
Методы кодирования данных (История кодирования)
Содержание:

ВВЕДЕНИЕ
Так устроено, что всякий человек познает мир, используя органы чувств. Ежедневно, вернее ежесекундно, любой индивидуум узнаёт что-то новое, естественно это «новое» откладывается в памяти для дальнейшего использования, иначе говоря, каждый человек накапливает и хранит познанную информацию. При общении человек передает информацию и принимает новую. Если же человеку необходимо решить какой-либо вопрос, то он обрабатывает ранее полученную информацию. Наглядно видно, что жизнь всякого человека информатизирована.
Очевидно, что человек не способен запомнить всё. В качестве помощника выступает компьютер. Всякая информация, поступающая на компьютер, подвергается кодированию.
Актуальность темы заключается в следующем: изначально вычислительная техника возникла для автоматизации вычислений. Далее начали обрабатывать текст. Затем появилось желание дополнить текст различными рисунками или графиками. Помимо использования разного вида информации в ПК, человеку также было важно и быстродействие компьютера. Поэтому учёными разрабатывались различные способы кодирования данных.
Целью данной курсовой работы является изучение методов кодирования данных.
Выделим основные задачи, необходимые для решения поставленной цели:
- Изучить историю кодирования;
- Ознакомиться с основными понятиями;
- Рассмотреть классификацию кодов;
- Рассмотреть способы представления кодов;
- Изучить методы кодирования данных.
Глава 1.Разнообразие методов кодирования
1.1.История кодирования
Потребность в кодировании информации (далее КИ) появилась намного раньше компьютеров. И речь, и азбука, и цифры – это единая система преобразования мыслей, речевых звуков и числовой информации. В технике необходимость КИ возникла сразу же после появления телеграфа, однако с созданием ЭВМ она стала наиболее важнее.
Теория кодирования изучает, как благоприятнее упаковать полученные данные, чтобы процесс выделения необходимой информации после передачи сигнала из данных был и достаточно лёгким, и надёжным.
Нередко под теорией кодирования подразумевают шифрование. Однако, вспомнив цель шифрования – усложнить получение нужной информации, видно явно ошибку в этом понимании.
С необходимостью КИ впервые столкнулись более полутораста лет назад, вскоре после появления телеграфа. К сожалению, каналы были ненадёжны и дороги, что поспособствовало актуализации проблемы в уменьшении стоимости и увеличения надёжности передачи телеграмм. Далее начали применять трансатлантические кабели, это же ещё хуже обострило данную проблему.
С 1845г. вошли в использование специальные кодовые книги; используя их, телеграфисты вручную совершали «компрессию» текстов (сообщений), заменяя распространенные последовательности слов наиболее короткими кодами. В то время появился контроль чётности, необходимый для проверки правильности ввода перфокарт в ЭВМ. В случае ненадёжности устройства ввода могла появиться ошибка. Для её коррекции процедуру ввода повторяли до того как высчитанная контрольная сумма не совпадёт с сохранённой на карте суммой. Данная схема совершенно неудобна и пропускает двойные ошибки.
Теоретическое решение проблемы передачи данных по зашумленным каналам первым предложил Клод Шеннон. Он написал работу «Математическая теория передачи сообщений» (1948), в которой и было изложено решение.
Практическое применение мыслей Шеннона было реализовано в деятельности Хэмминга. Учёный создал коды, которые способны исправлять ошибки и в каналах связи, и в магистралях передачи данных в ЭВМ, непосредственно между памятью и процессором. Данные коды используются и сейчас, просто они уже модифицированы.
В.А.Котельников также есть в истории КИ. Его имя есть в название одной из важнейших теорем теории кодирования, определяющей условия, при которых переданный сигнал может быть восстановлен без потери информации.
1.2.Основные понятия в кодировании
Что же такое кодирование? Кодирование – создание кода и его присвоение к одиночному объекту или же группировке классификации.
Код – либо одиночный знак, либо комплекс знаков, используемых для позиционирования объекта/группировки классификации.
Кодер – механизм, выполняющий кодирование.
Декодер – механизм, совершающий обратное преобразование.
Алфавит – изобилие возможных элементов (объектов) кода:
где . Число символов кода именуется основанием. Например, в случае двоичного кода , притом и .
Итоговый набор символов этого алфавита именуется кодовой комбинацией (или кодовым словом). Количество объектов в кодовом слове n именуется значностью/длиной комбинации.
Разряд кода – местонахождение знака.
Объёмом/мощностью кода N именуется количество разных кодовых слов
Если же - количество сообщений источника, то .
Изобилие состояний кода должно покрывать изобилие состояний объекта. Если полный и равномерный - значный код с основанием состоит из кодовых слов, то данный код именуется примитивным.
Существуют следующие алфавиты кодов:
- Цифровой;
- Буквенный;
- Буквенно-цифровой;
- Штриховой. Штрихи и пробелы – знаки кода.
Цель кодирования - систематизация объектов, применяя к ним отождествление, ранжирование и присвоение некоторого условного обозначения (кода), по которому можно обнаружить и опознать всякий объект среди изобилия других.
1.3.Классификация кодов
Рассмотрим классификацию кодов в таблице 1.3.1.
|
||||||||||||||||||
|
Таблица 1.3.1.Классификация кодов |
На основание данной классификации можно выделить следующие цели кодирования:
- Увеличение эффективности передачи данных, за счет достижения максимальной скорости передачи данных;
- Увеличение помехоустойчивости при передаче данных.
На основании данных целей выделяются два направления развития теории кодирования:
- Теория оптимального (эффективного, экономичного) кодирования направлена на поиск кодов, используя которые можно без помех увеличить эффективность передачи информации за счет устранения избыточности источника и наилучшего согласования скорости передачи, данных с пропускной способностью канала связи;
- Теория помехоустойчивого кодирования направлена на поиск кодов, увеличивающих достоверность передачи информации в каналах с помехами.
1.4.Способы представления кодов
Существуют различные способы представления кодов, рассмотрим наиболее часто используемые (Табл.1.4.1).
|
||||||||||||||
|
Таблица 1.4.1.Способы представления кодов |
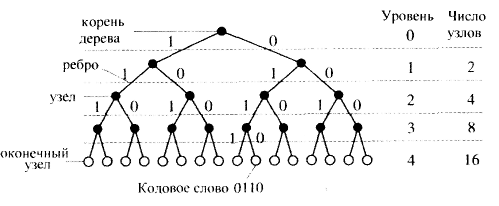
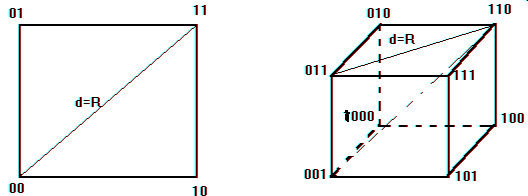
Глава 2.Методы кодирования данных
2.1.Кодирование символьной информации
При записи текста применяют изобилие символов, называемое алфавитом. Количество знаков в алфавите именуется его мощностью. Обычно в ПК применяют алфавит мощностью знаков. Притом один знак несёт 8 бит информации, поскольку . Однако 8 бит равно 1 байту, соответственно, двоичный код всякого знака заимствует 1 байт памяти ПК. Все знаки данного алфавита имеют нумерацию от до . Притом каждому номеру соответствует 8-разрядный двоичный код от до . Данный код – это порядковый номер знака в 2-ой с.с.
Процесс вывода знака на экран или же на печатающее устройство именуется декодирование – обратное преобразование.
Существуют разные таблицы кодировки для каждого вида ЭВМ. Данные таблицы различаются порядковым размещением знака в самой кодовой таблице. На ПК международным стандартом является таблица кодировки ASCII.
В ASCII цифры располагаются по возрастанию величины, а латинские буквы в алфавитном порядке.
В ASCII изначальные 128 знаков – стандартные: нумерация знаков от до . Сюда входят и цифры, и буквы латинского алфавита, и знаки препинания, и скобки, и иные знаки.
Последующие 128 знаков нумеруются от до . Они применяются для кодирования научных символов, символов псевдографики и национальных алфавитов.
Для кодирования русских букв есть таблицы КОИ-8, СР-1251, СР-866, ISO, Mac.
Для русского языка принята в качестве стандарта кодировка ISO 8859-5.
Сегодня наиболее распространена кодировка СР-1251. Это кодировка MS Windows.
Как правило, созданные тексты в одной кодировке в другой уже будут отображаться некорректно. Для решения данной проблемы разработаны программы. Но и в некоторых кодировках есть функция – конвертация.
К сожалению, с течением времени стало понятно, что 256 символов – это достаточно мало. Часто в различных профессиях при создании текста необходимо употреблять символы из разных алфавитов. Потому была создана новая универсальная система кодирования текста – Unicode. В ней отдельному знаку даётся не один байт, а два. Таким образом, доступно кодов.
Наиболее часто используют кодировки Unicode UTF-8 и UTF-16:
|
||||||
|
Таблица 2.1.1.Кодировки Unicode |
Рассмотрим на примере принцип кодирования текста. Пусть, необходимо закодировать слово «ЭВМ» в различных кодировках.
Даны таблицы кодировок[2], по которым и найдем ответ.
|
|
|
Рис.2.1.1.КОИ8-Р |

|
|
|
Рис.2.1.2. CP1251 |

|
|
|
Рис.2.1.3. CP866 |
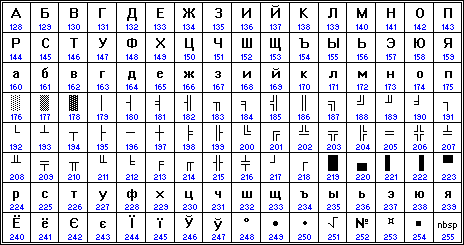
|
|
|
Рис.2.1.4. ISO 8859-5 |

|
|
|
Рис.2.1.5. ASCII |
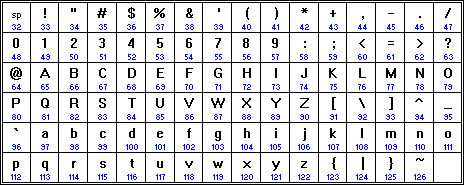
Решение: Находим в таблице необходимую букву и записываем её код.
Ответ:
|
КОИ8-Р |
252 247 237 |
|
CP1251 |
221 194 204 |
|
CP866 |
157 130 140 |
|
ISO 8859-5 |
205 178 188 |
|
ASCII |
- |
Над отдельными знаками текста выполняется главная операция – сравнение, при котором рассматриваются условия, наиболее важные из коих:
- Уникальность кода для каждого знака;
- Длина кода.
2.2.Кодирование числовой информации
Кодировка чисел имеет схожесть с кодировкой текста, а именно – операция сравнение – любое число должно обладать уникальным кодом.
Также есть и отличие между кодированием чисел и текста, а именно – помимо операции сравнения выполняются и математические операции. Математические операции – сложение, логарифм, умножение и другие.
Представление числовой информации может быть в двух формах – либо целые, либо вещественные числа.
Целые числа хранятся и обрабатываются в формате вещественных чисел с фиксированной запятой. А именно, всякому разряду ячейки памяти постоянно соответствует один и тот же разряд числа, притом запятая располагается справа от младшего разряда (вне разрядной сетки).
Для кодирования целых чисел со знаком выделяется байтабитов. Один разряд (1 бит) выделяется под знак числа ( для положительных и для отрицательных чисел). Другие битов – под цифры двоичного представления числа (Рис.2.2.1).
|
|
|
Рис.2.2.1.Кодирование целого числа[3] |

Вещественные же числа хранятся и обрабатываются в формате вещественных чисел с плавающей запятой. А именно, положение запятой незафиксировано (может меняться) в записи числа. Данный формат основан на экспоненциальной форме записи, в которой всякое число может быть представлено в двоичной с.с.:
|
(2.2.1) |
Здесь - мантисса числа; - порядок числа.
Пример:
Для хранения вещественных чисел выделяется байта бита. Притом первый бит выделяется под знак числа, последующие бита – под цифры мантиссы, а оставшиеся 8 битов – под порядок числа.
2.3.Кодирование графической информации
Впервые кодирование графики было применено в середине 50-х годов. Интенсивнее данное кодирование стало развиваться уже в 80–х годах.
Графическую информацию (ГИ) можно представить в двух видах:
- аналоговый;
- дискретный.
Картина, изменение цвета которой непрерывно – аналоговое представление. Дискретное же представление – это точечное изображение.
Разбивая графическое изображение на точки (дискритизация), аналоговая ГИ трансформируется в дискретную. Притом совершается кодирование ГИ.
При кодировке ГИ совершается пространственная дискретизация. Данная дискретизация подобна мозаике, изображение создаётся из маленьких разноцветных фрагментов. Притом всё изображение делится на индивидуальные точки, и всякому компоненту устанавливается личный код цвета. Причем качество кодирования ГИ определяется двумя параметрами:
-
- размер точки;
- число используемых цветов.
Зависимость следующая: чем меньше размер точки, тем больше число точек, а, значит, и качество изображения будет наиболее выше. Качество кодирования ГИ имеет следующую зависимость: при использовании большего числа цветов, увеличивается количество информации, которую несёт всякая точка, а, значит и качество кодирования возрастает.
Графические объекты могут существовать в нескольких видах:
- растровый;
- векторный;
- фрактальный;
- трёхмерная графика.
Изображение на экране представлено в растровом виде. Рисунок разбивается на точки, затем с левого угла передвигаясь построчно, последовательно кодируется цвет у каждой точки. Индивидуальная точка именуется пикселем. Произведение информационного числа точки на число пикселей определяет объём изображения. Разрешающая способность монитора определяет качество изображения. Зависимость прямая: чем разрешающая способность, тем качество.
Примеры разрешающей способности: и другие.
При кодировании ГИ: цвет пикселя есть его код. Для кодирования чёрно-белой иллюстрации достаточно одного бита памяти, соответственно – чёрный, а - белый. В случае изображений в виде комбинации точек с 256 градациями серого цвета (который общеприняты сегодня), вполне достаточно восьмиразрядного двоичного числа для кодировки.
Для кодирования цветного изображения используют соответствующие кодировки (Табл.2.3.1):
- HSB – удобна для человека;
- RGB – удобна для компьютера;
- CMYK – удобна для типографий.
Применение данных цветовых моделей поясняется тем, что световой поток может формироваться излучениями, представляющими собой комбинацию " чистых" спектральных цветов : красного, зеленого, синего или их производных. Различают аддитивное цветовоспроизведение (характерно для излучающих объектов) и субтрактивное цветовоспроизведение (характерно для отражающих объектов). В качестве примера объекта первого типа можно привести электронно-лучевую трубку монитора, второго типа - полиграфический отпечаток.
|
||||||||
|
Таблица 2.3.1.Цветовые модели |
Существует следующие режимы демонстрации цветной графики:
- полноцветный (True Color);
- High Color;
- индексный.
Для кодирования яркости составляющих при полноцветном режиме применяют по значений (восемь двоичных разрядов), а именно, на кодирование цвета пикселя (в RGB) необходимо затратить разряда. Это позволяет однозначно определять цветов. А это довольно близко к чувствительности человеческого глаза. При кодировании с помощью CMYK для демонстрации цветной графики нужно иметь двоичных разряда.
Режим High Color - это кодирование при помощи двоичных чисел, а именно, уменьшается число двоичных разрядов при кодировке всякой точки. Однако при этом значительно понижается диапазон кодируемых цветов.
При индексном кодировании цвета можно передать лишь цветовых оттенков. Всякий цвет кодируется с помощью восьми бит данных. Однако, поскольку значений не передают весь диапазон цветов, доступный человеческому глазу, то подразумевается, что к ГИ прилагается палитра (или же справочная таблица). Без неё демонстрация будет непонятная: море - красное, а листья - фиолетовые. Притом код точки растра в таком случае означает не сам цвет, а лишь его номер/индекс в палитре. Отсюда и вытекает название режима - индексный.
Соответствие между числом отображаемых цветов () и числом бит для кодировки () вычисляется по формуле 2.3.1.:
|
(2.3.1) |
Двоичный код выводимого на экран изображения хранится в видеопамяти. Видеопамять - это электронное энергозависимое запоминающее устройство. Размер видеопамяти зависит от разрешающей способности дисплея и количества цветов. Однако её наименьший объём вычисляется так, чтобы влез один кадр/одна страница изображения, а именно, как результат произведения разрешающей способности на размер кода пикселя.
|
(2.3.2) |
Векторное изображение - графический объект, состоящий из элементарных отрезков и дуг.
Базовым компонентом иллюстрации является линия, имеющая следующие свойства:
- форма (прямая, кривая);
- толщина;
- цвет;
- начертание (пунктирное, сплошное).
Замкнутые линии обладают свойством заполнения.
Линия – единый объект, поэтому в векторной графике объём данных для демонстрации объекта достаточно меньше, чем в растровой графике. ГИ о векторном изображении кодируется как обычная буквенно-цифровая и обрабатывается специальными программами: Adobe Illustrator, CorelDraw, трассировщики.
Фрактальная графика основывается также на математических вычислениях. Однако по сравнению с векторной её базовым компонентом является сама математическая формула. Потому в памяти ПК не хранится никаких объектов и изображение строится только по уравнениям. Используя данный способ можно создавать простейшие регулярные структуры, сложные иллюстрации, имитирующие ландшафты.
2.4.Кодирование Звуковой информации
Компьютер функционирует с цифровой информацией (ЦИ). Её можно вообразить в виде серии электрических импульсов - логических нулей и единиц. Однако человек слышит непрерывный звук. Данная звуковая волна, имеющая изменяющейся амплитуду и частоту, есть аналоговый сигнал. Для записи данного звука на ПК необходима его оцифровка. Это деятельность аналого-цифрового преобразователя (АЦП). АЦП для воспроизведения цифрового звука преобразует его в аналоговый.
Непрерывная звуковая волна разделяется на отдельные участки по времени, для каждого устанавливается своя величина амплитуды. Притом всякой ступеньке задаётся свой уровень громкости звука, который можно рассматривать как набор возможных состояний.
Звук обладает следующими характеристиками:
- Глубина кодирования звука - число бит на один звуковой сигнал. Современные звуковые карты обеспечивают глубину кодирования звука. Число уровней можно вычислить по формуле 2.4.1:
|
(2.4.1) |
- Частота дискретизации – число измерений уровней сигнала за секунду. Одно измерение в секунду соответствует частоте . Например, при записи на CD применяются значения, а частота дискретизации равна .
Данные параметры обеспечивают достаточно высокое качество звучания и речи, и музыки. Для стереозвука отдельно записывают данные и для левого, и для правого канала.
В случае преобразования звука в электрический сигнал, будет видно плавно изменяющееся с течением времени напряжение. Для ПК-обработки данный аналоговый сигнал необходимо каким-то образом преобразовать в последовательность двоичных чисел. Сначала измеряется напряжение через равные промежутки времени, затем заносятся полученные величины в память ПК. Данный процесс и есть дискретизация/оцифровка. Соответственно, устройство, реализующее процесс – АЦП.
Есть следующая взаимосвязь: чем больше частота дискретизации (число отсчетов за секунду) и чем больше разрядов выделяется для всякого отсчёта, тем качественнее получится звук. Однако при этом возрастает и размер звукового файла. Потому ориентируясь на характер звука, требования, предъявляемые к его качеству и объёму занимаемой памяти, выбираются некоторые компромиссные величины.
Заключение
В процессе выполнения данной курсовой работы были реализованы следующие задачи:
- Была изучена история кодирования;
- Ознакомился с основными понятиями;
- Рассмотрена классификацию кодов;
- Рассмотрены способы представления кодов;
- Изучены методы кодирования данных.
Список литературы
- Бройдо В.Л. Вычислительные системы, сети и телекоммуникации [Текст]: учеб. Пособие для вузов – СПб.: Питер, 2003. – 688 с.: ил. – ISBN 5-318-00530-6.
- Симонович С. В., Евсеев Г. А., Мураховский В. И., Бобровский С. И. Информатика. Базовый курс [Текст] : учеб. пособие для вузов / под ред. С.В. Симоновича. – СПб.: Питер, 2001. – 640 с.: ил. – ISBN 5-8046-0134-2.
- Макарова Н.В. Информатика [Текст]: учебник – 3-е перераб. изд. – М.: Финансы и статистика, 2005. – 768 с.: ил.
- Каймин, В. А. Информатика [Текст]: учеб. для вузов – 4-е изд. – М.: ИНФРА-М, 2004. – 285 с.
- Острейковский, В. А. Информатика [Текст]: учебник – М.: Высш. шк., 2001. – 511 с.
- Калугина О. Б., Люцарев В. С. Работа с текстовой информацией. Microsoft Office Word 2003 [Текст]: учеб. пособие– М.: Интернет – Ун-т Информ. технологий, 2005. – 152 с.
- Волков Ю. И., Каратыгин К.С., Петров И. М.. Microsoft Office 2000 Professional [Текст]: 6 книг в одной – М.: Лаб. Базовых Знаний, 2001. – 944 с.
- Могилев, А. В., Пак Н. И., Хеннер Е. К. Практикум по информатике [Текст]: учеб. пособие для вузов - М.: Академия, 2002. – 608 с.
- Стариченко, Б. Е. Теоретические основы информатики [Текст]: учебное пособие для вузов – 2-е изд. перераб. и доп. – М.: Горячая линия – Телеком, 2004. – 312 с.: ил. – ISBN 5-93517-090-6.
- ГоряевЮ.А. Информатика: Учебное пособие. – М., МИЭМП, 2005. – с.116
- Кудряшов Б.Д. Теория информации. Учебник для вузовИзд-во ПИТЕР, 2008. — 320с.
Электронные ресурсы
- https://studfiles.net/preview/3208480/page:7/;
- http://kuzelenkov.narod.ru/mati/book/inform/inform6.html;
(Информатика. Лекция №6. Представление информации в компьютере);
- http://www.lessons-tva.info/edu/e-inf1/e-inf1-2-5.html
(Представление информации в компьютере, единицы измерения информации. Курс дистанционного обучения).
-
http://bigpo.ru/potrb/Книга+составлена+таким+образом%2C+что+обе+части+«Информация»b/part-3.html ↑
-
https://studfiles.net/preview/3208480/page:7/ ↑
-
https://studfiles.net/preview/3208480/page:7/ ↑

- Применение процессного подхода для оптимизации бизнес-процессов (Принципы процессного подхода)
- Процесс построения модели управленческого решения (Обоснование необходимости принятия управленческих решений в целях повышения эффективности деятельности предприятия)
- Банковские риски и основы управления ими (ОАО "Газпромбанк")
- Общий порядок ведения кассовых операций в банке ( на примере ПАО Сбербанк)
- Формы и системы оплаты труда на предприятии (Организация оплаты труда в магазине «Солнышко»)
- Основы учета расчетов по оплате труда
- Процессы принятия решений в организации (Теоретические аспекты принятия решений)
- Расходы бюджетов субъектов Российской Федерации,их оптимизация
- Анализ показателей финансовой деятельности предприятия (Анализ финансовых показателей деятельности филиала в г. Череповце ОАО «Россельхозбанк»)
- Управленческие решения (Зарубежный опыт организации и контроля управленческих решений)
- Способы представления данных в информационных системах (Понятие информационной системы)
- Применение процессного подхода для оптимизации бизнес-процессов ( Принципы процессного подхода)