
Общие сведения об алгоритмах сортировки
Содержание:

Введение
Сортировка является одной из фундаментальных алгоритмических задач программирования. Решению проблем, связанных с сортировкой, посвящено множество научных исследований, разработано множество алгоритмов.
Сортировка представляет собой процесс перегруппировки некоторого множества объектов в определенном порядке. Сортировка применяется практически во всех областях программирования, от инженерных и математических программ до баз данных.
Соответственно, алгоритм для упорядочения заданного множества элементов называется алгоритмом сортировки. Чаще всего под алгоритмом сортировки подразумевают алгоритм упорядочивания множества элементов по возрастанию или убыванию.
В случае наличия элементов с одинаковыми значениями, в упорядоченной последовательности они располагаются рядом друг за другом в любом порядке. Однако иногда бывает полезно сохранять первоначальный порядок элементов с одинаковыми значениями.
В большинстве случаев лишь часть данных в алгоритмах сортировки используется в качестве ключа сортировки. Ключом сортировки – это атрибут (или несколько атрибутов), по значению которого определяется порядок элементов. Таким образом, при написании алгоритмов сортировок массивов следует учесть, что ключ полностью или частично совпадает с данными.
Практически каждый алгоритм сортировки можно разбить на 3 части:
- сравнение, т.е. определение упорядоченности пары элементов;
- перестановку, т.е. обмен пары элементов местами;
- сортирующий алгоритм, который и осуществляет сравнение и перестановку элементов до тех пор, пока все элементы множества не будут упорядочены.
Алгоритмы сортировки имеют большое практическое применение. Их можно встретить там, где речь идет об обработке и хранении больших объемов информации. Некоторые задачи обработки данных решаются проще, если данные заранее упорядочить.
Целью курсовой работы являются исследование и сравнительный анализ наиболее широко распространенных алгоритмов сортировки.
Глава 1. Общие сведения об алгоритмах сортировки
Что такое сортировка
Алгоритм сортировки — это алгоритм для упорядочивания элементов в списке. В случае, когда элемент списка имеет несколько полей, поле, служащее критерием порядка, называется ключом сортировки. На практике в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.
Применение сортировки
По утверждению Д.Кнута, наиболее важные применения сортировки следующие:
a) группировка – задача, требующая собрать вместе все элементы с одинаковым значением какого-либо признака. Например, если имеется 10000 расположенных в случайном порядке элементов, причем таких, что значения многих из них совпадают. Предположим, нам нужно упорядочить эту последовательность так, чтобы соседние позиции занимали элементы с равными значениями. Это и есть задача сортировки в самом широком смысле этого слова. Такая задача может быть решена путем сортировки файла в узком смысле слова, т.е. расположением элементов в неубывающем (или невозрастающем) порядке элемент1, элемент2, … элемент10000. Эффективность этой процедуры довольно низкая, что и объясняет изменение первоначального смысла слова "сортировка".
b) Если два или более набора элементов отсортировать в одном и том же порядке, то за один последовательный просмотр всех наборов можно будет отыскать в них все общие элементы без возвратов. Как правило, гораздо эффективнее последовательно просматривать весь список, а не перескакивать случайным образом с места на место. Это особенно актуально в случае больших списков, которые не помещаются целиком оперативной памяти. Вместо прямой адресации для больших файлов сортировка позволяет использовать последовательный доступ.
c) Сортировка часто помогает при поиске, с ее помощью можно сделать таблицы и отчеты более удобными для человеческого восприятия. Даже самый длинный листинг, отсортированный в алфавитном порядке, зачастую выглядит весьма внушительно и читается значительно легче, чем те же данные, представленные в произвольном порядке.
История
Уже в XIX веке появились первые прототипы современных методов сортировки. В 1890 году американец Герман Холлерит создал первый статистический табулятор для ускорения обработки данных переписи населения в США. Он представлял собой электромеханическую машину, которая была предназначена для автоматической обработки информации, хранящейся на перфокартах. Машины Холлерита имела специальный «сортировальный ящик». Ящик состоял из 26 внутренних отделений. Работа оператора заключалась в том, чтобы вставить перфокарту и опустить специальную рукоятку. Благодаря отверстиям, пробитым на перфокарте, определённая электрическая цепь замыкалась, и показание связанного с ней циферблата увеличивалось на единицу. В тот же момент открывалась соответствующая крышка сортировального ящика, одна из 26, и перфокарта перемещалась в соответствующее отделение, затем крышка закрывалась. Таким образом удавалось обрабатывать более 50 карт в минуту, что превышало ручную обработку данных в 3 раза. Холлерит усовершенствовал свою машину к переписи 1900 года. Теперь подача карт была автоматизирована. Работа сортировальной машины Холлерита основывалась на методах поразрядной сортировки. На машину был оформлен патент. Причем была обозначена сортировка «по отдельности для каждого столбца», но сам порядок сортировки не определён. В 1894 Джоном Гором был получен патент на аналогичную машину. Здесь уже упоминалась сортировка со столбца десятков. В конце 1930-х годов впервые появляется в литературе метод сортировки, начиная со столбца единиц. К этому времени сортировальные машины уже позволяли обрабатывать до 400 карт в минуту.
Как и следовало ожидать, вся дальнейшем история алгоритмов связана с развитием электронно-вычислительных машин. Как упоминают многие источники, первой программой для вычислительных машин стала именно программа сортировки. Некоторые конструкторы ЭВМ, в частности разработчики EDVAC, называли наиболее характерной нечисловой задачей для вычислительных машин именно задачу сортировки данных.
В 1945 году была разработана программа сортировки методом слияния. Автор Джон фон Нейман применил ее для тестирования ряда команд для EDVAC. Тогда же немецкий инженер Конрад Цузе разработал программу для сортировки методом простой вставки. К этому времени уже появились быстрые специализированные сортировальные машины, в сопоставлении с которыми и оценивалась эффективность разрабатываемых ЭВМ. Первым опубликованным обсуждением сортировки с помощью вычислительных машин стала лекция Джона Мокли, прочитанная им в 1946 году. Мокли показал, что сортировка может быть полезной также и для численных расчетов, описал методы сортировки простой вставки и бинарных вставок, а также поразрядную сортировку с частичными проходами. Позже организованная им совместно с инженером Джоном Эккертом компания «Eckert–Mauchly Computer Corporation» выпустила некоторые из самых ранних электронных вычислительных машин BINAC и UNIVAC.
Наряду с отмеченными алгоритмами внутренней сортировки, появлялись алгоритмы внешней сортировки, развитию которых способствовал ограниченный объём памяти первых вычислительных машин. В частности, были предложены методы сбалансированной двухпутевой поразрядной сортировки и сбалансированного двухпутевого слияния.
К 1952 году на практике уже применялись многие методы внутренней сортировки, но теория была развита сравнительно слабо. В октябре 1952 года Даниэль Гольденберг привёл пять методов сортировки с анализом наилучшего и наихудшего случаев для каждого из них. В 1954 году Гарольд Сьюворд развил идеи Гольденберга, а также проанализировал методы внешней сортировки. Говард Демут в 1956 году рассмотрел три абстрактные модели задачи сортировки: с использованием циклической памяти, линейной памяти и памяти с произвольным доступом. Для каждой из этих задач автор предложил оптимальные или почти оптимальные методы сортировки, что помогло связать теорию с практикой. Из-за малого числа людей, связанных с вычислительной техникой, эти доклады не появлялись в «открытой литературе». Первой большой обзорной статьёй о сортировке, появившейся в печати в 1955 году, стала работа Дж. Хоскена, в которой он описал всё имевшееся на тот момент оборудование специального назначения и методы сортировки для ЭВМ, основываясь на брошюрах фирм-изготовителей. В 1956 году Э. Френд в своей работе проанализировал математические свойства большого числа алгоритмов внутренней и внешней сортировки, предложив некоторые новые методы.
После этого было предложено множество различных алгоритмов сортировки: например, вычисление адреса в 1956 году; слияние с вставкой, обменная поразрядная сортировка, каскадное слияние и метод Шеллав 1959 году, многофазное слияние и вставки в дерево в 1960 году, осциллирующая сортировка и быстрая сортировка Хоара в 1962 году, пирамидальная сортировка Уильямса и обменная сортировка со слиянием Бэтчера в 1964 году. В конце 60-х годов произошло и интенсивное развитие теории сортировки. Появившиеся позже алгоритмы во многом являлись вариациями уже известных методов. Получили распространение адаптивные методы сортировки, ориентированные на более быстрое выполнение в случаях, когда входная последовательность удовлетворяет заранее установленным критериям.
Оценка алгоритмов сортировки
Ни одна другая проблема не породила такого количества разнообразнейших решений, как задача сортировки. Универсального, наилучшего алгоритма сортировки, подходящего для любой задачи, на данный момент не существует. Тем не менее, имея приблизительные характеристики входных данных, можно подобрать метод, работающий оптимальным образом. Для этого необходимо знать параметры, по которым будет производиться оценка алгоритмов.
Время сортировки – основной параметр, характеризующий быстродействие алгоритма.
Память – один из параметров, который характеризуется тем, что ряд алгоритмов сортировки требуют выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив данных и независящие от входной последовательности затраты, например, на хранение кода программы.
Устойчивость – это параметр, который отвечает за то, что сортировка не меняет взаимного расположения равных элементов.
Такое свойство может быть очень полезным, если они состоят из нескольких полей, как на рис. 1, а сортировка происходит по одному из них, например, по x.
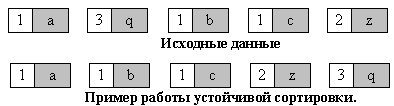
Рисунок 1. Результат устойчивой сортировки
Взаимное расположение равных элементов с ключом 1 и дополнительными полями "a", "b", "c" осталось прежним: элемент с полем "a", затем - с "b", затем - с "c".

Рисунок 2. Результат неустойчивой сортировки
Взаимное расположение равных элементов с ключом 1 и дополнительными полями "a", "b", "c" изменилось.
Естественность поведения – параметр, указывающий на эффективность метода при обработке полностью или частично отсортированных данных. Алгоритм ведет себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Классификация алгоритмов сортировок
Все разнообразие и многообразие алгоритмов сортировок можно классифицировать по различным признакам, например, по устойчивости, по поведению, по использованию операций сравнения, по потребности в дополнительной памяти, по потребности в знаниях о структуре данных, выходящих за рамки операции сравнения, и другие.
Классификация алгоритмов сортировки по сфере применения подразумевает использование дополнительной памяти для хранения промежуточных результатов сортировки, исходного и результирующего массивов. В основном выделяют внутреннюю и внешнюю сортировки.
Внутренняя сортировка – при использовании этого алгоритма в процессе упорядочивания данных используется только оперативная память компьютера. То есть оперативной памяти достаточно для помещения в нее сортируемого массива данных с произвольным доступом к любой ячейке и собственно для выполнения алгоритма. Внутренняя сортировка применяется во всех случаях, за исключением однопроходного считывания данных и однопроходной записи отсортированных данных. В зависимости от конкретного алгоритма и его реализации данные могут сортироваться в той же области памяти, либо использовать дополнительную оперативную память.
Внешняя сортировка – при использовании этого алгоритма для упорядочивания данных подключается внешняя память, как правило, жесткие диски. Внешняя сортировка разработана для обработки больших списков данных, которые не помещаются в оперативную память. Обращение к различным носителям накладывает некоторые дополнительные ограничения на данный алгоритм: доступ к носителю осуществляется последовательным образом, то есть в каждый момент времени можно считать или записать только элемент, следующий за текущим; объем данных не позволяет им разместиться в ОЗУ.
Внутренняя сортировка является базовой для любого алгоритма внешней сортировки – отдельные части массива данных сортируются в оперативной памяти и с помощью специального алгоритма сцепляются в один массив, упорядоченный по ключу.
Следует отметить, что внутренняя сортировка значительно эффективней внешней, так как на обращение к оперативной памяти затрачивается намного меньше времени, чем к носителям.
Классификация алгоритмов по поведению позволяет выделить квадратичные и субквадратичные, а также логарифмические и линейные алгоритмы.
Квадратичные и субквадратичные алгоритмы
- Сортировка выбором (SelectSort)
- Сортировка пузырьком (BubbleSort) и ее улучшения
- Сортировка простыми вставками (InsertSort)
- Cортировка Шелла (ShellSort)
Логарифмические и линейные алгоритмы
- Пирамидальная сортировка (HeapSort)
- Быстрая сортировка (QuickSort)
- Поразрядная сортировка (Radix sort)
Сравнение времени сортировок
Изображенный на рисунке 3 график иллюстрирует разницу в эффективности различных алгоритмов.
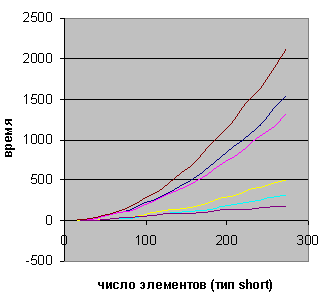
Рисунок 3. Скорость различных алгоритмов
- коричневая линия: сортировка пузырьком;
- синяя линия: шейкер-сортировка;
- розовая линия: сортировка выбором;
- желтая линия: сортировка вставками;
- голубая линия: сортировка вставками со сторожевым элементом;
- фиолетовая линия: сортировка Шелла.
Глава 2. Наиболее широко известные алгоритмы сортировки.
Сортировка выбором (Selection sort)
Для того, чтобы отсортировать массив в порядке возрастания, следует на каждой итерации найти элемент с наибольшим значением. С ним нужно поменять местами последний элемент. Следующий элемент с наибольшим значением становится уже на предпоследнее место. Так должно происходить, пока элементы, находящиеся на первых местах в массиве, не окажутся в надлежащем порядке (рис.4).
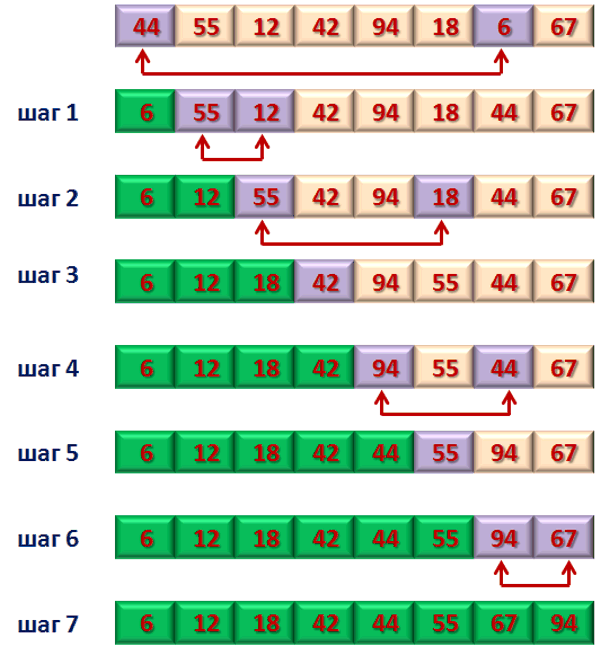
Рисунок 4. Алгоритм сортировки выбором
Анализ алгоритма прямым выбором
Число сравнений ключей С не зависит от порядка ключей:
C=½(n2-n).
Число перестановок минимально
Mmin=3(n-1)
в случае изначально упорядоченных ключей и максимально
Mmax= n2/4 +3(n-1),
если первоначально ключи располагаются в обратном порядке.
Среднее число пересылок
Mср≈n(ln n + g),
Где g = 0,577216... — константа Эйлера.
Резюме: как правило, сортировка прямым выбором предпочтительнее алгоритму прямого включения, однако, если ключи в начале упорядочены или почти упорядочены, прямое включение будет оставаться несколько более быстрым.
void selectionSort(int data[], int lenD)
{
int j = 0;
int tmp = 0;
for(int i=0; i<lenD; i++){
j = i;
for(int k = i; k<lenD; k++){
if(data[j]>data[k]){
j = k;
}
}
tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
}
Пузырьковая сортировка (Bubble sort)
При пузырьковой сортировке сравниваются соседние элементы и меняются местами, если следующий элемент меньше предыдущего. Требуется несколько проходов по данным. Во время первого прохода сравниваются первые два элемента в массиве. Если они не в порядке, они меняются местами и затем сравнивается элементы в следующей паре. При том же условии они так же меняются местами. Таким образом сортировка происходит в каждом цикле пока не будет достигнут конец массива (рис.5).
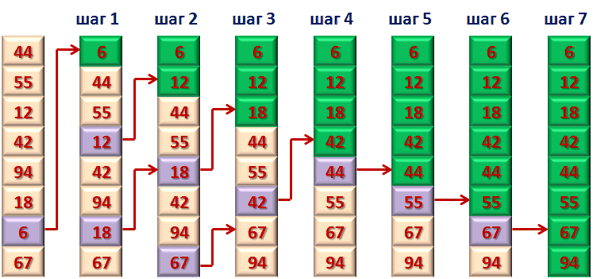
Рисунок 5. Алгоритм сортировки пузырьком
void bubbleSort(int data[], int lenD)
{
int tmp = 0;
for(int i = 0;i<lenD;i++){
for(int j = (lenD-1);j>=(i+1);j--){
if(data[j]<data[j-1]){
tmp = data[j];
data[j]=data[j-1];
data[j-1]=tmp;
}
}
}
}
Анализ алгоритма
Число сравнений в алгоритме прямого обмена
С = (n2 - n)/2,
а минимальное, среднее и максимальное число перемещений элементов равно соответственно
Mmin = 0,
Mср = 3(n2 - n)/2,
Mmax = 3(n2 - n)/4.
Резюме: «обменная сортировка» представляет собой нечто среднее между сортировками с помощью включений и с помощью выбора; фактически в пузырьковой сортировке нет ничего ценного, кроме привлекательного названия.
Сортировка вставками (Insertion sort)
При сортировке вставками массив разбивается на две области: упорядоченную и неупорядоченную. Изначально весь массив является неупорядоченной областью. При первом проходе первый элемент из неупорядоченной области изымается и помещается в правильном положении в упорядоченной области.
На каждом проходе размер упорядоченной области возрастает на 1, а размер неупорядоченной области сокращается на 1.
Основной цикл работает в интервале от 1 до N-1. На j-й итерации элемент [i] вставлен в правильное положение в упорядоченной области. Это сделано путем сдвига всех элементов упорядоченной области, которые больше, чем [i], на одну позицию вправо. [i] вставляется в интервал между теми элементами, которые меньше [i], и теми, которые больше [i] (рис.6).
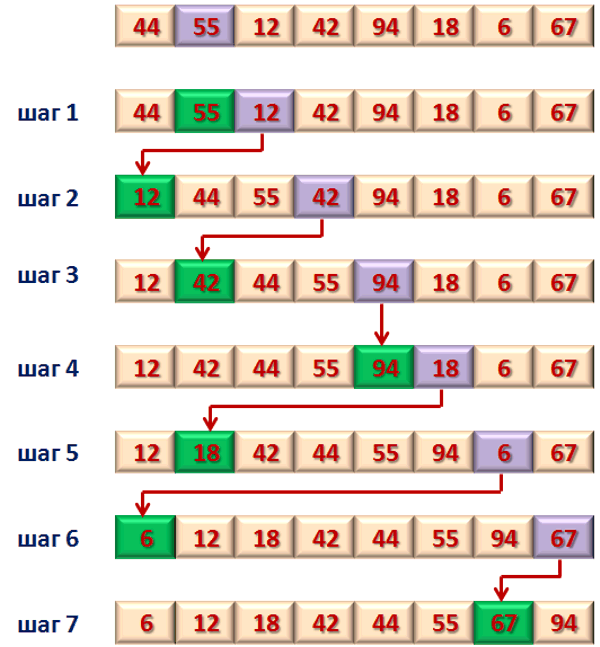
Рисунок 6. Алгоритм сортировки вставками
Анализ выполнения
Число сравнений ключей Ci при i-м просеивании составляет самое большое i-1, самое меньшее – 1. Если предположить, что все перестановки из n ключей равновероятны, то среднее число сравнений – i/2. Число пересылок
Mi = Ci+2.
Поэтому общее число сравнений и пересылок таковы:
Cmin=n-1; Mmin=3(n-1);
Cср=(n2+n-2)/4; Mср=(n2+9n-10)/4;
Cmax=(n2+n-4)/4; Mmax=(n2+3n-4)/2.
Минимальные оценки встречаются в случае уже упорядоченной исходной последовательности элементов, наихудшие оценки — когда элементы первоначально расположены в обратном порядке.
Резюме: сортировка методом прямого включения – не очень подходящий метод для компьютера, поскольку включение элемента с последующим сдвигом на одну позицию целой группы элементов неэффективно.
void insertionSort(int data[], int lenD)
{
int key = 0;
int i = 0;
for(int j = 1;j<lenD;j++){
key = data[j];
i = j-1;
while(i>=0 && data[i]>key){
data[i+1] = data[i];
i = i-1;
data[i+1]=key;
}
}
}
Сортировка слиянием (Merge sort)
При сортировке слиянием мы разделяем массив пополам до тех пор, пока каждый участок не станет длиной в один элемент. Затем эти участки возвращаются на место (сливаются) в правильном порядке.
Исходный массив приведен на рис.6.

Рисунок 6. Алгоритм сортировки слиянием
Разделим его пополам (рис.7).
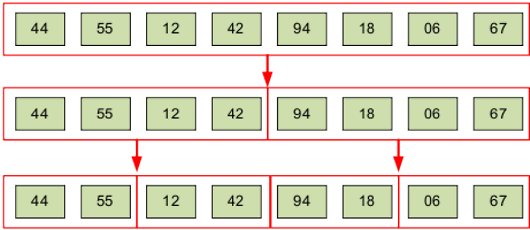
Рисунок 7. Алгоритм сортировки слиянием
И будем делить каждую часть пополам, пока не останутся части с одним элементом (рис.8).
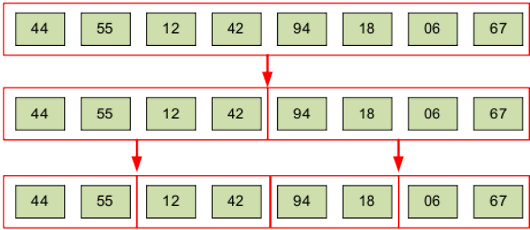
Рисунок 8. Алгоритм сортировки слиянием
Теперь, когда мы разделили массив на максимально короткие участки, мы сливаем их в правильном порядке.
Сначала мы получаем группы по два отсортированных элемента, потом «собираем» их в группы по четыре элемента и в конце собираем все вместе в отсортированный массив (рис.9).
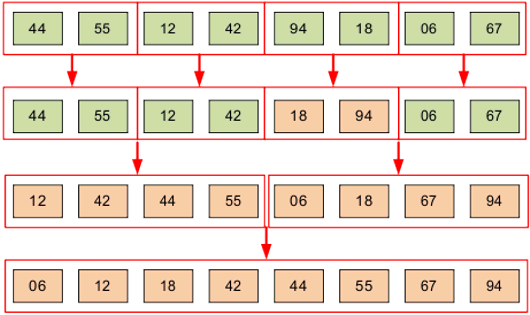
Рисунок 9. Алгоритм сортировки слиянием
Сортировка слиянием во многом похожа на метод быстрой сортировки. Производительность сортировки слиянием лежит между производительностью пирамидальной и быстрой сортировки. Но в отличие от пирамидальной и быстрой сортировок, метод сортировки слиянием ведет себя стабильно, поскольку он не зависит от перестановок элементов в массиве.
Еще одним достоинством сортировки слиянием является то, что он удобен для структур с последовательным доступом к элементам, таким как файлы на внешнем устройстве или связные списки. Этот метод, прежде всего, используется для внешней сортировки.
Недостатки метода заключаются в том, что он требует дополнительной памяти по объему равной объему сортируемого файла. Поэтому для больших файлов проблематично организовать сортировку слиянием в оперативной памяти.
В случаях, когда гарантированное время сортировки важно и размещение в оперативной памяти, возможно, следует предпочесть метод сортировки слиянием.
Для работы алгоритма мы должны реализовать следующие операции:
void mergeSort(int data[], int lenD)
{
if(lenD>1){
int middle = lenD/2;
int rem = lenD-middle;
int* L = new int[middle];
int* R = new int[rem];
for(int i=0;i<lenD;i++){
if(i<middle){
L[i] = data[i];
}
else{
R[i-middle] = data[i];
}
}
mergeSort(L,middle);
mergeSort(R,rem);
merge(data, lenD, L, middle, R, rem);
}
}
void merge(int merged[], int lenD, int L[], int lenL, int R[], int lenR){
int i = 0;
int j = 0;
while(i<lenL||j<lenR){
if (i<lenL & j<lenR){
if(L[i]<=R[j]){
merged[i+j] = L[i];
i++;
}
else{
merged[i+j] = R[j];
j++;
}
}
else if(i<lenL){
merged[i+j] = L[i];
i++;
}
else if(j<lenR){
merged[i+j] = R[j];
j++;
}
}
}
Быстрая сортировка (Quick sort)
Быстрая сортировка использует алгоритм "разделяй и властвуй". Она начинается с разбиения исходного массива на две области. Эти части находятся слева и справа от отмеченного элемента, называемого опорным. В конце процесса одна часть будет содержать элементы меньшие, чем опорный, а другая часть будет содержать элементы больше опорного (рис.10).
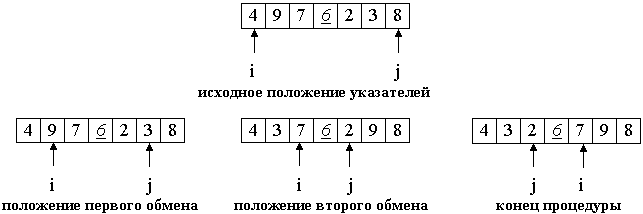
Рисунок 10. Алгоритм быстрой сортировки
void quickSort(int* data, int const len)
{
int const lenD = len;
int pivot = 0;
int ind = lenD/2;
int i,j = 0,k = 0;
if(lenD>1){
int* L = new int[lenD];
int* R = new int[lenD];
pivot = data[ind];
for(i=0;i<lenD;i++){
if(i!=ind){
if(data[i]<pivot){
L[j] = data[i];
j++;
}
else{
R[k] = data[i];
k++;
}
}
}
quickSort(L,j);
quickSort(R,k);
for(int cnt=0;cnt<lenD;cnt++){
if(cnt<j){
data[cnt] = L[cnt];;
}
else if(cnt==j){
data[cnt] = pivot;
}
else{
data[cnt] = R[cnt-(j+1)];
}
}
}
}
Глава 3. Решение задачи.
Для подтверждения полученных компетенций была спроектирована программа на языке С++, которая демонстрирует работу всех перечисленных алгоритмов сортировки и позволяет проанализировать количество проходов и перестановок элементов для каждого алгоритма.
Для удобства работы в программе предусмотрено меню, которое позволяет выбрать любой алгоритм, а также заполнить массив случайными числами, чтобы убедиться, какой алгоритм наиболее эффективен на отсортированном и неотсортированном массивах.
while (true)
{
cout << "Выберите действие: " << endl;
cout << "1 - Сортировка выбором(Selection sort) " << endl;
cout << "2 - Пузырьковая сортировка(Bubble sort) " << endl;
cout << "3 - Сортировка вставками(Insertion sort) " << endl;
cout << "4 - Сортировка слиянием(Merge sort) " << endl;
cout << "5 - Быстрая сортировка(Quick sort) " << endl;
cout << "6 - Заполнение массива случайными числами " << endl;
cout << "0 - Выход " << endl;
int otvet;
cin >> otvet;
switch(otvet)
{
case 0: exit(0);
case 1: clearPr(); selectionSort(); print(); break;
case 2: clearPr(); bubbleSort(); print(); break;
case 3: clearPr(); insertionSort(); print(); break;
case 4: clearPr(); mergeSort(m, SIZE_M); print(); break;
case 5: clearPr(); quickSort(m, SIZE_M); print(); break;
case 9: create_m(); print(); break;
}
}
Ниже приведены результаты выполнения программы на массиве из 100 элементов.
Сортировка выбором – один из самых медленных алгоритмов, количество проходов по массиву в этом случае максимальное (рис.11)
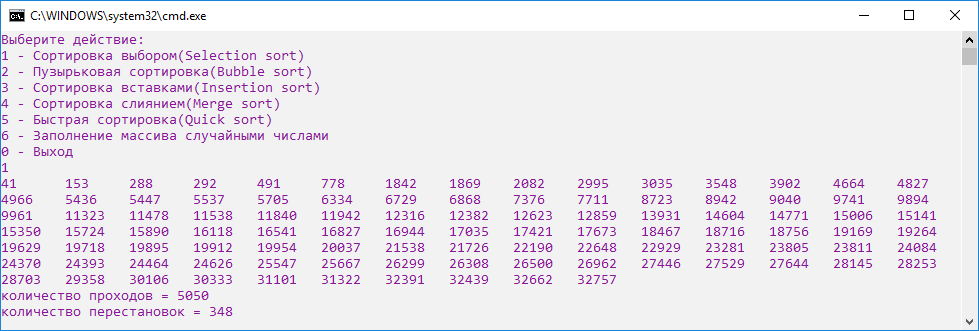
Рисунок 11. Скриншот сортировки выбором
Однако, при полностью отсортированном массиве сортировка выбором не выполняет излишних перестановок, что говорит об устойчивости алгоритма (рис.12).
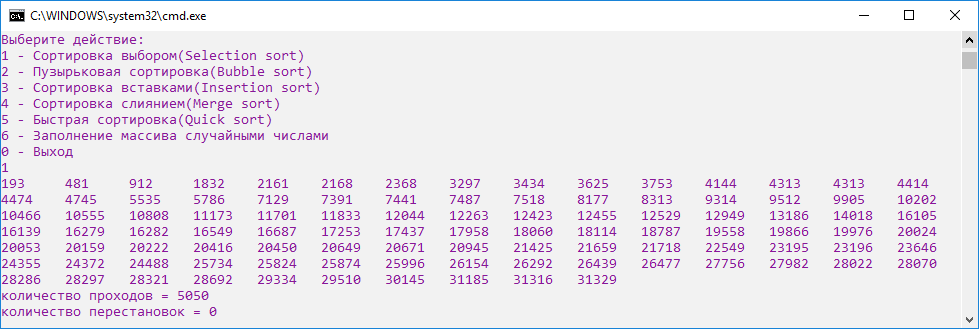
Рисунок 12. Скриншот сортировки выбором уже отсортированного массива
Количество проходов при сортировке пузырьковым методом ненамного меньше, зато значительно выше число перестановок (рис.13).
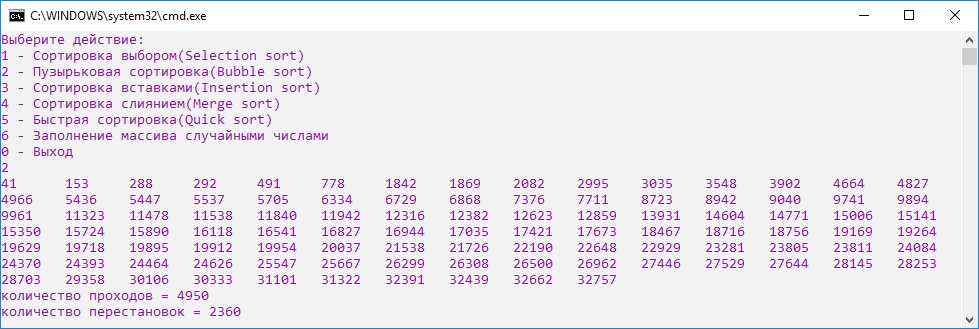
Рисунок 13. Скриншот сортировки пузырьковым методом
Сортировка вставками демонстрирует вдвое меньшее количество проходов, по сравнению с пузырьковой сортировкой. Но при этом количество перестановок очень велико (рис.14).
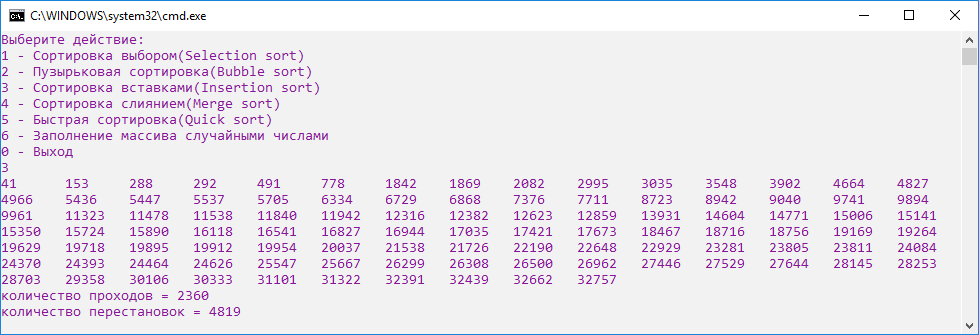
Рисунок 14. Скриншот сортировки вставками
Сортировка слиянием на данном примере продемонстрировала наилучший результат (рис.15).
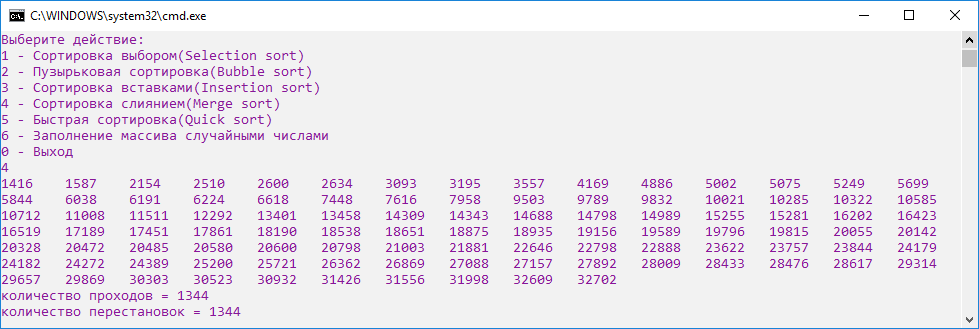
Рисунок 15. Скриншот сортировки слиянием
Быстрая сортировка оказалась не так хороша, как сортировка слияние, но результат все же неплохой (рис.16).
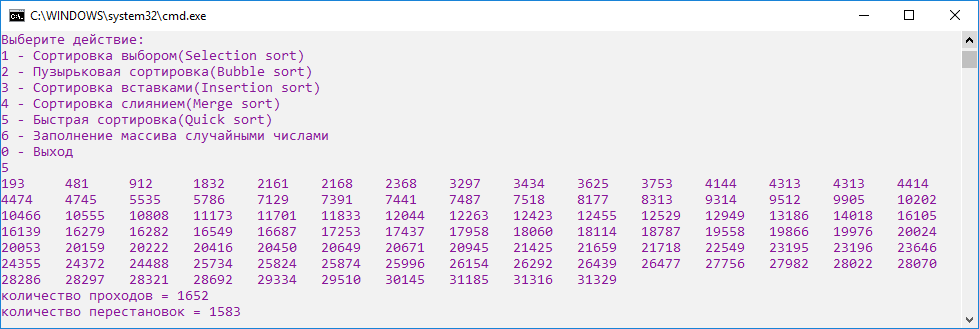
Рисунок 16. Скриншот быстрой сортировки
Однако, на уже отсортированном массиве быстрая сортировка выполняет очень большое число ненужных перестановок (рис.17).
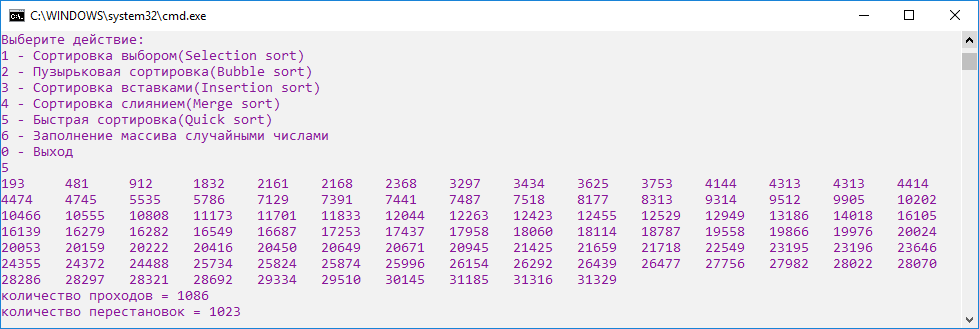
Рисунок 17. Скриншот быстрой сортировки на уже отсортированном массиве
Заключение
На основании проведенного исследования можно сделать вывод, что выбор используемого алгоритма сортировки зависит от многих критериев. Необходимо учитывать размер массива, степень его предварительной сортировки (несортированный, частично или полностью отсортированный), потребность в устойчивости алгоритма (т.е. отсутствие лишних перестановок), наконец, скорость чтения и записи данных (есть алгоритмы с высоким числом считываний, но с небольшим числом записей данных).
В результате выполнения данной курсовой работы были исследованы наиболее популярные алгоритмы сортировки и реализовано приложение с демонстрацией всех описанных алгоритмов.
Список использованной литературы
- https://ru.wikipedia.org Электронный ресурс
- Роберт Седжвик. Фундаментальные алгоритмы на С++. Части 1-4: Анализ/Структуры данных/Сортировка/Поиск. - К.: Издательство ДиаСофт?, 2001.
- Роберт Седжвик. Фундаментальные алгоритмы на С++. Часть 5: Алгоритмы на графах. - К.: Издательство ДиаСофт?, 2002.
- Роберт Седжвик. Фундаментальные алгоритмы на С. Части 1-4: Анализ/Структуры данных/Сортировка/Поиск. - К.: Издательство ДиаСофт?, 2003.
- Роберт Седжвик. Фундаментальные алгоритмы на С Часть 5: Алгоритмы на графах. - К.: Издательство ДиаСофт?, 2003.
- Джон Макгрегор, Девид Сайке. Тестирование объектно-ориентированного программного обеспечения. Практическое пособие. - К.: Издательство ДиаСофт?, 2002.
Приложения
#include <iostream>
#include <locale>
#include <math.h>
using namespace std;
const int SIZE_M = 100;
int m[SIZE_M];
int pr = 0, per = 0;
void clearPr()
{
pr = 0;
per = 0;
}
void print()
{
for (int i = 0; i < SIZE_M; i++)
{
cout << m[i] << "\t";
}
cout << endl;
cout << "количество проходов = " << pr << endl;
cout << "количество перестановок = " << per << endl;
}
void create_m()
{
for (int i = 0; i < SIZE_M; i++)
{
m[i] = rand();
}
}
void selectionSort()
{
int j = 0;
int tmp = 0;
for (int i = 0; i<SIZE_M; i++)
{
j = i;
for (int k = i; k<SIZE_M; k++)
{
pr++;
if (m[j]>m[k])
{
j = k;
per++;
}
}
tmp = m[i];
m[i] = m[j];
m[j] = tmp;
}
}
void bubbleSort()
{
int tmp = 0;
for (int i = 0; i<SIZE_M; i++)
{
for (int j = (SIZE_M - 1); j >= (i + 1); j--)
{
pr++;
if (m[j]<m[j - 1])
{
per++;
tmp = m[j];
m[j] = m[j - 1];
m[j - 1] = tmp;
}
}
}
}
void insertionSort()
{
int key = 0;
int i = 0;
for (int j = 1; j<SIZE_M; j++)
{
key = m[j]; per++;
i = j - 1;
while (i >= 0 && m[i]>key)
{
pr++;
m[i + 1] = m[i]; per++;
i = i - 1;
m[i + 1] = key; per++;
}
}
}
void merge(int merged[], int lenD, int L[], int lenL, int R[], int lenR){
int i = 0;
int j = 0;
while(i<lenL||j<lenR)
{
pr++;
if (i<lenL & j<lenR)
{
if(L[i]<=R[j])
{
merged[i+j] = L[i];
i++;
per++;
}
else
{
merged[i+j] = R[j];
j++;
per++;
}
}
else if(i<lenL)
{
merged[i+j] = L[i];
i++;
per++;
}
else if(j<lenR)
{
merged[i+j] = R[j];
j++;
per++;
}
}
}
void mergeSort(int data[], int lenD)
{
if (lenD>1) {
int middle = lenD / 2;
int rem = lenD - middle;
int* L = new int[middle];
int* R = new int[rem];
for (int i = 0; i<lenD; i++)
{
pr++;
if (i<middle)
{
L[i] = data[i];
per++;
}
else
{
R[i - middle] = data[i];
per++;
}
}
mergeSort(L, middle);
mergeSort(R, rem);
merge(data, lenD, L, middle, R, rem);
}
}
void quickSort(int* data, int const len)
{
int p = 0;
int ind = lenD / 2;
int i, j = 0, k = 0;
if (lenD>1) {
int* L = new int[len];
int* R = new int[len];
p = data[ind];
for (i = 0; i<lenD; i++)
{
pr++;
if (i != ind)
{
if (data[i]<p)
{
L[j] = data[i];
j++;
per++;
}
else
{
R[k] = data[i];
k++;
per++;
}
}
}
quickSort(L, j);
quickSort(R, k);
for (int cnt = 0; cnt<len; cnt++)
{
pr++;
if (cnt<j)
{
data[cnt] = L[cnt];
per++;
}
else if (cnt == j)
{
data[cnt] = p;
per++;
}
else
{
data[cnt] = R[cnt - (j + 1)];
per++;
}
}
}
}
void main()
{
setlocale(LC_CTYPE, "Russian");
cout << "заполнение массива случайными числами: " << endl;
create_m();
print();
while (true)
{
cout << "Выберите действие: " << endl;
cout << "1 - Сортировка выбором(Selection sort) " << endl;
cout << "2 - Пузырьковая сортировка(Bubble sort) " << endl;
cout << "3 - Сортировка вставками(Insertion sort) " << endl;
cout << "4 - Сортировка слиянием(Merge sort) " << endl;
cout << "5 - Быстрая сортировка(Quick sort) " << endl;
cout << "6 - Заполнение массива случайными числами " << endl;
cout << "0 - Выход " << endl;
int otvet;
cin >> otvet;
switch(otvet)
{
case 0: exit(0);
case 1: clearPr(); selectionSort(); print(); break;
case 2: clearPr(); bubbleSort(); print(); break;
case 3: clearPr(); insertionSort(); print(); break;
case 4: clearPr(); mergeSort(m, SIZE_M); print(); break;
case 5: clearPr(); quickSort(m, SIZE_M); print(); break;
case 6: create_m(); print(); break;
case 9: create_m(); print(); break;
}
}
}

- Организация управленческого учета в компании (ООО «Стройлон»)
- Понятие правоприменительной деятельности, её виды и принципы (отличие правоприменения от других форм реализации права)
- Государственный кредит (Характеристика государственного кредита)
- Денежный оборот: понятие, структура
- Презумпции и фикции в праве
- Проблемы профессиональных стрессов. Профессиональное выгорание
- Национальные традиции воспитания в России (Задачи современной системы национального воспитания)
- Возникновение права (Мораль как регулятор общественных отношений)
- Сравнительная характеристика организационно-правовых форм коммерческих организаций
- Факторы, влияющие на качество и конкурентоспособность товаров (на примере швейный товаров)
- Юридическая ответственность
- Проектирование реализации операций бизнес-процесса «Предоставление рекламных услуг» (Характеристика существующих бизнес – процессов)