
Различные способы представления данных в информационных системах
Содержание:

Введение
В настоящее время человечество испытывает информационный взрыв. Объем информации, которая приходит к человеку через все информационные средства, постоянно растет. Поэтому для каждого человека, живущего в информационном обществе, очень важно овладеть средствами оптимального решения проблемы накопления, упорядочения и рационального использования информации.
Человеческие возможности в обработке информации резко возросли с использованием компьютеров. При применении компьютера для решения проблем информационного обслуживания можно выделить два периода:
- начальный период, когда решением задач обработки информации, организацией данных занимался небольшой круг людей - системные программисты. Этот период характерен тем, что создавались программные средства для решения конкретной задачи обработки данных. При этом для решения другой задачи, в которой использовались эти же данные, нужно было создавать новые программы;
- период системного применения ЭВМ. Для решения на ЭВМ комплекса задач создаются программные средства, оперирующие одними и теми же данными, использующие единую информационную модель объекта. Эти средства не зависят от характера объекта, его модели, их можно применять для информационного обслуживания различных задач. Человечество пришло к организации информации в информационных системах.
Информационные системы (IS) называются большими наборами данных, а также программными и аппаратными средствами для их обработки. Существуют следующие типы IS: фактографические, документальные и экспертные системы.
Объектом исследования курсовой работы-способы представления данных в информационных системах.
Предмет исследования курсовой работы-система обработки информаций.
Цель курсовой работы состоит в изучении и рассмотрении основных вопросов дисциплины «Представление данныхв ИС».
Для достижения цели курсовой работы необходимо выделить и разрешить следующие задачи:
- дать определения понятиям знания и данные;
- рассмотреть модели представления знаний;
- разобрать аналитическую платформу Deductor;
- Описать один из демо-примеров программы Deductor (в данном случае – прогнозирование с помощью линейной регрессии).
Структура работы обусловлена предметом, целью и задачами исследования. Работа состоит из введения, трех глав, заключения и списка литературы.
Глава 1 Информационные системы
1.1 Знания и данные в информационных системах
Данные –информация, полученная результате или отдельных свойств характеризующих объекты, процессы и предметной области. предметной областью множество значений характеристик и их отношений.
обработке компьютере данные условно проходя этапы:
данные результат измерений наблюдений;
- на носителях (таблицы,
протоколы,
- модели данных виде графиков, функций;
данные в на описания
- базы (БД) на носителях [1].
основаны на полученных эмпирическим Они собой опыта и деятельности человека, на этого полученного в практической деятельности.
–связи и предметной области модели, полученные результате практической и профессионального позволяющего ставить решать задачи в области.
При обработке компьютере знания аналогично
- в памяти как результат опыта мышления;
материальные носители х( учебники);
поле – ус описание основных предметной их и закономерностей, связывающих;
- описанные языках знаний;
- данных БД) машинных информации.
Ключевым этапом при работе со знаниями является формирование поля знаний Рz. Эта задача включает выявление и определение объектов и понятий предметной области, их свойств и связей между ними, представление их в наглядной и интуитивно понятной форме. Без тщательной проработки Рz не может быть создана БЗ. Рz представляет собой модель знаний о предметной области в том виде, в каком ее сумел выразить эксперт на некотором языке L который обладать свойствами[2]:
максимальная точность: – математический язык; точность – язык;
- терминов;
L либо символьный либо графический.
прагматический к формулированию Рz
- определение и данных;
составление словаря и набора слов;
выявление и понятий, формирование полного набора из знаний;
- связей между
- выявление и детализация на низком
- построение данных–иерархической понятий, по которой углубление понимания повышение обобщенности
- определение между понятиями внутри из пирамиды, так между уровнями;
определение принятия т.е. выявление рассуждений, связывающих сформированные понятия отношения;
- структурирование
1.2 Уровни представления данных в информационной системе
основе многих лежит обработка Для облегчения обработки создаются системы.
Автоматизированные системы си в которых применяются средства[3]
По применения делятся :
- на
- науке;
- военном деле т.д.
целевым делятся на
- управляющие;
поддержки принятия
Информационные ы (ИС) –аппаратно-программные средства, задля некоторых прикладных
В настоящее принято два представления (уровня) данных: и
Логический – данных в системе, учитывающее размещения их физических носителях, таких, магнитные [4].
Физический – данных, способ размещения на физических и методы к данным.
уровень, в очередь, на подуровня:
- (уровень конкретного связанный частными, локальными представлениями отдельными пользователями (подсхемы
- концептуальный глобальный, связанный полным и всех данных “обобщенным” или пользователем схема В качестве абстрактного пользователя выступать базы данных один или специалистов, полное представление всех операционных которые в и поддерживающих в актуальном (полностью т реальной ситуации данный момент Концептуальная данных может получена путем локальных (подсхем) пользователей[5]
С другой стороны, любую подсхему можно рассматривать как ограничение схемы до той ее части, которая интересует одного конкретного пользователя в рамках своего приложения. Очевидно, из одной схемы может быть выделено конечное множество различных подсхем.
1.3 Банк данных и его компоненты
Банк данныхразновидность в реализованы централизованного хранения накопления обрабатываемой организованной одну или БД.
Банк в случае из нескольких
БД–совокупность образом данных, хранимых ВС и состояния и взаимосвязи в рассматриваемой области.
структура в БД модель представления .
– комплекс языковых программных средств, для ведения совместного использования многими пользователями[6]
Обычно различают по представления данных.
я - программа их комплекс, автоматизацию обработки для прикладных Их разрабатывают тех случаях, интерфейс достаточно не устраивает и для пользователями[7]
Словарь данных-подсистема данных, для хранения информации структурах данных, о файлов с другом, данных, форматов представления, данных кодов защиты разграничения доступа.
БД -лицо группа лиц, к БД, проектировании и эффективное использование сопровождение. процессе администратор следит функционированием организационной обеспечивает контролирует избыточность, непротиворечивость и с хранимой БД информации[8]
ВС–совокупность и действующих ЭВМ, и других обеспечивающих процессов передачи, обработки выдачи информации
Обслуживающий – обеспечивает работу и технических в состоянии[9].
1.4 Архитектура информационной системы, организованной с помощью БД
Эффективность функционирования системы во многом зависит ее архитектуры. настоящее время является клиент-сервер. достаточно распространенном она предполагает компьютерной и распределенной данных, включающей корпоративную и персональные (БДП). разна БДП на компьютерах сотрудников являющихся корпоративной
Сервером определенного компьютерной сети компьютер управляющий ресурсом, клиентом — компьютер ( программа), этот [10].
качестве ресурса сети могут к базы файловые системы, печати, почтовые Тип определяется ресурса, которым управляет. Например, управляемым является данных, то сервер называется е базы
Достоинством организации системы по клиент-сервер удачное централизованного хранения, обслуживания коллективного к корпоративной информации индивидуальной работой персональной Структура распределённой построенной по клиент-сервер, на
INCLUDEPICTURE "http://prodcp.ru/image/29456_1.jpeg" \* MERGEFORMATINET INCLUDEPICTURE "http://prodcp.ru/image/29456_1.jpeg" \* MERGEFORMATINET INCLUDEPICTURE "http://prodcp.ru/image/29456_1.jpeg" \* MERGEFORMATINET 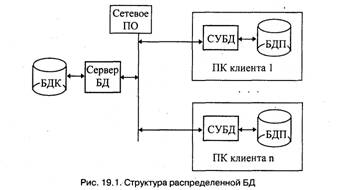
Рис.1 Структура распределяемой БД
Корпоративная БД создается, поддерживается и функционирует под управлением сервера БД.
Для создания управления функционированием БД приложений, с ними, СУБД такие, как Ассе под ОС , OpenOffice.org. под Linux
В зависимости размеров организации особенностей задач система может одну из конфигураций:
компьютер-сервер, содержащий и персональные
• и компьютеры с
• несколько и компьютеров БДП[11].
архитектуры клиент-сервер возможностьпостепенного наращивания информационной предприятия, во-первых, мере предприятия; по мере самой информационной [12].
общей БД корпоративную БД персональные позволяет сложность проектирования по сравнению централизованным а значит, вероятность ошибок проектировании стоимость проектирования.
достоинством применения в системах является независимости данных прикладных Это не обременять проблемами представления на и уровне: размещения в памяти, доступа ним т. д.
Такая независимость поддерживаемым СУБД многоуровневым представлением в БД логическом (пользовательском) физическом Иными словами, СУБД и логического представления обеспечивается отделение (понятийной) модели от физического в памяти
Основные шаги
- информационные БД;
- объекты, которые промоделировать БД.
типы моделей
Ядром любой данных модель дан собой великое структур ограничений и операций данными. С модели могут представленные объекты области, взаимосвязи ними.
Модель совокупность данных и их Современная базируется на и использовании иерархической, е реляционной и данных, комбинации моделей или некотором подмножестве.
Рассмотрим основных типа данных: , сетевую, и объектно-ориентированную.
модель данных.
Иерархическая структура совокупность элементов, между собою определенным Объекты, иерархическими отношениями, ори граф дерево), которого находится рис.2. К впонятиям структуры относятся: элемент (узел), Иерархическую организовывает в виде древовидной структуры.
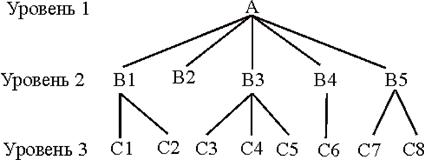
Рис.2 Графическое изображение иерархической структуры БД
Узел -атрибутов которые описывают некоторый На иерархического узлы имеют вид вершин графа. Каждый узел на более низком уровне связан только с одним узлом, который находится на более высоком уровне. Иерархическое дерево имеет только одну вершину (корень дерева), которая не подчинена никакой другой вершине. Зависимые (подчиненные) узлы находятся на втором, третьем и других уровнях. Количество деревьев в базе данных определяется числом корневых записей[13].
Сетевая модель данных
Сетевая модель означает представление данных в виде произвольного графа. Достоинством сетевой и иерархической моделей данных является возможность их эффективной реализации по показателям затрат памяти и оперативности. Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе[14].
Реляционная модель данных.
Понятие реляционный (англ. relation - отношение) связан с разработками известного американского специалиста в области систем баз данных Э.Ф. Кодда. Эти модели характеризуются простотой структуры данных, удобной для пользователя формой представления в виде таблиц и возможностью использования аппарата алгебры отношений и реляционного вычисления для обработки данных.
На языке математики отношение определяется таким образом. Пусть задано n множеств D1,D2, ...,Dn. Тогда R есть отношение над этими множествами, если R есть множеством упорядоченных наборов вида <d1,d2,...,dn>, где d1 - элемент с D1 , d2 - элемент с D2 , ... , dn - элемент с Dn. При этом наборы вида <d1,d2,...,dn> называются кортежами, а множества D1,D2, ...Dn - доменами. Каждый кортеж состоит из элементов, которые выбираются из своих доменов. Эти элементы называются атрибутами, а их значения - значениями атрибутов.
Итак, реляционной модель ориентирована на организацию данных в виде двумерных таблиц, любая из которых имеет следующие свойства:
- каждый элемент таблицы - это один элемент данных;
- все столбцы в таблицы - однородные, т.е все элементы в столбце имеют одинаковый тип (символьный, числовой и т.п.);
- каждый столбец носит уникальное имя;
- одинаковые строки в таблицы отсутствуют.
Таблицы имеют строки, которые отвечают записям (или кортежам), а столбцы -атрибутам отношений (доменам, полям).
Следующие термины являются эквивалентными:
отношение, таблица, файл (для локальных БД);
кортеж, строка, запись;
атрибут, столбик, поле.
Объектно-ориентированные БД объединяют в себе две модели данных, реляционную и сетевую, и используются для создания крупных БД со сложными структурами данных.
Реляционная БД есть совокупностью отношений, которые содержат всю необходимую информацию и объединенную разными связями.
БД считается нормализованной, если выполняются следующие о
- таблица имеет главный ключ;
- поля каждойтаблицы только от ключа;
- таблицах отсутвуютгруппы значений[15].
успешной работы многотабличными как надо установить ними связи.При пользуютсями «базовая (главная) и «подчиненная таблица». между получается благодаря двух одно которых в базовой а втрое в Эти поля иметь значение, повторяются. значение в поле записи таблицы в подчиненной совпадают, то записи связанными.
четыре типа отношений между таблицами: к один многим, много одному, много многим.
один к одному означает, что запись в таблице только записи в таблице.
Отношение один ко что запись из таблицы может связана чем с записью из таблицы.
таблица - которая содержит первичный ключ исоставляетчасть один в один ко
Внешний ключ это поле,содержащее же информации в блице стороны [16].
Глава 2 Различные способы представления данных в информационных системах. Модели представления знаний
Центральным вопросом посторяниясистем основанных на знаниях является выбор формы представления знаний.
Представление – о способ формального выражения о предметной в форме.
формализмы, обеспечивающие о представлении моделями знаний.
Распространенные представления знаний:
- модель;
- модель;
- сеть;
- Формально-логическая
Продукционная модель знаний.
модель модель, основанная правилах, позволяет знания виде типа «ЕСЛИ ТО (действие).Часть «ЕСЛИ» посылкой (антецедентом) состоит из предложений логическими И, а «ТО» выводом действием консеквентом), включает одно или несколько которые либо некоторый либо указание определенное подлежащее использованию[17]
В общем правило так:
А1 и и ….А, В».Это что если условия от до n истинными, то также истинно.
Системы обработки знаний, использующие представление данных продукционными правилами, получили название продукционных систем. В состав продукционных систем входит база правил, база данных и интерпретатор правил. База правил – это область памяти, которая содержит БЗ; БД – это область памяти, содержащая фактические данные. БД могут быть описаны как группа данных, содержащих имя данных, атрибуты и значения атрибутов(триплет: объект, атрибут, знание)[18].
Ввод
Вывод
Интерпретатор
Рабочая память
БД
Рис.3Фреймовая модель представления знаний
Фреймовая модель данных предложена ученым Минским 70- е ХХ века универсальная применимая любой предметной [19].
Фрейм- абстрактный для стереотипа объекта, или ситуации. абстрактным понимается обобщенная и модель или Например, вслух «комната» порождает слушающих образ т.е. помещения. может быть как форма знаний, очерчивает рассматриваемого мира использует для описания системы или [20].
Фрейм имя, для описываемого им понятия , содержит описаний слотов, помощью определяются структурные элементы понятия. слотами следуют в которые данные, текущие слотов. Слот содержать не конкретное но имя процедуры, позволяющей это по алгоритму.
Семантическая .
Семантическая сеть это граф, которого – а дуги отношения ними. – это устанавливающее отношения символами объектами, которые обозначают. Т.е. определяющая знаков[21]
Предложено несколько классификаций семантических сетей, связанных с типами отношений между понятиями:
- По количеству типов отношений:
- однородные ( с единственным типом отношений)
- неоднородные ( с различными типами отношений)
2. По типам отношений:
- бинарные, в которых отношения связывают два объекта;
- N- арные, в которых есть специальные отношения, связывающие более двух понятий.
Наиболее часто в семантических сетях используются следующие отношения:
- элемент класса ( роза- это цветок);
- атрибутивные связи / иметь свойство (память имеет свойство – емкость);
- значение свойства (цвет имеет значение – красный);
- пример элемента класса (роза, например, чайная);
- связи типа «часть- целое» (автомобиль имеет руль);
- функциональные связи («производит», «влияет»);
- количественные (больше, меньше);
- пространственные (далеко, близко, над, под);
- временные (раньше, позже);
- логические (и, или, не).
Рис.4 Формульно-логическая модель представления данных
Формально-логическая модель данных использует качестве теории предикатов первого Это формальный используемый представления между объектами для выявления отношений объектами основе существующих. Логика в со синтаксических правил предикатов имеет организацию, образуют предикаты порядка, второго …, -го однако на логика используется уровне предикатов порядка.
Исчисления перового порядка на высказываний. называется предложение, которого можно значениями: (Т) ложь (). Например: студент». (простое) высказывание разделить на Из высказываний формироваться сложные помощью слов: или, если, [22].
Логика оперирует логическими между ы то есть решает вопросы «Можно на высказывания А получить В?»; ли при истинности при этом высказываний имеет Элементарные высказывания рассматриваются переменные типа, которыми разрешены следующие операции:
(~) – отрицание;
- конъюнкция (логическое «или»);
- дизъюнкция (логическое «и»);
- импликация («если, то»);
- эквивалентность.
Аналитическая платформа Deductor.
Deductor является аналитической платформой - основой для создания законченных прикладных решений в области анализа данных. Реализованные в Deductor технологии позволяют на базе единой архитектуры пройти все этапы построения аналитической системы от создания хранилища данных до автоматического подбора моделей и визуализации полученных результатов.
Deductor состоит из пяти частей:
DeductorWarehouse многомерное хранилище аккумулирующее необходимую для предметной области Использование хранилища позволяет непротиворечивость данных централизованное а автоматически обеспечивает необходимую поддержку анализа Deductor оптимизирован для именно аналитических что сказывается скорости доступа данным. В рядеслучаев смыслотказаться традиционного хранилища и альтернативой- хранилищем Virtual[23].
Studio программа, реализующая импорта, обработки, и данных. Studio может функционировать без данных, информацию из других источников, наиболее является их использование. В Studio полный механизмов, позволяющий информацию из источника провести цикл обработки (очистку, данных, моделей), полученные результаты удобным образом таблицы, а деревья и и экспортировать в распространенные [24].
DeductorViewer - программа, ориентированная на конечного пользователя и предназначенная для просмотра подготовленных при помощи DeductorStudio отчетов. DeductorViewer позволяет минимизировать требования к пользователю системы, т.к. все требуемые операции выполняются автоматически при помощи подготовленных ранее сценариев обработки. Пользователю DeduсtorViewer нужно только выбрать и настроить вариант отображения полученных результатов.
DeductorServer – служба, обеспечивающая удаленную аналитическую обработку данных. Она позволяет автоматически обрабатывать данные и переобучать модели на сервере, оптимизирует выполнение сценариев за счет кэширования проектов и использования многопоточной обработки.
Deductor Client – клиентдоступакDeductor Server. Он обеспечивает доступ к серверу из сторонних приложений и управление его работой[25].
Реализованная в Deductor архитектура позволяет добиться максимальной гибкости при создании законченного решения. Благодаря данной архитектуре можно собрать в одном аналитическом приложении все необходимые инструменты анализа и реализовать автоматическое выполнение подготовленного сценария.
Технологическая платформа включает средства, позволяющие максимально сократить сроки разработки, быстро создавать и выводить на рынок новые прикладные решения, а также адаптировать их в соответствии с изменяющимися требованиями предприятий.
Создание законченного решения занимает очень мало времени: достаточно получить данные, определить сценарий обработки и задать место для экспорта полученных результатов. Наличие мощного набора механизмов обработки и визуализации позволяет двигаться по шагам, от наиболее простых способов анализа ко все более мощным. Первые результаты пользователь получает практически сразу, но при этом можно легко наращивать мощность решения.
Применение системы.
Система Deductor предназначена для решения широкого спектра задач, связанных с обработкой структурированных и представленных в виде таблиц данных. При этом область приложения системы может быть практически любой - механизмы, реализованные в системе, с успехом применяются на финансовых рынках, в страховании, торговле, телекоммуникациях, промышленности, медицине, в логических и маркетинговых задачах и множестве других.
Большинство задач анализа можно разделить на классы, внутри которых они решаются схожим образом. Этих классов немного, но для каждого необходимо использовать свои механизмы. Законченное решение может быть составлено из блоков, собранных из унифицированных компонентов для решения прикладной задачи. Именно возможность комбинировать различные механизмы анализа при создании прикладных решений позволяет говорить, что Deductor является аналитической платформой.
Глава 3 Практическая часть. Прогнозирование с помощью линейной регрессии
Линейная регрессия необходима тогда, когда предполагается, что зависимость между входными факторами и результатом линейная. В основном ее применяют для прогнозирования временного ряда. Достоинством ее можно назвать быстроту обработки входных данных.
Исходные данные
Для линейного регрессионного анализа необходимо запустить мастер обработки и выбрать в качестве обработки данных линейную регрессию. На втором шаге мастера настроим поля исходных данных. Очевидно, что факторами будут являться аргументы, а результатом – сумма. Поэтому необходимо указать назначение поля «СУММА» как выходное, а назначение остальных полей – как входные.

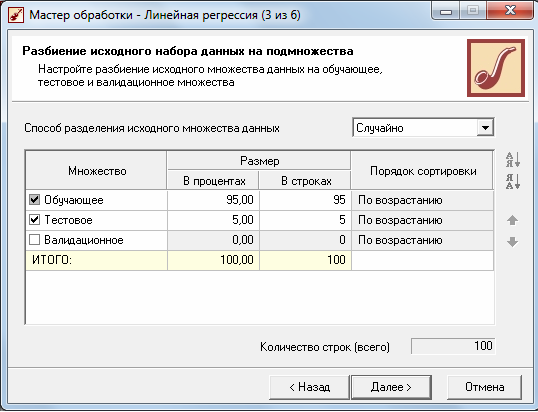
На следующем шаге необходимо настроить способ разделения исходного множества данных на тестовое и обучающее, а также количество примеров в том и другом множестве. Укажем, что данные из обоих множеств берутся случайным образом, а остальные параметры оставим без изменения.
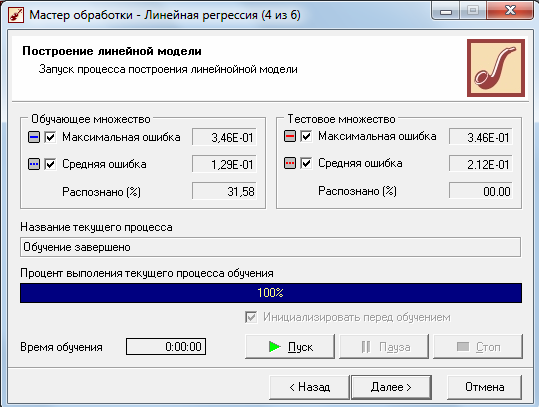
Следующий шаг мастера позволяет выполнить обработку, нажав на кнопку «Пуск». Во время обучения отображаются текущая величина ошибки и процент распознанных примеров.

Импортируем данные в DeductorStudio и просмотрим их в виде таблицы.
На диаграмме рассеяния видно, что данную зависимость линейная регрессия распознала с большой точностью.
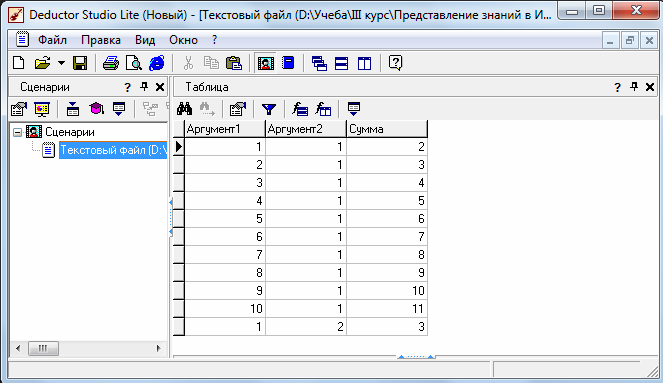
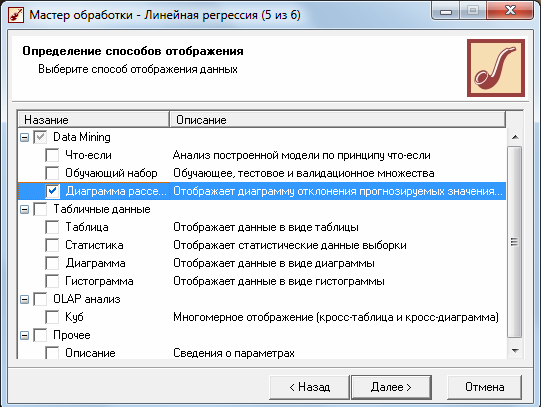
После построения модели, можно, воспользовавшись визуализатором «Диаграмма рассеяния» для просмотра качества построенной модели.

Прогнозирование суммы
Для линейного регрессионного анализа необходимо запустить мастер обработки и выбрать в качестве обработки данных линейную регрессию. На втором шаге мастера настроим поля исходных данных. Очевидно, что факторами будут являться аргументы, а результатом – сумма. Поэтому необходимо указать назначение поля «СУММА» как выходное, а назначение остальных полей – как входные.
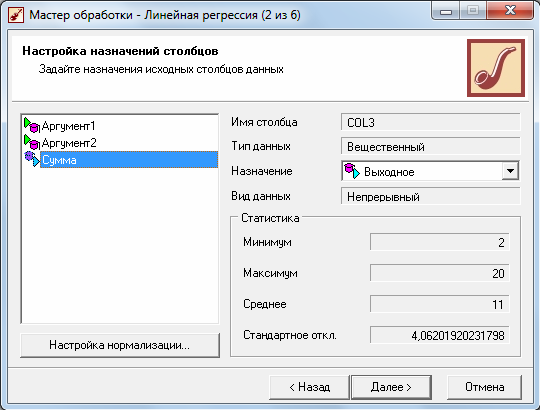
На следующем шаге необходимо настроить способ разделения исходного множества данных на тестовое и обучающее, а также количество примеров в том и другом множестве. Укажем, что данные из обоих множеств берутся случайным образом, а остальные параметры оставим без изменения.
Следующий шаг мастера позволяет выполнить обработку, нажав на кнопку «Пуск». Во время обучения отображаются текущая величина ошибки и процент распознанных примеров.
После построения модели, можно, воспользовавшись визуализатором «Диаграмма рассеяния» для просмотра качества построенной модели.
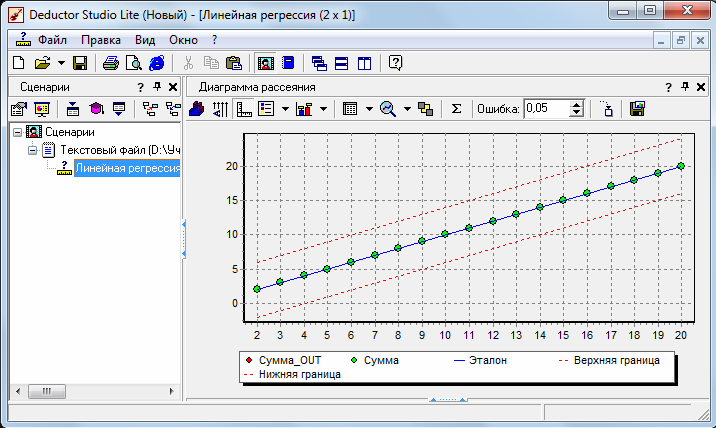
На диаграмме рассеяния, что данную зависимость линейная регрессия распознала с большой точностью.
Выводы
Данный пример показал целесообразность применения линейного регрессионного анализа для прогнозирования линейных зависимостей. Простота настроек и быстрота построения модели иногда бывают необходимы. Аналитику достаточно указать входные столбцы - факторы, выходные – результат, указать способ разбиения данных ни тестовое и обучающее множество и запустить процесс обучения. Причем после этого будут доступны все механизмы визуализации и анализа данных, позволяющие построить прогноз, провести эксперимент по принципу «Что-если», исследовать зависимость результата от значений входных факторов, оценить качество построенной модели по диаграмме рассеяния. Также по результатам работы этого алгоритма можно подтвердить или опровергнуть гипотезу о наличии линейной зависимости.
Заключение
В ходе выполнения работы была достигнута цель курсовой работы - изучены и рассмотрены основные вопросы дисциплины «Представление данных в ИС».
Для достижения цели курсовой работы были выделены и разрешены следующие задачи:
- дать определения понятиям знания и данные;
- рассмотреть модели представления знаний;
- разобрать аналитическую платформу Deductor;
- Описать один из демо-примеров программы Deductor (в данном случае – прогнозирование с помощью линейной регрессии).
Список использованной литературы
- Агальцов, В.П. Базы данных. В 2-х т.Т. 1. Локальные базы данных: Учебник / В.П. Агальцов. - М.: ИД ФОРУМ, НИЦ ИНФРА-М, 2013. - 352 c.
- Блиновская, Я.Ю. Введение в геоинформационные системы: Учебное пособие / Я.Ю. Блиновская, Д.С. Задоя. - М.: Форум, НИЦ ИНФРА-М, 2013. – 112 c.
- Бодров, О.А. Предметно-ориентированные экономические информационные системы: Учебник для вузов / О.А. Бодров. - М.: Гор. линия-Телеком, 2013. - 244 c.
- Варфоломеева, А.О. Информационные системы предприятия: Учебное пособие / А.О. Варфоломеева, А.В. Коряковский, В.П. Романов. - М.: НИЦ ИНФРА-М, 2013. - 283 c.
- Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2013. - 528 c.
- Вдовин, В.М. Предметно-ориентированные экономические информационные системы: Учебное пособие / В.М. Вдовин. - М.: Дашков и К, 2013. - 388 c.
- Горбенко, А.О. Информационные системы в экономике / А.О. Горбенко. - М.: БИНОМ. ЛЗ, 2012. - 292 c.
- Гришин, А.В. Промышленные информационные системы и сети: практическое руководство / А.В. Гришин. - М.: Радио и связь, 2010. - 176 c.
- Золотова, Е.В. Основы кадастра: Территориальные информационные системы: Учебник для вузов / Е.В. Золотова. - М.: Фонд "Мир", Акад. Проект, 2012. - 416 c.
- Исаев, Г.Н. Информационные системы в экономике: Учебник для студентов вузов / Г.Н. Исаев. - М.: Омега-Л, 2013. - 462 c.
- Мезенцев, К.Н. Автоматизированные информационные системы: Учебник для студентов учреждений среднего профессионального образования / К.Н. Мезенцев. - М.: ИЦ Академия, 2013. - 176 c.
- Норенков, И.П. Автоматизированные информационные системы: Учебное пособие / И.П. Норенков. - М.: МГТУ им. Баумана, 2011. - 342 c.
- Олейник, П.П. Корпоративные информационные системы: Учебник для вузов. Стандарт третьего поколения / П.П. Олейник. - СПб.: Питер, 2012. - 176 c.
- Патрушина, С.М. Информационные системы в экономике: Учебное пособие / С.М. Патрушина, Н.А. Аручиди. - М.: Мини Тайп, 2012. - 144 c.
- Пирогов, В.Ю. Информационные системы и базы данных: организация и проектирование: Учебное пособие / В.Ю. Пирогов. - СПб.: БХВ-Петербург, 2009. - 528 c.
- Рубичев, Н.А. Измерительные информационные системы / Н.А. Рубичев. - М.: Дрова, 2010. - 334 c.
- Рубичев, Н.А. Измерительные информационные системы: Учебное пособие / Н.А. Рубичев. - М.: Дрофа, 2010. - 334 c.
- Советов, Б.Я. Базы данных: теория и практика: Учебник для бакалавров / Б.Я. Советов, В.В. Цехановский, В.Д. Чертовской. - М.: Юрайт, 2013. - 463 c.
- Уткин, В.Б. Информационные системы в экономике: Учебник для студентов высших учебных заведений / В.Б. Уткин, К.В. Балдин. - М.: ИЦ Академия, 2012. - 288 c.
- Федорова, Г.Н. Информационные системы: Учебник для студ. учреждений сред. проф. образования / Г.Н. Федорова. - М.: ИЦ Академия, 2013. - 208 c.
- Чандра, А.М. Дистанционное зондирование и географические информационные системы / А.М. Чандра, С.К. Гош; Пер. с англ. А.В. Кирюшин. - М.: Техносфера, 2008. - 312 c.
- Ясенев, В.Н. Информационные системы и технологии в экономике.: Учебное пособие для студентов вузов / В.Н. Ясенев. - М.: ЮНИТИ-ДАНА, 2012. - 560 c.
- Семенов Н.А. Представление данных в информационных системах. (Конспект лекций). Тверь, 2010.
- Аналитическая платформа Deductor. Описание демонстрационного примера./BaseGroupLabs/2005.
-
Советов, Б.Я. Базы данных: теория и практика: Учебник для бакалавров / Б.Я. Советов, В.В. Цехановский, В.Д. Чертовской. - М.: Юрайт, 2013. – С.350 ↑
-
Мезенцев, К.Н. Автоматизированные информационные системы: Учебник для студентов учреждений среднего профессионального образования / К.Н. Мезенцев. - М.: ИЦ Академия, 2013. – С.99. ↑
-
Горбенко, А.О. Информационные системы в экономике / А.О. Горбенко. - М.: БИНОМ. ЛЗ, 2012. – С.122. ↑
-
Олейник, П.П. Корпоративные информационные системы: Учебник для вузов. Стандарт третьего поколения / П.П. Олейник. - СПб.: Питер, 2012. – С.101 ↑
-
Исаев, Г.Н. Информационные системы в экономике: Учебник для студентов вузов / Г.Н. Исаев. - М.: Омега-Л, 2013. – С.159 ↑
-
Федорова, Г.Н. Информационные системы: Учебник для студ. учреждений сред. проф. образования / Г.Н. Федорова. - М.: ИЦ Академия, 2013. – С.118-119 ↑
-
Варфоломеева, А.О. Информационные системы предприятия: Учебное пособие / А.О. Варфоломеева, А.В. Коряковский, В.П. Романов. - М.: НИЦ ИНФРА-М, 2013. - 283 c ↑
-
Чандра, А.М. Дистанционное зондирование и географические информационные системы / А.М. Чандра, С.К. Гош; Пер. с англ. А.В. Кирюшин. - М.: Техносфера, 2008. – С.256 ↑
-
Уткин, В.Б. Информационные системы в экономике: Учебник для студентов высших учебных заведений / В.Б. Уткин, К.В. Балдин. - М.: ИЦ Академия, 2012. – С. 222 ↑
-
Блиновская, Я.Ю. Введение в геоинформационные системы: Учебное пособие / Я.Ю. Блиновская, Д.С. Задоя. - М.: Форум, НИЦ ИНФРА-М, 2013. – С. 56 ↑
-
Исаев, Г.Н. Информационные системы в экономике: Учебник для студентов вузов / Г.Н. Исаев. - М.: Омега-Л, 2013. – С.211 ↑
-
Варфоломеева, А.О. Информационные системы предприятия: Учебное пособие / А.О. Варфоломеева, А.В. Коряковский, В.П. Романов. - М.: НИЦ ИНФРА-М, 2013. – С.156 ↑
-
Чандра, А.М. Дистанционное зондирование и географические информационные системы / А.М. Чандра, С.К. Гош; Пер. с англ. А.В. Кирюшин. - М.: Техносфера, 2008. – С.259 ↑
-
Гришин, А.В. Промышленные информационные системы и сети: практическое руководство / А.В. Гришин. - М.: Радио и связь, 2010. – С.78. ↑
-
Ясенев, В.Н. Информационные системы и технологии в экономике.: Учебное пособие для студентов вузов / В.Н. Ясенев. - М.: ЮНИТИ-ДАНА, 2012. – С.252-255 ↑
-
Чандра, А.М. Дистанционное зондирование и географические информационные системы / А.М. Чандра, С.К. Гош; Пер. с англ. А.В. Кирюшин. - М.: Техносфера, 2008. – С.122. ↑
-
Гришин, А.В. Промышленные информационные системы и сети: практическое руководство / А.В. Гришин. - М.: Радио и связь, 2010. – С.110 ↑
-
Норенков, И.П. Автоматизированные информационные системы: Учебное пособие / И.П. Норенков. - М.: МГТУ им. Баумана, 2011. – С.300. ↑
-
Ясенев, В.Н. Информационные системы и технологии в экономике.: Учебное пособие для студентов вузов / В.Н. Ясенев. - М.: ЮНИТИ-ДАНА, 2012. – С.353-356 ↑
-
Федорова, Г.Н. Информационные системы: Учебник для студ. учреждений сред. проф. образования / Г.Н. Федорова. - М.: ИЦ Академия, 2013. – С.155 ↑
-
Пирогов, В.Ю. Информационные системы и базы данных: организация и проектирование: Учебное пособие / В.Ю. Пирогов. - СПб.: БХВ-Петербург, 2009. – С.455 ↑
-
Бодров, О.А. Предметно-ориентированные экономические информационные системы: Учебник для вузов / О.А. Бодров. - М.: Гор. линия-Телеком, 2013. – С.122-123. ↑
-
Аналитическая платформа Deductor. Описание демонстрационного примера./BaseGroupLabs/2005. ↑
-
Аналитическая платформа Deductor. Описание демонстрационного примера./BaseGroupLabs/2005. ↑
-
Аналитическая платформа Deductor. Описание демонстрационного примера./BaseGroupLabs/2005. ↑

- Операции, производимые с данными (Методы для извлечения информации из данных)
- Разработка регламента выполнения процесса «Совершенствование существующих продуктов».
- Правовые отношения юридических лиц ( Общие положения юридических лиц как субъектов гражданских правоотношений)
- Нотариат в Российской Федерации (Понятие, значение и сущность нотариата)
- Управление поведением в конфликтных ситуациях (ПАО «Полевской молочный комбинат»)
- Основы программирования на языке Pascal. Особенности языка Паскаль как программирования
- Процессы принятия решений в организации (метод «Дельфи»)
- Разработка оперативного финансового плана Кофейни «СладкаяЖизнь».
- Европейские валютные биржи: участники и технология
- Политика мотивации персонала организации и оценка ее эффективности
- Разработка предложений по увеличению налоговых доходов бюджета городского округа Тольятти
- Методы и формы организации контроля за деятельностью органов муниципального управления( Особенности государственного контроля (надзора) за деятельностью органов местного самоуправления)