
Методы кодирования данных (Задача кодирования)
Содержание:

Введение
Возникновение кодов произошло в далекой древности, с появлением систем знаков для записи звуков, слов и информации, которые позднее преобразились в различные языки. Каждый из языков представляет собой сложную систему кодирования, включающую в себя грамматику, слова и сложную конструкцию алфавитов. Языки позволяют передавать полученную информацию в окружающем шуме с достаточно высокой скоростью и достоверностью.
Позднее, еще до нашей эры, появились криптограммы, что в переводе с греческого означает «тайнопись». Такими кодами пользовались для засекречивания сообщений. Уже в V в. до н. э. знаменитый греческий историк Геродот приводил примеры писем-криптограмм, понятных только одному адресату. Спартанцы имели специальный механический прибор, при помощи которого записывались сообщения–криптограммы, позволяющие сохранить тайну. Собственную секретную азбуку имел Юлий Цезарь (широко известный «шифр Цезаря»). В Средние века и эпоху Возрождения над изобретением тайных шифров работали многие выдающиеся умы, в том числе философ Фрэнсис Бэкон, математики Франсуа Виет, Джероламо Кардано. Криптографией занимались в монастырях, при дворах королей. Вместе с искусством шифрования сообщений развивалось и искусство их дешифрования. Многие оптимистично полагали, что вряд ли существует такая криптограмма, которую нельзя разгадать. И только в прошлом веке Клод Шеннон (1949 г.) показал, что существует совершенно секретный шифр – шифр Вернама, называемый также лентой однократного действия или шифром-блокнотом. В настоящее время теория кодирования имеет важное широкое практическое применение как средство экономной, удобной, быстрой, а также надежной передачи сообщений по линиям связи с различного вида шумами (телефон, телеграф, радио, телевидение, компьютерная и космическая связи, и т. д.). Подлинный взрыв развития теории связи начался в послевоенные годы, с 1948–1949 гг., с появлением классических работ Клода Шеннона и Норберта Винера. Труды Н. Винера были порождены исследованиями военного времени по автоматическому управлению огнем, труды К. Шеннона, знаменитые "Математическая теория связи" и "Связь при наличии шума" – исследованиями по шифрованию сообщений и их передачи по секретным каналам связи. Математические модели Н. Винера и К. Шеннона довольно сильно различались: сигнал по Н. Винеру может обрабатываться после воздействия шумом, по К. Шеннону сигнал можно обрабатывать как до, так и после передачи по каналу связи с шумами. В силу этого и других различий, Винеровские труды легли в основу теории автоматического управления, Шенноновские труды оказались основополагающими для задач эффективного использования каналов связи. Таким образом, с 1949 г., с фундаментальных работ К. Шеннона началось бурное развитие теории кодирования, как отдельной научной дисциплины, а также развитие таких тесно с нею связанных научных дисциплин, как сжатие информации и криптология в современном мире. С каждым днем в мире циркулирует все большее количество информации, как письменной, так и числовой, и звуковой.
Не все каналы связи являются совершенными, хоть и соответствуют основным стандартам и требованиям. Причиной всему служит наличие помех на каналах связи. Из за сбоев, при передаче информации между двумя объектами, может возникнуть искаженные дынных. Наиболее помехоустойчив русский язык, например: «По рзелульаттам илссеовадний одонго анлигйсокго унвиертисета, не иеемт занчнеия, в кокам пряокде рсапожолена бкувы в солве. Галвоне, чотбы преавя и пслоендяя бквуы блыи на мсете. Осатьлыне бкувы мгоут селдовтаь в плоонм бсепордяке, все-рвано ткест чтаитсея без побрелм. Пичрионй эгото ялвятеся то, что мы не чиатем кдаужю бкуву по отдльенотси, а все солво цликеом». В данной цитате изменена последовательность букв, но смысл остался понятен.
Актуальность: Современные системы связи основаны на передаче информации в цифровом виде. Актуальность методов кодирования данных становиться неотъемлемой частью при работе с компьютерами и средствами коммуникации.
Объект: процессы кодирования данных.
Цель исследования: изучить методы кодирования.
Задачи:
1) рассмотреть основные понятия.
2) изучить методы сетевого кодирования.
3) изучить методы программного кодирования.
4) изучить методы энтропийного кодирования.
5) изучить методы дельта-кодирования.
Глава 1. Теоретические основы
1.1. Задача кодирования
Перед началом изучения необходимо ознакомится с рядом понятий и определений.
Код – соответствие того или иного знака в одной системе символов равному знаку в другой.
Кодирование – это преобразование информации с одного языка на другой, говоря простыми словами - представление в другой системе символов.
Декодирование – операция, обратная кодированию, т.е. восстановление информации в первичном алфавите по полученной последовательности кодов.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо ее потерь.
Ярким примером обратимого кодирования является представление знаков и их передача после восстановления в телеграфном коде. Примером же кодирования необратимого можно считать перевод с одного языка на другой. Обратный же перевод не восстановит первоначального текста. Поэтому возможность восстановления информации является необходимым условием применения кодов.
Основными задачами кодирования являются:
- Обеспечение экономичности передачи информации посредством устранения избыточности.
- Обеспечение помехоустойчивости (надежности) передаваемой информации.
- Согласование пропускной способности и скорости передачи.
Кодирование является предшественником таких процессов как сбор, передача и хранения информации. При этом хранение - это фиксация информации в некотором состоянии, а передача – изменение с течением времени.
В конце 40-х годов с появлением работ Голея, Хэмминга и Шеннона возникла и сама теория кодирования. Голей и Хэмминг заложили основу алгебраическим методам кодирования, которые используются и по сей день, а Шеннон предложил и исследовал понятие случайного кодирования. Стоит заметить, что в современных информационных системах обеспечение безопасности является важнейшей частью. Настоящий “бум” у ученых и инженеров вызвало появление работ Шеннона. Казалось, решение подобного рода задач на практике будет таким же простым и понятным, как Шеннон сделал это математически. Но весь ажиотаж спал достаточно быстро, так как прямого решения найти не удалось. В то же время, поставленные Шенноном задачи и доказательство фундаментальных теорем теории информации дали толчок для поиска решения задач с использованием детерминированных (неслучайных) сигналов и алгебраических методов помехоустойчивого кодирования (защиты от помех и шифрование для обеспечения секретности информации).
В 50-е,70-е годы было разработано большое количество алгебраических кодов с исправлением ошибок, среди которых наиболее востребованными стали коды Боуза-Чоудхури-Хоквингема (БЧХ), Рида-Соломона (РС), Рида-Малера, Адамара, Юстенсена, Гоппы, циклические коды, сверточные коды с разными алгоритмами декодирования (последовательное декодирование, алгоритм Витерби), арифметические коды.
1.2. Сжатие данных
Сжатие данных (англ. data compression) – алгоритмическое преобразование данных, производимое с целью уменьшения занимаемого ими объёма. Применяется для более рационального использования устройств хранения и передачи данных. Синонимы – упаковка данных, компрессия, сжимающее кодирование, кодирование источника. Обратная процедура называется восстановлением данных (распаковкой, декомпрессией).
Сжатие основано на устранении избыточности, содержащейся в исходных данных. Простейшим примером избыточности является повторение в тексте фрагментов (например, слов естественного или машинного языка). Подобная избыточность обычно устраняется заменой повторяющейся последовательности ссылкой на уже закодированный фрагмент с указанием его длины. Другой вид избыточности связан с тем, что некоторые значения в сжимаемых данных встречаются чаще других. Сокращение объёма данных достигается за счёт замены часто встречающихся данных короткими кодовыми словами, а редких – длинными (энтропийное кодирование). Сжатие данных, не обладающих свойством избыточности (например, случайный сигнал или белый шум, зашифрованные сообщения), принципиально невозможно без потерь.
Сжатие без потерь позволяет полностью восстановить исходное сообщение, так как не уменьшает в нем количество информации, несмотря на уменьшение длины. Такая возможность появляется, только если распределение вероятностей на множестве сообщений не равномерное, например часть теоретически возможных в прежней кодировке сообщений на практике не встречается.
1.3. Принципы сжатия данных
В основе любого способа сжатия лежит модель источника данных, или, точнее, модель избыточности. Иными словами, для сжатия данных используются некоторые априорные сведения о том, какого рода данные сжимаются. Не обладая такими сведениями об источнике, невозможно сделать никаких предположений о преобразовании, которое позволило бы уменьшить объём сообщения. Модель избыточности может быть статической, неизменной для всего сжимаемого сообщения, либо строиться или параметризоваться на этапе сжатия (и восстановления). Методы, позволяющие на основе входных данных изменять модель избыточности информации, называются адаптивными. Неадаптивными являются обычно узкоспециализированные алгоритмы, применяемые для работы с данными, обладающими хорошо определёнными и неизменными характеристиками. Подавляющая часть достаточно универсальных алгоритмов является в той или иной мере адаптивными.
Все методы сжатия данных делятся на два основных класса:
Сжатие данных без потерь (англ. lossless data compression) – метод сжатия данных (видео, аудио, графики, документов, представленных в цифровом виде), при использовании которого закодированные данные однозначно могут быть восстановлены с точностью до бита, пикселя, вокселя и т.д. При этом оригинальные данные полностью восстанавливаются из сжатого состояния. Этот тип сжатия принципиально отличается от сжатия данных с потерями. Для каждого из типов цифровой информации, как правило, существуют свои оптимальные алгоритмы сжатия без потерь. Сжатие данных без потерь используется во многих приложениях. Например, оно используется во всех файловых архиваторах. Оно также используется как компонент в сжатии с потерями. Сжатие без потерь используется, когда важна идентичность сжатых данных оригиналу. Обычный пример – исполняемые файлы и исходный код. Некоторые графические файловые форматы (например PNG) используют только сжатие без потерь, тогда как другие (TIFF, FLIF или GIF) могут использовать сжатие как с потерями, так и без потерь.
Сжатие данных с потерями (англ. lossy compression) –метод сжатия (компрессии) данных, при использовании которого распакованные данные отличаются от исходных, но степень отличия не существенна с точки зрения их дальнейшего использования. Этот тип компрессии часто применяется для сжатия аудио- и видеоданных, статических изображений, в интернете (особенно в потоковой передаче данных) и цифровой телефонии. Альтернативой является сжатие без потерь.
При использовании сжатия без потерь возможно полное восстановление исходных данных, сжатие с потерями позволяет восстановить данные с искажениями, обычно несущественными с точки зрения дальнейшего использования восстановленных данных. Сжатие без потерь обычно используется для передачи и хранения текстовых данных, компьютерных программ, реже – для сокращения объёма аудио– и видеоданных, цифровых фотографий и т. п., в случаях, когда искажения недопустимы или нежелательны. Сжатие с потерями, обладающее значительно большей, чем сжатие без потерь, эффективностью, обычно применяется для сокращения объёма аудио- и видеоданных и цифровых фотографий в тех случаях, когда такое сокращение является приоритетным, а полное соответствие исходных и восстановленных данных не требуется.
1.4. Сжатие с потерями против сжатия без потерь
Преимущество методов сжатия с потерями над методами сжатия без потерь состоит в том, что первые делают возможной большую степень сжатия, продолжая удовлетворять поставленным требованиям, а именно — искажения должны быть в допустимых пределах чувствительности человеческих органов физических чувств.
Методы сжатия с потерями часто используются для сжатия аналоговых данных — чаще всего звука или изображений.
В таких случаях распакованный файл может очень сильно отличаться от оригинала на уровне сравнения «бит в бит», но практически неотличим для человека «на слух» и «на глаз» в большинстве применений.
Большое количество методов фокусируется на физических особенностях органов чувств человека. Психоаккустическая модель определяет то, как сильно звук может быть сжат без ухудшения воспринимаемого человеком качества звука. Недостатки, причинённые сжатием с потерями, которые заметны для человеческого уха или глаза, известны как артефакты сжатия.
Фотографии, записанные в формате JPEG, могут быть приняты судом в качестве доказательств, несмотря на то, что изображение сжато с потерями.
Недостатки все же присутствуют в обоих способах сжатия. При использовании сжатия с потерями необходимо учитывать, что повторное сжатие обычно приводит к деградации качества. Однако, если повторное сжатие выполняется без каких-либо изменений сжимаемых данных, качество не меняется. Так, например, сжатие изображения методом JPEG, восстановление его и повторное сжатие с теми же самыми параметрами не приведёт к снижению качества. То же справедливо и для метода JPEG-LS в режиме сжатия с ограниченными потерями. Но в общем случае, когда декодированные данные подвергаются редактированию, несжатый оригинал целесообразно сохранять (или сжимать без потери данных).
1.5. Прямая коррекция ошибок
Прямая коррекция ошибок (FEC) - это метод, который использовался в течении нескольких лет в оптоволоконных системах на подводных лодках. Этот метод позволяет с почти идеальной точностью передать данные, даже если передача осуществляется по каналу с большим количеством шумов. В настоящее время используется несколько алгоритмов FEC, таких как код Хэмминга, код Рида-Соломона и код БЧХ.
В качестве примера, рассмотрим работу мобильного телефона в условиях слабого сигнала сотовой сети. Допустим, вы хотели сказать человеку на другом конце линии некую последовательность чисел. Есть несколько методов, которые можно использовать для повышения точности. Предположим, что список чисел, которые вы хотите передать, это 7, 3, 8, 10, 12 и 21. Одним из способов может быть повтор списка чисел два раза. Запишите каждый список и сравните их, если они совпадают, передача данных, вероятно, корректна. Основным недостатком такого метода является то, что, поскольку данные передаются дважды, пропускная способность системы делится пополам и, если списки не совпадают, у вас не будет ни малейшего представления, который из них верный. Используя этот метод, для того, чтобы убедиться в хорошем качестве передачи и исправить некоторые ошибки, вам придется отправить данные три раза и проверить, что два из трех списков полностью совпадают. Второй способ будет выглядеть примерно так: в первую очередь, вы будете отправлять количество чисел, которые необходимо принять, затем саму последовательноcnm, и в конце последует передача числа, являющегося суммой последовательности. Передаваемое сообщение при этом примет следующий вид: 6, 7, 3, 8, 10, 12, 21, и 67. Человек, принимающий сообщение, будет смотреть на первое число, чтобы затем убедится, что будет получено правильное количество чисел в сообщении, а затем проверит, что число в конце последовательности действительно является суммой переданных чисел. Этот метод требует отправки значительно меньшего количества дополнительных данных. Если любое полученное число неверно или пропущено, то число контрольной суммы в конце передачи не будет соответствовать сумме, передаваемых чисел. Показанные выше методы представляют собой примеры кода обнаружения ошибок. Они позволяют определить, была ли передача точной, но не позволяют исправлять ошибки.
Примечание: Термин "Forward" в FEC означает, что исправление ошибок осуществляется путем передачи некоторой информации вместе с передачей данных.
Код исправления ошибок считается более сложным, в сравнении с кодом обнаружения ошибок и используется почти в каждом современном коммуникационном приложении. Также, коды исправления ошибок нашли широкое применение в CD и DVD проигрывателях. Для того, чтобы привести пример кода исправления ошибок, нужно ввести и объяснить два термина: двоичность и чётность. В предыдущих примерах кода обнаружения ошибок, мы использовали такие числа, как 7, 3, 8, и т.д. Это базовые числа системы исчисления, знакомой нам в повседневной жизни. Двоичные числа в основе имеют два числа, которые могут иметь только два возможных значения – 0 или 1. Бинарная система используется почти во всех коммуникационных и компьютерных системах. Второе определение, которое необходимо разобрать, называется четность. Чётность - термин, который используется в двоичных системах связи, чтобы указать, является ли число единиц в передаче четным или же нет. Если число единиц является четным, то чётность совпадает и наоборот.
Глава 2. Сетевое кодирование
2.1. Основы сетевого кодирования
Для вычисления линейных комбинаций входящих пакетов и передачи их далее для каждого из узлов необходимо сетевое кодирование. Это позволяет поддерживать работу сети в более стабильном состоянии при увеличении пропускной способности. Одним из важнейших параметров узла-источника сети является его пропускная способность, то есть максимальное число пакетов, которое может быть передано узлу-получателю за единицу времени.
При увеличении числа узлов-получателей время передачи будет считаться от начала операции до получения последним из получателей всех пакетов. При заданном протоколе передачи одни получатели могут принять все пакеты быстрее, чем другие.
Рассмотрим пример графа «Бабочка», который состоит из узла-источника S, четырех промежуточных узлов A, B, C, D и двух узлов получателей R1, R2. Сами же ребра имеют пропускную способность равную 1пакету/кадру. Двумя ребрами соединены лишь узлы С и D. Работа узлов выстраивается по принципу «принимай и передавай дальше». До передачи сам пакет хранится на промежуточном узле.
Узлы-получатели имеют возможность восстановить исходные пакеты из информации об одном полученном пакете и их комбинации. В результате увеличивается пропускная способность сети – по два пакета может быть передано двум получателям одновременно (за каждый такт), хотя минимальное сечение сети содержит всего три канала передачи данных.
Рассмотрим теперь усовершенствованную сеть, в которой каждый узел может совершать математические операции над пакетами, а конкретнее образовывать линейные комбинации полученных пакетов. Вычисление линейных комбинаций пакетов и называют сетевым кодированием. На практике получаем, что передача от источника к получателю осуществляется через цепочку промежуточных узлов по принципу «принимай, кодируй и передавай дальше». Далее в буферной памяти промежуточного узла запоминаются пакеты, поступившие и образовавшие линейные комбинации, затем, рассылая копии по своим выходным линиям, доставляя их получателям через другие узлы. В сетях с кодированием при одинаковой конфигурации пропускная способность будет больше, чем в сетях без кодирования. Таким образом, основной принцип сетевого кодирования состоит в том, что внутренний узел сети может создавать линейные комбинации нескольких принятых пакетов с коэффициентами из конечного поля и передавать дальше по сети вместо того, чтобы передавать каждый пакет в отдельности, как это делалось ранее.
2.2. Случайное сетевое кодирование
В этой части главы будет приведен пример случайного сетевого кодирования, основы которого были впервые затронуты в первых работах Кёттера, Кшиншагу и Сильвы. В отличие от статического сетевого кодирования, когда получателю известны все манипуляции, производимые с пакетом, также рассматривается вопрос о случайном сетевом кодировании, когда данная информация неизвестна. Данный подход также называют сетевым кодированием со случайными коэффициентами. Коэффициенты, под которыми начальные пакеты, передаваемые источником, войдут в результирующие пакеты, принимаемые получателем, с неизвестными коэффициентами, которые могут зависеть от текущей структуры сети и даже от случайных решений, принимаемых на промежуточных узлах.
В качестве основного способа рассматривается включение в передаваемый пакет дополнительной информации, идентифицирующей пакет в рамках некоторой сессии (считается, что комбинироваться могут пакеты, принадлежащие только одной сессии). Например, это может быть простое битовое поле. Для рассмотренной выше сети-бабочка данное битовое поле может состоять из двух бит для каждого пакета:
Первый получатель получит два пакета с битовыми полями «1 0» и «1 1», второй получатель – «0 1» и «1 1». Используя это поле как информацию о коэффициентах линейного уравнения для пакетов, получатель может восстановить исходные пакеты, если они были переданы без ошибок.
2.3. Защита информации от искажения
В рассматриваемых сетях важным показателем является защита, так как информация представляет ценность для абонентов. Сохранение конфиденциальности и есть защита информации. Чтобы определить необходимые и достаточные методы защиты информации, нужно в первую очередь сформулировать полный перечень (модель) угроз информации. Далее необходимо рассмотреть все возможные варианты перекрытия информации от приведенных угроз.
Для продолжения изложения необходимо ввести ряд понятий и определений. Сеть передачи данных – совокупность оконечных устройств (терминалов) связи, объединённых каналами передачи данных и коммутирующими устройствами (узлами сети), обеспечивающими обмен сообщениями между всеми оконечными устройствами. Узел сети – устройство, способное принимать, обрабатывать и передавать информацию. Абонент – пользователь оконечных устройств в сети передачи данных.
Сетевое кодирование – относительно новое понятие позволяющее достичь
максимального потока информации. Оно предполагает, что узлы, вместо обычной передачи пакетов, могут комбинировать несколько входных пакетов в один или в несколько выходных при помощи различных математических операций.
Любая из угроз имеет цель нарушить целостность потока между абонентами или хотя-бы минимально ему навредить, наблюдая за передачей данных и включая в нее свои сторонние пакеты, выдавая их за часть основного информационного потока. Угроза находится в защищенной, не ограниченной в ресурсах, знающей схемы кодирования и декодирования, знающей основы реализации, сети. На этом и основываются системы защиты информации. Они строятся на базе сетевого кодирования и способны обнаружить не только момент замены и искажения информации, но и наличие так называемого византийского узла, в котором и присутствует криптоаналитик. Стоит отметить, что данный принцип является рабочим только в том случае, если нарушитель является внутренним, когда можно однозначно сопоставить наличие помех в одном из наборов каналов с конкретным узлом (нарушителем), через который осуществлялась передача.
Для внешнего нарушителя задача обнаружения решается не до конца - модель сети и различные алгоритмы защиты информации позволяют обнаружить лишь каналы, в которых информация была изменена нарушителем. Сам факт наличия в сетях различных типов нарушителей подразумевает разделение проблемы защиты информации на две задачи: обнаружение нарушителей и защиту от нарушителей. Сторонний, он же внешний, нарушитель зашумляет каналы передачи, пытается дешифровать информацию, чаше всего подвергаются модели беспроводных сетей. Начиная с узла, исказившего даже один элемент хотя бы одного пакета, происходит лавинное размножение ошибок в сети передачи. И все получатели, связанные с отправителем через такой узел, примут некоторую часть или даже все пакеты искажёнными. При восстановлении исходных пакетов из полученных линейных комбинаций с высокой вероятностью искажёнными окажутся все исходные пакеты. Для борьбы с преднамеренными искажениями достаточно уметь обнаруживать наличие искажений (злоумышленника) и блокировать искажённые пакеты.
Если конечный получатель может выяснить, что данные искажены, то их придётся передавать вновь, что ведёт к росту объёмов передаваемых по сети данных для передачи фиксированного объёма полезных данных. Это можно расценивать как падение пропускной способности. Если падение из-за распространения искажений окажется больше прироста, то теряется смысл применения сетевого кодирования. В современных сетях распространен подход к обеспечению информационной безопасности, при котором процедуры передачи информации и её защиты применяются независимо друг от друга. Особенность сетевого кодирования состоит в том, что данные не просто передаются, а они ещё и подвергаются обработке. Обработка ведёт к тому, что появляются новые данные, которые изначально источником не передавались. В этом случае известными методами (криптографической) защиты можно воспользоваться только при восстановлении исходных данных. В случае невозможности восстановления получателем данные придётся передавать снова, а предыдущая работа промежуточных узлов по передаче данных окажется напрасной. Поэтому необходимы меры защиты с учётом сетевого кодирования. В данном разделе представим аналитический обзор работ, в которых используются криптографические методы для защиты информации в сети.
Для неслучайного сетевого кодирования можно использовать стандартные способы защиты от помех и искажений, используемых для простой передачи информации по сети. Однако, как отмечено в статье «LDPC coding schemes for error», пакеты, восстанавливаемые из линейных комбинаций, имеют большую вероятность быть принятыми с ошибкой, так как на них влияет вероятность ошибки сразу в двух пакетах, используемых для восстановления информации.
Рассматривая сеть «бабочка», можно показать, что для первого получателя вероятность принять пакет A без ошибок больше, чем для пакета B, даже если предположить одинаковые, но отличные от нуля вероятности ошибок в принятых получателем пакетах A и A B. Для того, чтобы уменьшить подобный эффект авторы предлагают модифицировать способ итеративного декодирования пакетов A и B (например, при использовании LDPC-кодирования), когда итерации декодирования пакетов проводятся одновременно и декодеры обмениваются между собой об информации о вероятностях ошибок в конкретных битах пакетов. Для полного избавления от данного эффекта авторы предлагают также разбить исходные пакеты на несколько частей и передавать их различными путями. Как показал численный эксперимент, это действительно уравнивает вероятности декодирования пакетов.
Методы, используемые для декодирования в случайном сетевом кодировании, рассматривают все принятые пакеты как единый объект (часто – матрицу), построенной из принятых пакетов-строк. Если первая часть пакета представляет собой битовое поле, то операции с матрицей сводятся во-первых, к приведению левой её части к диагональному виду (с помощью метода Гаусса), а во-вторых к исправлению ошибок в правой части матрицы.
Для исправления ошибок можно использовать ранговые коды, которые могут исправить не только ошибки в столбцах матрицы (из-за неправильно принятых битов данных), но и ошибки в строках матрицы (из-за ошибок передачи в битовом поле).
2.4. Способы коммутации
В традиционных телефонных сетях, связь абонентов между собой выполняется с помощью коммутации каналов связи. В начале коммутация телефонных каналов связи выполнялась вручную, далее коммутацию выполняли автоматические телефонные станции (АТС).
Аналогичный принцип используется и в вычислительных сетях. В качестве абонентов выступают территориально удаленные вычислительные машины в компьютерной сети. Физически не представляется возможным предоставить каждому компьютеру свою собственную некоммутируемую линию связи, которой они пользовались бы в течении всего времени. Поэтому, практически во всех компьютерных сетях всегда используется какой-либо способ коммутации абонентов (рабочих станций), выполняющий возможность доступа к существующим каналам связи для нескольких абонентов, для обеспечения одновременно нескольких сеансов связи.
Коммутация — это процесс соединения различных абонентов коммуникационной сети через транзитные узлы. Коммуникационные сети должны обеспечивать связь своих абонентов между собой. Абонентами могут выступать ЭВМ, сегменты локальных сетей, факс-аппараты или телефонные собеседники.
Рабочие станции подключаются к коммутаторам с помощью индивидуальных линий связи, каждая из которых используется в любой момент времени только одним, закрепленным за этой линией, абонентом. Коммутаторы соединяются между собой с использованием разделяемых линий связи (используются совместно несколькими абонентами).
Рассмотрим три основных наиболее распространенных способа коммутации абонентов в сетях:
- коммутация каналов (circuit switching);
- коммутация пакетов (packet switching);
- коммутация сообщений (message switching).
Коммутация каналов подразумевает образование непрерывного составного физического канала из последовательно соединенных отдельных канальных участков для прямой передачи данных между узлами. Отдельные каналы соединяются между собой специальной аппаратурой - коммутаторами, которые могут устанавливать связи между любыми конечными узлами сети. В сети с коммутацией каналов перед передачей данных всегда необходимо выполнить процедуру установления соединения, в процессе которой и создается составной канал.
Время передачи сообщения при этом определяется пропускной способностью канала, длинной связи и размером сообщения.
Коммутаторы, а также соединяющие их каналы, должны обеспечивать одновременную передачу данных нескольких абонентских каналов. Для этого они должны быть высокоскоростными и поддерживать какую-либо технику мультиплексирования абонентских каналов.
Достоинства коммутации каналов:
- постоянная и известная скорость передачи данных;
- правильная последовательность прихода данных;
- низкий и постоянный уровень задержки передачи данных через сеть.
Недостатки коммутации каналов:
- возможен отказ сети в обслуживании запроса на установление соединения;
- нерациональное использование пропускной способности физических каналов, в частности невозможность применения пользовательской аппаратуры, работающей с разной скоростью;
- отдельные части составного канала работают с одинаковой скоростью, так как сети с коммутацией каналов не буферизуют данные пользователей;
- обязательная задержка перед передачей данных из-за фазы установления соединения.
Коммутация сообщений – разбиение информации на сообщения, каждое из которых состоит из заголовка и информации. Это способ взаимодействия, при котором создается логический канал, путем последовательной передачи сообщений через узлы связи по адресу, указанному в заголовке сообщения.
При этом каждый узел принимает сообщение, записывает в память, обрабатывает заголовок, выбирает маршрут и выдает сообщение из памяти в следующий узел.
Время доставки сообщения определяется временем обработки в каждом узле, числом узлов и пропускной способностью сети. Когда заканчивается передача информации из узла А в узел связи В, то узел А становится свободным, и может участвовать в организации другой связи между абонентами, поэтому канал связи используется более эффективно, но система управления маршрутизации будет сложной.
Сегодня коммутация сообщений в чистом виде практически не существует.
Коммутация пакетов - это особый способ коммутации узлов сети, который специально создавался для наилучшей передачи компьютерного трафика (пульсирующего трафика). Опыты по разработке самых первых компьютерных сетей, в основе которых лежала техника коммутации каналов, показали, что этот вид коммутации не предоставляет возможности получить высокую пропускную способность вычислительной сети. Причина крылась в пульсирующем характере трафика, который генерируют типичные сетевые приложения.
При коммутации пакетов все передаваемые пользователем сети сообщения разбиваются в исходном узле на сравнительно небольшие части, называемые пакетами. Необходимо уточнить, что сообщением называется логически завершенная порция данных - запрос на передачу файла, ответ на этот запрос, содержащий весь файл, и т. п. Сообщения могут иметь произвольную длину, от нескольких байт до многих мегабайт. Напротив, пакеты обычно тоже могут иметь переменную длину, но в узких пределах, например от 46 до 1500 байт (EtherNet). Каждый пакет снабжается заголовком, в котором указывается адресная информация, необходимая для доставки пакета узлу назначения, а также номер пакета, который будет использоваться узлом назначения для сборки сообщения.
Коммутаторы пакетной сети отличаются от коммутаторов каналов тем, что они имеют внутреннюю буферную память для временного хранения пакетов, если выходной порт коммутатора в момент принятия пакета занят передачей другого пакета.
Достоинства коммутации пакетов:
- более устойчива к сбоям;
- высокая общая пропускная способность сети при передаче пульсирующего трафика;
- возможность динамически перераспределять пропускную способность физических каналов связи.
Недостатки коммутации пакетов:
- неопределенность скорости передачи данных между абонентами сети;
- переменная величина задержки пакетов данных;
- возможны потери данных из-за переполнения буферов;
- возможны нарушения последовательности прихода пакетов.
- в компьютерных сетях применяется коммутация пакетов.
Cпособы передачи пакетов в сетях:
- Дейтаграммный способ – передача осуществляется как совокупность независимых пакетов. Каждый пакет двигается по сети по своему маршруту и пользователю пакеты поступают в произвольном порядке.
Достоинства: простота процесса передачи.
Недостатки: низкая надежность за счет возможности потери пакетов и необходимость программного обеспечения для сборки пакетов и восстановления сообщений.
- Логический канал - это передача последовательности связанных в цепочки пакетов, сопровождающихся установкой предварительного соединения и подтверждением приема каждого пакета. Если i-ый пакет не принят, то все последующие пакеты не будут приняты.
- Виртуальный канал – это логический канал с передачей по фиксированному маршруту последовательности связанных в цепочки пакетов.
Достоинства: сохраняется естественная последовательность данных; устойчивые пути следования трафика; возможно резервирование ресурсов.
Недостатки: сложность аппаратной части.
Глава 3.Программное кодирование
3.1. Исходный код
Исходный код (также исходный текст) – текст компьютерной программы на каком-либо языке программирования или языке разметки, который может быть прочтён человеком.
В обобщённом смысле – любые входные данные для транслятора. Исходный код транслируется в исполняемый код целиком до запуска программы при помощи компилятора или может исполняться сразу при помощи интерпретатора. Исходный код либо используется для получения объектного кода, либо выполняется интерпретатором. Изменения выполняются только над исходным, с последующим повторным преобразованием в объектный. Другое важное назначение исходного кода – в качестве описания программы. По тексту программы можно восстановить логику её поведения. Для облегчения понимания исходного кода используются комментарии. Существуют также инструментальные средства, позволяющие автоматически получать документацию по исходному коду – т. н. генераторы документации. Кроме того, исходный код имеет много других применений. Он может использоваться как инструмент обучения; начинающим программистам бывает полезно исследовать существующий исходный код для изучения техники и методологии программирования. Он также используется как инструмент общения между опытными программистами благодаря своей лаконичной и недвусмысленной природе. Совместное использование кода разработчиками часто упоминается как фактор, способствующий улучшению опыта программистов.
Программисты часто переносят исходный код (в виде модулей, в имеющемся виде или с адаптацией) из одного проекта в другой, что носит название повторного использования кода. Исходный код – важнейший компонент для процесса портирования программного обеспечения на другие платформы. Без исходного кода какой-либо части ПО портирование либо слишком сложно, либо вообще невозможно.
3.2. Организация
Исходный код некоторой части ПО (модуля, компонента) может состоять из одного или нескольких файлов. Код программы не обязательно пишется только на одном языке программирования. Например, часто программы, написанные на языке Си, из соображений оптимизации, содержат вставки кода на языке ассемблера. Также возможны ситуации, когда некоторые компоненты или части программы пишутся на различных языках, с последующей сборкой в единый исполняемый модуль при помощи технологии, известной как компоновка библиотек (library linking).
Сложное программное обеспечение при сборке требует использования десятков или даже сотен файлов с исходным кодом. В таких случаях для упрощения сборки обычно используются файлы проектов, содержащие описание зависимостей между файлами с исходным кодом и описывающие процесс сборки. Эти файлы также могут содержать параметры для компилятора и среды проектирования. Для разных сред проектирования могут применяться разные файлы проекта, причём в некоторых средах эти файлы могут быть в текстовом формате, пригодном для непосредственного редактирования программистом с помощью универсальных текстовых редакторов, в других средах поддерживаются специальные форматы, а создание и изменение файлов производится с помощью специальных инструментальных программ. Файлы проектов обычно включают в понятие «исходный код». Часто под исходным кодом подразумевают и файлы ресурсов, содержащие различные данные, например графические изображения, нужные для сборки программы.
Для облегчения работы с исходным кодом и для совместной работы над кодом, командой программистов используются системы управления версиями.
В отличие от человека, для компьютера нет «хорошо написанного» или «плохо написанного» кода. Но то, как написан код, может сильно влиять на процесс сопровождения ПО. О качестве исходного кода можно судить по следующим параметрам:
- читаемость кода (в том числе наличие комментариев к коду);
- лёгкость в поддержке, тестировании, отладке и устранении ошибок, модификации и портировании;
- экономное использование ресурсов: памяти, процессора, дискового пространства;
- отсутствие замечаний, выводимых компилятором;
- отсутствие «мусора» — неиспользуемых переменных, недостижимых блоков кода, ненужных устаревших комментариев и т. д.;
- адекватная обработка ошибок;
- возможность интернационализации интерфейса.
3.3. Защита и хранение
Ключевым вопросом в исследованиях по комплексной защите информации в инфокоммуникационных системах (ИКС) является определение параметров и критериев защищенности информации. С этой целью разработаны методы формирования правил разграничения доступа, включающие в себя классификацию компонентов доступа и угроз безопасности информации, разработку модели нарушителя и оценку возможности реализации угроз. Исследования поведения ИКС под воздействием угроз нарушителя и правил разграничения доступа позволили определить функции системы разграничения доступа и ее структуру. С помощью разработанных моделей разграничения доступа к информации в ИКС, определены и исследованы параметры средств защиты каналов доступа, средств управления доступом к защищаемым данным и предложены методы их количественной оценки. Для безусловного разграничения доступа к ресурсам ИКС разработаны алгоритмы реализации правил разграничения доступа, гарантирующие их полноту и непротиворечивость в условиях неоднозначности распределения сведений между компонентами ИКС. Установлены характерные особенности и определены возможности выбора вариантов реализации алгоритмов управления доступом, исходя из критерия допустимого снижения суммарной ценности информации, доступной пользователям. Проведено исследование механизмов управления доступом к информации в узловых элементах ИКС. Установлено, что управление доступом в ИКС должно осуществляться на двух уровнях, причем на первом уровне должна осуществляться блокировка доступа к ресурсам неправомочных пользователей, а на втором уровне необходима реализация механизма избирательной модификации предоставляемых ресурсов в соответствии с установленными полномочиями доступа. Разработанные на основе теории автоматов, модели средств защиты каналов доступа к ресурсам ИКС позволили обосновать их структуру, принципы построения и определить основные функции, включающие обнаружение входного воздействия, определение его соответствия эталонному, разблокирование входа в ИКС и контроль исполнения.
Для реализации полномочного доступа пользователей в ИКС должна обеспечиваться защита программно-аппаратных средств и обрабатываемой информации от целенаправленного изменения, т.е. задача обеспечения контроля целостности программного обеспечения, массивов данных и передаваемых сообщений. Разработана методология проверки целостности множества сообщений, основанная на использовании специально выбранных функций. Получены выражения для определения значений вероятности необнаружения искажений и определена нижняя граница их допустимых значений. Развиты методы обеспечения целостности и неизменности хранимых данных и имитозащиты передаваемых сообщений. Установлено, что для широковещательных сетей наиболее предпочтительной является криптографическая схема аутентификации с предварительным сжатием текста защищаемого сообщения с помощью необратимых функций. В этом случае обеспечивается снижение временных затрат при обработке сообщения, величина которых пропорциональна длине сообщения и числу абонентов, получающих циркулярное сообщение. Важное место в системе защиты ИКС занимает контроль доступа к ее ресурсам. В большинстве конфигураций, где средства контроля доступа являются единственной связью между сетями, при перегрузках сети, в результате атаки, они могут стать единственной точкой отказа от обслуживания и блокировки трафика. Разрабатывались средства, обеспечивающие минимально возможную вероятность потери информации о нарушении доступа за нормированное время реакции и блокирования нарушения. Одной из важнейших задач комплексной безопасности является распознавание личности по голосу и речи. Были разработаны экспериментальные стенды верификации и идентификации для распознавания личности по голосу и парольной фразе для биометрических систем контроля доступа.
Вопросы контроля ошибок при передаче, обработке и хранении данных являются центральными в системах ответственного применения. Проведенные в конце 60-х гг. исследования по синтезу отказоустойчивых алгоритмов и вычислительных структур (цифровых автоматов) на основе применения корректирующих кодов (избыточного кодирования) и резервирования показали, что для эффективного использования избыточности необходимо знать статистические свойства ошибок в цифровых устройствах (интенсивность сбоев и отказов элементов, распределение ошибок по их кратностям, асимметрию ошибок и т.п.), особенности построения и работы цифровых устройств, характерные свойства применяемых корректирующих кодов (групповых, арифметических и др.), процедур их кодирования и декодирования, использование теории абстрактного и структурного синтеза цифровых автоматов, теории кодов, исправляющих ошибки, теорию графов. Было показано, что плодотворным оказывается путь введения избыточности не с выбора помехоустойчивого кода, а с устранения эффекта размножения ошибок. Для этого предварительно вводятся дополнительные элементы памяти для закрытия каналов распространения ошибок, а затем уже осуществляется кодирование состояний, использование восстанавливающих органов.
Необходимость построения надежных однородных микроэлектронных структур (БИС запоминающих устройств - ОЗУ, ПЗУ, ППЗУ, РПЗУ), устойчивых к отказам и сбоям элементов, технологическим дефектам при изготовлении кристаллов памяти, предопределило проведение исследований по введению избыточности в БИС ЗУ с целью повышения надежности при производстве и эксплуатации. Впервые в мире было предложено для повышения процента выхода СБИС ЗУ вводить избыточные элементы и подключать их на заключительном этапе производства для устранения влияния дефектных элементов. Были разработаны разнообразные способы, устройства и схемы по подключению резервных элементов, отличающихся видом вводимой избыточности, типом программируемых элементов, схемами их подключения, контролем ЗУ с резервом.
При использовании избыточного кодирования совокупность элементов памяти можно рассматривать как канал передачи информации, в котором последняя передается не в пространстве, а во времени. Эта особенность приводит к рассмотрению систем хранения как специфического канала передачи информации. Возникающие при этом ситуации хорошо описываются с помощью обобщенной модели канала хранения. Применение данной модели канала хранения информации позволяет более полно согласовать состояние канала с вводимой избыточностью, уменьшить ее, сформировать требования к корректирующему коду, предложить эффективные методы и коды для защиты памяти от многократных ошибок. Коды, исправляющие дефекты, как показано в работах, позволяют согласовать записываемую в ЗУ информацию с состоянием дефектов при использовании небольшой информационной избыточности и сложности обработки.
Глава 4. Энтропийное кодирование
4.1. Определения
Энтропийное кодирование – кодирование последовательности значений с возможностью однозначного восстановления с целью уменьшения объёма данных (длины последовательности) с помощью усреднения вероятностей появления элементов в закодированной последовательности.
Предполагается, что до кодирования отдельные элементы последовательности имеют различную вероятность появления. После кодирования в результирующей последовательности вероятности появления отдельных символов практически одинаковы (энтропия на символ максимальна).
Различают несколько вариантов кодов:
- сопоставление каждому элементу исходной последовательности различного числа элементов результирующей последовательности. Чем больше вероятность появления исходного элемента, тем короче соответствующая результирующая последовательность. Примером могут служить код Шеннона – Фано, код Хаффмана;
- сопоставление нескольким элементам исходной последовательности фиксированного числа элементов конечной последовательности. Примером является код Танстола;
- другие структурные коды, основанные на операциях с последовательностью символов. Примером является кодирование длин серий.
Если приблизительные характеристики энтропии потока данных предварительно известны, может быть полезен более простой статический код, такой как унарное кодирование, гамма-код Элиаса, код Фибоначчи, код Голомба или кодирование Райса.
Согласно теореме Шеннона, существует предел сжатия без потерь, зависящий от энтропии источника. Чем более предсказуемы получаемые данные, тем лучше их можно сжать. Случайная независимая равновероятная последовательность сжатию без потерь не поддаётся.
4.2. Энтропийное сжатие
Кодирование энтропии – кодирование словами (кодами) переменной длинны, при которой длина кода символа имеет обратную зависимость от вероятности появления символа в определенном сообщении.
Обычно энтропийные кодировщики используют для сжатия данных коды, длины которых пропорциональны отрицательному логарифму вероятности символа. Таким образом, наиболее вероятные символы используют наиболее короткие коды. Согласно теореме Шеннона, оптимальная длина кода для символа равна 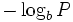 , где
, где 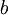 - это количествосимволов, использованных для изготовления выходного кода, и
- это количествосимволов, использованных для изготовления выходного кода, и 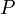 — вероятность входного символа.
— вероятность входного символа.
Три самых распространенных способа кодирования энтропии – это кодирование Хаффмана, кодирование длин серий и арифметическое кодирование.
Глава 5. Дельта-кодирование
5.1. Основы дельта-кодирования
Дельта-кодирование (англ. Delta encoding) – способ представления данных в виде разницы (дельты) между последовательными данными вместо самих данных. Пожалуй, наиболее простой пример заключается в сохранении значений байтов как различия (дельты) между последовательными значениями, в отличие от самих значений. Поэтому вместо 2, 4, 6, 9, 7, мы будем сохранять 2, 2, 2, 3, −2. Это не очень полезно в случае, когда используется само по себе, но может помочь в случае дальнейшей компрессии этих данных, в которых часто встречаются повторяющиеся значения. Например, звуковой формат IFF 8SVX применяет это кодирование к чистым звуковым данным перед тем, как применять к ним компрессию. Только 8-битные звуковые семплы хорошо сжимаются в случае дельта-кодирования, а в случае 16-битных и выше семплов этот метод работает хуже. Поэтому, алгоритмы компрессии часто выбирают дельта-кодирование только тогда, когда сжатие с ним лучше, чем без него. Однако в сжатии видео дельта-фреймы могут значительно уменьшать размер фрейма, и используются практически в каждом видеокодеке.
Вариация дельта-кодирования, которая кодирует различия между префиксами или суффиксами строк, называется инкрементным кодированием. Оно в частности эффективно для отсортированных списков с малыми различиями между строками, такими, например, как список слов из словаря.
В дельта-кодированной передаче по сети, где только единичная копия файла доступна на каждом конце коммуникационного канала, используются специальные коды коррекции ошибок для обнаружения того, какие части файла изменились со времени предыдущей версии.
Дельта-кодирование применяется как предварительный этап для многих алгоритмов сжатия, к примеру RLE, и в инвертированных индексах поисковых программ. Природа данных, которые будут закодированы, значительно влияет на эффективность сжатия. Дельта-кодирование повышает коэффициент сжатия в том случае, когда данные имеют маленькую или постоянную вариацию (как, к примеру, градиент на изображении); для данных, сгенерированных генератором случайных чисел с равномерным распределением, коэффициент сжатия изменится не сильно.
Дельта-кодирование делает невозможным произвольный доступ к данным, так как для обращения к элементу массива необходимо просуммировать значения всех предыдущих. Если это все же необходимо, применяется блочный вариант дельта-кодирования, в котором кодируются блоки некоторой заданной длины. Тогда необходимо лишь просуммировать значения с начала блока, которому принадлежит искомый элемент, но не всего файла. Размер блока выбирается в зависимости от приложения, обычно по результатам хронометража.
5.2. Дельта-модуляции
Дельта-модуляция – способ преобразования аналогового сигнала в цифровую форму. Метод дельта-модуляции был изобретён в 1946 г. В каждый момент отсчета преобразуемый сигнал сравнивается с пилообразным напряжением на каждом шаге дискретизации. Пилообразное напряжение поступает из интегратора, который замыкает цепь обратной связи дельта-модулятора. Таким образом, поступающий в сумматор сигнал сравнивается со значением сигнала в конце предыдущего шага дискретизации. Если в момент сравнения текущая величина сигнала превышает мгновенное значение пилообразного напряжения (выходное напряжение интегратора), то последнее нарастает до следующей точки дискретизации, в противном случае оно спадает. В простейшей системе модуль скорости изменения пилообразного напряжения сохраняется неизменным в процессе преобразования.
Полученный бинарный сигнал можно рассматривать как производную от пилообразного напряжения. Выбирая достаточно малым значение шага Δ, можно получить любую заданную точность представления сигнала. Фактически, дельта-модуляция представляет собой разновидность другого, более известного, способа преобразования – импульсно-кодовой модуляции (ИКМ), в которой число уровней квантования равно двум. При ДМ по каналу связи передаётся не абсолютное значение сигнала, а разность между исходным аналоговым сигналом и аппроксимирующим напряжением (сигнал ошибки). По сравнению с конкурирующими методами, ИКМ и АДИКМ, дельта-модуляция характеризуется меньшей сложностью технической реализации, более высокими помехозащищённостью и гибкостью изменения скорости передачи.
Преимущество дельта-модуляции по сравнению, например, с ИКМ, которая также генерирует бинарный сигнал, заключается не столько в реализуемой точности при заданной частоте дискретизации, сколько в простоте реализации. Основной недостаток ДМ состоит в том, что при быстрых изменениях сигнала дельта-кодер не успевает отслеживать изменения его уровня, вследствие чего возникает так называемая "перегрузка по крутизне". Существует большое число разновидностей ДМ, в которых используются различные способы устранения этого вида искажений. Большинство из них основаны на использовании мгновенного или инерционного компандирования аналогового сигнала, либо адаптивного изменения ступеньки аппроксимирующего напряжения в соответствии с крутизной входного сигнала.
Заключение
В данной курсовой работе, в результате исследований была достигнута поставленная цель, а именно – изучение методов кодирования данных. Рассмотрены основные понятия и принципы кодирования информации.
После выполнения целей и задач курсовой работы были сделаны следующие выводы.
Проблема кодирования информации имеет достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая обычно шла параллельно с историей развития проблем сжатия и шифровки информации.
Важнейшими задачами, которые выполняет кодирование, являются:
- разработка принципов наиболее экономичного кодирования информации;
- согласование параметров передаваемой информации с особенностями канала связи;
- разработка приемов, обеспечивающих надежность передачи информации по каналам связи, т. е. отсутствие потерь информации.
Развитие кодов и методов кодировки данных способствует уменьшению времени, затрачиваемого для передачи информации между двумя получателями и более. В свою очередь, сокращение времени обработки информации позволяет затрачивать меньшее количество ресурсов для ее хранения, и сбора.
Наиболее значимыми, и требующими дальнейшего изучения, являются методы сетевого и программного кодирования. Это обоснованно бесконечной модернизацией коммуникационных технологий, языков кодирования, источников сбора и хранения данных, что, в свою очередь, дает основу для безграничных исследований данных методов.
При написании курсовой работы по теме “Методы кодирования данных”, мною была изучена специальная литература, статьи по информационным технологиям, учебники по информатике.
Список литературы
1.Венчковский, Л.Б. Методы кодирования технико-экономической информации / Л.Б. Венчковский. - М.: Советское радио, 1978. - 120 c.
2.Елепин, А. П. Компьютерные информационные технологии. Теоретические основы профессиональной деятельности. Учебное пособие / А.П. Елепин, С.В. 3.Соколова. - М.: Академкнига/Учебник, 2005. - 160 c.
4.Сидоров, В. Д. Аппаратное обеспечение ЭВМ / В.Д. Сидоров, Н.В. Струмпэ. - М.: Академия, 2011. - 336 c.
5.Ш.-К.Чэн Принципы проектирования систем визуальной информации / Ш.-К.Чэн. - М.: Мир, 1994. - 416 c.
6.Зубов А.Ю. Совершенные шифры. - М.: Гелиос АРВ 2003
7.Конопелько В.К. Помехоустойчивое кодирование в РТС ПИ. Однородные коды. Минск, 1993.
8.Липницкий В.А., Конопелько В.К. Норменное декодирование помехоустойчивых кодов и алгебраические уравнения. Минск, 2007.
8.Молдовян, А. А. Криптография: скоростные шифры / А. А. Молдовян, H. A.
9.Молдовян, H. Д. Гуц, Б. В. Изотов. - СПб.: БХВ-Петербург, 2002. - 496 с
10.Лосев В.В., Конопелько В.К., Карякин Ю.Д. // Проблемы передачи информации. 1978. Т. 14, № 4
11.Корсунов Н.И., Муромцев В.В., Титов А.И. Метод расширения ключа для шифрования информации // Научные ведомости БелГУ. Серия: История, Политология, Экономика, Информатика. - 2010. - №19.
12.А., Назаров und К. Сычев Теоретические основы проектирования сетей связи следующего поколения / А. Назаров und К. Сычев. - М.: LAP Lambert Academic Publishing, 2012. - 536 c
13.Бобов М.Н., Силина Т.В. // Управление защитой информации. 2007. № 4. С.454-460.
14.Д. Ватолин, А. Ратушняк, М. Смирнов, В. Юкин. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео. — Диалог-МИФИ, 2002. — С. 384. — ISBN 5-86404-170-X. 3000 экз.
15.Д. Сэломон. Сжатие данных, изображения и звука. — М.: Техносфера, 2004. — С. 368. — ISBN 5-94836-027-X. 3000 экз.

- Разработка регламента выполнения процесса «Развитие и подготовка сотрудников»
- Baskerville. История создания, современные традиции использования
- Специальные (отраслевые) принципы оперативно-розыскной деятельности
- Предмет и принципы предпринимательского права
- Авторское право (Общие положения авторского права )
- Роль мотивации в поведении организации (Сущность и значение мотивации персонала)
- Финансовая политика и ее реализация в РФ (Сущность и функции финансовой политики)
- Процессы принятия решений в организации (Понятие управленческого решения)
- Анализ и оценка финансового состояния банка
- Виды договоров (Институт договора в гражданском праве)
- Основы проектирования программ. Этапы создания программного обеспечения
- Использование в деятельности менеджера современных концепций лидерства (Классические и современные теории лидерства)