
Применение алгоритмов поиска в массивах
Содержание:

ВВЕДЕНИЕ
Актуальность данной работы состоит в том, что на сегодняшний день больше половины жителей планеты земля пользуются компьютером. Большая часть из них начинают свою работу с поиска необходимой информации в различных источниках, будь то интернет, базы данных или поиск файлов на локальном диске, и если время поиска увеличить хотя бы на секунду, то общее время, затраченное всеми пользователями на поиск необходимой информации перевалит за 200 лет. Поэтому так важно разрабатывать, поддерживать и внедрять такие алгоритмы поиска, которые позволят сократить время поиска до минимума. По словам вице-президента по инфраструктуре Google Урса Хельцле: «У нас есть одно простое правило, чтобы поддержания скорости: не запускайте функции, которые замедляют процесс поиска. Можно изобрести отличный новый алгоритм, но если он замедляет поиск, вам придется либо забыть о нем, либо исправить его, либо придумать другое изменение, которое более чем компенсирует замедление. У нас есть то, что мы называем "фиксированным бюджетом задержки", который похож на семейный бюджет. Если вы хотите поехать в более приятный отпуск, но ваш бюджет не растягивается, вам нужно сократить его где-то еще».
Именно по этой причине во многих уважающих себя компаниях по разработке программного обеспечения, особое внимание отводится скорости работы программного обеспечения в общем и разработке эффективных поисковых алгоритмов в частности, постоянно отслеживается производительность, чтобы команда разработчиков могла видеть уровни задержки в сервисах. Вот почему несколько лет назад, когда все начало замедляться, основной упор был сделан на то, чтобы делать продукты быстрее. Скорость - это важная часть инженерной культуры.
Основой быстрого поиска является разработка эффективных поисковых алгоритмов, позволяющих не только быстро найти информацию, но и сделать так, чтобы данная информация соответствовала запросу, поэтому целью данной курсовой работы является изучение и анализ поисковых алгоритмов.
Для достижения поставленной цели в курсовой работе необходимо решить следующие задачи:
- Изучить виды поисковых алгоритмов в матрице
- Понять какие должны быть входные данные и как обработать полученные результат
- Реализовать изученные алгоритмы в программном коде.
- Сделать анализ алгоритма.
- Найти наиболее эффективный алгоритм поиска.
При написании курсовой работы использовалась специализированная литература следующих авторов: Джордж Хайнеман [1], Готтшлинг П. [2], Страуструп Б. [4]
1. ОСНОВНЫЕ ВИДЫ АЛГОРИТМОВ ПОИСКА В МАССИВАХ
1.1 Последовательный поиск
Последовательный поиск (Sequential Search), называемый также линейным поиском, является самым простым из всех алгоритмов поиска. Это метод поиска одного значения в коллекции “в лоб”. Он находит значение, начиная с первого элемента коллекции и исследуя каждый последующий элемент до тех пор, пока не просмотрит всю коллекцию или пока соответствующий элемент не будет найден. Для работы этого алгоритма должен иметься способ получения каждого элемента из коллекции, в которой выполняется поиск; порядок извлечения значения не имеет. Часто элементы коллекции могут быть доступны только через итератору который предназначен только для чтения и получает каждый элемент из коллекции.
Входные данные представляют собой непустую коллекцию и целевое значение, которое мы ищем. Поиск возвращает true, если коллекция содержит целевое значение и false в противном случае.
Зачастую требуется найти элемент в коллекции, которая может быть не упорядочена. Без дополнительных знаний об информации, хранящейся в коллекции, последовательный поиск выполняет работу методом “грубой силы”. Это единственный алгоритм поиска, который можно использовать, если коллекция доступна только через итератор.
Если коллекция неупорядоченная и хранится в виде связанного списка, то вставка элемента является операцией с константным временем выполнения (он просто добавляется в конец списка). Частые вставки в коллекцию на основе массива требуют управления динамической памятью, которое либо предоставляется базовым языком программирования, либо требует определенного внимания со стороны программиста.
Последовательный поиск накладывает наименьшее количество ограничений на типы искомых элементов. Единственным требованием является наличие функции проверки совпадения элементов, необходимой для выяснения, соответствует ли искомый элемент элементу коллекции; часто эта функция возлагается на сами элементы.
1.2 Бинарный поиск
Бинарный (двоичный) поиск обеспечивает лучшую производительность, чем последовательный поиск, поскольку работает с коллекцией, элементы которой уже отсортированы. Бинарный поиск многократно делит отсортированную коллекцию пополам, пока не будет найден искомый элемент или пока не будет установлено, что элемент в коллекции отсутствует.
Входными данными для бинарного поиска является индексируемая коллекция, элементы которой полностью упорядочены, а это означает, что для двух индексов, i и j, A[i] < A[j] только тогда, когда i < j. Сроится структура данных, которая хранит элементы (или указатели на элементы) и сохраняет порядок ключей. Выходные данные бинарного поиска, как и последовательного поиска — true или false.
Для поиска по упорядоченной коллекции в худшем случае необходимо логарифмическое количество проб.
Бинарный поиск поддерживают различные типы структур данных. Если коллекция никогда не изменяется, элементы следует поместить в массив (это позволяет легко перемещаться по коллекции). Однако, если необходимо добавить или удалить элементы из коллекции, этот подход становится неудачным и требует дополнительных расходов. Есть несколько структур данных, которые мы можем использовать в этом случае одной из наиболее известных является бинарное дерево поиска.
1.3 Поиск на основе Хеша
Если требуются более мощные методы поиска в больших коллекциях, в которых данные не обязательно упорядочены, то одним из наиболее распространенных подходов к решению этой задачи является использование хеш-функции для преобразования одной или нескольких характеристик искомого элемента в индекс в хеш-таблице. Поиск на основе хеша (Hash-Based Search) имеет в среднем случае производительность, которая лучше производительности любого другого алгоритма поиска.
В поиске на основе хеша элементы коллекции сначала загружаются в хеш-таблицу, структурированными в виде массива. Этот шаг предварительной обработки имеет свою отдельную производительность, но улучшает производительность будущих поисков с использованием концепции хеш-функции.
Хеш-функция представляет собой детерминированную функцию, которая отображает каждый элемент коллекции целочисленным значением. При загрузке элементов в хеш-таблицу элемент коллекции вставляется в ячейку хеш-таблицы. После того как все элементы будут вставлены, поиск элемента коллекции становится поиском этого элемента в хеш-таблице.
Может случиться так, что несколько элементов в коллекции имеют одинаковые значения хеша. Такая ситуация называется коллизией, и хеш-таблице необходима стратегия для урегулирования подобных ситуаций. Наиболее распространенным решением является хранение в каждой ячейке связанного списка (несмотря на то, что многие из этих связанных списков будут содержать только один элемент); при этом в хеш-таблице могут храниться все элементы, вызывающие коллизии. Поиск в связанных списках должен выполняться линейно, но он будет быстрым, потому что каждый из них может хранить максимум несколько элементов. Общая схема поиска на основе хеша показана на рис. 1. Ее компонентами являются:
• множество U, которое определяет множество возможных хеш-значений. Каждый элемент е ∈ С отображается на хеш-значение h ∈ U;
• хеш-таблица Н, содержащая b ячеек, в которых хранятся n элементов из исходной коллекции С;
• хеш-функция hash, которая вычисляет целочисленное значение h для каждого элемента е, где 0 ≤ h < b.

рис. 1. Схема хеширования
Эта информация хранится в памяти с использованием массивов и связанных списков.
У поиска на основе хеша имеются две основные проблемы: разработка хеш-функции и обработка коллизий. Плохо выбранная хеш-функция может привести к плохому распределению ключей в первичной памяти с двумя последствиями: а) многие ячейки в хеш-таблице могут остаться неиспользованными и зря тратить память, и б) будет иметься много коллизий, когда много ключей попадают в одну и ту же ячейку, что существенно ухудшает производительность поиска.
В отличие от бинарного поиска при поиске на основе хеша исходная коллекция не обязана быть упорядоченной. Действительно, даже если элементы коллекции были некоторым образом упорядочены, метод хеширования, вставляющий элементы в хеш-таблицу не пытается в ней воспроизвести этот порядок.
Входными данными для поиска на основе хеша являются вычисленная хеш-таблица и искомый элемент. Алгоритм возвращает true, если искомый элемент имеется в связанном списке, хранящемся в хеш-таблице. Если искомый элемент в связанном списке, хранящемся в хеш-таблице отсутствует, возвращается значение false, указывающее, что искомого значения нет в хеш-таблице (и, таким образом, его нет в коллекции).
При поиске на основе хеша количество сравнений строк связано с длиной связанных списков, а не с размером коллекции. Сначала необходимо определить хеш-функцию. Цель заключается в том, чтобы получить как можно больше различных значений, но не все эти значения обязаны быть уникальными. Хеширование изучалось на протяжении десятилетий, и в многочисленных работах описано множество эффективных хеш-функций, но они могут использоваться для гораздо большего, чем простой поиск. Например, специальные хеш-функции имеют важное значение для криптографии. Для поиска хеш-функция должна обладать хорошим равномерным распределением и быть быстро вычисляемой за малое количество тактов процессора.
1.4 Фильтр Блума
Фильтр Блума предоставляет альтернативную структуру битового массива, которая обеспечивает константную производительность при добавлении элементов из коллекции в битовый массив или проверку того, что элемент не был добавлен в этот массив. Как ни удивительно, то поведение не зависит от количества элементов, уже добавленных в массив. Однако имеется и ловушка: при проверке, находится ли некоторый элемент в массиве, фильтр Блума может возвратить ложный положительный результату даже если на самом деле элемент в коллекции отсутствует. Фильтр Блума позволяет точно определить, что элемент не был добавлен в массив, поэтому никогда не возвращает ложный отрицательный результат.
На рис. 2 в битовый массив вставлены два значения u и v. Таблица в верхней части рисунка показывает позиции битов, вычисленные хеш-функциями. Как можно видеть, фильтр Блума в состоянии быстро определить, что третье значение w не было вставлено в массив, поскольку одно из его вычисляемых хеш-функциями значений битов равно нулю (в данном случае это бит 6). Однако для значения х фильтр возвращает ложный положительный результат, поскольку, несмотря на то что это значение не было вставлено в массив, все вычисляемые значения битов равны единице.
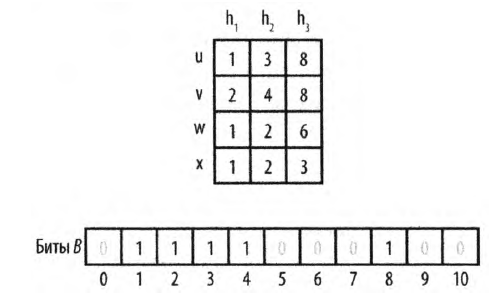
рис. 2. Фильтр Блума. Пример работы.
Фильтр Блума обрабатывает значения во многом так же, как и поиск на основе хеша. Алгоритм начинает работу с массива из битов, каждый из которых изначально равен нулю. Имеется несколько хеш-функций, вычисляющих при вставке значений (потенциально различные) позиции битов в этом массиве.
Фильтр Блума возвращает значение false, если может доказать, что целевой элемент еще не был вставлен в битовый массив и, соответственно, отсутствует в коллекции. Алгоритм может вернуть значение true, которое может быть ложным положительным результатом, если искомый элемент не был вставлен в массив.
Фильтр Блума демонстрирует эффективное использование памяти, но он полезен только тогда, когда допустимы ложные положительные результаты. Фильтр Блума используется для снижения количества дорогостоящих поисков путем отбрасывания тех, которые гарантированно обречены на провал, например, для подтверждения проведения дорогостоящего поиска на диске.
1.5 Бинарное дерево поиска
Бинарный поиск в массиве в памяти, как мы уже видели, достаточно эффективен. Однако, использование упорядоченных массивов становится гораздо менее эффективным при частых изменениях базовой коллекции. При работе с динамической коллекцией для поддержания приемлемой производительности поиска необходимо использовать иную структуру данных. Поиск на основе хеша может работать с динамическими коллекциями, но с целью эффективного использования ресурсов можно выбрать размер хеш-таблицы, который окажется слишком мал; зачастую нет априорного знания о количестве элементов, которые будут храниться в таблице, так что выбрать правильный размер хеш-таблицы оказывается очень трудной задачей. Кроме того, хеш-таблицы не позволяют обходить все элементы в порядке сортировки.
Альтернативной стратегией является использование дерева поиска для хранения динамических множеств данных. Деревья поиска хорошо работают как с первичной, так и со вторичной памятью и позволяют возвращать упорядоченные диапазоны элементов, на что не способны хеш-таблицы. Наиболее распространенным типом дерева поиска является бинарное дерево поиска (binary search tree — BST), которое состоит из узлов, как показано на рис. 3. Каждый узел содержит одно значение из множества и хранит ссылки на два (потенциальных) дочерних узла — левый (left) и правый (right).

рис. 3. Простое бинарное дерево поиска
Дерево поиска используется тогда, когда:
• требуется обход данных в возрастающем (или убывающем) порядке;
• размер множества данных неизвестен, а реализация должна быть в состоянии обработать любой возможный размер, помещающийся в памяти;
• множество данных — динамичное, с большим количеством вставок и удалений в процессе работы программы.
Входные и выходные данные для алгоритма с использованием деревьев поиска такие же, как и для бинарного поиска. Каждый элемент из коллекции, сохраняемый в бинарном дереве поиска, должен иметь одно или несколько свойств, которые могут использоваться в качестве ключа; эти ключи должны быть упорядочиваемы.
Когда значения в коллекциях являются примитивными типами (например, строками или целыми числами), ключами могут быть сами значения. В противном случае они являются ссылками на структуры, которые содержат значения [4].
Бинарное дерево поиска представляет собой непустой набор узлов, содержащих упорядоченные значения, именуемые ключами. Верхний корневой узел является предком для всех остальных узлов в BST. Каждый узел потенциально может указывать на два узла, каждый из которых является корнем BST — left и right соответственно. BST гарантирует выполнение свойства бинарного дерева поиска, а именно — того, что если k является ключом для узла, то все ключи в поддереве left не превышают значения k, а все ключи в поддереве right не меньше k. На рис. 3 показан небольшой пример BST, в котором каждый узел содержит целочисленное значение. Корень содержит значение 7; в дереве есть четыре листа со значениями 1,6, 10 и 17. Внутренний узел, например, 5, имеет родительский узел и некоторые дочерние узлы. Как видно из рисунка, поиск ключа в этом дереве требует изучения не более четырех узлов, начиная с корня.
BST может не быть сбалансированным; при добавлении элементов одни ветви могут оказаться относительно короткими, в то время как другие — более длинными. Это приводит к субоптимальному поиску по более длинным ветвям. В худшем случае структура BST может выродиться и превратиться в список. На рис. 4 показано вырожденное дерево с теми же значениями, что и дерево на рис. 3. Хотя структура такого дерева и соответствует строгому определению BST, фактически она представляет собой связанный список, так как правое поддерево каждого узла является пустым.
Необходимо сбалансировать дерево, чтобы избежать появления вырожденного перекошенного дерева, которое имеет несколько ветвей, гораздо более длинных, чем другие.

рис. 4. Вырожденное бинарное дерево поиска
2. РЕАЛИЗАЦИЯ И АНАЛИЗ АЛГОРИТМОВ
2.1 Последовательный поиск. Реализация. Анализ
Обычно реализация последовательного поиска тривиальна. В примере ниже
показана реализация на примере последовательного поиска из 20 значений:
cout << endl << endl << "Введите ключ : "; cin >> key; // считываем ключ
for (int i = 0; i < 20; i++) {
if (arr[i] == key) { // проверяем равен ли arr[i] ключу
ans[h++] = i;
}
}
if (h != 0) { // проверяем были ли совпадения
for (int i = 0; i < h; i++) {
cout << "Ключ " << key << " находится в ячейке " << ans[i] << endl; //выводим все индексы
}
Полный листинг в приложении А.
Если запрашиваемый элемент принадлежит коллекции и равновероятно может быть найден в любом из индексируемых местоположений (или, в качестве альтернативы, если он с одинаковой вероятностью может быть возвращен итератором в любой позиции), то в среднем последовательный поиск проверяет n/2 + 1/2. Таким образом, для каждого искомого элемента, имеющегося в коллекции, будет проверяться около всех половины элементов, так что производительность поиска оказывается равной О(n). В наилучшем случае, когда запрашиваемый элемент является первым элементом коллекции, производительность оказывается равной O(1). В среднем и наихудшем случаях алгоритм последовательного поиска обладает производительностью 0(n). Если размер коллекции вырастает в два раза, то и время, затрачиваемое на поиск в ней, примерно удваивается.
2.2 Бинарный поиск. Реализация. Анализ
Реализация бинарного поиска на примере поиска из 10 значений в отсортированном массиве:
cout << endl << "Введите ключ: ";
cin >> key; // считываем ключ
bool flag = false;
int l = 0; // левая граница
int r = 9; // правая граница
int mid;
while ((l <= r) && (flag != true)) {
mid = (l + r) / 2; // считываем срединный индекс отрезка [l,r]
if (arr[mid] == key) flag = true; //проверяем ключ со серединным элементом
if (arr[mid] > key) r = mid - 1; // проверяем, какую часть нужно отбросить
else l = mid + 1;
}
Полный листинг в приложении Б.
Производительность этого кода зависит от количества итераций цикла while. Для достижения большей производительности бинарный поиск может быть немного усложнен. Сложность увеличивается, если коллекция хранится не в виде структуры данных в памяти, такой как массив. Большая коллекция может потребовать размещения во вторичной памяти, такого, как в файле на диске. В таком случае доступ к i-му элементу осуществляется по смещению его местоположения в файле. При использовании вторичной памяти во времени, необходимом для поиска элемента, преобладают затраты на доступ к памяти; таким образом, может быть целесообразным использование других решений, связанных с бинарным поиском [3].
Двоичный поиск на каждой итерации уменьшает размер задачи примерно в два раза. Максимальное количество делений пополам для коллекции размером n равно |log n|+l. Если одной операции достаточно, чтобы определить, равны ли два элемента, меньше или больше один другого, то достаточно выполнить только |log n|+1 сравнений. Таким образом, алгоритм можно классифицировать как имеющий производительность O(log n).
Для поддержки операции “поиск или вставка” очевидно, что все допустимые индексы не могут быть отрицательными. В вариации алгоритма бинарного поиска можно применить возврат отрицательного число р при поиске элемента, который отсутствует в упорядоченном массиве.
Значение –(р+1) представляет собой индекс позиции, в которую следует вставить искомый элемент. Естественно, что при вставке следует перенести все значения с большими индексами, чтобы освободить место для нового элемента.
Вставка в упорядоченный массив (или удаление из него) с ростом размера массива становится неэффективной, потому что каждая запись массива должна содержать корректный элемент. Таким образом, вставка включает расширение массива (физическое или логическое) и перемещение в среднем половины элементов на одну позицию вперед. Удаление требует сжатия массива и перемещения половины элементов на одну позицию назад.
Из 100 испытаний по 524288 поисков элемента, хранящегося в коллекции размера n размещенной в памяти (размер коллекции колеблется в диапазоне от 4096 до 524288 элементов) с вероятностью наличия искомого элемента, равной р (и принимающей значения 1,0, 0,5 и 0,0) получаем результаты в табл. 1.
|
n |
Время последовательного поиска |
Время бинарного поиска |
||||
|
p = 1 |
p = 0,5 |
p = 0 |
p = 1 |
p = 0,5 |
p = 0 |
|
|
4096 |
3,0237 |
4,5324 |
6,0414 |
0,0379 |
0,0294 |
0,021 |
|
8192 |
6,0405 |
9,0587 |
12,0762 |
0,0410 |
0,0318 |
0,023 |
|
16384 |
12,0742 |
18,1086 |
24,1426 |
0,0441 |
0,0342 |
0,024 |
|
32768 |
24,1466 |
36,2124 |
48,2805 |
0,0473 |
0,0366 |
0,026 |
|
65536 |
48,2762 |
72,4129 |
96,5523 |
0,0508 |
0,0395 |
0,028 |
|
131072 |
* |
* |
* |
0,0553 |
0,0427 |
0,0300 |
|
262144 |
* |
* |
* |
0,0617 |
0,0473 |
0,033 |
|
524288 |
* |
* |
* |
0,0679 |
0,0516 |
0,036 |
|
262144 |
* |
* |
* |
0,0617 |
0,0473 |
0,033 |
|
524288 |
* |
* |
* |
0,0679 |
0,0516 |
0,036 |
Табл.1 Сравнение времени выполнения бинарных поисков в памяти с последовательным поиском таб. 1
В табл. 2 показано время выполнения 524288 поисков в коллекции, хранящейся на локальном диске. Выполнялись два варианта поиска — имеющегося в коллекции элемента (р = 1,0) и элемента, которого там нет (поиск значения -1 в коллекции [0, n)). Данные представляли собой просто файл возрастающих целых чисел, в котором каждое целое число упаковано в четыре байта. Доминирование времени обращения к диску очевидно, так как результаты в табл. 2 почти в 400 раз медленнее, чем в табл. 1. Так, как время поиска увеличивается на фиксированную величину при удвоении размера, это является четким подтверждением того факта, что производительность бинарного поиска — O(log n).
|
n |
p = 1 |
p = 0 |
|
4096 |
1,2286 |
1,2954 |
|
8192 |
1,3287 |
1,4015 |
|
16384 |
1,4417 |
1,5080 |
|
32768 |
6,7070 |
1,6170 |
|
65536 |
13,2027 |
12,0399 |
|
131072 |
19,2609 |
17,2848 |
|
262144 |
24,9942 |
22,7568 |
|
524288 |
30,3821 |
28,0204 |
Табл. 2. Бинарный поиск во вторичной памяти
2.3 Поиск на основе Хеша. Реализация. Анализ
Поиск на основе Хеша можно рассмотреть на примере полиноминального хеширования, при котором хеш-функция вычисляется как перевод из n-ичной системы в десятичную. В этом случае хеширование строк позволяет эффективно отвечать на вопрос о равенстве строк, сравнивая их хеш-коды. Хеш-код – целое число, вычисляемое по символам строки. Если две строки равны, то их хеш-коды тоже равны. Например, если есть строка s, основание BASE и кольцо вычетов по модулю MOD, то хеш-код строки будет вычисляться следующим образом: (s[0] * BASE0 + s[1] * BASE1 + ... + s[n – 1] * BASE(n-1)) % MOD. Или же наоборот: (s[0] * BASE(n-1) + s[1] * BASE(n-2) + .. + s[n – 1] * BASE0) % MOD.
Выбор направления расстановки степеней не принципиален. Главное – использовать такое простое основание BASE, чтобы оно было взаимно простым с MOD, и его значение было больше количества символов в алфавите. MOD также должен быть простым, как правило, он равен 109 + 7 или 109 + 9.
Для получения индекса символа s[i] в алфавите выполняется следующее решение: (int)s[i] – 'a' + 1. Но чтобы не загрязнять код, поступают проще, например, используют приведение к signed char, который вернёт значение от 0 до 255. При этом необходимо понимать, что основание должно быть больше максимального значения возвращаемого кода, поэтому берется BASE = 2011 или 2017.
Чтобы иметь возможность получать хеш любой подстроки s[l..r] строки s за O(1), используется хеш-функциея на префиксах. Пример: пусть максимальная длина строки – 106. Заведём массив hash[SIZE], хранящий 64-битовые числа. Далее заполняем массив простейшей динамикой по вышеописанным формулам. Приложение В.
Также понадобится массив степеней выбранного BASE. Заводится powers[SIZE], хранящий 64-битовые числа и заполняется по динамике: powers[i] = powers[i – 1] * BASE % MOD. Приложение В.
Для хеша подстроки, принцип получения такой же, как и при запросе суммы на диапазоне. От хеша с индексом r отнимается хеш с индексом l, умноженный на BASE в степени разности r и l. Приложение В.
Работа алгоритма хеширования рассмотрена на примере программы, сравнивающей две строки. Приложение В.
В ситуациях, когда строки по факту различны, но их хеши совпадают (коллизия), алгоритм заключает, что строки одинаковы, хотя на самом деле это не так.
Избавиться от коллизий при длине строк ~106 невозможно, потому что количество различных строк больше количества различных хеш-кодов. Вероятность коллизии можно свести к минимуму (почти к нулю), если написать ещё один хеш, т. е. написать первый хеш с основанием 2011 по модулю 109 + 7, а второй хеш – с основанием 2017 по модулю 109 + 9 и использовать оба хеша в сравнениях. [3]
Пока хеш-функция достаточно равномерно распределяет элементы коллекции, поиск, основанный на хеше, имеет отличную производительность. Среднее время, необходимое для поиска элемента, является константой, или 0(1). Поиск состоит из одного просмотра Н с последующим линейным поиском в коротком списке коллизий.
Компонентами поиска элемента в хеш-таблице являются:
• вычисление хеш-значения;
• доступ к элементу таблицы, индексированному хеш-значением;
• поиск требуемого элемента при наличии коллизий.
Все алгоритмы поиска на основе хеша используют первые два компонента; различное поведение может наблюдаться только в разных вариантах обработки коллизий. Стоимость вычисления хеш-значения должна быть ограничена фиксированной, константной верхней границей.
Время поиска элементов в хеш-таблице не зависит от количества элементов в хеш- таблице (поиск имеет фиксированную стоимость), так что алгоритм поиска на основе хеша имеет амортизированную производительность 0(1). [1]
2.4 Фильтр Блума. Реализация. Анализ
Реализовать структуру данных фильтра Блума можно разделив ее интрефейс на 3 основные функции:
- Конструктор
- Функция, чтобы добавить элемент к фильтру Блума
- Функция для запроса является ли искомый элемент элементом фильтра Блума.
Реализация фильтра Блума в приложении Г [4]. В данной реализации используется MurmurHash3 (https://github.com/aappleby/smhasher/tree/master
/src), для вычисления 128 битного хеша элемента.
Общее количество памяти, необходимое для работы фильтра Блума, фиксировано, и оно не увеличивается независимо от количества хранящихся значений. Кроме того, алгоритм требует только фиксированного количества испытаний k, поэтому каждая вставка и поиск могут быть выполнены за время 0(k), которое рассматривается как константное.
Основная сложность фильтра заключается в разработке эффективных хеш-функций, которые обеспечивают действительно равномерное распределение вычисляемых битов для вставляемых значений. Хотя размер битового массива является константой, для снижения количества ложных положительных срабатываний он может быть достаточно большим. И наконец, нет никакой возможности удаления элемента из фильтра, поскольку потенциально это может фатально нарушить обработку других значений.
Единственная причина для использования фильтра Блума заключается в том, что он имеет предсказуемую вероятность ложного положительного срабатывания в предположении, что к хеш-функций дают равномерно распределенные случайные величины.
2.5 Бинарное дерево поиска. Реализация. Анализ
В приложении Д реализовано простое несбалансированное бинарное дерево поиска.
В бинарном дереве поиска может быть несколько элементов с одинаковыми значениями, но, если необходимо ограничить дерево семантикой множества можно изменить код так, чтобы он предотвращал вставку повторяющихся ключей.
Эффективность реализации зависит от сбалансированности BST. Для сбалансированного дерева размер множества, в котором выполняется поиск, уменьшается в два раза при каждой итерации, что приводит к производительности O(log n). Однако для вырожденных бинарных деревьев, производительность равна О(n). Для сохранения оптимальной производительности необходимо балансировать BST после каждого добавления (и удаления).
AVL-деревья (названные так в честь их изобретателей, Адельсона-Вельского и Ландиса), изобретенные в 1962 году, были первыми самобалансирующимися BST. Высота листа равна 0, потому что он не имеет дочерних элементов. Высота узла, не являющегося листом, на 1 больше максимального значения высоты двух его дочерних узлов. Для обеспечения согласованности высота несуществующего дочернего узла считается равной -1. AVL-дерево гарантирует AVL-свойство для каждого узла, заключающееся в том, что разница высот для любого узла равна -1, 0 или 1. Разница высот определяется как height(left) - height(right), т.е. высота левого поддерева минус высота правого поддерева. AVL-дерево должно обеспечивать выполнение этого свойства всякий раз при вставке значения в дерево или удалении из него. Каждый узел в дереве AVL хранит свое значение высоты Height, что увеличивает общие требования к памяти.
На рис. 5 показано, что происходит при вставке значений 50, 30 и 10 в дерево в указанном порядке.

Рис. 5. Сбалансированное и несбалансированное бинарное дерево поиска.
Получаемое дерево не удовлетворяет AVL-свойству, так как высота корня левого поддерева равна 1, а высота его несуществующего поддерева справа равна -1, так что разница высот равна 2. Если “захватить” узел 30 исходного дерева и повернули дерево вправо (или по часовой стрелке) вокруг узла 30 так, чтобы сделать узел 30 корнем, создав тем самым сбалансированное дерево. При этом изменяется только высота узла 50 (снижается от 2 до 0) и AVL-свойство дерева восстанавливается.
Операция поворота вправо изменяет структуру поддерева в несбалансированном BST; очевидно, что имеется и аналогичная операция поворота влево. Если это дерево имеет и другие узлы, каждый из которых был сбалансирован и удовлетворял AVL-свойству, такое дерево можно модифицировать. На рис. 6 каждый из заштрихованных треугольников представляет собой потенциальное поддерево исходного дерева. Каждое из них помечено в соответствии с его позицией, так что поддерево 30R представляет собой правое поддерево узла 30. Корень является единственным узлом, который не поддерживает AVL-свойство. Различные показанные на рисунке высоты в дереве вычислены в предположении, что узел 10 имеет некоторую высоту k.

Рис.6 Сбалансированное AVL-дерево с поддеревьями
Модифицированное бинарное дерево поиска по-прежнему гарантирует свойство бинарного поиска. Все значения ключей в поддереве 30R больше или равны 30. Позиции других поддеревьев одно относительно другого не изменились, так что свойство бинарного поиска остается выполненным. Наконец значение 30 меньше значения 50, так что новый корневой узел вполне корректен.
Производительность поиска в сбалансированном AVL-дереве в среднем случае совпадает с производительностью бинарного поиска (т.е. равна 0(log n)). Следует отметить, что в процессе поиска никакие повороты не выполняются. Самобалансирующиеся бинарные деревья требуют более сложного кода вставки и удаления, чем простые бинарные деревья поиска. Пересмотрев методы поворотов, очевидно, что каждый из них состоит из фиксированного количества операций, так что их можно рассматривать как выполняющиеся за константное время. Высота сбалансированного AVL-дерева благодаря поворотам всегда будет иметь порядок 0(log n). Таким образом, при добавлении или удалении элемента никогда не будет выполняться больше чем 0(log n) поворотов. Таким образом, можно быть уверенным, что вставки и удаления могут выполняться за время 0(log n). Компромисс, состоящий в том, что AVL-деревья хранят значения высоты в каждом узле (что увеличивает расход памяти), обычно стоит получаемой при этом гарантированной производительности.
ЗАКЛЮЧЕНИЕ
В курсовой работе рассмотрены и изучены виды алгоритмов поиска в массивах, рассмотрены входные данные и получаемые результаты, по каждому алгоритму сделан анализ зависимости начальных данных к скорости работы.
Наиболее эффективный алгоритм найден не был, так как использование конкретных алгоритмов поиска сильно зависит от области и условий его применения. Так, например, последовательный поиск используется в небольших коллекциях данных и предлагает простейшую реализацию и во многих языках программирования реализуется в виде базовой конструкции, поэтому данный алгоритм используется, если коллекция доступна только последовательно, как при использовании итераторов. Бинарный поиск используется в условиях ограниченной памяти, когда коллекция представляет собой неизменный массив и есть необходимость сэкономить память. Поиск на основе хеша очевидно стоит использовать, когда данные часто динамически меняются. Так же в этом случае стоит применять и бинарное дерево поиска, так как данные алгоритмы обладают пониженной стоимостью, связанной с поддержанием их структур данных. Так же бинарное дерево стоит использовать в тех случаях, когда помимо поддержки постоянно меняющихся данных должна быть возможность обхода элементов коллекции в отсортированном порядке [2].
При выборе подходящего алгоритма не стоит забывать о стоимости предварительной обработки структур данных, которая может потребоваться алгоритму до начала выполнения поисковых запросов. Стоит выбирать подходящую структуру данных, которая не только ускоряет производительность отдельных запросов, но и сводит к минимуму общую стоимость поддержания структуры коллекции в условиях динамического доступа и многократных запросов.
Также стоит обращать внимание на то, что в коллекции могут иметься повторяющиеся значения, и поэтому ее нельзя рассматривать как множество (в котором не допускается наличие одинаковых элементов).
Учитывая, что все поставленные задачи курсовой работы решены, можно обоснованно утверждать, что главная цель исследования – достигнута.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Джордж Хайнеман, Гэри Пояяис, Стэняи Сеяков. Алгоритмы. Справочник с примерами на С, C++, Java и Python – 2017 [120-155]
- Готтшлинг П. - C++ для инженерных и научных расчетов (C++ In-Depth) – 2020 [159-163]
- Шлее М. - Qt 5.10. Профессиональное программирование на C++ (В подлиннике) – 2018 [91-95]
- Страуструп Б. - Язык программирования С++. Краткий курс – 2019 [211-219]
- Васильев А.Н. - Программирование на C++ в примерах и задачах (Российский компьютерный бестселлер) – 2017 [73-88]
Интернет ресурсы:
- https://codelessons.ru/cplusplus/algoritmy/linejnyj-poisk-po-massivu-c.html
- https://codelessons.ru/cplusplus/algoritmy/binarnyj-poisk-po-massivu-c.html
- https://proglib.io/p/must-have-algoritmy-dlya-raboty-so-strokami-na-c-2020-03-30
- https://habr.com/ru/company/ua-hosting/blog/281517/
- https://algor.skyparadise.org/read/7
ПРИЛОЖЕНИЯ
Приложение А
Последовательный поиск. Листинг.
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
int main() {
setlocale(LC_ALL, "rus");
int ans[20]; // создали массив для записи всех индексов
int h = 0;
int arr[20]; // создали массив на 20 элементов
int key; // создали переменную в которой будет находиться ключ
srand ( time(NULL) );
for (int i = 0; i < 20; i++) {
arr[i] = 1 + rand() % 20; // заполняем случайными числами ячейки
cout << arr[i] << " "; // выводим все ячейки массива
if (i == 9) {
cout << endl;
}
}
cout << endl << endl << "Введите ключ : "; cin >> key; // считываем ключ
for (int i = 0; i < 20; i++) {
if (arr[i] == key) { // проверяем равен ли arr[i] ключу
ans[h++] = i;
}
}
if (h != 0) { // проверяем были ли совпадения
for (int i = 0; i < h; i++) {
cout << "Ключ " << key << " находится в ячейке " << ans[i] << endl; //выводим все индексы
}
}
else {
cout << "Мы не нашли ключ " << key << " в массиве";
}
system("pause");
return 0;
}
Приложение Б
Бинарный поиск. Листинг.
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
setlocale(LC_ALL, "rus");
int arr[10]; // создали массив на 10 элементов
int key; // создали переменную в которой будет находиться ключ
cout << "Введите 10 чисел для заполнения массива: " << endl;
for (int i = 0; i < 10; i++) {
cin >> arr[i]; // считываем элементы массива
}
sort (arr, arr + 10); // сортируем с помощью функции sort (быстрая сортировка)
cout << endl << "Введите ключ: ";
cin >> key; // считываем ключ
bool flag = false;
int l = 0; // левая граница
int r = 9; // правая граница
int mid;
while ((l <= r) && (flag != true)) {
mid = (l + r) / 2; // считываем срединный индекс отрезка [l,r]
if (arr[mid] == key) flag = true; //проверяем ключ со серединным элементом
if (arr[mid] > key) r = mid - 1; // проверяем, какую часть нужно отбросить
else l = mid + 1;
}
if (flag) cout << "Индекс элемента " << key << " в массиве равен: " << mid;
else cout << "Извините, но такого элемента в массиве нет";
system("pause");
return 0;
}
Приложение В
Поиск на основе Хеша. Листинг.
#include <bits/stdc++.h>
using namespace std;
const int SIZE = 100100;
const int BASE = 2017;
const int MOD = 1000000009;
int64_t hash[SIZE];
void init_hash(const string &line, int64_t *h, int base, int mod)
{
h[0] = 0;
int n = line.length();
for (int i = 1; i <= n; ++i)
{
h[i] = h[i - 1] * base % mod + (signed char)line[i - 1] % mod;
}
}
int64_t powers[SIZE];
void init_powers(int64_t *p, int base, int mod)
{
p[0] = 1;
for (int i = 1; i < SIZE; ++i)
{
p[i] = p[i - 1] * base % mod;
}
}
int64_t get_hash(int l, int r, int64_t *h, int64_t *p, int mod)
{
return (h[r] - h[l] * p[r - l] % mod + mod) % mod;
}
#include <bits/stdc++.h>
using namespace std;
const int SIZE = 100100;
const int BASE = 2017;
const int MOD = 1000000009;
int64_t ahash[SIZE];
int64_t bhash[SIZE];
int64_t powers[SIZE];
void init_powers(int64_t *p, int base, int mod)
{
p[0] = 1;
for (int i = 1; i < SIZE; ++i)
{
p[i] = p[i - 1] * base % mod;
}
}
void init_hash(const string &line, int64_t *h, int base, int mod)
{
h[0] = 0;
int n = line.length();
for (int i = 1; i <= n; ++i)
{
h[i] = h[i - 1] * base % mod + (signed char)line[i - 1] % mod;
}
}
int64_t get_hash(int l, int r, int64_t *h, int64_t *p, int mod)
{
return (h[r] - h[l] * p[r - l] % mod + mod) % mod;
}
int main()
{
string a, b;
cin >> a >> b;
init_powers(powers, BASE, MOD);
init_hash(a, ahash, BASE, MOD);
init_hash(b, bhash, BASE, MOD);
int q;
cin >> q;
while (q--)
{
int al, ar, bl, br;
cin >> al >> ar >> bl >> br;
--al; --bl;
if (get_hash(al, ar, ahash, powers, MOD) == get_hash(bl, br, bhash, powers, MOD))
{
cout << "YES\n";
}
else
{
cout << "NO\n";
}
}
return 0;
}
Приложение Г
Фильтр Блума. Листинг.
#include <vector>
struct BloomFilter {
BloomFilter(uint64_t size, uint8_t numHashes);
void add(const uint8_t *data, std::size_t len);
bool possiblyContains(const uint8_t *data, std::size_t len) const;
private:
uint64_t m_size;
uint8_t m_numHashes;
std::vector<bool> m_bits;
};
#include "BloomFilter.h"
#include "MurmurHash3.h"
BloomFilter::BloomFilter(uint64_t size, uint8_t numHashes)
: m_size(size),
m_numHashes(numHashes) {
m_bits.resize(size);
}
std::array<uint64_t, 2> hash(const uint8_t *data,
std::size_t len) {
std::array<uint64_t, 2> hashValue;
MurmurHash3_x64_128(data, len, 0, hashValue.data());
return hashValue;
}
inline uint64_t nthHash(uint8_t n,
uint64_t hashA,
uint64_t hashB,
uint64_t filterSize) {
return (hashA + n * hashB) % filterSize;
}
void BloomFilter::add(const uint8_t *data, std::size_t len) {
auto hashValues = hash(data, len);
for (int n = 0; n < m_numHashes; n++) {
m_bits[nthHash(n, hashValues[0], hashValues[1], m_size)] = true;
}
}
bool BloomFilter::possiblyContains(const uint8_t *data, std::size_t len) const {
auto hashValues = hash(data, len);
for (int n = 0; n < m_numHashes; n++) {
if (!m_bits[nthHash(n, hashValues[0], hashValues[1], m_size)]) {
return false;
}
}
return true;
}
Приложение Д
Бинарное дерево поиска. Листинг.
#include <cstdlib>
#include <cstdio>
using namespace std;
typedef struct t_node {
int key;
struct t_node* left;
struct t_node* right;
} Node, *Tree;
Tree initTree() { return NULL; }
Tree createNode(int key, Node* left, Node* right) {
Tree root;
root = (Node*)malloc(sizeof(Node));
root->key = key;
root->left = left;
root->right = right;
return root;
}
void addNode(int key, Tree &root) {
if (root == NULL) root = createNode(key, NULL, NULL);
else if (key > root->key) {
// если в правое поддерево
addNode(key, root->right);
}
else if (key < root->key) {
// если в левое поддерево
addNode(key, root->left);
}
}
Tree findNode(int key, Tree root) {
int find = 0;
while ((root != NULL) && !(find)) {
if (key == root->key) find = 1;
else {
if (key < root->key) root = findNode(key, root->left);
else root = findNode(key, root->right);
}
}
return root;
}
Tree minNode(Tree root) {
if (root->left == NULL) return root;
return minNode(root->left);
}
Tree maxNode(Tree root) {
if (root->right == NULL) return root;
return maxNode(root->right);
}
Tree delNode(int key, Tree root) {
if (root == NULL) return root;
if (key < root->key)
root->left = delNode(key, root->left);
else
if (key > root->key) root->right = delNode(key, root->right);
else
if (root->left != NULL && root->right != NULL) {
root->key = minNode(root->right)->key;
root->right = delNode(root->right->key, root->right);
}
else
if (root->left != NULL)
root = root->left;
else
root = root->right;
return root;
}
void printTree(Tree root, int level = 0) {
if(level == 0)printf("-----------------\n");
if (root != NULL) {
printTree(root->right,level + 5);
printf("%*d %p\n", level, root->key, root);
printTree(root->left,level + 5);
}
}
int main(/* int argc, char *argv[] */) {
Tree tree = initTree();
addNode(4, tree);
printTree(tree);
addNode(5,tree);
printTree(tree);
addNode(1, tree);
printTree(tree);
addNode(2, tree);
printTree(tree);
addNode(7, tree);
printTree(tree);
return 0;
}

- Индивидуальное предпринимательство
- Особенности коммерческой деятельности в сфере оптовой торговли на предприятия ООО Фарго-С
- Разработка методики расследования инцидентов информационной безопасности, связанных с преднамеренной утечкой информации
- Система защиты информации в банковских системах (Информационная безопасность банков: меры, принципы, угрозы)
- Методы управления и руководства в строительстве (Основы теории управления в строительстве)
- Организация и управление в строительстве.Методы управления и руководства в строительстве
- Коммерческие риски в современной торговле и пути их снижения
- Мотивация и ее теории (Сущность и значение мотивационного менеджмента в организации)
- Законность и правопорядок (Взаимосвязь законности, правопорядка, демократии и государственной дисциплины)
- Коммерческие риски в современной торговле и пути их снижения (Понятие и сущность рисков)
- Собственная торговая марка как инструмент коммерческой деятельности (Теоретические аспекты исследования собственных торговых марок)
- Основания для проведения оперативно-розыскных мероприятий(Сущность понятия оперативно-розыскных мероприятий)