
Отладка и тестирование программ: основные подходы и ограничения (Метод черного ящика)
Содержание:

ВВЕДЕНИЕ
Тестирование и отладка являются важнейшими действиями во время цикла разработки программного обеспечения (ПО). Тестирование выполняется для того, чтобы проверить, содержит ли код ошибки, а отладка необходима для обнаружения и исправления этих ошибок. Тестирование может быть ручным или автоматическим и может быть разных типов: юнит-тестирование, интеграционное тестирование, системное тестирование, стресс-тестирование и т.д. Отладка также может быть ручной или автоматической. Эти два вида деятельности являются одинаково важными и привлекают внимание исследователей в последние годы. Несмотря на наличие различных инструментов для обеспечения качества программного обеспечения посредством тестирования, для большого количества проектов нет общего подтверждения того, в достаточной ли степени они протестированы. Это ключевой момент, поскольку влияние неполного тестирования может заключаться в значительном количестве необработанных сбоев, что приводит к низкому качеству программного обеспечения, более высоким затратам на его разработку и временным задержкам при выводе продукта на рынок. Исследование, проведенное Национальным институтом стандартов и технологий, показало, что недостаточное тестирование программного обеспечения обходится экономике США в 59,5 миллиардов долларов в год, т. е. Около 0,6% от ее ВВП [1.]. Количество ошибок, обнаруженных после завершения работы над кодом продукта, может ошеломить разработчиков проектов, если программное обеспечение не было тщательно протестировано. Например, комитет проекта Mozilla признал, что каждый день они получают почти 300 ошибок, которые требуют исправления [2.]. Поэтому важно иметь методы, которые могут помочь разработчикам быстро находить файлы с ошибками и быстрее устранять ошибки. Эти цифры подтверждают тот факт, что тестирование и отладка программного обеспечения имеют первостепенное значение для разработки высококачественного программного обеспечения.
Важным моментом является то, что тестирование программного обеспечения должно рассматриваться с разных точек зрения обеспечения качества программного обеспечения, которое связано со всеми областями бизнес-процесса, а не только с областями тестирования. Методы для проверки качества ПО могут быть выбраны по различным критериям (показателям качества): основанные на решениях о состоянии тестируемого приложения, времени выпуска программного обеспечения, о риске выпуска программного обеспечения и т.д. Тесты имеют разнообразные метрики, в том числе и гораздо более неопределенные. Чтобы выбрать подходящие для конкретного приложения методы, необходимо получить информацию о различных показателях и использовать ее.
В 2010 году технические неполадки возникли на токийской фондовой бирже – из-за проблем с работой системы она была приостановлена на 12 дней. Сообщалась и причина ошибки – сервер не инициализировал память. («не удалось инициализировать память при определенных условиях» [3.]). Таким образом, ясно, что для доставки нужного продукта до конечного пользователя и обеспечения его надежности, приложение должно быть полностью протестировано. Все ошибки и проблемы, которые делают приложение бесполезным, должны быть выявлены и устранены.
В предыдущих исследованиях, связанных с тестированием, было предложено много методов, таких как автоматическая генерация тестов, минимизация тестов, выбор тестовых наборов, расстановка приоритетов и эмпирические исследования качества тестового набора и его эффективности при обнаружении ошибок. В исследованиях, связанных с отладкой, были предложены новые методы поиска ошибок с использованием различных схем локализации ошибок, таких как спектральное тестирование, программный слайсинг, дельта-отладка и т.д. для точного и эффективного поиска ошибок. Однако даже после многолетних исследований программное обеспечение по-прежнему имеет ошибки, которые могут привести к значительным последствиям. Таким образом, важно учитывать текущее состояние методов тестирования и ожидания практикующих эти методы, чтобы понять, находят ли специалисты имеющиеся методы полезными или нет. Такой количественный и качественный анализ может дать понимание, полезное для исследователей и специалистов по тестированию.
Цели данной курсовой работы – рассмотреть основные принципы отладки и тестирования, получить подробное представление о методах тестирования, а также изучить понятия наблюдаемости и управляемости логики программного обеспечения на конкретном примере. Для достижения цели в курсовой работе были поставлены следующие задачи:
- выяснить, из чего складывается общая методика отладки и тестирования программного обеспечения;
- узнать о современном состоянии изучаемых технологий;
- выполнить обзор литературы, связанной с понятиями наблюдаемости и управляемости, используемыми на практике.
Основные принципы отладки и тестирования
Общая методика отладки программного обеспечения
Цель отладки состоит в том, чтобы найти и исправить вызывающий код, ответственный за симптом, нарушающий известную спецификацию. Отладка обычно происходит во время трех действий в разработке программного обеспечения, и уровень детализации анализа, требуемого для обнаружения дефекта, отличается в каждом из них [9.].
Первое действие происходит во время процесса кодирования, когда программист переводит дизайн в исполняемый код. В ходе этого процесса ошибки, допущенные программистом при написании кода, могут привести к дефектам, которые необходимо быстро обнаружить и исправить, прежде чем код перейдет к следующим этапам разработки. Чаще всего разработчик также выполняет модульное тестирование, чтобы выявить любые дефекты на уровне модуля или компонента. Второе место для отладки – на более поздних этапах тестирования, в которых участвуют несколько компонентов или целая система, когда можно обнаружить непредвиденное поведение, такое как неправильные коды возврата или ненормальное завершение программы (прерывание). Определенная отладка выполнения теста необходима для того, чтобы сделать вывод, что тестируемая программа является причиной неожиданного поведения, а не результатом плохого тестового примера из-за неправильной спецификации, несоответствующих данных или изменений в функциональной спецификации между различными версиями системы. Как только дефект подтвержден, следует отладка программы и определяется компонент неправильной работы и необходимое исправление. Третье место для отладки – в производстве или внедрении, когда тестируемое программное обеспечение сталкивается с реальными условиями эксплуатации. На этом этапе обнаруживаются некоторые нежелательные аспекты поведения программного обеспечения, такие как неадекватная производительность при серьезной рабочей нагрузке или неудовлетворительное восстановление после сбоя, и перед масштабным внедрением необходимо найти и исправить код, вызывающий сбой. Этот процесс также можно назвать «определение проблемы» из-за расширенного объема анализа, необходимого для локализации дефекта.
Современное состояние технологии отладки программного обеспечения
Как известно среди разработчиков программного обеспечения, большая часть усилий по отладке связана с поиском дефектов. Отладка выполняется с наименьшим уровнем детализации в процессе кодирования. В первые годы разработки программного обеспечения при компиляции и выполнении обнаруживались дефекты, которые не определялись по результатам инспекции кода. Через болезненный процесс (такой как вставка операторов печати для известных выходных данных в соответствующие места в программе) программист может определить точное местоположение ошибки и найти подходящее исправление.
Даже сегодня отладка остается искусством. Большая часть сообщества компьютерных наук в значительной степени проигнорировала проблему отладки [4.]. Эйзенштадт в своей работе [5.] изучил 59 анекдотичных случаев отладки, и его выводы были следующими: чуть более 50 процентов проблем возникли из-за временной и пространственной пропасти между симптомом и первопричиной или неадекватных средств отладки. Доминирующими методами поиска ошибок были сбор данных (например, выписка из печати) и ручное моделирование. Двумя основными причинами ошибок были перезапись памяти и дефекты поставляемого поставщиком оборудования или программного обеспечения.
Чтобы помочь разработчикам программного обеспечения в отладке программы во время процесса кодирования, было предложено много новых подходов. Кроме того, на сегодняшний день доступно большое количество коммерческих сред отладки. Интегрированные среды разработки обеспечивают способ поиска и исправления некоторых заранее определенных ошибок, зависящих от языка (например, пропущенных символов известного оператора, неопределенных переменных и т.д.) без необходимости компиляции. Одной из областей, которая привлекла внимание отрасли, является визуализация необходимых базовых программных конструкций как средства анализа программы [6., 7.].
Когда тестирование программного обеспечения приводит к сбою, и анализ показывает, что контрольный пример не является источником проблемы, следует отладка программы и определяется необходимое исправление. Отладка во время тестирования по-прежнему остается в целом ручной, несмотря на достижения в технологии выполнения тестов. Существует явная потребность в более сильной (автоматической) связи между разработкой программного обеспечения (тем, для чего предназначен код), созданием теста (тем, что пытается проверить тест) и выполнением теста (тем, что на самом деле тестируется), чтобы свести к минимуму сложность идентификации кода, вызывающего сбой, в случае неудачи контрольного примера. Отладка во время производства или после внедрения очень сложна. За исключением использования некоторых передовых методов определения проблем для определения конкретного дефекта или дефектов, которые привели к неожиданному поведению, эта отладка может быть болезненной, трудоемкой и очень дорогой. Проблемы усугубляются, когда в определении проблем участвуют несколько взаимодействующих программных продуктов. Поскольку отладка отходит от реального программирования исходного кода (например, в системном тесте или даже позже в бета-тестировании клиента), определение проблем становится еще более ручным и трудоемким.
Цели и задачи тестирования программного обеспечения
Целью тестирования программного обеспечения является получение знания о том, работает ли программа корректно, а также исправление найденных ошибок для улучшения качества ПО. Тестирование программного обеспечения обычно составляет 40% бюджета на разработку программного обеспечения [23.]. С этой точки зрения продукт тестирования программного обеспечения является таким же, как и прочие продукты. Но в отличие от «материальных» товаров, у программного обеспечения есть другие проблемы. Пользователи могут не обнаруживать проблем с программным приложением, если эти проблемы не проявляются при определенных обстоятельствах. При работе с «материальным» продуктом, возможно, проблемы удастся выявить до их возникновения. Другими словами, до тех пор, пока определенные условия не проверены, программное обеспечение в целом работает нормально.
Таким образом, можно сказать, что проблемы в приложении возникают из-за слабости (неполноты) их тестирования. В связи с растущей сложностью и распространением приложений важность тестирования программного обеспечения постепенно возрастает. Основные задачи тестирования программного обеспечения [8.]:
- Демонстрация: проверить работу функций в особых условиях и показать, что продукты готовы к интеграции или использованию;
- Обнаружение: обнаружить дефекты, ошибки и недостатки. Определить системные возможности и ограничения, качество компонентов, рабочих продуктов и системы;
- Предотвращение: предоставить информацию для предотвращения или уменьшения количества ошибок, уточнения технических характеристик и производительности системы. Определить способы избежать рисков и проблем в будущем;
- Улучшение качества: минимизировать ошибки и, следовательно, улучшить качество программного обеспечения.
Тестирование и отладка имеют ряд определенных различий. И тестирование, и отладка стремятся улучшить качество программного обеспечения, но в процессе отладки выявляются только программные ошибки, в то время как тестирование позволяет обнаружить также уязвимости программного обеспечения, которые включают аспекты той системы, в которой установлено и работает программное обеспечение [10.]. Другими словами, отладка обслуживает предопределенные недостатки, в то время как тестирование обнаруживает условия, которые затрудняют работу конечных пользователей. Проблема, выявленная в результате отладки, может привести к тому, что ожидаемая логика программного обеспечения не будет выполнена. С другой стороны, системные ошибки, которые выявляются при тестировании программного обеспечения, несут риски как для самих пользователей, так и для самого программного обеспечения. Программное обеспечение должно быть разработано и внедрено для предотвращения этих ошибок [11.]. Если программист используется в качестве тестера программного обеспечения, ошибка, скорее всего, не будет обнаружена при ее наличии [12.].
Как правило, перед кодированием программы анализ конструкции и проверка кода выполняются в рамках статического тестирования [13.]. Как только код написан, могут применяться различные другие методы статического анализа, основанные на исходном коде [14.]. Различные виды и этапы тестирования, предназначенные для разных уровней интеграции и различных режимов сбоев программного обеспечения, обсуждаются в большом количестве литературы [15., 16., 17.]. Например, тестирование, проводимое на более поздних этапах (например, тесты внешних функций, системные тесты и т. д.) – это тестирование «черного ящика», основанное на внешних спецификациях, и, следовательно, не подразумевающее понимания реализаций детального кода. Как правило, системное тестирование направлено на ключевые аспекты продукта, такие как восстановление, безопасность, производительность, конфигурация оборудования, программного обеспечения и т. д. Тестирование в процессе производства и внедрения обычно включает определенный уровень критериев приемлемости для клиента. Многие компании-разработчики разрабатывают предварительные бета-программы для своих клиентов.
Тестирование программного обеспечения имеет следующий жизненный цикл:
- Анализ потребностей: необходимо выполнить этап анализа потребностей жизненного цикла тестирования программного обеспечения;
- Анализ проекта: на этом этапе специалисты по тестированию и дизайна определяют, какая часть проекта и какие параметры должны использоваться при тестировании;
- Дизайн тестирования: на этом этапе стратегия тестирования становится понятной;
- Запуск тестирования: запуск тестирования – любые ошибки будут сообщены разработчику;
- Отчет об испытаниях: после завершения испытаний последние результаты публикуются в форме отчета, который определяет, является ли программное обеспечение пригодным для использования или нет.
Современное состояние технологии тестирования программного обеспечения
Критика Дейкстры [18.], «Тестирование программ может использоваться для выявления наличия ошибок, но не для выявления их отсутствия», хорошо известна. С его точки зрения, любой объем тестирования представляет собой лишь небольшую выборку из всех возможных вычислений и поэтому никогда не является достаточным для обеспечения ожидаемого поведения программы при всех возможных условиях. Он утверждал, что «степень, в которой может быть установлена корректность программы, является не просто функцией внешних спецификаций и поведения программы, а критически зависит от ее внутренней структуры». Однако тестирование стало предпочтительным процессом удовлетворения потребностей программного обеспечения. Это связано, прежде всего, с тем, что никакой другой подход, основанный на более формальных методах, не приблизился бы к обеспечению масштабируемости и удовлетворению интуитивных потребностей «разработчика» в программировании. Гамлет [19.] связал хорошее тестирование с измерением надежности тестируемого программного обеспечения в некотором статистическом смысле. Отсутствие или наличие сбоев, выявленных самим тестированием, не измеряет надежность программного обеспечения, если только не существует какого-либо способа количественно оценить свойства тестирования, чтобы убедиться, что адекватные параметры тестирования, включая тестируемость целевого программного обеспечения, были охвачены. Методы планирования тестирования, основанные на разделении функциональности, данных, рабочих профилей конечного пользователя [20.] и т.д. очень полезны и популярны в исследованиях тестирования и среди специалистов-практиков. Многие из современных технологий в тестировании основаны на этих идеях.
Как обсуждалось ранее, тестирование – это, по сути, выборка пространства выполнения программы. Следовательно, возникает естественный вопрос: когда мы должны прекратить тестирование? Учитывая то, что мы не можем реально показать, что в программе больше нет ошибок, мы можем использовать только эвристические аргументы, основанные на завершенности и изощренности усилий по тестированию, и тенденциях в результате обнаружения дефектов для того, чтобы доказать вероятность более низкого риска оставшихся дефектов. Примерами метрик, используемых в процессе тестирования [21.], которые нацелены на обнаружение дефектов и размер кода, являются: размер продукта и выпуска с течением времени, частота обнаружения дефектов с течением времени, отставание по дефектам с течением времени и так далее. Некоторые практические метрики, которые характеризуют процесс тестирования – прогресс тестирования во времени (запланированный, предпринятый, фактический), процент выполненных тестовых случаев и т.д. В некоторых организациях использование метрик покрытия тестов (например, охват кода) используется для описания завершенности тестирования. Использование методологии Ортогональной классификации дефектов [22.] позволяет дать более семантическую характеристику как природы обнаруженных дефектов, так и завершенности процесса тестирования.
Анализ исходного кода для выявления потенциальных дефектов является хорошо развитой отраслью разработки программного обеспечения [24.]. Типичный метод работы состоит в том, чтобы сделать целевой код доступным для инструмента анализа кода. Затем инструмент будет искать некий класс проблем и помечать их как потенциальных кандидатов для изучения и исправления. В анализе исходного кода есть явные преимущества: это можно сделать до того, как появится исполняемая версия программы. Определенный класс ошибок, например, утечки памяти, легче выявить при анализе, чем при тестировании. Неисправность легче локализовать, так как симптомы имеют тенденцию быть причиной. Типичный анализ выполняется с использованием компилятора или анализатора, привязанного к языку программы, который создает представление, такое как граф вызовов, граф управления или граф потока данных программы. Многие коммерческие и исследовательские инструменты доступны в этой области.
Любые действия с тестированием состоят из четырех основных частей: разработка тестового набора, создание тестового набора, выполнение тестового набора и отладка [28.]. Из-за большого объема необходимого тестирования большинство организаций переходят от тестирования в преимущественно ручном режиме к автоматизированному тестированию. Из-за сложности рассматриваемых вопросов наиболее легко поддающимся автоматизации является выполнение тестов. Это предполагает, что контрольные примеры уже определены и записаны вручную (или получены с помощью инструмента) и могут быть выполнены в автоматизированной среде выполнения тестов с точки зрения планирования, регистрации результатов (успех или неудача), захвата деталей отказавшей среды окружения, и так далее. Для тестирования, которое требует явного использования графических пользовательских интерфейсов, автоматизация выполнения тестовых примеров уже привела к значительному увеличению производительности в отрасли. Существует целый ряд коммерческих и исследовательских инструментов тестирования.
Автоматизация проектирования тестовых наборов (и, следовательно, создание тестовых наборов) – является еще одной областью для изучения [25.]. Чтобы автоматизировать разработку функциональных тестовых примеров, необходимо иметь формальное описание спецификаций поведения программного обеспечения, в результате чего получается модель поведения ПО. Как обсуждалось ранее, это формальное описание не охватывается типичными коммерческими организациями. В то время как использование технологии конечных автоматов [26.] начинает завоевывать популярность в сообществе валидации моделей, ее использование в более широком сообществе тестирования промышленного программного обеспечения в лучшем случае ограничено. Растущее принятие UML (Unified Modeling Language, рус. «унифицированный язык моделирования») разработчиками в качестве языка проектирования может предоставить возможность для получения более формального описания спецификаций программного обеспечения. Тем не менее, в UML все еще не хватает конструкций, чтобы быть эффективным языком для получения реалистичных спецификаций тестовых примеров [27.].
Для программного обеспечения, которое прошло через много версий, одним из острых вопросов была проверка спецификаций предыдущих релизов по сравнению с текущим [29.]. Обычно это делается посредством выполнения «регрессионных» тестовых случаев (которые использовались для проверки предыдущих релизов) по сравнению с текущим релизом. В большинстве реальных сред автоматическое отслеживание не установлено среди тестовых случаев (то есть никто не знает, почему тестовый пример был добавлен или он все еще действителен). Кроме того, связь между требованиями к коду и финальной реализацией не отслеживается между версиями. Следовательно, регрессионное тестирование не только проверяет, что более ранние спецификации все еще действительны, но также выявляет проблемы обратной совместимости. Хотя существует очевидная необходимость продолжать добавлять набор регрессионных тестов, исходя из опасений относительно совокупных спецификаций для текущей версии программы, собранная неадекватная информация делает невозможным сокращение набора регрессий по мере развития продукта [32.]. Это еще одна область, в которой может помочь проектирование автоматизированных тестовых наборов, поскольку тестовые наборы будут естественным образом связаны со спецификацией, а трассировка будет встроена.
Стратегии тестирования программного обеспечения
Метод черного ящика
Тестирование по методу черного ящика основано на предположении, что тест не знает содержимого и алгоритмов программного обеспечения, подразумевая только набор входных данных и предсказуемые выходные данные [31.]. Этот метод проводится командой специалистов по тестированию или конечными пользователями. Иногда его также называют функциональным тестом, который не имеет внутреннего механизма системы.
Этот метод включает в себя следующие техники:
- Разделение эквивалентности
Эта методика делит входную область программы на классы эквивалентности, из которых могут быть получены тестовые наборы, что позволяет сократить количество тестовых случаев.
- Анализ граничных значений
Основное внимание уделяется тестированию на границах или там, где выбраны крайние граничные значения. Он включает в себя минимум, максимум, области только внутри / вне границ, значения ошибок и типичные значения.
- Фаззинг
Эта методика подает случайное входное значение в приложение. Он используется для поиска ошибок реализации, используя внедрение некорректных данных в автоматическом или полуавтоматическом режиме.
- Причинно-следственная диаграмма
В этой методике тестирование начинается с создания диаграммы и установления связи между следствием и его причиной.
- Тестирование ортогональных массивов
Эта методика может применяться, когда входная область очень мала, но в то же время слишком велика для проведения исчерпывающего тестирования.
- Метод попарного тестирования
В этой методике тестовые случаи предназначены для выполнения всех возможных дискретных комбинаций каждой пары входных параметров. Ее главная цель – создать набор тестовых случаев, охватывающих все пары.
- Тестирование переходов состояний
Этот тип тестирования полезен для тестирования конечного автомата, а также для навигации по графическому интерфейсу пользователя.
Преимущества [30.]:
- Тестеры могут не иметь никаких специальных знаний конкретного языка программирования.
- Тестирование проводится с точки зрения пользователя.
- Тестирование помогает выявить любые неясности или несоответствия в спецификациях требований.
- Программист и тестер не зависят друг от друга.
Недостатки:
- Тестовые случаи сложно разработать без четких спецификаций.
- Велика вероятность повторения тестов, которые уже выполнены программистом.
- Некоторые части бэкенда вообще не тестируются.
Метод белого ящика
Тестирование белого ящика в основном сфокусировано на внутренней логике и структуре кода. Выполнение этого метода предполагает, что программист обладает методиками, полностью знающими структуру программы. С помощью этой техники можно протестировать каждую ветку и решение в программе [34.]. Метод белого ящика иногда называют структурным тестированием, в котором также проверяется внутренний механизм системы. Тестер знает код и структуру данных, предназначенных для тестирования конкретного метода, который будет выполняться с определенными параметрами. Поэтому, в отличие от тестирования по методу черного ящика, метод белого ящика требует знаний конкретного языка программирования.
Этот метод включает в себя следующие техники (см. рисунок 1):
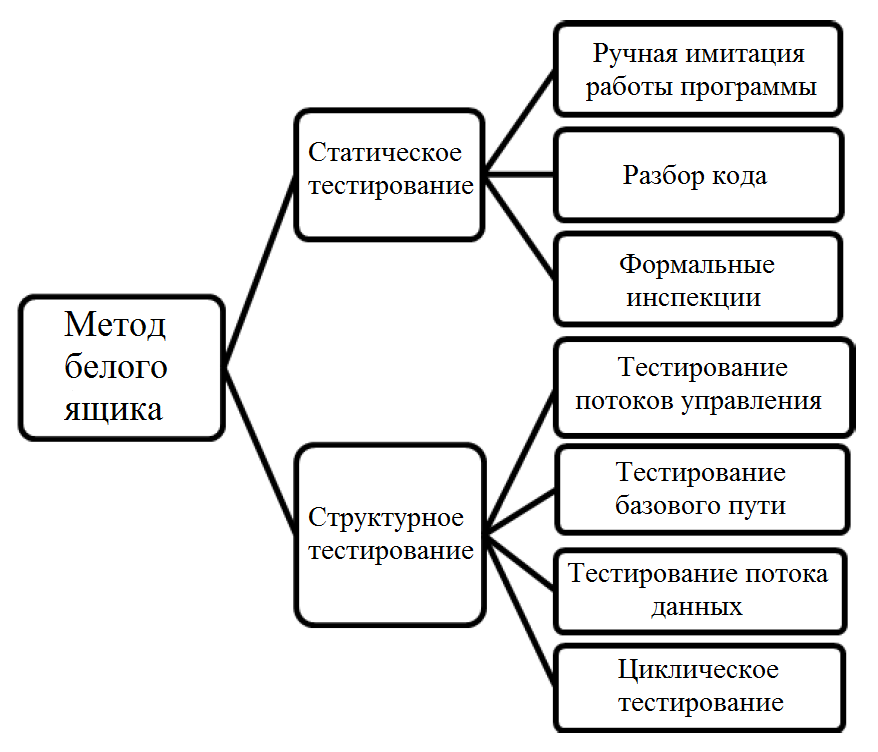
Рисунок 1. Представление различных видов тестирования по методу белого ящика
1) Ручная имитация работы программы
Это первичное тестирование кода. Специалисты, хорошо владеющие необходимым языком программирования, будут участвовать в контрольных тестах.
2) Разбор кода
В этом процессе тестирования группа технических специалистов подробно разбирает код. Это один из видов техники полуформального изложения.
3) Формальные инспекции
Инспекция – это формальный, эффективный и экономичный метод поиска ошибок в дизайне и коде. Это официальное ревью кода, направленное на выявление всех неисправностей, нарушений и других побочных эффектов.
4) Тестирование потоков управления
Это одна из техник тестирования, основанная на определении путей выполнения кода программного модуля и создания выполняемых тестовых кейсов для покрытия этих путей. Использует поток управления программой в качестве потока управления моделью и предпочитает более простые пути в обход усложненным.
5) Тестирование базового пути
Тестирование базового пути позволяет разработчику тестового примера создать логическую меру полноты процедурного проектирования, а затем использовать эту меру в качестве подхода для определения базового набора путей выполнения.
6) Тестирование потока данных
В этом типе тестирования граф потока управления сопровождается информацией о том, как программные переменные определяются и используются.
- Циклическое тестирование
Сосредоточено исключительно на валидности конструкции цикла.
Преимущества:
- Обнаруживает ошибку в скрытом коде, удаляя лишние строки кода.
- Максимальный охват достигается при написании тестового сценария [33.].
- Разработчик тщательно обосновывает причины реализации.
Недостатки:
- Для проведения этого тестирования необходим опытный специалист по тестированию, так как требуется знание внутренней структуры ПО.
- Многие пути останутся непроверенными, так как очень трудно заглянуть в каждый уголок и найти скрытые ошибки.
Метод серого ящика
Тестирование по методу серого ящика пытается и в целом успешно сочетает в себе преимущества тестирования как по методу черного, так и по методу белого ящика. Тестирование «серого ящика» использует прямой подход к тестированию «черного ящика», но также использует некоторые ограниченные знания о внутренней работе приложения. Белый ящик + черный ящик = серый ящик, это методика тестирования приложения с ограниченными знаниями о внутренней работе приложения, а также со знанием фундаментальных аспектов системы. Таким образом, тестер может проверить как вывод пользовательского интерфейса, так и процесс, который приводит к выводу этого пользовательского интерфейса. Тестирование по этому методу может быть применено к большинству этапов; однако в основном оно используется в интеграционном тестировании.
Этот метод включает в себя следующие техники:
- Тестирование ортогональных массивов
Этот тип тестирования используют в качестве подмножества всех возможных комбинаций.
- Матричное тестирование
В матричном тестировании указывается отчет о состоянии проекта.
- Регрессионное тестирование
Если в программное обеспечение вносятся новые изменения, регрессионное тестирование подразумевает выполнение тестовых случаев.
- Тестирование шаблонов
Тестирование шаблонов верифицирует качество приложения, то есть его архитектуры и дизайна.
Преимущества:
1. Данный метод обеспечивает совместное преимущество методов тестирования «черного ящика» и «белого ящика».
2. При тестировании по этому методу специалист может разработать отличные сценарии тестирования.
3. Беспристрастное тестирование.
Недостатки:
1. Тестовое покрытие в данном случае ограничено, так как доступ к исходному коду невозможен.
2. Многие пути программы остаются непроверенными.
3. Контрольные примеры могут быть избыточными.
Сравнение методов тестирования приведено в таблице ниже.
Сравнение методов тестирования по некоторым критериям
|
Номер критерия |
Метод черного ящика |
Метод белого ящика |
Метод серого ящика |
|
1 |
Анализирует только фундаментальные аспекты, т. е. нет знания внутренней работы |
Полное знание внутренней работы |
Частичное знание внутренней работы |
|
2 |
Это наименее исчерпывающий и трудоемкий процесс |
Потенциально наиболее исчерпывающий и отнимающий много времени |
Среднее между критериями для черного и белого ящиков |
Продолжение таблицы
|
Номер критерия |
Метод черного ящика |
Метод белого ящика |
Метод серого ящика |
|
3 |
Не подходит для тестирования алгоритмов |
Подходит для тестирования алгоритмов (любых) |
Не подходит для тестирования алгоритмов |
|
4 |
Степень точности тестирования низкая |
Степень точности тестирования высокая |
Степень точности тестирования средняя |
|
5 |
Выполняется конечными пользователями, а также специалистом по тестированию и разработчиками (приемочное тестирование пользователя) |
Выполняется специалистом по тестированию и разработчиками |
Выполняется конечными пользователями, а также специалистом по тестированию и разработчиками (приемочное тестирование пользователя) |
Наблюдаемость и управляемость логики программного обеспечения
Основные понятия
Тестирование и отладка программного обеспечения включают в себя наблюдаемость и управляемость логического поведения программного обеспечения и потребления ресурсов. Логическое поведение обычно определяется в терминах значения переменных и потока управления программы. Потребление ресурсов определяется как ресурсами, используемыми в каждой точке выполнения, так и объемом ресурсов, используемых каждым блоком кода, а также их типом. Таким образом, наблюдаемость и управляемость состояния переменных в программной системе являются двумя основными требованиями, позволяющими сделать программное обеспечение тестируемым и отлаживаемым.
Хотя существуют разные взгляды на наблюдаемость [36., 37.], все они в целом подразумевают способность тестировать различные функции программного обеспечения и наблюдать за результатами, с целью выяснить, соответствуют ли они спецификации программного обеспечения. Различные определения также имеет и управляемость. Грубо говоря, управляемость – это способность воспроизводить определенное поведение при выполнении программного обеспечения. Традиционные методы для достижения наблюдаемости и управляемости включают методы, которые вмешиваются в естественное выполнение программы. Примеры включают в себя использование точек останова, интерактивную отладку и добавление дополнительных операторов вывода. Эти методы часто не подходят (особенно для встроенного программного обеспечения), потому что они вызывают изменения в поведении синхронизации и потреблении ресурсов системы. Следовательно, наблюдаемый результат программного обеспечения создается видоизмененной программой, которая может нарушать правильность работы ПО. Эта программа может также вызвать проблемы с управляемостью. Например, ранее наблюдаемое поведение при выполнении может быть трудно воспроизводимым или невозможно воспроизводимым. Таким образом, в контексте тестирования и отладки программного обеспечения крайне желательно достичь наблюдаемости и управляемости программного обеспечения с наименьшими изменениями в поведении. В частности, во встроенном ПО это свойство действительно имеет решающее значение.
Проблема абстрактной диагностики в терминах наблюдаемости и управляемости программного обеспечения
Задача достижения наблюдаемости и управляемости программного обеспечения с наименьшими изменениями в поведении становится еще более сложной по мере усложнения систем, так как увеличивается набор функций, которые необходимо охватить на этапе тестирования и отладки. Это может привести к тому, что потребуется больше точек наблюдения и контроля, что увеличивает количество изменений, внесенных в программу. Например, тестерам потребуется больше операторов печати для извлечения данных, касающихся конкретной функции, которая вызывает больше побочных эффектов.
Рассмотрение вышеупомянутой проблемы следует начать с формализации понятий наблюдаемости и управляемости следующим образом. Общий взгляд на наблюдаемость основан на способности разработчиков, а также специалистов по тестированию и отладке отследить последовательность зависимостей данных и пронаблюдать значение переменной, начиная с набора переменных, которые наблюдаемы естественным образом (например, переменные ввода/вывода) или сделаны заметными. Управляемость – это другая сторона медали. Общий взгляд на управляемость позволяет изменять и контролировать значение переменной с помощью последовательности зависимостей данных, начиная с набора переменных, которые могут быть изменены (например, входные переменные). Таким образом, изучаемая проблема заключается в следующем. Исходя из исходного кода программы, цель состоит в том, чтобы определить минимальное количество переменных, которые необходимо сделать наблюдаемыми/контролируемыми, чтобы тестер или отладчик могли наблюдать/контролировать значение другого набора переменных, представляющих интерес.
Эта задача является примером известной абстрактной проблемы диагностики [38.]. Грубо говоря, в этой задаче дано описание цифровой схемы, значение сигналов ввода/вывода, набор компонентов и предикат, описывающий, какие компоненты могут потенциально работать некорректно. Теперь, если данное отношение ввода/вывода не соответствует описанию системы, цель проблемы состоит в том, чтобы найти минимальное количество неисправных компонентов, которые вызывают несоответствие. Общая проблема диагностики неразрешима, так как она так же сложна, как и решение формул логики первого порядка. Проблема наблюдаемости/управляемости может быть сформулирована как подзадача проблемы диагностики. В такой формулировке цель состоит не в том, чтобы найти, какие компоненты нарушают соответствие отношения ввода/вывода с описанием системы, а в том, чтобы найти минимальное количество компонентов, которые можно использовать для наблюдаемости/управляемости выполнения программного обеспечения при тестировании и отладке. Следуя этому конкретному решению проблемы абстрактной диагностики, сначала демонстрируется, что задача оптимизации является NP-полной, даже если предположить, что длина цепочек зависимостей данных не больше 2. Чтобы справиться с неизбежной экспоненциальной сложностью, необходимо перейти от общей проблемы, где длина цепочек зависимостей данных неизвестна, к целочисленному линейному программированию (ЦЛП). Хотя ЦЛП само по себе является полной NP-проблемой, существуют многочисленные методы и инструменты, которые позволяют решать целочисленные программы с тысячами переменных и ограничений.
Описанный подход полностью реализован в цепочке инструментов, состоящей из следующих трех этапов:
- Извлечение данных
Из исходного кода цепочки зависимостей данных извлекаются представляющие интерес переменные для диагностики.
- Преобразование в ЦЛП
Затем извлеченные зависимости данных и соответствующая задача оптимизации преобразуются в целочисленную линейную программу. Этот этап также включает перевод на язык ввода ЦЛП-решателя.
- Решение задачи оптимизации
Решается соответствующая задача ЦЛП по нахождению минимального набора переменных, необходимого для диагностики представляющих интерес переменных.
Используя эту цепочку инструментов, можно сообщить о результатах экспериментов с несколькими реальными приложениями. Эти приложения охватывают теоретико-графические задачи, алгоритмы шифрования, арифметические вычисления и кодирование в графическом формате. Проведенные эксперименты преследует две цели: диагностировать все переменные, включенные в фрагмент исходного кода, и диагностировать выбранный вручную набор переменных, обычно используемых разработчиком для отладки. Эксперименты показывают, что в то время как для первой цели метод значительно уменьшает число переменных, которые можно сделать непосредственно диагностируемыми, для второй процент сокращения напрямую зависит от структуры исходного кода и выбора интересных переменных. Поскольку решение сложных целочисленных программ отнимает много времени, экспериментальные наблюдения становятся причиной появления идеи разработки простой метрики для того, чтобы разумно предсказать, будет ли целесообразным применение оптимизации. Другое полезное последствие выполненной оптимизации заключается в сокращении времени выполнения кода. Выясняется, что общее время выполнения оптимизированного кода значительно лучше, чем соответствующее время для оригинального кода.
Обзор предшествующих достижений и дальнейшие перспективы
Как уже упоминалось ранее, вышеприведенная формулировка проблемы является примером теории абстрактной диагностики [38.]. Теория диагностики широко изучалась во многих контекстах. В работе [39.] Фиджани и Ватан предлагают два метода решения проблемы диагностики. В частности, они представляют собой преобразования из подзадачи проблемы диагностики в ЦЛП и задачу выполнимости. Предложенное ранее преобразование в ЦЛП носит более общий характер, поскольку рассматриваются цепочки зависимостей данных произвольной длины. Более того, авторы не приводят экспериментальные результаты и анализ.
В той же области исследований Абреу и ван Гемунд [40.] предлагают алгоритм приближения для решения задачи о минимальном множестве ударов. По сути, эта проблема очень близка к проблеме диагностики. Основное различие состоит в том, что рассматриваются зависимости данных произвольной длины. Таким образом, задача теории диагностики эквивалентна общей задаче с вложенным множеством. Более того, она преобразуется в ЦЛП, тогда как Абреу и ван Гемун непосредственно решают проблему множества ударов.
Болл и Ларус [41.] предлагают алгоритмы мониторинга кода для профилирования и трассировки программ: профилирование подсчитывает количество выполнений каждого основного блока в программе. Трассировка инструкций записывает последовательность основных блоков, пройденных при выполнении программы. Их алгоритмы принимают график потока управления данной программы в качестве входных данных и находят оптимальные контрольные точки для трассировки и профилирования. Напротив, в задаче абстрактной диагностики приходится иметь дело напрямую с исходным кодом и фактическими переменными. Болл и Ларус также отмечают, что профилирование вершин (что близко к задаче диагностики) является сложной проблемой, и их внимание сосредоточено на профилировании ребер.
Фудживара [42.] определяет наблюдаемость и управляемость для аппаратного обеспечения. Он рассматривает наблюдаемость как распространение значения всех сигнальных линий на выходные. Соответственно, управляемость приводит в исполнение определенное значение в сигнальной линии. Он отмечает, что, если наблюдаемость и управляемость не выполнены, в схему должны быть добавлены дополнительные выходы и входы. Это дополнение тесно связано с положением линии и типом схемы. Более того, в этой работе не рассматривается, как выбрать лучшую точку для добавления ножек микросхемы. Кроме того, каждый раз, когда меняется количество выводов, необходимо выполнить переоценку наблюдаемости/управляемости линий.
Фридман [36.], Воас и Миллер [37.] рассматривают наблюдаемость и управляемость с точки зрения тестирования черного ящика. Они считают функцию наблюдаемой, если вся внутренняя информация о состоянии, влияющая на вывод, доступна как ввод или вывод во время отладки и тестирования. Их метод влияет на временное поведение программного обеспечения и может предоставлять конфиденциальную информацию.
В контексте распределенных систем подход, используемый в работе Тейна [43., 44.], определяет поведение системы, которое должно наблюдаться, только если оно может быть однозначно определено набором параметров/условий. Целью данной работы является использование детерминированных инструментов с минимальными издержками для достижения наблюдаемости. Недостатком данной работы является то, что авторы не представляют методику поиска приборов с минимальными накладными расходами. Таким образом, Тейн считает поведение управляемым относительно набора переменных только тогда, когда набор является управляемым в любое время. Автор также предлагает операционную систему в реальном времени для достижения автономной управляемости.
Шутц [35., 45.] рассматривает наблюдаемость и управляемость для систем, запускаемых по времени и по событию. Однако авторский метод использует специальное оборудование для предотвращения воздействия эффектов непреднамеренных изменений системы. Шутц утверждает, что системы, запускаемые по времени, предлагают альтернативную гибкость по сравнению с запускаемыми по событию системами при обработке эффектов непреднамеренных изменений, вызванных принудительной наблюдаемостью. Соответственно, Шутц показывает, что в отличие от запускаемых по событию систем, запускаемые по времени системы имеют меньшие подобные эффекты в управляемости, поскольку отсутствует недостающая информация относительно их поведения и, следовательно, для сбора информации необходим дополнительный подход.
Подход, предложенный в работе [46.], по духу похож на предлагаемый подход, но в другом контексте. Автор анализирует структуру потока данных системы и определяет наблюдаемость и управляемость на основе количества информации, потерянной от входа к выходу системы. Его расчеты основаны на теории информации на битовом уровне. Этот метод оценивает управляемость потока на основе битов, доступных на входах модуля со входов программного обеспечения через поток. Соответственно, они оценивают наблюдаемость как биты, доступные на выходах программного обеспечения с выходов модуля через поток. Стоит заметить, что теоретико-информационный подход на уровне битов не подходит для анализа больших приложений реального мира, поскольку предлагаемый метод игнорирует тип операций, создающих поток данных, в то время как он влияет на наблюдение и управление данными, а также потому, что потерянные или поврежденные распространяемые биты в потоке могут привести к противоречивым наблюдения. Кроме того, несмотря на то, что объем информации, распространяемой по потоку, имеет большое значение, количество битов является неподходящим фактором измерения.
Для будущей работы есть несколько открытых проблем. Одна важная проблема – это расширение используемой формулировки до случая, когда появляется возможность обрабатывать структуры данных указателей. Метрики, которые включают сетевой поток или вычисляют непересекающиеся пути вершин, подходят лучше, поскольку эти концепции основаны на свойствах пути, а не на свойствах вершины. Доступ к интеллектуальным метрикам также желателен для разработки преобразований, генерирующих программы, которые могут быть оснащены более эффективно. Еще одно интересное направление исследований – разработка настраиваемой эвристики, алгоритмов аппроксимации и преобразований для решения рассматриваемой задачи оптимизации. Одним из таких преобразований может быть переход от задачи оптимизации к проблеме выполнимости для использования SAT-решателей.
ЗАКЛЮЧЕНИЕ
Тестирование и отладка программного обеспечения являются наиболее часто используемыми методами проверки и подтверждения качества программного обеспечения. Отладка представляет собой процедуру, состоящую в том, чтобы найти и исправить код, нарушающий программную спецификацию. В данной работе рассмотрена общая методика отладки приложений, изучено современное состояние этой технологии.
Тестирование программного обеспечения – это процедура выполнения программы или программной системы с целью обнаружения неисправностей. Тестирование программного обеспечения является важной деятельностью жизненного цикла разработки программного обеспечения. Обе этих процедур помогают разработчику обрести уверенность в том, что программа делает именно то, для чего она предназначена, уменьшить риски и затраты на разработку и внедрение. Другими словами, можно сказать, что это процесс выполнения программы с намерением найти ошибки. Цели и задачи тестирования вместе с современным состоянием также рассмотрены в этой работе.
На языке верификации и валидации тестирование черного ящика часто используется для валидации, а тестирование белого ящика – для верификации программного обеспечения. Тестирование по методу черного ящика основано на предположении, что тестер не знает содержимого и алгоритмов программного обеспечения, подразумевая только набор входных данных и предсказуемые выходные данные. Тестирование белого ящика в основном сфокусировано на внутренней логике и структуре кода. Выполнение этого метода предполагает, что программист обладает методиками, полностью знающими структуру программы. Промежуточным звеном между двумя этими методами выступает тестирование серого ящика, которое подразумевает прямой подход к тестированию по методу черного ящика, но также использует некоторые ограниченные знания о внутренней работе приложения. В данной работе были подробно описаны и изучены все вышеперечисленные методы, а также рассмотрены техники (виды) тестирования, которые относятся к стратегиям каждого из этих методов.
Проблема абстрактной диагностики является одной из важнейших проблем, возникающих в процессе тестирования программного обеспечения, если речь заходит о наблюдаемости и управляемости логики этого ПО. В данной работе рассмотрены общие понятия о наблюдаемости и управляемости, а также показаны некоторые направления для решения задачи диагностики.
Таким образом, цели и задачи курсовой работы выполнены в полном объеме.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Tassey G. The economic impacts of inadequate infrastructure for software testing. National Institute of Standards and Technology, RTI Project, 2017.
- Anvik J. L. Hiew, and G. C. Murphy. Coping with an open bug repository. In Proceedings of the 2005 OOPSLA Workshop on Eclipse Technology eXchange, pages 35–39, 2005.
- Nikkei IT pro, Tokyo Stock Exchange New Derivative Selling System Restored, due to initialization [Электронный ресурс] / URL: http://itpro.nikkeibp.co.jp/article/NEWS/20080212/293526 (Дата обращения: 13.08.2019)
- Lieberman H., The Debugging Scandal and What to Do About It,” Communications of the ACM 40, No. 4, 26–29 (April 1997).
- Eisenstadt M., “My Hairiest Bug War Stories,” Communications of the ACM 40, No. 4, 31–37 (April 1997).
- Baecker R., DiGiano C., and Marcus A., “Software Visualization for Debugging,” Communications of theACM40, No. 4, 44–54 (April 1997), and other papers in the same issue.
- Pauw W. De, Sevitsky G., “Visualizing Reference Patterns for Solving Memory Leaks in Java,” Lecture Notes in Computer Science 1628, Springer-Verlag, Heidelberg (1999), pp. 116–134 (Proceedings, European Conference on Object-Oriented Programming, Lisbon, Portugal).
- Zweben S., Heym W., Kimmich J. Systematic testing of data abstractions based on software specifications. J. Software Testing, Verificationand Reliability, 1992, 1(4): 39-55.
- Beizer B., Software Testing Techniques.London: International Thompson Computer Press, 2018.
- Godefroid P., Compositional Dynamic Test Generation.In Proceedings of POPL’2007 (34th ACM Symposium on Principles of Programming Languages), pages 47–54,Nice, January 2007.
- Copeland L., A Practitioner's Guide to Software Test Design. Boston: Artech House Publishers, 2017.
- Korel B., A Dynamic Approach of Test Data Generation. In IEEE Conference on Software Maintenance, pages 11–317, San Diego, November 1990.
- Fagan M. E., “Design and Code Inspections to Reduce Errors in Program Development,” IBM Systems Journal 15, No.3 (1976).
- Pressman R. S., Software Engineering: A Practitioner’s Approach, McGraw-Hill, New York (2015).
- Myers G. J., Software Reliability: Principles and Practices, John Wiley & Sons, Inc., New York (2016).
- Myers G. J., The Art of Software Testing, John Wiley & Sons, Inc., New York (2016).
- Beizer B., Software Testing Techniques, Van Nostrand Reinhold, New York (2018).
- Dijkstra E. W., “Notes on Structured Programming,” Structured Programming, O.-J. Dahl, E. W. Dijkstra, and C. A. R. Hoare, Editors, Academic Press, London (1972), pp. 1–82.
- Hamlet D., “Foundations of Software Testing: Dependability Theory,” Software Engineering Notes 19, No. 5 (Proceedings of the Second ACM SIGSOFT Symposium on Foundations of Software Engineering), 128–139 (1994).
- Musa J., Software Reliability Engineering, McGraw-Hill, Inc., New York (1998).
- Kan S. H., Parrish J., and Manlove D., “In-Process Metrics for Software Testing,” IBM Systems Journal 40, No. 1, 220–241 (2001).
- Bassin K., Kratschmer T., and Santhanam P., “Evaluating Software Development Objectively,” IEEE Software 15, No.6, 66–74 (1998).
- Saglietti F., Oster N., and Pinte F., “White and grey-box verification and validation approaches for safety- and security-critical software systems,” Information Security Technical Report, vol. 13, no. 1, pp. 10–16, 2008.
- Brand D., “ASoftware Falsifier,” Proceedings, Eleventh IEEE International Symposium on Software Reliability Engineering, San Jose, CA (October 8–11, 2000), pp. 174–185.
- Poston R. M., Automating Specification-Based Software Testing, IEEE Computer Society Press, Los Alamitos,CA(1996).
- Lee D., Yannakakis M., “Principles and Methods of Testing Finite State Machines—A Survey,” Proceedings of the IEEE 84, No. 8, 1090–1123 (1996).
- Paradkar A., “SALT—An Integrated Environment to Automate Generation of Function Tests for APIs,” Proceedings, Eleventh IEEE International Symposium on Software Reliability Engineering, San Jose,CA(October 8–11, 2000), pp. 304–316.
- Williams C., “Toward a Test-Ready Meta-Model for Use Cases,” Proceedings, Workshop on Practical UML-Based Rigorous Development Methods, Toronto, Canada (October 1, 2001), pp. 270–287.
- Whittaker J.A., “What Is Software Testing? And Why Is It So Hard?” IEEE Software 17, No. 1, 70–79 (January/February 2000).
- Srinivas N., and Dondeti J. "Black box and white box testing techniques- A Literature." International Journal of Embedded Systems & Applications 2.2 (2012).
- Mitra P., Chatterjee S., and Ali N., “Graphical analysis of MC/DC using automated software testing,”in Electronics Computer Technology (ICECT), 2011 3rd International Conference on, 2011, vol. 3, pp. 145 –149.
- Saglietti F., Oster N., and Pinte F. “White and grey-box verification and validation approaches for safety- and security-critical software systems,” Information Security Technical Report, vol. 13, no. 1, pp. 10–16, 2008.
- Mohd Ehmer K., and Khan F. "A Comparative Study of White Box, Black Box and Grey Box Testing Techniques." International Journal of Advanced Computer Sciences and Applications 3, no. 6 (2012): 12-15.
- Binder R.V. Design for Testability in Object-Oriented Systems. Communications of the ACM, 37(9):87–101, 2015.
- Schutz W. The Testability of Distributed Real-Time Systems. Kluwer Academic Publishers, Norwell, MA, USA, 2017.
- Freedman R.S. Testability of Software Components. IEEE Transactions on Software Engineering, 17(6):553–564, 2011.
- Voas J.M. and Miller K.W. Semantic Metrics for Software Testability. Journal of Systems and Software, 20(3):207–216, 2003.
- Reiter R. A theory of diagnosis from first principles. Artificial Intelligence, 32(1):57–95, 1987.
- Fijany A. and Vatan F. New high-performance algorithmic solution for diagnosis problem. In IEEE Aerospace Conference (IEEEAC), 2018.
- Abreu R. and van Gemund A. J. C. A low-cost approximate minimal hitting set algorithm and its application to model-based diagnosis. In Abstraction, Reformulation, and Approximation (SARA), 2009.
- Ball T. and Larus J.R. Optimally profiling and tracing programs. ACM Transactions on Programming Languages and Systems (TOPLAS), 16(4):1319–1360, 2019.
- Fujiwara H. Computational Complexity of Controllability/Observability Problems for Combinational Circuits. IEEE Transactions on Computers, 39(6):762–767, 1990.
- Thane H. and Hansson H. Towards Systematic Testing of Distributed Real-Time Systems. In Proceedings of the 20th IEEE RealTime Systems Symposium, pages 360–369, Washington, DC, USA, 1999. IEEE Computer Society.
- Thane H., Sundmark D., Huselius J., and Pettersson A. Replay Debugging of Real-Time Systems Using Time Machines. In Proceedings of the 17th International Symposium on Parallel and Distributed Processing, page 8, Washington, DC, USA, 2003. IEEE Computer Society.
- Schutz W. Fundamental Issues in Testing Distributed Real-Time Systems. Real-Time Systems, 7(2):129–157, 1994.
- Lattner C., and Adve V. LLVM: A Compilation Framework for Lifelong Program Analysis and Transformation. In Proceedings of the International Symposium on Code Generation and Optimization: Feedback directed and runtime Optimization, page 75, 2004.

- РАЗВИТИЕ ЭЛЕКТРОННЫХ ПЛАТЕЖНЫХ ТЕХНОЛОГИЙ (Понятие электронных платежных технологий)
- Особенности кредитного договора, порядок его заключения, изменения условий и расторжения. Меры, принимаемые банком при нарушении условий кредитного договора.
- История развития средств вычислительной техники (Информационных технологий)
- Организационная культура как инструмент преодоления кризисных ситуаций в развитии компании (Понятие и функции организационной культуры организации, типология корпоративных культур)
- Анализ ликвидности и платежеспособности коммерческого банка
- Выбор приоритетного критерия отбора кандидатов в состав резерва на выдвижение (Сущность формирования кадрового резерва)
- Юридическая ответственность (Обстоятельства, исключающие юридическую ответственность и обстоятельства, освобождающие от юридической ответственности)
- Фонд обязательного медицинского страхования РФ ( Теоретические и организационно-правовые основы Федерального фонда обязательного медицинского страхования )
- Сущность инфляции и факторы её возникновения (Последствия инфляции)
- Юридическая ответственность
- Юридическая ответственность (Правонарушение как основание юридической ответственности. Признаки и состав правонарушения)
- Понятие и виды источников права ( Общая характеристика источников права )