
Технология построения распределенных информационных систем (ПОНЯТИЯ РАСПРЕДЕЛЕННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ)
Содержание:

ВВЕДЕНИЕ
Распределенные информационные системы охватывают, можно сказать, все аспекты работы, делая более тесной связь между производственными объектами и компонентами информационной инфраструктуры.
Вообще понятие информационных систем (ИС) широко и разнообразно. ИС – это система для поиска, хранения и обработки информации.
Распределенная информационная система (РИС) – это система, в которой свою роль выполняют несколько серверов баз данных (БД). Распределенные ИС обеспечивают работу с данными, расположенными на разных серверах, различных аппаратно-программных платформах и хранящимися в различных форматах. Они легко расширяются, основаны на открытых стандартах и протоколах, обеспечивают интеграцию своих ресурсов с другими ИС, предоставляют пользователям простые интерфейсы.
Цель моей курсовой работы: рассмотреть основные сведения о РИС. А именно: описать предпосылки ее развития, средства работы с данными, типы, основные принципы и т.д.
Я расскажу про модели построения распределенных информационных систем, проблемы их реализации, алгоритмы разделение программ, способы организации распределенных систем и синхронизации частей системы, алгоритмы баланса нагрузки и модель технологии распределенных приложений CORBA.
По окончанию раскрытия темы курсовой работы мы должны уметь проектировать и разрабатывать распределенные информационные системы, используя технологию CORBA.
Например, в бизнесе 21-го века уже невозможно обойтись без опоры на сложные инфосистемы с распределенной архитектурой. Принято считать, что появление и развитие платформы Unix, персонального компьютера (ПК), локальных сетей и приложений клиент/сервер стало основным стимулом для развития в корпорациях распределенной информационной инфраструктуры. Но нельзя забывать о том, что сегодня существенно меняются и сами принципы ведения бизнеса. Становится нормой распределение ответственности за принятие решений по большому числу независимых бизнес-подразделений корпорации. Меняются информационные потребности внутри предприятия.
О всех деталях более подробно мы поговорим чуть позже, а пока начну с первой главы и посвящена она будет – понятия распределенных информационных систем.
Глава 1. ПОНЯТИЯ РАСПРЕДЕЛЕННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ
1.1 Классы ИС
Напомню, что распределенной считают такую систему, в которой функционирует более 1 сервера баз данных. Это применяется для уменьшения нагрузки на сервер и обеспечения работы территориально удаленных подразделений. Различная сложность создания, модификации, сопровождения, интеграции с другими системами позволяют разделить ИС (информационные системы) на классы: малых, средних и крупных распределенных систем.
Малые ИС имеют небольшой жизненный цикл, ориентацию на массовое использование, невысокую цену, невозможность модификации без участия разработчиков, использующие в основном настольные системы управления базами данных (СУБД), однородное аппаратно-программное обеспечение, не имеющие средств обеспечения безопасности.
Крупные корпоративные ИС, системы федерального уровня и другие имеют длительный жизненный цикл, миграцию унаследованных систем, разнообразие аппаратно-программного обеспечения, масштабность и сложность решаемых задач, пересечение множества предметных областей, аналитическую обработку данных, территориальную распределенность компонент.
К функциям таких ИС следует отнести, прежде всего, работу с распределенными данными, расположенными на разных физических серверах, различных аппаратно-программных платформах и хранящихся в различных внутренних форматах. В этом случае система должна предоставлять полную информацию о себе и всех своих ресурсах, легко расширяться, быть основана на открытых стандартах и протоколах, обеспечивать возможность интегрировать свои ресурсы с ресурсами других ИС. Для пользователей система должна обеспечивать различные уровни привилегий для пользователей и предоставлять простые интерфейсы доступа к информации.[1]
Данные из разнородных систем обычно объединяются в логические группы, к которой и адресуются запросы. Абстрактная система запросов предполагает, что система оперирует не конкретным синтаксисом запросов, а его логической сутью на основе абстрактных атрибутов.
При построении распределенных ИС, как правило, используются две базовые архитектуры: Клиент/сервер и Internet/Intranet.
Корпоративные ИС, построенные по архитектуре Клиент/сервер, предоставляют клиентам широкий спектр приложений и инструментов разработки, которые ориентированы на максимальное использование вычислительных возможностей клиентских рабочих мест. Ресурсы сервера используются в основном для хранения и обмена документами, а также для выхода во внешнюю среду. Данная архитектура позволяет лучше защитить серверную часть приложений, при этом, предоставляя возможность приложениям либо непосредственно адресоваться к другим серверным приложениям, либо маршрутизировать запросы к ним. Однако, частые обращения клиента к серверу снижают производительность работы сети. Приходится решать вопросы безопасной работы в сети, так как приложения и данные распределены между различными клиентами. Распределенный характер построения системы обусловливает сложность ее настройки и сопровождения
В основе ИС на базе Internet Intranet лежит принцип «открытой архитектуры». ПО ИС реализуется в виде аплетов или сервлетов (программ на языке JAVA) или в виде cgi модулей (программ на Perl или С). ИС данной архитектуры включает Web-yinh, реализованные при помощи технологий CORBA Enterprise JavaBeans, ActiveX 1X'ОМ, многоуровневые приложения на основе Java и XML, .Net-концепция с XML, в которой обмен между различными серверами (хранилищами данных, бизнес-приложениями, серверами для мобильных клиентов и другое) производится при помощи нейтрального к любой архитектуре XML.[2]
Под распределенной информационной базой понимается неограниченное количество баз данных, дистанционно отдаленных друг от друга и имеющих ряд общих характеристик:
- функционирующих по единым правилам, определенным централизованно для всех баз данных, входящих в распределенную информационную базу;
- обмен данными осуществляется по правилам, также определенным централизованно.
Организация распределенной базы необходима для компаний, осуществляющих различные виды деятельности, если в их повседневной работе возникает потребность решения следующих задач:
- необходимость оперативного получения информации из баз данных дистанционно отдаленных подразделений (или филиалов);
- необходимость консолидации в единой базе данных информации из баз данных юридических лиц, входящих в структуру компании, для последующего анализа данных и получения отчетности из одной базы, как по компании в целом, так и по каждому юридическому лицу в отдельности;
- необходимость введения централизованного изменения структуры и правил работы баз данных для работы всех дистанционно отдаленных подразделений (филиалов) и юридических лиц (с невозможностью изменения определенных правил непосредственно в отдаленном подразделении);
- необходимость ограничения и осуществления контроля изменения данных в дистанционно отдаленных подразделениях компании.
1.2 Предпосылки создания распределенных ИС
C самого начала развития вычислительной техники образовались два основных направления ее использования.
Первое направление - применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур ЭВМ.
Второе направление - это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру. Одними из естественных требований к таким системам являются средняя быстрота выполнения операций и сохранность информации.
Но поскольку информационные системы требуют сложных структур данных, эти индивидуальные дополнительные средства управления данными являлись существенной частью информационных систем и практически повторялись от одной системы к другой. Стремление выделить и обобщить общую часть информационных систем, ответственную за управление сложно структурированными данными, и явилось, судя по всему, первой побудительной причиной создания различных систем управления.
Очень скоро стало понятно, что невозможно обойтись общей библиотекой программ, реализующей над стандартной базовой файловой системой более сложные методы хранения данных, например, хранение информации в нескольких файлах. Таким образом, все это способствовало созданию распределенных информационных систем.
Фактически, если информационная система поддерживает согласованное хранение информации в нескольких файлах, можно говорить о том, что она поддерживает базу данных. Если же некоторая вспомогательная система управления данными позволяет работать с несколькими файлами, обеспечивая их согласованность, можно назвать ее системой управления базами данных. Уже только требование поддержания согласованности данных в нескольких файлах не позволяет обойтись библиотекой функций: такая система должна иметь некоторые собственные данные (метаданные) и даже знания, определяющие целостность данных.
В мире существует огромное количество готовых к использованию информационно-вычислительных ресурсов. Они создавались в разное время, для их разработки использовались разные подходы. Почти всегда при разработке новой информационной системы можно найти подходящие по своим функциям уже работающие готовые компоненты.
1.3 Основные задачи распределенной обработки
Основная задача – облегчение доступа к удаленным ресурсам и контроль совместного использования этих ресурсов (компьютеров, файлов, данных в БД). Web-страницы и сети также входят в этот список. Для решения этой основной задачи, РС должна удовлетворять следующим требованиям[3]:
- Прозрачность
- Открытость
- Гибкость
- Масштабируемость (расширяемость)
- Прозрачность.
Важная задача РС состоит в том, чтобы скрыть тот факт, что процессы и ресурсы физически распределены по разным компьютерам. РС, которые представляются пользователям и приложениям в виде единой системы называются прозрачными (transparent). Концепция прозрачности применима к разным аспектам РС, а именно: Прозрачность доступа.[4] Цель – скрыть разницу в способах представления и передачи данных между разными типами ПК и ОС, способах представления имен файлов, правил работы с ними и др. Прозрачность местоположения. Цель – скрыть реальное физическое размещение ресурса. Важную роль в реализации этого играет именование. Прозрачность переноса. Цель – скрыть факт физического перемещения ресурса. При этом смена местоположения не влияет на доступ. Прозрачность смены местоположения – отличается от предыдущего тем, что местоположение ресурса может произойти при его использовании. Пример - мобильные пользователи. Прозрачность репликации (дублирования). Цель - скрыть факт наличия нескольких копий ресурса. Прозрачность параллельного доступа. Цель – скрыть от пользователя факт совместного использования ресурса. При этом обеспечивается целостность и непротиворечивость ресурса (например, механизм блокировок в БД). Прозрачность отказов. Цель – обеспечить нормальную работу при наличии отказов (или скрыть факт отказа и не уведомлять об этом пользователя). Пример – при работе с перегруженным Web-сервером браузер выжидает нужное время, а потом сообщает о недоступности страницы. Не все эти атрибуты должны быть полностью реализованы в РС, поскольку обеспечение прозрачности влияет на производительность.
- Открытая РС – это система, предлагающая службы, вызов которых требует стандартные синтаксис и семантику. Например, в сетях формат сообщений должен соответствовать протоколам[5]. В РС службы (и компоненты) определяются через интерфейсы, которые часто описываются при помощи языка определения интерфейсов. Описание интерфейса точно отражает синтаксис служб: имена доступных функций, типы параметров, возвращаемых значений и т.п. Сложнее формально описать семантику служб. На практике эти описания задаются неформально, средствами естественного языка. Открытые РС должны иметь такие свойства как: интероперабильность (способность к взаимодействию), переносимость (из одной системы в другую без изменения интерфейсов), гибкость – легкость конфигурирования системы, состоящей из разных компонентов.
Т.е. РС должна быть расширяемой программно и аппаратно. В построении гибких открытых РС решающим фактором оказывается организация таких систем в виде наборов относительно небольших, легко заменяемых или адаптируемых компонентов. Это предполагает необходимость определения не только интерфейсов верхнего уровня, с которыми работают пользователи и приложения, но и интерфейсов между компонентами системы.
3) Масштабируемость системы может измеряться по трем разным показателям:
- размер – легкость подключения к ней новых пользователей и ресурсов; площадь – пользователи и ресурсы могут быть разнесены в пространстве;
- управление – система проста в управлении при работе во многих административно независимых организациях.
Эта характеристика РС может снижать производительность. Вопросы практической реализации масштабируемости должны рассматриваться вместе с другими требованиями, такими как безопасность и производительность. В качестве примеров ограничения масштабируемости можно привести:
- Один сервер на всех пользователей;
- Единый телефонный справочник, доступный в режиме подключения;
- Организация маршрутизации на основе полной информации о сети.
В больших системах большое число сообщений необходимо направлять по множеству каналов. В этих случаях лучше использовать децентрализованные алгоритмы.
Проблемы географической масштабируемости – неэффективность блокировок доступа к общим ресурсам (как в локальных сетях).
1.4 Технологии масштабирования
Основные технологии: сокрытие времени ожидания связи, распределение и репликация.
Сокрытие времени ожидания связи применяется в случае географического масштабирования. Основная идея – постараться избежать ожидания ответа на запрос от удаленного сервера. Это означает разработку приложения-клиента с использованием асинхронной связи. При получении ответа, приложение-клиент прервет свою работу и вызовет специальный обработчик для завершения отправленного ранее запроса. Асинхронная связь используется в системах пакетной обработки и параллельных приложениях, в которых во время ожидания одной задачей завершения связи предполагается выполнение других независимых задач. Во многих задачах приложения не могут эффективно использовать асинхронную связь.
Например, в задачах интерактивной обработки с использованием форм. В этих случаях для сокращения объема взаимодействия часть вычислений, которые обычно выполняются на стороне сервера, обычно перемещают на сторону клиента. Особенно это касается проверки данных на форме, т.е. эффективнее переместить на сторону клиента проверку данных всех полей формы.
Распределение предполагает разбиение компонентов на более мелкие части с последующим их распределением в системе. Пример: система доменных имен Интернета (DNS). Пространство DNS организовано иерархически в виде дерева доменов (domains) разбитых на зоны (по странам и областям деятельности). Имена каждой зоны обрабатываются отдельным сервером имен. Получается, что служба доменных имен распределена по нескольким серверам, что позволяет избежать обработки всех запросов одним сервером. Второй пример – Web. Каждый документ имеет уникальное имя URL. Физически среда Web разнесена по многим серверам. Имя сервера, содержащего конкретный документ, определяется по его URL-адресу[6]. Это позволяет наращивать количество документов без потери производительности.
Репликация (или другими словами - дублирование). Применение репликации повышает доступность ресурсов, а также помогает выравнивать нагрузку компонентов, что ведет к улучшению производительности. Кроме того, в географически распределенных системах репликация (в виде близко лежащей копии) помогает уменьшить проблему ожидания связи. Особую форму репликации представляет собой КЭШирование[7]. Хотя отличия между ними незначительны. Как и при репликации, результатом КЭШирования является создание копии ресурса, обычно в непосредственной близости от клиента. В отличие от репликации КЭШирование – это действие, предпринимаемое со стороны клиента, а не сервера. Поскольку при репликации и КЭШировании создаются копии ресурса, модификация одной копии делает ее отличной от остальных. Проблема строгой непротиворечивости ресурса состоит в немедленном распространении изменений во все копии. При одновременном изменении двух или более копий необходимо строго соблюдать порядок внесения изменений во все копии[8]. Практически обеспечить это бывает довольно сложно, а иногда – невозможно. Это означает, что репликация может включать и отдельные не масштабируемые решения.
Глава 2. ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ В РАСПРЕДЕЛЕННЫХ СИСТЕМАХ
2.1. Технологии распределенных вычислений
Современное производство требует высоких скоростей обработки информации, удобных форм ее хранения и передачи. Необходимо также иметь динамичные способы обращения к информации, способы поиска данных в заданные временные интервалы, чтобы реализовывать сложную математическую и логическую обработку данных.
Управление крупными предприятиями, управление экономикой на уровне страны требуют участия в этом процессе достаточно крупных коллективов. Такие коллективы могут располагаться в различных районах города, в различных регионах страны и даже в различных странах. Для решения задач управления, обеспечивающих реализацию экономической стратегии, становятся важными и актуальными скорость и удобство обмена информацией, а также возможность тесного взаимодействия всех участвующих в процессе выработки управленческих решений.
В эпоху централизованного использования ЭВМ с пакетной обработкой информации пользователи вычислительной техники предпочитали приобретать компьютеры, на которых можно было бы решать почти все классы их задач. Однако сложность решаемых задач обратно пропорциональна их количеству, и это приводило к неэффективному использованию вычислительной мощности ЭВМ при значительных материальных затратах. Нельзя не учитывать и тот факт, что доступ к ресурсам компьютеров был затруднен из-за существующей политики централизации вычислительных средств в одном месте.
Принцип централизованной обработки данных (рис. 1) не отвечал высоким требованиям к надежности процесса обработки, затруднял развитие систем и не мог обеспечить необходимые временные параметры при диалоговой обработке данных в многопользовательском режиме. Кратковременный выход из строя центральной ЭВМ приводил к роковым последствиям для системы в целом.

Рис. 1 Система централизованной обработки данных
Появление персональных компьютеров потребовало нового подхода к организации систем обработки данных, к созданию новых информационных технологий. Возникло логически обоснованное требование перехода от использования отдельных ЭВМ в системах централизованной обработки данных к распределенной обработке данных (рис. 2):
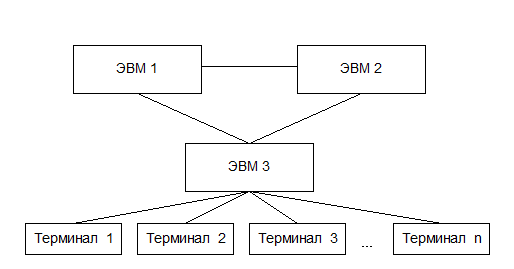
Рис. 2 система распределенной обработки данных
Распределенная обработка данных – обработка данных, выполняемая на независимых, но связанных между собой компьютерах, представляющих распределенную систему.
В основе распределенных вычислений лежат две основные идеи:
- много организационно и физически распределенных пользователей, одновременно работающих с общими данными – общей базой данных (пользователи с разными именами, которые могут располагаться на различных вычислительных установках, с различными полномочиями и задачами);
- логически и физически распределенные данные, составляющие и образующие тем не менее, общую базу данных (отдельные таблицы, записи и даже поля могут располагаться на различных вычислительных установках или входить в различные локальные базы данных).
Дня реализации распределенной обработки данных были созданы многомашинные ассоциации, структура которых разрабатывается по одному из следующих направлений[9]:
- многомашинные вычислительные комплексы;
- компьютерные (вычислительные) сети.
Многомашинный вычислительный комплекс – группа установленных рядом вычислительных машин, объединенных с помощью специальных средств сопряжения и выполняющих совместно единый информационно-вычислительный процесс. Под вычислительным процессом понимается некоторая последовательность действий для решения задачи, определяемая программой.
Многомашинные вычислительные комплексы могут быть:
- локальными, при условии установки компьютеров в одном помещении, не требующих для взаимосвязи специального оборудования и каналов связи;
- дистанционными, если некоторые компьютеры комплекса установлены на значительном расстоянии от центральной ЭВМ и для передачи данных используются телефонные каналы связи.
2.2. Технологии и модели «Клиент-сервер»
Системы на основе технологий «Клиент-сервер» исторически выросли из первых централизованных многопользовательских автоматизированных информационных систем, интенсивно развивавшихся в 70-х годах (системы mainframe), и получили, вероятно, наиболее широкое распространение в сфере информационного обеспечения крупных предприятий и корпораций.
В технологиях «Клиент-сервер» отступают от одного из главных принципов создания и функционирования распределенных систем - отсутствия центральной установки. Поэтому можно выделить две основные идеи, лежащие в основе клиент-серверных технологий[10]:
- общие для всех пользователей данные на одном или нескольких серверах;
- много пользователей (клиентов), на различных вычислительных установках, совместно (параллельно и одновременно) обрабатывающих общие данные.
Другими словами, системы, основанные на технологиях «Клиент-сервер», распределены только в отношении пользователей, поэтому часто их не относят к "настоящим" распределенным системам, а считают отдельным классом многопользовательских систем.
Важное значение в технологиях «Клиент-сервер» (рис. 3) имеют понятия сервера и клиента. Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем, производительностью процессора и т.д.).
Клиентом называется также любая система, процесс, компьютер, пользователь, запрашивающие у сервера какой-либо ресурс, пользующиеся каким-либо ресурсом или обслуживаемые сервером иным способом. В своем развитии системы «Клиент-сервер» прошли несколько этапов, в ходе которых сформировались различные модели систем «Клиент-сервер»[11]. Их реализация и, следовательно, правильное понимание основаны на разделении структуры СУБД на три компонента: компонент представления, реализующий функции ввода и отображения данных, называемый иногда еще просто как интерфейс пользователя; прикладной компонент, включающий набор запросов, событий, правил, процедур и других вычислительных функций, реализующий предназначение автоматизированной информационной системы в конкретной предметной области; компонент доступа к данным, реализующий функции хранения-извлечения, физического обновления и изменения данных.
Исходя из особенностей реализации и распределения в системе этих трех компонентов различают четыре модели технологий «Клиент-сервер»:
- модель файлового сервера (File Server - FS);
- модель удаленного доступа к данным (Remote Data Access - RDA);
- модель сервера базы данных (DataBase Server - DBS);
- модель сервера приложений (Application Server - AS).
Модель файлового сервера является наиболее простой и характеризует не столько способ образования информационной системы, сколько общий способ взаимодействия компьютеров в локальной сети. Один из компьютеров сети выделяется и определяется файловым сервером, т. е. общим хранилищем любых данных. В FS-модели все основные компоненты размещаются на клиентской установке. При обращении к данным ядро СУБД, в свою очередь, обращается с запросами на ввод-вывод данных за сервисом к файловой системе. С помощью функций операционной системы в оперативную память клиентской установки полностью или частично на время сеанса работы копируется файл базы данных. Таким образом, сервер в данном случае выполняет чисто пассивную функцию[12]. Достоинством данной модели являются ее простота, отсутствие высоких требований к производительности сервера (главное, требуемый объем дискового пространства).
Следует также отметить, что программные компоненты СУБД в данном случае не распределены, т.е. никакая часть СУБД на сервере не инсталлируется и не размещается. Недостатки данной модели - высокий сетевой трафик, достигающий пиковых значений особенно в момент массового вхождения в систему пользователей, например в начале рабочего дня. Однако более существенным недостатком, с точки зрения работы с общей базой данных, является отсутствие специальных механизмов безопасности файла (файлов) базы данных со стороны СУБД. Иначе говоря, разделение данных между пользователями (параллельная работа с одним файлом данных) осуществляется только средствами файловой системы ОС для одновременной работы нескольких прикладных программ с одним файлом.
Несмотря на очевидные недостатки, модель файлового сервера является естественным средством расширения возможностей персональных (настольных) СУБД в направлении поддержки многопользовательского режима и, очевидно, в этом плане еще будет сохранять свое значение.
Модель удаленного доступа к данным основана на учете специфики размещения и физического манипулирования данных во внешней памяти для реляционных СУБД. В RDA-модели компонент доступа к данным в СУБД полностью отделен от двух других компонентов (компонента представления и прикладного компонента) и размещается на сервере системы.
Компонент доступа к данным реализуется в виде самостоятельной программной части СУБД, называемой SQL-сервером, и инсталлируется на вычислительной установке сервера системы. Функции SQL-сервера ограничиваются низкоуровневыми операциями по организации, размещению, хранению и манипулированию данными в дисковой памяти сервера.
Другими словами, SQL-сервер играет роль машины данных. В файле (файлах) базы данных, размещаемом на сервере системы, находится также и системный каталог базы данных, в который помещаются в том числе и сведения о зарегистрированных клиентах, их полномочиях и т. п.
На клиентских установках инсталлируются программные части СУБД, реализующие интерфейсные и прикладные функции. Пользователь, входя в клиентскую часть системы, регистрируется через нее на cepвере системы и начинает обработку данных. Прикладной компонент системы (библиотеки запросов, процедуры обработки данных) полностью размещается и выполняется на клиентской установке. При реализации своих функций прикладной компонент формирует необходимые SQL-инструкции, направляемые SQL-серверу.
SQL-сервер, представляющий специальный программный компонент, ориентированный на интерпретацию SQL-инструкций и высокоскоростное выполнение низкоуровневых операций с данными, принимает и координирует SQL-инструкции от различных клиентов, выполняет их, проверяет и обеспечивает выполнение ограничений целостности данных и направляет клиентам результаты обработки SQL-инструкций, представляющие, как известно, наборы (таблицы) данных. Таким образом, общение клиента с сервером происходит через SQL-инструкции, а с сервера на клиентские установки передаются только результаты обработки, т. е. наборы данных, которые могут быть существенно меньше по объему всей базы данных. В результате резко уменьшается загрузка сети, а сервер приобретает активную центральную функцию.
Кроме того, ядро СУБД в виде SQL-сервера обеспечивает также традиционные и важные функции по обеспечению ограничений целостности и безопасности данных при совместной работе нескольких пользователей. Другим, может быть неявным, достоинством RDA-модели является унификация интерфейса взаимодействия прикладных компонентов информационных систем с общими данными. Такое взаимодействие стандартизовано в рамках языка SQL специальным протоколом ODBC (Open Database Connectivity - открытый доступ к базам данных), играющим важную роль в обеспечении интероперабельности (многопротокольность), т.е. независимости от типа СУБД на клиентских установках в распределенных системах. Интероперабельность (многопротокольность) СУБД - способность СУБД обслуживать прикладные программы, первоначально ориентированные на разные типы СУБД. Простыми словами, специальный компонент ядра СУБД на сервере (так называемый драйвер ODBC) способен воспринимать, обрабатывать запросы и направлять результаты их обработки на клиентские установки, функционирующие под управлением реляционных СУБД других, не «своих» типов.
Такая возможность существенно повышает гибкость в создании распределенных информационных систем на базе интеграции уже существующих в какой-либо организации локальных баз данных под управлением настольных или другого типа реляционных СУБД. К недостаткам RDA-модели можно отнести высокие требования к клиентским вычислительным установкам, так как прикладные программы обработки данных, определяемые спецификой предметной области информационной системы, выполняются на них. Другим недостатком является все же существенный трафик сети, обусловленный тем, что с сервера базы данных клиентам направляются наборы (таблицы) данных, которые в определенных случаях могут занимать достаточно существенный объем.
Модель сервера базы данных (DBS-модель). Развитием PDA-модели стала модель сервера базы данных. Ее сердцевиной является механизм хранимых процедур. В отличие от RDA-модели, определенные для конкретной предметной области информационной системы события, правила и процедуры, описанные средствами языка SQL, хранятся вместе с данными на сервере системы и на нем же выполняются. Т.е. прикладной компонент полностью размещается и выполняется на сервере системы.
Модель сервера базы данных (DBS-модель)[13] На клиентских установках в DBS-модели размещается только интерфейсный компонент (компонент представления), что существенно снижает требования к вычислительной установке клиента. Пользователь через интерфейс системы на клиентской установке направляет на сервер базы данных только лишь вызовы необходимых процедур, запросов и других функций по обработке данных. Все затратные операции по доступу и обработке данных выполняются на сервере и клиенту направляются лишь результаты обработки, а не наборы данных, как в RDA-модели. Этим обеспечивается существенное снижение трафика сети в DBS-модели по сравнению с RDA - моделью[14].
Следует заметить, что на сервере системы выполняются процедуры прикладных задач одновременно всех пользователей системы. В результате резко возрастают требования к вычислительной установке сервера, причем как к объему дискового пространства и оперативной памяти, так и к быстродействию. Это основной недостаток DBS-модели. К достоинствам же DBS-модели, помимо разгрузки сети, относится и более активная роль сервера сети, размещение, хранение и выполнение на нем механизма событий, правил и процедур, возможность более адекватно и эффективно "настраивать" распределенную информационную систему на все нюансы предметной области. Также более надежно обеспечивается согласованность состояния и изменения данных и, вследствие этого, повышается надежность хранения и обработки данных, эффективно координируется коллективная работа пользователей с общими данными.
Модель сервера приложений (AS-модели). Чтобы разнести требования к вычислительным ресурсам сервера в отношении быстродействия и памяти по разным вычислительным установкам, используется модель сервера приложений. Суть AS-модели заключается в переносе прикладного компонента информационной системы на специализированный в отношении повышенных ресурсов по быстродействию дополнительный сервер системы. Как и в DBS-модели, на клиентских установках располагается только интерфейсная часть системы, т.е. компонент представления.
Однако вызовы функций обработки данных направляются на сервер приложений, где эти функции совместно выполняются для всех пользователей системы. За выполнением низкоуровневых операций по доступу и изменению данных сервер приложений, как в RDA-модели, обращается к SQL-серверу, направляя ему вызовы SQL-процедур, и получая, соответственно, от него наборы данных. Как известно, последовательная совокупность операций над данными (SQL-инструкций), имеющая отдельное смысловое значение, называется транзакцией. В этом отношении сервер приложений управляет формированием транзакций, которые выполняет SQL-сервер.
Поэтому программный компонент СУБД, инсталлируемый на сервере приложений, еще называют монитором обработки транзакций (Transaction Processing Monitors - TRM), или просто монитором транзакций. AS-модель, сохраняя сильные стороны DBS-модели, позволяет оптимально построить вычислительную схему информационной системы, однако, как и в случае RDA-модели, повышает трафик сети[15].
В практических случаях используются смешанные модели, когда простейшие прикладные функции и обеспечение ограничений целостности данных поддерживаются хранимыми на сервере процедурами (DBS-модель), а более сложные функции предметной области (так называемые правила бизнеса) реализуются прикладными программами на клиентских установках (RDA-модель) или на сервере приложений (AS-модель)[16].

Рис. 3 Взаимодействие модели «Клиент-сервер»
2.3. Распределенные базы данных
Системы распределенных вычислений появляются, прежде всего, по той причине, что в крупных автоматизированных информационных системах, построенных на основе корпоративных сетей, не всегда удается организовать централизованное размещение всех баз данных и СУБД на одном узле сети. Поэтому системы распределенных вычислений тесно связаны с системами управления распределенными базами данных.
Распределенная база дынных – это совокупность логически взаимосвязанных баз данных, распределенных в компьютерной сети.
Система управления распределенной базой данных – это программная система, которая обеспечивает управление распределенной базой данных и прозрачность ее распределенности для пользователей.
Распределенная база данных может объединять базы данных, поддерживающие любые модели (иерархические, сетевые, реляционные и объектно-ориентированные базы данных) в рамках единой глобальной схемы. Подобная конфигурация должна обеспечивать для всех приложений прозрачный доступ к любым данным независимо от их местоположения и формата.
Основные принципы создания и функционирования распределенных баз данных:
- прозрачность расположения данных для пользователя (иначе говоря, для пользователя распределенная база данных должна представляться и выглядеть точно так же, как и нераспределенная);
- изолированность пользователей друг от друга (пользователь должен "не чувствовать", "не видеть" работу других пользователей в тот момент, когда он изменяет, обновляет, удаляет данные);
- синхронизация и согласованность (непротиворечивость) состояния данных в любой момент времени.
Из основных вытекает ряд дополнительных принципов:
- локальная автономия (ни одна вычислительная установка для своего успешного функционирования не должна зависеть от любой другой установки);
- отсутствие центральной установки (следствие предыдущего пункта);
независимость от местоположения (пользователю все равно, где физически находятся данные, он работает так, как будто они находятся на его локальной установке);
- непрерывность функционирования (отсутствие плановых отключений системы в целом, например для подключения новой установки или обновления версии СУБД);
- независимость от фрагментации данных (как от горизонтальной фрагментации, когда различные группы записей одной таблицы размещены на различных установках или в различных локальных базах, так и от вертикальной фрагментации, когда различные поля-столбцы одной таблицы размещены на разных установках);
- независимость от реплицирования (дублирования) данных (когда какая-либо таблица базы данных (или ее часть) физически может быть представлена несколькими копиями, расположенными на различных установках);
- распределенная обработка запросов (оптимизация запросов должна носить распределенный характер – сначала глобальная оптимизация, а далее локальная оптимизация на каждой из задействованных установок);
- распределенное управление транзакциями (в распределенной системе отдельная транзакция может требовать выполнения действий на разных установках, транзакция считается завершенной, если она успешно завершена на всех вовлеченных установках);
- независимость от аппаратуры (желательно, чтобы система могла функционировать на установках, включающих компьютеры разных типов);
- независимость от типа операционной системы (система должна функционировать вне зависимости от возможного различия операционных систем на различных вычислительных установках);
- независимость от коммуникационной сети (возможность функционирования в разных коммуникационных средах);
- независимость от СУБД (на разных установках могут функционировать СУБД различного типа, на практике ограничиваемые кругом СУБД, поддерживающих SQL).
В обиходе СУБД, на основе которых создаются распределенные информационные системы, также характеризуют термином «распределенные СУБД», и, соответственно, используют термин «распределенные базы данных».
Практическая реализация распределенных вычислений осуществляется через отступление от некоторых рассмотренных выше принципов создания и функционирования распределенных систем. В зависимости от того, какой принцип приносится в «жертву» (отсутствие центральной установки, непрерывность функционирования, согласованного состояния данных и др.) выделились несколько самостоятельных направлений в технологиях распределенных систем – технологии «Клиент-сервер», технологии реплицирования, технологии объектного связывания.
Реальные распределенные информационные системы, как правило, построены на основе сочетания всех трех технологий, но в методическом плане их целесообразно рассмотреть отдельно.
2.4. Технологии реплицирования данных
Во многих случаях узким местом распределенных систем, построенных на основе технологий «Клиент-сервер» или объектного связывания данных, является недостаточно высокая производительность из-за необходимости передачи по сети большого количества данных. Определенную альтернативу построения быстродействующих распределенных систем предоставляют технологии реплицирования данных. Репликой называют особую копию базы данных для размещения на другом компьютере сети с целью автономной работы пользователей с одинаковыми (согласованными) данными общего пользования. Основная идея реплицирования заключается в том, что пользователи работают автономно с одинаковыми (общими) данными, растиражированными по локальным базам данных, обеспечивая с учетом отсутствия необходимости передачи и обмена данными по сети максимальную для своих вычислительных установок производительность.
Тиражирование (или репликация) - создание дублирующих копий (репликатов) объектов данных на разных узлах с целью повышения доступности и/или сокращения времени доступа к критически важным данным. Программное обеспечение СУБД для реализации такого подхода соответственно дополняется функциями тиражирования (реплицирования) баз данных, включая тиражирование как самих данных и их структуры, так и системного каталога с информацией о размещении реплик, иначе говоря, с информацией о конфигурировании построенной таким образом распределенной системы.
При этом, однако, возникают две проблемы обеспечения одного из основополагающих принципов построения и функционирования распределенных систем (а именно, непрерывности согласованного состояния данных):
- обеспечение согласованного состояния во всех репликах количества и значений общих данных;
- обеспечение согласованного состояния во всех репликах структуры данных.
Обеспечение согласованного состояния общих данных, в свою очередь, основывается на реализации одного из двух принципов:
- принципа непрерывного размножения обновлений (любое обновление данных в любой реплике должно быть немедленно размножено);
- принципа отложенных обновлений (обновления реплик могут быть отложены до специальной команды или ситуации).
Принцип непрерывного размножения обновлений является основополагающим при построении так называемых систем реального времени, таких, например, как системы управления воздушным движением, системы бронирования билетов пассажирского транспорта и т.п., где требуется непрерывное и точное соответствие реплик или других растиражированных данных во всех узлах и компонентах подобных распределенных систем.
Реализация принципа непрерывного размножения обновлений заключается в том, что любая транзакция считается успешно завершенной, если она успешно завершена на всех репликах системы. На практике реализация этого принципа встречает существенные затруднения. В целом ряде предметных областей распределенных информационных систем режим реального времени с точки зрения непрерывности согласования данных не требуется. Такие системы автоматизируют те организационно-технологические структуры, в которых информационные процессы не столь динамичны. В этом случае обновление реплик распределенной информационной системы, если она будет построена на технологии реплицирования, требуется, скажем, только лишь один раз за каждый рабочий час, или за каждый рабочий день. Такого рода информационные системы строятся на основе принципа отложенных обновлений. Накопленные в какой-либо реплике изменения данных специальной командой пользователя направляются для обновления всех остальных реплик систем. Такая операция называется синхронизацией реплик. Решение второй проблемы согласованности данных, а именно: согласованности структуры данных, осуществляется через частичное отступление, как и в системах «Клиент-сервер», от принципа отсутствия центральной установки и основывается на технике главной реплики, т.е. одна из реплик базы данных объявляется главной. При этом изменять структуру базы данных можно только в главной реплике. Эти изменения структуры данных тиражируются на основе принципа отложенных обновлений, т.е. через специальную синхронизацию реплик.
Частичность отступления от принципа отсутствия центральной установки заключается в том, что в отличие от чисто централизованных систем, выход из строя главной реплики не влечет сразу гибель всей распределенной системы, так как остальные реплики продолжают функционировать автономно.
Более того, на практике СУБД, поддерживающие технологию реплицирования, позволяют пользователю с определенными полномочиями (администратору системы) преобразовать любую реплику в главную и тем самым полностью восстановить работоспособность всей системы. Технологии репликации данных в тех случаях, когда не требуется обеспечивать большие потоки и интенсивность обновляемых в информационной сети данных, являются экономичным решением проблемы создания распределенных информационных систем с элементами централизации по сравнению с использованием дорогостоящих клиент-серверных систем.
На практике для совместной коллективной обработки данных применяются смешанные технологии, включающие элементы объектного связывания данных, репликаций и клиент-серверных решений. При этом дополнительно к проблеме логического проектирования, т. е. проектирования логической схемы организации данных (таблицы, поля, ключи, связи, ограничения целостности), добавляется не менее сложная проблема транспортно-технологического проектирования информационных потоков, разграничения доступа и т.д.
К сожалению, пока не проработаны теоретико-методологические и инструментальные подходы для автоматизации проектирования распределенных информационных систем с учетом факторов как логики, так и информационно-технологической инфраструктуры предметной области[17].
Тем не менее, развитие и все более широкое распространение распределенных информационных систем, определяемое самой распределенной природой информационных потоков и технологий, является основной перспективой развития автоматизированных информационных систем[18].
ГЛАВА 3. ТЕХНОЛОГИИ COM И CORBA
3.1. Общие понятия технологий
Технология СОМ применяется при описании API и двоичного стандарта для связи объектов различных языков и сред программирования. СОМ предоставляет модель взаимодействия между компонентами и приложениями.
Технология СОМ работает с так называемыми СОМ-объектами. СОМ-объекты похожи на обычные объекты визуальной библиотеки компонентов Delphi. В отличие от объектов VCL Delphi, СОМ-объекты содержат свойства, методы и интерфейсы[19].
Технология CORBA, разрабатываемая с 1989 года консорциумом OMG (Object Management Group), является результатом работы ведущих специалистов из более чем 800 компаний и организаций. Четкий процесс стандартизации, включая аспекты взаимодействия реализаций CORBA от разных поставщиков (интероперабельность), независимость от языков программирования и операционных сред, фундаментальная поддержка ООП и многие другие уникальные характеристики, сделали CORBA[20] ведущим стандартом в области инфраструктурного middleware.
Развитие СОМ-технологий. Одной из важнейших задач, которые ставила перед собой фирма Microsoft, когда продвигала операционную систему Windows, была задача по обеспечению эффективного взаимодействия между различными программами, работающими в Windows[21].
3.2. Технология COM
Одним из главных достоинств Delphi является поддержка технологий СОМ и ActiveX. В этой главе мы рассмотрим, что представляет собой технология СОМ, в чем различие между технологиями COM, ActiveX и OLE.
COM (Component Object Model) - это объектная модель компонентов. Данная технология является базовой для технологий ActiveX и OLE. Технологии OLE и ActiveX - всего лишь надстройки над данной технологией. В качестве примера можно привести объект TObject[22], как базовый объект VCL Delphi. В этой главе мы рассмотрим, что представляет собой технология СОМ, в чем различие между технологиями COM, ActiveX и OLE.
Обычный СОМ-объект включает в себя один или несколько интерфейсов. Каждый из этих интерфейсов имеет собственный указатель.
Хоть технология СОМ обладает явными плюсами, она имеет также и минусы, среди которых зависимость от платформы. То есть, данная технология применима только в операционной системе Windows и на платформе Intel.
Все СОМ-объекты обычно содержатся в файлах с расширением DLL или OCX. Один такой файл может содержать как одиночный СОМ-объект, так и несколько СОМ-объектов.
Ключевым аспектом технологии СОМ является возможность предоставления связи и взаимодействия между компонентами и приложениями, а также реализация клиент-серверных взаимодействий при помощи интерфейсов.
Технология СОМ реализуется с помощью СОМ-библиотек (в число которых входят такие файлы операционной системы, как OLE32.DLL и OLE-Aut32.DLL). СОМ-библиотеки содержат набор стандартных интерфейсов, которые обеспечивают функциональность СОМ-объекта, а также небольшой набор функций API, отвечающих за создание и управление СОМ-объектов.
В Delphi реализация и поддержка технологии СОМ называется каркасом Delphi ActiveX (Delphi ActiveX framework, DAX). Реализация DAX описана в модуле Axctris.
3.3. Развитие СОМ-технологий
Одной из важнейших задач, которые ставила перед собой фирма Microsoft, когда продвигала операционную систему Windows, была задача по обеспечению эффективного взаимодействия между различными программами, работающими в Windows.
Самыми первыми попытками решить эту непростую задачу были буфер обмена, разделяемые файлы и технология динамического обмена данными (Dynamic Data Exchange, DDE).
После чего была разработана технология связывания и внедрения объектов (Object Linking and Embedding, OLE). Первоначальная версия OLE 1 предназначалась для создания составных документов. Эта версия была признана несовершенной и на смену ей пришла версия OLE 2. Новая версия позволяла решить вопросы предоставления друг другу различными программами собственных функций. Данная технология активно внедрялась до 1996 года, после чего ей на смену пришла технология ActiveX, которая включает в себя автоматизацию (OLE-автоматизацию), контейнеры, управляющие элементы, Web-технологию и т. д.
3.4. Технология OMG CORBA
Технология CORBA, разрабатываемая с 1989 года консорциумом OMG (Object Management Group), является результатом работы ведущих специалистов из более чем 800 компаний и организаций. Четкий процесс стандартизации, включая аспекты взаимодействия реализаций CORBA от разных поставщиков (интероперабельность), независимость от языков программирования и операционных сред, фундаментальная поддержка ООП и многие другие уникальные характеристики, сделали CORBA ведущим стандартом в области инфраструктурного middleware.
Основой технологии CORBA являются:
- Interface Definition Language - язык, позволяющий описать все аспекты удаленного взаимодействия;
- схемы отображения IDL-объявлений на конкретные языки программирования;
- Object Request Broker - объектная магистраль, позволяющая передавать запросы от клиентов к серверам и обратно;
- сервисы (Common Object Services) CORBA;
Распределенная система, использующая CORBA, не ориентирована на применение конкретных операционных систем, двоичных стандартов, сетевых протоколов и языков программирования. Получается, что это единственная технология, которая обеспечивает возможность использования практически любых языков программирования и функционирование программного обеспечения практически на любых аппаратно-программных платформах.
При использовании технологии CORBA вся система представляет собой набор работающих в сети приложений, предоставляющих друг другу какие-либо ресурсы или обеспечивающие выполнение каких-либо задач.
При этом отдельными независимыми приложениями могут являться компоненты доступа к базе данных, служебные сервисы системы (типа сервиса хранения настроек объектов или сервиса безопасности), драйверы работы с оборудованием, функциональные модули (работы с планами помещений, генерации отчетов, работы с БД пользователей и др.), а также пользовательские приложения, обеспечивающие отображение состояния объектов системы и возможность управления ими.
Данная технология обеспечивает четкое разделение модулей системы на клиентские (пользовательские приложения) и серверные (драйверы оборудования). Технология обеспечивает удаленную стыковку модулей.
Благодаря использованию стандартной технологии стыковки между собой всех модулей системы сторонним разработчикам предоставляется возможность расширения системы за счет разработки своих собственных модулей, реализующих дополнительные возможности системы или поддержку нового специализированного оборудования.
Технология CORBA позволяет вести разработку практически на любом языке программирования (C++, Java, Delphi и др.) и под любую аппаратно-программную платформу (Mi-crosoft Windows - Intel, Linux, Sun Microsystems Solaris - SPARC). Однако использование языка программирования Java позволяет получить дополнительное преимущество переносимости программного комплекса не только без его доработки, но даже и без его перекомпиляции.
В случае использования языка Java для разработки ПК разработчику доступна стандартная технология взаимодействия с различными серверами баз данных JDBC (Java DataBase Connectivity). Основными частями технологии JDBC являются JDBC API (набор классов и методов, к которым обращается прикладной программист) и JDBC-драйверы, которые транслируют эти вызовы в команды API конкретной СУБД. Используя данную технологию можно получить систему, независимую от используемого сервера БД и, соответственно, иметь возможность выбора сервера непосредственно для каждого заказчика в соответствии с особенностями объекта.
Для хранения настроек объектов, конфигурации рабочих мест и прочей информации в БД можно применять стандартную реляционную модель, при которой данные объектов каждого типа сохраняются в отдельной таблице, содержащей набор колонок, соответствующих списку свойств этих объектов. Такой вариант хранения обеспечивает быстрые сохранение, поиск и выборку данных из БД, и удобен в информационных системах.
Системы безопасности же имеют свою специфику. С одной стороны, здесь нет острой необходимости в быстром поиске среди миллионов записей (количество обслуживаемых аппаратных объектов обычно все-таки существенно меньше). С другой стороны, при расширении системы может возникнуть необходимость в добавлении новых типов объектов, что часто приводит к перестройке структуры БД, что, в свою очередь, затрудняет процесс установки и поддержки системы. В качестве возможной альтернативы можно рассмотреть хранение настроек объектов системы в полях типа BLOB формате XML.
Используя для построения системы технологию CORBA для решения стандартных системных задач, можно воспользоваться стандартными сервисами CORBA. Сервисы CORBA решают задачи поиска, установления отношений между объектами, сохранения их состояний, управления транзакциями и безопасностью, синхронного и асинхронного уведомления о тех или иных событиях и многое другое. Одними из самых распространенных сервисов являются Сервис Событий (Event Service) или идущий ему на смену и являющийся его развитием и обобщением Сервис Уведомлений (Notification Service). Эти сервисы позволяют универсальным образом уведомлять объекты распределенной системы о происходящих событиях. Обеспечение безопасности.
При построении системы безопасности на базе стандартных технологий необходимо особое внимание уделить безопасности самого комплекса. Для решения этой задачи создан специальный Сервис Безопасности (Security Service). Это очень сложный сервис, спецификация его состоит почти из 300 страниц. Самое поразительное, что при всей его сложности и многочисленности решаемых им проблем, он практически не «виден» для прикладного программиста - все действия выполняются автоматически, в том числе и распространение контекста безопасности.
ЗАКЛЮЧЕНИЕ
На сегодняшний день можно с легкостью сказать, что распределенные базы данных - тема достаточно локальная и далеко не так актуальная, как, например, архитектура данных.
По моему мнению, революционные шаги произойдут в сторону архитектуры корпоративных информационных систем.
Технологический взрыв в intertet, создание и «пышное» развитие Всемирной паутины, технология java, неизбежно отразятся на организации инфраструктуры корпораций. Как я считаю, очевидные преимущества гипертекстовой организации данных (гибкость, открытость, простота развития и расширения) перед жесткими структурами реляционных баз данных, по своей натуре плохо приспособленными для расширения, предопределяют использование html в качестве одного из основных средств создания информационного пространства компании.
То, что сейчас называют intranet - это прообраз будущей корпоративной информационной системы.
Мы рассмотрели достаточно детально тему распределенных информационных систем, а также их технологию построения. Прошлись по классам ИС, разобрали модели технологий «Клиент-сервер» и научились различать типы РИС от принципов.
Как мы выяснили, один из самых важных сервисов CORBA – это технология, сервер, архитектура и интерфейс. Сервис CORBA решает многие проблемы, а именно:
- идентификации пользователя;
- определения прав доступа к объектам;
- режимов делегирования полномочий при цепочке последовательных вызовов объектов друг другом;
- системы аудита;
- защиты информации при передаче;
- ведение достоверной истории взаимодействия объектов и т.д.
Как я считаю, технология СОМ имеет два явных плюса. Создание СОМ-объектов не зависит от языка программирования[23]. Поэтому СОМ-объекты могут быть написаны на различных языках, во-первых. А во-вторых, СОМ-объекты могут быть использованы в любой среде программирования под Windows. В число этих сред входят Delphi, Visual C++, C++Builder, Visual Basic и т.д.
Технологии построения распределенных информационных систем очень важны в нашей жизни и всегда актуальны[24].
БИБЛИОГРАФИЯ
1. Бойко В.В. / Савинков В.М. Проектирование баз данных информационных систем (издание 2): «Финансы и статистика», 1989 год, с. 349.
2. Морозевич А.Н. Информатика / Зеневич А.М., 2006 год, с. 116-118.
3. Коннолли Т. / Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика, 2003 год, с. 433.
4. Бойко В.В. / Савинков В.М. Проектирование баз данных информационных систем (издание 2): «Финансы и статистика», 1989 год, с. 311-314, 316.
5. Волков Г.Г. / Глинский О.Ю. Компьютерные информационные технологии, 2010 год, с. 86.
6. Трофимова В.В. Информационные системы и технологии в экономике и управлении (издание 3), 2011 год, с. 521-522.
7. Олифер В. Г. Компьютерные сети: принципы, технологии, протоколы, 2009 год, с. 955-958.
8. Технологии создания распределенных информационных систем. URL: http://citforum.ru/database/oraclepr/oraclepr_03.shtml
9. Общие принципы построения распределенных систем. URL: http://studopedia.su/13_27124_obshchie-printsipi-postroeniya-raspredelennih-sistem.html
10. Абламейко С.В. / Абрамов С.М. / Анищенко С.В. / Парамонов Н.Н. / Чиж О.П. Суперкомпьютерные конфигурации СКИФ. Мн.: ОИПИ, 2005 год, с. 163-166, 174, 180.
ПРИЛОЖЕНИЕ

Рис. 4 Модель файлового сервера

Рис. 5 Информационные взаимосвязи компонентов WEB узла

Рис. 6 Двухуровневая архитектура «Клиент-сервер»
-
Бойко В.В. / Савинков В.М. Проектирование баз данных информационных систем (издание 2): «Финансы и статистика», 1989 год, с. 349. ↑
-
Бойко В.В. / Савинков В.М. Проектирование баз данных информационных систем (издание 2): «Финансы и статистика», 1989 год, с. 311-314. ↑
-
Бойко В.В. / Савинков В.М. Проектирование баз данных информационных систем (издание 2): «Финансы и статистика», 1989 год, с. 316. ↑
-
Технологии создания распределенных информационных систем. URL: http://citforum.ru/database/oraclepr/oraclepr_03.shtml ↑
-
Бойко В.В. / Савинков В.М. Проектирование баз данных информационных систем (издание 2): «Финансы и статистика», 1989 год, с. 349. ↑
-
Морозевич А.Н. Информатика / Зеневич А.М., 2006 год, с. 116-118. ↑
-
Коннолли Т. / Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика, 2003 год, с. 433. ↑
-
Общие принципы построения распределенных систем. URL: http://studopedia.su/13_27124_obshchie-printsipi-postroeniya-raspredelennih-sistem.html ↑
-
Абламейко С.В. / Абрамов С.М. / Анищенко С.В. / Парамонов Н.Н. / Чиж О.П. Суперкомпьютерные конфигурации СКИФ. Мн.: ОИПИ, 2005 год, с. 174. ↑
-
. Олифер В. Г. Компьютерные сети: принципы, технологии, протоколы, 2009 год, с. 955-958. ↑
-
Общие принципы построения распределенных систем. URL: http://studopedia.su/13_27124_obshchie-printsipi-postroeniya-raspredelennih-sistem.html ↑
-
Волков Г.Г. / Глинский О.Ю. Компьютерные информационные технологии, 2010 год, с. 86. ↑
-
Коннолли Т. / Бегг К. Базы данных. Проектирование, реализация и сопровождение. Теория и практика, 2003 год, с. 433. ↑
-
Абламейко С.В. / Абрамов С.М. / Анищенко С.В. / Парамонов Н.Н. / Чиж О.П. Суперкомпьютерные конфигурации СКИФ. Мн.: ОИПИ, 2005 год, с. 163-166. ↑
-
Олифер В. Г. Компьютерные сети: принципы, технологии, протоколы, 2009 год, с. 955-958. ↑
-
Волков Г.Г. / Глинский О.Ю. Компьютерные информационные технологии, 2010 год, с. 86. ↑
-
Трофимова В.В. Информационные системы и технологии в экономике и управлении (издание 3), 2011 год, с. 521. ↑
-
Морозевич А.Н. Информатика / Зеневич А.М., 2006 год, с. 117. ↑
-
Морозевич А.Н. Информатика / Зеневич А.М., 2006 год, с. 116-118. ↑
-
Олифер В. Г. Компьютерные сети: принципы, технологии, протоколы, 2009 год, с. 955-958. ↑
-
Волков Г.Г. / Глинский О.Ю. Компьютерные информационные технологии, 2010 год, с. 86. ↑
-
Абламейко С.В. / Абрамов С.М. / Анищенко С.В. / Парамонов Н.Н. / Чиж О.П. Суперкомпьютерные конфигурации СКИФ. Мн.: ОИПИ, 2005 год, с. 163-166, 180. ↑
-
Бойко В.В. / Савинков В.М. Проектирование баз данных информационных систем (издание 2): «Финансы и статистика», 1989 год, с. 311-314, 316. ↑
-
Технологии создания распределенных информационных систем. URL: http://citforum.ru/database/oraclepr/oraclepr_03.shtml ↑

- изучение перевода словосочетаний и терминологических клише (на материале технических инструкций к техническим использованиям)
- История возникновения и развития будущего времени в английском языке (Родственные языки)
- Виды научного перевода (Что такое перевод)
- Рынок ценных бумаг (Теоретические аспекты функционирования рынка ценных бумаг)
- Российский нотариат его задачи и функции
- Виды договоров (Виды договоров и их классификация)
- Понятие и виды ценных бумаг (Оборот ценных бумаг)
- История развития прикладного программного обеспечения (Виды программного обеспечения)
- Языки гипертекстовой разметки (Определение основных понятий)
- Мультипроцессоры (Конвейерная и векторная обработка)
- Профессиональная мотивация служащих (ДИАГНОСТИКА ОСОБЕННОСТЕЙ ПРОФЕССИОНАЛЬНОЙ МОТИВАЦИИ СЛУЖАЩИХ ОРГАНИЗАЦИИ)
- ГЕНДЕРНЫЕ РАЗЛИЧИЯ ПРОЯВЛЕНИЙ ПРОФЕССИОНАЛЬНОГО СТРЕССА (Понятие стресса. Профессиональный стресс)