
Алгоритмы сортировки данных (Типы и структуры данных)
Содержание:

Введение
Актуальность темы исследования курсовой работы связана с тем, что на данный момент сортировка является неотъемлемой частью обработки данных и очень обширно используется в мире программирования, вычислительных программ и баз данных. Алгоритмы сортировки данных обладают большим спектром применений, но их чаще всего можно встретить в работе над большими объемами данных. Также можно решить некоторые проблемы связанных с обработкой данных заранее их упорядочив.
Для различных данных существуют определенные методы сортировок, повышающие производительность и скорость сортировки именно для этого типа данных. Рассматриваемые в данной работе сортировки методы сортировки являются относительно простыми, хотя их эффективность ниже чем у более сложных и совершенных методов, но они так же имеют ряд преимуществ, и к тому же лежат в основе большинства других методов сортировки.
Цель и задачи курсовой работы изучить и понять работу существующих на данный момент алгоритмов сортировок данных, выполнить небольшие сравнения некоторых алгоритмов и также дать оценку их эффективности (сортировка включением (метод Шелла), обменая сортировка (метод Пузырька и Шейкерная сортировка), сортировка выбором, сортировка разделением (quicksort), сортировка при помощи дерева (heapsort), пирамидальная сортировка, сортировка Хоара, сортировка слиянием, многофазная сортировка).
1. Типы и структуры данных
Типы и структуры данных представляют собой фундамент, на котором строится вся современная технология программирования. Программирования в широком смысле, включая не только непосредственно написание и отладку программ, но и проектирование программных систем разной сложности; проектирование, реализацию и использование баз данных и информационных систем и т.д. Сегодня только большие любители обходятся без использования безтиповых языков программирования (например, языков ассемблера) или неструктурированных или нетипизированных хранилищ данных во внешней памяти.
1.1. Понятие типа данных
Существует много подходов к определению понятия типа данных от полностью математических, основанных на аппаратах абстрактной алгебры или математической логики, до полностью житейских, ориентированных исключительно на интуицию.
Основным принципом типизации, принятым в языках программирования и базах данных является то, что любая константа, переменная, выражение и функция относится к некоторому типу, характеризующему прежде всего множество значений, к которым относятся константы, которые могут принимать переменные и выражения и которые могут формировать функции. При описании любых используемых констант, переменных и функций явно или неявно указывается их тип. В первую очередь это дает возможность компилятору или системе управления базами данных выделить для хранения объекта данных ровно тот объем памяти, который определяется допустимым диапазоном значений типа. Однако концепция типа этим не исчерпывается.
Следующим исключительно важным свойством типа данных является инкапсуляция внутреннего представления его значений. К значению типа данных (значения констант, переменных, выражений и функций) можно обращаться только с помощью операций, предопределенных в описании этого типа. Эти операции могут быть явными (например, арифметические операции "+", "-", "?" и "/" для числовых типов) или неявными (например, операция преобразования значения целого типа к значению плавающего типа; заметим, что в некоторых языках, в частности, в Си и Си++, допускаются и явные преобразования типов).
Наличие типовых описаний констант, переменных и функций и предписанные правила определения типов выражений вместе с поддержкой свойства инкапсуляции типов дают возможность компиляторам языков программирования и языков баз данных производить существенный контроль допустимости языковых конструкций на этапе компиляции, что позволяет сократить число проверок на стадии выполнения программ и облегчить их отладку.
Один из характерных примеров преимущества использования типизированных языков программирования представляет история операционной системы UNIX. Как известно, система первоначально была написана на языке ассемблера PDP-7. При переходе к использованию PDP-11 ОС UNIX была переписана на языке более высокого уровня B, который являлся прямым наследником безтипового языка программирования BCPL. В очень скором времени по мере роста размеров системы ее разработчикам стало понятно, что бесчисленные проверки времени выполнения очень усложняют отладку и замедляют работу системы. Это явилось исходным толчком к внедрению в язык B системы типов и созданию типизированного языка Си, опора на который обеспечила более чем 25-летнюю плодотворную жизнь системы.
Можно приводить различные классификации типов данных, например, простые и составные типы, предопределенные и определяемые типы и т.д. Существенно то, что несмотря на многолетнее использование типов данных в отечественном программировании, так и не сложилась устойчивая и общепринятая русскоязычная терминология.
Выделим следующие категории типов:
- Встроенные типы данных, т.е. типы, предопределенные в языке программирования или языке баз данных. Обычно в языке фиксируются внешнее представление значений этих типов (вид литеральных констант) и набор операций с описанием их семантики. Внутреннее представление и реализация операций выбираются в конкретных компиляторах и подсистемах поддержки выполнения программ.
- Под термином "уточняемый тип данных" мы понимаем возможность определения типа на основе встроенного типа данных, значения которого упорядочены. В частности, к категории уточняемых типов относится тип поддиапазона целых чисел в языках линии Паскаль.
- Категорию перечисляемых типов данных составляют явно определяемые целые типы с конечным числом именованных значений. Это очень простой и легко реализуемый механизм, часто являющийся очень полезным.
Замечание: использование уточняемых и перечисляемых типов порождает потребность в динамической проверке корректности значений - выхода значения за пределы явно (в случае уточняемых типов) или неявно (в случае перечисляемых типов) диапазона. - Конструируемые типы (иногда их называют составными) обладают той особенностью, что в языке предопределены средства спецификации таких типов и некоторый набор операций, дающих возможность доступа к компонентам составных значений. Мы обсудим наиболее распространенные разновидности конструируемых типов: типы массивов, записей и множеств, а также различия в понимании этих типов в разных языках.
- Указательные типы дают возможность работы с типизированными множествами абстрактных адресов переменных, содержащих значения некоторого типа. В сильно типизированных языках (Паскаль, Модула, Ада и т.д.) работа с указателями сильно ограничена. В частности, невозможно получить значение указателя явно определенной переменной и/или применять к известным значениям указателей адресную арифметику. В языках с более слабой типизацией (например, Си/Си++) допускаются практически неограниченные манипуляции указателями.
- Вообще говоря, упоминавшиеся выше уточняемые, перечисляемые и конструируемые типы данных являются типами, определяемыми пользователями. Но эти определения не могут включать спецификацию операций над значениями типов. Допустимые операции либо предопределены, либо наследуются от некоторого определенного ранее или встроенного типа. Под термином "определяемый пользователем тип данных" (ранее был больше распространен термин "абстрактный тип данных", однако мы не будем здесь его использовать, поскольку, на наш взгляд, он не точно отражает смысл понятия) мы будем понимать возможность полного определения нового типа, включая явную или неявную спецификацию множества значений, спецификацию внутреннего представления значений типа и спецификацию набора операций над значениями определяемого типа.
Наконец, под термином "полнотиповая система" мы понимаем систему типов, в которых типы, определяемые пользователем, равноправны с предопределенными типами, т.е. можно, например, определить тип массива с элементами любого определенного типа, можно использовать определяемый пользователем тип на основе любого определенного типа и т.д.
2. Понятие алгоритма
Алгоритм - набор инструкций, описывающих порядок действий исполнителя для достижения некоторого результата. В старой трактовке вместо слова «порядок» использовалось слово «последовательность», но по мере развития параллельности в работе компьютеров слово «последовательность» стали заменять более общим словом «порядок». Независимые инструкции могут выполняться в произвольном порядке, параллельно, если это позволяют используемые исполнители.
Ранее в русском языке писали «алгорифм», сейчас такое написание используется редко, но, тем не менее, имеет место исключение (нормальный алгорифм Маркова).
Часто в качестве исполнителя выступает компьютер, но понятие алгоритма необязательно относится к компьютерным программам, так, например, чётко описанный рецепт приготовления блюда также является алгоритмом, в таком случае исполнителем является человек (а может быть и некоторый механизм, ткацкий станок, и пр.).
Можно выделить алгоритмы вычислительные (о них в основном идет далее речь), и управляющие. Вычислительные по сути преобразуют некоторые начальные данные в выходные, реализуя вычисление некоторой функции. Семантика управляющих алгоритмов существенным образом может отличаться и сводиться к выдаче необходимых управляющих воздействий либо в заданные моменты времени, либо в качестве реакции на внешние события (в этом случае, в отличие от вычислительного алгоритма, управляющий может оставаться корректным при бесконечном выполнении).
Понятие алгоритма относится к первоначальным, основным, базисным понятиям математики. Вычислительные процессы алгоритмического характера (арифметические действия над целыми числами, нахождение наибольшего общего делителя двух чисел и т. д.) известны человечеству с глубокой древности. Однако в явном виде понятие алгоритма сформировалось лишь в начале XX века.
2.1. Свойства алгоритмов
Различные определения алгоритма в явной или неявной форме содержат следующий ряд общих требований:
- Дискретность - алгоритм должен представлять процесс решения задачи как последовательное выполнение некоторых простых шагов. При этом для выполнения каждого шага алгоритма требуется конечный отрезок времени, то есть преобразование исходных данных в результат осуществляется во времени дискретно.
- Детерминированность (определённость). В каждый момент времени следующий шаг работы однозначно определяется состоянием системы. Таким образом, алгоритм выдаёт один и тот же результат (ответ) для одних и тех же исходных данных. В современной трактовке у разных реализаций одного и того же алгоритма должен быть изоморфный граф. С другой стороны, существуют вероятностные алгоритмы, в которых следующий шаг работы зависит от текущего состояния системы и генерируемого случайного числа. Однако при включении метода генерации случайных чисел в список «исходных данных» вероятностный алгоритм становится подвидом обычного.
- Понятность - алгоритм должен включать только те команды, которые доступны исполнителю и входят в его систему команд.
- Завершаемость (конечность) - в более узком понимании алгоритма как математической функции, при правильно заданных начальных данных алгоритм должен завершать работу и выдавать результат за определённое число шагов. Дональд Кнут процедуру, которая удовлетворяет всем свойствам алгоритма, кроме, возможно, конечности, называет методом вычисления. Однако довольно часто определение алгоритма не включает завершаемость за конечное время. В этом случае алгоритм (метод вычисления) определяет частичную функцию. Для вероятностных алгоритмов завершаемость как правило означает, что алгоритм выдаёт результат с вероятностью 1 для любых правильно заданных начальных данных (то есть может в некоторых случаях не завершиться, но вероятность этого должна быть равна 0).
- Массовость (универсальность) - алгоритм должен быть применим к разным наборам начальных данных.
- Результативность - завершение алгоритма определёнными результатами.
2.2. Виды алгоритмов
Виды алгоритмов как логико-математических средств отражают указанные компоненты человеческой деятельности и тенденции, а сами алгоритмы в зависимости от цели, начальных условий задачи, путей её решения. Следует подчеркнуть принципиальную разницу между алгоритмами вычислительного характера, преобразующими некоторые входные данные в выходные (именно их формализацией являются упомянутые выше машины Тьюринга, Поста, РАМ, нормальные алгорифмы Маркова и рекурсивные функции), и интерактивными алгоритмами (уже у Тьюринга встречается C-машина, ожидающая внешнего воздействия, в отличие от классической A-машины, где все начальные данные заданы до начала вычисления и выходные данные недоступны до окончания вычисления). Последние предназначены для взаимодействия с некоторым объектом управления и призваны обеспечить корректную выдачу управляющих воздействий в зависимости от складывающейся ситуации, отражаемой поступающими от объекта управления сигналами. В некоторых случаях алгоритм управления вообще не предусматривает окончания работы (например, поддерживает бесконечный цикл ожидания событий, на которые выдается соответствующая реакция), несмотря на это, являясь полностью правильным.
Можно также выделить алгоритмы:
- Механические алгоритмы, или иначе детерминированные, жесткие (например, алгоритм работы машины, двигателя и т. п.) - задают определенные действия, обозначая их в единственной и достоверной последовательности, обеспечивая тем самым однозначный требуемый или искомый результат, если выполняются те условия процесса, задачи, для которых разработан алгоритм.
- Гибкие алгоритмы, например, стохастические, то есть вероятностные и эвристические.
- Вероятностный (стохастический) алгоритм дает программу решения задачи несколькими путями или способами, приводящими к вероятному достижению результата.
- Эвристический алгоритм (от греческого слова «эврика») - алгоритм, использующий различные разумные соображения без строгих обоснований.
- Линейный алгоритм - набор команд (указаний), выполняемых последовательно во времени друг за другом.
- Разветвляющийся алгоритм - алгоритм, содержащий хотя бы одно условие, в результате проверки которого может осуществляться разделение на несколько альтернативных ветвей алгоритма.
- Циклический алгоритм - алгоритм, предусматривающий многократное повторение одного и того же действия (одних и тех же операций) над новыми исходными данными. К циклическим алгоритмам сводится большинство методов вычислений, перебора вариантов. Цикл программы - последовательность команд (серия, тело цикла), которая может выполняться многократно (для новых исходных данных) до удовлетворения некоторого условия.
- Вспомогательный алгоритм - алгоритм, ранее разработанный и целиком используемый при алгоритмизации конкретной задачи. В некоторых случаях при наличии одинаковых последовательностей указаний (команд) для различных данных с целью сокращения записи также выделяют вспомогательный алгоритм. На всех этапах подготовки к алгоритмизации задачи широко используется структурное представление алгоритма.
- Структурная блок-схема, граф-схема алгоритма - графическое изображение алгоритма в виде схемы связанных между собой с помощью стрелок (линий перехода) блоков - графических символов, каждый из которых соответствует одному шагу алгоритма. Внутри блока дается описание соответствующего действия. Графическое изображение алгоритма широко используется перед программированием задачи вследствие его наглядности, так как зрительное восприятие обычно облегчает процесс написания программы, её корректировки при возможных ошибках, осмысливание процесса обработки информации. Можно встретить даже такое утверждение: «Внешне алгоритм представляет собой схему - набор прямоугольников и других символов, внутри которых записывается, что вычисляется, что вводится в машину и что выдается на печать и другие средства отображения информации».
3. Понятие сортировки
Сортировка - один из наиболее распространенных процессов современной обработки данных. Задачи на сортировку данных встречаются на компьютере очень часто. Главным образом, это связано с тем, что разбираться в отсортированных данных намного проще, чем в неотсортированных.
Алгоритм сортировки - это порядок действий для упорядочения элементов в списке. Обычно говорят о сортировке записей (содержащих любые данные) по ключам – фрагментам этих записей, допускающих отношение упорядочения. Например, ключи могут быть числами (в этом случае используется естественный математический порядок возрастания или убывания чисел) или строковыми значениями (в этом случае упорядочение производится по алфавиту).
Наверно, никакая другая проблема не породила такого количества разнообразнейших решений, как задача сортировки.
3.1. Оценка алгоритма сортировки
Для того чтобы обоснованно сделать выбор метода сортировки, рассмотрим параметры, по которым будет производиться оценка алгоритмов.
• Время сортировки. Основной параметр, характеризующий быстродействие алгоритма. Называется также вычислительной сложностью.
• Память. Ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы.
• Устойчивость. Устойчивая сортировка не меняет взаимного расположения равных элементов. Такое свойство может быть очень полезным, если они состоят из нескольких полей, а сортировка происходит по одному из них.
• Естественность поведения - эффективность метода при обработке уже
отсортированных, или частично отсортированных данных. Алгоритм ведёт себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Ещё одним важным свойством алгоритма является его сфера применения. Здесь основных типов сортировки две:
• Внутренняя сортировка оперирует с массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно сортируются на том же месте, без дополнительных затрат.
• Внешняя сортировка оперирует с запоминающими устройствами большого объёма, но с доступом не произвольным, а последовательным (сортировка файлов), то есть в данный момент мы «видим» только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это накладывает некоторые дополнительные ограничения на алгоритм и приводит к специальным методам сортировки, обычно использующим дополнительное дисковое пространство. Кроме того, доступ к данным на носителе производится намного медленнее, чем операции с оперативной памятью.
4. Методы внутренней сортировки
Внутренняя сортировка - разновидность алгоритмов сортировки или их реализаций, при которой объема оперативной памяти достаточно для помещения в неё сортируемого массива данных с произвольным доступом к любой ячейке и, собственно, для выполнения алгоритма. В этом случае сортировка происходит максимально быстро, так как скорость доступа к оперативной памяти значительно выше, чем к периферийным устройствам (соответственно, время доступа значительно меньше). В зависимости от конкретного алгоритма и его реализации данные могут сортироваться в той же области памяти, либо использовать дополнительную оперативную память. Внутренняя сортировка является базовой для любого алгоритма внешней сортировки - отдельные части массива данных сортируются в оперативной памяти и с помощью специального алгоритма сцепляются в один массив, упорядоченный по ключу.
В современных архитектурах компьютеров и системных архитектурах широко применяется подкачка и кэширование памяти. Поэтому в большинстве случаев имеется возможность использовать внутреннюю сортировку даже для задач, в которых объём данных несколько превышает выделяемую процессу оперативную память. Однако, в последнем случае алгоритм сортировки должен хорошо сочетаться с применяемыми операционной системой алгоритмами кэширования и подкачки. В противном случае необходимо использовать подходящий алгоритм внешней сортировки.
В общей постановке задача ставится следующим образом. Имеется последовательность однотипных записей, одно из полей которых выбрано в качестве ключевого (далее мы будем называть его ключом сортировки). Тип данных ключа должен включать операции сравнения ("=", ">", "<", ">=" и "<="). Задачей сортировки является преобразование исходной последовательности в последовательность, содержащую те же записи, но в порядке возрастания (или убывания) значений ключа. Метод сортировки называется устойчивым, если при его применении не изменяется относительное положение записей с равными значениями ключа.
Различают сортировку массивов записей, целиком расположенных в основной памяти (внутреннюю сортировку), и сортировку файлов, хранящихся во внешней памяти и не помещающихся полностью в основной памяти (внешнюю сортировку). Для внутренней и внешней сортировки требуются существенно разные методы. В этой части мы рассмотрим наиболее известные методы внутренней сортировки, начиная с простых и понятных, но не слишком быстрых, и заканчивая не столь просто понимаемыми усложненными методами.
Естественным условием, предъявляемым к любому методу внутренней сортировки является то, что эти методы не должны требовать дополнительной памяти: все перестановки с целью упорядочения элементов массива должны производиться в пределах того же массива. Мерой эффективности алгоритма внутренней сортировки являются число требуемых сравнений значений ключа (C) и число перестановок элементов (M).
Заметим, что поскольку сортировка основана только на значениях ключа и никак не затрагивает оставшиеся поля записей, можно говорить о сортировке массивов ключей. В следующих разделах, чтобы не привязываться к конкретному языку программирования и его синтаксическим особенностям, мы будем описывать алгоритмы словами и иллюстрировать их на простых примерах.
4.1. Сортировка включением (метод Шелла)
Одним из наиболее простых и естественных методов внутренней сортировки является сортировка с простыми включениями. Идея алгоритма очень проста. Пусть имеется массив ключей a[1], a[2], ..., a[n]. Для каждого элемента массива, начиная со второго, производится сравнение с элементами с меньшим индексом (элемент a[i] последовательно сравнивается с элементами a[i-1], a[i-2] ...) и до тех пор, пока для очередного элемента a[j] выполняется соотношение a[j] > a[i], a[i] и a[j] меняются местами. Если удается встретить такой элемент a[j], что a[j] <= a[i], или если достигнута нижняя граница массива, производится переход к обработке элемента a[i+1] (пока не будет достигнута верхняя граница массива).
Легко видеть, что в лучшем случае (когда массив уже упорядочен) для выполнения алгоритма с массивом из n элементов потребуется n-1 сравнение и 0 пересылок. В худшем случае (когда массив упорядочен в обратном порядке) потребуется n?(n-1)/2 сравнений и столько же пересылок. Таким образом, можно оценивать сложность метода простых включений как O(n2).
Можно сократить число сравнений, применяемых в методе простых включений, если воспользоваться тем фактом, что при обработке элемента a[i] массива элементы a[1], a[2], ..., a[i-1] уже упорядочены, и воспользоваться для поиска элемента, с которым должна быть произведена перестановка, методом двоичного деления. В этом случае оценка числа требуемых сравнений становится O(n?log n). Заметим, что поскольку при выполнении перестановки требуется сдвижка на один элемент нескольких элементов, то оценка числа пересылок остается O(n2).
Таблица 4.1.1 Пример сортировки методом простого включения
|
Начальное состояние массива |
8 23 5 65 44 33 1 6 |
|
Шаг 1 |
8 23 5 65 44 33 1 6 |
|
Шаг 2 |
8 5 23 65 44 33 1 6 5 8 23 65 44 33 1 6 |
|
Шаг 3 |
5 8 23 65 44 33 1 6 |
|
Шаг 4 |
5 8 23 44 65 33 1 6 |
|
Шаг 5 |
5 8 23 44 33 65 1 6 5 8 23 33 44 65 1 6 |
|
Шаг 6 |
5 8 23 33 44 1 65 6 5 8 23 33 1 44 65 6 5 8 23 1 33 44 65 6 5 8 1 23 33 44 65 6 5 1 8 23 33 44 65 6 1 5 8 23 33 44 65 6 |
|
Шаг 7 |
1 5 8 23 33 44 6 65 1 5 8 23 33 6 44 65 1 5 8 23 6 33 44 65 1 5 8 6 23 33 44 65 1 5 6 8 23 33 44 65 |
Дальнейшим развитием метода сортировки с включениями является сортировка методом Шелла, называемая по-другому сортировкой включениями с уменьшающимся расстоянием. Мы не будем описывать алгоритм в общем виде, а ограничимся случаем, когда число элементов в сортируемом массиве является степенью числа 2. Для массива с 2n элементами алгоритм работает следующим образом. На первой фазе производится сортировка включением всех пар элементов массива, расстояние между которыми есть 2(n-1). На второй фазе производится сортировка включением элементов полученного массива, расстояние между которыми есть 2(n-2). И так далее, пока мы не дойдем до фазы с расстоянием между элементами, равным единице, и не выполним завершающую сортировку с включениями. Применение метода Шелла к массиву, используемому в наших примерах, показано в таблице 4.1.2.
Таблица 4.1.2 Пример сортировки методом Шелл
|
Начальное состояние массива |
8 23 5 65 44 33 1 6 |
|
Фаза 1 (сортируются элементы, расстояние между которыми четыре) |
8 23 5 65 44 33 1 6 8 23 5 65 44 33 1 6 8 23 1 65 44 33 5 6 8 23 1 6 44 33 5 65 |
|
Фаза 2 (сортируются элементы, расстояние между которыми два) |
1 23 8 6 44 33 5 65 1 23 8 6 44 33 5 65 1 23 8 6 5 33 44 65 1 23 5 6 8 33 44 65 1 6 5 23 8 33 44 65 1 6 5 23 8 33 44 65 1 6 5 23 8 33 44 65 |
|
Фаза 3 (сортируются элементы, расстояние между которыми один) |
1 6 5 23 8 33 44 65 1 5 6 23 8 33 44 65 1 5 6 23 8 33 44 65 1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 |
В общем случае алгоритм Шелла естественно переформулируется для заданной последовательности из t расстояний между элементами h1, h2, ..., ht, для которых выполняются условия h1 = 1 и h(i+1) < hi. Дональд Кнут показал, что при правильно подобранных t и h сложность алгоритма Шелла является O(n(1.2)), что существенно меньше сложности простых алгоритмов сортировки.
При сортировке Шелла сначала сравниваются и сортируются между собой значения, стоящие один от другого на некотором расстоянии d. После этого процедура повторяется для некоторых меньших значений d, а завершается сортировка Шелла упорядочиванием элементов при d=1 (то есть обычной сортировкой вставками). Эффективность сортировки Шелла в определённых случаях обеспечивается тем, что элементы «быстрее» встают на свои места (в простых методах сортировки, например, пузырьковой, каждая перестановка двух элементов уменьшает количество инверсий в списке максимум на 1, а при сортировке Шелла это число может быть больше).
Невзирая на то, что сортировка Шелла во многих случаях медленнее, чем быстрая сортировка, она имеет ряд преимуществ:
- отсутствие потребности в памяти под стек;
- отсутствие деградации при неудачных наборах данных - быстрая сортировка легко деградирует до O(n²), что хуже, чем худшее гарантированное время для сортировки Шелла.
4.2. Обменная сортировка (метод Пузырька и Шейкерная сортировка)
Простая обменная сортировка (в просторечии называемая "методом пузырька") для массива a[1], a[2], ..., a[n] работает следующим образом. Начиная с конца массива сравниваются два соседних элемента (a[n] и a[n-1]). Если выполняется условие a[n-1] > a[n], то значения элементов меняются местами. Процесс продолжается для a[n-1] и a[n-2] и т.д., пока не будет произведено сравнение a[2] и a[1]. Понятно, что после этого на месте a[1] окажется элемент массива с наименьшим значением. На втором шаге процесс повторяется, но последними сравниваются a[3] и a[2]. И так далее. На последнем шаге будут сравниваться только текущие значения a[n] и a[n-1]. Понятна аналогия с пузырьком, поскольку наименьшие элементы (самые "легкие") постепенно "всплывают" к верхней границе массива. Пример сортировки методом пузырька показан в таблице 4.2.1.
Таблица 4.2.1 Пример сортировки методом пузырька
|
Начальное состояние массива |
8 23 5 65 44 33 1 6 |
|
Шаг 1 |
8 23 5 65 44 33 1 6 8 23 5 65 44 1 33 6 8 23 5 65 1 44 33 6 8 23 5 1 65 44 33 6 8 23 1 5 65 44 33 6 8 1 23 5 65 44 33 6 1 8 23 5 65 44 33 6 |
|
Шаг 2 |
1 8 23 5 65 44 6 33 1 8 23 5 65 6 44 33 1 8 23 5 6 65 44 33 1 8 23 5 6 65 44 33 1 8 5 23 6 65 44 33 1 5 8 23 6 65 44 33 |
|
Шаг 3 |
1 5 8 23 6 65 33 44 1 5 8 23 6 33 65 44 1 5 8 23 6 33 65 44 1 5 8 6 23 33 65 44 1 5 6 8 23 33 65 44 |
|
Шаг 4 |
1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 |
|
Шаг 5 |
1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 |
|
Шаг 6 |
1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 |
|
Шаг 7 |
1 5 6 8 23 33 44 65 |
Для метода простой обменной сортировки требуется число сравнений nx(n-1)/2, минимальное число пересылок 0, а среднее и максимальное число пересылок - O(n2).
Метод пузырька допускает три простых усовершенствования. Во-первых, как показывает таблица 2.3, на четырех последних шагах расположение значений элементов не менялось (массив оказался уже упорядоченным). Поэтому, если на некотором шаге не было произведено ни одного обмена, то выполнение алгоритма можно прекращать. Во-вторых, можно запоминать наименьшее значение индекса массива, для которого на текущем шаге выполнялись перестановки. Очевидно, что верхняя часть массива до элемента с этим индексом уже отсортирована, и на следующем шаге можно прекращать сравнения значений соседних элементов при достижении такого значения индекса. В-третьих, метод пузырька работает неравноправно для "легких" и "тяжелых" значений. Легкое значение попадает на нужное место за один шаг, а тяжелое на каждом шаге опускается по направлению к нужному месту на одну позицию.
На этих наблюдениях основан метод шейкерной сортировки (ShakerSort). При его применении на каждом следующем шаге меняется направление последовательного просмотра. В результате на одном шаге "всплывает" очередной наиболее легкий элемент, а на другом "тонет" очередной самый тяжелый. Пример шейкерной сортировки приведен в таблице 4.2.2.
Таблица 4.2.2 Пример шейкерной сортировки
|
Начальное состояние массива |
8 23 5 65 44 33 1 6 |
|
Шаг 1 |
8 23 5 65 44 33 1 6 8 23 5 65 44 1 33 6 8 23 5 65 1 44 33 6 8 23 5 1 65 44 33 6 8 23 1 5 65 44 33 6 8 1 23 5 65 44 33 6 1 8 23 5 65 44 33 6 |
|
Шаг 2 |
1 8 23 5 65 44 33 6 1 8 5 23 65 44 33 6 1 8 5 23 65 44 33 6 1 8 5 23 44 65 33 6 1 8 5 23 44 33 65 6 1 8 5 23 44 33 6 65 |
|
Шаг 3 |
1 8 5 23 44 6 33 65 1 8 5 23 6 44 33 65 1 8 5 6 23 44 33 65 1 8 5 6 23 44 33 65 1 5 8 6 23 44 33 65 |
|
Шаг 4 |
1 5 6 8 23 44 33 65 1 5 6 8 23 44 33 65 1 5 6 8 23 44 33 65 1 5 6 8 23 33 44 65 |
|
Шаг 5 |
1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 1 5 6 8 23 33 44 65 |
Шейкерная сортировка позволяет сократить число сравнений (по оценке Кнута средним числом сравнений является (n2 - n?(const + ln n)), хотя порядком оценки по-прежнему остается n2. Число же пересылок, вообще говоря, не меняется.
Сортировка пузырьком считается учебным и практически не применяется вне учебной литературы, вместо него на практике применяются более эффективные алгоритмы сортировки. В то же время метод сортировки обменами лежит в основе некоторых более совершенных алгоритмов, таких как шейкерная сортировка, пирамидальная сортировка и быстрая сортировка.
Шейкерную сортировку рекомендуется использовать в тех случаях, когда известно, что массив "почти упорядочен".
4.3. Сортировка выбором
При сортировке массива a[1], a[2], ..., a[n] методом простого выбора среди всех элементов находится элемент с наименьшим значением a[i], и a[1] и a[i] обмениваются значениями. Затем этот процесс повторяется для получаемых подмассивов a[2], a[3], ..., a[n], ... a[j], a[j+1], ..., a[n] до тех пор, пока мы не дойдем до подмассива a[n], содержащего к этому моменту наибольшее значение. Работа алгоритма иллюстрируется примером в таблице 4.3.1.
Таблица 4.3.1 Пример сортировки простым выбором
|
Начальное состояние массива |
8 23 5 65 44 33 1 6 |
|
Шаг 1 |
1 23 5 65 44 33 8 6 |
|
Шаг 2 |
1 5 23 65 44 33 8 6 |
|
Шаг 3 |
1 5 6 65 44 33 8 23 |
|
Шаг 4 |
1 5 6 8 44 33 65 23 |
|
Шаг 5 |
1 5 6 8 33 44 65 23 |
|
Шаг 6 |
1 5 6 8 23 44 65 33 |
|
Шаг 7 |
1 5 6 8 23 33 65 44 |
|
Шаг 8 |
1 5 6 8 23 33 44 65 |
Для метода сортировки простым выбором требуемое число сравнений - nx(n-1)/2. Порядок требуемого числа пересылок (включая те, которые требуются для выбора минимального элемента) в худшем случае составляет O(n2). Однако порядок среднего числа пересылок есть O(n?ln n), что в ряде случаев делает этот метод предпочтительным.
Сортировка выбором некий гибрид между пузырьковой и сортировкой вставками. Как и сортировка пузырьком, этот алгоритм проходит по массиву раз за разом, перемещая одно значение на правильную позицию. Однако, в отличие от пузырьковой сортировки, он выбирает наименьшее неотсортированное значение вместо наибольшего. Как и при сортировке вставками, упорядоченная часть массива расположена в начале, в то время как в пузырьковой сортировке она находится в конце.
4.4. Сортировка разделением (Quicksort)
Метод сортировки разделением был предложен Чарльзом Хоаром (он любит называть себя Тони) в 1962 г. Этот метод является развитием метода простого обмена и настолько эффективен, что его стали называть "методом быстрой сортировки - Quicksort".
Основная идея алгоритма состоит в том, что случайным образом выбирается некоторый элемент массива x, после чего массив просматривается слева, пока не встретится элемент a[i] такой, что a[i] > x, а затем массив просматривается справа, пока не встретится элемент a[j] такой, что a[j] < x. Эти два элемента меняются местами, и процесс просмотра, сравнения и обмена продолжается, пока мы не дойдем до элемента x. В результате массив окажется разбитым на две части - левую, в которой значения ключей будут меньше x, и правую со значениями ключей, большими x. Далее процесс рекурсивно продолжается для левой и правой частей массива до тех пор, пока каждая часть не будет содержать в точности один элемент. Понятно, что как обычно, рекурсию можно заменить итерациями, если запоминать соответствующие индексы массива. Проследим этот процесс на примере нашего стандартного массива (таблица 4.4.1).
Таблица 4.4.1 Пример быстрой сортировки
|
Начальное состояние массива |
8 23 5 65 |44| 33 1 6 |
|
Шаг 1 (в качестве x выбирается a[5]) |
|--------| 8 23 5 6 44 33 1 65 |---| 8 23 5 6 1 33 44 65 |
|
Шаг 2 (в подмассиве a[1], a[5] в качестве x выбирается a[3]) |
8 23 |5| 6 1 33 44 65 |--------| 1 23 5 6 8 33 44 65 |--| 1 5 23 6 8 33 44 65 |
|
Шаг 3 (в подмассиве a[3], a[5] в качестве x выбирается a[4]) |
1 5 23 |6| 8 33 44 65 |----| 1 5 8 6 23 33 44 65 |
|
Шаг 4 (в подмассиве a[3], a[4] выбирается a[4]) |
1 5 8 |6| 23 33 44 65 |--| 1 5 6 8 23 33 44 65 |
Алгоритм недаром называется быстрой сортировкой, поскольку для него оценкой числа сравнений и обменов является O(n?log n). На самом деле, в большинстве утилит, выполняющих сортировку массивов, используется именно этот алгоритм.
Общая сложность алгоритма определяется лишь количеством разделений, то есть глубиной рекурсии. Глубина рекурсии, в свою очередь, зависит от сочетания входных данных и способа определения опорного элемента. Операция разделения массива на две части относительно опорного элемента занимает время O(n). Поскольку все операции разделения, проделываемые на одной глубине рекурсии, обрабатывают разные части исходного массива, размер которого постоянен, суммарно на каждом уровне рекурсии потребуется также O(n) операций.
Достоинства:
- Один из самых быстродействующих (на практике) из алгоритмов внутренней сортировки общего назначения.
- Прост в реализации.
- Хорошо сочетается с механизмами кэширования и виртуальной памяти.
- Допускает естественное распараллеливание (сортировка выделенных подмассивов в параллельно выполняющихся подпроцессах).
- Допускает эффективную модификацию для сортировки по нескольким ключам (в частности - алгоритм Седжвика для сортировки строк): благодаря тому, что в процессе разделения автоматически выделяется отрезок элементов, равных опорному, этот отрезок можно сразу же сортировать по следующему ключу.
- Работает на связных списках и других структурах с последовательным доступом, допускающих эффективный проход как от начала к концу, так и от конца к началу.
Недостатки:
- Сильно деградирует по скорости (до O(n^2)) в худшем или близком к нему случае, что может случиться при неудачных входных данных.
- Прямая реализация в виде функции с двумя рекурсивными вызовами может привести к ошибке переполнения стека, так как в худшем случае ей может потребоваться сделать O(n) вложенных рекурсивных вызовов.
- Неустойчив.
4.5. Сортировка с помощью дерева (Heapsort)
Начнем с простого метода сортировки с помощью дерева, при использовании которого явно строится двоичное дерево сравнения ключей. Построение дерева начинается с листьев, которые содержат все элементы массива. Из каждой соседней пары выбирается наименьший элемент, и эти элементы образуют следующий (ближе к корню уровень дерева). Из каждой соседней пары выбирается наименьший элемент и т.д., пока не будет построен корень, содержащий наименьший элемент массива. Двоичное дерево сравнения для массива, используемого в наших примерах, показано на рисунке 4.5.1. Имея наименьшее значение элементов массива. Для того, чтобы получить следующий по величине элемент, спустимся от корня по пути, ведущему к листу с наименьшим значением. В этой листовой вершине проставляется фиктивный ключ с "бесконечно большим" значением, а во все промежуточные узлы, занимавшиеся наименьшим элементом, заносится наименьшее значение из узлов - непосредственных потомков (рисунок. 4.5.2). Процесс продолжается до тех пор, пока все узлы дерева не будут заполнены фиктивными ключами (рисунки 4.5.1 - 4.5.8).
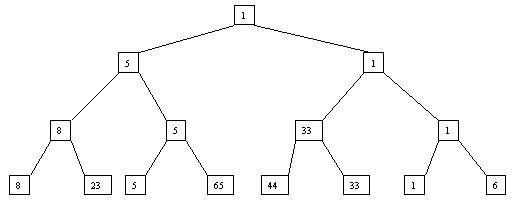
Рисунок. 4.5.1 Первый шаг
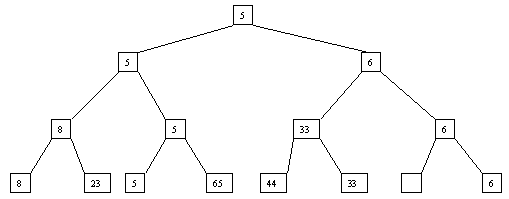
Рисунок. 4.5.2 Второй шаг
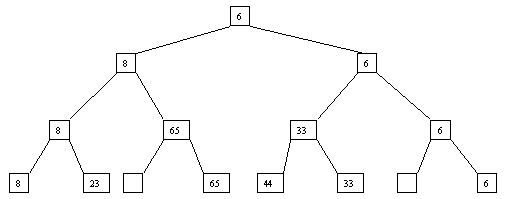
Рисунок. 4.5.3 Третий шаг
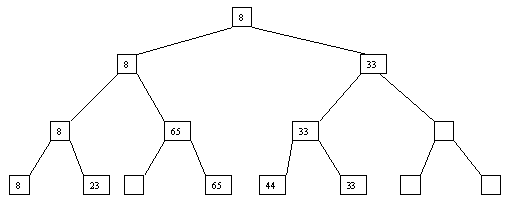
Рисунок. 4.5.4 четвертый шаг
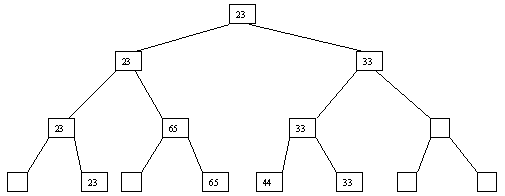
Рисунок. 4.5.5 Пятый шаг
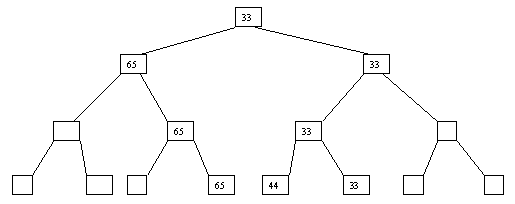
Рисунок. 4.5.6 Шестой шаг
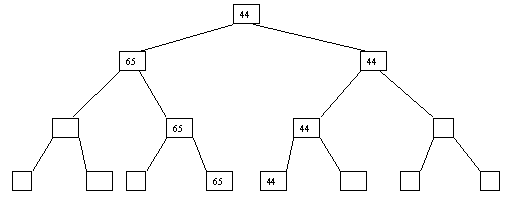
Рисунок. 4.5.7 Седьмой шаг
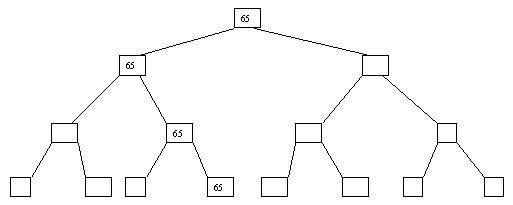
Рисунок. 4.5.8 Восьмой шаг
На каждом из n шагов, требуемых для сортировки массива, нужно log n (двоичный) сравнений. Следовательно, всего потребуется n?log n сравнений, но для представления дерева понадобится 2n - 1 дополнительных единиц памяти.
Имеется более совершенный алгоритм, который принято называть пирамидальной сортировкой (Heapsort). Его идея состоит в том, что вместо полного дерева сравнения исходный массив a[1], a[2], ..., a[n] преобразуется в пирамиду, обладающую тем свойством, что для каждого a[i] выполняются условия a[i] <= a[2i] и a[i] <= a[2i+1]. Затем пирамида используется для сортировки.
Наиболее наглядно метод построения пирамиды выглядит при древовидном представлении массива, показанном на рисунке 4.5.9. Массив представляется в виде двоичного дерева, корень которого соответствует элементу массива a[1]. На втором ярусе находятся элементы a[2] и a[3]. На третьем - a[4], a[5], a[6], a[7] и т.д. Как видно, для массива с нечетным количеством элементов соответствующее дерево будет сбалансированным, а для массива с четным количеством элементов n элемент a[n] будет единственным (самым левым) листом "почти" сбалансированного дерева.
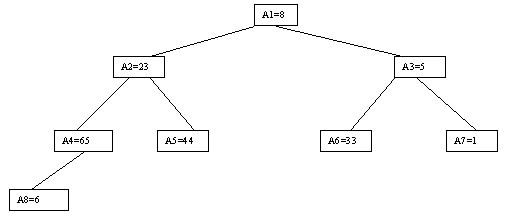
Рисунок. 4.5.9 Построение пирамиды
Очевидно, что при построении пирамиды нас будут интересовать элементы a[n/2], a[n/2-1], ..., a[1] для массивов с четным числом элементов и элементы a[(n-1)/2], a[(n-1)/2-1], ..., a[1] для массивов с нечетным числом элементов (поскольку только для таких элементов существенны ограничения пирамиды). Пусть i - наибольший индекс из числа индексов элементов, для которых существенны ограничения пирамиды. Тогда берется элемент a[i] в построенном дереве и для него выполняется процедура просеивания, состоящая в том, что выбирается ветвь дерева, соответствующая min(a[2?i], a[2?i+1]), и значение a[i] меняется местами со значением соответствующего элемента. Если этот элемент не является листом дерева, для него выполняется аналогичная процедура и т.д. Такие действия выполняются последовательно для a[i], a[i-1], ..., a[1]. Легко видеть, что в результате мы получим древовидное представление пирамиды для исходного массива (последовательность шагов для используемого в наших примерах массива показана на рисунках 4.5.10-4.5.13).
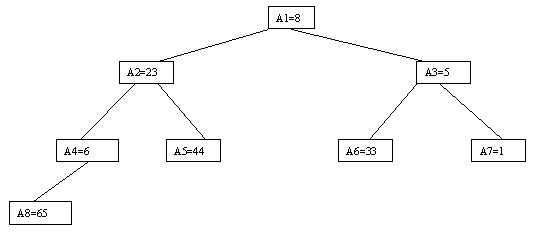
Рисунок. 4.5.10
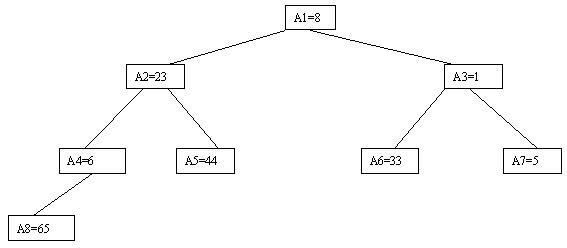
Рисунок. 4.5.11
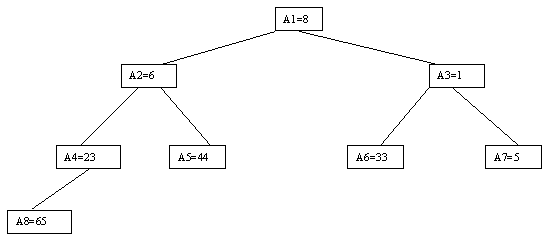
Рисунок. 4.5.12
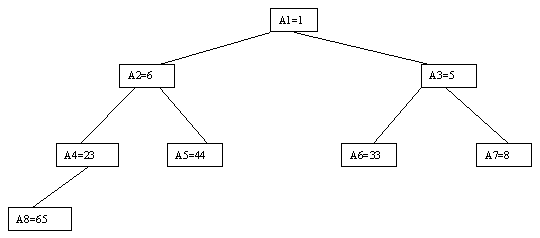
Рисунок. 4.5.13
В 1964 г. Флойд предложил метод построения пирамиды без явного построения дерева (хотя метод основан на тех же идеях). Построение пирамиды методом Флойда для нашего стандартного массива показано в таблице 4.5.1.
Таблица 4.5.1 Пример построения пирамиды
|
Начальное состояние массива |
8 23 5 |65| 44 33 1 6 |
|
Шаг 1 |
8 23 |5| 6 44 33 1 65 |
|
Шаг 2 |
8 |23| 1 6 44 33 5 65 |
|
Шаг 3 |
|8| 6 1 23 44 33 5 65 |
|
Шаг 4 |
1 6 8 23 44 33 5 65 1 6 5 23 44 33 8 65 |
В таблице 4.5.2 показано, как производится сортировка с использованием построенной пирамиды. Суть алгоритма заключается в следующем. Пусть i - наибольший индекс массива, для которого существенны условия пирамиды. Тогда начиная с a[1] до a[i] выполняются следующие действия. На каждом шаге выбирается последний элемент пирамиды (в нашем случае первым будет выбран элемент a[8]). Его значение меняется со значением a[1], после чего для a[1] выполняется просеивание. При этом на каждом шаге число элементов в пирамиде уменьшается на 1 (после первого шага в качестве элементов пирамиды рассматриваются a[1], a[2], ..., a[n-1]; после второго - a[1], a[2], ..., a[n-2] и т.д., пока в пирамиде не останется один элемент). Легко видеть (это иллюстрируется в таблице 4.5.2), что в результате мы получим массив, упорядоченный в порядке убывания. Можно модифицировать метод построения пирамиды и сортировки, чтобы получить упорядочение в порядке возрастания, если изменить условие пирамиды на a[i] >= a[2?i] и a[1] >= a[2?i+1] для всех осмысленных значений индекса i.
Таблица 4.5.2 Сортировка с помощью пирамиды
|
Исходная пирамида |
1 6 5 23 44 33 8 65 |
|
Шаг 1 |
65 6 5 23 44 33 8 1 5 6 65 23 44 33 8 1 5 6 8 23 44 33 65 1 |
|
Шаг 2 |
65 6 8 23 44 33 5 1 6 65 8 23 44 33 5 1 6 23 8 65 44 33 5 1 |
|
Шаг 3 |
33 23 8 65 44 6 5 1 8 23 33 65 44 6 5 1 |
|
Шаг 4 |
44 23 33 65 8 6 5 1 23 44 33 65 8 6 5 1 |
|
Шаг 5 |
65 44 33 23 8 6 5 1 33 44 65 23 8 6 5 1 |
|
Шаг 6 |
65 44 33 23 8 6 5 1 44 65 33 23 8 6 5 1 |
|
Шаг 7 |
65 44 33 23 8 6 5 1 |
Процедура сортировки с использованием пирамиды требует выполнения порядка nxlog n шагов (логарифм - двоичный) в худшем случае, что делает ее особо привлекательной для сортировки больших массивов.
Пирамидальная сортировка может рассматриваться как усовершенствованная сортировка пузырьком, в которой элемент всплывает (min-heap) / тонет (max-heap) по многим путям.
Достоинства:
- Имеет доказанную оценку худшего случая O(n * log n).
- Сортирует на месте, то есть требует всего O(1) дополнительной памяти (если дерево организовывать так, как показано выше).
Недостатки:
- Сложен в реализации.
- Неустойчив - для обеспечения устойчивости нужно расширять ключ.
- На почти отсортированных массивах работает столь же долго, как и на хаотических данных.
- На одном шаге выборку приходится делать хаотично по всей длине массива - поэтому алгоритм плохо сочетается с кэшированием и подкачкой памяти.
- Методу требуется «мгновенный» прямой доступ; не работает на связанных списках и других структурах памяти последовательного доступа.
- Сортировка слиянием при расходе памяти O(n) быстрее (O(n * log n) с меньшей константой) и не подвержена деградации на неудачных данных.
- Из-за сложности алгоритма выигрыш получается только на больших n. На небольших n (до нескольких тысяч) быстрее сортировка Шелла.
4.6. Сортировка со слиянием
Сортировки со слиянием, как правило, применяются в тех случаях, когда требуется отсортировать последовательный файл, не помещающийся целиком в основной памяти. Методам внешней сортировки посвящается следующая часть книги, в которой основное внимание будет уделяться методам минимизации числа обменов с внешней памятью. Однако существуют и эффективные методы внутренней сортировки, основанные на разбиениях и слияниях.
Один из популярных алгоритмов внутренней сортировки со слияниями основан на следующих идеях (для простоты будем считать, что число элементов в массиве, как и в нашем примере, является степенью числа 2). Сначала поясним, что такое слияние. Пусть имеются два отсортированных в порядке возрастания массива p[1], p[2], ..., p[n] и q[1], q[2], ..., q[n] и имеется пустой массив r[1], r[2], ..., r[2?n], который мы хотим заполнить значениями массивов p и q в порядке возрастания. Для слияния выполняются следующие действия: сравниваются p[1] и q[1], и меньшее из значений записывается в r[1]. Предположим, что это значение p[1]. Тогда p[2] сравнивается с q[1] и меньшее из значений заносится в r[2]. Предположим, что это значение q[1]. Тогда на следующем шаге сравниваются значения p[2] и q[2] и т.д., пока мы не достигнем границ одного из массивов. Тогда остаток другого массива просто дописывается в "хвост" массива r.
Пример слияния двух массивов показан на рисунке 4.6.1.
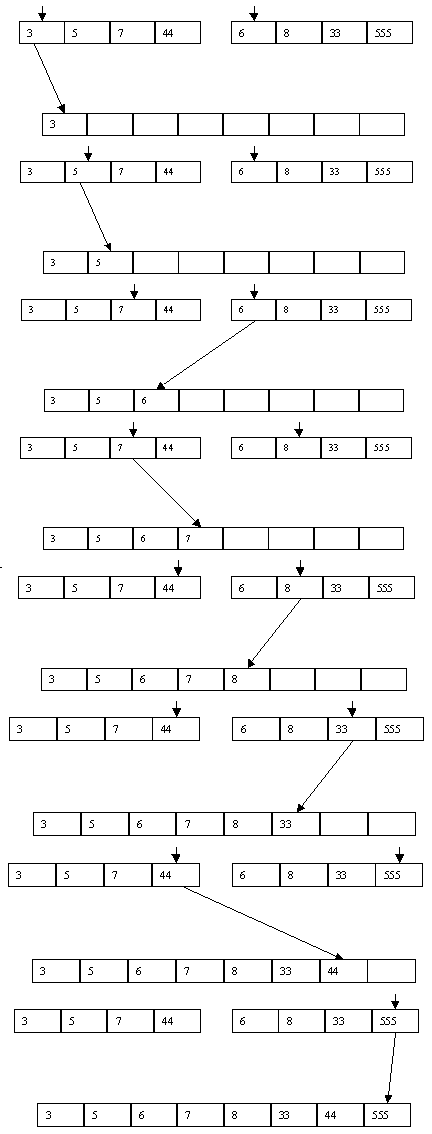
Рисунок. 4.6.1
Для сортировки со слиянием массива a[1], a[2], ..., a[n] заводится парный массив b[1], b[2], ..., b[n]. На первом шаге производится слияние a[1] и a[n] с размещением результата в b[1], b[2], слияние a[2] и a[n-1] с размещением результата в b[3], b[4], ..., слияние a[n/2] и a[n/2+1] с помещением результата в b[n-1], b[n]. На втором шаге производится слияние пар b[1], b[2] и b[n-1], b[n] с помещением результата в a[1], a[2], a[3], a[4], слияние пар b[3], b[4] и b[n-3], b[n-2] с помещением результата в a[5], a[6], a[7], a[8], ..., слияние пар b[n/2-1], b[n/2] и b[n/2+1], b[n/2+2] с помещением результата в a[n-3], a[n-2], a[n-1], a[n]. И т.д. На последнем шаге, например (в зависимости от значения n), производится слияние последовательностей элементов массива длиной n/2 a[1], a[2], ..., a[n/2] и a[n/2+1], a[n/2+2], ..., a[n] с помещением результата в b[1], b[2], ..., b[n].
Для случая массива, используемого в наших примерах, последовательность шагов показана в таблице 4.6.1.
Таблица 4.6.1 Пример сортировки со слиянием
|
Начальное состояние массива |
8 23 5 65 44 33 1 6 |
|
Шаг 1 |
6 8 1 23 5 33 44 65 |
|
Шаг 2 |
6 8 44 65 1 5 23 33 |
|
Шаг 3 |
1 5 6 8 23 33 44 65 |
При применении сортировки со слиянием число сравнений ключей и число пересылок оценивается как O(n?log n). Но следует учитывать, что для выполнения алгоритма для сортировки массива размера n требуется 2?n элементов памяти.
Достоинства:
- Работает даже на структурах данных последовательного доступа.
- Хорошо сочетается с подкачкой и кэшированием памяти.
- Неплохо работает в параллельном варианте: легко разбить задачи между процессорами поровну, но трудно сделать так, чтобы другие процессоры взяли на себя работу, в случае если один процессор задержится.
- Не имеет «трудных» входных данных.
- Устойчивая - сохраняет порядок равных элементов (принадлежащих одному классу эквивалентности по сравнению).
Недостатки:
- На «почти отсортированных» массивах работает столь же долго, как на хаотичных.
- Требует дополнительной памяти по размеру исходного массива.
4.7. Сравнение методов внутренней сортировки
Для рассмотренных в начале этой части простых методов сортировки существуют точные формулы, вычисление которых дает минимальное, максимальное и среднее число сравнений ключей (C) и пересылок элементов массива (M).
Таблица 4.7.1 Характеристики простых методов сортировки
|
Min |
Avg |
Max |
|
|
Прямое включение |
C = n-1 |
(n2 + n - 2)/4 |
(n2 -n)/2 - 1 |
|
Прямой выбор |
C = (n2 - n)/2 |
(n2 - n)/2 |
(n2 - n)/2 |
|
Прямой обмен |
C = (n2 - n)/2 |
(n2 - n)/2 |
(n2 - n)/2 |
Для оценок сложности усовершенствованных методов сортировки точных формул нет. Известно лишь, что для сортировки методом Шелла порядок C и M есть O(n(1.2)), а для методов Quicksort, Heapsort и сортировки со слиянием - O(n?log n). Однако результаты экспериментов показывают, что Quicksort показывает результаты в 2-3 раза лучшие, чем Heapsort (в таблице 4.7.2 приводится выборка результатов из таблицы). Видимо, по этой причине именно Quicksort обычно используется в стандартных утилитах сортировки (в частности, в утилите sort, поставляемой с операционной системой UNIX).
Таблица 4.7.2 Время работы программ сортировки
|
Упорядоченный массив |
Случайный массив |
В обратном порядке |
|
|
n = 256 |
|||
|
Heapsort |
0.20 |
0.08 |
0.18 |
|
n = 2048 |
|||
|
Heapsort |
2.32 |
0.72 |
1.98 |
4.8. Общий анализ приведенных сортировок
Приведем выводы по простым методам сортировки:
Время сортировки пропорционально квадрату размерности массива
Более точные оценки производительности простых методов сортировки показывают, что наиболее быстрой является сортировка вставками, а наиболее медленной - сортировка обменом.
Несмотря на плохое быстродействие, простые алгоритмы сортировки следует применять при малой размерности сортируемого массива.
При больших размерностях массива они обеспечивают существенный выигрыш.
Сравним простые и сложные методы сортировки по производительности:
Таблица 4.8.1 Сравнительные показатели производительности различных методов сортировки массивов
|
Простые методы сортировки |
|||
|
Метод сортировки |
Время сортировки для размера 256, миллисекунд |
Время сортировки для размера 512, миллисекунд |
Соотношение методов по производительности (относительное время сортировки) |
|
Вставками (метод простых вставок) |
356 |
1444 |
1 |
|
Выбором |
509 |
1956 |
1.3 |
|
Обменом (пузырек) |
1026 |
4054 |
3 |
|
Сложные методы сортировки |
|||
|
Обменом (Хоара) |
60 |
116 |
1 |
|
Выбором (с помощью двоичного дерева |
110 |
241 |
1.7 |
|
Вставками (Шелла) |
127 |
349 |
2.1 |
Из приведенных в таблице данных следует, в частности, для относительно небольшого массива в 512 элементов:
Худшая по производительности из простых сортировок (сортировка обменом) работает в 35 раз медленнее быстрой сортировки Хоара.
Самая быстрая из простых сортировок (простая сортировка вставками) работает медленнее в 4.2 раза чем худшая по производительности из сложных сортировок (сортировка Шелла).
При увеличении размера массива указанные выше эффекты проявляются в большей степени.
4.9. Теоретическое сравнение сортировок методом простых вставок и методом пузырька
Сделаем теоретическое сравнение сортировок методом простых вставок и методом пузырька. Основным критерием сравнения сортировок является их эффективность, то есть число сравнений и число пересылок. Данные показатели также влияют на время сортировки. Укажем основные формулы, использующиеся для вычисления эффективности данных сортировок:
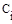
- число сравнений ключей элементов при i-ом просеивании;
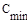
- минимальное число сравнений ключей;
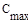
- максимальное число сравнений ключей;
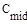
- среднее число сравнений ключей;
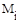
- число пересылок (присваиваний) элементов при i-ом просеивании;
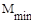
- минимальное число пересылок
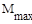
- максимальное число пересылок
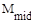
- среднее число пересылок
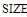
- размер массива;
Рассмотрим сортировку методом простых вставок
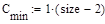
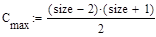
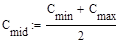
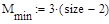
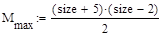
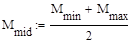
Рассмотрим сортировку методом пузырька
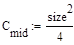
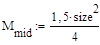
На основе данных формул составим сравнительную таблицу для сортировок методом простых вставок и методом пузырька:
Таблица 4.9.1 Сравнительный анализ сортировок методом простых вставок и методом пузырька
|
Размер массива |
Метод простых вставок |
Метод пузырька |
||
|
Число сравнений ключей (среднее значение) |
Число пересылок (среднее значение) |
Число сравнений ключей (среднее значение) |
Число пересылок (среднее значение) |
|
|
32 |
263 |
329 |
256 |
384 |
|
64 |
1039 |
1163 |
1024 |
1536 |
|
128 |
4127 |
4379 |
4096 |
6144 |
|
256 |
16447 |
16953 |
16384 |
24576 |
|
512 |
65663 |
131835 |
65536 |
98304 |
|
1024 |
262399 |
264443 |
262144 |
393216 |
На основе полученных в таблице 2 значений составим сравнительные графики, для числа сравнений ключей и для числа пересылок по обоим методам сортировки:
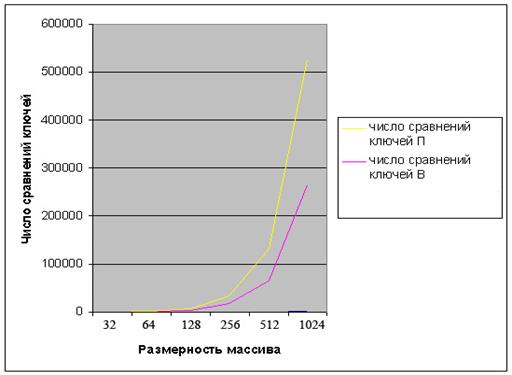
Рисунок. 4.9.1
Графики числа сравнений ключей: число сравнений ключей П - для метода пузырька, число сравнений ключей В - для метода простых вставок.
На основе полученных графиков можно сказать, что число сравнений ключей в сортировке методом пузырька число сравнений больше, чем в сортировке методом вставок. Следовательно по данному критерию эффективность сортировки методом простых вставок выше, чем методом пузырька.
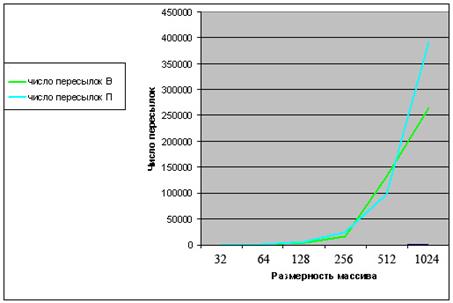
Рисунок. 4.9.2
Графики числа пересылок в сортировках: число пересылок П - для метода пузырька, число пересылок В - для метода простых вставок.
Основываясь на полученных графиках можно сказать, что при малых значениях размерности массива число пересылок для обоих методов примерно одинаково. При относительно больших размерах массива (от 512 и более) число пересылок в методе пузырька возрастает быстрее, чем в методе простых вставок. Следовательно, эффективность метода вставок выше по данной характеристике.
Ссылаясь на таблицу 1 можно также отметить, что сортировка методом пузырька требует больше времени, чем сортировка методом вставок.
Из чего следует, что в целом сортировка методом простых вставок эффективнее сортировки методом пузырька.
Заключение
В заключении можно сказать что были изучены работы существующих на данный момент алгоритмов сортировок данных, также была сделана оценка их эффективности (сортировка включением (метод Шелла), обменая сортировка (метод Пузырька и Шейкерная сортировка), сортировка выбором, сортировка разделением (quicksort), сортировка при помощи дерева (heapsort), пирамидальная сортировка, сортировка Хоара, сортировка слиянием, многофазная сортировка).
Был сделан вывод, что методы сложных сортировок (сортировки использующие копирование массива), более эффективны в целом, чем методы простых сортировок. Причем самая эффективная из простых сортировок менее эффективна, чем худшая по производительности из сложных сортировок.
Также было выполнено теоретическое сравнение сортировок методом простых вставок и методом пузырька, рассматриваемых в рамках курсового проекта, построены соответствующие графики. В ходе теоретического сравнения было выявлено, что сортировка методом вставок эффективнее сортировки методом пузырька, благодаря меньшему числу сравнений ключей и меньшему количеству пересылок.
На данный момент не существует самого оптимального алгоритма сортировки. Выбор алгоритма очень сильно зависит от условия задачи, которую необходимо решить.
Список литературы
- Д. Кнут. Искусство программирования для ЭВМ. Т.1. Основные алгоритмы. М., "Мир", 1976 г., переиздание - М., Изд-во "Вильямс", 2000 - 720с.
- Д. Кнут, Искусство программирования для ЭВМ. Т.3. Сортировка и поиск. - М., "Мир", 1978 г., переиздание - М., Изд-во "Вильямс", 2000. - 832с.
- Н. Вирт, Алгоритмы и структуры данных. - М., Издат-во "Вильямс", 1998 - 360с.
- Гагарина Л.Г., Колдаев В.Д., Алгоритмы и структуры данных. - М.: Финансы и статистика; ИНФРА-М, 2009. - 304с.
- Алгоритмы сортировки - Википедия. http://ru.wikipedia.org/wiki/

- Проектирование реализации операций бизнес-процесса «Управление документооборотом» (Характеристика документооборота, возникающего при решении задачи)
- Налоговая декларация в налоговом учете (Общие положения о налоговом контроле)
- «Финансовая политика и ее реализация в РФ»
- ИНТЕРНЕТ-МАРКЕТИНГОВЫЕ РЕШЕНИЯ ДЛЯ КАНЦЕЛЯРСКОГО МАГАЗИНА (Бизнес-модели розничной торговли в Интернете)
- Роль рекламы в современном маркетинге (На примере конкретной организации) (История создания и особенности организационной характеристики предприятия)
- Понятие и виды ценных бумаг (Проблемы и перспективы развития рынка ценных бумаг в России)
- Роль рекламы в современном маркетинге (На примере конкретной организации) (Понятие и сущность маркетинговой деятельности)
- Понятие и виды наследования (Особенности наследования видов имущества)
- Ценные бумаги: понятие, виды, общие положения о правовом режиме (Понятие и виды ценных бумаг)
- Понятие и виды наследования (Наследование земельных участков)
- Аппарат государственной власти (Теоретически основы государственного аппарата в управлении государством)
- Принципы построения и функционирования DLP-систем