
Основы проектирования программ. Этапы создания программного обеспеченияКурсовая работа
Содержание:

ВВЕДЕНИЕ
По словам известного американского изобретателя и футуролога Рэя Курцвейла развитие технологий в последние два десятилетия имеет экспоненциальную скорость [1]. «We won’t experience 100 years of progress in the 21st century—it will be more like 20,000 years of progress (at today’s rate)». Ещё десять лет назад смартфон не существовал, а первый персональный компьютер появился только 40 лет назад. Однако, за такой короткий промежуток времени развития уже в конце второго десятилетия 21 века почти невозможно представить жизнь людей без смартфонов, ноутбуков и прочих «умных» устройств, так как они очень глубоко успели засесть в нашей учёбе, работе, развлечениях и личной жизни.
По данным на август 2018 года количество пользователей самых популярных социальных сетей таких, как Facebook, YouTube и Instagram достигло 2 230, 1 900 и 1000 миллионов соответственно [2], то есть фактически почти треть людей планеты постоянно общаются, покупают онлайн, смотрят видео, играют, комментируют и прочее. Благодаря этому одним из результатов таких показателей является то, что невидимая преграда, разделяющая производителя и потребителя, начала быстро исчезать. Теперь потребитель очень легко может выразить через отзывы и комментарии своё мнение по поводу тех, или иных товаров или информационного контента, откуда и появилась потребность обрабатывать их для определения отношений пользователей к тому или иному объекту. Но количество таких отзывов, особенно на крупных платформах, может достигать нескольких сотен или даже тысяч, а обработка всего этого «вручную» будет слишком энерго- и время-затратной операцией. Поэтому готовые программные решения, которые позволили бы справляться с подобными задачами, имеют высокую практическую значимость для крупных социальных сетей, производителей, которые продают свои товары онлайн, социологов, PR-специалистов, маркетологов, СМИ, чтобы отслеживать общественное мнение по поводу различных событий и т.д.
В последние годы начало бурно развиваться такое направление, как контент-анализ в компьютерной лингвистике, в частности, анализ тональности текста или сентимент-анализ. Он предназначен для автоматизированного выявления в текстах эмоционально окрашенной лексики и эмоциональной оценки авторов (мнений) по отношению к объектам, речь о которых идёт в тексте. Анализ тональности текста включает в себя такие основные задачи, как определение субъективности или объективности текста по отношению к субъекту и оценка полярности мнения (позитивное, негативное или нейтральное), которая сводится к задаче классификации [3].
Актуальность данной работы также будет заключаться в практически полном отсутствии реализованных решений данной проблемы для контента на русском языке.
Целью этой работы является разработка математического и программного обеспечения для классификации текстового контента на русском языке по типу эмоционального окраса на несколько категорий: позитивные, негативные, реклама/поздравления и неопределенные по отношению к конкретному объекту. Для достижения этой цели необходимо выполнить ряд задач:
- изучение степени проработанности данного класса задач и существующих методов решения;
- адаптация выбранного метода под решение данной задачи;
- его реализация в виде web-приложения.
ГЛАВА 1 ПОСТАНОВКА ПРОБЛЕМЫ ПРОЕКТИРОВАНИЯ ПРОГРАММЫ
Существующие подходы к классификации текстов
Существует два основных подхода к классификации текстов по их тональности: один основан на использовании заранее составленных словарей тональности (каждому слову поставлено в соответствие его значение тональности), второй – на методах машинного обучение (machine learning).
Метод с использованием специализированных словарей проводится в несколько этапов [4]:
- Делается лингвистический анализ текста, с помощью которого происходит лемматизация всех слов (приведение в начальную форму), определяются части речи, его падеж, число, род, роль каждой лексемы в предложении (подлежащее, сказуемое, обстоятельство и т.д.), его тип (физ. лицо, юр. лицо, имя собственное и т.д.).
- Каждому слову и словосочетанию ставятся в соответствие два значения: одно указывает на тональность, другое – на силу тональной оценки. Если же лексема не была найдена в словаре, то по умолчанию она становится нейтральной.
- Далее делается синтаксический анализ, при котором слова и словосочетания объединяются в тональные цепочки в виде предложений, выделяется субъект, предикат и объект. При этом определяются деепричастные и причастные обороты, подчинительные предложения и т.д.
- Определяется объект, в отношении которого применяется эмотивная лексика, и, в зависимости от его месторасположения в предложении, делается вывод об общей оценке тональности.
Этот метод обладает рядом недостатков: составление словарей тональности является очень энерго-затратной работой; ограничивается разнородность корпуса, из которой следует неполнота лексического покрытия, а это, в свою очередь, приводит к потере точности; сложно также дать количественную оценку позитивности-негативности исследуемого текста.
Машинное обучение является подразделом науки об искусственном интеллекте, исследующий построение алгоритмов, способных обучаться [5]. Основную задачу очень чётко можно сформулировать через термин, который был введен В. Н. Вапником: «восстановление зависимостей по эмпирическим данным». Другими словами, имеется множество объектов и их описаний (обучающая выборка) – требуется вывести общие зависимости и взаимосвязи, с помощью которых в дальнейшем можно исследовать данные, которые не были в составе обучающей выборки.
В машинном обучении следует выделить искусственные нейронные сети (ИНС) [6]. Они представляют собой нелинейные математические модели, имеющие структуру нейронных сетей биологического происхождения, которые в состоянии обучаться для решения определенного ряда задач таких как: классификация, кластеризация, прогнозирование, распознавание, визуализация и многих других.
Состоят они из искусственных нейронов, способных обрабатывать данные. В общем виде нейронная сеть представляет собой 3 связных слоя: входной, скрытый и выходной слои. Входной слой принимает данные и передаёт их в скрытый слой, где происходит их обработка, в свою очередь обработанные данные поступают на выход.
Сами же нейроны имеют входы с весами, так называемыми синапсами, функции активации, один выход. Синапсы представляются в виде параметров, которые в ходе обучения нейронных сетей меняют своё значение.
Целью обучения нейронных сетей является поиск оптимальных значений весов, при которых значение ошибки результата работы нейронной сети (классификация, прогнозирование и т.д.) будет минимально. Обучение обычно осуществляется в несколько эпох, при этом одна эпоха значит, что весь датасет прошёл через нейронную сеть в прямом и обратном направлении один раз. Широко используемым методом при обучении является метод обратного распространения ошибки. Коротко говоря, прямое распространение – это вложенные друг в друга функций активации, которые соответствуют разным слоям, а обратное – это производная этой сложной функции по правилу цепочки. На примере это выглядит таким образом:
f(x) = A(B(C(x))) (1)
где A, B, C – функции активации;
f’(x) = f’(A) A’(B) B’(C) C’(x) (2)
где f’ – искомая производная.
Существует два основных типа машинного обучения:
- «с учителем» (supervised) – обучающая выборка представляет собой пару «объект, класс». Требуется найти функцию, которая описывает зависимость класса от объекта, и построить алгоритм, который на вход будет принимать описание объекта и по итогу своей работы выдавать ответ.
- «без учителя» (unsupervised) – на вход подаются объекты, между которыми необходимо искать зависимости. Ответы не задаются.
Второй подход для анализа текстов, не говоря уже об их классификации по тональности, показывает низкие результаты [8]. Наиболее популярным и эффективным подходом для нашей задачи является машинное обучение с учителем, что было уже неоднократно доказано на соревнованиях SemEval (Semantic Evaluation) [9].
Формализуем понятие задачи классификации. Пусть существуют множество Х – заданные объекты, конечное множество Y – номера классов и неизвестная функция f: X Y. Значения этого отображения известны только на конечном множестве объектов из Х: Хm = {(x1,y1),(x2,y2),…,(xm,ym)}, которое называется обучающей выборкой. Требуется найти такой алгоритм f*, что любому объекту из Х будет ставиться в соответствие значение из Y (машинное обучение с учителем). Далее оценивается работа найденного классификатора на тестовой выборке – это X \ Xm.
Существуют различные типы задач классификации, разнообразие которых зависит от вида входных данных и типа классов. На вход классификатору могут подаваться матрица расстояний между объектами (каждый объект задаётся набором расстояний до остальных объектов выборки), признаковое поле (заданный набор характеристик объекта), изображение или видео, временной ряд, представляющий собой последовательность измерений во времени. Также существуют и более сложные случаи, когда входными данными могут быть текст, графы, запрос к базе данных. Однако, в таких случаях обычно делается предобработка, сводящая к первому или второму случаю. По типу выходных данных можно выделить бинарную классификацию, мульти-классовую (более 2-ух классов), пересекающиеся классы (объект может принадлежать одновременно к нескольким категориям), нечеткие классы (определяется степень принадлежности объектов к каждому из классов в виде, к примеру, действительного числа от 0 до 1) [10].
Конкретно наша задача будет представлять собою разработку web-сервиса, в частности, мульти-классового классификатора, где входными данными будут посты из социальной сети Twitter, а выходными – одна из категорий для каждого поста: позитивная, негативная, реклама/поздравление или неопределенная. При этом итоговый результат будет выводиться на экран пользователя в виде графика.
Классификация текстового контента на несколько категорий является не тривиальной и достаточно субъективной задачей. Даже человек может допускать ошибки при решении данного вопроса, не говоря уже о компьютерных системах. Всё это является следствием того, что люди в Интернете при написании какого-либо текста могут делать опечатки, шутить, использовать жаргон, сленг, изобиловать сарказмом и прочее.
Более того, тексты – это объекты, не имеющие определенную структуру, что осложняет работу с ними. Также разработанные системы классификации, показывающие хорошие результаты для одной предметной области, могут плохо работать с другой. К примеру, слово «большой» при описании дисплея смартфона будет иметь положительную тональность, а при описании стиральной машины – отрицательную.
Вдобавок, сложностью создания классификатора для текстов на русском языке является почти полное отсутствие размеченных корпусов текстов и наличие огромного количества форм одного и того же слова, к примеру, для слова «огромный»: огроменный, огромнейший, огромного, огромная и т.д.
Оценка качества работы классификатора
Как говорилось выше, оценивается качество работы классификатора на тестовой выборке. В машинном обучении наиболее популярными абсолютными показателями качества работы алгоритмов являются метрики: точность (precision), полнота (recall) и F-мера.
Но прежде чем перейти к формулировкам данных метрик и к тому, как они вычисляются, необходимо дать понятие матрицы ошибок (табл. 1) [11]. Она является очень полезным инструментом для быстрого вычисления точности и полноты. На ней изображены 4 результата работы модели классификатора: истинно положительные – количество объектов, правильно присвоенных положительному классу (True Positive), ложно положительные - количество объектов, неверно присвоенных положительному классу (False Positive), ложно отрицательные - количество объектов, неверно присвоенных отрицательному классу (False Negative), истинно отрицательные - количество объектов, правильно присвоенных отрицательному классу (True Negative).
Таблица 1
Матрица ошибок
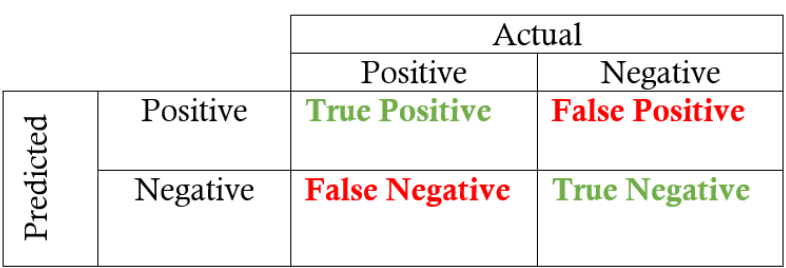
Сразу стоит внести ясность, почему мы отказываемся от использования метрики accuracy (точность), которая вычисляется как доля объектов, для которых правильно предсказан результат, из всех объектов. При неравенстве классов эта метрика перестаёт быть достоверной.
Precision – это доля всех объектов, которые в самом деле принадлежат данному классу, из всех объектов, которые были отнесены к этому классу классификатором. Вычисляется она по формуле (3):
Precision = TP/(TP+FP) (3)
Recall – это доля объектов, принадлежащих классу и найденных системой, из всех объектов данного класса (4):
Recall = TP/(TP+FN) (4)
F-мера – это метрика, которая позволяет объединить в себе и точность, и полноту благодаря вычислению гармонического среднего (5):
F = 2(Precision*Recall) / (Precision + Recall) (5)
Данная формула придаёт равные веса полноте и точности [12].
Методы предобработки текстов
Как упоминалось выше, текст – это объект, не имеющий определенную структуру, поэтому для того, чтобы классификатор мог работать с ним, необходимо произвести предобработку. Целью этого этапа является приведение текстов к единому формату.
В сфере обработки естественного языка (Natural Language Processing или NLP) существует задача, именуемая word embedding. Основной целью данного раздела NLP является преобразование слов с языка, который понимает человек, в язык, который понимает компьютер [13]. Результатом word embedding является векторное представление слова. Наиболее популярными методами для решения данной задачи являются LSA, Word2Vec и GloVe. Все три подхода основываются на идее того, что описание слова зависит от контекста, в котором он расположен.
Латентно-семантический анализ (Latent semantic analysis, LSA) [14] – это статистический метод, состоящий из двух этапов:
1. Строится матрица М зависимости слова от документа, где каждая строка соответствует слову, а столбец – документу. Элемент (i, j) матрицы – частота появления i-того слова в j-том документе.
2. Делается сингулярное разложение матрицы М на три матрицы (6). U и Vt – ортогональные матрицы, W – диагональная. Суть этого разложения состоит в том, что оно показывает ключевые элементы матрицы М: меньшие сингулярные значения из диагональной матрицы W соответствуют столбцам и строкам элементов, которые делают наименьший вклад в произведение. Таким образом, для того, чтобы убрать шумы и тем самым уменьшить семантическое пространство, векторы из матриц U и Vt, соответствующие наименьшим сингулярным значениям, удаляются из матриц.
M = U * W * Vt (6)
Этот подход к word embedding основывается на таких главных параметрах, как: локальные и глобальные частоты встречаемости слов и размер семантического пространства.
Этот метод был представлен в 2014 году департаментом Компьютерных Наук университета Стенфорд [15]. Сутью этого метода является вычисление частоты появления слова в корпусе текстов. Реализовывается метод в два шага:
1. Создаётся матрица смежностей Х, где каждый её элемент (i, j) – это количество появлений слова i в контексте слова j. Тогда Xi = ∑k Xik – количество появлений какого-либо слова в контексте слова i или, иными словами, количество слова i в корпусе.
2. Pij = P(j|i) = Xij / Xi – вероятность появления слова j в контексте слова i. Но для построения векторного отображения слов имеет значение не сама вероятность, а коэффициент, который получается при Pik / Pjk, зависящий от трёх слов i, j, k. Этот скаляр кодирует разность векторов. В более общем виде модель имеет вид (7).
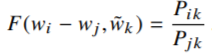 (7)
(7)
w ϵ Rd – вектора слов, 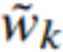 ϵ Rd – вектор контекстного слова.
ϵ Rd – вектор контекстного слова.
Однако, для сохранения линейности и предотвращения смешивания размерностей используется скалярное произведение (8).
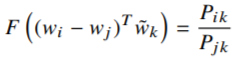 (8)
(8)
Заметим, что для матрицы смежностей разница между словом и контекстным словом произвольна, и их роли можно свободно менять между собой. Но если делается замена 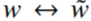 , то должна и происходить замена
, то должна и происходить замена 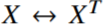 . Чтобы свойство симметрии выполнялось, необходимо сделать преобразование (9).
. Чтобы свойство симметрии выполнялось, необходимо сделать преобразование (9).
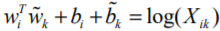 (9)
(9)
Таким образом, авторы этого подхода решили использовать метод наименьших квадратов. В итоге, формула будет иметь вид (10), где V – размер словаря.
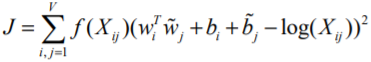 (10)
(10)
Word2Vec – это метод, позволяющий реализовать отображение слов в векторное пространство. Впервые был предложен Миколовым в 2013 году [16]. В его основе лежат две архитектуры – непрерывный мешок слов (Continuous Bag-of-Words или CBoW) и Skip-gram.
Но прежде чем перейти непосредственно к описанию CBoW и Skip-gram, необходимо описать алгоритм работы самого метода. По своей сути Word2Vec состоит из 5 шагов [17]:
1. Вычисляется частота каждого слова в корпусе. Учитывая эти данные, массив отсортировывается.
2. Словарь кодируется двоичным деревом Хаффмана (Huffman binary tree): лексемам с наибольшей частотой присваивается свой двоичный код. Благодаря этому происходит существенное снижение времени работы и вычислительной сложности алгоритма.
Приведём пример, где будут кодироваться не слова, а символы бессмысленной строчки «boop beep beer!» с помощью дерева Хаффмана [17].
Вычислим частоты каждого символа (табл.2).
Отсортируем символы по увеличению частоты (рис.1).
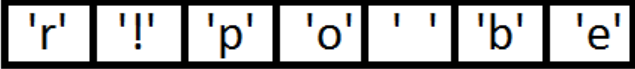
Рис. 1.
Таблица 2
Частоты символов
|
Символ |
Частота |
|
‘b’ |
3 |
|
‘e’ |
4 |
|
‘p’ |
2 |
|
‘ ’ |
2 |
|
‘o’ |
2 |
|
‘r’ |
1 |
|
‘!’ |
1 |
Возьмём два символа с наименьшей частотой, свяжем их, тем самым создав узел будущего дерева. Вес этого узла будет равен весу этих символов. Поставим его обратно в очередь (рис. 2).
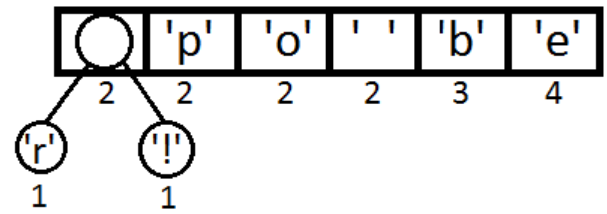
Рис. 2
Далее, выполняя последовательно вышеописанное действие, получим следующие результаты (рис. 3, рис. 4, рис. 5, рис. 6).
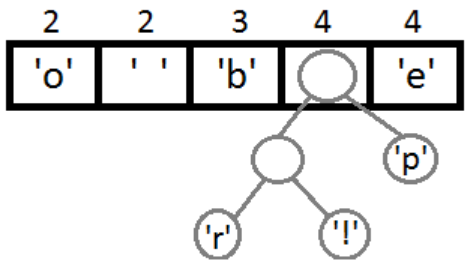
Рис. 2
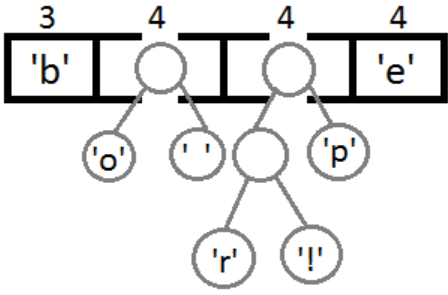
Рис. 3
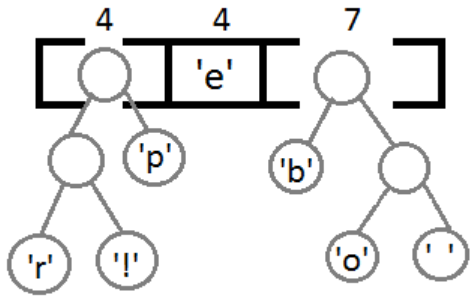
Рис. 4
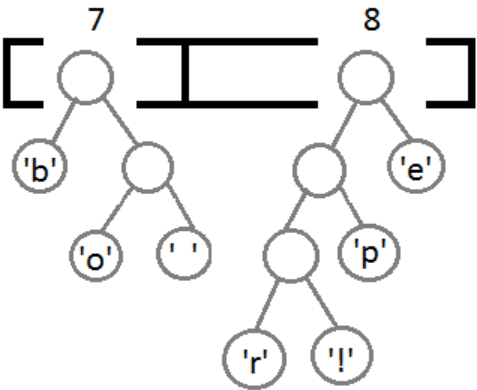
Рис. 5
На конечном этапе создаём узел, связывающий оба этих дерева, и проставляем веса для каждого перехода (рис. 7): влево – 0, вправо – 1.
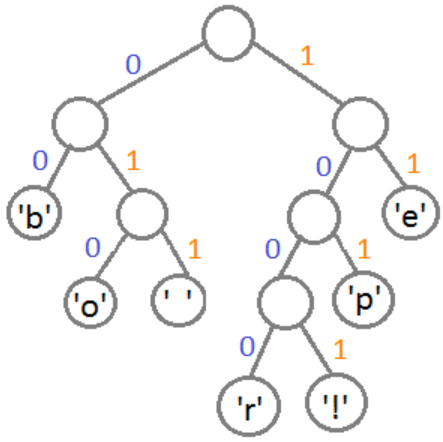
Рис. 7
Таким образом, получили таблицу (табл. 3) с кодом для каждого из символов.
Таблица 3
Таблица Хаффмана
|
Символ |
Код |
|
‘b’ |
00 |
|
‘e’ |
11 |
продолжение таблицы 3
|
‘p’ |
101 |
|
‘ ’ |
011 |
|
‘o’ |
010 |
|
‘r’ |
1000 |
|
‘!’ |
1001 |
3. Осуществляется субсэмплирование (sub-sampling) каждого предложения из корпуса, то есть наиболее часто встречаемые слова удаляются. Таким образом, происходит повышение качества работы будущей модели.
4. Далее по каждому предложению проходят окном (максимальное расстояние между предсказываемым и текущим словом) для формирования блока из n-грам, например, для размера окна равным 3 предложение «Сегодня утро было солнечным» после обработки будет выглядеть так: «сегодня утро было», «утро было солнечным».
5. В работу включаются нейронные сети прямого распространения (сигнал направляется строго от входного к выходному слою), соответствующие CBoW и Skip-gram, с функцией активации иерархический софтмакс (hierarchical softmax) [19]. Его суть заключается в том, что при фиксированном контексте нам интересно только прогнозируемое слово. Формула вероятности, что w – искомое слово (11):
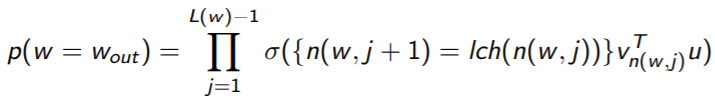 (11)
(11)
где L(w) – длина пути в дереве Хаффмана от корня до искомого слова w; n(w,j) – j-ая вершина в этом пути;  (x) = 1/(1 + e-x) –сигмоидальная функция; lch(n) – левый поток вершины;
(x) = 1/(1 + e-x) –сигмоидальная функция; lch(n) – левый поток вершины; 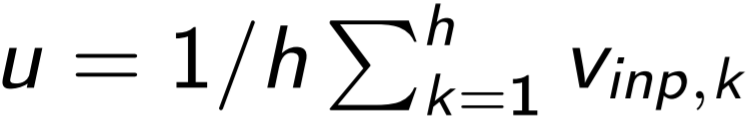 - усредненный вектор контекста при использовании CBoW,
- усредненный вектор контекста при использовании CBoW, 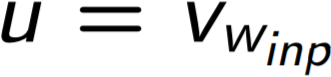 - при использовании skip-gram.
- при использовании skip-gram.
Вычисляются при этом также вероятности того, что путь от определенного узла может продолжится как налево, так и направо (12, 13):
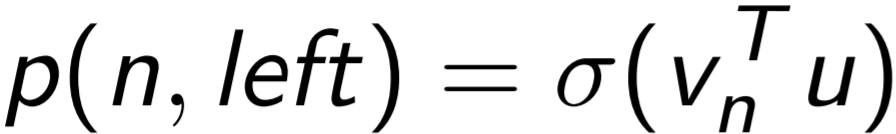 (12)
(12)
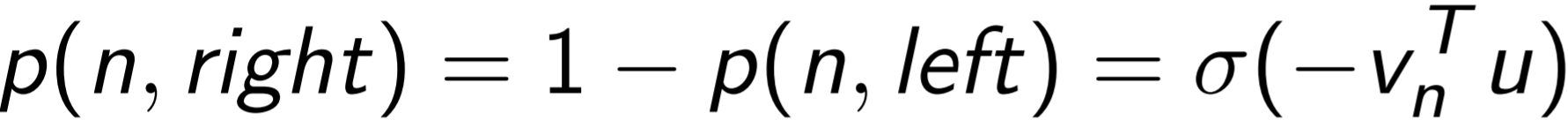 (13)
(13)
CBoW основывается на идее, что слова, расположенные в похожих контекстах, имеют одинаковую семантику. Состоит из трёх слоёв (рис. 8):
- Входной слой (input layer). На вход ему подаётся N ближайших соседей исследуемого слова. Они кодируются как one-hot векторы. В NLP one-hot вектор – это вектор размерностью V, состоящий из «0», за исключением одной «1», которая ставится на место k, где k – номер слова в словаре, а V – это размер словаря (рис. 9). Таким образом, мы теряем информацию о последовательности слов в предложении, и именно поэтому этот подход называют мешок слов (bag-of-words). Однако, это не влияет на работу следующего слоя.
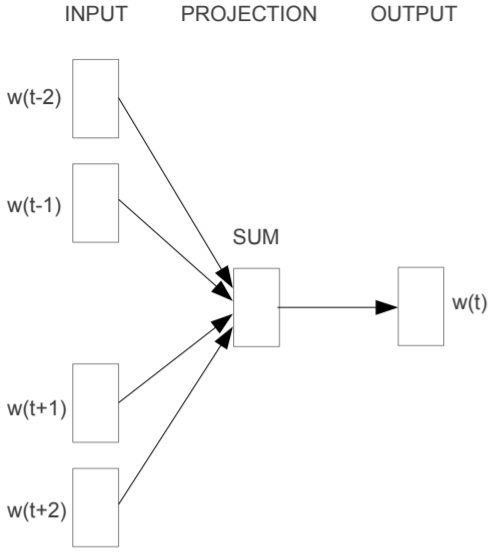
Рис. 6. Архитектура нейронной сети CBoW

Рис. 7. One-Hot кодирование
- Слой проекции (projection layer). Каждый нейрон этого слоя представлен строкой матрицы весов, длина которой равняется размеру словаря. Каждое слово из контекста, который был подан на входной слой, проецируется на последний выходной слой с помощью этой матрицы (рис. 10). То есть слову, представленному one-hot вектором, у которого на i-том месте стоит «1», ставится в соответствие i-тый столбец матрицы.
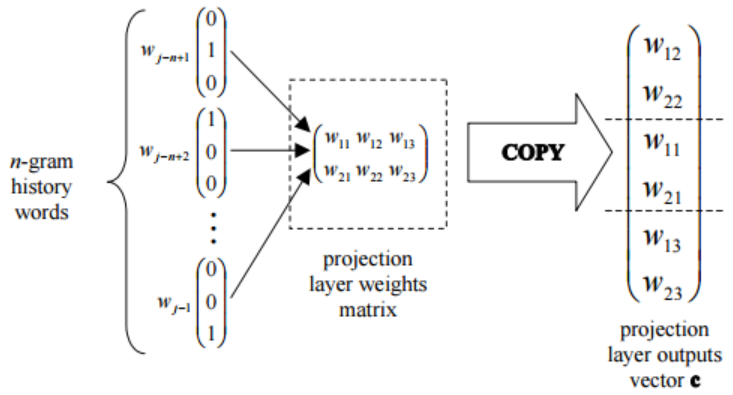
Рис. 8. Пример работы слоя проекции
- Выходной слой (output layer). Получаем вектор слова из слоя проекции.
Для корректировки отображения слова в векторное пространство на последнем этапе сравнивается полученный на выходе результат с самим словом. Это делается при помощи метода обратного распространения ошибки. То есть в итоге задача заключается в максимизации уравнения (14):
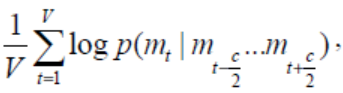 (14)
(14)
где V – это размер словаря, с – размер окна, которым проходим по каждому предложению в 4 пункте для получения контекста слова.
Архитектура метода skip-gram точно такая же, как и у CBoW, но вместо предсказывания слова по его контексту этот метод пытается максимизировать классификацию слова на основе другого слова из этого же предложения (рис. 11). Если же выражаться более точно, используется каждое текущее слово в качестве входных данных и прогнозируются слова в определенном диапазоне до и после текущего слова.
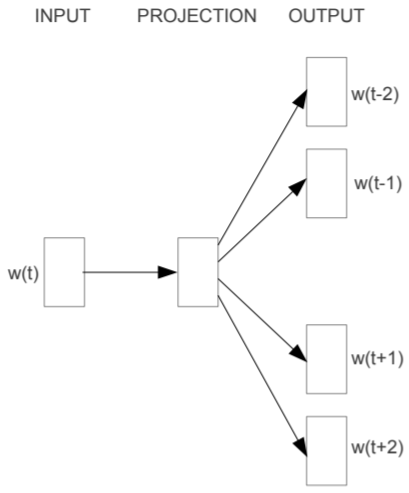
Рис. 11. Архитектура нейронной сети skip-gram
Последний этап данного алгоритма основывается на корректировании векторного отображения слов, сравнивая их с каждым словом из контекста, при помощи метода обратного распространения ошибки. Таким образом, осуществляется максимизация уравнения (15):
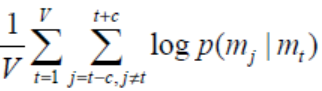 (15)
(15)
Метод CBoW работает быстрее и лучше с наиболее частотными словами для корпусов текстов с большой размерностью. Skip-gram же подходит для небольших корпусов и лучше работает с редкими словами.
Задача Microsoft Sentence Completion Challenge была недавно представлена как задача для развития языкового моделирования и других методов NLP [20]. Эта задача состоит из 1040 предложений, где в каждом предложении отсутствует одно слово, и цель состоит в том, чтобы выбрать слово, которое наиболее соответствует остальной части предложения, с учетом списка из пяти разумных вариантов. На этом наборе уже сообщалось о выполнении нескольких методов, в том числе и вышеописанного метода латентно-семантического анализа (LSA). Миколов в своей работе приводит результаты выполнения своих методов для решения этой задачи (табл. 4) [16]. Видим, что точность моделей CBoW и Skip-gram очень близка друг к другу, однако, значительно обходят модель LSA.
Таблица 4
Сравнение моделей в задаче Microsoft Sentence Completion Challenge
|
Архитектура |
Точность (%) |
|
LSA |
49 |
|
CBoW |
57.3 |
|
Skip-gram |
58.9 |
В своей работе Пеннингтон приводит сравнение своего метода GloVe с несколькими другими, в том числе и с CBoW на пяти различных датасетах
(табл. 5) [21]. Отсюда видно, что на некоторых входных данных GloVe демонстрирует преимущество над CBoW.
Таблица 5
Сравнение модели CBoW и GloVe
|
Model |
WS353 |
MC |
RG |
SCWS |
RW |
|
CBoW |
57.2 |
65.6 |
68.2 |
57.0 |
32.5 |
|
GloVe |
65.8 |
72.7 |
77.8 |
53.9 |
38.1 |
Однако, что касается классификации текстов по их тональности на три класса: позитивный, негативный, нейтральный, интересные результаты использования Word2Vec и GloVe в совокупности с нейронными сетями показывает один из победителей соревнований SemEval-2017 Task4 по анализу тональности постов из Twitter Мэтью Клише (табл. 6) [22]. Видно, что при использовании Word2Vec точность классификации текстов выше, чем при использовании каких-либо других методов word embedding.
В итоге, для решения задачи отображения слов в векторное пространство (word embedding) был выбран метод Word2Vec, а именно CBoW, так как он быстрее Skip-gram и работа предстоит для больших корпусов текстов. Огромная популярность его использования для задач NLP послужила созданию множества библиотек на разных языках программирования, где он полностью реализован, из-за чего очень удобно применять его на практике. У метода GloVe, который появился немногим позже, не смотря на его незначительное преимущество в показателях точности, ситуация обстоит иначе и, более того, для использования его в программном коде требуется предустановка большого количества различного функционала, таких как компиляторы, Microsoft Visual Studio и многое другое, что делает его менее привлекательным. И основная причина заключается в том, что упор в данной работе делается на сентимент-анализ текста, а для этого метод Word2Vec показывает более высокие результаты.
Таблица 6
Точность классификации постов из Twitter по их тональности на тестовой выборке, состоящей из: 3813 твитов – в 2013 г., 1853 твитов – в 2014 г., 2392 твитов – в 2015 г., 20632 твитов – в 2016 г.
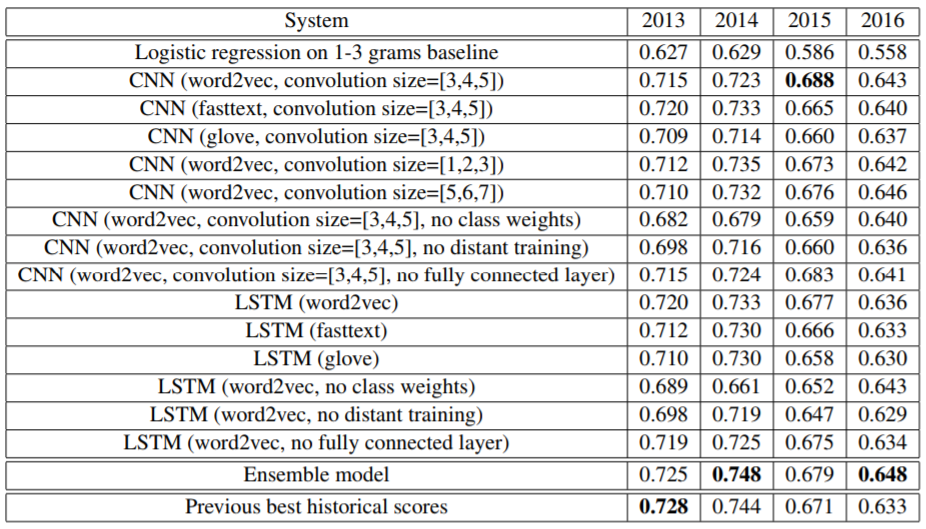
Методы классификации текстов по их тональности
Как упоминалось выше наиболее подходящими методами для анализа тональности текстов являются методы машинного обучения с учителем. Кратко опишем суть наиболее эффективных и популярных из них и выберем наиболее подходящий для решения нашей задачи.
Наивный байесовский классификатор
Алгоритм наивного байесовского классификатора, как правило, является базовым решением для решения задачи анализа тональности текстов [23]. Основная идея состоит в том, чтобы находить вероятность принадлежности текста к определенному классу, используя совместные вероятности слов и классов.
Дана зависимость вектора признаков (x₁,…, xn) и класса Ck. Теорема Байеса математически формулируется как следующее отношение (16):
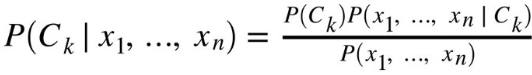 (16)
(16)
Согласно «наивным» предположениям об условной независимости для данного класса Ck каждый признак вектора xi условно не зависит от любого другого признака xj при i ≠ j (17):
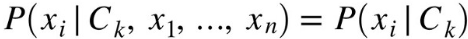 (17)
(17)
Таким образом, отношение (16) упрощается до такого вида (18):
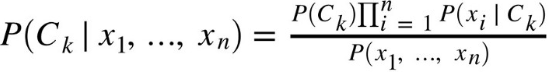 (18)
(18)
Так как знаменатель представляет собой константу, из (18) можно получить следующее отношение (19), по которому будет определяться класс, к которому принадлежит текст:
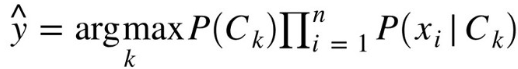 (19)
(19)
Как и в методе наивного байесовского классификатора, изначально дан вектор признаков (x₁,…, xk) и класса Ck. Зависимость между ними определяется бинарной функцией fi, её ещё называют классификационным индикатором [24]. Она принимает значение «1», если данный признак принадлежит классу, и «0», если наоборот (табл. 7).
Таблица 7
Взаимосвязь признаков и классов
|
С1 |
С2 |
|
|
х1 |
f1 |
f2 |
|
х2 |
f3 |
f4 |
продолжение таблицы 7
|
х3 |
f5 |
f6 |
Сама классификация осуществляется по формуле (20):
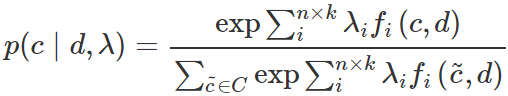 , (20)
, (20)
где n – количество классов; k – количество признаков; fi – бинарная функция; 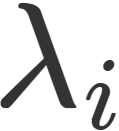 - вес i-ого индикатора fi; С – множество классов; d – классифицируемый текст.
- вес i-ого индикатора fi; С – множество классов; d – классифицируемый текст.
Даны объекты di, представляющие собой векторы, принадлежащие многомерному пространству Rn, и ci, которые принимают значения «-1» или «1», соответствующие одному из классов. Суть метода опорных векторов заключается в поиске гиперплоскости с максимальной разностью (margin), которая разделит в пространстве объекты, принадлежащие разным классам [25].
Разделяющая гиперплоскость записывается в виде (21):
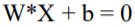 , (21)
, (21)
где W = {w1, w2, …, wn} – вектор нормали, которая однозначно определяет гиперплоскость (вектор весов), b – смещение гиперплоскости.
Поиск этого вектора происходит по формуле (22):
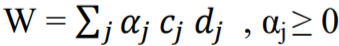 , (22)
, (22)
где j получаем благодаря решению задачи двойной оптимизации.
Рекуррентные нейронные сети (RNN) – это очень популярная модель, повсеместно использующая для обработки текстовой информации [26]. Её идея заключается в том, RNN обладает так называемой «памятью» - происходит учёт предыдущей информации. Название рекуррентные они получили по причине того, что происходит выполнение одной и той же задачи для каждого элемента и при этом данные, получаемые на выходе, зависимы от предыдущих вычислений.
Архитектура рекуррентной нейронной сети представлена на рис. 12. Обратим внимание, что нейроны получают информацию о состоянии сети от своих предшественников. Это позволяет качественно работать с информацией, которая представлена в последовательном изложении (текст, музыка, видео).
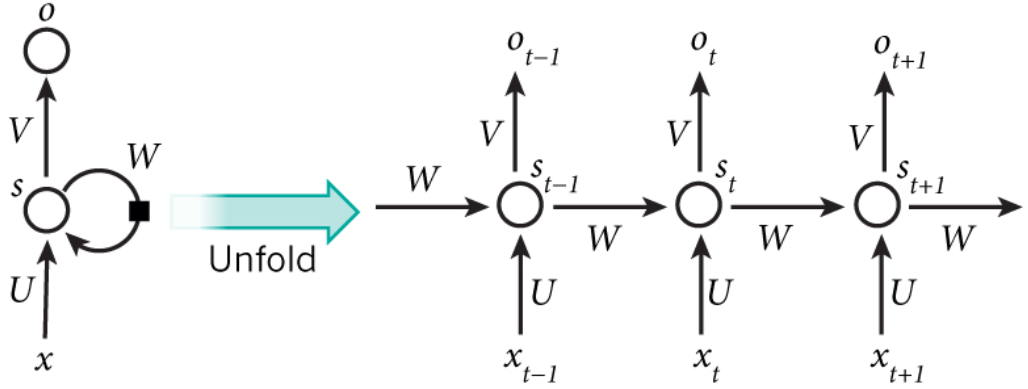
Рис. 12. Архитектура рекуррентной нейронной сети в развернутом состоянии
Разберем, что представлено на данном рисунке:
- хt – входные данные на t-ом шаге;
- st – функция, зависящая от данных, получаемых от предыдущего нейрона, и новых данных, которые поступают на вход st = f(Wst-1 +Uxt), где f – нелинейная функция, зачастую представимая в виде гиперболического тангенса: tahn(x) = (е2x-1)/( е2x+1), или ReLU: f(x) = max(0, x). st в данном контексте можно назвать «памятью» нейронной сети;
- U, W, V – параметры нейронной сети. Они не меняются при переходе на следующий шаг. В этом и заключается рекурентность сети. Также это позволяет уменьшить количество параметров, которые необходимо обучать;
- ot – выход t-ом шаге. Однако, в зависимости от задачи, в нашем случае это определение тональности текста, выход понадобится только на последнем шаге.
Рекурсивная нейронная сеть (RecNN) является одним из видов рекуррентных нейронных сетей [27]. Она имеет древовидную структуру с фиксированным количеством ветвей (рис. 13). На вход ей подаётся n-грама, где каждое слово представлено в виде вектора. В случае бинарного дерева вектор скрытого состояния текущего узла вычисляется из векторов скрытого состояния левого и правого дочерних узлов следующим образом:
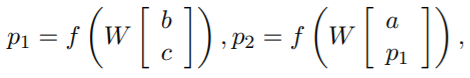 (23)
(23)
где f = tahn – нелинейная функция гиперболического тангенса; W∈Rdx2d – параметры, которые будут меняться в ходе обучения.
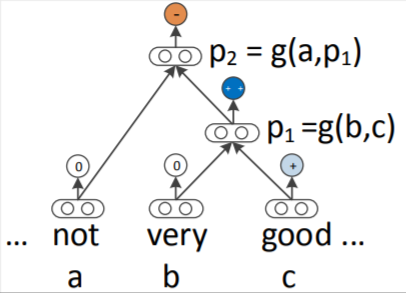
Рис. 13. Архитектура модели рекурсивной нейронной сети
Эта операция последовательно рассчитывается от конечных узлов к корневому узлу. Ожидается, что рекурсивная нейронная сеть будет выражать отношения между дальними элементами по сравнению с рекуррентной нейронной сетью, потому что глубины достаточно с log2(T), если число элементов равно Т.
На данный момент свёрточные нейронные сети являются не менее популярными для решения задач NLP, чем рекуррентные. Одними из первых, кто максимально подробно изложил про применение этой архитектуры (рис.14) для анализа тональности текстов, являются Ye Zhang и Byron C. Wallace [28].
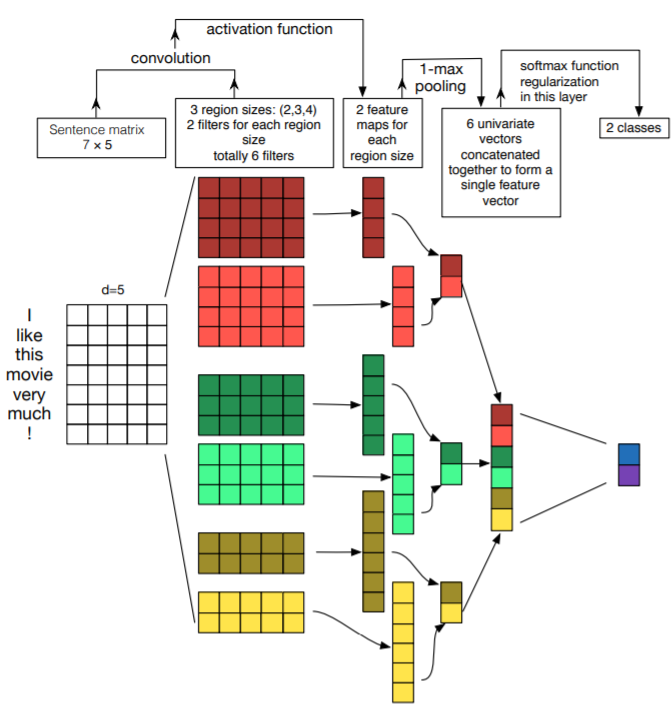
Рис. 14. Пример архитектуры свёрточной нейронной сети для классификации текстов. Используется по два свёрточных слоя для каждого размера фильтра: 2, 3, 4
Исследуемое предложение токенизируется (разбивается на лексемы), затем преобразуется в матрицу, где каждая строка представлена вектором токена. Зачастую отображение слов в векторное пространство делается с помощью вектора Word2Vec или GloVe. Обозначим размерность векторов слова через d. Если размер данного предложения равняется s, что размер матрицы будет s х d.
Затем мы можем эффективно работать с матрицей, как с изображением, выполняя свёртку с помощью фильтров. Это происходит на первом шаге работы нейронной сети с помощью свёрточного слоя. Поскольку строки представляют собой векторы слов одинакового размера, то разумно использовать фильтры с шириной равной d. Таким образом, меняется только высота фильтров h. Этот параметр определяет, сколько соседних строк матрицы будут подвергаться обработке фильтром совместно.
Предположим, что существует фильтр, параметризованный весовой матрицей w с размером области h; w будет содержать h · d параметров для оценки. Мы обозначаем матрицу предложений через A ∈ Rs x d и используем A [i : j] для представления подматрицы A от строки i до строки j. Выходная последовательность o ∈ Rs-h-1 оператора свертки получается путем многократного применения фильтра к подматрицам матрицы A:
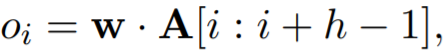 (24)
(24)
где i = 1…s – h +1, а · - это скалярное произведение между подматрицей и фильтром (сумма по поэлементным произведениям). Добавляем смещение b ∈ R и функцию активации f к каждому oi, и, таким образом, получаем карту признаков c ∈ Rs-h+1 для этого фильтра:
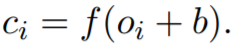 (25)
(25)
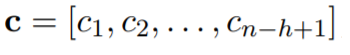 (26)
(26)
Можно использовать несколько фильтров одного и того же размера, чтобы изучить дополнительные свойства каждой области. Можно также использовать несколько фильтров разной высоты.
Размерность карты признаков, созданной каждым фильтром, будет зависеть от длины предложения и высоты самого фильтра. Затем они подаются на вход слою субдискретизации (уплотнение), где к каждой полученной карте применяется операция 1-max pooling: 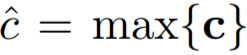 , которая получает максимальное значение, таким образом, уменьшая размерность карт признаков. Идея этой операции заключаются в том, что мы получаем по одному самому важному признаку из соответствующих карт. Другими словами, слои свёртки и субдискретизации позволяют извлекать из матрицы наиболее значимые n-грамы.
, которая получает максимальное значение, таким образом, уменьшая размерность карт признаков. Идея этой операции заключаются в том, что мы получаем по одному самому важному признаку из соответствующих карт. Другими словами, слои свёртки и субдискретизации позволяют извлекать из матрицы наиболее значимые n-грамы.
Затем мы конкатенируем полученные данные из слоя субдискретизации в один общий вектор и подаём его на вход выходного слоя, где функция softmax осуществляет классификацию. Она выводит вектор, который представляет собой распределение вероятностей потенциальных результатов (рис. 15).
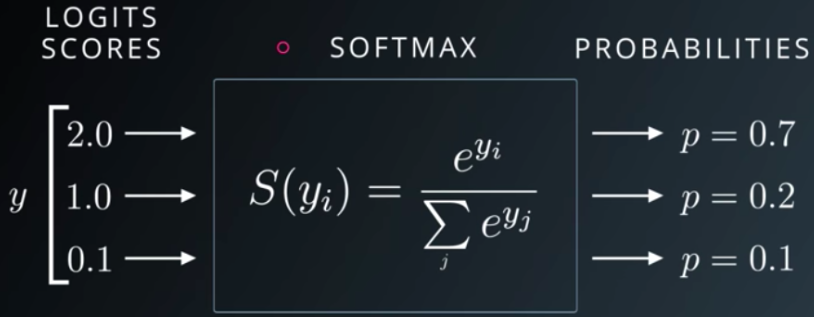
Рис. 15. Демонстрация работы функции активации softmax
Существует такая проблема как переобучение. В результате нейронная сеть хорошо работает с обучающей выборкой, но, не обретая свойства обобщения, плохо работает на тестовом наборе. Другими словами, переобучение – это результат чрезмерной подгонки сети к обучающим примерам. Соответственно, чтобы избежать этого, применяются различные методы, в том числе и регуляризация. В случае нашей свёрточной сети зачастую используется исключающий (dropout) слой. При обучении он исключает из сети с вероятностью p нейроны. Это означает, что при любых входных данных он выдаст в виде результата «0».
Сравнение и результат обзора методов анализа тональности текстов
SemEval – это ежегодные соревнования международного масштаба по решению различных задач NLP. В 2017 году были проведены соревнования (SemEval-2017 Task 4) по созданию системы, которая будет осуществлять анализ тональности постов, сделанных в социальной сети Twitter [9].
Соревнования заключались в решении нескольких задач, среди которых была задача определить принадлежность твита к одному из классов: позитивному, негативному или нейтральному. В решении данной проблемы принимало участие 41 команда, среди которых минимум 20 использовали нейронные сети, остальные же использовали такие методы, как Наивный Байес, метод опорных векторов, максимальная энтропия и другие.
Лучшие показатели не только по этой задаче, но и по большинству остальных, принадлежат команде BB_twtr (табл. 8):
Таблица 8
Топ-10 команд по решению задачи классификации твитов на 3 класса: положительный, негативный, нейтральный
|
# |
System |
Recall |
F1 |
Accuracy |
|
1 |
BB_twtr |
0.681 |
0.685 |
0.658 |
|
2 |
DataStories |
0.681 |
0.677 |
0.651 |
|
3 |
LIA |
0.676 |
0.674 |
0.661 |
|
4 |
Senti17 |
0.674 |
0.665 |
0.652 |
|
5 |
NNEMBs |
0.669 |
0.658 |
0.664 |
|
6 |
Tweester |
0.659 |
0.648 |
0.648 |
|
7 |
INGEOTEC |
0.649 |
0.645 |
0.633 |
|
8 |
SiTAKA |
0.645 |
0.628 |
0.643 |
|
9 |
TSA-INF |
0.643 |
0.620 |
0.616 |
|
10 |
UCAC-NLP |
0.642 |
0.624 |
0.565 |
За основу своей разработанной системы они взяли свёрточную нейронную сеть в совокупности с LSTM (Long short-term memory –подвид рекуррентных нейронных сетей). Следующие 4 команды также использовали глубокое обучение и ансамбли нейронных сетей. Команды INGEOTEC, SiTAKA и UCAC-NLP за основу своих работ взяли SVM классификатор.
Также в совместной работе специалистов из Intel и университета Карнеги-Меллона (Carnegie-Mellon University) было продемонстрировано преимущество свёрточной нейронной сети над рекуррентной, в частности, над LSTM [29].
Таким образом, за основу web-сервиса была взята именно свёрточная нейронная сеть, так как она продемонстрировала высокие показатели в решении задач NLP, в частности, в классификации текстов по их тональности.
ГЛАВА 2 РАЗРАБОТКА ПРОГРАММЫ
2.1 Используемый функционал на языке программирования Python
Для реализации web-сервиса для классификации постов из Twitter на 4 класса: позитивный, негативный, реклама/поздравление и неопределенный использовался высокоуровневый язык программирования Python. Он как нельзя лучше подходит для реализации нейронных сетей, в нашем случае – свёрточных сетей и метода Word2Vec из-за наличия множества библиотек, в которых уже реализована немалая часть функционала, фреймворка Django и Jupyter Notebook.
Основные библиотеки, которые использовали для реализации ПО:
- NLTK – это пакет библиотек и программ для работы с данными на естественном языке [30]. Её мы используем для токенизации предложений и стемминга слов (выделение основы слова).
- Gensim – библиотека для тематического моделирования (извлечения основных тем, которым посвящен обрабатываемый текст) и дистрибутивной семантики (вычисление семантической близости слов) [31]. Из неё берется реализованный метод Word2Vec.
- Keras - это нейросетевая библиотека, представляющая собой надстройку над фреймворками Deeplearning4j, TensorFlow и Theano [32]. Используется для оперативной работы с нейронными сетями. В нашем случае применяется для реализации сверточной нейронной сети;
- python-twitter – библиотека, обеспечивающая работу с функционалом API Twitter [33];
- pymorphy2 – морфологический анализатор. Библиотека, обеспечивающая получение лексемы (всех форм) слова.
Фреймворк Django является полнофункциональным серверным web-фреймворком, который очень популярен среди разработчиков [34]. Он позволяет оперативно реализовывать любые web-сайты, начиная с систем управления контента и заканчивая социальными сетями, из-за своей гибкой структуры и наличием всего необходимого «в коробке», из-за чего можно полностью сосредоточиться на написании своего приложения. Именно по этим причинам он нам подходит для реализации поставленной задачи.
Jupyter Notebook - это интерактивная оболочка языка программирования Python, которая представляет собой инструмент, позволяющий объединить код, текст и диаграммы. Он применялся для реализации и обучения метода Word2Vec и сверточной нейронной сети.
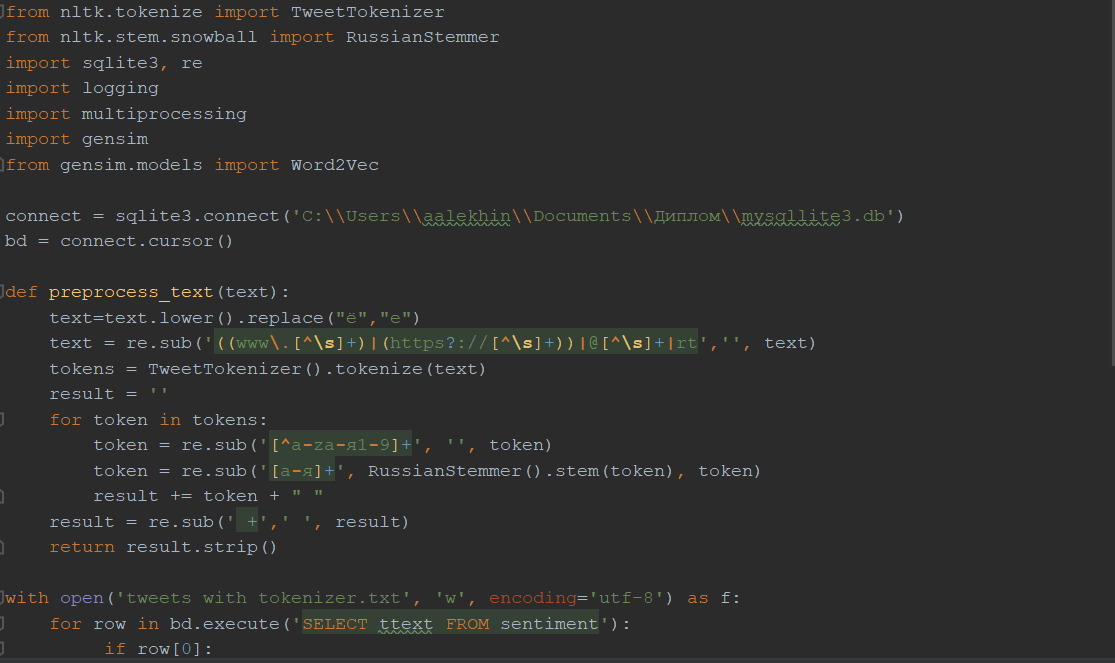
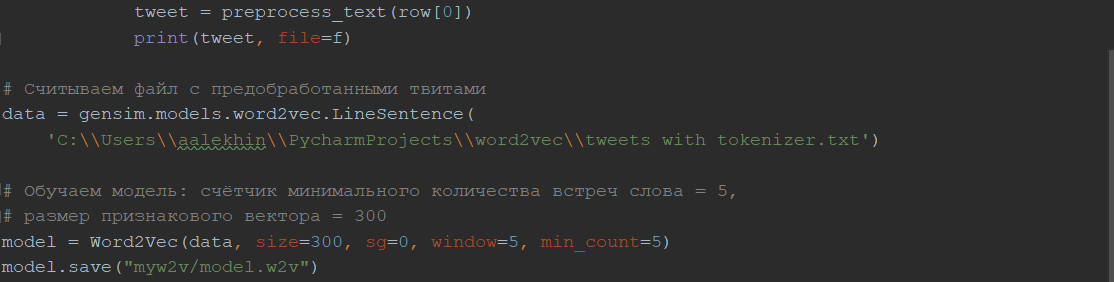
Реализация и обучение Word2Vec
Данные для обучения были взяты с персонального сайта Юлии Рубцовой, где представлен корпус русскоязычных сообщений из Twitter, который содержит в себе 114 991 записей с положительным тональным окрасом и 111 923 с негативным окрасом (в виде файлов с расширением .sql и .csv), а также 17 639 674 неопределенных (файл с расширением .sql) [35].
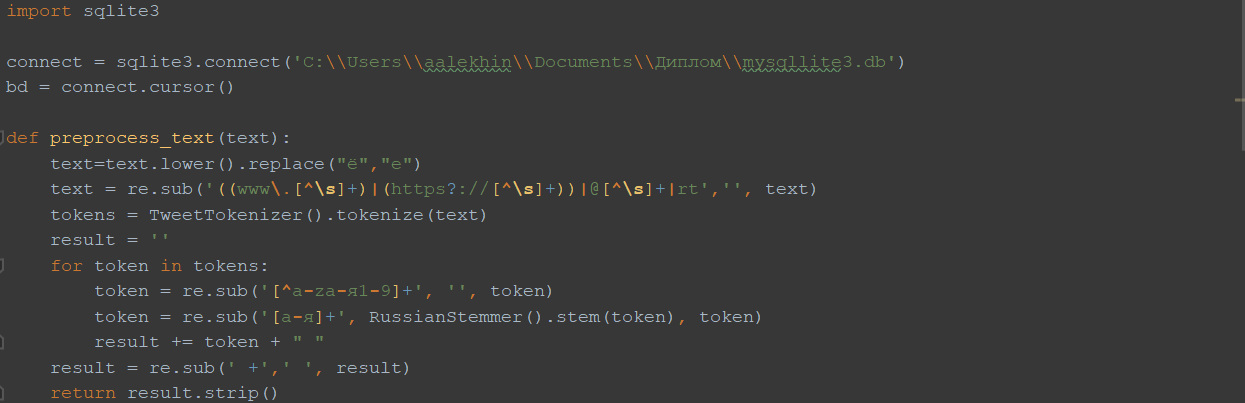
Изначально, база с неопределенными твитами была конвертирована в формат SQLite с помощью специально скрипта для удобства работы с ней [36]. Затем все твиты предобрабатываются:
- все символы переведены в нижний регистр;
- буква «ё» заменена буквой «е»;
- все ссылки, значки ретвитов, обращения к другим пользователям удалены;
- удалены все символы, кроме букв русского и английского алфавита, и цифр;
- стемминг русскоязычных слов.
Далее происходит обучение модели Word2Vec, с заданными значениями параметров:
- size=300 – размер признакового пространства, куда будут отображаться слова;
- sg=0 – «0» - соответствует методу CBoW, «1» - методу Skip-gram;
- window=5 – размер окна, которым будем проходить по предложения для выделения n-грам;
- min_count=5 – если слово встретилось меньше 5 раз, оно не учитывается.
Сохраняем модель.
Результат работы модели представлен на рисунке 16. Для слов «баскетбол», «музыка», «ненависть», «oxxxymiron» выведены по 20 наиболее близких к ним по значению слов.
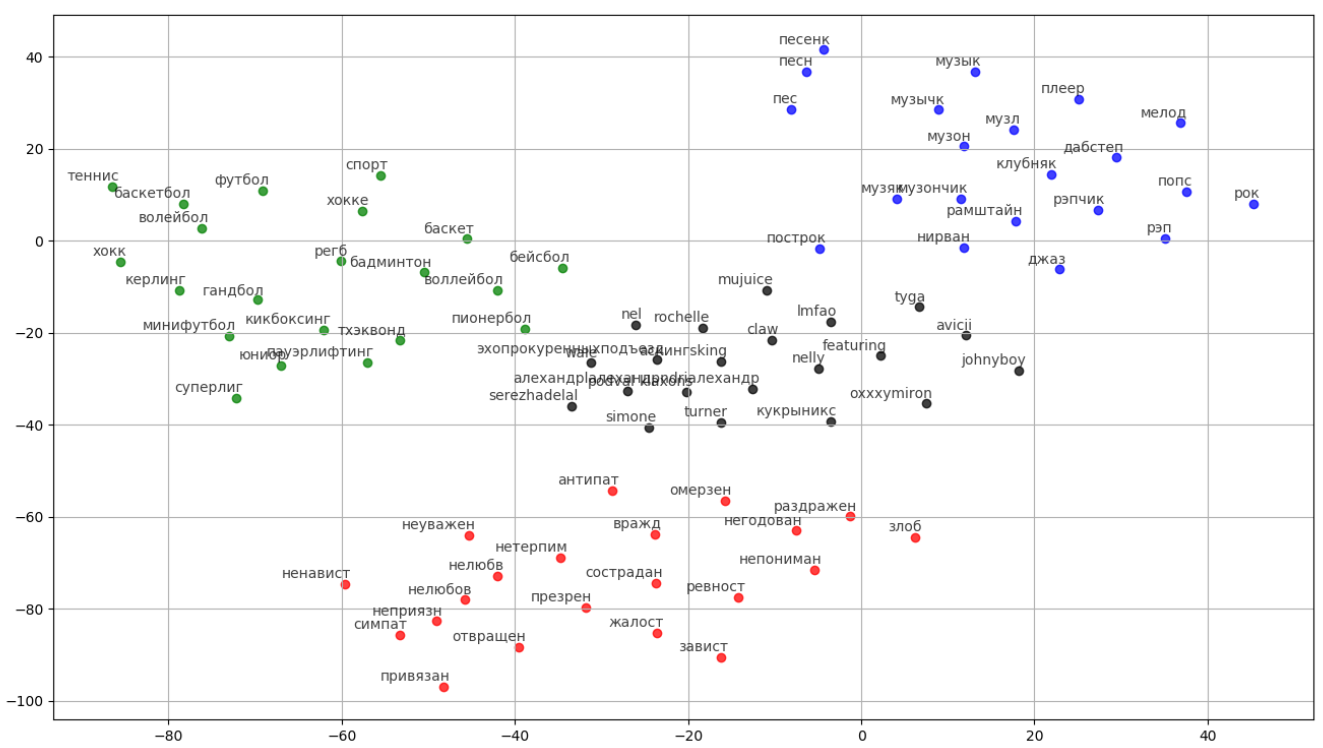
Рис. 16. Результат работы метода Word2Vec
Код представлен в приложении 1.
Создание баз с неопределенными твитами и твитами с рекламой и поздравлениями
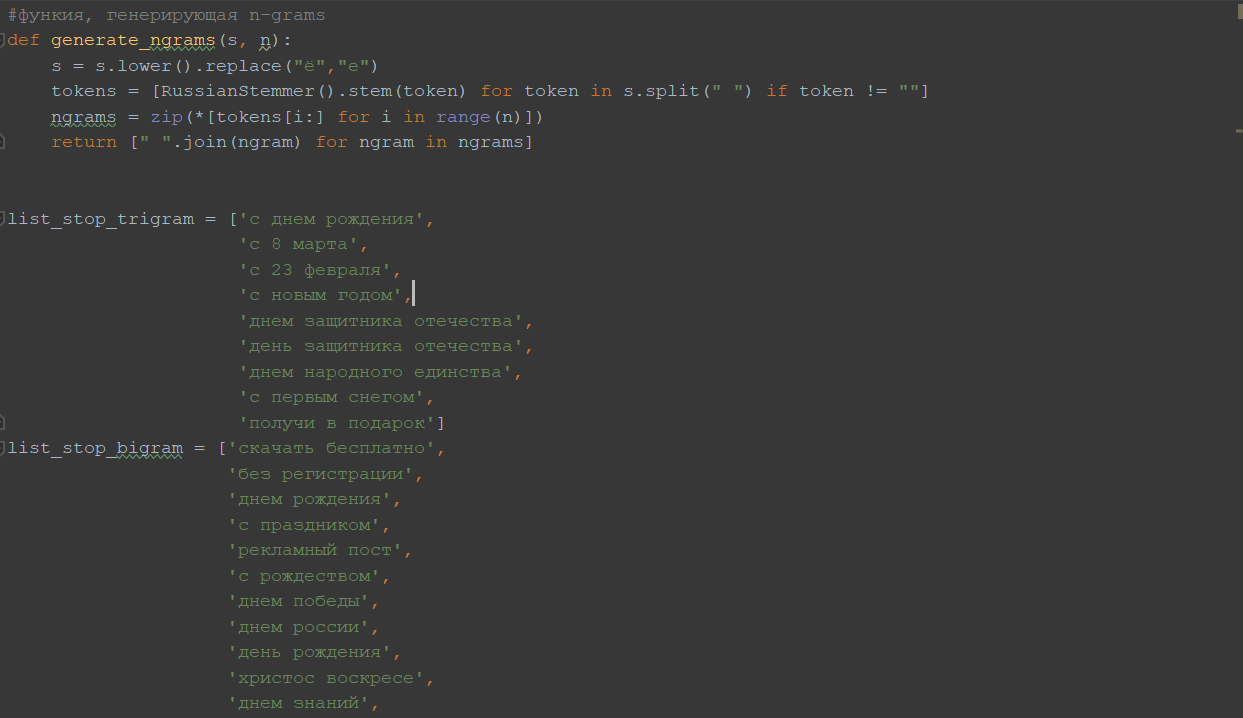
Для обучения нейронной сети требуются данные. В нашем случае необходимы твиты, размеченные по 4 классам: позитивный, негативный, неопределенный и реклама/поздравления. К сожалению, используемый корпус неопределенных твитов был перемешан с рекламой и поздравлениями. Для того, чтобы выделить их в отдельные базы были составлены списки стоп-слов и фраз, по которым отфильтровывались твиты с поздравлением и рекламой и сохранялись в отдельный файл.
Список стоп-слов из униграм: 'скачать', 'бесплатно', 'поздравляю'.
Список стоп-фраз из биграм: 'скачать бесплатно', 'без регистрации', 'днем рождения', 'с праздником', 'рекламный пост', 'с рождеством', 'днем победы', 'днем россии', 'день рождения', 'христос воскресе', 'днем знаний', 'с пасхой', 'с рождением', 'по ссылке', 'смотреть бесплатно', 'смотреть онлайн', 'регистрируйся бесплатно', 'получи бонус', 'получи скидку', 'в подарок'.
Список стоп-фраз из триграм: 'c днем рождения', 'с 8 марта', 'с 23 февраля', 'с новым годом', 'днем защитника отечества', 'день защитника отечества', 'днем народного единства', 'с первым снегом', 'получи в подарок'.
Таким образом, поочередно брались твиты, делились на n-грамы, где n – количество слов, и сравнивались с соответствующими списками стоп-слов.
Код представлен в приложении 2.
2.2Реализация и обучение свёрточной нейронной сети
Изначально загружаем файлы с размеченными по классам твитам, уравниваем их количество, осуществляем их предобработку, которая была описана в пункте 3.2, конвертируем метки классов в one-hot векторы (метка в виде целого числа «1», относящаяся к положительному классу, конвертируется в вектор [1, 0, 0, 0], где единица стоит на том месте, которое соответствует твиту с положительной тональностью).
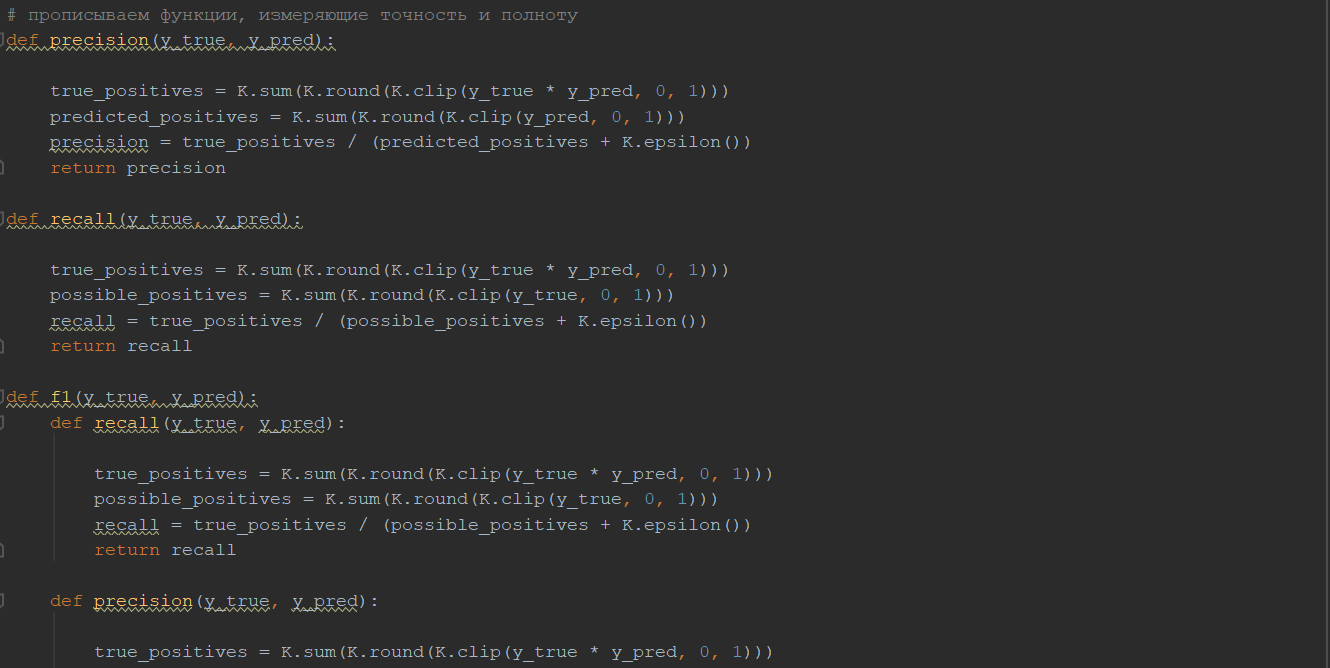
Затем разделяем твиты на обучающую и тестовую выборки в пропорции 80 на 20. Далее реализовываем функции precision(y_true, y_pred), recall(y_true, y_pred), f1(y_true, y_pred), которые будут оценивать работу нашего классификатора, где y_true – это правильный ответ для поданного на вход твита, y_pred – предсказанный ответ классификатором.
Ищем наиболее подходящий размер матрицы (рис. 17), которая будет обрабатываться после embedding слоя остальными слоями. Выводим процент, который соответствует количеству твитов длины меньше, чем представленная. Выбран размер матрицы 30 на 300, так как при таком размере покрывается 99.991% всех твитов.
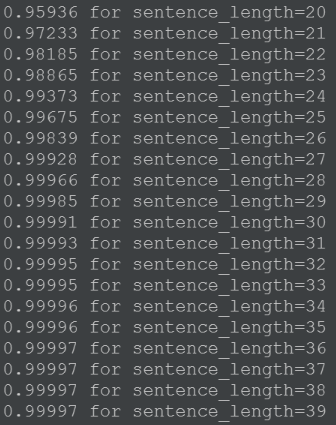
Рис. 17.
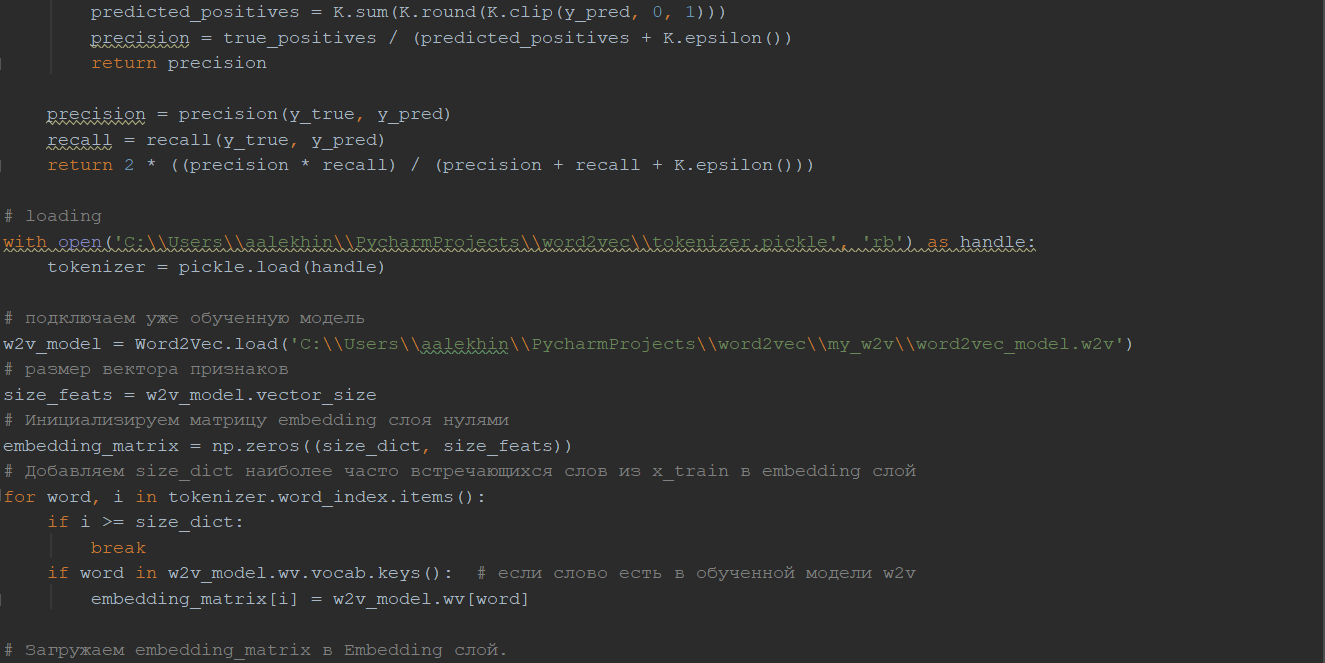
Определяем размер словаря равным 90 000 слов. Обучаем токенизатор (на 90 000 самых частых слов из корпуса) и переводим каждый текст в массив идентификаторов токенов. Таким образом, теперь каждый твит представлен последовательностью из 30 чисел, где каждое число является уникальным для каждого слова. Если длина предложения меньше 30, то оставшееся место в массиве заполняется нулями.
Подключаем уже обученную модель Word2Vec. Создаём матрицу для embedding слоя размером 90 000 на 300, где каждая строка будет векторным отображением слова из уже обученного токенизатора.
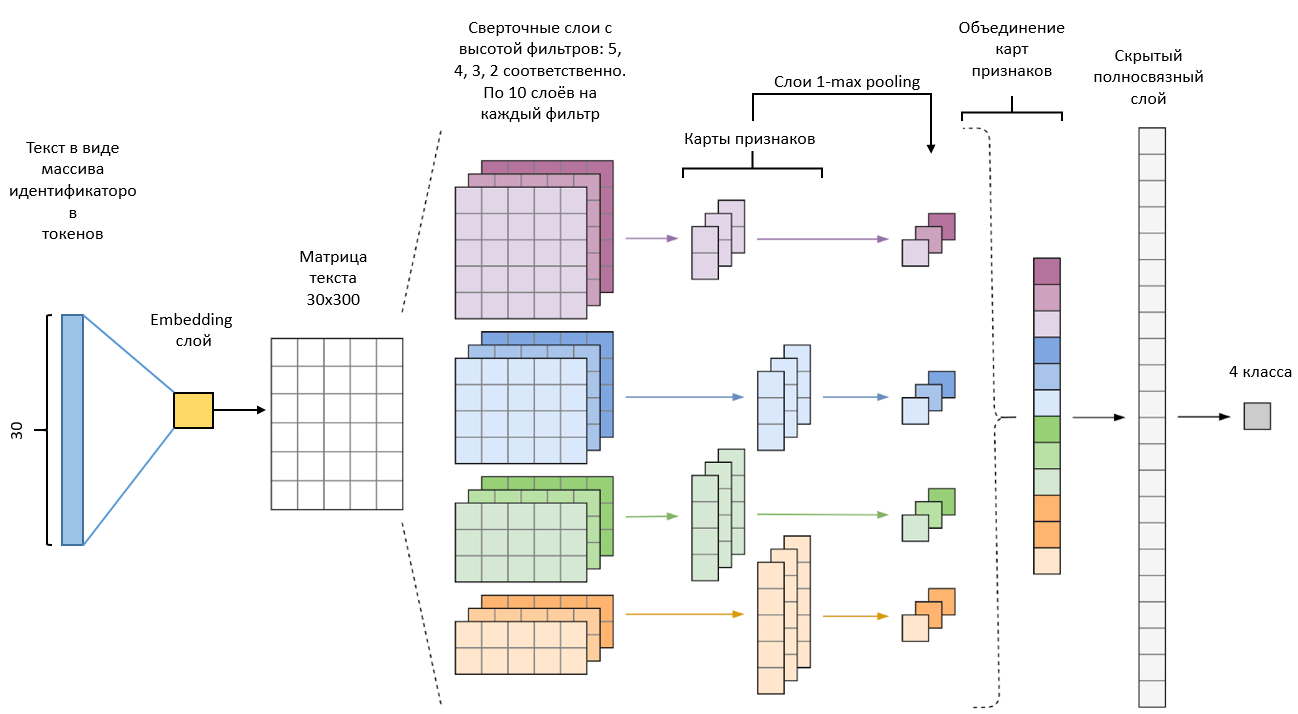
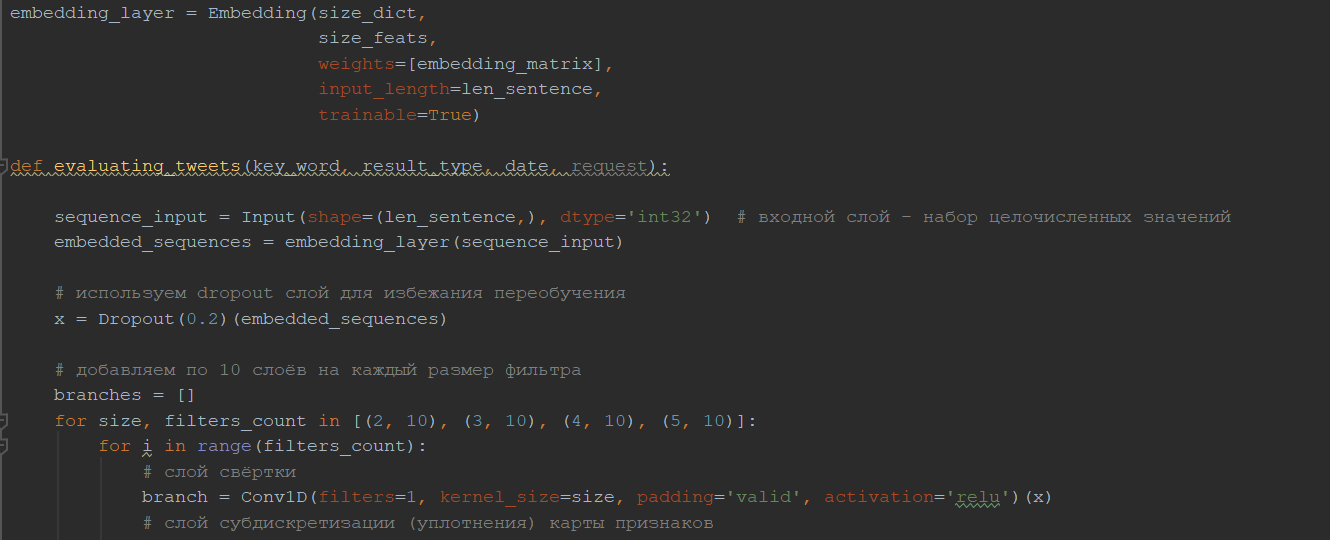
Рис. 18. Архитектура свёрточной нейронной сети
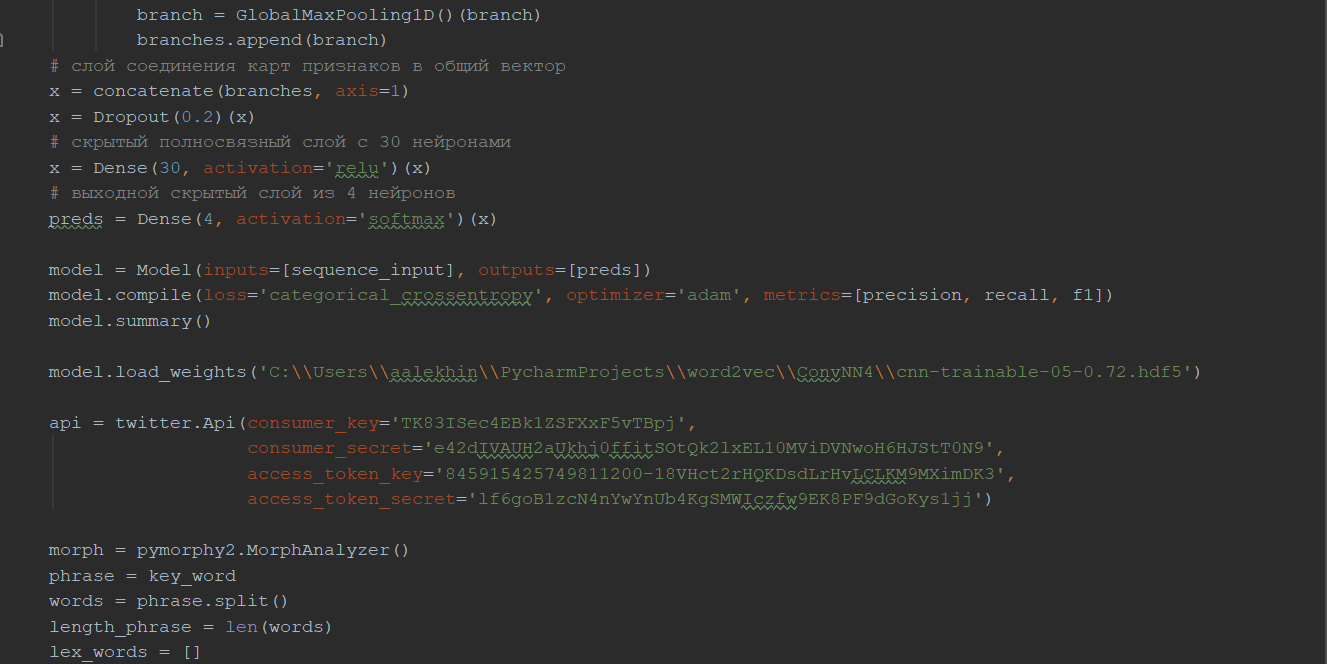
Архитектура нашей сверточной нейронной сети (рис. 18) имеет такой же вид, как и описанная в пункте 2.5.6 сеть, за исключение того, что будет присутствовать входной слой, который принимает тексты в виде последовательностей идентификаторов токенов, embedding слой, который будет отображать идентификаторы в векторное пространство, добавленных dropout слоёв со значением вероятности 0.2 после embedding слоя и слоя конкатенации карт признаков в один общий вектор. Также перед выходным слоем был добавлен скрытый слой из 30 нейронов с функцией активации ReLU, чтобы улучшить качество классификации, по примеру из работы Мэтью Клише, который занял 1 первое в классификации твитов по тональности [22]. Сам же выходной слой представляет собой 4 нейрона функцией активации softmax, по каждому нейрону на класс. В виде функции обратного распространения ошибки была взята функция категориальной кросс-энтропии (27):
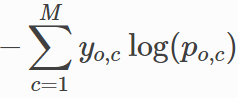 (27)
(27)
Где M –количество классов, log – натуральный логарифм, y – индикатор метки класса, o – объект классификации, c – класс, p – предсказанная вероятность принадлежности объекта к корректному классу.
Более того, согласно работе Ye Zhang и Byron C. Wallace наиболее оптимальной высотой фильтров для датасетов с достаточно небольшими текстами (в Twitter ограничение на количество символов в 280) являются 2, 3, 4, 5 [28]. Мы возьмём по 10 таких фильтров для получения более качественных карт признаков.
Компилируем модель и обучаем на протяжении 12 эпох. Необходимо обучить 27 043 394 параметра. Размер батча (партии) равняется 32, таким образом, нейронная сеть каждый раз после пропуска через себя 32 примеров будет настраивать веса. Это поможет использовать меньше памяти и скорость обучения станет выше. Размер валидационной выборки равен 25%. После каждой эпохи сравниваем показатель f1-меры модели с предыдущими и наилучшую сохраняем.
Каждая эпоха занимала около 50 минут на процессоре Intel(R) Core(TM) i5-8250U CPU @ 1.60 GHz 1.80 GHz. Занимаемая память обученной модели 317 231 КБ.
Результаты по каждой метрике для каждого класса лучшей модели на тестовой выборке представлены на рис.19:
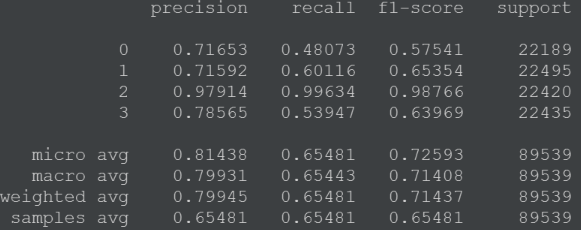
Рис. 19.
Средняя точность классификации твитов по их тональности на 4 класса: позитивный, негативный, реклама/поздравления и неопределенные равна 0.81438 %. Взяли результат micro avg, так как размер классов отличается друг от друга.
На рис. 20 представлены результаты классификации четырёх предложений: «Замечательный фильм, его стоит посмотреть», «Погода этим утром - ужас», «Товарищи, с Новым годом», «Каждое утро надо чистить зубы».
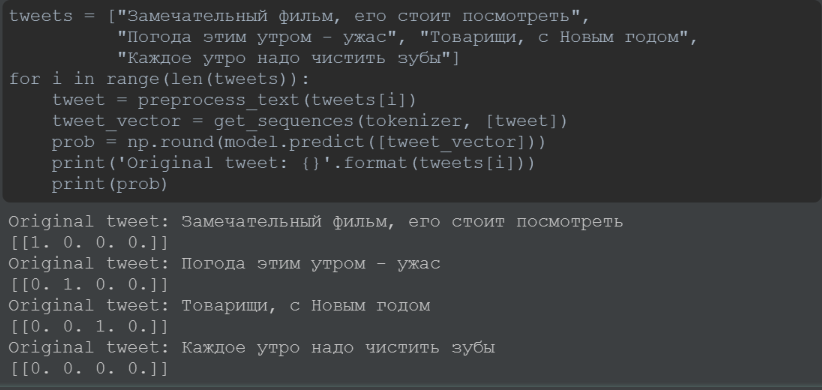
Рис. 20. Пример результата классификации отдельных текстов
Ссылаясь на таблицу 8, проведём сравнение показателей (табл. 9) нашей модели с результатами модели (Word2Vec + свёрточная нейронная сеть + LSTM) Мэтью Клише при классификации текстов на 3 класса: позитивный, негативный и нейтральный.
Таблица 9
Сравнение результатов модели с моделью Мэтью Клише
|
precision |
recall |
f1-мера |
accuracy |
|
|
Модель Мэтью Клише |
- |
0.681 |
0.685 |
0.658 |
|
Моя модель |
0.79931 |
0.65443 |
0.71408 |
- |
Однако, такое сравнение не совсем корректно, так как в данной работе классификация проходила на 4 класса: позитивный, негативный, неопределенный, реклама/поздравления. За счёт высоких показателей для последнего класса эта модель кажется предпочтительнее на фоне модели Мэтью Клише.
Прежде, чем начать пользоваться API Twitter, необходимо зарегистрироваться в самой социальной сети, а затем зарегистрировать своё приложение на сайте [37].
После этого получаем токены доступа (Access token и Access Token secret) и пользовательские ключи (consumer_key, consumer_secret), с помощью которых можем подключаться к API и использовать его функционал.
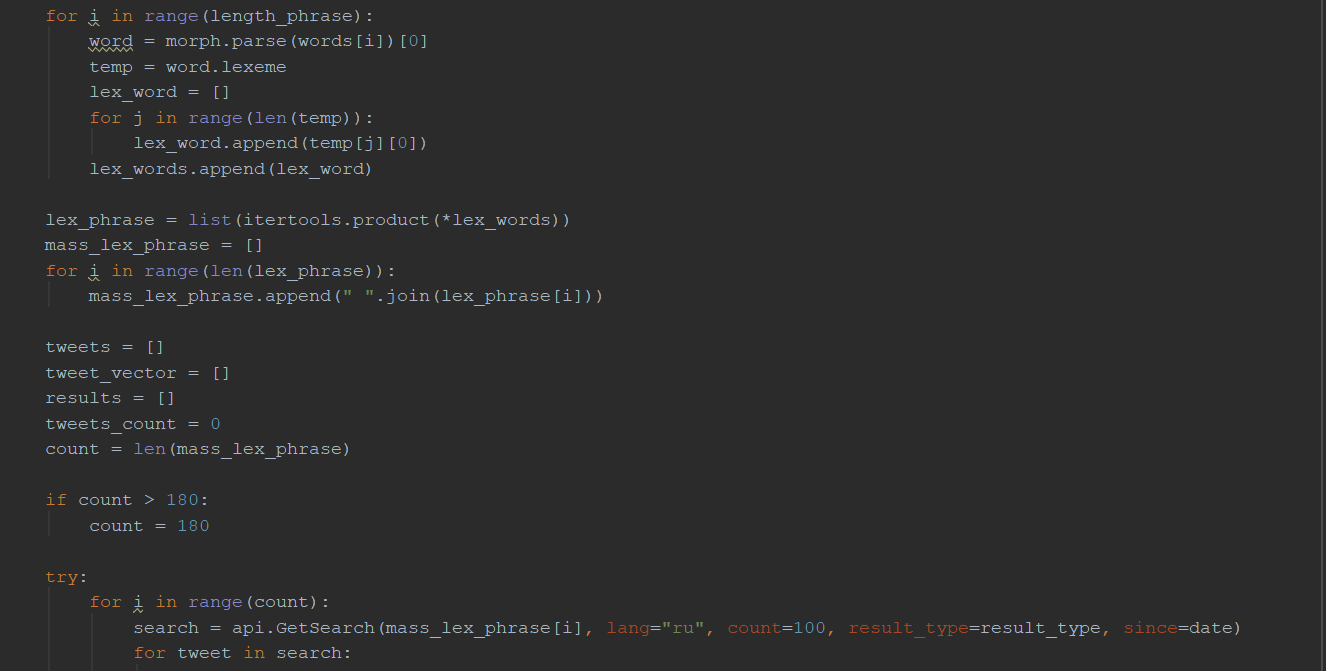
Нам необходима для использования только одна функция GetSearch(key_word, lang="ru", count=100, result_type=result_type, since=date), где key_word – слово или фраза, по которой будет происходить поиск, lang – параметр, указывающий на то, на каком языке искать твиты, count – максимальное количество записей, которое можно получить при поиске, result_type принимает на вход «recent» или «popular», соответственно поиск идёт по популярным твитам, либо по последним по дате опубликования, since – указывает дата, с которой будет начинаться поиск.
К сожалению, с недавних пор у Twitter появилось много ограничений по доступу к их API: поиск происходит только по точным совпадениям с поисковым запросом, максимальное число твитов, которое можно получить с одного запроса, равняется 100, глубина поиска ограничена неделей, количество запросов за 15 минут не должно превышать 180.
Таким образом, чтобы частично избежать этих проблем, было решено использовать библиотеку pymorphy2, благодаря которой запрос пользователя предобрабатывается: находятся все словоформы, из них образуются все возможные комбинации, по каждому из которых делается запрос на сервер Twitter.
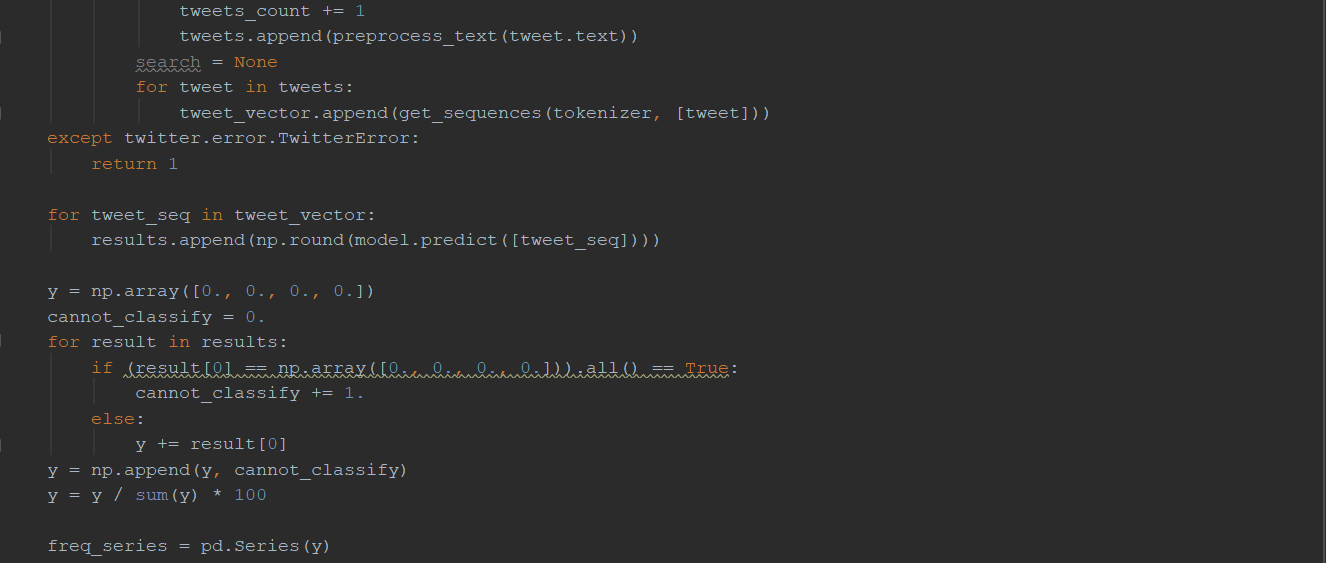
Далее найденные твиты по каждому из запросов проходят анализ тональности. Если количество всех комбинаций превышает число 180, то поиск осуществляется по первым 180 из них.
Для понимания структуры созданного web-сервиса представим дерево файлов и каталогов:
-
-
- diploma
- settings.py (приложение 4)
- urls.py (приложение 5)
- wsgi.py (приложение 6)
- SentAnalyzer
- static
- style.css (приложение 7)
- templates
- SentAnalyzer
- static
- diploma
-
error.html (приложение 8)
home_page.html (приложение 9)
-
-
-
-
- apps.py (приложение 10)
- forms.py (приложение 11)
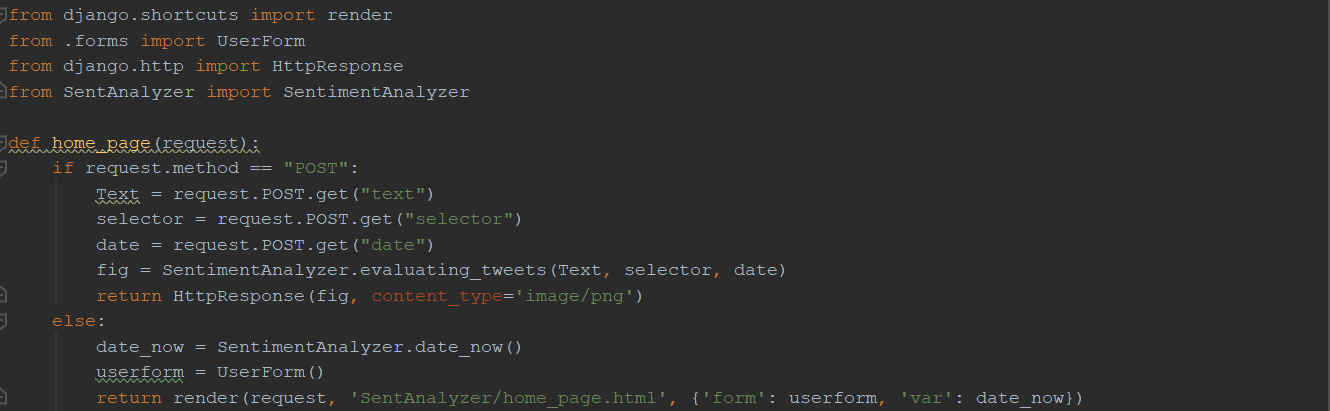
- SentimentAnalyzer.py (приложение 12)
- urls.py (приложение 13)
- views.py (приложение 14)
-
-
-
На стартовой странице (рис. 21) сервиса находится поле, в которое надо ввести слово или фразу, по которому будет осуществляться поиск в Twitter. Также можно выбрать между поиском по популярным или последним твитам. Более того, можно осуществить выбор даты, с которой будет осуществляться поиск. Заполнив все поля, жмём кнопку «Отправить».
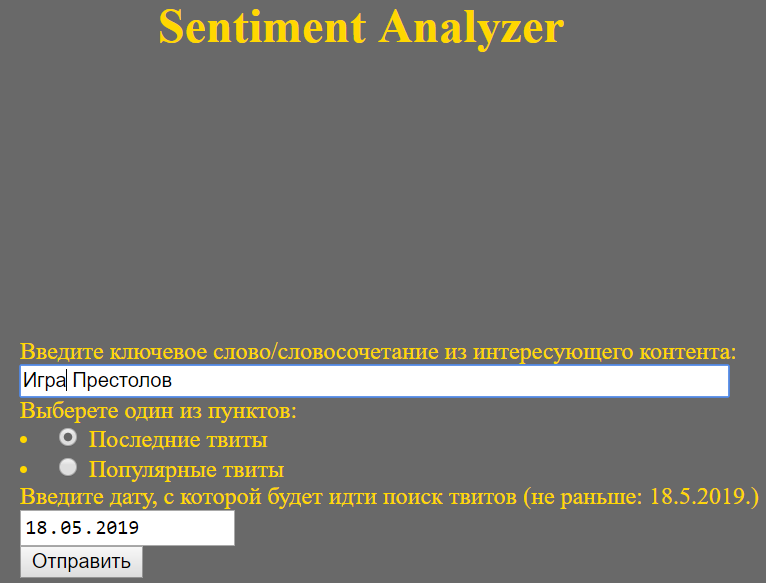
Рис. 21. Интерфейс web-сервиса
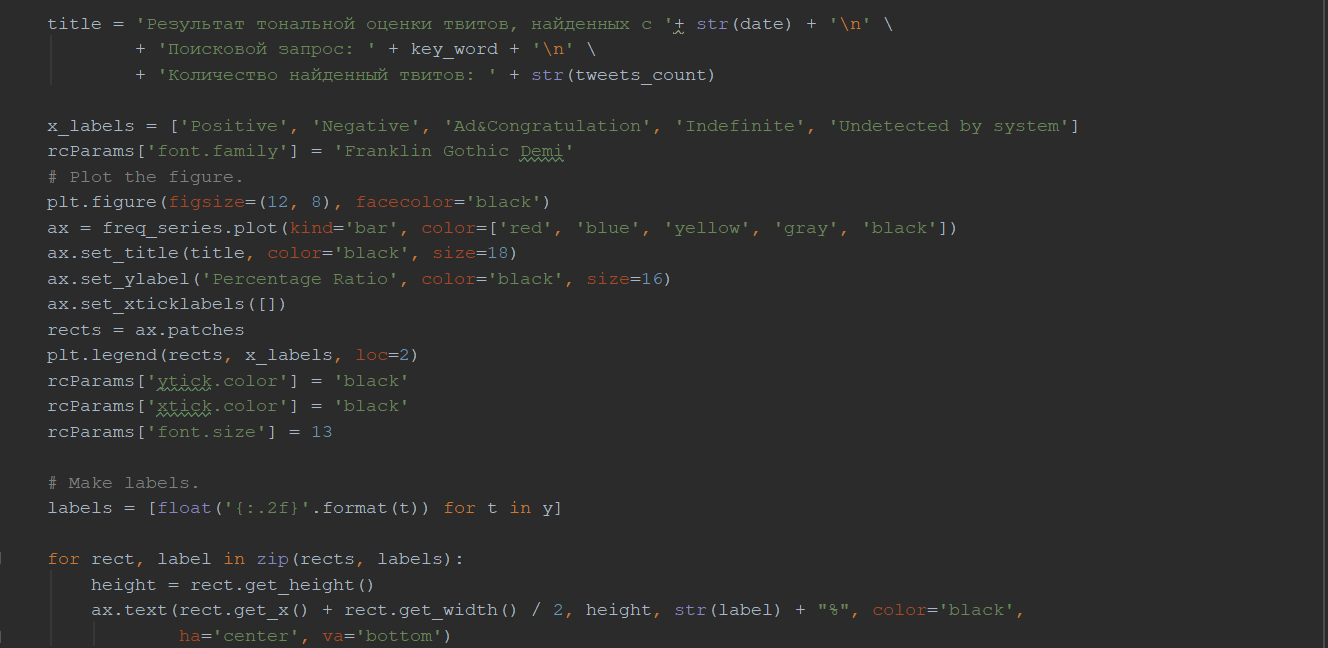
Затем пользователя перенаправляют на страницу с результатами (рис. 22), которые представлены в виде графика. Черный столбец показывает процентное соотношение твитов, которые свёрточная нейросеть не смогла отнести ни к одному из классов.
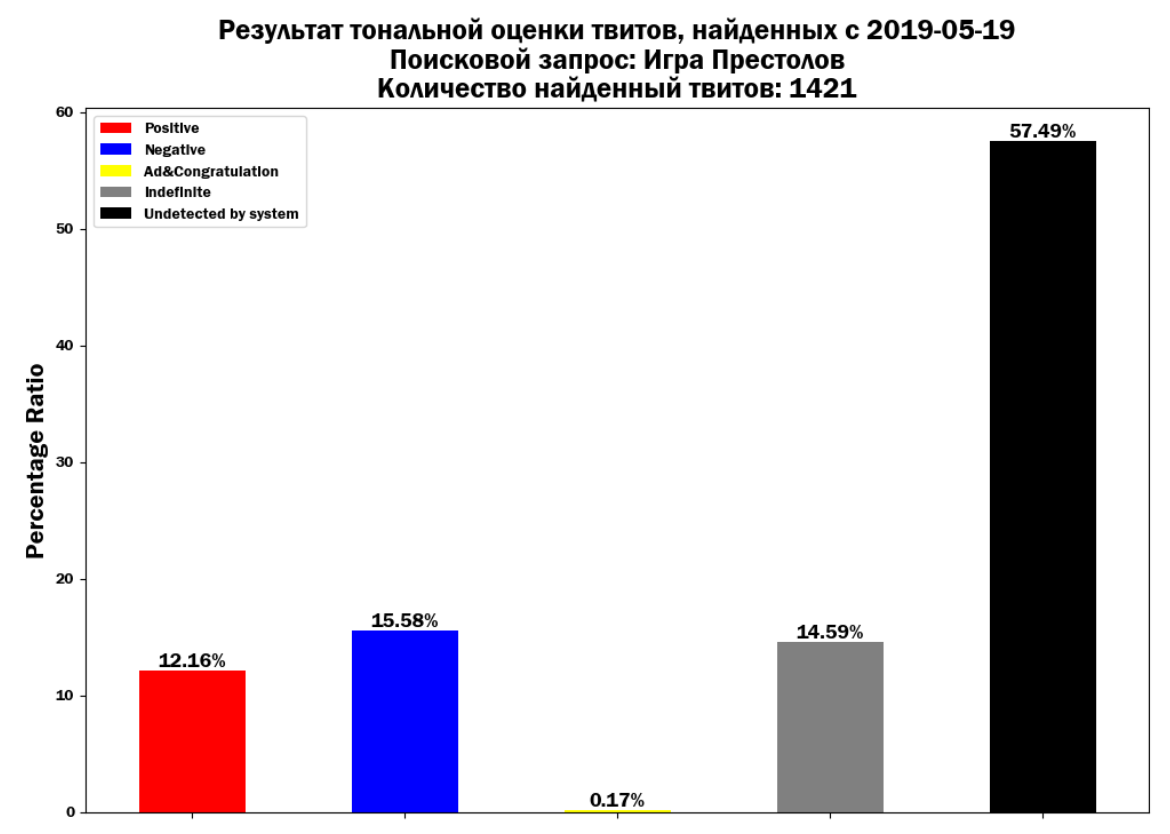
Рис. 22. Результат работы web-сервиса
Если пользователь достиг лимита по количеству запросов (180) менее, чем за 15 минут. То ему выводится на экран сообщение (рис. 23).
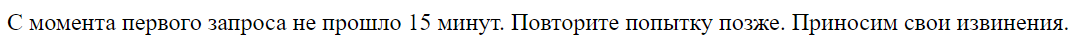
ЗАКЛЮЧЕНИЕ
Целью данной работы являлась реализация web-сервиса, способного классифицировать сообщения из социальной сети Twitter на 4 класса: позитивный, негативный, реклама/поздравления и неопределенный.
В ходе данной работы был осуществлён анализ существующих подходов и методов для предобработки и дальнейшей классификации текстов, по результатам которого были выбраны метод Word2Vec в совокупности со свёрточной нейронной сетью. Реализация данного подхода была осуществлена на языке программирования Python. По результатам обучения этих методов была достигнута точность классификации на тестовой выборке: для позитивного класса - 0.71653 %, для негативного - 0.71592 %, для класса с рекламой/поздравлениями - 0.97914 %, для неопределенного класса - 0.78565 %. Реализация самого web-сервиса проходила с использованием фреймворка Django и API Twitter.
СПИСОК ЛИТЕРАТУРЫ
[1] Technology Feels Like It’s Accelerating — Because It Actually Is. URL: https://singularityhub.com/2016/03/22/technology-feels-like-its-accelerating-because-it-actually-is/#sm.0000111fb880veofw901qi52f9mu9 (дата обращения: 26.08.2019)
[2] Top 15 Most Popular Social Networking Sites and Apps [August 2018]. URL: https://www.dreamgrow.com/top-15-most-popular-social-networking-sites/ (дата обращения: 26.08.2019)
[3] MonkeyLearn. Sentiment Analysis. Nearly Everything You Need to Know. URL: https://monkeylearn.com/sentiment-analysis/ (дата обращения: 26.08.2019)
[4] Пазельская А.Г., Соловьев А.Н. Метод определения эмоций в текстах на русском языке. С. 510 – 520. URL: http://www.dialog-21.ru/digests/dialog2011/materials/ru/pdf/50.pdf (дата обращения: 26.08.2019)
[5] Машинное обучение. URL: http://www.machinelearning.ru/wiki/index.php?title=%D0%9C%D0%B0%D1%88%D0%B8%D0%BD%D0%BD%D0%BE%D0%B5_%D0%BE%D0%B1%D1%83%D1%87%D0%B5%D0%BD%D0%B8%D0%B5 (дата обращения: 26.08.2019)
[6] Artificial neural network. URL: https://en.wikipedia.org/wiki/Artificial_neural_network (дата обращения: 26.08.2019)
[7] Метод обратного распространения ошибки. URL: https://neurohive.io/ru/osnovy-data-science/obratnoe-rasprostranenie/ (дата обращения: 26.08.2019)
[8] Д. А. Кормалев. Приложения методов машинного обучения в задачах анализа текста. URL: https://docplayer.ru/26889690-Prilozheniya-metodov-mashinnogo-obucheniya-v-zadachah-analiza-teksta.html (дата обращения: 26.08.2019)
[9] Sara Rosenthal, Noura Farra, Preslav Nakov. SemEval-2017 Task 4: Sentiment Analysis in Twitter. URL: https://www.aclweb.org/anthology/S17-2088 (дата обращения: 26.08.2019)
[10] Классификация. URL: http://www.machinelearning.ru/wiki/index.php?title=%D0%9A%D0%BB%D0%B0%D1%81%D1%81%D0%B8%D1%84%D0%B8%D0%BA%D0%B0%D1%86%D0%B8%D1%8F (дата обращения: 26.08.2019)
[11] Beyond Accuracy: Precision and Recall. URL: https://towardsdatascience.com/beyond-accuracy-precision-and-recall-3da06bea9f6c (дата обращения: 26.08.2019)
[12] Оценка классификатора (точность, полнота, F-мера). URL: http://bazhenov.me/blog/2012/07/21/classification-performance-evaluation.html (дата обращения: 26.08.2019)
[13] Word Embeddings in NLP and its Applications. URL: https://hackernoon.com/word-embeddings-in-nlp-and-its-applications-fab15eaf7430 (дата обращения: 26.08.2019)
[14] Deerwester S., Dumais S.T., Furnas G.W., Landauer T.K., Harshman R. Indexing by Latent Semantic Analysis // The American Society for Information Science. 1990. Vol. 41. P. 391-407. URL: http://lsa.colorado.edu/papers/JASIS.lsi.90.pdf (дата обращения: 26.08.2019)
[15] Jeffrey Pennington, Richard Socher, Christopher D. Manning. GloVe: Global Vectors for Word Representation. URL: https://nlp.stanford.edu/pubs/glove.pdf (дата обращения: 26.08.2019)
[16] Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space URL: https://arxiv.org/pdf/1301.3781v1.pdf (дата обращения: 26.08.2019)
[17] NLPx Tales of Data Science. Word2Vec. URL: http://nlpx.net/archives/179 (дата обращения: 26.08.2019)
[18] Artificial neural network. URL: https://arxiv.org/pdf/1812.05737.pdf (дата обращения: 26.08.2019)
[19] Abdul Arfat Mohammed, Venkatesh Umaashankar. Effectiveness of Hierarchical Softmax in Large Scale Classification Task. URL: https://arxiv.org/pdf/1812.05737.pdf (дата обращения: 26.08.2019)
[20] G. Zweig, C.J.C. Burges. The Microsoft Research Sentence Completion Challenge, Microsoft Research Technical Report MSR-TR-2011-129, 2011.
[21] Jeffrey Pennington, Richard Socher, Christopher D. Manning. GloVe: Global Vectors for Word Representation. URL: https://nlp.stanford.edu/pubs/glove.pdf (дата обращения: 26.08.2019)
[22] Mathieu Cliche. BB twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs URL: https://arxiv.org/pdf/1704.06125.pdf (дата обращения: 26.08.2019)
[23] Andrew McCallumzy Kamal Nigam. A Comparison of Event Models for Naive Bayes Text Classification. URL: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.65.9324&rep=rep1&type=pdf (дата обращения: 26.08.2019)
[24] Kamal Nigamy, John Lafferty, Andrew McCallum. Using Maximum Entropy for Text Classification. URL: http://www.kamalnigam.com/papers/maxent-ijcaiws99.pdf (дата обращения: 26.08.2019)
[25] Glenn M. Fung, O. L. Mangasarian. Multicategory Proximal Support Vector Machine Classifiers. URL: https://link.springer.com/content/pdf/10.1007%2Fs10994-005-0463-6.pdf (дата обращения: 26.08.2019)
[26] Duyu Tang, Bing Qin, Ting Liu. Document Modeling with Gated Recurrent Neural Network for Sentiment Classification. URL: https://www.aclweb.org/anthology/D15-1167 (дата обращения: 26.08.2019)
[27] Yoon Kim. Convolutional Neural Networks for Sentence Classification. URL: https://arxiv.org/pdf/1408.5882.pdf (дата обращения: 26.08.2019)
[28] Ye Zhang, Byron C. Wallace. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification URL: https://arxiv.org/pdf/1510.03820.pdf (дата обращения: 26.08.2019)
[29] Shaojie Bai, J. Zico Kolter, Vladlen Koltun. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. URL: https://arxiv.org/pdf/1803.01271.pdf (дата обращения: 26.08.2019)
[30] NLTK 3.4.1 documentation. URL: https://www.nltk.org (дата обращения: 26.08.2019)
[31] Gensim. URL: https://radimrehurek.com/gensim/ (дата обращения: 26.08.2019)
[32] Keras documentation. URL: https://keras.io/ (дата обращения: 26.08.2019)
[33] Python-twitter’s documentation. URL: https://python-twitter.readthedocs.io/en/latest/index.html (дата обращения: 26.08.2019)
[34] Web framework Django. URL: https://www.djangoproject.com/start/overview/ (дата обращения: 26.08.2019)
[35] Рубцова Ю. Корпус русскоязычных текстов из социальной сети Twitter. URL: http://study.mokoron.com/ (дата обращения: 26.08.2019)
[36] Converts MySQL dump to SQLite3 compatible dump. URL: https://github.com/dumblob/mysql2sqlite (дата обращения: 26.08.2019)
[37] Twitter API. URL: https://developer.twitter.com/en/docs.html (дата обращения: 26.08.2019)
Приложение 1. Реализация и обучение Word2Vec
Приложение 2. Создание баз с неопределенными твитами и твитами с рекламой и поздравлениями
Приложение 3. Реализация и обучение свёрточной нейронной сети
Приложение 4. Файл settings.py
Приложение 5. Файл urls.py

Приложение 6. Файл wsgi.py

Приложение 7. Файл style.css

Приложение 8. Файл error.html
Приложение 9. Файл home_page.html

Приложение 10. Файл apps.py

Приложение 11. Файл forms.py

Приложение 12. Файл SentimentAnalyzer.py
Приложение 13. Файл urls.py

Приложение 14. Файл views.py

- Инновационные бизнес-модели предприятия (Теоретические аспекты инновационных бизнес-моделей предприятия)
- ПОДХОДЫ К УПРАВЛЕНИЮ ЧЕЛОВЕЧЕСКИМИ РЕСУРСАМИ (Теоретические основы управления человеческими ресурсами)
- Уголовная ответственность и предупреждение преступлений
- Понятие и виды наследования (Права супруга при наследовании)
- Реинжиниринг бизнес-процессов (Понятие бизнес-процесса и процессного подхода)
- Управление поведением в конфликтных ситуациях( О конфликте и его классификации)
- Теоретические основы кодирования информации
- Сущность, классификация и методы принятия управленческих решений (ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ ПРИНЯТИЯ РЕШЕНИЙ)
- ОПТОВАЯ ТОРГОВЛЯ В СИСТЕМЕ ХОЗЯЙСТВЕННЫХ СВЯЗЕЙ РЫНОЧНОЙ ЭКОНОМИКИ
- ТРУДОВАЯ МОТИВАЦИЯ: ТЕОРЕТИЧЕСКИЕ ПОДХОДЫ И ПРАКТИЧЕСКОЕ ПРИМЕНЕНИЕ
- «Жизненный цикл организации и управление организацией»
- Законодательные органы государственной власти (Полномочия Совета Федерации России по формированию органов государственной власти)