
Сортировка слиянием
Содержание:

ВВЕДЕНИЕ
Данная курсовая работа по предмету «Основы алгоритмизации и программирования» посвящена методам сортировки данных: их эволюции и сравнительному анализу, а также примерам использования. Прежде чем приступить к исследованию методов сортировки данных, необходимо отметить, что такое сортировка. Сортировка - это процесс упорядочивания наборов данных одного типа по возрастанию или убыванию значения какого-либо признака. Существует довольно много различных методов сортировки, отличающихся друг от друга степенью эффективности, под которой понимается количество сравнений и количество обменов, произведенных в процессе сортировки, время выполнения и объем занимаемой операционный памяти. Значимость темы «методов сортировки данных» основана на том, что массивы информации могут быт быстро и точно обработаны только тогда, когда информация однородна и отсортирована.
Объектом исследования курсовой работы являются массивы данных, предметом – алгоритмы сортировки. Целью курсовой работы является исследование исторического аспекта методов сортировки данных, описание различных методов сортировки данных и их сравнительный анализ.
Исходя из цели, следует сформулировать задачи, которые предстоит решить для наиболее полного раскрытия информации, необходимой в достижении поставленной цели.
Таким образом, задачами курсовой работы являются: историческая справка методов сортировки данных; рассмотреть различные методы сортировки данных; провести сравнительный анализ; показать примеры использования методов сортировки данных; написать программу, использующую все рассматриваемые методы сортировки.
Тема, связанная с сортировкой данных богата и разнообразна в рамках данной курсовой работы невозможно рассмотреть все аспекты. В курсовой работе более подробно будут освещены следующие аспекты – эволюция методов сортировки, элементарные методы сортировки, быстрая сортировка, будет проведен их сравнительный анализ. Рассматриваемые элементарные методы сортировок в силу своей простоты хорошо подходят для изучения свойств большинства принципов сортировки. Программы, основанные на данных методах, имеют короткий алгоритм и легки для изучения - это также позволяет экономить память, занимаемую программой. В меньшей степени, будет затронута тема сортировки слиянием, очереди по приоритетам и пирамидальная сортировка и методы сортировки специального назначения. Но здесь важно отметить, что хотя сложные алгоритмы требуют меньшего числа операций, но эти операции являются более сложными.
Основным источниками для ссылок к курсовой работе является 3-й том многотомной монографии американского ученого, преподавателя программирования Дональда Эрвина Кнута, посвященный вопросам сортировки и поиска, и книга «Фундаментальные алгоритмы на С++» другого американского ученого в области информатики Роберта Седжвика (защита диссертации про алгоритм быстрой сортировки под руководством Д.Кнута). Множество деталей, касающихся математического анализа и практических эффектов многих модификаций и усовершенствований, появившихся после широкого распространения алгоритма быстрой сортировки, можно найти в статье Седжвика за 1978 г.
Следует сказать, что вопросами исследования алгоритмов, их классификацией, анализом и способами их программирования в разное время занимались такие ученые как: Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест, Клиффорд Штайн, Ахо А. В., Хопкрофт Д. Э., Ульман Д. Д., Макконнелл Дж. Также при написании курсовой работы были использованы материалы, полученные от отечественных авторов – профессор МЭИ Зубов В.С., Полунов Ю. Исторический аспект методов эволюции изучался у таких авторов как Гук М.Ю., Заславская О.Ю., Кравец О.Я., Частиков А.
1. Эволюция методов сортировки данных
1.1. Понятие сортировки
Сортировка является одной из фундаментальных алгоритмических задач программирования. Решению проблем, связанных с сортировкой, посвящено множество научных исследований, разработано множество алгоритмов [10, С. 249].
В общем случае сортировку следует понимать как процесс перегруппировки заданного множества объектов в определенном порядке. Сортировка применяется во всех без исключения областях программирования, будь то базы данных или математические программы.
Алгоритмом сортировки называется алгоритм для упорядочения некоторого множества элементов. Обычно под алгоритмом сортировки подразумевают алгоритм упорядочивания множества элементов по возрастанию или убыванию [10, С. 250].
В случае наличия элементов с одинаковыми значениями, в упорядоченной последовательности они располагаются рядом друг за другом в любом порядке. Однако иногда бывает полезно сохранять первоначальный порядок элементов с одинаковыми значениями.
В алгоритмах сортировки лишь часть данных используется в качестве ключа сортировки. Ключом сортировки называется атрибут (или несколько атрибутов), по значению которого определяется порядок элементов. Таким образом, при написании алгоритмов сортировок массивов следует учесть, что ключ полностью или частично совпадает с данными [10, С. 250].
Практически каждый алгоритм сортировки можно разбить на 3 части:
- сравнение, определяющее упорядоченность пары элементов;
- перестановку, меняющую местами пару элементов;
- собственно сортирующий алгоритм, который осуществляет сравнение и перестановку элементов до тех пор, пока все элементы множества не будут упорядочены.
Алгоритмы сортировки имеют большое практическое применение. Их можно встретить там, где речь идет об обработке и хранении больших объемов информации. Некоторые задачи обработки данных решаются проще, если данные заранее упорядочить.
Ни одна другая проблема не породила такого количества разнообразнейших решений, как задача сортировки. Универсального, наилучшего алгоритма сортировки на данный момент не существует. Однако, имея приблизительные характеристики входных данных, можно подобрать метод, работающий оптимальным образом. Для этого необходимо знать параметры, по которым будет производиться оценка алгоритмов [7, С. 99].
Время сортировки – основной параметр, характеризующий быстродействие алгоритма.
Память – один из параметров, который характеризуется тем, что ряд алгоритмов сортировки требуют выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив данных и независящие от входной последовательности затраты, например, на хранение кода программы.
Устойчивость – это параметр, который отвечает за то, что сортировка не меняет взаимного расположения равных элементов.
Естественность поведения – параметр, которой указывает на эффективность метода при обработке уже отсортированных, или частично отсортированных данных. Алгоритм ведет себя естественно, если учитывает эту характеристику входной последовательности и работает лучше [6, С. 103].
1.2. Методы сортировки в XIX веке
Первые прототипы современных методов сортировки появились уже в XIX веке.
В конце XIX в. перепись населения как одна из важнейших статистических задач проводилась регулярно - через 10 лет, это требование статистики строго соблюдали все развитые страны. Обработка полученных данных проводилась в течение нескольких лет, как правило, вручную или с помощью механических вычислительных машин [3, С. 105].
Впервые проблемой механизированной обработки статистической информации занялся талантливый американский изобретатель Герман Холлерит. Его трудовая деятельность началась в Бюро цензов США. Это статистическое управление при министерстве внутренних дел занималось проведением переписей населения и обработкой результатов. Здесь в 1880 г. Холлерит познакомился с доктором Джоном Биллингсом, который сыграл важную роль в его дальнейшей судьбе, предложив заняться исследованиями в области механизированной обработки статистических данных и использовать в качестве основного элемента записи информации, получаемой в процессе переписей и ее последующей обработки, перфорированные карты [1, С. 503].
Г. Холлерит долго придерживался другой точки зрения, он был уверен, что наиболее эффективно использовать для записей статистических данных перфоленты и придумал конструкцию специального барабана, на который наматывалась перфолента, и счетчиками отсчитывались отверстия. И все-таки изобретатель был вынужден признать свою идею несостоятельной, т. к. перфолента не способствовала оперативной работе с той или иной записью на длинной бумажной ленте. Он вернулся к предложению Дж. Биллингса и разработал специальную перфокарту, куда в виде пробивок наносились все данные об одном человеке.
Идея перфокарт уже была известна в мире и нашла практическое применение в ткацких станках Ж. Жаккара (1804) и вычислительной машине Ч. Бэббиджа (1833). Не исключено, что Г. Холлерит знал об этом, но как он сам вспоминал, к этой идее его подтолкнула работа кондуктора. Оказывается, в США, чтобы предотвратить мошенничество на железных дорогах и кражу билетов, кондукторы "записывали" физические особенности пассажиров (цвет волос, глаз и т. п.) компостером в специально отведенных местах на билете [6, С. 430].
Замысел Г. Холлерита состоял в том, чтобы на каждого человека завести личную карточку и все подлежащие обработке данные представить отверстиями в фиксированных местах (позициях). Эта перфокарта по виду была не похожа на железнодорожный билет или уже известные карты, а являлась оригинальной авторской запатентованной разработкой. Она была сделана из плотного картона размером приблизительно с долларовую бумажку, но размер карточки мог колебаться в зависимости от количества позиций, каждая из которых отвечала за определенный признак (пол, семейное положение, вероисповедание и т. д.), например, в австрийской переписи 1890 г. применялись перфокарты, имеющие 20х12 позиций, в российской переписи 1897 г. - 22х12 позиций [6, С. 431].
Сведения заносились на перфокарту вручную с помощью пробивного устройства - пантографа или перфоратора. На лицевой панели перфоратора имеется таблица признаков в виде карты-шаблона с отверстиями по всей координатной сетке, над которой по радиусу перемещается рычаг со штифтом на конце. Если в специальную раму для карточки положить чистую перфокарту и опустить штифт в отверстие, соответствующее какому-либо признаку, то специальное устройство в раме в той же позиции перфокарты пробьет идентичный признак. За час на перфораторе можно заполнить не более 80 карточек.
Теперь можно было либо подсчитать отверстия на всех перфокартах на основной машине - табуляторе, либо распределить их по тому же принципу на сортировке [6, С. 432].
1.3. Развитие в первой половине ХХ века
Дальнейшее развитие алгоритмов связано с развитием электронно-вычислительных машин, поэтому следующим этапом в эволюции сортировки данных можно считать компьютер EDVAC и программу сортировки для нее, написанную Джоном фон Нейманом (28 декабря 1903 — 8 февраля 1957). Ряд исследователей считают фон Неймана одним из основателей вычислительной техники. Дональд Кнут называет фон Неймана изобретателем, который в 1945 году разработал алгоритм сортировки слиянием, в котором первая и вторая половины массива сортируются рекуррентно, а потом сливаются [6, С. 418].
При создании EDVAC рассматривались различные варианты построения ЭВМ, в том числе вариант, предусматривающий использование ртутных ультразвуковых линий задержки (РУЛЗ) в качестве оперативной памяти в машине, которую авторы назвали “Электронной вычислительной машиной с переменной дискретностью” (Electronic Discrete Variable Computer, EDVAC) [6, С. 419].
Вычислительную машину фон Нейман определял как “устройство [device], которое может выполнять команды для вычислений значительной сложности” [9, С. 8]. Он отмечал, что команды, управляющие выполнением вычислительных и других операций, необходимо сообщать устройству с максимально допустимой детализацией; устройство должно иметь возможность их воспринимать и все команды полностью выполнять без какого-либо вмешательства человека. Последнее требуется лишь при обнаружении и исправлении допущенных при вычислениях ошибок, неизбежных в процессе функционирования устройства (ввиду его сложности и большого числа выполняемых операций). Впрочем, такое вмешательство можно сократить до минимума, поскольку устройство может самостоятельно определять часто повторяющиеся ошибки и либо автоматически корректировать их и продолжать вычисления, либо прекращать процесс [9, С. 8].
Фон Нейман планировал EDVAC как синхронную ЭВМ с АУ последовательного действия, выполняющим операции над числами с фиксированной запятой. Длина адресного поля составляла 13 двоичных разрядов (восемь разрядов определяли номер РУЛЗ, остальные пять — адрес машинного слова); для данных было отведено 30 разрядов (плюс знаковый разряд), отрицательные числа представлялись в форме двоичного дополнения. Еще один разряд был отведен под признак (tag): наличие в нем нуля означало, что машинное слово представляет собой число. В качестве памяти использовались 256 РУЛЗ, работавших на тактовой частоте 1,0 МГц. Каждая из них могла хранить 32 тридцатидвухразрядных слова, таким образом, емкость памяти составляла 8К слов [6, С. 418]. АУ содержало три неадресуемых регистра, организованных наподобие стека: данные всегда вводились в первый (верхний) регистр, при этом его содержимое выталкивалось во второй регистр; третий регистр был аккумулятором: он выполнял операции над операндами, находившимися в первых двух регистрах, и сохранял результат, который мог быть направлен из него в другие блоки. У команд EDVAC была сложная иерархическая структура, состоявшая из восьми базовых кодов (basic codes), десяти дополнительных кодов (sub-codes) и одного модификатора (modifier). Машина имела последовательное, или, как иногда говорят, естественное управление операциями: в начале работы в командный регистр вводился адрес первой команды, она извлекалась из памяти, декодировалась и выполнялась, после чего содержимое программного счетчика увеличивалось на единицу, из памяти извлекалась следующая команда, и машинный цикл повторялся (если в разряде признака очередного машинного слова находился нуль, оно загружалось в верхний регистр АУ). Исключение составляли команды безусловной и условной передачи управления (выполнение последней зависело от знака числа в аккумуляторе). По оценкам фон Неймана, EDVAC должна была содержать примерно 2000—3000 электронных ламп [6, С. 420].
1.4. Развитие методов сортировки во второй половине ХХ века
Из-за ограниченного объема памяти в ранних машинах приходилось думать о внешней сортировке наравне с внутренней. И в докладе "Progress Report on the EDVAC", подготовленном Дж. П. Эккертом и Дж У. Мочли для школы Мура по электротехнике, указывалось, что ЭВМ, оснащенная устройством с магнитной проволокой или лентой, могла бы моделировать действия карточного оборудования, достигая при этом большей скорости сортировки. Этот доклад описывал сбалансированную двухпутевую поразрядную сортировку и сбалансированное двухпутевое слияние с использованием четырех устройств с магнитной проволокой или лентой, читающих или записывающих "не менее 5000 импульсов в секунду" [2, С. 105].
Джон Мочли выступил с лекцией о "сортировке и слиянии" на специальной сессии по вычислениям, созывавшейся в школе Мура в 1946 г., и в записях его лекции содержится первое опубликованное обсуждение сортировки с помощью вычислительных машин [2, С. 106]. Он описал простые вставки и бинарные вставки, заметив, что в первом методе в среднем требуется около N2=4сравнений, в то время как в последнем их никогда не требуется более N log2 N. Однако бинарные вставки требуют весьма сложной структуры данных, и Мочли затем показал, что при двухпутевом слиянии достигается столь же малое число сравнений, но используется только последовательное прохождение списков. Последняя часть записей его лекций посвящена разбору методов поразрядной сортировки с частичными проходами, которые моделируют цифровую карточную сортировку на четырех лентах, затрачивая менее четырех проходов на цифру [6, С. 450].
Вскоре после этого Эккерт и Мочли организовали компанию, которая выпускала некоторые из самых ранних электронных вычислительных машин BINAC (для военных приложений) и. UNIVAC (для коммерческих приложений). Вновь Бюро переписи США сыграло роль в этом развитии, приобретя первый UNIVAC. В это время вовсе не было ясно, что ЭВМ станут экономически выгодными: вычислительные машины могли сортировать быстрее, но они дороже стоили. Поэтому программисты UNIVAC под руководством Франсис Э. Гольбертон приложили значительные усилия к созданию программ внешней сортировки, работающих с высокой скоростью, и их первые программы повлияли также на разработку оборудования. По их оценкам, 100 миллионов записей по 10 слов могли быть отсортированы на UNIVAC за 9000 ч (т. е. 375 дней) [11, С. 320].
UNIVAC I, официально объявленная в июле 1951 г., имела внутреннюю память в 1000 12литерных (72-битовых) слов. В ней предусматривалось чтение и запись на ленту блоков по 60 слов со скоростью 500 слов в секунду; чтение могло быть прямым или обратным, допускалось одновременное чтение /запись/ вычисления. В 1948 г. миссис Гольбертон придумала интересный способ выполнения двухпутевого слияния с полным совмещением чтения, записи и вычислений с использованием шести буферов ввода. Пусть для каждого вводного файла имеются один "текущий буфер" и два "вспомогательных буфера"; сливать можно таким образом, что всякий раз, когда приходит время вывести один блок, два текущих буфера ввода содержат вместе количество данных, равное одному блоку [6, С. 451].
Кульминационной точкой в этой работе стал генератор программ сортировки, который был первой крупной программой, разработанной для автоматического программирования. Пользователь указывал размер записи, позиции ключей (до пяти) в частичных полях каждой записи и «концевые» ключи, отмечающие конец файла, и генератор сортировки порождал требуемую программу сортировки для файлов на одной бобине [9, С. 9].
К 1952 г. многие методы внутренней сортировки прочно вошли в программистский фольклор, но теория была развита сравнительно слабо. Даниэль Голденберг запрограммировал для машины Whirlwind пять различных методов и провел анализ наилучшего и наихудшего случаев для каждой программы. Он нашел, что для сортировки сотни 15-битовых записей по 8-битовому ключу наилучшие по скорости результаты получаются в том случае, если используется таблица из 256 слов и каждая запись помещается в единственную соответствующую ее ключу позицию, а затем эта таблица сжимается. Однако этот метод имел очевидный недостаток, ибо он уничтожал запись, если последующая имела тот же ключ. Остальные четыре проанализированных метода были упорядочены следующим образом: прямое двухпутевое слияние лучше поразрядной сортировки с основанием 2, которая лучше простого выбора, который в свою очередь лучше метода пузырька [9, С. 9].
Эти результаты получили дальнейшее развитие в диссертации Гарольда X. Сьюворда в 1954 г. Сьюворд высказал идеи распределяющего подсчета и выбора с замещением.
Еще более достойная внимания диссертация – на этот раз докторская - была написана Говардом Б. Демутом в 1956 г. Эта работа помогла заложить основы теории сложности вычислений. В ней рассматривались три абстрактные модели задачи сортировки: с использованием циклической памяти, линейной памяти и памяти с произвольным доступом. Для каждой модели были разработаны оптимальные или почти оптимальные методы. Хотя непосредственно из диссертации Демута не вытекает никаких практических следствий, в ней содержатся важные идеи о том, как связать теорию с практикой [9, С. 9].
Таким образом, история сортировки была тесно связана со многими исхоженными тропами в вычислениях: с первыми машинами для обработки данных, первыми запоминаемыми программами, первым программным обеспечением, первыми методами буферизации, первой работой по анализу алгоритмов и сложности вычислений.
Ни один из документов относительно ЭВМ, упомянутых до сих пор, не появлялся в «открытой литературе». Так уж случилось, что большая часть ранней истории вычислительных машин содержится в сравнительно недоступных докладах, поскольку относительно немногие лица были в то время связаны с ЭВМ. Наконец в 1955–1956 гг. литература о сортировке проникает в печать в виде трех больших обзорных статей. Первая статья была подготовлена Дж. К. Хоскеном. Хоскен описал все оборудование специального назначения, имевшееся в продаже, а также методы сортировки на ЭВМ. Его библиография из 54 пунктов основана большей частью на брошюрах фирм-изготовителей [9, С. 9].
Подробная статья Э. X. Фрэнда явилась важной вехой в развитии сортировки. Хотя за прошедшее с 1956 г. время были разработаны многочисленные методы, эта статья все еще необычно современна во многих отношениях. Фрэнд дал тщательное описание весьма большого числа алгоритмов внутренней и внешней сортировки и обратил особое внимание на методы буферизации и характеристики магнитных лентопротяжных устройств.
Третий обзор по сортировке, который появился в то время, был подготовлен Д. У. Дэвайсом. В последующие годы еще несколько выдающихся обзоров было опубликовано Д. А. Беллом, А. Ш. Дугласом, Д. Д.Мак-Кракеном,Г. Вейссом и Ц. Ли, А. Флоресом, К. Э. Айверсоном, К. К. Готлибом, Т. Н. Хиббардом, М. А. Готцем [11, С. 22].
В ноябре 1962 г. ACM организовала симпозиум по сортировке (большая часть работ, представленных на этом симпозиуме, опубликована в мае 1963 г. в выпуске CACM). Они дают хорошее представление о состоянии этой области в то время. Обзор К. К. Готлиба о современных генераторах сортировки, обзор Т. Н. Хиббарда о внутренней сортировке с минимальной памятью и раннее исследование Дж. А. Хаббэрда о сортировке файлов на дисках – наиболее заслуживающие внимания статьи в этом собрании [11, С. 23].
За прошедший период были открыты новые методы сортировки: вычисление адреса (1956), слияние с вставкой (1959), обменная поразрядная сортировка (1959), каскадное слияние (1959), метод Шелла с убывающим шагом (1959), многофазное слияние (1960), вставки в дерево (1960), осциллирующая сортировка (1962), быстрая сортировка Хоара (1962), пирамидальная сортировка Уильямса (1964), обменная сортировка со слиянием Бэтчера (1964). Конец 60-хгодов нашего столетия ознаменовался интенсивным развитием соответствующей теории.
2. Сравнительный анализ методов сортировки данных
2.1. Оценка алгоритмов сортировки
Для каждого метода сортировки имеется много алгоритмов. Каждый алгоритм имеет свои достоинства, но в целом оценка алгоритма сортировки зависит от ответов, которые будут получены на следующие вопросы:
- с какой средней скоростью этот алгоритм сортирует информацию?;
- какова скорость для лучшего случая и для худшего случая?;
- поведение алгоритма является естественным или является неестественным?;
- выполняется ли перестановка элементов для одинаковых ключей.
Для конкретного алгоритма большое значение имеет скорость сортировки. Скорость, с которой массив может быть упорядочен, прямо зависит от числа сравнений и числа необходимых операций обмена, причем операции обмена занимают большее время [10, С. 257]. Ниже будет показано, что для некоторых алгоритмов время сортировки зависит экспоненциально от числа элементов, а для других алгоритмов это время находится в логарифмической зависимости от числа элементов сортировки.
Время работы алгоритма для лучшего и худшего случаев важно учитывать, когда ожидается их частое появление. Часто сортировка имеет хорошую среднюю скорость, но очень плохую скорость для худшего случая, и наоборот [10, С. 262].
Считается поведение алгоритма сортировки естественным, если время сортировки наименьшее при упорядоченном списке элементов, время сортировки увеличивается при менее упорядоченном списке элементов и время сортировки становится наихудшим, когда список элементов упорядочен в обратном порядке. Время сортировки зависит от числа операций сравнения и операций обмена.
Для того, чтобы понять важность перегруппировки элементов с одинаковыми ключами сортировки, представим базу данных, которая упорядочена по основному ключу и дополнительному ключу. /Например, список почтовых отправлений с почтовым индексом в качестве основного ключа и фамилией в качестве дополнительного ключа в рамках одного почтового индекса/. Когда новый адрес добавляется в список и список вновь сортируется, вам не требуется перестановка дополнительных ключей. Для обеспечения этого сортировка не должна выполнять операции обмена для основных ключей с одинаковыми значениями [10, С. 258].
2.2. Элементарные методы сортировки
В начале, более подробно остановимся на нескольких элементарных методах, которые целесообразно использовать для сортировки файлов небольших размеров либо для сортировки файлов со специальной структурой. Прежде всего, они позволяют изучить терминологию и базовые механизмы алгоритмов сортировки. Во-вторых, эти простые методы во многих приложениях сортировки показали себя, по сути дела, более эффективными, чем мощные универсальные методы. В-третьих, некоторые из простых методов допускают расширение в более эффективные универсальные методы или же могут оказаться полезными в плане повышения эффективности совершенных методов сортировки [10, С. 249].
Многие из возможных приложений сортировки часто отдают предпочтение простейшим алгоритмам. Во-первых, очень часто программа сортировки используется всего лишь один или небольшое число раз. После того как удалось "решить" проблему сортировки для некоторого набора данных, в дальнейшем потребность в программе сортировки в приложениях, которые манипулируют этими данными, отпадает. Если элементарная сортировка работает не медленней других частей приложения, осуществляющего обработку данных — например, считывание данных или их вывод на печать — то отпадает необходимость в поиске более быстрых методов сортировки. Если число сортируемых элементов не очень большое (скажем, не превышает нескольких сотен элементов), можно просто воспользоваться простым методом и не ломать голову над тем, как работает интерфейс для системной сортировки, или как написать и отладить программу, реализующую какой-нибудь сложный метод сортировки. Во-вторых, элементарные методы всегда годятся для файлов небольших размеров (состоящих из нескольких десятков элементов) — сложные алгоритмы в общем случае обусловливают непроизводительные затраты ресурсов, а это приводит к тому, что на файлах небольших размеров они работают медленнее элементарных методов сортировки. Эта проблема не попадет в фокус нашего внимания до тех пор, пока не возникнет необходимость сортировки большого числа файлов небольших размеров, однако следует иметь в виду, что приложения с подобного рода требованиями встречаются достаточно часто. Другими типами файлов, сортировка которых существенно упрощена, являются файлы, с почти (или уже) завершенной сортировкой или файлы, которые содержат большое число дублированных ключей. Далее можно будет убедиться в том, что некоторые методы из числа простейших особенно эффективны при сортировке хорошо структурированных файлов [6, С. 452].
Сортировка выбором. Один из самых простых алгоритмов сортировки работает следующим образом. Сначала отыскивается наименьший элемент массива, затем он меняется местами с элементом, стоящим первым в сортируемом массиве. Далее, находится второй наименьший элемент и меняется местами с элементом, стоящим вторым в исходном массиве. Этот процесс продолжается до тех пор, пока весь массив не будет отсортирован [10, С. 257].
Данный метод называется сортировкой выбором, поскольку он работает по принципу выбора наименьшего элемента из числа неотсортированных. Допустим необходимо отсортировать массив по возрастанию. В исходном массиве находим минимальный элемент, меняем его местами с первым элементом массива. Уже, из всех элементов массива один элемент стоит на своём месте. Теперь рассматрим не отсортированную часть массива, то есть все элементы массива, кроме первого. В неотсортированной части массива опять ищем минимальный элемент. Найденный минимальный элемент меняем местами со вторым элементом массива и т. д. Таким образом, суть алгоритма сортировки выбором сводится к многократному поиску минимального (максимального) элементов в неотсортированной части массива. На рис. 1 представлен пример работы этого метода [10, С. 257].

Рис. 1. Пример сортировки выбором
В этом примере первый проход ничего не меняет, поскольку в массиве нет элемента, меньшего самого левого элемента А. На втором проходе наименьшим среди оставшихся оказался другой элемент А, поэтому он меняется местами с элементом S, занимающим вторую позицию. На третьем проходе элемент Е из середины массива обменивается с О в третьей позиции, на четвертом проходе еще один элемент Е меняется местами с R в четвертой позиции и т.д. [10, С. 257].
Недостаток сортировки выбором заключается в том, что время ее выполнения лишь в малой степени зависит от того, насколько упорядочен исходный файл. Процесс нахождения минимального элемента за один проход файла дает очень мало сведений о том, где может находиться минимальный элемент на следующем проходе этого файла. Например, пользователь, применяющий этот метод, будет немало удивлен, когда узнает, что на сортировку почти отсортированного файла или файла, записи которого имеют одинаковые ключи, требуется столько же времени, сколько и на сортировку файла, упорядоченного случайным образом. Другие методы с большим успехом используют преимущества присутствия порядка в исходном файле [6, С. 459].
Несмотря на всю ее простоту и очевидный примитивизм подхода, сортировка выбором превосходит более совершенные методы в одном из важных приложений: этому методу сортировки файлов отдается предпочтение в тех случаях, когда записи файла огромны, а ключи занимают незначительное пространство. В подобного рода приложениях затраты ресурсов на перемещения записей намного превосходят стоимость операций сравнения, а что касается перемещения данных, то никакой алгоритм не способен выполнить сортировку файла с меньшим числом перемещений данных, нежели метод выбора [10, С. 259].
Сортировка вставками. Метод сортировки, который часто применяют игроки в бридж по отношению к картам на руках, заключается в том, что отдельно анализируется каждый конкретный элемент, который затем помещается в надлежащее место среди других, уже отсортированных элементов. В условиях компьютерной реализации следует позаботиться о том, чтобы освободить место для вставляемого элемента путем смещения больших элементов на одну позицию вправо, после чего на освободившееся место помещается вставляемый элемент [10, С. 259].
Сортируемый массив можно разделить на две части — отсортированная часть и неотсортированная. В начале сортировки первый элемент массива считается отсортированным, все остальные — не отсортированные. Начиная со второго элемента массива и заканчивая последним, алгоритм вставляет неотсортированный элемент массива в нужную позицию в отсортированной части массива. Таким образом, за один шаг сортировки отсортированная часть массива увеличивается на один элемент, а неотсортированная часть массива уменьшается на один элемент. Как и в случае с сортировкой выбора, элементы, находящиеся слева от текущего индекса, отсортированы в соответствующем порядке, тем не менее, они еще не занимают свои окончательные позиции, ибо могут быть передвинуты с целью освобождения места под меньшие элементы, которые обнаруживаются позже. Массив будет полностью отсортирован, когда индекс достигнет правой границы массива.

Рис. 2. Пример выполнения сортировки вставками
Во время первого прохода сортировки вставками элемент S во второй позиции больше A, так что перемещать его не надо. На втором проходе элемент O в третьей позиции меняется местами с S, так что получается упорядоченная последовательность A O S и т.д. Не заштрихованные и обведенные кружками элементы — это те, которые были сдвинуты на одну позицию вправо [10, С. 257].
Часто применяется альтернативный способ: сортируемые ключи хранятся в элементах массива от a[1] до a[N], а в a[0] заносится сигнальный ключ (sentinel key), значение которого по крайней мере не больше наименьшего ключа в сортируемом массиве. Тогда проверка, найден ли меньший ключ, проверяет сразу оба условия, и в результате внутренний цикл становится меньше, а быстродействие программы повышается.
Сигнальные ключи не всегда удобны: иногда бывает трудно определить значение минимально возможного ключа, а иногда в вызывающей программе нет места для дополнительного ключа. На рис. 2 предлагается один из способов обойти сразу обе эти проблемы: сначала выполняется отдельный проход по массиву, который помещает в первую позицию элемент с минимальным ключом. Затем сортируется остальной массив, а первый, он же наименьший, элемент служит в качестве сигнального ключа [10, С. 259].
Пузырьковая сортировка. Метод сортировки, который многие обычно осваивают раньше других из-за его исключительной простоты, называется пузырьковой сортировкой (bubble sort), в рамках которой выполняются следующие действия: проход по файлу с обменом местами соседних элементов, нарушающих заданный порядок, до тех пор, пока файл не будет окончательно отсортирован. Основное достоинство пузырьковой сортировки заключается в том, что его легко реализовать в виде программы, однако вопрос о том, какой из методов сортировки реализуется легче других — пузырьковый, метод вставок или метод выбора — остается открытым [10, С. 261].
Сортировка пузырьком - самый естественный, он же самый медленный алгоритм сортировки. Алгоритм пузырьковой сортировки просматривает массив чисел от начала до конца до тех пор, пока любые два рядом стоящих числа не будут расположены по возрастанию. Для этого два неверно расположенные одно относительно другого числа меняются местами. При этом наименьшее число, как пузырёк, постепенно всплывает к началу массива (а наибольшее сразу "тонет" как камень!), отсюда и название алгоритма. Время сортировки пузырьком пропорционально квадрату количества чисел в массиве [10, С. 262].
Количество проходов алгоритма пузырьковой сортировки в худшем случае будет равно количеству элементов в массиве.

Рис. 3. Пример выполнения пузырьковой сортировки
В пузырьковой сортировке ключи с малыми значениями постепенно сдвигаются влево. Поскольку проходы выполняются справа налево, каждый ключ меняется местами с ключом слева до тех пор, пока не будет обнаружен ключ с меньшим значением. На первом проходе E меняется местами с L, P и M и останавливается справа от A; затем A продвигается к началу файла, пока не остановится перед другим A, который уже находится на свом месте. Как и в случае сортировки выбором, после i-го прохода i-й по величине ключ устанавливается в окончательное положение, но при этом другие ключи также приближаются к своим окончательным позициям [10, С. 262].
2.3. Производительность элементарных методов сортировки
Алгоритмы сортировки выбором, вставками и пузырьковая сортировка по времени выполнения находятся в квадратичной зависимости от числа элементов как в наиболее трудных, так и в обычных случаях, но в то же время они не нуждаются в дополнительной памяти. Таким образом, время их выполнения отличается только постоянным коэффициентом пропорциональности этой зависимости, хотя принципы их работы существенно различаются, о чем свидетельствуют рис. 4,5,6 [10, С. 263].
В общем случае время выполнения алгоритма сортировки пропорционально количеству операций сравнения, выполняемых этим алгоритмом, количеству перемещений или перемен местами элементов, а, возможно, и обоим сразу. В случае ввода данных, упорядоченных случайным образом, сравнение указанных методов сортировки предполагает изучение различий между соответствующими постоянными коэффициентами пропорциональности в зависимости от числа выполняемых операций сравнении и перемены сортируемых элементов местами, а также различий соответствующих постоянных коэффициентов пропорциональности в зависимости от числа выполняемых операций во внутренних циклах. В случае ввода данных со специальными характеристиками времена выполнения различных видов сортировок могут отличаться в большей степени, нежели по значениям указанных выше постоянных коэффициентов пропорциональности [10, С. 263].

Рис. 4. Динамические характеристики сортировки выбором и вставки
Эти снимки сортировки вставками (снизу) и выбором (сверху) на примере случайной последовательности иллюстрируют протекание процессов сортировки указанными выше методами [10, С. 264].
На рисунке процесс сортировки показан в виде графика зависимости a[i] от i для каждого i. Перед началом сортировки на графике представлена равномерно распределенная случайная величина; по окончании сортировки график представлен диагональю, проходящий из левой нижнего угла в правый верхний угол. Сортировка вставками никогда не забегает вперед по отношению к текущей позиции в массиве, в то время как сортировка выбором никогда не возвращается назад [10, С. 265].
На диаграмме ниже (рис. 5) показаны различия в том, как сортировки вставками, выбором, а также пузырьковая сортировка приводят конкретный файл в порядок. Сортируемый файл представлен в виде отрезков, которые сортируются по углу наклона. Черные отрезки соответствуют элементам, к которым в процессе сортировки производится доступ на каждом проходе; серые отрезки соответствуют элементам, которые не затрагиваются. В условиях сортировки вставками (слева) вставляемый элемент проходит примерно половину пути назад через отсортированную часть на каждом проходе. Сортировка выбором (в центре) и пузырьковая сортировка (справа) проходят на каждом проходе через всю неотсортированную часть массива с целью обнаружения там следующего наименьшего элемента; различие между этими методами заключается в том, что пузырьковая сортировка меняет местами каждую пару соседних элементов, нарушающих порядок, которые ей удается обнаружить, в то время как сортировка выбором помещает минимальный элемент в окончательную позицию. Это различие проявляется в том, что по мере выполнения пузырьковой сортировки, неотсортированная часть массива становится все более упорядоченной [10, С. 265].

Рис. 5. Операции сравнения и обмена элементов в условиях элементарных методов сортировки
Стандартная пузырьковая сортировка (слева) похожа на сортировку выбором тем, что на каждом проходе один элемент занимает свою окончательную позицию, но одновременно она асимметрично привносит упорядоченность в остальную часть массива. Поочередная смена направления просмотра массива (т.е. просмотр от начала до конца массива меняется на просмотр от конца до начала и наоборот) дает новую разновидность пузырьковой сортировки, получившей название шейкерной сортировки (справа), которая заканчивается быстрее [6, С. 450].
В общем случае время выполнения алгоритма сортировки пропорционально количеству операций сравнения, выполняемых этим алгоритмом, количеству перемещений или обменов элементов, а, возможно, и тому, и другому сразу. Для случайно упорядоченных данных сравнение элементарных методов сортировки сводится к изучению постоянных коэффициентов, на которые отличаются количества выполняемых операций сравнений и обменов, а также постоянных коэффициентов, на которые отличаются длины внутренних циклов. В случае входных данных с особыми характеристиками времена выполнения различных видов сортировок могут отличаться и более чем на постоянный коэффициент [10, С. 266].
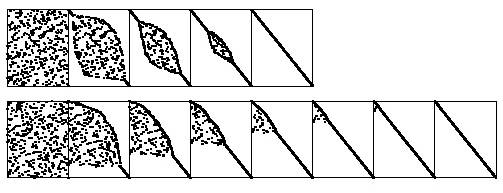
Рис. 6. Динамические характеристики двух пузырьковых сортировок
Алгоритмы сортировки выбором, вставками и пузырьковая сортировка по времени выполнения находятся в квадратичной зависимости от числа элементов как в наиболее трудных, так и в обычных случаях, но в то же время они не нуждаются в дополнительной памяти. Таким образом, время их выполнения отличается только постоянным коэффициентом пропорциональности этой зависимости, хотя принципы их работы существенно различаются [10, С. 266].
Сортировка вставками не относится к категории быстродействующих, поскольку единственный вид операции обмена, который она использует, выполняется над двумя соседними элементами, в связи, с чем элемент может передвигаться вдоль массива лишь на одно место за один раз. Например, если элемент с наименьшим значением ключа оказывается в конце массива, потребуется сделать N шагов, чтобы поместить его в надлежащее место.
Сортировка методом Шелла представляет собой простейшее расширение метода вставок, быстродействие которого выше за счет обеспечения возможности обмена местами элементов, которые находятся далеко один от другого. Сортировка Шелла была названа в честь ее изобретателя – Дональда Шелла, который опубликовал этот алгоритм в 1959 году. Такая модификация метода сортировки позволяет быстро переставлять далекие неупорядоченные пары значений (сортировка таких пар обычно требует большого количества перестановок, если используется сравнение только соседних элементов) [10, С. 269].
Идея заключается в переупорядочении файла таким образом, чтобы придать ему следующее свойство: совокупность h-ых элементов исходного файла (начиная с любого) образует отсортированный файл. В таком случае говорят, что файл h-упорядочен (h-sorted). Другими словами, h-упорядоченный файл представляет собой h независимо отсортированных взаимно проникающих друг в друга файлов. В процессе h -сортировки при достаточно больших значениях h можно менять местами элементы массива, расположенные достаточно далеко друг от друга, и тем самым ускорить последующую h -сортировку при меньших значениях h. Использование такого рода процедуры для любой последовательности значений h, которая заканчивается единицей, завершается получением упорядоченного файла: именно в этом и заключается суть сортировки методом Шелла [10, С. 270].
2.4. Быстрая сортировка
Метод быстрой сортировки был впервые описан Ч.А.Р. Хоаром в 1962 году. Быстрая сортировка – это общее название ряда алгоритмов, которые отражают различные подходы к получению критичного параметра, влияющего на производительность метода.
Быстрая сортировка популярна, прежде всего, потому, что ее нетрудно реализовать, она хорошо работает на различных видах входных данных и во многих случаях требует меньше ресурсов по сравнению с другими методами сортировки [4, С. 62].
Алгоритм быстрой сортировки обладает и другими привлекательными особенностями: он принадлежит к категории обменных сортировок (использует лишь небольшой вспомогательный стек), на упорядочение N элементов в среднем затрачивает время, пропорциональное N log N, и имеет исключительно короткий внутренний цикл. Его недостатком является то, что он неустойчив, выполняет в худшем случае N 2 операций и ненадежен в том смысле, что простая ошибка в реализации может остаться незамеченной, но существенно понизить производительность на некоторых видах файлов [4, С. 64].
Работа быстрой сортировки проста для понимания. Алгоритм был подвергнут тщательному математическому анализу, и существуют точные оценки его эффективности. Этот анализ был подтвержден обширными эмпирическими экспериментами, а сам алгоритм отшлифован до такой степени, что ему отдается предпочтение в широком диапазоне практических применений сортировки. Поэтому эффективной реализации алгоритма быстрой сортировки стоит уделить гораздо большее внимание, чем реализациям других алгоритмов. Аналогичные методы реализации пригодны и для других алгоритмов; но для быстрой сортировки их можно применять с полной уверенностью, поскольку точно известно их влияние на эффективность сортировки [4, С. 64].
Многие пытаются разработать способы улучшения быстрой сортировки: ускорение алгоритмов сортировки играет роль "изобретения велосипеда" в компьютерных науках, а быстрая сортировка представляет собой почтенный метод, который так и хочется улучшить. Его усовершенствованные версии стали появляться в литературе практически с момента опубликования Хоаром. Предлагалось и анализировалось множество идей, но при оценке этих улучшений легко ошибиться, поскольку данный алгоритм настолько удачно сбалансирован, что небольшое усовершенствование одной части программы может привести к резкому ухудшению работы другой ее части [10, С. 299].
Тщательно настроенная версия быстрой сортировки обычно работает быстрее любого другого метода сортировки на большинстве компьютеров, поэтому быстрая сортировка широко используется как библиотечная программа сортировки и в других серьезных приложениях сортировки. Утилита сортировки из стандартной библиотеки С++ называется qsort, т.к. ее различные реализации обычно основаны на алгоритме быстрой сортировки. Однако время выполнения быстрой сортировки зависит от организации входных данных и колеблется между линейной и квадратичной зависимостью от количества сортируемых элементов, и пользователи иногда бывают неприятно удивлены неожиданно неудовлетворительной работой сортировки на некоторых видах входных данных, особенно при использовании хорошо отлаженных версий этого алгоритма. Если приложение работает настолько плохо, что возникает подозрение в наличии дефектов в реализации быстрой сортировки, то более надежным выбором может оказаться сортировка Шелла, хорошо работающая при меньших затратах на реализацию. Однако в случае особо крупных файлов быстрая сортировка обычно выполняется в пять-десять раз быстрее сортировки Шелла, а для некоторых видов файлов, часто встречающихся на практике, ее можно адаптировать для еще большего повышения эффективности [10, С. 300].
Алгоритм быстрой сортировки Хоара - пусть дан массив x[n] размерности n.
Шаг 1. Выбирается опорный элемент массива.
Шаг 2. Массив разбивается на два – левый и правый – относительно опорного элемента. Реорганизуем массив таким образом, чтобы все элементы, меньшие опорного элемента, оказались слева от него, а все элементы, большие опорного – справа от него.
Шаг 3. Далее повторяется шаг 2 для каждого из двух вновь образованных массивов. Каждый раз при повторении преобразования очередная часть массива разбивается на два меньших и т. д., пока не получится массив из двух элементов (рис. 7).
Быстрая сортировка стала популярной прежде всего потому, что ее нетрудно реализовать, она хорошо работает на различных видах входных данных и во многих случаях требует меньше затрат ресурсов по сравнению с другими методами сортировки [6, С. 462].
Выберем в качестве опорного элемент, расположенный на средней позиции.
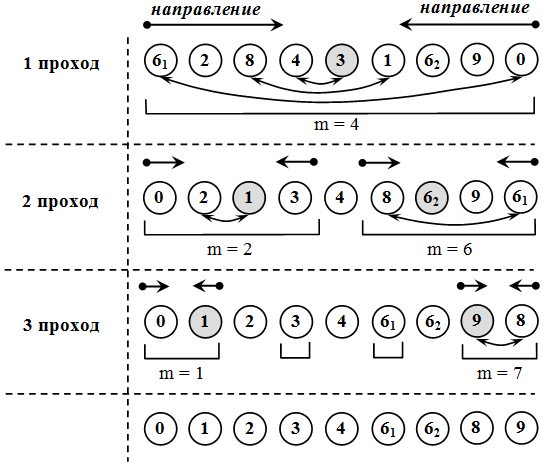
Рис. 7. Демонстрация быстрой сортировки Хоара по неубыванию
Эффективность быстрой сортировки в значительной степени определяется правильностью выбора опорных (ведущих) элементов при формировании блоков. В худшем случае трудоемкость метода имеет ту же сложность, что и пузырьковая сортировка, то есть порядка O(n2). При оптимальном выборе ведущих элементов, когда разделение каждого блока происходит на равные по размеру части, трудоемкость алгоритма совпадает с быстродействием наиболее эффективных способов сортировки, то есть порядка O(n log n). В среднем случае количество операций, выполняемых алгоритмом быстрой сортировки, определяется выражением T(n) = O(1.4n log n) [4, С. 64].
Размер стека. Для быстрой сортировки можно применить явный стек магазинного типа, используя его для хранения информации о еще не обработанных подфайлах, которые ожидают сортировки. Каждый раз, когда нужно обработать подфайл, он выталкивается из стека. При разбиении файла получаются два не обработанных подфайла, и они помещаются в стек [10, С. 309].
Для случайно упорядоченных файлов максимальный раздел стека пропорционален log N, но в вырожденных случаях стек может вырасти до размера, пропорционального N, что показано на рис. 8. Ведь наихудший случай - это когда входной файл уже отсортирован. Потенциальная возможность роста стека до размера, пропорционального размеру входного файла представляет собой не очевидную, но вполне реальную проблему для рекурсивной реализации быстрой сортировки: стек, пусть и неявно, используется всегда, а вырожденный файл большого размера может стать причиной аварийного завершения программы из-за нехватки памяти. Конечно, для библиотечной программы сортировки такое поведение недопустимо. На самом деле программе скорее не хватит времени, чем памяти [10, С. 310].
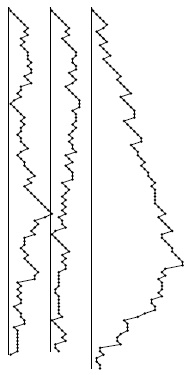
Рис. 8. Размер стека при работе быстрой сортировки
Рекурсивный стек для быстрой сортировки не бывает большим при обработке случайно упорядоченных файлов, но в вырожденных случаях он может занимать очень большой объем памяти. Здесь приведены графики размеров стека для двух случайно упорядоченных файлов (слева и в центре) и для частично упорядоченного файла (справа).
Трудно гарантированно исключить такое поведение программы, но в полнее вероятно предусмотреть специальные средства, которые сведут вероятность возникновения таких вырожденных случаев почти к нулю.
На рис. 9 показана стратегия, которая решает эту проблему, проверяя размеры обоих подфайлов и первым помещая в стек больший из них. Сравнивая данный пример с приведенным на рис. 7, можно увидеть, что это правило не изменяет подфайлы, меняется лишь порядок их обработки. Так это экономит память без изменения времени выполнения [410, С. 310].
Нерекурсивная быстрая сортировка. Данная нерекурсивная реализация быстрой сортировки использует явный стек магазинного типа, заменяя рекурсивные вызовы помещением в стек параметров, а рекурсивные вызовы процедур и выходы из них - циклом, выталкивающим параметры из стека и обрабатывающим их, пока стек не пуст. Больший из двух подфайлов помещается в стек первым, чтобы максимальная глубина стека при сортировке N элементов не превосходила lgN [10, С. 310].
Рис. 9. Пример работы быстрой сортировки (вначале упорядочивается меньший подфайл)
Порядок обработки подфайлов не влияет ни на корректность работы алгоритма быстрой сортировки, ни на время выполнения, однако он может повлиять на размер стека, необходимого для поддержки рекурсивной структуры. Здесь после каждого разбиения вначале обрабатывается меньший из двух подфайлов.
Правило, согласно которому больший из двух подфайлов помещается в стек первым, обеспечивает, что каждый элемент стека имеет размер, не больший половины элемента под ним, так что стеку нужна память только для порядка lgN элементов. Это максимальное заполнение стека имеет место, если разбиение всегда попадает в центр файла. Для случайно упорядоченных файлов реальный максимальный размер стека гораздо меньше; для вырожденных файлов он обычно мал.
Быстрая сортировка является наиболее эффективным алгоритмом из всех известных методов сортировки, но все усовершенствованные методы имеют один общий недостаток – невысокую скорость работы при малых значениях n.
Рекурсивная реализация быстрой сортировки позволяет устранить этот недостаток путем включения прямого метода сортировки для частей массива с небольшим количеством элементов. Анализ вычислительной сложности таких алгоритмов показывает, что если подмассив имеет девять или менее элементов, то целесообразно использовать прямой метод (сортировку простыми вставками) [10, С. 311].
2.5. Сортировка слиянием
Алгоритм сортировки слиянием был изобретен Джоном фон Нейманом в 1945 году. Он является одним из самых быстрых способов сортировки.
Слияние – это объединение двух или более упорядоченных массивов в один упорядоченный [6, С. 423].
Сортировка слиянием является одним из самых простых алгоритмов сортировки (среди быстрых алгоритмов). Особенностью этого алгоритма является то, что он работает с элементами массива преимущественно последовательно, благодаря чему именно этот алгоритм используется при сортировке в системах с различными аппаратными ограничениями (например, при сортировке данных на жестком диске). Кроме того, сортировка слиянием является алгоритмом, который может быть эффективно использован для сортировки таких структур данных, как связанные списки [6, С. 425].
Данный алгоритм применяется тогда, когда есть возможность использовать для хранения промежуточных результатов память, сравнимую с размером исходного массива. Он построен на принципе "разделяй и властвуй". Сначала задача разбивается на несколько подзадач меньшего размера. Затем эти задачи решаются с помощью рекурсивного вызова или непосредственно, если их размер достаточно мал. Далее их решения комбинируются, и получается решение исходной задачи (рис. 10).
Процедура слияния требует два отсортированных массива. Заметим, что массив из одного элемента по определению является отсортированным.
Алгоритм сортировки слиянием
Шаг 1. Разбить имеющиеся элементы массива на пары и осуществить слияние элементов каждой пары, получив отсортированные цепочки длины 2 (кроме, быть может, одного элемента, для которого не нашлось пары).
Шаг 2. Разбить имеющиеся отсортированные цепочки на пары, и осуществить слияние цепочек каждой пары.
Шаг 3. Если число отсортированных цепочек больше единицы, перейти к шагу 2.

Рис. 10. Демонстрация сортировки слиянием по неубыванию
Недостаток алгоритма заключается в том, что он требует дополнительную память размером порядка n (для хранения вспомогательного массива). Кроме того, он не гарантирует сохранение порядка элементов с одинаковыми значениями. Но его временная сложность всегда пропорциональна O(n log n) [6, С. 425].
Выборка и слияние - противоположные операции в том смысле, что выборка разбивает файл на два независимых файла, а слияние объединяет два независимых файла в один. Контраст между этими двумя операциями становится очевидным при применении принципа «разделяй и властвуй» для создания конкретных методов сортировки. Можно переупорядочить файл таким образом, что если отсортировать обе части файла, становится упорядоченным и весь файл; и наоборот, можно разбить файл на две части, отсортировать их, а затем объединить упорядоченные части и получить весь файл в упорядоченном виде. В первом случае получается: быстрая сортировка, состоящая из процедуры выборки, за которой следуют два рекурсивных вызова [6, С. 425]. Далее рассмотрим сортировку слиянием (mergesort), которая является противоположностью быстрой сортировки, поскольку состоит из двух рекурсивных вызовов с последующей процедурой слияния.
Одним из наиболее привлекательных свойств сортировки слиянием является тот факт, что она сортирует файл, состоящий из N элементов, за время, пропорциональное N logN, независимо от характера входных данных.
Основной недостаток сортировки слиянием заключается в том, что простые реализации этого алгоритма требуют объема дополнительной памяти, пропорционального N. Это препятствие можно преодолеть, однако способы сделать это настолько сложны, что практически неприменимы, особенно если учесть, что можно воспользоваться пирамидальной сортировкой. Кодирование сортировки слиянием не труднее кодирования пирамидальной сортировки, а длина ее внутреннего цикла находится между аналогичными показателями быстрой сортировки и пирамидальной сортировки; так что сортировка методом слияния достойна внимания, если важно быстродействие, недопустимо ухудшение производительности на " неудобных " входных данных и доступна дополнительная память [10, С. 331].
Гарантированное время выполнения, пропорциональное NlogN, может быть и недостатком. Например, существуют методы, которые могут быть адаптированы таким образом, что в некоторых особых ситуациях время их выполнения может быть линейным - например, при достаточно высокой упорядоченности файла либо при наличии лишь нескольких различных ключей. В противоположность этому время выполнения сортировки слиянием зависит главным образом от числа ключей входного файла и практически не чувствительно к их упорядоченности [10, С. 332].
Сортировка слиянием является устойчивой, и это склоняет чашу весов в ее пользу в тех приложениях, в которых устойчивость важна. Конкурирующие с ней методы, такие как быстрая сортировка или пирамидальная сортировка, не относятся к числу устойчивых. Различные приемы, обеспечивающие устойчивость этих методов, обычно требуют дополнительной памяти; поэтому если на первый план выдвигается устойчивость, то требование дополнительной памяти для сортировки слиянием становится менее важным [10, С. 332].
У сортировки слиянием есть еще одно, иногда очень важное, свойство: она обычно реализуется таким образом, что обращается к данным в основном последовательно (один элемент за другим). Поэтому сортировка слиянием удобна для упорядочения связных списков, для которых применим только метод последовательного доступа. На слиянии часто основываются методы сортировки для специализированных и высокопроизводительных машин, поскольку в таких вычислительных средах последовательный доступ к данным является самым быстрым.
В таблице 1 показана относительная эффективность различных рассмотренных нами усовершенствований. Как это часто бывает, оказывается, что если направить усилия на оптимизацию внутреннего цикла алгоритма сортировки, то время выполнения сортировки можно сократить наполовину и даже больше [10, С. 335].
Также можно добиться дальнейшего повышения производительности, поместив наименьшие элементы обоих массивов в простые переменные или машинные регистры процессора и избежав, таким образом, лишних обращений к массивам. Тогда внутренний цикл сортировки слиянием можно свести к сравнению (с условным переходом), увеличению на единицу значений двух счетчиков (k и либо i, либо j) и проверке условия завершения цикла с условным переходом. Общее количество команд в таком внутреннем цикле несколько больше, чем для быстрой сортировки, но эти команды выполняются всего лишь Nlg N раз, в то время как команды внутреннего цикла быстрой сортировки выполняются на 39% чаще (или на 29% для варианта с вычислением медианы из трех). Для более точного сравнения этих двух алгоритмов в различных средах нужна их тщательная реализация и подробный анализ. Однако точно известно, что внутренний цикл сортировки слиянием несколько длиннее внутреннего цикла быстрой сортировки [10, С. 335].
В данном случае сортировка слиянием обладает несомненным преимуществом перед быстрой сортировкой в том, что она устойчива и гарантирует высокую скорость (вне зависимости от характера входных данных), но проигрывает в том, что использует дополнительный объем памяти, пропорциональный размеру массива [10, С. 335].
Представленные здесь относительные временные показатели различных видов сортировки для случайно упорядоченных файлов чисел с плавающей точкой различного размера N показывают, что: стандартная быстрая сортировка примерно в два раза быстрее стандартной сортировки слиянием; добавление отсечения небольших файлов снижает время выполнения и нисходящей, и восходящей сортировок слиянием примерно на 15%; для указанных в таблице размеров файлов быстродействие нисходящей сортировки слиянием приблизительно на 10% выше, чем восходящей; даже если устранить затраты на копирование файла, то и в этом случае сортировка слиянием случайно упорядоченных файлов на 50-60% медленнее обычной быстрой сортировки (см. таблица 1).
Таблица 1. Эмпирическое сравнение алгоритмов сортировки слиянием
|
N |
Q |
Нисходящая |
Восходящая |
|||
|
T |
T* |
O |
B |
B* |
||
|
12 500 |
2 |
5 |
4 |
4 |
5 |
4 |
|
25 000 |
5 |
12 |
8 |
8 |
11 |
9 |
|
50 000 |
11 |
23 |
20 |
17 |
26 |
23 |
|
100 000 |
24 |
53 |
43 |
37 |
59 |
53 |
|
200 000 |
52 |
111 |
92 |
78 |
127 |
110 |
|
400 000 |
109 |
237 |
198 |
168 |
267 |
232 |
|
800 000 |
241 |
524 |
426 |
358 |
568 |
496 |
Q - Стандартная быстрая сортировка
T - Стандартная нисходящая сортировка слиянием
T* - Нисходящая сортировка слиянием с отсечением небольших файлов
O - Нисходящая сортировка слиянием с отсечением и без копирования массива
B - Стандартная восходящая сортировка слиянием
B* - Восходящая сортировка слиянием с отсечением небольших файлов
Если эти факторы склоняются в пользу сортировки слиянием (и быстродействие имеет большое значение), то рассмотренные усовершенствования заслуживают внимательного рассмотрения - наряду с тщательным изучением компилированного кода, особенностей архитектуры компьютера и пр. [10, С. 336].
Возможно, быструю сортировку было бы точнее назвать алгоритмом «властвуй и разделяй»: в рекурсивных реализациях при каждом обращении большая часть работы выполняется перед рекурсивными вызовами. А вот рекурсивная сортировка слиянием более соответствует принципу «разделяй и властвуй» : вначале файл делится на две части, и затем каждая часть обрабатывается отдельно. Сортировка слиянием сначала выполняется для небольших задач, а в заключение обрабатывается самый большой подфайл. Быстрая сортировка начинается с обработки наибольшего подфайла и завершается обработкой подфайлов небольших размеров. Любопытно сравнение этих алгоритмов по аналогии с управлением коллективом сотрудников: быстрая сортировка соответствует тому, что каждый руководитель затрачивает свои усилия на правильное разбиение задачи на подзадачи, так что после выполнения всех подзадач работа будет успешно выполнена; сортировка слиянием соответствует тому, что каждый руководитель быстро и произвольно делит задачу пополам, а затем, после решения подзадач, затрачивает свои усилия на объединение результатов [10, С. 336].
Это различие ясно видно в нерекурсивных реализациях. Быстрой сортировке нужен стек - для хранения больших подзадач, разбиение на которые зависит от входных данных. Сортировка слиянием допускает простые нерекурсивные реализации, поскольку способ разбиения файла на части не зависит от данных, и становится возможным изменение очередности решения подзадач, что позволяет упростить программу.
Существует точка зрения, что быструю сортировку естественнее рассматривать как нисходящий алгоритм, поскольку он начинает работу на вершине дерева рекурсии, а затем для завершения сортировки опускается вниз. Можно обдумать и нерекурсивный вариант быстрой сортировки, которая обходит дерево рекурсии сверху вниз, но по уровням. Таким образом, сортировка многократно проходит по массиву, разбивая файлы на меньшие подфайлы. Для массивов этот метод не годится из-за большого объема затрат на хранение информации о подфайлах, а для связных списков он аналогичен восходящей сортировке слиянием [4, С. 67].
Сортировка слиянием и быстрая сортировка отличаются по признаку устойчивости. Если подфайлы при сортировке слиянием упорядочены с соблюдением устойчивости, то вполне достаточно обеспечить устойчивость слияния, что сделать совсем нетрудно. Рекурсивная структура алгоритма автоматически приводит к индуктивному доказательству устойчивости. Но для реализации быстрой сортировки с использованием массивов нет очевидного простого способа разбиения файлов, обеспечивающего устойчивость, так что устойчивость исключается еще до вступления в дело рекурсии. Хотя примитивная реализация быстрой сортировки для связных списков является устойчивой [4, С. 67].
2.6. Пирамидальная сортировка
Пирамидальная сортировка была предложение Дж. Уильямсом в 1964 году. Это алгоритм сортировки массива произвольных элементов; требуемый им дополнительный объём памяти не зависит от количества исходных данных. Время работы алгоритма в среднем, а также в лучшем и худшем случаях.
В основе пирамидальной сортировки лежит специальный тип бинарного дерева, называемый пирамидой; значение корня в любом поддереве такого дерева больше, чем значение каждого из его потомков. Непосредственные потомки каждого узла не упорядочены, поэтому иногда левый непосредственный потомок оказывается больше правого, а иногда наоборот. Пирамида представляет собой полное дерево, в котором заполнение нового уровня начинается только после того, как предыдущий уровень заполнен целиком, а все узлы на одном уровне заполняются слева направо.
Сортировка начинается с построения пирамиды. При этом максимальный элемент списка оказывается в вершине дерева: ведь потомки вершины обязательно должны быть меньше. Затем корень записывается последним элементом списка, а пирамида с удаленным максимальным элементом переформировывается. В результате в корне оказывается второй по величине элемент, он копируется в список, и процедура повторяется пока все элементы не окажутся возвращенными в список. [10, С. 362].
2.7. Поразрядная сортировка
Во многих приложениях сортировки ключи, используемые для упорядочения записей в файлах, могут быть весьма сложными. Представьте, например, насколько сложны ключи, используемые в телефонной книге или в библиотечном каталоге.
Часто нет необходимости в полной обработке ключей на каждом этапе: при поиске в телефонном справочнике, чтобы найти страницу с номером какого-либо абонента, достаточно проверить лишь несколько первых букв его фамилии. Чтобы добиться такой же эффективности алгоритмов сортировки, перейдем от абстрактной операции сравнения ключей к абстракции, в которой ключи разбиваются на последовательность частей фиксированного размера — байтов. Двоичные числа представляют собой последовательности битов, строки — последовательности символов, десятичные числа — последовательности цифр, аналогично могут рассматриваться и многие другие (хотя и не все) типы ключей. Методы сортировки, основанные на обработке ключей по частям, называются поразрядными методами сортировки (radix sort). Эти методы не просто сравнивают ключи, а обрабатывают и сравнивают части ключей [10, С. 401].
Алгоритмы поразрядной сортировки интерпретируют ключи как числа, представленные в системе счисления с основанием R, при различных значениях R (основание системы счисления — radix), и работают с отдельными цифрами этих чисел. Например, когда почтово-сортировочная машина обрабатывает пачку конвертов, каждый из которых помечен 5-значным десятичным числом, она распределяет эту пачку на десять отдельных пачек: в одной находятся пакеты, номера которых начинаются с 0, в другой находятся пакеты с номерами, начинающимися с 1, в третьей — с 2 и т.д. Каждая пачка может быть обработана отдельно с помощью того же метода, по следующей цифре, или более простым способом, если в пачке всего лишь несколько пакетов. Если теперь собрать пакеты из пачек в порядке от 0 до 9 и в таком же порядке внутри каждой пачки, то они окажутся упорядоченными. Эта процедура представляет собой поразрядную сортировку с R = 10, и такой метод удобен в приложениях, использующих сортировку, где ключами являются десятичные числа, содержащие от 5 до 10 цифр — наподобие почтовых кодов, телефонных номеров или идентификационных номеров [10, С. 404].
Алгоритмы поразрядной сортировки основаны на абстрактной операции «извлечь i-ю цифру ключа». К счастью, в С++ есть низкоуровневые операции, позволяющие реализовать такие действия просто и эффективно. Это очень важно, поскольку некоторые языки программирования (например, Pascal), поощряя машинно-независимое программирование, намеренно затрудняют написание программ, зависящих от способа представления чисел в конкретной машине. В таких языках трудно реализовать многие виды битовых операций, удобные для выполнения на большинстве компьютеров. В частности, жертвой этой " прогрессивной " философии стала и поразрядная сортировка. Однако создатели С и С++ поняли, что прямые операции с битами часто бывают весьма полезны, и при реализации поразрядной сортировки можно воспользоваться низкоуровневыми языковыми средствами [10, С. 405].
Нужна и хорошая аппаратная поддержка; нельзя считать ее само собой разумеющимся фактом. В некоторых машинах имеются эффективные способы доступа к малым порциям данных, но некоторые другие типы машин существенно снижают быстродействие на этих операциях. Поскольку алгоритмы поразрядной сортировки достаточно просто выражаются через операции извлечения разряда числа, задача достижения максимальной производительности алгоритма поразрядной сортировки может оказаться увлекательным введением в аппаратное и программное обеспечение [10, С. 405].
3. Программа сортировки данных
Программа написана на языке С++ (код программы представлен в приложении). В программе реализованы все рассматриваемые в работе алгоритмы сортировки для сортировки массива целых чисел, а именно: сортировка выбором, сортировка вставками, пузырьковая сортировка, сортировка Шелла, быстрая сортировка, сортировка слиянием, пирамидальная сортировка, поразрядная сортировка.
Первая часть программы демонстрирует работоспособность наших функций сортировки для сортировки массива из 10 элементов.
Вторая часть программы измеряет и выводит на экран время работы наших функций сначала при сортировке массива из 1000000 случайных элементов, затем (через запятую) время при сортировке уже отсортированного массива из 1000000 элементов.
Результат работы программы выглядит следующим образом

Эти данные позволяют оценить быстродействие алгоритмов в сравнении друг с другом, а так же естественность этих алгоритмов. Очевидно, что элементарные методы сортировки (выбором, вставками, пузырьком) сильно проигрывают по скорости более современным методам при сортировке случайной последовательности. Однако сортировки вставками и пузырьком, имея минимальное время выполнения при обработке уже отсортированных данных, ведут себя наиболее естественно. Из-за чего им вполне может быть отдано предпочтение при выборе для решения некоторых задач. Но для решения большинства простых задач закономерным выбором будет быстрая сортировка. Именно этот алгоритм и его модификация, например, использованы в стандартных библиотечных функциях C/C++ qsort и std::sort.
ЗАКЛЮЧЕНИЕ
Наверно, никакая другая проблема не породила такого количества разнообразнейших решений, как задача сортировки. Существует ли некий «абсолютный» алгоритм? Скорей всего, нет. Выбор алгоритма очень сильно зависит от условия задачи, которую необходимо решить. Однако, имея приблизительные характеристики исходных данных, можно подобрать метод, работающий оптимальным образом.
Методы сортировки являются критическими компонентами многих прикладных систем. Довольно часто предпринимаются специальные меры, чтобы сортировка работала максимально быстро или могла обрабатывать очень большие файлы. Нередко появляются усовершенствования вычислительных систем, или специальные аппаратные средства, повышающие производительность сортировки, или просто новые компьютерные системы, основанные на новых архитектурных решениях. В таких случаях представления об относительной стоимости операций, выполняемых над сортируемыми данными, могут оказаться неверными.
Проблема поддержки эффективных методов сортировки рано или поздно встает перед любой новой компьютерной архитектурой. В самом деле, исторически сложилось так, что сортировка служит своеобразным испытательным полигоном при разработке новой архитектуры, поскольку она и практически важна, и легка для понимания. Хочется знать не только то, какой из известных алгоритмов и в силу каких причин выполняется на новой машине лучше других, но также и то, можно ли при разработке нового алгоритма воспользоваться конструктивными особенностями конкретной машины.
Сортировка является одной из фундаментальных алгоритмических задач программирования. Практически каждый алгоритм сортировки можно разбить на 3 части: сравнение, определяющее упорядоченность пары элементов; перестановку, меняющую местами пару элементов; собственно сортирующий алгоритм, который осуществляет сравнение и перестановку элементов до тех пор, пока все элементы множества не будут упорядочены.
Для оценки трудоемкости алгоритмов сортировки используются параметры: время сортировки, дополнительная память, устойчивость и естественность поведения
По сфере применения алгоритмы сортировок классифицируются на алгоритмы внутренних и внешних сортировок.
Таким образом, в первой главе курсовой работы был рассмотрен исторический аспект методов сортировки данных с конца XIX века по настоящее время, приведены ключевые фигуры, сыгравшие роль в развитии алгоритмов сортировки.
Во второй главе были рассмотрены несколько методов сортировки данных. Более подробно – элементарные методы сортировки – сортировка выбором, сортировка вставками, пузырьковая сортировка, сортировка методом Шелла, быстрая сортировка. Также в курсовой работе были затронуты метод сортировки слиянием и пирамидальная сортировка.
В третий главе описана программа, в которой реализованы все рассматриваемые в работе алгоритмы сортировки для сортировки массива целых чисел.
Сортировка играет исключительно важную роль во многих практических приложениях, и разработка эффективных методов сортировки часто является одной из первых задач, решаемых на новых компьютерных архитектурах и в новых средах программирования. Учитывая то, что новые разработки строятся на старом опыте, важно иметь представление о наборе технических средств, рассмотренных в курсовой работе.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Алгоритмы. Построение и анализ/ Томас Х. Кормен, Чарльз И. Лейзерсон, Рональд Л. Ривест, Клиффорд Штайн. – М.: Вильямс, 2012. – 1296 с.
- Ахо А. В., Хопкрофт Д. Э., Ульман Д. Д. Структуры данных и алгоритмы / Под ред. А. А. Минько. — М.: Вильямс, 2000. — С. 231
- Заславская О.Ю., Кравец, О.Я., Говорский А.Э. Архитектура компьютера и вычислительных систем (лекции, лабораторные работы, контрольные задания): Учебник/О.Ю. Заславская, О.Я. Кравец, А.Э. 4. Говорский; под ред. чл.-корр.РАО, д-ра техн. наук профессора С.Г. Григорьева. – Воронеж: «Научная книга», 2011. – 300 с.
- Зубов В.С., Фальк В.Н. Новый алгоритм быстрой сортировки выбором //Вестник МЭИ. 2006. №6. С. 62-68.
- Зубов В.С., Шевченко И.В. О статусе пирамидальной сортировки // Вестник МЭИ. 2005. №3. С.89.
- Кнут Д. Искусство программирования. Том 3. Сортировка и поиск. – М.: Вильямс, 2014. – 824 с.
- Левитин А. В. Алгоритмы. Введение в разработку и анализ — М.: Вильямс, 2006. — С. 144–146. — 576 с.
- Макконнелл Дж. Основы современных алгоритмов / Под ред. С. К. Ландо. — М.: Техносфера, 2004. — С. 72-76.
- Полунов Ю. АВТОРА!!! // PCWeek/RE. - 2006. – №20.
- Седжвик Р. Алгоритмы на C++. - М.: Вильямс, 2011 - 1056 с.
- Частиков А. Архитекторы компьютерного мира. – СПб.: БХВ-Петербург, 2002 – 384 с.
Приложение 1
Программа сортировки данных
#include <iostream>
#include <time.h>
using std::cout;
using std::cin;
//функция swap меняет местами значения элементов
//используется в большинстве наших функций сортировки
void swap(int& a, int& b)
{
int temp;
temp = a;
a = b;
b = temp;
}
//сортировка выбором
void selection_sort(int *arr, int size)
{
for (int i = 0; i < size - 1; i++)
{
int min_index = i; // индекс минимального элемента
//ищем минимальный из всех элементов правее i
for (int j = i + 1; j < size; j++)
{
if (arr[j] < arr[min_index])
{
min_index = j; //запоминаем индекс
}
}
if (min_index != i)
{
//перестановка текущего элемента с минимальным
swap(arr[i], arr[min_index]);
}
}
}
// сортировка вставками
void insertion_sort(int *arr, int size)
{
int temp; // временная переменная для хранения значения элемента сортируемого массива
for (int i = 1; i < size; i++)
{
temp = arr[i]; // запоминаем значение текущего элемента массива
int j = i - 1; // запоминаем индекс предыдущего элемента массива
while (j >= 0 && arr[j] > temp) // пока индекс не равен 0 и предыдущий элемент массива больше текущего
{
// перестановка элементов массива
arr[j + 1] = arr[j];
arr[j] = temp;
j--;
}
}
}
// пузырьковая сортировка
void bubble_sort(int *arr, int size)
{
bool exit = false; // булевая переменная для выхода из цикла, если массив отсортирован
while (!exit) // пока массив не отсортирован
{
exit = true;
for (int i = 0; i < (size - 1); i++) // внутренний цикл
{
if (arr[i] > arr[i + 1]) // сравниваем два соседних элемента
{
// выполняем перестановку элементов массива
swap(arr[i], arr[i + 1]);
exit = false; // на очередной итерации была произведена перестановка элементов
}
}
}
}
//сортировка Шелла
void shells_sort(int *arr, int size)
{
for (int step = size / 2; step > 0; step = step / 2)
{
for (int i = 0; i < (size - step); i++)
{
//будем идти начиная с i-го элемента
for (int j = i; j >= 0 && arr[j] > arr[j + step]; j--)
//пока не пришли к началу массива
//и пока рассматриваемый элемент больше
//чем элемент находящийся на расстоянии шага
{
//меняем их местами
swap(arr[j], arr[j + step]);
}
}
}
}
//рекурсивная быстрая сортировка
// left - левая граница массива (индекс первого элемента)
// right - правая граница массива (индекс последнего элемента)
void quick_sort(int *arr, int left, int right)
{
// middle - центральный опорный элемент
int middle = arr[left + (right - left) / 2];
int i = left;
int j = right;
// цикл продолжается, пока индексы i и j не сойдутся
while (i <= j)
{
while (arr[i] < middle) i++; // пока i-ый элемент не превысит опорный
while (arr[j] > middle) j--; // пока j-ый элемент не окажется меньше опорного
if (i <= j)
{
swap(arr[i++], arr[j--]);
}
}
// рекурсивные вызовы, если есть, что сортировать
if (i < right)
quick_sort(arr, i, right);
if (left < j)
quick_sort(arr, left, j);
}
// рекурсивная сортировка слиянием
// up - массив, который нужно сортировать
// down - массив с таким же размером как у 'up', используется как буфер
// left - левая граница массива (индекс первого элемента)
// right - правая граница массива (индекс последнего элемента)
// возвращает указатель на отсортированный массив
// (из-за особенностей работы данной реализации отсортированная версия массива может оказаться либо в 'up', либо в 'down').
int* merge_sort(int *up, int *down, int left, int right)
{
if (left == right)
{
down[left] = up[left];
return down;
}
// middle - индекс центрального опорного элемента
int middle = left + (right - left) / 2;
// разделяй и сортируй
int *l_buff = merge_sort(up, down, left, middle);
int *r_buff = merge_sort(up, down, middle + 1, right);
// слияние двух отсортированных половин
int *target = l_buff == up ? down : up;
int width = right - left, l_cur = left, r_cur = middle + 1;
for (int i = left; i <= right; i++)
{
if (l_cur <= middle && r_cur <= right)
{
if (l_buff[l_cur] < r_buff[r_cur])
{
target[i] = l_buff[l_cur];
l_cur++;
}
else
{
target[i] = r_buff[r_cur];
r_cur++;
}
}
else if (l_cur <= middle)
{
target[i] = l_buff[l_cur];
l_cur++;
}
else
{
target[i] = r_buff[r_cur];
r_cur++;
}
}
return target;
}
// подфункция для heap_sort
// функция "просеивания" через кучу - формирование кучи
void sift(int *arr, int root, int bottom)
{
int max_сhild; // индекс максимального потомка
bool done = false; // флаг того, что куча сформирована
// Пока не дошли до последнего ряда
while ((root * 2 <= bottom) && (!done))
{
if (root * 2 == bottom) // если в последнем ряду,
max_сhild = root * 2; // запоминаем левый потомок
// иначе запоминаем больший потомок из двух
else if (arr[root * 2] > arr[root * 2 + 1])
max_сhild = root * 2;
else
max_сhild = root * 2 + 1;
// если элемент вершины меньше максимального потомка
if (arr[root] < arr[max_сhild])
{
// меняем их местами
swap(arr[root], arr[max_сhild]);
root = max_сhild;
}
else // иначе
done = true; // пирамида сформирована
}
}
// пирамидальная сортировка (сортировка кучей)
void heap_sort(int *arr, int size)
{
// Формируем нижний ряд пирамиды
for (int i = (size / 2) - 1; i >= 0; i--)
sift(arr, i, size - 1);
// Просеиваем через пирамиду остальные элементы
for (int i = size - 1; i >= 1; i--)
{
swap(arr[0], arr[i]);
sift(arr, 0, i - 1);
}
}
// поразрядная рекурсивная MSD сортировка
// bit - маска двоичного разряда
void radix_sort(int *arr, int size, unsigned bit = 0x80000000)
{
if (!bit) // если маска разяряда равна 0, ничего не делаем
return;
if (size < 2) // если массив из менее чем двух элементов, ничего не делаем
return;
int last = 0;
if (bit == 0x80000000) // старший бит в int определяет знак числа, поэтому
{
// сортируем так, чтобы все элементы со знаком -,
// оказались перед элементами со значком +
for (int i = 0; i < size; i++)
{
if ((arr[i] & bit))
swap(arr[last++], arr[i]);
}
}
else //для остальных разрядов
{
// сортируем так, чтобы все элементы со значением двоичного разряда,
//определенного маской bit, равным 0 оказались перед элементами со значением этого разряда равным 1
for (int i = 0; i < size; i++)
{
if ((arr[i] & bit) == 0)
swap(arr[last++], arr[i]);
}
}
// повторяем для каждой из получившихся частей со следующим разрядом
radix_sort(arr, last, bit >> 1);
radix_sort(arr + last, size - last, bit >> 1);
}
int main(int argc, char* argv[])
{
// Первая часть программы
// демонстрирует работоспособность наших функций для сортировки
// массива из 10 элементов, заполненного случайными двухзначными числами.
const int sz = 10; // размер массива
int a[sz]; // исходный неотсортированный массив
int b[sz]; // массив для сортировки
int c[sz]; // буфер для функции merge_sort
int* r; // переменная для получения результата работы функции merge_sort
//заполняем массив a случайными числами от -99 до 99
//и выводим на экран
for (int i = 0; i < sz; i++)
{
a[i] = rand() % 100 * (rand() % 2 ? -1 : 1);
cout << a[i] << " ";
}
memcpy(b, a, sz * sizeof(int)); // копируем массив а в b
selection_sort(b, sz); // сортируем массив b
cout << "\n" << "selection_sort: ";
for (int i = 0; i < sz; i++) cout << b[i] << " "; // выводим массив на экран
memcpy(b, a, sz * sizeof(int)); // копируем массив а в b
insertion_sort(b, sz); // сортируем массив b
cout << "\n" << "insertion_sort: ";
for (int i = 0; i < sz; i++) cout << b[i] << " "; // выводим массив на экран
memcpy(b, a, sz * sizeof(int)); // копируем массив а в b
bubble_sort(b, sz); // сортируем массив b
cout << "\n" << "bubble_sort: ";
for (int i = 0; i < sz; i++) cout << b[i] << " "; // выводим массив на экран
memcpy(b, a, sz * sizeof(int)); // копируем массив а в b
shells_sort(b, sz); // сортируем массив b
cout << "\n" << "shells_sort: ";
for (int i = 0; i < sz; i++) cout << b[i] << " "; // выводим массив на экран
memcpy(b, a, sz * sizeof(int)); // копируем массив а в b
quick_sort(b, 0, sz - 1); // сортируем массив b
cout << "\n" << "quick_sort: ";
for (int i = 0; i < sz; i++) cout << b[i] << " "; // выводим массив на экран
memcpy(b, a, sz * sizeof(int)); // копируем массив а в b
r = merge_sort(b, c, 0, sz - 1); // сортируем массив b
cout << "\n" << "merge_sort: ";
for (int i = 0; i < sz; i++) cout << r[i] << " "; // выводим массив на экран
memcpy(b, a, sz * sizeof(int)); // копируем массив а в b
heap_sort(b, sz); // сортируем массив b
cout << "\n" << "heap_sort: ";
for (int i = 0; i < sz; i++) cout << b[i] << " "; // выводим массив на экран
memcpy(b, a, sz * sizeof(int)); // копируем массив а в b
radix_sort(b, sz); // сортируем массив b
cout << "\n" << "radix_sort: ";
for (int i = 0; i < sz; i++) cout << b[i] << " "; // выводим массив на экран
cout << "\n";
// Вторая часть программы измеряет и выводит на экран время выполнения
// каждой из наших функций сортировки при сортировке сначала массива из 1000000
// случайных чисел, а затем сортировке уже отсортированного массива.
const int SZ = 1000000; // размер массива
int* A = new int[SZ]; // исходный неотсортированный массив
int* B = new int[SZ]; // массив для сортировки
int* C = new int[SZ]; // буфер для функции merge_sort
int* R; // переменная для получения результата работы функции merge_sort
unsigned t; // переменная для сохранения текущего времени перед началом сортировки
// заполняем массив А случайными числами
for (int i = 0; i < SZ; i++)
{
A[i] = rand();
}
memcpy(B, A, SZ * sizeof(int)); // копируем массив A в B
t = clock(); // запомниаем исходное время
selection_sort(B, SZ); //сортируем массив B
cout << "\n" << "selection_sort: " << clock() - t; //выводим время выполнения
t = clock(); // запомниаем исходное время
selection_sort(B, SZ); //сортируем уже отсортированный массив B
cout << ", " << clock() - t; //выводим время выполнения
memcpy(B, A, SZ * sizeof(int)); // копируем массив A в B
t = clock(); // запомниаем исходное время
insertion_sort(B, SZ); //сортируем массив B
cout << "\n" << "insertion_sort: " << clock() - t; //выводим время выполнения
t = clock(); // запомниаем исходное время
insertion_sort(B, SZ);//сортируем уже отсортированный массив B
cout << ", " << clock() - t; //выводим время выполнения
memcpy(B, A, SZ * sizeof(int)); // копируем массив A в B
t = clock(); // запомниаем исходное время
bubble_sort(B, SZ); //сортируем массив B
cout << "\n" << "bubble_sort: " << clock() - t; //выводим время выполнения
t = clock(); // запомниаем исходное время
bubble_sort(B, SZ);//сортируем уже отсортированный массив B
cout << ", " << clock() - t; //выводим время выполнения
memcpy(B, A, SZ * sizeof(int)); // копируем массив A в B
t = clock(); // запомниаем исходное время
shells_sort(B, SZ); //сортируем массив B
cout << "\n" << "shells_sort: " << clock() - t; //выводим время выполнения
t = clock(); // запомниаем исходное время
shells_sort(B, SZ); //сортируем уже отсортированный массив B
cout << ", " << clock() - t; //выводим время выполнения
memcpy(B, A, SZ * sizeof(int)); // копируем массив A в B
t = clock(); // запомниаем исходное время
quick_sort(B, 0, SZ - 1); //сортируем массив B
cout << "\n" << "quick_sort: " << clock() - t; //выводим время выполнения
t = clock(); // запомниаем исходное время
quick_sort(B, 0, SZ - 1); //сортируем уже отсортированный массив B
cout << ", " << clock() - t; //выводим время выполнения
memcpy(B, A, SZ * sizeof(int)); // копируем массив A в B
t = clock(); // запомниаем исходное время
R = merge_sort(B, C, 0, SZ - 1); //сортируем массив B
cout << "\n" << "merge_sort: " << clock() - t; //выводим время выполнения
t = clock(); // запомниаем исходное время
R = merge_sort(R, R == C ? B : C, 0, SZ - 1); //сортируем уже отсортированный массив R
cout << ", " << clock() - t; //выводим время выполнения
memcpy(B, A, SZ * sizeof(int)); // копируем массив A в B
t = clock(); // запомниаем исходное время
heap_sort(B, SZ); //сортируем массив B
cout << "\n" << "heap_sort: " << clock() - t; //выводим время выполнения
t = clock(); // запомниаем исходное время
heap_sort(B, SZ); //сортируем уже отсортированный массив B
cout << ", " << clock() - t; //выводим время выполнения
memcpy(B, A, SZ * sizeof(int)); // копируем массив A в B
t = clock(); // запомниаем исходное время
radix_sort(B, SZ); //сортируем массив B
cout << "\n" << "radix_sort: " << clock() - t; //выводим время выполнения
t = clock(); // запомниаем исходное время
radix_sort(B, SZ); //сортируем уже отсортированный массив B
cout << ", " << clock() - t; //выводим время выполнения
cin.get();
//освобождаем память
delete[] A;
delete[] B;
delete[] C;
}

- Разработка регламента выполнения процесса «Расчет заработной платы» (Автоматизация в бухгалтерском учете)
- История и развитие методологии объектно-ориентированного программирования. Сферы применения»
- Изучение правового регулирования валютного рынка
- Задачи и функции нотариата в Российской Федерации
- Исправление ошибок в учетных регистрах
- Процесс монополизации рынка в теории и на практике (практические аспекты монополизации рынка в России)
- Человеческий фактор в управлении организацией (Человеческие ресурсы как объект управления)
- Анализ организационной культуры (в конкретной организации)
- Особенности политики регулирования численности персонала в организациях бюджетной сферы
- Эффективность менеджмента организации (Анализ эффективности менеджмента ООО «Костромастрой»)
- Формирование лояльности в поведении персонала (на примере ООО «Деймос»)
- Разработка регламента выполнения процесса «Расчет заработной платы» (моделирование существующих бизнес-процессов в организации и разработка предполагаемых мероприятий по улучшению расчета заработной платы)