
Рекурсивные и итерационные алгоритмы: особенности и примеры использования (Структура итерационного алгоритма)
Содержание:

Введение
Тема данной курсовой работы «Рекурсивные и итерационные алгоритмы: особенности и примеры использования» выбрана не случайно. По моему убеждению, для успешного освоения навыков программирования необходимы глубокие знания базы, на которой строятся практически все популярные в наши дни языки программирования. В частности, так называемые объектно-ориентированные языки программирования, например, C и C++, JavaScript, Python, по сути, имеют схожую структуру, и для освоения базовых навыков можно использовать основные структуры алгоритмов, в том числе и группу рассматриваемых в этой работе.
Наша задача при написании данной работы заключается в знакомстве с двумя базовыми структурами, используемыми при составлении алгоритмов компьютерных программ, а также с некоторыми примерами их использования.
В главе 1 рассмотрим основные понятия – что такое алгоритм, итерация и рекурсия, вспомним, что такое базовые структуры алгоритмов. Более детальное внимание структурам итерационных и рекурсивных алгоритмов уделяется в главах 2 и 4 соответственно, а об их использовании поговорим в главах 3 и 5 соответственно. В главе 6 уделим внимание практической необходимости использования алгоритмов сортировки и поиска, основанных на рассматриваемых базовых структурах.
Основными учебными материалами, использованными при написании данной работы, являются учебные пособия В. А. Голикова «Теория программирования»[1] и Е. А. Роганова «Основы информатики и программирования»[2], а также небезызвестные учебники Томаса Х. Кормена «Алгоритмы: вводный курс»[3] и в меньшей степени его труд вместе с соавторами «Алгоритмы: построение и анализ»[4], а также книга Джона Маккормика «Девять алгоритмов, изменивших мир»[5] (John McCormick’s “Nine Algorithms That Changed the Future”), А. Левитина «Алгоритмы: введение в разработку и анализ» [6]. Все перечисленные пособия являются проверенным инструментом в обучении программированию и имеют под собой глубокую теоретическую базу. Также использовался международный ресурс онлайн-обучения программированию codecademy.com [7], где имеются не только теоретические справки и задания, но и возможность редактировать и выполнять программный код.
Глава 1. Понятие алгоритма, итерационного, рекурсивного алгоритмов.
Алгоритм – это последовательность действий (команд, инструкций), заданный исполнителю. Этим исполнителем может быть и сам задающий. Алгоритмом в том числе является и компьютерная программа – по сути, это алгоритм, заданный компьютеру на специальном языке – языке программирования. Компьютерные алгоритмы, в отличие от «человеческих» не могут толковаться неоднозначно. В результате выполнения алгоритма для компьютера должна решаться поставленная ему задача. Это означает, что главное в алгоритме – именно результат его работы, который может быть достигнут различными способами. Также требуется максимально точное описание каждой команды, так как неоднозначная трактовка компьютером инструкции недопустима. При этом совершенно очевидно, что необходимо эффективно использовать ресурсы компьютера . Помимо учета технических характеристик компьютера, который будет исполнять алгоритм, важным показателем является время работы алгоритма. Алгоритм, который дает правильное решение, но требует большого времени для его получения, не имеет практической ценности [3]. Именно для оптимизации структуры алгоритма существуют так называемые базовые структуры.
Рассмотрим такое понятие, как структурный подход к построению алгоритма: он предполагает использование только нескольких основных структур, комбинация которых дает все многообразие алгоритмов и программ [1]. Базовых структур имеется ограниченное количество, и все они в различных сочетаниях способны описать любой алгоритм.
В данной работе будут подробно разобраны итерационные и рекурсивные структуры.
Понятие итерация происходит от латинского iteratio – повторяю. Вспомним, что такое цикл – это базовая структура, в которой некоторая часть программы, выполняемая многократно, после проверки некоторого условия в какой-то момент осуществляется выход из нее [1]. Эта часть программы называется телом цикла, а единичное выполнение тела цикла – итерацией. Итерационным циклом при этом считается такой цикл, где количество повторений заранее неизвестно [1]. Если же требуемое количество повторений действия уже известно, используется счетчик цикла – переменная, связанная с номером итерации.
Важно отметить, что рекурсия (в программировании так называют такой способ организации обработки данных, при котором программа вызывает сама себя непосредственно либо с помощью других программ [2]) в случае итерационного цикла недопустима, многократное повторение действий происходит без обращений программы к части самой себя.
В следующей главе будет более подробно рассмотрена структура итерационных алгоритмов.
Глава 2. Структура итерационного алгоритма
Итерационные алгоритмы применяются в тех случаях, когда некоторое действие требуется повторить несколько раз. Очевидно, что просто последовательное выполнение команд будет неэффективно как с точки зрения удобства, так и рациональности использования ресурсов компьютера[2, 3, 4]. Тем более это необходимо, когда количество повторений действия заранее не определено. Поэтому вводится специальное условие (обычно это логическое выражение): при истинности будет происходить итерация цикла, а при ложности – выход из цикла.
На рисунке 1 базовые структуры алгоритмов приведены в виде блок-схем. Под буквой б видим так называемый цикл «До» - он же цикл с постусловием, в JavaScript используется оператор do…while[7]. Буквой в отмечен цикл «Пока» - соответственно, цикл с предусловием, или же “While” Loop [7]. Существуют и циклы без условия (они являются бесконечными, и для выхода из них требуется специальная команда прерывания или выхода [2], в рамках данной работы они рассматриваться не будут).
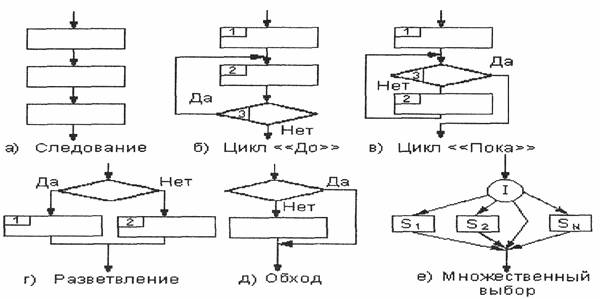
Рис. 1: Основные структуры алгоритмов (Источник: [1])
Цикл «До» используется тогда, когда требуется выполнить действие хотя бы 1 раз. Сначала выполняется команда, а затем проверяется условие итерации. Если условие не соблюдается, мы получаем результат первой команды, но не входим в цикл. Иначе цикл будет выполняться до ложности условия итерации.
Итак, приведем пример записи цикла с постусловием на языке JavaScript с помощью оператора «Do… While”.
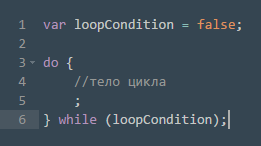
Рис. 2: Использование оператора do…while для записи цикла с постусловием
Здесь в строке 1 задается переменная, содержащая значение условия выхода из цикла. Сразу присваиваем ей значение false – «ложно». Оператор do содержит тело цикла, а оператор while выполняет проверку истинности условия. Видим, что так как изначально условию присвоено ложное значение, тело цикла выполнится, и сразу произойдет выход из цикла. В ходе выполнения тела цикла условие будет изменяться, и рано или поздно мы выйдем из цикла. В противном случае получаем бесконечный цикл.
Перейдем к циклу с предусловием. Конструкция очень похожа, но проверка условия цикла будет происходить до выполнения тела цикла. Это значит в первую очередь то, что если условие выполения цикла ложно изначально, то тело цикла не выполнится ни одного раза. В JavaScript для его записи используется, как правило, оператор while.
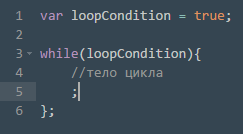
Рис. 3: Использование оператора while для записи цикла с предусловием
На рисунке 3 заранее присвоено истинное значение, в теле цикла также должно быть изменение условия на ложное, иначе получим бесконечный цикл.
Несмотря на то, что оператор for по большей части используется для циклов по счетчику [7], с помощью него также можно написать цикл с предусловием.
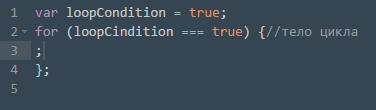
Рис. 4: Использование оператора for для записи цикла с предусловием
Глава 3. Примеры использования итерационных алгоритмов
3.1 Алгоритмы линейного поиска
При работе с массивами данных зачастую требуется найти какой-либо элемент и произвести с ним действие. Для этого переменной условия выхода из цикла присваивается искомое значение, и идет просмотр элементов массива. Для относительно простых задач по поиску необходимых элементов массива будет достаточно использовать линейный поиск.
Сразу отметим очевидность использование базовых структур с итерацией либо рекурсией для математических вычислений, поэтому в рамках данной работы эти примеры рассматривать не будем.
В самом простом варианте используется линейный поиск с использованием цикла со счетчиком: просматриваются все элементы массива на предмет совпадения с искомым значением.
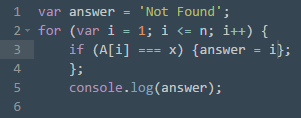
Рис. 5: Линейный поиск (на основе [3])
Видим, что если искомое значение не найдется, программа дает ответ «не найдено», заданный заранее. n здесь – переменная, обозначающая последний элемент массива, i – счетчик (ее значение также является номером просматриваемого элемента массива), x – искомое значение. Счетчик увеличивает значение на 1 после каждой итерации. Обратим внимание, что если искомых элементов в массиве несколько, в результате показан будет только последний из них, а не все.
Недостаток данного алгоритма в том, что даже если искомое значение найдено, все равно продолжается просмотр элементов массива. Чтобы оптимизировать этот алгоритм, можно останавливать его при первом же нахождении нужного значения – добавляется команда break и выводится результат. В противном случае просмотр элементов пройдет до конца, и в результате получим ответ not found [3].
В обоих случаях происходит две проверки каждого элемента массива: проверка условия (не вышли ли мы за пределы от 1 до n) и сверка с искомым значением. Чтобы отбросить первый этап, можно воспользоваться алгоритмом линейного поиска с ограничителем. Здесь вместо оператора for используется while, что делает алгоритм более эффективным [4].
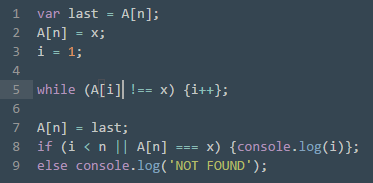
Рис. 6: Линейный поиск с ограничителем (на основе [3]);
Мы вводим переменную last и помещаем в нее значение последнего элемента массива. Счетчику задается значение 1, а искомое значение помещаем в последний элемент (то есть у нас теперь гарантированно есть искомый результат, в конце просто нужно будет сверить исходное значение последнего элемента массива с искомым). Затем до тех пор, пока значение просматриваемого элемента не совпадает с искомым, происходит увеличение счетчика. Присваиваем последнему элементу его исходное значение. Затем у нас идет ветвление: если найденное значение не последнее, выводим его значение. Если окажется, что замененное значение A[n] и было истинным, у нас также есть ответ. В противном случае, ответ not found.
3.2 Алгоритмы сортировки
Для более сложных задач перед поиском желательно предварительно провести сортировку массива. Для этой процедуры у каждого элемента массива мы имеем в виду два атрибута: ключ сортировки (то свойство, по которому необходимо сортировать элементы) и сопутствующие данные (все остальные атрибуты элемента) [3].
Один из простых вариантов – это сортировка выбором. Она подойдет лучше всего для небольших массивов. В этом варианте мы находим самое малое значение ключа сортировки и помещаем этот элемент на первое место массива, затем находим второй по величине элемент и перемещаем на второе, и так далее до предпоследнего. Здесь работает алгоритм линейного поиска, рассмотренный выше.
Также часто используется сортировка вставкой.
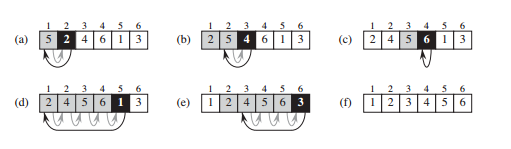
Рис. 7: Наглядное представление сортировки вставкой (Источник: [4])
Смысл ее состоит в том, что текущий элемент массива (A[j]) сравнивается со всеми уже отсортированными элементами. Если его ключ меньше элемента из отсортированной части массива (A[i]), он занимает его место, и все последующие элементы сдвигаются на 1.

Рис. 8: Программный код для сортировки вставкой (Источник: [4])
На рисунке 8 легко узнается цикл с предусловием.
Один из самых популярных в учебной литературе алгоритмов сортировки – это сортировка пузырьком. Ее смысл заключается в попарном сравнении ключей элементов массива, больший и меньший элемент меняются местами так, что постепенно элемент с наименьшим ключом как бы всплывает в начало массива. Неудобство метода состоит в том, что требуется много проходов по всему массиву, поэтому данный способ сортировки является, скорее, учебным, однако, на его основе были разработаны более совершенные методики – например, перемешиванием, быстрая [7].
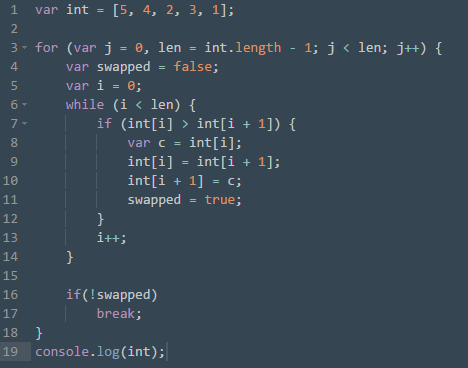
Рис. 9: Сортировка пузырьком
Видим, что цикл сравнения i-того и i+1-го элемента повторяется, пока сортировки не перестанут требоваться.
Данные три типа сортировки помогут, когда необходимо отсортировать относительно небольшой массив и сразу получить результат. Рассмотрим еще несколько весьма эффективных типа сортировки, но сначала нам понадобится ознакомиться с рекурсивными алгоритмами.
Глава 4. Структура рекурсивного алгоритма
Как уже упоминалось, рекурсивный алгоритм подразумевает обращение программы к части самой себя. Для целесообразности использования этого метода требуется соблюдение нескольких условий. Во-первых, должен существовать один или несколько базовых случаев, когда вычисления проводятся непосредственно, без рекурсии. Во-вторых, каждый рекурсивный вызов процедуры должен быть меньшим экземпляром той же самой задачи, так что в конечном итоге будет достигнут один из базовых случаев [3].
Наиболее часто приводится пример с вычислением факториала числа с использованием рекурсии.
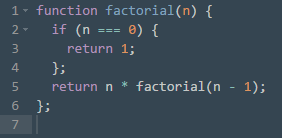
Рис. 9: Вычисление факториала на JavaScript
Интересен сам процесс выполнения программы с рекурсией. При заданном значении n вызывается функция factorial для вычисления factorial(n); затем выполнение функции будет приостановлено, и вызывается эта же функция factorial для вычисления factorial (n - 1) и так далее до n = 0 – а это уже базовый случай. Таким образом, у нас появляется стек вызовов функции (n+1 вызов), которые будут выполняться от 0 до n [2].
Прямую связь с рекурсивными алгоритмами имеет метод программирования, называемый «Разделяй и властвуй» (divide-and-conquer, [4]). В общих чертах, соблюдается три этапа моделирования алгоритма:
1) Разделение основной задачи на подзадачи;
2) Рекурсивное решение подзадач (они также могут, в свою очередь, разбиваться на подзадачи, а достаточно малые подзадачи будут решаться как базовые случаи);
3) Слияние найденных решений подзадач в одно общее решение.
Этот метод будет необходим при рассмотрении некоторых других типов алгоритмов сортировки и поиска.
Глава 5. Примеры использования рекурсивных алгоритмов
5.1 Алгоритм бинарного поиска
Суть данного алгоритма заключается в том, что уже отсортированный массив разбивается на две части, и поиск проходит в части массива. Возможно представить его и в итерационном виде, но мы воспользуемся подходом divide-and-conquer.

Рис. 10: Описание процедуры бинарного поиска в рекурсивном представлении с использованием псевдокода (Источник: [3])
Что происходит при выполнении кода? Выбираем элемент массива с индексом середины массива и сравниваем ее ключ с искомым. Если найденный ключ больше искомого, рассматриваем часть массива от 1 до найденного, и наоборот. С просматриваемой частью массива процедура повторяется, пока сверяемый элемент не окажется искомым либо пока размер просматриваемой части массива не станет равен 0 – это приведет к результату Not Found.
5.2 Алгоритмы сортировки с использованием подхода divide-and-conquer
Ярким примером парадигмы divide-and-conquer является сортировка слиянием [4]. Рассмотрим ее общий смысл.
Разделение массива из n элементов на 2 подмассива размера n/2;
- Рекурсивно сортируем подмассивы (то есть при сортировке двух подмассивов их также разбиваем пополам);
- Соединяем получившиеся отсортированные подмассивы в один массив.
Недостаток данного алгоритма в том, что в отличие методов сортировки, рассмотренных выше, он более требователен к памяти, так как требуется сохранять не по одному элементу массива, а целые массивы и подмассивы [3].

Рис. 11: Сортировка слиянием, описанная с помощью псевдокода (Источник: [3])
На процедуре MERGE заострять внимание в рамках этой работы мы не будем.
Сортировка слиянием, как было уже выше сказано, более требовательна к памяти, чем следующий алгоритм – быстрая сортировка. Этот способ также основан на подходе divide-and-conquer, но так же, как и пузырьковая сортировка, будет осуществляться «на месте» [3].
Необходимо выбрать один элемент массива – будем называть его опорным. Затем происходит процедура разбиения массива относительно ключа опорного элемента – массив делится на две части относительно опорного элемента так, что всем элементам с ключом меньше либо равным присваиваются меньшие индексы, чем индекс опорного элемента, с большим ключом, соответственно, большие индексы. Теперь рекурсивно сортируем обе части массива, выбирая новые опорные элементы, этап слияния массива не потребуется, так как по завершении обе части массива уже отсортированы.
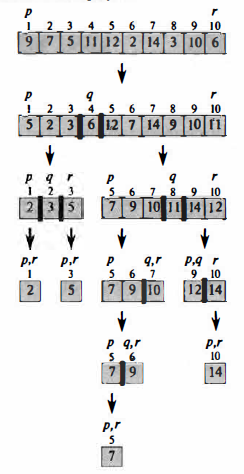
Рис. 12: Наглядное изображение работы алгоритма быстрой сортировки (Источник: [3])
Важно отметить, что каждый элемент сравнивается с опорным по одному разу, при этом выполняется не более одного обмена при сравнении с опорным элементом.
Прежде чем перейти к практическим аспектам, подведем небольшой итог.
Мы рассмотрели два типа алгоритмов поиска – линейный (несколько его вариантов) и бинарный. С одной стороны, выполнение алгоритма бинарного поиска быстрее [4], но, в отличие от линейного, для его работы требуется предварительная сортировка элементов массива.
Также мы познакомились с пятью методами сортировки массива. Это сортировки выбором, вставкой, пузырьком, слиянием и быстрая. Две последних производятся с помощью парадигмы divide-and-conquer, используя рекурсию, первые же три решают поставленную задачу «в лоб» (так называемый метод грубой силы [6]). За исключением сортировки слиянием, все перечисленные способы сортировки дают в результате готовые отсортированные массивы. Последним этапом сортировки слиянием будет собственно слияние полученных отсортированных подмассивов.
Глава 6. Практические задачи использования алгоритмов сортировки и поиска
Помимо очевидной работы вышеперечисленных алгоритмов при работе с массивами данных в решении учебных задач, обратимся к более глобальным задачам.
Например, поговорим о механизмах сопоставления и ранжирования, используемых в поисковых системах. Недостаточно только найти совпадения на веб-страницах с поисковым запросом, требуется также расположить эти страницы в порядке релевантности для удобства пользователя. Поисковая система Google смогла стать лучшей в своей нише именно благодаря совершенствованию алгоритмов ранжирования [5].
Одной из первых поисковых машин стала AltaVista, появившаяся в 1995 году. Основой работы поисковой системы служит принцип индексирования – с каждым словом или фразой сопоставляется номер страницы, на которой оно встречается (аналогия – алфавитный указатель в конце книги). Такой индексированный список, очевидно, отсортирован, что помогает произвести в нем поиск. Также индексируются положения слов на странице – таким образом, у каждого слова как у объекта поиска есть два атрибута – номер страницы и номер положения на странице. Это существенно облегчает поиск по фразам, а также приближает нас к возможности найти релевантный ответ на свой запрос. Для этого искомые слова на найденной странице должны встречаться рядом. Также в AltaVista использовался и поиск в названии или теле веб-страницы с помощью метаслов, относящихся к коду страницы и не отображающихся в браузере. [5]
Но именно алгоритм PageRank, осуществляющий ранжирование найденных страниц по их релевантности к поисковому запросу помог вырваться Google на вершину успеха [5].
Данный алгоритм включает в себя несколько методов. Учитывается количество гиперссылок, ведущих к найденным страницам (алгоритмы поиска) плюс авторитетность страниц, откуда идут эти ссылки (больше ссылок к ним – больше авторитетность), а также модель случайного посещения страниц (возможность остановки перехода по ссылкам и перезапуска поиска). Именно сочетание этих методов позволит показать наиболее релевантные страницы. Представление списка страниц по релевантности, очевидно также происходит с помощью алгоритмов сортировки.
Также описанные в данной работе алгоритмы работают во всех программах, работающих с базами данных. Это и табличный процессор MS Excel, и такие СУБД, как Access или SQL, и более сложные компьютерные системы, в которых требуется поиск и/или каталогизация документов. Очень распространены CRM-системы, позволяющие хранить и просматривать все обращения конкретного клиента в компанию, отправлять и запрашивать документы, и многое другое (яркий пример - MS CRM). Программы Siri и OK Google, являющиеся, по сути, искусственным интеллектом [5], из нескольких возможных вариантов ответа на запрос также должны выдать адекватный ответ, идет в том числе поиск нужного ответа в базе возможных.
Продолжать этот список можно довольно долго. Главный вывод – на основе рассматриваемых базовых структур работают одни из самых важных с прикладной точки зрения алгоритмов – сортировка и поиск.
Заключение.
В ходе выполнения данной работы были рассмотрены итерационные и рекурсивные алгоритмы с двух точек зрения – теоретической и практической.
Итак, мы рассмотрели такие понятия, как базовая структура алгоритма, сами понятия итерации и рекурсии в алгоритмах. Были даны понятия итерационного и рекурсивного алгоритма. Подробно разобраны структуры итерационных алгоритмов – построение и работа циклов с предусловием и постусловием, в рамках языка JavaScript описано использование операторов do…while, while и for. Далее перешли к алгоритмам поиска и сортировки, работающим «методом грубой силы» [6]. Затем дано определение рекурсивного алгоритма, а также уделено внимание другому очень важному методу построения алгоритмов – divide-and-conquer, использующему рекурсию как основное средство [4]. Также приведены алгоритмы поиска и сортировки, использующие последний подход. Напоследок приведены некоторые особо значимые примеры использования перечисленных алгоритмов.
Таким образом, задача, поставленная во введении к работе, была полностью выполнена.
Библиография
[1] Голиков В.А. Теория программирования. / Московская финансово-промышленная академия. – М., 48 с.
[2] Роганов Е. А. Основы информатики и программирования: Учебное пособие. — М.: МГИУ, 2001. – 315 c.
[3] Кормен, Томас Х. / Алгоритмы: вводный курс.: Пер. с англ. - М.: ООО "И.Д. Вильямc", 2014. – 208 c.
[4] Кормен Т., Лейзерсон Ч., Ривест Р., Штайн К. / Алгоритмы: построение и анализ, 3-е издание. - М.: ООО "И.Д. Вильямс", 2013. – 1328 с.
[5] MacCormick, John / Nine algorithms that changed the future : the ingenious ideas that drive today's computers / Princeton University Press, 2012. – 232 pp.
[6] Левитин А. / Алгоритмы: введение в разработку и анализ.: Пер. с англ. – Издательский дом «Вильямс», 2006 – 576 c.
[7] https://www.codecademy.com/learn/javascript (обращение в период 1.08.2016 - 16.09.2016)

- «Право собственности на землю
- Особенности сервиса в гостинично-ресторанном бизнесе города Краснодар на примере ресторана Камелот
- Теоретические аспекты рекламы
- Реклама в современном маркетинге
- Понятие и основные свойства алгоритмов
- «Приемка товаров по качеству и количеству на примере ИП “Земрау”
- Понятие и виды государственных пенсий (Условия назначения государственных пенсий)
- Особенности организации в коммуникации.
- Психологические теории интеллекта
- «Оценка качества товаров» .
- «Проблемы диагностики и управления организационной культурой»
- «Анализ конкурентов на рынке и определение собственной конкурентоспособности (на примере конкретной организации)