
Упорядочивание массива
Содержание:

Введение.
1 глава - общая теоретическая (8-10 стр):
- языки программирования:
- Pascal, JavaScript, Python
- Использую язык JavaScript в работе.
Цель: Рассмотреть основные алгоритмы обработки массивов к практическому их применению.
Что такое Массив:
- Массив - это структура, представляющая собой упорядоченную совокупность элементов одного типа, объединенных одним именем. Массивы используются при обработке набора данных одного типа.
- Для получения доступа к элементу массива - используется индекс. Индекс определяет местоположения элемента в массиве, является величиной целого типа.
- Каждому массиву отводится место в памяти, последовательно расположенных друг за другом ячеек, в каждую из которых записывается значение соответствующего элемента.
история криптографии:
- Шифрование в наше время достигается за счет использования алгоритмов, которые имеют ключ для шифрования и дешифрования информации. Эти ключи преобразования сообщений и данных в «цифровой бредом» с помощью шифрования, а затем вернуть их в первоначальном виде через дешифрования. В общем, чем длиннее ключ, тем труднее взломать код. Это справедливо, потому что расшифровка зашифрованного сообщения с помощью грубой силы требует атакующего попробовать каждый возможный ключ.
- Чтобы поместить это в контексте, каждый двоичный блок информации, или бита, имеет значение, равное 0 или 1. 8-битный ключ будет тогда иметь 256 или 2 ^ 8 возможных ключей. A 56-битный ключ будет иметь 2 ^ 56, или 72 квадриллионов, возможные ключи, чтобы попытаться расшифровать сообщение.
- С современной технологией, шифры с помощью клавиш с этими длинами становится легче расшифровать. DES, раннее правительство США одобрило шифр, имеет эффективную длину ключа 56 бита, и тестовые сообщения, использующие этот шифр было разбиты перебор ключа поиском. Тем не менее, по мере развития техники, так что делает качество шифрования. После Второй мировой войны, один из наиболее заметных достижений в изучении криптографии является введением асимметричных ключевых Cyphers (иногда называют открытым ключом шифров). Эти алгоритмы, которые используют два математически связанных ключей для шифрования одного и того же сообщения. Некоторые из этих алгоритмов позволяют публикации одного из ключей, из-за его чрезвычайно трудно определить один ключ просто от знания других.
- Начиная примерно с 1990 года, использование Интернета в коммерческих целях , и введение торговых сделок через Интернет призвал к широко распространенному стандарту для шифрования. Перед введением Advanced Encryption Standard (AES), информация , посланная через Интернет, например, финансовые данные, была зашифрована , если вообще, чаще всего с использованием стандарта шифрования данных (DES). Это было одобрено NBS (агентство правительства США) для своей безопасности, после того, как публичный призыв к и конкуренции среди, кандидатов для такого шифровальщика алгоритма. DES был одобрен в течение короткого периода, но видел Продолжительное использование из - за сложные споры по поводу использования общественности высокого шифрования качества. DES был окончательно заменен AES после очередного публичного конкурса , организованного правопреемника агентством НБС, NIST. Примерно в конце 1990 - х до начала 2000 - х, использование открытых ключей алгоритмов стало более распространенным подходом для шифрования, и вскоре гибрид два схем стало наиболее приемлемым способом для операций электронной коммерции , чтобы продолжить. Кроме того, создание нового протокола , известного как Secure Socket Layer или SSL, проложили путь для онлайн - транзакций, чтобы иметь место. Сделки , начиная от покупки товаров в интернет - оплаты счетов и банковских услуг используется протокол SSL. Кроме того, как беспроводное подключение к Интернету стало более распространенным среди домохозяйств, необходимость шифрования выросла, как уровень безопасности был необходим в этих повседневных ситуациях.
- Клод Шеннон-Claude E. Shannon , по мнению многих, является отцом математической криптографии. Шеннон работал в течение нескольких лет в Bell Labs, и во время своего пребывания там, он подготовил статью под названием «Математическая теория криптографии». Эта статья была написана в 1945 году и в конце концов , была опубликована в Bell System Technical Journal в 1949 году Принято считать , что этот документ стал отправной точкой для развития современной криптографии. Шеннон был вдохновлен во время войны для решения «[т] он проблемы криптографии [потому что] секретность система обставить интересное применение теории коммуникации». Шеннон определил две основные цели: криптография секретности и подлинности. Его внимание было сосредоточено на изучении секретности и тридцать пять лет спустя, ГДж Симмонс будет рассматривать вопрос о подлинности. Шеннон написал еще статью под названием «Математическая теория связи» , который выдвигает на первый план один из наиболее важных аспектов его работы: переход криптографии от искусства к науке.
- В своих работах, Шеннон описал два основных типа систем секретности. Первый являются те, разработаны с целью защиты от хакеров и злоумышленников, которые имеют бесконечные ресурсы, с помощью которых можно расшифровать сообщение (теоретическую тайну, в настоящее время безусловной безопасности), а второй являются те, которые предназначены для защиты от хакеров и атак с ограниченными ресурсами, с которыми расшифровать сообщение (практическое секретность, в настоящее время вычислительная безопасности). Большая часть работы Шеннона сосредоточена вокруг теоретической тайны; здесь, Шеннон ввел определение для «неразрушимости» шифра. Если шифр был определен «нерушимый», считалось иметь «совершенную секретность». При доказательстве «совершенной секретности», Шеннон определил, что это может быть получен только с помощью секретного ключа, длина которого дано в двоичных цифр было больше или равно количеству битов, содержащихся в информации шифруется. Кроме того, Шеннон разработал «Юнисити расстояние», определяемое как «сумма открытого текста, что ... определяет секретный ключ.»
- работа Шеннона влияния на дальнейшее исследование криптографии - в 1970-х годах, как с открытым ключом разработчиков криптографическими, ME Hellman и W. Diffie процитировали исследование Шеннона в качестве основного влияния. Его работа также повлияли современные конструкции секретных ключевых шифров. В конце работы Шеннона с криптографией, прогресс замедлился до Хеллман и Дифй не представили свои бумаги с участием «криптографии с открытым ключом».
- В середине 1970-х годов увидел двух крупных общественных (то есть, не секрет) авансов. Во- первых стала публикация проекта Data Encryption Standard в США Federal Register 17 марта 1975 г. Предложенный DES Шифр был представлен исследовательской группой в IBM , по приглашению Национального бюро стандартов (теперь NIST ), в целях разработать надежные средства электронной связи для предприятий , таких как банки и другие крупные финансовые организации. После консультации и модификации по АНБ , действуя за кулисами, она была принята и опубликована как Federal Information Processing Standard Публикация в 1977 году ( в настоящее время FIPS 46-3 ). DES был первым общедоступным шифром , чтобы быть «благословляли» национальным агентством такого как АНБ. Высвобождение его спецификации НБС стимулируется взрыв общественного и академического интереса к криптографии.
- Старение DES был официально заменен Advanced Encryption Standard (AES) в 2001 году , когда NIST объявил FIPS 197. После проведения открытого конкурса, NIST выбран Rijndael , который был представлен двумя бельгийскими криптографами, быть AES. DES, и более безопасные варианты него (например, Triple DES ), все еще используются сегодня, будучи включены во многие национальные и организационные стандарты. Тем не менее, его 56-битный ключ размера было показано, что недостаточно для защиты от грубой силы (одна такая атака, предпринятая кибер группы гражданских прав Электронный фонд Frontier в 1997 году, удалось в 56 часов.) В результате, использование прямого шифрования DES теперь , без сомнения , небезопасного для использования в новых конструкциях криптосистемы и сообщения , защищенные с помощью старых криптосистем DES, да и вообще все сообщений , отправленных с 1976 года с использованием DES, также подвержены риском. Независимо от присущего качества DES», считалось , что размер DES ключ (56-бит) , чтобы быть слишком мал , некоторые даже в 1976 году, возможно , наиболее публично Диффи . Было подозрение , что правительственные организации даже тогда имели достаточную вычислительную мощность , чтобы сломать сообщения DES; очевидно , другие достигли этой возможности.
- Второе развитие, в 1976 году, было , пожалуй , еще более важно, она коренным образом изменила способ криптосистемы может работать. Это была публикация бумажными Новые направления в криптографии по Диффи и Мартина Хеллмана. Он ввел радикально новый метод распространения криптографических ключей, которые пошли далеко в сторону решения одной из фундаментальных проблем криптографии, распределения ключей, и стал известен как обмен ключами Диффи-Хеллмана. В статье также стимулировала почти сразу же общественное развитие нового класса алгоритмов шифрования, в асимметричных ключевых алгоритмов .
- До этого времени все полезные современные алгоритмы шифрования были симметричным ключом алгоритмы , в которых тот же криптографический ключ используется с базовым алгоритмом на отправителя и получателя, который должен и держать его в тайне. Все электромеханических машин , используемых во время Второй мировой войны были этим логического класс, как были Цезарь и Atbash шифры и практически все системы шифрования на протяжении всей истории. «Ключ» для кода, конечно же , кодовая книга, которая также должна быть распределена и держится в секрете, и поэтому акции большинство тех же проблем на практике.
- По необходимости, ключ в каждой такой системе должны был быть обменен между взаимодействующими сторонами в каком - то безопасном способе предварительного любого использования системы (термин обычно используется «через защищенный канал ») , такие как надежный курьер с портфелем в наручниках к запястью, или лицом к лицу контакта, или верного голубиной. Это требование никогда не тривиальна и очень быстро становится неуправляемой , как число участников увеличивается, или когда защищенные каналы не доступны для обмена ключами, или когда, как разумно криптографической практике, ключи часто меняются. В частности, если сообщения предназначены для защищенных от других пользователей, отдельный ключ требуется для каждой возможной пары пользователей. Система такого типа известна как секретный ключ, или симметричный ключ криптосистема. DH обмена ключами (и последующие усовершенствования и варианты) сделали работу этих систем намного проще и безопаснее, чем когда - либо было возможно прежде всего истории.
- В противоположность этому , ключ асимметричного шифрования использует пару математически связанных ключей, каждый из которых расшифровывает шифрование выполняется с помощью другого. Некоторые, но не все из этих алгоритмов имеют дополнительное свойство , что один из парных ключей не может быть выведены из других любого известного способа , кроме проб и ошибок. Алгоритм такого рода известен как открытый ключ или асимметричный ключ система. Использование такого алгоритма, только одна пара ключей необходима для каждого пользователя. Обозначив один ключ из пары , как частные (всегда тайна), а другой , как общественные (часто широко доступны), не защищенный канал не требуется для обмена ключами. До тех пор , как секретный ключ остается в тайне, открытый ключ может быть широко известны в течение очень долгого времени без ущерба для безопасности, что делает его безопасным для повторного использования той же пары ключей на неопределенный срок.
- Для два пользователей алгоритма асимметричного ключа для безопасного обмена данных через незащищенный канал, каждый пользователь должен знать свои собственные открытые и закрытые ключи, а также открытый ключ другого пользователя. Возьмите этот базовый сценарий: Алиса и Боб имеют пару ключей они использовали в течение многих лет со многими другими пользователями. В начале своего сообщения, они обмениваются открытыми ключами, в незашифрованном виде по незащищенной линии. Затем Алиса шифрует сообщение с помощью своего закрытого ключа, а затем повторно шифрует , что результат , используя открытый ключ Боба. Сообщение дважды шифруется затем посылается в виде цифровых данных по проводам от Алисы к Бобу. Боб принимает битовый поток и расшифровывает его используя свой закрытый ключ, а затем расшифровывает этот поток битов , используя открытый ключ Алисы. Если конечный результат узнаваем как сообщение, Боб может быть уверен , что сообщение действительно пришло от кого - то , кто знает секретный ключ Алисы (предположительно на самом деле ее , если она была осторожнее с ее закрытым ключом), и что кто -то подслушивали на канале будет нуждаться Боб Секретный ключ для того , чтобы понять сообщение.
- Асимметричные алгоритмы основываются: на их эффективность на классе задач по математике называемых односторонние функции, которые требуют сравнительно небольшой вычислительной мощности для выполнения, но огромное количество силы , чтобы обратить вспять, если разворот возможно. Классический пример функции односторонний является умножением очень больших простых чисел. Это довольно быстро перемножить два больших простых чисел, но очень трудно найти факторы произведение двух больших простых чисел. Из математики односторонних функций, большинство возможных ключей являются плохим выбором в качестве криптографических ключей; лишь малая часть из возможных ключей заданной длины являются подходящими, так и асимметричные алгоритмы требуют очень длинные ключи , чтобы достичь того же уровня безопасности , предоставляемой относительно коротких симметричных ключей. Необходимость как генерировать пары ключей, а также выполнять шифрование / дешифрование операции делают асимметричные алгоритмы вычислительных затрат, по сравнению с большинством симметричных алгоритмов. Так как симметричные алгоритмы часто можно использовать любую последовательность (случайные, или по крайней мере непредсказуемых) бит в качестве ключа, одноразовый ключ сеанса может быть быстро генерируется для кратковременного использования. Следовательно, это обычная практика , чтобы использовать длинный асимметричный ключ для обмена одноразового, гораздо короче (но столь же сильный) ключа симметричного. Медленнее алгоритм асимметричный надежно посылает симметричный ключ сеанса, и тем быстрее симметричный алгоритм берет на себя в течение оставшейся части сообщения.
- Асимметричная ключом: Диффи-Хеллмана обмена ключами, и самый известный из открытого ключа / закрытого ключа алгоритма (т.е. то, что обычно называется алгоритм RSA), все, кажется, были независимо друг от друга разработали в разведслужбы Великобритании до публичного объявления Диффи и Хеллман в 1976 году ЦПС выпустила документы, утверждая, что они разработали криптографию с открытым ключом перед публикацией статьи Диффи и Хеллман. Различные объявления документы были написаны в ЦПС в течение 1960-х и 1970-х годов, которые в конечном счете привели к схемам, по существу, идентичных шифрования RSA и для обмена ключами Диффи-Хеллмана в 1973 и 1974 годах Некоторые из них уже были опубликованы, и изобретатели (Джеймс Х. Эллис Клиффорд петухи, и Malcolm Williamson) обнародовали (некоторые) их работы.
- Хэш- это распространенный метод используется в криптографии для кодирования информации быстро , используя типичные алгоритмы. Как правило, алгоритм применяется к строке текста, и результирующая строка становится «хэш - значение». Это создает «цифровой отпечаток» сообщений, так как конкретное значение хэша используется для идентификации конкретного сообщения. Выход из алгоритма также упоминается как «дайджеста сообщения» или «контрольной суммы». Хэш хорош для определения , если информация была изменена в передаче. Если хэш - значение отличается от приема , чем после отправки, есть свидетельства того , как сообщение было изменено. После того, как алгоритм был применен к данным , которые будут хэшированными, хэш - функция производит выход фиксированной длиной. По существу, все, что прошло через хэш - функции должны решить к тому же выходной длины , как и все остальное передается через ту же хэш - функции. Важно отметить , что хеширование не то же самое , как шифрование. Хеширование является односторонняя операция, которая используется для преобразования данных в сжатом дайджеста сообщения. Кроме того, целостность сообщения может быть измерена с хэширования. С другой стороны , шифрование является двунаправленной операцией, которая используется для преобразования открытого текста в шифре текст , а затем наоборот. В шифровании, конфиденциальность сообщения гарантируется.
- Хэш - функции могут быть использованы для проверки цифровых подписей, так что при подписании документов через Интернет, подпись применяется к одному конкретному человеку. Многое , как рукописной подписи, эти подписи проверяются путем присвоения их точного хэш - код для человека. Кроме того, хэширования применяется к паролям для компьютерных систем. Хеширования паролей начал с UNIX операционной системы. Пользователь в системе будет первым создать пароль. Этот пароль будет хэшированным, используя алгоритм или ключ, а затем хранится в файле пароли. Это по - прежнему видным сегодня, как веб - приложений , которые требуют пароли часто пароли хэш - пользователя и хранить их в базе данных.
- Общественные события 1970 -ых лет нарушили монополию на высоком качестве криптографии проводимой правительственных организаций (см S Левите Crypto для журналистского учета некоторых политических противоречий времени в США). Впервые в истории эти внешние правительственные организации имели доступ к криптографии не легко разрушаемый никто (включая правительство). Значительные споры и конфликты, как государственные , так и частные, стали более или менее сразу, иногда называют крипто войну . Они еще не утихли. Во многих странах, например, экспорт криптографии подлежит ограничениям. До 1996 года экспорт из США криптографии с использованием ключей длиной более 40 бит (слишком мал , чтобы быть очень защищенным от знающего злоумышленником) был резко ограничен. Совсем недавно , в 2004 году, бывшее ФБР директор Луис Фри , свидетельствуя перед Комиссией 9/11 , призвали новые законы против публичного использования шифрования.
- Одним из самых значимых людей в пользу сильного шифрования для общественного пользования был Фил Циммерман . Он писал , а затем в 1991 году выпустили PGP (Pretty Good Privacy), очень высокое качество системы шифрования . Он распространил бесплатную версию PGP , когда он чувствовал угрозу законодательства затем при рассмотрении правительства США , что потребует лазейки должны быть включено во всех криптографических продуктах , разработанных в США. Его система была выпущена во всем мире вскоре после того, как он выпустил его в США, и что началось длительное расследование уголовного дела о его отделом правительства США юстиции за якобы нарушение экспортных ограничений. Министерство юстиции в конце концов отказался от своего дела против Циммермана, и бесплатное распространение PGP продолжает по всему миру. PGP даже в конечном счете , стал открытым интернет - стандарт ( RFC 2440 или OpenPGP ).
- В то время как современные шифры , такие как AES и более высокого качества асимметричных шифров широко считается нерушимой, плохие проекты и реализации до сих пор иногда приняты и произошли важные криптографические разрывы развернутых криптографических систем в последние годы. Известные примеры сломанных криптографических конструкций включают первую Wi-Fi схему шифрования WEP , то Content скремблирования System используется для шифрования и контроля использования DVD, A5 / 1 и A5 / 2 шифров , используемых в GSM сотовых телефонов и Crypto-1 шифр , используемые в широко используется MIFARE Классические смарт - карт от компании NXP Semiconductors , прядильного от деления Philips Electronics . Все эти симметричные шифры. До сих пор не один из математических идей , лежащих в основе криптографии с открытым ключом было доказано, что «нерушимой», и поэтому некоторые будущие авансовый математический анализ могли бы сделать системы , опираясь на них небезопасно. В то время как несколько информированных наблюдателей предвидеть такой прорыв, размер ключа рекомендуется для обеспечения безопасности , как лучшая практика продолжает расти , как увеличение вычислительной мощности, необходимую для ломающихся кодов становится дешевле и доступнее.
2 глава - практического решения конкретной задачи, которое отражено в названии темы курсовой работы (10-12 стр):
2.1. Описание задачи:
2.1.1. Формулировка задачи(Язык , JavaScript):
В Формулировке задачи разделе: дается понятие констант, переменных, показываются основные команды для работы с ними
После вступления о способе хранения данных в программе «всякая обрабатываемая величина занимает своё место – поле в памяти компьютера » излагается о 3х основных типах величин, изучаемых в учебнике: числовой, символьный, логический, устанавливаются различия между константами и переменными:
- «константы записываются своими десятичными записями в памяти, их значение не изменяется во время работы программы»;
- «переменные обозначаются, как в математике, символьными именами - идентификаторами».
Далее рассматриваются основные операции над переменными:
- Присваивание
<переменная>:=<выражение>
Пример : Z:=X+Y
|
До присваивания |
X |
2 |
Y |
5 |
Z |
- |
|
После присваивания |
X |
2 |
Y |
5 |
Z |
7 |
- Команда ввода:
Ввод<список переменных>
Пример: ввод A, B, C
2.1.2.Примеры применения задачи:
Примеры:
1. обмен значениями 2х переменных. Для решения применяется аналогия с двумя стаканами (с молоком и водой) для смены значений которых используется третий, после которой решение становится очевидным.
2. даны 2 правильные дроби, найти дробь – результат деления одной на вторую.
Решение сводится к правилам учебника математики.
Задания по разделу:
Массивы предоставляют множество методов. Чтобы было проще, в этой главе они разбиты на группы.
1.1. Добавление/удаление элементов:
Я уже знаю методы, которые добавляют и удаляют элементы из начала или конца:
- arr.push(...items) – добавляет элементы в конец;
- arr.pop() – извлекает элемент из конца;
- arr.shift() – извлекает элемент из начала;
- arr.unshift(...items) – добавляет элементы в начало.
Есть и другие.
Как удалить элемент из массива?
Так как массивы – это объекты, то можно попробовать delete:
let arr = ["I", "go", "home"];
delete arr[1]; // удалить "go"
alert( arr[1] ); // undefined
// теперь arr = ["I", , "home"];
alert( arr.length ); // 3
Вроде бы, элемент и был удалён, но при проверке оказывается, что массив всё ещё имеет 3 элемента arr.length == 3.
Это нормально, потому что всё, что делает delete obj.key – это удаляет значение с данным ключом key. Это нормально для объектов, но для массивов мы обычно хотим, чтобы оставшиеся элементы сдвинулись и заняли освободившееся место. Мы ждём, что массив станет короче.
Поэтому для этого нужно использовать специальные методы.
Метод arr.splice(str) – это универсальный «швейцарский нож» для работы с массивами. Умеет всё: добавлять, удалять и заменять элементы.
Его синтаксис:
arr.splice(index[, deleteCount, elem1, ..., elemN])
Он начинает с позиции index, удаляет deleteCount элементов и вставляет elem1, ..., elemN на их место. Возвращает массив из удалённых элементов.
Этот метод проще всего понять, рассмотрев примеры.
Начну с удаления:
let arr = ["Я", "изучаю", "JavaScript"];
arr.splice(1, 1); // начиная с позиции 1, удалить 1 элемент
alert( arr ); // осталось ["Я", "JavaScript"]
Легко, правда? Начиная с позиции 1, он убрал 1 элемент.
В следующем примере мы удалим 3 элемента и заменим их двумя другими.
1.3. Метод slice.
Метод arr.slice намного проще, чем похожий на него arr.splice.
Его синтаксис:
arr.slice([start], [end])
Он возвращает новый массив, в который копирует элементы, начиная с индекса start и до end (не включая end). Оба индекса start и end могут быть отрицательными. В таком случае отсчёт будет осуществляться с конца массива.
Это похоже на строковый метод str.slice, но вместо подстрок возвращает подмассивы.
Например:
let arr = ["t", "e", "s", "t"];
alert( arr.slice(1, 3) ); // e,s (копирует с 1 до 3)
alert( arr.slice(-2) ); // s,t (копирует с -2 до конца)
Можно вызвать slice и вообще без аргументов: arr.slice() создаёт копию массива arr. Это часто используют, чтобы создать копию массива для дальнейших преобразований, которые не должны менять исходный массив.
Метод arr.concat создаёт новый массив, в который копирует данные из других массивов и дополнительные значения.
Его синтаксис:
arr.concat(arg1, arg2...)
Он принимает любое количество аргументов, которые могут быть как массивами, так и простыми значениями.
В результате мы получаем новый массив, включающий в себя элементы из arr, а также arg1, arg2 и так далее…
Если аргумент argN – массив, то все его элементы копируются. Иначе скопируется сам аргумент.
Например:
let arr = [1, 2];
// создать массив из: arr и [3,4]
alert( arr.concat([3, 4]) ); // 1,2,3,4
// создать массив из: arr и [3,4] и [5,6]
alert( arr.concat([3, 4], [5, 6]) ); // 1,2,3,4,5,6
// создать массив из: arr и [3,4], потом добавить значения 5 и 6
alert( arr.concat([3, 4], 5, 6) ); // 1,2,3,4,5,6
Обычно он просто копирует элементы из массивов. Другие объекты, даже если они выглядят как массивы, добавляются как есть:
let arr = [1, 2];
let arrayLike = {
0: "что-то",
length: 1
};
alert( arr.concat(arrayLike) ); // 1,2,[object Object]
…Но если объект имеет специальное свойство Symbol.isConcatSpreadable, то он обрабатывается concat как массив: вместо него добавляются его числовые свойства.
Для корректной обработки в объекте должны быть числовые свойства и length:
let arr = [1, 2];
let arrayLike = {
0: "что-то",
1: "ещё",
[Symbol.isConcatSpreadable]: true,
length: 2
};
alert( arr.concat(arrayLike) ); // 1,2,что-то,ещё
1.5.Перебор: forEach.
Метод arr.forEach позволяет запускать функцию для каждого элемента массива.
Его синтаксис:
arr.forEach(function(item, index, array) {
// ... делать что-то с item
});
Например, этот код выведет на экран каждый элемент массива:
// Вызов alert для каждого элемента
["Bilbo", "Gandalf", "Nazgul"].forEach(alert);
А этот вдобавок расскажет и о своей позиции в массиве:
["Bilbo", "Gandalf", "Nazgul"].forEach((item, index, array) => {
alert(`${item} имеет позицию ${index} в ${array}`);
});
Результат функции (если она вообще что-то возвращает) отбрасывается и игнорируется.
let arr = ["Я", "изучаю", "JavaScript", "прямо", "сейчас"];
// удалить 3 первых элемента и заменить их другими
arr.splice(0, 3, "Давай", "танцевать");
alert( arr ) // теперь ["Давай", "танцевать", "прямо", "сейчас"]
Здесь видно, что splice возвращает массив из удалённых элементов:
let arr = ["Я", "изучаю", "JavaScript", "прямо", "сейчас"];
// удалить 2 первых элемента
let removed = arr.splice(0, 2);
alert( removed ); // "Я", "изучаю" <-- массив из удалённых элементов
Метод splice также может вставлять элементы без удаления, для этого достаточно установить deleteCount в 0:
let arr = ["Я", "изучаю", "JavaScript"];
// с позиции 2
// удалить 0 элементов
// вставить "сложный", "язык"
arr.splice(2, 0, "сложный", "язык");
alert( arr ); // "Я", "изучаю", "сложный", "язык", "JavaScript"
Отрицательные индексы разрешены
В этом и в других методах массива допускается использование отрицательного индекса. Он позволяет начать отсчёт элементов с конца, как тут:
let arr = [1, 2, 5];
// начиная с индекса -1 (перед последним элементом)
// удалить 0 элементов,
// затем вставить числа 3 и 4
arr.splice(-1, 0, 3, 4);
alert( arr ); // 1,2,3,4,5
В этом параграфе вводятся основные понятия о массивах: определение, описание, ввод значений на ШАЯ, пример задачи – расчет среднего значения элементов массива.
Школьники уже знакомы с принципом табличной организации данных из БД.
Что такое массив:
Дается определение массива: М – представление таблиц в языках программирования.
Пример – запись температуры воздуха по месяцам
|
Месяц |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
|
Температура |
23 |
12 |
1 |
0 |
-1 |
-12 |
-1,2 |
2,2 |
2 |
3 |
0 |
-1 |
.
На основе этого примера вводится понятие линейной таблицы с индексированными именами, которая
«в программировании называется одномерным массивом .
В примере: Запись Т[1] в данном примере показывает температуру в 1 месяце. Т - имя массива. Порядковый номер элемента – его индекс.
Каждый элемент обозначается так: < имя массива>[<индекс>]»
Так вводится имя массива и его элементов. Далее говорится, что элементы массива должны иметь одинаковый тип . (в примере - вещественный).
Пофантазируйте: пусть это будет сложный шифр или нахождение площади произвольной фигуры, а не треугольника и прочее.
2.2.3. Интерфейс пользователя (картинка) с обоснованием эргономики:
2.2. Техническое задание:
Алгоритм "Сортировка выбором".
Является одним из самых простых алгоритмов сортировки массива. Смысл в том, чтобы идти по массиву и каждый раз искать минимальный элемент массива, обменивая его с начальным элементом не отсортированной части массива. На небольших массивах может оказаться даже эффективнее, чем более сложные алгоритмы сортировки, но в любом случае проигрывает на больших массивах. Число обменов элементов по сравнению с "пузырьковым" алгоритмом N/2, где N - число элементов массива.
Алгоритм Выполнения:
1. Находим минимальный элемент в массиве.
2. Меняем местами минимальный и первый элемент местами.
3. Опять ищем минимальный элемент в не отсортированной части массива
4. Меняем местами уже второй элемент массива и минимальный найденный, потому как первый элемент массива является отсортированной частью.
5. Ищем минимальные значения и меняем местами элементы, пока массив не будет отсортирован до конца.
//Сортировка выбором {---
Функция СортировкаВыбором(Знач Массив)
Мин = 0;
Для i = 0 По Массив.ВГраница() Цикл
Мин = i;
Для j = i + 1 ПО Массив.ВГраница() Цикл //Ищем минимальный элемент в массиве
Если Массив[j] < Массив[Мин] Тогда
Мин = j;
КонецЕсли;
КонецЦикла;
Если Массив [Мин] = Массив [i] Тогда //Если мин. элемент массива = первому элементу неот. части массива, то пропускаем.
Продолжить;
КонецЕсли;
Смена = Массив[i]; //Производим замену элементов массива.
Массив[i] = Массив[Мин];
Массив[Мин] = Смена;
КонецЦикла;
Возврат Массив;
КонецФункции
2.2.1. Входные и выходные данные – их типы и ограничения:
Программа состоит из трех главных модулей:
- Модуль нахождения Минимального ил;
- Модуль по изменению местами первый элемента в Массиве;
- Тестовый модуль (в Упорядочивании Массива).
2.2.2. Возможные ошибки пользователя и их обработка:
В случае ошибок программистов моя цель ясна. Мне надо найти их и исправить.
Таковые ошибки варьируются от простых опечаток, на которые компьютер пожалуется сразу же, как только увидит программу, до скрытых ошибок в нашем понимании того, как программа работает, которые приводят к неправильным результатам в особых случаях. Ошибки последнего рода можно искать неделями.
Разные языки по-разному могут помогать вам в поиске ошибок. К сожалению, JavaScript находится на конце этой шкалы, обозначенном как «вообще почти не помогает». Некоторым языкам надо точно знать типы всех переменных и выражений ещё до запуска программы, и они сразу сообщат вам, если типы использованы некорректно. JavaScript рассматривает типы только во время исполнения программ, и даже тогда он разрешает делать не очень осмысленные вещи без всяких жалоб, например:
x = true * "обезьяна"
На некоторые вещи JavaScript всё-таки жалуется. Написание синтаксически неправильной программы сразу вызовет ошибку. Другие ошибки, например вызов чего-либо, не являющегося функцией, или обращение к свойству неопределённой переменной, возникнут при выполнении программы, когда она сталкивается с такой бессмысленной ситуацией.
Но часто ваши бессмысленные вычисления просто породят NaN (not a number) или undefined. Программа радостно продолжит, будучи уверенной в том, что она делает что-то осмысленное. Ошибка проявит себя позже, когда такое фиктивное значение уже пройдёт через несколько функций. Она может вообще не вызвать сообщение об ошибке, а просто привести к неправильному результату выполнения. Поиск источника таких проблем – сложная задача.
Процесс поиска ошибок (bugs) в программах называется отладкой (debugging).
Строгий режим (strict mode)
JavaScript можно заставить быть построже, переведя его в строгий режим. Для этого наверху файла или тела функции пишется «use strict». Пример:
function canYouSpotTheProblem() {
"use strict";
for (counter = 0; counter < 10; counter++)
console.log("Всё будет офигенно");
}
canYouSpotTheProblem();
// → ReferenceError: counter is not defined
Обычно, когда ты забываешь написать var перед переменной, как в примере перед counter, JavaScript по-тихому создаёт глобальную переменную и использует её. В строгом режиме выдаётся ошибка. Это очень удобно. Однако, ошибка не выдаётся, когда глобальная переменная уже существует – только тогда, когда присваивание создаёт новую переменную.
Ещё одно изменение – привязка this содержит undefined в тех функциях, которые вызывали не как методы. Когда мы вызываем функцию не в строгом режиме, this ссылается на объект глобальной области видимости. Поэтому если вы случайно неправильно вызовете метод в строгом режиме, JavaScript выдаст ошибку, если попытается прочесть что-то из this, а не будет радостно работать с глобальным объектом.
2.2.3. Выбор языка программирования:
Для Упорядочивание массива я выбрал язык JavaScript.
2.3. Решение задачи:
Программа представляет собой Упорядочивании массива.
После запуска программы открывается окно регистрации, в котором пользователь может зарегистрироваться, нажав соответствующую кнопку, или продолжить работу, выбрав свое имя из списка и введя свой пароль.
Для контроля работы пользователей, в программе предусмотрена функция «показать оценки».
Древесная сортировка:
Задача. Упорядочить заданный набор (возможно, с повторениями) некоторых элементов (чисел, слов, т.п.).
Алгоритм Выполнения TreeSort:
- Для сортируемого множества элементов построить дерево двоичного поиска:
- первый элемент занести в корень дерева;
- для всех остальных элементов: начать проверку с корня; двигаться влево или вправо (в зависимости от результата сравнения с текущей вершиной дерева) до тех пор, пока не встретится такой же элемент, либо пока не встретится nil. Во втором случае нужно создать новый лист в дереве, куда и будет записано значение нового элемента.
- Совершить синтаксический обход построенного дерева, печатая каждую встреченную вершину столько раз, сколько было ее вхождений в сортируемый набор.
Реализация:
Мы приведем реализацию первого шага алгоритма, сортирующего числа (для элементов другой природы потребуется изменить только процесс считывания):
new(root);
read(f,root^.chislo);
root^.kol:= 1;
root^.left:= nil;
root^.right:= nil;
while not eof(f) do
begin
read(f,x);
p:= root;
while true do
begin
if x = p^.chislo
then begin inc(p^.kol);
break
end;
if x > p^.chislo
then if p^.right <> nil
then p:= p^.right
else begin new(p^.right);
p:= p^.right;
p^.chislo:= x;
p^.kol:= 1;
p^.left:= nil;
p^.right:= nil;
break
end
(* x < p^.chislo *)
else if p^.left <> nil
then p:= p^.left
else begin new(p^.left);
p:= p^.left;
p^.chislo:= x;
p^.kol:= 1;
p^.left:= nil;
p^.right:= nil;
break
end
end;
end;
Алгоритм Комп Связ-Итер:
Прочитать начало и конец очередного ребра. Далее возможны 4 различные ситуации:
- Оба конца ребра еще не относятся ни к одной из ранее встретившихся компонент связности ( mark[u]=0 и mark[v]=0 ). В этом случае количество компонент связности kol увеличивается на единицу, а новая компонента связности получает очередной номер ks+1.
- Один конец ребра уже относится к какой-то компоненте связности, а второй - еще нет ( mark[u]=0, а mark[v]<>0 ). В этом случае общее количество компонент связности kol остается прежним, а непомеченный конец ребра получает ту же пометку, что и второй его конец.
- Оба конца нового ребра относятся к одной и той же компоненте связности ( mark[u]= mark[v]<>0 ). В этом случае не нужно производить никаких действий.
- Концы нового ребра относятся к разным компонентам связности (
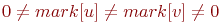 ). В этом случае нужно объединить две ранее созданные компоненты связности в одну. Общее количество компонент связности kol уменьшается на 1, а все вершины, принадлежавшие к более новой компоненте связности (больший номер), получают новую пометку. Заметим, что переменная ks, обозначающая очередной свободный номер для следующей компоненты связности, в данном случае изменяться не должна, поскольку нет никакой гарантии, что изменен будет номер именно самой последней компоненты связности.
). В этом случае нужно объединить две ранее созданные компоненты связности в одну. Общее количество компонент связности kol уменьшается на 1, а все вершины, принадлежавшие к более новой компоненте связности (больший номер), получают новую пометку. Заметим, что переменная ks, обозначающая очередной свободный номер для следующей компоненты связности, в данном случае изменяться не должна, поскольку нет никакой гарантии, что изменен будет номер именно самой последней компоненты связности.
По окончании работы этого алгоритма в массиве mark будет записано S различных целых чисел, каждое из которых будет означать отдельную компоненту связности. Кроме того, в массиве могут остаться нулевые компоненты: каждая из них будет соответствовать изолированной вершине, которая тоже является отдельной компонентой связности. Следовательно, количество нулей должно быть прибавлено к количеству компонент, найденному в процессе работы основного алгоритма.
Реализация задачи:
kol:=0;
ks:=0;
while not eof(f) do
begin
readln(f,u,v);
if mark[u]=0
then if mark[v]=0
then begin {случай 1}
inc(kol);
inc(ks);
mark[u]:= ks;
mark[v]:= ks;
end
else mark[u]:= mark[v] {случай 2}
else if mark[v]=0
then mark[v]:= mark[u]
{случай 2 - симметричный}
else if mark[u]<>mark[v] {случай 4}
then begin
max:= v;
min:= u;
if u>v then begin
max:= u;
min:= v end;
for i:= 1 to n do
if mark[i]= max
then mark[i]:= min;
dec(kol);
end
end;
for i:=1 to N do
if mark[i]=0 then inc(kol);
2.3.2. Описание переменных: идентификатор, тип:
javascript удалить элемент массива можно при помощи оператора delete:
var myColors = new Array("red", "green", "blue");
- При сравнении 40 и 100 метод sort() вызывает функцию сравнения (40,100).
- Функция вычисляет 40-100, и возвращает -60 (отрицательное значение).
- Функция сортировки сортирует 40 как значение ниже 100.
- Этот фрагмент кода можно использовать для сортировки чисел и сортировки по алфавиту:
<button onclick="myFunction1()">Сортировать по алфавиту</button>
<button onclick="myFunction2()">Сортировать по числам</button>
<p id="demo"></p>
<script>
var points = [40, 100, 1, 5, 25, 10];
document.getElementById("demo").innerHTML = points;
function myFunction1() {
points.sort();
document.getElementById("demo").innerHTML = points;
}
function myFunction2() {
points.sort(function(a, b){return a - b});
document.getElementById("demo").innerHTML = points;
}
</script>
Листинг программы в текстовом редакторе. Скриншот листинга в окне компилятора
Найти наибольшее или наименьшее значение массива:
Нет встроенных функций для нахождения максимального и минимального значение в массиве.
Однако, у вас есть отсортированный массив, вы можете использовать индекс для получения самых высоких и самых низких значений.
Сортировка по возрастанию:
Пример
var points = [40, 100, 1, 5, 25, 10];
points.sort(function(a, b){return a - b});
// теперь points[0] содержит наименьшее значение
// и points[points.length-1] содержит наибольшее значение
Сортировка по убыванию:
Пример
var points = [40, 100, 1, 5, 25, 10];
points.sort(function(a, b){return b - a});
// теперь points[0] содержит наибольшее значение
// и points[points.length-1] содержит наименьшее значение
Три разных варианта входных данных + варианты ошибок пользователя
Заключение:
Цель Выполнена по: Рассмотрению основных алгоритмов по обработке массивов к практическому их применению.
Для достижения данного результата была выполнена следующая работа:
- Рассмотрена предметная область по Упорядочиванию массива в нахождение Минимального числа.
- Рассмотрен комплекс задач по Упорядочиванию Массива, которые указаны в пункте Контрольного примера;
- Рассмотрено обеспечение задачи: по выполнению Массива рассмотрены используемые задачи, по результативности Нахождении Минимальных чисел или Сортировки по алфавиту Массива или;
- Рассмотрено программное обеспечение по выполнению Macromedia_Flash_8;
- Приведен контрольный пример реализации системы: описана работа базы данных, входные и выходные формы.
В данной работе была рассмотрена автоматизация учёта банковских операций.
Таким образом, целью данной курсовой работы было повышение эффективности по Упорядочиванию Массива- и рассмотрены виды по решению Массива в его Упорядочивании Минимального числа нахождения, Сортировки по алфавиту или числу.
Список литературы:
1.Информатика курс для обучения. Учебник для Вузов/под ред. С.В. Симоновича, - СПб.: Питер, 2014. – 250 с.
2.Симонович С. В., Евсеев Г.А., Практическая информатика, Учебное пособие. М.: АСТпресс, 2015. – 150 с.
3.Фигурнов В. Э. IBM PC для пользователя. М.: Инфра-М, 2014 г. – 250 с.
4.Операционные системы - http://www.asvu.ru/page.php?id=183

- Разработка устава проекта
- Автоматизация складского учета
- Ситуационный подход к менеджменту (ТЕОРЕТИЧЕСКИК АСПЕКТЫ СИТУАЦИОННОГО ПОДХОДА К МЕНЕДЖМЕНТУ)
- Правоотношения по социальному обслуживанию
- Суверенитет народа и формы его реализации
- ОРГАНЫ СУДЕБНОЙ ВЛАСТИ (Понятие судебной системы)
- Технология работы по организации отдыха и развлечений в гостинице (Типология гостиниц)
- Проблемы коммуникаций в современных организациях (Внутрикорпоративные коммуникации организации)
- Система органов местного самоуправления(Теоретические основы и этапы становления органов местного самоуправления )
- Управление миграционными процессами (Понятие миграция)
- Система управления качеством проекта
- Система управления качеством проекта(Управление качеством проекта: сущность и требования к качеству)