
Методы кодирования данных (История кодирования и что это такое)
Содержание:

Введение
Актуальность темы исследования обоснована тем, что кодирование используется абсолютно везде в нашей жизни и для этого применяются его разные методы. Мы постоянно занимаемся кодированием, например, человек мыслит весьма расплывчатыми понятиями, и, чтобы донести мысль до другого человека, мы применяем язык, как систему кодирования понятий. Также, чтобы записать слова языка, мы используем азбуку. Заниматься проблемой кодирования информации люди начали еще до изобретения электронных вычислительных машин. Надо понимать, что чертежи, ноты, математические выкладки являются тоже некоторым кодированием разных информационных объектов. Аналогично, универсальная система кодирования требуется для того, чтобы превратить одну информационную форму в другую или другими словами, преобразовать данные в вид, удобный для обработки, чтения и передачи. С созданием электронных вычислительных машин появилась потребность кодировать практически все типы информационных данных, с которыми связано всё мировое общество в целом. Для этого были придуманы разные методы кодирования данных, о которых и пойдет речь в данной курсовой.
В целом, методы кодирования данных довольно подробно исследованы в литературе, то есть исследуемая тема обладает высоким уровнем теоретической разработанности. Вопросам кодирования данных и его методам посвящен широкий ряд учебных пособий, научных статей, монографий и статей различных авторов. Абсолютно точно следует выделить труды следующих авторов: Р. Хэмминг, К. Шеннон, В.А. Котельников, Э. Борель, Э. Уиттекер, К. Огура.
В наше время почти всё завязано с техникой, она есть в каждом доме, у каждого человека есть мобильные телефоны и почти у каждого телевизор или компьютер. Но совершенно верно утверждение, что большая часть «пользователей» не понимает и не хочет понимать принципы работы процессов «внутри» техники.
Актуальность и степень разработанности проблемы обуславливают выбор объекта, предмета, целей и задач работы.
Объект исследования – кодирование данных.
Предмет исследования – методы кодирования данных.
Целью работы является исследование понятий и процессов, поиск и изучение методов кодирования данных.
В соответствии с этой целью в работе решаются следующие задачи:
- рассмотреть общие понятия кодирования
- изучить виды кодирования информации
- ознакомиться с историей кодирования данных
- разобрать и изучить методы кодирования данных
Теоретической и методологической основой исследования послужили труды отечественных и зарубежных ученых в области информационных технологий.
В качестве основных методов исследования послужили, как общенаучные методы анализа и сравнения, так и методы структурно-логического анализа и др.
Курсовая работа на тему: «Методы кодирования данных» состоит из введения, двух глав, шести параграфов, заключения, списка использованных источников и приложений.
История кодирования и что это такое
Для полного понимания и изучение темы, нам необходимо знать общие базовые понятия и термины. А также ознакомиться с историей, ведь куда без нее.
Что такое кодирование и основные понятия
Итак, кодирование – это представление сигнала в определенной форме, удобной или пригодной для последующего использования сигнала. Говоря строже, это правило, описывающее отображение одного набора знаков в другой набор знаков. Тогда отображаемый набор знаков называется исходным алфавитом, а набор знаков, который используется для отображения, – кодовым алфавитом, или алфавитом для кодирования. При этом кодированию подлежат как отдельные символы исходного алфавита, так и их комбинации. Аналогично для построения кода используются как отдельные символы кодового алфавита, так и их комбинации. Совокупность символов кодового алфавита, применяемых для кодирования одного символа (или одной комбинации символов) исходного алфавита, называется кодовой комбинацией, или, короче, кодом символа. При этом кодовая комбинация может содержать один символ кодового алфавита. Процесс восстановления сообщения из комбинации символов называется декодированием.
Символ или комбинация символов исходного алфавита, которому соответствует кодовая комбинация, называется исходным символом.
Код – это система символов и определенных правил, с помощью которых информация может быть закодирована в виде набора из таких символов для передачи, обработки и запоминания. Или более простым языком, код – это система условных обозначений, передающих информацию. Конечная последовательность кодовых знаков называется словом.
Взаимосвязь символов (или комбинаций символов, если кодируются не отдельные символы исходного алфавита) исходного алфавита с их кодовыми комбинациями составляет таблицу соответствия (или таблицу кодов).
В качестве примера можно привести систему записи математических выражений, азбуку Морзе, морскую флажковую азбуку, систему Брайля для слепых и др. Азбука Морзе является общеизвестным кодом из символов телеграфного алфавита, в котором буквам русского языка соответствуют кодовые слова из «точек» и «тире».
Алфавит [alphabetos, от названий первых двух букв греческого А. - альфа и бета; аналогично: азбука — от аз и буки], совокупность графических знаков — букв (например, латинский, русский А.) или слоговых знаков (например, индийский А. деванагари), расположенных в традиционно установленном порядке.
Знак - соглашение (явное или неявное) о приписывании чему-либо (означающему) какого-либо определённого смысла (означаемого). Знак — это материально выраженная замена предметов, явлений, понятий в процессе обмена информацией в коллективе. Знаком также называют конкретный случай использования такого соглашения для передачи информации. Знак может быть составным, то есть состоять из нескольких других знаков. Буквы и слова человеческого языка являются знаками. Цифры и числа являются знаками. Наука о знаковых системах называется семиотикой.
Символы (в компьютере) - цифры, буквы, иероглифы и т.п.
Кодер - программист, специализирующийся на кодировании - написании исходного кода по заданным спецификациям.
Кодер - одна из двух компонент кодека (пары кодер – декодер).
Декодер - некоторое звено, которое преобразует информацию из внешнего вида в вид, применяемый внутри узла. В программном обеспечении: модуль программы или самостоятельное приложение, которое преобразует файл или информационный поток из внешнего вида в вид, который поддерживает другое программное обеспечение.
1.2 История кодирования
Необходимость кодирования информации возникла задолго до появления компьютеров и техники в целом. Азбука, речь и цифры – есть не что иное, как система моделирования мыслей, речевых звуков и числовой информации. В технике потребность кодирования возникла сразу после создания телеграфа, но особенно важной она стала с изобретение компьютеров.
Область действия теории кодирования распространяется на передачу данных по реальным или зашумленным каналам, а предметом является обеспечение корректности переданной информации. Иными словами, она изучает, как лучше упаковать данные, чтобы после передачи сигнала из данных можно было надежно и просто выделить полезную информацию. Иногда теорию кодирования путают с шифрованием, но это неверно: криптография решает обратную задачу, ее цель - затруднить получение информации из данных.
С необходимостью кодирования данных впервые столкнулись более полутораста лет назад, вскоре после изобретения телеграфа. Каналы были дороги и ненадежны, что сделало актуальной задачу минимизации стоимости и повышения надёжности передачи телеграмм. Проблема ещё более обострилась в связи с прокладкой трансатлантических кабелей. С 1845 вошли в употребление специальные кодовые книги; с их помощью телеграфисты вручную выполняли «компрессию» сообщений, заменяя распространенные последовательности слов более короткими кодами. Тогда же для проверки правильности передачи стали использовать контроль чётности, метод, который применялся для проверки правильности ввода перфокарт ещё и в компьютерах первых поколений. Для этого во вводимую колоду последней вкладывали специально подготовленную карту с контрольной суммой. Если устройство ввода было не слишком надежным или колода - слишком большой, то могла возникнуть ошибка. Чтобы исправить её, процедуру ввода повторяли до тех пор, пока подсчитанная контрольная сумма не совпадала с суммой, сохраненной на карте. Эта схема неудобна, и к тому же пропускает двойные ошибки. С развитием каналов связи потребовался более эффективный механизм контроля
Первым теоретическое решение проблемы передачи данных по зашумленным каналам предложил Клод Шеннон, основоположник статистической теории информации. Работая в Bell Labs, Шеннон написал работу «Математическая теория передачи сообщений» (1948), где показал, что если пропускная способность канала выше энтропии источника сообщений, то сообщение можно закодировать так, что оно будет передано без излишних задержек. В одной из теорем Шеннон доказал, что при наличии канала с достаточной пропускной способностью сообщение может быть передано с некоторыми временными задержками. Кроме того, он показал возможность достоверной передачи при наличии шума в канале. Формула C = W log ((P+N)/N), высечена на скромном памятнике Шеннону, установленном в его родном городе в штате Мичиган.
Труды Шеннона дали пищу для множества дальнейших исследований в области теории информации, но практического инженерного приложения они не имели. Переход от теории к практике стал возможен благодаря усилиям Ричарда Хэмминга, коллеги Шеннона по Bell Labs, получившего известность за открытие класса кодов «коды Хэмминга». Существует легенда, что к изобретению своих кодов Хэмминга подтолкнуло неудобство в работе с перфокартами на релейной счетной машине Bell Model V в середине 40-х годов. Ему давали время для работы на машине в выходные дни, когда не было операторов, и ему самому приходилось возиться с вводом. Хэмминг предложил коды, способные корректировать ошибки в каналах связи, в том числе и в магистралях передачи данных в компьютерах, прежде всего между процессором и памятью. Коды Хэмминга показали, как можно практически реализовать возможности теоремы Шеннона. Хэмминг опубликовал свою статью в 1950, хотя во внутренних отчетах его теория кодирования датируется 1947. Поэтому некоторые считают, что отцом теории кодирования следует считать Хэмминга, а не Шеннона.
Ричард Хэмминг (1915 - 1998) получил степень бакалавра в Чикагском университете в 1937. В 1939 он получил степень магистра в Университете Небраски, а степень доктора по математике – в Университете Иллинойса. В 1945 Хэмминг начал работать в рамках Манхэттенского проекта. В1946 поступил на работу в Bell Telephone Laboratories, где работал с Шенноном. В 1976 получил кафедру в военно-морской аспирантуре в Монтерей в Калифорнии. Труд, сделавший его знаменитым, фундаментальное исследование кодов обнаружения и исправления ошибок, Хэмминг опубликовал в 1950. В 1956 он принимал участие в работе над IBM 650. Его работы заложили основу языка программирования, который позднее эволюционировал в языки программирования высокого уровня. В знак признания заслуг Хэмминга в области информатики институт IEEE учредил медаль за выдающиеся заслуги в развитии информатики и теории систем, которую назвал его именем.
Хэмминг первым предложил «коды с исправлением ошибок» (Error-Correcting Code, ECC). Современные модификации этих кодов используются во всех системах хранения данных и для обмена между процессором и оперативной памятью. Один из их вариантов, коды Рида-Соломона применяются в компакт-дисках, позволяя воспроизводить записи без скрипов и шумов, вызванных царапинами и пылинками. Существует множество версий кодов, построенных «по мотивам» Хэмминга, они различаются алгоритмами кодирования и количеством проверочных битов. Особое значение подобные коды приобрели в связи с развитием дальней космической связи с межпланетными станциями.
Среди новейших кодов ECC следует назвать коды LDPC (Low-Density Parity-check Code). Вообще-то они известны лет тридцать, но особый интерес к ним обнаружился именно в последние годы, когда стало развиваться телевидение высокой чёткости. Коды LDPC не обладают 100-процентной достоверностью, но вероятность ошибки может быть доведена до желаемой, и при этом с максимальной полнотой используется пропускная способность канала. К ним близки «турбокоды» (Turbo Code), они эффективны при работе с объектами, находящимися в условиях далекого космоса и ограниченной пропускной способности канала.
В историю теории кодирования прочно вписано имя В. А. Котельникова. В 1933 в «Материалах по радиосвязи к I Всесоюзному съезду по вопросам технической реконструкции связи» он опубликовал работу «О пропускной способности «эфира» и «проволоки». Имя Котельникова входит в название одной из важнейших теорем теории кодирования, определяющей условия, при которых переданный сигнал может быть восстановлен без потери информации. Эту теорему называют по-разному, в том числе «теоремой WKS» (аббревиатура WKS взята от Whittaker, Kotelnikov, Shannon). В некоторых источниках используют и Nyquist-Shannon sampling theorem, и Whittaker-Shannon sampling theorem, а в отечественных вузовских учебниках чаще всего встречается просто «теорема Котельникова». На самом же деле теорема имеет более долгую историю. Ее первую часть в 1897 доказал французский математик Э. Борель. Свой вклад в 1915 внес Э. Уиттекер. В 1920 японец К. Огура опубликовал поправки к исследованиям Уиттекера, а в 1928 американец Гарри Найквист уточнил принципы оцифровки и восстановления аналогового сигнала.
1.3 Двоичная система счисления
Нам необходимо понимать, что такое двоичная система счисления, так как она широко применяется в практике кодирования сигналов.
При работе с компьютерами приходится параллельно использовать несколько позиционных систем счисления, чаще всего двоичную, поэтому большое практическое значение имеют процедуры перевода чисел из одной системы счисления в другую.
Для начала поймем, что же такое система счисления. Это символический метод записи числе; представление чисел с помощью письменных знаков. Система счисления: дает представления множества целых или вещественных чисел; дает каждому числу уникальное представление; отражает алгебраическую и арифметическую структуру чисел. Все системы счисления можно разделить на два класса: позиционные и непозиционные. Для записи чисел в различных системах счисления используется некоторое количество отличных друг от друга знаков. Число таких знаков в позиционной системе счисления называется основанием системы счисления.
Двоичная система счисления – это позиционная система счисления с основанием 2В этой системе счисления натуральные числа записываются с помощью всего лишь двух символов (в роли которых обычно выступают цифры 0 и 1).
Двоичная система используется в цифровых устройствах, т.к. является наиболее простой и соответствует требованиям: 1) Чем меньше значений существует в системе, тем проще изготовить отдельные элементы, оперирующие этими значениями. В частности, две цифры двоичной системы счисления могут быть легко представлены многими физическими явлениями: есть ток — нет тока, индукция магнитного поля больше пороговой величины или нет и т. д. 2) Чем меньше количество состояний у элемента, тем выше помехоустойчивость и тем быстрее он может работать. Например, чтобы закодировать три состояния через величину индукции магнитного поля, потребуется ввести два пороговых значения, что не будет способствовать помехоустойчивости и надёжности хранения информации. 3) Двоичная арифметика является довольно простой. Простыми являются таблицы сложения и умножения - основных действий над числами. 4) Возможно применение аппарата алгебры логики для выполнения побитовых операций над числами.
В цифровой электронике одному двоичному разряду в двоичной системе счисления соответствует один двоичный логический элемент (инвертор с логикой на входе) с двумя состояниями (открыт, закрыт).
1 + 0 = 1
1 + 1 = 10
10 + 10 = 100
Таблица умножения двоичных чисел
0 • 0 = 0
0 • 1 = 0
1 • 0 = 0
1 • 1 = 1
Использование двоичной системы при измерении дюймами
При указании линейных размеров в дюймах по традиции используют двоичные дроби, а не десятичные, например:  и т.д.
и т.д.
Преобразование чисел
Для преобразования из двоичной системы в десятичную используют следующую таблицу степеней основания 2:
512 256 128 64 32 16 8 4 2 1
Начиная с цифры 1 все цифры умножаются на два. Точка, которая стоит после 1 называется двоичной точкой.
Преобразование двоичных чисел в десятичные
Допустим, вам дано двоичное число 110001. Для перевода в десятичное просто запишите его справа налево как сумму по разрядам следующим образом:
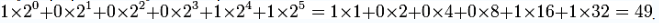
Можно записать это в виде таблицы следующим образом:
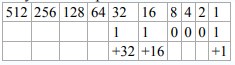
Точно так же, начиная с двоичной точки, двигайтесь справа налево. Под каждой двоичной единицей напишите её эквивалент в строчке ниже. Сложите получившиеся десятичные числа. Таким образом, двоичное число 110001 равнозначно десятичному 49.
Для того, чтобы преобразовывать числа из двоичной в десятичную систему данным методом, надо суммировать цифры слева-направо, умножая ранее полученный результат на основу системы (в данном случае 2). Например, двоичное число 1011011 переводится в десятичную систему так:
0*2+1=1>>1*2+0=2>>2*2+1=5>>5*2+1=11>>11*2+0=22>>22*2+1=45>> 45*2+1=91. В десятичной системе это число будет записано как 91. Или число 101111 переводится в десятичную систему так:
0*2+1=1>>1*2+0=2>>2*2+1=5>>5*2+1=11>> 11*2+1=23 >> 23*2+1=47 То есть в десятичной системе это число будет записано как 47.
Преобразование десятичных чисел к ближайшей степени двойки, не меньшей этого числа. Ниже приведена функция, возвращающая число, не меньшее аргумента, и являющееся степенью двух.
unsigned int to_deg_2(unsigned int num){int i; if ( num == 1 ) return 2;for( num-=1,i=1; i < sizeof (unsigned int)*8; i*=2 ) num = num|(num>>i); return num+1;}
Допустим, нужно перевести число 19 в двоичное. Следует воспользоваться следующей процедурой:
19 /2 = 9 с остатком 1
9 /2 = 4 c остатком 1
4 /2 = 2 с остатком 0
2 /2 = 1 с остатком 0
1 /2 = 0 с остатком 1
Итак, мы делим каждое частное на 2 и записываем в остаток 1 или 0. Продолжать деление надо пока в делимом не будет 1. Ставим числа из остатка друг за другом, начиная с конца. В результате получаем число 19 в двоичной записи (начиная с конца): 10011.
1.4 Виды кодирования информации
Кодирование является центральным вопросом при решении самых разных задач программирования, таких как: представление данных произвольной структуры в памяти компьютера; обеспечение помехоустойчивости при передаче данных по каналам связи; сжатие информации в базах данных. Именно для таких задач используются разные виды кодирования данных. Давайте углубимся и поговорим о каждом виде более конкретно.
Итак, начнем с кодирования текстовой информации. Мы уже понимаем, что текст состоит из некой последовательности символов и, что символами могут быть буквы, цифры, знаки препинания и т.д. Так вот, текстовая информация, как и любая другая, хранится в памяти компьютера в двоичном виде. Для этого каждому в соответствии ставится некоторое неотрицательное число, которое зовется кодом символа, и это число записывается в память электронной вычислительно машины в двоичном виде. Конкретное соотношение между символами и их кодами называется системой кодировки. В персональных компьютерах обычно используется система ASCII (American Standart Code for Informational Interchange). К кодированию текстовой информации можно отнести: криптографию (наука, занимающаяся методами шифрования), стенографию (быстрый способ записи устной речи).
Следующим видом кодирования информации является кодирование цвета. Чтобы сохранить фотографию в двоичном коде, ее сначала разделяют на множество мелких цветных точек, называемых пикселями. После разбивки на точки цвет каждого пикселя кодируется в бинарный код и записывается на запоминающем устройстве. Как пример, если размер изображения составляет 100 на 100 точек, то это значит, что они представляют собой матрицу, образованную из 10000 пикселей. Качество кодирования фотографий в бинарный код зависит не только от количества пикселей, но также и от их цветового разнообразия. Существует несколько алгоритмов записи цвета в двоичном коде. Самый распространенный из них это RGB. Расшифровывается как red – green – blue, то есть первые буквы названий трёх основных цветов. Смешивая эти три цвета в любой последовательности и пропорции, можно получить абсолютно любой цвет и любой оттенок. На этом и построен алгоритм RGB. Каждый пиксель записывается в двоичном коде путем указания количества красного, зеленого и синего цвета, участвующего в его формировании. Чем больше битов выделяется для кодирования пикселя, тем больше вариантов смешивания этих трёх каналов можно использовать и тем значительнее будет цветовая насыщенность изображения.
Кодирование графической информации чем-то схожа с кодированием цвета, но если описанная выше техника формирования изображений из мелких точек (растровая графика) является более распространенной, то существует и другая техника, которая используется в компьютерах – векторная графика. Векторные изображения создаются только с помощью компьютера и формируются не из пикселей, а из графических примитивов, таких как: линии, окружности, многоугольники и т.д. Векторная графика – это чертежная графика. Она очень удобна для компьютерного «рисования» и широко используется дизайнерами при графическом оформлении печатной продукции, в том числе создании огромных рекламных плакатов и в других похожих ситуациях. Векторное изображение в двоичном коде записывается как совокупность примитивов с указанием их размеров, цвета заливки, места расположения на холсте и некоторых других свойств. Однако, векторный способ кодирования не позволяет записывать в двоичном коде реалистичные фото. Поэтому все фотокамеры работают только по принципу растровой графики. Рядовому пользователю не часто приходится иметь дело с векторной графикой. Как пример, для сравнения, чтобы записать на запоминающем устройстве векторное изображение круга, компьютеру достаточно в двоичный код закодировать тип объекта, координаты его центра на холсте, длину радиуса, цвет и толщину линии, цвет заливки. Но если мы говорим о растровой системе, то пришлось бы кодировать цвет каждого пикселя. И если размер изображения большой, для его хранения понадобилось бы значительно больше места на запоминающем устройстве.
При кодировании чисел учитывается цель, с которой цифра была введена в систему: для арифметических вычислений или просто для вывода. Все данные, кодируемые в двоичной системе, шифруются с помощью единиц и нолей. Эти символы еще называют битами. Этот метод кодировки является наиболее популярным, ведь его легче всего организовать в технологическом плане: присутствие сигнала – 1, отсутствие – 0. У двоичного шифрования есть лишь один недостаток – это длина комбинаций из символов. Но с технической точки зрения легче орудовать кучей простых, однотипных компонентов, чем малым числом более сложных. Целые числа кодируются просто переводом чисел из одной системы счисления в другую. Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число преобразуют в стандартный вид.
Кодирование звуковой информации. Для начала нам потребуется знать несколько определений звука. Итак, любой звук, слышимый человеком, является колебанием воздуха, которое характеризируется двумя основными показателями: частотой и амплитудой. Амплитуда колебаний - это степень отклонения состояния воздуха от начального при каждом колебании. Она воспринимается нами как громкость звука. Частота колебаний - это количество отклонений состояний воздуха от начального за единицу времени. Она воспринимается как высота звука. Так, тихий комариный писк - это звук с высокой частотой, но с небольшой амплитудой. Звук грозы наоборот имеет большую амплитуду, но низкую частоту.
Схему работы компьютера со звуком в общих чертах можно описать так. Микрофон превращает колебания воздуха в аналогичные по характеристикам электрических колебаний. Звуковая карта компьютера преобразовывает электрические колебания в двоичный код, который записывается на запоминающем устройстве. При воспроизведении такой записи происходит обратный процесс (декодирование) - двоичный код преобразуется в электрические колебания, которые поступают в аудиосистему или наушники. Динамики акустической системы или наушников имеют противоположное микрофону действие. Они превращают электрические колебания в колебания воздуха. Принцип разделения звуковой волны на мелкие участки лежит в основе двоичного кодирования звука. Аудиокарта компьютера разделяет звук на очень мелкие временные участки и кодирует степень интенсивности каждого из них в двоичный код. Такое дробление звука на части называется дискретизацией. Чем выше частота дискретизации, тем точнее фиксируется геометрия звуковой волны и тем качественней получается запись. Качество записи сильно зависит также от количества битов, используемых компьютером для кодирования каждого участка звука, полученного в результате дискретизации. Количество битов, используемых для кодирования каждого участка звука, полученного при дискретизации, называется глубиной звука.
Кодирование видеозаписи. Видеозапись состоит из двух компонентов: звукового и графического. Кодирование звуковой дорожки видеофайла в двоичный код осуществляется по тем же алгоритмам, что и кодирование обычных звуковых данных. Принципы кодирования видеоизображения схожи с кодированием растровой графики (рассмотрено выше), хотя и имеют некоторые особенности. Как известно, видеозапись - это последовательность быстро меняющихся статических изображений (кадров). Одна секунда видео может состоять из 25 и больше картинок. При этом, каждый следующий кадр лишь незначительно отличается от предыдущего. Учитывая эту особенность, алгоритмы кодирования видео, как правило, предусматривают запись лишь первого (базового) кадра. Каждый же последующий кадр формируются путем записи его отличий от предыдущего.
Коды по образцу. Данный вид кодирования применяется для представления дискретного сигнала на том или ином машинном носителе. Большинство кодов, используемых в информатике для кодирования по образцу, имеют одинаковую длину и используют двоичную систему для представления кода (и, возможно, шестнадцатеричную как средство промежуточного представления).
Криптографические коды. Криптографические коды используются для защиты сообщений от несанкционированного доступа, потому называются также шифрованными. В качестве символов кодирования могут использоваться как символы произвольного алфавита, так и двоичные коды. Существуют различные методы, рассмотрим два из них: метод простой подстановки и метод Вижинера.
Эффективное кодирование. Этот вид кодирования используется для уменьшения объемов информации на носителе - сигнале. Для кодирования символов исходного алфавита используют двоичные коды переменной длины: чем больше частота символа, тем короче его код.
Эффективность кода определяется средним числом двоичных разрядов для кодирования одного символа – Iср по формуле
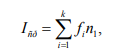
где k – число символов исходного алфавита; ns – число двоичных разрядов для кодирования символа s; fs – частота символа s; причем
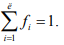
При эффективном кодировании существует предел сжатия, ниже которого не «спускается» ни один метод эффективного кодирования - иначе будет потеряна информация. Этот параметр определяется предельным значением двоичных разрядов возможного эффективного кода – Inp:
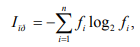
где n – мощность кодируемого алфавита, fi – частота i-го символа кодируемого алфавита.
2 Методы кодирования данных
Существуют два классических метода эффективного кодирования: метод Шеннона-Фано и метод Хаффмана. Входными данными для обоих методов является заданное множество исходных символов для кодирования с их частотами; результат - эффективные коды.
2.1 Метод Шеннона-Фано
Этот метод требует упорядочения исходного множества символов по не
возрастанию их частот. Затем выполняются следующие шаги:
а) список символов делится на две части (назовем их первой и второй частями) так, чтобы суммы частот обеих частей (назовем их Σ1 и Σ2) были точно или примерно равны. В случае, когда точного равенства достичь не удается, разница между суммами должна быть минимальна;
б) кодовым комбинациям первой части дописывается 1, кодовым комбинациям второй части дописывается 0;
в) анализируют первую часть: если она содержит только один символ, работа с ней заканчивается, – считается, что код для ее символов построен, и выполняется переход к шагу (г) для построения кода второй части. Если символов больше одного, переходят к шагу (а) и процедура повторяется с первой частью как с самостоятельным упорядоченным списком;
г) анализируют вторую часть: если она содержит только один символ, работа с ней заканчивается и выполняется обращение к оставшемуся списку (шаг д). Если символов больше одного, переходят к шагу (а) и процедура повторяется со второй частью как с самостоятельным списком;
д) анализируется оставшийся список: если он пуст – код построен, работа заканчивается. Если нет, – выполняется шаг (а).
Пример 1. Даны символы a, b, c, d с частотами fa = 0,5; fb = 0,25; fc = 0,125; fd = 0,125. Построить эффективный код методом Шеннона-Фано. Сведем исходные данные в таблицу, упорядочив их по невозрастанию частот:
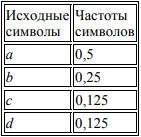
Первая линия деления проходит под символом a: соответствующие суммы Σ1 и Σ2 равны между собой и равны 0,5. Тогда формируемым кодовым комбинациям дописывается 1 для верхней (первой) части и 0 для нижней (второй) части. Поскольку это первый шаг формирования кода, двоичные цифры не дописываются, а только начинают формировать код:
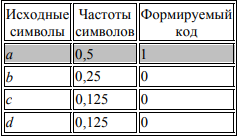
В силу того, что верхняя часть списка содержит только один элемент (символ а), работа с ней заканчивается, а эффективный код для этого символа считается сформированным (в таблице, приведенной выше, эта часть списка частот символов выделена заливкой). Второе деление выполняется под символом b: суммы частот Σ1 и Σ2 вновь равны между собой и равны 0,25. Тогда кодовой комбинации символов верхней части дописывается 1, а нижней части – 0. Таким образом, к полученным на первом шаге фрагментам кода, равным 0, добавляются новые символы:
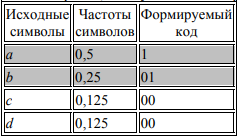
Поскольку верхняя часть нового списка содержит только один символ (b), формирование кода для него закончено (соответствующая строка таблицы вновь выделена заливкой). Третье деление проходит между символами c и d: к кодовой комбинации символа c приписывается 1, коду символа d приписывается 0:
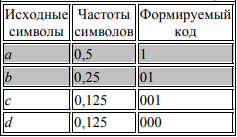
Поскольку обе оставшиеся половины исходного списка содержат по одному элементу, работа со списком в целом заканчивается.
Таким образом, получили коды:
а - 1, b - 01, c - 001, d - 000.
Определим эффективность построенного кода по формуле:
Icp = 0,5*1 + 0,25*01 + 0,125*3 + 0,125*3 = 1,75.
Поскольку при кодировании четырех символов кодом постоянной длины требуется два двоичных разряда, сэкономлено 0,25 двоичного разряда в среднем на один символ.
Сокращение времени передачи сообщения (при отсутствии помех) за счет использования оптимальных последовательностей кодов является несомненным достоинством кодирования по Шеннону—Фано. Эффект достигается благодаря присвоению высоковероятным сообщениям более коротких КК, и наоборот.
Недостатки кода:
1) поскольку код не обладает избыточностью, каждая ошибка ведет к искажению информации;
2) так как код неравномерный, некоторые символы кодируются длинными последовательностями, что приводит к длительным временным задержкам;
3) метод Шеннона—Фано не всегда приводит к однозначному построению кода, так как при разбиении на подгруппы большей по вероятности можно сделать как верхнюю, так и нижнюю подгруппы.
От последнего недостатка свободен код Хаффмана.
2.2 Метод Хаффмана
Этот метод имеет два преимущества по сравнению с методом Шеннона-Фано: он устраняет неоднозначность кодирования, возникающую из-за примерного равенства сумм частот при разделении списка на две части (линия деления проводится неоднозначно), и имеет, в общем случае, большую эффективность кода. Исходное множество символов упорядочивается по не возрастанию частоты и выполняются следующие шаги:
1) объединение частот:
две последние частоты списка складываются, а соответствующие символы исключаются из списка; оставшийся после исключения символов список пополняется суммой частот и вновь упорядочивается; предыдущие шаги повторяются до тех пор, пока ни получится единица в результате суммирования и список ни уменьшится до одного символа;
2) построение кодового дерева:
строится двоичное кодовое дерево (двоичное дерево - дерево, у которого из всех узлов, кроме листьев, выходит ровно по две дуги.): корнем его является вершина, полученная в результате объединения частот, равная 1; листьями – исходные вершины; остальные вершины соответствуют либо суммарным, либо исходным частотам, причем для каждой вершины левая подчиненная вершина соответствует большему слагаемому, а правая – меньшему; ребра дерева связывают вершины-суммы с вершинами-слагаемыми. Структура дерева показывает, как происходило объединение частот; ребра дерева кодируются: каждое левое кодируется единицей, каждое правое – нулём; 3) формирование кода:
для получения кодов листьев (исходных кодируемых символов) продвигаются от корня к нужной вершине и «собирают» веса проходимых рёбер.
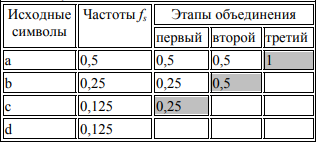
Пример 1. Даны символы a, b, c, d с частотами fa = 0,5; fb = 0,25; fc = 0,125; fd= 0,125. Построить эффективный код методом Хаффмена.
1)объединение частот (результат объединения двух последних частот в списке выделен в правом соседнем столбце заливкой):
2) построение кодового дерева
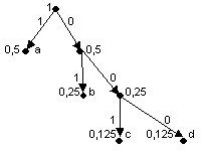
3) формирование кода:
a - 1; b - 01; c - 001; d -000.
Как видно, полученные коды совпадают с теми, что были сформированы методом Шеннона-Фано, следовательно, они имеют одинаковую эффективность.
Заключение
На основании, написанной курсовой, на тему «методы кодирования данных», можно сделать вывод, что существует несколько методов кодирования информации, но основными и часто применяемыми являются всего два метода – Шеннона-Фано и Хаффмана. Проводя параллель между этими методами, можно понять их схожесть и различия, например, они имеют одинаковую эффективность. Также мы выявили недостатки каждого метода.
В ходе курсовой работы были решены все задачи, а именно: были изучены общие понятия кодирования и теории информации; мы рассмотрели виды кодирования информации; мы ознакомились с историей, а также основателями теории кодирования информации; и самое главное, были выявлены основные методы кодирования данных.
При написании курсовой работы по теме исследования нами была изучена специальная литература, включающая научные статьи по информационным технологиям, учебники по информатике.
Список использованных источников
Колесник В.Д., Полтырев Г.Ш. Курс теории информации. М.: Наука, 20
Бекман, И.Н. Кодирование информации / И.Н. Бекман // Лекции по информатике. C. 3 - 4.
Кудряшов, Б.Д. Теория информации / Б.Д. Кудряшов. / СПб: учебник для вузов, 2008. -- 320с.
Могилев А.В. Информатика / А.В. Могилев, Н.И. Пак, Е.К. Хённер. / М.: учебное пособие, 2004. -- 848 с.
Чечета, С. И. Введение в дискретную теорию информации и кодирования. Учебное пособие / С.И. Чечета. - М.: МЦНМО, 2014. - 224 c.
Д.Сэломон. Сжатие данных, изображений и звука - Москва: Техносфера, 2004. - 368с.
Шавенько, Н.К. Основы теории информации и кодирования. / Учебное пособие. – М,: Изд-во МИИГАиК, 2012. – 125 с.

- Роль мотивации в поведении организации (Основные определения, действующие в теории мотивации)
- Классификация языков программирования. Критерии выборы среды и языка разработки программ
- Управление процессом реализации изменений и нововведений (Понятие управления изменениями)
- Организационная культура и ее роль в современных организациях (на примере ООО «Пумори-Спорт», г. Екатеринбург)»
- Японская модель менеджмента (История зарождения и развития менеджмента)
- Формирование межличностных отношений в детском коллективе (ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ФОРМИРОВАНИЯ МЕЖЛИЧНОСТНЫХ ОТНОШЕНИЙ СТАРШИХ ДОШКОЛЬНИКОВ)
- Корпоративная культура в организации (Сущность и соотношение понятий корпоративная и организационная культуры)
- Основные функции в системе менеджмента (Особенности процесса управления)
- Организация оплаты труда на примере ООО «ОкнаДвери
- Тенденции развития международной валютной системы (Теоретические аспекты международной валютной системы)
- Организация управленческого учета в компании мебели и интерьера «Идея» в г.Псков
- Отчет о финансовых результатах: методика и техника составления на примере ООО «Торговый дом «Семья»