
Сортировка слиянием без копирования
Содержание:

ВВЕДЕНИЕ
Век высоких технологий принес свои плоды и теперь с помощью языков программирования есть возможность описать и даже упростить любые действия. При этом нет необходимости описывать действия, которые повторяются шаг за шагом, а достаточно только использовать циклические алгоритмы.
Именно с помощью таких алгоритмов выполняется фундаментальное действие над массивами данных – сортировка.
Циклом называется специальный вид управляющих конструкций, что применяются в высокоуровневых языках, предназначаются для организации многоразовой работы инструкций.
Также циклов считается любое многократно исполняемый перечень инструкций.
Исполнение любого цикла может включать как первоначальную инициализацию счетчиков или проверку условий для выхода с итеративного цикла, так и реализацию основных операторов при обновлении счетчика.
Кроме этого, все языки программирования (ЯП) нынешнего времени предоставляют в испоьзование встроенные средства по быстрому и досрочному окончанию циклов – операторы перехода, завершения структур циклического типа.
Для этого применяются также известные операторы, такие как continue, для них самым основным свойством является механизм передачи управления в указанную точку программного продукта, для проверки непосредственно само условия цикла.
Актуальность данной темы состоит в том, что алгоритмы сортировки являются одними из основных составляющий почти всех программ. И их изучение считается одним из базовых постулатов в подготовке квалифицированных программистов.
Целью работы является рассмотрение алгоритма сортировки по убыванию методом вставки.
В соответствии к цели работы поставлены такие основные задания:
– рассмотреть понятие алгоритма и терминологии, которая с ним связана;
– выполнить описание операторов цикла на С++;
– рассмотреть применение массивов в С++, как объекта сортировки;
– рассмотреть основные типы сортировки данных;
– дать характеристику и на практике описать программу для сортировки методом слияния без копирования.
1.Понятие алгоритмов
1.1.Алгоритмы, их свойства
Понятие алгоритма – краеугольный камень многих наук: математики, информатики, физики и других. Отметим, что данное понятие не выражается через какие-то другие термины.
Иными словами, единого какого-то определения для понятия алгоритма вовсе не существует, хотя для его исследования присутствуют разные подходы, что часто могут использоваться для выполнения описания рассматриваемого термина, также в соответствии с данным определенным сектором применимых знаний. [14]
Алгоритмом называется четкая и корректно определенная последовательность операций, приводящая к результату решения некоторой задачи.
В данной четкой последовательности также можно задать инструкции для выполнения разных операций в сформированном разработчиком порядке, правила для их реализации.[5]
Ученые выделяют такие типы основных алгоритмов (рисунок 1): [6]
Рисунок 1 – Классы алгоритмов
Вычислительные алгоритмы – это структуры команд и операций, что являются последовательностями, которые могут обрабатывать простые (числовые) данные (рисунок 2): [13]
Рисунок 2 – Простые типы
Под информационными алгоритмами часто понимаются наборы простых методов, процедур, которые выполняют обработку информации. Фундаментальным примером таких процедур является методика поиска информации. [19]
Эффективность работы для всяких случаев алгоритма также зависит и от информации, с которой они работают наиболее часто.
Управляющие типы алгоритмов реализуют самые различные данные, что поступают с внешних подключенных к ним устройствам или они возникают при подключении разных внешних процессов.
Конечной информацией в работе различных алгоритмов есть выработка управляющей реакции по изменениям начальной информации для программы.
Любой известный алгоритм обладает основными свойствами (рисунок 3):[13]
Рисунок 3 – Алгоритмические свойства
- Детерминированность алгоритмов (определенность). Это такое свойство, что может заключаться в задании одинаковых входных параметров для используемого алгоритма, а сам алгоритм будет выполняться полностью одинаково при этом, то есть получаться аналогичный результат при вычислениях. [4]
Свойство определенности часто проявляется тогда, когда при каждом шаге в конкретном алгоритме всегда точно известно разным пользователям, в каком направлении нужно двигаться далее или каждое действие алгоритма однозначно и является понятным практически всем без исключения исполнителям, а также оно не будет истолковано неправильным образом другими пользователями.
Благодаря такому свойству в применении алгоритмов используется некоторый механический характер информации.[1]
2. Массовость – выражение такого свойства алгоритма, при котором с постоянным использованием алгоритма можно также решать не только одну определенную задачу, а любую из класса стандартных однотипных задач предметной области. [13]
3. Результативность алгоритмов значит, что при выполнении только конкретного алгоритма обязательно будет решена поставленная пользователем задача, либо к сообщениям об указанных исходных ошибочных величинах.
4. Дискретность алгоритма значит, что все алгоритмы используют последовательность этапов – специальные элементарные действия, что непосредственно выполняются и не представляющих какой-то большой сложности.
С помощью рассматриваемого выше свойства алгоритм может быть выполнен с использованием ПК.[1]
5. Конечность алгоритма – рассматриваемая рабочая последовательность специально выполненных действий не может являться неограниченной.
6. Корректность – специальное свойство, что обозначает следующий факт: если алгоритм создан с реализацией описания для какой-то задачи, он должен давать аналогичный правильный результат для абсолютно всех исходных данных. [11]
1.2.Способы описания алгоритмов
Чтобы как-то понять выполнение конкретных алгоритмов их пользователями, они должны быть формализованы по разным определенным критериям.
Все такие методы, которые применяются в этом плане, определяют также квалификацию исполнителей.
К методам записи алгоритмов можно отнести следующие категории (рисунок 4): [1]
Рисунок 4 – Описание алгоритмических структур
Словесная методология может основываться на обработке последовательности разработки для конкретно определенном и указанном векторе действий с использованием самых разнообразных математических символов.[10]
Блок-схемы алгоритма – специфический метод графического изображения выполняемых процессов для выполнения разных задач некоторой последовательностей составных блоков по их характеристике, что отражают определенную специфику их преобразования. [8]
Внутри блоков описывается часто определенный этап решения задачи с помощью алгоритма.
Рассмотрим некоторые фигуры, которые могут применяться для описания (рисунки 5 – 9):[5]
Рисунок 5 – Блок для решения

Рисунок 6 – Процесс вычисления
Рисунок 7 – Линия процесса

Рисунок 8 – Обозначение процесса

Рисунок 9 – Конец, начало алгоритма
Стоит заметить, что для реализации блок-схем применяются часто MS Visio, Dia и другие приложения.[9]
1.3. Понятие о циклических структурах данных
Алгоритм, что может выполнять разные повторяемые действия, часто называется циклическим алгоритмом. А сами повторяющиеся действия называют телом цикла.
Каждый алгоритмический цикл может содержать в себе следующие элементы:
- инициализация счетчика;
- проверка условий цикла;
- выполнение тела;
- изменения переменной.
Общая численность всех повторений тела определяется не только структурой алгоритма, но и поставленным условием, что имеет часто название «условие цикла».
При использовании такой проверки будет выполнено осуществление выбора: повторять еще раз код цикла для рассматриваемого циклического алгоритма или же выполнить другие действия.[15]
В теории алгоритмов различают часто 2 разновидности таких основных алгоритмов:[12]
- циклы с послеусловием;
- циклы с предусловием (рисунок 11).[1]
В циклах предусловием непосредственно условие может формулироваться и для повторного выполнения, пока его проверка будет истинной (рисунок 10). [3]
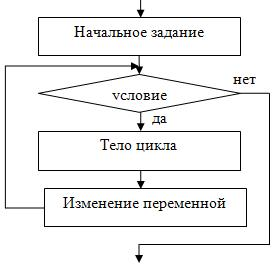
Рисунок 10 – Структура циклов с предусловием
Для циклов с постусловием выполняются тело сначала цикла, условия выполнения цикла. Сам же циклический алгоритм с постусловием рассмотрен ниже на рисунке 11:[11]
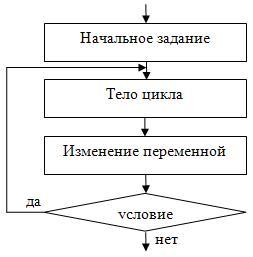
Рисунок 11 – Структура цикла с постусловием
В первом разделе работы рассмотрены базовые понятия по теории алгоритмов: определение, описание их свойств, методов передачи алгоритмов пользователям, структуры циклических алгоритмов, а также применения блок-схем.
2. Применение массивов в программировании
2.1.Реализация циклических алгоритмов в С++
Как было описано в первом разделе, циклические процессы используются, когда нужно вычислить несколько раз какое-то значение по одним и тем же формулам, но с разными значениями переменных, которые изменяются на указанном отрезке с определенным шагом. Как известно, эта переменная – счетчик цикла.[7]
Для реализации циклического процесса в С++ существуют 3 циклических оператора:
- Оператор цикла с предусловием while. Его интерфейс:[2]
while (логическое_выражение)
{
Тело цикла
}
Если параметр оператора while принимает значение истина, то будут выполнятся операторы тела циклической части. После этого опять проверяется условие и если логическое выражение имеет значение истина – снова выполняется тело цикла.
Указанный процесс будет выполняться до тех пор, пока логическое выражение не примет значение ложь.[2]
Пример 1.
l=0;
while(l<=5)
{
a=pow(l,2);
cout<<a<<” “;
l++;
}
Описанный в примере алгоритм будет выполняться пока значение переменной l будет меньше равно 5. В противоположном случае произойдет выход с циклического алгоритма.[8]
- Оператор цикла с послеусловием do … while имеет следующий синтаксис:
do
{
Тело цикла
}
while (логическое_выражение)
В данном операторе сначала происходят вычисления, а затем проверяется логическое условие. При чем, если условие возвращает значение истина, то имеющейся цикл проходит еще круг, если ложь – управление передается другим операторам.[4]
Пример 2.
с=1;
do
{
p=pow(c,2);
cout<<p<<” “;
c++;
}
Как видно в двух примерах, перед циклическим оператором нужно указать начальное значение счетчика цикла, а в теле цикла указать шаг приращения переменной цикла.[4]
- Циклический оператор for использует такой синтаксис:
for (инициализация; условие; приращение)
{
Тело цикла
}
Описанный выше оператор часто используется при реализации вычислений в массивах. В нем инициализируется переменная цикла, потом сразу проверяется условие окончания цикла. Если цикл выполняется, то операторы циклической части проводя вычисления, иначе идет переход к операторам, которые следуют за оператором for.[13]
Пример 3.
for(w=1;w<=15;w++)
{
a=pow(w,2);
cout<<w<<" ";
}
2.2. Применение массивов в программировании
Одной из самых распространенных структур, которая реализуется практически на всех языках программирования является массив.[10]
Массивы - это именованная группа данных одного типа, которые хранятся в последовательно размещенных ячейках памяти. При этом каждая ячейка содержит один элемент массива. Элементы массива нумеруются по порядку, начиная с нуля.
Стоит отметить, что массивы состоят из определенного числа компонент и все его компоненты имеют одинаковый тип данных с остальными. Такой формат называется базовым.
Структура массива является однородной. То есть, массив может состоять из компонентов типа real. integer или char, или других пользовательских типов данных. [13]
Другая особенность массивов состоит в том, что ко всем его компонентам можно обратится произвольным образом. Программа сразу получает необходимый ей элемент по его индексу (порядковому номеру). Индекс – переменная целого типа.
Стоит отметить, что в одномерном массиве (векторе) элементы нумеруются с помощью одного индекса. Индекс ячейки массива – не является содержимым. А содержимым являются данные, хранимые в ячейках, а индексы лишь указывают на них. [9]
В памяти ПК элементы массива располагаются последовательно. Каждый индекс массива находится в диапазоне «начальный элемент – конечный элемент).
Причем последний элемент больше или равен начальному элементу. У разных массивов форматы данных могут несколько различаться. [1]
Массив в языке С++ – это сложный тип данных, определяется следующем методом.
<тип данных> переменная[размерность];
Например,
int a[100];
char s[22];
Для того чтоб ввести значения в массив, необходимо последовательно изменить значение индекса, начиная от нулевого до последнего, и ввести соответствующий элемент. Для выполнения этих действий удобно применить цикл с определенным числом повторений, то есть простой арифметический цикл, в котором параметром цикла выступает переменная – счетчик массива. Значения элементов могут вводится с клавиатуры или определены через оператор присваивания.
Массивы бывают таких видов:[15]
1. Одномерные, в котором каждый элемент получает один индекс (например, а[2]).
2. Многомерные, в котором каждый элемент получает 2 и более индексов (с[1,1,k]).
Проще всего представлять массив в виде таблицы, в которой каждое значение находится в определенной ячейке. Место положения ячейки в таблице однозначно определяется набором индексов.
Для работы с двумерными массивами используют обращение а[i][j]. Для инициализации массива используют запись:[1]
int a[100][100].
В памяти ПК двумерный массив представляется точно так же как и одномерный, только он использует два индекса.
2.3. Понятие динамического массива
Кроме обычной памяти (стека), в которой автоматически размещаются сменные при их объявления, существует еще и динамическая память (heap - куча), в которой переменные могут размещаться динамично. Это означает, что память выделяется во время выполнения программы, и только тогда, когда в программе встретится специальная инструкция. Основная потребность в динамическом выделении памяти возникает, когда размер или количество данных заранее есть неизвестные, а определяются в процессе выполнения программы.[20]
В С ++ существует несколько команд для выделения динамической памяти. Чаще всего используется оператор new, который в общем виде записывается как:
<Тип> * <имя_указателя> = new <тип>;
Например:
1) int * p = new int;
Здесь выделяется место в памяти под целое число и адрес этого участка памяти записывается в переменную-указатель p. Обратиться к этому числу можно будет через указатель на него *p = 2;
2) int * p = new int (5);
Эта команда не только выделит место в памяти под целое число, но и запишет в эту ячейку памяти значение 5. Адрес первой ячейки выделенного участка памяти присваивается переменной-указателе p. Обратиться к числу, на которое указывает p, можно аналогично предыдущему примеру. Например, чтобы увеличить такое число на 2, следует написать: (* p) + = 2;[9]
3) int * p = new int [5];
В этом случае выделяется память под 5 целых чисел, то есть фактически создается так называемый динамический массив из 5-ти элементов. Обратиться к каждому из этих цифр можно по его номеру: p[0] p[1] и т. д. или через указатель *p - то же именно, что p [0]; *(P + 1) - то же самое, что p[1] и т.д.
Память, которая была выделена динамически, автоматически не будет освобождается, поэтому программист должен обязательно освободить ее самостоятельно с помощью специальной команды. При выделении памяти с помощью оператора new, для освобождения памяти используется оператор delete:[5]
delete <указатель>;
Например:
delete a;
Если оператором new было выделено память под несколько значений одновременно, используется форма команды delete [9]
delete [] <указатель>;
Квадратные скобки должны быть пустыми, операционная система контролирует количество выделенной памяти и при освобождении ей известно нужное количество байтов.
Кроме операторов new и delete, существуют функции, которые перешли к С ++ с С, но они используются на практике гораздо реже.
Функция void * malloc (size_t size) (от англ. "Memory allocation" - выделение памяти) делает запрос к ядру операционной системы о выделении участка памяти заданного количества байтов. Единственный аргумент этой функции size - количество байтов, которое нужно выделить. Функция возвращает указатель на начало выделенной памяти. Если для размещения данного количества байтов недостаточно памяти, то функция malloc() возвращает NULL.[3]
Содержание участка остается неизменным, то есть там может остаться "грязь", если аргумент size равен 0, функция возвращает NULL. Например, команда
int * a = (int *) malloc (sizeof (int));
выделяет память под целое число и адрес начала этого участка памяти записывает в указатель а.[2]
Выделение памяти под 10 действительных чисел с помощью этой функции:[3]
float * a = (float *) malloc (sizeof (float) * 10)
Функция
void * calloc (size_t num, size_t size)
выделяет блок памяти "памяти размером num х size (под num элементов по size байтов каждый) и возвращает указатель на выделенный блок. Каждый элемент выделенного блока инициализируется нулевым значением (в отличие от функции malloc). Функция calloc () возвращает NULL, если не хватает памяти для выделения нового блока, или если значение num или size равны 0.[3]
Двумерный динамический массив с m строк и n столбцов занимает в памяти "памяти соседние m x n ячеек, то есть сохраняется так же, как и одномерный массив с m x n элементов. При размещении элементы двумерных массивов располагаются в памяти подряд друг за другом с первого до последнего без промежутков.
Например, вещественный массив 3 × 5 сохраняется в пам "яти следующим образом:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
0-ю строчка
1-я строка
2-я строка
В таком массиве первые пять элементов относятся к первой строке, следующие пять - ко второй и последние пять - к третьему.[7]
Напомним, что a - указатель на начало массива, то есть на элемент a[0][0]. Чтобы обратиться, например, к элементу a[1][3], следует "перепрыгнуть" от начала массива через 5 элементов нулевого строки и 3 элемента первого столбца, то есть написать * (a + 1 * 5 + 3) . В общем случае к элементу a [i] [j] можно обратиться следующим образом: * (a + i * 5 + j). Но этот способ работы с двумерным массивом не слишком удобен, так как в программе при обращении к элементу массива приходится преобразовывать указатель и вычислять индекс элемента.[7]
3.Сортировка массивов
3.1. Описание популярных алгоритмов сортировки
Алгоритм сортировки разного рода информации используется в практически любом программном продукте: от обычной программы для обработки числовых массивов – до интернет-магазинов.
Целью алгоритмов выполнения сортировки является упорядочение определенной последовательности элементов любых форматов. Поиск элемента в обрабатываемой последовательности отсортированных данных часто занимает время, которое пропорциональное логарифму численности элементов в последовательности, а сам поиск элемента в массиве не отсортированных данных также занимает время, что пропорционально количеству элементов в массиве, то есть значительно больше. Существует также множество различных методов и инструментов сортировки данных. Однако всякий алгоритм сортировки разбивается три основные части:
- Сравнение элементов;
- Перестановка;
– Собственно сортирующий алгоритм.
Важнейшей характеристикой для любого алгоритма сортировки считается скорость его работы, которая определяется специальной функциональной зависимостью усредненного времени сортировки последовательностей данных, заданной длинны. [3]
Время сортировки считается пропорциональным количеству сравнений и числа перестановки элементов.
3.1.1.Метод пузырька
Идея рассматриваемого метода отражена в его непосредственном названии.
Заметим, что самые легкие элементы массива будут "всплывать" наверх, при этом самые "тяжелые" – тонуть.
Последовательность из N компонентов просматривается от самого первого элемента до конца так, чтобы стоящие рядом объекты менялись местами, если же первый из них будет меньше ("легче") второго (рисунок 12). Таким образом, после указанного просмотра самый "легкий" или «тяжелый» объект "выталкивается" в конец массива.[6]

Рисунок 12 – Пример сортировки пузырьком
Если повторить теперь такой просмотр еще ровно N – 1 раз, то вся заданная последовательность элементов окажется от сортированной.
3.1.2. Сортировка выбором
Один из простейших методов сортировки работает так: находим наименьший объект в массиве и сразу обмениваем его с объектом находящимся первым.
Далее повторяем процесс с второй позиции в файле, а найденный элемент обмениваем с вторым объектом и т.д.
Этот метод называются сортировка выбором, ведь он работает циклически, при этом выбирая наименьший с оставшихся объектов (рисунок 13).
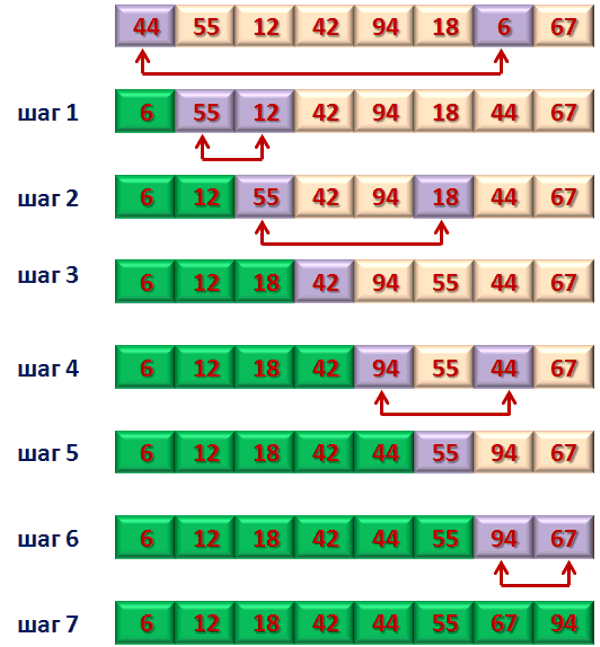
Рисунок 13 – Пример сортировки выбором
Этот метод работает оптимально для небольших файлов или массивов. Кроме того, хотя рассматриваемая сортировка выбором является методом так называемой «грубой силы», он располагает очень важным применением, а именно, поскольку каждый элемент будет передвигаться не более чем один раз, то он является хорошим для больших записей, что содержат малые ключи.
3.1.3.Сортировка вставкой
Метод сортировки вставкой, является таким же простым, как и сортировка выбором. Этот метод применяют часто при сортировке карт, а именно: берем один элемент, а далее вставляем его в определенное место среди тех элементов, что уже были обработаны (тем самым, делая их отсортированными).[8]
Каждый рассматриваемый элемент вставляется посредством передвижения наибольшего элемента на одно место вправо и потом размещением меньшего в освободившуюся позицию.
Такой процесс реализован на рисунке 14.
Также, как и при сортировке указанным алгоритмом, в процессе сортировки все элементы слева от имеющегося указателя i уже отсортированные, но они находятся не обязательно в своей окончательной позиции, так как их еще могут сдвинуть вправо.
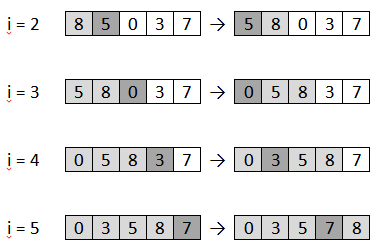
Рисунок 14 – Пример сортировки вставкой
Массив будет полностью сортированным, когда индекс (или указатель) достигает правого края.
3.2. Сортировка массива методом слияния без копирования
В качестве усовершенствования алгоритмов сортировки надо рассмотреть возможность сведения к нулевому времени копирования информации во вспомогательный массив, что применяется в процедуре слияния.
Поступая этим образом, надо так организовать используемые рекурсивные вызовы, что весь процесс вычисления будет сам изменять в нужный момент разные роли вспомогательного и входного массивов на каждом из уровней.[4]
Один из методов реализации этого подхода заключается в применении двух вариантов программ:
– для приема исходных данных и для пересылки выходных данных в файл,
– для приема начальных данных в файл и пересылки выходных в конечный файл.
Данный метод дает возможность избежать копирования массива при использовании включения внутреннего цикла проверки с использованием определения, когда все входные данные будут исчерпаны.
Такую потерю можно восполнить при использовании реализации той же описанной идеи: надо писать программу как алгоритм слияния, одну для представления определенного массива в порядке его возрастания, а иную – для представления компонентов массива в порядке их убывания. Вооружившись такой методикой, можно снова обратиться рекурсивно к ней и устроить так, чтобы внутреннему циклу слияния не понадобились никогда служебные метки. [11]
Можно также подумать об увеличении производительности сортировки слиянием тогда, когда в файле достигнута уже высокая степень упорядоченности игнорированием вызова функции merge, в случае установления порядка в файле, но данная стратегия не будет эффективной на многих форматах файлов.
Рекурсивная программа предусматривает выполнение сортировки файла b, а результат сортировки будет помещаться в файл а. В результате, рекурсивные вызовы сформулированы так, что их результаты будут оставаться в файле b и в файле а.
Таким образом, все такие перемещения данных выполняются при реализации слияния.
Листинг алгоритма приведен ниже:
template <class Item>
void mergeAB(Item c[], Item a[], int N, Item b[], int M ) {
for (int i = 0, j = 0, k = 0; k < N+M; k++) {
if (i == N) { c[k] = b[j++]; continue; }
if (j == M) { c[k] = a[i++]; continue; }
c[k] = (a[i] < b[j]) ? a[i++] : b[j++];
}
}
template <class Item>
void mergesortABr(Item a[], Item b[], int l, int r) {
if (r-l <= 10) { insertion(a, l, r); return; }
int m = (l+r)/2;
mergesortABr(b, a, l, m);
mergesortABr(b, a, m+1, r);
mergeAB(a+l, b+l, m-l+1, b+m+1, r-m);
}
ЗАКЛЮЧЕНИЕ
Циклические вычислительные процессы могут также характеризоваться и повторением данных для аналогических математических вычислений над любыми данными.
Отметим, что рассмотренные циклы с постусловием будут выполняться всегда хотя бы 1 раз, а цикл с предусловием – не выполняется ни разу, если условие будет ложным.
Данные 2 вида циклических операторов являются самыми основными в ЯП высокого уровня.
Для реализации разнообразных циклических схем на высокоуровневых ЯП вводятся операторы для осуществления перехода, что могут применяться только внутри самых циклов.
Стоит отметить, что они позволяют выполнять выход с цикла принудительно или может его продолжать. В процессе применения циклов до полного их завершения также могут возникать дополнительные условия.
Само понятие «программирования цикла» достаточно для определять условие, но управляющее количеством всех итераций, описать операторы, что могут образуют тело цикла.
Программировать на С ++ можно как для Windows, так и для Unix, причем для каждой из операционных систем существует значительное количество средств разработки: от компиляторов до мощных интерактивных сред, как, например, Borland С ++ Builder, Microsoft Visual C ++ или Visual Studio .NET.
В процессе написания курсовой работы рассмотрены примеры использования алгоритма сортировки.
К курсовой работе была написана пояснительная записка, которая позволила приобрести навыки оформления документации на программные средств.
В процессе написания курсовой работы были реализованы следующие задачи:
– рассмотреть понятие алгоритма и терминологии, которая с ним связана;
– выполнить описание операторов цикла на С++;
– рассмотреть применение массивов в С++, как объекта сортировки;
– рассмотреть основные типы сортировки данных;
– дать характеристику и на практике описать программу для сортировки методом слияния без копирования.
Также были рассмотрены примеры использования алгоритмов сортировки, а так же выяснили, какой из алгоритмов является более оптимальным для определеннных условий.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Динман М.И. С++. Освой на примерах. – СПб.: БХВ-Петербург, 2012.– 260 с.
- Дэвид Гриффитс, Дон Гриффитс. Изучаем программирование на С. Издательство «Эксмо». – 2013. – 400 с.
- Кнут, Дональд, Эрвин. Искусство программирования. Том : Уч. пос. М.: Издательский дом. «Вильямс», 2014.– 720с.
- Кубенский А.А. Структуры и алгоритмы обработки данных: объектно-ориентированный подход. – СПб.: БХВ-Петербург, 2013. – 464с.
- Лаптев В.В. С++. Объектно-ориентированное программирование. Задачи и упражнения. – СПб.: Питер. 2013. – 288 с.
- Майерс С. Эффективное использование С++. – М.: ДМК Пресс; – СПб.: Питер. 2013.–240с.
- Прата С. Язык программирования С++. Издание 6. Издательский дом «Вильямс» – 2016. – 304 с.
- Р. Лафоре. Объектно-ориентированное программирование в С++. Издательство «Питер». Издание 4. – 2014. – 628 с.
- С++ Стандартная библиотека. Для профессионалов./Н. Джосьютис. – СП Питер, 2012. – 350 с.
- Седжвик Роберт. Фундаментальные алгоритмы на С++. К.: Издательство «ДиаСофт», – 2014. – 500 с.
- Скляров В.А. Язык С++ и объектно-ориентированное программирование. – Минск. «Вышейшая школа». – 2012. – 478с.
- Харви Дейтел, Пол Дейтел. Как программировать на С++. Пер. с англ. – М.: ЗАО «Издательство БИНОМ», 2012. – 430 с.
- Хусаинов Б.С. Структуры и алгоритмы обработки данных. Примеры на языке Си. Учеб. пособие. – Финансы и статистика, 2014. – 464с.
- Штерн Виктор. Основы С++: Методы программной инженерии.– Издательство «Лори», 2013. – 860с.
- Язык С++: Учеб. Пособие /И.Ф. Астахова, С.В. Власов, В.В. Фертиков, А.В. Ларин.–Мн.: Новое знание, 2013. – 203 с.

- Применение процессного подхода для оптимизации бизнес-процессов (Характеристика управления организацией)
- Корпоративная культура в организации (ООО «Яндекс»)
- Классификация юридических фактов
- Понятие пенсии по случаю потери кормильца в России
- Лидерство, влияние, власть.
- Использование результатов ОРД в качестве информации в процессе доказывания (Тактические основы оперативно-розыскной деятельности)
- Разработка регламента выполнения процесса «Складской учет» ( Обоснование выбора средств разработки)
- Комплексный анализ отдельных характеристик института гарантий прав и свобод человека
- Понятие пенсии по потере кормильца в России
- Международные и отечественные стандарты языков программирования. Сходство и отличие стандартов.
- Управление поведением в конфликтных ситуациях (на примере ООО «ТоргАльянс»)
- Языки гипертекстовой разметки (Общие сведения)