
Виды данных. Операции, производимые с данными
Содержание:

Введение
В связи с появлением, настойчивым развитием и влиянием на социум информационных технологий, возникает необходимость изучения в школах и вузах информатики. Информатика - наука об общих свойствах и закономерностях информации, методах её поиска, передачи, хранения, обработки и использования в различных сферах деятельности человека. Информация представляет собой отражение окружающего реального мира, то есть сведения, которые один реальный объект содержит о другом реальном объекте – неотъемлемое свойство живой природы.
Наряду с информацией в информатике часто употребляется понятие «данные». Данные – это информация, представленная в виде, пригодном для обработки её автоматическими средствами при возможном участии человека. Полученные извне данные обобщаются, группируются, систематизируются, сравниваются, то есть подвергаются различным операциям с целью их применения для достижения поставленных целей. Необработанные данные остаются всего лишь бесполезной чередой сигналов окружающей среды.
Появление и широкое распространение компьютеров создает новые возможности поиска, получения, накопления, передачи и, наконец, обработки информации. Следует заметить, что существует несколько видов данных. В зависимости от вида данных применяются различные способы их обработки, которые мы рассмотрим далее.
Глава 1. Виды данных
Виды данных и способы их получения
Обычно для классификации объектов одной природы используется то или иное свойство, либо набор свойств объектов. Нас интересует классификация информации в плане автоматизации основных информационных процессов. Первоначально вычислительные машины применялись для обработки только числовой информации. Но в настоящее время их возможности не ограничиваются только работой с числами. Далеко не вся информация окружающего нас мира может быть обработана компьютером. Поэтому, говоря об информации, необходимо выделить те её виды, которые компьютер воспримет и позволит человеку использовать свои ресурсы для обработки, хранения и передачи такой информации. Компьютер может работать с текстовой, числовой, табличной, графической информацией, а так же со звуковой, анимационной и видеоинформацией. Так же компьютер воспринимает специальную двоичную информацию.[1]
Различают основные виды информации, которые классифицируют по ее форме представления, способам ее кодирования и хранения: графическая – один из древнейших видов, с помощью которого хранили информацию об окружающем мире в виде наскальных рисунков, а затем в виде картин, фотографий, схем, чертежей на различных материалах (бумага, холст, мрамор и др.), которые изображают картины реального мира; звуковая (акустическая) – для хранения звуковой информации в 1877 г. было изобретено звукозаписывающее устройство, а для музыкальной информации – разработан способ кодирования с использованием специальных символов, который дает возможность хранить ее как графическую информацию; текстовая – кодирует речь человека с помощью специальных символов – букв (для каждого народа свои); для хранения используется бумага (записи в тетради, книгопечатание и т.п.); числовая – кодирует количественную меру объектов и их свойств в окружающем мире с помощью специальных символов – цифр (для каждой системы кодирования свои); особенно важной стала с развитием торговли, экономики и денежного обмена; видеоинформация – способ хранения «живых» картин окружающего мира, который появился с изобретением кино. Существуют также виды информации, для которых еще не изобретены способы кодирования и хранения – тактильная информация, органолептическая и др.[2]
С практической точки зрения информация всегда представляется в виде сообщения. Информационное сообщение связано с источником сообщения, получателем сообщения и каналом связи. Сообщение от источника к приемнику передается в материально-энергетической форме (электрический, световой, звуковой сигналы и т.д.). Человек воспринимает сообщения посредством органов чувств. Приемники информации в технике воспринимают сообщения с помощью различных измерительных датчиков и регистрирующей аппаратуры. В обоих случаях с приемом информации связано изменение во времени какой-либо величины, характеризующей состояние приемника.
В настоящее время имеются разнообразные устройства, выполняющие функции ввода информации в составе компьютера. Они называются устройствами ввода, так как обеспечивают ввод в компьютер данных в различных формах: чисел, текстов, изображений, звуков.
Устройства ввода преобразуют эту информацию из формы, понятной человеку, в цифровую форму, воспринимаемую компьютером.
Современные компьютеры могут обрабатывать числовую, текстовую, графическую, звуковую и видеоинформацию.
Итак, устройства ввода:
-клавиатура, служит для набора текстов;
-микрофон, используется для ввода звуковой информации, подключается к входу звуковой карты;
-сканнер, переводит графическую информацию в цифровую;
- веб-камера — малоразмерная цифровая видео или фотокамера, способная в реальном времени фиксировать видеоизображения, предназначенные для дальнейшей передачи по компьютерной сети;
-сенсорный экран;
- графический планшет (дигитайзер). Графический планшет (со световым пером) — это устройство для ввода рисунков от руки и рукописного текста непосредственно в компьютер;
- специальные датчики, присоединяемые к компьютеру, позволяют измерять и вводить в его память такие числовые характеристики окружающей среды как температура, влажность, давление и многое другое;
- устройства речевого ввода. Средства речевого ввода позволяют пользователю вместо клавиатуры, мыши и других устройств использовать речевые команды (или проговаривать текст, который должен быть заранее занесен в память компьютера). [3]
1.2 Носители данных
Самым распространенным носителем данных, пусть и не экономичным, является бумага. На бумаге данные регистрируются путём изменения оптических характеристик её поверхности. Для хранения компьютерных данных используются специальные носители, на которых сохраняется кодированная информация. В компьютере для хранения информации предназначена память, которая подразделяется на основную (энергозависимую), участвующую только в процессе обработки информации, и внешнюю (энергонезависимую).
Внешняя память в зависимости от характера носителя подразделяется на несколько типов:
-память на магнитных носителях – гибкие и жесткие магнитные диски, ziv-диски и магнитные ленты;
-память на оптических носителях – компакт диски с однократной и многократной записью
-энергонезависимая электронная память флеш-память.[4]
Самый первый носитель магнитной записи был изобретен в 19 веке. Это была стальная проволока диаметром до 1 мм, которая записывала только звук. В начале 20-го столетия для этих целей использовалась стальная катаная лента. А в 1906 году был выдан первый патент на магнитный диск.[5]
Энергозависимая память - это временная оперативная память (ОЗУ) установленная на ПК. Это тип памяти которая хранит файлы программ и ОС, с которыми пользователь активно работает, но она не сохраняет своё содержимое, когда пользователь отключает компьютер. ОЗУ работает намного быстрее, чем постоянное запоминающее устройство, которое имеет компьютер, поэтому она хорошо выполняет свою работу. Но временный характер энергозависимой памяти является недостатком, поскольку пользователь потеряет любые несохраненные данные, если его или её компьютер неожиданно потеряет электроэнергию или если компьютер не заработает. Существует несколько областей применения энергозависимых запоминающих устройств. Они даже могут использоваться в качестве основного хранилища данных. Кроме того, свойство энергозависимости помогает защитить сведения ограниченного доступа, поскольку они становятся недоступными при отключении источника питания. [6]
Глава 2. Операции, производимые с данными
2.1 Этапы обработки данных
Современный компьютер является сложным и многофункциональным прибором, но выполняет те же действия по обработке данных, что и обычный калькулятор: ввод, обработка и вывод.
Первый этап обработки данных – ввод их в компьютер, т.е. любой способ передачи данных из внешнего мира в процессор компьютера.
Второй этап – обработка информации в процессе вычисления.
Третий этап – представление данных в форме, удобной для человека. Это вывод на печать, графические изображения (иллюстрации, графики, диаграммы и т.д.), звук и т.д.[7]
Следует заметить, что компьютер является весьма полезным помощником человека в повседневной деятельности. В частности, в бухгалтериях воинских частей (в коммерческих организациях ЭВМ появились раньше) примерно до 2000 года компьютер являлся редкостью. Бухгалтерские данные обрабатывались вручную, на калькуляторе; платежные поручения для представления их в банк печатались на печатных машинках; ведомости на выплату денежного довольствия и заработной платы переписывались от руки из месяца в месяц; самой трудоемкой работой было ведение главной книги.
С возникновением автоматизации обработки данных трудоемкость бухгалтерской работы значительно снизилась.
2.2 Операции, производимые с данными
В ходе информационного процесса данные преобразуются из одного вида в другой. Обработка данных включает в себя следующие операции:
-сбор данных – накопление информации с целью обеспеения достаточной полноты для принятия решений;
-формализация данных – приведение данных, поступающих из разных источников, к одинаковой форме для того, чтобы их сделать сопоставимыми между собой;
-сортировка данных – упорядочивание данных по заданному признаку с целью удобства их использования; сортировка данных повышает доступность информации;
-фильтрация данных – отсеивание лишних данных, в которых нет необходимости для принятия решений; при этом достоверность данных должна возрастать;
-архивация данных – организация хранения данных в компактной сжатой форме; архивация данных повышает общую надежность информационного процесса и используется для снижения затрат по хранению данных;
-защита данных – комплекс мер, направленных на предотвращение утраты, воспроизведение и изменения данных;[8]
-преобразование данных – перевод данных из одной формы в другую; преобразование данных часто связано с изменением носителя;
-приём и передача данных – процессы, осуществляемые между участниками информационного процесса; при этом источник данных в информатике принято называть сервером, а потребителя – клиентом.
Любая информация, независимо от природы ее происхождения, при вводе в компьютер подвергается кодировке. Дело в том, что компьютер способен обрабатывать и хранить только один вид представления данных – цифровой. Под кодированием понимают процесс представления информации в виде последовательности условных обозначений. Кодом называют множество слов – последовательностей символов из некоторого алфавита, используемых при кодировании информации.[9]
В вычислительной технике система кодирования называется двоичным кодированием и основана на представлении данных последовательностью двух цифр: 0 и 1. Эти знаки называются двоичными цифрами, по-английски -- binary digit или сокращенно bit (бит). Чтобы прочитать, увидеть или услышать записанную (то есть закодированную) посредством ЭВМ информацию, необходимо ей придать первоначальную форму. В этих целях применяется декодирование. Декодирование - это процесс восстановления содержания закодированного сообщения. При таком подходе процесс записи текста с помощью русского алфавита можно рассматривать в качестве кодирования, а его чтение - это декодирование.
Кодирование чисел с помощью единиц и нулей впервые применил в своей вычислительной (механической) машине немецкий мыслитель Готфрид Вильгельм Лейбниц в конце 17-го века. Затем, уже в середине 20-го века, двоичное кодирование информации стало применяться повсеместно для ЭВМ.
Чаще всего используется равномерный код, когда все символы исходного сообщения кодируются с помощью одинакового количества двоичных знаков. Каждый знак соответствует выбору одного из двух вариантов (0 или 1), поэтому несет 1 бит информации.[10]
Рассмотрим способы (системы) кодирования каждого вида информации.
- Кодирование текстовой информации. Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы. Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера.
Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI – American National Standard Institute) ввел в действие систему кодированияASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США). В системеASCII закреплены две таблицы кодирования –базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII приведена в таблице 1
Таблица 1 – Базовая таблица кодировки ASCII
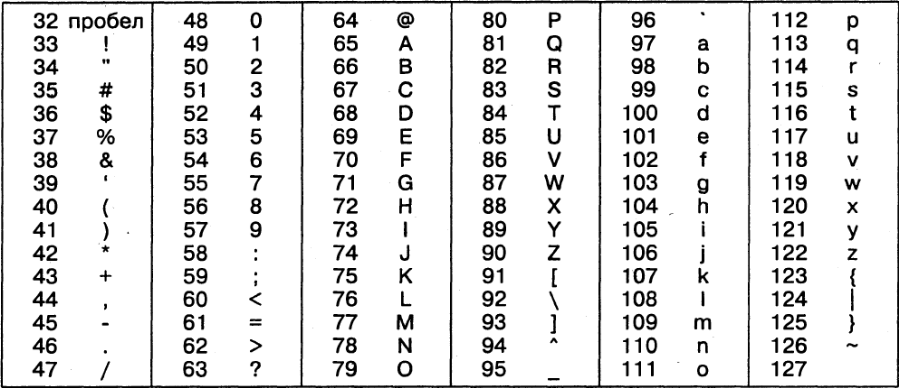
Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ-7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский кодASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена компанией Microsoft, и, поэтому она глубоко закрепилась и нашла широкое распространение (таблица 2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
Таблица 2 – Кодировка Windows1251
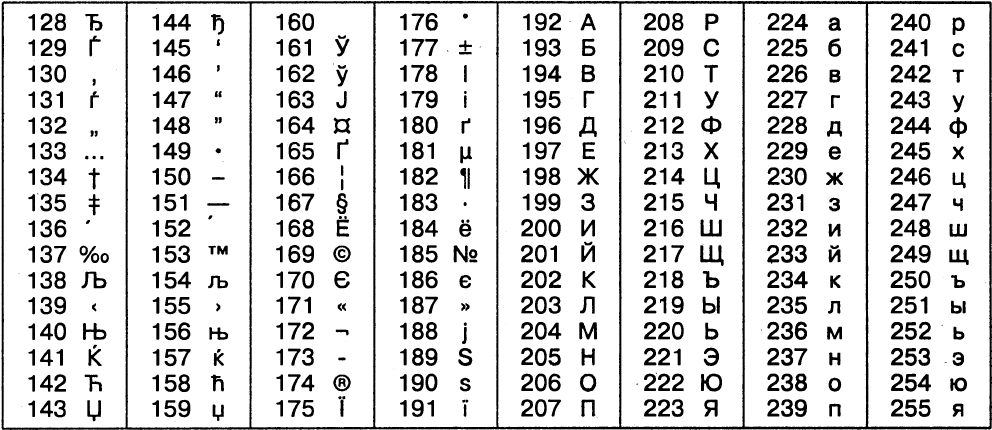
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время, очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше. Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной – UNICODE. Шестнадцать разрядов позволяют обеспечить уникальные коды для 65 536 различных символов – этого поля достаточно для размещения в одной таблице символов большинства языков планеты.
2. Кодирование графической информации. Графическое изображение при его увеличении может быть представлено в виде мельчайших точек, которые образуют характерный узор – растр. Эти точки настолько близки друг к другу, что глаз не замечает промежутков между ними, поэтому изображение воспринимается как непрерывное, сплошное. [13]Таким образом, любое изображение можно закодировать с помощью координат точек, имеющих индивидуальную яркость. Любое черно-белое изображение можно передать с помощью 256 градаций серого цвета (от белого до черного), тем самым яркость каждой точки черно-белого изображения можно закодировать 8-разрядным двоичным числом – одним байтом.
Для кодирования цветных графических изображений применяется принцип декомпозиции (разложения) цвета на основные составляющие: красный (Red), зеленый (Green) и синий (Blue). Этот принцип базируется на том, что любой цвет можно получить путем смешения трех указанных цветов. Система кодирования по первым буквам названий основных смешиваемых цветов называется системой RGB и описывает поведение аддитивной цветовой модели, свойства которой иллюстрируют при помощи цветовых кругов (рис. 1). Если для кодирования яркости каждого составляющего цвета использовать 256 градаций (8-разрядное число), как это принято для черно-белого изображения, то для кодирования цветной точки растра достаточно 24-разрядного двоичного числа.
Такой режим представления цветной графики называется полноцветным (True Color) и позволяет зафиксировать около 16,5 млн различных цветовых оттенков при помощи 3 байт. Каждому из основных цветов можно поставить в соответствие дополнительный цвет, т.е. цвет, дополняющий основной до белого. К дополнительным цветам относятся: голубой (Cyan), пурпурный (Magenta) и желтый (Yellow). Принцип декомпозиции применим и для дополнительных цветов, т.е. любой цвет может быть получен путем их смешения. Такой метод кодирования цвета применяется в полиграфии, где используется дополнительно еще и четвертая краска – черная (Black). Эта система кодирования носит название CMYK (черный цвет указан в названии последней буквой своего названия для того, чтобы не путать его в со-
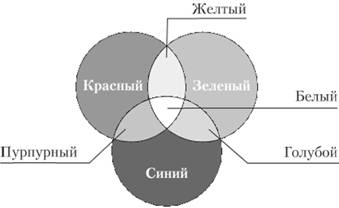
Рис. 1. Система RGB в виде цветовых кругов
крашениях и аббревиатурах с синим – Blue). Данный режим представления графики использует 32 разряда и тоже называется полноцветным (Тruе Color). Если уменьшить количество двоичных разрядов, используемых для кодировки каждой точки, в два раза, то можно сократить объем данных, но диапазон цветов при этом уменьшится до 65 536 оттенков. Такое кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color.
При работе с цветной графикой применяется индексный метод кодирования. Здесь код каждой точки растра хранит не цвет, а только его номер (индекс) в некоей справочной таблице, называемой палитрой, которая должна обязательно прикладываться к графическим данным.
Графическая информация на экране дисплея формируется из точек (пикселей). Пиксел – от picture element, что означает элемент изображения. В современных компьютерах разрешающая способность (количество точек на экране дисплея) зависит от видеоадаптера и может меняться программно. Цветные изображения могут иметь различные режимы: 16 цветов, 256 цветов, 65 536 цветов (High Color), 16 777 216 цветов ( True Color). Таким образом, например, для режима High Color на один пиксель приходится 16 бит памяти и при разрешающей способности экрана 800 × 600 точек требуемый для хранения его изображения объем видеопамяти составит V = 2 байта • 480000 = 960 000 байт = 937,5 Кбайт. Аналогично рассчитывается объем видеопамяти, необходимый для хранения битовой карты изображения при других видеорежимах. В видеопамяти компьютера хранится битовый план, представляющий собой двоичный код изображения, который считывается в соответствии с частотой кадровой развертки и отображается на экране монитора.[14]
3. Кодирование звуковой информации. В основе кодирования звука с использованием ПК лежит процесс преобразования колебаний воздуха в колебания электрического тока и последующая дискретизация аналогового электрического сигнала.
До 80-х годов все записи музыки выходили на виниловых пластинках и кассетах. В настоящее время широкое распространение получили компакт-диски. Если имеется компьютер, на котором установлена студийная звуковая плата, с подключенными к ней MIDI-клавиатурой и микрофоном, то можно работать со специализированным музыкальным программным обеспечением.
Условно его можно разбить на несколько видов:
1. всевозможные служебные программы и драйверы, предназначенные для работы с конкретными звуковыми платами и внешними устройствами;
2. аудиоредакторы, которые предназначены для работы со звуковыми файлами, позволяют производить с ними любые операции - от разбиения на части до обработки эффектами;
3. программные синтезаторы, которые появились сравнительно недавно и корректно работают только на мощных компьютерах. Они позволяют экспериментировать с созданием различных звуков и другие.
К первой группе относятся все служебные программы операционной системы. Так, например, Windows имеет свои собственные программы микшеры и утилиты для воспроизведения/записи звука, проигрывания компакт-дисков и стандартных MIDI - файлов. Установив звуковую плату можно при помощи этих программ проверить ее работоспособность. Если необходимо сделать звукозапись, то нужно определиться с качеством звука, так как именно от нее зависит продолжительность звукозаписи. Возможная продолжительность звучания тем меньше, чем выше качество записи.
А как же происходит кодирование звука? С самого детства мы сталкиваемся с записями музыки на разных носителях: грампластинках, кассетах, компакт-дисках и т.д. В настоящее время существует два основных способах записи звука: аналоговый и цифровой. Но для того чтобы записать звук на какой-нибудь носитель его нужно преобразовать в электрический сигнал.
Это делается с помощью микрофона. Самые простые микрофоны имеют мембрану, которая колеблется под воздействием звуковых волн. К мембране присоединена катушка, перемещающаяся синхронно с мембраной в магнитном поле. В катушке возникает переменный электрический ток. Изменения напряжения тока точно отражают звуковые волны.
Переменный электрический ток, который появляется на выходе микрофона, называется аналоговым сигналом. Применительно к электрическому сигналу «аналоговый» обозначает, что этот сигнал непрерывен по времени и амплитуде. Он точно отражает форму звуковой волны, которая распространяется в воздухе.
Звуковую информацию можно представить в дискретной или аналоговой форме. Их отличие в том, что при дискретном представлении информации физическая величина изменяется скачкообразно («лесенкой»), принимая конечное множество значений. Если же информацию представить в аналоговой форме, то физическая величина может принимать бесконечное количество значений, непрерывно изменяющихся.
Виниловая пластинка является примером аналогового хранения звуковой информации, так как звуковая дорожка свою форму изменяет непрерывно. Но у аналоговых записей на магнитную ленту есть большой недостаток - старение носителя. За год фонограмма, которая имела нормальный уровень высоких частот, может их потерять. Виниловые пластинки при проигрывании их несколько раз теряют качество. Поэтому преимущество отдают цифровой записи.
В начале 80-х годов появились компакт-диски. Они являются примером дискретного хранения звуковой информации, так как звуковая дорожка компакт - диска содержит участки с различной отражающей способностью. Теоретически эти цифровые диски могут служить вечно, если их не царапать, т.е. их преимуществами являются долговечность и неподверженность механическому старению. Другое преимущество заключается в том, что при цифровой перезаписи нет потери качества звука.
Кодирование и воспроизведение звуковой информации осуществляется с помощью специальных программ (редактор звукозаписи). Качество воспроизведения закодированного звука зависит от частоты дискретизации и её разрешения (глубины кодирования звука).
Цифровой звук -- это аналоговый звуковой сигнал, представленный посредством дискретных численных значений его амплитуды. Оцифровка звука - технология деления временным шагом и последующей записи полученных значений в численном виде.
Другое название оцифровки звука -- аналогово-цифровое преобразование звука. Звуковые волны при помощи микрофона превращаются в аналоговый переменный электрический сигнал. Он проходит через звуковой тракт и попадает в аналого-цифровой преобразователь (АЦП) - устройство, которое переводит сигнал в цифровую форму.
Оцифровка звука включает в себя два процесса:
процесс дискретизации (осуществление выборки) сигнала по времени
процесс квантования по амплитуде. Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть преобразован в цифровую дискретную форму с помощью временной дискретизации.
Процесс дискретизации по времени -- процесс получения значений сигнала, который преобразуется, с определенным временным шагом -- шагом дискретизации . Количество замеров величины сигнала, осуществляемых в одну секунду, называют частотой дискретизации или частотой выборки, или частотой семплирования (от англ. « sampling» -- «выборка»). Чем меньше шаг дискретизации, тем выше частота дискретизации и тем более точное представление о сигнале нами будет получено.
Это подтверждается теоремой Котельникова (в зарубежной литературе встречается как теорема Шеннона, Shannon). Согласно ей, аналоговый сигнал с ограниченным спектром точно описуем дискретной последовательностью значений его амплитуды, если эти значения берутся с частотой, как минимум вдвое превышающей наивысшую частоту спектра сигнала. То есть, аналоговый сигнал, в котором наивысшая частота спектра равна Fm, может быть точно представлен последовательностью дискретных значений амплитуды, если для частоты дискретизации Fd выполняется: Fd>2Fm.
На практике это означает, что для того, чтобы оцифрованный сигнал содержал информацию о всем диапазоне слышимых частот исходного аналогового сигнала (0 -- 20 кГц) необходимо, чтобы выбранное значение частоты дискретизации составляло не менее 40 кГц. Количество замеров амплитуды в секунду называют частотой дискретизации (в случае, если шаг дискретизации постоянен).
Основная трудность оцифровки заключается в невозможности записать измеренные значения сигнала с идеальной точностью.
Таким образом, непрерывная зависимость громкости звука от времени A(t) заменяется на дискретную последовательность уровней громкости.
4. Обработка видеоинформации. Чтобы хранить и обрабатывать видео на компьютере, необходимо закодировать его особым образом. При этом кодирование звукового сопровождения видеоинформации ничем не отличается от кодирования звука, описанного в предыдущей теме. Изображение в видео состоит из отдельных кадров, которые меняются с определенной частотой. Кадр кодируется как обычное растровое изображение, то есть разбивается на множество пикселей. Закодировав отдельные кадры и собрав их вместе, можно описать все видео.
Видеоданные характеризуются частотой кадров и экранным разрешением. Скорость воспроизведения видеосигнала составляет 30 или 25 кадров в секунду, в зависимости от телевизионного стандарта. Наиболее известными из таких стандартов являются: SECAM, принятый в России и Франции, PAL, используемый в Европе, и NTSC, распространенный в Северной Америке и Японии. Разрешение для стандарта NTSC составляет 768 на 484 точек, а для PAL и SECAM – 768 на 576 точек.
Не все пиксели используются для хранения видеоинформации. Так, при стандартном разрешении 768 на 576 пикселей, на экране телевизора отображается всего 704 на 540 пикселей. Поэтому для хранения видеоинформации в компьютере или цифровой видеокамере, размер кадра может отличаться от телевизионного. Например, в формате Digital Video или, как его еще называют DV, размер кадра составляет 720 на 576 пикселей. Такое же разрешение имеет кадр стандарта DVD Video. Размер кадра формата Video-CD составляет 352 на 288 пикселей.
В основе кодирования цветного видео лежит известная модель RGB. В телевидении же используется другая модель представления цвета изображения, а именно модель YUV. В такой модели цвет кодируется с помощью яркости Y и двух цветоразностных компонент U и V, определяющих цветность. Цветоразностная компонента образуется путем вычитания из яркостной компоненты красного и зеленого цвета. Обычно используется один байт для каждой компоненты цвета, то есть всего для обозначения цвета используется три байта информации. При этом яркость и сигналы цветности имеют равное число независимых значений. Такая модель имеет обозначение 4:4:4.
Опытным путем было установлено, что человеческий глаз менее чувствителен к цветовым изменениям, чем к яркостным. Без видимой потери качества изображения можно уменьшить количество цветовых оттенков в два раза. Такая модель обозначается как 4:2:2 и принята в телевидении. Для бытового видео допускается еще большее уменьшении размерности цветовых составляющих, до 4:2:0.
Если представить каждый кадр изображения как отдельный рисунок указанного выше размера, то видеоизображение будет занимать очень большой объем, например, одна секунда записи в системе PAL будет занимать 25 Мбайт, а одна минута – уже 1,5 Гбайт. Поэтому на практике используются различные алгоритмы сжатия для уменьшения скорости и объема потока видеоинформации. Если использовать сжатие без потерь, то самые эффективные алгоритмы позволяют уменьшить поток информации не более чем в два раза. Для более существенного снижения объемов видеоинформации используют сжатие с потерями.
Среди алгоритмов с потерями одним из наиболее известных является MotionJPEG или MJPEG. Приставка Motion говорит, что алгоритм JPEG используется для сжатия не одного, а нескольких кадров. При кодировании видео принято, что качеству VHS соответствует кодирование MJPEG с потоком около 2 Мбит/с, S-VHS – 4 Мбит/с. Свое развитие алгоритм MJPEG получил в алгоритме DV, который обеспечивает лучшее качество при таком же потоке данных. Это объясняется тем, что алгоритм DV использует более гибкую схему компрессии, основанную на адаптивном подборе коэффициента сжатия для различных кадров видео и различных частей одного кадра.
Для малоинформативных частей кадра, например, краев изображения, сжатие увеличивается, а для блоков с большим количеством мелких деталей уменьшается. Еще одним методом сжатия видеосигнала является MPEG. Поскольку видеосигнал транслируется в реальном времени, то нет возможности обработать все кадры одновременно. В алгоритме MPEG запоминается несколько кадров.
Основной принцип состоит в предположении того, что соседние кадры мало отличаются друг от друга. Поэтому можно сохранить один кадр, который называют исходным, а затем сохраняются только изменения от исходного кадра, называемые предсказуемыми кадрами. Считается, что за 10-15 кадров картинка изменится настолько, что необходим новый исходный кадр. В результате при использовании MPEG можно добиться уменьшения объема информации более чем в двести раз, хотя это и приводит к некоторой потере качества.
В настоящее время используются алгоритм сжатия MPEG-1, разработанный для хранения видео на компакт-дисках с качеством VHS, MPEG-2, используемый в цифровом, спутниковом телевидении и DVD, а также алгоритм MPEG-4, разработанный для передачи информации по компьютерным сетям и широко используемый в цифровых видеокамерах и для домашнего хранения видеофильмов.[15]
Отдельное внимание следует уделить ошибкам в данных, возможным на всех этапах обработки. В стандартном процессе обработки данных имеется ряд источников ошибок:
- ошибки в первичных данных (ошибки измерений, сбои информационно – измерительных систем) - намеренный ввод неправильных сведений в оперативном режиме, сокращение текста при вводе данных операторами, ошибки в данных, полученных путем обмена, ввод ошибочных данных клиентами, использование различных форматов данных в разных системах;
- ошибки, возникающие в процессе эксплуатации технологий обработки данных;
- ошибки, связанные со сбоями вычислительной техники, программных средств.
Ошибки вычислительной техники на несколько порядков менее вероятны, чем ошибки при занесении данных на носитель. Ошибки в первичных данных возникают из-за несовершенства измерительных систем, средств регистрации и передачи информации. В результате могут появиться значения параметров, выходящие за физически допустимые пределы, ошибки в кодировании значений ключевых характеристик, появление двух одинаковых экземпляров свойств объекта и др.
Можно выделить четыре категории ошибок: неполные данные (в них имеются отсутствующие записи), неправильные данные (неправильное применение кодов, изначально неправильные расчеты), непонятные данные (хранение значений атрибутов в разных полях, ошибок несовместимости, непродуманное использование схем форматирования), непоследовательные данные (непоследовательная дата, непоследовательная агрегация данных).
Учитывая характер наиболее массовых ошибок, целесообразно предусматривать три категории алгоритмов качества данных на каждом этапе преобразования информации:
- контроль соблюдения форматов записи данных на носитель (синтаксический контроль);
- контроль числовых значений параметров и ключевых характеристик измерений при вводе данных (семантический контроль);
- контроль выходной информации из БД (прагматический контроль).
Синтаксический – это по существу контроль достоверности данных, не затрагивающий содержательного смыслового аспекта информации. Предметом этого контроля являются контроль форматов представления данных, шаблонов и масок ввода данных, наличия атрибутов (их номенклатуры), порядка следования, наличие служебных признаков в структуре сообщения, упорядоченности данных, появления запрещенных символов, комбинаций, полноты поступления первичной информации и сопровождающих ее метаданных.
Семантический контроль оценивает смысловое содержание информации, его логичность, непротиворечивость, диапазон возможных значений параметров (предельные значения, область значений), динамику их изменения, возможных отклонений.
Прагматический контроль определяет потребительскую ценность (полезность) информации для пользователя, своевременность и актуальность данных, их полноту и доступность. Реализуется экспертной и социологической оценкой данных.[16]
ЗАКЛЮЧЕНИЕ
Информация окружает нас с момента нашего рождения. Естественно, наш организм начинает сразу её фиксировать и обрабатывать с целью дальнейшего развития. Информация извне воспринимается нашими рецепторами (глаза, уши, нос, кожа, вкусовые сосочки на языке и т.д., где находятся нервные окончания); информация о состоянии организма в настоящий момент времени также нами воспринимается (зубная боль, боль в пояснице, желудке и т.д.). Все эти данные просто необходимы для нашего выживания. При этом имеет большое значение своевременность, достоверность и скорость обработки полученной информации. К примеру, когда наша рука автоматически отдергивается от раскаленного металла. Мы даже не успели подумать об опасности, а наш организм сам принял решение за нас. Такой же процесс происходит и в принятии нами жизненно важных решений: достоверность, своевременность получения информации и скорость её обработки ведут к положительному результату.
Как следствие собственного жизненного опыта и приобретенных знаний, начиная со школьной программы, приходит осознание того, что наш головной мозг напичкан мощными генетическими программами, записанной генетической памятью, ведущими к выживанию человека в отдельности и общества в целом. Восприятие (ввод) информации (органы чувств организма), её обработка (головной мозг с заложенными в него программами обработки поступивших извне или изнутри данных) и вывод данных (наши дальнейшие действия после принятия решений), заложены в нас с момента появления на свет.
Поэтому особого удивления не вызывает факт появления такой науки, как информатика, появления вычислительных машин. Ведь человек создает многие вещи «по образу и подобию своему». Ну а в процессе развития интеллекта люди изобрели различные способы и методы получения и обработки информации для достижения наибольшего эргономического эффекта во многих сферах жизнедеятельности.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Михеева Е.В. Информатика: учебник для студ. учреждений сред. проф. образования.-М.:Издательский центр «Академия»,2016.-352.
- Информатика. Информационные процессы и информация. URL:https://spravochnick.ru/informatika/informacionnye_processy_i_informaciya.
- Босова Л.Л. Информатика:учебник для 5 класса-3 изд.-М.:БИНОМ. Лаборатория знания,2015.-184с.
- И.Г.Семакин, Е.К.Хеннер, Т.Ю.Шеина. Информатика: учебник для 10-го класса.-М.:БИНОМ. Лаборатория знаний,2015.-264с.
- Компьютеры. Оборудование. URL: https://fb.ru/category/80/hardware.
- И.Г.Семакин, Т.Ю.Шеина, Л.В.Шестакова Информатика:учебник для 10-го класса. .-М.:БИНОМ. Лаборатория знаний,2014.-363с.
- К.Ю.Поляков, Е.А.Еремин Информатика:учебник для 10-го класса. .-М.:БИНОМ. Лаборатория знаний,2013.-78с.
- Южно-Уральский государственный университет/Лекции по информатике. Раздел 1. URL: https://studfile.net/preview/3582389/page:11/
- Информатика и информационные технологии. Кодирование графических данных. URL:https://studme.org/97174/informatika/kodirovanie_chisel#842.
- Кодирование видеоинформации. Информатика (теория информации).URL:https://foxford.ru/wiki/informatika/kodirovanie-videoinformatsii.
- Обнинский институт атомной энергетики НИЯУ МИФИ. Лекция 15. Достоверность информации. URL:https://studfile.net/preview/4635619/page:3.
-
Михеева Е.В. Информатика: учебник для студ. учреждений сред. проф. образования.-М.:Издательский центр «Академия»,2016.-15,16с. ↑
-
Информатика. Информационные процессы и информация. URL:https://spravochnick.ru/informatika/informacionnye_processy_i_informaciya. (Дата обращения:21.11.2019) ↑
-
Босова Л.Л. Информатика:учебник для 5 класса-3 изд.-М.:БИНОМ. Лаборатория знания,2015.-17с. ↑
-
Михеева Е.В. Информатика: учебник для студ. учреждений сред. проф. образования.-М.:Издательский центр «Академия»,2016.-15,14с. ↑
-
И.Г.Семакин, Е.К.Хеннер, Т.Ю.Шеина. Информатика: учебник для 10-го класса.-М.:БИНОМ. Лаборатория знаний,2015.-54,55с. ↑
-
Компьютеры. Оборудование. URL: https://fb.ru/category/80/hardware. (Дата обращения:21.11.2019) ↑
-
Михеева Е.В. Информатика: учебник для студ. учреждений сред. проф. образования.-М.:Издательский центр «Академия»,2016.-15,35с. ↑
-
Михеева Е.В. Информатика: учебник для студ. учреждений сред. проф. образования.-М.:Издательский центр «Академия»,2016.-15,13,14с. ↑
-
И.Г.Семакин, Т.Ю.Шеина, Л.В.Шестакова Информатика:учебник для 10-го класса. .-М.:БИНОМ. Лаборатория знаний,2014.-56,57с. ↑
-
К.Ю.Поляков, Е.А.Еремин Информатика:учебник для 10-го класса. .-М.:БИНОМ. Лаборатория знаний,2013.-63с. ↑
-
Южно-Уральский государственный университет/Лекции по информатике. Раздел 1. URL: https://studfile.net/preview/3582389/page:11/ (Дата обращения:21.11.2019) ↑
-
Южно-Уральский государственный университет/Лекции по информатике. Раздел 1. URL: https://studfile.net/preview/3582389/page:11/ (Дата обращения:21.11.2019) ↑
-
И.Г.Семакин, Е.К.Хеннер, Т.Ю.Шеина. Информатика: учебник для 10-го класса.-М.:БИНОМ. Лаборатория знаний,2015.-45с. ↑
-
Информатика и информационные технологии. Кодирование графических данных. URL:https://studme.org/97174/informatika/kodirovanie_chisel#842. (Дата обращения:21.11.2019) ↑
-
Кодирование видеоинформации. Информатика (теория информации).URL:https://foxford.ru/wiki/informatika/kodirovanie-videoinformatsii. (Дата обращения:21.11.2019) ↑
-
Обнинский институт атомной энергетики НИЯУ МИФИ. Лекция 15. Достоверность информации. URL:https://studfile.net/preview/4635619/page:3. (Дата обращения:21.11.2019) ↑

- Осуществление финансового контроля в России
- Состав и свойства вычислительных систем. Информационное и математическое обеспечение вычислительных систем
- Американизмы в английском языке (Вопрос статуса американского варианта английского языка)
- Разработка конфигурации «Складской учет» в среде 1С:Предприятие.
- Классификация языков программирования высокого уровня
- Роль мотивации в поведении организации
- Особенности реализации кадровой стратегии на различных стадиях жизненного цикла организации (анализ влияния внешних и внутренних факторов)
- Основы программирования на языке HTML
- Анализ эффективности формирования портфеля ценных бумаг коммерческого банка (на примере ГПБ)
- Сводная и консолидированная бухгалтерская отчетность
- Учет затрат на производство по системе «Стандарт-кост» возможности применения на отечественном предприятии
- Типологии сообщений интегрированных коммуникаций (Интегрированные коммуникации организации)