
Применение объектно-ориентированного подхода при проектировании информационной системы (Задачи и этапы предпроектного обследования)
Содержание:

ВВЕДЕНИЕ
Создание ИС – это логически сложная, трудоемкая и длительная работа, требующая высокой квалификации участвующих в ней специалистов. Но не-редко создание таких систем выполняется на интуитивном уровне с примене-нием неформализованных методов, основанных на искусстве, практическом опыте, экспертных оценках и дорогостоящих экспериментальных проверках качества функционирования системы. Эксплуатационные расходы, возникающие после сдачи таких систем, могут существенно превышать расходы на их создание. Исследования показывают, что на обнаружение ошибок, допущенных на стадии проектирования, расходуется примерно в два раза больше времени, чем на исправление ошибок, допущенных на последующих фазах. При этом исправление ошибки на стадии проектирования стоит в 2 раза, на стадии тестирования – в 10 раз, а на стадии эксплуатации системы – в 100 раз дороже, чем на стадии анализа. Кроме того, ошибки анализа и проектирования обнаруживаются часто самими пользователями, что вызывает их недовольство и осложняет сопровождение ИС.
Актуальность исследования заключается в том, что из существующих подходов к проектированию информационных систем объектно-ориентированный в настоящее время считается наиболее эффективным т.к. оперирует абстракциями реальных объектов и операций. Т.е. при построении модели имеющейся предметной области, выделении бизнес-процессов и пр. строится и модель будущей информационной системы (ИС). К тому же одной из важных особенностей объектно-ориентированного подхода является унифицированность процесса разработки ИС, неотъемлемой частью которого является унифицированный язык моделирования UML. Данная особенность обеспечивает упорядоченный подход к распределению задач и обязанностей при проектировании ИС, охватывающий весь ее жизненный цикл. Именно поэтому основы объектно-ориентированного подхода, а также принципы унифицированного моделирования широко используются при проектировании автоматизированных информационных систем.
Объектом исследования данной работы является объектно-ориентированный подход к проектированию информационных систем. Предметом исследования является унифицированный язык моделирования.
Цель данной работы является обзор и анализ основных принципов и особенностей объектно-ориентированного подхода, а также его неотъемлемого инструмента унифицированного языка моделирования (UML).
1. ПРЕДПРОЕКТНОЕ ОБСЛЕДОВАНИЕ ОБЪЕКТА
1.1. Задачи и этапы предпроектного обследования
Обследование предприятия является важным и определяющим этапом проектирования ИС и при правильном подходе позволяет сократить эксплуатационные расходы и время на исправление ошибок, обнаруживаемых после сдачи системы. Предпроектное обследование обычно состоит из трех этапов:
1) предварительное обследование (сбор сведений об объекте);
2) анализ сведений (описание и моделирование предметной области);
3) оценка эффективности и целесообразности ИТ-проекта.
На каждом этапе применяются различные методы исследования систем управления (ИСУ). Цели ИСУ: улучшение, изменение (реинжиниринг) или автоматизация систем управления. Предмет исследования, то есть то, что изучает исследователь с целью решения проблем на объекте, это: система знаний, умений и навыков; методы и способы; факторы внешней и внутренней среды; процессы, происходящие в организации. Объектом исследования является организация и ее подсистемы – реальные физические объекты, измеряемые качественными и количественными показателями. Научное исследование, как правило, проводится в предметных рамках определенного научного подхода с использованием группы научных методов. Цели исследования системы управления: улучшение, изменение (реинжиниринг) или автоматизация систем управления. Метод исследования – это способ получения нового знания, а также инструментарий, с помощью которого проводится исследование; совокупность приемов обработки информации, позволяющих достичь целей исследования.
Выбор методов исследования, интеграция различных методов при проведении предпроектного обследования определяется знанием, опытом и интуицией специалистов, проводящих исследование. Методы исследования предметной области проектирования ИС можно разбить на следующие группы:
• основанные на использовании знаний и интуиции специалистов (экспертные методы);
• формализованного представления систем, основанные на использовании математических, экономико-математических методов и методов моделирования, среди которых при проектировании информационных систем особое место занимают графические, включающие различные методы графического представления информации.
• комплексированные – сформировались путем интеграции экспертных и формализованных методов (комбинаторика, ситуационное моделирование, топология, графосемиотика и др).
Сбор сведений об объекте
На предварительном этапе обследования решаются следующие задачи:
• предварительное выявление требований к будущей системе;
• определение структуры организации;
• определение перечня целевых функций организации;
• анализ распределения функций по подразделениям и сотрудникам;
• выявление функциональных взаимодействий между подразделениями, информационных потоков внутри подразделений и между ними, внешних информационных воздействий;
• анализ существующих средств автоматизации организации и др. Длительность предварительного обследования обычно составляет 1-2 недели. В течение этого времени системный аналитик должен обследовать не более 2-3 видов деятельности (учет кадров, бухгалтерия, перевозки, маркетинг и др.). Сбор информации для построения полной бизнес-модели организации часто сводится к изучению документированных информационных потоков и функций подразделений, а также производится путем интервьюирования и анкетирования. К началу работ по обследованию организация обычно предоставляет комплект документов, в состав которого обычно входят:
1) сводная информация о деятельности предприятия (оргструктура, информация об управленческой, финансово-экономической, производственной деятельности предприятия, сведения об учетной политике и отчетности);
2) регулярный документооборот предприятия (реестры входящей, исходящей и внутренней информации (табл. 1.);
3) сведения об инфраструктуре предприятия;
4) сведения об ответственных лицах и исполнителях.
Реестры информации
|
Реестр входящей информации |
||||||
|
Наименование предприятия |
Наименование подразделения |
Характеристики обработки документов |
||||
|
№ |
Наименование и назначение документа |
Кто обрабатывает |
Откуда поступает |
Трудоемкость |
Периодичность, регламент |
Способ получения |
|
Реестр внутренней информации |
||||||
|
Наименование предприятия |
Наименование подразделения |
Характеристики обработки документов |
||||
|
№ |
Наименование и назначение документа |
Кто обрабатывает |
Кому передает |
Трудоемкость |
Периодичность, регламент |
Способ получения |
|
Реестр исходящей информации |
||||||
|
Наименование предприятия |
Наименование подразделения |
Характеристики обработки документов |
||||
|
№ |
Наименование и назначение документа |
Кто обрабатывает |
Куда поступает |
Трудоемкость |
Периодичность, регламент |
Способ получения |
Таблица 1
Один из методов исследования, который может быть применен на этапе сбора сведений – интервьюирование. Списки вопросов для интервьюирования и анкетирования составляются по каждому обследуемому подразделению и утверждаются руководителем компании. Это делается с целью:
• предотвращения доступа к конфиденциальной информации;
• усиления целевой направленности обследования;
•минимизации отвлечения сотрудников предприятий от выполнения должностных обязанностей. Общий перечень вопросов (с их последующей детализацией) включает следующие пункты:
• основные задачи подразделений;
• собираемая и регистрируемая информация;
• отчетность;
• взаимодействие с другими подразделениями.
Анкеты для руководителей и специалистов могут содержать следующие вопросы:
• каковы (с позиций вашего подразделения) должны быть цели создания интегрированной системы управления предприятием;
• организационная структура подразделения;
• задачи подразделения;
• последовательность действий при выполнении задач;
• с какими типами внешних организаций (банк, заказчик, поставщик и т.п.) взаимодействует подразделение и какой информацией обменивается;
• каким справочным материалом вы пользуетесь;
• сколько времени (в минутах) вы тратите на исполнение основных операций; на какие даты приходятся «пиковые нагрузки» (периодичность в месяц, квартал, год и т.д.); техническое оснащение подразделения (компьютеры, сеть, модем и т.п.); используемые программные продукты для автоматизации бизнес-процессов;
• какие отчеты и как часто вы готовите для руководства; ключевые специалисты подразделения, способные ответить на любые вопросы по бизнеспроцессам, применяемым в подразделении;
• характеристики удаленных объектов управления;
• документооборот на рабочем месте. Собранные таким образом данные, как правило, не охватывают всех существенных сторон организационной деятельности и обладают высокой степенью субъективности. И самое главное, что такого рода обследования не выявляют устойчивых факторов, связанных со специфическими особенностями организации, воздействовать на которые можно исключительно методами функциональной настройки организационной системы. Анализ опросов руководителей обследуемых организаций и предприятий показывает, что их представления о структуре организации, общих и локальных целях функционирования, задачах и функциях подразделений, а также подчиненности работников иногда имеют противоречивый характер. Кроме того, эти представления подчас расходятся с официально декларируемыми целями и правилами или противоречат фактической деятельности. Если структуру информационных потоков можно выявить по образцам документов и конфигурациям компьютерных сетей и баз данных, то структура реальных микропроцессов, осуществляемых персоналом в информационных контактах (в значительной мере недокументированных) остается неизвестной. Ответы на эти вопросы может дать структурно-функциональная диагностика, основанная на методах сплошной (или выборочной) фотографии рабочего времени персонала. Цель диагностики – получение достоверного знания об организации и организационных отношениях ее функциональных элементов. В связи с этим к важнейшим задачам функциональной диагностики организационных структур относятся:
• классификация субъектов функционирования (категорий и групп работников);
• классификация элементов процесса функционирования (действий, процедур);
• классификация направлений (решаемых проблем), целей функционирования;
• классификация элементов информационных потоков;
• проведение обследования деятельности персонала организации;
• исследование распределения (по времени и частоте) организационных характеристик: процедур, контактов персонала, направлений деятельности, элементов информационных потоков – по отдельности и в комбинациях друг с другом по категориям работников, видам процедур и их направлениям (согласно результатам и логике исследований);
• выявление реальной структуры функциональных, информационных, иерархических, временных, проблемных отношений между руководителями, сотрудниками и подразделениями;
• установление структуры распределения рабочего времени руководителей и персонала относительно функций, проблем и целей организации;
• выявление основных технологий функционирования организации (информационных процессов, включая и недокументированные), их целеполагания в сравнении с декларируемыми целями организации;
• выявление однородных по специфике деятельности, целевой ориентации и реальной подчиненности групп работников, формирование реальной модели организационной структуры и сравнение ее с декларируемой;
• определение причин рассогласования декларируемой и реальной структуры организационных отношений.
Сплошной «фотографией» рабочего времени называется непрерывное наблюдение и регистрация характеристик работников в процессе функционирования в течение всего рабочего дня. Информация последовательно вносятся в заранее заготовленную рабочую таблицу, которая по окончании процедуры обследования пополняется дополнительными характеристиками: технологическая ветвь, системная функция, предмет, аспект, эмоциональный фон и др. Часть показателей, те, что помечены звездочкой, заполняются в процессе обследования, остальные – после. Содержание рабочей таблицы может быть следующим:
• номер (по порядку);
• агент (должность обследуемого работника);
• время, в течение которого выполнялась процедура;
• процедура (наименование содержания совокупности элементарных действий, объединенных общностью решаемой частной задачи);
• содержание (суть процедуры, которая должна быть классифицирована);
• информация (направление движения информации между агентом и контрагентом);
• инициатива (инициатор начала выполнения данной процедуры);
• контрагент (должность работника, который находится с обследуемым в контакте);
• отношение (отражающая субординацию агента и контрагента форма взаимодействия в данной процедуре);
• проблема (словесная характеристика решаемой проблемы).
Результатом предпроектного обследования должен явиться «Отчет об экспресс-обследовании предприятия», который включает следующее:
• краткое схематичное описание бизнес-процессов (например: управление закупками и запасами, управление производством, управление продажами, управление финансовыми ресурсами);
• основные требования и приоритеты автоматизации;
• оценка необходимых для обеспечения проекта ресурсов заказчика;
• оценка возможности автоматизации, предложения по созданию автоматизированной системы с оценкой примерных сроков и стоимости.
Документы, входящие в отчет об обследовании, могут быть представлены в виде текстового описания или таблиц с описанием операций, исполнителей и документов бизнес процессов. Информация, полученная в результате предпроектного обследования, анализируется с помощью методов структурного и/или объектного анализа и используется для построения моделей деятельности организации. Модель организации предполагает построение двух видов моделей:
• модели «как есть», отражающей существующее на момент обследования положение дел в организации и позволяющей понять, каким образом функционирует данная организация, а также выявить узкие места и сформулировать предложения по улучшению;
• модели «как должно быть», отражающей представление о новых технологиях работы организации. Каждая из моделей включает в себя полную функциональную и информационную модель деятельности организации, а также модель, описывающую динамику поведения организации (в случае необходимости). В качестве основного каркаса, объединяющего и систематизирующего все знания по бизнес-модели, можно использовать различные эталонные (референтные) модели.
Классификация бизнес процессов
Реализация процессного подхода требует четкой структуризации бизнес процессов. Первой попыткой классифицировать бизнес-процессы была разработка модели цепочки создания добавленной стоимости (Value Chain), предложенная Майклом Портером (табл.) в 1980 году. БП было предложено делить на основные и вспомогательные. Классификация М. Портера получила развитие в результате реализации норвежского проекта TOPP (The Productivity Program of the Technology Industry – программа повышения производительности промышленности) по сравнительному бенчмаркингу. Так же посредством бенчмаркинга Американский центр производительности и качества APQC (American Productivity & Quality Center) разработал кросс-отраслевую структуру классификации процессов PCF (Process Classification Framework). В настоящее время многие предприятия используют классификацию, предложенную в стандарте ГОСТ Р ИСО 9001-2008.
Подходы к классификации БП
|
М.Портер |
ТОРР |
APQC |
ГОСТ Р ИСО 9001-2008 |
|
1) основные 2)вспомогательные |
1)первичные 2)поддерживающие 3)развития |
1)операционные 2)управления и поддержки |
1)процессы высшего руководства 2)процессы менеджмента ресурсов 3)процессы измерения, анализа и улучшения 4)процессы жизненного цикла продукции |
Таблица 2.
По APQC делятся на 12 категорий (каждая категория разбивается на группы), из которых 5 категорий – операционные процессы, 7 – процессы управления и поддержки: категории операционных процессов (operating processes):
• разработка стратегии (Develop Vision and Strategy);
• разработка и управление продуктами и услугами (Develop and Manage Products and Services);
• рынок и продажа продуктов и услуг (Market and Sell Products and Services);
• доставка продуктов и услуг (Deliver Products and Services);
• управление обслуживанием клиентов (Manage Customer Service); категории процессов управления и поддержки (management and support services):
• разработка и поддержка человеческого капитала (Develop and Manage Human Capital);
• управление информационными технологиями (Manage Information Technology);
• управление финансовыми ресурсами (Manage Financial Resources);
• приобретение, строительство и управление собственностью (Acquire, Construct, and Manage Property);
• управление охраной окружающей среды (Manage Environmental Health and Safety (EHS));
• управление внешними связями (Manage External Relationships);
• управление знаниями, улучшениями и изменениями (Manage Knowledge, Improvement, and Change).
Существуют другие способы классификации БП: по степени сложности, детализации, по месту в оргструктуре, иерархии целей и т.д.
Основные процессы – это процессы ЖЦ продукции компании. Это «горизонтальные» процессы, направленные на создание и реализацию товара или услуги, представляющих ценность для клиента и обеспечивающие доход компании.
Основные процессы принято описывать по следующей производственно коммерческой цепочке:
1) первичное взаимодействие с клиентом и определение его потребностей;
2) реализация запроса (заявки, заказа, контракта и т.п.) клиента;
3) послепродажное сопровождение;
4) мониторинг удовлетворения потребностей. Процесс «реализация (запроса клиента)» может быть декомпозирован на следующие подпроцессы (процессы более низкого уровня):
• разработка (проектирование) продукции;
• закупка (товаров, материалов, комплектующих изделий), в том числе: o транспортировка (закупленного); o разгрузка, приемка на склад и хранение (закупленного);
• производство (со своим технологическим циклом и внутренней логистикой);
• приемка на склад и хранение (готовой продукции);
• отгрузка, в том числе, консервация и упаковка, погрузка, доставка);
• пуско-наладка;
• оказание услуг (предусмотренных контрактом на поставку или имеющих самостоятельное значение) и т.п.
Процессы управления – это процессы планирования, организации, мотивации и контроля, направленные на выработку и реализацию управленческих решений. Управленческие решения могут приниматься относительно организации в целом, отдельной функциональной области или отдельных бизнес процессов, например:
• стратегическое управление;
• организационное проектирование (структуризация);
• маркетинг;
• финансово-экономическое управление;
• логистика и организация процессов;
• менеджмент качества;
• управление персоналом. При процессном описании управленческую деятельность можно «развертывать» по так называемому «управленческому циклу» (принятия решения), который включает следующие процессы:
1) сбор и анализ информации (проверка на достоверность);
2) подготовка альтернатив;
3) выбор альтернативы (принятие решения);
4) организация реализации решения;
5) контроль исполнения;
6) анализ;
7) коррекция (регулирование).
В основе цикла организационного менеджмента лежит структурное или процессное моделирование и процедурный контроль:
1) определение состава задач (обособленных функций, операций);
2) выбор исполнителей (распределение зон и степени ответственности);
3) проектирование процедур (последовательности и порядка исполнения);
4) согласование и утверждение регламента исполнения (- процесса, плана мероприятий);
5) отчетность об исполнении;
6) контроль исполнения (процедурный контроль);
7) анализ причин отклонений и регулирование (возврат к 1, 2 или 3).
Таким образом, на определенных шагах декомпозиции необходимо определить, какие стадии управленческого цикла реализуются по каждой из ранее выделенных задач управления.
Построение дерева БП
Основанием для построения иерархии процессов целесообразно использовать классификационные стандарты (см. «Классификация бизнеспроцессов»). Пример дерева БП приведен на рис. 2.2. «Ветками» первого уровня будут процессы основные, обеспечивающие и управления. Названия «веток» следующих уровней должны браиться из текстового описания процессов.
Таким образом, работы, перечисленные на этапе текстового описания, «распределяются» по «веткам» классификационного дерева.
Примеры БП управления (второй уровень дерева на ветке «БП управления»): планирование бюджета; составление штатного расписания; планирование закупок; планирование продаж и т.д. Для крупных предприятий БП можно объединять в подкатегории и подгруппы. Например, для БП управления это могут быть следующие категории: управление закупками и запасами; управление производством; управление продажами; управление финансами и т.д. Следующим шагом при проектировании ИС является выбор объекта автоматизации – группы процессов, которые будут осуществляться при помощи средств вычислительной техники. Это могут быть все основные процессы (для разработки автоматизированной системы учета основной деятельности), часть основных, например, для автоматизации продаж, для автоматизации производства, могут включать процессы управления или часть процессов управления при проектировании АСУ. В результате происходит «сужение» предметной области, и процессы, оставшиеся за ее пределами, попадают в область «внешней среды». В IDEF0 инструментом построения иерархии процессов является «дерево узлов» (Node Tree) (рис. 2.3.).
2. СТРУКТУРНЫЙ АНАЛИЗ И СТРУКТУРНОЕ ПРОЕКТИРОВАНИЕ
2.1. Основные понятия структурного анализа и структурного проектирования
Структурным анализом принято называть метод исследования системы, которое начинается с ее общего обзора и затем детализируется, приобретая иерархическую структуру с все большим числом уровней. Решение трудных проблем путем их разбиения на множество меньших независимых задач (так называемых «черных ящиков») и организация этих задач в древовидные иерархические структуры значительно повышают понимание сложных систем. В инженерии ПО (software engineering), Структурный анализ (Structured Analysis, SA) и одноименное с ним Структурное проектирование (Structured Design, SD) – это методы для анализа и преобразования бизнес-требований в спецификации и, в конечном счете, в компьютерные программы, конфигурации аппаратного обеспечения и связанные с ними ручные процедуры. Структурный анализ, СА (Structured Analysis, SA) и Структурное проектирование, СП (Structured Design, SD) являются фундаментальными инструментами системного анализа и развивались из классического системного анализа 1960-70-х годов (см. гл. 1.1). Структурный подход заключается в поэтапной декомпозиции системы при сохранении целостного о ней представления Основные принципы структурного подхода (первые два являются основными): 1) принцип «разделяй и властвуй» – принцип решения сложных проблем путем их разбиения на множество меньших независимых задач, легких для понимания и решения;
2) принцип иерархического упорядочивания – принцип организации составных частей проблемы в иерархические древовидные структуры с добавлением новых деталей на каждом уровне.
3) принцип абстрагирования – заключается в выделении существенных аспектов системы и отвлечения от несущественных;
4) принцип формализации – заключается в необходимости строгого методического подхода к решению проблемы;
5) принцип непротиворечивости – заключается в обоснованности и согласованности элементов.
2.2. Метод структурного анализа и проектирования SADT
SADT (Structured Analysis and Design Technique) – это методология инженерии разработки ПО (software engineering) для описания систем в виде иерархии функций (функциональной структуры).
Основы SADT
SADT использует два типа диаграмм:
1) модели деятельности (activity models);
2) модели данных (data models).
SADT использует стрелки для построения этих диаграмм и имеет следующее графическое представление:
• главный блок (box), где определено названиее процесса или действия;
• с левой стороны блока – входящие стрелки: входы действия;
• сверху – входящие стрелки: данные, необходимые для действия;
• внизу – входящие стрелки: средства, используемые для действия;
• справа – исходящие стрелки: выход действия.
SADT использует декомпозицию на основе подхода «сверху вниз». Каждый уровень декомпозиции содержит до 6 блоков.
SADT начинается с уровня (level) 0, затем может быть детализирован на более низкие уровни (1, 2, 3, ...). Например, на уровне 1, блок уровня 0 будет детализирован на несколько элементарных блоков и так далее …
На уровне 1 действие «Manufacture computers», может быть разбито (declined), например на 4 блока:
1) получить электронные компоненты («receive electronic components»);
2) сохранить электронные компоненты («store electronic components»);
3) доставить электронные компоненты на сборочную линию («bring electronic components to the assembly line»);
4) собрать компьютеры («Assemble computers»).
Семантика стрелок для действий (activities):
• входы (Inputs) входят слева и представляют данные или предметы потребления (consumables), нужные действию (that are needed by the activity); • выходы (Outputs) выходят справа и представляют данные или продукты, производимые действием (activity);
• управления (Controls) входят сверху и представляют команды, которые влияют на исполнение действия, но не потребляются. В последней редакции IDEF0 – условия, требуемые для получения корректного выхода. Данные или объекты, моделируемые как управления, могут быть трансформированы функцией, создающей выход;
• механизмы означают средства, компоненты или инструменты, используемые для выполнения действия; представляют размещение (allocation) действий.
Семантика стрелок для данных (data):
• входы (Inputs) – это действия, которые генерируют эти данные (are activities that produce the data);
• выходы (Outputs) потребляют эти данные (consume the data);
• управления (Controls) влияют на внутреннее состояние этих данных (influence the internal state of the data).
Роли SADT-процесса: • авторы (Authors) – разработчики SADT модели;
• комментаторы (Commenters) – рецензируют (review) работу авторов;
• читатели (Readers) – возможные (the eventual) пользователи SADT диаграмм;
• эксперты (Experts) – те, от кого авторы получают специальную информацию о требованиях и ограничениях;
• технический комитет (Technical committee) – технический персонал, ответственный за рецензирование (reviewing) SADT модели на каждом уровне;
• библиотекарь проекта (Project librarian) – ответственный за все документы проекта;
• менеджер проекта (Project manager) – имеет полную техническую ответственность за системный анализ и проектирование (has overall technical responsibility the system analysis and design);
• аналитик (Monitor) (Chief analyst) – эксперт в области SADT, помогающий и консультирующий персонал проекта по использованию SADT;
• инструктор (Instructor) – обучает авторов и комментаторов SADT.
Этапы моделирования. Разработка SADT модели представляет собой итеративный процесс и состоит из нижеследующих условных этапов.
1. Создание модели группой специалистов, относящихся к различным сферам деятельности предприятия. На этом этапе авторы опрашивают компетентных лиц, получая ответы на следующие вопросы:
• что поступает в предметную область на «входе»;
• какие функции и в какой последовательности выполняются в рамках предметной области;
• кто является ответственным за выполнение каждой из функций;
• чем руководствуется исполнитель при выполнении каждой из функций;
• что является результатом работы объекта (на выходе)? На основе полученных результатов опросов создается черновик модели (Model Draft).
2. Распространение черновика для рассмотрения, получения комментариев и согласования модели с читателями. При этом каждая из диаграмм черновика письменно критикуется и комментируется, а затем передается автору. Автор, в свою очередь, также письменно соглашается с критикой или отвергает ее с изложением логики принятия решения и вновь возвращает откорректированный черновик для дальнейшего рассмотрения. Этот цикл продолжается до тех пор, пока авторы и читатели не придут к единому мнению.
3. Официальное утверждение модели. Утверждение согласованной модели происходит руководителем рабочей группы в том случае, если у авторов модели и читателей отсутствуют разногласия по поводу ее адекватности. Окончательная модель представляет собой согласованное представление о системе с заданной точки зрения и для заданной цели.
Метод SADT получил дальнейшее развитие. На его основе в 1981 году разработана известная методология функционального моделирования IDEF0.
Методология функционального моделирования IDEF0
IDEF0 (Integration Definition for Function Modeling) – методология функционального моделирования для описания функций предприятия, предлагающая язык функционального моделирования для анализа, разработки, реинжиниринга и интеграции информационных систем бизнес процессов; или анализа инженерии разработки ПО (or software engineering analysis). Модель IDEF0 – это графическое описание (информационной) системы или предметной области (subject), которое разрабатывается с определенной целью с выбранной точки зрения. Модель IDEF0 представляет собой набор из одной или более (иерархически связанных) IDEF0-диаграмм, которые описывают функции системы или предметной области (subject area) с помощью графики, текста и глоссария.
Применение IDEF0
IDEF0 используется для создания функциональной модели, то есть результатом применения методологии IDEF0 к системе есть функциональная модель IDEF0. Функциональная модель – это структурное представление функций, деятельности или процессов в пределах моделируемой системы или предметной области. Методология IDEF0 может быть использована для моделирования широкого спектра как автоматизированных, так и неавтоматизированных систем. Для проектируемых систем IDEF0 может быть использована сначала для определения требований и функций, и затем для реализации, удовлетворяющей этим требованиям и исполняющей эти функции. Для существующих систем IDEF0 может быть использована для анализа функций, выполняемых системой, а также для учета механизмов, с помощью которых эти функции выполняются.
Цели стандарта IDEF0
Основные цели (objectives) стандарта:
1) задокументировать и разъяснить технику моделирования IDEF0 и правила ее использования;
2) обеспечить средства для полного и единообразного (consistently) моделирования функций системы или предметной области, а также данных и объектов, которые связывают эти функции;
3) обеспечить язык моделирования, который независим от CASE методов или средств, но может быть использован при помощи этих методов и средств;
4) обеспечить язык моделирования, который имеет следующие характеристики:
• общий (generic) – для анализа как (информационных) систем, так и предметных областей;
• строгий и точный (rigorous and precise) – для создания корректных, пригодных к использованию моделей;
• краткий (concise) – для облегчения понимания, коммуникации, согласия между заинтересованными лицами и проверки. (to facilitate understanding, communication, consensus and validation);
• абстрактный (conceptual) – для представления функциональных требований, независимых от физических или организационных реализаций;
• гибкий – для поддержки различных фаз жизненного цикла проекта.
Строгость и точность (Rigor and Precision). Правила IDEF0 требуют достаточной строгости и точности для удовлетворения нужд аналитика без чрезмерных ограничений (to satisfy needs without overly constraining the analyst). IDEF0 правила включают следующее:
• управление детализацией (control of the details communicated at each level) – от трех до шести функциональных блоков на каждом уровне декомпозиции;
• связанный контекст (Bounded Context) – не должно быть недостающийх или лишних, выходящих за установленные рамки деталей;
• связанность интерфейса диаграмм (Diagram Interface Connectivity) – наличие номеров узлов, функциональных блоков, С-номеров (C-numbers) и подробных ссылочных выражений (Detail Reference Expression);
• связанность структуры данных. (Data Structure Connectivity) – коды ICOM и использование круглых скобок (ICOM codes and the use of parentheses);
• уникальные метки и заголовки (Unique Labels and Titles) – отсутствие повторяющихся названий в метках и заголовках;
• синтаксические правила для графики (Syntax Rules for Graphics) – функциональные блоки и стрелки;
• ограничения на разветвления стрелок данных (Data Arrow Branch Constraint) – метки для ограничений потоков данных на разветвлениях;
• разделение данных на Вход и Управление (Input versus Control Separation) – правило для определения роли данных);
• маркировка стрелок данных. Data Arrow Label Requirements (minimum labeling rules);
• наличие Управления (Minimum Control of Function) – все функции должны иметь минимум одно Управление;
• цель и точка зрения (Purpose and Viewpoint) – все модели имеют формулировку цели и точки зрения.
Ограничения сложности. Обычно IDEF0-модели несут в себе сложную и концентрированную информацию, и для того, чтобы ограничить их перегруженность и сделать удобочитаемыми, в стандарте приняты соответствующие ограничения сложности, которые носят рекомендательный характер. При том, что, что на диаграмме рекомендуется представлять от трех до шести функциональных блоков, количество подходящих к одному функциональному блоку (выходящих из одного функционального блока) интерфейсных дуг предполагается не более четырех.
Основные понятия IDEF0
В основе методологии лежат четыре основных понятия:
• функциональный блок;
• интерфейсная дуга;
• декомпозиция;
• глоссарий.
Функциональный блок (Activity Box) представляет собой некоторую конкретную функцию в рамках рассматриваемой системы. По требованиям стандарта название каждого функционального блока должно быть сформулировано в глагольном наклонении (например, «производить услуги»). На диаграмме функциональный блок изображается прямоугольником (рис.). Каждая из четырех сторон функционального блока имеет свое определенное значение (роль), при этом:
• верхняя сторона имеет значение «Управление» (Control);
• левая сторона имеет значение «Вход» (Input);
• правая сторона имеет значение «Выход» (Output);
• нижняя сторона имеет значение «Механизм» (Mechanism).
ICOM. В IDEF0 принята система маркирования, позволяющая аналитику точно идентифицировать и проверять связи по стрелкам между диаграммами. Эта схема кодирования стрелок получила название ICOM – название по первым буквам английских эквивалентов слов вход (Input), управление (Control), выход (Output), механизм (Mechanism). ICOM – это коды, предназначенные для идентификации граничных стрелок, содержат префикс, соответствующий типу стрелки (I, С, О или М), и порядковый номер. Буква следует перед числом, определяющим относительное положение точки подключения стрелки к родительскому блоку; это положение определяется слева направо или сверху вниз.
Основной ICOM-код – это узловой номер, который появляется там, где выполняется декомпозиция функционального блока и создается его подробное описание на дочерней диаграмме. Все остальные ссылочные коды базируются на узловых номерах. Например, код «C3», написанный возле граничной стрелки на дочерней диаграмме, указывает, что эта стрелка соответствует третьей (слева) управляющей стрелке родительского блока. ICOM-коды представляют собой ссылочные выражения, которые присваиваются всем элементам модели: диаграммам, блокам, стрелкам и примечаниям. Коды используются в различных контекстах для точного указания на нужный элемент модели. Например, кодирование связывает каждую дочернюю диаграмму со своим родительским блоком. Если блоки на дочерней диаграмме подвергаются дальнейшей декомпозиции и подробно описываются на дочерних диаграммах следующего уровня, то на каждую новую диаграмму назначаются новые ICOM коды, связывающие граничные стрелки этих диаграмм со стрелками их родительских блоков. Иногда буквенные ICOM-коды, определяющие роли граничных стрелок (вход, управление, механизм), могут меняться при переходе от родительского блока к дочерней диаграмме. Например, управляющая стрелка в родительском блоке может быть входом на дочерней диаграмме. Аналогично, вход родительского блока может быть управлением для одного или более дочерних блоков. Коды ICOM позволяют:
• быстро проверять согласованность внешних стрелок диаграммы с граничными стрелками соответствующего блока родительской диаграммы;
• связывать граничные стрелки на дочерней диаграмме со стрелками родительского блока;
• обеспечивать согласованность декомпозиции, поскольку все стрелки, входящие в диаграмму и выходящие из нее, должны быть учтены;
• обеспечивать требуемую строгость;
• создавать совокупность неявных связующих звеньев между страницами, которые можно быстро изменить при изменении границ;
• облегчать процесс чтения и рецензирования IDEF0-диаграмм;
• облегчать проверку согласованности декомпозиции;
• упрощать внесение локальных изменений в диаграмму;
• объединять различные варианты диаграмм в модели.
В моделях сбои часто происходят в точках интерфейса. Для IDEF диаграмм интерфейсными являются места соединения диаграмм со своими родителями, именно поэтому каждую декомпозицию необходимо аккуратно соединять со своим родителем, используя ICOM-метки. При построении диаграммы с меньшей доминантностью стрелки, касающиеся декомпозируемого блока, используются в качестве источников и приемников для стрелок, которые создаются на новой диаграмме. После завершения создания диаграммы-потомка для обеспечения согласованности ее внешние стрелки стыкуются с родительской диаграммой. Одним из способов такой стыковки служит присваивание кодов ICOM внешним стрелкам новой диаграммы согласно следующему алгоритму:
1) прежде чем составлять список данных, записать имена и коды для всех стрелок, образующих границу. Это поможет при декомпозиции уменьшить вероятность пропуска части граничных стрелок;
2) аналитик должен представить себе рисунок новой диаграммы как бы внутри декомпозируемого блока;
3) зрительно продлить внешние стрелки почти до края диаграммы и зрительно соединить каждую внешнюю стрелку диаграммы с соответствующей граничной стрелкой декомпозируемого блока;
4) присвоить код каждой зрительной связи (I -для входных стрелок, С – для связей между стрелками управления, О – для связей между выходными стрелками, М – для связей между стрелками механизма;
5) добавить после каждой буквы цифру, соответствующую положению данной стрелки среди других стрелок того же типа, касающихся родительского блока. Причем входные и выходные стрелки пересчитываются сверху вниз, а стрелки управлений и механизмов пересчитываются слева направо;
6) записать каждый код около окончания каждой внешней стрелки;
7) для выделения связи внешних стрелок с соответствующими граничными стрелками, границу субъекта изобразить жирной линией;
8) выполнив декомпозицию, вернуться назад к исходному блоку родительской диаграммы и соединить каждую внешнюю стрелку новой диаграммы с соответствующей стрелкой, касающейся этого блока. Это позволит избежать пропуска необходимого соединения.
Декомпозиция (Decomposition) является основным понятием стандарта IDEF0. Принцип декомпозиции применяется при разбиении сложного процесса на составляющие его функции. При этом уровень детализации процесса определяется непосредственно разработчиком модели. Декомпозиция позволяет постепенно и структурированно представлять модель системы в виде иерархической структуры отдельных диаграмм, что делает ее менее перегруженной и легко усваиваемой.
Диаграмма – это основная единица описания системы, расположенная на отдельном листе, представляющая функции и интерфейсы в виде блоков и дуг. Место соединения дуги с блоком определяет тип интерфейса. Диаграммы являются графическим представлением знаний экспертов о моделируемой системе и предметом обсуждения со специалистами конкретной предметной области. Аналитик представляет знания экспертов, изложенные с помощью естественного языка, используя графическую нотацию IDEF0, давая более наглядное, лаконичное и однозначное описание системы, не жертвуя при этом качеством представления. Таким образом, в ходе разработки диаграмм знания экспертов структурируются, и устраняется неоднозначность описаний за счет:
• стандартизации интерпретации графических обозначений. Так, например, содержание контекстной диаграммы интерпретируется следующим образом: «Процесс преобразует Вход в Выход при выполнении условий, заданных в Управление с помощью Механизма»;
• декомпозиции блоков диаграмм более высокого уровня, когда за счет более точных описаний на диаграммах-потомках устраняется неоднозначность возможных интерпретаций.
Моделирование IDEF0 всегда начинается с представления системы как единого целого – одного функционального блока с интерфейсными дугами, простирающимися за пределы рассматриваемой области. Такая диаграмма с одним функциональным блоком называется контекстной диаграммой.
Контекстная диаграмма – это IDEF0-диаграмма, расположенная на вершине иерархии диаграмм, представляющая собой самое общее описание системы, состоит из одного блока, описывающего функцию верхнего уровня, стрелок и пояснительного текста, определяющего точку зрения и цель моделирования. Эти утверждения помогают руководить разработкой модели и ввести этот процесс в определенные рамки. Контекстная диаграмма имеет узловой номер A-n (n = 0), которая представляет контекст модели. Диаграмма верхнего уровня обозначается идентификатором «А-0» (произносится «А минус ноль»), на которой объект моделирования представлен единственным блоком с граничными стрелками, отображающими связь системы с окружающей средой, устанавливает область моделирования, определяет границы модели и является обязательной диаграммой IDEF0-модели. Поскольку единственный блок представляет весь объект, то его имя – общее для всего проекта. Это же справедливо и для всех стрелок диаграммы, поскольку они представляют полный комплект внешних интерфейсов объекта.
В пояснительном тексте к контекстной диаграмме должна быть указана цель (Purpose) построения диаграммы в виде краткого описания и зафиксирована точка зрения (Viewpoint).
Определение и формализация цели разработки IDEF0-модели является крайне важным моментом. Фактически цель определяет соответствующие области в исследуемой системе, на которых необходимо фокусироваться в первую очередь.
Точка зрения. С определением модели тесно связана позиция, с которой наблюдается система и создается ее модель. Поскольку качество описания системы резко снижается, если оно ни на чем не сфокусировано, SADT требует, чтобы модель рассматривалась все время с одной и той же позиции. Эта позиция называется «точкой зрения» данной модели. Точка зрения определяет основное направление развития модели, уровень необходимой детализации, что и в каком разрезе можно увидеть в пределах модели. Четкое фиксирование точки зрения позволяет разгрузить модель, отказавшись от детализации и исследования отдельных элементов, не являющихся необходимыми, исходя из выбранной точки зрения на систему. Изменение точки зрения приводит к рассмотрению других аспектов объекта. Аспекты, важные с одной точки зрения, могут не появиться в модели, разрабатываемой с другой точки зрения на тот же самый объект. У модели может быть только одна точка зрения. Правильный выбор точки зрения существенно сокращает временные затраты на построение конечной модели. Точка зрения определяет субъект моделирования и что, соответственно, будет в дальнейшем рассматриваться как элементы/компоненты системы, а что – как внешняя среда/воздействие.
Имя функции, записываемое в блоке контекстной диаграммы, является общей функцией системы с выбранной точки зрения и конкретной целью построения модели.
Построение IDEF0-модели начинается с контекстной диаграммы, т.е. представления всей системы в виде простейшей компоненты – одного блока и дуг, изображающих интерфейсы с функциями вне системы. Затем блок, который представляет систему в качестве единого модуля, детализируется на другой диаграмме с помощью нескольких блоков, соединенных интерфейсными дугами. Эти блоки представляют основные подфункции исходной функции. Каждая из этих подфункций может быть декомпозирована подобным образом для более детального представления. При этом каждая подфункция может содержать только те элементы, которые входят в исходную функцию.
Таким образом, в процессе декомпозиции функциональные блоки диаграммы подвергаются детализации на другой диаграмме, которая называется дочерней (Child Diagram) по отношению к детализируемому блоку. Каждый из функциональных блоков, принадлежащих дочерней диаграмме, называется дочерним блоком (Child Box). В свою очередь, функциональный блок-предок называется родительским блоком по отношению к дочерней диаграмме (Parent Box), а диаграмма, к которой он принадлежит – родительской диаграммой (Parent Diagram). Каждый блок дочерней диаграммы может быть далее детализирован аналогичным образом, став родительским по отношению с соответствующей диаграмме его детализации.
2.3. Метод структурного системного анализа и проектирования SSADM
SSADM (Structured Systems Analysis and Design Method) – системный подход к анализу и проектированию ИС. SSADM как комплект стандартов для системного анализа и разработки приложений был разработан в начале 1980-х для Центрального агентства по компьютерам и телекоммуникациям (Central Computer and Telecommunications Agency, сейчас это Office of Government Commerce) – государственного учреждения UK, заинтересованного в использовании технологии в управлении. Позже SSADM широко использовался для государственных ИТ-проектов в UK, затем нашел широкое применение во всем мире для проектирования ИС. SSADM использует комбинацию текста и диаграмм для проектирования системы на всем ее жизненном цикле, от идеи до реального физического проекта приложения SSADM использует комбинацию из трех методологий моделирования.
1. Логическое моделирование данных (Logical Data Modeling, LDM) – процесс идентификации, моделирования и документирования требований к разрабатываемой системе. Элементы логической модели данных:
• сущности (entities) – то, о чем фирме нужно записать информацию;
• связи (relationships) – ассоциации между сущностями.
2. Моделирование потоков данных (Data Flow Modeling) – процесс идентификации, моделирования и документирования движения данных в ИС. Моделирование потоков данных исследует:
• процессы (processes) – деятельность по преобразованию данных из одной формы в другую;
• накопители данных (data stores) – области (промежуточного) хранения данных (the holding areas for data);
• внешние сущности (external entities) – сущности, которые посылают данные в систему или получают данные из системы;
• потоки данных – маршруты, по которым данные могут двигаться.
3. Моделирование поведения сущностей (Entity Behavior Modeling) – процесс идентификации, моделирования и документирования событий, которые влияют на каждую сущность и последовательности, в которой эти события происходят. Каждая их этих трех моделей системы обеспечивает различные точки зрения на одну и ту же систему, и каждая из точек зрения необходима для формирования полной модели проектируемой системы. Все три методологии во взаимосвязи друг с другом (are cross-referenced against each other) дают гарантию полноты и точности всего приложения.
Проект разработки SSADM приложения делится на пять модулей, которые в дальнейшем разбиваются на иерархию из стадий, этапов и задач. Модули проекта приведены ниже.
1. Анализ осуществимости проектного решения (Feasibility Study) – анализ предметной области для определения сможет ли проектируемая система удовлетворить бизнес-требованиям.
2. Анализ требований (Requirements Analysis). На этом этапе определяются подлежащие разработке системные требования и моделируется текущая среда предприятия в терминах процессов с включением структур данных.
3. Спецификация требований (Requirements Specification). На этом этапе определяются детальные функциональные и нефункциональные требования и вводятся новые методики для определения необходимых процессов и структур данных.
4. Логическая системная спецификация (Logical System Specification). На этом этапе вырабатываются опции технической системы, логический проект обновлений, обработка запросов и системные диалоги.
5. Физический проект (Physical Design). На этапе физического проектирования создается физический проект базы данных и комплект программных спецификаций с использованием логической и технической системных спецификаций. В отличие от RAD (см. гл. 1.5), который подразумевает параллельное выполнение этапов, SSADM строит каждый этап на основе работы, которая была предписана на предыдущем этапе без отклонений от модели.
По причине жесткой структуры методологии, SSADM хороша с точки зрения контроля проектов и способности разрабатывать системы лучшего качества.
Проектирование модели данных
Существует два типа проектирования модели данных: прямое и обратное.
Прямое проектирование (Forward Engineering) – процесс генерации физической схемы БД из логической модели, состоящий из следующих этапов:
1) разработка логической модели;
2) выбор СУБД и автоматическое создание физической модели на основе логической;
3) генерация системного каталога СУБД или соответствующего SQLскрипта на основе физической модели. ERwin при генерации физической схемы включает триггеры ссылочной целостности, хранимые процедуры, индексы, ограничения и другие возможности, доступные при определении таблиц в выбранной СУБД. Прямое проектирование обеспечивает масштабируемость – создав одну логическую модель данных, можно сгенерировать физические модели под любые СУБД. Обратное проектирование (Reverse Engineering) – процесс генерации логической модели из физической БД. Обратное проектирование решает задачу позволяет конвертировать БД из одной СУБД в другую. После создания логической модели БД путем обратного проектирования можно переключиться на другой сервер и произвести прямое проектирование. 1) по содержимому системного каталога или SQL-скрипту воссоздается логическая модель данных; 2) на основе полученной логической модели данных генерируется физическая модель для другой СУБД; 3) создается системный каталог этой СУБД. Обратное проектирование решает задачу по переносу структуры данных с одного сервера на другой.
Создание логической модели данных
Информационное (концептуальное) моделирование
Цель информационного моделирования – обеспечение разработчиков ИС концептуальной схемой базы данных в форме одной модели или нескольких локальных моделей данных, которые относительно легко могут быть отображены в любую систему баз данных. Концептуальная схема представляет собой карту понятий и отношений между ними, т.е. семантику организации (а не дизайн базы данных) и может существовать на различных уровнях абстракции. Если функциональная схема представляет собой определенную точку зрения на мир и не является гибкой (меняется мир – должна поменяться схема), то концептуальная схема объединяет в себе все точки зрения и дает более абстрактное представление об объекте, описывая фундаментальные понятия, лишь с экземплярами которых человек имеет дело. В инженерии ПО, моделирование «сущность-связь» (Entity-Relationship Model, ERM) – это пример абстрактного и концептуального представление данных; это метод моделирования БД, используемый для создания концептуальной схемы или семантической модели данных системы (часто реляционной БД), а также требований к системе в форме «сверху-вниз». Диаграммы, созданные таким способом, называются диаграммами «сущность-связь» (entity-relationship diagrams) или ER-диаграммами, или кратко ERD. ERD является наиболее распространенным средством документирования данных. С их помощью определяются важные для предметной области объекты (сущности), их свойства (атрибуты) и отношения друг с другом (связи). ERD непосредственно используются для проектирования реляционных баз данных. На уровне физической модели сущности соответствует таблица; экземпляру сущности – строка в таблице; атрибуту – колонка таблицы.
Различают три уровня логической модели, отличающихся по глубине представления информации о данных: диаграмма сущность-связь, модель данных, основанная на ключах и полная атрибутивная модель.
1. Диаграмма сущность-связь (Entity Relationship Diagram, ERD) представляет собой модель данных верхнего уровня. Она включает сущности и взаимосвязи, отражающие основные правила предметной области. Такая диаграмма не слишком детализирована, в нее включаются основные сущности и связи между ними, которые удовлетворяют основным требованиям, предъявляемым к ИС. Диаграмма сущность-связь может включать связи «многие-комногим» и не включать описание ключей. Как правило, ERD используется для презентаций и обсуждения структуры данных с экспертами предметной области.
2. Модель данных, основанная на ключах (Key Based model, KB) – более подробное представление данных. Она включает описание всех сущностей и первичных ключей и предназначена для представления структуры данных и ключей, которые соответствуют предметной области.
3. Полная атрибутивная модель (Fully Attributed model, FA) – наиболее детальное представление структуры данных: представляет данные в третьей нормальной форме и включает все сущности, атрибуты и связи.
Существует несколько соглашений для ERD. Классическая нотация связана, главным образом, с концептуальным моделированием. При этом существует ряд нотаций, применяемых для логического и физического проектирования БД, например IDEF1X. Диаграмма структуры данных DSD (data structure diagram) – это модель данных для описания концептуальных моделей данных с помощью графических нотаций, которые документируют сущности и связи между ними, а также условия по ограничению связей (и the constraints that binds them). Диаграммы структуры данных DSD являются расширением E-R-модели (entity-relationship model, E-R model).
Case-метод Баркера Нотация ERD была впервые введена П. Ченом (Chen) и получила дальнейшее развитие в работах Баркера.
Первый этап моделирования – выделение сущностей. Сущность (Entity) – реальный либо воображаемый объект, имеющий существенное значение для рассматриваемой предметной области, информация о котором подлежит хранению. Графическое изображение сущности показано на рис. 3.2.
Рис. 3.2. Графическое изображение сущности
Следующим шагом моделирования является идентификация связей. Изображение связей, их степени и обязательности показано на рис. 3.3.
Последним шагом моделирования является идентификация атрибутов. Атрибут – любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Экземпляр атрибута – это определенная характеристика отдельного элемента множества. Экземпляр атрибута определяется типом характеристики и ее значением, называемым значением атрибута. В ER-модели атрибуты ассоциируются с конкретными сущностями. Таким образом, экземпляр сущности должен обладать единственным определенным значением для ассоциированного атрибута. Атрибут может быть либо обязательным, либо необязательным (рис. 3.4). Обязательность означает, что атрибут не может принимать неопределенных значений (null values).
Атрибут может быть либо описательным (т.е. обычным дескриптором сущности), либо входить в состав уникального идентификатора (первичного ключа). Уникальный идентификатор – это атрибут или совокупность атрибутов и/или связей, предназначенная для уникальной идентификации каждого экземпляра данного типа сущности. В случае полной идентификации каждый экземпляр данного типа сущности полностью идентифицируется своими собственными ключевыми атрибутами, в противном случае в его идентификации участвуют также атрибуты другой сущности-родителя (рис. 3.5).
Каждый атрибут идентифицируется уникальным именем, выражаемым грамматическим оборотом существительного, описывающим представляемую атрибутом характеристику. Атрибуты изображаются в виде списка имен внутри блока ассоциированной сущности, причем каждый атрибут занимает отдельную строку. Атрибуты, определяющие первичный ключ, размещаются наверху списка и выделяются знаком «#». Каждая сущность должна обладать хотя бы одним возможным ключом. Возможный ключ сущности – это один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. При существовании нескольких возможных ключей один из них обозначается в качестве первичного ключа, а остальные – как альтернативные ключи. Помимо перечисленных основных конструкций модель данных может содержать ряд дополнительных.
Методология IDEF1X
Метод IDEF1, разработанный Т.Рэмей (T.Ramey), также основан на подходе П.Чена и позволяет построить модель данных, эквивалентную реляционной модели в третьей нормальной форме. В настоящее время на основе совершенствования методологии IDEF1 создана ее новая версия – методология IDEF1X. IDEF1X разработана с учетом таких требований, как простота изучения и возможность автоматизации. IDEF1X-диаграммы используются рядом распространенных CASE-средств (в частности, ERwin, Design/IDEF).
Сущность в методологии IDEF1X является независимой от идентификаторов или просто независимой, если каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями. Сущность называется зависимой от идентификаторов или просто зависимой, если однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности (рис. 3.6).
Каждой сущности присваивается уникальное имя и номер, разделяемые косой чертой "/" и помещаемые над блоком.
Связь является логическим соотношением между сущностями. Каждая связь должна именоваться глаголом или глагольной фразой (рис. 3.7.).
Связь может дополнительно определяться с помощью указания степени или мощности (количества экземпляров сущности-потомка, которое может существовать для каждого экземпляра сущности-родителя). В IDEF1X могут быть выражены следующие мощности связей:
• каждый экземпляр сущности-родителя может иметь ноль, один или более связанных с ним экземпляров сущности-потомка;
• каждый экземпляр сущности-родителя должен иметь не менее одного связанного с ним экземпляра сущности-потомка;
• каждый экземпляр сущности-родителя должен иметь не более одного связанного с ним экземпляра сущности-потомка;
• каждый экземпляр сущности-родителя связан с некоторым фиксированным числом экземпляров сущности-потомка. Если экземпляр сущности-потомка однозначно определяется своей связью с сущностью-родителем, то связь называется идентифицирующей, в противном случае – неидентифицирующей. Связь изображается линией, проводимой между сущностью-родителем и сущностью-потомком с точкой на конце линии у сущности-потомка. Мощность связи обозначается как показано на рис. 3.8. (мощность по умолчанию – N).
Идентифицирующая связь между сущностью-родителем и сущностьюпотомком изображается сплошной линией (рис. 3.9.).
Сущность-потомок в идентифицирующей связи является зависимой от идентификатора сущностью. Сущность-родитель в идентифицирующей связи может быть как независимой, так и зависимой от идентификатора сущностью (это определяется ее связями с другими сущностями). Пунктирная линия изображает неидентифицирующую связь (рис. 3.10). Сущность-потомок в неидентифицирующей связи будет независимой от идентификатора, если она не является также сущностью-потомком в какой-либо идентифицирующей связи.
Атрибуты изображаются в виде списка имен внутри блока сущности. Атрибуты, определяющие первичный ключ, размещаются наверху списка и отделяются от других атрибутов горизонтальной чертой (рис. 3.11).
Сущности могут иметь также внешние ключи (Foreign Key), которые могут использоваться в качестве части или целого первичного ключа или неключевого атрибута. Внешний ключ изображается с помощью помещения внутрь блока сущности имен атрибутов, после которых следуют буквы FK в скобках (рис. 3.12).
Когда рисуется идентифицирующая связь, ERwin автоматически преобразует дочернюю сущность в зависимую. Зависимая сущность изображается прямоугольником со скругленными углами (рис. 3.13).
Экземпляр зависимой сущности определяется только через отношение к родительской сущности. При установлении идентифицирующей связи атрибуты первичного ключа родительской сущности автоматически переносятся в состав первичного ключа дочерней сущности. Эта операция дополнения атрибутов дочерней сущности при создании связи называется миграцией атрибутов. В дочерней сущности новые атрибуты помечаются как внешний ключ – (FK).
Типы сущностей и иерархия наследования
Как уже было сказано, связи определяют, является ли сущность независимой или зависимой. Различают несколько типов зависимых сущностей:
• характеристическая – зависимая дочерняя сущность, которая связана только с одной родительской и по смыслу хранит информацию о характеристиках родительской сущности.
• ассоциативная – сущность, связанная с несколькими родительскими сущностями. Такая сущность содержит информацию о связях сущностей.
• именующая – частный случай ассоциативной сущности, не имеющей собственных атрибутов (только атрибуты родительских сущностей, мигрировавших в качестве внешнего ключа).
• категориальная – дочерняя сущность в иерархии наследования. Иерархия наследования (или иерархия категорий) представляет собой особый тип объединения сущностей, которые разделяют общие характеристики. Обычно иерархию наследования создают, когда несколько сущностей имеют общие по смыслу атрибуты, либо когда сущности имеют общие по смыслу связи, либо когда это диктуется бизнес-правилами. Для каждой категории можно указать дискриминатор – атрибут родового предка, который показывает, как отличить одну категориальную сущность от другой. Иерархии категорий делятся на два типа – полные и неполные. В полной категории одному экземпляру родового предка обязательно соответствует экземпляр в каком-либо потомке. Если категория еще не выстроена полностью и в родовом предке могут существовать экземпляры, которые не имеют соответствующих экземпляров в потомках, то такая категория будет неполной. Полная категория помечается кружком с двумя горизонтальными чертами, неполная – кружком с одной чертой. Возможна комбинация полной и неполной категорий (рис. 3.14).
Имитационное моделирование
Имитационное моделирование может служить для получения оценочных аспектов моделирования предметной области, которые связаны с разрабатываемыми показателями эффективности автоматизируемых процессов. Имитационное моделирование заключается в построении и исследовании имитационной модели. Имитационные модели – это динамические модели, учитывающие время выполнения операций, и позволяющие анализировать динамику бизнес-процессов. Имитационные модели описывают не только сущности, потоки информации и управление, но и различные метрики. Полученную модель можно «проиграть» во времени и получить статистику происходящих процессов так, как это было бы в реальности. В имитационной модели изменения процессов и данных ассоциируются с событиями. «Проигрывание» модели заключается в последовательном переходе от одного события к другому.
Имитационная модель включает следующие основные элементы:
1) источники и стоки (Create и Dispose). Источники – это элементы, от которых в модель поступает информация или материальные объекты. По смыслу они близки к понятиям «внешняя сущность» на DFD или «объект ссылки» на диаграммах IDEF3. Скорость поступления данных или объектов от источника обычно задается статистической функцией. Сток – это устройство для приема информации или объектов;
2) очереди (Queues). Понятие очереди близко к понятию «хранилища данных» на DFD-диаграммах – это место, где объекты ожидают обработки. Время обработки объектов в разных работах может быть разным. В результате перед некоторыми работами могут накапливаться объекты, ожидающие своей очереди. Часто целью имитационного моделирования является минимизация количества объектов в очередях;
3) процессы (Process) – это аналог работ в функциональной модели. В имитационной модели может быть задана производительность процессов.
Функциональные и имитационные модели взаимосвязаны и дополняют друг друга. Имитационная модель дает больше информации для анализа системы, в свою очередь результаты такого анализа могут быть причиной модификации модели процессов. Существует также возможность преобразования функциональной модели в имитационную модель. Целесообразно сначала строить функциональную модель, а на ее основе – имитационную. Построение модели производится с помощью специальных CASE средств путем переноса из панели инструментов в рабочее пространство модулей Create, Dispose и Process. Связи между модулями устанавливаются автоматически, но могут быть переопределены вручную. Далее модулям назначаются свойства. Для контроля проигрывания модели необходимо в модель добавить модуль Simulate и задать для него параметры. Результаты проигрывания модели отображаются в автоматически генерируемых отчетах.
BPwin не имеет собственных инструментов, позволяющих создавать имитационные модели, однако дает возможность экспортировать модель IDEF3 в специализированное средство создания таких моделей. Для экспорта модели необходимо настроить свойства, определяемые пользователем UDP, специально включенные в BPwin для целей экспорта.
ЗАКЛЮЧЕНИЕ
Объектно-ориентированный подход в настоящее время считается наиболее эффективным т.к. оперирует абстракциями реальных объектов и операций. Т.е. при построении модели имеющейся предметной области, выделении бизнес-процессов и пр. строится и модель будущей информационной системы (ИС).
Объектно-ориентированное проектирование и объектно-ориентированное программирование улучшают возможности нисходящего проектирования, концентрируя больше внимание на данных системы, а не на том, что система делает. Это подход позволяет создавать системы, которые легче сопровождать, они более гибкие, более устойчивые и более приспособлены к многократному использованию, чем создаваемые при нисходящем структурном подходе.
Одно из достоинств объектно-ориентированного подхода состоит в упрощении накопления типовых проектных решений с тем, чтобы в дальнейших разработках новых информационных систем осуществить сбор новой системы из готовых компонент. Эта особенность связана с тем, что классы объектов повторяются в определенной мере при переходе от одной информационной системы к другой, а для повторяющихся классов уже запрограммированы методы, разработаны и описаны структуры объектов данных.
Библиографический список
1. Инюшкина О.Г., Кормышев В.М. Исследование систем управления при проектировании информационных систем: учебное пособие. / О.Г. Инюшкина, В.М. Кормышев. Екатеринбург: «Форт-Диалог Исеть», 2013. 370 с.
2. Гольдштейн С.Л., Инюшкина О.Г. Практика использования информационных технологий и систем (на примерах управления организацией): учебное пособие / С.Л. Гольдштейн, О.Г. Инюшкина. Екатеринбург: УрФУ, 2010. 185 с.
3. Инюшкина О.Г., Кормышев В.М. Управление знаниями в информационных системах (монография). / О.Г. Инюшкина, В.М. Кормышев, Екатеринбург: УрФУ, 2012. 212 с.
4. Rob M.A. Issues of Structured vs. Object-Oriented methodology of systems analysis and design. [Электронный ресурс] Режим доступа: PDF.
5. Буч Г., Рамбо Д., Джекобсон А. Язык UML Руководство пользователя. [Электронный ресурс] Режим доступа: PDF.
6. Маклаков С.В. «ERwin и BPwin. CASE-средства разработки информацион
ных систем» / С.В. Маклаков, 2-е изд., испр. и доп., М. : Диалог-Мифи, 2001. – 304 с.М: «Диалг-МИФИ», 2001.
7. Дэвид А. Марка, Клемент МакГоуэн. Предисловие Дугласа Т. Росса. Методология структурного анализа и проектирования SADT Structured Analysis & Design Technique. [Электронный ресурс] Режим доступа: www.pqm-online.com/assets/files/lib/mar
Приложения
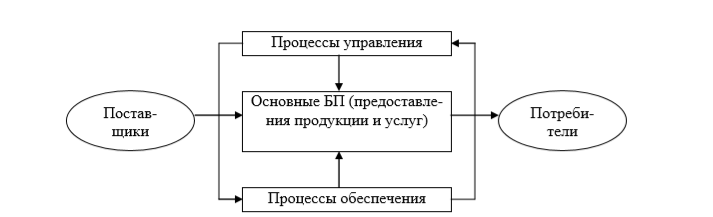
Рис. 2.1. Упрощенная модель деятельности компании
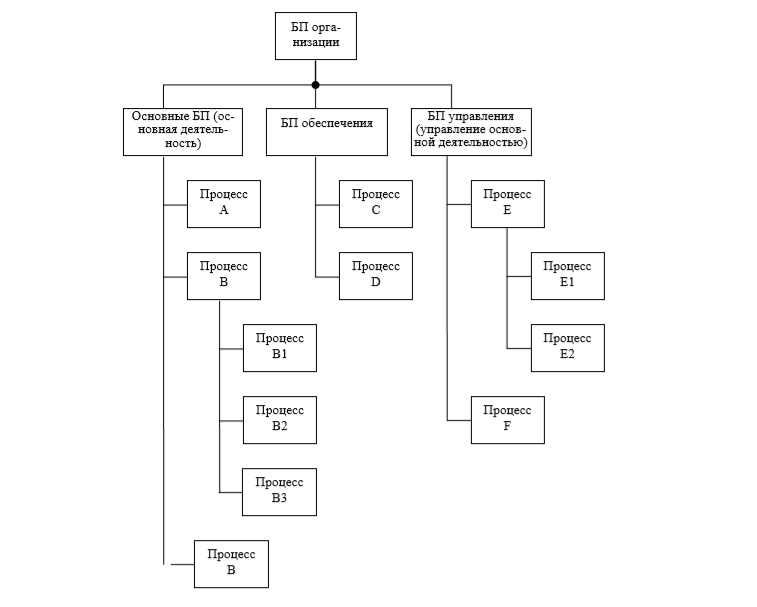
Рис. 2.2. Дерево бизнес процессов
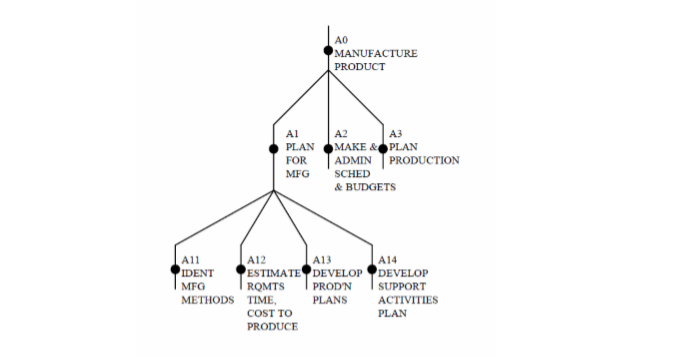
Рис. 2.3. Пример стандартного дерева узлов
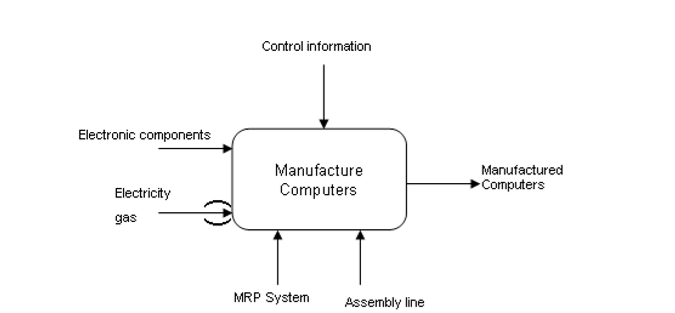
Рис. 3.1. Пример уровня 0
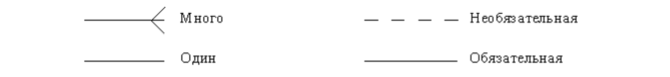
Рис. 3.3. Графическое изображение связей

Рис. 3.4. Обязательные и необязательные атрибуты
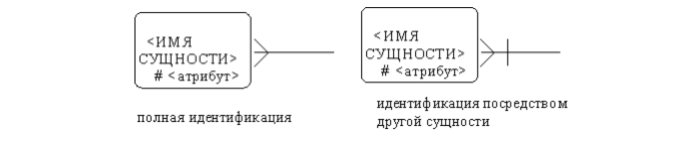
Рис. 3.5. Идентификация атрибутов
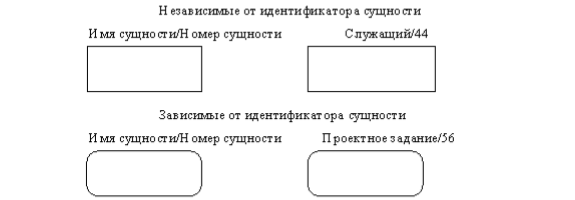
Рис. 3.6. Независимые и зависимые сущности
Рис. 3.7. Связь

Рис. 3.8. Мощность связи
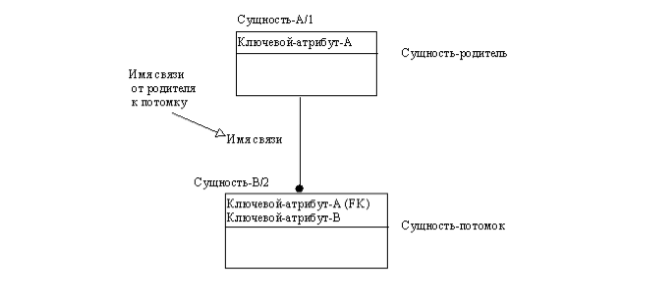
Рис. 3.9. Идентифицирующая связь
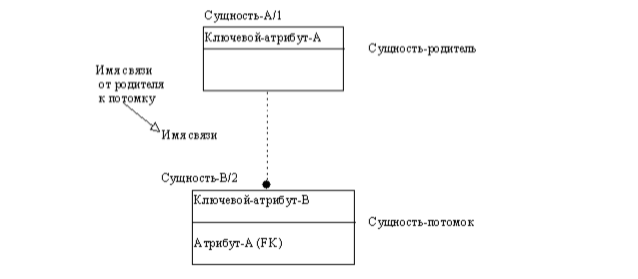
Рис. 3.10. Неидентифицирующая связь
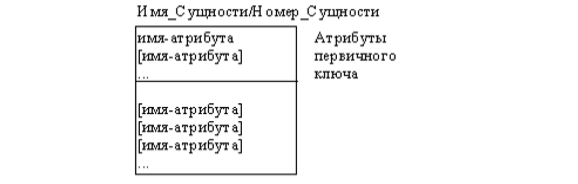
Рис.3.11 Атрибуты, определяющие первичный ключ, размещаются наверху списка и отделяются от других атрибутов горизонтальной чертой.

Рис. 3.12. Примеры внешних ключей
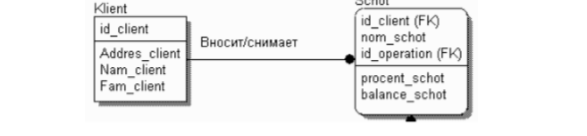
Рис. 3.13. Изображение зависимой сущности
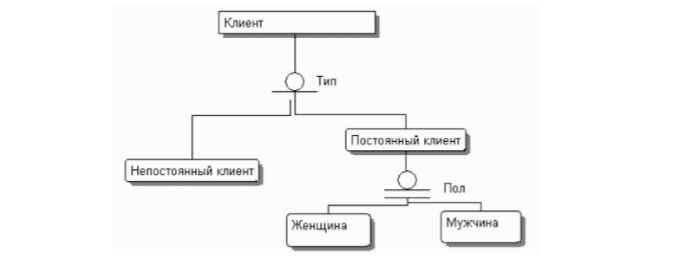
Рис. 3.14. Комбинация полной и неполной категорий

- ДЕМОГРАФИЧЕСКОЕ ПРОГНОЗИРОВАНИЕ (Современное состояние демографической политики РФ)
- Соотношение государства и гражданского общества (Теоретико-правовые основы гражданского общества)
- Обеспечение мотивации обучения в начальных классах (Описание модели педагогических условий формирования мотивации учебной деятельности у младших школьников )
- Детско-юношеские спортивные школы как система спортивного образования (Специфика детского спортивного движения в российской практике и государственное управление в данной сфере общественных отношений )
- Физкультурное воспитание в системе воспитания детей школьного возраста (СУЩНОСТЬ И ОСНОВНЫЕ ЗАДАЧИ ФИЗИЧЕСКОГО ВОСПИТАНИЯ ДЕТЕЙ ШКОЛЬНОГО ВОЗРАСТА)
- Восприятие временной перспективы в зависимости от возраста
- Корпоративная культура в организации (Теоретические основы формирования корпоративной культуры в организации )
- Методы сбора и обработки первичной маркетинговой информации
- Понятие и значение приватизации (Понятие и значение приватизации )
- Виды юридических лиц (ОБЩАЯ ХАРАКТЕРИСТИКА ЮРИДИЧЕСКОГО ЛИЦА)
- Понятие и виды наследования (Наследование как институт российского права)
- Диалектическое единство методов и данных в информационном процессе