
Понятие переменной в программировании. Виды и типы переменных
Содержание:

ВВЕДЕНИЕ
Прогресс информационных компьютерных технологий определил направление процесса появления новых разнообразных систем для записи разных алгоритмов – языков программирования (ЯП). Смысл появления их – оснащенный набор формул для дополнительной информации, который превращает данный набор непосредственно в алгоритм.
Каждый ЯП служит двум связанным целям:
– дает программисту аппарат по заданию действий, что должны быть выполнены;
– формирует концепции, в соответствии с которыми работает программист.
Идеально для первой цели отвечает язык, который «близок к машине», что всеми машинными аспектами можно просто оперировать достаточно очевидным образом для программиста.
Второй цели отвечает язык, который очень «близок к решаемой задаче», чтоб концепции ее решения выражалось прямо и коротко.
Имеющаяся вязь между языком, на котором работает разработчик и задачами и решениями, очень близка. По данной причине ограничивать свойства ЯП только целями исключения разного рода ошибок программиста – опасно.
Актуальность курсовой работы состоит в применении переменных структурированных типов данных ЯП высокого уровня, поскольку они являются главными компонентами для всех современных программ.
Объект работы – ЯП высокого уровня.
Предмет – использование переменных в ЯП высокого уровня.
Цель работы – проведение анализа применения переменных в программировании, описать виды и типы переменных.
В соответствии с целью работы выделены задачи:
– рассмотреть понятия о языках программирования;
– дать характеристику главным понятия, что связанные с понятием переменной;
– описать типы данных, которые применяются в описании переменных;
– описать применение переменных в массивах данных;
– привести примеры алгоритмов, используя переменные для обработки структурированных типов данных.
Проблему исследования переменных для ЯП высокого уровня изучали: М. Хортон [1], П. Страуструп [4], Е. Прата [12], Д. Лафорт [13].
1. ЯЗЫКИ ПРОГРАММИРОВАНИЯ
1.1 Определение, понятия и классификация языков программирования
В отличие от классических человеческих языков, ЯП более простые, так как они состоят из ограниченной численности слов, предназначенных исключительно для использования при записи алгоритмов.
Стоит заметить, что также они могут различаться, по близости к пониманию для обычного человека, по выразительным способностям и простоте. [3]
Вытекающая изо всех алгоритмов последовательность действий должна быть записана таким образом, чтоб персональный компьютер (ПК) легко ее смог разобрать.
В данном случае любая фраза (часть кода), что описывается на ЯП также должна подчинятся синтаксису языка.
Практически все современные программы, написанные на ЯП высокого уровня вводятся в компьютер при применении обычного текста, а сам ПК, зная, о свойствах написанного кода программы преобразует его в машинный код. [5]
Обычно, такие языки программирования создаются и для удобства решения задач для определенного направления.
К примеру, язык программирования под названием Алгол (рисунок 1) создавался в свое время средствами и инструментами международной ассоциацией ученых по написанию и публикации в журналах разных алгоритмов.
Стоит отметить, что он также был задуман в качестве интернационального языка для всех компьютеров того времени. [11]

Рисунок 1 – Образец кода языка АЛГОЛ
Для решения всех основных задач в направлении коммерции со временем был специально создан язык, который имел название КОБОЛ, для обработки текстовых документов использовался ПРОЛОГ, при реализации процесса обучения студентов навыкам программирования были придуманы ЛИСП, БЕЙСИК, при выполнении математических вычислений – ФОРТРАН, в облегчении процесса программирования для аппаратной части ПК – язык С++. [10]
Ученые и инженеры в данное время работают над созданием универсального специального языка, на котором возможно описывать самые разные алгоритмы. [20]
В то же время, активно может развиваться направление машинных специальных языков, имеющее использование только в строго определенных областях.
Все ЯП также занимают самое разное промежуточное положение, которое характеризуется состоянием между естественными и формализованными ЯП. [15]
Основные назначение для практически всех языков программирования – являться средством для выполнения программирования: [19]
– реализовывать программы;
– писать программы на ПК.
Практически все ЯП используются в секторе формирования и описания алгоритмов, а также выполнения их в последующем на ПК, алгоритм при этом может также записываться с различным уровнем его детализации. [20]
Конкретная степень детализации для алгоритма также зависит от того, насколько учитывается архитектура компьютера при процессе написании программ.
Очень часто полагают, что опытные программисты могут писать программные продукты не для определенного ПК, а некоторой вычислительной машины (в общих понятиях). [4]
Чем больше деталей непосредственно в вычислительных устройствах ПК будет в описании, тем будет ниже уровень его абстракции.
На одном с высших уровней абстракции может содержаться полное представление для ПК как о фоннеймановской машине, что состоит с основных частей:
– памяти;
– устройств для ввода/вывода;
– процессора.
Следует учитывать при этом, что все реально работающие программы могут выполняться в среде какой-то ранее компьютер на ПК операционной системы.
ОС представляет собой специальный программный комплекс при реализации управления практически всеми устройствами ПК. [8]
В нынешнее время очень популярными ОС считаются:
– Microsoft Windows;
– Linux;
– UNIX.
В случае, когда абстрактной вычислительной машине можно добавить операционную систему – в результате получим так называемую виртуальную машину. [12]
Различные программы могут быть написаны для любой абстрактной машины или виртуальной машины, а также будут создаваться некоторые основные трансляторы, среды для разработки ПО.
Для написания программ на низких уровнях языков программирования используются специальные ЯП, которые называются низкоуровневыми.
Языки низкого уровня часто используются для очень детального описания операций, которых при этом учитывает архитектура ПК, а также устройство его процессора.
Практически все языки таких уровней являются машинными кодами, ассемблерами. Ассемблер имеет также несколько более применяемых способов создания программных продуктов.[16]
Каждая из программ на языке Ассемблер будет очень длинной в написании, так как значительно увеличивается вероятность возникновения ошибок. При составлении программ требуется также знание основных архитектур компонентов компьютера (например, процессора).
Программа оказывается также связанной к определенной архитектуре. Все это можно посчитать недостатками для программирования в ЯП низкого уровня.
Самым главным и основным преимуществом будет является возможность «выжать» с ресурсов компьютера практически все его возможности.
ЯП высокого уровня были разработаны для того, чтобы преодолеть недостатки некоторых ранних методов низкоуровневого программирования. Все они позволяли применять многие различные операции, вообще не заботясь при этом о деталях создания. [2]
Программы при этом также будут короткими, надежными и намного универсальными, а сам процесс для их составления значительно сократится. Программы, что были написаны с помощью языков высокого уровня читать легче.
Высокоуровневые языки можно разделить на виды (рисунок 2): [3]
Рисунок 2 – Классы языков программирования
Самыми основоположными объектами для императивных языков являются:[14]
– переменные;
– стандартные алгоритмические конструкции;
– операторы присваивания.
Императивные ЯП привязываются к традиционной архитектуре фон Неймана. [6]
Для всех ЯП функционального направления применяются функции, значения для которых определяются с непосредственным указанием параметров.
Все традиционные операторы, переменные при этом не рассматриваются.
В программных продуктах, что написаны с использованием логических ЯП, нет какого-то фиксированного или определенного порядка для реализации разных правил алгоритма.
Сам выбор подходящей для этого последовательности операций алгоритма будет возлагаться на саму систему. [9]
Объектно-ориентированные языки в значительной степени могут упростить программирование с использованием объектно-ориентированного программирования.
1.2 Описание популярных высокоуровневых ЯП
Delphi – многофункциональный язык, созданным на основе языка Object Pascal. Он также является очень популярным из-за наличия диалектов и многих компиляторов. [11]
Все программисты часто используют диалект, который наиболее лучше подходит в его направлении написания программ.
В целом, ЯП Delphi является императивным, объектно-ориентированным.
Именно с использованием ЯП Delphi созданы программы The KMPlayer, AIMP, Light Alloy, Total Commander, графический интерфейс для программы Skype.
Само наличие большого количества таких диалектов является также и достоинством, и определенным недостатком указанного языка, ведь программу, что написана с его помощью, другой компилятор не всегда сможет открыть. [12]
Язык С++ – один из самых основных объектно-ориентированных ЯП, невероятно популярный до нынешнего времени, который просто обязан изучить каждый современный программист.
Стоит отметить, не нужно начинать изучение принципов программирования с указанного ЯП, хотя со временем С++ будет наиболее используемым. [18]
С момента возникновения язык прошёл несколько лицензирований, стандартизаций и благодаря этому остаётся очень актуальным он в нынешнее время.
ЯП Питон – это один с самых новых и популярных на сегодняшний день ЯП, суть его сводится к тому, что с помощью него можно очень легко создавать сложные программы.
ЯП также создан на основании одних из ранних языков, он в себя впитал их наработки, стал совершеннее. [2]
К тому же он обновляется постоянно, а самая последняя версия выпущена в 2017 г.
Основные положительные характеристики:
– простота;
– многофункциональность;
– минимализм.
В свою очередь, часто приходится платить также за минимализм несколько сниженным быстродействием, наличием ошибок в коде, некоторые присутствуют и в последних релизах.
Visual Basic фирмы Microsoft используют многие опытные программисты, поскольку большинство на нём познавало начала работы в началах программирования. Он очень многофункционален, прост, а также прекрасно подходит к быстрому проектированию программ. [14]
Он имеет все возможности по созданию ПО, также можно конструировать удобный пользовательский интерфейс программы.
VB применяют профессионалы из Microsoft для создания разного рода своих программ.
В первом разделе работы описаны некоторые самые основные понятия теории языков программирования, приведены соответственные определения, дана характеристика основным языкам, которые используются опытными программистами.[18]
2. ПОНЯТИЕ О ПЕРЕМЕННЫХ И ТИПАХ ДАННЫХ
2.1. Понятие переменной. Виды переменных
Для хранения различных данных в языках программирования используют переменные. Переменной называется область памяти, имеющая имя, которое иначе называют идентификатором.
Давая переменной имя, программист одновременно тем же именем называет и область памяти, куда будут записываться значения переменной для хранения.[13]
Хорошим стилем является осмысленное именование переменных. Разрешается использовать строчные и прописные буквы, цифры и символ подчёркивания, который в С++ считается буквой. Первым символом обязательно должна быть буква, в имени переменной не должно быть пробелов. В современных версиях компиляторов длина имени практически не ограничена. Имя переменной не может совпадать с зарезервированными ключевыми словами. Заглавные и строчные буквы в именах переменных различаются, переменные a и A — разные переменные.[2]
В программировании особе внимание уделяется концепции о локальных и глобальных переменных, а также связанное с ними представление об областях видимости. Соответственно, локальные переменные видны только в локальной области видимости, которой может выступать отдельно взятая функция. Глобальные переменные видны во всей программе. "Видны" – значит, известны, доступны. К ним можно обратиться по имени и получить связанное с ними значение.[6]
К глобальной переменной можно обратиться из локальной области видимости. К локальной переменной нельзя обратиться из глобальной области видимости, потому что локальная переменная существует только в момент выполнения тела функции. При выходе из нее, локальные переменные исчезают. Компьютерная память, которая под них отводилась, освобождается. Когда функция будет снова вызвана, локальные переменные будут созданы заново.
2.2. Общие понятия о типах данных в С++
Тип данных определяет все множество значений, а также множество операций и метод представления данных непосредственно в памяти компьютера. [9]
Сама концепция типа данных является самым важнейшим базовым понятием для любого языка программирования. В языках с строгой типизацией, для которых относится, к примеру, Паскаль, существенно повышается надежность разработки программного кода, поскольку большое число ошибок для несоответствия типов удается обнаруживать еще на стадии предварительной компиляции кода. [1]
Низкоуровневые возможности C++ не позволяют считать его типизированным языком, но, тип данных является одним из базовых понятий в нем.
Рассмотрим простейшие скалярные типы данных в С++ (рисунок 3):[16]
Рисунок 3 – Скалярные типы данных
Стоит отметить, что могут также использоваться и модификации этих основных типов. Производные (модифицированные) форматы данных задаются при помощи 4 спецификаторов типа, что изменяют диапазон значений основного типа (рисунок 4).[7]
Рисунок 4 – Спецификаторы длины типа
Стоит отметить, что спецификатор signed определяет знаковый (как положительные, так и отрицательные значения), а спецификатор unsigned –беззнаковый (лишь положительные значения).
Кроме этого, в C++ определяется специальный тип void – скалярный тип, у которого множество значений пусто.[17]
По умолчанию также используются спецификаторы signed и short, то есть отсутствие спецификатора длины будет соответствовать значению «короткий», а отсутствие спецификатора знака – значениям «знаковый».
Особенность типа под названием char в C++ может состоять в двойственности трактовки. [11]
Значения указанного типа могут рассматриваться и как целые числа, над которыми выполняются соответствующие операции, или же как байтовый код для символов.
Значения типа char (или символьные константы) заключаются в одинарные кавычки: 'g’, 'a'; к типу char также относятся и некоторые спецсимволы (двухсимвольные значения), к примеру, ‘\n’ – это переход к последующей строке.[18]
Заметим, что в C++ все строковые константы заключаются в двойных кавычках, например, “stroka”. Поэтому ‘a’ – символьное значение (литерал), “a” – строковое значение, то есть строка, что состоит с одного символа.[13]
Размер формата int стандартом не определяется и зависит только от разрядности процессора, а также особенностей компилятора. Спецификатор short устанавливает независимо от разрядности применяемого процессора размер памяти целого типа 2 байта, а спецификатор long определяет уже 4 байта.[9]
Объем памяти, что соответствует типу данных, можно определять с помощью функции под названием sizeof:
sizeof(<название типа>) – размер в байтах указанного типа,
sizeof < название переменной> – размер в байтах формата данных, соответствующего указанной переменной.
Даже не устанавливая конкретных значений для объема памяти типов данных, стандарт С++ определяет следующие соотношения для них:[17]
sizeof(char) < sizeof(short) < sizeof(int) < sizeof(long),
sizeof(float) < sizeof(double) < sizeof(long double).
В таблице 1 указаны характеристики типов для 32 разрядного процессора.
Таблица 1 – Характеристика скалярных типов для 16-разрядного процессора
|
Тип |
Диапазон |
Размер (байты) |
|
bool |
true (1), false (0) |
1 |
|
char |
-127 .. 128 |
1 |
|
signed char |
-127 .. 128 |
1 |
|
unsigned char |
0 .. 255 |
1 |
|
int |
-32767 .. 32768 |
2 |
|
signed int |
-32767 .. 32768 |
2 |
|
unsigned int |
0 .. 65536 |
2 |
|
short int |
-32767 .. 32768 |
2 |
|
signed short int |
-32767 .. 32768 |
2 |
|
unsigned short int |
0 .. 65536 |
2 |
|
long int |
-2147484648 .. 2147484647 |
4 |
|
signed long int |
-2147484648 .. 2147484647 |
4 |
|
unsigned long int |
0 .. 4294567295 |
4 |
|
float |
3.4e-37 .. 3.4e+37 |
4 |
|
short float |
3.4e-37 .. 3.4e+37 |
4 |
|
long float |
1.7e-307 .. 1.7e+307 |
8 |
|
double |
1.7e-307 .. 1.7e+307 |
8 |
|
short double |
1.7e-307 .. 1.7e+307 |
8 |
|
long double |
3.4e-4933 .. 3.4e+4933 |
10 |
Заметим, что в некоторых системах программирования C++ для типа данных char может определяться диапазон значений от 0 до 255, в таком случае тип char будет совпадать с unsigned char, но не с signed char. [8]
Также, очевидно, в таблице 1 есть типы данных, что имеют различную спецификацию, хотя по существу они ничем не отличающиеся, к примеру, int или signed int. [19]
Этот факт позволяет ограничиться самым минимальным набором простых спецификаций типа.[3]
2.2. Структурированные типы данных в С++
2.2.1. Массивы.
Как и на языке Паскаль, массив представляет собой упорядоченную последовательность хранимых данных одного типа, что занимают последовательные ячейки памяти. [4]
При упорядочивании используется индексация всех элементов массива, то есть приписывание каждому элементу определенное значения индекса. В отличие от языка Паскаль, где при выборе индексного типа имеется большая свобода, на C++ индекс представляет целое положительное число или же ноль. Таким образом, все элементы массива упорядочиваются обычным приписыванием каждому с них порядкового номера, при этом нумерация начинается с нуля, не с единицы, то есть первый элемент массива будет иметь индекс ноль.[4]
Общий вид описания стандартного массива следующий:
<базовый тип> <название массива> [<константа целого типа>];
К примеру:
int a, b[6], c;
const float n=11;
double s1[n];
Здесь определяется массив b, что состоит из 6 основных элементов типа int, а именно: b[0] b[1] … b[5] и массив s1 из 11 элементов типа double: s1[0] s1[1] … s[10].
При определении массив также может быть проинициализирован:
int a1[5]={2, 4, -3, 5, 38};
Во разных случаях удобно бывает определять новый тип-массив для этого используется оператор typedef:[6]
typedef long float mas[10];
mas a1,b1d;
В программе все элементы массива представляются переменными с индексами.
При работе с одномерными массивами необходимо иметь также в виду, что на C++ не контролируются значения для индексов на предмет их выхода за пределы имеющегося массива. [15]
Все это означает, что когда при обращении к массивам в программе будет формироваться значение индекса, что превышает допустимое, могут при этом быть изменены значения разных других переменных, что занимают смежную с рассматриваемым массивом область памяти.
Весь контроль этой ситуации возлагается полностью на программиста.[6]
Двумерные массивы определяются следующим образом:
int a1 [5][3];
В памяти все двумерные массивы располагаются также по строкам, то есть так, что быстрее будет изменяться второй индекс. Такое правило распространяется также на массивы с большей размерностью. При инициализации элементы 2-мерного массива располагаются в соответствующем порядке, то есть по строкам.[3]
К примеру:
int a1 [2][3]={{3, 6, -2}, //первая строка
{5, 23, 0}}; //вторая строка
Все такие операции над массивами, включая ввод-вывод, присваивание, выполняются поэлементно.
Например, ввод 2-мерного массива:
for (int i1=0; i1<5; i1++)
for (int j1=0; j1<3; j1++)
cin >>a1[i][j];
2.2.2. Символьные строки.
Символьная строка является полным аналогом типа string в Паскале. В C++ она будет объявляться как массив символов, хотя при этом дополняется в конце нуль-символом ‘\0’:
char str1[10]=”alfa”; // str1[0]=’a’ str1[1]=’l’ str1[2]=’f’ str1[3]=’a’ str1[4]=’\0’
При инициализации также можно было опускать длину строки:[7]
char str1[]=”alfa”;
хотя при этом было под нее бы выделено не все 10 байт, а лишь 5.
Строки можно применять в операторах ввода и вывода, однако при вводе строк с клавиатуры необходимо брать во внимание то, что оператор >> в качестве признаков конца строки рассматривает символ пробела, табуляции или же Enter и, встретив только один из них, завершает ввод. [9]
Эта проблема может разрешаться при использовании библиотечной функции:
gets(<название массива>)
с стандартной библиотеки stdio.h, что должна быть подключена директивой #include <stdio.h>.
Так как строка является массивом, то для нее не определяются операции присваивания или сравнения. Эти операции выполняются поэлементно или с применением функций стандартной библиотеки string.h, что должна быть подключена к программе.
2.2.3. Структуры
Структура (struct) на C++ является аналогом типа данных record в Паскале.
Структуры имеют возможность группировать данные для разных типов. Определение структуры выглядит так:[11]
struct <название типа> {
<тип для поля> <название поля>;
<тип для поля> < название поля>;
……………..
<тип для поля> < название поля>;
}
К примеру:[3]
struct anketa {
char name1[20];
enum {man1, woman1} pol;
int born1;
}
anketa a[4], b1;
Можно определять переменные структуры, не определяя новые имена типа, то есть используя анонимный тип.
Такое описание переменных структуры будет выглядеть так:[11]
struct {
<тип для поля> <название поля>;
<тип для поля> < название поля>;
……………..
<тип для поля> < название поля>;
} <список переменных>;
Во втором разделе курсовой работы рассмотрены основные понятия о типах данных:[10]
– приведены определения и примеры переменных базовых типов;
– рассмотрены основные понятие структурированных типов данных на языке С++.
3. ИСПОЛЬЗОВАНИЕ ПЕРЕМЕННЫХ НА ЯЗЫКЕ С++
3.1. Использование переменных в массивах в С++
Рассмотрим на примере использование массивов (одномерных и двумерных) реализацию их обработки. Стоит заметить, что каких-то стандартных функций для обработки числовых массивов в С++ не используется.
Пусть дана прямоугольная матрица А(M,N). Нужно составить программу, вычисляющую сумму элементов каждой строки. Из сумм надо сформировать одномерный массив, упорядочить его по убыванию методом пузырька (Bubble Sort).
Преобразовать этот массив, заменив все положительные элементы единицами, а все отрицательные элементы нулями.
Необходимо вывести на экран исходную матрицу, отсортированный массив и преобразованный массив.
//подключение заголовочных файлов
#include <iostream>
#include <conio.h>
//определение пространства имен
using namespace std;
int main()
{
//объявление переменных
float a2[20][20],b2[20],s;
int i,j,n2,m2;
//ввод размерности
cout<<"n=";
cin>>n2;
cout<<"m=";
cin>>m2;
//ввод матрицы
cout<<"Array:"<<endl;
for(i2=0;i2<n2;i2++)
for(j2=0;j2<m2;j2++)
cin>>a[i2][j2];
//вычисление сумм по строкам
for(i2=0;i2<n2;i2++)
{
s=0;
for(j2=0;j2<m2;j2++)
s=s+a2[i2][j2];
b2[i2]=s;
}
//вывод одномерного массива
cout<<"Vector:"<<endl;
for(i2=0;i2<n2;i2++)
cout<<b2[i2]<<" ";
//сортировка одномерного массива
for(i2=0;i2<n2;i2++)
for(j2=0;j2<m2;j2++)
if(b2[i2]<b2[j2])
swap(b2[i2],b2[j2]);
cout<<endl;
//вывод отсортированного вектора
cout<<"Sorted Vector:"<<endl;
for(i2=0;i2<n2;i2++)
cout<<b2[i2]<<" ";
getch();
return 0;
}
В результате получим (рисунок 5):
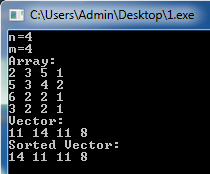
Рисунок 5 – Результат обработки массивов
3.2. Использование переменных для работы со строками
Стоит заметить, что для обработки строк используется в С++ множество разных функций. Рассмотрим их подробнее.
Функция для копирования строки s2 в строку s1. В результате возвращается значение s1.
сhar *strcpy(char s1, char s2);
Функция для копирования не более, чем n символов с строки s2 в массив s1.
сhar *strncpy(char s1, char s2, size_t n);
Функция добавляет строку s2 в строку s1. Первый символ для строки s2 записывается поверх нулевого символа строки s1. Как результат возвращается значение s1.
сhar *strcat(char s1, char s2);
Функция добавляет не более n символов для строки s2 непосредственно в строку s1. Самый первый символ строки s2 будет записываться поверх завершающего нулевого символа s1.
сhar *strncat(char s1, char s2, size_t n) ;
Функция сравнивает строки s2 и s1 и возвращает 0, если они равны; значение меньше 0, когда s1 меньше s2, значение больше 0, когда s1 больше s2.[3]
int strcmp(char s1, char s2) ;
Функция сравнивает до n символов и строк, возвращает 0, если строки равны; а также значение меньше 0, при s1 меньше s2 и больше 0, при s1 больше s2.
int strncmp(char s1, char s2, size_t n);
Функция определяет длину строки s1. Возвращает количество символов, что предшествуют завершающему нулевому символу строки.
size_t strlen(char *s1) ;
Функция находит позицию первого вхождения искомого символа c1 в текстовую строку s1. Если c1 найден, функция возвращает указатель на c1 в строке s1, иначе возвращается NULL.[14]
char *strchr(char *s1,int c1) ;
Функция определяет длину начального сегмента для строки s1, содержащего символы, которые не имеются в s2.
size_t strcspn(char s1, char s2) ;
Функция находит в строке s позицию первого вхождения для любого из символов s2. Если символ найден, возвращается указатель на такой символ в строке s, иначе возвращается NULL.[15]
char * strpbrk(char s1, char s2);
Функция находит позицию для последнего вхождения символа c1 в строку s1. Если c1 найден, функция возвращает указатель для этого символ, иначе будет возвращен NULL.
char * strrchr(char s1, int c1) ;
Функция находит позицию первого вхождения подстроки s в строку s1. Когда подстрока найдена, то функция возвращает указатель для подстроки в строке s1, в противоположном случае возвращается NULL.
char * strstr(char s1, char s2) ;
Приведем пример использования некоторых функций.
Введем строку и выведем ее лексемы.
//заголовочные файлы
#include <iostream>
#include <conio.h>
//пространство имен
using namespace std;
int main ()
{
//описание переменных
char s1[80], *t;
puts("Text: ");
//функция для ввода текста
gets(s1);
puts("\n Lexems: ");
//функция для отделения лексем
t=strtok(s1, " .,;?!-");
//вывод лексем
while (t != NULL)
{
puts(t);
t = strtok(NULL, " .,;?!-");
}
getch();
return 0;
}
Результат выполнения показан на рисунке 6:
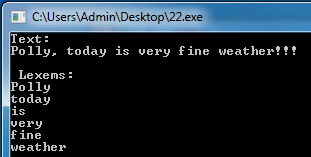
Рисунок 6 – Результат обработки строк
3.3. Использование переменных в структурах в С++
На складе ведется учет товаров по информации:
- название товара;
- цена товара;
- вес товара;
- срок годности.
Создать в структуре функцию, с помощью которой вывести на экран данные о товарах, срок годности которых менее 3 месяцев.
#include <iostream>
#include <conio.h>
using namespace std;
struct tovar
{
char title[10];
float price, weight;
int time;
void func(tovar b)
{
if (b.time<3)
cout<<b.title<<' '<<b.price<<' '<<b.weight<<' '<<b.time<<endl;
}
} a[5];
int main()
{
int i;
for(i=0;i<5;i++)
{
cout<<"Input title: ";
cin>>a[i].title;
cout<<"Input price: ";
cin>>a[i].price;
cout<<"Input weight: ";
cin>>a[i].weight;
cout<<"Input time: ";
cin>>a[i].time;
}
for(i=0;i<4;i++)
a[i].func(a[i]);
getch();
return 0;
}
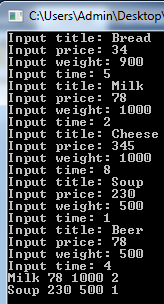
Рисунок 7 – Результат программы
В разделе 3 курсовой работы подробно рассмотрены основные методы и функции для обработки структурированных типов данных. В результате на практике созданы 3 программы.
ЗАКЛЮЧЕНИЕ
Изобретение языков программирования высшего уровня позволяет общаться с машиной, а также понимать её.
Сегодня программирование – одно из наиболее быстро развивающихся отраслей производства ПО.
Еще в конце 20 столетия общение с компьютерами могло реализовываться исключительно с применением программирования, именно поэтому процесс программирования стали изучать фактически во всех образовательных заведениях.
Информационные технологии развивались, а общение с компьютерами происходило при помощи уже готовых компьютерных программ. Все современные пакеты прикладных программ содержат дополнительные средства, при использовании которых пользователи могут значительно расширять функциональные возможности для имеющегося программного обеспечения.
К примеру, практически в любом пакете Microsoft Office есть среда программирования языка VBA.
Таким образом, под понятием программирование понимается принципиально новый подход, что является обязательным пунктом для процесса подготовки специалистов с информационных технологий.
В работе были выполнены такие задачи:
– рассмотрены понятия о языках программирования;
– дана характеристика главным понятия, что связанные с понятием переменной;
– описаны типы данных, которые применяются в описании переменных;
– описано применение переменных в массивах данных;
– приведены примеры алгоритмов, используя переменные для обработки структурированных типов данных.
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- Айвор Хортон. Visual C++ 2010. Полный курс. Издательский дом «Вильямс». – 2017. – 300 с.
- Борис Пахомов. С/С++ и MS Visual C++ 2010 для начинающих. БХВ-Петербург. – 2017. – 436 с.
- Брайан Керниган Алгоритмизация и программирование. Издательство «Невский диалект». – 2017. – 320 с.
- Бьерн Страуструп. Программирование. Принципы и практика использования. Издательский дом «Вильямс». – 2015. – 258 с.
- Джесс Либерти. Освой самостоятельно С++ за 21 день. Издательский дом «Вильямс». – 2017. – 230 с.
- Динман М.И. Алгоритмизация и программирование. Освой на примерах. – СПб.: БХВ-Петербург, 2017.– 260 с.
- Дэвид Гриффитс, Дон Гриффитс. Изучаем программирование на С. Издательство «Эксмо». – 2018. – 400 с.
- Кнут, Дональд, Эрвин. Искусство программирования. Том 1. Основные алгоритмы. 3-е изд. Пер. с англ. – : Уч. пос. М.: Издательский дом. «Вильямс», 2017.– 720с.
- Кубенский А.А. Структуры и алгоритмы обработки данных: объектно-ориентированный подход и реализация на С++. – СПб.: БХВ-Петербург, 2018. – 464с.
- Лаптев В.В., Морозов А.В., Бокова А.В. Объектно-ориентированное программирование. Задачи и упражнения. – СПб.: Питер. 2018. – 288 с.
- Майерс С. Эффективное использование алгоритмизации. 50 рекомендаций по улучшению ваших программ и проектов. Пер. с англ. – М.: ДМК Пресс; – СПб.: Питер. 2018.–240с.
- Прата С. Язык программирования С++. Издание 6. Издательский дом «Вильямс» – 2016. – 304 с.
- Р. Лафоре. Объектно-ориентированное программирование в С++. Издательство «Питер». Издание 4. – 2017. – 628 с.
- С++ Стандартная библиотека. Для профессионалов./Н. Джосьютис. – СП Питер, 2017. – 350 с.
- Седжвик Роберт. Фундаментальные алгоритмы. Анализ/Структуры данных/Сортировка/Поиск: Пер. с англ./ Седжвик Роберт. К.: Издательство «ДиаСофт», – 2017. – 500 с.
- Скляров В.А. Язык С++ и объектно-ориентированное программирование. Справочное пособие. – Минск. «Вышейшая школа». – 2017. – 478с.
- Харви Дейтел, Пол Дейтел. Как программировать на С++. Пер. с англ. – М.: ЗАО «Издательство БИНОМ», 2017. – 430 с.
- Хусаинов Б.С. Структуры и алгоритмы обработки данных. Примеры на языке Си. Учеб. пособие. – Финансы и статистика, 2017. – 464с.
- Штерн Виктор. Основы С++: Методы программной инженерии.– Издательство «Лори», 2018. – 860с.
- Язык С++: Учеб. Пособие /И.Ф. Астахова, С.В. Власов, В.В. Фертиков, А.В. Ларин.–Мн.: Новое знание, 2018. – 203 с.

- Роль мотивации в поведении организации ООО «Континент»
- Планирование туризма в регионе как основа устойчивого развития территории (Сущность и экономическое содержание туризма)
- Влияние кадровой стратегии на работу службы персонала ООО «Автодар»
- Основные функции в системе менеджмента
- Управление качеством. Контрольные карты Шухарта. Схемы Исикава. Диаграммы Парето. (Карпова О.В.)
- Понятие и классификация функций государства (Методология )
- Налоги, как цена услуг государства
- Процессор персонального компьютера. Назначение, функции, классификация процессора
- Современные проблемы финансов предприятий ООО «Ренессанс Девелопмент»
- Управление поведением в конфликтных ситуациях
- Статус нотариуса (Статус нотариуса)
- Статус нотариуса (Нотариат в современной России)