
Сортировка слиянием без копирования»
Содержание:

ВВЕДЕНИЕ
В повседневной жизни встречаются довольно часто действия, которые повторяются. Выполняя их, тратится время, и как-то упростить этот алгоритм не всегда получается.
В мире существует огромное количество языков программирования, хотя большинство из них отличается лишь методом компиляции и синтаксисом.
Век высоких технологий принес свои плоды и теперь с помощью языков программирования есть возможность описать и даже упростить любые действия. При этом нет необходимости описывать действия, которые повторяются шаг за шагом, а достаточно только использовать циклические алгоритмы.
Именно с помощью таких алгоритмов выполняется фундаментальное действие над массивами данных – сортировка.
Актуальность данной темы состоит в том, что алгоритмы сортировки являются одними из основных составляющий почти всех программ. И их изучение является одним из краеугольных камней в подготовке квалифицированных программистов.
Целью работы является рассмотрение алгоритма сортировки без копирования.
Предметом написания курсовой работы являются алгоритмы сортировки на примере упорядочивания элементов массивов.
В соответствии к цели работы поставлены такие основные задания:
– выполнить описание основных типов алгоритмов и их базовых структур;
– рассмотреть циклические операторы языка программирования С++;
– описать использование массивов в С++;
– описать алгоритмы сортировки данных;
– написать программу для демонстрации алгоритма сортировки без копирования.
В данной курсовой работе используется язык программирования С++, поскольку он в нынешнее время является одним из наиболее распространенных и используемых.
В результате написания работы создана программа для демонстрации метода сортировки элементов массивов.
Стоит отметить, что исследованиями по выборе оптимальных алгоритмов сортировки занимались многие ученые и программисты: Б. Страуструп, Н. Вирт, А. Макаренко, результаты которых нашли свое воплощение в учебниках и пособиях.
1.Теоретические основы алгоритмизации
В повседневной деятельности постоянно приходится сталкиваться с разными правилами, которые описывают последовательность действий с целью достичь определенного необходимого результата. Данные правила являются многочисленными. Например, мы придерживаемся определенных правил, чтобы позвонить, приготовить лекарство, сварить суп или вычислить какое-то математическое уравнение. Указанные примеры можно объединить понятием «алгоритм». [2]
Понятие алгоритма, относится к фундаментальным концепциям информатики и возникло задолго до появления персональных компьютеров и стало основным понятием математики. Понятие «алгоритм» происходит от имени узбекского математика Мугаммада бен Муса аль-Хорезми. Algorithmi – это латинское транскрипция имени аль-Хорезми, данное слово использовалось для обозначения правил выполнения таких арифметических действий: вычитание, сложение, умножение и деление над числами. Совокупность этих правил в Европе стали называть «алгоризм». Впоследствии это слово переродилось в алгоритм и стало собирательным названием отдельных правил определенного вида и не только правил арифметических действий. В течение длительного времени его употребляли только математики, обозначая правила решения различных задач.
Алгоритм – это точное правило, определяющее процесс преобразования исходных данных для получения конечных результатов при решении определенного класса задач. [1] В этом правиле задаются указания к выполнению некоторой системы операций в определенном порядке и правила их применения к начальным данным для решения задачи.
Алгоритм является фундаментальным понятием программирования. Ученые выделяют три основных класса алгоритмов: вычислительные, информационные и управляющие [3].
Вычислительные алгоритмы – это алгоритмы, которые работают со сравнительно простыми типами данных, например числами, векторами, матрицами.
Информационные алгоритмы представляют собой набор простых процедур, которые обрабатывают большие объемы информации. Примером такой процедуры может быть поиск необходимой числовой или символьной информации, что соответствует определенным критериям. Эффективность работы данных алгоритмов зависит от организации данных.[11]
Управляющие алгоритмы характерны тем, что данные для них поступают от внешних процессов, которыми они управляют. Результатами работы этих алгоритмов является выработка своевременной управляющей реакции на быстрое изменение входных данных.
Попытки найти и сформулировать в жестких терминах приемы и формы построения алгоритмов привели к возникновению самостоятельной дисциплины – теории алгоритмов, в которой раскрываются теоретические возможности разработки эффективных алгоритмов вычислительных процессов и их применения в прикладных приложениях.[15]
Любой алгоритм обладает следующими свойствами:[4]
1. Массовость – применимость алгоритма к любым задачам определенного класса. Это свойство обеспечивает решение любой задачи из класса однотипных задач при любых исходных данных. Так, алгоритм вычисления площади треугольника применим к любым треугольникам. Вместе с тем, существуют и такие алгоритмы, которые применяются только к единому набору исходных данных данных. К их числу относятся алгоритмы, используемые различными автоматами, например, автоматом для продажи газет или телефоном-автоматом.
2. Определенность (детерминированность) – набор указаний должен быть точен и не зависеть от исполнителя. Эта характеристика обеспечивает определенность и однозначность результата процесса, описываемого при заданных исходных данных. Каждый шаг должен быть четко и недвусмысленно определен и не должен допускать произвольной трактовки исполнителем.
3. Дискретность – разбиение процесса, который определяется алгоритмом, на отдельные элементарные операции, возможность выполнения которых человеком или машиной не вызывает сомнений. Процесс, который определяется алгоритмом, должен иметь дискретный характер, то есть представлять собой последовательность отдельных шагов.[7]
4. Ясность – понимание исполнителя о том, что надо делать для выполнения этого алгоритма. При этом исполнитель алгоритма, выполняя его, действует «механически», поэтому формулировка алгоритма должна быть очень точной и однозначной.
5. Результативность – это завершение процесса преобразования входной информации в результатную. Данное свойство указывает на то, что применение алгоритма к любому допустимому набору исходных данных за конечное число шагов обеспечивает получение определенного результата. [9]
6. Формальность – результат выполнения алгоритма не должен зависеть от каких-либо факторов, которые не являются частью этого алгоритма. Любой исполнитель, способный воспринимать и выполнять указания алгоритма (даже не понимая их содержания), действуя по нему, может выполнить поставленную задачу.
Чтобы довести к пользователю алгоритмы, они должны быть формализованы по определенным правилам с помощью конкретных изобразительных средств. Методы, используемые для записи алгоритмов, в значительной степени определяются тем, для какого исполнителя назначается алгоритм. К основным методам записи алгоритмов относятся: словесный, формульно-словесный, блок-схемы алгоритмов, языки программирования. [10]
В словесной записи алгоритма каждая операция формулируется на естественном языке в виде правила. Правила нумеруются, чтобы иметь возможность на них ссылаться, и указывается порядок их выполнения.
Формульно-словесный метод записи алгоритма основывается на инструкциях о выполнении конкретных действий в определенной последовательности с использованием математических символов и выражений пояснениями на естественном языке.[10]
Блок-схема алгоритма представляет собой графическое изображение процесса решения задачи в виде последовательности блоков специального вида, отражающих специфику преобразования информации и соединенных между собой линиями или стрелками. Внутри каждого блока кратко описывается содержание конкретного этапа решения алгоритма задачи. [2]
Рассмотрим основные геометрические фигуры, применимые в блок-схемах (таблица 1)
Таблица 1.
Основные геометрические фигуры, применимые в блок-схемах
|
Фигура |
Применение |
|
Начало или конец алгоритма |
|
|
Операции вычисления или присваивания |
|
|
Ввод или вывод данных |
|
|
Проверка условия |
Различают обобщенную и подробную блок-схемы алгоритма. Обобщенная схема алгоритма изображает вычислительный процесс в общем плане на уровне типовых процессов обработки данных. [3]
Например, во время обработки экономических данных типичными процессами является ввод данных, корректировка, сортировка, обработка данных и т. д.
К составлению подробных схем приступают после тщательного анализа обобщенных схем алгоритмов.
Сейчас самым совершенным методом для записи алгоритма являются языки программирования, которые позволяют автоматизировать вычислительный процесс за счет того, что перевод инструкции с алгоритмического языка на язык персонального компьютера осуществляется автоматически с помощью специальных программ-трансляторов.[11]
1.2. Базовые структуры алгоритмов
Появление языков программирования сблизила понятия алгоритма и программы.
Любой алгоритм содержит описание команд и определяет последовательность их выполнения.
На первый взгляд кажется, что команды алгоритма всегда выполняются одна за другой, однако это не так. [3]
Для обеспечения такого свойства алгоритма, как массовость, его создают с учетом ввода любого набора допустимых данных.
Из-за этого во многих случаях нельзя заранее предсказать, каким именно должен быть следующий шаг алгоритма.
Отсюда возникает потребность в таких указаниях исполнителю, которые позволяли бы управлять его действиями по складывающейся ситуацией в процессе выполнения алгоритма.
По характеру управления различают три основных вида алгоритмов: линейные, разветвляющиеся и цикличные.
В простейшем случае алгоритм осуществляет одновременное выполнение всех по очереди заданных действий независимо от значений входных данных задачи.
Например, для нахождения объема призмы нужно найти площадь ее основания, определить высоту призмы, найти их произведение. Эти действия нужно выполнить для расчета объема любой призмы.[6]
Алгоритм, который осуществляет выполнение одной и той же последовательности действий при любых допустимых входных данных задачи, называется линейным (рисунок 1).[7]
Действие 1
Действие 2
Действиеn
…
Рисунок 1 – Линейная структура алгоритмов
Алгоритмы, которые предусматривают два возможных варианта действий, являются более сложными, чем линейные. Например, в алгоритме решения квадратного уравнения сначала нужно найти значение дискриминанта, а затем, в зависимости от знака, или сообщить об отсутствии действительных корней (если значение дискриминанта отрицательное) или найти их по соответствующим формулам (в противном случае).[1]
Алгоритм, который осуществляет выполнение тех или иных действий в зависимости от результата проверки условия, называется алгоритмом с разветвлением или разветвляющимся (рисунок 2):[8]
Условие
Действие 1
Действие 2
Да
Нет
Рисунок 2 –Структура разветвляющегося алгоритма
Поскольку такой алгоритм содержит описание действий для обоих возможных вариантов, при каждом его выполнении реализуется только один из них. Который именно – зависит от заданного набора входных данных.
Третий вид алгоритмов составляют в случае повторного выполнения определенной последовательности действий.[12]
Например, для подсчета суммы двух целых чисел (в столбик) нужно сначала вычислить сумму последних цифр чисел-слагаемых, записать последнюю цифру результата и перенести, если нужно, единицу в следующий разряд. Далее по аналогичному правилу нужно вычислить сумму предпоследних цифр чисел-слагаемых и т.д. Процедура повторяется, пока все цифры чисел-слагаемых не будут исчерпаны. Количество повторений зависит от количества цифр в заданных числах.[14]
Алгоритм, осуществляющий повторное выполнение действий, называется алгоритмом с повторением или циклическим алгоритмом. Повторяющееся действие или группа действий называется телом цикла. Количество повторений тела цикла определяется поставленным условием, которое называется условием цикла. По результатам проверки условия осуществляется выбор: еще раз повторить тело цикла или перейти к другим действиям.
Стоит отметить, что циклические алгоритмы используются при выполнении сортировки данных.[8]
Различают две основные разновидности циклов: циклы с предусловием (рисунок 3) и циклы с постусловием (рисунок 4).
В цикле с предусловием условие цикла формулируется таким образом, чтобы повторное выполнение операций производилось, пока проверка условия дает результат «да». Поэтому такие циклы называют еще циклами «пока».
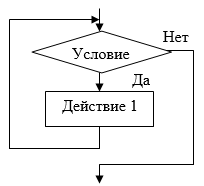
Рисунок 3 – Циклическая структура с предусловием
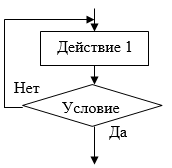
Рисунок 4 – Циклическая структура с постусловием
Цикл с предусловием можно прочитать следующим образом:
пока проверка условия дает результат «да», выполнять действие.
Если при очередной проверке условия будет получено результат «нет», повторное выполнение действия будет прекращено и произойдет выход из цикла.[13]
Например, для подсчета остатка от деления целого числа t на целое число n с помощью вычитания можно воспользоваться циклом:
пока t> n, уменьшить t на n.
В цикле с постусловием (рисунок 4) условие цикла формулируется противоположным образом: если очередная проверка условия дает результат "да", происходит выход из цикла. Цикл с постусловием можно сокращенно прочитать так:[7]
повторять действие до получения результата «да» при проверке условия.
Например, подсчет остатка от деления целого числа t на целое число n (t> n) можно реализовать с помощью цикла:[9]
повторять уменьшить t на n до t <n.
Стоит обратить внимание на то, что является общим для обоих типов цикла:
– обе базовые структуры цикла являются замкнутыми;
– количество повторений цикла определяется его условием;
– выход из цикла происходит только через проверку условия цикла.
Наиболее существенная разница между типами циклов заключается в том, что тело цикла с постусловием обязательно выполняется хотя бы один раз – до первой проверки условия, а цикл с предусловием может не выполнятся ни разу, если при первой же проверке условия имеем результат «нет». Поэтому рассмотренные типы циклов не являются взаимозаменяемыми: цикл с постусловием можно заменить циклом с предусловием, а наоборот – нет.[12]
В первом разделе рассмотрены теоретические основы алгоритмизации, поскольку алгоритмы сортировки являются нетривиальными алгоритмами, которые содержат и вложенные циклы, и проверку условий, и линейные части алгоритмов.
2. Массивы данных и их сортировка
2.1. Реализация циклических алгоритмов на языке программирования С++
Поскольку алгоритмы сортировки будут рассматриваться на примере массивов данных и циклических алгоритмов, рассмотрим основные методы реализации работы с ними.[4]
Рассмотрим реализацию циклических алгоритмов на языке С++, в котором существую три разновидности операторов цикла:[1]
– оператор цикла for;
– оператор цикла с предусловием while;
– оператор цикла с постусловием do ... while.
Все операторы цикла непременно содержат следующие составные части:
– присваивания исходных значений (инициализация);
– условие продолжения цикла;
– тело цикла;
– изменение параметра (счетчика) цикла.
Оператор for обычно используется, когда есть заранее известное количество повторений или когда условие продолжения выполнения цикла записывается кратким выражением. Примерами использования данного оператора являются вычисления сумм заданного количества слагаемых, поиск минимального (максимального) элемента последовательности чисел, сортировки элементов массива по возрастанию (убыванию) и т.д.[7]
Синтаксис оператора следующий:
for (<инициализация>; <условие>; <модификации>)
{
<тело цикла>;
}
Конструкция этого оператора состоит из трех основных блоков, размещенных в круглых скобках и отделенных друг от друга точкой с запятой (;) и команд (тела цикла), которые могут многократно повторятся. В начале выполнения оператора цикла, однократно, в блоке инициализации задаются начальные значения переменных, которые управляют циклом. Затем проверяется условие и, если оно выполняется, то управление переходит к выполнению тела цикла. Блок модификации меняет параметры цикла и, в случае истинности условия, выполнение цикла продолжается. Если условие не выполняется (false или равно нулю), то цикл прерывается и управление передается на оператор, следующий за оператором for. Существенным является то, что проверка условия выполняется в начале цикла. Это значит, что тело цикла может не выполниться ни разу, если условие сначала ошибочное. Каждое повторение (шаг) цикла называется итерацией.[10]
Простой пример для вычисления суммы проиллюстрирует использования оператора for:
int s = 0;
for (int i = 1; i<= 10; i ++)
s + = i;
Этот оператор цикла можно прочитать так: "выполнить команду s + = i 10 раз (для значений i от 1 до 10 включительно, где i при каждой итерации увеличивается на 1)". В этом примере есть два присваивания начальных значений: s = 0 и i = 1, условие продолжения цикла: (i <= 10) и изменение параметра: i ++. Телом цикла является команда s + = i.[8]
Порядок выполнения этого цикла компьютером такой:
1) присваиваются начальные значения (s = 0, i = 1);
2) проверяется условие (i <= 10);
3) если условие истинное (true), выполняется команда (или команды) тела цикла: к сумме, полученной на предыдущей итерации, добавляется новое число;
4) параметр цикла увеличивается на 1.
Далее возвращаемся к пункту 2. Если условие в пункте 2 не будет выполнено (false), произойдет выход из цикла.[5]
В операторе возможные конструкции, когда отсутствует тот или иной блок: инициализация может отсутствовать, если начальное значение задать предварительно; условие – если предполагается, что условие всегда истинно, то есть следует непременно выполнять тело цикла, пока не встретится оператор break; а модификации – если прирост параметра осуществлять в теле цикла. В этих случаях само выражение блока упускается, но точку с запятой обязательно нужно оставить. [7]
Для заблаговременного выхода из цикла применяют операторы break (выход из конструкции) или return (выход из текущей функции). [9]
Некоторые варианты применения оператора for повышают его гибкость за счет возможности использования нескольких переменных-параметров цикла.
Циклы могут быть вложены друг в друга. При использовании вложенных циклов надо составлять программу таким образом, чтобы внутренний цикл полностью укладывался в тело внешнего цикла, то есть циклы не должны пересекаться. В свою очередь, внутренний цикл может содержать собственные вложенные циклы. Имена параметров внешнего и внутреннего циклов должны быть разными. Допускаются следующие конструкции:[5]
fог(k = 1; k <= 10; k ++)
{
fог (i = 1; i<= 10; i ++)
{
fог (t = 1; t <= 10; t ++)
{
...
}
}
}
Вложенные циклы используются для выполнения сортировок различными методами.
Операторы с предусловием и постусловием используются для организации циклов и являются альтернативными к оператору for. Обычно цикл с предусловием используется, если количество повторений заранее неизвестно, а для многократного повторения тела цикла известно условие, при истинности которого цикл продолжает выполнение. Это условие следует проверять каждый раз перед очередной итерацией. Например, при считывании данных из файла условием цикла является наличие данных непосредственно в файле, то есть повторять чтение данных следует до тех пор, пока указатель не будет указывать на конец файла.[13]
Синтаксис цикла с предусловием следующий:
while (<условие>)
{
<тело цикла>
};
Последовательность операторов (тело цикла) выполняется пока условие является истинным, а выход из цикла осуществляется, когда условие станет ложным. Если условие является ошибочным при вхождении в цикл, то последовательность операторов ни разу не выполнится, а управление будет передаваться к следующему оператору программы.
Цикл с постусловием используется, если есть необходимость проверять истинность условия каждый раз после очередной итерации. Как отмечалось выше, отличие цикла с предусловием от цикла с постусловием заключается в первой итерации: цикл с постусловием всегда выполняется по крайней мере один раз независимо от условия.[7]
Синтаксис цикла с постусловием следующий:[1]
do
{
<тело цикла>
}
while (<условие>);
Последовательность операторов (тело цикла) выполняется один или несколько раз, пока условие станет ложным. Оператор цикла do ... while используется в тех случаях, когда есть необходимость выполнить тело цикла хотя бы один раз, поскольку проверка условия осуществляется после выполнения операторов.[4]
Если тело цикла состоит из одного оператора, то операторные скобки {} не является обязательны.
Операторы while и do ... while могут преждевременного завершиться при выполнении операторов break и return внутри тела цикла.
2.2. Использование и обработка массивов с помощью операторов цикла
Поскольку алгоритмы сортировки принято использовать в обработке массивов, рассмотрим основные понятия о них.[3]
Часто, в процессе разработки программы, возникает потребность хранить большое количество однотипных значений, которые должны поддаваться одинаковым методам обработки. Например, экзаменационные оценки студентов, следует вводить, выводить, анализировать (сравнение с "2" или "5"), изменять при необходимости и тому подобное. Такие однотипные значения имеет смысл хранить в одной переменной, перенумеровать их внутри этой переменной, предоставить доступ к этим значениям по индексу и обрабатывать эти значения в цикле (номер индекса должен совпадать с значением параметра цикла).[9]
Массив – это упорядоченная совокупность однотипных элементов. Массивы широко применяются для хранения и обработки однородной информации, например таблиц, векторов, матриц, коэффициентов уравнений и т.д. [1]
Каждый элемент массива однозначно можно определить по имени массива и индексе. Имя массива (идентификатор) подбирают по тем же правилам, что и для переменных. Индексы определяют местонахождение элемента в массиве. К примеру, элементы вектора имеют один индекс – номер по порядку; элементы матриц или таблиц имеют по два индекса: первый означает номер строки, второй – номер столбца. Количество индексов определяет размерность массива. Например, векторы в программах – это одномерные массивы, матрицы – двумерные.[3]
Индексами могут быть только переменные, константы или выражения целого типа. Значения индексов записывают после имени массива в квадратных скобках. При объявлении массивов в квадратных скобках указывается количество элементов, а нумерация элементов всегда начинается с нуля.
Различия массива от обычных переменных следующие:[14]
– общее имя для всех значений;
– доступ к конкретному значению по его номеру (индексу)
– возможность обработки в цикле.
Одномерный массив объявляется в программе следующим образом:
<тип данных><имя_массива> [<размер массива>];
Тип данных задает тип элементов массива. Элементами массива не могут быть функции и элементы типа void. Размер массива в квадратных скобках задает количество элементов массива. В отличие от других языков, в C++ не проверяется выход за пределы массива, поэтому, чтобы избежать ошибок в программе, следует следить за размерностью объявленных массивов. Значение размера массива при объявлении может быть не указано в следующих случаях:[15]
– при объявлении массив инициализируется;
– массив объявлен как формальный параметр функции;
– массив объявлен как ссылка на массив, явно определенный в другом модуле.
Используя имя массива и индекс, можно обращаться к элементам массива:
<имя_массива> [<значение_ индекса>]
Значения индексов должны находиться в диапазоне от нуля до величины, на единицу меньше размера массива, который определен при его объявлении, поскольку в C ++ нумерация индексов начинается с нуля.[12]
Например,
intA[10];
объявляет массив с именем А, содержащий 10 целых чисел; при этом выделяет и закрепляет за этим массивом оперативную память для всех 10-ти элементов соответствующего типа (int – 4 байта), то есть 40 байтов, следующим образом (рисунок 5):
|
A[0] |
A[1] |
A[2] |
A[3] |
A[4] |
A[5] |
A[6] |
A[7] |
A[8] |
A[9] |
Рисунок 5 Изображение одномерного массива
Следовательно, при объявлении массива выделяется память, необходимая для размещения всех его элементов. Элементы массива с первого до последнего запоминаются в последовательно возрастающих адресах памяти. Между элементами массива в памяти промежутков нет. Элементы массива записываются один за другим поэлементно.[13]
Для получения доступа к i-му элементу массива А, можно написать А[і], где i – переменная цикла (счетчик цикла), которая может принимать значения от 0 до 9. При этом величина i умножается на размер типа int и представляет собой адрес i-го элемента массива А от его начала, после чего осуществляется выбор элемента массива А по сложившейся адресу.[2]
При объявлении массивов можно присваивать начальные значения его массива (необязательно всем), которые в дальнейшем в программе могут быть изменены. Если реальное количество инициализированных значений является меньше размерность массива, то остальные элементы массива приобретают значение 0.
Например,
inta[5] = {9, 33, -23, 8, 1}; // а [0] = 9, а [1] = 33, а [2] = - 23, а [3] = 8, а [4] = 1;
floatb[10] = {1.5, -3.8, 10}; // B [0] = 1.5, b [1] = - 3.8, b [2] = 10, b [3] = ... = b [9] = 0;
Все операции с массивами выполняются с помощью операторов цикла. Например, ввод информации в массив:
for (inti = 0; i<n; i ++)
cin>> a [i];
Вывод информации из массива:
for (int i = 0; i<n; i ++)
cout<<a [i] << "";
Для многих структур данных изображения в виде одномерного массива является неприемлемым. Например, результаты матчей футбольного чемпионата удобнее подавать в виде квадратной таблицы. Для хранения таких структур данных применяют многомерные массивы, среди которых наиболее широко используются двумерные массивы (матрицы).[6]
Как отмечалось в данном разделе, размерность массива определяется количеством индексов. Элементы одномерного массива имеют один индекс, двумерного массива (матрицы, таблицы) – два индекса: первый из них – номер строки, второй – номер столбца. При размещении элементов массива в памяти компьютера сначала меняется крайний правый индекс, затем остальные - справа налево. [11]
Многомерный массив объявляется в программе следующим образом:
<тип><имя_массива> [<размерность1>] [<размерность2>] ... [<размерностьN>];
Количество элементов массива равна произведению количества элементов по каждому индексу. Например,
int a [3][4];
объявлено двумерный массив из 3-х строк и 4-х колонок (12-ти элементов) целого типа:[5]
a [0] [0] a [0] [1], a [0] [2], a [0] [3],
a [1] [0], a [1] [1], a [1] [2], a [1] [3],
a [2] [0], a [2] [1], a [2] [2], a [2] [3];
Приведем еще несколько примеров объявления массивов:
float Mas1 [5] [5]; // Матрица 5х5 = 25 элементов вещественного типа.
char Mas2 [10] [3]; // Двумерный массив с 10х3 = 30 элементов символьного типа
double Mas3 [4] [5] [4]; // Трехмерный массив с 4х5х4 = 80 элементов вещественного типа
При объявлении массива можно присваивать начальные значения его элементов, причем необязательно всех, например:[7]
1) int w [3] [3] = {{2, 3, 4}, {3, 4, 8}, {1, 0, 9}};
2) float C [4] [3] = {1.1, 2, 3, 3.4, 0.5, 6.8, 9.7, 0.9};
В первом примере объявлено и инициализирован массив целых чисел w[3][3]. Элементам массива присвоено значение из списка: w[0][0] = 2, w[0][1] = 3, w[0][2] = 4, w[1][0] = 3 и т.д.
Во втором разделе описаны практические приемы использования циклических операторов языка программирования С++, а именно:[3]
–оператор for;
- оператор while;
- оператор do…while.
Также рассмотрены понятия одномерного и многомерного массивов, поскольку они являются базовыми терминами для использования алгоритмов сортировки.
3.Алгоритмы сортировки данных
3.1. Описание популярных алгоритмов сортировки
Сортировка пузырьком – самый простейший алгоритм сортировки, который применяется для учебных целей. Какого-то практического применения этому алгоритму нет, поскольку он не эффективен, если необходимо отсортировать массивы больших размеров. К плюсам сортировки относится простота реализации.[15]
Алгоритм сортировки пузырьком сводят к повторению проходов по сортируемом массиве. Проход по элементам выполняет внутренний цикл.
По каждому проходу сравниваются два элемента-соседи, и если порядок элементов немерный, то меняются местами. Внешние циклы будут работать до тех пор, пока весь массив не будет отсортирован.
Внешний цикл контролирует общее количество срабатываний для внутреннего цикла.[13]
Если при очередном проходе массива не будет выполнено ни одной перестановки, то он будет считаться отсортированным. [5]
Рассмотрим блок-схему алгоритма сортировок пузырьком.

Рисунок 6 – Блок-схема алгоритма сортировки пузырьком
Сортировка слиянием — алгоритм сортировки, что упорядочиваетмассивы в определённом порядке. Сортировка слиянием — хороший пример применения принципа «разделяй и властвуй». [11]
Задача разбивается на подзадачи меньшего размера. Потом эти задачи решаются при помощи рекурсивного вызова и непосредственно, если же их размер мал. Потом, их решения комбинируются, получается решение задачи.
Для решения задачи этапы выглядят так:[7]
- Сортируемые массивы разбиваются на две части одинакового размера;
- Каждая из частей сортируется отдельно;
- Два упорядоченных массива половинного размера соединяются.
1.1. — 2.1. Рекурсивное разбиение задачи происходит до тех пор, пока размер не достигнет единицы.
3.1. Соединение двух массивов в один.
Основную идею слияния отсортированных массивов можно объяснить на примере. Если мы имеем 2 уже отсортированных по подмассива. Тогда:
3.2. Слияние 2 подмассивов в третий массив.
На каждом шаге берём меньший из 2 первых элементов подмассивов, записываем его в окончательный массив. Счётчики номеров элементов окончательного массива и подмассива увеличиваем на 1.[9]
3.3. «Прицепление» остатка.
Когда один из подмассивов закончился, то мы добавляем все элементы второго подмассива в результирующий.
Рассмотрим блок-схему алгоритма сортировок слиянием.



Рисунок 7 – Блок-схема алгоритма сортировки слиянием
Использование данного алгоритма сортировки является более выгодным в массивах с большим количеством элементов нежели алгоритм сортировки пузырьком.
3.2.Сортировка массива с помощью слияния без копирования
В качестве усовершенствования целесообразно рассмотреть возможность сведения к нулю времени копирования данных во вспомогательный массив, используемый процедурой слияния.
Поступая таким образом, следует так организовать рекурсивные вызовы, что процесс вычисления сам меняет в нужный момент роли входного и вспомогательного массивов на каждом уровне. Один из способов реализации такого подхода заключается в создании двух вариантов программ — одного для приема входных данных в файл а и пересылки выходных данных в файл aux, а другого для приема входных данных в файл aux и пересылки выходных данных в файл а, после чего обе версии поочередно вызывают одна другую.
Данный метод позволяет избежать копирования массива ценой включения во внутренний цикл проверки с целью определения, когда входные файлы будут исчерпаны. Эту потерю можно восполнить посредством реализации той же идеи: мы пишем программы как слияния, так и сортировки слиянием, одну для представления массива в порядке возрастания, а другую — для представления массива в порядке убывания. Вооружившись такой стратегией, можно снова обратиться к стратегии и устроить так, что внутреннему циклу слияния никогда не понадобятся служебные метки.
Принимая во внимание тот факт, что такая оптимизация использует четыре копии базовых программ и рекурсивные переключения аргументов, она может быть рекомендована экспертам, но в то же время она существенно ускоряет сортировку слиянием. Эти показатели зависят от реализации и от машины, однако подобные результаты возможны в различных ситуациях.
Другие реализации слияния, требующие выполнения явно заданных проверок на предмет исчерпания первого файла, могут привести к более заметным колебаниям значений времени выполнения в зависимости от характера входных данных, но эта зависимость все еще остается незначительной. В файлах с произвольной организацией размер другого подфайла, когда исчерпывается первый файл, будет небольшим, и стоимость перемещения во вспомогательный файл все еще остается пропорциональной размеру этого подфайла.
Можно подумать о повышении производительности сортировки слиянием в тех случаях, когда в файле уже достигнута высокая степень упорядоченности, за счет игнорирования вызова функции merge, когда в файле уже установлен порядок, однако данная стратегия не эффективна на многих типах файлов.
Рекурсивная программа предусматривает сортировку файла Ь, а результат сортировки помещается в файл а. Следовательно, рекурсивные вызовы сформулированы таким образом, что их результаты остаются в файле Ь, и мы применяем программу 2.1 для слияния файлов, помещенных в b с файлом из а, а их результаты остаются в файле а. Таким образом, все перемещения данных выполняются в процессе слияния.
Листинг алгоритма приведен ниже:
template<classItem>
void mergeAB(Item c[], Item a[], int N, Item b[], int M ) {
for (int i = 0, j = 0, k = 0; k < N+M; k++) {
if (i == N) { c[k] = b[j++]; continue; }
if (j == M) { c[k] = a[i++]; continue; }
c[k] = (a[i] < b[j]) ? a[i++] : b[j++];
}
}
template <class Item>
void mergesortABr(Item a[], Item b[], int l, int r) {
if (r-l <= 10) { insertion(a, l, r); return; }
int m = (l+r)/2;
mergesortABr(b, a, l, m);
mergesortABr(b, a, m+1, r);
mergeAB(a+l, b+l, m-l+1, b+m+1, r-m);
}
Результат программы показан ниже:
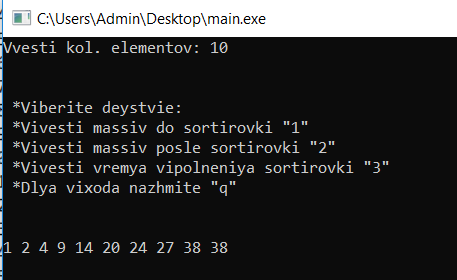
Рисунок 8 – Результат сортировки
В третьем разделе детально рассмотрены самые популярные методы сортировки элементов массива: метод пузырька и метод слияния (с копированием и без него); приведены блок-схемы указанных алгоритмов, а также и программная реализация на языке программирования С++.
ЗАКЛЮЧЕНИЕ
Наиболее распространенным языком программирования в течение нескольких последних десятилетий, вне всякого сомнения, является язык С++, на основе которого "выросли" многие современные языки программирования и программные среды.
Этому способствовали такие его свойства, как лаконичность, мощность, гибкость, мобильность, возможность доступа ко всем функциональным средствам системы.
Программировать на С ++ можно как для Windows, так и для Unix, причем для каждой из операционных систем существует значительное количество средств разработки: от компиляторов до мощных интерактивных сред, как, например, Borland С ++ Builder, MicrosoftVisual C ++ или VisualStudio .NET.
В курсовой работе рассмотрены алгоритмы сортировки на примере числовых массивов.
Стоит отметить, что сортировка используется во многих направлениях программирования и веб-дизайна:
– электронные магазины (сортировка товаров по стоимости и другим критериям;
– развлекательные порталы (упорядочивание контента по популярности или рейтингу);
– программные продукты для учета различных товаров, услуг (сортировка данных по количеству, качеству и т.д.).
В процессе написания курсовой работы были реализованы следующие задачи:
– выполнить описание основных типов алгоритмов и их базовых структур;
– рассмотреть циклические операторы языка программирования С++;
– описать использование массивов в С++;
– описать алгоритмы сортировки данных;
– написать программу для демонстрации алгоритма сортировки без копирования.
Также были рассмотрены примеры использования алгоритмов сортировки, а так же выяснили, какой из алгоритмов является более оптимальным для определеннных условий.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Аммерааль Л. STL для программистов на С++: Пер. с англ. — М.: ДМК, 2011. — 240 с.
- Бочков С. О., Субботин Д. М. Язык программирования Си для персонального компьютера. — М.: Радио и связь, 2011. — 384 с.
- Бобровский С. Самоучитель програмирования на языке C++ в среде Borland C++ Builder М.: ИНФРА-М, 2011.–251 c.
- Бруно Бабэ. Просто и ясно о Borland C++: Пер. с англ. - Москва: БИНОМ, 2014. – 400с.
- Джосьютис Н. М. C++. Стандартная библиотека. Для профессионалов: Пер. с англ. — СПб.: Питер, 2014. — 730 с.
- Керниган Б. В., Ритчи Д. М. Язык программирования Си: Пер. с англ. — 3-е изд. — СПб.: Невский Диалект, 2011. — 352 с.
- Липпман С. Б. Основы программирования на C++: Пер. с англ. — М.: Вильямс, 2012. — 256 с.
- Липпман С. Б., Лажойе Ж. Язык программирования С++. Вводный курс: Пер. с англ. — 3-е изд. — М.: ДМК, 2011. — 1104 с.
- Лишнер Р. STL. Карманный справочник: Пер. с англ. — СПб.: Питер, 2015. — 187 с.
- Мейерс С. Эффективное использование STL: Пер. с англ. — СПб.: Питер, 2013. — 224 с.
- Оллисон Ч. Философия С++. Практическое программирование. С.Петербург 2014. – 608 с.:ил.
- ПоследБ.С. Borland C++ Builder 6. Разработка приложений баз. М.: 2013г. -360 г.
- Стенли Б. Липпман. C++ для начинающих: Пер. с англ. 2тт. - Москва: Унитех; Рязань: Гэлион, 2012. – 345с.
- Страуструп Б. Язык программирования C++: Пер. с англ. — 3-е спец. изд. — М.: Бином, 2013. — 1104 с.
- Страуструп Б. Дизайн и эволюция языка C++. Объектно- ориентированный язык программирования: Пер. с англ. — М.: ДМК пресс, Питер, 2013. — 448 с.

- Применение процессного подхода для оптимизации бизнес- процессов
- Особенности перевода английских фразеологизмов (Перевод фразеологических единиц)
- Понятие и виды источников права (Пути формирования источников права)
- Процессы принятия решений в организации («МИРАЖ»)
- Первичные учетные документы (Система документооборота первичных учётных документов)
- Страхование и его роль в развитии экономики (Проблемы развития страхового рынка)
- Транспортный налог (ООО «Спецпожсервис»)
- Конкурентные стратегии фирм на внутреннем и/или мировом рынках;
- анализ системы мотивации персонала
- Анализ внешней и внутренней среды организации(Жизненный цикл ООО «Соломон»)
- Организационная культура и ее роль в современных организациях (Теоретическая характеристика понятия организационной культуры))
- Языки гипертекстовой разметки (Язык Java)