
Технологии программирования. Методы кодирования данных .
Содержание:

Введение
Актуальность выполнения данной работы обусловлена тем, что примечательная особенность современного периода - переход от индустриального общества к информационному, в котором информация становится более важным ресурсом, чем материальные или энергические ресурсы. Ресурсами называют элементы экономического потенциала, которыми располагает общество, и которое при необходимости могут быть использованы для достижения конкретной цели хозяйственной деятельности.
Информационные ресурсы являются собственностью, находятся в ведении соответствующих органов и организаций, подлежат учету и защите, так как информацию можно использовать не только для товаров и услуг, но и превратить ее в наличность, продав кому-нибудь, или, что еще хуже, уничтожить. Собственная информация для производителя представляет значительную ценность, так как нередко получение такой информации - весьма трудоемкий и дорогостоящий процесс. Очевидно, что ценность информации определяется в первую очередь приносимыми доходами. В этих условиях проблема использования криптографических методов защиты информации от несанкционированного доступа выходит на первый план.
Теория кодирования информации является одним из разделов теоретической информатики. К основным задачам, решаемым в данном разделе, необходимо отнести следующие: разработка принципов наиболее экономичного кодирования информации; согласование параметров передаваемой информации с особенностями канала связи; разработка приемов, обеспечивающих надежность передачи информации по каналам связи, т.е. отсутствие потерь информации.
Две последние задачи связаны с процессами передачи информации. Первая же задача – кодирование информации – касается не только передачи, но и обработки, и хранения информации, т.е. охватывает широкий круг проблем; частным их решением будет представление информации в компьютере.
Кодирование информации - процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки (цифровое кодирование, аналоговое кодирование, таблично-символьное кодирование, числовое кодирование). Процесс преобразования сообщения в комбинацию символов в соответствии с кодом называется кодированием, процесс восстановления сообщения из комбинации символов называется декодированием.
В зависимости от целей кодирования, различают следующие его виды: кодирование по образцу - используется всякий раз при вводе информации в компьютер для её внутреннего представления; криптографическое кодирование, или шифрование, – используется, когда нужно защитить информацию от несанкционированного доступа; эффективное, или оптимальное, кодирование – используется для устранения избыточности информации, т.е. снижения ее объема, например, в архиваторах; помехозащитное, или помехоустойчивое, кодирование – используется для обеспечения заданной достоверности в случае, когда на сигнал накладывается помеха, например, при передаче информации по каналам связи.
Объект исследования – теория кодирования информации.
Предмет исследования – методы кодирования.
Целью данной работы является изучение методов кодирования данных.
В соответствии с целью была определена необходимость постановки и решения следующих задач:
– раскрыть понятие кодирования;
– описать методы кодирования данных;
– выполнить постановку задачи;
– описать основные алгоритмы программы;
– описать порядок работы с программой.
1. Теоретическая часть
1.1. Кодирование
Кодирование – способ представления информации в удобном для хранения и передачи виде. По своей сути кодовые системы (или просто коды) аналогичны шифрам однозначной замены, в которых элементам кодируемой информации соответствуют кодовые обозначения. Отличие заключается в том, что в шифрах присутствует переменная часть (ключ), которая для определенного исходного сообщения при одном и том же алгоритме шифрования может выдавать разные шифртексты.
Другой отличительной особенностью кодирования является применение кодовых обозначений (замен) целиком для слов, фраз или чисел (совокупности цифр). Замена элементов кодируемой информации кодовыми обозначениями может быть выполнена на основе соответствующей таблицы (наподобие таблицы шифрозамен) либо определена посредством функции или алгоритма кодирования.
В связи с развитием информационных технологий кодирование является центральным вопросом при решении самых разных задач программирования, таких как:
– представление данных произвольной структуры (числа, текст, графика) в памяти компьютера;
– обеспечение помехоустойчивости при передаче данных по каналам связи;
– сжатие информации в базах данных [6].
Основной моделью, которую изучает теория информации, является модель системы передачи сигналов, рис. 1.
Начальным звеном в приведенной модели является источник информации. Здесь рассматриваются дискретные источники без памяти, в которых выходом является последовательность символов некоторого фиксированного алфавита.
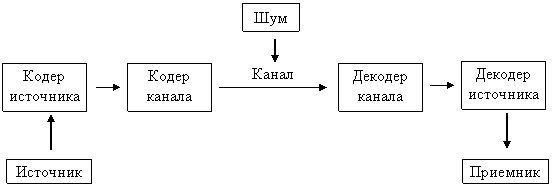
Рисунок 1 – Модель системы передачи сигналов
Множество всех различных символов, порождаемых некоторым источником, называется алфавитом источника, а количество символов в этом множестве – размером алфавита источника. Например, можно считать, что текст на русском языке порождается источником с алфавитом из 33 русских букв, пробела и знаков препинания.
Кодирование дискретного источника заключается в сопоставлении символов алфавита А источника символам некоторого другого алфавита В. Причем обычно символу исходного алфавита А ставится в соответствие не один, а группа символов алфавита В, которая называется кодовым словом. Кодовый алфавит – множество различных символов, используемых для записи кодовых слов. Кодом называется совокупность всех кодовых слов, применяемых для представления порождаемых источником символов [3].
Дадим строгое определение кодирования. Пусть даны алфавит источника , кодовый алфавит . Обозначим множество всевозможных последовательностей в алфавите А (В). Множество всех возможных сообщений в алфавите А обозначим S. Тогда отображение , которое преобразует множество сообщений в кодовые слова в алфавите В, называется кодированием. Если , то – кодовое слово. Обратное отображение (если оно существует) называется декодированием.
Задача кодирования сообщения ставится следующим образом. Требуется при заданных алфавитах А и В и множестве сообщений S найти такое кодирование F, которое обладает определенными свойствами и оптимально в некотором смысле. Свойства, которые требуются от кодирования, могут быть различными. Приведем некоторые из них:
– существование декодирования;
– помехоустойчивость или исправление ошибок при кодировании: декодирование обладает свойством , β~β (эквивалентно β с ошибкой);
– обладает заданной трудоемкостью (время, объем памяти) [1].
В вычислительной технике используется двоичное кодирование, основанное на представлении данных последовательностью из двух символов: 0 и 1. Эти знаки называются двоичными цифрами, по-английски digit или сокращенно bit (бит).
Одним битом можно выразить два понятия: да или нет, черное или белое, истина или ложь, 0 или 1. Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
Тремя битами можно закодировать 8 понятий:
001 011 100 101 110 111.
Увеличивая на единицу количество разрядов, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть
N = 2m
где N – количество кодируемых значений;
m – количество двоичных разрядов.
Кодирование целых чисел. Любое целое число можно представить в виде разложения в полином с основанием два. Коэффициентами полинома являются числа 0 и 1. Например, число 11 может быть представлено в такой форме:
1 x 23 + 0 x 22 + 1 x 21 + 1 x 20 = 11
Коэффициенты этого полинома образуют двоичную запись числа 11: 1011.
Для преобразования целого числа в двоичный код надо делить его пополам до тех пор, пока в остатке не образуется ноль или единица. Совокупность остатков от каждого деления, записанных справа налево, образует двоичный код десятичного числа.
1.2. Методы кодирования данных
Существуют два классических метода эффективного кодирования: метод Шеннона-Фано и метод Хаффмена. Входными данными для обоих методов является заданное множество исходных символов для кодирования с их частотами; результат - эффективные коды.
Метод Шеннона-Фано. Этот метод требует упорядочения исходного множества символов по не возрастанию их частот. Затем выполняются следующие шаги:
а) список символов делится на две части (назовем их первой и второй частями) так, чтобы суммы частот обеих частей (назовем их Σ1 и Σ2) были точно или примерно равны. В случае, когда точного равенства достичь не удается, разница между суммами должна быть минимальна;
б) кодовым комбинациям первой части дописывается 1, кодовым комбинациям второй части дописывается 0;
в) анализируют первую часть: если она содержит только один символ, работа с ней заканчивается, – считается, что код для ее символов построен, и выполняется переход к шагу г) для построения кода второй части. Если символов больше одного, переходят к шагу а) и процедура повторяется с первой частью как с самостоятельным упорядоченным списком;
г) анализируют вторую часть: если она содержит только один символ, работа с ней заканчивается и выполняется обращение к оставшемуся списку (шаг д). Если символов больше одного, переходят к шагу а) и процедура повторяется со второй частью как с самостоятельным списком;
д) анализируется оставшийся список: если он пуст – код построен, работа заканчивается. Если нет, – выполняется шаг а) [10].
Метод Хаффмена. Этот метод имеет два преимущества по сравнению с методом Шеннона-Фано: он устраняет неоднозначность кодирования, возникающую из-за примерного равенства сумм частот при разделении списка на две части (линия деления проводится неоднозначно), и имеет, в общем случае, большую эффективность кода. Исходное множество символов упорядочивается по не возрастанию частоты и выполняются следующие шаги:
1) объединение частот: две последние частоты списка складываются, а соответствующие символы исключаются из списка; оставшийся после исключения символов список пополняется суммой частот и вновь упорядочивается; предыдущие шаги повторяются до тех пор, пока ни получится единица в результате суммирования и список ни уменьшится до одного символа;
2) построение кодового дерева: строится двоичное кодовое дерево: корнем его является вершина, полученная в результате объединения частот, равная 1; листьями – исходные вершины; остальные вершины соответствуют либо суммарным, либо исходным частотам, причем для каждой вершины левая подчиненная вершина соответствует большему слагаемому, а правая – меньшему; ребра дерева связывают вершины-суммы с вершинами-слагаемыми. Структура дерева показывает, как происходило объединение частот; ребра дерева кодируются: каждое левое кодируется единицей, каждое правое – нулём;
3) формирование кода: для получения кодов листьев (исходных кодируемых символов) продвигаются от корня к нужной вершине и «собирают» веса проходимых рёбер.
Адаптивный код Хаффмана используется как составная часть во многих методах сжатия данных. В нем кодирование осуществляется на основе информации, содержащейся в окне длины W. Алгоритм такого кодирования заключается в выполнении следующих действий:
- Перед кодированием очередной буквы подсчитываются частоты появления в окне всех символов исходного алфавита А={a1, a2, ..., an}. Обозначим эти частоты как q(a1), q(a2), ..., q(an). Вероятности символов исходного алфавита оцениваются на основе значений частот символов в окне
P(a1)= q(a1)/W, P(a2) =q(a2)/W, ..., P(an)= q(an)/W.
- По полученному распределению вероятностей строится код Хаффмана для алфавита А.
- Очередная буква кодируется при помощи построенного кода.
- Окно передвигается на один символ вправо, вновь подсчитываются частоты встреч в окне букв алфавита, строится новый код для очередного символа, и так далее, пока не будет получен код всего сообщения [8].
Метод Фано построения префиксного почти оптимального кода, для которого , заключается в следующем. Упорядоченный по убыванию вероятностей список букв алфавита источника делится на две части так, чтобы суммы вероятностей букв, входящих в эти части, как можно меньше отличались друг от друга. Буквам первой части приписывается 0, а буквам из второй части – 1. Далее также поступают с каждой из полученных частей. Процесс продолжается до тех пор, пока весь список не разобьется на части, содержащие по одной букве.
В 1990 году Б. Я. Рябко предложил алгоритм кодирования, использующий алфавитный код Гилберта-Мура, и названный частотным. Частотный код относится к адаптивным методам сжатия с постоянной избыточностью. Средняя длина кодового слова для этого метода определяется только длиной окна, по которому оценивается статистика кодируемых данных, к тому же частотный код имеет достаточно высокую скорость кодирования и декодирования.
Рассмотрим алгоритм построения частотного кода для источника с алфавитом А={a1, a2, ..., an}. Пусть используется окно длины W, т.е. при кодировании символа xi исходной последовательности учитываются W предыдущих символов:
Возьмем размер окна такой, что W=(2r 1)·n, где n=2k размер исходного алфавита, r, k целые числа.
Порядок построения кодовой последовательности следующий:
- Сначала оценивается число встреч в окне xi-W...xi-1 всех букв исходного алфавита. Обозначим эти величины через P(aj), j=1,…,n
- P(aj) увеличивается на единицу и обозначается как
- Вычисляются суммы Qi , i=1,…,n
…
- Для кодового слова символа аj берется k знаков от двоичного разложения Qj, где .
- Далее окно сдвигается на один символ вправо и для кодирования следующего символа алгоритм вновь повторяется.
Кодирование с использованием адаптивного словаря.
В этих словарных методах для хранения слов используется адаптивный словарь, заполняющийся в процессе кодирования. Перед началом кодирования в словарь включаются все символы алфавита источника. При кодировании сообщения Х=х1х2х3х4… сначала читаются два символа х1х2, поскольку это слово отсутствует в словаре, то передается код символа х1 (обычно это номер строки, содержащей найденный символ или слово) [13]. В свободную строку таблицы записывается слово х1х2, далее читается символ х3 и осуществляется поиск в словаре слова х2х3. Если это слово есть в словаре, то проверяется наличие слова х2х3х4 и так далее. Таким образом, слово из наибольшего количества входных символов, найденное в словаре, кодируется как номер строки, его содержащей.
Среди популярных схем кодирования, которые применяются в локальных сетях можно выделить: манчестерское кодирование; дифференциальное манчестерское кодирование; AMI/ABP; PAM 5 и др.
Manchester encoding – двухфазное полярное/униполярное самосинхронизирующееся кодирование. Текущий бит узнается по направлению смены состояния в середине битового интервала: от -V к +V: 1. От +V к -V: 0. Переход в начале интервала может и не быть. Применяется в Ethernet. (В начальных версиях – униполярное), рис. 2.
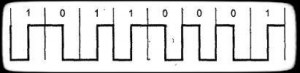
Рисунок 2 – Манчестерское кодирование
Differential manchester encoding – двухфазное полярное/униполярное самосинхронизирующиеся код. Текущий бит узнается по наличию перехода в начале битового интервала (рис. 3.а), например 0 – есть переход (Вертикальный фрагмент), 1 – нет перехода (горизонтальный фрагмент). Можно и наоборот определять 0 и 1.В середине битового интервала переход есть всегда. Он нужен для синхронизации. В Token Ring применяется измененная версия такой схемы, где кроме бит 0 и 1 определенны также два бита j и k (рис. 3.б) [11]. Здесь нет переходов в середине интервала. Бит К имеет переход в начале интервала, а j – нет.

а) б)
Рисунок 3 – Дифференциальное манчестерское кодирование
AMI – Alternate Mark Inversion или же ABP – Alternate bipolare, биполярная схема, которая использует значения +V, 0V и -V. Все нулевые биты имеют значения 0V, единичные — чередующимися значениями +V, -V (рис.4). Применяется в DSx (DS1 – DS4), ISDN. Такая схема не есть полностью самосинхронизирующейся – длинная цепочка нулей приведет к потере синхронизации.
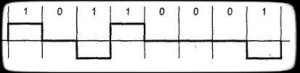
Рисунок 4 – Кодирование AMI/ABP
PAM 5 – Pulse Amplitude Modulation, пятиуровневое биполярное кодирование, где пара бит в зависимости от предыстории оказывается одним из 5 уровней потенциала. Нужен неширокая полоса частот (вдвое ниже битовой скорости). Используется в 1000BaseT [2].
Схемы, которые не являются самосинхронизирующими, вместе с логическим кодированием и определением фиксированной длительности битовых интервалов разрешают достигать синхронизации. Старт-бит и стоп-бит служат для синхронизации, а контрольный бит вводит избыточность для повышения достоверности приема.
Кодирование текстовых данных.
Если каждому символу алфавита сопоставить целое число, то можно с помощью двоичного кода кодировать текстовые данные. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватает, чтобы закодировать все строчные и прописные буквы английского или русского алфавита, а также знаки препинания, цифры, символы основных арифметических операций и некоторые специальные символы, например «%» [15].
Технически это просто, но существуют организационные сложности. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это трудно осуществить из-за использования различных символов в национальных алфавитах. Сейчас по ряду причин наибольшее распространение получил стандарт США ANСII (American National Code for Information Interchange) – Американский национальный код для обмена информацией. В системе кодирования ANСII закреплены две таблицы кодирования: базовая со значениями кодов от 0 до 127 и расширенная с кодами от 128 до 255.
Изначально ASCII была разработана как 7-битная для представления 128 символов, при использовании в компьютерах на символ выделялось 8 бит (1 байт), где 8-ой бит служил для контроля целостности (бит четности). Позднее, с задействованием 8 бита для представления дополнительных символов (всего 256 символов), например букв национальных алфавитов, стала восприниматься как половина 8-битной [16].
В частности на основе ASCII были разработаны кодировки, содержащие буквы русского алфавита: для операционной системы MS-DOS - cp866 (англ. code page – кодовая страница), для операционной системы MS Windows – Windows 1251, для различных операционных систем – КОИ-8 (код обмена информацией, 8 битов), ISO 8859-5 и другие.
Коды от 0 до 31 базовой таблицы содержат так называемые управляющие коды, которым не соответствуют символы языка. Они служат для управления устройствами ввода-вывода. Коды с 32 по 127 служат для кодирования символов английского алфавита, знаков препинания, цифр и некоторых других символов. Расширенная таблица с кодами от 128 до 255 содержит набор специальных символов.
Аналогичные системы кодирования разработаны и в других странах. В России большое распространение имеет код КОИ-8.
Трудности создания единой системы кодирования текстовых данных связаны с ограниченным набором кодов (256). Если кодировать символы не 8-разрядными двоичными числами, а 16-разрядными, это позволит иметь набор из 65 536 различных кодов. Этого достаточно, чтобы в одной таблице разместить символы большинства языков [17]. Такая система кодирования называется Unicode – универсальный код. Переход к этой системе долго сдерживался из-за недостатка памяти компьютеров, так как в системе Unicode все текстовые документы становятся вдвое длиннее. В настоящее время технические сложности преодолены и происходит постепенный переход на универсальную систему кодирования.
Unicode - стандарт кодирования символов, позволяющий представить знаки почти всех письменных языков. Стандарт был предложен в 1991 г. некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.).
Применение этого стандарта позволяет закодировать большее число символов (чем в ASCII и прочих кодировках) за счет двухбайтового кодирования символов (всего 65536 символов). В документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы [4].
Коды в стандарте Unicode разделены на несколько разделов. Первые 128 кодов соответствуют кодировке ASCII. Далее расположены разделы букв различных письменностей, знаки пунктуации и технические символы. В частности прописным и строчным буквам русского алфавита соответствуют коды 1025 (Ё), 1040-1103 (А-я) и 1105 (ё).
Метод кодирования информации, известный как метод кодирования длин серий и предложенный П. Элиасом, при построении использует коды целых чисел. Входной поток для кодирования рассматривается как последовательность из нулей и единиц. Идея кодирования заключается в том, чтобы кодировать последовательности одинаковых элементов (например, нулей) как целые числа, указывающие количество элементов в этой последовательности. Последовательность одинаковых элементов называется серией, количество элементов в ней – длиной серии.
Пример. Входную последовательность (общая длина 31бит) можно разбить на серии, а затем закодировать их длины.
000000 1 00000 1 0000000 1 1 00000000 1
Используем, например, γ-код Элиаса. Поскольку в коде нет кодового слова для нуля, то будем кодировать длину серии +1, т.е. последовательность 7 6 8 1 9:
7 6 8 1 9 00111 00110 0001000 1 0001001
Длина полученной кодовой последовательности равна 25 бит.
Метод длин серий актуален для кодирования данных, в которых есть длинные последовательности одинаковых бит. В нашем примере, если .
Кодирование графических данных.
Общепринятым сегодня считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета. При этом для кодирования яркости любой точки достаточно 8-разрядного двоичного числа.
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на три основных – красный, зелёный и синий. Для кодирования яркости каждой составляющей используется 256 значений (8 двоичных разрядов). Для кодирования цвета используются 24 разряда. Такая система кодирования обеспечивает представление 16,5 млн различных цветов.
Кодирование звука.
Как всякий звук, музыка является не чем иным, как звуковыми колебаниями, зарегистрировав которые достаточно точно, можно этот звук безошибочно воспроизвести. Нужно только непрерывный сигнал, которым является звук, преобразовать в последовательность нулей и единиц. С помощью микрофона звук можно превратить в электрические колебания и измерить их амплитуду через равные промежутки времени (несколько десятков тысяч раз в секунду). Каждое измерение записывается в двоичном коде. Этот процесс называется дискретизацией.
Устройство для выполнения дискретизации называется аналогово-цифровым преобразователем (АЦП) [7]. Воспроизведение такого звука ведётся при помощи цифро-аналогового преобразователя (ЦАП). Полученный ступенчатый сигнал сглаживается и преобразуется в звук при помощи усилителя и динамика. На качество воспроизведения влияют частота дискретизации и разрешение (размер ячейки, отведённой под запись значения амплитуды). Например, при записи музыки на компакт-диски используются 16-разрядные значения и частота дискретизации 44 032 Гц.
Описанный способ кодирования звуковой информации достаточно универсален, он позволяет представить любой звук и преобразовывать его самыми разными способами. Но бывают случаи, когда выгодней действовать по-иному.
Издавна используется достаточно компактный способ представления музыки – нотная запись. В ней с помощью специальных символов указывается высота и длительность, общий темп исполнения и как сыграть. Фактически, такую запись можно считать алгоритмом для музыканта, записанным на особом формальном языке. В 1983 г. ведущие производители компьютеров и музыкальных синтезаторов разработали стандарт, определивший такую систему кодов.
Он получил название MIDI (Musical Instrument Digital Interface). При таком кодировании запись компактна, легко меняется инструмент исполнителя, тональность звучания, одна и та же запись воспроизводится как на синтезаторе, так и на компьютере [5].
Конечно, такая система кодирования позволяет записать далеко не всякий звук, она годится только для инструментальной музыки. Но есть у нее и преимущества: чрезвычайно компактная запись, естественность для музыканта (практически любой MIDI-редактор позволяет работать с музыкой в виде обычных нот), легкость замены инструментов, изменения темпа и тональности мелодии.
Есть и другие форматы записи музыки. Среди них – формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку, при этом вместо 18 – 20 музыкальных композиций на стандартном компакт-диске (CDROM) помещается около 200. Одна песня занимает примерно 3,5 Mb, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.
1.3. Шифрование данных
Криптографические коды используются для защиты сообщений от несанкционированного доступа, потому называются также шифрованными. В качестве символов кодирования могут использоваться как символы произвольного алфавита, так и двоичные коды.
Среди разнообразнейших способов шифрования можно выделить следующие основные методы:
– алгоритмы по замене или подстановке – символы исходных текстов заменяются на символы из другого алфавита в соответствии с заранее определенной схемой, которая и будет ключом этого шифра. Данный метод шифрования характеризуется низкой криптоскойкостью и отдельно не используется;
– алгоритмы перестановки – символы оригинальных текстов меняются местами по определенной схемой, которая является секретным ключом к этому алгоритму [9]. Данный метод шифрования характеризуется низкой криптоскойкостью, но в отличии от предыдущего является составным в очень многих современных криптосистемах;
– алгоритмы гаммирования – символы оригинальных текстов складываются с символами определенной последовательности. Пример данного шифрования, является шифрование файлов «имя пользователя.рwl», в которых операционная система Windows хранит пароли к сетевым ресурсам определенного пользователя. При вводе пароля при входе в Windows из файла с расширением .рwl, при помощи алгоритма шифрования RC4 происходит генерация гаммы, которая применяется для шифрования сетевых паролей;
– алгоритмы, которые основаны на использовании сложных математических вычислений исходных текстов по определенной формуле. Многие из таких алгоритмов используют в процессе решения нерешенных математических задач. Например, в алгоритме шифрования RSA используются свойства простых чисел;
– комбинированные методы предполагают использование последовательного шифрования исходных текстов с помощью нескольких методов шифрования.
В современных системах управления базами данных поддерживается один из двух наиболее подходов к обеспечению безопасности данных: обязательный подход и избирательный подход. В обоих подходах единицей данных, для которых должна быть создана система безопасности, может быть как вся база данных целиком, так и любой объект внутри базы данных [12]. Вид незашифрованного файла базы данных SQLite представлен на рис. 5. Вид зашифрованного файла базы данных SQLite представлен на рис. 6.

Рисунок 5 – Вид незашифрованного файла
Обязательный и избирательный подходы отличаются своими свойствами. В случае избирательного управления некоторый пользователь обладает различными правами при работе с данными объектами. Разные пользователи могут обладать разными правами доступа к одному и тому же объекту. Избирательные права характеризуются значительной гибкостью.

Рисунок 6 – Вид зашифрованного файла
В случае избирательного управления, наоборот, каждому объекту данных присваивается некоторый классификационный уровень, а каждый пользователь обладает некоторым уровнем допуска. При таком подходе доступом к определенному объекту данных обладают только пользователи с соответствующим уровнем допуска.
Шифр Цезаря, также известный как шифр сдвига, код Цезаря или сдвиг Цезаря – один из самых простых и наиболее широко известных методов шифрования.
Шифр Цезаря – это вид шифра подстановки, в котором каждый символ в открытом тексте заменяется символом, находящимся на некотором постоянном числе позиций левее или правее него в алфавите. Например, в шифре со сдвигом вправо на 3, А была бы заменена на Г, Б станет Д, и так далее.
Шифр назван в честь римского полководца Гая Юлия Цезаря, использовавшего его для секретной переписки со своими генералами.
Шаг шифрования, выполняемый шифром Цезаря, часто включается как часть более сложных схем, таких как шифр Виженера, и всё ещё имеет современное приложение в системе ROT13 [18]. Как и все моноалфавитные шифры, шифр Цезаря легко взламывается и не имеет почти никакого применения на практике.
Шифр Цезаря со сдвигом на 3:
– A заменяется на D;
– B заменяется на E;
– и так далее;
– Z заменяется на C [14].
Схематическое представление шифра Цезаря представлено на следующем рис. 7.
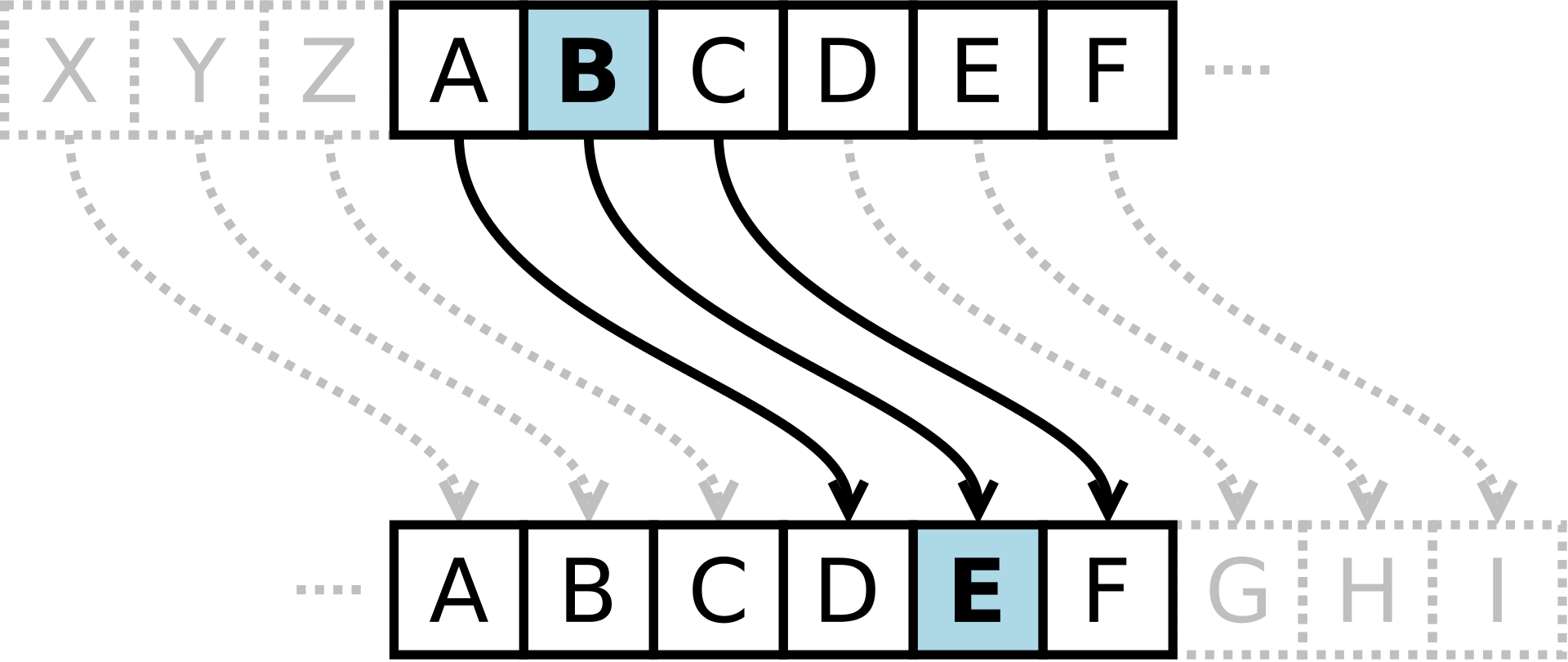
Рисунок 7 – Шифр Цезаря со сдвигом на 3
Математическая модель шифра Цезаря заключается в следующих положениях.
Если сопоставить каждому символу алфавита его порядковый номер (нумеруя с 0), то шифрование и дешифрование можно выразить формулами модульной арифметики:
y=(x+k) mod n
x=(y-k) mod n,
где x – символ открытого текста,
y – символ шифрованного текста,
n – мощность алфавита,
k – ключ.
С точки зрения математики шифр Цезаря является частным случаем аффинного шифра.
В качестве примера реализации шифра Цезаря можно привести пару задач.
Используя русский алфавит из 33 букв, зашифруйте сообщение классическим шифром Цезаря со сдвигом на пять (пробелы между словами не используются). Сообщение ПЛАТФОРМАПЯТЬ.
Для шифрования сообщения классическим шифром Цезаря со сдвигом пять составим таблицу шифрования, рис. 8. При помощи которой можно быстро зашифровать необходимое сообщение, например, для шифрования буквы П, воспользовавшись таблицей получим Ф; для шифрования буквы Л, воспользовавшись таблицей получим Р и т.д.
|
А |
Б |
В |
Г |
Д |
Е |
Ё |
Ж |
З |
И |
Й |
К |
Л |
М |
Н |
О |
П |
Р |
С |
Т |
У |
Ф |
Х |
Ц |
Ч |
Ш |
Щ |
Ы |
Ь |
Ъ |
Э |
Ю |
Я |
|
Е |
Ё |
Ж |
З |
И |
Й |
К |
Л |
М |
Н |
О |
П |
Р |
С |
Т |
У |
Ф |
Х |
Ц |
Ч |
Ш |
Щ |
Ы |
Ь |
Ъ |
Э |
Ю |
Я |
А |
Б |
В |
Г |
Д |
Рисунок 8 – Таблица шифрозамен для шифра Цезаря
В результате получим:
ПЛАТФОРМАПЯТЬ (платформа пять)
ФРЕЧЩУХСЕФДЧА
Используя русский алфавит из 33 букв, дешифруйте сообщение, зашифрованное классическим шифром Цезаря. Сообщение НЦУФСЖЛРНЖЕЦП
Для дешифрования сообщения была использована таблица шифрования Цезаря со сдвигом три, рис. 9. При помощи которой можно быстро дешифровать необходимое сообщение, например, для дешифрования буквы Н, воспользовавшить таблицей получим К; для дешифрования буквы Л, воспользовавшить таблицей получим И и т.д. Только, необходимые буквы для дешифрования смотрим во второй строке, а аналог в первой.
|
А |
Б |
В |
Г |
Д |
Е |
Ё |
Ж |
З |
И |
Й |
К |
Л |
М |
Н |
О |
П |
Р |
С |
Т |
У |
Ф |
Х |
Ц |
Ч |
Ш |
Щ |
Ы |
Ь |
Ъ |
Э |
Ю |
Я |
|
Г |
Д |
Е |
Ё |
Ж |
З |
И |
Й |
К |
Л |
М |
Н |
О |
П |
Р |
С |
Т |
У |
Ф |
Х |
Ц |
Ч |
Ш |
Щ |
Ы |
Ь |
Ъ |
Э |
Ю |
Я |
А |
Б |
В |
Рисунок 9 – Таблица шифрозамен для шифра Цезаря
В результате получим:
НЦУФСЖЛРНЖЕЦП
КУРСОДИНКДВУМ (курс один к двум)
Таким образом, была дана характеристика шифру Цезаря и представлены несколько примеров шифрования данным алгоритмом шифрования.
2. Практическая часть
2.1. Постановка задачи
В рамках выполнения практической части данной работы необходимо разработать программу, реализующую шифр Цезаря. Для разработки программной системы необходимо использовать средства языка программирования С++.
2.2. Алгоритмизация программы
Рассмотрим основные алгоритмические решения используемые для реализации шифра Цезаря средствами языка программирования С++. Исходный код программы представлен в Приложении.
Для обеспечения работоспособности программы подключили необходимые библиотеки
#include "stdafx.h"
#include "iostream"
#include <stdio.h>
#include <stdlib.h>
#include <conio.h>
#include <locale.h>
#include <string.h>
#include <Windows.h>
using namespace std;
Разработали несколько прототипов функций, выполняющих отдельные части алгоритма
// Функция производит шифровку используя шифр Цезаря
char encryption(char letter, int key);
// Функция производит ltшифровку используя шифр Цезаря
char disencryption(char letter, int key);
// Функция проверяет является ли буква прописной
int isUpper(char letter);
// Функция проверяет является ли буква строчной
int isLower(char letter);
Функция шифрования данных шифром Цезаря имеет следующий вид, представленный далее
char encryption(char letter, int key)
{
if (isUpper(letter))
{
letter += key;
if ((int)letter > 90)
{
key = letter - 90;
letter = 65 + key - 1;
}
}
if (isLower(letter))
{
letter += key;
if ((int)letter > 122)
{
key = letter - 122;
letter = 97 + key - 1;
}
}
return letter;
}
Таким образом, были представлены основные алгоритмические решения, позволяющие реализовать шифр Цезаря средствами языка программирования С++.
2.3. Описание порядка работы с программой
Работа с программной системой выполняется по средствам инициализации исполняемого файла program.exe. После запуска программы пользователю нужно ввести текст, который следует зашифровать, как это представлено на рис. 10.
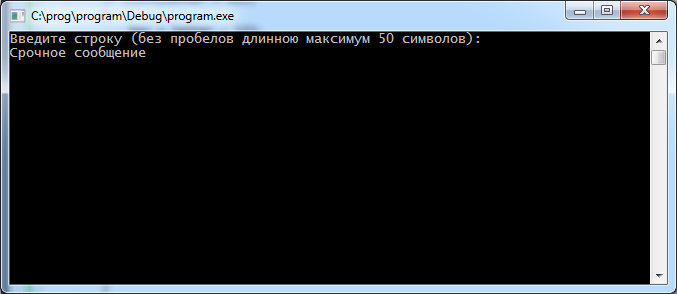
Рисунок 10 – Ввод текста шифрования
Далее пользователю программной системы нужно ввести число сдвигов букв для продолжения шифрования, рис. 11.
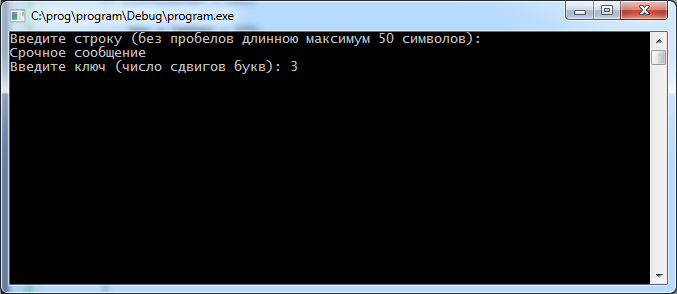
Рисунок 11 – Ввод числа сдвигов букв
После чего, программа обработает текст и выведет сообщение с зашифрованным текстом. Результат выполнения программы будет представлен на рис. 12.
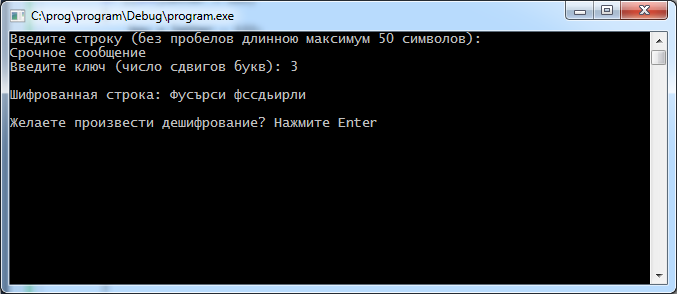
Рисунок 12 – Вывод зашифрованного текста
Также, разработанная программная система позволяет выполнить расшифровку зашифрованного текста. Для этого нужно подтвердить свое согласие на расшифровку сообщение, как это показано на рис. 13. В результате будет выведено исходное сообщение.
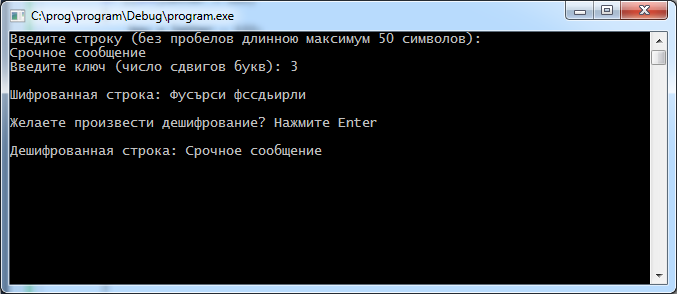
Рисунок 13 – Ввод числа сдвигов букв
Таким образом, была разработана программная система, позволяющая шифровать текст шифром Цезаря и расшифровывать зашифрованный текст средствами языка программирования С++.
Заключение
В процессе выполнения данной работы были получены следующие результаты. Установлено, что кодирование – способ представления информации в удобном для хранения и передачи виде. По своей сути кодовые системы (или просто коды) аналогичны шифрам однозначной замены, в которых элементам кодируемой информации соответствуют кодовые обозначения. Отличие заключается в том, что в шифрах присутствует переменная часть (ключ), которая для определенного исходного сообщения при одном и том же алгоритме шифрования может выдавать разные шифртексты.
Существуют два классических метода эффективного кодирования: метод Шеннона-Фано и метод Хаффмена. Входными данными для обоих методов является заданное множество исходных символов для кодирования с их частотами; результат - эффективные коды.
Среди популярных схем кодирования, которые применяются в локальных сетях можно выделить: манчестерское кодирование; дифференциальное манчестерское кодирование; AMI/ABP; PAM 5 и др.
Кодирование текстовых данных осущеставляется, например, на базе ANСII, Unicode кодировке.
Криптографические коды используются для защиты сообщений от несанкционированного доступа, потому называются также шифрованными. В качестве символов кодирования могут использоваться как символы произвольного алфавита, так и двоичные коды.
В качестве демонстрации возможностей кодирования данных была выбран шифр Цезаря.
Шифр Цезаря, также известный как шифр сдвига, код Цезаря или сдвиг Цезаря – один из самых простых и наиболее широко известных методов шифрования. Шифр Цезаря – это вид шифра подстановки, в котором каждый символ в открытом тексте заменяется символом, находящимся на некотором постоянном числе позиций левее или правее него в алфавите.
Разработка программы, реализующий шифр Цезаря будет выполнена средствами языка программирования С++, который представляет собой компилируемый, статически типизированный язык программирования общего назначения. Поддерживает такие парадигмы программирования, как процедурное программирование, объектно-ориентированное программирование, обобщённое программирование.
В рамках выполнения практической части данной работы была разработана программа, реализующая шифр Цезаря. Для разработки программной системы были использованы средства языка программирования С++.
Список использованной литературы
- Архипенков С. Хранилища данных. От концепции до внедрения / С. Архипенков, Д. Голубев, О. Максименко. - М.: Диалог-Мифи, 2017. – 528 c.
- Архитектура и проектирование программных систем : монография / С.В. Назаров. – 2-е изд., перераб. и доп. – М. : ИНФРА-М, 2018. – 374 с.
- Борзунов С.В. Практикум по параллельному программированию: учеб. пособие / С.В. Борзунов, С.Д. Кургалин, А.В. Флегель. – СПб.: БХВ, 2017. – 236 с.
- Гаврилов М.В. Информатика и информационные технологии: Учебник / М.В. Гаврилов, В.А. Климов. - Люберцы: Юрайт, 2016. – 383 c.
- Гвоздева В.А. Основы построения автоматизированных информационных систем [Текст]: учебник. - Москва: ИД «ФОРУМ»: ИНФРА-М, 2017. – 320 с.
- Дарков А.В. Информационные технологии: теоретические основы: Учебное пособие / А.В. Дарков, Н.Н. Шапошников. - СПб.: Лань, 2016. – 448 c.
- Довек Ж. Введение в теорию языков программирования / Ж. Довек, Ж.-Ж. Леви. - М.: ДМК, 2016. – 134 c.
- Информатика (курс лекций) : учеб. пособие / В.Т. Безручко. – М. : ИД «ФОРУМ» : ИНФРА-М, 2018. – 432 с.
- Информационные технологии: Учебное пособие / Л.Г. Гагарина, Я.О. Теплова, Е.Л. Румянцева и др.; Под ред. Л.Г. Гагариной - М.: ИД ФОРУМ: НИЦ ИНФРА-М, 2015. – 320 c.
- Информационные технологии в профессиональной деятельности : учеб. пособие / Е.Л. Федотова. – М. : ИД «ФОРУМ» : ИНФРА-М, 2018. – 367 с.
- Кулямин В.В. Технологии программирования. Компонентный подход / В.В. Кулямин. - М.: Интуит, 2014. – 463 c.
- Программирование в алгоритмах / Окулов С.М., – 6-е изд., (эл.) - М.:Лаборатория знаний, 2017. – 386 с.
- Программирование графики на С++. Теория и примеры : учеб. пособие / В.И. Корнеев, Л.Г. Гагарина, М.В. Корнеева. – М. : ИД «ФОРУМ» : ИНФРА-М, 2018. – 517 с.
- Программирование в алгоритмах / Окулов С.М., – 6-е изд., (эл.) - М.:Лаборатория знаний, 2017. – 386 с.
- Программирование на языке высокого уровня. Программирование на языке С++: учеб. пособие / Т.И. Немцова, С.Ю. Голова, А.И. Терентьев ; под ред. Л.Г. Гагариной. – М. : ИД «ФОРУМ» : ИНФРА-М, 2018. – 512 с.
- Сальникова Л.С. Современные коммуникационные технологии в бизнесе: Учебник / Л.С. Сальникова. - М.: Аспект-Пресс, 2015. – 296 c.
- Скабцов Н. Аудит безопасности информационных систем. – СПб.: Питер, 2018. – 272 с.
- Советов Б.Я. Информационные технологии: теоретические основы: Учебное пособие / Б.Я. Советов, В.В. Цехановский. - СПб.: Лань, 2016. – 448 c.
Исходный код программы
#include "stdafx.h"
#include "iostream"
#include <stdio.h>
#include <stdlib.h>
#include <conio.h>
#include <locale.h>
#include <string.h>
#include <Windows.h>
using namespace std;
// Функция проверяет является ли буква прописной
int isUpper(char letter);
// Функция проверяет является ли буква строчной
int isLower(char letter);
// Функция производит шифровку используя шифр Цезаря
char encryption(char letter, int key);
char disencryption(char letter, int key);
int main()
{
int c;
SetConsoleCP(1251);// установка кодовой страницы win-cp 1251 в поток ввода
SetConsoleOutputCP(1251); // установка кодовой страницы win-cp 1251 в поток вывода
char string[10];
int key;
cout<<"Введите строку (без пробелов длинною максимум 50 символов):"<<endl;
gets(string);
cout<<"Введите ключ (число сдвигов букв): "<<endl;
scanf("%d", &key);
int i;
for (i = 0; i < 50; i++)
{
string[i] = encryption(string[i], key);
}
cout<<"Шифрованная строка: "<<endl;
puts(string);
cout<<"Желаете произвести дешифрование? Нажмите Enter\n"<<endl;
c = _getch();
if(c==13)
{
for (i = 0; i < 50; i++)
{
string[i] = disencryption(string[i], key);
}
cout<<"\nДешифрованная строка: "<<endl;
puts(string);
}
else
exit (0);
getch();
return 0;
}
int isUpper(char letter)
{
int result = 0;
// Если символ больше либо равна 'А' и меньше либо равна 'Я', то вернуть 1(true)
if (letter >= 'А' && letter <= 'Я')
result = 1;
return result;
}
int isLower(char letter)
{
int result = 0;
// Если символ больше либо равен 'а' и меньше либо равна 'я', то вернуть 1(true)
if (letter >= 'а' && letter <= 'я')
result = 1;
return result;
}
char encryption(char letter, int key)
{
if (isUpper(letter))
{
letter += key;
if ((int)letter > 90)
{
key = letter - 90;
letter = 65 + key - 1;
}
}
if (isLower(letter))
{
letter += key;
if ((int)letter > 122)
{
key = letter - 122;
letter = 97 + key - 1;
}
}
return letter;
}
char disencryption(char letter, int key)
{
if (isUpper(letter))
{
letter -= key;
if ((int)letter > 90)
{
key = letter + 90;
letter = 65 - key + 1;
}
}
if (isLower(letter))
{
letter -= key;
if ((int)letter > 122)
{
key = letter + 122;
letter = 97 - key + 1;
}
}
return letter;
}

- Применение объектно-ориентированного подхода при проектировании информационной системы ( Аналитическая часть )
- Активные и пассивные операции банков ( Активные операции банков )
- Центральный банк РФ (Центральный банк и его функции)
- АКТИВНЫЕ И ПАСсИВНЫЕ ОПЕРАЦИИ БАНКов (Кассовые операции)
- CУЩНОСТЬ И ФУНКЦИИ ФИНАНСОВ
- Психологические аспекты восприятия рекламы (Реклама как явление новой современности)
- Состав правонарушения (Юридический анализ состава правонарушения)
- Способы выражения сравнения в английском языке (Научно-теоретическое обоснование)
- Шекспиризмы в современном английском языке
- Виды научного перевода (Понятие перевода, подходы к переводу текста)
- Принципы эффективного контроля деятельности предприятия (Сущность эффективного управления деятельности предприятия)
- Понятие правового отношения»