
Способы представления данных в информационных системах (Классификация информации в информационных системах)
Содержание:

Введение
Современное понимание информационной системы включает использование персонального компьютера в качестве основного технического инструмента для обработки информации.
Под информационной системой понимается взаимосвязанный набор информационных, технических, программных, математических, организационных, правовых, эргономических, лингвистических, технологических и других средств, а также персонала, предназначенный для сбора, обработки, хранения и выдачи экономической информации и принятия управленческих решений.
В более широком смысле понятие информационной системы трактуется Федеральным законом Российской Федерации от 27 июля 2006 г. № 149-ФЗ «Об информации, информационных технологиях и защите информации»: «Информационная система - это совокупность информации, содержащейся в базах данных, и их обработка с использованием информационных технологий и технических средств» [1].
Основные понятия, используемые в информационных технологиях, включают в себя: данные, информацию и знания. Эти понятия часто используются как синонимы, однако между этими понятиями существуют фундаментальные различия.
Определение данных происходит от слова data - факт, а информация (informatio) означает объяснение, изложение, т.е. сведения или сообщение.
Данные - это набор информации, записанный на конкретном носителе, пригодный для хранения, передачи и постоянной обработки. Преобразование и обработка данных позволяет получать информацию.
Актуальность курсовой работы обусловлена тем, что информационные системы значительно проникли в нашу жизнь.
Объектом курсовой работы выступает информационная система.
Предметом - являются способы представления данных в информационных системах.
Целью исследования является изучение способов представления данных в информационных системах.
Из цели работы вытекают ее задачи:
- изучение теоретических основ представления данных в информационных системах;
- изучение форм представления данных;
- изучение функций информационных систем.
В курсовой работе использовались общенаучные (историко-диалектический, метод анализа и синтеза) и специально-научные (системный, сравнительный и др.) методы.
Структура: курсовая работа состоит из введения, трех глав, заключения, библиографии.
В первой главе рассмотрены теоретические основы информационных систем.
Во второй главе проведен анализ функций информационных систем.
В третьей главе изучены типы данных существующих в информационных системах.
В заключении представлены выводы теоретического и эмпирического исследования.
Общий объем курсовой работы составляет 42 страницы, включающих в себя библиографию.
Для написания работы изучена литература, представленная законодательными актами, учебниками и учебными пособиями. Основными источниками информации по теме «Способы представления данных в информационных системах являются учебники по «Информатике» Сименовича и Глушакова.
Глава 1. О СИСТЕМАХ БАЗ ДАННЫХ
1.1. Классификация информации в информационных системах
В современных информационных системах и компьютерных технологиях базы данных стали не только источником информации, отвечающей различным информационным потребностям пользователей, но и платформой, на основе которой можно создавать интегрированные данные, как для принятия управленческих решений, так и для прогнозирования и моделирования поведения исследуемой системы [3, с. 7].
Весь спектр информации, окружающей нас, можно классифицировать по различным критериям. Итак, на основе «области происхождения» информация, отражающая процессы, явления неживой природы, называется элементарными, или механическими, процессами животного и растительного мира - биологическими, человеческое общество – социальными [5].
Существует 3 области, о которых можно говорить как характеризующих данные в информационных системах:
- предметная область;
- информация;
- сами данные.
Первая область - это реальный мир, в котором есть много объектов, обладающих определенными свойствами. В реальном мире существует определенная тематическая область, которая является частью реального мира. Примеры тем включают науку, животных, книгу, автомобиль, компьютер, язык программирования, изучаемый предмет, техническую литературу, сеанс, живопись, кино, спорт, флору, фауну, транспорт, связь, больницу, аэропорт, институт, театр и т.д.
В предметной области можно выделить один или несколько объектов. Объект может быть человеком, объектом, событием, местом, явлением или концепцией. Каждый объект должен иметь несколько свойств.
Пример 1. Для предметной области «Больница» можно выделить такие объекты как «Больница», «Больной», «Врач», «Палата», «Отделение», «Младший медперсонал», «Лаборатория», «Лекарства» и т.д. К примеру, объект «Больница» возможно описать при помощи свойств как «Номер больницы», «Наименование больницы», «Фамилия главного врача», «Количество койко-мест», «Количество персонала», «Фонд заработной платы» и т.д. Объект «Больной» возможно описать при помощи таких свойств как «Фамилия и инициалы больного», «Номер лечебной карточки», «Номер палаты», «Диагноз», «Лечение», «Фамилия лечащего врача» и т.д. [3, с. 9]
Точность, полнота и объем описания, как в тематической области, так и в отдельных объектах, зависят от решаемой проблемы, функций информационной системы и потребностей пользователей в информации.
Вторая область - это область информации, существующая в сознании людей. На практике информация отражает все, что доступно в реальном мире. Информация стала ресурсом, может быть извлечена, обработана, использована, распространена.
Информация является одним из наиболее ценных ресурсов общества наряду с традиционными видами сырья, такими как нефть, газ, минералы и т.д. В области информации они говорят об атрибутах объектов и символически определяют атрибуты на естественном языке или языке программирования или в другой форме.
Атрибутам приписывают значения. Например, для атрибута «Фамилия и инициалы больного» объекта «Больной» можно ввести такие обозначения: «ФИО», «ФИО больного», «FIO», «Bolnoy».
Третья область - это диапазон данных, хранящихся на компьютере. Элемент данных является действительными данными, которые соответствуют определенному атрибуту, связанному с конкретным субъектом из предметной области. Значения элементов данных в памяти компьютера являются символьными или битовыми строками.
В зависимости от того, как элементы данных описывают объект, они могут быть количественными, качественными или описательными. Значения элементов данных могут существовать независимо от информации, которая хранится с их помощью. Но они приобретут смысл только тогда, когда они прикреплены к определенному элементу.
Информация, созданная и используемая человеком в общественных целях, может быть разделена на три типа:
- личная,
- массовая
- специальная.
Личная информация предназначена для конкретного, массивного человека, для которого необходимо использовать ее (общественные науки, популярная политика и т. д.), и специальную информацию для использования узким кругом людей, вовлеченных в решение сложных специальных проблем в области науки, технологии, экономика и пр.
Информация может быть объективной и субъективной.
Объективная информация отражает явления природы и человеческого общества.
Субъективная информация создаётся людьми и отражает их взгляд на объективные явления [10].
В автоматизированных информационных системах выделяют:
- структурная информация (информация преобразования) объектов системы, содержащаяся в структурах системы, ее элементах управления, алгоритмах и программах обработки информации;
- содержательная (преимущественно информационная, измерительная, контрольная, научная, техническая, технологическая и т. д.) информация из информационных полей (сообщений, команд и т. д.) об индивидуальной модели предметного поля (человек, подсистема).
Первый связан с качеством информационных процессов в системе, с внутренними технологическими эффектами, затратами на обработку информации. Второй - как правило, с внешним целевым (материальным) эффектом [11].
Один из возможных вариантов классификации информации в автоматизированных системах:
по отношению к объекту:
- внутренняя;
- внешняя;
по форме проявления в задачах управления:
- осведомляющая;
- преобразующая;
- управляющая;
связь с целью:
- синтаксическая;
- семантическая;
- прагматическая;
по качеству проявления:
- полезная;
- бесполезная (пустая);
- дезинформация;
по содержанию источника информации:
- о состоянии управляемого объекта;
- о внешней среде;
- о целях;
- о других системах;
по полноте отображения:
- полная;
- неполная;
по характеру генерирования:
- объективная;
- субъективная;
в зависимости от вида носителя:
- документальная;
- акустическая (речевая);
- телекоммуникационная;
по отношению к элементу системы:
‒статическая;
‒динамическая;
по степени стабильности:
‒условно-постоянная;
‒переменная;
по целям использования:
‒нормативная;
‒справочная;
‒плановая;
‒отчётная;
‒аналитическая;
‒оперативно-технологическая;
по форме представления:
‒аналоговая;
‒дискретная.
При реализации информационных процессов информация (сообщение) может передаваться от источника к получателю с использованием любого материального носителя (бумага, магнитная лента и т. Д.) Или физического процесса (звуковые или электромагнитные волны) [12].
Следующие типы информации различаются в зависимости от типа носителя:
- документальную;
- акустическую (речевую);
- телекоммуникационную.
Информация документации представлена в графической или буквенно-цифровой форме на бумаге, а также в электронном виде на магнитных и других носителях.
Голосовая информация возникает в ходе ведения разговоров, а также при работе систем звукоусиления и воспроизведения звука. Носителем речевой информации являются акустические колебания (механические колебания частиц упругой среды, распространяющиеся от источника колебаний в окружающее пространство в виде волн различной длины) в диапазоне частот от 200-300 Гц до 4-6 кГц [6].
Телекоммуникационная информация циркулирует в технических средствах обработки и хранения информации, а также в каналах связи при ее передаче. Носителем информации при ее обработке техническими средствами и передаче по проводным каналам связи является электрический ток, а при передаче по радио и оптическим каналам - электромагнитные волны.
Источник информации может генерировать непрерывное сообщение (сигнал), в этом случае информация называется непрерывной или дискретной - информация называется дискретной.
Например, сигналы, передаваемые по радио и телевидению, а также сигналы, используемые в магнитной записи, имеют форму непрерывных зависимостей, которые быстро развиваются. Эти сигналы называются непрерывными или аналоговыми сигналами. С другой стороны, в телеграфии и информатике сигналы являются импульсными и называются дискретными сигналами [5].
Непрерывные и дискретные формы представления информации имеют особое значение при рассмотрении вопросов создания, хранения, передачи и обработки информации с использованием компьютерных технологий.
В настоящее время во всех компьютерах информация представлена с помощью электрических сигналов. В этом случае возможны две формы представления числового значения переменной, например:
- в виде одного сигнала — например, электрического напряжения, которое сравнимо с величиной (аналогично ей). Например, при единицам на вход вычислительного устройства можно подать напряжение 2,003 В (масштаб представления 0,001 В/ед.) или 10,015 В (масштаб представления 0,005 В/ед);
- в виде нескольких сигналов — нескольких импульсов напряжений.
Первая форма представления информации (используя аналогичное количество - аналог) называется аналоговой или непрерывной. Значения, представленные в этой форме, могут принимать практически любое значение в определенном диапазоне.
Количество значений, которые может принимать такое значение, бесконечно велико. Отсюда и название - непрерывное количество и непрерывная информация. Непрерывность слова четко подчеркивает основное свойство таких величин - отсутствие пробелов, пробелов между значениями, которые может принимать эта аналоговая величина.
Вторая форма представления информации называется дискретной (используется серия напряжений, каждая из которых соответствует одной из цифр представленного значения). Эти величины, принимающие не все возможные, а только достаточно определенные значения, называются дискретными (прерывистыми). В отличие от непрерывного количества, число значений дискретного количества всегда будет закончено.
Сравнивая непрерывную и дискретную формы представления информации, легко увидеть, что использование непрерывной формы для создания компьютера требует меньше устройств (каждое значение представлено одним, а не несколькими сигналами), но эти устройства будут более сложными (они должны различать значительно большее количество состояний сигнала).
Непрерывная форма представления используется в аналоговых вычислительных машинах (АВМ). Эти машины в основном предназначены для решения задач, описываемых системами дифференциальных уравнений: изучения поведения движущихся объектов, процессов и систем моделирования, решения задач параметрической оптимизации и оптимального управления. Устройства непрерывной обработки сигналов имеют более высокую скорость, они могут интегрировать сигнал, выполнять любое функциональное преобразование и так далее [8].
Однако из-за сложности технической реализации устройств выполнения логических операций с непрерывными сигналами, длительного хранения таких сигналов, их точного измерения АВМ не могут эффективно решать задачи, связанные с хранением и обработкой больших объёмов информации, которые легко решаются при использовании цифровой (дискретной) формы представления информации, реализуемой цифровыми электронными вычислительными машинами (ЭВМ).
1.2. Модели представления данных в информационных системах
Модель представления данных или модель данных - это набор допустимых типов данных и отношений между ними, ограничений и действий в отношении этих типов данных и отношений. Многие важные типы данных и отношения называются структурами данных. Модель данных является ядром базы данных [10].
Наиболее популярными являются три модели данных: иерархическая, сетевая и реляционная.
Иерархическая модель дает возможность строить БД с иерархической структурой в виде дерева.
Дерево — это связный неориентированный граф, который не содержит циклов. Обычно при работе с деревом выделяют какую-то конкретную вершину, определяют ее как корень дерева и рассматривают особо — в эту вершину не заходит ни одно ребро. В этом случае дерево становится ориентированным. Ориентация определяется от корня. Конечные вершины, то есть вершины, из которых не выходит ни одной дуги, называются листьями дерева [0].
Иерархическая модель является самой простой, поэтому исторически она появилась первой. Преимущества иерархической модели включают в себя довольно эффективное использование памяти и хорошие показатели производительности времени для операций с данными. Недостатками являются довольно сложные логические связи, определенная сложность в обработке данных и сложность включения новых объектов в заданное структурное «дерево».
Сетевая модель данных
На разработку этого стандарта большое влияние оказал американский ученый Ч. Бахман. Основные принципы модели данных сети были разработаны в середине 1960-х годов, эталонная версия модели данных сети описана в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г.). Сетевая модель - это структура, в которой любой элемент может быть связан с любым другим элементом. Организация данных в сетевой модели соответствует структурированию данных по версии CODASYL. В соответствии с ней описание схемы БД осуществляется на языке COBOL, а манипулирование данными — с помощью включающего языка программирования высокого уровня [6].
В каждой вершине графа хранятся экземпляры сущностей (записей) и информация о групповых отношениях с сущностями других типов. Каждая запись может хранить произвольное количество значений атрибутов (элементов данных и агрегатов), соответствующих экземпляру объекта.
Основным преимуществом сетевой модели данных является ее высокая эффективность и экономичность использования памяти. К недостаткам относится сложность понимания базовой схемы, а также сложность понимания, программирования и контроля целостности из-за допустимости установления произвольных отношений.
Реляционная модель данных была предложена математиком Э.Ф. Коддом в1970 г. Это наиболее широко используемая модель данных и единственная из трех основных моделей данных, для которых была разработана теоретическая основа с использованием теории множеств.
Информация об объектах определенного типа хранится в таблице, каждое поле (столбец таблицы), содержащее значения определенного признака объектов, и запись (строка таблицы) представляют собой описание отдельного объекта. Даже при запросе информации из одной или нескольких таблиц результат запроса представляется в виде таблицы.
При построении реляционных моделей применяется строгая математическая теория отношений. В этом случае термин отношения связан с концом таблицы [5].
Атрибут, значение которого уникально идентифицирует кортежи, называется ключом (или просто ключом). В нашем случае ключом является атрибут «Номер персонала», поскольку его значение уникально для каждого сотрудника компании. Если ключ состоит из нескольких атрибутов, он называется составным. Там может быть больше ключей; Первичный ключ является первичным ключом; его значения не могут быть обновлены.
Кроме первичного ключа в таблице могут быть вторичные ключи, называемые еще внешними ключами, или индексами.
Индекс — это поле или совокупность полей, чьи значения имеются в нескольких таблицах и которое является первичным ключом в одной из них. Значения индекса могут повторяться в некоторой таблице [6].
По первичному ключу всегда отыскивается только одна строка, а по вторичному — может отыскиваться группа строк с одинаковыми значениями первичного ключа. Ключи нужны для однозначной идентификации и упорядочения записей таблицы, а индексы для упорядочения и ускорения поиска.
Связь устанавливается посредством связи ключей, содержащих общую информацию для обоих отношений. Связь существует трех основных типов:
- один-к-одному (1:1);
- один-ко-многим (1:М);
- многие-к-одному (М:1).
глава 2. О СПОСОБАХ ПРЕДСТАВЛЕНИЯ ДАННЫХ В ИНФОРМАЦИОННЫХ СИСТЕМАХ
2.1. Способы представления данных в БД Access
При рассмотрении концепции информационного обеспечения в контексте обработки информации важна концепция данных. Данные отличаются от информации в конкретной форме представления и являются подмножеством, определяемым целями и задачами сбора и обработки информации.
Например, данные о сотрудниках организации в виде формализованных учетных карточек отдела кадров содержат только определенный перечень необходимой информации (имя, год рождения, образование, семейное положение, должность и т. д.), В отличие от огромного количества информации, которая характеризует каждого конкретного человека.
Поэтому мы определяем данные как информацию, которая отражает конкретное состояние конкретной тематической области в конкретной форме представления и содержит только наиболее значимые элементы изображения отраженного фрагмента реальности с точки зрения целей и задач сбора и обработки информации [4].
Структура данных связана с концепцией представления информации и определяется (функциональной, логической, технологической и т. д.
Структурой предметной области, сведения о которой содержат данные. В то же время данные могут быть представлены в неструктурированной форме, определяющей технологические особенности их накопления и обработки. Таким образом, можно выделить неструктурированную и структурированную форму представления данных.
В качестве примера неструктурированной формы можно привести:
-
- связный текст (т. е. документ на естественном языке, на литературном, официально-деловом и т. д.);
- графические данные в виде фотографий, картинок и прочих неструктурированных изображений.
Примерами структурированной формы данных являются:
-
- анкеты;
- таблицы;
- графические данные в виде чертежей, схем, диаграмм.
С точки зрения управления информацией в процессах создания (генерации), сбора, доставки и потребления важна концепция документированной информации или просто документа [3].
Можно сказать, что в большом количестве случаев информация появляется и появляется в образе документа, исключая ту часть информационных процессов, которые работают исключительно с данными, как, например, в автоматизированных системах управления процессами - АСУТП, где информация порождается в виде показаний датчиков (входные данные), обрабатывается, выдается и потребляется в виде управляющих сигналов (выходные данные) на технологическое оборудование [5].
Типы данных в ИС могут быть разными.
Текстовые данные
Значение каждого текстового (символьного) данного представлено совокупностью произвольных алфавитно-цифровых символов, длина которой не превышает 255 (например, 5, 40, 140).
Текстовыми данными в ИС представляют:
а) фамилии и должности людей, названия фирм, продуктов;
б) данные состоящие из совокупностей текста и чисел, например, адрес;
в) числа, не требующие вычислений, например, номер телефона, инвентарный номер, почтовый индекс [8].
Поэтому для текстового поля обязательно нужно указать минимально достаточное число знаков: 1 или 2, или 3, ..., или 20, ..., или 40, ... и т.д. до 255. В конкретном случае значением текстовых данных может быть имя файла, содержащего неструктурированную информацию.
Фактически это структурированная ссылка, позволяющая значительно расширить содержание табличной информации [7].
Данные типа МЕМО вводится в виде длинный текст или числа, например, примечания или описания: длиной до 64 000 символов
Числовое данное
Этот тип данных часто используется для представления атрибутов со значениями, из которых могут быть выполнены арифметические операции. Числовые данные, как правило, имеют дополнительные характеристики, например: 2-байтовое целое число, число с плавающей запятой (4 байта) в фиксированном формате и т. д.
- байт (информационный объем 1 байт) – допускает ввод чисел от 0 до 255;
- целое (информационный объем до 2 байта) - допускает ввод чисел от -32768 до 32767;
- длинное целое (инф. объем до 4 байта) - допускает ввод чисел от -2147483648 до 2147483647;
- одинарное с плавающей точкой (инф. объем до 4 байта) – десятичное число простой точности от -3,402823Е-38 до 3,402823Е38, т.е. число мантисса которого содержит не более семи цифр затем ставится знак Е и целое число, представляющее степень десяти;
- двойное с плавающей точкой (инф. объем до 8 байта) – десятичное число двойной точности от -1,79769313486231Е-308 до 1,79769313486231Е-308, т.е. число мантисса которого содержит не более пятнадцати цифр затем ставится знак Е и целое число, представляющее степень десяти.
- код репликации – допускает ввод чисел с информационным объемом до 16 байт;
- действительное – значения данных не должны быть мнимыми [8].
Данные типа даты или времени.
Данное типа даты задается в известном машине формате, например, ДД.ММ.ТТТТ (день, месяц, год). Кажется, что данный тип даты является частным случаем данного текста. Использование специального типа данных для информационных систем имеет следующие преимущества:
- Система способна проводить жесткий контроль, например, значение месяца может быть дискретным в диапазоне от 01 до 12.
- Существует возможность автоматического отображения формата даты в зависимости от традиций страны.
- Арифметические операции с датами значительно упрощены.
Данные типа дата или время указываются в виде:
- полный формат даты: формат записи, например, 19.08.2019 17:34:23;
- длинный формат даты: формат записи, например, 19 июня 2019 г.;
- средний формат даты: формат записи, например, 19-июн-2019;
- краткий формат даты: формат записи, например, 19.06.2019;
- полный формат даты: формат записи, например, 17:34:23;
- средний формат даты: формат записи, например, 5:34;
- краткий формат даты): формат записи, например, 17:34 [3].
Денежный тип данных
Для типа данных «Денежные» принимаются предопределенные типы денежных единиц. В значении денежных данных в общей части используется до 15 цифр, а в дробной части - до 4 цифр, что позволяет избежать округления данных при расчетах.
Для свойств типа денег принимаются следующие:
- Основным является действительное число в виде десятичной дроби;
- Деньги - число в виде десятичной дроби с предварительно согласованной денежной единицей;
- Евро - число в виде десятичной дроби с денежной единицей евро-ро;
- Исправлено - десятичное число с последовательной цифрой;
- С разделителями разрядов – число в виде десятичной дроби, где число от запятой в лево разделены по три цифры;
- Процентный – десятичная дробь в процентном виде;
- Экспоненциальный - целая часть которого состоит из одной цифры, и после мантиссы числа указывается знак E, за которым следует число, соответствующее степени 10 [7].
Тип данных счетчик
В свойствах данных типа Счетчик указываются
- Длинное целое – может быть числом от 1 до 2147 483 647 увеличивающееся на 1, обычно используется для вывода порядкового номера;
- Код репликации – используется для ввода чисел с информационным объемом до 16 байт.
Логические данные.
Данные этого типа могут иметь одно из двух взаимоисключающих значений - «Да» или «Нет», «Истина» или «Ложь». Поэтому логический тип удобно использовать для атрибутов, которые могут принимать одно из двух значений, которые являются взаимоисключающими, например, наличие водительских прав (да - нет) [6].
Объект ОLE.
«Значением» такого данного может быть любой объект ОLE (графика, звук, видео). Объектам OLE можно отнести объекты, поддерживающие OLE протокол и подготовленные другими приложениями среды Windows, например, документ Microsoft Word, электронная таблица Microsoft Excel, рисунки, звуки и другие объекты с информационными объемами не превышающие 1 гигабайт [6].
«Гиперссылка» такого типа данные представляют путь к быстрому просмотру нужного внешнего документа.
Данные типа Вложение
Вложение позволяет встраивать данные, подготовленные другими программами: рисунки, изображения, двоичные файлы, файлы Office, но они не могут вводить текстовые или цифровые данные любым способом.
Мастер подстановок не относится к типу данных. Он используется для ввода двух типов списка: список данных и поле замены [7].
Каждый тип данных характеризуется определенными свойствами, которые указываются в полях:
«Размер поля» - для типа данных «Текст», «Числовой» или «Счетчик» необходимо указать максимальное, но минимально достаточное значение данных.
«Формат поля» - желательно указать «По умолчанию». Однако вы должны указать соответствующий формат для данных даты / времени.
«Количество десятичных разрядов» - введите количество символов в дробной части числа.
«Маска ввода»: указывает символы, которые помогают вводить данные.
«Подпись»: текст, который автоматически появляется в форме, в отчете и в запросе, вставляется.
«Значение по умолчанию»: показанное здесь значение автоматически появляется в поле при добавлении новой записи.
В качестве значения свойства «Условие на значение» нужно указать правило верификации.
Правило верификации это условие, которому должен удовлетворять значение данного поля, т.е. логическое выражение которое должно принимать значение «Истина» при вводе данного в это поле, например: >=1 And <=12, система признает ошибочным ввод в это поле любого значения менее 1 и более 12 [7].
«Сообщение об ошибке» - вводится сообщение, которое должно отображаться, если значение не соответствует выражению в свойстве Условие на значение.
«Обязательное поле» определяет необходимость ввода данных в поле: можно указать «Да» (пустые значения допускаются) или «Нет» (пустые значения не допускаются).
«Индексированное поле» - создав индекс, можно ускорить доступ к данным в поле, например, нужно выбрать «Да, совпадения не допускаются», если данное поле является ключевым полем.
«Смарт-теги» - добавление данных распознанных и помеченных как особый тип, например имя пользователя или получателя.
«Выравнивание текста» указывается способ выравнивания текста по умолчанию.
«Пустые строки», если для этого свойства указано «Да», то для текстовых полей и полей MEMO можно вводить пустые строки.
Сжатие Unicode определяет необходимость сжатия текста, хранящегося в поле, если его размер меньше 4096 символов.
«Режим IME» - свойство, управляющее преобразованием предложений в восточноазиатской версии Windows.
«Режим предложений IME» - это свойство, которое управляет преобразованием предложений в восточноазиатской версии Windows [4].
2.2. Способы представления данных в БД Excel
Окно обработчика электронных таблиц Excel предназначено для ввода электронной таблицы и содержит следующее:
- стандартные элементы окна Windows;
- поле имени содержит имя или адрес активной ячейки или диапазона ячеек;
- строка формулы используется для отображения и редактирования содержимого активной ячейки;
- в строке состояния отображается информация о режиме работы, состоянии индикаторов режима и клавиатуры.
В рабочей области окна расположена рабочая книга. Рабочая книга - это файл, предназначенный для хранения электронной таблицы, имеет расширение.xls. Рабочая книга состоит из рабочих листов. По умолчанию во вновь создаваемой книге содержится 3 рабочих листа. Пользователь может управлять этим количеством с помощью установки значения параметра Листов в новой книге на вкладке Общие диалогового окна команды Параметры меню Сервис [7].
Рабочий лист представляет собой сетку из строк и столбцов. Максимальный размер рабочего листа - 256 столбцов, 65536 строк. Столбцы именуются латинскими буквами от А до Z и от АА до IV. Строки именуются числами от 1 до 65536
На пересечении строки и столбцов рабочего листа расположены ячейки (клетки). Каждая ячейка имеет адрес, который образуется: <имя столбца><имя строки>, например А10. Ввод и редактирование данных производится в активной ячейке. Активная ячейка выделяется жирной рамкой Ее имя содержится в поле имени. Существует также понятие диапазона ячеек. Диапазон (блок, интервал) ячеек - это прямоугольная область в таблице, содержащая несколько выделенных ячеек. Адрес диапазона образуется как: <адрес 1-й ячейки>: <адрес последней ячейки>, например А1:А10, A10:D20 [7].
Два типа данных могут быть введены в ячейки таблицы: константы и формулы. Константы - это значения, которые не изменяются до тех пор, пока они не будут намеренно изменены. Константы могут быть следующих типов: числовые, текстовые (надписи), дата и время дня, а также два специальных типа - логические значения и ошибочные значения.
Число в Excel может состоять только из следующих символов: цифры от 0 до 9, +, -, (,), /, $, %, (.), Е, е. Запятая в числе интерпретируется как разделитель десятичных разрядов. Символ разделителя может быть изменен в приложении Язык и стандарты панели управления Windows.
Существуют следующие правила ввода чисел:
1. Если ввод числа начинается со знака «+» или «-», пиксел опускает «+» и сохраняет «-», интерпретируя введенное значение как отрицательное число.
2. Числовые значения, заключенные в круглые скобки, интерпретируются как отрицательные. Например, (5) интерпретируется, как -5.
3. Символ Е или е используется при вводе чисел в потенциальном представлении. Например, 1Е6 интерпретируется как 1 000 000 (единица, умноженная на десять в шестой степени).
4. При вводе больших чисел можно вставить пробел, отделяющий сотни от тысяч, тысячи от миллионов и т. Д. При этом вводе числа отображаются в ячейках с пробелами и в строке формул без пробелов.
5. Если вы введете число с символом валюты, формат ячейки будет применен к ячейке.
6. Когда число заканчивается знаком%, к ячейке применяется процентный формат.
7. Перед вводом рациональной дроби введите 0 и пробел, e. Например, 3/4, 0 3/4, чтобы Excel не интерпретировал это как дату. Числа могут быть введены в разных форматах. В Excel имеется ряд стандартных числовых форматов, которые вы можете изменять по мере необходимости. Вы также можете создавать свои собственные форматы.
Как правило, числа вводятся в общем числовом формате. Соответственно, числа в ячейке представлены в обычном виде. Если длина числа не превышает ширину ячейки, она будет отображаться в том виде, в котором она была набрана. Если оно превышено, число отображается в экспоненциальной форме. Если значение числа превышает допустимое значение в формате, в ячейке появляется символ переполнения - ####. Вы можете изменить формат по умолчанию на вкладке «Вид» команды «Ячейки» в меню «Формат».
Ввод текста аналогичен вводу числовых значений. Текст - это произвольная строка символов, не воспринимаемая как число, дата, время дня или формула. При вводе длинного текста, который не может быть полностью отображен в ячейке, Excel может отобразить его, заменив соседние ячейки. Но в то же время текст все равно будет храниться только в одной ячейке. Когда вы вводите текст в одну ячейку, перекрывая содержимое другой ячейки, перекрывающийся текст усекается. Когда ячейка с длинным текстом активирована, в строке формул отображается весь текст, хранящийся в ней.
Вы можете увидеть длинный текст в ячейке, развернув столбец, дважды щелкнув границу столбца в его заголовке. Ширина столбца настраивается на максимальную ширину значений в этом столбце. Обтекание текстом также может облегчить чтение длинных значений. Этот режим позволяет вводить длинные текстовые значения путем перехода к следующим строкам без наложения текста в других ячейках. В этом случае Excel увеличивает высоту строки, содержащей ячейку с дополнительными строками. Чтобы установить этот режим, установите флажок «Разрыв слова» на вкладке «Выравнивание» команды «Ячейки» в меню «Формат».
Иногда требуется ввести число со знаком «+» перед ним. При простом наборе «плюс число» Excel воспримет ввводимое значение как числовое, и знак «+» опустит. Чтобы заставить Excel обращаться со специальными символами, как с обычными, нужно ввести числовой текст. Числовой текст может состоять из текста и чисел или только из чисел. Если значение, вводимое в ячейку, будет состоять из текста и чисел, оно будет интерпретироваться как текстовое.
Для того чтобы создать текстовое значение, состоящее целиком из числовых символов, следует начать ввод с апострофа или ввести сначала знак равенства, а затем значение, заключенное в кавычки. Знак равенства с кавычками или апостроф появляются в строчке формул, но не выводятся в ячейке. В то время как числовые значения по умолчанию выравниваются по правому краю, числовой текст, как и обычный, выравнивается по левому [7].
В Excel дата и время дня интерпретируются как числа. Базовая единица времени в Excel - день. Они представлены последовательными десятичными значениями от 1 до 65380. Базовая дата, представленная 1 десятичным знаком, - воскресенье, 1 января 1900 года. Максимальное значение десятичной даты; 65380 подарков 31 декабря 2078 года.
Когда вы вводите дату в Excel, сохраните ее как десятичное значение, которое равно количеству дней между указанной датой и базовой датой. Время дня - это десятичная дробь, которая представляет часть дня между началом (12:00 ночью) и указанным временем. Например, 12:00 вечера, кажется, 0,5.
Внешнее представление в ячейках рабочего листа зависит от формата, назначенного ячейке. В форматах даты и времени используются следующие разделители: «.», «/ », « - » - для даты; «> - для времени.
При вводе даты между 1920 и 2019 гг. можно указывать только две последние цифры года. При вводе даты вне этого диапазона год нужно записывать полностью.
Чтобы ввести текущее время в ячейку или в формулу, следует одновременно нажать клавиши Ctrl, Shift и «:». Для ввода текущей даты в ячейку или формулу следует одновременно нажать клавиши Ctrl и «;».
При вводе даты и времени нет разницы между прописными и строчными буквами. Если вы используете 12-часовой формат, после ввода времени вы должны ввести AP (A) с пробелом, чтобы ввести время до полудня, и РM (P), чтобы ввести время во второй половине дня. Например, 15:00 означает 15:00. Дата и время могут быть введены в ячейку. Тогда они должны быть разделены пробелом.
Такие данные, как дата и время дня, могут участвовать в вычислениях (сложение, вычитание), а также быть частью формул в виде текста (поэтому они должны быть заключены в двойные кавычки) [4].
2.3. Представление данных с использованием многомерной модели представления данных
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление информационной структуры в описании и операциях манипулирования данными. По сравнению с реляционной моделью, многомерная модель обладает большей наглядностью и информативностью.
В таблице 2.1. представлена реляционная модель представления данных
Таблица 2.1 - Представление данных в виде реляционной модели
|
Модель автомобиля |
Месяц |
Объем продаж |
|
Alfa Romeo |
Январь |
70 |
|
Audi |
Февраль |
50 |
|
BMW |
Март |
40 |
|
Bentley |
Апрель |
60 |
|
Bugatti |
Май |
30 |
В таблице 2.2. представлены данные в виде многомерной модели
Таблица 2 - Многомерная модель представления данных
|
Модель автомобиля |
Январь |
Февраль |
Март |
|
Alfa Romeo |
70 |
60 |
55 |
|
Audi |
50 |
50 |
60 |
|
BMW |
40 |
30 |
50 |
|
Bentley |
60 |
20 |
54 |
|
Bugatti |
30 |
45 |
64 |
СУБД на основе многомерной модели данных предназначена для интерактивной обработки аналитической информации. Используются основные понятия, такие как агрегирование, историчность и предсказуемость данных.
Агрегирование данных означает рассмотрение информации на разных уровнях ее обобщения. В IP степень детализации в представлении информации пользователю зависит от его уровня: аналитик, оператор пользователя, менеджер, менеджер.
Историчность данных влечет за собой гарантию высокого уровня статичности (неизменности) данных и их взаимосвязей, а также обязательного связывания данных в то время. Статические данные позволяют использовать специализированные методы обработки для архивирования, загрузки, индексации и выбора. Связывание данных за час необходимо, потому что запросы обычно содержат время и дату в критериях выбора данных. Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Основными понятиями многомерной модели данных являются:
- Индикатор - это величина (обычно числовой тип), которая фактически является предметом анализа. Например, это объем продаж конкретного продукта или продажи от продажи продукта. Куб OLAP может иметь один или несколько индикаторов;
- измерение - это набор объектов одного или нескольких типов, которые организованы в иерархическую структуру и предоставляют информационный контекст числового индикатора. Обычно визуализируют измерение как грань многомерного куба;
- члены измерений (members) – объекты, совокупность которых и образует измерение. Члены измерений визуализируют как точки или участки, откладываемые на осях гиперкуба. Например, временное измерение: день, месяц, квартал, год – наиболее часто используются в анализе, может содержать следующие члены: 8 мая 2019 года, май 2019 года, 2-ой квартал 2019 года и 2019 год. Объекты в измерениях могут быть различного типа, например «производители – марки автомобиля» или «годы – кварталы»;
- ячейка (cell) - атомная структура куба, соответствующая конкретному значению определенного показателя. Клетки во время визуализации находятся внутри куба. Здесь принято отображать соответствующее значение индикатора.
В многомерных СУБД применяют два основных варианта организации данных (схемы):
1) поликубическую схему, когда в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней;
2) гиперкубическую схему, когда в БД все показатели определяются одним и тем же набором измерений; при наличии нескольких гиперкубов все они имеют одинаковую размерность и совпадающие измерения [3, с. 75].
2.4. Объектно-ориентированный способ представления данных в информационных системах
В объектно-ориентированной модели при представлении данных вы можете идентифицировать отдельные записи базы данных. Отношения между записями базы данных и их функциями обработки устанавливаются с использованием аналогичных инструментальных механизмов в объектно-ориентированных языках программирования.
Пример логической структуры объектно-ориентированной БД для предметной области «Обслуживание в библиотеке» представлен на рис. 2.9. Объект «Библиотека» является родителем для объектов - экземпляров классов «Абонент», «Каталог» и «Выдача». Различные объекты типа «Книга» могут иметь одного или разных родителей. Объекты типа «Книга», имеющие одного и того же родителя, должны различать по крайней мере номером (уникален для каждого экземпляра книги), но могут иметь одинаковые значения свойств isbn, удк, название и автор.
Логическая структура базы данных объекта выглядит аналогично иерархической структуре базы данных. Основным отличием между ними являются методы манипулирования данными. Для выполнения действий с данными в объектно-ориентированной базе данных используются логические операции, усиленные объектно-ориентированной инкапсуляцией, механизмами наследования и полиморфизма. Создание и изменение базы данных сопровождается автоматической генерацией, а затем настройкой индексов, содержащих информацию для быстрого поиска данных.
Инкапсуляция ограничивает область действия имени свойства пределами объекта, в котором оно определено. Итак, если мы добавим свойство телефона автора книги к объекту типа «Каталог», мы получим свойства объектов «Каталог» и «Подписчик» с одинаковым именем. Смысл этого свойства будет определяться объектом, в который оно заключено.
Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта. Так, всем объектам типа «Книга», являющимся потомками объекта типа «Каталог», можно приписать свойства объекта родителя: isbn, удк, название и автор. Если необходимо расширить действие механизма наследования на объекты, которые не являются непосредственными родственниками (например, между двумя потомками одного и того же родителя), свойство абстрактного abs устанавливается для его общего предка. Таким образом, установка абстрактных свойств заявки и номера в объекте библиотеки приводит к наследованию этих свойств всеми дочерними объектами «Подписчик», «Каталог» и «Выпуск». Вот почему значения свойств классов заявок «Подписчик» и «Проблема» совпадают.
Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнородными данными. На практике это означает, что в объектах разных типов можно иметь методы (процедуры, функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы работают с разными объектами в зависимости от типа аргумента. Применительно к объектно-ориентированной базе данных полиморфизм означает, что объекты класса «Книга», имеющие разных родителей из класса «Каталог», могут иметь другой набор свойств. Следовательно, программы работы с объектами класса «Книга» могут содержать полиморфный код.
Заключение главы 2. Теория баз данных и практика их применения активно развиваются. Огромные объемы данных, накапливаемых и обрабатываемых информационными системами, становятся доступны пользователям в любое время и в любой части мира. Быстрое развитие технологий хранения, связи и обработки данных позволяет перемещать всю информацию в киберпространстве, которое пересекает национальные границы. Программное обеспечение для идентификации, поиска и отображения информации в Интернете является ключом к созданию, доступу и обработке данных. Сегодня базы данных хранят не только графические и текстовые данные, но и более сложные формы данных: графику, звук, видеоизображения, географические карты, фотографии. Мультимедийные базы данных и маршруты доступа являются краеугольными камнями путешествия человечества в киберпространство.
ГЛАВА 3. О ПРАКТИЧЕСКОМ ПРИМЕНЕНИИ ДАННЫХ В ИНФОРМАЦИОННЫХ СИСТЕМАХ
3.1. Технология практического применения данных в Access
Ввод данных. По окончании ввода значений всех полей нажимают клавишу Tab для перехода к следующей записи. Созданная таблица заполняется данными.
Перемещение по таблице. Текущая запись отмечается стрелкой в левой части окна (в области маркировки записей). Для перемещения по таблице служат кнопки переходов в строке состояния (слева направо: переход к первой записи таблицы, к предыдущей записи, к следующей записи и к последней записи таблицы).
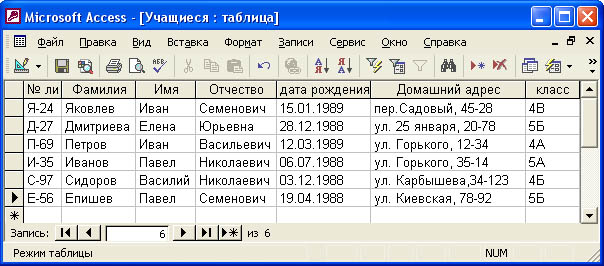
Чтобы переместить текстовый курсор в произвольную ячейку таблицы, можно просто щелкнуть на ячейке мышью. Кроме того, по таблице можно перемещаться с помощью клавиш Tab, Shift+Tab, стрелок курсора.
Редактирование таблицы. При вводе данных используется основной стандарт редактирования. Закончив ввод или модификацию данных в конкретном поле, нажмите Tab или Enter (или щелкните мышью в другой ячейке таблицы).
Для ввода (внедрения) объекта OLE надо щелкнуть правой кнопкой мыши на его поле в таблице и выбрать OLE-сервер из списка, как показано на рис. 2.4. После внедрения OLE-объекта отображаемым в таблице значением его поля будет название соответствующего OLE-сервера (например, Точечный рисунок). Чтобы просмотреть или отредактировать объект (или чтобы воспроизвести звукозапись), надо дважды щелкнуть на этом названии.
Операции с записями и столбцами. С помощью команд меню и кнопок панели инструментов можно проводить множество стандартных операций с записями и столбцами: вырезать и копировать в буфер, удалять записи, скрывать столбцы и т. д.
Для определения свойств нового поля переключите таблицу в режим Конструктора, выбрав команду Конструктор в меню Вид.
Возможно осуществлять сортировку данных в таблице по алфавиту, по возрастанию щелкнув по определенному полю.
Использование фильтра для отбора данных в таблице
Работая с таблицей в оперативном режиме, можно установить фильтр, т.е. задать логическое выражение, которое позволит выдавать на экран только записи, для которых это выражение принимает значение True («Истина»).
Для отбора записей, удовлетворяющих более сложным условиям отбора, используется расширенный фильтр.
Чтобы упростить отображение, ввод и изменение данных в конкретной таблице, вы можете создать для нее один или несколько модулей. Форма - это документ, в окне которого, как правило, отображается элемент таблицы, и пользователь имеет возможность по своему усмотрению размещать поля в форме. Таблица и форма являются основными объектами в современных информационных системах. Они неотделимы друг от друга и размещены в окне документа MS Access на разных вкладках. Формы используются для следующих целей:
- ввода/редактирования данных, помещенных в таблицу;
- организации диалога выбора, предварительного просмотра и печати нужного отчета;
- открытия других форм и отчетов с помощью кнопок данной формы.
3.2. Технология практического применения данных в Excel
В ячейки можно вводить данные различных типов: текст, числа, даты, время, формулы (которые могут включать числа, знаки арифметических, логических или других действий, выполняемых с данными из других ячеек, адреса ячеек или их имена, имена встроенных в функциях), функции (частный случай формулы).
В качестве текста можно вводить различные комбинации букв и цифр. Текст по умолчанию выравнивается по левому краю, а числа – по правому.
Ввод и редактирование данных в Exel происходит непосредственно в текущей ячейке или строке формул. Место ввода помечено курсором. Чтобы ввести ячейку, выберите нужную ячейку и введите необходимую информацию с клавиатуры. Введенные символы отображаются как в ячейке, так и в строке формул. Когда вы закончите ввод, нажмите клавишу. Затем введенная информация будет сохранена в ячейке.
Форматирование содержимого ячеек
Форматирование содержимого ячейки
Чтобы изменить формат отображения данных в текущей ячейке или выбранном диапазоне, используйте команду МЕНЮ Формат/Ячейки или команду контекстного меню Формат ячеек.
Основные вкладки в диалоговом окне «Формат ячеек» включают в себя:
Число - позволяет выбрать числовой формат вводимых значений (общий формат позволяет вводить текстовую и числовую информацию, другие форматы позволяют вводить только информацию вашего типа);
Выравнивание - позволяет определить метод выравнивания и ориентации информации в ячейке, а также определить метод переноса строк и объединить соседние ячейки;
Шрифт - позволяет изменить настройки шрифта в выбранных ячейках;
Граница: позволяет создавать различные способы обрамления таблицы;
Вид: позволяет установить различные способы раскраски таблицы.
Типичные технологические операции с клеточными блоками
Часто в операциях обработки используется не одна ячейка, а блок ячеек.
Блок: прямоугольная область смежных или несмежных ячеек (расположенных в разных местах).
Правила выполнения операций блокировки ячеек
Последовательность выполнения:
выделен блок ячейки - объект действия;
Команда меню выбрана для выполнения действия.
Выбор несмежного блока ячеек выполняется при нажатии кнопки.
Операции перемещения, копирования, вставки и удаления выполняются только для соседнего блока ячеек.
При работе в Excel вычисления часто выполняются быстрее, чем ввод исходных данных. Excel предоставляет различные элементы управления для ввода данных. Например, вы можете указать диапазон значений, в который должно быть включено число.
В Excel существует несколько способов, которые позволяют упростить и ускорить процесс ввода данных:
- повторный ввод (копирование) уже существующих данных;
- автозаполнение;
- ввод прогрессий.
Для повтора (копирования) существующих данных следует:
1) выделить ячейку;
2) Навести указатель мыши на маркер автозаполнения, и перетащить рамку выбора во все ячейки. В правом нижнем углу рамки текущей ячейки есть черная рамка - это маркер автозаполнения. Когда вы наводите указатель мыши на него (обычно он выглядит как толстый белый крест), он принимает форму тонкого черного креста. Перетаскивание маркера автозаполнения считается операцией «умножения» содержимого ячейки в горизонтальном или вертикальном направлении.
Чтобы перетащить текущую ячейку (выбранный диапазон) и ее содержимое с помощью перетаскивания, поместите указатель мыши на рамку текущей ячейки (она появится в виде стрелки). Теперь вы можете перетащить ячейку в любое место на листе (точка вставки помечена).
Чтобы выбрать метод для выполнения этой операции, а также более надежный элемент управления, рекомендуется использовать специальное перетаскивание правой кнопкой мыши. В этом случае, когда вы отпускаете кнопку, появляется специальное меню, в котором вы можете выбрать конкретную операцию для выполнения.
Возможно копирование или перемещение данных через буфер обмена. Передача информации через буфер обмена имеет в программе Excel определенные особенности, связанные со сложностью контроля над этой операцией. Сначала необходимо выделить копируемый (вырезаемый) диапазон и дать команду на его помещение в буфер обмена: Правка > Копировать или Правка > Вырезать. Вставка данных в рабочий лист возможна лишь немедленно после их помещения в буфер обмена. Попытка выполнить любую другую операцию приводит к отмене начатого процесса копирования или перемещения. Однако утраты данных не происходит, поскольку «вырезанные» данные удаляются из места их исходного размещения только, когда вставка будет успешно завершена [5].
Место вставки определяется путем указания ячейки, соответствующей верхнему левому углу диапазона, помещенного в буфер обмена, или путем выделения диапазона, который по размерам в точности равен копируемому (перемещаемому). Вставка выполняется командой Правка > Вставить. Для управления способом вставки можно использовать команду Правка > Специальная вставка. В этом случае правило вставки данных из буфера обмена задается в открывшемся диалоговом окне [5].
Автозаполнение – заполняет выделенные ячейки выбранными (либо созданными дополнительно) последовательностями.
3.3. Практическое применение данных в многомерных моделях
Для многомерной модели используют ряд определенных операций.
1) «Срез» (Slice) –является подмножеством гиперкуба, полученного путем определения одного или нескольких измерений. Разрезание выполняется для ограничения значений, используемых пользователем, поскольку все значения гиперкуба почти никогда не используются одновременно. Пример: если вы ограничите значения измерения «модель автомобиля» в гиперкубе для марки «BMW», вы получите двумерную таблицу для продажи этой марки разными менеджерами по годам.
2) «Вращение» (Rotate) – используется для двумерного представления данных. Суть операции заключается в изменении порядка измерений при визуальном представлении данных. Пример: «вращение» изменит внешний вид таблицы таким образом, что марка автомобиля будет находиться вдоль оси X, а месяцы - вдоль оси Y. Эта операция также может быть обобщена на многомерный случай, если ее понимать как процедуру изменения последовательности измерений.
3) «Агрегация» (Drill Up) - переход к более общему порядку представления информации пользователю из гиперкуба.
4) «Drill Down» - переход к более подробному представлению информации пользователю из гиперкуба. Эта операция противоположна «агрегации».
Преимущества многомерной модели: удобство и эффективность аналитической обработки больших объемов временных данных. Организовав аналогичную обработку данных в реляционную модель, происходит нелинейное увеличение сложности операций в зависимости от размера базы данных и значительное увеличение стоимости оперативной памяти для хранения индексных файлов.
Недостатки многомерной модели: громоздкость модели для простейших задач обычной обработки оперативной информации.
Примеры СУБД, поддерживающих многомерную модель: Essbase (Arbor Software), Media Multi-matrix (Speedware), Oracle Express Server (Oracle), Cache (InterSystems) и др. Некоторые системы, например, Media Multi-matrix, позволяют одновременно работать с многомерными и реляционными БД. С СУБД Cache, где внутренней моделью является многомерная модель, реализованы три способа доступа к данным: прямой (на уровне узлов многомерных массивов), объектный и реляционный [3].
Заключение
Достижения в развитии компьютерных технологий сделали возможным переход от ручной обработки бумаги к современным средствам поиска и обработки информации. Ожидается, что этот прогресс в мире компьютерных технологий продолжится и в будущем. Пакеты программного обеспечения для управления данными развивались параллельно с развитием компьютерных технологий. Ориентированные на записи и ориентированные на наборы данных системы проложили путь к реляционным системам, которые теперь превратились в объектно-реляционные СУБД.
Благодаря своей мощности и гибкости объектно-ориентированные системы СУБД способны удовлетворить постоянно растущие требования к размеру и сложности данных. Предоставляя хранилище для больших и сложных объектов и отслеживая их поведение, объектно-реляционные СУБД могут значительно повысить удобство использования и ценность баз данных с точки зрения их семантического содержания. Реляционная модель, параллельные системы баз данных, активные базы данных и базы данных реляционных объектов родились в академических и промышленных исследовательских лабораториях. Развитие теории баз данных является классическим примером успешного сотрудничества между академическими кругами и промышленностью.
Важно понимать, что информационные системы напрямую поддерживают практически все аспекты управленческой деятельности в таких функциональных областях, как бухгалтерский учет, финансы, управление персоналом, маркетинг и управление производством.
Реальные информационные системы обычно представляют собой комбинации нескольких типов информационных систем, упомянутых в этом эссе, потому что концептуальные классификации информационных систем предназначены для выделения различных ролей информационных систем. На практике эти роли интегрируются со сложными или взаимосвязанными ИТ-системами, которые предоставляют ряд функций. Вот почему большинство ИТ-систем предназначены для предоставления информации и поддержки принятия решений на разных уровнях управления и в разных функциональных областях.
Современные программные системы становятся все более сложными, требуя решения глобальных проблем, таких как создание единой системы корпоративного управления. При проектировании этих систем важно представить современные подходы к разработке информационных систем и основные возникающие трудности.
Необходимо понимать разницу между компьютерами и информационными системами. Компьютеры, оснащенные специальным программным обеспечением, являются технической базой и инструментом для информационных систем. Информационная система немыслима без взаимодействия персонала с компьютерами и телекоммуникациями. Технология работы в компьютерной информационной системе понятна специалисту в области вне компьютера и может быть успешно использована для контроля и управления профессиональными процессами.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
Описание нормативно-правовых актов органов законодательной и исполнительной власти
- Федеральный закон Российской Федерации от 27 июля 2006 г. № 149-ФЗ «Об информации, информационных технологиях и о защите информации».
- Федеральный закон «О персональных данных» от 27.07.2006 N 152-ФЗ (последняя редакция)
Описание учебников и учебных пособий
- Абдуллина В.З. Базы данных в информационных системах: Учебник. – Алматы: КазНТУ, 2015. – 288 с.
- Баженов Р. И., Лопатин Д. К. О применении современных технологий в разработке интеллектуальных систем // Журнал научных публикаций аспирантов и докторантов. – 2014. – № 3 (93). – С. 263-264.
- Глушаков С.В. Информатика. Курс лекций для студентов первого курса МГУ 2009 г.
- Избачков Ю. С., Петров В. Н., Васильев А. А., Телина И. С. Информационные системы: Учебник для вузов. – СПб.: Питер, 2011. – 544 с.
- Могилев А. В., Пак Н. И., Хеннер Е. К. Информатика: учеб. пособие для студ. пед. вузов / под ред. Е. К. Хеннера. – М., 2012. – 848 с.
- Панов А.А. «Основы Microsoft Office» 2008 г.
- Размахнина А. Н., Баженов Р. И. О применении экспертных систем в различных областях // Постулат. – 2017. – № 1 (15). – С. 38.
- Симонович С. В., Евсеев Г.А., Практическая информатика, Учебное пособие. М.: АСТпресс, 1999
- Симонович С.В., Евсеев Г.А., Алексеев А.Г. Специальная информатика, Учебное пособие. М.: АСТпресс, 1999
- Тюрин Ю.Н., Макаров А.А. Статистический анализ данных на компьютере. Под ред. В.Э. Фигурнова. М.: ИНФРА-М, 1998
- Шкаев А.В. Руководство по работе на персональном компьютере. Спра-вочник. М.: Радио и связь, 1994 г.

- Состав и свойства вычислительных систем.
- Применение объектно-ориентированного подхода при проектировании информационной системы
- Мотивации персонала и проектирование систем стимулирования труда (Мотивация и стимулирование работников на рынке труда)
- Виды юридических лиц (Правосубъектность и органы лица)
- Метод экспертных оценок и область его применения решений (на примере банковской деятельности))
- Налоги с физических лиц и их экономическое значение (Виды налогов, взимаемых с физических лиц в Российской Федерации)
- Трудовые конфликты в организации: типичные причины
- Процесс построения модели управленческого решения (Природа моделей в управлении)
- Ответственность за нарушение законодательства о рекламе (Реклама: понятие, признаки, правовое регулирование)
- Создание правового механизма в сфере обеспечения банковской тайны
- Нотариат в РФ (Появление нотариата)
- Сравнительный анализ теорий конкуренции (Развитие теорий конкуренции)