
Методы кодирования данных (Классификация информации)
Содержание:

Введение
Веками человечество накапливало знания, навыки работы, сведения об окружающем нас мире, иными словами, собирало информацию. Вначале информация передавалась из поколения в поколение в виде преданий и устных рассказов. Возникновение и развитие книжного дела позволило передавать и хранить информацию в более надежном письменном виде. Открытия в области электричества привели к появлению телеграфа, телефона, радио, телевидения - средств, позволяющих оперативно передавать и накапливать информацию. Развитие прогресса обусловило резкий рост информации, в связи, с чем вопрос о её сохранении и переработке становился год от года острее. С появлением вычислительной техники значительно упростились способы хранения, а главное, обработки информации. Развитие вычислительной техники на базе микропроцессоров приводит к совершенствованию компьютеров и программного обеспечения. Появляются программы, способные обработать большие потоки информации. С помощью таких программ создаются информационные системы. Целью любой информационной системы является обработка данных об объектах и явлениях реального мира и предоставление нужной человеку информации о них.
В данной работе рассматривается что такое информация и данные, чем они различаются; методы классификации информации, виды форм предоставления информации и методы кодирования данных.
1. Что такое информация и данные
Информация и данные — это базовые понятия, которые используются в информатике. Эта наука занимается вопросами систематизации, хранения, обработки и передачи данных и информации средствами вычислительной техники. Эти понятия зачастую используются как синонимы, но между ними существуют и принципиальные различия.
Данные — это совокупность сведений, которые зафиксированы на каком-либо носителе - бумаге, диске, пленке. Эти сведения должны быть в форме, пригодной для хранения, передачи и обработки. Дальнейшее преобразование данных позволяет получить информацию. Таким образом, информацией можно назвать результат анализа и преобразования данных. В базе хранятся различные данные, а система управления базой может выдавать по определенному запросу требуемую информацию. К примеру, можно узнать из школьной базы данных, кто из учеников живет на определенной улице или, кто в течение года не получил плохой отметки и др. Данные превращаются в информацию тогда, когда ими заинтересуются. Можно утверждать, что информация — это используемые данные.
Слово «информация» произошло от латинского informatio, что значит «сведения, изложение, разъяснение». Также информацией называют сведения об объектах, явлениях окружающей среды, их свойствах, которые уменьшают степень неопределенности, неполноты знаний. В результате обмена сведениями формируется более полное представление о предмете, повышается уровень осведомленности.
Информация не существует изолированно, сама по себе. Всегда есть источник, который ее производит и приемник, ее воспринимающий. В роли источника или приемника выступает любой объект - человек, компьютер, животное, растение. Информация всегда предназначается конкретному объекту. Человек получает информацию из самых разных источников - при чтении, прослушивании радио, просмотре телепередач, когда он дотрагивается до предмета, пробует на вкус еду. Одну и ту же информацию разные люди могут воспринимать по-разному. В зависимости от сферы использования существует научная, техническая, экономическая и другие виды информации. Это сильнейшее средство воздействия на личность и на общество в целом. Согласно известному выражению, кто владеет наибольшей информацией по какому-либо вопросу, тот владеет миром, то есть, находится в выигрышном положении в сравнении с другими. В повседневной жизни от информации зависит развитие общества, здоровье и жизнь людей. На протяжении тысячелетий человечество накопило огромные запасы знаний, которые все продолжают увеличиваться. Объем информации в наши дни удваивается каждые два года. В любой ситуации, даже самой обыденной, эффективна лишь актуальная, полная, достоверная и понятная информация. Только актуальные, то есть, вовремя полученные сведения могут принести пользу людям.
Таким образом человечество пришло к тому, что появилась необходимость классифицировать информацию.
Для того чтобы классифицированная информация стала средством для создания эффективной системы хранения и инструментом обработки информации, ее поиска и информационного обмена, она должна быть дополнена системой условных обозначений, присваиваемых объектам и классификационным группировкам. Такие обозначения в разных классификационных справочниках могут называться индексами или кодами, а процесс их присвоения объектам классификации или классификационным группировкам, индексированием или кодированием.
Знаки, составляющие индекс или код, называются их алфавитом. Такой алфавит может включать буквы, цифры, знаки пунктуации в их различных комбинациях. Так, индекс дела в номенклатуре дел представляет собой комбинацию знаков, которая включает индекс структурного подразделения, в котором создается и хранится дело, и порядковый номер дела внутри раздела, соответствующего данному структурному подразделению. Индекс какого-либо документа в универсальной десятичной классификации кроме индекса, отражающего основное содержание документа, может дополнительно включать индексы признаков, характеризующих документ (язык документа, исторический период, автор, тип документа и другие).
Индекс или код являются идентификаторами объекта классификации или классификационной группировки, и их основное назначение состоит в однозначном обозначении объектов классификации. Это своего рода формализованное имя объекта, которое должно обеспечивать возможность точного определения объекта классификации. Поэтому разработчики классификационных схем стремятся сделать индексы или коды мнемоничными, то есть такими, чтобы даже по внешнему виду, алфавиту кода пользователь мог определить объект и узнать возможно больше информации о характере объекта классификации, для обозначения которого использован этот код.
Кодирование есть процесс преобразования одного алфавита сообщения в другой алфавит. Применительно к документам, кодирование можно рассматривать как процесс присвоения документу единственного обозначения - кода, которое отличает один документ от другого, т.е. идентифицирует документ. С другой стороны, кодирование документа можно рассматривать как процесс преобразования документа на естественном языке в язык кодов.
Основное назначение кодирования состоит в приспособлении информационного сообщения к каналу связи. Кодирование документов и документной информации направлено на приспособление документа к возможностям его обработки с помощью средств вычислительной техники. С помощью кодирования информации обеспечивается возможность ее представления в компактной форме, ускоряется запись данных в первичных документах и в документах на машинных носителях и последующая обработка этих данных. Кодирование документной информации обеспечивает ее защиту от несанкционированного доступа.
Кодирование информации как сложный технологический процесс прошло длительный путь развития со времени появления письменности до современного широкого внедрения новых информационных технологий.
2. Теоретические основы кодирования информации
2.1 Основы и основные понятия кодирования информации
Рассмотрим основные понятия, связанные с кодированием информации. Для передачи в канал связи сообщения преобразуются в сигналы. Символы, при помощи которых создаются сообщения, образуют первичный алфавит, при этом каждый символ характеризуется вероятностью его появления в сообщении. Каждому сообщению однозначно соответствует сигнал, представляющий определенную последовательность элементарных дискретных символов, называемых кодовыми комбинациями.
Кодирование — это преобразование сообщений в сигнал, т.е. преобразование сообщений в кодовые комбинации. Код - система соответствия между элементами сообщений и кодовыми комбинациями. Кодер - устройство, осуществляющее кодирование. Декодер - устройство, осуществляющее обратную операцию, т.е. преобразование кодовой комбинации в сообщение. Алфавит - множество возможных элементов кода, т.е. элементарных символов (кодовых символов) X = {xi}, где i = 1, 2,..., m. Количество элементов кода - m называется его основанием. Для двоичного кода xi = {0, 1} и m = 2. Конечная последовательность символов данного алфавита называется кодовой комбинацией (кодовым словом). Число элементов в кодовой комбинации - n называется значностью (длиной комбинации). Число различных кодовых комбинаций (N = mn) называется объемом или мощностью кода.
Цели кодирования:
Повышение эффективности передачи данных, за счет достижения максимальной скорости передачи данных.
Повышение помехоустойчивости при передаче данных.
В соответствии с этими целями теория кодирования развивается в двух основных направлениях:
Теория экономичного (эффективного, оптимального) кодирования занимается поиском кодов, позволяющих в каналах без помех повысить эффективность передачи информации за счет устранения избыточности источника и наилучшего согласования скорости передачи данных с пропускной способностью канала связи.
Теория помехоустойчивого кодирования занимается поиском кодов, повышающих достоверность передачи информации в каналах с помехами.
Научные основы кодирования были описаны К. Шенноном, который исследовал процессы передачи информации по техническим каналам связи (теория связи, теория кодирования). При таком подходе кодирование понимается в более узком смысле: как переход от представления информации в одной символьной системе к представлению в другой символьной системе. Например, преобразование письменного русского текста в код азбуки Морзе для передачи его по телеграфной связи или радиосвязи. Такое кодирование связано с потребностью приспособить код к используемым техническим средствам работы с информацией.
Декодирование - процесс обратного преобразования кода к форме исходной символьной системы, т.е. получение исходного сообщения. Например: перевод с азбуки Морзе в письменный текст на русском языке.
В более широком смысле декодирование — это процесс восстановления содержания закодированного сообщения. При таком подходе процесс записи текста с помощью русского алфавита можно рассматривать в качестве кодирования, а его чтение — это декодирование.
Способ кодирования одного и того же сообщения может быть разным. Например, русский текст мы привыкли записывать с помощью русского алфавита. Но то же самое можно сделать, используя английский алфавит. Иногда так приходится поступать, посылая SMS по мобильному телефону, на котором нет русских букв, или отправляя электронное письмо на русском языке из-за границы, если на компьютере нет русифицированного программного обеспечения. Например, фразу: «Здравствуй, дорогой Саша!» приходится писать так: «Zdravstvui, dorogoi Sasha!».
Существуют и другие способы кодирования речи. Например, стенография - быстрый способ записи устной речи. Ею владеют лишь немногие специально обученные люди - стенографисты. Стенографист успевает записывать текст синхронно с речью говорящего человека. В стенограмме один значок обозначал целое слово или словосочетание. Расшифровать (декодировать) стенограмму может только стенографист.
Приведенные примеры иллюстрируют следующее важное правило: для кодирования одной и той же информации могут быть использованы разные способы; их выбор зависит от ряда обстоятельств: цели кодирования, условий, имеющихся средств. Если надо записать текст в темпе речи - используем стенографию; если надо передать текст за границу - используем английский алфавит; если надо представить текст в виде, понятном для грамотного русского человека, - записываем его по правилам грамматики русского языка.
Еще одно важное обстоятельство: выбор способа кодирования информации может быть связан с предполагаемым способом ее обработки. Покажем это на примере представления чисел - количественной информации. Используя русский алфавит, можно записать число «тридцать пять». Используя же алфавит арабской десятичной системы счисления, пишем: «35». Второй способ не только короче первого, но и удобнее для выполнения вычислений. Какая запись удобнее для выполнения расчетов: «тридцать пять умножить на сто двадцать семь» или «35 х 127»? Очевидно - вторая.
Однако если важно сохранить число без искажения, то его лучше записать в текстовой форме. Например, в денежных документах часто сумму записывают в текстовой форме: «триста семьдесят пять руб.» вместо «375 руб.». Во втором случае искажение одной цифры изменит все значение. При использовании текстовой формы даже грамматические ошибки могут не изменить смысла. Например, малограмотный человек написал: «Тристо семдесять пят руб.». Однако смысл сохранился.
В некоторых случаях возникает потребность засекречивания текста сообщения или документа, для того чтобы его не смогли прочитать те, кому не положено. Это называется защитой от несанкционированного доступа. В таком случае секретный текст шифруется. Шифрование представляет собой процесс превращения открытого текста в зашифрованный, а дешифрование - процесс обратного преобразования, при котором восстанавливается исходный текст. Шифрование — это тоже кодирование, но с засекреченным методом, известным только источнику и адресату. Методами шифрования занимается наука под названием криптография.
Пусть имеется сообщение, записанное при помощи некоторого «алфавита», содержащего п «букв». Требуется «закодировать» это сообщение, т.е. указать правило, сопоставляющее каждому такому сообщению определенную последовательность из т различных «элементарных сигналов», составляющих «алфавит» передачи. Мы будем считать кодирование тем более выгодным, чем меньше элементарных сигналов приходится затратить на передачу сообщения. Если считать, что каждый из элементарных сигналов продолжается одно и то же время, то наиболее выгодный код позволит затратить на передачу сообщения меньше всего времени.
Главным свойством случайных событий является отсутствие полной уверенности в их наступлении, создающее известную неопределенность при выполнении связанных с этими событиями опытов. Однако совершенно ясно, что степень этой неопределенности в различных случаях будет совершенно разной. Для практики важно уметь численно оценивать степень неопределенности самых разнообразных опытов, чтобы иметь возможность сравнить их с этой стороны.
Рассмотрим простейший случай сообщений, записанных при помощи некоторых п «букв», частоты проявления которых на любом месте сообщения полностью характеризуется вероятностями р1, р2, … …, рп, где, разумеется, р1 + р2 + … + рп = 1, при котором вероятность pi проявления i-й буквы на любом месте сообщения предполагается одной и той же, вне зависимости от того, какие буквы стояли на всех предыдущих местах, т.е. последовательные буквы сообщения независимы друг от друга. На самом деле в реальных сообщениях это чаще бывает не так; в частности, в русском языке вероятность появления той или иной буквы существенно зависит от предыдущей буквы. Однако строгий учет взаимной зависимости букв сделал бы все дельнейшие рассмотрения очень сложными, но никак не изменит будущие результаты.
Мы будем пока рассматривать двоичные коды; обобщение полученных при этом результатов на коды, использующие произвольное число т элементарных сигналов, является, как всегда, крайне простым. Начнем с простейшего случая кодов, сопоставляющих отдельное кодовое обозначение - последовательность цифр 0 и 1 - каждой «букве» сообщения. Каждому двоичному коду для п-буквенного алфавита может быть сопоставлен некоторый метод отгадывания некоторого загаданного числа х, не превосходящего п, при помощи вопросов, на которые можно ответить лишь «да» (1) или «нет» (0), что и приводит нас к двоичному коду. При заданных вероятностях р1, р2, … …, рп отдельных букв передача многобуквенного сообщения наиболее экономный код будет тот, для которого при этих именно вероятностях п значений х среднее значение числа задаваемых вопросов (двоичных знаков: 0 и 1 или элементарных сигналов) оказывается наименьшим.
Прежде всего, среднее число двоичных элементарных сигналов, приходящихся в закодированном сообщении на одну букву исходного сообщения, не может быть меньше Н, где Н = - p1 log p1 - p2 log p2 - … - pn log pn - энтропия опыта, состоящего в распознавании одной буквы текста (или, короче, просто энтропия
одной буквы). Отсюда сразу следует, что при любом методе кодирования для записи длинного сообщения из М букв требуется не меньше, чем МН двоичных знаков, и никак не может превосходить одного бита.
Если вероятности р1, р2, … …, рп не все равны между собой, то Н < log n; поэтому естественно думать, что учет статистических закономерностей сообщения может позволить построить код более экономичный, чем наилучший равномерный код, требующий не менее М log n двоичных знаков для записи текста из М букв.
2.2 Классификация назначения и способы представления кодов
Коды можно классифицировать по различным признакам:
- По основанию (количеству символов в алфавите): бинарные (двоичные m=2) и не бинарные (m № 2).
- По длине кодовых комбинаций (слов): равномерные, если все кодовые комбинации имеют одинаковую длину и неравномерные, если длина кодовой комбинации не постоянна.
- По способам передачи: последовательные и параллельные; блочные - данные сначала помещаются в буфер, а потом передаются в канал и бинарные непрерывные.
- По помехоустойчивости: простые (примитивные, полные) - для передачи информации используют все возможные кодовые комбинации (без избыточности); корректирующие (помехозащищенные) - для передачи сообщений используют не все, а только часть (разрешенных) кодовых комбинаций.
В зависимости от назначения и применения условно можно выделить следующие типы кодов:
Внутренние коды — это коды, используемые внутри устройств. Это машинные коды, а также коды, базирующиеся на использовании позиционных систем счисления (двоичный, десятичный, двоично-десятичный, восьмеричный, шестнадцатеричный и др.). Наиболее распространенным кодом в ЭВМ является двоичный код, который позволяет просто реализовать аппаратное устройства для хранения, обработки и передачи данных в двоичном коде. Он обеспечивает высокую надежность устройств и простоту выполнения операций над данными в двоичном коде. Двоичные данные, объединенные в группы по 4, образуют шестнадцатеричный код, который хорошо согласуется с архитектурой ЭВМ, работающей с данными кратными байту (8 бит).
Коды для обмена данными и их передачи по каналам связи. Широкое распространение в ПК получил код ASCII (American Standard Code for Information Interchange). ASCII — это 7-битный код буквенно-цифровых и других символов. Поскольку ЭВМ работают с байтами, то 8-й разряд используется для синхронизации или проверки на четность, или расширения кода. В ЭВМ фирмы IBM используется расширенный двоично-десятичный код для обмена информацией EBCDIC (Extended Binary Coded Decimal Interchange Code). В каналах связи широко используется телетайпный код МККТТ (международный консультативный комитет по телефонии и телеграфии) и его модификации (МТК и др.).
При кодировании информации для передачи по каналам связи, в том числе внутри аппаратным трактам, используются коды, обеспечивающие максимальную скорость передачи информации, за счет ее сжатия и устранения избыточности (например: коды Хаффмана и Шеннона-Фано), и коды обеспечивающие достоверность передачи данных, за счет введения избыточности в передаваемые сообщения (например: групповые коды, Хэмминга, циклические и их разновидности).
Коды для специальных применений — это коды, предназначенные для решения специальных задач передачи и обработки данных. Примерами таких кодов является циклический код Грея, который широко используется в АЦП угловых и линейных перемещений. Коды Фибоначчи используются для построения быстродействующих и помехоустойчивых АЦП.
В зависимости от применяемых методов кодирования, используют различные математические модели кодов, при этом наиболее часто применяется представление кодов в виде: кодовых матриц; кодовых деревьев; многочленов; геометрических фигур и т.д. Рассмотрим основные способы представления кодов.
Матричное представление кодов. Используется для представления равномерных n - значных кодов. Для примитивного (полного и равномерного) кода матрица содержит n - столбцов и 2n - строк, т.е. код использует все сочетания. Для помехоустойчивых (корректирующих, обнаруживающих и исправляющих ошибки) матрица содержит n - столбцов (n = k+m, где k-число информационных, а m - число проверочных разрядов) и 2k - строк (где 2k - число разрешенных кодовых комбинаций). При больших значениях n и k матрица будет слишком громоздкой, при этом код записывается в сокращенном виде. Матричное представление кодов используется, например, в линейных групповых кодах, кодах Хэмминга и т.д.
Представление кодов в виде кодовых деревьев. Кодовое дерево - связной граф, не содержащий циклов. Связной граф - граф, в котором для любой пары вершин существует путь, соединяющий эти вершины. Граф состоит из узлов (вершин) и ребер (ветвей), соединяющих узлы, расположенные на разных уровнях. Для построения дерева равномерного двоичного кода выбирают вершину, называемую корнем дерева (истоком) и из нее проводят ребра в следующие две вершины и т.д.
2.3 Классификация информации
Классификация – это разделение множества объектов на подмножества по их сходству или различию в соответствии с принятыми методами. Классификация фиксирует закономерные связи между классами объектов с целью определения места объекта в системе, которое указывает на его свойства. Под объектом понимается любой предмет, процесс, явление материального или нематериального свойства.
Система классификации позволяет сгруппировать объекты и выделить определенные классы, которые будут характеризоваться рядом общих свойств. Классификация объектов – та процедура группировки на качественном уровне, направленная на выделение однородных свойств.
Применительно к информации как к объекту классификации выделенные классы называют информационными объектами. С этой точки зрения классификация информации является важнейшим средством создания систем хранения и поиска информации, без которых сегодня невозможно эффективное функционирование информационного обеспечения управления. Классификатор – систематизированный свод однородных наименований, т.е. классифицируемых объектов и их кодовых обозначений.
Классификатор (классификационная схема) – систематизированный перечень наименований объектов, каждому из которых в соответствии дан уникальный код. Систематизация объектов производится согласно правилам распределения заданного множества объектов на подмножества (классификационные группировки) в соответствии с установленными признаками их различия и сходства. Применяется в автоматизированных системах управления и обработки информации. Классификатор является стандартным кодовым языком документов, финансовых отчетов и автоматизированных систем.
Структура классификатора, как правило, должна иметь три блока:
- блок идентификации, включающий коды объектов классификации и классификационных группировок,
- блок наименований объектов и классификационных группировок на естественном языке,
- блок дополнительных признаков объектов, включающий наименования и коды дополнительных признаков объектов классификации.
Кроме трехблочной структуры классификаторы могут иметь и двухблочную структуру, когда выделяются только блоки идентификации и наименований. В структуре классификаторов могут выделяться и другие виды блоков, а также разделы. Выбор структуры построения классификаторов определяется характером объектов классификации, типом задач, для решения которых предназначен классификатор, и используемыми методами классификации и кодирования.
3. Методы классификации информации
В классификаторах технико-экономической и социальной информации используются иерархический и фасадный методы классификации. Эти методы классификации должны отвечать следующим основным требованиям:
- обладать достаточной емкостью;
- иметь достаточную и экономически оправданную глубину;
- обладать определенной гибкостью и избыточностью для возможности расширения множества классифицируемых объектов, группировок и признаков, и внесения необходимых изменений без нарушения структуры классификации;
- учитывать необходимость сопряжения с другими классификациями однородных объектов;
- обеспечивать наибольшую эффективность обработки информации средствами вычислительной техники при решении комплекса конкретных задач АСУ как внутри данной системы, так и при обмене информацией с взаимодействующими системами;
- предоставлять возможность ведения создаваемого классификатора как в ручном, так и автоматизированном варианте организации процессов ведения.
3.1 Иерархический метод
Иерархический метод является более традиционным. При использовании иерархического метода происходит «последовательное разделение множества объектов на подчиненные, зависимые классификационные группировки». Получаемая на основе этого классификационная схема имеет иерархическую структуру. В ней первоначальный объём классифицируемых объектов детализируется на каждой следующей ступени классификации. В общем виде иерархическую классификационную схему можно представить в следующем виде:
Классификаторы, построенные на основе иерархического принципа, имеют неограниченную ёмкость, величина которой зависит от глубины классификации (числа ступеней деления) и количества объектов классификации, которое можно расположить на каждой ступени. Количество же объектов на каждой ступени классификации определяется основанием кода, то есть числом знаков в алфавите кода. Выбор необходимой глубины классификации и структуры кода зависит от характера объектов классификации и характера задач, для решения которых предназначен классификатор.
Серьёзным недостатком иерархического метода классификации является жесткость классификационной схемы. Она обусловлена заранее установленным выбором признаков классификации и порядком их использования по ступеням классификации. Это ведёт к тому, что при изменении состава объектов классификации, их характеристик или характера решаемых при помощи классификатора задач требуется коренная переработка классификационной схем. Поэтому при разработке классификаторов следует учитывать, что иерархический метод классификации более предпочтителен для объектов с относительно стабильными признаками и для решения стабильного комплекса задач.
К классификационным схемам (классификаторам), построенным на основе иерархического метода классификации, предъявляются определенные требования, соблюдение которых повышает их качество и эффективность применения.
Первым таким требованием является непересекаемость классификационных группировок, расположенных на одной ступени классификации. Это означает, что классификационные группировки, расположенные на одной и той же ступени классификации, не должны включать аналогичных понятий.
Второе общее правило заключается в том, что для разделения любой классификационной группировки на подчиненные группировки должен использоваться только один признак. Но это требование соблюдается только при использовании последовательного метода кодирования, при использовании же параллельного метода кодирования на определенной ступени классификации при иерархическом методе классификации могут одновременно использоваться несколько признаков, выбор которых определяется характером решаемых задач.
Третьим требованием к иерархическому методу классификации является логичность и последовательность деления группировок на нижестоящие и полнота этого деления. В соответствии с этим требованием на верхних ступенях классификации должны использоваться признаки, к которым в дальнейшем будет обращено наибольшее число запросов. Полнота деления означает, что сумма подмножества всегда должна давать делимое множество объектов, не должна оставаться какая-то часть объектов, не вошедшая в состав классификационных группировок.
При построении классификаторов иерархическим методом классификации необходимо соблюдать следующие правила:
- деление каждой классификационной группировки должно производиться только по одному основанию;
- получаемые в результате деления группировки не должны пересекаться, то есть содержать аналогичной информации, и должны относиться только к одной вышестоящей группировке,
- деление исходного множества на подмножества должно быть последовательным, без пропусков и без добавления промежуточного уровня классификации;
- классифицирование должно производиться таким образом, чтобы сумма подмножества деления составляла делимое множество.
Иерархический метод характеризуется глубиной классификации и емкостью. Количество ступеней определяет глубину классификации, которая устанавливается в зависимости от степени конкретизации группировок и числа признаков, необходимых для решения конкретных задач. От глубины и количества группировок, образуемых на каждой ступени, зависит емкость системы. Как правило, наибольшее количество последующих группировок устанавливается постоянным, либо для всей классификации, либо для данной ступени. Для систем классификации технико- экономической информации это число всегда равно десяти или кратному десяти.
При иерархическом методе классификации практически не ограничивается глубина классификации информации, что дает возможность более детально анализировать предметы, явления или документы. Большая информационная емкость иерархического метода классификации позволяет использовать его для кодирования больших объемов технико-экономической информации. Несмотря на вышеперечисленные преимущества, этот метод имеет ряд существенных недостатков. Во-первых, это недостаточная гибкость структуры, обусловленная фиксированностью признаков классификации и заранее установленным порядком их следования, не допускающим включения новых объектов и классификационных группировок. Вследствие этого, изменение любого признака ведет к перераспределению классификационных группировок и необходимости переработки классификатора. Поэтому в классификаторах, построенных на основе иерархического метода, должны предусматриваться значительные резервные емкости. Во-вторых, этот метод классификации не позволяет осуществлять информационный поиск по любому произвольному сочетанию признаков.
Вместе с этим у иерархического метода классификации есть достоинства, которые обеспечили ему широкое использование в различных классификационных схемах.
3.2 Фасетный метод
В современных классификационных схемах (классификаторах технико-экономической и социальной информации) широко используется и второй метод классификации – фасетный метод. Под этим методом понимается «параллельное разделение множества объектов на независимые классификационные группировки». При этом методе классификации заранее жесткой классификационной схемы и конечных группировок не создается. Разрабатывается лишь система таблиц признаков объектов классификации, называемых фасетами. При необходимости создания классификационной группировки для решения конкретной задачи осуществляется выборка необходимых признаков из фасетов и их объединение в определенной последовательности. В общем виде фасетную классификационную схему можно представить в следующем виде:
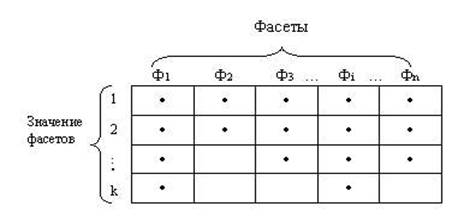
Такой принцип построения классификационных группировок делает классификатор на основе фасетного метода классификации очень гибким, хорошо приспособленным для использования в условиях большой динамичности характера решаемых задач. При изменении характера задач или характеристик объектов классификации разрабатываются новые фасеты или дополняются новыми признаками уже существующие фасеты без коренной перестройки структуры всего классификатора.
При построении классификаторов на основе фасетного метода необходимо соблюдать следующие правила:
- значения признаков из различных фасетов не должны пересекаться;
- из всевозможных фасетов, характеризующих классифицируемое множество объектов, отбираются только существенные, то есть фасеты, обеспечивающие решение конкретных технико-экономических задач;
- фасеты должны занимать в классификаторе строго определенное место и иметь определенные идентификационные коды.
Основные преимущества фасетного метода классификации обусловлены его гибкостью. Изменения в любом из фасетов не оказывают влияния на остальные. Большая гибкость обуславливает приспосабливаемость метода классификации к меняющемуся характеру решаемых задач, для которых он создается. Фасетный метод классификации позволяет не только образовывать новые классификационные группировки из имеющихся фасетов, но и включать новые и исключать старые фасеты. Гибкость системы дает возможность осуществлять информационный поиск по любому сочетанию признаков. Это определяет хорошую приспосабливаемость метода к машинной обработке информации
В современных классификационных схемах часто одновременно используются оба метода классификации. Это обеспечивает возможность снизить влияние недостатков методов классификации и расширить возможность использования классификатора как конкретной формы реализации классификации информации в информационном обеспечении управления.
4. Кодирование и методы кодирования
Итак, напомним, что кодирование представляет собой процесс перевода информации, выраженной одной системой знаков, в другую систему, то есть перевод записи на естественном языке в запись с помощью кодов.
Код – представляет собой условное обозначение объекта знаком или группой знаков по определенным правилам, установленным системами кодирования. Коды могут быть цифровыми, буквенными, комбинированными.
К кодам предъявляются ряд требовании:
- должны охватывать все объекты, подлежащие кодированию, и делать им однозначное обозначение;
- предоставлять возможность расширения объектов кодирования без изменения правил их обозначения;
- быть едиными для разных задач внутри одного экономического объекта (например, коды материалов, подразделений должны быть едиными для задач бухгалтерского учета и технической поддержки производства);
- отличаться стабильностью, удобством восприятия и запоминания кодовых обозначений, обеспечивающим простоту заполнения, чтения и обработки;
- обладать максимальной информированностью кода при минимальной его значности;
- иметь возможность использования кодов для автоматического получения сводных итогов и автоматического контроля кодовых обозначений с целью обнаружения ошибок.
Назначение кодов состоит в:
- обеспечении группировки информации в машине,
- подведении итогов по всем группировочным признакам и их печати в сводных таблицах,
- выполнении процедур поиска, хранения, выборки информации,передачи информации по каналам связи.
Процесс присвоения объектам кодовых обозначений называется кодированием. Основная цель кодирования состоит в однозначном обозначении объектов, а также в обеспечении необходимой достоверности кодируемой информации. С помощью кодирования обеспечивается выполнение основных функций, связанных с обработкой экономический информации:
- минимизация объема призрачной информации при вводе ее в вычислительную систему и передаче по каналам связи,
- сортировка и поиск информации по ключевым признакам;
- разработка сводных отчетов по различным признакам,
- декодирование при переходе от кодов-признаков к их наименованиям при печати сводных экономических отчетов.
Представление информации в компактной форме приспосабливает ее к лучшей обработке средствами ЭВМ. С помощью кодирования упрощается и ускоряется запись данных первичного документа и последующая обработка на машинных носителях.
Для того, чтобы классификационная схема стала средством для создания эффективной системы хранения документов обработки информации, ее поиска и информационного обмена, она должна быть дополнена системой условных обозначений, присваиваемых объектам и классификационным группировкам. Такие обозначения в разных классификационных справочниках могут называться индексами или кодами, a процесс их присвоения объектам классификации или классификационным группировкам – индексированием или кодированием.
Знаки, составляющие индекс или код, называются их алфавитом. Такой алфавит может включать буквы, цифры, знаки пунктуации в их различных комбинациях. Так, индекс дела в номенклатуре дел представляет собой комбинацию знаков, которая включает индекс структурного подразделения, в котором создается и хранится дело, и порядковый номер дела внутри раздела, соответствующего данному структурному подразделению. Индекс какого-либо документа в универсальной десятичной классификации кроме индекса, отражающего основное содержание документа, может дополнительно включать индексы признаков, характеризующих документ (язык документа, исторический период, автор, тип документа и другие).
Индекс или код являются идентификаторами объекта классификации или классификационной группировки, и их основное назначение состоит в однозначном обозначении объектов классификации. Это своего рода формализованное имя объекта, которое должно обеспечивать возможность точного определения объекта классификации. Поэтому разработчики классификационных схем стремятся сделать индексы или коды мнемоничными, то есть такими, чтобы даже по внешнему виду, алфавиту кода пользователь мог определить объект и узнать возможно больше информации о характере объекта классификации, для обозначения которого использован этот код. Например, буквенный код России по Общероссийскому классификатору стран мира (ОКСМ) – RU, а код США – US. Соответственно код российского рубля по Общероссийскому классификатору валют (ОКВ) RUR, а доллара США – USD.
К методам кодирования предъявляются определенные требования, соблюдение которых способствует повышению качества классификатора.
Метод кодирования должен:
- код метода должен содержать необходимую информацию об объекте и осуществлять в пределах заданного множества объектов классификации его идентификацию
- предусматривать использование в качестве алфавита кода десятичных цифр и букв;
- обеспечивать по возможности минимальную длину кода и достаточный резерв незанятых позиций для кодирования новых объектов без нарушения структуры классификатора;
- быть максимально ориентированным на автоматизированную обработку информации.
Методы кодирования могут носить самостоятельный характер – регистрационные методы кодирования, или быть основанными на предварительной классификации объектов – классификационные методы кодирования.
4.1 Регистрационные методы
Регистрационные методы кодирование бывают двух видов: порядковый и серийно-порядковый.
1. Порядковый метод кодирования – это такой метод, при котором кодами служат числа натурального ряда. В этом случае каждый из объектов классифицируемого множества кодируется путем присвоения ему текущего порядкового номера. Данный метод кодирования обеспечивает довольно большую долговечность классификатора при незначительной избыточности кода. Этот метод обладает наибольшей простотой, использует наиболее короткие коды и лучше обеспечивает однозначность каждого объекта классификации. Кроме того, он обеспечивает наиболее простое присвоение кодов новым объектам, появляющимся в процессе ведения классификатора. Существенным недостатком порядкового метода кодирования является отсутствие в коде какой-либо конкретной информации о свойствах объекта, а также сложность машинной обработки информации при получении итогов по группе объектов классификации с одинаковыми признаками. Этот метод кодирования не обеспечивает возможности размещения вновь появившихся объектов классификации в необходимом месте классификатора, так как резервные коды располагаются в конце ряда. По этим причинам порядковый метод отдельно редко применяется при создании классификаторов. Чаще всего он применяется в сочетании с другими методами кодирования.
2. Серийно-порядковый метод кодирования – метод, при котором кодами служат числа натурального ряда с закреплением отдельных серий этих чисел (интервалов натурального ряда) за объектами классификации с одинаковыми признаками. В каждой серии, кроме кодов имеющихся объектов классификации, предусматривается определенное количество кодов для резерва. Резерв кодов располагается в середине или в конце кода. Это является большим преимущество данного метода по сравнению с порядковым методом кодирования. Серийно-порядковый метод кодирования целесообразно применять для объектов, имеющих два соподчиненных признака. Данный метод кодирования обладает всеми преимуществами и недостатками порядкового метода кодирования. Несмотря на наличие в кодах, построенных по этому методу кодирования, определенных элементов классификации, они чаще всего используются для идентификации объектов в сочетании с классификационными методами кодирования.
4.2 Классификационные методы
Классификационные методы кодирования бывают двух видов: последовательный и параллельный.
1. Последовательный метод кодирования – метод, при котором код классификационной группировки и (или) объекта классификации образуется с использованием кодов последовательно расположенных подчиненных группировок, полученных при иерархическом методе кодирования. В этом случае код нижестоящей группировки образуется путем добавления соответствующего количества разрядов к коду вышестоящей группировки. Последовательный метод кодирования чаще всего используется при иерархическом методе классификации.
Преимущества последовательного метода кодирования являются логичность построения кода и большая емкость. Вместе с тем он обладает всеми недостатками, присущими иерархическому методу классификации, а также ограниченными возможностями идентификации объектов. Использование последовательного метода кодирования связано с определенными трудностями, обусловленными тем, что в результате зависимости последующих разрядов кода от предыдущих применять этот код по частям нельзя, группировать объекты по различным сочетаниям имеющихся признаков сложно, практически невозможно вносить новые признаки и производить изменения в коде без коренной перестройки классификатора. Поэтому применять последовательный метод кодирования целесообразно в тех случаях, когда набор признаков классификации и их последовательность стабильны в течение длительного времени.
2. Параллельный метод кодирования – метод, при котором код классификационной группировки и (или) объекта классификации образует с использованием независимых группировок, полученных при фасетном методе классификации. При этом методе кодирования признаки объекта кодируются независимо друг от друга. Для параллельного метода кодирования возможны два варианта записи кодов объекта.
- каждый фасет и признак внутри фасета имеют свои коды, которые включаются в состав кода объекта. Такой способ записи удобно применять тогда, когда объекты характеризуются неодинаковым набором признаков и различны их числом. При формировании кода какого-либо объекта берутся только необходимые признаки.
- для определения групп объектов выделяется фиксированный набор признаков и устанавливается стабильный порядок их следования, то есть устанавливается фасетная формула. В этом случае не надо каждый раз указывать, значение какого признака приведено в определенных разрядах кода объекта.
Параллельный метод кодирования имеет ряд преимуществ. К достоинствам рассматриваемого метода следует отнести гибкость структуры кода, обусловленная независимостью признаков, из кодов которых строится код объекта классификации. Метод позволяет использовать при решении конкретных технико-экономических и социальных коды только тех признаков объектов, которые необходимы, что дет возможность работать в каждом отдельном случае с кодами небольшой длины. При этом методе кодирования можно осуществлять группировку объектов по любому сочетанию признаков. Параллельный метод кодирования хорошо приспособлен для машинной обработки информации. По конкретной кодовой комбинации легко узнать, набором каких характеристик обладает рассматриваемый объект. При этом из небольшого числа признаков можно образовать большое число кодовых комбинаций. набор признаков при необходимости может легко пополняться присоединением кода нового признака. Это свойство параллельного метода кодирования особенно важно при решении технико-экономических задач, состав которых часто меняется.
Параллельный метод кодирования целесообразно использовать для кодирования однородных объектов, так как в противном случае реальной становится лишь незначительная часть сочетаний признаков, и емкость классификатора будет использоваться не полностью. Это является недостатком данного метода кодирования.
Перечисленные классификационные методы кодирования характеризуются тем, что даже при глубокой классификации объектов код несет информацию о классификационной группировке, но не всегда идентифицирует конкретный объект, а коды, полученные на основе идентификационных методов, хорошо выполняя функцию идентификации объектов, практически не несут информацию об их свойствах. Поэтому идентификационные и классификационные методы кодирования чаще всего применяются в классификаторах в сочетании друг с другом.
Одним из наиболее узких мест во всей технологии использования классификаторов информации является кодирование и ввод данных. С целью устранения этого проводятся исследования по автоматизации процесса кодирования информации. Однако для реализации автоматизированного процесса кодирования требуются большие объемы памяти, так как вначале вся информация вводится на естественном языке, и связанные с этим большие трудозатраты. Другим направлением снижения трудозатрат в процессе кодирования и ускорения этого процесса является использование штриховых (линейных) кодов.
4.3 Штриховые (линейные) коды
Преимущества штриховых кодов состоят в следующем:
- резкое снижение числа ошибок при вводе информации в виде штриховых кодов по сравнению с вводом информации с клавиатуры на естественном языке;
- легкость считывания штриховых кодов "электронными оптическими системами по сравнению с буквенно-цифровыми символами;
- высокая экономическая эффективность применения систем на основе штриховых кодов вследствие резкого снижения стоимости ввода данных в систему.
Штриховой (линейный) код представляет собой комбинацию вертикальных полосок разной ширины и пробелов между ними. При этом за базу принимается ширина узкого элемента (полоски) кода. Широкие полоски должны быть кратными им по ширине или находиться с ними в определенных соотношениях. В основе штрихового кода лежит цифровой код.
В разных странах используются различные виды штриховых кодов. В каждом из них установлено определенное соотношение между широкими узкими полосками и между полосками и интервалами между ними. Так, в «Коде 39» каждому знаку цифрового кода соответствует комбинация из девяти элементов (три широких полоски и шесть узких) и из них пять штрихов и четыре интервала между ними.
Разработка штриховых кодов осуществляется Международной ассоциацией по нумерации (ЕАН), коды которой являются наиболее распространенными в Европе. Наша страна с 1987 года также стала членом ЕАН.
В 1988 году Госстандарт СССР утвердил РД 50-666-88 "Методические указания. Присвоение цифровых кодов товарам народного потребления". Этим документом устанавливались правила присвоения товарам народного потребления цифровых (торговых) кодов. Эти цифровые коды служат основой для штриховых кодов, наносимых на ярлыки, упаковку и этикетки товаров. Такой цифровой (торговый) код строится в полном соответствии с кодом ЕАН-13. Он состоит из тринадцати разрядов и имеет следующую структуру:
- 2 знака – идентификатор страны-изготовителя товара;
- 5 знаков – идентификатор фирмы-изготовителя товара;
- 5 знаков – идентификатор товара;
- 1 знак – контрольное число.
В этом коде, например, США и Канада имеют идентификаторы с 00 до 09, Франция – с 30 до 37, ФРГ – с 40 до 43, СНГ – 46, Япония – 49, Италия – с 80 до 83, Корея – 88 и так далее.
В штриховом коде, построенном на основе ЕАН-13, каждому знаку цифрового кода соответствует комбинация из семи элементов – штрихов и пробелов между ними. Штриховой (линейный) код имеет следующий вид:

9785870"574165
Штриховые коды могут использоваться кроме торговли также в таких областях, как медицина, банковское дело, промышленность и других. При этом в качестве цифровых кодов для них могут использоваться коды классификаторов технико-экономической и социальной информации.
Использование кодов технико-экономической и социальной информации требует обеспечения высокой степени достоверности кодированной информации. В классификаторах технико-экономической и социальной информации для выявления ошибок в кодах используется метод контрольных чисел.
Контроль правильности записи кодов при обработке информация основан на принципе делимости чисел. Иначе его называют контролем по модулю. Суть метода заключается в том, что к коду добавляется еще один проверочный знак (контрольное число), связанный с кодом определенной математической зависимостью. При вводе кодированной информации в базу данных, ее обработке или использовании в ЭВМ специальной программой контроля выполняется проверка этой зависимости по каждому коду. Если зависимость нарушается, машина выдает информацию о наличии ошибки в коде.
Заключение
Контроль по модулю широко используется в классификаторах технико-экономической и социальной информации как у нас в стране, так и за рубежом. В качестве модуля используют различные числа, но наибольшее распространение получил в настоящее время контроль по модулю 11. Для общероссийских классификаторов расчет контрольных чисел осуществляется в соответствии с методикой, разработанной Всероссийским научно-исследовательским институтом классификации, терминологии и информации по стандартизации и качеству. В соответствии с этой методикой контрольным числом является остаток от деления на 11 суммы произведений весов на значения разрядов кода. Весом (весовым коэффициентом) является порядковый номер разряда в коде слева направо.
Методика Всероссийского научно-исследовательского института классификации, терминологии и информации по стандартизации и качеству предлагает использовать в качестве весов натуральный ряд чисел от 1 до 10. Если разрядность кода больше 10, то набор весов повторяется. При использовании данного метода остаток может получить значение от 0 до 10. Так как методика предусматривает использование одноразрядных контрольных чисел, то при получении остатка, равного 10, следует сделать повторный расчет контрольного числа со сдвигом строки весов. В этом случае весовой ряд начинается с 3 до 10, а если разрядность кода больше, то дальше веса идут с 1 до 10. В случае повторного получения контрольного числа, равного 10, в качестве контрольного числа используется 0. В случае, если сумма произведений весов на значения разрядов получается меньше 10, то эта сумма и является контрольным числом.
Использование контрольных чисел обеспечивает возможность обнаруживать и исправлять ошибки в кодированной документной информации, что повышает ее достоверность.
Список литературы
- ГОСТ 6.01.1-87 Единая система классификации и кодирования технико-экономической информации. Основные положения. - М.: Изд. стандартов, 1987.
- ГОСТ Р 1.2-92 Государственная система стандартизации (ГСС) РФ. Порядок разработки государственных стандартов
- Постановление Правительства РФ "О развитии единой системы классификации и кодирования технико-экономической и социальной информации" № 1212 от 1 ноября 1999 г. // Вестник Госстандарта России. - 2000. - № 1.
- ПР 50-733-93. Правила по стандартизации. Основные положения Единой системы классификации и кодирования технико-экономической и социальной информации и унифицированных систем документации Российской Федерации. - М., 1995.
- Костомаров М.Н. Классификация и кодирование документов и документной информации (классификация документов) // Секретарское дело. - 2003. - № 11.
- Костомаров М.Н. Классификация и кодирование документов и документной информации (классификация документов) // Секретарское дело. - 2003. - № 10.
- Костомаров М.Н. Разработка общероссийских классификаторов технико-экономической и социальной информации) // Секретарское дело. - 2001. - № 3.
- Костомаров М.Н., Соколов А.В., Степанов Е.А. Информационное обеспечение управления. - М.: МГИАИ,1990.
- Волков В.Б. Информатика / В.Б. Волков, Н.В. Макарова - СПб.: Питер, 2011
- Галисеев Г.В. Программирование в среде Delphi 7 / Г.В. Галисеев - М.: Вильямс, 2004.
- Иванова Г.С. Технология программирования / Г.С. Иванова - М.: Изд-во МГТУ им. Н.Э. Баумана, 2004
- Канер С. Тестирование программного обеспечения. Фундаментальные концепции менеджмента бизнес-приложений / С. Канер, Д. Фолк, Е.К Нгуен - Киев: ДиаСофт, 2005
- Меняев М.Ф. Информатика и основы программирования / М.Ф. Меняев - М.: Омега-Л, 2007

- Роль мотивации в поведении организации («СБЕРБАНК РОССИИ»)
- Россия в системе международных кредитных отношений .
- Роль финансового рынка в мобилизации и распределении финансовых ресурсов
- Международный валютный фонд: цели, функции, особенности (История возникновения и основные цели функционирования Международного валютного фонда)
- Международный валютный фонд: цели, функции, особенности
- Налоговая система РФ и проблемы ее совершенствования
- Доказательства трудового стажа
- Анализ внешней и внутренней среды организации (ΠΑΟ «Мегафон»)
- Правовые основы организации нотариата(Правовые основы организации нотариальной деятельности)
- Нотариат в РФ
- Трудовой стаж, порядок его исчисления
- Теоретические понятия организационного проектирования