
Распределенные системы обработки информации (Понятие информации и данных )
Содержание:

ВВЕДЕНИЕ
С самого начала развития вычислительной техники образовались два основных направления ее использования. Первое направление – это применение вычислительной техники для выполнения численных расчетов, которые слишком долго или вообще невозможно производить вручную. Становление этого направления способствовало интенсификации методов численного решения сложных математических задач, развитию класса языков программирования, ориентированных на удобную запись численных алгоритмов, становлению обратной связи с разработчиками новых архитектур.
Второе направление - это использование средств вычислительной техники в автоматических или автоматизированных информационных системах. В самом широком смысле информационная система представляет собой программный комплекс, функции которого состоят в поддержке надежного хранения информации в памяти компьютера, выполнении специфических для данного приложения преобразований информации и/или вычислений, предоставлении пользователям удобного и легко осваиваемого интерфейса.
Обычно объемы информации, с которыми приходится иметь дело таким системам, достаточно велики, а сама информация имеет достаточно сложную структуру.
Для упорядоченного хранения и обработки больших объемов информации информационная система требует создания динамически обновляемой модели внешнего мира с использованием единого хранилища – базы данных. База данных обеспечивает хранение информации и представляет собой поименованную совокупность данных, организованных по определенным правилам, включающим общие принципы описания, хранения и манипулирования данными.
Объектом данной курсовой работы являются информационные системы.
Предмет работы – модели данных.
Целью курсовой работы является изучение основных моделей представления данных в информационных системах.
Для достижения указанной цели необходимо решение следующих задач:
- дать определение понятию информации и данных;
- рассмотреть понятие и сущность информационной системы;
- дать характеристику основным моделям представления данных в информационных системах: абстрактной, реляционной, иерархической, сетевой, постреляционной, многомерной и объектно-ориентированной.
Теоретической основой для написания курсовой работы послужили труды таких отечественных и зарубежных авторов как А.В. Васильков, А.А. Васильков, И.А. Васильков, Т.Я. Данелян, К.Дж. Дейт, В.Н. Редько, И.Г. Семакин и других.
При написании курсовой работы применялись следующие методы научного исследования: анализ литературынх источников по теме работы, синтез полученной информации, обобщение, моделирование, табличный и графический методы представления информации.
Структура курсовой работы включает в себя введение, две главы, заключение и список использованных источников.
ГЛАВА 1. ПОНЯТИЕ ДАННЫХ И ИНФОРМАЦИОННЫХ СИСТЕМ
1.1 Понятие информации и данных
Информация - это сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состояниях, которые уменьшают имеющуюся о них степень неопределенности, неполноты знаний [4, с. 29].
Информатика рассматривает информацию как связанные между собой сведения, изменяющие наши представления о явлении или объекте окружающего мира. С этой точки зрения информацию можно рассматривать как совокупность знаний о фактических данных и зависимостях между ними.
В процессе обработки информация может менять структуру и форму. Признаком структуры являются элементы информации и их взаимосвязь. Формы представления информации могут быть различны. Основными из них являются: символьная (основана на использовании различных символов), текстовая (текст - это символы, расположенные в определенном порядке), графическая (различные виды изображений), звуковая.
В повседневной практике такие понятия, как информация и данные, часто рассматриваются как синонимы. На самом деле между ними имеются различия. Данными называется информация, представленная в удобном для обработки виде. Данные могут быть представлены в виде текста, графики, аудио-визуального ряда. Представление данных называется языком информатики, представляющим собой совокупность символов, соглашений и правил, используемых для общения, отображения, передачи информации в электронном виде.
1.2 Понятие и сущность информационной системы
Информационная система (ИС) – это организационная совокупность технических и обеспечивающих средств, технологических процессов и кадров, реализующих функции сбора, обработки, хранения, поиска, выдачи и передачи информации.
Основной целью создания ИС является «удовлетворение информационных потребностей пользователей путем предоставления необходимой им информации на основе хранимых данных» [2, с. 8].
ИС применяется практически во всех сферах человеческой деятельности: в управлении предприятием, учреждением, производством; при организации научных исследований; в библиотечном деле, в обучении, при выполнении конструкторских и проектных работ.
Современной формой ИС являются банки данных, которые включают в свой состав вычислительную систему, одну или несколько баз данных, систему управления базами данных и набор прикладных программ. Основными функциями банков данных являются:
- хранение данных и их защита;
- изменение (обновление, добавление и удаление) хранимых данных;
- поиск и отбор данных по запросам пользователей;
- обработка данных и вывод результатов.
База данных (БД) – это именованная совокупность данных, отражающая состояние объектов и их отношений в конкретной предметной области.
«Система управления базами данных (СУБД) – совокупность языковых и программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями» [2, с. 7].
Прикладные программы (приложения) в составе банков данных служат для обработки данных, вычислений и формирования выходных документов по заданной форме.
Процесс создания ИС обычно включает следующие этапы:
- проектирование БД;
- создание БД (формирование и связывание таблиц, первичный ввод данных);
- создание меню, форм, запросов и отчетов;
- создание приложения.
Приведенный перечень этапов не является строгим в смысле очередности и обязательности. Процесс создания ИС, как правило, имеет итерационный характер.
Приложение представляет собой программу или комплекс программ, использующих БД и обеспечивающих автоматизацию обработки информации из некоторой предметной области. Приложения могут создаваться как в среде СУБД, так и вне СУБД – с помощью системы программирования, использующей средства доступа к БД.
Для работы с БД во многих случаях можно обойтись только средствами СУБД, создавая запросы и отчеты. Приложения разрабатывают главным образом в тех случаях, когда требуется обеспечить удобство работы с БД неквалифицированным пользователям или интерфейс СУБД не устраивает пользователя.
ГЛАВА 2. МОДЕЛИ ПРЕДСТАВЛЕНИЯ ДАННЫХ В ИНФОРМАЦИОННЫХ СИСТЕМАХ
2.1 Абстрактная модель представления данных
Как правило, данные (факты, значения) и их интерпретация (семантика) фиксируются совместно, так как естественный язык достаточно гибок для представления того и другого. Пример: «рост 180 см», «180» – данное, а его семантика – «рост в см». При компьютерной обработке данные отделяются от их интерпретации, что и приводит к понятию модели данных.
Модель данных – это абстрактное логическое определение объектов, операторов и других элементов, в совокупности составляющих абстрактную машину, с которой взаимодействуют пользователи. Объекты позволяют моделировать структуру данных, а операторы – моделировать поведение данных.
В стандарте ISO 11179 приведено следующее определение: «модель данных (data model) - графическое и (или) словесное представление данных, задающее их структуру и взаимосвязи» [1].
Модель данных можно рассматривать как сочетание трех компонентов:
- структурная часть – набор правил, по которым может быть построена база данных;
- управляющая часть – определяет типы допустимых операций с данными, таких как обновление и извлечение данных, а также модификация структуры данных;
- набор ограничений поддержки целостности данных, гарантирующих корректность используемых данных [11, с. 53].
Модель данных – это средство абстракции, которое дает возможность увидеть информационное содержание данных («лес»), а не конкретные значения данных («отдельные деревья»).
Рассмотрим модель реального мира и свойства, которые она отображает. Эти свойства делятся на два класса:
1) статические – свойства инвариантны ко времени, всегда справедливы и неизменны;
2) динамические – свойства соответствуют эволюционной природе мира.
Определим модель данных M как множество правил порождения G и множество операций OР:
M = < G, OР > .
Множество правил порождения выражает статические свойства модели данных и соотносится с языком описания данных (ЯОД). Средствами ЯОД определяются допустимые структуры данных – объекты и связи, а также допустимые реализации данных.
В некоторых моделях правила порождения G разделяются на два вида:
Gs – правила порождения структур,
Gc – правила порождения ограничений.
Пример: в СУБД Access для объекта «автомобиль» атрибут «гос. номер» является ключом. Тогда Gs (правило порождения структур) имеет вид: атрибут «гос. номер» принадлежит объекту «автомобиль». А Gc (правило порождения ограничений) имеет вид: значения атрибута «гос. номер» не должны повторяться.
Динамические свойства выражаются множеством операций OP, которые соотносятся с языком манипулирования данными (ЯМД). Множество операций определяет допустимые действия над реализацией БД Di для преобразования ее в другую реализацию БД Dj :
{ Di, OP} → Dj .
При проектировании баз данных для различных ИС используются три основные модели представления данных: реляционная модель, иерархическая модель, сетевая модель. Так же применяются постреляционная, многомерная и объектно-ориентированная модели.
2.2 Реляционная модель представления данных
Реляционная модель представления данных построена на системе отношений. Название идет от английского слова relation – отношение. Автором модели является E. Codd (Е. Кодд). В реляционной модели используются понятия отношение – атрибут. Объект представляется в виде отношения, а его свойства – в виде совокупности атрибутов. Базу данных можно представить в следующем виде:
R1 (A11, A12,..., A1N1)
R2 (A21, A22,..., A2N2)
. . .
Rm (Am1, Am2,..., AmNm)
где Ri, i = 1,m – множество отношений, Aij , i= 1,m , j = 1, Ni – множество атрибутов. Экземпляр каждого отношения представляется в виде таблицы. Совокупность всех значений одного атрибута называется доменом. Строка в таблице называется кортежем. Практически это описание всех используемых свойств реального объекта.
Основной особенностью реляционной модели является то, что связи между кортежами представлены исключительно значениями данных в столбцах, полученных из общего домена. Обработка отношений осуществляется с помощью операций реляционной алгебры, предложенных Е. Коддом. Кроме того, можно использовать традиционные операции над множествами [8, с. 104].
В качестве примера представления данных в виде реляционной модели рассмотрим описание объекта «студент». Пусть R – отношение «студент», которое включает следующие атрибуты: A1 – номер зачетки, A2 – фамилия студента, A3 – дата рождения, A4 – номер группы. В таблице 1 представлен экземпляр рассматриваемого отношения.
Таблица 1
Отношение R
|
А1 |
А2 |
А3 |
А4 |
|
224596 |
Иванов |
11.03.2001 |
АБ-11-02к |
|
327845 |
Петров |
25.11.2000 |
ВБ-14-01а |
|
623212 |
Сидоров |
13.01.2001 |
АБ-11-02к |
|
… |
… |
… |
|
|
112536 |
Васин |
14.07.2002 |
ВБ-14-01а |
К достоинствам реляционной модели относятся простота и наглядность представления данных; наличие теоретического обоснования, так как модель основана на хорошо проработанной теории отношений; наличие математического аппарата – реляционной алгебры. К недостаткам модели относится сложность реализации связей 1 : М и М : М, которая ведет к дублированию данных.
Примеры СУБД для реляционной модели: dBase, DB2, R:Base, FoxBase, FoxPro, Visual Foxpro, Clarion, Paradox, Access, Ingress, Oracle, ПАЛЬМА (ИК АН УССР), HyTech (МИФИ) и др.
2.3 Иерархическая модель представления данных
Рассмотрим, как можно представить данные, подлежащие хранению в БД, с помощью иерархической модели (рис. 1).
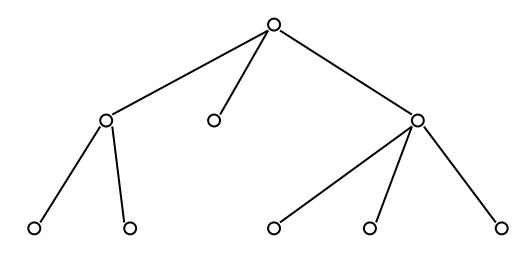
Рисунок 1 - Представление данных в виде иерархической модели [7, с. 61]
В иерархической модели связь между данными является иерархической с четко установленными уровнями вложенности. Данные представляются в виде поле – сегмент – запись. С помощью сегментов описываются объекты предметной области. Сегмент состоит из множества полей, которые описывают свойства объектов. Запись представляет собой полную совокупность иерархически упорядоченных сегментов на всем иерархическом пути. Всегда имеется один корневой сегмент.
Между сегментами существует связь «исходный - порожденный», которая может быть взаимосвязью 1 : 1 или 1: М. В иерархической модели представление данных подчиняется следующим правилам:
1) каждая запись содержит только один корневой сегмент;
2) корневой сегмент может иметь произвольное число порожденных сегментов;
3) каждый порожденный сегмент имеет только один исходный сегмент и множество порожденных сегментов (на практике до 15 уровней вложенности и до 255 типов сегментов в одной записи).
В качестве примера рассмотрим базу данных «Обучение», в которой будет представлено 5 сегментов: «курс», «предварительный курс», «цикл занятий», «преподаватель», «студент». Структура БД для иерархической модели представлена на рисунке 2. Экземпляр одной записи для этой БД представлен на рисунке 3. Практически запись представляется в виде дерева.
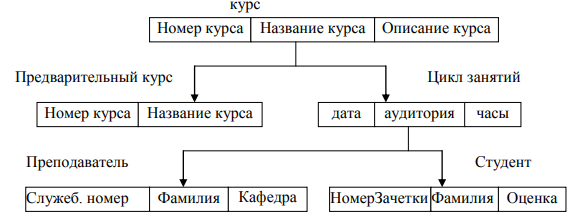
Рисунок 2 - Структура БД «Обучение» для иерархической модели [7, 63]
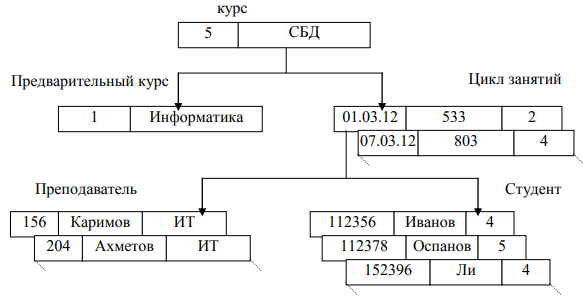
Рисунок 3 - Экземпляр записи для иерархической модели [7, с. 63]
Иерархическая база данных представляет собой упорядоченную совокупность экземпляров данных типа «дерево», содержащих экземпляры типа «запись». Часто отношения родства между типами переносятся на отношения между самими записями. Обход всех элементов иерархической БД обычно производится сверху вниз и слева направо. Команды ЯОД для иерархической модели включают операторы по описанию базы данных, сегментов и полей. Команды ЯМД для иерархической модели содержат операторы, организующие поиск (например, «дать уникальный» - специфицирует путь от экземпляра корневого сегмента до искомого сегмента, «дать следующий», «дать следующий под исходным»), включение нового сегмента, удаление сегмента, замену сегмента и др.
При выполнении ряда операций, таких как включение и удаление, возникают трудности. При удалении, например, будут удалены экземпляры всех подчиненных сегментов. К достоинствам иерархической модели относятся простота понимания и использования, наличие хорошо зарекомендовавших себя СУБД, простота оценки операционных характеристик благодаря заранее заданным взаимосвязям. К недостаткам модели относится трудность организации выполнения таких операций как включение, добавление и удаление данных, возможность доступа к любому сегменту только через все предшествующие сегменты включая обязательно корневой сегмент и другие проблемы, связанные со спецификой модели.
Примеры СУБД для иерархической модели: IMS, PC/FOCUS, Team-Up, Data Edge, Adabas, ОКА, ИНЭС, МИРИС и др.
2.4 Сетевая модель представления данных
Рассмотрим, как можно представить данные, подлежащие хранению в БД, с помощью сетевой модели (рис. 4).
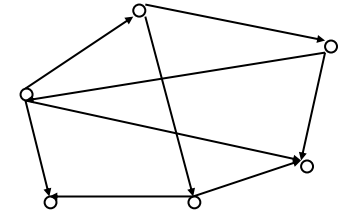
Рисунок 4 - Представление данных в виде сетевой модели [7, с. 85]
В сетевой модели используются понятия элемент – запись – набор и успешно реализуется взаимосвязь М : М. Объект описывается в виде записи, а его свойства – в виде совокупности элементов, составляющих запись. Набор служит для организации связей между записями. Каждая порожденная запись может иметь более одной исходной записи. Сетевая структура бывает простой или сложной в зависимости от того, какова связь «исходный – порожденный», может содержать циклы. Сеть по сравнению с иерархией является более общей структурой.
Введем понятие набора. Если m – отображение вида М : 1 записей типа R в записи типа S, то с каждой записью r типа R можно ассоциировать множество Sr записей s типа S таким образом, что m(s)=r . Тогда каждое множество Sr вместе с записью r называется экземпляром набора. Запись r называется владельцем набора, а каждая запись s такая, что m(s)=r – членом этого набора.
Приведем пример набора (рис. 5). Между записью типа R и записью типа S имеется взаимосвязь 1: М. В экземпляр набора для записи-владельца r1 как члены набора входят записи-члены s1 и s2 (множество Sr1). В экземпляр набора для записи-владельца r2 как члены набора входят записи-члены s1, s5 и s11 (множество Sr2)
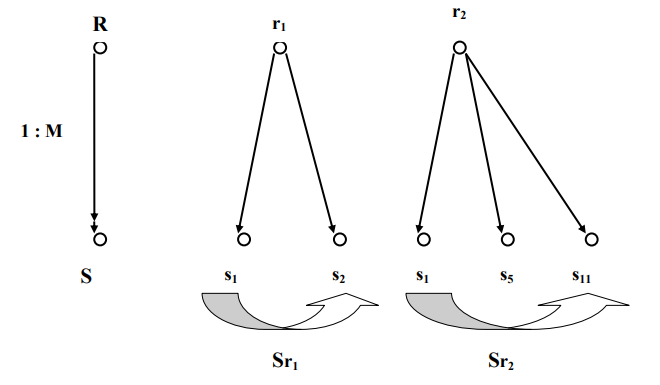
Рисунок 5 - Пример набора [7, с. 89]
Рассмотрим в качестве примера БД «Поставляемые изделия». Имеются три записи: 1) запись P «поставщик» с элементами «Номер поставщика», «Фамилия», «Город»; 2) запись IZ «Изделие» с элементами «Номер изделия», «Название», «Цвет», «Завод»; 3) запись PC «Поставка» с элементами «Номер поставщика», «Номер изделия», «Количество». Для реализации взаимосвязей создано два набора: набор P-PC – «Поставщик - Поставка»; набор IZ-PC – «Изделие - Поставка». Структура этой базы данных в виде сетевой модели представлена на рисуноке 6.
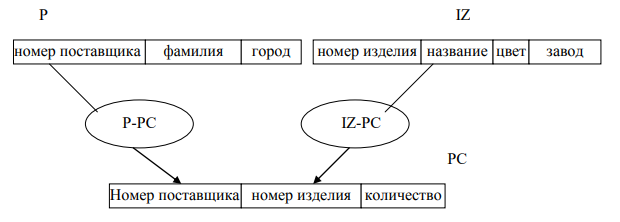
Рисунок 6 - Структура БД «Поставляемые изделия» [7, с. 90]
К достоинствам сетевой модели относится простота реализации взаимосвязи М : М, разделение данных и связей, легкость выполнения операций включения и удаления. К недостаткам относится сложность представления данных как на логическом, так и на физическом уровне, сложность программ при реализации СУБД для сетевой модели.
Примеры СУБД для сетевой модели: IDMS, СЕТЬ, db-Vista, СЕТОР, КОМПАС и др.
2.5 Постреляционная модель представления данных
Постреляционная модель представления данных является расширенной реляционной моделью, в которой снято ограничение неделимости данных, хранящихся в записях таблиц БД. В постреляционной модели допускаются многозначные поля, значения в которых являются множеством. Набор значений многозначных полей является самостоятельной таблицей, встроенной в основную таблицу. В таблице 2 приведен пример представления данных в виде постреляционной модели.
Таблица 2
Пример данных в виде постреляционной модели
|
Код заказа |
Фамилия клиента |
Наименование товара |
Стоимость за единицу товара |
Количество товара |
|
95 |
Иванов |
стул стол |
2000 7000 |
2 1 |
|
96 |
Петров |
шкаф-купе |
37000 |
1 |
|
97 |
Сидоров |
прикроватная тумба |
9700 |
2 |
В постреляционной модели данные хранятся более эффективно по сравнению с реляционной моделью. При обработке не требуется выполнять операцию «соединение» для двух таблиц. Кроме того, в постреляционной модели поддерживаются ассоциированные многозначные поля (множественные группы). Совокупность ассоциированных полей называется ассоциацией. В строке таблицы первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. В постреляционной модели на длину и количество полей в записях таблицы не накладывается требование постоянства, что делает структуру данных и таблиц более гибкой.
В постреляционной модели допускается хранение в таблицах БД ненормализованных данных, вследствие чего возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается путем включения в СУБД на основе постреляционной модели инструментов, подобных хранимым процедурам в клиент-серверных системах. Для поддержки функций контроля значений в полях таблиц БД создаются специальные процедуры – коды конверсии и коды корреляции, которые автоматически запускаются на обработку как до, так и после обращения к данным. При этом коды корреляции выполняются сразу после чтения данных, перед их обработкой, а коды конверсии выполняются сразу после обработки данных [12, с. 65].
Достоинства постреляционной модели: возможность представления совокупности связанных реляционных таблиц в виде одной постреляционной таблицы; высокая наглядность представления информации; повышение эффективности обработки данных в БД. Недостатки постреляционной модели: сложность решения проблемы обеспечения целостности и непротиворечивости данных.
Примеры СУБД на основе постреляционной модели: uniVers, Bubba, Dasdb и др.
2.6 Многомерная модель представления данных
Многомерная модель представления данных появилась почти одновременно с реляционной моделью, но интерес к этой модели возрос только с середины 90-ых годов прошлого столетия. Codd E. опубликовал статью (1993 г.), в которой сформулировал 12 основных принципов к системам класса OLAP (OnLine Analytical Processing – оперативная аналитическая обработка), важнейшие из которых связаны с возможностями концептуального представления и обработки многомерных данных. Системы с использованием многомерной модели позволяют оперативно обрабатывать информацию для проведения анализа и принятия решений.
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными. По сравнению с реляционной моделью многомерная модель обладает более высокой наглядностью и информативностью. В таблицах 3 и 4 приведены соответственно реляционное и многомерное представления одних и тех же данных.
Таблица 3
Данные в виде реляционной модели
|
Модель телефона |
Месяц |
Объем продаж |
|
Samsung Galaxy J5 |
июнь |
70 |
|
Samsung Galaxy J5 |
июль |
60 |
|
Samsung Galaxy J5 |
август |
50 |
|
Microsoft Lumia 650 |
июнь |
20 |
|
Microsoft Lumia 650 |
июль |
35 |
|
LG K10 K430n |
июль |
45 |
Таблица 4
Данные в виде многомерной модели
|
Модель телефона |
июнь |
июль |
август |
|
Samsung Galaxy J5 |
70 |
60 |
50 |
|
Microsoft Lumia 650 |
20 |
35 |
- |
|
LG K10 K430n |
- |
45 |
- |
В развитии концепции информационных систем можно выделить два направления:
- системы оперативной (транзакционной) обработки – такие ИС создаются на основе баз данных, построенных на реляционной модели;
- системы аналитической обработки (системы поддержки принятия решений) – такие ИС создаются на основе баз данных, построенных на многомерной модели, которая обеспечивает более эффективную обработку данных [8, с. 122].
СУБД на основе многомерной модели данных предназначены для интерактивной аналитической обработки информации. Здесь используют такие основные понятия, как агрегируемость, историчность и прогнозируемость данных.
Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. В ИС степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользовательоператор, менеджер, руководитель.
Историчность данных предполагает обеспечение высокого уровня статичности (неизменности) собственно данных и их взаимосвязей, а также обязательную привязку данных к времени. Статичность данных позволяет использовать при их обработке специализированные методы хранения, загрузки, индексации и выборки. Привязка данных к времени необходима, поскольку запросы, как правило, содержат в критерии на выборку данных время и дату.
Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Основными понятиями многомерной модели данных являются:
- показатель – это величина (обычно числового типа), которая собственно и является предметом анализа. Это, например, объем продаж некоторого товара, или выручка от продаж товара. Один OLAP-куб может обладать одним или несколькими показателями;
- измерение (dimension) – это множество объектов одного или нескольких типов, организованных в виде иерархической структуры и обеспечивающих информационный контекст числового показателя. Измерение принято визуализировать в виде ребра многомерного куба;
- члены измерений (members) – объекты, совокупность которых и образует измерение. Члены измерений визуализируют как точки или участки, откладываемые на осях гиперкуба. Например, временное измерение: день, месяц, квартал, год – наиболее часто используются в анализе, может содержать следующие члены: 28 ноября 2018 года, ноябрь 2018 года, четвертый квартал 2018 года и 2018 год. Объекты в измерениях могут быть различного типа, например, «производители – марки автомобиля» или «годы – кварталы»;
- ячейка (cell) – атомарная структура куба, соответствующая конкретному значению некоторого показателя. Ячейки при визуализации располагаются внутри куба. Здесь же принято отображать соответствующее значение показателя [8, с. 130].
Пример многомерной модели данных представлен на рисунке 7. Для многомерной модели с мерностью больше двух необязательно информацию представлять в виде многомерных объектов (трех-, четырех- и более мерных гиперкубов). Пользователю зачастую более удобно иметь дело с двухмерными таблицами, которые представляют собой «срезы» многомерных данных, выполненные с разной степенью детализации.
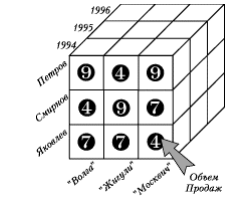
Рисунок 2.7 - OLAP-куб c тремя измерениями [3, с. 211]
В многомерных СУБД применяют два основных варианта организации данных (схемы):
1) поликубическую схему, когда в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней;
2) гиперкубическую схему, когда в БД все показатели определяются одним и тем же набором измерений; при наличии нескольких гиперкубов все они имеют одинаковую размерность и совпадающие измерения.
Для многомерной модели применяют ряд специальных операций.
1) «Срез» (Slice) –представляет собой подмножество гиперкуба, полученное в результате фиксации одного или нескольких измерений. Формирование срезов выполняется для ограничения используемых пользователем значений, поскольку все значения гиперкуба практически никогда одновременно не используются. Пример: если ограничить значения измерения «модель авто» в гиперкубе (рис. 7) маркой «Жигули», то получится двухмерная таблица продаж этой марки различными менеджерами по годам (табл. 5).
Таблица 5
Продажи автомобилей «Жигули»
|
Продавец \ год |
1994 |
1995 |
1996 |
|
Петров |
4 |
10 |
2 |
|
Смирнов |
9 |
3 |
8 |
|
Яковлев |
7 |
5 |
6 |
2) «Вращение» (Rotate) – применяется при двухмерном представлении данных. Суть операции заключается в изменении порядка следования измерений при визуальном представлении данных. Пример: «вращение» (табл. 4) приведет к изменению вида таблицы таким образом, что по оси Х будет марка телефона, а по оси Y – месяцы. Эту операцию можно обобщить и на многомерный случай, если под ней понимать процедуру изменения порядка следования измерений.
3) «Агрегация» (Drill Up) – переход к более общему порядку представления информации пользователю из гиперкуба. Пример: пусть имеется гиперкуб с измерениями: Год, Менеджер, Модель авто, Подразделение, Регион, Фирма, Страна. В этом случае в гиперкубе существует иерархия (снизу вверх) отношений между измерениями:
Менеджер
Подразделение
Регион
Фирма
Страна
Пусть в гиперкубе определено, насколько успешно менеджер Петров в 1995 году продавал автомобили марки «Жигули» и «Волга». Тогда, поднимаясь на уровень выше по иерархии, с помощью операции «агрегация» можно выяснить, как выглядит соотношение продаж этих же марок на уровне подразделения, где работает Петров.
4) «Детализация» (Drill Down) – переход к более детальному представлению информации пользователю из гиперкуба. Эта операция противоположна «агрегации».
Достоинства многомерной модели: удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных в реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размера базы данных и существенное увеличение затрат оперативной памяти на хранение индексных файлов. Недостатки многомерной модели: громоздкость модели для простейших задач обычной оперативной обработки информации.
Примеры СУБД, поддерживающих многомерную модель: Essbase (Arbor Software), Media Multi-matrix (Speedware), Oracle Express Server (Oracle), Cache (InterSystems) и др. Некоторые системы, например, Media Multi-matrix, позволяют одновременно работать с многомерными и реляционными БД. С СУБД Cache, где внутренней моделью является многомерная модель, реализованы три способа доступа к данным: прямой (на уровне узлов многомерных массивов), объектный и реляционный.
2.7 Объектно-ориентированная модель представления данных
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи БД. Между записями БД и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, аналогичных подобным средствам в объектно-ориентированных языках программирования.
Стандартизированная объектно-ориентированная модель описана в рекомендациях стандарта ODMG-93 (Object Database Management Group – группа управления объектно-ориентированными БД). Рассмотрим несколько упрощенную объектно-ориентированную модель, поскольку в полном объеме рекомендации ODMG-93 пока не реализованы.
Структура объектно-ориентированной БД графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом (например, string) или типом, создаваемым пользователем (определяется как class). Значением свойства типа string является строка символов. Значением свойства типа class является объект, представляющий собой экземпляр соответствующего класса. Каждый объект- экземпляр класса считается потомком объекта, в котором он определен как свойство. Объект - экземпляр класса принадлежит своему классу и имеет одного родителя. Родовые отношения в объектно-ориентированной БД образуют связную иерархию объектов.
Пример логической структуры объектно-ориентированной БД для предметной области «Обслуживание в библиотеке» представлен на рис. 8.
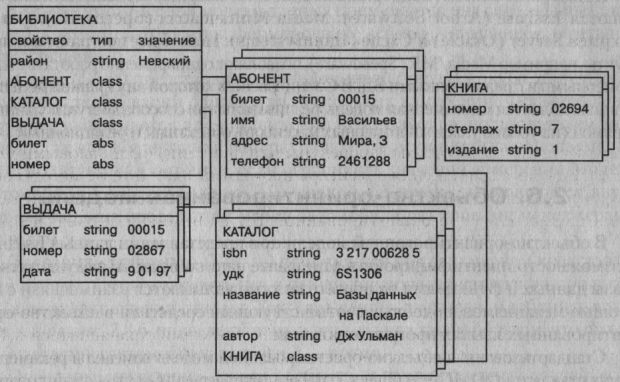
Рисунок 2.8 - Логическая структура объектно-ориентированной БД [5, с. 160]
Объект «Библиотека» является родителем для объектов- экземпляров классов «Абонент», «Каталог» и «Выдача». Различные объекты типа «Книга» могут иметь одного или разных родителей. Объекты типа «Книга», имеющие одного и того же родителя, должны различать по крайней мере номером (уникален для каждого экземпляра книги), но могут иметь одинаковые значения свойств isbn, удк, название и автор.
Логическая структура объектно-ориентированной БД внешне похожа на структуру иерархической БД. Основное отличие между ними заключается в методах манипулирования данными. Для выполнения действий над данными в объектно-ориентированной БД применяются логические операции, усиленные объектно-ориентированными механизмами инкапсуляции, наследования и полиморфизма. Создание и модификация БД сопровождается автоматическим формированием и последующей корректировкой индексов, содержащих информацию для быстрого поиска данных.
Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Так, если в объект типа «Каталог» добавить свойство телефон для автора книги, то мы получим одноименные свойства у объектов «Каталог» и «Абонент». Смысл такого свойства будет определяться тем объектом, в котором оно инкапсулировано.
Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта. Так, всем объектам типа «Книга», являющимся потомками объекта типа «Каталог», можно приписать свойства объектародителя: isbn, удк, название и автор. Если необходимо расширить действие механизма наследования на объекты, не являющиеся непосредственными родственниками (например, между двумя потомками одного родителя), то в их общем предке определяется абстрактное свойство abs. Так, определение абстрактных свойств билет и номер в объекте «Библиотека» приводит к наследованию этих свойств всеми дочерними объектами «Абонент», «Каталог» и «Выдача». Именно поэтому значения свойства билет классов «Абонент» и «Выдача» одинаковые (00015 – на рис. 8).
Полиморфизм в объектно-ориентированных языках программирования означает способность одного и того же программного кода работать с разнотипными данными. Практически это означает, что в объектах разного типа можно иметь методы (процедуры, функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента. Применительно к объектно-ориентированной БД полиморфизм означает, что объекты класса «Книга», имеющие разных родителей из класса «Каталог», могут иметь разный набор свойств. Следовательно, программы работы с объектами класса «Книга» могут содержать полиморфный код.
Поиск в объектно-ориентированной БД заключается в выяснении сходства между объектом, задаваемым пользователем, и объектами, хранящимися в БД. Определяемый пользователем объект, называемый объектом-целью (свойство объекта имеет тип goal), в общем случае может представлять собой подмножество всей хранимой в БД иерархии объектов. Как объект-цель, так и результат выполнения запроса, могут храниться в БД.
Пример запроса о номерах читательских билетов и именах читателей, получивших в библиотеке хотя бы одну книгу, приведен на рисунке 9.
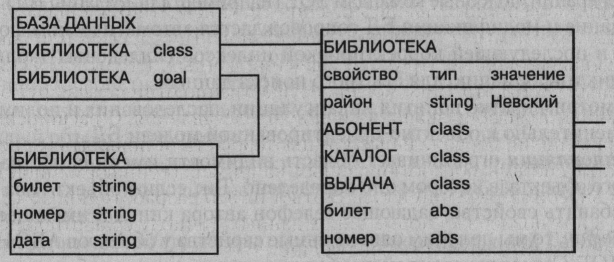
Рисунок 2.9 - Фрагмент БД с объектом-целью [5, с. 163]
Достоинства объектно-ориентированной модели: возможность отображения информации о сложных взаимосвязях объектов, возможность идентифицировать отдельную запись БД и определить для нее функции обработки. Недостатки объектно-ориентированной модели: высокая понятийная сложность, неудобство обработки данных, низкая скорость выполнения запросов.
СУБД на основе объектно-ориентированной модели: G-Base (Grapael), GemStone (Servio-Logic совместно с OGI), Statice (Symbolics), ObjectStore (Object Design), Objectivity/DB (Objectivity), Versant (Versant Technologies), O2 (Ardent Software), ODB-Jupiter (НПЦ «Интелтек Плюс»), Iris, Orion, Postgres и др.
ЗАКЛЮЧЕНИЕ
Таким образом, информационная система – это совокупность базы данных и всего комплекса аппаратно-программных средств для ее хранения, изменения и поиска информации, для взаимодействия с пользователем.
База данных является основой информационной системы, объект ее обработки. База данных (БД) является совокупностью сведений о конкретных объектах реального мира в какой-либо предметной области или ее разделе.
В информационных системах существуют различные модели представления данных.
Модель данных – это абстрактное логическое определение объектов, операторов и других элементов, в совокупности составляющих абстрактную машину, с которой взаимодействуют пользователи. Модель данных - это графическое и (или) словесное представление данных, задающее их структуру и взаимосвязи.
При проектировании баз данных для различных ИС используются три основные модели представления данных: реляционная модель, иерархическая модель, сетевая модель. Так же применяются постреляционная, многомерная и объектно-ориентированная модели.
К достоинствам реляционной модели относятся простота и наглядность представления данных; наличие теоретического обоснования, так как модель основана на хорошо проработанной теории отношений; наличие математического аппарата – реляционной алгебры. К недостаткам модели относится сложность реализации связей 1 : М и М : М, которая ведет к дублированию данных.
К достоинствам иерархической модели относятся простота понимания и использования, наличие хорошо зарекомендовавших себя СУБД, простота оценки операционных характеристик благодаря заранее заданным взаимосвязям. К недостаткам модели относится трудность организации выполнения таких операций как включение, добавление и удаление данных, возможность доступа к любому сегменту только через все предшествующие сегменты включая обязательно корневой сегмент и другие проблемы, связанные со спецификой модели.
К достоинствам сетевой модели относится простота реализации взаимосвязи М : М, разделение данных и связей, легкость выполнения операций включения и удаления. К недостаткам относится сложность представления данных как на логическом, так и на физическом уровне, сложность программ при реализации СУБД для сетевой модели.
Достоинства постреляционной модели: возможность представления совокупности связанных реляционных таблиц в виде одной постреляционной таблицы; высокая наглядность представления информации; повышение эффективности обработки данных в БД. Недостатки постреляционной модели: сложность решения проблемы обеспечения целостности и непротиворечивости данных.
Достоинства многомерной модели: удобство и эффективность аналитической обработки больших объемов данных, связанных со временем. При организации обработки аналогичных данных в реляционной модели происходит нелинейный рост трудоемкости операций в зависимости от размера базы данных и существенное увеличение затрат оперативной памяти на хранение индексных файлов. Недостатки многомерной модели: громоздкость модели для простейших задач обычной оперативной обработки информации.
Достоинства объектно-ориентированной модели: возможность отображения информации о сложных взаимосвязях объектов, возможность идентифицировать отдельную запись БД и определить для нее функции обработки. Недостатки объектно-ориентированной модели: высокая понятийная сложность, неудобство обработки данных, низкая скорость выполнения запросов.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. ГОСТ Р ИСО/МЭК 11179-1-2010 Информационная технология (ИТ). Регистры метаданных (РМД). Часть 1. Основные положения // [Электронный ресурс]. - Режим доступа: http://docs.cntd.ru/document/1200087954 (дата обращения: 04.09.2019).
2. Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2013. - 528 c.
3. Гвоздева, В.А. Информатика, автоматизированные информационные технологии и системы: Учебник / В.А. Гвоздева. - М.: ИНФРА-М, 2013. - 544 c.
4. Данелян, Т.Я. Экономические информационные системы (ЭИС) предприятий и организаций: Монография. / Т.Я. Данелян. - М.: ЮНИТИ, 2015. - 284 c.
5. Дейт, К.Дж. Введение в системы баз данных / К.Дж. Дейт; пер. с англ. В.В. Егорова. - изд. 6-е, перераб. и доп. - К.: Диалектика, 2015. - 784 c.
6. Корпоративные информационные системы управления: Учебник / Под науч. ред. Н.М. Абдикеева, О.В. Китовой. – М.: ИНФРА-М, 2014. - 356 с.
7. Овчаров, Л.А. Автоматизированные банки данных / Л.А. Овчаров, С.Н. Селетков. - М.: Финансы и статистика, 2013. - 262 c.
8. Пирогов, В. Информационные системы и базы данных: организация и проектирование: Учебное пособие / В. Пирогов. - СПб.: BHV, 2013. - 528 c.
9. Поляков, В.П. Информатика для экономистов: учебник для бакалавров / под ред. В.П. Полякова. – М.: Юрайт, 2013. - 411 с.
10. Редько, В.Н. Базы данных и информационные системы / В.Н. Редько, И.А. Басараб. - М.: Знание, 2017. - 341 c.
11. Семакин, И.Г. Основы программирования и баз данных: Учебник / И.Г. Семакин. - М.: Академия, 2014. - 224 c.
12. Фуфаев, Э.В. Базы данных: Учебное пособие / Э.В. Фуфаев, Д.Э. Фуфаев. - М.: Академия, 2012. - 320 c.

- Анализ фитнес корпорации “World Class”
- Инновационные модели бизнес-предприятия
- Международные стандарты гостиничного обслуживания.
- Особенности политики мотивации персонала корпораций ( «Домашние деньги»)
- «Статус нотариуса» . .
- Разработка Интернет магазина занимающегося предоставлением услуг туристического комплекса через Интернет
- Управление рентабельностью организаций гостиничного, ресторанного бизнеса (ГЛАВА 1. ТЕОРЕТИЧЕСКИЕ АСПЕКТЫ УПРАВЛЕНИЯ РЕНТАБЕЛЬНОСТЬЮ В ГОСТИНИЧНОМ И РЕСТОРАННОМ БИЗНЕСЕ)
- Управление эффективностью организации гостиничного (ресторанного ) бизнеса
- Проведение маркетингового исследования реально существующей организации ( ЗАО «Тандер»)
- Устройство Компьютера
- Проектный офис, принципы и этапы формирования (Характеристика понятий «проект» и «проектный офис»)
- Анализ масштаба и потенциала рынка