
Анализ и оценка средств реализации структурных методов анализа и проектирования экономической информационной системы
Содержание:

ВВЕДЕНИЕ
Структурный анализ и структурное проектирование являются фундаментальными инструментами системного анализа.
Структурным анализом принято называть метод исследования системы, которое начинается с ее общего обзора и затем детализируется, приобретая иерархическую структуру с все большим числом уровней. Решение трудных проблем путем их разбиения на множество меньших независимых задач значительно повышают понимание сложных систем.
Вопрос анализа и оценки средств реализации структурных методов анализа и проектирования экономической информационной системы очень актуален, так как это даст возможность выбрать наиболее подходящий метод для проектирования. [1]
Цель данной курсовой работы – провести анализ и оценку средств реализации структурных методов анализа и проектирования экономической информационной системы.
Задачи исследования:
- рассмотреть основные определения и историю структурного анализа и структурного проектирования;
- рассмотреть метод структурного анализа и проектирования SADT;
- рассмотреть метод структурного анализа и проектирования SSADM
Предмет исследования — структурные методы анализа и проектирования экономической информационной системы
Объектом исследования выступают экономические информационные системы.
Методы исследования. В процессе работы использовались такие методы как анализ, классификация, описание и системный подход.
Структура работы: курсовая работа состоит из введения, трех глав, заключения и списка литературы.
Глава I. Структурный анализ и структурное проектирование
В инженерии ПО (software engineering), Структурный анализ (Structured Analysis, SA) и одноименное с ним Структурное проектирование (Structured Design, SD) – это методы для анализа и преобразования бизнес-требований в спецификации и, в конечном счете, в компьютерные программы, конфигурации аппаратного обеспечения и связанные с ними ручные процедуры.
Структурный подход заключается в поэтапной декомпозиции системы при сохранении целостного о ней представления Основные принципы структурного подхода (первые два являются основными):
1) принцип «разделяй и властвуй»;
2) принцип иерархического упорядочивания;
3) принцип непротиворечивости.
4) принцип формализации;
5) принцип абстрагирования;
Структурный анализ – это часть серии структурных методов, представляющих набор методологий анализа, проектирования и программирования, которые были разработаны в ответ на проблемы, с которыми столкнулся мир ПО в период с 1960 по 1980 гг. В этот период большинство программ было создано на Cobol и Fortran, потом на C и BASIC.
Это было новым положительным сдвигом в направлении проектирования и программирования, но при этом не было стандартных методологий для документирования требований и самих проектов. По мере укрупнения и усложнения систем, все более затруднительным становился процесс их разработки.
Когда большинство специалистов билось над созданием программного обеспечения, немногие старались разрешить более сложную задачу создания крупномасштабных систем, включающих как людей и машины, так и программное обеспечение, аналогичных системам, применяемым в телефонной связи, промышленности, управлении и контроле вооружения. В то время специалисты, традиционно занимавшиеся созданием крупномасштабных систем, стали осознавать необходимость большей упорядоченности. Таким образом, разработчики начали формализовать процесс создания системы, разбивая его на следующие фазы:
1) анализ – определение того, что система будет делать;
2) проектирование – определение подсистем и их взаимодействие;
3) реализация – разработка подсистем по отдельности;
4) объединение – соединение подсистем в единое целое;
5) тестирование – проверка работы системы;
6) установка – введение системы в действие;
7) функционирование – использование системы. [3]
Проектировщики знали, что сложность систем возрастает и что определены они часто весьма слабо.
Вскоре был выдвинут тезис: совершенствование методов анализа есть ключ к созданию систем, эффективных по стоимости, производительности и надежности. Для решения ключевых проблем традиционного создания систем широкого профиля требовались новые методы, специально предназначенные для использования на ранних стадиях процесса.
Для помощи в управлении большим и сложным ПО появляется множество разнообразных структурных методов программирования, проектирования и анализа. Эти методы позволяют гораздо лучше понять рассматриваемую проблему. А это сокращает затраты как на создание и эксплуатацию системы, и повышают ее надежность. [5]
Глава II. Метод структурного анализа и проектирования SADT
2.1 Основы метода SADT
SADT использует два типа диаграмм:
1) модели данных.
2) модели деятельности.
SADT использует стрелки для построения этих диаграмм и имеет следующее графическое представление:
- главный блок, где определено название процесса или действия;
- справа – исходящие стрелки: выход действия.
- внизу – входящие стрелки: средства, используемые для действия;
- с левой стороны блока – входящие стрелки: входы действия;
- сверху – входящие стрелки: данные, необходимые для действия;
SADT использует декомпозицию на основе подхода «сверху вниз». Каждый уровень декомпозиции содержит до 6 блоков.
SADT начинается с уровня 0, затем может быть детализирован на более низкие уровни (1, 2, 3, ...). Например, на уровне 1, блок уровня 0 будет детализирован на несколько элементарных блоков и так далее.
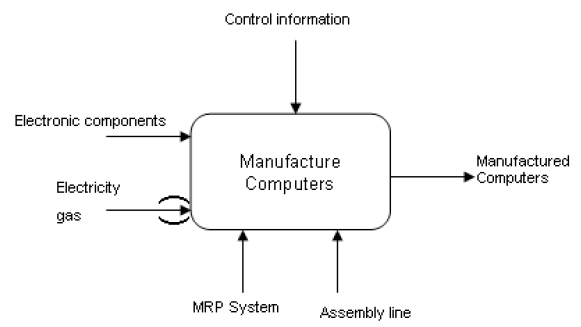
Рисунок 1 – Пример уровня 0
Семантика стрелок для действий:
- входы входят слева и представляют данные или предметы потребления, необходимые для выполнения действия;
- выходы выходят справа и представляют данные или продукты, производимые действием;
- управления входят сверху и представляют команды, которые влияют на выполнение действия, но не потребляются. В последней редакции IDEF0 – условия, требуемые для получения корректного выхода. Данные или объекты, моделируемые как управления, могут быть трансформированы функцией, создающей выход; механизмы означают средства, компоненты или инструменты, используемые для выполнения действия; представляют размещение действий.
Семантика стрелок для данных:
- управления влияют на внутреннее состояние этих данных;
- выходы потребляют эти данные;
- входы – это действия, которые генерируют эти данные;
Этапы моделирования. Разработка SADT модели представляет собой итеративный процесс и состоит из нижеследующих условных этапов.
1. Создание модели специалистами, относящихся к различным сферам деятельности организации. На этом этапе авторы опрашивают компетентных лиц, получая ответы.
На основе полученных результатов опросов создается черновик модели.
2. Распространение черновика для рассмотрения, получения комментариев и согласования модели с читателями.
3. Официальное утверждение модели.
Метод SADT получил дальнейшее развитие. На его основе в 1981 году разработана методология функционального моделирования IDEF0.[7]
2.2. Методология функционального моделирования IDEF0
IDEF0 (Integration Definition for Function Modeling) – это методология функционального моделирования для описания функций организаций, которая предлагает язык функционального моделирования для разработки, анализа, реинжиниринга и интеграции ИС бизнес процессов.
Модель IDEF0 – это графическое описание ИС или предметной области, которое разрабатывается с определенной целью и точкой зрения. Модель IDEF0 это набор из иерархически связанных IDEF0-диаграмм, описывающих функции ИС или предметной области с помощью графиков, текста и глоссария.
IDEF0 – Integration DEFinition language 0 – основан на методе SADT и в своей исходной форме включает одновременно:
1) определение языка графического моделирования;
2) описание полной методологии разработки моделей.
IDEF0 используют для создания функциональной модели, то есть результатом применения методологии IDEF0 к ИС является функциональная модель IDEF0. Функциональная модель – это структурное представление функций, работы или процессов в пределах проектируемой ИС или предметной области.
Методология IDEF0 может использоваться для проектирования широкого спектра как автоматизированных, так и неавтоматизированных ИС.
Для проектируемых систем IDEF0 может быть использована сначала для определения требований к ИС, и затем для реализации, удовлетворяющей этим требованиям функции.
Для существующих систем IDEF0 может быть использована для анализа функций, выполняемых системой, а также для учета механизмов, с помощью которых эти функции выполняются.
Основные цели стандарта:
1) обеспечить средства для полного и единообразного моделирования функций системы или предметной области, а также данных и объектов, которые связывают эти функции;
2) задокументировать и разъяснить технику моделирования IDEF0 и правила ее использования;
3) обеспечить язык моделирования.
4) обеспечить язык моделирования, который независим от CASE методов или средств, но может быть использован при помощи этих методов и средств; [6]
Правила IDEF0 требуют большой строгости и точности для удовлетворения нужд пользователя без чрезмерных ограничений.
Обычно IDEF0-модели несут в себе сложную и концентрированную информацию, и для того, чтобы ограничить их перегруженность и сделать удобочитаемыми, в стандарте приняты соответствующие ограничения сложности, которые носят рекомендательный характер. При том, что, что на диаграмме рекомендуется представлять от трех до шести функциональных блоков, количество подходящих к одному функциональному блоку (выходящих из одного функционального блока) интерфейсных дуг предполагается не более четырех.
В основе IDEF0 лежат четыре основных понятия:
- глоссарий;
- функциональный блок;
- декомпозиция;
- интерфейсная дуга.
Функциональный блок представляет собой некоторую конкретную функцию в рамках рассматриваемой системы.
По требованиям стандарта название каждого функционального блока должно быть сформулировано в глагольном наклонении (например, «производить услуги»).
На диаграмме функциональный блок изображается прямоугольником (рис.). Каждая из четырех сторон функционального блока имеет свое определенное значение (роль), при этом:
- левая сторона имеет значение «Вход» (Input);
- верхняя сторона имеет значение «Управление» (Control);
- нижняя сторона имеет значение «Механизм» (Mechanism).
- правая сторона имеет значение «Выход» (Output);
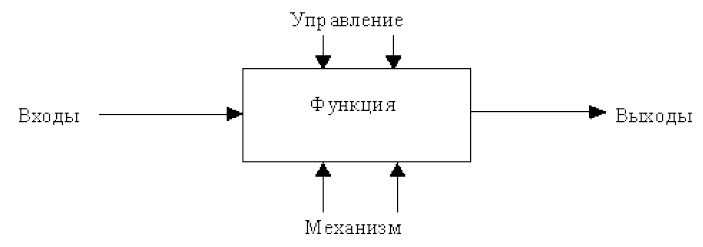
Рисунок 2 – Функциональный блок
Интерфейсная дуга/стрелка это элемент системы, который обрабатывается функциональным блоком или оказывает другое влияние на функцию, представленную данным функциональным блоком. Интерфейсные дуги часто называют потоками или стрелками.
С помощью интерфейсных дуг отображают различные объекты, в той или иной степени определяющие процессы, происходящие в системе. Такими объектами могут быть элементы реального мира или потоки данных.
В зависимости от того, к какой из сторон функционального блока подходит данная интерфейсная дуга, она носит название «входящей», «исходящей» или «управляющей».
Необходимо отметить, что любой функциональный блок по требованиям стандарта должен иметь, по крайней мере, одну управляющую интерфейсную дугу и одну исходящую.
Обязательное наличие управляющих интерфейсных дуг является одним из главных отличий стандарта IDEF0 от других методологий классов DFD (Data Flow Diagram) и WFD (Work Flow Diagram).
Механизмы показывают средства, с помощью которых осуществляется выполнение функций (рис.3).
Рисунок 3 – Пример механизма
По типу связываемых элементов интерфейсные дуги (стрелки) подразделяют на граничные, стрелки вызова, внутренние стрелки. Граничные стрелки на контекстной диаграмме применяются для описания взаимодействия системы с окружающим миром. Они могут начинаться у границы диаграммы и заканчиваться у функции, или наоборот. На обычной (не контекстной) диаграмме граничные стрелки представляют входы, управления, выходы или механизмы родительского блока диаграммы. Граничные стрелки обеспечивают правильное соединение диаграмм для получения согласованной модели состоящей из отдельных диаграмм.
Стрелки вызова – специальная стрелка, указывающая на другую модель работы. Стрелка вызова используется для указания того, что некоторая функция выполняется за пределами моделируемой системы.
Внутренние стрелки – это стрелки IDEF0-диаграммы, характеризующие четыре основных отношения, концы которой связывают источник и потребителя, являющиеся блоками одной диаграммы. Внутренние стрелки не касаются границы диаграммы и не выходят за ее пределы, а начинаются у одного и кончаются у другого блока.
В IDEFO различают пять типов связей для внутренних стрелок по их направленности:
- связь «выход-управление», является простейшей связью, поскольку она отражает прямые воздействия, которые интуитивно понятны и очень просты. При такой связи выход вышестоящей работы направляется непосредственно на управление нижестоящей, таким образом показывая доминирование вышестоящей функции;
- связь «выход-вход» является простейшей связью, поскольку она отражает прямые воздействия, которые интуитивно понятны и очень просты. Связь возникает тогда, когда выход одного блока становится входом для другого. Связь по «выход-вход» показывает доминирование вышестоящей работы.
- обратная связь «выход-вход» является более сложной, поскольку представляют итерацию или рекурсию. Такая связь, как правило, используется для описания циклов. В такой связи выход нижестоящей работы направляется на вход вышестоящей. Обратные связи могут выступать в виде комментариев, замечаний, исправлений и т.д. (рис.4).
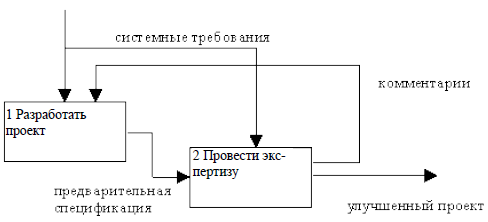
Рисунок 4 – Пример обратной связи
- обратная связь «выход-управление» является более сложной, поскольку представляют итерацию или рекурсию (выходы из одной функции влияют на будущее выполнение других функций, что впоследствии влияет на исходную функцию). Обратная связь по управлению часто свидетельствует об эффективности процесса;
- связь «выход-механизм», когда выход одной работы направляется на механизм другой. Эта взаимосвязь встречаются нечасто, и используется реже остальных. Она показывает, что одна работа подготавливает ресурсы, необходимые для проведения другой работы.
Одним из важных моментов при проектировании ИС с помощью методологии IDEF0 является точная согласованность типов внутренних связей по их характеру (табл.1).
Таблица 1 - Типы и связей и их значимость
|
Тип связи |
Относительная значимость |
|
|
Случайная |
0 |
|
|
Логическая |
1 |
|
|
Временная |
2 |
|
|
Процедурная |
3 |
|
|
Коммуникационная |
4 |
|
|
Последовательная |
5 |
|
|
Функциональная |
6 |
(0) Тип случайной связности: менее желателен. Случайная связность возникает, когда конкретная связь между функциями мала или полностью отсутствует. Это относится к ситуации, когда имена данных на IDEF0-дугах в одной диаграмме имеют малую связь друг с другом.
(1) Тип логической связности. Логическое связывание происходит тогда, когда данные и функции собираются вместе вследствие того, что они попадают в общий класс или набор элементов, но необходимых функциональных отношений между ними не обнаруживается.
(2) Тип временной связности. Связанные по времени элементы возникают вследствие того, что они представляют функции, связанные во времени, когда данные используются одновременно или функции включаются параллельно, а не последовательно.
(3) Тип процедурной связности. Процедурно-связанные элементы появляются сгруппированными вместе вследствие того, что они выполняются в течение одной и той же части цикла или процесса. Пример процедурно-связанной диаграммы приведен на рис. 5.
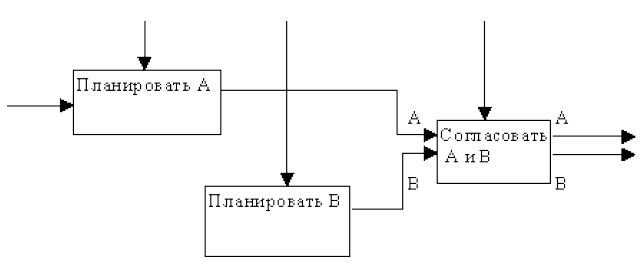
Рисунок 5 - Процедурная связность
(4) Тип коммуникационной связности. Диаграммы демонстрируют коммуникационные связи, когда блоки группируются вследствие того, что они используют одни и те же входные данные и/или производят одни и те же выходные данные (рис. 6).
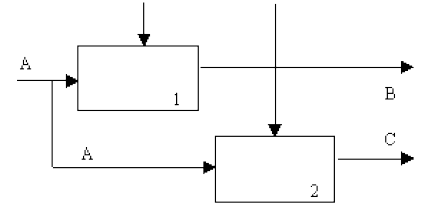
Рисунок 6 - Коммуникационная связность
(5) Тип последовательной связности. На диаграммах, имеющих последовательные связи, выход одной функции служит входными данными для следующей функции. Связь между элементами на диаграмме является более тесной, чем на рассмотренных выше уровнях связок, поскольку моделируются причинно-следственные зависимости (рис. 7).
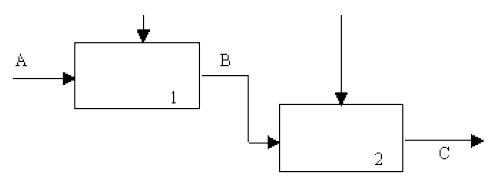
Рисунок 7 - Последовательная связность
(6) Тип функциональной связности. Диаграмма отражает полную функциональную связность, при наличии полной зависимости одной функции от другой. Одним из способов определения функционально-связанных диаграмм является рассмотрение двух блоков, связанных через управляющие дуги, как показано на рис. 8
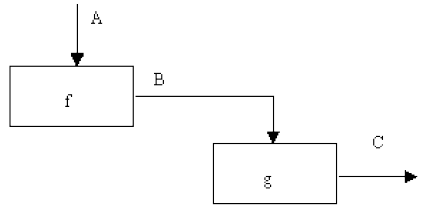
Рисунок 8 - Функциональная связность
В математических терминах необходимое условие для простейшего типа функциональной связности, показанной на рис.8, имеет следующий вид: C = g(B) = g (f(A))
На самом деле, из отдельной диаграммы редко можно понять полную иерархию стрелки. Обычно это требует чтения большей части модели, а иногда из-за выбранной точки зрения подробности отдельных стрелок не раскрываются совсем. Вот почему IDEF предусматривает дополнительное описание полной иерархии объектов системы посредством формирования глоссария для каждой диаграммы модели и объединения этих глоссариев в словарь стрелок.
Таким образом, словарь стрелок, важное дополнение модели, становится основным хранилищем полной иерархии объектов системы.
Чтобы стрелки и их сегменты правильно описывали связи между блоками-источниками и блоками-приемниками, используются метки для каждой ветви стрелок.
Ветвление стрелки – это разделение ее на два или большее число сегментов, изображенных в виде расходящихся линий, и означающее, что все содержимое стрелок или его часть может появиться в каждом ответвлении стрелки. Стрелка всегда помечается до разветвления, чтобы дать название всему набору.
Иногда функция разделяет стрелку на ее компоненты в этом случае для получения дополнительных сведений о содержании компонент и взаимосвязях между ними важно изучить, что выполняет эта функция.
Слияние стрелок – это объединение двух или большего числа стрелок, изображенных в виде сходящихся вместе линий и означающее, что содержимое каждой ветви идет на формирование метки для стрелки, являющейся результатом слияния исходных.
При описании сложных систем для их корректного и подробного представления используется большое число стрелок.
Часто стрелки могут быть объединены (слиты), но встречаются случаи, когда при описании новых деталей появляются достаточно важные объекты системы, не показанные ранее на более высоких уровнях иерархии модели. Однако, эти детали не столь важны, чтобы их показывать на более высоких уровнях модели.
Достаточно часто встречается другой случай, когда отдельные интерфейсные стрелки не стоит рассматривать в дочерних диаграммах ниже определенного уровня – это будет только перегружать их и делать сложными для восприятия. Возникает необходимость избавиться от отдельных «концептуальных» интерфейсных стрелок и не детализировать их глубже некоторого уровня.
Для решения подобных задач в стандарте IDEF0 предусмотрен механизм туннелирования.
Символ «туннеля» в виде двух круглых скобок вокруг начала интерфейсной дуги обозначает, что эта дуга не была унаследована от функционального родительского блока и появилась (из «туннеля») только на этой диаграмме.
В IDEF0 принята система маркирования, позволяющая аналитику точно идентифицировать и проверять связи по стрелкам между диаграммами. Эта схема кодирования стрелок получила название ICOM – название по первым буквам английских эквивалентов слов вход, управление, выход, механизм.
ICOM – это коды, предназначенные для идентификации граничных стрелок, содержат префикс, соответствующий типу стрелки (I, С, О или М), и порядковый номер. Буква следует перед числом, определяющим относительное положение точки подключения стрелки к родительскому блоку; это положение определяется слева направо или сверху вниз. Основной ICOM-код – это узловой номер, который появляется там, где выполняется декомпозиция функционального блока и создается его подробное описание на дочерней диаграмме..
Декомпозиция является основным понятием стандарта IDEF0. Принцип декомпозиции применяется при разбиении сложного процесса на составляющие его функции. При этом уровень детализации процесса определяется непосредственно разработчиком модели.
Декомпозиция позволяет постепенно и структурированно представлять модель системы в виде иерархической структуры отдельных диаграмм, что делает ее менее перегруженной и легко усваиваемой.
Диаграмма – это основная единица описания системы, расположенная на отдельном листе, представляющая функции и интерфейсы в виде блоков и дуг. Место соединения дуги с блоком определяет тип интерфейса. [4]
Моделирование IDEF0 всегда начинается с представления системы как единого целого – одного функционального блока с интерфейсными дугами, простирающимися за пределы рассматриваемой области. Такая диаграмма с одним функциональным блоком называется контекстной диаграммой.
Контекстная диаграмма – это IDEF0-диаграмма, расположенная на вершине иерархии диаграмм, представляющая собой самое общее описание системы, состоит из одного блока, описывающего функцию верхнего уровня, стрелок и пояснительного текста, определяющего точку зрения и цель моделирования. Эти утверждения помогают руководить разработкой модели и ввести этот процесс в определенные рамки.
Контекстная диаграмма имеет узловой номер A-n (n = 0), которая представляет контекст модели. Диаграмма верхнего уровня обозначается идентификатором «А-0» (произносится «А минус ноль»), на которой объект моделирования представлен единственным блоком с граничными стрелками, отображающими связь системы с окружающей средой.
Поскольку единственный блок представляет весь объект, то его имя – общее для всего проекта. Это же справедливо и для всех стрелок диаграммы, поскольку они представляют полный комплект внешних интерфейсов объекта.
В пояснительном тексте к контекстной диаграмме должна быть указана цель построения диаграммы в виде краткого описания и зафиксирована точка зрения.
Определение и формализация цели разработки IDEF0-модели является крайне важным моментом. Фактически цель определяет соответствующие области в исследуемой системе, на которых необходимо фокусироваться в первую очередь.
С определением модели тесно связана позиция, с которой наблюдается система и создается ее модель. SADT требует, чтобы модель рассматривалась все время с одной и той же позиции. Эта позиция называется «точкой зрения» данной модели.
Точка зрения определяет основное направление развития модели, уровень необходимой детализации, что и в каком разрезе можно увидеть в пределах модели. Четкое фиксирование точки зрения позволяет разгрузить модель.
Изменение точки зрения приводит к рассмотрению других аспектов объекта. Аспекты, важные с одной точки зрения, могут не появиться в модели, разрабатываемой с другой точки зрения на тот же самый объект.
У модели может быть только одна точка зрения.
Имя функции, записываемое в блоке контекстной диаграммы, является общей функцией системы с выбранной точки зрения и конкретной целью построения модели.
Построение IDEF0-модели начинается с контекстной диаграммы, т.е. представления всей системы в виде простейшей компоненты – одного блока и дуг, изображающих интерфейсы с функциями вне системы. Затем блок, который представляет систему в качестве единого модуля, детализируется на другой диаграмме с помощью нескольких блоков, соединенных интерфейсными дугами.
Эти блоки представляют основные подфункции исходной функции. Каждая из этих подфункций может быть декомпозирована подобным образом для более детального представления.
При этом каждая подфункция может содержать только те элементы, которые входят в исходную функцию.
Таким образом, в процессе декомпозиции функциональные блоки диаграммы подвергаются детализации на другой диаграмме, которая называется дочерней по отношению к детализируемому блоку.
Каждый из функциональных блоков, принадлежащих дочерней диаграмме, называется дочерним блоком.
Каждый блок дочерней диаграммы может быть далее детализирован аналогичным образом, став родительским по отношению с соответствующей диаграмме его детализации.
Каждый блок на диаграмме имеет свой номер. Блок любой диаграммы может быть далее описан диаграммой нижнего уровня, кото-рая, в свою очередь, может быть далее детализирована с помощью необходимого числа диаграмм. Таким образом, формируется иерархия диаграмм.
Для того чтобы указать положение любой диаграммы в иерархии, используются номера диаграмм. На рис. 9 показано дерево диаграмм.
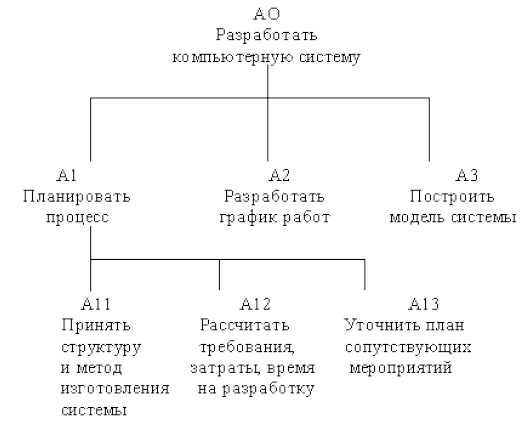
Рисунок 9 – Дерево диаграмм
Глоссарий. Последним из понятий IDEF0 является глоссарий. Для каждого из элементов IDEF0 – диаграмм, функциональных блоков, интерфейсных дуг – существующий стандарт подразумевает создание и поддержание набора соответствующих определений, ключевых слов, повествовательных изложений и т.д., которые характеризуют объект, отображенный данным элементом. [7]
Глава III. Метод структурного системного анализа и проектирования SSADM
3.1 Основные понятия метода SSADM
SSADM (Structured Systems Analysis and Design Method) – системный подход к анализу и проектированию ИС.
SSADM использует комбинацию из трех методологий моделирования.
1. Логическое моделирование данных– процесс идентификации, моделирования и документирования требований к разрабатываемой системе. Элементы логической модели данных:
- связи – ассоциации между сущностями.
- сущности – то, о чем фирме нужно записать информацию;
2. Моделирование потоков данных– процесс идентификации, моделирования и документирования движения данных в ИС. Моделирование потоков данных исследует:
- потоки данных – маршруты, по которым данные могут двигаться.
- процессы – деятельность по преобразованию данных из одной формы в другую;
- внешние сущности – сущности, которые посылают данные в систему или получают данные из системы;
- накопители данных – области (промежуточного) хранения
3. Моделирование поведения сущностей – процесс идентификации, моделирования и документирования событий, которые влияют на каждую сущность и последовательности, в которой эти события происходят.
Каждая из этих трех моделей системы обеспечивает различные точки зрения на одну и ту же систему, и каждая из точек зрения необходима для формирования полной модели проектируемой системы.
Все три методологии во взаимосвязи друг с другом дают гарантию полноты и точности всего приложения.
Проект разработки SSADM приложения делится на пять модулей, которые в дальнейшем разбиваются на иерархию из стадий, этапов и задач. Модули проекта приведены ниже.
1. Анализ осуществимости проектного решения– анализ предметной области для определения сможет ли проектируемая система удовлетворить бизнес-требованиям.
2. Анализ требований. На этом этапе определяются подлежащие разработке системные требования и моделируется текущая среда предприятия в терминах процессов с включением структур данных.
3. Спецификация требований. На этом этапе определяются детальные функциональные и нефункциональные требования и вводятся новые методики для определения необходимых процессов и структур данных.
4. Логическая системная спецификация. На этом этапе вырабатываются опции технической системы, логический проект обновлений, обработка запросов и системные диалоги.
5. Физический проект. На этапе физического проектирования создается физический проект базы данных и комплект программных спецификаций с использованием логической и технической системных спецификаций.
По причине жесткой структуры методологии, SSADM хороша с точки зрения контроля проектов и способности разрабатывать системы лучшего качества. [2]
3.2 Моделирование данных
Существует два уровня представления модели данных – логический и физический.
Логическая модель – это абстрактное представление данных. В логической модели данные представляются и могут называться так, как выглядят и называются в реальном мире, например «Постоянный клиент», «Отдел» или «Фамилия сотрудника». Объекты модели, представляемые на логическом уровне, называются сущностями и атрибутами.
В физической модели содержится информация обо всех объектах БД. Поскольку стандартов на объекты БД не существует, физическая модель зависит от конкретной реализации СУБД, фактически являясь отображением ее системного каталога. Следовательно, одной и той же логической модели могут соответствовать несколько разных физических моделей. Особенности документирования физической модели заключаются в следующем:
1) кроме того, проектировщики БД нередко злоупотребляют «техническими» наименованиями, в результате таблица и колонки получают наименования типа RTD_324 или CUST_A12 и т.д. Полученную в результате структуру могут понять только специалисты (а чаще всего – только авторы модели), ее невозможно обсуждать с экспертами предметной области.
2) многие СУБД имеют ограничение на именование объектов (например, ограничение на длину имени таблицы или запрет использования специальных символов – пробела и т. п.);
3) в нелокализованных версиях СУБД объекты БД могут называться короткими словами, только латинскими символами и без использования специальных символов (т.е. нельзя назвать таблицу, используя предложение – ее можно назвать только одним словом);
Разделение модели на логическую и физическую позволяет решить эту проблему. На физическом уровне объекты БД могут называться так, как того требуют ограничения СУБД. На логическом уровне можно этим объектам дать синонимы – имена более понятные неспециалистам, в том числе на кириллице и с использованием специальных символов.
Существует два типа проектирования модели данных: прямое и обратное.
Прямое проектирование – процесс генерации физической схемы БД из логической модели, состоящий из следующих этапов:
1) разработка логической модели;
2) выбор СУБД и автоматическое создание физической модели на основе логической;
3) генерация системного каталога СУБД или соответствующего SQL-скрипта на основе физической модели.
Прямое проектирование обеспечивает масштабируемость – создав одну логическую модель данных, можно сгенерировать физические модели под любые СУБД.
Обратное проектирование – процесс генерации логической модели из физической БД. Обратное проектирование решает задачу позволяет конвертировать БД из одной СУБД в другую. После создания логической модели БД путем обратного проектирования можно переключиться на другой сервер и произвести прямое проектирование.
1) по содержимому системного каталога или SQL-скрипту воссоздается логическая модель данных;
2) на основе полученной логической модели данных генерируется физическая модель для другой СУБД;
3) создается системный каталог этой СУБД.
Обратное проектирование решает задачу по переносу структуры данных с одного сервера на другой.
Цель информационного моделирования – обеспечение разработчиков ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей данных, которые относительно легко могут быть отображены в любую систему баз данных.
Концептуальная схема представляет собой карту понятий и отношений между ними. Если функциональная схема представляет собой определенную точку зрения на мир и не является гибкой (меняется мир – должна поменяться схема), то концептуальная схема объединяет в себе все точки зрения и дает более абстрактное представление об объекте, описывая фундаментальные понятия, лишь с экземплярами которых человек имеет дело.
В инженерии ПО, моделирование «сущность-связь»– это пример абстрактного и концептуального представление данных; это метод моделирования БД, используемый для создания концептуальной схемы или семантической модели данных системы (часто реляционной БД), а также требований к системе в форме «сверху-вниз». Диаграммы, созданные таким способом, называются диаграммами «сущность-связь» или ER-диаграммами, или кратко ERD.
ERD является наиболее распространенным средством документирования данных. С их помощью определяются важные для предметной области сущности, их атрибуты и связи друг с другом. ERD непосредственно используются для проектирования реляционных баз данных. На уровне физической модели сущности соответствует таблица; экземпляру сущности – строка в таблице; атрибуту – колонка таблицы.
Различают три уровня логической модели, отличающихся по глубине представления информации о данных:
1. Модель данных, основанная на ключах– более подробное представление данных. Она включает описание всех сущностей и первичных ключей и предназначена для представления структуры данных и ключей, которые соответствуют предметной области.
2. Диаграмма сущность-связь представляет собой модель данных верхнего уровня. Она включает сущности и взаимосвязи, отражающие основные правила предметной области. Такая диаграмма не слишком детализирована, в нее включаются основные сущности и связи между ними, которые удовлетворяют основным требованиям, предъявляемым к ИС. Диаграмма сущность-связь может включать связи «многие-ко-многим» и не включать описание ключей. Как правило, ERD используется для презентаций и обсуждения структуры данных с экспертами предметной области.
3. Полная атрибутивная модель– наиболее детальное представление структуры данных: представляет данные в третьей нормальной форме и включает все сущности, связи и атрибуты.
Существует несколько соглашений для ERD. Классическая нотация связана, главным образом, с концептуальным моделированием. При этом существует ряд нотаций, применяемых для логического и физического проектирования БД, например IDEF1X. Диаграмма структуры данных DSD – это модель данных для описания концептуальных моделей данных с помощью графических нотаций, которые документируют сущности и связи между ними, а также условия по ограничению связей. Диаграммы структуры данных DSD являются расширением E-R-модели.
Первый этап моделирования – выделение сущностей. Сущность – реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению. Графическое изображение сущности показано на рис. 11.
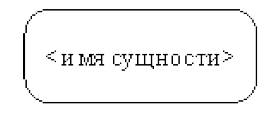
Рисунок 11 - Графическое изображение сущности
Следующим шагом моделирования является идентификация связей. Изображение связей, их степени и обязательности показано на рис. 12
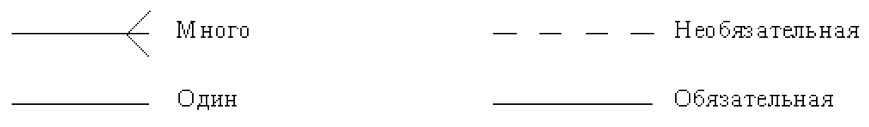
Рисунок 12 - Графическое изображение связей
Последним этапом моделирования является идентификация атрибутов. Атрибут – любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Экземпляр атрибута – это определенная характеристика отдельного элемента множества. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями.
Атрибут может быть либо обязательным, либо необязательным (рис. 13). Обязательность означает, что атрибут не может принимать неопределенных значений.

Рисунок 13 - Обязательные и необязательные атрибуты
Атрибут может быть либо описательным, либо входить в состав уникального идентификатора. В случае полной идентификации каждый экземпляр данного типа сущности полностью идентифицируется своими собственными ключевыми атрибутами, в противном случае в его идентификации участвуют атрибуты другой сущности-родителя (рис. 14).
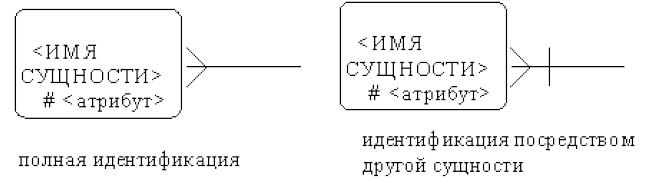
Рисунок 14 - Идентификация атрибутов
Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком «#».
Каждая сущность должна обладать хотя бы одним возможным ключом.
3.3 Методология IDEF1X
IDEF1X разработана с учетом таких требований, как простота изучения и возможность автоматизации.
Сущность в методологии IDEF1X является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности (рис. 19).
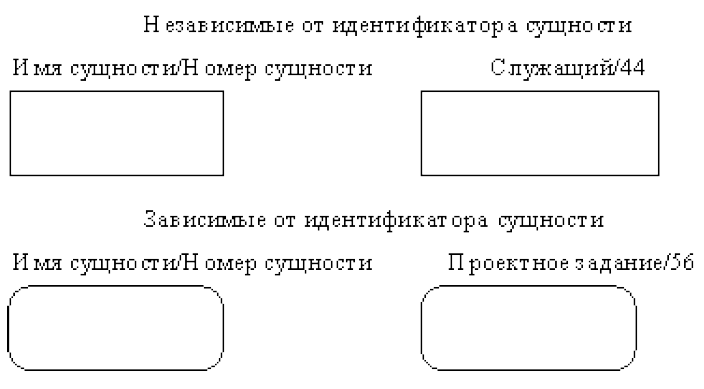
Рисунок 19 - Независимые и зависимые сущности
Каждой сущности присваивается уникальное имя и номер, разделяемые косой чертой "/" и помещаемые над блоком.
Связь является логическим соотношением между сущностями. Каждая связь должна именоваться глаголом или глагольной фразой (рис. 20).
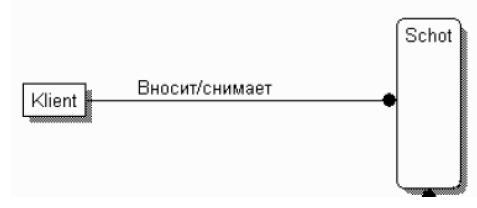
Рисунок 20 - Связь
Связь может дополнительно определяться с помощью указания степени или мощности (количества экземпляров сущности-потомка, которое может существовать для каждого экземпляра сущности-родителя). В IDEF1X могут быть выражены следующие мощности связей:
- каждый экземпляр сущности-родителя связан с некоторым фиксированным числом экземпляров сущности-потомка.
- каждый экземпляр сущности-родителя должен иметь не менее одного связанного с ним экземпляра сущности-потомка;
- каждый экземпляр сущности-родителя должен иметь не более одного связанного с ним экземпляра сущности-потомка;
- каждый экземпляр сущности-родителя может иметь ноль, один или более связанных с ним экземпляров сущности-потомка;
Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то связь называется идентифицирующей, в противном случае – неидентифицирующей.
Связь изображается линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка. Идентифицирующая связь между сущностью-родителем и сущностью-потомком изображается сплошной линией (рис. 21).
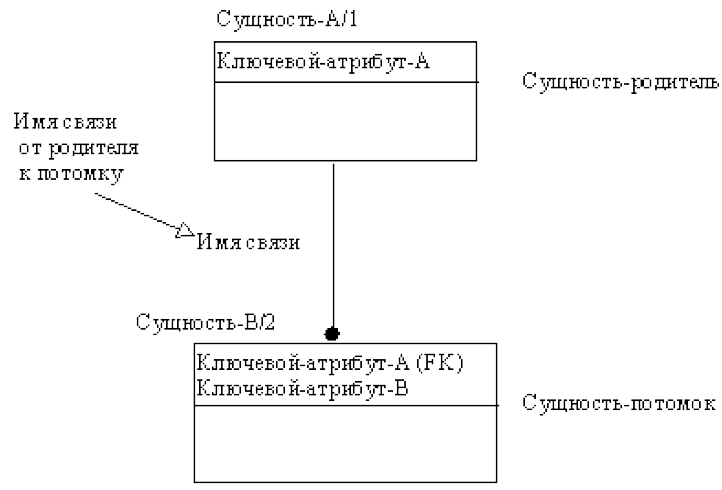
Рисунок 21 - Идентифицирующая связь
Сущность-потомок в идентифицирующей связи является зависимой от идентификатора сущностью. Сущность-родитель в идентифицирующей связи может быть как независимой, так и зависимой от идентификатора сущностью (это определяется ее связями с другими сущностями).
Пунктирная линия изображает неидентифицирующую связь (рис. 22). Сущность-потомок в неидентифицирующей связи будет независимой от идентификатора, если она не является также сущностью-потомком в какой-либо идентифицирующей связи.
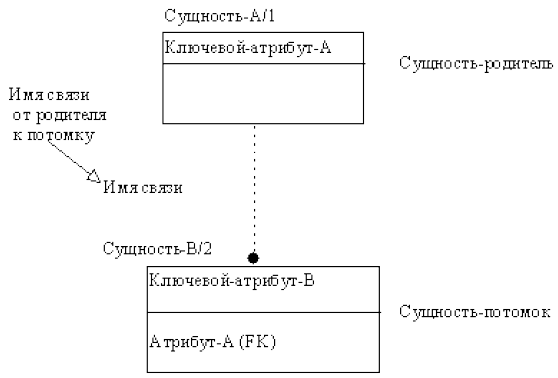
Рисунок 22 - Неидентифицирующая связь
Атрибуты изображаются в виде списка имен внутри блока сущности. Атрибуты, определяющие первичный ключ, размещаются наверху списка и отделяются от других атрибутов горизонтальной чертой (рис. 23).
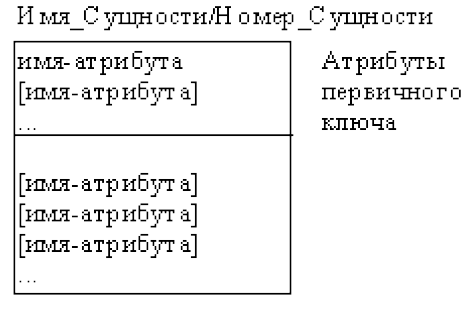
Рисунок 23 – Атрибуты
Сущности могут иметь также внешние ключи, которые могут использоваться в качестве части или неключевого атрибута. Внешний ключ изображается с помощью помещения внутрь блока сущности имен атрибутов, после которых следуют буквы FK в скобках (рис. 24).
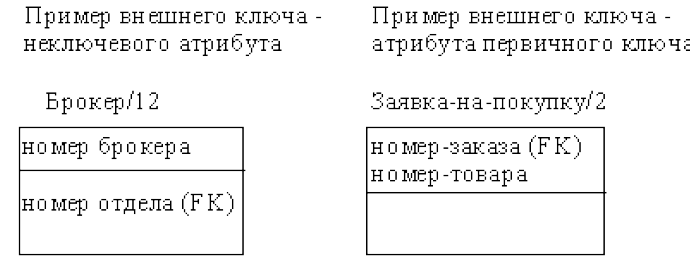
Рисунок 24 - Примеры внешних ключей
Зависимая сущность изображается прямоугольником со скругленными углами (рис. 25).
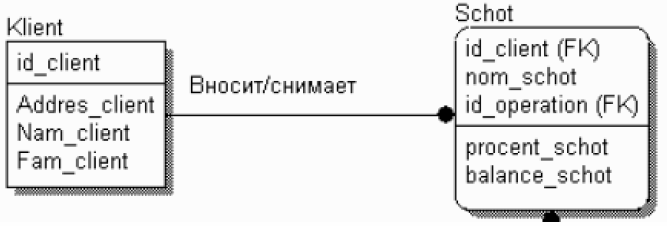
Рисунок 25 - Изображение зависимой сущности
Экземпляр зависимой сущности определяется только через отношение к родительской сущности. При установлении идентифицирующей связи атрибуты первичного ключа родительской сущности автоматически переносятся в состав первичного ключа дочерней сущности. Эта операция дополнения атрибутов дочерней сущности при создании связи называется миграцией атрибутов. В дочерней сущности новые атрибуты помечаются как внешний ключ – (FK).
В дальнейшем, при генерации схемы БД, атрибуты первичного ключа получат признак NOT NULL, что означает невозможность внесения записи в таблицу заказов без информации о номере клиента.
При установлении неидентифицирующей связи дочерняя сущность остается независимой, а атрибуты первичного ключа родительской сущности мигрируют в состав неключевых компонентов родительской сущности. Неидентифицирующая связь (рис. 26) служит для связывания независимых сущностей.
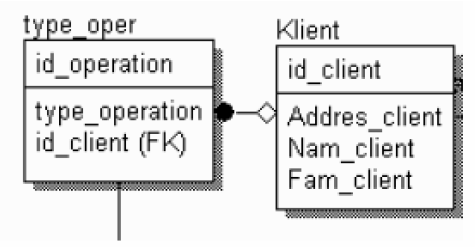
Рисунок 26 - Неидентифицирующая связь
Связь многие-ко-многим возможна только на уровне логической модели данных. Такая связь обозначается сплошной линией с двумя точками на концах (рис. 27).
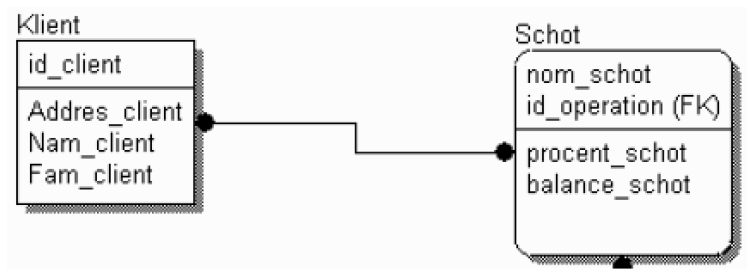
Рисунок 27 - Связь «многие-ко-многим»
Связь многие-ко-многим должна именоваться двумя фразами – в обе стороны. Это облегчает чтение диаграммы.
При переходе к физическому уровню ERwin автоматически преобразует связь многие-ко-многим, добавляя новую таблицу и устанавливая две новые связи один-ко-многим от старых к новой таблице. При этом имя новой таблице автоматически присваивается как «Имя1_Имя2».
Иерархия наследования (или иерархия категорий) представляет собой особый тип объединения сущностей, которые разделяют общие характеристики.
Иерархии категорий делятся на два типа – полные и неполные. В полной категории одному экземпляру родового предка обязательно соответствует экземпляр в каком-либо потомке. Полная категория помечается кружком с двумя горизонтальными чертами, неполная – кружком с одной чертой. Возможна комбинация полной и неполной категорий (рис. 28).
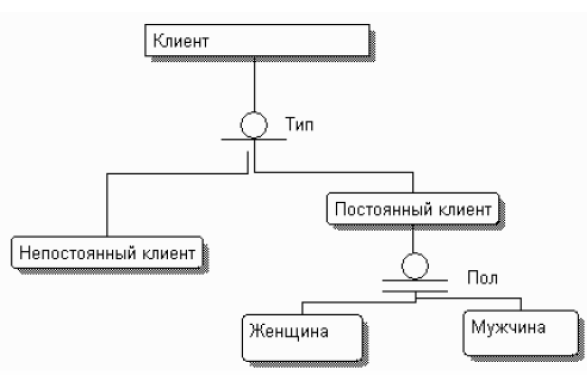
Рисунок 28 - Комбинация полной и неполной категорий
Методологию моделирования потоков данных используют при анализе ИС – проектируемых или реально существующих. Получаемая в результате модель потоков данных DFDs является графическим представлением «потоков данных» через ИС, а также одним из трех основных ракурсов методологии SSADM. Основные объекты нотации:
- внешние сущности – отображают объекты, с которыми происходит взаимодействие.
- работы – отображают процессы обработки и изменения информации;
- хранилища данных – отображают данные, к которым осуществляется доступ, эти данные используются, создаются или изменяются работами;
- стрелки – отображают информационные потоки;
Работы (процессы) представляют собой функции системы по преобразованию входных потоков данных в выходные в соответствии с определенным алгоритмом.
Процесс на диаграмме потоков данных изображается прямоугольниками со скругленными углами, как показано на рис. 29.
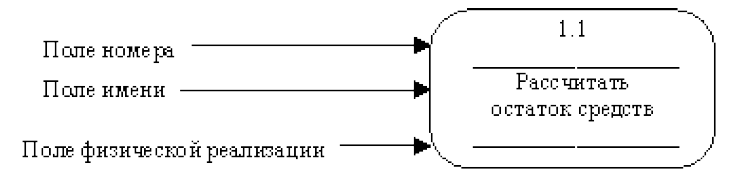
Рисунок 29 – Процесс
Номер процесса служит для его идентификации. Каждый процесс имеет уникальный номер для ссылок на него внутри диаграммы, который может использоваться совместно с номером диаграммы для получения уникального индекса процесса во всей модели.
В поле имени вводится наименование процесса в виде предложения с активным недвусмысленным глаголом в неопределенной форме (вычислить, рассчитать, проверить, определить, создать, получить), за которым следуют существительные в винительном падеже, обозначающие объект преобразования.
Назначение процесса (работы) состоит в продуцировании выходных потоков из входных в соответствии с действием, задаваемым именем процесса.
Информация в поле физической реализации показывает, какое подразделение организации, программа или аппаратное устройство выполняет данный процесс.
Внешняя сущность представляет собой субъект окружающей среды (юридическое или физическое лицо, иногда материальный предмет), представляющее собой источник или приемник информации, например, заказчики, поставщики, клиенты, склад.
Внешняя сущность обозначается прямоугольником (рис. 30), расположенным как бы «над» диаграммой и бросающим на нее тень, для того, чтобы можно было выделить этот символ среди других обозначений.
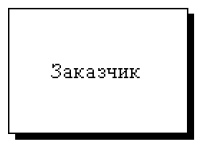
Рисунок 30 - Внешняя сущность
Внешние сущности обычно располагаются по краям диаграммы. Одна внешняя сущность может быть использована многократно на одной или нескольких диаграммах.
Потоки данных описывают движение информации из одной части системы в другую. Поток данных на диаграмме изображается линией, оканчивающейся стрелкой, которая показывает направление потока (рис. 31).
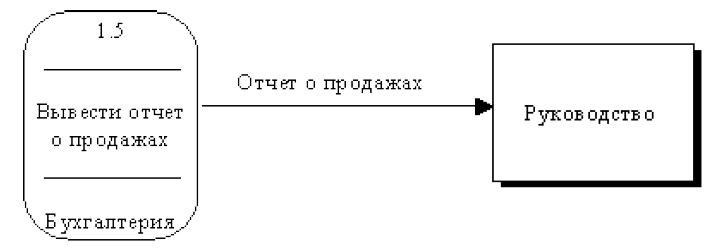
Рисунок 31 - Поток данных
Поскольку в DFD каждая сторона работы не имеет четкого назначения, как в IDEF0, стрелки могут подходить и выходить из любой грани прямоугольника работы.
Источники информации (внешние сущности) порождают информационные потоки (потоки данных), переносящие информацию к подсистемам или процессам. Те в свою очередь преобразуют информацию и порождают новые потоки, которые переносят информацию к другим процессам или подсистемам.[4]
ЗАКЛЮЧЕНИЕ
Структурным анализом принято называть метод исследования системы, которое начинается с ее общего обзора и затем детализируется, приобретая иерархическую структуру с все большим числом уровней. Решение трудных проблем путем их разбиения на множество меньших независимых задач значительно повышают понимание сложных систем, а также повышают их надежность.
В ходе выполнения данной курсовой работы была подтверждена актуальность анализа и оценки средств реализации структурных методов анализа и проектирования экономической информационной системы. Это дает возможность выбрать наиболее подходящий метод для проектирования.
В ходе выполнения данной курсовой работы были решены следующие задачи исследования:
- рассмотрены основные определения и историю структурного анализа и структурного проектирования;
- рассмотрен метод структурного анализа и проектирования SADT;
- рассмотрен метод структурного анализа и проектирования SSADM
СПИСОК ЛИТЕРАТУРЫ
1 Инюшкина О.Г., Кормышев В.М. Исследование систем управления при
проектировании информационных систем: учебное пособие./О.Г. Инюшкина, В.М. Кормышев. Екатеринбург: «Форт-Диалог Исеть», 2013. - 370 с.
2 Инюшкина О.Г., Гольдштейн С.Л. Практика использования информационных технологий и систем (на примерах управления организацией): учебное пособие / С.Л. Гольдштейн, О.Г. Инюшкина. Екатеринбург: УрФУ, 2010. - 185 с.
3 Инюшкина О.Г., Кормышев В.М. Управление знаниями в информационных системах (монография). / О.Г. Инюшкина, В.М. Кормышев, Екатеринбург: УрФУ, 2012. - 212 с.
4 Маклаков С.В. «ERwin и BPwin. CASE-средства разработки информационных систем» / С.В. Маклаков, 2-е изд., испр. и доп., М. : Диалог-Мифи, 2001. – 304 с. М: «Диалг-МИФИ», 2001.
5 Вендров А.М. CASE-технологии. Современные методы и средства проектирования информационных систем / А.М. Вендров. – М. : Финансы и статистика, 1998. – 176 с. Программное обеспечение. [Электронный ресурс]
Режим доступа: www.interface.ru.
6 Руководство по применению ГОСТ Р ИСО/МЭК 12207 при управлении
проектом. PDF, www.complexdoc.ru.
7 Дэвид А. Марка, Клемент МакГоуэн. Предисловие Дугласа Т. Росса. Методология структурного анализа и проектирования SADT Structured
Analysis & Design Technique. [Электронный ресурс] Режим доступа:
www.pqm-online.com/assets/files/lib/mar

- Организационно-методологические аспекты формирования коммерческой деятельности предприятиями на рынке товаров и услуг (Общие принципы организации коммерческой деятельности)
- Отличие бухгалтерского учета от налогового учета (ООО «Директ»)
- Основные функции в системе менеджмента (Понятие функций менеджмента и системы менеджмента)
- Предотвращение допинга в спорте и борьба с ним (Организация, порядок проведения допинг-контроля)
- Процессы принятия решений в организации (Практический подход принятия решений в легкой промышленности на примере ОАО "Гермес")
- Процессы принятия решений в организации (Влияние факторов на деятельность ОАО "Гермес" и процесс принятия руководителем качественных решений)
- Основные функции в системе менеджмента (Организация как функция управления. Мотивация как одна из основных функций менеджмента)
- Гражданско-правовая охрана личности гражданина
- Правовое регулирование рекламной деятельности (Правовые аспекты рекламной деятельности)
- Нотариат в РФ
- Цель и задачи налогового учета
- Финансовая политика и ее реализация в Российской Федерации