
Технология «клиент-сервер» (Основные понятия серверов)
Содержание:

ВВЕДЕНИЕ
Обработка данных в эпоху персональных компьютеров и настольных систем управления базами данных (СУБД) в 70-х годах прошлого столетия осуществлялась с помощью мэйнфреймов и мини-ЭВМ. Преимущество данного способа заключалась в централизации хранения и обработки данных. Однако, с ростом популярности ЭВМ, число пользователей и объем обрабатываемых данных стало огромным, что привело к снижению производительности приложений. Связано это было в первую очередь с обработкой данных в клиентском приложении.
Решением проблемы сетевого трафика и других проблем, возникающих при увеличении количества пользователей и объема данных, стал переход к архитектуре «Клиент-сервер». В данной архитектуре используется сервер баз данных, на котором и хранятся и управляются избыточные для клиента данные, производится обработка запросов.
В настоящее время технология «Клиент-сервер» получает все большее распространения, хотя дает лишь общую информацию об организации современных информационных систем. Рассматриваемая технология является основной технологией глобальной сети Internet, поэтому изучение клиент-серверной архитектуры является для меня важным аспектом, позволяя дать представление об использовании технологии на практике.
Цель: дать теоретическое и практическое представление об архитектуре и настройке клиент-серверной платформы.
Задачи:
- Рассмотреть архитектуру «Клиент-сервер», модель, настройки сети.
- Проанализировать работу клиент-серверной платформы в предприятии.
- Представить методические рекомендации по настройке архитектуры «Клиент-сервер».
Объект исследования: учебные пособия, ЭВМ.
Предмет исследования: архитектура «Клиент-сервер», способы настройки клиент-серверной платформы.
При написании курсовой работы рассмотрен ГОСТ Р ИСО/МЭК ТО 10735-2000, предъявляющий требования к передаче информации между системами. Использование данного ГОСТа в моей работе необходимо, т.к. он представляет собой нормативно-правовой документ, требований которого должна придерживаться любая организация. Учебное пособие для вузов «Вычислительная техника, сети и телекоммуникации», написанное Гребешковым А.Ю. в 2016 году является понятным для изучения пособием и позволяет разобраться в основных понятиях сетей. Учебник «Вычислительные системы, сети и телекоммуникации», написанный Гусевой А.И. в 2016 году дополняет учебное пособие Гребешкова А.Ю.. Для изучения работы клиент-серверной платформы на предприятии рассмотрен и изучен сайт «1С: Предприятие 8». Рекомендации по настройке клиент-серверной архитектуры были написаны с помощью учебных пособий «Компьютерные сети» под редакцией Кузина А.В., написанное в 2018 году, и «Сети и телекоммуникации» под редакцией Соболева А.В., написанное в 2015 году. Для более детального и углубленного изучения теоретического и практического материала были изучены новые книги ведущих авторов в области компьютерных сетей: Куроуз, Дж. «Компьютерные сети: Нисходящий подход» 2018 года, Олифер, В. «Компьютерные сети» 2016 года, Таненбаум, Э. «Компьютерные сети» 2019 года.
1. Технология клиент-сервер и модели ее реализации
1.1 Серверы. Основные понятия серверов
Сервер (от англ. server, обслуживающий). В зависимости от предназначения существует несколько определений понятия сервер.
1. Сервер (сеть) — логический или физический узел сети, обслуживающий запросы к одному адресу и/или доменному имени (смежным доменным именам), состоящий из одного или системы аппаратных серверов, на котором выполняются один или система серверных программ [1].
2. Сервер (программное обеспечение) — программное обеспечение, принимающее запросы от клиентов (в архитектуре клиент-сервер [2].
3. Сервер (аппаратное обеспечение) — компьютер (или специальное компьютерное оборудование) выделенный и/или специализированный для выполнения определенных сервисных функций [3].
4. Сервер в информационных технологиях — программный компонент вычислительной системы, выполняющий сервисные функции по запросу клиента, предоставляя ему доступ к определённым ресурсам [6].
Взаимосвязь понятий. Серверное приложение (сервер) запускается на компьютере, так же называемом "сервер", при этом при рассмотрении топологии сети, такой узел называют "сервером". В общем случае может быть так, что серверное приложение запущено на обычной рабочей станции, или серверное приложение, запущенное на серверном компьютере в рамках рассматриваемой топологии выступает в роли клиента (т.е. не является сервером с точки зрения сетевой топологии).
Как правило, каждый сервер обслуживает один (или несколько схожих) протоколов и серверы можно классифицировать по типу услуг, которые они предоставляют.
Технология «Клиент – сервер» - это архитектура программного комплекса, в которой происходит распределение прикладной программы по двум логически различным компонентам (клиент и сервер), взаимодействующим по схеме «запрос-ответ» и решающим свои определенные задачи (рисунок 1).

Рисунок 1. Архитектура "Клиент-сервер"
Сервер - компьютер (или программа), управляющий и/или владеющий каким-либо ресурсом [3].
Клиент - компьютер (или программа), запрашивающий и пользующийся каким-либо ресурсом [3].
Клиент и сервер могут находиться как на одном компьютере (ПК), так и на разных ПК в сети. Также может возникать такая ситуация, когда некоторый программный блок будет одновременно выполнять функции сервера по отношению к одному блоку и клиента по отношению к другому.
Основной принцип технологии «Клиент-сервер» заключается в разделении функций приложения как минимум на три группы [2]:
- Модули интерфейса с пользователем:
Через эту группу пользователи взаимодействуют с приложением. Независимо от конкретных характеристик логики представления (интерфейс командной строки, сложные графические пользовательские интерфейсы, интерфейсы через посредника) ее задача состоит в том, чтобы обеспечить средства для наиболее эффективного обмена информацией между пользователем и информационной системой.
- Модули хранения данных:
Эту группу также называют бизнес-логикой. Бизнес-логика определяет, для чего конкретно предназначено приложение (например, прикладные функции, характерные для данной предметной области). Разделение приложения по границам между программами обеспечивает естественную основу для распределения приложения на нескольких компьютерах.
- Модули обработки данных:
Эту группу также называют логикой доступа к данным или алгоритмами доступа к данным. Алгоритмы доступа к данным исторически рассматривались как специфический для конкретного приложения интерфейс к механизму постоянного хранения данных наподобие файловой системы или СУБД. При помощи модулей обработки данных организуется специфический для приложения интерфейс к СУБД. При помощи интерфейса приложение управляет соединениями с базой данных и запросами к ней (перевод специфических для конкретного приложения запросов на язык SQL, получение результатов и перевод этих результатов обратно в специфические для конкретного приложения структуры данных).
Каждая из этих групп может быть реализована независимо от двух других. Например, не изменяя программ, используемых для хранения и обработки данных, можно изменить интерфейс с пользователем таким образом, что одни и те же данные будут отображаться в виде таблиц, графиков или гистограмм. Очень простые приложения часто способны собрать все три части в единственную программу, и подобное разделение соответствует функциональным границам [2].
В соответствии с разделением функций в любом приложении выделяются следующие компоненты [1]:
- компонент представления данных;
- прикладной компонент;
- компонент управления ресурсом.
В классической архитектуре клиент-сервер приходится распределять три основные части приложения по двум физическим модулям. Обычно прикладной компонент располагается на сервере (например, сервере базы данных), компонент представления данных - на стороне клиента, а компонент управления ресурсом распределяется между клиентской и серверной частями. В этом заключается основной недостаток классической двухуровневой архитектуры [9].
В двухзвенной архитектуре при разбиении алгоритмов обработки данных разработчики должны иметь полную информацию о последних изменениях, внесенных в систему, и понимать эти изменения, что создает большие сложности при разработке клиент-серверных систем, их установке и сопровождении, поскольку необходимо тратить значительные усилия на координацию действий разных групп специалистов. В действиях разработчиков часто возникают противоречия, а это тормозит развитие системы и вынуждает изменять уже готовые и проверенные элементы [6].
Чтобы избежать несогласованности различных элементов архитектуры были созданы две модификации двухзвенной архитектуры «Клиент – сервер»: «Толстый клиент» («Тонкий сервер») и «Тонкий клиент» («Толстый сервер»).
В данных архитектурах разработчики попытались выполнять обработку данных на одной из двух физических частей - либо на стороне клиента («Толстый клиент»), либо на сервере («Тонкий клиент).
Каждый подход имеет свои недостатки. В первом случае неоправданно перегружается сеть, потому что по ней передаются необработанные, а значит, избыточные данные. Кроме того, усложняется поддержка системы и ее изменение, так как замена алгоритма вычислений или исправление ошибки требует одновременной полной замены всех интерфейсных программ, а иначе могут возникнуть ошибки или несогласованность данных. Если же вся обработка информации выполняется на сервере, то возникает проблема описания встроенных процедур и их отладки. Систему с обработкой информации на сервере абсолютно невозможно перенести на другую платформу (ОС), что является серьезным недостатком.
Формат запросов клиента и ответов сервера определяется протоколом. Спецификации открытых протоколов описываются открытыми стандартами, например, протоколы Интернета определяются в документах RFC [1].
В зависимости от выполняемых задач одни серверы, при отсутствии запросов на обслуживание, могут простаивать в ожидании. Другие могут выполнять какую-то работу (например, работу по сбору информации), у таких серверов работа с клиентами может быть второстепенной задачей.
Передача информации в клиент-серверной архитектуре
Технология клиент-сервер в общем случае предназначена для использования с объемными информационными сетями. От одного абонента до другого данные могут проходить сложный путь по разным физическим каналам и сетям. Путь доставки данных может меняться в зависимости от состояния отдельных элементов сети. Какие-то компоненты сети могут не работать в этот момент, тогда данные пойдут другим путем. Может изменяться время доставки. Данные могут даже пропасть, не дойти до адресата [2].
Поэтому простая передача данных в цикле в сложных сетях совершенно невозможна. Информация передается ограниченными порциями – пакетами. На передающей стороне информация разбивается на пакеты, а на приемной “склеивается” из пакетов в цельные данные. Объем пакетов обычно не больше нескольких килобайт.
Пакет это аналог обычного почтового письма. Он также, кроме информации, должен содержать адрес получателя и адрес отправителя [3].
Пакет состоит из заголовка и информационной части. Заголовок содержит адреса получателя и отправителя, а также служебную информацию, необходимую для “склейки” пакетов на приемной стороне. Сетевое оборудование использует заголовок для определения, куда передавать пакет.
Основные параметры, используемые для адресации пакетов [6]:
- IP-адрес устройства;
- маску подсети;
- доменное имя;
- IP-адрес сетевого шлюза;
- MAC-адрес;
- порт.
Рассмотрим подробнее каждый параметр.
IP-адрес
IP-адрес (Internet Protocol Address) - уникальный номер каждого устройства, подключенного к сети. IP-адрес присваивается не устройству (компьютеру), а интерфейсу подключения. В принципе устройства могут иметь несколько точек подключения, а значит несколько различных IP-адресов [2].
IP-адрес - это 32х разрядное число или 4 байта. Для наглядности принято записывать его в виде 4 десятичных чисел от 0 до 255, разделенных точками. Например, 192.168.0.116.
Для того чтобы сетевому оборудованию было проще выстраивать маршрут доставки пакетов в формат IP-адреса введена логическая адресация. IP-адрес разбит на 2 логических поля: номер сети и номер узла. Размеры этих полей зависят от значения первого (старшего) октета IP-адреса и разбиты на 5 групп – классов. Это так называемый метод классовой маршрутизации.
Таблица 1. Метод классовой маршрутизации
|
Класс |
Старший октет |
Формат (С-сеть, |
Начальный адрес |
Конечный адрес |
Количество сетей |
Количество узлов |
|
A |
0 |
С.У.У.У |
0.0.0.0 |
127.255.255.255 |
128 |
16777216 |
|
B |
10 |
С.С.У.У |
128.0.0.0 |
191.255.255.255 |
16384 |
65534 |
|
C |
110 |
С.С.С.У |
192.0.0.0 |
223.255.255.255 |
2097152 |
254 |
|
D |
1110 |
Групповой адрес |
224.0.0.0 |
239.255.255.255 |
- |
228 |
|
E |
1111 |
Резерв |
240.0.0.0 |
255.255.255.255 |
- |
227 |
Класс A предназначен для применения в больших сетях. Класс B используется в сетях средних размеров. Класс C предназначен для сетей с небольшим числом узлов. Класс D используется для обращения к группам узлов, а адреса класса E зарезервированы [1].
Существуют ограничения на выбор IP-адресов:
- Адрес 127.0.0.1 называется loopback и используется для тестирования программ в пределах одного устройства. Данные, посланные по этому адресу, не передаются по сети, а возвращаются программе верхнего уровня, как принятые.
- “Серые” адреса – это IP-адреса разрешенные только для устройств, работающих в локальных сетях без выхода в Интернет. Эти адреса никогда не обрабатываются маршрутизаторами. Их используют в локальных сетях.
- Класс A: 10.0.0.0 – 10.255.255.255
- Класс B: 172.16.0.0 – 172.31.255.255
- Класс C: 192.168.0.0 – 192.168.255.255
- Если поле номера сети содержит все 0, то это означает, что узел принадлежит той же самой сети, что и узел, который отправил пакет [2].
Маска
При классовом методе маршрутизации число битов адресов сети и узла в IP-адресе задается типом класса. А классов всего 5, реально используется 3. Поэтому метод классовой маршрутизации в большинстве случаях не позволяет оптимально выбрать размер сети, что приводит к неэкономному использованию пространства IP-адресов.
В 1993 году был введен бесклассовый способ маршрутизации, который в данный момент является основным. Он позволяет гибко, а значит и рационально выбирать требуемое количество узлов сети. В этом методе адресации применяются маски подсети переменной длины [9].
Сетевому узлу присваивается не только IP-адрес, но и маска подсети. Она имеет такой же размер, как и IP-адрес, 32 бит. Маска подсети и определяет, какая часть IP-адреса относится к сети, а какая к узлу.
Каждый бит маски подсети соответствует биту IP-адреса в том же разряде. Единица в бите маски говорит о том, что соответствующий бит IP-адреса принадлежит сетевому адресу, а бит маски со значением 0 определяет принадлежность бита IP-адреса к узлу [2].
При передаче пакета, узел с помощью маски выделяет из своего IP-адреса сетевую часть, сравнивает ее с адресом назначения, и если они совпадают, то это означает, что передающий и приемный узлы находятся в одной сети. Тогда пакет доставляется локально. В противном случае пакет передается через сетевой интерфейс в другую сеть. Маска подсети не является частью пакета, она влияет только на логику маршрутизации узла [3].
По сути, маска позволяет одну большую сеть разбить на несколько подсетей. Размер любой подсети (число IP-адресов) должен быть кратным степени числа 2. Т.е. 4, 8, 16 и т.д. Это условие определяется тем, что биты полей адресов сети и узлов должны идти подряд.
Пример формы записи сети с четырьмя узлами выглядит так:
Сеть 192.168.0.32, маска 255.255.255.252
Маска подсети всегда состоит из подряд идущих единиц (признаков адреса сети) и подряд идущих нулей (признаков адреса узла). Основываясь на этом принципе, существует другой способ записи той же адресной информации.
Сеть 192.168.0.32/30
/30 - это число единиц в маске подсети. В данном примере остается два нуля, что соответствует 2 разрядам адреса узла или четырем узлам.
Руководствуясь этим правилом, можно представить таблицу:
Таблица 2. Зависимость между размером сети и маской
|
Размер сети (количество узлов) |
Длинная маска |
Короткая маска |
|
4 |
255.255.255.252 |
/30 |
|
8 |
255.255.255.248 |
/29 |
|
16 |
255.255.255.240 |
/28 |
|
32 |
255.255.255.224 |
/27 |
|
64 |
255.255.255.192 |
/26 |
|
128 |
255.255.255.128 |
/25 |
|
256 |
255.255.255.0 |
/24 |
Доменное имя
Человеку неудобно работать с IP-адресами. Это наборы чисел, а человек привык читать буквы, еще лучше связно написанные буквы, т.е. слова. Для того, чтобы людям было удобнее работать с сетями используется другая система идентификации сетевых устройств [2].
Любому IP-адресу может быть присвоен буквенный идентификатор, более понятный человеку. Идентификатор называется доменным именем или доменом.
Доменное имя это последовательность из двух или более слов, разделенных точками. Последнее слово это домен первого уровня, предпоследнее – домен второго уровня и т.д. [5].
Связь между IP-адресами и доменными именами происходит через распределенную базу данных, с использованием DNS-серверов. DNS-сервер должен иметь каждый владелец домена второго уровня. DNS-серверы объединены в сложную иерархическую структуру и способны обмениваться между собой данными о соответствии IP-адресов и доменных имен.
Любой клиент или сервер может обратиться к DNS-серверу с DNS-запросом, т.е. с запросом о соответствии IP-адрес – доменное имя или наоборот доменное имя – IP-адрес. Если DNS-сервер обладает информацией о соответствии IP-адреса и домена, то он отвечает. Если не знает, то ищет информацию на других DNS-серверах и после этого сообщает клиенту.
Сетевой шлюз
Сетевой шлюз это аппаратный маршрутизатор или программа для сопряжения сетей с разными протоколами [5]. В общем случае его задача конвертировать протоколы одного типа сети в протоколы другой сети. Как правило, сети имеют разные физические среды передачи данных.
Пример – локальная сеть из компьютеров, подключенная к Интернету. В пределах своей локальной сети (подсети) компьютеры связываются без необходимости в каком-либо промежуточном устройстве. Но как только компьютер должен связаться с другой сетью, например выйти в Интернет, он использует маршрутизатор, который выполняет функции сетевого шлюза [2].
Роутеры, которые есть у каждого, кто подключен к проводному интернету, являются одним из примеров сетевого шлюза. Сетевой шлюз это точка, через которую обеспечивается выход в Интернет.
MAC-адрес
MAC-адрес это уникальный идентификатор устройств локальной сети. Как правило, он записывается на заводе-производителе оборудования в постоянную память устройства [5].
Адрес состоит из 6 байтов. Принято записывать его в шестнадцатеричной системе исчисления в следующих форматах: c4-0b-cb-8b-c3-3a или c4:0b:cb:8b:c3:3a. Первые три байта это уникальный идентификатор организации-производителя. Остальные байты называются ”Номер интерфейса” и их значение является уникальным для каждого конкретного устройства.
IP-адрес является логическим и устанавливается администратором. MAC-адрес – это физический, постоянный адрес. Именно он используется для адресации фреймов, например, в локальных сетях Ethernet. При передаче пакета по определенному IP-адресу компьютер определяет соответствующий MAC-адрес с помощью специальной ARP-таблицы. Если в таблице отсутствуют данные о MAC-адресе, то компьютер запрашивает его с помощью специального протокола. Если MAC-адрес определить не удается, то пакеты этому устройству посылаться не будут [9].
Порты
С помощью IP-адреса сетевое оборудование определяет получателя данных. Но на устройстве, например сервере, могут работать несколько приложений. Для того чтобы определить какому приложению предназначены данные в заголовок добавлено еще одно число – номер порта [3].
Порт используется для определения процесса приемника пакета в пределах одного IP-адреса [5].
Под номер порта выделено 16 бит, что соответствует числам от 0 до 65535. Первые 1024 портов зарезервированы под стандартные процессы, такие как почта, веб-сайты и т.п. В своих приложениях их лучше не использовать.
Выводы по главе 1
- Архитектура «Клиент-сервер» пришла на смену устаревшей «мэйнфреймовой» архитектуре. Новые технологии позволили решить проблемы сетевого трафика и рациональнее использовать вычислительные ресурсы.
- Во избежание несогласованности различных элементов архитектуры были созданы две модификации двухзвенной архитектуры «Клиент – сервер»: «Толстый клиент» («Тонкий сервер») и «Тонкий клиент» («Толстый сервер»), придающие гибкость клиент-серверной архитектуре.
- Для доставки пакетов от клиента к серверу и обратно необходимо настроить такие параметры, как: IP-адрес источника, маска сети, доменное имя, сетевой шлюз, порт. Большинство этих параметров настраивается автоматически.
2. Реализация клиент-серверной технологии на предприятии
Один из альтернативных вариантов работы платформы «1С: Предприятие» 8.2, является клиент - серверный. «Клиент - сервер» выполнен на основе архитектуры трех уровней.
Архитектура клиент-сервера делит работающую систему на три части, которые обусловленным образом взаимодействуют между собой [8] (рисунок 2):
клиентское приложение;
кластер - серверов «1С: Предприятия»;
сервер баз данных.

Рисунок 2. Трехуровневая архитектура системы «1С: Предприятие» 8.2
Клиентское приложение любого пользователя, работая с кластером серверов «1С: Предприятие» 8.2 при необходимости обращается к базе данных на сервере.
При этом совершенно не обязательно чтобы сервер базы данных и кластер серверов «1С: Предприятие» 8.2 находился на одном компьютере, это может быть и другой компьютер. Такие возможности помогут пропорционально разделить нагрузку между серверами.
Применение кластера серверов «1С: Предприятие» 8.2, это возможность сконцентрировать на нем осуществление объемных операций по обработке баз данных. Это могут быть выполнение объемных сложных запросов, и в этом случае программа пользователя получит только необходимую информацию в виде тематической выборки, а вся обработка будет происходить непосредственно на сервере. Такая возможность дает значительно облегчить работу, ведь увеличить мощность кластера намного легче, чем обновление программных систем целого ряда компьютеров [8].
Еще одно достоинство трехуровневой архитектуры, это возможность свободно администрировать и контролировать доступ всех пользователей к информации базы данных [7]. И совершенно не обязательно пользователю вникать в расположение баз данных или конфигурации, весь доступ происходит через кластер серверов платформы «1С: Предприятие» 8.2. При вводе запроса достаточно указать название информационной базы и имя необходимого кластера, сообщив при этом пароль.
В данном случае платформа «1С: Предприятие» 8.2 для результативной выборки информации сама оперирует всеми базами данных [8]:
Специальные механизмы запросов направлены на самую максимальную эксплуатацию СУБД для выполнения необходимых видов работ связанных с расчетами и оформлением отчетов;
Возможность избежать огромного числа запросов к базе данных при большом объеме запрашиваемой информации. Действия упрощаются за счет существующих настроек отбора и сортировки данных, увеличивая при этом эффективность поиска.
Формирование клиент-серверной версии, и ее администрирование не требует специальных навыков. Создание баз данных выполняется вовремя запуска конфигуратора, то же самое и для файлового варианта.
Клиентские приложения расположены на компьютерах пользователей системы 1С – у бухгалтеров, работников кадровой службы, заведующих складами, продавцов, и т.д. [4].
Основным компонентом системы «1С: Предприятие» 8.2, с помощью которого взаимодействуют пользователи с системой баз данных при работе с клиент сервером, является кластер серверов.
Существование кластера делает возможной бесперебойную, отказоустойчивую, работу значительного числа пользователей с большими информационными базами.
Сервер баз данных
В качестве сервера баз данных используются [8]:
База Microsoft SQL Server
База PostgreSQL
База IBM DB2
База Oracle Database
Администрирование клиент-серверного варианта работы 8.2
В комплект платформы входит специальная утилита, которая позволяет администрировать клиент-сервер и управлять администратору всеми подключенными пользователями и информационными базами.
Выполнение на сервере
Вся работа с необходимыми объектами, чтение баз данных и запись осуществляется непосредственно на сервере. Все функции командного интерфейса и определенных форм выполняются тоже на сервере [8].
Подготовка всевозможных форм, запись произведенных изменений и их расположение все эти функции, это задача сервера. Клиент отображает уже готовые формы, которые могут заполняться пользователем, вызов сервера осуществляется через поле ввод.
Командный интерфейс формируется аналогично на сервере, и все отчеты выводятся на клиенте.
При этом сам механизм платформы направлен на то чтобы объем данных запрошенных данных был минимальным, за счет сортировки данных на сервере. Обработанные данные же поступают с сервера после просмотра их пользователем (данные списков, таблицы, отчеты)
На сервере выполняются следующее [8]:
Запросы к базам данных
Запись всех данных
Проводка документов
Разные расчеты
Проведение обработок
Формирование готовых отчетов
Подготовка форм к показу.
На клиенте выполняется следующее [8]:
Передача и открытие форм
Показ форм
Получение пользователем сообщений, предупреждений
Проведение быстрых расчетов по простым формулам
Операции с локальными файлами
Операции с торговым оборудованием.
Таким образом, для реализации клиент-серверного варианта работы в минимальной конфигурации достаточно одного дополнительного компьютера с высокими показателями быстродействия и надёжности, на котором будут функционировать и кластер серверов 1С, и сервер базы данных [8].
Количество дополнительных компьютеров повышенного качества, на которых будут располагаться кластер серверов «1С: Предприятие» 8.2 и сервер базы данных, определяются количеством рабочих мест, которые вам необходимы.
В клиент-серверном варианте работы системы «1С: Предприятие» 8.2 клиентские приложения, установленные на компьютерах конечных пользователей, могут подключаться к кластеру серверов с помощью клиентов одного из трёх типов – Толстый клиент, Тонкий клиент и Веб-клиент [8].
- Толстый клиент способен работать только по протоколу TCP/IP.
- Тонкий клиент может обеспечить подключение клиентского приложения к кластеру и по протоколу TCP/IP, и по протоколу HTTPS.
- Веб-клиент обеспечивает подключение только по протоколу HTTPS.
Вышеизложенное иллюстрируется на рисунке 3.

Рисунок 3. Варианты подключения к кластеру серверов системы «1С: Предприятие» 8.2
Выводы по главе 2
- Клиент-серверная архитектура в работе платформы «1С: Предприятие» 8.2 представлена в виде клиентского приложения и кластера серверов «1С: Предприятие», к которым подключен сервер баз данных.
- Применение архитектуры «клиент-сервер» дает возможность осуществление объемных операций по обработке баз данных, администрировать и контролировать доступ всех пользователей к информации базы данных, максимально эффективно эксплуатировать СУБД, эффективный поиск за счет существующих настроек отбора и сортировки данных на сервере.
3. Рекомендации по настройке клиент-серверной архитектуры
Для того, чтобы отработать на практике теоретические вопросы, связанные с настройкой клиент-серверной архитектуры используем метод моделирования. В качестве клиента используется ЭВМ, в качестве сервера - сервер Google. Взаимодействие будет происходить через маршрутизатор домашней сети (по пути до доступа к серверам Google расположено не мало сетевых устройств). Так же смоделируем ситуацию настройки клиент-серверной архитектуры между двумя ЭВМ в локальной сети, где взаимодействие происходит по кабелю. Принципиальное отличие заключается в настройке IP-адресов. В случае с доступом к серверам Google, адресация по умолчанию автоматическая, тогда как для доступа по локальной сети, сетевые настройки придется настроить вручную.
«Клиент-сервер» в модели «ЭВМ-сервер Google»
Как уже было сказано ранее, настройка сети происходит в автоматическом режиме. Проблему ручной настройки сети решается с помощью применения динамических IP-адресов. Динамические адреса выдаются клиентам на ограниченное время, пока они непрерывно находятся в сети. Распределение динамических адресов происходит под управлением протокола DHCP.
DHCP – это сетевой протокол, позволяющий устройствам автоматически получать IP-адреса и другие параметры, необходимые для работы в сети [5].
На этапе конфигурации устройство-клиент обращается к серверу DHCP, и получает от него необходимые параметры. Может быть задан диапазон адресов, распределяемых среди сетевых устройств [6].
Существует много способов, как узнать IP-адрес или MAC-адрес своей сетевой карты. Самый простой – это использовать CMD команды операционной системы [6]. Рассмотрим это на примере Windows 7.
В папке Windows\System32 находится файл cmd.exe. Это интерпретатор командной строки. С помощь него можно получать системную информацию и конфигурировать систему.
Открываем окно выполнить. Для этого выполняем меню Пуск -> Выполнить или нажимаем комбинацию клавиш Win + R (рис. 4).
Рисунок 4. Вызов командной строки
Набираем cmd и нажимаем OK или Enter. Появляется окно интерпретатора команд (рис. 5).
Рисунок 5. Командная строка
Теперь можно задавать любые из многочисленных команд. Пока нас интересуют команды для просмотра конфигурации сетевых устройств.
Прежде всего, это команда ipconfig, которая отображает настройки сетевых плат (рис. 6).
Рисунок 6. Отображение настройки сетевых плат
Подробный вариант ipconfig/all (рис. 7).
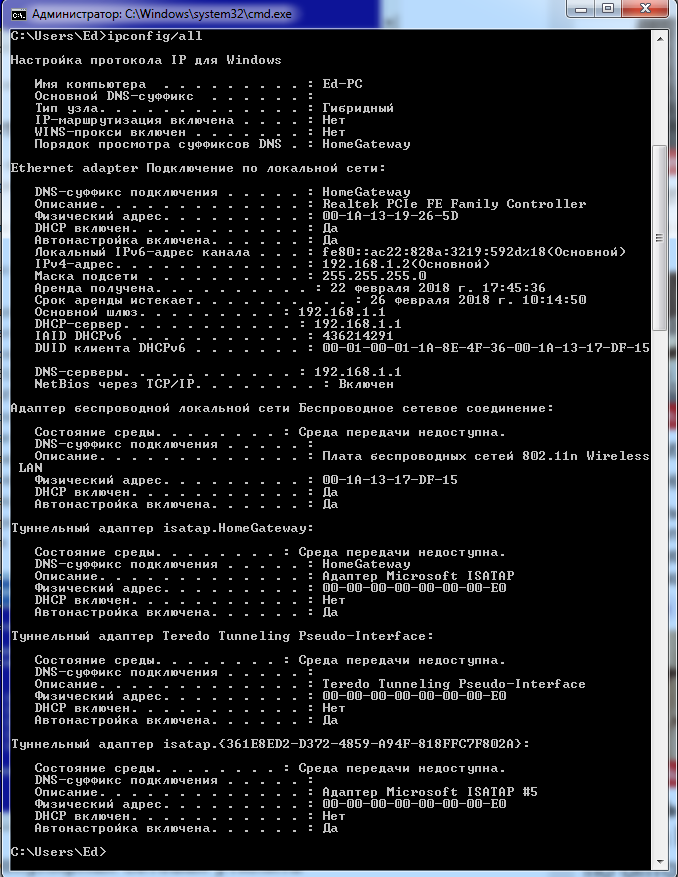
Рисунок 7. Вывод полной информации о сетевых платах
Только MAC-адреса показывает команда getmac (рис. 8).
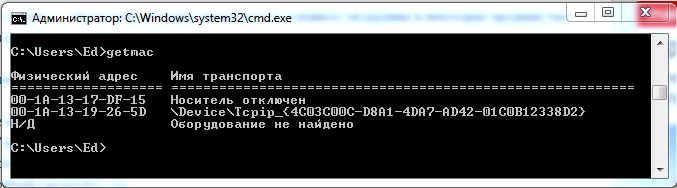
Рисунок 8. Вывод информации о MAC-адресах
Таблицу соответствия IP и MAC адресов (ARP таблицу) показывает команда arp –a (рис. 9).
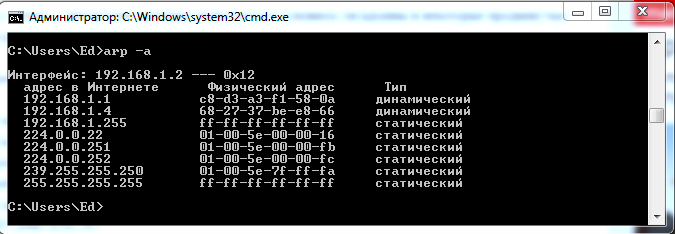
Рисунок 9. Вывод соответствия IP и MAC адресов
Проверить связь с сетевым устройством можно командой ping. Выполним команду: ping google.com (рис. 10).
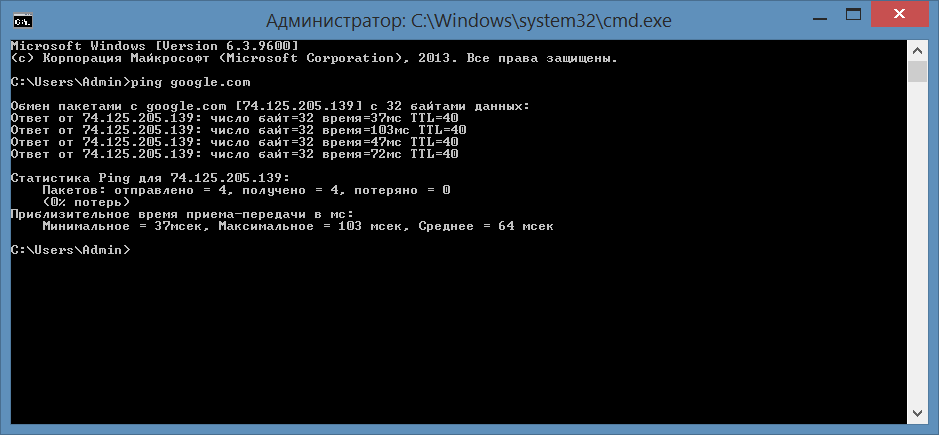
Рисунок 10. Тестирование доступа к серверу Google
На основании того, что из 4 отправленных потерь вернулось 4, можно сделать вывод, что сервер Google доступен.
«Клиент-сервер» в модели «ЭВМ-ЭВМ»
Для реализации данной модели, соединим два компьютера с помощью кабеля Ethernet. Предположим, что второй компьютер выступает в роли сервера. Настройка сети происходит вручную. Для организации взаимодействия необходимо определить оба компьютера в одну сеть. Для этого выберем знак сети в панели задач (рис. 11), в котором выберем параметр: «Центр управления сетями и общим доступом» (рис. 12).

Рисунок 11. Иконки панели задач
Рисунок 12. Центр управления сетями и общим доступом
Выберем подключение: «Ethernet 2» (рис. 13).
Рисунок 13. Подключение «Ethernet 2»
Перейдем во вкладку свойства (рис. 14).
Рисунок 14. Подключение «Ethernet 2»
Выберем свойства «Протокола Интернета версии 4», где добавим IP-адрес и маску подсети для нашей ЭВМ (рис. 15).
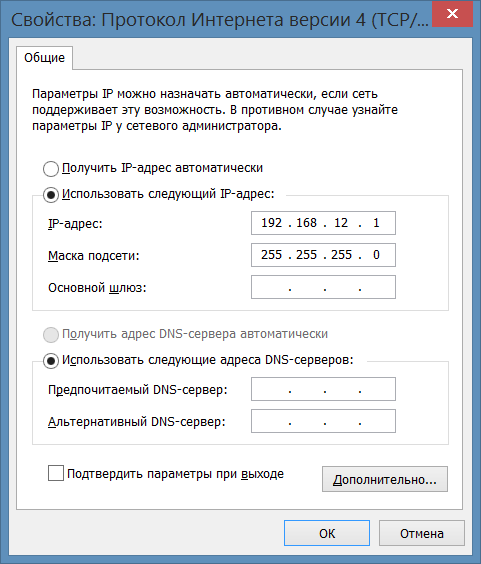
Рисунок 15. Настройка IP-адреса и маски подсети
Таким же образом добавим IP-адрес 192.168.1.2 и маску подсети 255.255.255.0 второй ЭВМ выполним команду ping (рис.16).
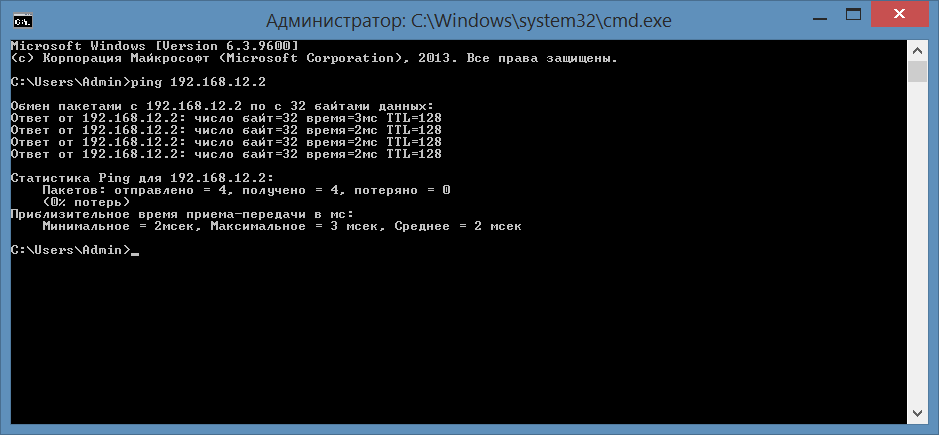
Рисунок 16. Тестирование доступа ко второй ЭВМ
На основании того, что из 4 отправленных потерь вернулось 4, можно сделать вывод, что вторая ЭВМ доступна.
Выводы по главе 3
- С помощью протокола DHCP настройка сети с участием сетевых устройств происходит в автоматическом режиме.
- При настройке сети между двумя узлами настройка сети происходит в ручном режиме, где необходимые параметры прописываются в «Центре управления сетями и общим доступом».
- С помощью командной строки можно легко проверить настройки сети с помощью команды ipconfig, а проверить доступность сервера с помощью команды ping.
ЗАКЛЮЧЕНИЕ
В данной работе была изучена клиент-серверная платформа, которая пришла на смену устаревшей «мэйнфреймовой». Основное преимущество заключается в увеличении вычислительной мощности за счет осуществления обработки данных на сервере и возвращения обработанных данных клиенту. Ярким примером клиент-серверной архитектуры является работа платформы «1С: Предприятие» 8.2, где с помощью клиентского приложения осуществляется доступ к кластеру серверов, где происходит работа с необходимыми объектами, чтение баз данных и запись, которая осуществляется непосредственно на сервере. Для бесперебойной работы клиент-серверной платформы обязательным параметров является правильно настроенная сеть. В данной работе представлены методические рекомендации по настройке сети. В случае удаленного расположения сервера и наличия сетевых устройств, настройка сетевых параметров сети происходит в автоматическом режиме с помощью протокола DHCP. Если же появилась необходимость связать клиент и сервер локально, например, с помощью кабеля, настройка сети происходит вручную через «Центр управления сетями и общим доступом».
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. ГОСТ Р ИСО/МЭК ТО 10735-2000 «Информационные технологии. Передача данных и обмен информацией между системами. Стандартные групповые адреса на подуровне управления доступом к среде» [Текст]. – Введ. 2000–04–06.
2. Гребешков, А.Ю. Вычислительная техника, сети и телекоммуникации: Учебное пособие для вузов. / А.Ю. Гребешков. - М.: ГЛТ, 2016. – 190 с.
3. Гусева, А.И. Вычислительные системы, сети и телекоммуникации: Учебник / А.И. Гусева. - М.: Академия, 2016. - 336 c.
4. Кузин, А.В. Компьютерные сети: Учебное пособие / А.В. Кузин, Д.А. Кузин. - М.: Форум, 2018. - 704 c.
5. Куроуз, Дж. Компьютерные сети: Нисходящий подход / Дж. Куроуз. - М.: Эксмо, 2018. - 800 c.
6. Олифер, В. Компьютерные сети. Принципы, технологии, протоколы: Учебник / В. Олифер, Н. Олифер. - СПб.: Питер, 2016. - 318 c.
7. Соболь, Б.В. Сети и телекоммуникации: Учебное пособие / Б.В. Соболь. - Рн/Д: Феникс, 2015. - 522 c.
8. Сайт «1С: Предприятие 8» [Электронный ресурс]. – URL: http://v8.1c.ru/ (дата обращения: 08.05.2019).
9. Таненбаум, Э. Компьютерные сети / Э. Таненбаум. - СПб.: Питер, 2019. - 960 c.

- Функции операционных систем персональных компьютеров (Функциональные возможности и задачи ОС 8)
- Разработка регламента выполнения процесса «Расчет заработной платы»
- Управление ликвидностью предприятия
- Банковская система, ее элементы и важнейшие свойства
- Финансы акционерных обществ (Факторы, определяющие уровень финансовой устойчивости)
- Комплексный экономический анализ хозяйственной деятельности
- Семья и ее социальные функции
- Методы оценки эффективности финансово-кредитных институтов
- Методы оценки эффективности финансово-кредитных институтов на примере «Банк ВТБ (ПАО)»
- Понятие денежной системы, генезис её названия
- Характеристика общей теории права и государства как науки и учебной дисциплины (Развитие системы юридических наук)
- Объекты авторского права