
Мультипроцессоры (Конвейерная и векторная обработка)
Содержание:

ВВЕДЕНИЕ
Среди всех изменений, которые произошли в области, связанной с научными исследованиями вычислительной техники, некоторые из них повлияли на изменение функций рабочих станций. Подчеркиваю:
1) рост мощи станций, оснащаемых человеко-машинными интерфейсами;
2) появление процессоров, предназначенных для специальных видов обработки данных;
3) расширение возможностей в области хранения информации;
4) появление средств, облегчающих доступ к ресурсам, распределенным по сети.
Прогресс в этих областях предоставляет все более новые возможности в том, что касается управления данными и эффективности обработки данных. После определения того, что представляет из себя мультипроцессорная и мультимашинная архитектура, мы автоматизируем основные понятия, на которых строятся возможности применения ресурсов нескольких машин:
- распределение или разделение;
- возможность взаимодействия;
- прозрачность;
- модель "клиент-сервер".
Цель темы моей курсовой работы заключается в описании мультипроцессорных систем и их классификации с различной архитектурой.
В настоящее время сфера применения мультипроцессорных систем (МПС) стабильно расширяется, охватывая все новые области в абсолютно различных отраслях науки, производства и бизнеса. Огромное развитие кластерных систем создает условия для использования мультипроцессорной техники в настоящем секторе экономики.
Потребность решения сложных прикладных задач с большим объемом вычислений и принципиальная ограниченность максимального быстродействия "классических" - по схеме фон Неймана - ЭВМ привели к появлению мультипроцессорных систем.
Использование таких средств вычислительной техники позволяет существенно увеличивать производительность электронно-вычислительных машин при любом уровне развития компьютерного оборудования.
Подробнее я расскажу о всех деталях, касаемых моей темы, в своей работе. Постараюсь раскрыть все моменты вычислительной техники, не упустив ничего важного и интересного.
Глава 1. МУЛЬТИПРОЦЕССОРЫ И МУЛЬТИМАШИНЫ
Мультипроцессоры
Мультипроцессор – это компьютерная система, которая содержит несколько процессоров и одно адресное пространство, видимое для всех процессоров. Мультипроцессор запускает одну копию операционной системы с одним набором таблиц, а также тех, которые следят, какие страницы памяти свободны.
В первой главе речь пойдет об аппаратной архитектуре, на базе которой функционируют методы распределенной обработки данных, а именно – архитектуре, которую мы называем мультимашиной, чтобы отличить ее от мультипроцессорной архитектуры.
Мы увидим, что это отличие не особо заметно, поскольку технический прогресс ведет к размыванию границ, не все так просто.
В целях увеличения вычислительных возможностей и для достижения большего параллелизма по сравнению с мультипрограммированием, предлагаемым ОС, на классические монопроцессорные машины с фоннеймановской архитектурой были установлены еще дополнительные процессоры.
Мультипроцессорные машины подразделяются на два типа:
- Жестко связанные мультипроцессоры (еще их называют жестко соединенные), в которых процессоры связаны через общую память (рис.1):
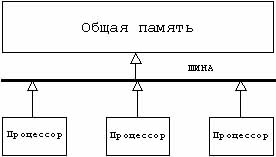
Рис 1. Жестко связанные мультипроцессоры[1]
- Слабо связанные мультипроцессоры (второе название – слабо соединенные), в которых процессоры связаны через средство связи (как правило, шину), отличное от общей памяти (рис.2.):

Рис. 2 Слабо связанные процессы[2]
Одной из основных проблем архитектуры многопроцессорных систем с общей памятью, которые возникают при организации параллельных вычислений на такого типа системах, является доступ с разных процессоров к общим данным и обеспечение, в связи с этим, однозначности содержимого разных КЭШей.
Все потому, что при наличии общих данных копии значений одних и тех же переменных могут оказаться в КЭШах разных процессоров. Если в такой ситуации один из процессоров выполнит изменение значения разделяемой переменной, то значения копий в КЭШах других процессоров окажутся не соответствующими действительности и их использование приведет к некорректности вычислений. Обеспечение однозначности КЭШей обычно реализуется на аппаратном уровне – для этого после изменения значения общей переменной все копии этой переменной в КЭШах отмечаются как недействительные и последующий доступ к переменной потребует обязательного обращения к основной памяти.
Стоит заметить, что необходимость обеспечения когерентности приводит к снижению скорости вычислений и затрудняет создание систем с достаточно большим количеством процессоров.
Конвейерная и векторная обработка
В основе конвейерной обработки лежит раздельное выполнение операций в несколько этапов с передачей данных одного этапа следующему. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняются сразу несколько операций. Конвейеризация эффективна только тогда, когда загрузка конвейера близка к полной, а скорость подачи соответствует максимальной производительности конвейера.
Если происходит задержка, то параллельно будет выполняться меньше операций и суммарная производительность снизится. Идеальную возможность полной загрузки вычислительного конвейера обеспечивают векторные операции.
Машины типа SIMD
Машины типа SIMD состоят из большого числа идентичных процессорных элементов, имеющих собственную память. Все ПЭ в такой машине выполняют одну и ту же программу[3].
Понятно, что такая машина, составленная из большого числа процессоров, может обеспечить очень высокую производительность только на тех задачах, в которых все процессоры могут делать одну и ту же работу.
Модель вычислений для машины SIMD очень похожа на модель вычислений для векторного процессора: одиночная операция выполняется над большим блоком данных. Модели вычислений на векторных и матричных вычислительных машинах настолько схожи, что эти ВМ часто рассматриваются как эквивалентные.
Машины типа MIMD
Термин "мультипроцессор" покрывает большинство машин типа MIMD и часто используется в качестве синонима для машин типа MIMD.
В МПС каждый процессорный элемент выполняет свою программу независимо от других ПЭ. Процессорные элементы, должны как-то связываться друг с другом, и в МПС с общей памятью (сильно связанных) имеется память данных и команд, доступная всем ПЭ. С общей памятью ПЭ связываются с помощью общей шины или сети обмена.
В противоположность этому варианту в слабосвязанных МПС (машинах с локальной памятью) вся память делится между ПЭ и каждый блок памяти доступен только связанному с ним процессору. Сеть обмена связывает процессорные элементы друг с другом.
МПС с SIMD-процессорами
Многие современные вычислительные системы представляют собой многопроцессорные системы, в которых в качестве процессоров используются векторные процессоры или процессоры типа SIMD. Такие машины относятся к машинам класса MSIMD.
Языки программирования и соответствующие компиляторы для машин типа MSIMD обычно обеспечивают языковые конструкции, которые позволяют программисту описывать параллелизм. В пределах каждой задачи компилятор автоматически векторизует подходящие циклы.
Многопроцессорные системы за годы развития вычислительной техники прошли ряд этапов своего развития. Исторически первой стала осваиваться технология SIMD. Но в настоящее время наметился устойчивый интерес к архитектурам MIMD. Этот интерес главным образом определяется двумя факторами[4]:
- Архитектура MIMD дает большую гибкость: при наличии адекватной поддержки со стороны аппаратных средств и программного обеспечения. MIMD может работать как однопользовательская система, обеспечивая высокопроизводительную обработку данных для одной прикладной задачи, как многопрограммная машина, выполняющая множество задач параллельно, и как некоторая комбинация этих возможностей.
- Архитектура MIMD может использовать все преимущества современной МПС технологии на основе учета соотношения стоимость/производительность. В действительности практически все современные МПС строятся на тех же микропроцессорах, которые можно найти в персональных компьютерах, рабочих станциях и небольших однопроцессорных серверах.
Одной из отличительных особенностей МПС является сеть обмена, с помощью которой процессоры соединяются друг с другом или с памятью. Модель обмена настолько важна для МПС, что многие характеристики производительности и другие оценки выражаются отношением времени обработки к времени обмена, соответствующим решаемым задачам.
Существуют две основные модели межпроцессорного обмена: одна основана на передаче сообщений, а другая - на использовании общей памяти.
В МПС с общей памятью один процессор осуществляет запись в конкретную ячейку, а другой процессор производит считывание из этой ячейки памяти. Чтобы обеспечить согласованность данных и синхронизацию процессов, обмен часто реализуется по принципу взаимно исключающего доступа к общей памяти методом "почтового ящика". Модель системы с общей памятью хороша и очень удобна для программирования и иногда рассматривается как высокоуровневое средство оценки влияния обмена на работу системы. И не помеха, если основная система в действительности реализована с применением локальной памяти и принципа передачи сообщений.
В МПС с локальной памятью разделение памяти невозможно. Вместо этого процессоры получают доступ к совместно используемым данным посредством передачи сообщений по сети обмена. Эффективность схемы коммуникаций зависит от протоколов обмена, основных сетей обмена и пропускной способности памяти и каналов обмена. В сетях с коммутацией каналов по мере возрастания требований к обмену следует учитывать возможность перегрузки сети. Здесь межпроцессорный обмен связывает сетевые ресурсы. К ним относятся буферы сообщений, каналы и процессоры. Объем передаваемой информации может быть сокращен за счет тщательной функциональной декомпозиции задачи, а также диспетчирования выполняемых функций.
Поэтому существующие МПС распадаются на две основные группы.
К первой группе относятся МПС с общей (разделяемой) основной памятью, объединяющие до нескольких десятков процессоров. Обычно это количество составляет менее 32. Небольшое количество процессоров в таких машинах позволяет иметь одну централизованную общую память и объединить процессоры и память с помощью всего лишь одной шины.
При наличии у процессоров КЭШ-памяти достаточного объема высокопроизводительная шина и общая память могут удовлетворить обращения к памяти, поступающие от нескольких процессоров. Из-за того, что имеется единственная память с одним и тем же временем доступа, эти МПС иногда называют – Uniform Memory Access. Сокращенно: UMA Такой способ организации со сравнительно небольшой разделяемой памятью в настоящее время является наиболее популярным.
Вторую группу МПС составляют крупномасштабные системы с распределенной памятью. Для того чтобы поддерживать большое количество процессоров приходится распределять основную память между ними. Либо полосы пропускания памяти просто может не хватить для удовлетворения запросов, поступающих от очень большого числа процессоров. Естественно при таком подходе также требуется реализовать связь процессоров между собой.
Глава 2. РАСПРЕДЕЛЕННАЯ ОБРАБОТКА ДАННЫХ
Что называют распределенной обработкой данных
Распределенная обработка данных – это обработка данных, проводимая в распределенной системе, при которой каждый из технологических или функциональных узлов системы может независимо обрабатывать локальные данные и принимать соответствующие решения[5].
Распределенная обработка данных позволяет разместить базу данных (или несколько БД) в различных узлах компьютерной сети. Таким образом, каждый компонент базы данных располагается по месту наличия техники и ее обработки.
Распределенная обработка данных (РОД) характерна для сетей ПЭВМ и создаваемых на их основе АРМ РОД и позволяет решать сложные задачи с использованием схемы распараллеливания вычислительного процесса. РОД характеризуется децентрализацией обработки информации с помощью рассредоточенных микро - ЭВМ, которые соединены линиями связи и имеют программно-информационную совместимость. РОД позволяет строить системы, в которых гибко сочетаются достоинства централизации и децентрализации. При разделении вычислительного потенциала системы между несколькими подразделениями предприятия предоставляется возможность локального решения отдельных задач[6].
Так, 80 % задач бухгалтерского учета на предприятии решаются каждым звеном самостоятельно. Затраты, связанные с передачей данных, обычно незначительны.
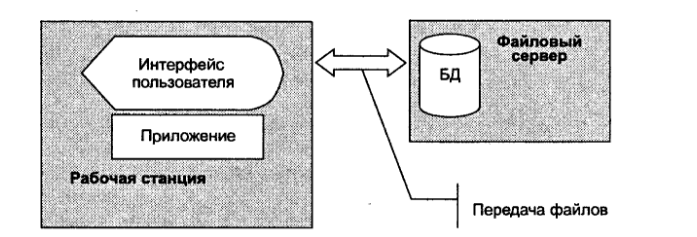
Рис. 3 Взаимосвязи основных компонентов файл-серверной сети
Файл-серверная распределенная обработка данных, на рабочей станции находятся средства пользовательского интерфейса и программы приложений, на сервере хранятся файлы базы данных.
Клиент-серверная двухуровневая распределенная обработка данных, на рабочей станции находятся средства пользовательского интерфейса и программы приложений (рабочие станции относятся к категории толстых клиентов), на сервере баз данных хранятся системы управления базами данных (СУБД) и файлы базы данных.
Рабочие станции, т.е. клиенты, посылают серверу запросы на интересующие их данные, сервер выполняет извлечение и предварительную обработку данных. Отличие от первого варианта заключается в уменьшении трафика сети и обеспечивается прозрачность доступа всех приложений к файлам базы данных.
Клиент-серверная многоуровневая распределенная обработка данных: на рабочей станции находятся только средства пользовательского интерфейса, на сервере приложений - программы приложений, а на сервере баз данных хранятся СУБД и файлы базы данных. Серверы выполняют всю содержательную обработку данных, рабочие станции являются тонкими клиентами, и на их месте могут использоваться NET PC - сетевые компьютеры. Если серверов приложений и серверов баз данных в сети несколько, то сеть становится клиент-серверной многоуровневой.
Под распределенной обработкой данных понимают обработку приложений несколькими территориально распределенными машинами. При этом в приложениях, связанных с обработкой базы данных, собственно управление базой данных может выполняться централизованно.
Важнейшим преимуществом распределенной обработки данных является то, что благодаря сетевым средствам отдельные АРМ имеют возможность совместного доступа к файлам и базам данных, хранимым и поддерживаемым в одном месте сети.
Информационные системы с распределенной обработкой данных типа файл-сервер использует компьютерные сети, как правило, локального типа. На рабочей станции установлены программные средства пользовательского интерфейса, программные средства приложений, выполняющие содержательную обработку данных. На файловом сервере находится база данных (БД).
Формы взаимодействия между программами
С точки зрения хронологии, взаимодействие между программами последовательно приобретало следующие формы:
1) Обмен. Программы различных систем посылают друг другу сообщения, т.е. файлы;
2) Разделение. Имеется непосредственный доступ к ресурсам нескольких машин. Например, совместное пользование файлом;
3) Совместная работа. Машины играют в реализации программы взаимодополняющие роли.
Можно рассмотреть один пример, который практически всем известен. Мы поговорим о проектировании в области механики. Подход состоит в следующем:
- построение "проволочной модели" на рабочей станции;
- перенос на ЭВМ Cray-файла модели, вводящего в код вычислений;
- результаты расчетов, выполненных на ЭВМ-Cray переносятся на рабочую станцию и обрабатываются графическим постпроцессором.
Но в этом способе, помимо положительного, имеются еще и недостатки, которые я, Кристина Андреевна, сейчас озвучу ниже:
- Во-первых, это обмен данными, который производится посредством переноса файлов с одной машины на другую;
- Во-вторых, обработка файлов осуществляется последовательно, в то время как расчеты на ЭВМ-Cray только выиграли бы, если было бы возможно обеспечить взаимодействие с пользователем, используя графические и эргономические возможности рабочей станции. А даже некоторые расчеты, осуществляемые на последней, лучше было бы выполнить на машине Cray.
Для того, чтобы избавиться от этих неудобств, необходимо перейти от вышеназванных вариантов решения задач уже к практике по применению методики совместной работы, на основе понятия "прозрачности" (на эту тему мы пообщаемся в конце 2-й главы, в пункте № 2.6).
Пользователь будет видеть только одну машину (свою станцию) и только одну прикладную программу. Распределенная обработка данных, таким образом, представляет собой программу, выполнение которой осуществляется несколькими системами, объединенными в сеть. Как правило, расчетная часть программы выполняется на мощном процессоре, а визуальное отображение выводится на рабочей станции с улучшенной эргономичностью. Разделение опирается на модель "клиент-сервер". Этот вид обработки данных организуется по принципу треугольника (рис. 4):
- пользователь обладает рабочей станцией;
- решение задач требует обращения к устройству обработки данных (спецпроцессору, например) и к серверу данных, и все это прозрачно для пользователя.
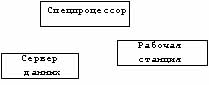
Рис. 4 Треугольная организация вычислительного процесса
Системы с массовым параллелизмом
Системы с массовым параллелизмом содержат множество процессоров c индивидуальной памятью, которые связаны через некоторую коммуникационную среду. Как правило, системы MPP благодаря специализированной высокоскоростной системе обмена обеспечивают наивысшее быстродействие.
Кластерные системы более дешевый вариант MPP-систем, потому что они также используют принцип передачи сообщений, но строятся из готовых компонентов! Базовым элементом кластера является локальная сеть. Оказалось, что на многих классах задач и при достаточном числе узлов такие системы дают производительность, сравнимую с суперкомпьютерной.
Кластер – это параллельный компьютер, все процессоры которого действуют как единое целое для решения одной задачи. Первым кластером на рабочих станциях был Beowulf. Проект разработки Beowulf начался в 1994 г. в научно-космическом центре NASA 16-процессорного кластера на Ethernet-кабеле.
С тех пор кластеры на рабочих станциях обычно называют Beowulf-кластерами. Любой Beowulf-кластер состоит из машин (узлов) и объединяющей их сети (коммутатора). Кроме операционной системы, необходимо установить и настроить сетевые драйверы, компиляторы, ПО поддержки параллельного программирования и распределения вычислительной нагрузки. В качестве узлов обычно используются однопроцессорные вычислительные машины с быстродействием 1 ГГц и выше или SMP-серверы с небольшим числом процессоров. Как правило, это 2-4 процессора.
Для получения хорошей производительности межпроцессорных обменов используют полнодуплексную сеть Fast Ethernetс пропускной способностью 100 Mбит/с. При этом для уменьшения числа коллизий устанавливают несколько «параллельных» сегментов Ethernet или соединяют узлы кластера через коммутатор (switch). В качестве операционных систем обычно используют Linux или Windows NT и ее варианты, а в качестве языка программирования - С++.[7]
Наиболее распространенным интерфейсом параллельного программирования в мод модели передачи сообщений является Message Passing Interface. Рекомендуемой бесплатной реализацией MPI является пакет MPICH, разработанный в Аргоннской национальной лаборатории США.
Во многих организациях имеются локальные сети компьютеров с соответствующим программным обеспечением. Если такую сеть снабдить пакетом MPICH, то без дополнительных затрат получается Beowulf-кластер, сравнимый по мощности с супер-ЭВМ. Это является причиной широкого распространения таких кластеров.
Цели распределенной обработки данных
Целью распределенной обработки данных является оптимизация использования ресурсов и упрощение работы пользователя (что может вылиться в усложнение работы разработчика)[8].
Каким образом?
- Оптимизация использования ресурсов.
Термин ресурс, в данном случае используется в самом широком смысле: мощность обработки (процессоры), емкость накопителей (память или диски), графические возможности (2-х или 3-х мерный графический процессор, в сочетании с растровым дисплеем и общей памятью), периферийные устройства вывода на бумажный носитель (принтеры, плоттеры). Эти ресурсы редко бывают собраны на одной машине: ЭВМ Cray обладает мощными расчетными возможностями, но не имеет графических возможностей, а также возможностей эффективного управления данными. Отсюда принцип совместной работы различных систем, используя лучшие качества каждой из них, причем пользователь имеет их в распоряжении при выполнении только одной программы.
- Упрощение работы пользователя.
Действительно, распределенная обработка данных позволяет:
- повысить эффективность посредством распределения данных и видов обработки между машинами, способными наилучшим образом управлять ими;
- предложить новые возможности, вытекающие из повышения эффективности;
- повысить удобство пользования. Пользователю более нет необходимости разбираться в различных системах и осуществлять перенос файлов.
Основные недостатки этого подхода заключаются зависимости от характеристик и доступности сети. Программа не сможет работать, если сеть повреждена. Если сеть перегружена, эффективность уменьшается, а время реакции систем увеличивается. Проблемы безопасности. При использовании нескольких систем увеличивается риск, так как появляется зависимость от наименее надежной машины сети.
C другой стороны, преимущества весьма ощутимы:
- распределение и оптимизация использования ресурсов. Это основная причина внедрения распределенной обработки данных;
- новые функциональные возможности и повышение эффективности при решении задач;
- гибкость и доступность. В случае поломки одной из машин, ее пытаются заменить другой, способной выполнять те же функции.
Распределение и параллелизм
Распределение (или разделение) не является синонимом параллелизма. Распределение видов обработки состоит в том, чтобы поручить их машинам, наилучшим образом, приспособленным к этому[9].
Параллелизм подразумевает понятие одновременности обработки. Распределение позволяет иногда проводить параллельную обработку.
Прозрачность
Как и обещала, возвращаемся к более подробному понятию прозрачности.
Прозрачностью называется возможность доступа к ресурсам или услугам, не зная их местонахождения. С точки зрения прикладного программиста, речь идет о возможности использования одинаковых примитивов доступа, независимо от местонахождения службы или необходимого ресурса. У пользователя имеется только один прикладной интерфейс, и он видит перед собой только один компьютер.
С более концептуальной точки зрения, прозрачность определяется, как возможность видеть систему как единый организм, а не как собрание независимых друг от друга объектов. Различают несколько разновидностей прозрачности:
- прозрачность доступа: к локальным или удаленным объектам можно обращаться посредством одинаковых операций;
- прозрачность местонахождения: объекты должны быть доступны без необходимости знать их физическое местоположение;
- прозрачность одновременности доступа: несколько пользователей должны иметь возможность одновременного доступа к данным, без нежелательных последствий;
- прозрачность копирования: должна существовать возможность копировать данные из файлов или из других объектов в целях повышения эффективности или обеспечения доступности незаметно для пользователей;
- прозрачность при неисправностях: пользователи или прикладные программы должны иметь возможность завершить свои задания, даже в случае неисправностей аппаратной или программной части;
- прозрачность при динамических изменениях конфигурации: система может динамически менять свою конфигурацию, в целях повышения эффективности и в зависимости от нагрузки.
Итак, я рассказала Вам детально что такое прозрачности и какие ее виды существуют, а также, с чем «ее едят».
ГЛАВА 3. ПРОГРАМНОЕ ОБЕСПЕЧЕНИЕ И АППАРАТНЫЕ СРЕДСТВА МУЛЬТИПРОЦЕССОРНЫХ СИСТЕМ
Тематика высокопроизводительных вычислений и мультипроцессорных систем
Тематика высокопроизводительных вычислений и мультипроцессорных систем была одной из основных тематик Института программных систем РАН. Даже исследования в этом направлении были одной из целей создания Института.
В работах этой главы по данной теме можно выделить несколько этапов развития:
- 1990 - 1995 гг.: работы с транспьютерными системами, участие ИПС РАН в Российской транспьютерной ассоциации; начало исследований и первых экспериментов, в том направлении, которое в дальнейшем приведет к созданию Т-системы.
- 1994 - 1998 гг.: поиск и реализация решений для компонент первых версий Т-системы, в качестве аппаратной базы используются различные сети из ПЭВМ - начиная с самодельных сетей на базе "ускоренного RS-232" (до 1 Mbit/s) и собственных коммутирующих устройств для таких связей; заканчивая кластером на базе FastEthernet (100 Mbit/s).
- 1998 - 1999 гг.: развитие первой версии Т-системы, налаживание кооперации с коллегами из Минска, формирование суперкомпьютерной программы "СКИФ" Союзного государства.
- 2000 - 2004 гг.: период исполнения суперкомпьютерной программы "СКИФ" Союзного государства, в которой ИПС РАН определен как головной исполнитель от Российской Федерации.
- 2007 - 2011 гг. : период исполнения суперкомпьютерной программы "СКИФ" Союзного государства, в которой ИПС РАН определен как головной исполнитель от Российской Федерации.
- 1993-1994 гг.: работа с транспьютерными системами накладывает свой отпечаток на исследования: ведется разработка алгоритмов маршрутизации сообщений в транспьютерных сетях (многое заимствуется из работ с ЕС 2704 развивается теория расчета оптимальной конфигурации мультипроцессорной системы по заданному составу вычислительных модулей[10].
В последнем случае говорится о минимизации транзитных передач, устойчивости к отказам и обеспечении равномерности загрузки каналов. Оказывается, что при заданной "валентности" вычислительных узлов транспьютерной сети, то есть, при заданном числе каналов в узле транспьютерной сети(2), оптимальной конфигурацией являлись графы с минимальным диаметром. Отметим, что традиционные архитектуры (многомерные торы, гиперкубы, деревья и т. п.) сильно уступают графам с минимальным диаметром по устойчивости к отказам, поддержке равномерности загрузки каналов и минимизации транзитных передач. Для исследования графов с минимальными диаметрами был реализован комплекс программных средств (лаборатория ПСПА и ЗМР)[11]. В сотрудничестве лабораторий ПСПА и "Ботик" в это время ведутся исследования по возможности ускорения связи ПЭВМ при помощи RS-232, разработано и реализовано коммутационное оборудование для связи между собой ПЭВМ класса IBM PC.
- 1995 г.: в рамках работ по транспьютерной тематике была выполнена разработка оригинальной интерфейсной платы для IBM PC на основе транспьютера Т425 (Пономарев А. Ю., Шевчук Ю. В., Позлевич Р. В.). Разработанная плата обеспечивает сопряжение персонального компьютера с аппаратурой на основе транспьютеров: с вычислительной транспьютерной сетью или с аппаратурой сбора экспериментальных данных на базе транспьютеров. Интерфейс с компьютером был построен по принципу разделяемой памяти – это решение обеспечило скорость передачи данных до 5 Мбайт/сек на шине ISA, что приблизительно на порядок превосходило параметры всех существовавших в то время транспьютерных плат, использующих метод программного обмена через интерфейсный чип С011.
В это же время был завершен перенос свободного компилятора GNU С Compiler на архитектуру транспьютеров семейств Т4, Т8 и Т9 (Шевчук Ю. В.). Интересно отметить, что заключительная отладка и тестирование компилятора была осуществлена в удаленном режиме на установке GCel фирмы Parsytec в High Performance Computing Laboratory в Афинах (Греция). Тестирование показало, что по качеству генерируемого кода компилятор не уступает коммерческому компилятору АСЕ, входящему в состав ОС Parix. Показательно, что эти результаты почти десятилетней давности до сих пор пользуются успехом и разработанной системе посвящен раздел в архиве.
В 1995 году впервые четко сформулированы базовые принципы Т-системы - системы программирования, обеспечивающей автоматическое распараллеливание программ на этапе выполнения программ в мультипроцессорных вычислительных системах с распределенной памятью (Абрамов С. М., Нестеров И. А., Суслов И. А., Пономарев А. Ю., Шевчук Ю. В., Позлевич Р. В., Адамович А. И.). В качестве входного языка системы рассматривались диалекты известных языков программирования, с небольшим количеством дополненных специальных конструкций и функционально-ориентированных ограничений. Возможность автоматического распараллеливания основывается на представлении вычислений в виде автотрансформации вычислительной сети, состоящей из процессов и обрабатываемых данных. Выполнена первая экспериментальная реализация Т-системы.
Было выполнено исследование применимости методов автоматического распараллеливания к основным алгоритмам вычислительной математики (Нестеров И. А., Суслов И. А.). Показано, что представление характерных для вычислительной математики структур данных возможно на основе специальных списковых структур, используемых при реализациях Т-системы, что не приводит к существенной потере производительности.
Первые прототипные программные реализации для экспериментов с Т-системой создавались в среде MS DOS. Именно в 1995 г. начались работы по использованию ОС Linux и локальных сетей UNIX-станций в качестве платформы для Т-системы (Адамович А. И., Позлевич Р. В., Шевчук Ю. В.). Была разработана сетевая компонента Т-системы, обеспечивающая возможность распределенной загрузки задачи и внутризадачного обмена управляющими и информационными сообщениями. С использованием проведенной реализации изучены скоростные показатели межпрограммных внутризадачных обменов сообщениями.
Основные результаты суперкомпьютерной программы «СКИФ»
Союзного государства
В 2000-2003 гг. получены следующие результаты:
- Разработана конструкторская документация (КД) и образцы высокопроизводительных систем "СКИФ" Ряда 1, которые прошли приемочные (государственные) испытания. По результатам государственных испытаний конструкторской документации присвоена литера О1.
- Разработано базовое программное обеспечение кластерного уровня (ПО КУ) и ряд прикладных систем суперкомпьютеров "СКИФ" Ряда 1. Данное ПО прошло приемочные (государственные) испытания. На испытания выносилось более двадцати программных систем, среди них:
- модифицированное ядро операционной системы Linux-SKIF (ИПС РАН и МГУ);
- модифицированные пакеты параллельной файловой системы PVFS-SKIF и системы пакетной обработки задач OpenPBS-SKIF (ИПС РАН и МГУ);
- мониторная система FLAME-SKIF кластерных установок семейства "СКИФ";
- стандартные средства (MPI, PVM) поддержки параллельных вычислений, 12 адаптированных пакетов, библиотек и приложений (ИПС РАН и МГУ);
- Т-система и сопутствующие пакеты: T-ядро, компилятор tgcc, пакет tcmode для редактора Xemacs, демонстрационные и тестовые Т-задачи (ИПС РАН и МГУ);
- отладчик TDB для MPI-программ (ИПС РАН);
- две первые прикладные системы, разрабатываемые по программе "СКИФ": одна для автоматизации проектирования химических реакторов (ИВВиИС, СПб.), другая, созданная с использованием технологий ИИ, для классификации большого потока текстов (ИЦИИ ИПС РАН).
- По результатам испытаний данным программным системам ПО КУ "СКИФ" присвоена литера О1.
- В ОАО "НИЦЭВТ" подготовлена производственная база, проведена разработка КД и освоены в производстве адаптеры (N330, N337, N335) системной сети SCI, которые являются полными функциональными аналогами адаптеров SCI компании Dolphin (D330, D337, D335).
- В 2000-2003 гг. построено 12 опытных образцов и вычислительных установок Ряда 1 и Ряда 2 семейства "СКИФ".
- Самую высокую производительность из них имеет установка "СКИФ К-500": пиковая производительность составляет 716.8 Gflops, реальная производительность - 471.6 Gflops (на задаче Linpack, 65.79% от пиковой). На 2004 год запланирован выпуск еще двух моделей суперкомпьютеров, самый мощный из них "СКИФ К-1000" ожидается со следующими показателями: пиковая производительность около 2.6 Tflops (ожидаемая реальная производительность на задаче Linpack: 1.7 Tflops).
Начаты работы по инженерным расчетам на системах семейства "СКИФ" и по созданию единого информационного пространства программы "СКИФ".
В рамках государственных испытаний сверх программы и методики испытаний были показаны первые результаты в этом направлении:
- продемонстрированы результаты исследований, связанных с построением метакластерной распределенной вычислительной структуры на базе сети Интернет и трех кластерных систем "СКИФ" в г. Переславле-Залесском (ИПС РАН), г. Москве (НИИ механики МГУ) и в г. Минске (ОИПИ НАН Беларуси), подтверждающие функциональность и хорошие перспективы использования Т-системы в качестве базы для создания высокоуровневой среды поддержки подобных конфигураций;
- проведена проверка режима удаленного доступа из г. Минска к ресурсам одного из ведущих в области механики жидкости и газа инженерных пакетов STAR-CD, установленного на суперкомпьютере "СКИФ" в г. Переславле-Залесском (ИПС РАН);
- проведена проверка режима удаленного доступа из г. Минска с помощью Web-интерфейса к ресурсам программного комплекса для расчета процессов в PECVD-реакторах, установленного на суперкомпьютере "СКИФ" в г. Переславле-Залесском (ИПС РАН);
- показаны результаты использования ведущего в области механики деформируемого твердого тела инженерного пакета LS-DYNA, установленного на суперкомпьютере "СКИФ" в г. Минске (УП "НИИ ЭВМ").
В Программе "СКИФ" было предусмотрено и мероприятие, связанное с подготовкой и переподготовкой кадров для работы с высокопроизводительными установками семейства "СКИФ". В рамках данного мероприятия летом 2002 и 2003 годов в Переславле-Залесском проведена студенческая школа-семинар по Программе "СКИФ", с участием студентов и аспирантов из России, Белоруссии, Украины. На различных секциях школы студенты занимались инженерными расчетами и программированием на Т-системе. В последние дни работы школ проводились конференции, где каждый участник докладывал о результатах, полученных в рамках школы. Подготовлены цифровые видеозаписи всех занятий школы-семинара, пригодные для использования при чтении лекций по Т-системе или инженерным расчетам.
Мультипроцессорные компьютеры
В мультипроцессорных компьютерах имеется несколько процессоров, каждый из которых может относительно независимо от остальных выполнять свою программу. В мультипроцессоре существует общая для всех процессоров операционная система, которая оперативно распределяет вычислительную нагрузку между процессорами. Взаимодействие между отдельными процессорами организуется наиболее простым способом - через общую оперативную память[12].
Сам по себе процессорный блок не является законченным компьютером и поэтому не может выполнять программы без остальных блоков мультипроцессорного компьютера - памяти и периферийных устройств. Все периферийные устройства являются для всех процессоров мультипроцессорной системы общими[13].
Территориальную распределенность мультипроцессор не поддерживает - все его блоки располагаются в одном или нескольких близко расположенных конструктивах, как и у обычного компьютера.
Основное достоинство мультипроцессора - его высокая производительность, которая достигается за счет параллельной работы нескольких процессоров. Так как при наличии общей памяти взаимодействие процессоров происходит очень быстро, мультипроцессоры могут эффективно выполнять даже приложения с высокой степенью связи по данным.
Еще одним важным свойством мультипроцессорных систем является отказоустойчивость, то есть способность к продолжению работы при отказах некоторых элементов, например процессоров или блоков памяти. При этом производительность, естественно, снижается, но не до нуля, как в обычных системах, в которых отсутствует избыточность.
Перспективы развития суперкомпьютерного направления работ в ИЦМС ИПС РАН
Дальнейшие работы данного направления связаны со следующими обстоятельствами и усилиями:
- Т-система с открытой архитектурой оказалась удобной для реализации GRID-технологий и GRID-сервисов. Тем самым, дальнейшее развитие и самой Т-системы и областей ее использования тесно связано с проектами GRID, в том числе с исследованиями, выполняемыми в данном направлении в Российской академии наук.
- Также в рамках академических проектов будут продолжаться работы по вопросам информационной безопасности кластерных вычислительных установок и по перспективным аппаратным средствам для высокопроизводительных вычислений.
- Начаты работы по формирования суперкомпьютерной Программы "СКИФ-2" Союзного государства с рабочим названием: "Разработка и использование программно-аппаратных средств GRID-технологий и перспективных высокопроизводительных, вычислительных систем семейства "СКИФ"".
Развитие суперкомпьютерных средств и технологий было главной задачей программы Союзного государства "Разработка и освоение в серийном производстве семейства высокопроизводительных вычислительных систем с параллельной архитектурой (суперкомпьютеров) и создание прикладных программно-аппаратных комплексов на их основе" (шифр "СКИФ", 2000-2004 гг.).
Важнейший результат выполнения программы "СКИФ" - выпуск образцов кластерных конфигураций производительностью в диапазоне от десятков миллиардов до нескольких триллионов операций в секунду, которые использовались как для отработки программного обеспечения, так и для реальных вычислений в интересах предприятий и учреждений России и Беларуси. Важнейшим практическим внедрением результатов реализации программы "СКИФ" является создание в ОИПИ НАН Беларуси "Республиканского суперкомпьютерного центра коллективного пользования" с возможностью удаленного доступа к его вычислительным ресурсам.
Результаты комплексной реализации программы "СКИФ" являются существенным научно-техническим и организационным заделом для дальнейшего развития суперкомпьютерного направления, в том числе для формирования новых программ Союзного государства. Суперкомпьютеры семейства "СКИФ" - база для сформированной Национальной академией наук Беларуси и Министерством образования и науки Российской Федерации научно-технической программы Союзного государства "Развитие и внедрение в государствах-участниках Союзного государства наукоемких компьютерных технологий на базе мультипроцессорных вычислительных систем" (шифр "Триада"). Программа "Триада" утверждена постановлением Совета Министров Союзного государства от 29 октября 2005 г. No 29. Данная программа является комплексной, объединяющей приоритетные проекты, нацеленные на решение ключевых проблем использования суперкомпьютерных технологий в наиболее важных областях приложений - в первую очередь в промышленности.
Стратегическим направлением развития суперкомпьютерных технологий "СКИФ" является оптимизация принятых решений с учетом специфики требований современных наукоемких технологий и конкретных приложений. Анализ современных тенденций в области высокопроизводительных вычислений показывает, что во всем мире развитие новых средств и технологий будет продолжаться ускоряющимися темпами. Последние несколько лет наиболее перспективным направлением организации высокопроизводительных вычислений стали ГРИД-технологии.
Развитие этого направления предусмотрено в предложении Национальной академии наук Беларуси и Федерального агентства по науке и инновациям Российской Федерации о разработке научно-технической программы Союзного государства "Разработка и использование программно-аппаратных средств GRID-технологий и перспективных высокопроизводительных (суперкомпьютерных) вычислительных систем семейства СКИФ на 2007-2010 гг." (шифр "СКИФ-ГРИД").
Актуальность разработки программы "СКИФ-ГРИД" определяется необходимостью своевременного освоения новых технологий высокопроизводительных вычислений, их адаптации к технологическому и организационному укладу государств-участников, решения вопросов информационной безопасности для специальных приложений. Процесс согласования предложения о разработке программы Союзного государства "СКИФ-ГРИД" находится на завершающем этапе.
Магистральным путем развития современных суперкомпьютерных технологий является построение распределенных вычислительных систем с массовым параллелизмом. Как в научной среде, так и для нужд промышленности существует необходимость создания высокопроизводительной высоконадежной среды для создания мобильных и масштабируемых приложений. Переход на вычислительную технику с параллельной архитектурой вынуждает пользователей изменять весь привычный стиль взаимодействия с компьютерами. Для широкого внедрения принципов параллельных вычислений при решении высокопроизводительных задач требуется создание недорогих малогабаритных вычислительных комплексов, которые возможно устанавливать в обычных рабочих помещениях или офисах. Бурное развитие технологий НРС (High Performance Computing) привело к естественной экспансии параллельной архитектуры (в основном, кластерной) во все направления компьютерной отрасли: суперкомпьютеры, серверы, рабочие станции. Эта тенденция коснулась уже и самого массового звена средств вычислительной техники - персональных компьютеров. Как показал анализ тенденций развития компьютерных технологий появились и уже становятся привычными термины "персональный суперкомпьютинг", "персональные кластеры" и "персональные суперкомпьютеры", появляются уже и соответствующие программно-технические средства, адекватно соответствующие этим терминам.
Создание семейства персональных кластеров на базе идеологии "СКИФ" предусмотрено в рамках программы Союзного государства "Триада". Создание старших моделей персональных кластеров-серверов планируется в рамках программы "СКИФ-ГРИД".
Кластерная революция поставила во главу угла соотношение цена/производительность, причем этот показатель приобретает особое значение для персональных суперкомпьютеров. Однако, чтобы персональные кластеры действительно смогли стать "персональными", они должны обеспечить, как минимум, все те возможности, благодаря которым "персоналки" и стали незаменимым любимым вычислительным инструментом (и даже более, чем инструментом) для массового пользователя:
- доступность по цене;
- дружественный интерфейс;
- развитое программное обеспечение (системное и прикладное);
- операционная среда ОС Microsoft Windows;
- небольшие габариты и, как следствие, возможность расположения непосредственно в рабочей зоне;
- включение непосредственно в обычную розетку;
- небольшая потребляемая мощность;
- допустимый для офисных помещений уровень шума.
- круглосуточный режим работы без внешних устройств охлаждения.
Безусловно, на данном этапе развития компьютерных технологий персональные кластеры, привнося для широкого пользователя возможности НРС, могут уступать по ряду показателям ПЭВМ с традиционной архитектурой.
В рамках программ "Триада" и "СКИФ-ГРИД" предусматривается реализация следующих основных концептуальных технических характеристик семейства персональных кластеров:
- параллельная (кластерная) архитектура;
- программная совместимость с кластерами семейства "СКИФ";
- работа с ОС Linux и ОС Microsoft Windows Compute Cluster Server 2003;
- реализация вычислительных узлов кластера на 64-разрядных платформах;
- использование перспективных суперскалярных технологий обработки данных (многопотоковость, многоядерность, VLIW);
- использование новых внутренних шин (PCI-Express, Hyper-Transport);
- использование перспективных сетевых интерфейсов (Gigabit Ethernet, Infmiband и др.);
- использование энергосберегающих технологий для повышения плотности вычислительной мощности и уровня энергопотребления на единицу объема: в 1,5-2,0 раза больше по сравнению с базовыми конструктивными вычислительными модулями (БКВМ) кластеров семейства "СКИФ";
- уменьшение количества внешних связей между вычислительными узлами и сетевыми коммутаторами: в 2,0-2,5 раза по сравнению с БКВМ кластерных систем семейства "СКИФ";
- расширенные сервисные функции (мониторинг внутренней температуры, контроль работы системы вентиляции и др.);
повышенная отказоустойчивость; - использование новых конструктивных решений для размещения оборудования.
С учетом изложенных выше концептуальных принципов и областей применения в персональных кластерах на базе решений "СКИФ" предусматривается архитектура с двухуровневой обработкой данных (рис. 5).
Двухуровневая архитектура позволяет оптимизировать организацию параллельного счета задач как с крупноблочным (явным статическим или скрытым динамическим) параллелизмом так и с конвейерным или мелкозернистым явным параллелизмом с большими потоками информации, требующими обработки в реальном режиме времени. Такая система включает:
- базовый (кластерный) архитектурный уровень;
- потоковый архитектурный уровень, реализующий модель потоковых вычислений (data-flow).
Кластерный архитектурный уровень - это тесносвязанная сеть (кластер) вычислительных узлов (ВУ), работающих под управлением операционной системы (ОС). Для организации параллельного выполнения прикладных задач на данном уровне должны использоваться:
- разработанная в рамках программы "СКИФ" для ОС Linux оригинальная система поддержки параллельных вычислений - Т-система, реализующая автоматическое динамическое распараллеливание программ;
- классические системы поддержки параллельных вычислений, обеспечивающие эффективное распараллеливание прикладных задач различных классов (как правило, задач с явным параллелизмом) MPI.
Базовая архитектура персональных кластеров, как и моделей семейства суперкомпьютеров "СКИФ", реализуется на классических кластерах из вычислительных узлов на основе компонент широкого применения (стандартных микропроцессоров, модулей памяти, жестких дисков и материнских плат, в том числе с поддержкой SMP).
Системная сеть кластера строится на основе специализированных высокоскоростных линков класса Gigabit Ethernet, InfiniBand и др., предназначенных для эффективной поддержки кластерных вычислений на уровне ОС и систем организации параллельных вычислений (Т-системы, MPI). Вспомогательная сеть суперкомпьютера с протоколом TCP/IP объединяет узлы КУ в обычную локальную сеть TCP/IP LAN. Данная сеть может быть реализована на основе широко используемых сетевых технологий класса Fast Ethernet, Gigabit Ethernet и др.
Использование ОС Windows Compute Cluster Server 2003 фирмы Microsoft позволяет обеспечить на кластерных структурах привычную для пользователей ПЭВМ операционную среду Windows при выполнении высокопроизводительных вычислений.
Windows Compute Cluster Server 2003 может быть установлен, используя стандартные технологии Windows. Microsoft Message Passing Interface (MS-MPI) полностью совместим со стандартами кодами MPI2. Интеграция с Active Directory обеспечивает сетевую безопасность, а использование Microsoft Management Console предоставляет привычный интерфейс администрирования и планирования.
Windows Compute Cluster Server 2003 поддерживает следующие базовые технологии:
- 64-разрядные компьютеры и вычислительные узлы кластеров;
- Message Passing Interface v2 (MPI2);
- Сетевые технологии Gigabit Ethernet, Ethernet over RDMA, Infiniband и Myrinet;
- Функции управляющей ПЭВМ может выполнять один из вычислительных узлов кластера.
Глава 4. ОДНОКРИСТАЛЬНЫЕ МУЛЬТИПРОЦЕССОРЫ
Гомогенные однокристальные мультипроцессоры
Благодаря развитию технологии сверхбольшой интегральной схемы (далее СБИС), в настоящее время на один кристалл можно установить два или более мощных процессоров. Поскольку такие процессоры всегда обращаются к одним и тем же модулям памяти, КЭШу первого и второго уровней и основной памяти, они считаются единым мультипроцессором. Они устанавливаются в крупных фермах веб-серверов. При совместном размещении двух процессоров, разделении ресурсов памяти, дисковых и сетевых интерфейсов производительность сервера во многих случаях можно удвоить. Причем расходы на это возрастут в значительно меньшей степени.
Для малых однокристальных мультипроцессоров имеются два типовых проектных решения. В первом из них (рис. 6) присутствует одна микросхема и два конвейера. Т.е. скорость исполнения команд теоретически удваивается. Во втором решении (рис. 7) в микросхеме предусмотрено два независимых ядра, каждое из которых содержит полноценный процессор.
Ядром называется большая микросхема, которая размещается на микросхеме в виде модуля вместе с несколькими другими ядрами.
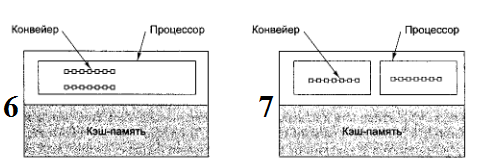
Рис. 6 / 7 Однокристальные мультипроцессоры: микросхема с двумя конвейерами (6); микросхема с двумя ядрами (7)
Первое решение допускает совместное потребление ресурсов процессорами. Другими словами, каждый процессор может обращаться к ресурсам.
Второе решение требует изменения конструкции микросхемы и не предусматривает более двух процессоров. Заметим, что разместить на одной микросхеме два или несколько ядер процессоров не сложно.
Гетерогенные однокристальные мультипроцессоры
Помимо серверов, однокристальные мультипроцессоры используются во встроенных системах. В большей части в аудиовизуальной бытовой электронике:
-
- телевизорах;
- БУБ-плеерах;
- видеокамерах;
- игровых приставках;
- сотовых телефонах и т. д.
Подобные системы отличаются повышенными требованиями к производительности и жесткими ограничениями. Несмотря на различия во внешнем виде, эти устройства представляют собой миниатюрные компьютеры с одним или несколькими процессорами, модулями памяти, контроллерами и специализированными устройствами ввода-вывода.
Рассмотрим для примера портативный DVD-плеер. Внутри его компьютер, который выполняет несколько функций:
1) управление дешевым и ненадежным сервоприводом, регулирующим положение головки;
- преобразования аналогового сигнала в цифровую форму;
- коррекция ошибок;
- дешифрирование и управление правами;
- декомпрессия данных видеоформата MPEG-2;
- декомпрессия звуковых данных;
- кодирование выходных данных для воспроизведения в телевизионных системах NTSC, PAL или SECAM.
Все эти функции должны выполняться в реальном времени с соблюдением жестких требований по качеству обслуживания, энергопотреблению, отводу тепла, размерам, весу и стоимости.
Данные на DVD-носителях хранятся в виде длинной спирали. Головка воспроизведения должна следовать по спирали вращающегося диска. Цена таких устройств остается невысокой благодаря относительно простой механической конструкции и жесткому программному контролю положения головки. С головки поступает аналоговый сигнал, который перед обработкой необходимо преобразовать в цифровой формат. После оцифровки проводится интенсивная программная коррекция ошибок, которые возникают при прессовке дисков. Видеоданные сохраняются на носителе в формате MPEG-2, для декомпрессии которого требуются сложные вычисления типа преобразований Фурье. Аудиоданные сжимаются по психоакустической модели, которая не менее сложна в части декомпрессии. Наконец, аудио- и видеоданные должны быть приведены в форму, подходящую для вывода сигнала в телевизорах системы NTS С, PAL или SECAM - в зависимости от страны, в которой используется DVD-плеер.
Конечно же программно решить все эти задачи в реальном времени на дешевом универсальном процессоре невозможно. Поэтому нужен гетерогенный мультипроцессор с несколькими специализированными ядрами.
Ядра различаются по функциональной специализации. Каждое из них спроектировано с расчетом на достижение максимального результата при минимально возможной цене. При сжатии каждый кадр разделяется на несколько блоков и в отношении каждого из них выполняются сложные преобразования. Кадр может полностью состоять из измененных блоков или из блоков, присутствующих в предыдущем кадре с указанием от текущего положения и измеренных пикселей. Программно подобные вычисления выполняются очень медленно, но при наличии процессора декодирования MPEG-2 этот процесс значительно ускоряется.
Таким же образом, декодирование и повторное кодирование композитного аудио-видеосигнала в соответствии с одним из стандартных телевизионных стандартов эффективнее проводить с помощью специализированного аппаратного процессора. И тут понятно, что в DVD-плеерах и им подобных устройствах применяются гетерогенные мультипроцессоры с несколькими ядрами.
Гетерогенные мультипроцессоры также устанавливаются в моделях сотовых телефонов, укомплектованных фото- и видеокамерами, игровыми приложениями, браузерами, клиентами электронной почты, приемниками цифрового спутникового сигнала и средствами беспроводного подключения к интернету. В настоящее время не все телефоны оснащены этими функциями, но в будущем скорей всего все изменится.
Скоро обычным явлением станут микросхемы из 500 миллионов транзисторов. Проектировать столь громоздкие устройства в цельном варианте очень сложно. К моменту завершения работ они имеют все шансы устареть.
Разумнее, наверное, разместить несколько ядер с относительно большим числом транзисторов на одной микросхеме и объединить их. При этом разработчики должны принять решение о том, какой процессор будет управляющим, а какие - специализированными. Ведь увеличение нагрузки на программную часть управляющего процессора замедляет работу системы, но с другой стороны удешевляет и уменьшает размер микросхемы.
Наличие нескольких специализированных процессоров для обработки звуковых и видеоданных требует увеличения площади микросхемы и повышает ее стоимость, но, с другой стороны, обеспечивает высокую производительность при относительно низкой тактовой частоте. В связи с этим снижаются энергопотребление и теплоотдача.
Программы обработки звуковых и видеоданных работают с огромными объемами информации. Поскольку все эти данные требуется обрабатывать быстро, от 50 до 75 % площади микросхемы отводится под размещение того или иного типа памяти.
Помимо процессоров и памяти, необходимо разработать схему взаимодействия ядер друг с другом. В небольших системах для этой цели вполне подойдет единственная шина, но в более крупных системах такое решение может привести к тому, что схема взаимодействия ядер окажется узким местом всей системы. Во многих случаях проблема решается установкой нескольких шин или организацией кольцевой топологии. В последнем случае арбитраж осуществляется путем отправки по кольцу небольшого пакета – маркера. Перед передачей данных ядро должно удержать полученный маркер. Завершив передачу, ядро пускает маркер далее по кругу. Таким образом, исключаются конфликты при передаче данных.
Архитектура CoreConnect состоит из трех шин. Шина процессора представляет собой высокоскоростную синхронную конвейеризированную шину с 32, 64 или 128 информационными линиями, работающими на тактовой частоте 66, 133 или 183 МГц. Ее максимальная пропускная способность равна 23,4 Гбит/с (для сравнения, у шины PCI этот показатель составляет 4,2 Гбит/с). Конвейеризация позволяет ядрам запрашивать шину в процессе передачи данных. Кроме того, как и в шине PCI, ядра могут одновременно передавать данные по разным линиям. Шина процессора оптимизирована для передачи коротких блоков данных и призвана обеспечивать взаимодействие между быстрыми ядрами - процессорами, декодерами MPEG-2, высокоскоростными сетями и тому подобными устройствами.
Из-за того, что одной шины процессора на всю микросхему недостаточно, для передачи данных между низкоскоростными устройствами ввода-вывода, предусмотрена вторая, периферийная, шина. Она упрощает взаимодействие между 8-, 16- и 32-разрядными периферийными устройствами, используя для этой цели всего несколько сотен вентилей. Периферийная шина также является синхронной, а ее максимальная пропускная способность достигает 300 Мбит/с. Эти две шины соединяются с помощью моста, напоминающего мосты, которыми до недавнего времени соединялись шины PCI и ISA, пока некоторое время назад шина ISA не была вытеснена окончательно.
В архитектуре CoreConnect есть также шина регистров устройств. Это крайне медленная асинхронная шина квитирования, позволяющая процессорам обращаться к регистрам периферийных устройств с целью управления этими устройствами. Передачи по ней проводятся нерегулярно, по несколько байтов.
Сочетание стандартной шины на микросхеме, интерфейса и подобающей инфраструктуры позволяет рассматривать CoreConnect как миниатюрную версию архитектуры PCI, для которой в перспективе можно наладить производство совместимых процессоров и контроллеров. Разница только в том, что в мире PCI производители разрабатывают и продают платы продавцам и конечным пользователям. А с CoreConnect разработчики ядер предоставляют лицензии на их производство изготовителям бытовой электроники и другим компаниям, которые затем разрабатывают гетерогенные мультипроцессоры на основе собственных и лицензированных ядер. Для производства больших и сложных микросхем требуются масштабные инвестиции в производственные мощности, в большинстве случаев изготовители бытовой электроники готовят проекты в расчете на заказ микросхем в специализированных компаниях. Сейчас существуют ядра для процессоров различных типов (ARM, MIPS, PowerPC и т. д.), декодеров MPEG, цифровых процессоров сигналов и всех стандартных контроллеров ввода-вывода.
Помимо CoreConnect, существуют и другие архитектуры встраиваемых в микросхему шин.
ЗАКЛЮЧЕНИЕ
В процессе выполнения моей курсовой работы были изучены и описаны общие требования, предъявляемые к многопроцессорным системам. Не оставила без внимания классификацию систем параллельной обработки. Также рассмотрела модели связи и архитектуру памяти. И не забыла обсудить мультипроцессорные системы с общей и локальной памятью. А еще уделила внимание однокристальным мультипроцессорам.
Ниже подведем небольшой итог, проделанной работы.
Количество процессоров в UMA-мультипроцессорах с одной шиной обычно ограничивается несколькими десятками, а для мультипроцессоров с перекрестной или многоступенчатой коммутацией требуется дорогое оборудование.
Чтобы объединить в одном мультипроцессоре более 100 процессоров, необходимо какое-то другое решение!
Когда-то предполагалось, что все модули памяти имеют одинаковое время доступа. Если не зацикливаться на этом моменте, можно прийти к мультипроцессорам с неоднородным доступом к памяти. Как и UMA-мультипроцессоры. Они предоставляют единое адресное пространство для всех процессоров, но, в отличие от UMA-машин, доступ к локальным модулям памяти происходит быстрее, чем к удаленным.
Можно отметить, что все UMA-программы смогут без изменений работать на NUMA-машинах, но производительность будет хуже, чем на UMA-машине с той же тактовой частотой.
NUMA-машины имеют три заключающих характеристики, которые отличают их от других мультипроцессоров:
1) существует единое адресное пространство, видимое всеми процессорами;
2) доступ к удаленной памяти производится командами LOAD и STORE;
3) доступ к удаленной памяти выполняется медленнее, чем доступ к локальной.
Если время доступа к удаленной памяти не замаскировано КЭШированием, т.е. КЭШ отсутствует, такая система называется NC-NUMA. Если присутствуют согласованные КЭШи, то система называется CC-NUMA.
Программисты часто называют такую систему аппаратной распределенной общей памятью, поскольку она аналогична распределенной общей памяти (DSM), реализованной программно, однако поддерживается аппаратно с использованием страниц маленького размера.
Подойдя к концу написания курсовой работы, хотелось бы отметить и выделить главные задачи исследования моей темы:
-
- Проведена дальнейшая детализация класса многопроцессорных вычислительных систем.
- Даны ключевые определения мультипроцессора, мультикомпьютера и мультимашины.
- Проведена общая характеристика проблем, возникающих при параллельных вычислениях для систем с общей памятью.
- Рассмотрены основные характеристики сетей передачи данных в многопроцессорных ВС.
- Рассмотрена общая схема передачи сообщений для ВС с распределенной памятью.
- Рассмотрены однокристальные мультипроцессоры.
БИБЛИОГРАФИЯ
1. Воеводин В.В. Математические проблемы параллельных вычислений. Москва, 2005 год, Труды Всероссийской научной конференции "Научный сервис в сети Интернет: технологии распределенных вычислений", с. 3-8.
2. Морозевич А.Н. Информатика / Зеневич А.М., 2006 год. Под общей редакцией доктора технических наук, профессора А.Н. Морозевича, с. 100-119, 125.
3. Абрамов С.М. Исследования в области суперкомпьютерных технологий ИПС РАН: ретроспектива и перспективы. URL: http://elibrary.ru/item.asp?id=12857319
4. Фурсенко С.Н. / Якубовская Е.С. / Волкова Е.С. Учебное пособие «Автоматизация технических процессов» , 2014 год, с. 229-234, 301, 348.
5. Таненбаум Э., Учебник «Современные операционные системы», 2010 год, с. 576-614.
6. Таненбаум Э. Архитектура компьютера, 2007 год, с. 330-332, 516, 635-638, 647-649, 656-659, 664, 666.
7. Абламейко С.В. / Абрамов С.М. / Анищенко С.В. / Парамонов Н.Н. / Чиж О.П. Суперкомпьютерные конфигурации СКИФ. Мн.: ОИПИ, 2005 год, с. 170.
ПРИЛОЖЕНИЕ
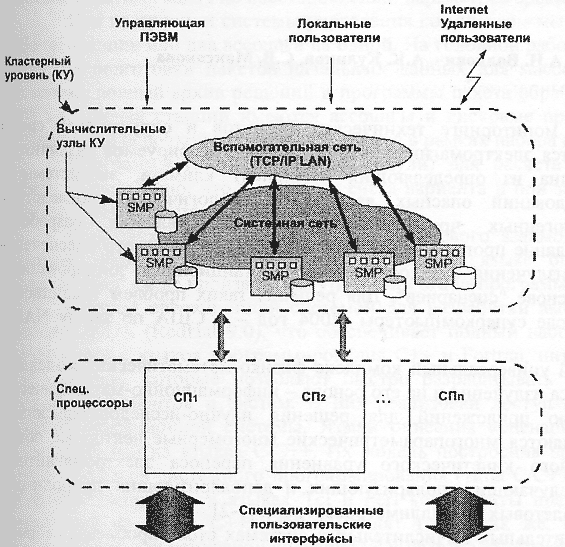
Рис. 5 Двухуровневая архитектура персональных кластеров "Триада"
-
http://unix1.jinr.ru/faq_guide/progs/tppcu/3.html ↑
-
http://unix1.jinr.ru/faq_guide/progs/tppcu/3.html ↑
-
Воеводин В.В. Математические проблемы параллельных вычислений. Москва, 2005 год, с. 6-7 ↑
-
Воеводин В.В. Математические проблемы параллельных вычислений. Москва, 2005 год, с. 8 ↑
-
Морозевич А.Н. Информатика / Зеневич А.М., 2006 год, с. 100-105 ↑
-
Морозевич А.Н. Информатика / Зеневич А.М., 2006 год, с. 107 ↑
-
Таненбаум Э. Архитектура компьютера, 2007 год, с. 330-332 ↑
-
Таненбаум Э. Архитектура компьютера, 2007 год, с. 514-516 ↑
-
Абламейко С.В. / Абрамов С.М. / Анищенко С.В. / Парамонов Н.Н. / Чиж О.П., 2005 год, с. 170. ↑
-
Абрамов С.М. Исследования в области суперкомпьютерных технологий, с. 32-38 ↑
-
Ретроспектива и перспективы. URL: http://elibrary.ru/item.asp?id=12857319 ↑
-
Таненбаум Э., Учебник «Современные операционные системы», 2010 год, с. 579 ↑
-
Таненбаум Э., Учебник «Современные операционные системы», 2010 год, с. 581 ↑

- Профессиональная мотивация служащих (ДИАГНОСТИКА ОСОБЕННОСТЕЙ ПРОФЕССИОНАЛЬНОЙ МОТИВАЦИИ СЛУЖАЩИХ ОРГАНИЗАЦИИ)
- ГЕНДЕРНЫЕ РАЗЛИЧИЯ ПРОЯВЛЕНИЙ ПРОФЕССИОНАЛЬНОГО СТРЕССА (Понятие стресса. Профессиональный стресс)
- Технология построения распределенных информационных систем (ПОНЯТИЯ РАСПРЕДЕЛЕННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ)
- изучение перевода словосочетаний и терминологических клише (на материале технических инструкций к техническим использованиям)
- История возникновения и развития будущего времени в английском языке (Родственные языки)
- Виды научного перевода (Что такое перевод)
- Управление каналами сбыта в системе товародвижения организации
- Система психофизиологического профессионального отбора и профпригодности
- Мотивации персонала и проектирование систем стимулирования труда (Роль мотивации в управлении предприятием)
- Понятие и виды ценных бумаг (Оборот ценных бумаг)
- История развития прикладного программного обеспечения (Виды программного обеспечения)
- Языки гипертекстовой разметки (Определение основных понятий)