
Методы кодирования данных (Кодирование информации. История, понятие и виды)
Содержание:

ВВЕДЕНИЕ
С каждым днем процессы в жизни современного общества становятся все более автоматизированными – современный пользователь может в момент получить необходимую информацию, осуществить сложные вычислительные операции, общаться с другими людьми, которые находятся на другом конце света. Словом, делать то, что раньше было невозможным и даже немыслимым. Подобная автоматизация реализуется благодаря множеству различных процессов, выполняемых современными электронно–вычислительными машинами.
Получение и эффективная обработка данных есть неотделимое от жизни явление, ведь от этого зависит любое живое существо. От простейших до высших млекопитающих – любое животное воспринимает данные из окружающей среды, обрабатывает их и благодаря этому благостно существует в природе. Кроме того, любое живое существо представляет собой носитель определенного набора генетической информации, которая потом передастся потомкам. Генетические данные определяют строение, здоровье, внутренний и внешний вид и развитие живого существа, которому принадлежат.
Если говорить в частности о человеке, то людьми окружающая действительность воспринимается посредством органов чувств, после чего она обрабатывается мозгом и предоставляет субъективную информацию об объективной реальности. Иначе говоря – человек формирует, а после и живет в мире информации.
И сегодня, чем дальше развивается человечество, тем более изощренные способы и методы ее обработки появляются. Это, в некоторой степени связано и с тем, что потоки информации огромны и всеобъемлющи, и одной из наиболее зависимых сфер является экономическая сфера. Так, в зависимости от скорости обработки информации, та или иная организация может быть более или менее конкурентоспособной на своем рынке. И правда, сегодня сложно представить современную организацию без автоматизированной системы обработки информации. А информацию необходимо обрабатывать корректно и сделать это таким образом, чтобы был сохранен баланс компьютер–человек.
Современный компьютер предоставляет множество возможностей по оперативной обработке данных, и осуществляется она посредством применения особых методов кодирования информации, которые развивались и менялись на протяжении продолжительного времени. Сегодня известны определенные методы кодирования данных, которые применяются для кодировки различных типов информации – текстовой, графической и звуковой.
Для того чтобы подробнее разобраться в вопросе, необходимо достичь цели исследования – изучить методы кодирования данных.
Для достижения данной цели необходимо выполнить следующие задачи:
- проанализировать историю кодирования данных;
- рассмотреть понятие и виды кодирования данных;
- охарактеризовать методы кодирования данных:
- NRZ;
- NRZI;
- RZ;
- AMI;
- HDB3;
- PE;
- подвести итоги выполнения работы.
Объектом исследования является кодирование данных, а предметом – методы кодирования данных.
Структура работы включает две главы – два и четыре параграфа соответственно, а также введение, заключение и список использованной литературы.
1. Кодирование информации. История, понятие и виды
История кодирования данных
С глубокой древности люди искали эффективные способы передачи информации:
Движение факелов использовал древнегреческий историк Полибий (II в. до н.э.).
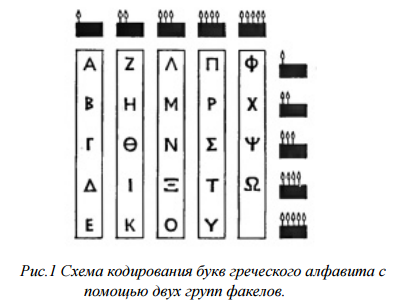
Рисунок 1 – Схема кодирования букв греческого алфавита с помощью двух групп факелов
Оптический телеграф – семафор – впервые использовал Клод Шапп в 1791 г..
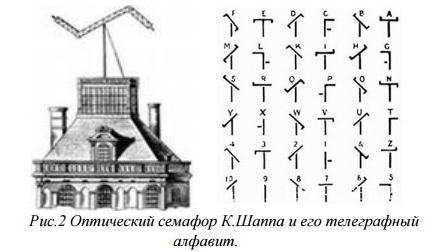
Рисунок 2 – Оптический семафор К. Шаппа и его телеграфный алфавит
Движение электромагнитной стрелки в электромагнитных телеграфных аппаратах впервые применили русский физик П.Л. Шиллинг (1832) и профессора Гёттингенского университета Вебер и Гаусс (1833).
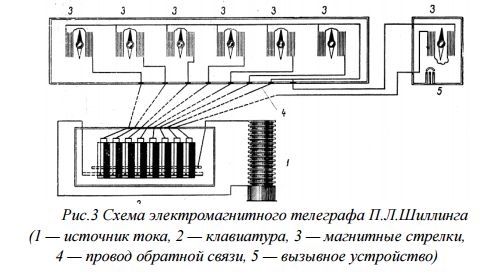
Рисунок 3 – Схема электромагнитного телеграфа П. Л. Шиллинга
Азбука и телеграфный аппарат Самюэла Морзе (1837).
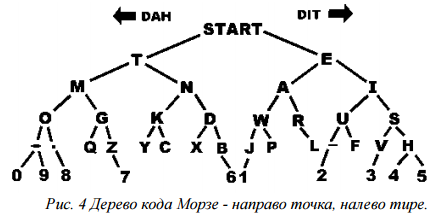
Рисунок 4 – Дерево кода Морзе
Международный флажковый код для передачи информации оптическими сигналами впервые ввел капитан Фредерик Марьят в 1861 г. на основе свода корабельных сигналов [2].

Рисунок 5 – Морская азбука сигнальных флажков
Беспроволочный телеграф (радиопередатчик) был изобретен А. С.Поповым в 1895 г. И Маркони в 1897 г. независимо друг от друга.
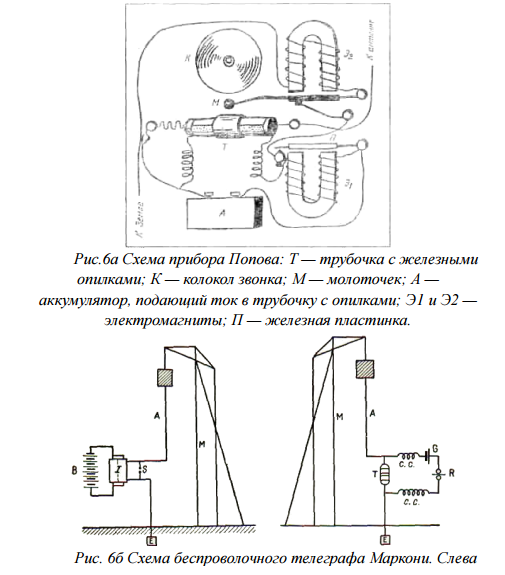
Рисунок 6 – Схема прибора Попова
Беспроволочный телефон, телевидение (1935), затем и ЭВМ – новые средства связи, появившиеся в XX в., с которыми связана новая эпоха в информатизации общества [2].
Одновременно с потребностью передавать информацию люди искали способы скрыть смысл передаваемых сообщений от посторонних любопытных глаз. Императоры, торговцы, политики и шпионы искали способы шифрования своих посланий. Образцы тайнописи можно встретить еще у Геродота (V в. до н. э.). К тайнописи – криптографии прибегал Гай Юлий Цезарь, заменяя в своих тайных записях одни буквы другими. Использовали шифрование не только древнегреческие жрецы, но и ученые Средневековья: математики итальянец Джероламо Кардано и француз Франсуа Виет, нидерландский гуманист, историк, юрист Гроций, выдающийся английский философ Фрэнсис Бэкон. Отцом криптографии считается архитектор Леон Баттиста Альберти (1404–1472), который ввел шифрующие коды и многоалфавитные подстановки [2].
Сэр Фрэнсис Бэкон (1561 – 1626), автор двухлитерного кода, доказал в 1580 г., что для передачи информации достаточно двух знаков. Также Ф.Бэкон сформулировал требования к шифру:
1. Шифр должен быть несложен, прост в работе;
2. Шифр должен быть надежен, труден для дешифровки 10 посторонним;
3. Шифр должен быть скрытен, по возможности не должен вызывать подозрений [14].
Шифры Бэкона – сочетание шифрованного текста с дезинформацией в виде нулей. Таким образом, двузначные коды и шифры использовались задолго до появления ЭВМ. Новый толчок развитию теории кодирования дало создание в 1948 году Клодом Эльвудом Шенноном (1916 – 2001) теории информации. Идеи, изложенные Шенноном в статье «Математическая теория связи», легли в основу современных теорий и техник обработки, передачи и хранения информации. Результаты его научных исследований способствовали развитию помехоустойчивого кодирования и простых методов декодирования сообщений.
Первым техническим средством передачи информации на расстояние стал телеграф, изобретенный в 1837 году американцем Сэмюэлем Морзе. Телеграфное сообщение – это последовательность электрических сигналов, передаваемая от одного телеграфного аппарата по проводам к другому телеграфному аппарату. Эти технические обстоятельства привели С. Морзе к идее использования всего двух видов сигналов – короткого и длинного – для кодирования сообщения, передаваемого по линиям телеграфной связи [14].

Рисунок 7 – Сэмюэль Финли Бриз Морзе (1791–1872), США
Такой способ кодирования получил название азбуки Морзе. В ней каждая буква алфавита кодируется последовательностью коротких сигналов (точек) и длинных сигналов (тире). Буквы отделяются друг от друга паузами – отсутствием сигналов.
Самым знаменитым телеграфным сообщением является сигнал бедствия «SOS» (Save Our Souls – спасите наши души). Вот как он выглядит в коде азбуки Морзе, применяемом к английскому алфавиту:
••• ––– •••
Три точки (буква S), три тире (буква О), три точки (буква S). Две паузы отделяют буквы друг от друга.
На рисунке показана азбука Морзе применительно к русскому алфавиту. Специальных знаков препинания не было. Их записывали словами: «тчк» – точка, «зпт» – запятая и т.п.
Характерной особенностью азбуки Морзе является переменная длина кода разных букв, поэтому код Морзе называют неравномерным кодом. Буквы, которые встречаются в тексте чаще, имеют более короткий код, чем редкие буквы. Например, код буквы «Е» – одна точка, а код твердого знака состоит из шести знаков. Это сделано для того, чтобы сократить длину всего сообщения. Но из–за переменной длины кода букв возникает проблема отделения букв друг от друга в тексте. Поэтому приходится для разделения использовать паузу (пропуск). Следовательно, телеграфный алфавит Морзе является троичным, т.к. в нем используется три знака: точка, тире, пропуск [14].

Рисунок 8 – Азбука Морзе
Равномерный телеграфный код был изобретен французом Жаном Морисом Бодо в конце XIX века. В нем использовалось всего два разных вида сигналов. Не важно, как их назвать: точка и тире, плюс и минус, ноль и единица. Это два отличающихся друг от друга электрических сигнала. Длина кода всех символов одинаковая и равна пяти. В таком случае не возникает проблемы отделения букв друг от друга: каждая пятерка сигналов – это знак текста. Поэтому пропуск не нужен [17].

Рисунок 9 – Жан Морис Эмиль Бодо (1845–1903), Франция
Код Бодо – это первый в истории техники способ двоичного кодирования информации. Благодаря этой идее удалось создать буквопечатающий телеграфный аппарат, имеющий вид пишущей машинки. Нажатие на клавишу с определенной буквой вырабатывает соответствующий пятиимпульсный сигнал, который передается по линии связи. Принимающий аппарат под воздействием этого сигнала печатает ту же букву на бумажной ленте. В современных компьютерах для кодирования текстов также применяется равномерный двоичный код [17].
Основные понятия кодирования информации
Код – система условных знаков (символов) для передачи, обработки и хранения информации (сообщения). Кодирование – процесс представления информации (сообщения) в виде кода.
Все множество символов, используемых для кодирования, называется алфавитом кодирования. Например, в памяти компьютера любая информация кодируется с помощью двоичного алфавита, содержащего всего два символа: 0 и 1.
Научные основы кодирования были описаны К.Шенноном, который исследовал процессы передачи информации по техническим каналам связи (теория связи, теория кодирования). При таком подходе кодирование понимается в более узком смысле: как переход от представления информации в одной символьной системе к представлению в другой символьной системе. Например, преобразование письменного русского текста в код азбуки Морзе для передачи его по телеграфной связи или радиосвязи. Такое кодирование связано с потребностью приспособить код к используемым техническим средствам работы с информацией [19].
Декодирование – процесс обратного преобразования кода к форме исходной символьной системы, т.е. получение исходного сообщения. Например: перевод с азбуки Морзе в письменный текст на русском языке.
В более широком смысле декодирование – это процесс восстановления содержания закодированного сообщения. При таком подходе процесс записи текста с помощью русского алфавита можно рассматривать в качестве кодирования, а его чтение – это декодирование.
Код имеет следующие основные характеристики:
1. Основание кода (q) или число признаков, равное числу отличающихся друг от друга символов (признаков). Наибольшее распространение получили коды с q=2, называемые бинарными, двоичными. Они характеризуются наиболее высокой надежностью передачи признаков по сравнению с кодами, имеющими другие основания.
2. Длина кодовой комбинации (n), называемая также разрядностью кода или длиной слова, она равна числу символов (элементарных сигналов) в кодовой комбинации. Код называется равномерным, если все кодовые комбинации одинаковы по длине, и неравномерным, если величина n в коде непостоянна. В телемеханике обычно используют равномерные коды, в которых легко контролировать длину слова для повышения помехоустойчивости.
3. Число кодовых комбинаций (N) в коде, каждая из которых может передавать свое отдельное сообщение. Этот показатель называют также объемом кода. Максимальный объем кода N=qn .
4. Вес кода (w), под которым понимают число единиц в кодовой комбинации [3].
Общая классификация кодов производится по нескольким критериям.
1. По области применения различают:
1.1. Телемеханические коды.
1.2. Телеграфный код.
1.3. Коды цифровой техники (ЭВМ).
1.4. Специальные (морской, коммерческий, дипломатический, военный) коды.
2. В зависимости от цели, достигаемой кодированием, различают:
2.1. Первичные коды представления данных, или первичные коды. Они используются для отображения данных, получаемых либо при исходном кодировании дискретных величин, либо при преобразовании непрерывной величины в дискретную.
2.2. Оптимальные (эффективные) коды. Это коды, в которых принятый критерий оптимальности имеет экстремальное значение. Наиболее распространёнными являются коды с минимальным числом разрядов, приходящихся на одно сообщение. Передача таких кодов в последовательной форме, например, по линии связи, производится за минимальное время. При такой передаче недопустимы искажения, так как любое искажение приводит к необнаруживаемой ошибке воспроизведения исходной информации, поэтому такие коды в телемеханике не используются.
2.3. Помехозащищённые (корректирующие) коды. Это коды, которые способны либо обнаружить, либо обнаружить и исправить искажение, возникшее, например, при передаче. Благодаря этому свойству корректирующие коды широко применяются в телемеханике и в технике передачи данных [6].
3. По закономерностям кодообразования:
3.1. Числовые (взвешенные) коды, называемые еще цифровыми, имеют кодовые комбинации, образующие ряд возрастающих по весу чисел, определяемый системой счисления. Они применяются для кодирования количественной информации (например, при телеизмерении)
3.2. Нечисловые (не взвешенные) коды не имеют систем счисления и не образуют ряда возрастающих по весу кодовых комбинаций. Нечисловые коды применяются при передаче качественной информации (например, команды телеуправления). Они разделяются на следующие виды:
3.2.1. Комбинаторные, построенные по законам теории соединений.
3.2.2. Защищённые, имеющие специальные закономерности построения [9].
Для представления кодов применяются следующие основные способы:
Таблица комбинаций.
Кодовое дерево.
Геометрическая модель.
1. Таблица кодовых комбинаций представляет собой таблицу, в которой записаны все комбинации кода вместе с соответствующими числами. Например, таблица комбинаций трёхразрядного двоичного нормального (натурального) кода имеет следующий вид (табл. 1 [15]).
Таблица 1
Комбинации трёхразрядного двоичного натурального кода
|
Десятичное число |
Двоичный натуральный код |
||||
|
0 |
0 |
0 |
0 |
0 |
0 |
|
1 |
0 |
0 |
0 |
0 |
1 |
|
2 |
0 |
0 |
0 |
1 |
0 |
|
3 |
0 |
0 |
0 |
1 |
1 |
|
4 |
0 |
0 |
1 |
0 |
0 |
|
5 |
0 |
0 |
1 |
0 |
1 |
|
6 |
0 |
0 |
1 |
1 |
0 |
|
7 |
0 |
0 |
1 |
1 |
1 |
2. Кодовое дерево представляет собой графическое отображение множества кодовых комбинаций (рис. 10).
3. Геометрическая модель является другим способом графического представления кодов. Любой n–мерный двоичный код представляется n–мерным кубом, в котором каждая вершина отображает кодовую комбинацию, а длина ребра куба соответствует одной единице. В таком кубе расстояние между вершинами (кодовыми комбинациями) измеряются минимальным количеством ребер между ними (рис. 11) [15].
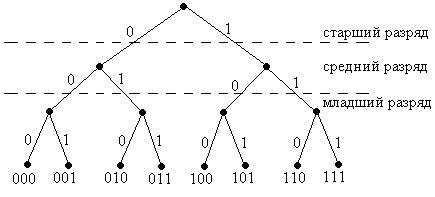
Рисунок 10 – Кодовое дерево трёхразрядного двоичного натурального кода
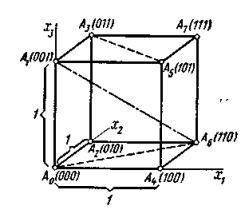
Рисунок 11 – Геометрическая модель трёхразрядного двоичного натурального кода
Методы кодирования данных
NRZ – Non Return to Zero (без возврата к нулю) и NRZ I – Non Return to Zero Invertive (инверсное кодирование без возврата к нулю)
Код NRZ (Non Return to Zero – без возврата к нулю) – это простейший код, представляющий собой обычный цифровой сигнал. Логическому нулю соответствует высокий уровень напряжения в кабеле, логической единице – низкий уровень напряжения (или наоборот, что не принципиально). Уровни могут быть разной полярности или же одной полярности. В течение битового интервала, то есть времени передачи одного бита никаких изменений уровня сигнала в кабеле не происходит.
К несомненным достоинствам кода NRZ относятся его довольно простая реализация (исходный сигнал не надо ни специально кодировать на передающем конце, ни декодировать на приемном конце), а также минимальная среди других кодов пропускная способность линии связи, требуемая при данной скорости передачи. Ведь наиболее частое изменение сигнала в сети будет при непрерывном чередовании единиц и нулей, то есть при последовательности 1010101010..., поэтому при скорости передачи, равной 10 Мбит/с (длительность одного бита равна 100 нс) частота изменения сигнала и соответственно требуемая пропускная способность линии составит 1 / 200нс = 5 МГц (рис. 12).
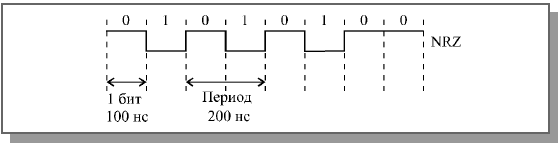
Рисунок 12 – Скорость передачи и требуемая пропускная способность при коде NRZ
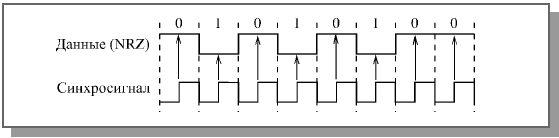
Рисунок 13 – Передача в коде NRZ с синхросигналом
Самый большой недостаток кода NRZ – это возможность потери синхронизации приемником во время приема слишком длинных блоков (пакетов) информации. Приемник может привязывать момент начала приема только к первому (стартовому) биту пакета, а в течение приема пакета он вынужден пользоваться только внутренним тактовым генератором (внутренними часами). Например, если передается последовательность нулей или последовательность единиц, то приемник может определить, где проходят границы битовых интервалов, только по внутренним часам. И если часы приемника расходятся с часами передатчика, то временной сдвиг к концу приема пакета может превысить длительность одного или даже нескольких бит. В результате произойдет потеря переданных данных. Так, при длине пакета в 10000 бит допустимое расхождение часов составит не более 0,01% даже при идеальной передаче формы сигнала по кабелю.
Во избежание потери синхронизации, можно было бы ввести вторую линию связи для синхросигнала (Рис. 13). Но при этом требуемое количество кабеля, число приемников и передатчиков увеличивается в два раза. При большой длине сети и значительном количестве абонентов это невыгодно.
В связи с этим код NRZ используется только для передачи короткими пакетами (обычно до 1 Кбита) [17].
Значительный недостаток кода NRZ состоит еще и в том, что он может обеспечить обмен сообщениями (последовательностями, пакетами) только фиксированной, заранее обговоренной длины. Дело в том, что по принимаемой информации приемник не может определить, идет ли еще передача или уже закончилась. Для синхронизации начала приема пакета используется стартовый служебный бит, чей уровень отличается от пассивного состояния линии связи (например, пассивное состояние линии при отсутствии передачи – 0, стартовый бит – 1). Заканчивается прием после отсчета приемником заданного количества бит последовательности (Рисунок 14).
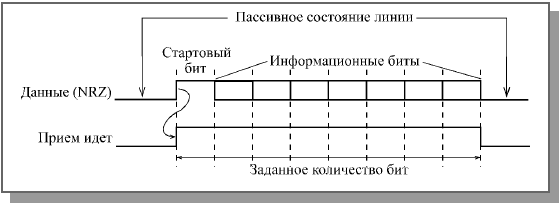
Рисунок 14 – Определение окончания последовательности при коде NRZ
Код NRZI (без возврата к нулю с инверсией единиц) предполагает, что уровень сигнала меняется на противоположный в начале единичного битового интервала и не меняется при передаче нулевого битового интервала. При последовательности единиц на границах битовых интервалов имеются переходы, при последовательности нулей – переходов нет. В этом смысле код NRZI лучше синхронизируется, чем NRZ (там нет переходов ни при последовательности нулей, ни при последовательности единиц) [4].
Этот метод кодирования использует следующие представления битов цифрового потока: * биты 0 представляются нулевым напряжением (0 В); * биты 1 представляются напряжением 0 или +V в зависимости от предшествовавшего этому биту напряжения. Если предыдущее напряжение было равно 0, единица будет представлена значением +V, а в случаях, когда предыдущий уровень составлял +V для представления единицы, будет использовано напряжение 0 В. Этот алгоритм обеспечивает малую полосу (как при методе NRZ) в сочетании с частыми изменениями напряжения (как в RZ), а кроме того, обеспечивает неполярный сигнал (т. е. проводники в линии можно поменять местами) [17]
RZ – Return to Zero (возврат к нулю)
Код RZ (Return to Zero – с возвратом к нулю) – этот трехуровневый код получил такое название потому, что после значащего уровня сигнала в первой половине битового интервала следует возврат к некоему «нулевому», среднему уровню (например, к нулевому потенциалу). Переход к нему происходит в середине каждого битового интервала. Логическому нулю, таким образом, соответствует положительный импульс, логической единице – отрицательный (или наоборот) в первой половине битового интервала.
В центре битового интервала всегда есть переход сигнала (положительный или отрицательный), следовательно, из этого кода приемник легко может выделить синхроимпульс (строб). Возможна временная привязка не только к началу пакета, как в случае кода NRZ, но и к каждому отдельному биту, поэтому потери синхронизации не произойдет при любой длине пакета.
Еще одно важное достоинство кода RZ – простая временная привязка приема, как к началу последовательности, так и к ее концу. Приемник просто должен анализировать, есть изменение уровня сигнала в течение битового интервала или нет. Первый битовый интервал без изменения уровня сигнала соответствует окончанию принимаемой последовательности бит (рисунок 15). Поэтому в коде RZ можно использовать передачу последовательностями переменной длины [12].
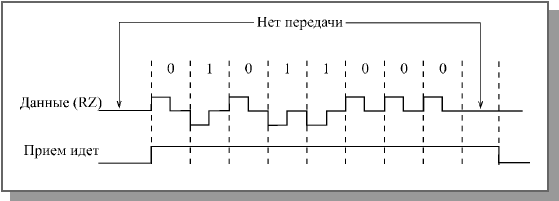
Рисунок 15 – Определение начала и конца приема при коде RZ
Недостаток кода RZ состоит в том, что для него требуется вдвое большая полоса пропускания канала при той же скорости передачи по сравнению с NRZ (так как здесь на один битовый интервал приходится два изменения уровня сигнала). Например, для скорости передачи информации 10 Мбит/с требуется пропускная способность линии связи 10 МГц, а не 5 МГц, как при коде NRZ (рис. 16).
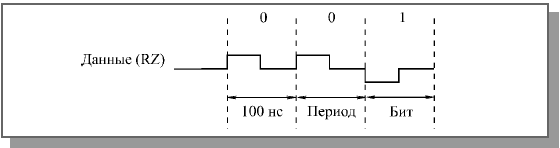
Рисунок 16 – Скорость передачи и пропускная способность при коде RZ
Другой важный недостаток – наличие трех уровней, что всегда усложняет аппаратуру как передатчика, так и приемника.
Код RZ применяется не только в сетях на основе электрического кабеля, но и в оптоволоконных сетях. Правда, в них не существует положительных и отрицательных уровней сигнала, поэтому используется три следующие уровня: отсутствие света, «средний» свет, «сильный» свет. Это очень удобно: даже когда нет передачи информации, свет все равно присутствует, что позволяет легко определить целостность оптоволоконной линии связи без дополнительных мер (рисунок 17) [5].
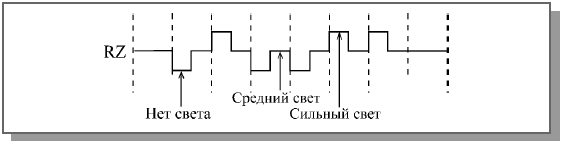
Рисунок 17 – Использование кода RZ в оптоволоконных сетях
AMI – Alternate Mark Inversion (поочередная инверсия единиц)
AMI код (от англ. Alternate Mark Inversion, иногда в литературе встречается название «биполярный AMI код») – один из способов линейного кодирования (физического кодирования, канального кодирования, цифровое кодирование, манипуляция сигнала, импульсно–кодовая модуляция). Является трехуровневым кодом, при поступлении на вход кодера логической единицы осуществляется смена потенциала либо на верхний, либо на нижний уровень, в зависимости от предыдущего уровня, на котором передавалась логическая единица. В процессе синхронизации, физическая привязка к синхронной последовательности на приемной стороне осуществляется при передаче смены логической единицы и логического нуля, либо за счет скремблирования.
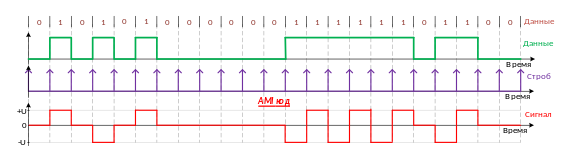
Рисунок 18 – Линейное кодирование
Преимущества:
- Самосинхронизирующийся код (слабая синхронизация в сравнении с манчестерским кодированием, поскольку синхронизация не производится при передаче логических нулей)
- Спектр сигнала уже, чем у NRZ
- Сравнительно простая в реализации
Недостатки:
- Мощность передатчика должна быть выше в сравнение с двухуровневым кодированием
- Сложность построения аппаратуры в сравнение с двухуровневым кодированием
Этот метод кодирования использует следующие представления битов: * биты 0 представляются нулевым напряжением (0 В); * биты 1' представляются поочередно значениями +V и –V. Этот метод подобен алгоритму RZ, но обеспечивает в линии нулевой уровень постоянного напряжения. Недостатком метода AMI является ограничение на плотность нулей в потоке данных, поскольку длинные последовательности 0 ведут к потере синхронизации [11]
HDB3 – High Density Bipolar 3 (биполярное кодирование с высокой плотностью) и PE – Phase Encode (фазовое кодирование)
Для высоких скоростей передачи используются биполярное кодирование с высокой плотностью (High density bipolar code of order 3 – HDB3). Представление битов в методе HDB3 лишь незначительно отличается от представления, используемого алгоритмом AMI. При наличии в потоке данных 4 последовательных битов 0 последовательность изменяется на 000V, где полярность бита V такая же, как для предшествующего ненулевого.
High Density Bipolar code – Биполярный код высокой плотности второго (третьего) порядка. Эквивалентен коду с возвратом к нулю (RZ) и с инверсией для логических 1. Последовательность 000 (соответственно 0000) заменяется на 00V или B0V (соответственно 000V или B00V). Число B сигналов между V–сигналами всегда нечетно. В результате возникает трехуровневый код
Представление битов в методе HDB3 лишь незначительно отличается от представления, используемого алгоритмом AMI: При наличии в потоке данных 4 последовательных битов 0 последовательность изменяется на 000V, где полярность бита V такая же, как для предшествующего ненулевого импульса (в отличие от кодирования битов 1, для которых знак сигнала V изменяется поочередно для каждой единицы в потоке данных). Этот алгоритм снимает ограничения на плотность 0, присущие кодированию AMI, но порождает взамен новую проблему – в линии появляется отличный от нуля уровень постоянного напряжения за счет того, что полярность отличных от нуля импульсов совпадает [15].
Для решения этой проблемы полярность бита V изменяется по сравнению с полярностью предшествующего бита V. Когда это происходит, битовый поток изменяется на B00V, где полярность бита B совпадает с полярностью бита V. Когда приемник получает бит B, он думает, что этот сигнал соответствует значению 1, но после получения бита V (с такой же полярностью) приемник может корректно трактовать биты B и V как 0. Метод HDB3 удовлетворяет всем требованиям, предъявляемым к алгоритмам цифрового кодирования, но при использовании этого метода могут возникать некоторые проблемы.
Ни в одной из версий Ethernet не применяется прямое двоичное кодирование бита 0 напряжением О В и бита 1 – напряжением 5В, так как такой способ приводит к неоднозначности. Если одна станция посылает битовую строку 00010000, то другая может интерпретировать ее как 10000000 или 01000000, так как они не смогут отличить отсутствие сигнала (О В) от бита О (О В). Можно, конечно, кодировать единицу положительным напряжением +1 В, а ноль – отрицательным напряжением –1В. Но при этом все равно возникает проблема, связанная с синхронизацией передатчика и приемника. Разные частоты работы их системных часов могу привести к рассинхронизации и неверной интерпретации данных. В результате приемник может потерять границу битового интервала. Особенно велика вероятность этого в случае длинной последовательности нулей или единиц [9].
Таким образом, принимающей машине нужен способ однозначного определения начала, конца и середины каждого бита без помощи внешнего таймера. Это реализуется с помощью двух методов: манчестерского кодирования и разностного манчестерского кодирования. В манчестерском коде каждый временной интервал передачи одного бита делится на два равных периода. Бит со значением 1 кодируется высоким уровнем напряжения в первой половине интервала и низким – во второй половине, а нулевой бит кодируется обратной последовательностью – сначала низкое напряжение, затем высокое. Такая схема гарантирует смену напряжения в середине периода битов, что позволяет приемнику синхронизироваться с передатчиком. Недостатком манчестерского кодирования является то, что оно требует двойной пропускной способности линии по отношению к прямому двоичному кодированию, так как импульсы имеют половинную ширину. Например, для того чтобы отправлять данные со скоростью 10 Мбит/с, необходимо изменять сигнал 20 миллионов раз в секунду. Манчестерское кодирование показано ниже, на схеме «б» (Рис.19).
Разностное манчестерское кодирование, показанное на схеме «в» (Рис. 19), является вариантом основного манчестерского кодирования. В нем бит 0 кодируется изменением состояния в начале интервала, а бит 1 – сохранением предыдущего уровня. В обоих случаях в середине интервала обязательно присутствует переход. Разностная схема требует более сложного оборудования, зато обладает хорошей защищенностью от шума. Во всех сетях Ethernet используется манчестерское кодирование благодаря его простоте. Высокий сигнал кодируется напряжением в +0,85 В, а низкий сигнал––0,85 В, в результате чего постоянная составляющая напряжения равна О В. Разностное манчестерское кодирование в Ethernet не используется, но используется в других ЛВС (например, стандарт 802.5, маркерное кольцо) [15].
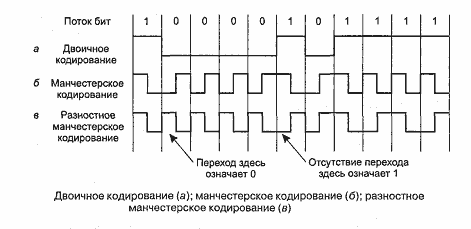
Рисунок 19 – Потоковое кодирование информации
ЗАКЛЮЧЕНИЕ
В ходе работы достигнута цель исследования – осуществлен анализ методов кодирования данных. Для достижения цели были выполнены следующие задачи:
- проанализирована история кодирования данных;
- рассмотрены понятие и виды кодирования данных;
- охарактеризованы методы кодирования данных:
- NRZ;
- NRZI;
- RZ;
- AMI;
- HDB3;
- PE.
Информация – ключевой ресурс в развивающейся современной цивилизации, и методы, средства и способы ее обработки и кодирования будут только усложняться, множиться и совершенствоваться. В связи с этим проблему нельзя назвать до конца изученной – ведь материал для новых исследований будет только прибывать.
Также при выполнении работы определено, что методы кодирования данных могут варьироваться в зависимости от того, какой именно тип данных обрабатывается. В то же время, к сегодняшнему дню сформировались определенные системы, позволяющие в некоторой степени унифицировать процесс кодирования данных того или иного типа.
В любом случае, нельзя назвать проблему до конца изученной, так как развитие современных информационных технологий не останавливается – следовательно, развитие методов кодирования данных не только возможно, но со временем станет необходимым.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Белоногов, Г. Г. Автоматизация процессов накопления, поиска и обобщения информации / Г. Г. Белоногов, А. П. Новоселов. – М.: Наука, 2016. – 256 c.
- Берлекэмп, Э. Алгебраическая теория кодирования / Э. Берлекэмп. – М., 2016. – 281 c.
- Вдовин, В. М. Информационные технологии в финансово–банковской сфере: Учебное пособие / В. М. Вдовин, Л. Е. Суркова. – М.: Дашков и К, 2016. – 304 c.
- Венделева, М. А. Информационные технологии в управлении.: Учебное пособие для бакалавров / М. А. Венделева, Ю. В. Вертакова. – Люберцы: Юрайт, 2016. – 462 c.
- Ветитнев, А. М. Информационные технологии в социально–культурном сервисе и туризме. Оргтехника: Учебное пособие / А. М. Ветитнев, В. В. Коваленко, В. В. Коваленко. – М.: Форум, 2018. – 128 c.
- Гавриленкова, И. В. Информационные технологии в естественнонаучном образовании и обучении. Практика, проблемы и перспективы профессиональной ориентаци. Монографии / И. В. Гавриленкова. – М.: КноРус, 2018. – 284 c.
- Гаврилов, Л. П. Информационные технологии в коммерции: Учебное пособие / Л. П. Гаврилов. – М.: Инфра–М, 2018. – 47 c.
- Гаврилов, М. В. Информатика и информационные технологии: Учебник для прикладного бакалавриата / М. В. Гаврилов, В. А. Климов. – Люберцы: Юрайт, 2016. – 383 c.
- Гоппа, В. Д. Введение в алгебраическую теорию информации / В. Д. Гоппа. – М., 2017. – 370 c.
- Гохберг, Г. С. Информационные технологии: Учебник / Г. С. Гохберг. – М.: Академия, 2015. – 368 c.
- Кадомцев, Б. Б. Динамика и информация / Б. Б. Кадомцев. – М. 2015. – 140 c.
- Кельберт, М. Я. Вероятность и статистика в примерах и задачах. Том 3. Теория информации и кодирования / М. Я. Кельберт. – М.: МЦНМО, 2016. – 614 c.
- Коломейченко, А. С. Информационные технологии: Учебное пособие / А. С. Коломейченко, Н. В. Польшакова, О.В. Чеха. – СПб.: Лань, 2018. – 228 c.
- Коноплева, И. А. Информационные технологии. / И. А. Коноплева, О. А. Хохлова, А. В. Денисов. – М.: Проспект, 2015. – 328 c.
- Костров, Б. В. Основы цифровой передачи и кодирования информации / Б. В. Костров. – ТехБук, 2017 г., 192 стр.
- Кузнецова, Е. Ю. Информатика. Информация. Кодирование и измерение. 7–9 классы. Дидактические материалы. ФГОС / Е. Ю. Кузнецова. – М.: Бином. Лаборатория знаний, 2018. – 249 c.
- Макарова, Н. В. «Информатика»: Учебник / Н. В. Макарова. – М.: Финансы и статистика, 2015 г. – 768 с.
- Мальцев, Ю. Н. Введение в дискретную математику. Элементы комбинаторики, теории графов и теории кодирования / Ю. Н. Мальцев, Е. П. Петров. – М., 2017. – 430 c.
- Степаненко, О. С. Персональный компьютер. Самоучитель / О. С. Степаненко. – Диалектика. 2015, 28 стр.
- Хазен, А. М. Введение меры информации в аксиоматическую базу механики / А. М. Хазен. – М., 2013. – 986 c.
- Холево, А. С. Введение в квантовую теорию информации / А. С. Холево. – М., 2016. – 961 c.
- Цымбал, В. П. Задачник по теории информации и кодированию / В. П. Цымбал. – Москва: Машиностроение, 2014. – 512 c.
- Чечета, С. В. Введение в дискретную теорию информации и кодирования / С. В. Чечета. – М.: Московский центр непрерывного математического образования (МЦНМО), 2017. – 713 c.

- Факторы, влияющие на эффективность управленческих решений (ПОНЯТИЕ УПРАВЛЕНЧЕСКИХ РЕШЕНИЙ И ИХ ЭФФЕКТИВНОСТЬ)
- Основы проектирования программ. Этапы создания программного обеспечения (Понятие базы данных и основы проектирования программ)
- Управление финансами и пути его совершенствования в РФ (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ УПРАВЛЕНИЯ ФИНАНСАМИ)
- Формы правления в прошлом и настоящем
- Разработка и управление инвестиционным проектом (Понятие и классификация инвестиционных проектов)
- Дидактическая игра как метод обучения (Теоретические основы проблемы обучения детей)
- Корпоративная культура в организации ( ПОДДЕРЖАНИЕ И ФОРМИРОВАНИЕ КОРПОРАТИВНОЙ КУЛЬТУРЫ КАК ФУНКЦИЯ УПРАВЛЕНИЯ ПЕРСОНАЛОМ)
- Роль мотивации в поведении организации (на примере ООО «Адамант Тур» г. Москва)»
- Менеджмент человеческих ресурсов (Теоретические аспекты человеческих ресурсов: сущность и соотношение)
- Здоровьесберегающие технологии в образовательном процессе начальной школы
- Особенности проблемного обучения
- Местное самоуправление в Российской Федерации: тенденции и перспективы развития (Федеральное законодательство в сфере местного самоуправления, его изменение)