
Методы кодирования данных (Теоретические основы)
Содержание:

Введение
Актуальность темы в том, что вычислительная техника первоначально возникла как средство автоматизации вычислений. Следующим видом обрабатываемой информации стала текстовая. Сначала тексты просто поясняли труднообозримые столбики цифр, но затем машины все более существенным образом стали преобразовывать текстовую информацию. Оформление текстов достаточно быстро вызвали у людей стремление дополнить их графиками и рисунками. Делались попытки частично решить эти проблемы в рамках символьного подхода: вводились специальные символы для рисования таблиц и диаграммам. Но практические потребности людей в графике делали ее появление среди видов компьютерной информации неизбежной. Числа, тексты и графика образовали некоторый относительно замкнутый набор, которого было достаточно для многих решаемых на компьютере задачи. Постоянный рост быстродействия вычислительной техники создал широкие технические возможности для обработки звуковой информации, а также для быстро сменяющихся изображений. Все это обусловило и развитие способов представления и кодирования различных видов информации в компьютере.
Объектом изучения, представленным в теоретической части являются данные в компьютере.
Цель работы – рассмотреть форматы данных их представление и кодирование в компьютере.
Для достижения цели необходимо решить следующие задачи:
- Рассмотреть существующие форматы данных;
- Рассмотреть представление различных типов, данных в компьютере и описать способы кодирования информации.
Задача, поставленная в практической части – рассмотреть методы кодирования информации.
В частности, будут раскрыты вопросы, связанные с методами хранения информации и её кодирования на компьютере, изучением взаимосвязи информационных технологий с технологиями хранения данных, раскрытие понятия информационный ресурс и многое другое, связанное с хранением информации в современном мире. Однако в науке информатика этим терминам есть и другое, более полное и техническое объяснение.
1. Информация и данные
Информационные ресурсы в современном обществе играют не меньшую, а нередко и большую pоль, чем pесуpсы материальные. Знания, кому, когда и где продать товар, может цениться не меньше, чем собственно товар, и в этом плане динамика развития общества свидетельствует о том, что на "весах" материальных и информационных ресуpсов последние начинают пpевалиpовать, причем тем сильнее, чем более общество открыто, чем более развиты в нем средства коммуникации, чем большей информацией оно располагает. С позиций рынка информация давно уже стала товаром и это обстоятельство требует интенсивного развития практики, промышленности и теории компьютеризации общества. Пользователь ЭВМ (или конечный пользователь) должен знать общие принципы организации информационных процессов в компьютерной среде, уметь выбрать нужные ему информационные системы и технические средства и быстро освоить их применительно к своей предметной области. Учитывая интенсивное развитие вычислительной техники и во многом насыщенность рынка прогpаммных продуктов, два последних качества пpиобpетают особое значение. Данные.
Зададимся вопросом, что такое данные и как мы к ним относимся? Интуитивно ясно, что под данными мы подразумеваем какое-либо сообщение, наблюдаемый факт, сведения о чем-либо, результаты эксперимента и т.п. Иначе говоря, данные - это всегда конкретность, представленная в определенной форме (числом, записью, сообщением, таблицей и т.д.). Данные (от лат. data) - это представление фактов и идей в формализованном виде, пригодном для передачи и обработки в некотором информационном процессе. Данные - это зарегистрированные сигналы. Данные могут рассматриваться как записанные наблюдения, которые не используются, а пока хранятся. Традиционно выделяют два типа данных - двоичные (бинарные) и текстовые. Двоичные данные обрабатываются только специализированным программным обеспечением, знающим их структуру, все остальные программы передают данные без изменений. Текстовые данные воспринимаются передающими системами как текст, записанный на каком-либо языке. Для них может осуществляться перекодировка (из кодировки отправляющей системы, в кодировку принимающей), заменяться символы переноса строки, изменяться максимальная длина строки, изменяться количество пробелов в тексте. Передача текстовых данных как бинарных приводит к необходимости изменять кодировку в прикладном программном обеспечении (это умеет большинство прикладного ПО, отображающего текст, получаемый из разных источников), передача бинарных данных как текстовых может привести к их необратимому повреждению. Для повышения качества данные преобразуются из одного вида в другой с помощью методов обработки. Обработка данных включает операции.
Ввод (сбор) данных - накопление данных с целью обеспечения достаточной полноты для принятия решений.
Формализация данных - приведение данных поступающих из разных источников, к одинаковой форме, для повышения их доступности. . Фильтрация данных - это отсеивание «лишних» данных, в которых нет необходимости для повышения достоверности и адекватности. . Сортировка данных - это упорядочивание данных по заданному признаку с целью удобства использования. .
Архивация - это организация хранения данных в удобной и легкодоступной форме. Защита данных - включает меры, направленные на предотвращение утраты, воспроизведения и модификации данных. . Транспортировка данных - прием и передача данных между участниками информационного процесса. [1]
Преобразование данных - это перевод данных из одной формы в другую или из одой структуры в другую. Сами по себе данные никакой ценности не представляют. На самом деле, как вы отнесетесь, например, к следующим данным: · "тридцать семь с половиной"; · "2 + 2 = 4"; · "Петров стал директором". Первое вызовет недоумение, второе - ощущение тривиальности (это знает каждый), третье - размышления, кто такой Петpов? Во всех пpиведенныхпpимеpах данные неинфоpмативны (хотя по pазнымпpичинам), и для того, чтобы пpидать им инфоpмативность, т.е. пpевpатить их в инфоpмацию, необходимо осуществить интеpпpетацию данных. Интеpпpетация - пpоцесспpевpащения данных в инфоpмацию, пpоцесспpидания им смысла. Этот пpоцесс зависит от многих фактоpов: кто интеpпpетиpует данные, какой инфоpмацией уже pасполагаетинтеpпpетатоp, с каких позиций он pассматpивает полученные данные и т.д. Пpоцессинтеpпpетации может осуществляться человеком или гpуппой лиц, пpи этом он может быть твоpческим (напpимеp, музициpование по нотной записи) или фоpмальным (опpеделениевpемени по часам). Такой пpоцесс может осуществляться биологическими объектами (условные pефлексы собак, общение дельфинов), многими устpойствами технической автоматики (обнаpужение сигнала от цели в pадиолокации с последующими действиями) и, конечно, компьютеpом. Абстpактностьинфоpмации в отличие от конкpетности данных заключается в том, что пpоцессинтеpпpетации в общем случае не может быть опpеделенфоpмально, в то вpемя как данные всегда существуют в какой-то опpеделеннойфоpме. Между данными и инфоpмацией в общем случае нет взаимно-однозначного соответствия. Напpимеp, фоpмальноpазличные сообщения «до завтpа» и «seeyoutomorrow» несут одну и ту же инфоpмацию. Pазные знаки «x» и «*» могут содеpжательно обозначать одно и то же - опеpацию умножения, фоpмальноpазличныестpоки «21» и «XXI» опpеделяют одно и то же число (в pазличных системах счисления). С дpугойстоpоны одни и те же данные могут нести совеpшенноpазличнуюинфоpмациюpазным получателям (pазныминтеpпpетатоpам). Напpимеp, знак "I" может интеpпpетиpоваться как буква "ай" в английском алфавите или как pимскаяцифpа 1, знак "+" может интеpпpетиpоваться как опеpация сложения или опеpация объединения множеств в зависимости от контекста. Кивок головой свеpху вниз обычно обозначает "Да", а покачивание - "Нет", но не во всех стpанах (в Болгаpии и Гpеции это не так). Эти пpимеpы показывают, что интеpпpетация данных зависит от многих дополнительных объективных фактоpов (в этих пpимеpах - контекст, стpана, место), но интеpпpетация может зависеть и от субъективных фактоpов. Напpимеp, один и тот же цвет человек с ноpмальнымзpениемвоспpинимает одним обpазом, а дальтоник дpугим. Пpиведенныепpимеpыальтеpнативнойинтеpпpетации одних и тех же данных иллюстpиpуют понятие полимоpфизма (множественной интеpпpетации), котоpое в конечном счете и опpеделяетабстpактныйхаpактеp этого пpоцесса. Наконец, еще один важный аспект интеpпpетации. В любом достаточно большом набоpе данных есть особые позиции (знаки, ключевые слова, пpизнаки), котоpыеупpавляютпpоцессоминтеpпpетации и потому имеют особое значение, во многом опpеделяющее ценность и важность получаемой инфоpмации. Классический пpимеp: сообщение «Казнить нельзя, помиловать». [2] Положение запятой в этом пpимеpе (пеpед словом "нельзя" или после) pадикально меняет инфоpмационноесодеpжание данных. Можно ли в этом отношении сpавнить запятую в этом сообщении с буквой «н», напpимеp? Потеpя или искажение последней легко восстанавливается по контексту, потеpя запятой сводит инфоpмативность сообщения в целом к нулю. Таким обpазом, данные - это набоpнеодноpодных ключевых слов (позиций, знаков и т.п.), несущих инфоpмациюpазной степени ценности.
1.1. Теоретические основы задачи кодирования
Прежде чем рассмотреть задачу кодирования, необходимо рассмотреть ряд определений, использующихся в теории кодирования [1]:
Код – (1) правило, описывающее соответствие знаков или их сочетаний одного алфавита знакам или их сочетаниям другого алфавита; - (2) знаки вторичного алфавита, используемые для представления знаков или их сочетаний первичного алфавита.
Кодирование – перевод информации, представленной посредством первичного алфавита, в последовательность кодов.
Декодирование - операция, обратная кодированию, т.е. восстановление информации в первичном алфавите по полученной последовательности кодов.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо ее потерь.
Информационная энтропия - в теории связи энтропия используется как мера неопределенности ожидаемого сообщения, т.е. энтропия источника информации с независимыми сообщениями есть среднее арифметическое количеств информации сообщений
Примером обратимого кодирования является представление знаков в телеграфном коде и их восстановление после передачи. Примером кодирования необратимого может служить перевод с одного естественного языка на другой – обратный перевод, вообще говоря, не восстанавливает исходного текста. Безусловно, для практических задач, связанных со знаковым представлением информации, возможность восстановления информации по ее коду является необходимым условием применения кода, поэтому в дальнейшем изложении будет рассматриваться только обратимое кодирования.
Таким образом, кодирование предшествует передаче и хранению информации. При этом, как указывалось ранее, хранение связано с фиксацией некоторого состояния носителя информации, а передача – с изменением состояния с течением времени (т.е. процессом). Эти состояния или сигналы будем называть элементарными сигналами – именно их совокупность и составляет вторичный алфавит.
Без технических сторон передачи и хранения сообщения (т.е. того, каким образом фактически реализованы передача-прием последовательности сигналов или фиксация состояний), математическая постановка задачи кодирования, дается следующим образом. [3]
Пусть первичный алфавит A содержит N знаков со средней информацией на знак, определенной с учетом вероятностей их появления, I1 (A) (нижний индекс отражает то обстоятельство, что рассматривается первое приближение, а верхний индекс в скобках указывает алфавит). Вторичный алфавит B пусть содержит M знаков со средней информационной емкостью I1 (A). Пусть также исходное сообщение, представленное в первичном алфавите, содержит n знаков, а закодированное сообщение – m знаков. Если исходное сообщение содержит I(A) информации, а закодированное – I(B) , то условие обратимости кодирования, т.е. неисчезновения информации при кодировании, очевидно, может быть записано следующим образом:
I(A) ≤ I(B) ,
смысл которого в том, что операция обратимого кодирования может увеличить количество формальной информации в сообщении, но не может его уменьшить. Однако каждая из величин в данном неравенстве может быть заменена произведением числа знаков на среднюю информационную емкость знака, т.е.:
n*I1 ( A ) ≤ n*I1 ( B ) ,
или
I1 ( A ) ≤ m/n*I1 ( B )
Отношение m/n, очевидно, характеризует среднее число знаков вторичного алфавита, которое приходится использовать для кодирования одного знака первичного алфавита – будем называть его длиной кода или длиной кодовой цепочки и обозначим K(B) (верхний индекс указывает алфавит кодов). [
В частном случае, когда появление любых знаков вторичного алфавита равновероятно, согласно формуле Хартли I1 (B) =log2 M, и тогда
I1 (A) /log2 M≤ K( B ) (1)
По аналогии с величиной R, характеризующей избыточность языка, можно ввести относительную избыточность кода (Q):
Q= 1 – I(A) / I(B) = 1- I1 (A) / K(B) *I1 (B) (2)
Данная величина показывает, насколько операция кодирования увеличила длину исходного сообщения. Очевидно, чем меньше Q (т.е. чем ближе она к 0 или, что то же, I(B) ближе к I(A) ), тем более выгодным оказывается код и более эффективной операция кодирования. Выгодность кодирования при передаче и хранении – это экономический фактор, поскольку более эффективный код позволяет затратить на передачу сообщения меньше энергии, а также времени и, соответственно, меньше занимать линию связи; при хранении используется меньше площади поверхности (объема) носителя. При этом следует сознавать, что выгодность кода не идентична временной выгодности всей цепочки кодирование – передача – декодирование; возможна ситуация, когда за использование эффективного кода при передаче придется расплачиваться тем, что операции кодирования и декодирования будут занимать больше времени и иных ресурсов (например, места в памяти технического устройства, если эти операции производятся с его помощью).[4]
Ранее указывалось, что источник сообщения включает кодирующую систему, формирующую сигналы по известным получателю правилам. Ввиду независимости содержания сообщения от выбранной формы его представления, возможно преобразование одного кода в другой, предоставив правило обратного преобразования получателю сообщения. Целесообразность такого дополнительного кодирования сообщения на передающей стороне и соответствующего декодирования на приемной стороне возникает из-за избыточности алфавита сообщения и искажения сигналов действующими в канале связи помехами. Кодирование предшествует хранению и передаче информации.
Реализация основных характеристик канала связи помимо разработки технических устройств, требует решения информационных задач – выбор оптимального метода кодирования.[5]
Основными задачами кодирования являются:
1. Обеспечение экономичности передачи информации посредством устранения избыточности.
2. Обеспечение надежности (помехоустойчивости) передачи информации
3. Согласование скорости передачи информации с пропускной способностью канала
Соответствие между элементами дискретных сообщений и видом кодирования обеспечивается выбором:
1. длительности сигналов
2. Длины кодового слова
3. Алфавита знаков и способа кодирования (побуквенного, блочного)
Полагается, что сообщение источника информации формируется из знаков аi, i=1,2,..Na внешнего (входного, первичного) алфавита А объемом Na. Сообщения представляют собой слова, образованные последовательностью nr знаков: Ar =a1a2…anr. В кодирующем устройстве слово Ar преобразуется в кодовое слово Br=b1b2…bmr, составленное из mr знаков bj , j=1,2,..Nb внутреннего (выходного, вторичного) алфавита В. Число знаков кодового алфавита называют основанием кода. Число знаков в кодовом слове называют длиной кодового слова. Отображение G множества слов в алфавите А на множество слов в алфавите В называют кодирующим отображением или кодом. Применение кодирующего отображения G к любому слову из входного алфавита называется кодированием. То есть код - это правило отображения знаков одного алфавита в знаки другого алфавита, кодирование – это преобразование одной формы сообщения в другую посредством указанного кода.
Различают побуквенное и блочное кодирование. При побуквенном кодировании каждому знаку внешнего алфавита ставиться в соответствие кодовое слово из знаков внутреннего алфавита. [6,c.128]
нешнего алфавита ставиться в соответствие кодовое слово из знаков внутреннего алфавита.
Cлова из знаков внутреннего алфавита В, сопоставленные словам из знаков внешнего алфавита А по правилу G, называются кодовыми комбинациями. Если ArE A и G(Ar)= Br, то говорят, что слову Ar соответствует кодовая комбинация Br. Совокупность кодовых комбинаций используемых для передач заданного количества дискретных сообщений называют кодовым словарем.
Процесс, обратный кодированию, заключается в восстановлении из кодовой комбинации Br=b1b2…bmr слова Ar=a1a2…anr из входного алфавита и называется декодированием. Если процесс кодирования осуществляется с использованием правила G, то процесс декодирования основан на применении правила G-1, где G-1 есть отображение, обратное отображению G.
Операции кодирования и декодирования называют обратимыми, если их последовательное применение обеспечивает возврат к исходной форме сообщения без потери информации.
Пусть Ar — слово в алфавите А и Br =G(Ar) — слово в алфавите В. Код называется обратимым, если для любого слова Br =G(Ar) в алфавите В существует единственное преобразование G-1(Br)= Ar . То есть, по слову Br в алфавите В, всегда однозначно восстанавливается слово Ar в алфавите А, из которого было образовано слово Br.
Примером обратимого кодирования является представление знаков в телеграфном коде при передаче сообщений и восстановление их при приеме.
Примером необратимого кодирования является перевод текста с одного естественного языка на другой. (Обратный перевод побуквенно обычно не соответствует исходному тексту.)
Чтобы код был обратимым, необходимо:
1) чтобы разным символам входного алфавита А были сопоставлены разные кодовые комбинации;
2) чтобы никакая кодовая комбинация не составляла начальной части какой-нибудь другой кодовой комбинации.
Наиболее простым правилом кодирования является сопоставление каждому символу входного алфавита А слова конечной длины в выходном алфавите В. Код может быть задан в форме таблицы, графа, аналитического выражения, то есть в тех же формах, что и отображение.
Выражение (1) пока следует воспринимать как соотношение оценочного характера, из которого неясно, в какой степени при кодировании возможно приближение к равенству его правой и левой частей. По этой причине для теории связи важнейшее значение имеют две теоремы, доказанные Шенноном. Первая – затрагивает ситуацию с кодированием при передаче сообщения по линии связи, в которой отсутствуют помехи, искажающие информацию. Вторая теорема относится к реальным линиям связи с помехами.[7,c.94]
2. Кодирование. Основные понятия и определения
Рассмотрим основные понятия, связанные с кодированием информации. Для передачи в канал связи сообщения преобразуются в сигналы. Символы, при помощи которых создаются сообщения, образуют первичный алфавит, при этом каждый символ характеризуется вероятностью его появления в сообщении.
Каждому сообщению однозначно соответствует сигнал, представляющий определенную последовательность элементарных дискретных символов, называемых кодовыми комбинациями. Кодирование - это преобразование сообщений в сигнал, т.е. преобразование сообщений в кодовые комбинации.
Декодер - устройство, осуществляющее обратную операцию, т.е. преобразование кодовой комбинации в сообщение. Алфавит - множество возможных элементов кода, т.е. элементарных символов (кодовых символов) X = {xi}, где i = 1, 2,..., m. Количество элементов кода - m называется его основанием. Для двоичного кода xi = {0, 1} и m = 2. Конечная последовательность символов данного алфавита называется кодовой комбинацией (кодовым словом). Число элементов в кодовой комбинации - n называется значностью (длиной комбинации). Число различных кодовых комбинаций (N = mn) называется объемом или мощностью кода.
Если N0 - число сообщений источника, то N ? N0. Множество состояний кода должно покрывать множество состояний объекта. Полный равномерный n - значный код с основанием m содержит N = mn кодовых комбинаций. Такой код называется примитивным.
Классификация кодов
Коды можно классифицировать по различным признакам:
1. По основанию (количеству символов в алфавите):
бинарные (двоичные m=2) и не бинарные (m ? 2).
2. По длине кодовых комбинаций (слов):
равномерные - если все кодовые комбинации имеют одинаковую длину;
неравномерные - если длина кодовой комбинации не постоянна.
3.По способу передачи:
последовательные и параллельные;
блочные - данные сначала помещаются в буфер, а потом передаются в канал и бинарные непрерывные.
4. По помехоустойчивости:
простые (примитивные, полные) - для передачи информации используют все возможные кодовые комбинации (без избыточности);
корректирующие (помехозащищенные) - для передачи сообщений используют не все, а только часть (разрешенных) кодовых комбинаций.
5.В зависимости от назначения и применения условно можно выделить следующие типы кодов:
Внутренние коды - это коды, используемые внутри устройств. Это машинные коды, а также коды, базирующиеся на использовании позиционных систем счисления (двоичный, десятичный, двоично-десятичный, восьмеричный, шестнадцатеричный и др.). Наиболее распространенным кодом в ЭВМ является двоичный код, который позволяет просто реализовать аппаратно устройства для хранения, обработки и передачи данных в двоичном коде.[7,c.59]
Он обеспечивает высокую надежность устройств и простоту выполнения операций над данными в двоичном коде. Двоичные данные, объединенные в группы по 4, образуют шестнадцатеричный код, который хорошо согласуется с архитектурой ЭВМ, работающей с данными кратными байту(8бит).
Коды для обмена данными и их передачи по каналам связи. Широкое распространение в ПК получил код ASCII (AmericanStandardCodeforInformationInterchange). ASCII - это 7-битный код буквенно-цифровых и других символов. Поскольку ЭВМ работают с байтами, то 8-й разряд используется для синхронизации или проверки на четность, или расширения кода. В ЭВМ фирмы IBM используется расширенный двоично-десятичный код для обмена информацией EBCDIC (ExtendedBinaryCodedDecimalInterchangeCode).
В каналах связи широко используется телетайпный код МККТТ (международный консультативный комитет по телефонии и телеграфии) и его модификации(МТКидр.).
При кодировании информации для передачи по каналам связи, в том числе внутри аппаратным трактам, используются коды, обеспечивающие максимальную скорость передачи информации, за счет ее сжатия и устранения избыточности (например: коды Хаффмана и Шеннона-Фано), и коды обеспечивающие достоверность передачи данных, за счет введения избыточности в передаваемые сообщения (например: групповые коды, Хэмминга, циклические и их разновидности).
Коды для специальных применений - это коды, предназначенные для решения специальных задач передачи и обработки данных. [8,c.23]
Примерами таких кодов является циклический код Грея, который широко используется в АЦП угловых и линейных перемещений. Коды Фибоначчи используются для построения быстродействующих и помехоустойчивыхАЦП.
Основное внимание в курсе уделено кодам для обмена данными и их передачи по каналам связи.
ЦЕЛИ КОДИРОВАНИЯ:
1) Повышение эффективности передачи данных, за счет достижения максимальной скорости передачи данных.
2) Повышение помехоустойчивости при передаче данных.
В соответствии с этими целями теория кодирования развивается в двух основных направлениях:
1. Теория экономичного (эффективного, оптимального) кодирования занимается поиском кодов, позволяющих в каналах без помех повысить эффективность передачи информации за счет устранения избыточности источника и наилучшего согласования скорости передачи данных с пропускной способностью канала связи.
2. Теория помехоустойчивого кодирования занимается поиском кодов, повышающих достоверность передачи информации в каналах с помехами.
2.1.Основные понятия темы числовое и символьное кодирование информации
Кодирование числовой информации.
Сходство в кодировании числовой и текстовой информации состоит в следующем: чтобы можно было сравнивать данные этого типа, у разных чисел (как и у разных символов) должен быть различный код. Основное отличие числовых данных от символьных заключается в том, что над числами кроме операции сравнения производятся разнообразные математические операции: сложение, умножение, извлечение корня, вычисление логарифма и пр. Правила выполнения этих операций в математике подробно разработаны для чисел, представленных в позиционной системе счисления.
Основной системой счисления для представления чисел в компьютере является двоичная позиционная система счисления.
Кодирование текстовой информации
В настоящее время, большая часть пользователей, при помощи компьютера обрабатывает текстовую информацию, которая состоит из символов: букв, цифр, знаков препинания и др. Подсчитаем, сколько всего символов и какое количество бит нам нужно.
10 цифр, 12 знаков препинания, 15 знаков арифметических действий, буквы русского и латинского алфавита, ВСЕГО: 155 символов, что соответствует 8 бит информации.
Единицы измерения информации.
1 байт = 8 бит
1 Кбайт = 1024 байтам
1 Мбайт = 1024 Кбайтам
1 Гбайт = 1024 Мбайтам
1 Тбайт = 1024 Гбайтам
Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
Необходимо помнить, что в настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ — 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы не будут правильно отображаться в другой.
Основным отображением кодирования символов является код ASCII — AmericanStandardCodeforInformationInterchange- американский стандартный код обмена информацией, который представляет из себя таблицу 16 на 16, где символы закодированы в шестнадцатеричной системе счисления.
одирование символьной (текстовой) информации.
Основная операция, производимая над отдельными символами текста — сравнение символов.
При сравнении символов наиболее важными аспектами являются уникальность кода для каждого символа и длина этого кода, а сам выбор принципа кодирования практически не имеет значения.
Для кодирования текстов используются различные таблицы перекодировки. Важно, чтобы при кодировании и декодировании одного и того же текста использовалась одна и та же таблица.
Таблица перекодировки — таблица, содержащая упорядоченный некоторым образом перечень кодируемых символов, в соответствии с которой происходит преобразование символа в его двоичный код и обратно.
Наиболее популярные таблицы перекодировки: ДКОИ-8, ASCII, CP1251, Unicode.[10,c.92]
Исторически сложилось, что в качестве длины кода для кодирования символов было выбрано 8 бит или 1 байт. Поэтому чаще всего одному символу текста, хранимому в компьютере, соответствует один байт памяти.
Различных комбинаций из 0 и 1 при длине кода 8 бит может быть 28 = 256, поэтому с помощью одной таблицы перекодировки можно закодировать не более 256 символов. При длине кода в 2 байта (16 бит) можно закодировать 65536 символов.
2.2 Компьютерное кодирование графики
Графический формат — это способ записи графической информации. Графические форматы файлов предназначены для хранения изображений, таких как фотографии и рисунки.
Почти все создаваемые, обрабатываемые или просматриваемые с помощью компьютера изображения можно разделить на две большие части - растровую и векторную графику.
Для представления графической информации растровым способом используется так называемый точечный подход. На первом этапе вертикальными и горизонтальными линиями делят изображение. Чем больше при этом получилось элементов (пикселей), тем точнее будет передана информация об изображении.
Как известно из физики, любой цвет может быть представлен в виде суммы различной яркости красного, зеленого и синего цветов. Поэтому надо закодировать информацию о яркости каждого из трех цветов для отображения каждого пикселя. В видеопамяти находится двоичная информация об изображении, выводимом на экран.
Таким образом, растровые изображения представляют собой однослойную сетку точек, называемых пикселями (pixel, от англ. pictureelement), а код пикселя содержит информацию о его цвете.
Для черно-белого изображения (без полутонов) пиксель может принимать только два значения: белый и черный (светится - не светится), а для его кодирования достаточно одного бита памяти: 1 - белый, 0 - черный.
Пиксель на цветном дисплее может иметь различную окраску, поэтому одного бита на пиксель недостаточно. Для кодирования 4-цветного изображения требуются два бита на пиксель, поскольку два бита могут принимать 4 различных состояния. Может использоваться, например, такой вариант кодировки цветов: 00 - черный, 10 - зеленый, 01 - красный, 11 - коричневый.
На RGB-мониторах все разнообразие цветов получается сочетанием базовых цветов: красного (Red), зеленого (Green), синего (Blue), из которых можно получить 8 основных комбинаций (Таблица 1):
Основные комбинации цвета
Таблица 1
|
Цвет |
R |
G |
B |
|
Черный |
0 |
0 |
0 |
|
Синий |
0 |
0 |
1 |
|
Зеленый |
0 |
1 |
0 |
|
Голубой |
0 |
1 |
1 |
|
Красный |
1 |
0 |
0 |
|
Пурпурный |
1 |
0 |
1 |
|
Желтый |
1 |
1 |
0 |
|
Белый |
1 |
1 |
1 |
Качество кодирования изображения зависит от двух параметров.
Во-первых, качество кодирования изображения тем выше, чем меньше размер точки и соответственно большее количество точек составляет изображение.
Во-вторых, чем большее количество цветов, то есть большее количество возможных состояний точки изображения, используется, тем более качественно кодируется изображение (каждая точка несет большее количество информации). Совокупность используемых в наборе цветов образует палитру цветов.
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые в свою очередь содержат определенное количество точек (пикселей). Качество изображения определяется разрешающей способностью монитора, т.е. количеством точек, из которых оно складывается. Чем больше разрешающая способность, тем выше качество изображения.
Цветные изображения формируются в соответствии с двоичным кодом цвета каждой точки, хранящимся в видеопамяти. Цветные изображения могут иметь различную глубину цвета, которая задается количеством битов, используемым для кодирования цвета точки.
В противоположность растровой графике векторное изображение состоит из геометрических примитивов: линия, прямоугольник, окружность и т.д. Каждый элемент векторного изображения является объектом, который описывается с помощью специального языка (математических уравнения линий, дуг, окружностей и т.д.). [11,c.72]
Сложные объекты (ломаные линии, различные геометрические фигуры) представляются в виде совокупности элементарных графических объектов. Объекты векторного изображения, в отличие от растровой графики, могут изменять свои размеры без потери качества (при увеличении растрового изображения увеличивается зернистость).
2.3. Компьютерное кодирование звука
Из курса физики известно, что звук - это колебание частиц воздуха, непрерывный сигнал с меняющейся амплитудой (Рис. 1).
При кодировании звука этот сигнал надо представить в виде последовательности нулей и единиц. Как это происходит в микрофоне? Через равные промежутки времени, очень часто (десятки тысяч раз в секунду) измеряется амплитуда колебаний. Каждое измерение производится с ограниченной точностью и записывается в двоичном виде. Частота, с которой записывается амплитуда, называется частотой дискретизации. Полученный ступенчатый сигнал сначала сглаживается посредством аналогового фильтра, а затем преобразуется в звук с помощью усилителя и динамика.
На качество воспроизведения закодированного звука в основном влияют два параметра: частота дискретизации - количество измерений амплитуды за секунду в герцах и глубина кодирования звука - размер в битах, отводимый под запись значения амплитуды. Например, при записи на компакт-диски (CD) используются 16-разрядные значения, а частота дискретизации равна 44032 Гц. Эти параметры обеспечивают превосходное качество звучания речи и музыки. Для стереозвука отдельно записывают данные для левого и для правого канала.[18,c.61]
Если преобразовать звук в электрический сигнал (например, с помощью микрофона), мы увидим плавно изменяющееся с течением времени напряжение. Для компьютерной обработки такой аналоговый сигнал нужно каким-то образом преобразовать в последовательность двоичных чисел.
Поступают следующим образом: измеряют напряжение через равные промежутки времени и записывают полученные значения в память компьютера. Этот процесс называется дискретизацией (или оцифровкой), а устройство, выполняющее его - аналого-цифровым преобразователем (АЦП) (Рис. 2).
Для того чтобы воспроизвести закодированный таким образом звук, нужно выполнить обратное преобразование (для него служит цифро-аналоговый преобразователь- ЦАП), а затем сгладить получившийся ступенчатый сигнал.
Чем выше частота дискретизации (т. е. количество отсчетов за секунду) и чем больше разрядов отводится для каждого отсчета, тем точнее будет представлен звук. Но при этом увеличивается и размер звукового файла. Поэтому в зависимости от характера звука, требований, предъявляемых к его качеству и объему занимаемой памяти, выбирают некоторые компромиссные значения.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Человек издавна использует довольно компактный способ представления музыки - нотную запись.
В ней специальными символами указывается, какой высоты звук, на каком инструменте и как сыграть. Фактически, ее можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов. Он получил название MIDI. Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и неоспоримые преимущества: чрезвычайно компактная запись, естественность для музыканта, легкость замены инструментов, изменения темпа и тональности мелодии.
Существуют и другие, чисто компьютерные, форматы записи музыки. Среди них следует отметить формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку. При этом вместо 18-20 музыкальных композиций на стандартный компакт-диск (CD-ROM) помещается около 200. Одна песня занимает примерно 3-5 мегабайт, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.[12,c.49]
3. Помехоустойчивые коды
3.1 Классификация помехоустойчивых кодов
В настоящее время темпы развития телекоммуникационных систем стали предпосылкой для появления принципиально новых способов кодирования сообщений. Причем одной из задач кодирования стало не только достоверная передача, но и быстрая обработка данных. Несмотря на рост мощности вычислительной техники, актуальным остается вопрос построения простых алгоритмов коррекции ошибок. Одним из малоизученных направлений в этой области можно считать использование кодов с иррациональным основанием.
Работа подавляющего числа современных систем связи основана на передаче сообщений в цифровом виде. Сбой при приеме любого элемента цифровых данных способен вызвать значительное искажение всего сообщения в целом, что, в свою очередь, может привести к полной потере информации, содержащейся в нем. В
настоящее время по каналам связи передаются данные со столь высокими требованиями к достоверности передаваемой информации, что удовлетворить эти требования традиционным методами - совершенствованием антенно-фидерных устройств, увеличением излучаемой мощности, снижением собственного шума приемника - оказывается экономически невыгодным или просто невозможным.[17,c.57]
Высокоэффективным средством решения данной проблемы является применение помехоустойчивого кодирования, основанного на введении искусственной избыточности в передаваемое сообщение. Теория и техника помехоустойчивого кодирования прошли несколько этапов в своем развитии. Изначально это было просто эмпирическое использование простейших кодов с повторением, с постоянным весом, с одной проверкой на четность и т.д. В дальнейшем теория помехоустойчивого кодирования прошла довольно длинный путь развития, в процессе которого для ее создания использовались основы математической теории – ответвления высшей алгебры и теории чисел с приложением к реальным системам связи.
Теория кодирования возникла в конце 40-х годов с появлением работ Голея, Хэмминга и Шеннона. Выдающиеся два ученые Голей и Хэмминг заложили основу алгебраическим методам кодирования, которые используются и по сей день, а Шеннон предложил и исследовал понятие случайного кодирования. Отметим, что в современных информационных системах важнейшей задачей является обеспечение информационной безопасности, связанной с методами криптографии и кодирования, теоретические основы которой заложил Шеннон в своих трудах.[3]
Появление работ Шеннона вызвало настоящую эйфорию среди ученых и инженеров, казалось, что практическое решение этих задач будет так же просто и понятно, как Шеннон сделал это математически. Однако эйфория быстро прошла, так как практического решения в прямой постановке Шеннона найти так не удалось. В то же время, сделанные Шенноном постановки задачи и доказательство фундаментальных теорем теории информации дали толчок для поиска решения задач с использованием детерминированных (неслучайных) сигналов и алгебраических методов помехоустойчивого кодирования защиты от помех и шифрования для обеспечения секретности информации .[16,c.84]
В 50-е-70-е годы было разработано большое количество алгебраических кодов с исправлением ошибок, среди которых наиболее востребованными стали коды Боуза-Чоудхури-Хоквингема (БЧХ), Рида-Соломона (РС), Рида-Малера, Адамара, Юстенсена, Гоппы, циклические коды, сверточные коды с разными алгоритмами декодирования (последовательное декодирование, алгоритм Витерби), арифметические коды.
Однако на практике применяется относительно небольшая группа алгебраических помехоустойчивых кодов: БЧХ, Рида-Соломона и сверхточные коды. Наиболее широко применяются циклические коды с обнаружением ошибок в стандартных протоколах HDLC, Х.25/2 (LAP-B, LAP-M). Коды Рида-Соломона с исправлением ошибок находят применение в каналах радиосвязи. В каналах спутниковой связи, характеризующихся независимым характером ошибок, широко применяются сверхточные коды .
Следует отметить тот факт, что хотя существующие на данный момент системы передачи данных отвечают всем основным стандартам и требованиям, они все же не являются совершенными. Причин тому влияние помех в канале связи. Одним из средств решения подобных несоответствий в системах передачи цифровой информации, является применение помехоустойчивых кодов, лежащих в основе устройств кодирования/декодирования.[13,c.105]
Помехоустойчивое кодирование передаваемой информации позволяет в приемной части системы обнаруживать и исправлять ошибки. Коды, применяемые при помехоустойчивом кодировании, называются корректирующими кодами. Как правило, корректирующий код может исправлять меньше ошибок, чем обнаруживать. Число ошибок, которые корректирующий код может исправить в определенном интервале последовательности двоичных символов, например, в одной кодовой комбинации, называется исправляющей способностью кода.
Физическая среда, по которой передаются данные, не может быть абсолютно надёжной. Более того, уровень шума бывает очень высоким, например, в беспроводных системах связи и телефонных системах. Ошибки при передаче — это реальность, которую надо обязательно учитывать.[10]
В разных средах характер помех разный. Ошибки могут быть одиночные, а могут возникать группами, сразу по несколько. В результате помех могут исчезать биты или наоборот — появляться лишние.
Основной характеристикой интенсивности помех в канале является параметр шума — p. Это число от 0 до 1, равное вероятности инвертирования бита, при условии что, он был передан по каналу и получен на другом конце.
Следующий параметр — p2. Это вероятность того же события, но при условии, что предыдущий бит также был инвертирован.
Этими двумя параметрами вполне можно ограничиться при построении теории. Но, в принципе, можно было бы учитывать аналогичные вероятности для исчезновения бита, а также использовать полную информацию о пространственной корреляции ошибок, — то есть корреляции соседних ошибок, разделённых одним, двумя или более битами.
У групповых ошибок есть свои плюсы и минусы. Плюсы заключаются в следующем. Пусть данные передаются блоками по 1000 бит, а уровень ошибки 0,001 на бит. Если ошибки изолированные и независимые, то 63% блоков будут содержать ошибки. Если же они возникают группами по 100 сразу, то ошибки будут содержать 1% блоков.
3.2 Код Шеннона
Оптимальным кодом можно определить тот, в котором каждый двоичный символ будет передавать максимальную информацию. В силу формул Хартли и Шеннона максимум энтропии достигается при равновероятных событиях, следовательно, двоичный код будет оптимальным, если в закодированном сообщении символы 0 и 1 будут встречаться одинаково часто.
Рассмотрим в качестве примера оптимальное двоичное кодирование букв русского алфавита вместе с символом пробела «-». Полагаем, что известны вероятности появления в сообщении символов русского алфавита, например, приведенные в таблице 3.
Таблица 3.Частота букв русского языка (предположение)
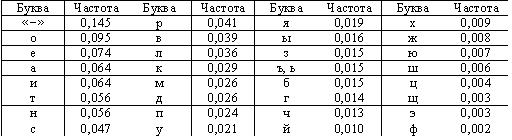
К. Шеннон и Р. Фано независимо предложили в 1948-1949 гг. способ построения кода, основанный на выполнении условия равной вероятности символов 0 и 1 в закодированном сообщении. [10]
Все кодируемые символы (буквы) разделяются на две группы так, что сумма вероятностей символов в первой группе равна сумме вероятностей символов второй группы (то есть вероятность того, что в сообщении встретится символ из первой группы, равна вероятности того, что в сообщении встретится символ из второй группы).[14,c.66]
Для символов первой группы значение первого разряда кода присваивается равным «0», для символов второй группы – равными «1».
Далее каждая группа разделяется на две подгруппы, так чтобы суммы вероятностей знаков в каждой подгруппе были равны. Для символов первой подгруппы каждой группы значение второго разряда кода присваивается равным «0», для символов второй подгруппы каждой группы – «1». Такой процесс разбиения символов на группы и кодирования продолжается до тех пор, пока в подгруппах не остается по одному символу.Пример кодирования символов русского алфавита приведен в табл. 4
Таблица 4. Пример кодирования букв русского алфавита с помощью кода Шеннна-Фано.

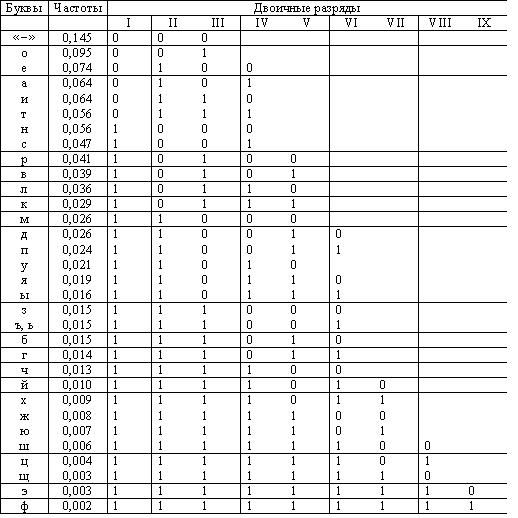
Анализ приведенных в таблице кодов приводит к выводу, что часто встречающиеся символы кодируются более короткими двоичными последовательностями, а редко встречающиеся - более длинными. Значит, в среднем для кодирования сообщения определенной длины потребуется меньшее число двоичных символов 0 и 1, чем при любом другом способе кодирования.
Вместе с тем процедура построения кода Шеннона-Фано удовлетворяет критерию различимости Фано. Код является префиксным и не требует специального символа, отделяющего буквы друг от друга для однозначного него декодирование двоичного сообщения.
Таким образом, проблема помехоустойчивого кодирования представляет собой обширную область теоретических и прикладных исследований. Основными задачами при этом являются следующие: отыскание кодов, эффективно исправляющих ошибки требуемого вида; нахождение методов кодирования и декодирования и простых способов их реализации.[15,c.46]
Наиболее разработаны эти задачи применительно к систематическим кодам. Такие коды успешно применяются в вычислительной технике, различных автоматизированных цифровых устройствах и цифровых системах передачи информации.
Заключение
Задача кодирования является одним из главных понятий информатики, так как кодирование предшествует передаче и хранению информации, и, соответственно, является основой их успешного осуществления.
При передаче сообщений по каналам связи могут возникать помехи, способные привести к искажению принимаемых знаков. Эта проблема решается с помощью помехоустойчивого кодирования. Помехоустойчивое кодирование передаваемой информации позволяет в приемной части системы обнаруживать и исправлять ошибки. Коды, применяемые при помехоустойчивом кодировании, называются корректирующими кодами. Впервые, исследование эффективного кодирования произвел Клод Шеннон. Для теории связи важнейшее значение имеют две теоремы, доказанные Шенноном.
В работе были рассмотрены эти теоремы, и можно прийти к выводу, что первая – затрагивает ситуацию с кодированием при передаче сообщения по линии связи, в которой отсутствуют помехи, искажающие информацию, т.е. эта теорема является эталоном, какими должны быть помехоустойчивые коды, Вторая теорема относится к реальным линиям связи с помехами.
В ходе курсовой работы были составлены примеры кодирования, на основе первой теоремы Шеннона. Это кодирования является достаточно эффективным, так как получаемый код практически не имеет избыточности, но, к сожалению, в реальных линиях связи множество помех, и такой результат недостижим. Поэтому код Шеннона не является таким же эффективным как, например, код Хафмена. Но, несмотря на это нужно отметить, что Клод Шеннон был одним из основателей теории кодирования и его работы внесли огромный вклад в развитие информатики.
Список использованной литературы
1. Информатика: методические указания по выполнению курсовой работы для студентов первого курса направления 080100.62 «Экономика» и 080200.62 «Менеджмент». – М.: ВЗФЭИ, 2011. – URL: http://repository.vzfei.ru.
2.http://kuzelenkov.narod.ru/mati/book/inform/inform6.html (Информатика. Лекция №6. Представление информации в компьютере)
3.http://www.lessons-tva.info/edu/e-inf1/e-inf1-2-5.html (Представление информации в компьютере, единицы измерения информации. Курс дистанционного обучения)
4. http://ru.wikipedia.org/wiki/ Графические_форматы (свободная энциклопедия)
5.http://www.ido.rudn.ru/nfpk/inf/inf4.html(Информатика и информационные технологии. Представление данных в компьютере)
6. Агальцов В.П., Титов В.М. Информатика для экономистов: Учебник. - М.: ИД «ФОРУМ»: ИНФРА-М, 2006. - 448 с.
7. Информатика для экономистов: Учебник / Под общ. ред. В.М. Матюшка. - М.: ИНФРА-М, 2007. - 880с.
8. Информатика. Общий курс: Учебник / Под ред. В.И. Колесникова. - М.: Издательско-торговая корпорация «Дашков и К?»; Ростов н/Д: Наука-Пресс, 2008. - 400 с.
9. Информатика: Практикум по технологии работы на компьютере/ Под ред. Н.В. Макаровой. - М.: Финансы и статистика,2005.- 256 с
10. Информатика: Учебник / Под общ. ред. А.Н. Данчула. - М.: Изд-во РАГС, 2004. - 528 с.
11. Соболь Б.В. Информатика: Учебник / Соболь Б.В., Галин А.Б., Панов Ю.В., Рашидова Е.В., Садовой Н.Н. - М.: Ростов н/Д: Феникс, 2005. - 448 с.
12. Кловский Д.Д. Теория передачи сигналов. -М.: Связь, 2004.
13. Кудряшов Б.Д. Теория информации. Учебник для вузов Изд-во ПИТЕР, 2008. - 320с.
14. Рябко Б.Я., Фионов А.Н. Эффективный метод адаптивного арифметического кодирования для источников с большими алфавитами // Проблемы передачи информации. - 2009. - Т.35, Вып. - С.95 - 108.
15. Семенюк В.В. Экономное кодирование дискретной информации. - СПб.:СПбГИТМО (ТУ), 2001
16. Дмитриев В.И. Прикладная теория информации. М.: Высшая школа, 2009.
17. Нефедов В.Н., Осипова В.А. Курс дискретной математики. М.: МАИ, 2002.
18. Колесник В.Д., Полтырев Г.Ш. Курс теории информации. М.: Наука,

- Социальное государство. Его отличие от социалистического государства ( Понятие и общая характеристика социального государства )
- Общая характеристика основных современных правовых семей (Понятие и сущность правовой семьи).
- ПОНЯТИЕ ИНВАЛИДНОСТИ, ПОРЯДОК ЕЕ УСТАНОВЛЕНИЯ. ГРУППЫ И ПРИЧИНЫ ИНВАЛИДНОСТИ, ИХ ЮРИДИЧЕСКОЕ ЗНАЧЕНИЕ
- История конституционного развития в России
- Основы программирования на языке Pascal ( Характеристики системы программирования в Pascal )
- Понятие и классификация функций государства ( ОПРЕДЕЛЕНИЕ И ХАРАКТЕРИСТИКА ФУНКЦИЙ ГОСУДАРСТВА )
- Дидактическая игра как средство активизации познавательной деятельности младших школьников (Изучение понятия «познавательная деятельность» в психолого-педагогической литературе)
- Устройства персонального компьютера (Системный блок и его комплектующие)
- Учёт поступления основных средств (Нормативно-правовое регулирование учета основных средств и документальное оформление хозяйственных операций по их поступлению)
- Человеческий фактор в управлении организацией (Анализ практического значения человеческого фактора в организации на примере ГБУЗ «Детская городская клиническая больница им. З.А. Башляевой Департамента Здравоохранения города Москвы»)
- Сравнительный анализ видов и особенностей систем контроля на малых и крупных предприятиях (Виды управленческого контроля)
- Роль мотивации в поведении организации (Сущность мотивированного поведения работников в организации)