько часов, работа их синхронизируется таким образом, что все они изменяют свои показания с одинаковой скоростью.
В одних мультипроцессорных системах только определенные процессоры имеют доступ к устройствам ввода-вывода и, следовательно, имеют специальную функцию ввода-вывода.
Мультипроцессоры содержат многоядерные процессоры, которые имеют свои характеристики.
Многоядерный процессор — центральный процессор, содержащий два и более вычислительных ядра на одном процессорном кристалле или в одном корпусе.
Многоядерные процессоры можно подразделить по наличию поддержки когерентности кеш-памяти между ядрами. Бывают процессоры с такой поддержкой и без неё.
Способ связи между ядрами:
- разделяемая шина
- сеть (Mesh) на каналах точка-точка
- сеть с коммутатором
- общая кеш-память
Кеш-память: Во всех существующих на сегодня многоядерных процессорах кеш-памятью 1-го уровня обладает каждое ядро в отдельности, а кеш-память 2-го уровня существует в нескольких вариантах:
- разделяемая — расположена на одном кристалле с ядрами и доступна каждому из них в полном объёме. Используется в процессорах семейств Intel Core.
- индивидуальная — отдельные кеши равного объёма, интегрированные в каждое из ядер. Обмен данными из кешей 2-го уровня между ядрами осуществляется через контроллер памяти — интегрированный (Athlon 64 X2, Turion X2, Phenom) или внешний (использовался вPentium D, в дальнейшем Intel отказалась от такого подхода).
В приложениях, оптимизированных под многопоточность, наблюдается прирост производительности на многоядерном процессоре. Однако, если приложение не оптимизировано, то оно не будет получать практически никакой выгоды от дополнительных ядер, а может даже выполняться медленнее, чем на процессоре с меньшим количеством ядер, но большей тактовой частотой. Это в основном приложения, разработанные до появления многоядерных процессоров, либо приложения, в принципе не использующие многопоточность.
Согласно классификации по Флину [1] мультипроцессорные системы (МПС) относятся к классу MIMD (Multiple Instructionstream Multiple Datastream - несколько потоков команд с несколькими потоками данных). В классе MIMD имеется подкласс мультипроцессоров, который делится на три типа:
- UMA (Uniform Memory Access) - однородный доступ к памяти, когда все процессоры имеют связь со всеми модулями памяти;
- NUMA (NonUniform Memory Access) - неоднородный доступ к памяти, у каждого процессора имеется промежуточная память (например кэш);
- COMA (Cache Only Memory Access) - доступ только к кэш-памяти, любой из имеющихся процессоров содержит в своем составе локальную кэш-память большой емкости.
Подобное разбиение на подклассы весьма удобно, так как в крупных мультипроцессорных системах память часто делится на несколько модулей. Для UMA-машин, любой процессор имеет одинаковое время доступа к каждому модулю памяти. То есть, слово извлекается из памяти с той же скоростью, что и любое другое слово. Если подобный процесс невозможен, то быстрые операции замедляются, чтобы соответствовать самым медленным, что соответствует принципу - «однородный» доступ. Подобная однородность позволяет контролировать производительность, что немало важно для создания эффективных программ [2].
В NUMA-машинах, вышеописанная однородность отсутствует. Так как каждый процессор имеет модуль памяти, который размещен рядом, относительно других модулей, соответственно доступ к этому модулю памяти производится намного быстрее, чем к другим. Обращение к COMA-машинам также является неоднородным.
UMA-мультипроцессоры. Наиболее популярный вид UMA-мультипроцессоров имеют одну общую шину [3, 4]. От двух и более микропроцессоров и от одного и нескольких модулей памяти используют эту шину для обмена данными. Этот процесс выполняется следующим образом, процессору для считывания слова из памяти, необходимо проверить, что шина не занята. Если на шине не наблюдается обмен данными, процессор отправляет адрес необходимого слова на шину, устанавливает некоторые управляющие сигналы и ожидает реакцию памяти, которая выдает данные на шину по запрошенному адресу. В случае занятости шины, процессор находится в режиме ожидания до тех пор, пока шина не освободится. В данной схеме имеется существенный недостаток. Когда используется от двух до трех процессоров, контролировать доступ к шине не составляет труда, сложности появляются, при количестве процессоров 32 или 64. Производительность системы в данном варианте в основном характеризуется пропускной способностью шины, и большинство процессоров вынуждены значительное время простаивать.
NUMA-мультипроцессоры. Число процессоров в UMA-мультипроцессорах с одиночной шиной как правило ограничивается от 16 до 32, а для того чтобы использовать в одной мультипроцессорной системе более 100 процессоров, необходимо использовать другое решение. В архитектуре UMA считается, что все модули памяти организуют доступ за одинаковое время. Если изменить подобную организацию доступа, то получаем концепцию мультипроцессоров с неоднородным доступом к памяти (NonUniform Memory Access, NUMA).
Как в архитектуре UMA, мультипроцессоры NUMA имеют общее адресное пространство для каждого процессора, но с той разницей, что доступ к локальным модулям памяти выполняется быстрее, чем к удаленным [3, 4]. Соответственно, все UMA- программы будут выполняться на NUMA- машинах, но с худшей производительностью, чем на UMA-машине с аналогичной тактовой частотой. В системах NUMA есть три основные характеристики, которые позволяют различать NUMA-мультипроцессоры от иных мультипроцессоров[2]: имеется общее адресное пространство, доступное для всех процессоров; обращение к удаленной памяти выполняется командами LOAD и STORE; обращение к удаленной памяти производится медленнее, чем обращение к локальной.
Время обращения к удаленной памяти, которое не замаскировано кэшированием (нет кэш), то подобная система имеет название NC-NUMA (No Caching NUMA - NUMA без кэширования). При наличии согласованных кэш, система будет иметь назвние CC
NUMA (Coherent Cache NUMA - NUMA с согласованными кэшами). Разработчики вычислительных систем обычно называют подобную систему аппаратной распределенной общей памятью. Данный мультипроцессор включает в себя набор процессоров, где каждый имеет свою памятью, доступ к которой выполнялся по локальной шине. Также, процессоры соединены друг с другом системной шиной. При организации доступа к памяти, запрос направляется к диспетчеру памяти, который определяет, имеется ли необходимое слово в локальной памяти или нет. Если да, то запрос отправляется по локальной шине, если нет, запрос отправляется по системной шине в ту систему, в которой имеется вышеуказанное слово. Исходя из этого, для второго процесса запроса необходимо намного больше времени, чем для первого. Соответственно обработка программы, размещенной, в удаленной памяти, занимало в 10 раз больше времени, чем обработка той же программы, размещенной локально.
Так как в NC-NUMA-машине нет кэшпамяти, то непосредственно обеспечивается согласованность памяти. Если каждое слово памяти имеет возможность храниться только в одном месте, следовательно, отсутствует ситуация наличии копии с устаревшими данными.
CC-NUMA-мультипроцессоры. Один из часто используемых принципов к построению сложных мультипроцессоров, принадлежащих к системам CC-NUMA, применен в мультипроцессоре на основе каталога. Главный смысл заключается в хранении базы данных с информацией о том, где располагается каждая строка кэша и ее статус. При доступе к строке кэша в базу данных отправляется запрос о нахождении строки и является она «чистой» или «грязной» (модифицированной). Т.к. опрос базы данных необходимо выполнять при исполнении любой команды доступа к памяти, следовательно, необходимо специализированное аппаратное обеспечение для поддержки базы данных, которое может обработать запрос за доли шинного цикла.
COMA-мультипроцессоры. Исходя из того, что доступ к удаленной памяти обрабатывается намного медленнее, чем к локальной в NUMA- и CC-NUMA-машинах, необходимо иное архитектурное решение. Данным решением на сегодня является система, в которой основная память каждого процессора применяется в качестве кэшпамяти. Название этой системы COMA (Cache Only Memory Access - доступ только к кэш-памяти). В COMA-машине физическое адресное пространство разделяется на строки кэша, которые по запросу свободно передаются в системе. Для каждого блока памяти нет своей машин. Память, которая при необходимости привлекает строки, называется притягивающей. Применение основной памяти в качестве емкого кэша увеличивает процент кэш-попаданий, следовательно, и производительность. В COMA-машинах имеется два проблемных вопроса, каким образом располагаются строки кэша и что делать, когда удаляемая из памяти строка является конечной копией.
SUMA-мультипроцессоры. В одной из серии процессоров фирмы AMD применяется архитектурная организация, сочетающая преимущества UMA и NUMA систем, что дает возможность реализовывать гибкие и масштабируемые мультипроцессорные системы. В подобной системе (рисунок 3) для каждого процессорного узла встраивается контроллер памяти, также разработана специализированная шина с высокой пропускной способностью HyperTransport (HT), которая организует обмен между процессором и памятью без значительных задержек. В результате компания AMD назвала эту архитектуру SUMA (Slightly Uniform Memory Architecture - почти однородная память) [4, 5].
Главное достоинство архитектуры SUMA это последовательная межпроцессорная шина HyperTransport, для связи процессоров по типу точка-точка применяется одна часть соединений HT, другая часть необходима для связи с периферийными устройствами. Изначально AMD проектировала шину HyperTransport для архитектуры чипов типа AMD64, специализированных процессоров со встроенным контроллером памяти. Шина HyperTransport гарантирует пропускную способность сопоставимую с пропускной способностью оперативной памяти, а также наименьшие задержки при обмене данных по шине.
Контроллер памяти. Для предотвращения конфликтов на общей шине и организации эффективной работы подсистемы «процессор-память» применяют различные аппаратные решения, называемые контроллерами памяти или буферными устройствами. Во время непрерывного выполнения операции (транзакции) записи или чтения один из процессоров захватывает шину до тех пор, пока обработка транзакции не будет завершена. Следовательно, шина и процессоры переходят в режим ожидания, пока память не выполнит физические операции чтения или записи. Таким образом, циклы шины, которые могли быть обработанными другими ЦП, теряются. Чтобы повысить пропускную способность общей шины и минимизировать временные потери необходимо поддерживать для шины режимы расщепления транзакций чтения и буферизации транзакций записи. Операция физического чтения выполняется в памяти автономно под управлением контроллера памяти, по окончании операции физического чтения контроллер памяти сигнализирует запрашивающий процессор о готовности данных. В ответ процессор снова запрашивает общую шину и читает слово данных из контроллера памяти. Буферизация операций записи происходит следующим образом: процессор выставляет на общую шину адрес ячейки памяти и данные которые необходимо записать. Они записываются в регистрах контроллера памяти, после этого процессор отключается от шины, так как ответ от памяти в данном случае не нужен. Операция физической записи в память выполняется под управлением контроллера памяти.
Некоторыми из основных задач, при проектировании многопроцессорных вычислительных систем с общей шиной, являются разрешение конфликтных ситуаций во время доступа процессоров к памяти, уменьшение задержек на шине при выполнении операций обмена данными, а также масштабируемость системы. При построении МПС применяются различные методы доступа в подсистему «процессор-память». Анализ применяемых методов доступа к памяти обозначил ряд имеющихся проблем. Методы, использующие общую память, реализуются в виде архитектур типа UMA, а те системы, которые используют принцип разделения памяти, находят применения в архитектурах типа NUMA и ее модификаций. Первый метод позволяет процессорам за равный промежуток времени предоставить доступ к каждому модулю памяти. Таким образом, возможен контроль над производительностью системы, но если процессоров более трех, то возникает проблемы урегулирования доступа к общей шине. Второй метод, позволяет регулировать масштабируемость системы, но из-за неоднородности памяти, доступ к удаленной памяти намного медленнее, чем к локальной, что понижает производительность системы. Исходя из этого, могут возникать значительные задержки при обращении к памяти, простои или отказы в работе процессоров при предельных нагрузках и/или ограниченном времени ожидания. Однако, практическое решение проблем доступа в подсистему «процессор-память» является достаточно сложным и имеет неоднозначный ответ. В данной области необходимо учитывать, что в реальных системах, имеются ограничения на количество процессоров и систем коммутации в шине обмена процессора с памятью, связанную с дороговизной реализации. Задача разработки методов доступа в подсистему «процессор- память», особенно как для архитектур с общей памятью, так и с разделяемой памятью связанных со сбором, обработкой и передачей информации с многочисленных источников является чрезвычайно актуальной и важной.
1.2 Мультипроцессорные компьютеры
В мультипроцессорных компьютерах имеется несколько процессоров, каждый из которых может относительно независимо от остальных выполнять свою программу. В мультипроцессоре существует общая для всех процессоров операционная система, которая оперативно распределяет вычислительную нагрузку между процессорами. Взаимодействие между отдельными процессорами организуется наиболее простым способом - через общую оперативную память.
Сам по себе процессорный блок не является законченным компьютером и поэтому не может выполнять программы без остальных блоков мультипроцессорного компьютера - памяти и периферийных устройств. Все периферийные устройства являются для всех процессоров мультипроцессорной системы общими. Территориальную распределенность мультипроцессор не поддерживает - все его блоки располагаются в одном или нескольких близко расположенных конструктивах, как и у обычного компьютера.
Основное достоинство мультипроцессора - его высокая производительность, которая достигается за счет параллельной работы нескольких процессоров. Так как при наличии общей памяти взаимодействие процессоров происходит очень быстро, мультипроцессоры могут эффективно выполнять даже приложения с высокой степенью связи по данным.
Еще одним важным свойством мультипроцессорных систем является отказоустойчивость, то есть способность к продолжению работы при отказах некоторых элементов, например процессоров или блоков памяти. При этом производительность, естественно, снижается, но не до нуля, как в обычных системах, в которых отсутствует избыточность.
1) Принцип разомкнутого управления. Состоит в том, что программа управления жестко задана в задающем устройстве или внешним воздействием и управление не учитывает влияние возмущений на параметры процессов.
2) Принцип компенсации. Применяется для нейтрализации известных возмущающих воздействий , если они могут искажать состояние объекта управления до недопустимых пределов.
3) Принцип обратной связи. Управляющее воздействие корректируется в зависимости от выходной величины.
Виды систем управления:
1) Системы стабилизации. Обеспечивают неизменное значение управляемой величины при всех видах возмущений.
2) Программные системы. Изменение управляющего воздействия на основе заложенной программы.
3) Следящие системы. Отличаются от программных тем, что программа заранее не известна. В качестве устройства управления выступает устройство, следящее за изменением какого-либо внешнего параметра.
4) Самонастраивающиеся системы.
5) Экстремальные системы. Системы, в которых выходная величина должна всегда принимать экстремальное значение из всех возможных.
6) Адаптивные системы. Предусмотрена возможность автоматической перенастройки параметров или изменение принципиальной схемы систем управления с целью приспособления к изменяющимся внешним условиям.
В зависимости от того, в какой системе (большой, сложной, большой) происходит управления, различают системы автоматического управления и автоматизированные системы управления. Автоматическое управление осуществляется, как правило, в простых системах, в которых заранее известны описание объекта управления и алгоритм управления им.
По принципу управления системы автоматического управления могут быть разомкнутыми и замкнутыми.
Мульти компьютеры – это совокупность объединенных сетью отдельных вычислительных модулей, каждый из которых управляется собственной операционной системой. Узлы мульти компьютера не имеют общих структур кроме сети, обладают высокой степенью автономности и могут состоять из отдельных компьютеров или представлять собой различные комбинации кластеров. Для распределенной операционной системы мульти компьютер выглядит как виртуальный однопроцессорный ресурс; взаимодействие процессов реализуется с помощью явно заданных операций связи между отдельными вычислителями. Обычно в мульти компьютере реализуется согласованный сетевой протокол, и нет единой очереди выполняющихся процессов.
Кластер – это набор компьютеров, рассматриваемый операционной системой, системным программным обеспечение, программными приложениями и пользователями как единая система. Кластеры получили широкое распространение благодаря высокому уровню готовности при относительно низких затратах. Высокая готовность объясняется отсутствием совместно используемой оперативной памяти и наличием в каждом узле копий ОС. Специальной ПО производит контроль работоспособности узлов. Если какой-либо узел кластера считается вышедшим из строя, то его ресурсы и программы переназначаются на другие узлы.
Два типичных способа организации кластеров – это архитектура с разделяемыми дисками и архитектура без разделяемых дисков.
Симметричные мультипроцессоры . SMP системы состоят из нескольких десятков процессоров, разделяющих общую основную (оперативную) память и объединенных общей коммуникационной системой.
Каждый процессор имеет доступ ко всей основной памяти, может прерывать другие процессоры и выполнять операции ввода/вывода. Пропускная способность коммуникационной системы достаточна для поддержания быстрого доступа к памяти. У отдельных процессоров имеется один или несколько уровней собственной кэш памяти. При этом возникает проблема сохранения когерентности данных, то есть согласованных изменений содержимого КЭШей и общей памяти.
Когда предотвращается использование копий данных в КЭШе какого-либо процессора, если они подверглись модификации в другом процессоре. Следовательно, если модифицируется одна из копий данных, остальные копии должны либо также модифицироваться, либо объявляться недостоверными.
Достаточный объем КЭШа и сравнительно небольшое количество процессоров в SMP системах позволяет удовлетворить обращение к основной памяти, поступающих от нескольких процессоров. Так, что время доступа к общей памяти примерно одинаково для всех процессоров. Это объясняет еще одно название таких архитектур UMA (Uniform Memory Access). Передача данных в таких системах между КЭШами разных процессоров выполняется значительно быстрее, чем обмен данными между узлами кластера или мультикомпьютера.
Поэтому SMP архитектуры хорошо масштабируются с целью увеличения производительности и обработки большого числа коротких транзакций, свойственных банковским приложениям.
Сохранение когерентности требует специальных аппаратных средств быстрой модификации копий данных. Если при этом следовать модели строгой согласованности, когда каждая операция возвращает последнее записанное значение, то снижение производительности системы неизбежно. Невысокая степень готовности SMP систем объясняется сильной связанностью процессоров и наличием одной операционной системы, разделяемой всеми процессорами.
1.3 Основы мультитредовой архитектуры
При всем различии подходов к созданию мультитредовых микропроцессоров, общим для них является введение множества устройств выборки команд, каждое из которых организует окно исполнения для одного треда. В рамках одного треда выполняется предсказание переходов, переименование регистров, динамическая подготовка команд к исполнению. Тем самым, общее число команд, находящихся в обработке, значительно превышает размер окна исполнения однотредового процессора, с одной стороны, и тактовая частота не лимитируется размером окна исполнения, с другой стороны.
Выявление тредов может выполняться компилятором при анализе исходного кода на языке высокого уровня или исполняемого кода программы. Однако компиляторы не всегда могут разрешить проблемы зависимостей при использовании регистров и ячеек памяти между тредами, что требуется уже в ходе исполнения тредов. Для этого в микропроцессор вводится специальная аппаратура условного исполнения тредов, предусматривающая возврат с отбрасыванием наработанных результатов при обнаружении нарушения зависимостей между тредами. Нарушением зависимости, например, может служить запись по вычисляемому адресу в одном треде в ту же ячейку памяти, из которой выполняется чтение, которое должно следовать за этой записью, в другом треде. В случае, если адреса записи и чтения не совпадают, нарушение отсутствует. При совпадении адресов фиксируется нарушение, которое должно вернуть исполнение треда к команде чтения правильного значения.
Интерфейс между аппаратурой мультитредового процессора, поддерживающей протекание каждого отдельного треда и аппаратурой, общей для исполнения всех тредов, может быть установлен как сразу после устройств выборки команд тредов, так и на уровне доступа к разделяемой памяти. В первом случае все треды используют один регистровый файл и один набор функциональных устройств. Тесная связь по ресурсам позволяет эффективно исполнять последовательные программы с сильной зависимостью между тредами. В этом случае имеет место именно реализация мультискалярного мультитредового процессора[1].
ГЛАВА 2. ВИДЫ МУЛЬТИПРОЦЕССОРНЫХ СИСТЕМ
2.1 Мультипроцессорные системы общего назначения
В мультипроцессорных системах (МПС) имеется несколько процессоров, каждый из которых может относительно независимо от остальных выполнять свою программу. В МПС существует общая для всех процессоров операционная система, которая оперативно распределяет вычислительную нагрузку между процессорами. Важным свойством МПС является отказоустойчивость, то есть способность к продолжению работы при отказах некоторых элементов, например процессоров или блоков памяти. При этом производительность, естественно, снижается, но не до нуля, как в обычных системах, в которых отсутствует избыточность[2].
Любая вычислительная система достигает своей наивысшей производительности благодаря использованию высокоскоростных процессорных элементов (ПЭ) и параллельному выполнению большого числа операций[3].
UMA состоит из n процессоров, k модулей памяти и коммуникационной сети, связывающей процессоры и память. Сеть может стать причиной значительной задержки при обращении процессора к памяти. Система, в которой такая задержка одинакова для всех операций доступа к памяти, называется мультипроцессорной системой с однородным доступом к общей памяти (Uniform Memory Access, UMA) или системой с общей памятью. Поскольку процессоры выполняют команды с огромной скоростью, слишком большие задержки на выборку из памяти команд и данных для них не приемлемы. Однако коммуникационные сети с малым временем задержки имеют очень сложную структуру и высокую стоимость.
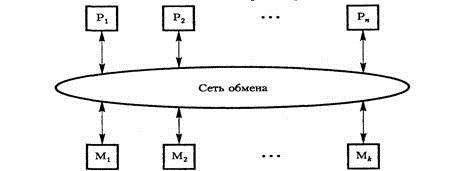
Рис. 2. Мультипроцессорная система типа UMA
NUMA каждый процессор имеет доступ не только к собственной локальной памяти, но и к памяти других процессоров сети. Но поскольку при обращении к памяти других процессоров запросы проходят через сеть, они выполняются дольше, чем обращения к локальной памяти. Системы этого типа называются мультипроцессорными системами с неоднородным доступом к памяти (Non-Uniform Memory Access, NUMA).
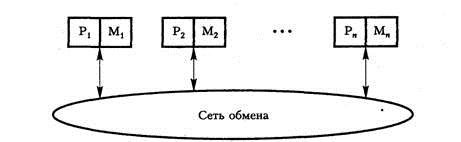
Рис. 3. Мультипроцессорная система типа NUMA
Ни один из процессоров не может обратиться к удаленной памяти без взаимодействия с удаленным процессором, которому она принадлежит
Взаимодействие между этими двумя процессорами осуществляется в форме обмена сообщениями. Системы такого типа называются системами с распределенной памятью и высокоскоростным протоколом передачи сообщений.
CC-NUMA (cache coherent NUMA) - система с кэш-когерентным доступом к неоднородной памяти. В отличие от классической архитектуры NUMA, при использовании кэш-когерентного доступа к неоднородной памяти все процессоры объединены в один узел, причем первый уровень иерархии памяти образует кэш-память процессоров. Архитектура ccNUMA поддерживает когерентность кэш памяти внутри узла аппаратно. Аппаратная когерентность кэш-памяти означает, что не требуется никакого программного обеспечения для поддержки актуальности множества копий данных.
В системе сс-NUMA физически распределенная память объединяется, как в любой другой SMP-архитектуре, в единый массив. Не происходит никакого копирования страниц или данных между ячейками памяти. Нет никакой программно-реализованной передачи сообщений. Существует просто одна карта памяти, с частями, физически связанными медным кабелем, и очень умные (в большей степени, чем объединительная плата) аппаратные средства. Аппаратно-реализованная кэш-когерентность означает, что не требуется какого-либо программного обеспечения для сохранения множества копий обновленных данных или для передачи их между множеством экземпляров операционной системы и приложений. Со всем этим справляется аппаратный уровень точно так же, как в любом SMP-узле, с одной копией операционной системы и несколькими процессорами.
При использовании большого числа кэшей возникает та же проблема что и в архитектуре UMA: необходимо поддерживать актуальность кэшированных данных. Практически это означает, что изменение любой ячейки памяти, копия которой находится в некотором кэше, должно быть повторено для всех её копий. Учитывая, что число копий может быть велико, это становится сложной технической задачей[4].
2.2 Практическое применение многопроцессорных систем
С появлением доступных многопроцессорных систем возник у пользователей: как использовать мощность компьютерной техники. При использовании обыкновенного программного обеспечения количество процессоров системы в основном простаивает.
Практическим примером может служить, например преобразование музыкальных файлов flac → ogg. Можно, например использовать консольный запрос:
for i in *.flac ; do oggenc --quality=10 "$i" ; done
Но при большом количестве файлов простаивающие процессоры слегка вызывают раздражение. Для того, чтобы оценить мощность производительной техники нужно параллельное программное обеспечение.
Предлагается использовать хорошую программу на языке Lisp2D, которая запускает параллельно конвертацию файлов, заключённых в директориях. Количество одновременно запущенных задач будет всегда равно количеству процессоров.
(('freemans defclass) defvar
n signal lock nwaitsignal)
('freemans defmethod freemans ()
(nil setq
n (nil nprocs)
signal ('signal newobject)
lock ('lock newobject)
nwaitsignal (0 copy)))
('freemans defmethod enter ()
(lock progn
(nil when (n = 0)
(nwaitsignal += 1)
(signal wait lock))
(n -= 1)))
('freemans defmethod exit ()
(lock progn
(n += 1)
(nil when (nwaitsignal > 0)
(nwaitsignal -= 1)
(signal send))))
('string defmethod flactoogg (q freemans)
(nil let (s (d ('dir newobject this)))
(nil while ('s set (d read))
(nil let ((fullname (this + "/" s)))
(nil cond
((s = "."))
((s = ".."))
((fullname regp) ; is a file
(nil let ((ss (s size)))
(nil if (ss > 5)
(nil when (((s part (ss - 5)) lower) = ".flac")
(freemans enter)
(nil fork
(nil if (0 = ("oggenc" system ("--quality=" + q) fullname))
(fullname unlink)
(cerr writeln "crash oggenc for " fullname))
(freemans exit))))))
((fullname dirp) ; is dir
(fullname flactoogg q freemans)))))
(d close)))
("." flactoogg (arg first) ('freemans newobject))
Результатом использования параллельно запущенных процессов станет полноценная загрузка процессоров полезной работой. И огромная экономия личного времени.
ЗАКЛЮЧЕНИЕ
Несмотря на то, что сегодня известно множество способов повышения производительности микропроцессоров с суперскалярной архитектурой, имеется также ряд препятствий и ограничений, исключающих возможность дальнейшего наращивания быстродействия. В данной главе показаны способы повышения производительности суперскалярных микропроцессоров на примере архитектур Alpha 21364 и Power4. Разбираются вопросы перехода к принципиально новой, так называемой мультитредовой архитектуре, позволяющей существенно изменить возможности нынешних микропроцессоров.
История развития микропроцессоров в полной мере подчиняется диалектике эволюционного усовершенствования архитектуры. Начиная от машины ENIAC, содержавшей 19 тыс. ламп, производительность компьютеров росла на порядок каждые пять лет. Большое число транзисторов на современном кристалле делает возможным применить в одном микропроцессоре все известные способы повышения производительности, сообразуясь только с их совместимостью. Однако для полного использования возможностей аппаратуры уже недостаточно ограничиться только аппаратно реализованными алгоритмами управления, достаточно единообразно функционирующими во всех ситуациях. Поэтому при реализации усложненной логики управления используется программное обеспечение, для поддержки которого вводятся дополнительные команды и регистры управления микропроцессора. В свою очередь, формирование программ для потактного управления микропроцессором под силу только компилятору. Таким образом, в современных микропроцессорах возник симбиоз программных и аппаратных средств. Этот симбиоз представляет собой нечто большее, нежели эволюционный ход развития, а смену самого направления развития микропроцессоров, выражающуюся в переходе к мультитредовым и многопроцессорным архитектурам.
С позиции реализации такого симбиоза открываются следующие способы повышения производительности:
1) увеличение емкости памяти внутри кристалла;
2) увеличение количества арифметико-логических устройств;
3) введение блоков обработки мультимедийных данных, ранее использовавшихся, например, в сигнальных микропроцессорах;
4) интеграция на кристалле функций управления памятью и периферийными устройствами, для исполнения которых в традиционных микропроцессорах используются наборы микросхем («чипсеты»);
5) интеграция на кристалле интерфейсов сетевых и телекоммуникационных систем, что позволяет соединять эти микропроцессоры друг с другом и телекоммуникационными и вычислительными сетями без дополнительных адаптеров.
Принципы универсальных машинных вычислений (по фон Нейману) легли в основу компьютеров первых поколений. На их основе работает и большая часть нынешних компьютеров. Но эти аксиомы существенно ограничивают способы реализации машинного счета. Они диктуют последовательную (команда за командой) реализацию. Такое ограничение сильно сужает разнообразие архитектурных решений и лишает их перспектив к наращиванию производительности за счет увеличения числа одновременно работающих над одной задачей процессоров.
Искусство творения компьютеров имеет свои вершины мастерства. Многопроцессорные высокопараллельные архитектуры, выходя за пределы юрисдикции классической модели последовательного счета, требуют от создателей нестандартного, многомерного, но очень здравого мышления. (Здесь мысли могут взлетать очень высоко, чтобы затем разбиться о жесткие реалии.) В этой запредельной, рекордной области компьютеростроения архитектурных тайн и сегодня остается значительно больше, чем найдено решений. И тем ценнее достижения, прошедшие проверку практикой. Через положительный опыт открывается путь к новейшим многокомпонентным архитектурам, способным к полному погружению в микромир новых СБИС-технологий и обладающим за счет этого огромным вычислительным потенциалом.
СПИСОК ЛИТЕРАТУРЫ
- Бирюков А. Я., Голован Н. И., Медведев И. Л., Набатов А. С., Фищенко Е. А. Решающие поля многопроцессорных вычислительных систем. В кн.: Многопроцессорные вычислительные системы с общим потоком команд. М., ИПУ, 2016. - с. 22-32.
- Затуливетер Ю. С., Медведев И. Л. О групповом параллелизме и двойственной реализации параллельных вычислений. В кн.: вопросы кибернетики. Вып. 48. Вычислительные машины и системы с перестраиваемой структурой. М., Н. С. по комплексной проблеме "Кибернетика" АН СССР, 2016. - с. 44-63.
- Медведев И. Л. Принципы построения многопроцессорных вычислительных систем с общим потоком команд. В кн.: Многопроцессорные вычислительные системы с общим потоком команд. М., ИПУ, 2014. - с. 5-21.
- Медведев И. Л. Проектирование ядра структуры параллельных процессоров. М., Институт проблем управления, 2012. - 60 с.
- Медведев И. Л., Фищенко Е. А. Об одном способе описания программно-доступных средств параллельного процессора. В кн.: Вопросы кибернетики. Вып. 92. М., НС по комплексной проблеме "Кибернетика" АН СССР, 2012. - с. 43-67.
- Фищенко Е. А . Выбор системы команд для многопроцессорной вычислительной системы с общим потоком команд. В кн.: Многопроцессорные вычислительные системы с общим потоком команд. М., ИПУ, 2013. - с. 33-39.
- Экспедиционные геофизические комплексы на базе многопроцессорной ЭВМ ПС-2000. / В. А. Трапезников, И. В. Прангишвили, А. А. Новохатный, В. В. Резанов. - Приборы и системы управления, 2011. - с. 29-31.
- Прангишвили И. В., Виленкин С. Я., Медведев И. Л. Многопроцессорные вычислительные системы с общим управлением. - М., Энергоатомиздат, 2013. - 312 с.
- Фищенко Е. А. Принципы построения мнемокода многопроцессорных вычислительных систем с общим управлением. В сб.: Всесоюзное научно-техническое совещание "Проблемы создания и использования высокопроизводительных машин". М., ИПУ, 2012. - с.108-110.
-
Затуливетер Ю. С., Медведев И. Л. О групповом параллелизме и двойственной реализации параллельных вычислений. В кн.: вопросы кибернетики. Вып. 48. Вычислительные машины и системы с перестраиваемой структурой. М., Н. С. по комплексной проблеме "Кибернетика" АН СССР, 2016. - с. 44-63. ↑
-
Медведев И. Л. Принципы построения многопроцессорных вычислительных систем с общим потоком команд. В кн.: Многопроцессорные вычислительные системы с общим потоком команд. М., ИПУ, 2014. - с. 5-21. ↑
-
Фищенко Е. А. Принципы построения мнемокода многопроцессорных вычислительных систем с общим управлением. В сб.: Всесоюзное научно-техническое совещание "Проблемы создания и использования высокопроизводительных машин". М., ИПУ, 2012. - с.108-110. ↑
-
Затуливетер Ю. С., Медведев И. Л. О групповом параллелизме и двойственной реализации параллельных вычислений. В кн.: вопросы кибернетики. Вып. 48. Вычислительные машины и системы с перестраиваемой структурой. М., Н. С. по комплексной проблеме "Кибернетика" АН СССР, 2016. - с. 44-63. ↑

- Анализ и оценка средств реализации структурных методов и проектирования экономической информационной системы
- Устройство персонального компьютера
- Предмет и метод правового регулирования предпринимательского права
- Ценные бумаги: понятие, виды, общие положения о правовом режиме (Гражданско-правовая характеристика ценных бумаг)
- Статус нотариуса (Публично-правовой статус нотариуса Российской Федерации)
- Особенности политики мотивации персонала малых предприятий
- Теория менеджмента (Задачи и цели)
- Проектирование организации(Теоретические основы организационного проектирования)
- Выбор стиля руководства организаций
- Управление миграционными процессами
- Ручной этап развития средств вычислительной техники
- Разработка регламента выполнения процесса «ТРАНСПОРТНАЯ ДОСТАВКА ЗАКАЗОВ»