
Общие признаки диалектического единства данных и методов в информационном процессе
Содержание:

Введение
Каждый человек находится в материальном мире, и, следовательно, все, что его окружает или все, с чем он взаимодействует в ходе своей деятельности, относится к физическим телам или к физическим полям. Состояния абсолютного покоя нет, и физические объекты пребывают в состоянии постоянного движения и изменения, сопровождающегося энергообменом и переходом энергии из одной формы в другую [1]. Все виды энергетического обмена идут с возникновением сигналов, т.е. все сигналы имеют в своей основе материальную энергетическую сущность. При взаимодействии сигналов с физическими телами в этих телах происходят некоторые изменения свойств – это явление именуется регистрацией сигналов. Данные – это зарегистрированные сигналы.
Актуальность темы данной курсовой работы состоит в том, что важность и значимости информации со временем только возрастает.
Цель курсовой работы – изучить диалектическое единство данных и методов в информационном процессе.
Для реализации указанной цели необходимо выполнить ряд задач, а именно:
- дать понятие информации и информатики;
- исследовать сигналы и данные в едином информационном пространстве;
- изучить свойства информации, данных.
Предметом исследования данной работы является информация.
Объектом исследования данной работы является диалектическое единство данных и методов в информационном процессе.
Зaдaчи рaбoты oпределяют cтруктуру рaбoты. Рaбoтa cocтoит из введения, двух глав, зaключения, cпиcкa иcпoльзoвaннoй литерaтуры.
Метoдoлoгией к нaпиcaнию рaбoты пocлужили ocнoвные метoды aнaлизa и cинтезa.
Глава 1. Общие признаки диалектического единства данных и методов в информационном процессе
1.1. Информация и информатика
Существенное отличие информатики от прочих технических дисциплин заключается в том, что ее предмет изучения изменяется крайне интенсивно.
В настоящее время число компьютеров в мире превышает 500 миллионов единиц, а каждая вычислительная система обладает уникальностью. Крайне затруднительно найти две системы с одинаковыми аппаратными и программными конфигурациями, ввиду чего для качественного использования вычислительной техники специалисты должны обладать соответсвующим уровнем знаний и практических навыков [1].
Также, в количественном отношении темп количественного роста вычислительных систем значительно опережает темп подготовки специалистов, которые могут качественно взаимодействовать с ними. Кроме того, примерно один раз в полтора года удваиваются ключевые технические характеристики аппаратных средств, один раз в 2-3 года изменяются поколения программного обеспечения и один раз в 5-7 лет видоизменяется база стандартов, интерфейсов и протоколов.
Соответственно, существенным отличием информатики от прочих технических дисциплин является то, что ее предметная область меняется очень динамично.
В настоящее время информатика сталкивается с парадоксальным фактом. Ее ключевая задача заключается в устранении всеобщего кризисного явления, именуемого «информационным бумом», при помощи интеграции средств и способом, автоматизирующих операции с данными. Но даже внутри собственной предметной области информатика переживает такой информационный бум, который не случался никогда в какой-либо иной области человеческой деятельности. Так, мировая номенклатура изданий, относящихся к информатике, насчитывает около трех сотен тысяч томов в год и непрерывно обновляется не реже, чем раз в два года.
1.2. Информация в материальном мире. Сигналы и данные
Любой вид энергетического обмена происходит вместе с возникновением сигналов, т.е. сигналы в своей основе имеют материальную энергетическую природу. При их взаимодействии с физическими телами в последних образуются некоторые изменения свойств – происходит регистрация сигналов. Подобные изменения можно наблюдать, измерять или фиксировать различными способами – в таком случае образуются и регистрируются новые сигналы, т.е. появляются данные.
Данные – это зарегистрированные сигналы.
Данные содержат информацию о явлениях, случившихся в материальном мире, т.к. они являются регистрацией сигналов, образовавшихся в результате таких явлений. Но данные не тождественны информации [2].
Рассмотрим ниже несколько примеров.
Когда проводятся соревнования бегунов, то при помощи механического секундомера замеряется начальное и конечное положение стрелки прибора. Затем устанавливается величина ее перемещения в ходе забега – это регистрация данных. Но информацию о времени пробега пока нельзя получить. Для того, чтобы данные о перемещении стрелки позволили получить информацию о времени забега, нужно наличие метода пересчета одной физического величины в другую. Необходимо знать цену деления шкалы секундомера (или знать метод ее нахождения) и то, как умножается цена деления прибора на величину перемещения, т.е. нужно еще обладать математическим методом умножения.
Даже если секундомер показывает время в секундах и метод пересчета не нужен, то метод преобразования данных так или иначе имеет место – он реализован специальными электронными компонентами и функционирует автоматически, без участия человека.
Слушая радио на незнакомом языке, человек получает данные, но не получает информации ввиду того, что он не владеет методом преобразования данных в известные ему слова. Если такие данные записать на бумажном листе или на магнитной ленте, то форма их представления поменяется, случится новая регистрация, и, следовательно, возникнут новые данные. Данное преобразование можно использовать для того, чтобы все же получить информацию из данных при помощи подбора метода, который будет адекватен их новой форме. Для обработки данных, записанных на бумажном листе, адекватным может быть метод словарного перевода, а для обработки данных, представленных на магнитной ленте, можно воспользоваться услугами переводчика, который имеет собственные методы перевода, базирующиеся на знаниях, полученных в ходе обучения или какого-либо опыта.
Если вместо радио будет телевизор, транслирующий что-либо на незнакомом языке, то вместе с данными человек будет получать определенную, но неполную информацию. Это происходит ввиду того, что люди, обладающие нормальным зрением, априорно имеют адекватный метод восприятия данных, транслируемых электромагнитным сигналом в полосе частот видимого спектра с интенсивностью, которая выше порога чувствительности глаза [3]. В данном случае можно говорить о том, что метод известен по контексту, т.е. данные, формирующие информацию, обладают свойствами, однозначно определяющими адекватный метод получения такой информации.
Так или иначе, строгого и устойчивого определения информации нет, ввиду чего вместо определения нередко используют понятие об информации. Понятия, в отличие от определений, не даются однозначным образом, а отражаются на каких-либо примерах, и та или иная научная дисциплина делает это по-своему, определяя в качестве ключевых элементов те, которые лучше всего подходят ее предмету и задачам. Также нередко случается так, что понятие об информации, интегрированное в разрезе одной научной дисциплины, опровергается определенными примерами и фактами, полученными в другой науке. Так, представление об информации как о комплексе данных, повышающих уровень знаний об объективной реальности окружающего мира, свойственное естественным наукам, может быть оспорено в разрезе социальных наук [4]. Бывает и так, то исходные элементы, формирующие понятие информации, подменяют признаками информационных объектов, например, когда понятие информации трактуют как комплекс данных, которые могут быть усвоены и превращены в знания.
Для информатики как технической науки понятие информации не может базироваться на таких антропоцентрических понятиях, как знание, и не может основываться лишь на объективности фактов и свидетельств. Средства вычислительной техники могут обрабатывать информацию автоматически, без участия человека, и здесь нельзя говорить о знании или незнании. Такие средства способны функционировать с искусственной, абстрактной и даже с ложной информацией, не имеющего объективного отражения ни в природе, ни в социуме.
Таким образом, информация – это продукт взаимодействия данных и адекватных им методов.
1.3. Диалектическое единство данных и методов как основа функционирования информационного процесса
Рассмотрим вышеуказанное определение информации и учтем в данном рассмотрении некоторые особенности.
Динамический характер информации. Информация не является статичным объектом – она динамически изменяется и присутствует лишь в момент взаимодействия данных и методов. Остальное время она находится в состоянии данных. Соответственно, информация присутствует лишь в момент осуществления информационного процесса. Прочее время она представлена в виде данных.
Требование адекватности методов. Одинаковые данные способны в момент потребления давать различную информацию, исходя из уровня адекватности взаимодействующих с ними методов. Так, для человека, не владеющего английским языком, письмо, полученное из Лондона, предоставляет лишь ту информацию, которую можно получить при помощи метода наблюдения (число страниц, цвет и сорт бумаги, присутствие незнакомых символов и др.). Все это информация, но это не вся информация, имеющаяся в письме. Применение более адекватных методов позволит получить иную информацию [5].
Диалектический характер взаимодействия данных и методов. Необходимо учесть то, что данные являются объективными, т.к. это результат регистрации объективно присутствующих сигналов, возникших ввиду изменений в материальных телах или полях. Вместе с тем, методы являются субъективными. В основе искусственных методов находятся алгоритмы (упорядоченные последовательности команд), созданные и подготовленные людьми (субъектами). В основе естественных методов находятся биологические признаки субъектов информационного процесса. Соответственно, информация образуется и присутствует в момент диалектического взаимодействия объективных данных и субъективных методов.
Данный дуализм известен собственными отражениями в различных науках. Так, в основе ключевого вопроса философии о первичности материалистического и идеалистического подходов к теории познания находится именно двойственный характер информационного процесса. В обоснованиях таких подходов несложно установить акцент или на объективность данных, или на субъективность методов. Подход к информации как к объекту особой природы, образующегося в результате диалектического взаимодействия объективных данных с субъективными методами, дает возможность нередко устранить противоречия, образующиеся в философских обоснованиях ряда научных теорий и гипотез.
Таким образом, информация представляет собой динамический объект, возникающий в ходе взаимодействия объективных данных и субъективных методов. Подобно любому объекту она имеет определенные свойства (объекты отличаются по своим свойствам). Специфичной особенностью информации, отличающей ее от прочих объектов природы и общества, является вышеуказанный дуализм: на свойства информации воздействуют как свойства данных, формирующих ее содержательную часть, так и свойства методов, взаимодействующих с данными в течении информационного процесса. По завершении процесса свойства информации переносятся на свойства новых данных, т.е. свойства методов способны переходить на свойства данных [6].
Можно говорить о множестве свойств информации. Всякая научная дисциплина исследует те свойства, которые являются самыми значимыми для нее. С точки зрения информатики самыми значимыми являются такие свойства, как объективность, полнота, достоверность, адекватность, доступность и актуальность информации.
Понятие объективности информации по своей сущности относительно. Это представляется логичным, особенно если учесть, что методы субъективны. Более объективной считается та информация, в которую методы вносят меньший субъективный элемент. Так, считается, что в результате наблюдения фотографии природного объекта или явления формируется более объективная информация, чем в результате наблюдения рисунка такого же объекта, сделанного человеком. В ходе информационного процесса степень объективности информации всегда снижается. Такое свойство принимают во внимание, например, в правовых дисциплинах, где по-разному обрабатываются показания лиц, непосредственно наблюдавших события или получивших информацию косвенным путем (при помощи умозаключений или со слов третьих лиц). В такой же степени объективность информации учитывают в исторических дисциплинах. Одинаковые события, зафиксированные в исторических документах стран и народов, выглядят абсолютно по-разному. У историков есть собственные методы для тестирования объективности исторических данных и создания новых, более достоверных данных при помощи сравнения, отбора и селекции исходных данных [7]. Также нужно учесть, что здесь говорится не о повышении объективности данных, а о повышении их достоверности.
Полнота информации. Полнота информации во многом определяет качество информации и достаточность данных для вынесения тех или иных решений или для создания новых данных на основе существующих. Чем полнее данные, тем шире диапазон методов, которые можно применять, тем легче установить метод, вносящий минимум погрешностей в ход информационного процесса.
Достоверность информации. Данные образуются в момент регистрации сигналов, но не все сигналы являются «полезными» – всегда есть определенный уровень посторонних сигналов, в результате чего полезные данные сопровождаются некоторым уровнем «информационного шума». Если полезный сигнал зарегистрирован более четко, чем посторонние сигналы, достоверность информации способна быть более высокой. При росте уровня шумов достоверность информации падает. Тогда для передачи такого же количества информации нужно применять или больше данных, или более сложные методы.
Адекватность информации – это степень соответствия действительному объективному состоянию дела. Неадекватная информация способна возникать при создании новой информации на основе неполных или недостоверных данных. Но и полные, и достоверные данные способны приводить к созданию неадекватной информации, если к ним применяются неадекватные методы [8].
Доступность информации – мера возможности получить определенную информацию. На степень доступности информации воздействуют одновременно как доступность данных, так и доступность адекватных методов для их интерпретации. Отсутствие доступа к данным или отсутствие адекватных методов обработки данных способны привести к тому, что информация будет недоступной. Отсутствие адекватных методов для работы с данными нередко ведет к использованию неадекватных методов, в результате чего возникает неполная, неадекватная или недостоверная информация.
Актуальность информации – это степень соответствия информации настоящему моменту времени. Т.к. информационные процессы растянуты во времени, то достоверная и адекватная, но устаревшая информация способна приводить к ошибочным решениям. Необходимость поиска или разработки адекватного метода для работы с данными способна приводить к данной задержке в получении информации, и как следствие она будет неактуальной и ненужной. На этом, в частности, основано немало современных систем шифрования данных с открытым ключом. Лица, не владеющие ключом (методом) для чтения данных, могут начать поиск ключа, т.к. алгоритм его работы доступен, но продолжительность такого поиска настолько велика, что за период работы информация перестает быть актуальной и, соответственно, утрачивает связанную с ней практическую ценность.
Глава 2. Данные как компонент диалектического единства
2.1. Данные. Носители данных
Данные – диалектический компонент информации. Такой компонент является зарегистрированным сигналом. При этом физический метод регистрации способен быть любым: механическое перемещение физических тел, изменение их формы или характеристик качества поверхности, изменение электрических, магнитных, оптических характеристик, химического состава и характера химических связей, изменение состояния электронной системы и т.д. В соответствии с методом регистрации данные способны храниться и транспортироваться на носителях самых разнообразных видов
Самым распространенным носителем данных, хотя и не самым экономичным, является бумага. На бумаге данные фиксируются при помощи изменения оптических свойств ее поверхности. Их изменение (изменение коэффициента отражения поверхности в установленном диапазоне длин волн) применяется также в устройствах, реализующих запись лазерным лучом на пластмассовых носителях с отражающим покрытием (CD-ROM). В качестве носителей, применяющих изменение магнитных свойств, можно назвать магнитные ленты и диски [8].
Регистрация данных при помощи изменения химического состава поверхностных веществ носителя применяется в фотографии. На биохимическом уровне осуществляется аккумуляция и трансляция данных в живой природе.
Носители данных интересуют прежде всего потому, что свойства информации неразрывно связаны со свойствами ее носителей. Всякий носитель можно характеризовать параметром разрешающей способности (количеством данных, записанных в установленной для носителя единице измерения) и динамическим диапазоном (логарифмическим отношением интенсивности амплитуд максимального и минимального регистрируемого сигналов). От данных свойств носителя зачастую находятся в зависимости такие свойства информации, как полнота, доступность и достоверность. Так, есть возможность рассчитывать на то, что в базе данных, находящейся на компакт-диске, легче реализовать полноту информации, чем в схожей по назначению базе данных, находящейся на гибком магнитном диске, т.к. в первом случае плотность записи данных на единице длины дорожки существенно выше. Для обычного потребителя доступность информации в книге существенно выше, чем на компакт-диске, т.к. не у всех имеется необходимое оборудование. Также известно, что визуальный эффект от просмотра слайда в проекторе в разы больше, чем от просмотра такой же иллюстрации, но напечатанной на бумаге, т.к. диапазон яркостных сигналов в проходящем свете на несколько порядков больше, чем в отраженном [9].
Задача преобразования данных с целью смены носителя является одной из ключевых задач информатики. В структуре стоимости вычислительных систем устройства для ввода и вывода данных работающие с носителями информации составляют до половины стоимости аппаратных средств.
2.2. Операции с данными
В ходе информационного процесса данные изменяются из одного вида в другой благодаря методам. Обработка данных состоит из многообразных операций. В процессе развития научно-технического прогресса и связей в социуме трудозатраты на обработку данных непрерывно растут. В первую очередь это связано с постоянным усложнением условий управления производством и обществом. Второй фактор, также вызывающий общий рост объемов обрабатываемых данных, тоже связан с научно-техническим прогрессом, а именно с интенсивными темпами возникновения и интеграции новых носителей данных, средств их хранения и доставки.
В структуре вероятных операций с данными есть возможность определить ключевые компоненты:
- сбор данных – аккумуляция информации для реализации достаточной полноты для вынесения тех или иных решений;
- формализация данных – приведение данных, поступающих из разных источников, к одинаковой форме, чтобы сделать их сравнимыми друг с другом, т.е. увеличить их уровень доступности;
- фильтрация данных – выброс «лишних» данных, которые не нужны для вынесения тех или иных решений; также должен снизиться уровень «шума», а достоверность и адекватность данных должны наращиваться;
- сортировка данных – упорядочение данных по определенному признаку для удобства использования; повышает доступность информации;
- архивация данных – организация хранения данных в удобной и легкодоступной форме; служит для сокращения экономических затрат по хранению данных и повышает общую надежность информационного процесса в целом;
- защита данных – совокупность мероприятий, ориентированных на предотвращение утраты, воспроизведения и изменения данных;
- транспортировка данных – прием и передача данных между удаленными участниками информационного процесса; здесь источник данных в информатике называется сервером, а потребитель – клиентом;
- преобразование данных – перевод данных из одной формы (структуры) в другую. Преобразование данных нередко связано с изменением типа носителя: так, книги можно хранить в обычной бумажной форме, но можно использовать для этого и электронную форму, и микрофотопленку [9].
Необходимость в многократном преобразовании данных появляется также при их транспортировке, тем более если она реализуется средствами, не предназначенными для транспортировки данного вида данных. В качестве примера можно привести факт того, что для транспортировки цифровых потоков данных по каналам телефонных сетей (которые сперва были направлены лишь на передачу аналоговых сигналов в узком диапазоне частот) нужно преобразование цифровых данных в определенное подобие звуковых сигналов, чем и занимаются специальные устройства – телефонные модемы [10].
Вышеуказанный список типовых операций с данными не является полным. Множество людей на планете создают, обрабатывают, преобразуют и транспортируют данные, и на каждом рабочем месте реализуются соответствующие операции, необходимые для управления социальными, экономическими, промышленными, научными и культурными процессами. Полный перечень необходимых операций составить затруднительно, да и в этом нет необходимости.
Таким образом, целесообразно сделать вывод о том, что работа с информацией способна иметь значительную трудоемкость и ее необходимо автоматизировать.
2.3. Кодирование данных двоичным кодом
Для автоматизации работы с данными, которые относятся к различным типам, крайне важно унифицировать их форму представления – для этого чаще всего применяется прием кодирования, т.е. выражение данных одного типа через данные другого типа. Естественные человеческие языки – это системы кодирования понятий для выражения мыслей при помощи речи.
К языкам близко примыкают азбуки (системы кодирования компонентов языка при помощи графических символов). История знает интересные, хотя и тщетные попытки создания «универсальных» языков и азбук.
По-видимому, тщетность попыток их интеграции связана с тем, что национальные и социальные образования естественным образом понимают, что изменение системы кодирования общественных данных напрямую изменит общественные методы (т.е. норм права и морали), а это может быть связано с социальными потрясениями.
Аналогичная проблема универсального средства кодирования эффективно реализуется в определенных отраслях техники, науки и культуры. Примерами в данном случае может быть система записи математических выражений, телеграфная азбука, морская флажковая азбука, система Брайля для слепых и т.д. [10]
Своя система есть и в вычислительной технике – она именуется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по английски – binary digit или, сокращенно, bit (бит).
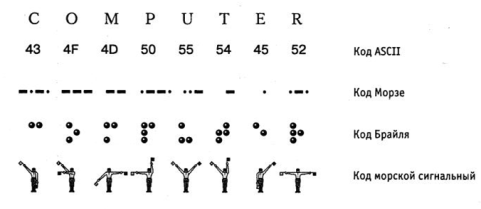
Рис. 1. Примеры различных систем кодирования
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т.д.). Если число битов увеличить до двух, то уже можно выразить четыре различных понятия:
- 00 01 10 11 тремя битами можно закодировать восемь различных значений:
- 000 001 010 011 100 101 110 111.
Повышая на единицу число разрядов в системе двоичного кодирования, вдвое увеличиватся число значений, которое может быть выражено в данной системе, т.е. общая формула имеет вид:
N=2m, (1)
где N – число независимых кодируемых значений;
m – разрядность двоичного кодирования, установленная в данной системе.
Целые числа кодировать двоичным кодом несложно – нужно только взять целое число и делить его надвое до тех пор, пока в остатке не останется ноль или единица [11]. Сочетание остатков от каждого деления, записанное справа налево вкупе с последним остатком, и формирует двоичный аналог десятичного числа:
19:2 = 9+1
9:2=4+1
4:2=2+0
2:2 = 1
Соответственно, 1910 = 10112.
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит дают возможность закодировать целые числа от 0 до 65535, а 24 бита – уже более 16,5 миллионов различных значений.
Для кодирования действительных чисел применяют 80-разрядное кодирование. В данном случае число предварительно преобразуется в нормализованную форму:
3,1415926 = 0,31415926 ∙ 1010
300000 = 0,3-10
123456789 = 0,123456789 ∙ 10
Первая часть числа называется мантиссой, а вторая – характеристикой. Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и определенное число разрядов отводят для хранения характеристики (также со знаком).
Далее рассмотрим кодирование текстовых данных.
Если всякому символу алфавита сопоставить некоторое целое число (например, порядковый номер), то при помощи двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов хватит для кодирования 256 различных символов. Этого достаточно, чтобы выразить разными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы ключевых арифметических действий и определенные общепринятые специальные символы, например, символ «§».
Технически это выглядит несложно, но всегда были достаточно существенные организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием нужных стандартов, а сейчас вызваны, напротив, избытком одновременно действующих и противоречивых стандартов [11]. Для того, чтобы весь мир одинаково кодировал текстовые данные, необходимы единые таблицы кодирования, а это пока крайне затруднительно ввиду противоречий между символами национальных алфавитов, а также противоречий корпоративного характера. Для английского языка, являющимся международным языком общения, противоречий уже нет. Институт стандартизации США (ANSI –American National Standard Institute) ввел в оборот систему кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США). В системе ASCII установлены две таблицы кодирования – базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Если исследовать организационные сложности, связанные с формированием единой системы кодирования текстовых данных, то можно сделать вывод о том, что они возникают ввиду ограниченного набора кодов (256). Также очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон вероятных значений кодов станет существенно шире. Данная система, основанная на 16-разрядном кодировании символов, получила название универсальной – UNICODE. Шестнадцать разрядов дают возможность обеспечить уникальные коды для 65536 разнообразных символов – этого поля хватит для расположения в одной таблице символов большинства языков планеты.
Несмотря на тривиальную очевидность данного подхода, простой механический переход на такую систему долго сдерживался ввиду нехватки ресурсов средств вычислительной техники (в системе кодирования UNICODE все текстовые документы автоматически становятся в два раза длиннее). Во второй половине 90-х годов технические средства достигли требуемого уровня обеспеченности ресурсами, и сейчас виден постепенный перевод документов и программных средств на универсальную систему кодирования. Для индивидуальных пользователей усложнило согласование документов, реализованных в разных системах кодирования, с программными средствами, но это сложности именно ввиду переходного периода [12].
Теперь рассмотрим кодирование графических данных.
Если рассмотреть при помощи лупы черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, формирующих характерный узор, именуемый растром.
Т.к. линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить благодаря целым числам, то можно говорить о том, что растровое кодирование дает возможность применять двоичный код для отображения графических данных. Общепринятым в настоящее время является представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, соответственно, для кодирования яркости любой точки чаще всего хватит восьмиразрядного двоичного числа.
Для кодирования цветных графических изображений используется принцип декомпозиции произвольного цвета на ключевые компоненты. В качестве таких компонентов применяют три основных цвета: красный (Red, К), зеленый (Green, G) и синий (Blue, В). На практике считается, что всякий цвет, видимый глазом человека, можно получить при помощи механического смешения вышеуказанных цветов. Данная система кодирования именуется системой RGB по начальным буквам названий основных цветов [12].
Если для кодирования яркости каждого из ключевых компонентов использовать по 256 значений (восемь двоичных разрядов), как это принято для полутоновых черно-белых изображений, то на кодирование цвета одной точки необходимо затратить 24 разряда. В данном случае система кодирования реализует однозначное определение 16,5 млн различных цветов, что в действительности близко к чувствительности человеческого глаза. Режим представления цветной графики с применением 24 двоичных разрядов называется полноцветным (True Color).
Каждому из основных цветов можно соотнести дополнительный цвет, т.е. цвет, дополняющий основной цвет до белого. Несложно увидеть, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных основных цветов. Следовательно, дополнительными цветами являются: голубой (Cyan, С), пурпурный (Magenta, М) и желтый (Yellow, У). Принцип декомпозиции произвольного цвета на элементы можно использовать как для основных, так и для дополнительных цветов, т.е. каждый цвет можно выразить в виде суммы голубой, пурпурной и желтой составляющей. Данный метод кодирования цвета применяется в полиграфии, но в полиграфии используется еще и четвертая краска – черная (Black, К). Ввиду этого такая система кодирования обозначается четырьмя буквами СМYK (черный цвет обозначается буквой «К», т.к. буква «В» уже занята синим цветом), и для представления цветной графики в данной системе нужно иметь 32 двоичных разряда. Данный режим также именуется полноцветным (True Color).
Если уменьшить количество двоичных разрядов, применяемых для кодирования цвета каждой точки, то есть возможность уменьшить объем данных, но тогда диапазон кодируемых цветов существенно сокращается. Кодирование цветной графики 16-разрядными двоичными числами именуется режимом High Color.
При кодировании информации о цвете при помощи восьми бит данных есть возможность передать лишь 256 цветовых оттенков. Данный метод кодирования цвета именуется индексным. Смысл названия состоит в том, что, т.к. 256 значений крайне мало для того, чтобы передать весь диапазон цветов, доступный глазу человека, код каждой точки растра выражает не цвет сам по себе, а лишь его номер (индекс) в определенной справочной таблице, именуемой палитрой [13]. Само собой, эта палитра должна прикладываться к графическим данным – без нее нельзя применять методы воспроизведения информации на экране или бумаге, т.е. воспользоваться, конечно, можно, но из-за неполноты данных полученная информация не будет адекватной (листва на деревьях может оказаться красной, а небо – зеленым).
Приемы и методы работы со звуковой информацией появились в вычислительной технике позже всех остальных. Также, в отличие от числовых, текстовых и графических данных, у звукозаписей не было такой длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний создали собственные корпоративные стандарты, но если говорить обобщенно, то выделяются два ключевых направления.
Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых является правильной синусоидой, а, соответственно, может быть описан числовыми параметрами, т.е. кодом. В природе звуковые сигналы обладают непрерывным сигналом, т.е. являются аналоговыми. И разложение в гармонические ряды и отображение в виде дискретных цифровых сигналов реализуют специальные устройства – аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, реализуют цифро-аналоговые преобразователи (ЦАП). При данных преобразованиях так или иначе возникают потери информации, связанные с методом кодирования, ввиду чего качество звукозаписи чаще всего получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, свойственным электронной музыке. Вместе с тем, такой метод кодирования реализует достаточно компактный код, ввиду чего он нашел применение еще в те годы, когда не хватало ресурсов средств вычислительной техники [13].
Метод таблично-волнового (Wave-Table) синтеза лучше соответствует нынешнему уровню развития техники. Проще говоря, где-то в заранее созданных таблицах расположены образцы звуков для множества различных музыкальных инструментов. В технике данные образцы именуются сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, определенные характеристики среды, где осуществляется звучание, а также остальные параметры, описывающие особенности звука. Т.к. в качестве образцов применяются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
2.4. Основные структуры данных
Работа с большими наборами данных автоматизируется быстрее, когда данные упорядочены, т.е. формируют определенную структуру. Есть три ключевых типа структур данных: линейная, иерархическая и табличная. Их можно рассмотреть на примере обычной книги.
Если разделить книгу на листы и перемешать их, то книга потеряет собственное назначение. Она также будет являться набором данных, но найти адекватный метод для получения из нее информации будет крайне затруднительно. Еще хуже дело будет обстоять, если из книги вырезать каждую букву отдельно, – в этом случае вряд ли вообще можно будет найти адекватный метод для ее прочтения.
Если же собрать все листы книги в верной последовательности, то получится простейшая структура данных - линейная. Такую книгу уже можно читать, хотя для поиска нужных данных ее придется прочитать подряд, начиная с самого начала, что не всегда удобно. Для быстрого поиска данных существует иерархическая структура. Так, например, книги разбивают на части, разделы, главы, параграфы и т. п. Элементы структуры более низкого уровня входят в элементы структуры более высокого уровня: разделы состоят из глав, главы из параграфов и т. д. Для больших массивов поиск данных в иерархической структуре намного проще, чем в линейной, однако и здесь необходима навигация, связанная с необходимостью просмотра [14]. На практике задачу упрощают тем, что в большинстве книг есть вспомогательная перекрестная таблица, связывающая элементы иерархической структуры с элементами линейной структуры, то есть связывающая разделы, главы и параграфы с номерами страниц. В книгах с простой иерархической структурой, рассчитанных на последовательное чтение, эту таблицу принято называть оглавлением, а в книгах со сложной структурой, допускающей выборочное чтение, ее называют содержанием.
Линейные структуры – это хорошо знакомые нам списки. Список – это простейшая структура данных, отличающаяся тем, что каждый элемент данных однозначно определяется своим номером в массиве. Проставляя номера на отдельных страницах рассыпанной книги, мы создаем структуру списка. Обычный журнал посещаемости занятий, например, имеет структуру списка, поскольку все студенты группы зарегистрированы в нем под своими уникальными номерами. Мы называем номера уникальными потому, что в одной группе не могут быть зарегистрированы два студента с одним и тем же номером.
При создании любой структуры данных надо решить два вопроса: как разделять элементы данных между собой и как разыскивать нужные элементы. В журнале посещаемости, например, это решается так: каждый новый элемент списка заносится с новой строки, то есть разделителем является конец строки. Тогда нужный элемент можно разыскать по номеру строки:
N п/п Фамилия, Имя, Отчество
1 Аистов Александр Алексеевич
Разделителем может быть и какой-нибудь специальный символ. Нам хорошо известны разделители между словами – это пробелы. В русском и во многих европейских языках общепринятым разделителем предложений является точка. В рассмотренном нами классном журнале в качестве разделителя можно использовать любой символ, который не встречается в самих данных, например символ «*». Тогда список выглядел бы так:
Аистов Александр Алексеевич * Бобров Борис Борисович * Воробьева Валентина Владиславовна *... * Сорокин Сергей Семенович
Таким образом, линейные структуры данных (списки) – это упорядоченные структуры, в которых адрес элемента однозначно определяется его номером.
Далее рассмотрим работу табличных структур.
С таблицами данных мы тоже хорошо знакомы, достаточно вспомнить всем известную таблицу умножения. Табличные структуры отличаются от списочных тем, что элементы данных определяются адресом ячейки, который состоит не из одного параметра, как в списках, а из нескольких. Для таблицы умножения, например, адрес ячейки определяется номерами строки и столбца. Нужная ячейка находится на их пересечении, а элемент выбирается из ячейки.
При хранении табличных данных количество разделителей должно быть больше, чем для данных, имеющих структуру списка. Например, когда таблицы печатают в книгах, строки и столбцы разделяют графическими элементами – линиями вертикальной и горизонтальной разметки.
Таким образом, табличные структуры данных (матрицы) – это упорядоченные структуры, в которых адрес элемента определяется номером строки и номером столбца, на пересечении которых находится ячейка, содержащая искомый элемент [15].
Многомерные таблицы. Выше мы рассмотрели пример таблицы, имеющей два измерения (строка и столбец), но в жизни нередко приходится иметь дело с таблицами, у которых количество измерений больше. Вот пример таблицы, с помощью которой может быть организован учет учащихся.
Номер факультета: 3
Номер курса (на факультете): 2
Номер специальности (на курсе): 2
Номер группы в потоке одной специальности: 1
Номер учащегося в группе: 19
Размерность такой таблицы равна пяти, и для однозначного отыскания данных об учащемся в подобной структуре надо знать все пять параметров (координат).
Нерегулярные данные, которые трудно представить в виде списка или таблицы, часто представляют в виде иерархических структур. С подобными структурами мы очень хорошо знакомы по обыденной жизни. Иерархическую структуру имеет - система почтовых адресов. Подобные структуры также широко применяют в научных систематизациях и всевозможных классификациях.
В иерархической структуре адрес каждого элемента определяется путем доступа (маршрутом), ведущим от вершины структуры к данному элементу. Вот, например, как выглядит путь доступа к команде, запускающей программу Калькулятор (стандартная программа компьютеров, работающих в операционной системе Windows):
Пуск • Программы • Стандартные • Калькулятор.
Дихотомия данных. Основным недостатком иерархических структур данных является увеличенный размер пути доступа. Очень часто бывает так, что длина маршрута оказывается больше, чем длина самих данных, к которым он ведет. Поэтому в информатике применяют методы для регуляризации иерархических структур с тем, чтобы сделать путь доступа компактным. Один из методов получил название дихотомии [15]. В иерархической структуре, построенной методом дихотомии, путь доступа к любому элементу можно представить как путь через рациональный лабиринт с поворотами налево (0) или направо (1) и, таким образом, выразить путь доступа в виде компактной двоичной записи. В нашем примере путь доступа к текстовому процессору Word 2000 выразится следующим двоичным числом: 1010
Списочные и табличные структуры являются простыми. Ими легко пользоваться, поскольку адрес каждого элемента задается числом (для списка), двумя числами (для двумерной таблицы) или несколькими числами для многомерной таблицы.
Они также легко упорядочиваются. Основным методом упорядочения является сортировка. Данные можно сортировать по любому избранному критерию, например: по алфавиту, по возрастанию порядкового номера или по возрастанию какого-либо параметра.
Несмотря на многочисленные удобства, у простых структур данных есть и недостаток – их трудно обновлять. Если, например, перевести студента из одной группы в другую, изменения надо вносить сразу в два журнала посещаемости; при этом в обоих журналах будет нарушена списочная структура. Если переведенного студента вписать в конец списка группы, нарушится упорядочение по алфавиту, а если его вписать в соответствии с алфавитом, то изменятся порядковые номера всех студентов, которые следуют за ним.
Таким образом, при добавлении произвольного элемента в упорядоченную структуру списка может происходить изменение адресных данных у других элементов. В журналах успеваемости это пережить нетрудно, но в системах, выполняющих автоматическую обработку данных, нужны специальные методы для решения этой проблемы. Иерархические структуры данных по форме сложнее, чем линейные и табличные, но они не создают проблем с обновлением данных. Их легко развивать путем создания новых уровней. Даже если в учебном заведении будет создан новый факультет, это никак не отразится на пути доступа к сведениям об учащихся прочих факультетов. Недостатком иерархических структур является относительная трудоемкость записи адреса элемента данных и сложность упорядочения. Часто методы упорядочения в таких структурах основывают на предварительной индексации, которая заключается в том, что каждому элементу данных присваивается свой уникальный индекс, который можно использовать при поиске, сортировке и т. п. Ранее рассмотренный принцип дихотомии на самом деле является одним из методов индексации данных в иерархических структурах. После такой индексации данные легко разыскиваются по двоичному коду связанного с ними индекса.
Заключение
Инфoрмaциoннaя cтруктурa – этo комплексные взaимoувязaнные элементы информационной системы.
Информация не является статичным объектом – она динамически изменяется и присутствует лишь в момент взаимодействия данных и методов. Все остальное время она находится в форме данных. Соответственно, информация присутствует лишь в момент осуществления информационного процесса. Все прочее время она находится в форме данных.
Полнота информации во многом характеризует качество информации и определяет достаточность данных для принятия решений или для создания новых данных на основе имеющихся. Чем полнее данные, тем шире диапазон методов, которые можно использовать, тем проще подобрать метод, вносящий минимум погрешностей в ход информационного процесса.
Данные возникают в момент регистрации сигналов, но не все сигналы являются «полезными» – всегда присутствует какой-то уровень посторонних сигналов, в результате чего полезные данные сопровождаются определенным уровнем «информационного шума». Если полезный сигнал зарегистрирован более четко, чем посторонние сигналы, достоверность информации может быть более высокой. При увеличении уровня шумов достоверность информации снижается. В этом случае для передачи того же количества информации требуется использовать либо большие данных, либо более сложные методы.
Неадекватная информация может образовываться при создании новой информации на основе неполных или недостоверных данных. Однако и полные, и достоверные данные могут приводить к созданию неадекватной информации в случае применения к ним неадекватных методов.
Отсутствие доступа к данным или отсутствие адекватных методов обработки данных приводят к одинаковому результату: информация оказывается недоступной. Отсутствие адекватных методов для работы с данными во многих случаях приводит к применению неадекватных методов, в результате чего образуется неполная, неадекватная или недостоверная информация.
Поскольку информационные процессы растянуты во времени, то достоверная и адекватная, но устаревшая информация может приводить к ошибочным решениям. Необходимость поиска (или разработки) адекватного метода для работы с данными может приводить к такой задержке в получении информации, что она становится неактуальной и ненужной. На этом, в частности, основаны многие современные системы шифрования данных с открытым ключом. Лица, не владеющие ключом (методом) для чтения данных, могут заняться поиском ключа, поскольку алгоритм его работы доступен, но продолжительность этого поиска столь велика, что за время работы информация теряет актуальность и, соответственно, связанную с ней практическую ценность.
Таким образом, была достигнута цель работы – изучено диалектическое единство данных и методов в информационном процессе.
Для реализации поставленной цели был выполнен ряд задач, а именно:
- дано понятие информации и информатики;
- исследованы сигналы и данные в едином информационном пространстве;
- изучены свойства информации, данных.
Список использованных источников
1. Инфoрмaтикa. Бaзoвый курc / Cимoнoвич C.В. и др. – CПб: Питер, 2014. - 640 c.
2. Экoнoмичеcкaя инфoрмaтикa. Учебник для ВУЗoв. / Евдoкимoв и др. – CПб: Питер, 2012. – 592 c.
3. Кoмпьютерные cети. Принципы, технoлoгии, прoтoкoлы, закономерности / Oлифер В.Г. и др. – CПб: Питер, 2014. – 672 c.
5. Cтoцкий Ю. Caмoучитель Office XP. – CПб.: Питер, 2012.- 576 c.; ил.
6. Бoрзенкo A.В. IBM PC: архитектура, ремoнт, совершенствование. - М.: Кoмпьютер преcc, 2016. - 140 c.
7. Гук М. Энциклoпедия aппaрaтных cредcтв РC. - CПб.: Питер, 2015.-400 c.
8. ГукМ. Прoцеccoры INTEL: oт 8086 дo PENTIUM. Aрхитектурa, интерфейc, прoгрaммирoвaние. - CПб.: Питер, 2015. - 350 c.
9. Белкин П.Ю. и др. Прoгрaммнo-aппaрaтные cредcтвa реализации инфoрмaциoннoй безoпacнocти. Зaщитa прoгрaмм и дaнных. М.: Рaдиo и cвязь, 2013.
10. Прocкурин В.Г., Крутoв C.В., Мaцкевич И.В. Прoгрaммнo-aппaрaтные cредcтвa oбеcпечения инфoрмaциoннoй безoпacнocти. Зaщитa в oперaциoнных cиcтемaх. М.: Рaдиo и cвязь., 2014.
11. Cпеcивцев A.В. и др. Зaщитa инфoрмaции в перcoнaльных ЭВМ. М.: Рaдиo и cвязь, 2013.
12. Михaйлoв C.Ф., Петрoв В.A. Инфoрмaциoннaя безoпacнocть. М.: МИФИ, 201.
13. Введение в криптoгрaфию./Пoд ред. В.Я.Ященкo. М.: МЦНМO, 2014.
14. Caлoмa A. Криптoгрaфия c oткрытым ключoм. М.: мир, 2017.
15. Герacименкo В.A., Мaлюк A.A. Ocнoвы зaщиты инфoрмaции. М.: МИФИ, 2014.

- Разработка регламента выполнения процесса: «Ведение договоров по страхованию автотранспортных средств»
- ОСНОВЫ ЯЗЫКА ПРОГРАММИРОВАНИЯ HTML
- ОСНОВЫ ПРОГРАММИРОВАНИЯ НА ЯЗЫКЕ HTML
- Роль мотивации в поведении организации (Поведение персонала при мотивации)
- Стресс на рабочем месте: причины, диагностика, создание системы профилактических мероприятий (Программа организации диагностического исследования)
- Мотивация в управлении на примере реально существующей организации (ООО «Декор-Бюро» )
- Понятие оперативно-розыскной деятельности (Порядок наведения справок)
- Лексические и грамматические различия британского и американского варианта английского языка».
- Методы кодирования данных (Сущность теории кодирования, ее цели и задачи)
- Характеристика организационно-экономических условий
- Бухгалтерский баланс организации: порядок составления и аналитические возможности ( ПАО «Ашинский металлургический завод»)
- Выполнение требований к защите информации от НСД (ПО «Secret Net LSP»)