
Тестирование производительности программ: подходы в зависимости от категорий приложений
Содержание:

ВВЕДЕНИЕ
Повышение интереса к тестированию программного обеспечения пришлось на 90-е годы XX века в США. Стремительный рост систем автоматизированной разработки программного обеспечения и компьютерных сетей привел к увеличению производства программного обеспечения и к разработке подходов к обеспечению качества и надёжности разрабатываемых приложений. Рост конкуренции между создателями программного обеспечения потребовал определенного внимания к качеству производимых приложений, так как у пользователей появился выбор: разработчики предоставляли свои программы по достаточно приемлемым ценам, что позволяло обращаться к тому, кто разработает необходимый продукт не только дёшево и быстро, но и качественно[3].
В настоящее время компьютеризация вошла практически во все сферы человеческой жизни. Поэтому качество программного обеспечения приобрело особую важность: в современном мире это уже не только удобство в работе программ – программное обеспечение управляет работой диспетчерских систем в аэропортах, оборудования в больницах, космических кораблей, атомных реакторов и т.д [5].
Анализ актуальности обусловили выбор темы исследования: «Тестирование производительности программ: подходы в зависимости от категорий приложений».
Объектом исследования является процесс тестирования программного обеспечения.
Предметом исследования являются техники тестирования производительности программного обеспечения.
Цель исследования состоит в изучении процесса тестирования, основных технологий тестирования производительности программного обеспечения.
Для достижения поставленной цели необходимо решить следующие задачи:
- определить место, которое занимает процесс тестирования в разработке программного обеспечения;
- ознакомиться с процессом тестирования;
- изучить технологии тестирования программного обеспечения.
1. ОСНОВНЫЕ АСПЕКТЫ ТЕСТИРОВАНИЯ И ОТЛАДКИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
1.1 Понятия тестирования и отладки программного обеспечения
Тестированием программного обеспечения (software testing) является процесс эксплуатации или анализа программного обеспечения для выявления дефектов[1].
Разберём более подробно данное определение. Понятие «процесс» используется выделения того, что тестирование является плановой, упорядоченной деятельностью. На это необходимо обратить внимание, так как хорошо организованная, систематическая проверка упрощает обнаружение программных ошибок, в сравнении с плохо спланированным тестированием.
Из определения следует, что тестирование подразумевает «эксплуатацию» или «анализ» программного обеспечения. Тестирование, при котором выполняется анализ результатов разработки программного продукта, называют статическим тестированием (static testing), в которое включается проверка кода программы, сквозной контроль и проверка «за столом» (desk checks) , т.е. проверка программного продукта без запуска на компьютере. В отличие от статического тестирования, тестовая деятельность, в которой предусмотрена эксплуатация программы, называется динамическим тестированием (dynamic testing). Эти два типа тестирования дополняют друг друга, реализуя в отдельности собственный подход к определению ошибок в программе.
Понятие дефекта (bug), использующееся в определении, представляет собой программную ошибку, изъян в разработке программы, в результате вызывающий несоответствие ожидаемых и фактически полученных результатов выполнения программного продукта. Дефект может возникнуть на этапе формулирования требований, на этапе проектирования, или на этапе кодирования, также причиной дефекта может быть неправильная конфигурация программы или данных. Дефект может состоять в чём-то другом, что не соответствует требованиям заказчика программного продукта и или не определено в спецификации созданной программы.
Отладкой называют процесс по выявлению источников ошибок, и внесение в программный продукт соответствующих корректировок.
Отладка – это процесс поиска того оператора программы, который вызвал ошибку вычислительного процесса и исправления найденной ошибки, обнаруженной в процессе тестирования программного обеспечения. Чтобы исправить ошибку необходимо выявить ее причину [2]. Различают следующие типы ошибок:
- синтаксические ошибки. Данные ошибки определяются транслятором или компилятором в результате синтаксического и семантического анализа и могут сопровождаться комментариями, в которых указанно их местоположение;
- ошибки компоновки определяются редактором связей (компоновщиком) в процессе объединения программных модулей;
- ошибки выполнения определяются операционной системой, аппаратными средствами или пользователем в процессе выполнения программы.
1.2 Цели и задачи тестирования программного обеспечения
Целями тестирования программного обеспечения являются[8]:
- повышение вероятности правильной работы приложения в различных обстоятельствах;
- повышение вероятности соответствия приложения всем необходимым требованиям.
- проведение полного тестирования приложения в короткие сроки.
Задачами тестирования являются:
- проверка работоспособности системы в соответствии с определенными критериями;
- проверка верности выполнения наиболее критических последовательностей действий пользователя с конечной системой;
- проверка работы пользовательских интерфейсов;
- проверка того, что модификации в базах данных не влияют на выполняемые программные компоненты;
- минимизация переработки тестов при возможных модификациях приложения;
- использование средств автоматизированного тестирования;
- проведение тестирования не только для обнаружения, но и предупреждения дефектов.
1.3 Этапы тестирования программного обеспечения
Первым действием при планировании тестирования программного обеспечения является разработка стратегии испытаний на высоком уровне. В общем, стратегия определяет объем тестовых испытаний, методики тестирования, применяемых для нахождения дефектов, процедуры, которые уведомляют о найденном дефекте и устраняющие его, условия входа и выхода из теста, управляющие различными типами тестов. Учитывая принцип интеграции разработки и тестирования улучшения графика разработки, стратегия испытаний должна включать разнообразные виды тестов жизненного цикла разработки. При разработке общей стратегии должны использоваться тестирования как статического, так и динамического типа.
При использовании автоматизации различных видов тестовой деятельности, данная стратегия должна входить составной частью в общую стратегию тестирования. При автоматизации необходимо выполнение определенных тщательно спланированных параллельных работ, которые должны выполняться только так, чтобы это не приводило к снижению производительности[12].
Существуют несколько подходов при формулировании стратегии тестирования[4]:
1. Определение объемов тестовых испытаний, анализируя документы, которые содержат требования к программе (технические условия), для выяснения, что нужно проверять. При этом необходимо учитывать виды тестов, которые непосредственно не следуют из документов с требованиями, например, возможность установки и увеличение функционала программного продукта, простота и удобство обслуживания программы, а также возможность её взаимодействия с различной аппаратной архитектурой, имеющейся у заказчика.
2. Определение типа тестовых испытаний из разнообразия статических и динамических тестов на каждом этапе разработки. При этом необходимо включение описания всех программных элементов, которые готовятся тестовой группой.
3. Определение условий входа и выхода на каждом этапе тестирования, определение всех точек контроля качества.
4. Определение стратегии автоматизации при использовании автоматизации определенного вида тестовых испытаний.
При определении объемов тестовых работ нет возможности протестировать абсолютно все, поэтому необходимость выбора того, что нужно протестировать очевидна. При избыточности тестового покрытия, времени для отладки программы потребуется значительно больше, что повлияет на срок сдачи работы. Если же тестовое покрытие будет недостаточным, то повысится риск пропуска ошибок, устранение которых после сдачи программного продукта в заказчику будет стоить дороже. Определить норму тестовых испытаний можно при использовании различных способов измерения успешности тестирования.
Можно выделить несколько рекомендаций по разработке стратегии тестирования, использование которых могут обеспечить оптимальное тестовое покрытие[7]:
- в первую очередь необходимо тестирование требований с высоким приоритетом;
- проверка нового функционала программы и программного кода, который был модифицирован для совершенствования или исправления устаревших функциональных возможностей;
- тестирование участков с наиболее вероятным присутствием ошибок;
- использование разбиения на эквивалентные классы и выполнение анализа граничных условий для уменьшения затрат на тестирование;
- сосредоточение внимания на конфигурациях и функциях, с которые наиболее чаще всего будут использованы.
При определении тестированию необходимо вначале исследовать каждый этап жизненного цикла разработки для отбора тестов статического и динамического типов, которые будут использованы на соответствующем этапе. При этом могут быть использованы различные модели жизненного цикла разработки, такие как каскадная, спиралевидная или модель с итеративными версиями. Для примера рассмотрим каскадную модель и определим, какие виды тестирования могут в ней использоваться[4]:
- этап, на котором формулируются требования;
- этап системного проектирования;
- этап, на котором тестируются проекты программы, программные коды, производится модульное тестирование и комплексные испытания;
- системное тестирование;
- приемочное тестирование;
- регрессионное тестирование.
Выбранный подход к тестированию необходимо отразить в документах, которые содержат план проведения тестирования.
Для определения критериев тестирования и точек контроля качества перед началом системного тестирования используют следующие пять типов[6]:
- В критерии входа определяется, что необходимо выполнить сделать перед началом испытания.
- В критерии выхода определяется, что необходимо для завершения испытания.
- В критерии приостановки/возобновления описывается, что будет, если при возникновении дефекта продолжение испытания станет невозможным.
- В критерии успешного/неудачного прохождения теста задаются заранее известные результаты каждого испытания.
- В других критериях, которые определяются стандартами или процессом, задаются соответствующие условия работы программы.
Определение стратегии автоматизации целесообразно при создании любой многократно выполняемой задачи. При этом на автоматизацию задачи требуется намного больше времени, чем на ее выполнение, поэтому необходимо вначале проанализировать потенциальный выигрыша от автоматизации, принимая во внимание, что сама автоматизация имеет отдельный жизненный цикл.
Плохо организованная автоматизация может привести не только к напрасному расходу ресурсов, но и к нарушению графика выполняемых работ, по причине затраты времени на отладку средств автоматизации.
1.4 Комплексное тестирование программного обеспечения
Комплексное тестирование состоит в проверке корректного согласования каждого модуля приложения с остальными его модулями. При этом могут использоваться технологии обработки снизу вверх и сверху вниз, при которых каждый модуль, в виде листа в дереве системы, интегрируется с модулями более высокого или более низкого уровня, пока не будет сформировано дерево программного продукта. Такая технология тестирования необходима для проверки как параметров, передающихся между двумя модулями, так и для проверки глобальных параметров[10].
Отдельные процедуры комплексного тестирования состоят из тестовых кодов верхнего уровня, моделирующих выполнение программой определенного задания. При этом применяются модульные тесты нижнего уровня с определенными параметрами для тестирования интерфейса. После анализа отчетов об обнаруженных дефектах модульного тестирования выполняют объединение модулей инкрементно для их совместного тестирования на основе управляющей логики. Так как в модули могут входить другие модули, то часть комплексного тестирования может проводиться при модульном тестировании. Если коды модульного тестирования создавались с помощью средств автоматизированного тестирования, то возможно их объединение и добавление новых скриптов для проверки межмодульных связей.
Комплексное тестирование выполняется и определенным образом уточняется, при этом отчеты о проблемах документируются и отслеживаются. Отчеты классифицируются по степени их серьезности в четырёхбалльной шкале (4 является наименее критическим состоянием, 1 – наиболее). Обработав отчеты о проблемах необходимо провести регрессионное тестирование, показывающее полное устранение проблемы.
1.5 Восходящее и нисходящее тестирование
Одним из способов локализации ошибок является восходящее тестирование. При обнаружении ошибки в одном модуле при его тестировании, очевидно, что именно в нем она и содержится. Нет необходимости в анализе кода всей системы для поиска источника дефекта. Если же дефект проявляется при совместном тестировании двух модулей, значит, проблема в их интерфейсе. Преимущество восходящего тестирования состоит в том, что концентрация внимания происходит на небольшой области кода, вследствие чего проверка происходит более успешно и с большей вероятностью выявления дефектов.
Недостаток восходящего тестирования состоит в необходимости создания специального скрипта-оболочки, который бы вызывал тестируемый модуль, и «заглушки» для других модулей – имитации вызываемой функции, которая возвращает только данные, ничего больше не выполняя.
Создание оболочек и заглушек приводит к замедлению разработки программы, а для готового приложения не нужны. Однако, эти элементы можно использовать повторно при каждой модификации приложения.
В отличие от восходящего тестирования, при целостном тестировании отдельные модули не проходят особо тщательной проверки до полной интеграции системы.
Достоинствами такого подхода является отсутствие необходимости создания дополнительных скриптов. Поэтому многие разработчики пользуются этим способом для экономии времени. При этом разрабатываются необходимые тесты, с помощью которых проверяется вся система сразу. При этом возникает ряд трудностей[3]:
- Возникает проблема в выявлении источника ошибки. Так как модули не проверяются тщательно, то большинство из них имеет дефекты. При этом неизвестно, какой из дефектов во всех работающих модулях привел к неправильному результату. При наложении дефектов нескольких модулей проблему намного труднее найти.
Также дефект одного модуля может помешать тестированию другого. Как проверить один модуль, если вызывающий его модуль имеет дефект? Тогда для проверяемого модуля необходимо создавать программу-оболочку, или ждать отладки вызывающего модуля, что приводит к потере времени в проверке зависимого модуля.
-
- Проблемы в организации исправления ошибок. При написании программы несколькими программистами, и при этом непонятно, в какой части кода ошибка, необходимо определить, кто будет её устранять.
- Недостаточная автоматизация комплексного тестирования, обусловлена отсутствием необходимости создавать оболочки и заглушки. Программа в процессе разработки постоянно меняется, что приводит к необходимости её частого тестирования. А единожды созданные оболочки и заглушки облегчают автоматизацию этого однообразного труда.
Используют еще один подход в организации тестирования, в котором приложение тестируется по отдельным модулям. В отличие от восходящего тестировании сначала проверяются модули самого верхнего уровня иерархии, а от них тестирование постепенно направляется вниз. Такой подход называется нисходящим тестированием. Оба подхода, и восходящий и нисходящий, называют инкрементальными тестированиями.
В технологии нисходящего тестирования отсутствует необходимость написания оболочек, но написание заглушек нужно. В ходе тестирования заглушки в нужный момент заменяются соответствующими модулями.
Мнения разработчиков об эффективности этих двух инкрементальных подходов тестирования разнятся[4, 9, 11]. Практически выбор стратегии тестирования производится следующим образом: все модули по возможности тестируется сразу после их создания, поэтому тестирование одних частей программы может происходить в восходящей последовательности, а других – в нисходящей.
2. РАЗЛИЧНЫЕ ПОДХОДЫ К ТЕСТИРОВАНИЮ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
2.1 Метод сандвича
Метод сандвича является компромиссным методом между восходящими и нисходящими технологиями тестирования. Здесь делается попытка воспользоваться достоинствами обоих методов, избежав их недостатков. В данном методе нисходящее и восходящее тестирование начинают одновременно, проверяя код как сверху, так и снизу и заканчивая проверку где-то в середине иерархии модулей. Место окончания проверки зависит от программы, которая тестируется и заранее определяется при разборе ее структуры. Например, если программа может быть представлена как совокупность, включающую в себя прикладные модули, затем модули обработки запросов, уровни примитивных функций, то программист может применить нисходящий метод при тестировании прикладных модулей (создавая заглушки, замещающие модули обработки запросов), а остальные модули проверять восходящим методом. Метод сандвича применяется при проверке больших программ, например, операционных систем или пакетов прикладных программ[4].
Достоинством метода сандвича состоит в интеграции системы в самом начале тестирования, что также проявляется в восходящем и нисходящем подходе. Так как верхние уровни программных модулей вступают в проверку рано, то, как в нисходящем методе, уже вначале проверки получается работающий каркас программы. Так как нижние уровни программных модулей проверяются восходящим методом, то исчезают недостатки нисходящего метода, связанные с невозможностью проверять некоторые условия во внутренних модулях программы.
Однако тестирование методом сандвича сохраняет та недостатки нисходящего подхода, состоящие в том, что нет возможности тщательно протестировать отдельные модули. Восходящая часть проверки методом сандвича убирает этот недостаток для модулей нижних уровней, однако он остаётся актуальным для нижней части верхнего уровня модулей программы. Существует модифицированный метод сандвича, в котором верхние уровни модулей вначале проверяются по отдельности, а затем тестируются нисходящим способом, а модули нижних уровней тестируются восходящим.
2.2 Метод «белого ящика»
Метод «белый ящик» состоит в том, что при создании тестовых случаев программисты используют все данные о внутренней структуре программы и её или коде. Технологии, которые применяются при тестировании методом «белого ящика» представляют собой технологии статического тестирования[8].
Этот метод не выявляет синтаксические ошибки, ткоторые обнаруживаются компилятором. Метод «белого ящика» направлен на поиск дефектов, выявить которые сложно, на обнаружение логических ошибок и проверку степени покрытия тестами.
В тестовых испытаниях методом «белого ящика» применяют управляющую логику процедур. Они выполняют следующие функции:
- предоставляют гарантию проверки того по крайней мере один раз всех независимых путей в модуле;
- проверяют истинность или ложность всех логических решений;
- выполняют все циклы с использованием граничных значений внутри операционных границ;
- исследуют структуру внутренних данных для того, чтобы проверить их достоверность.
Метод «белого ящика» является разновидностью стратегии модульного тестирования, при которой тестирование производится на функциональном или модульном уровне и тестирование направлено на исследование внутренней структуры модуля. Такой тип тестирования также носит название модульного тестирования или тестирования «прозрачного ящика» (clear box) или прозрачным (translucent) тестированием, так как специалисты, кторые проводят тестирование, знают весь программный код и видят работу программы изнутри. Подход к тестированию, основанный на открытости кода, ещё называют структурным подходом.
При тестировании на данном уровне выполняется проверка управляющей логики, которая работает на модульном уровне. Для того, все логические решения рассмотрены во всевозможных условиях, чтобы все пути в данном модуле были проверены хотя бы один раз, циклы были выполнены с использованием верхних и нижних границ в данном методе используют тестовые драйверы.
2.3 Методы тестирования на основе стратегии «белого ящика»
2.3.1 Ввод неверных значений
Вводя неверные значения при тестировании программы, программист делает так, чтобы коды возврата показывали ошибки, и смотрит на ответную реакцию кода. Таким способом можно моделировать определенные события, такие как переполнение диска, нехватку памяти и т.д. Такой метод еще называется тестированием ошибочных входных данных, когда проводят проверку работы программы, как при верно, так и неверно введенных входных данных. Программист для этого может выбрать значения, которые входят в границы входных и выходных параметров, а также значения, не выходящие в данный диапазон.
2.3.2 Модульное тестирование
Разработка отдельных модулей программы сопровождается модульным тестированием, в результате которого проверяется, работоспособность кода, верность его работы и корректность реализации интерфейса. Модульное тестирование проверяет новый код на соответствие архитектуры; изучаются пути в коде, определяется, что ниспадающие меню, экраны и сообщения отформатированы должным образом; выполняется проверка диапазона и типов вводимых данных, а также генерацию исключений и возврата ошибок (error returns). Тестирование отдельных модулей программы выполняется для проверки корректности алгоритмов и логики соответствия предъявляемым требованиям функциональности. В результате модульного тестирования определяются ошибки, которые относятся к времени работы, логике программы, выходу из диапазона, перегрузке и утечке памяти.
2.3.3 Тестирование обработки ошибок
Н практике признается, что каждое возможное условие возникновения ошибки проверить невозможно. Поэтому производят сглаживание последствий возникновения неожиданных ошибок с помощью обработки ошибок. Программист должен проверить, что программа правильно выдает сообщения об ошибке.
2.3.4 Утечка памяти
Проверка утечки памяти предполагает исследование приложения на обнаружение ситуаций, в которых не происходит освобождения выделенной памяти, из-за чего уменьшается производительность программы. В данной технологии используется как для проверки готового программного продукта, так и для тестирования версии программы. Инструменты тестирования способны отслеживать использование памяти приложением в течение определенного времени, проверяя, происходит ли рост объема используемой памяти. С помощью инструментов тестирования выявляют те участки программы, в которых не происходит освобождение выделенной памяти.
2.3.5 Комплексное тестирование
При комплексном тестировании выполняется проверка каждого модуля программы на корректную работу со всеми модулями. Данный метод тестирования может использовать технологии обработки снизу вверх и сверху вниз, при которых все модули, являющиеся листьями в дереве системы, соединяются со следующим модулем более высокого или более низкого уровня, пока не будет создано дерево программного продукта. Такой подход к тестированию проверяет не только параметры, передающиеся между двумя компонентами, но и глобальные параметры.
2.3.6 Тестирование цепочек
Метод «Тестирование цепочек» используется для проверки нескольких модулей, которые составляют функцию программы. Данный метод выявляет, надежно ли работают модули для образования единого модуля, и выдают ли модули программы правильные и согласованные результаты.
2.3.7 Исследование покрытия
Выбор средств для исследования покрытия состоит в том, что группа тестирования должна проанализировать тип покрытия, который необходим для программы. Исследование покрытия проводят с помощью разнообразных технологий. Метод покрытия операторов часто называют C1, что также означает покрытие узлов. Эти измерения показывают, был ли проверен каждый исполняемый оператор. Данный метод тестирования обычно использует программу протоколирования (profiler) производительности.
2.3.8 Покрытие решений
Метод покрытия решений направлен на определение (в процентном соотношении) всех возможных исходов решений, которые были проверены с помощью комплекта тестовых процедур. Метод покрытия решений иногда относят к покрытию ветвей и называют C2. Он требует: чтобы каждая точка входа и выхода в программе была достигнута хотя бы единожды, чтобы все возможные условия для решений в программе были проверены не менее одного раза, и чтобы каждое решение в программе хотя бы единожды было протестировано при использовании всех возможных исходов.
2.3.9Покрытие условий
Покрытие условий похоже на покрытие решений. Оно направлено на проверку точности истинных или ложных результатов каждого логического выражения. Этот метод включает в себя тесты, которые проверяют выражения независимо друг от друга. Результаты этих проверок аналогичны тем, что получают при применении метода покрытия решений, за исключением того, что метод покрытия решений более чувствителен к управляющей логике программы.
2.4 Метод «черного ящика»
Тестирование на основе стратегии черного ящика возможно лишь при наличии установленных открытых интерфейсов, таких как интерфейс пользователя или программный интерфейс приложения (API). Если тестирование на основе стратегии белого ящика исследует внутреннюю работу программы, то методы тестирования черного ящика сравнивают поведение приложения с соответствующими требованиями. Кроме того, эти методы обычно направлены на выявление трех основных видов ошибок: функциональности, поддерживаемой программным продуктом; производимых вычислений; допустимого диапазона или области действия значений данных, которые могут быть обработаны программным продуктом. На этом уровне тестировщики не исследуют внутреннюю работу компонентов программного продукта, тем не менее, они проверяются неявно. Группа тестирования изучает входные и выходные данные программного продукта. В этом ракурсе тестирование с помощью методов черного ящика рассматривается как синоним тестирования на уровне системы, хотя методы черного ящика могут также применяться во время модульного или компонентного тестирования.
При тестировании методами черного ящика важно участие пользователей, поскольку именно они лучше всего знают, каких результатов следует ожидать от бизнес-функций. Ключом к успешному завершению системного тестирования является корректность данных. Поэтому на фазе создания данных для тестирования крайне важно, чтобы конечные пользователи предоставили как можно больше входных данных.
Тестирование при помощи методов черного ящика направлено на получение множеств входных данных, которые наиболее полно проверяют все функциональные требования системы. Это не альтернатива тестированию по методу белого ящика. Этот тип тестирования нацелен на поиск ошибок, относящихся к целому ряду категорий, среди них[9]:
- неверная или пропущенная функциональность;
- ошибки интерфейса;
- проблемы удобства использования;
- методы тестирования на основе автоматизированных инструментов;
- ошибки в структурах данных или ошибки доступа к внешним базам данных;
- проблемы снижения производительности и другие ошибки производительности;
- ошибки загрузки;
- ошибки многопользовательского доступа;
- ошибки инициализации и завершения;
- проблемы сохранения резервных копий и способности к восстановлению работы;
- проблемы безопасности.
2.5 Методы тестирования на основе стратегии «черного ящика»
2.5.1Эквивалентное разбиение
Исчерпывающее тестирование входных данных, как правило, неосуществимо. Поэтому следует проводить тестирование с использованием подмножества входных данных.
При тестировании ошибок, связанных с выходом за пределы области допустимых значений, применяют три основных типа эквивалентных классов: значения внутри границы диапазона, за границей диапазона и на границе. Оправдывает себя практика создания тестовых процедур, которые проверяют граничные случаи плюс/минус один во избежание пропуска ошибок «на единицу больше» или «на единицу меньше». Кроме разработки тестовых процедур, использующих сильно структурированные классы эквивалентности, группа тестирования должна провести исследовательское тестирование. Тестовые процедуры, при выполнении которых выдаются ожидаемые результаты, называются правильными тестами. Тестовые процедуры, проведение которых должно привести к ошибке, носят название неправильных тестов[7].
2.5.2 Анализ граничных значений
Анализ граничных значений можно применить как на структурном, так и на функциональном уровне тестирования. Границы определяют данные трех типов: правильные, неправильные и лежащие на границе. Тестирование границ использует значения, лежащие внутри или на границе (например, крайние точки), и максимальные/минимальные значения (например, длины полей). При таком исследовании всегда должны учитываться значения на единицу больше и меньше граничного. При тестировании за пределами границы используется репрезентативный образец данных, выходящих за границу, т.е. неверные значения.
2.5.3 Диаграммы причинно-следственных связей
Составление диаграмм причинно-следственных связей - это метод, дающий четкое представление о логических условиях и соответствующих действиях. Метод предполагает четыре этапа. Первый этап заключается в составлении перечня причин (условий ввода) и следствий (действий) для модуля и в присвоении идентификатора каждому модулю. На втором этапе разрабатывается диаграмма причинно-следственных связей. На третьем этапе диаграмма преобразуется в таблицу решений. Четвертый этап включает в себя установление причин и следствий в процессе чтения спецификации функций. Каждой причине и следствию присваивается собственный идентификатор. Причины перечисляются в столбике с левой стороны листа бумаги, а следствия - с правой. Затем причины и следствия соединяются линиями так, чтобы были отражены имеющиеся между ними соответствия. На диаграмме проставляются булевы выражения, которые объединяют две или более причин, связанных со следствием. Далее правила таблицы решений преобразуются в тестовые процедуры.
2.5.4 Системное тестирование
Термин «системное тестирование» часто употребляется как синоним «тестирования с помощью методов черного ящика», поскольку во время системного тестирования группа тестирования рассматривает в основном «внешнее поведение» приложения. Системное тестирование включает в себя несколько подтипов тестирования, в том числе функциональное, регрессионное, безопасности, перегрузок, производительности, удобства использования, случайное, целостности данных, преобразования данных, сохранения резервных копий и способности к восстановлению, готовности к работе, приемо-сдаточные испытания и альфа/бета тестирование.
2.5.5 Функциональное тестирование
Функциональное тестирование проверяет системное приложение в отношении функциональных требований с целью обнаружения несоответствия требованиям конечного пользователя. Для большинства программ тестирования программного продукта данный метод тестирования является главным. Его основная задача – оценка того, работает ли приложение в соответствии с предъявляемыми требованиями.
2.5.6 Регрессионное тестирование.
Смысл проведения тестирования заключается в обнаружении дефектов, их документировании и отслеживании вплоть до устранения. Тестировщик должен быть уверен в том, что меры, принимаемые для устранения найденных ошибок, не породят в свою очередь новых ошибок в других областях системы. Регрессионное тестирование позволяет выяснить, не появились ли какие-либо ошибки в результате ликвидации уже обнаруженных ошибок. Именно для регрессионного тестирования применение инструментов автоматизированного тестирования дает наибольшую отдачу. Все созданные ранее скрипты можно использовать снова для подтверждения того, что в результате изменений, внесенных при устранении ошибки, не появились новые дефекты. Эта цель легко достижима, поскольку скрипты можно выполнять без ручного вмешательства и использовать столько раз, сколько необходимо для обнаружения ошибок.
2.5.7 Тестирование безопасности
Тестирование безопасности включает в себя проверку работы механизмов доступа к системе и к данным. Для этого придумывают тестовые процедуры, которые пытаются преодолеть защиту системы. Тестировщик проверяет степень безопасности и ограничения доступа, определяя таким образом, соответствие установленным требованиям к безопасности и всем применяемым правилам по безопасности системы.
2.5.8 Тестирование перегрузок
При тестировании перегрузок выполняется проверка системы без учета ограничений архитектуры с целью выявления технических ограничений системы. Эти тесты проводятся на пике обработки транзакций и при непрерывной загрузке большого объема данных. Тестирование перегрузок измеряет пропускную способность системы и ее эластичность (resiliency) на всех аппаратных платформах. Этот метод подразумевает одновременное обращение со стороны многих пользователей к определенным функциям системы, причем некоторые вводят значения, выходящие за пределы нормы. От системы требуется обработка огромного количества данных или выполнение большого числа функциональных запросов в течение короткого периода времени.
2.5.9 Тестирование производительности
Тесты производительности проверяют, удовлетворяет ли системное приложение требованиям по производительности. Применяя тестирование производительности, можно замерить и составить отчеты по таким показателям, как скорость передачи входных и выходных данных, общее число действий по вводу и выводу данных, среднее время, затрачиваемое базой данных на отклик на запрос, и интенсивность использования центрального процессора. Как правило, для автоматической проверки степени производительности, проводимой в рамках тестирования производительности, используются те же инструменты, что и при тестировании перегрузок.
2.5.10 Тестирование удобства использования
Тесты удобства использования направлены на подтверждение простоты применения системы и того, что пользовательский интерфейс выглядит привлекательно. Такие тесты учитывают человеческий фактор в работе системы. Тестировщику нужно оценить приложение с точки зрения конечного пользователя.
3. ТЕСТИРОВАНИЕ ПРОИЗВОДИТЕЛЬНОСТИ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
3.1 Виды тестирования производительности
Современный этап развития многопользовательских программных средств ставит перед разработчиками сложный комплекс задач по обеспечению требуемого уровня производительности создаваемого программного обеспечения. Показатели производительности не только выступают как самостоятельный критерий качества, но и значительно влияют на показатели стабильности, отказоустойчивости, безопасности и живучести программных средств.
Специфика предметной области не позволяет в полной мере использовать классические подходы к обеспечению качества с применением ручного функционального тестирования, что приводит к необходимости поиска новых эффективных решений.
Одним из таких решений является автоматизация тестирования производительности – применение технологий и специального программного обеспечения, позволяющего создать в искусственной среде условия, в необходимой мере имитирующие реальные ситуации, в которых могут проявиться дефекты программного средства, связанные с его производительностью.
В настоящий момент наиболее исследованными направлениями тестирования, затрагивающими показатели производительности программных средств, являются:
- тестирование производительности (performance testing) – исследование показателей скорости реакции приложения на внешние воздействия при различной по характеру и интенсивности нагрузке;
- нагрузочное тестирование (load testing) – исследование способности приложения сохранять заданные показатели качества при нагрузке в допустимых пределах и некотором превышении этих пределов (определение «запаса прочности»);
- стрессовое тестирование (stress testing) – исследование поведения приложения при нештатных изменениях нагрузки, значительно превышающих расчётный уровень;
- объёмное тестирование (volume testing) – исследование производительности приложения при обработке различных (как правило, больших) объёмов данных.
Цели различных видов тестирования производительности
|
Тестирование производительности |
оценка времени выполнения операций при определённой интенсивности и очерёдности выполнения этих операций; оценка реакции на изменение количества пользователей, одновременно работающих с приложением; оценка границ интенсивности нагрузки, при которых производительность выходит за рамки приемлемой; оценка показателей масштабируемости приложения. |
|
Нагрузочное тестирование |
оценка скорости реакции приложения на различные значения нагрузки в допустимых пределах; оценка использования приложением системных ресурсов при различных значениях нагрузки; оценка изменения со временем поведения приложения при сохранении допустимой нагрузки длительное время. |
|
Стрессовое тестирование |
оценка реакции приложения на нестандартные и стрессовые случаи изменения нагрузки, в т.ч.: резкое непредсказуемое изменение интенсивности нагрузки, значительное превышение предельно допустимой нагрузки, интенсивное использование функций приложения, являющихся «узким местом» в производительности. |
|
Объёмное тестирование |
оценка показателей производительности приложения в случаях приёма, обработки и генерации данных различного объёма и с различными показателями вычислительной сложности обработки; оценка способности приложения обрабатывать большие объёмы данных в условиях высокой загрузки системных вычислительных ресурсов; оценка способности приложения обрабатывать большие объёмы данных при недостатке оперативной памяти. |
Анализ данных, представленных в таблице , позволяет сделать вывод о том, что прямыми или косвенными целями любого тестирования, так или иначе затрагивающего вопросы производительности, является:
- определение «узких мест» системы (функций программно-аппаратного комплекса, обращение к которым приводит к наибольшему падению показателей производительности);
- определение лучшей архитектуры системы, выбор наилучшей платформы, средств и языков реализации;
- определение оптимального способа хранения файлов;
- оценка и оптимизация схемы базы данных в контексте повышения производительности;
- оценка максимальной и минимальной производительности системы и условий их достижения;
- определение характера увеличения времени отклика системы при увеличении нагрузки;
- определение максимального числа одновременно работающих пользователей, превышение которого делает использование системы невозможным;
- определение влияния конфигурации системы на производительность;
- оценка показателей масштабируемости системы;
- оценка соответствия сетевой инфраструктуры требованиям производительности.
3.2 Основные тесты производительности
В рамках нагрузочного тестирования и тестирования производительности, как правило, выполняются следующие основные тесты.
Тест на определение максимальных возможностей системы (capacity test) позволяет определить т.н. «точку насыщения системы» (system saturation point) – уровень нагрузки, при котором дальнейшее наращивание числа пользователей ведёт к увеличению времени отклика системы либо ухудшению стабильности системы, но не к увеличению в единицу времени количества полезных операций, обработанных системой. Данный тест направлен на оценку производительности системы как аппаратно-программного комплекса, поскольку учитывает доступные аппаратные ресурсы и эффективность их использования.
Проведение нескольких тестов на определение максимальных возможностей системы с добавлением аппаратных ресурсов позволяет определить показатели масштабируемости (scalability) системы, которая определяется как способность приложения увеличивать производительность пропорционально добавлению аппаратных ресурсов системы.
Низко-, средне- и высоконагруженная работа (low-, mid-, high-load tests) – позволяет оценить время отклика (response time) системы в некоторых заданных диапазонах нагрузки. Данная информация может быть использована при составлении перечня требований к условиям эксплуатации системы.
Тест на выживаемость (longevity test) показывает способность системы работать длительное время под высокой нагрузкой. Одной из наиболее опасных проблем, выявляемых данным тестом, является утечка памяти и иное снижение эффективности использования аппаратных ресурсов из-за накапливающихся со временем ошибок в работе приложения.
Тест «часа пик» (rush hour test) позволяет оценить реакцию системы на резкое изменение нагрузки. Во время теста проверяется способность системы выдержать скачкообразное увеличение нагрузки во время «часа пик», а также способность системы вернуться к изначальным показателям производительности после завершения «часа пик» (восстановления исходных показателей нагрузки на систему). Такой тест позволяет выявить проблемы с синхронизацией выполнения отдельных участков кода, а также проблемы с управлением всеми видами межкомпонентного взаимодействия (в т.ч. сетевых и локальных соединений) на всех уровнях системы.
Тест «точки рандеву» (rendezvous point test) подразумевает такую настройку профиля нагрузки и поведения виртуальных пользователей, чтобы в некоторый момент все они одновременно выполняли одну и ту же операцию: как правило, синхронную операцию сохранения, записи, и т.п. В отличие от теста «часа пик» этот тест не подразумевает увеличения числа одновременно работающих с системой пользователей, а подразумевает исследование ситуации конкуренции пользователей за некоторые ресурсы, совместное использование которых не представляется возможным или сопряжено с повышенной нагрузкой на системные ресурсы. В частности, этот тест позволяет выявить проблемы с разделением ресурсов на уровне баз данных.
3.3 Примеры тестирования на производительность
Обслуживание пользователя - это всегда последовательность задач.
Возьмем для примера, WEB приложение, которое получило запрос пользователя (например «открыть приходную накладную номер 123»). Конвейер задач выглядит так:
- HTTP POST request
- Find and load Session
- Check Permissions
- Try load object from Cache
- Load object from Database
- Write to usage tracking log
- Send Request back to client.

Рис. 1. Конвейер задач
Каждая задача имеет «длину», т.е. продолжительность задачи в миллисекундах.
Каждая задача имеет «ширину», т.е. затраты процессорного времени/памяти/производительности дискового ввода-вывода.

Рис. 2. Продолжительность задач
Суммарная продолжительность задач при выполнении одного запроса – это скорость, с которой приложение отвечает пользователю (Response time, оно же Latency). Это то, что конечный пользователь называет производительностью.
Количество запросов, которое приложение способно выполнить в минуту (час/день), обслуживая необходимое для бизнеса количество пользователей(скажем 10 000) – это пропускная способность (Bandwitch).
Пример: «1 миллион просмотров страницы товара в сутки, при количестве одновременных пользователей до 10 000».
От чего будет зависеть пропускная способность?
- От «пространства», которое приложению требуется, чтобы обслужить одни запрос, т.е. произведения ширины и длины задач.
Например, чем больше CPU time (RAM/Network bandwitch, и т.д.) приложению требуется для задачи «Проверить наличие товара на складе» (или чем дольше оно эту задачу выполняет) - тем меньше его остается для обслуживания других пользователей.
- От пропускной способности «трубы» (pipe) в которой запросы выполняются. Больше места в «трубе» – больше запросов можно обслужить одновременно. Пропускную способность «трубы» определяют, прежде всего, аппаратное обеспечение (hardware), потом OS и Middleware.
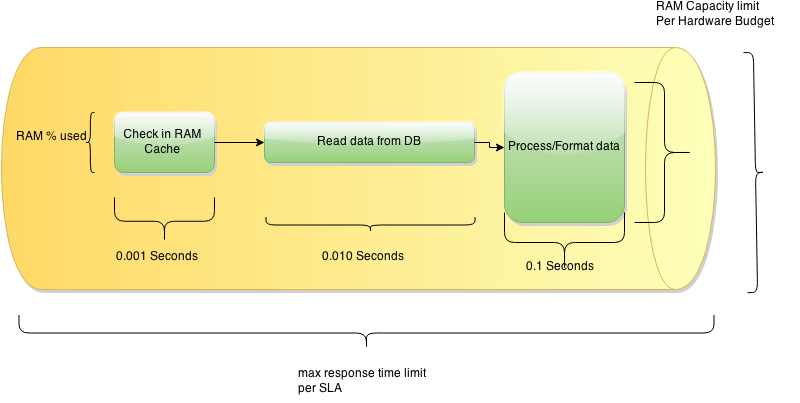
Рис. 3. Пропускная способность трубы
Виды ресурсов и фундаментальные ограничения
|
Операций в секунду |
Пропускная способность (Bandwitch) |
Скорость ответа (Latency) |
|
|
Процессор |
2.0 - 3.5 GHz |
N/A |
N/A |
|
Диск(HDD) |
~350 IOPs |
~ 50 - 120 MB / sec |
~10 - 20 ms |
|
Диск(SDD) |
~ 100,000 - 130,000 IOPs |
~ 200 - 6,000 MB /sec |
0.1 ms |
|
Сеть |
100 - 1000 Mbit / sec |
LAN: 100Mbit - 1,000 Mbit WAN: 2Mbit - 20 Mbit |
LAN ~ 0.1 - 1 ms WAN ~20 - 300 ms |
|
Оперативная память |
Operational Freq: 166 - 255 MHz |
~ 8,500 - 17,000 MB / sec |
0.000,010 - 0.000,02 ms |
Входное условие для тестирования – количество одновременных пользователей. Следует проводить тестирование не только на требуемой заказчиком возможной нагрузке, но так же и ниже/выше ее:
- Если система имеет высокую производительность на максимальном количестве пользователей - это не означает что она не имеет проблем на среднем.
- Нужно знать, достигнут ли «потолок», насколько большой запас производительности имеется в системе.
Показатели, которые следует измерять для нагрузочного тестирования:
- Скорость ответа (далее Latency) - какая средняя скорость ответа? Какая максимальная и минимальная?
- Пропускная способность(далее Bandwitch) - сколько запросов в минуту выполнено?
- Количество ошибок (далее Error rate) - сколько запросов приложение не смогло выполнить?
Когда система подвергается большей нагрузке, чем способна обработать, у нее есть три варианта поведения:
- Правильный. Поставить входящие запросы в очередь и обработать их когда освободятся ресурсы
Пример: Наш электронный магазин предоставляет HTTP REST API партнерам, позволяя им закупать у нас товары оптом. Наш сервер API способен обслуживать 40 одновременных запросов. Что произойдет, когда мы получим одновременно 41 запрос? Нам придется поставить один запрос в очередь, и заставить его ждать, пока не освободится какой то из потоков, которые обслуживают сейчас предыдущих 40 пользователей. А если мы получим 60 одновременных запросов? Поставим в очередь 20 из них.
- Правильный. Если количество запросов настолько велико, что их невозможно обработать за требуемое время - отбрасывать запросы
Пример: Продолжая пример выше, что, если мы получим 240 запросов? Мы конечно можем поставить 200 запросов в очередь, но чем больше у нас ожидающих в очереди, тем хуже средняя скорость ответа. С точки зрения пользователя, система которая «зависла», т.е.,отвечает слишком медленно, ничем не лучше системы которая «сломана», т.е., не отвечает вообще. (Да, с точки зрения инженера, который обслуживает системы и знает их изнутри, разница большая, но заказчика это не интересует). Система, которая сразу сигнализирует о том, что перегружена/получила больше работы, чем может выполнить в срок, намного лучше, чем та которая молча заставляет клиентов ждать слишком долго/вечно. Нужно поставить лимит на длину очереди и отбрасывать (например, через HTTP 500) запросы которые не уместились в нее.
Если SLA(Service Level Agreement) «запрос должен быть обработан не больше чем за 6 секунды» и скорость выполнения запроса 3 секунды - какая максимальная длина очереди имеет смысл? Ответ – 40. Более длинная очередь не позволит выполнить SLA.
- Неправильный. Пытаться сделать больше работы, чем система способна выполнить. Это приведет лишь к неконтролируемому снижению производительности (из-за swopping’а памяти, перегрузки CPU/HDD/IO, и т.д.)
- Неправильный. Все остальное. Повредить данные, выдавать пользователю мусор вместо требуемого HTML/XML, не выдавать никакого ответа и так далее.

Рис. 4.
Типичный график нагрузочного тестирования. Система способна обработать не больше 100 запросов в секунду. Запихивание в систему большего объема работы (300 запросов) только создает длинную очередь из 200 ждущих запросов.
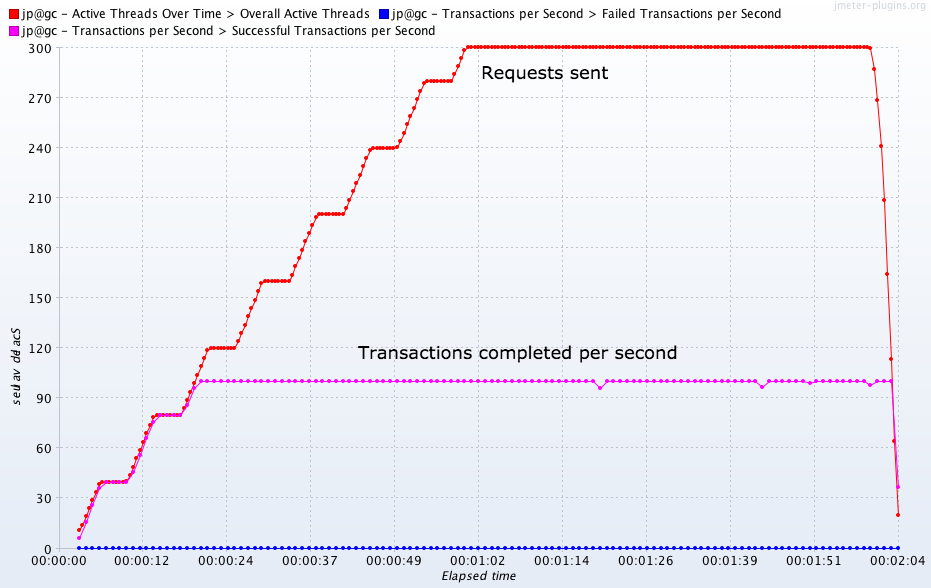
Рис. 5. График тестирования
Тестирование, естественно, должно быть автоматизированным (как иначе имитировать работу сотен пользователей). Есть хороший выбор инструментов тестирования (Jmeter, Grinder, Load Runner).
Тестирование должно быть повторяемым (любой тест можно воспроизвести и сравнить производительность приложения до оптимизаций и после).
Любой участник команды (разработчик или тестировщик) должен иметь возможность провести тест на выбранном стенде в DEV или QA или на собственном компьютере, чтобы провести эксперимент или ревью:
- Тестовые скрипты, их настройки, тестовые данные, скрипты генерации тестовых данных - в Version Control System
- конфигурационные файлы приложения, OC и middleware (MongoDB, Elastic Search/ и т.д.) в Version Control System.
- Инструмент тестирования - любой разработчик может легко скачать и установить его на свой компьютер (нужны лицензии или инструмент должен быть open source).
- Отчет о тестировании должен показывать:
- Производительность по каждой тестируемой задаче («полнотекстовый поиск», «просмотр накладной» и т.д.) по результатам последнего теста.
- Тренд в разрезе задача/производительность/количество пользователей за период, чтобы отследить, как недавние изменения в продукте повлияли на производительность
Необходимо отдельно тестировать производительность в режиме «кеширование включено» и «кеширование выключено». Иначе мы можем получить завышенные результаты. Кеширование - может сильно повысить производительность и ,поэтому, используется, и в нашем продукте и во всех лежащих в его фундаменте Middleware (Веб сервер, СУБД,и т.д.). Но, в зависимости от того, как пользователи используют наш продукт, кеширование может дать как значительный выигрыш, так и нулевой и даже отрицательный (т.е., снизить производительность). Например, функция веб сайта «пользователь просматривает свой приватный профиль» не выигрывает от использования кеширования:
- пользователь не будет просматривать свой профиль несколько раз подряд,
- другим пользователям доступ к этим данным запрещен,
- в целом этой функцией редко пользуются.
Нагрузочное тестирование для такой функции покажет завышенную производительность. Потому что тест выполнит много запросов подряд, и, естественно, кеширование увеличит производительность - в тесте, но не в реальной жизни! Решение – выключить кеширование, прежде чем тестировать такую функцию ( в настройках нашего приложения, веб сервера, базы данных, и т.д.).
В ходе тестировании желательно фиксировать показатели нагрузки на железо/middleware. Это может помочь найти узкие места (далее bottleneck) в системе.
3.4 Способы повышения производительности
Чтобы получить высокую производительность:
- Уменьшайте длину задач (т.е. Latency)
- Но не за счет излишнего увеличения их «ширины». Например, слишком агрессивное кеширование памяти в задаче «сгенерировать веб страницу» ускорит ее выполнение, но заодно увеличит расход памяти на каждого пользователя - и ,в результате, сократит Bandwitch
- Уменьшайте ширину задач в конвейере
- Уменьшайте количество задач в конвейере
Есть 3 способа достичь этого:
- Ускорить задачу, выполнять ее быстрее
- Распараллелить задачи
- Исключить задачу, совсем обойтись без нее
Основные способы ускорения выполнения задачи:
- Кеширование
- Предварительная калькуляция
- Предварительная инициализация
- Пакетные операции
Идея - мы вычислили/добыли данные один раз и кладем их поближе, чтобы в следующий раз далеко не тянуться.
Пример:
Прочитали данные с диска - запомнили в оперативной памяти. Сэкономим в следующий раз на ожидании дискового ввода-вывода.
Не имеет смысла кешировать данные, которые не будут повторно востребованы. Такое кеширование только понизит производительность - из за накладных расходов на помещение данных в кеш/поиск в кеше.
Пример: Кеширует ли Google результаты поиска (вот этот набор из 100 000 ссылок по поисковой фразе «database performance»)? Предположим, что если и кеширует, то на короткий промежуток времени. Вероятность того, что много разных людей будут искать одно и то же - невелика. Вероятность, что они сформулируют свой поисковый запрос одинаково, слово в слово – еще меньше.
Решение принимается по каждому виду данных/бизнес сущности отдельно. Ищется баланс с учетом размера данных, стоимости их вычисления/чтения с HDD, вероятности их повторной востребованности, размера, который они занимают в кеше/частоты изменения данных/того, насколько «болезненно» будет для пользователя получение «устаревших» данных из кеша.
Если отмерить для кеша слишком мало памяти – не хватит места для данных, слишком много – будет тратиться больше времени на поиск в нем. Ищем баланс, используем статистику использования кеша.
Дедупликацией называют, когда разные модули системы совместно используют кешированные общие данные, вместо того чтобы дублировать их.
Зависимости между кешированным данными, удаляются из кеша устаревшие данные, нужно удалить и те, которые от них зависят.
Говоря об имплементации, потребуется
- спецификация для имен ключей в кеше;
- спецификация формата данных в кеше;
- спецификация зависимостей («когда чистите в кеше Пользователя, вычистите и его Профиль»)
Желательно иметь библиотеку- wrapper, которая одновременно и документирует спецификации в коде и вынуждает, в хорошем смысле, программистов выполнять их.
Базы данных используют кеширование двояко:
- Низкоуровневый кеш блоков данных
- Кеш запросов (где ключом является «SELECT FistName,LastName from Users Where ID=123», а значением - прочитанный набор записей)
Кеш запросов хорошо помогает при READ-ONLY доступе к небольшому объему данных(чтобы полностью уместился в кеше). Следует понимать, это не замена полноценному кешированию на уровне приложения.
Дело в том, что СУБД «не знает» бизнес-логики приложения и оперирует только текстами SQL запросов. Это создает проблемы c дубликацией/запихиванием слишком большого объема данных в кеш/излишне агрессивном сбросе кеша.
Например, база данных получила SQL два запроса подряд:
- SELECT * from user_profile where ID=123;
- UPDATE user_profile SET compensation_coeffcient=1.5 WHERE employee_grade=4;
Устарели ли результаты «SELECT …»? С точки зрения приложения - нет, потому что поле compensation_coeffcient им не используется, либо пользователь с ID==123 не имеет «employee_grade==4». Но СУБД либо не может этого знать либо не может эффективно отследить.
Поэтому явный контроль над кешированием на уровне приложения дает наибольший выигрыш в производительности.
Когда стоимость вычисления данных велика, вероятность повторного обращения к тем же данным значительна и частота изменений данных мала - имеет смысл предварительно вычислить их и сохранить в persistent storage.
Пример:
Чтение из СУБД неких редко изменяемых, но часто требуемых данных выполняется медленно из-за сложных SQL запросов со множеством JOIN’ов. Изменить структуру СУБД мы не хотим(другие бизнес-процессы требуют именно такой структуры).
Решение - Выполнять чтение и преобразование данных фоновым процессом, который сохраняет уже обработанные данные в «кеширующей таблице» в СУБД.
Объединение задач в «пакет» (batch) позволяет экономить на накладных расходах.
Типичное серверное приложение извлекает, по запросу пользователя, данные из СУБД(Сервера поиска/внешней системы/и т.д.)
Установка нового соединения съедает время (network latency/инициализация нового потока на стороне СУБД). Пул заранее открытых соединений к серверу СУБД решает эту проблему. С другой стороны, больше открытых соединений - больший расход ресурсов.
Без пула соединений, цикл прост:
- Приложение получило задачу на выполнение
- Открыло соединение (новое, «чистое»)
- Послало запрос
- Получило ответ
- Закрыло соединение (если в приложении до этого произошел сбой, СУБД сама закроет, когда сработает timeout )
Типовые проблемы при использовании пула соединений:
- Шаг №2 может надолго заблокировать поток. Например, приложение содержит ошибку и не всегда возвращает соединение в пул. В результате все незанятые соединения в пуле оказались исчерпаны. И реализация метода «openConnection» в пуле ждет, когда освободится одно из занятых сейчас соединений, пока не сработает таймаут(или вечно...)
- Полученное на шаге №2 соединение уже использовалось ранее и могло «унаследовать» от предыдущего потока целую россыпь проблем (НЕзакрытая транзакция/НЕснятые блокировки/мусорные настройки Transaction Isoloation Level|Charset conversion/мусор в server side SQL variables).
- Соединение может быть уже закрыто сервером СУБД из-за ошибок, либо длительной неактивности.
- Полученный на шаге №4 ответ может быть вовсе не ответом на посланный в №3 запрос. Это может быть ответ на запрос, посланный предыдущим «пользователем» соединения.
Поэтому использование persistent соединений требуют поддержки на уровне реализации пула/протокола/драйвера БД/СУБД.
- Сброс состояния соединение при возвращении в пул - СУБД должно предоставлять такую возможность и драйвер в приложении должен ею пользоваться.
- Идентификация на уровне драйвера/протокола - к какому посланному ранее запросу относится полученный драйвером от СУБД ответ.
- Отслеживание и четкое разграничение драйвером ошибок на сетевом уровне(timeout/connection closed) от ошибок уровня приложения (SQL query has error). Первые делают невозможным использование соединения/требуют выбросить его из пула. Вторые позволяют продолжить его использование.
- Необходим лимит на количество в пуле (не больше, чем сервер приложений может обработать параллельно).
- Лимит на начальное количество соединений в пуле.
- Настройка - Сколько добавлять в пул за раз, когда не хватает.
- Timeout на извлечение из пула. Добавление нового соединения может занять от доли секунды до часов(перегруженный сервер СУБД/сбой или неправильная настройка в файерволе или load balancer’е). Последнее, чего мы хотим - толпа потоков в сервере приложений, заблокированных навечно, потому что в пуле закончились соединения и он заблокировался при добавлении нового.
Параллельное выполнение задач ускоряет процесс - если мы не пытаемся выполнить параллельно больше работы, чем можем.
Например, у нас есть сервер - калькулятор. Пользователи посылают ему арифметические выражения, например «2+2» и сервер вычисляет результат – в нашем примере «4». Аппаратное обеспечение - 1 (один) CPU, с одним ядром. Сколько пользователей сервер может обслужить параллельно? Ответ – только одного! Потому что используемый ресурс - только CPU и RAM.
Представьте, что для выполнения одного запроса серверу требуется одна секунда времени CPU.
Представьте, что к серверу обратились 60 пользователей одновременно.
Сколько времени нужно, чтобы их обслужить используя один поток? Одна секунда * 60 пользователей = одна минута. Одного пользователя сервер обслужит за 1 секунду, второму придется подождать 2, самому невезучему – 60. Хотя бы 30 пользователей будут обслужены быстрее чем за 30 секунд.
Если мы распараллелим работу внутри сервера между 60 потоками, каждый обслуживает один запрос, все запроcы обрабатываются строго параллельно – сколько времени пользователи будут ждать ответа? 60 секунд. Причем, все пользователи будут ждать по 60 секунд. Многопоточность/параллелизм только ухудшают производительность, когда мы пытаемся запихнуть в систему больше работы, чем она способна выполнить.
Другой пример – WEB сервер, раздающий HTML/JS/CSS файлы. Аппаратное обеспечение – 4 ядра CPU. Сколько пользователей сервер может обслужить параллельно? Намного больше 4-х, потому используемые ресурсы - не столько CPU/RAM, сколько Disk I/O. Серверу следует создать намного больше 4-x потоков – они все равно будут ждать, когда завершится чтение с диска. Если потоков будет слишком мало – тогда уже их количество станет «бутылочным горлышком».
ЗАКЛЮЧЕНИЕ
В современной работе программиста тестирование занимает важную часть процесса производства программного обеспечения. Качественно организованное тестирование своевременно выявляет и исправляет ошибки, что позволяет уменьшить риски и затраты на разработку приложений. Автоматизация тестирования повышает качество и скорость проверки, что приводит к еще большему повышению качества и уменьшению издержек.
В данной курсовой работе были рассмотрены принципы тестирования, цели и задачи тестирования, основные этапы тестирования.
Были изучены стратегии тестирования, такие как стратегии белого и черного ящиков, и методы тестирования, основанные на данных стратегиях. К стратегии белого ящика относят следующие методы: ввод неверных значений, модульное тестирование, тестирование обработки ошибок, утечка памяти, комплексное тестирование, тестирование цепочек, исследование покрытия, покрытие решений, покрытие условий. К стратегии черного ящик относятся методы эквивалентного разбиения, анализа граничных значений, диаграммы причинно-следственных связей, системного тестирования, функционального тестирования, регрессионного тестирования, тестирования безопасности, тестирования перегрузок, тестирования производительности, тестирования удобства использования.
Также в работе были изучены методы тестирования производительности программного обеспечения и рассмотрена общая методика отладки приложений.
Ключевая метафора для понимания производительности - это «конвейер задач», которые прокачиваются через «трубу». Количество и последовательность задач в конвейере определяются требованиями заказчика и техническими решениями программиста.
Пропускная способность трубы определяется ее шириной (Bandwitch) и длиной (Latency). Которые, в свою очередь, определены лежащим в фундаменте системы Hardware/Software.
Пропускная способность системы в целом определяется тем, сколько задач можно прокачать через трубу в единицу времени. Здесь важны «ширина» (объем используемого CPU/RAM/IO) и «длина» (продолжительность выполнения) задач.
Производительность может быть повышена следующими способами:
- сокращением «длины» и/или «ширины» задач;
- выполнением задач параллельно, если в «трубе» есть для этого место;
- исключением задач из конвейера – выполнением их асинхронно.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Бейзер Б. Тестирование черного ящика. Технологии функционального тестирования программного обеспечения и систем [текст] / Б. Бейзер; - Питер, 2004, 320 с. ISBN 5-94723-698-2.
- Брауде Э.Д. Технология разработки программного обеспечения [текст] / Э.Д. Брауде; - Питер, 2004, 656 с. ISBN 5-94723-663-X.
- Винниченко И.В. Автоматизация процессов тестирования [текст] / И. В. Винниченко; - Питер, 2005, 208 с. ISBN 5-469-00798-7.
- Канер С. Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений [текст] / С. Канер; - ДиаСофт, 2001, 544 с, ISBN 966-7393-87-9.
- Калбертсон Р. Быстрое тестирование [текст] / Р. Калбертсон, К. Браун, Г. Кобб; - Вильямс, 2002, 384 с. ISBN 5-8459-0336-X.
- Коликова Т.В. Основы тестирования программного обеспечения. Учебное пособие [текст] / Т.В. Коликова, В.П. Котляров; - Интуит, 2006, - 285 с. ISBN 5-85582-186-2.
- Касперски К. Техника отладки программ без исходных текстов [текст] / К. Касперски; - БХВ-Петербург, 2005, 832 с. ISBN 5-94157-229-8.
- Макгрегор Д. Тестирование объектно-ориентированного программного обеспечения. Практическое пособие [текст] / Д. Макгрегор, Д. Сайкс; - ТИД «ДС», 2004, 432 с. ISBN 966-7992-12-8.
- Плаксин М. Тестирование и отладка программ - для профессионалов будущих и настоящих [текст] / М. Пласкин; - Бином. Лаборатория знаний, 2007, - 168 с. ISBN 978-5-94774-458-3.
- Роберт М. Быстрая разработка программ: принципы, примеры, практика [текст] / М. Роберт, Д. Ньюкирк; - Вильямс, 2004, 752 с. ISBN 5-8459-0558-3.
- Фолк Д. Тестирование программного обеспечения [текст] / Д. Фолк, Е. К. Нгуен, С. Канер; - Диасофт, 2003 , 400 с. ISBN 966-7393-87-9.
- Элфрид Д. Автоматизированное тестирование программного обеспечения. Внедрение, управление и эксплуатация [текст] / Элфрид Д., Джефф Р., Джон П.;- Лори, 2003, ISBN 5-85582-186-2.

- Разработка регламента выполнения процесса «Предоставление рекламных услуг» (Описание предметной области. Постановка задачи)
- Разработка проекта информационной системы обработки заказа клиента в интернет-фирме, включая обработку заказа и проверку, и обработку оплаты
- ОТВЕТСТВЕННОСТЬ РУКОВОДИТЕЛЯ ЗА УПРАВЛЕНЧЕСКОЕ РЕШЕНИЕ
- Трудовая пенсия по старости
- Задачи оперативно-розыскной деятельности
- Общая характеристика оперативно-розыскных мероприятий
- Роль мотивации в поведении организации
- Цветопередача и сущность картины О.К.Моне "Дама в саду Сент-Адресс"
- Понятие и признаки государства
- Размер пенсии по старости (Общие положения о пенсиях по старости)
- Основания досрочного выхода на пенсию
- Особенности создание бизнеса без образование юридического лица