
Поиск заданного слова в упорядоченном массиве
Содержание:

ВВЕДЕНИЕ
Тема данной курсовой работы: «Поиск слова в упорядоченном массиве».
При решении многих задач часто возникает необходимость установить, содержит ли массив определенную информацию или нет. Например, проверить, есть ли в массиве фамилий фамилия Петров. Задачи такого типа называются поиском в массиве.
Массивы – это набор элементов, имеющих одинаковый тип данных, или, по-другому, массивы – это набор элементов, имеющих одинаковое имя и один и тот же тип данных. Индекс массива начинается с 0 до n-1.
Актуальность данной темы обуславливается тем, что текстовые массивы данных встречаются повсюду. Это и электронные книги, и страницы сайтов, и документы и многое другое. Найти необходимое слово – частая и распространенная задача. Рассмотрение принципов поиска слова позволит понять данную задачу и способы её дальнейшей автоматизации. Массивы очень широко используются при разработке различного рода приложений. Массивы являются распространенным и полезным способом сохранения многих различных частей связанных данных. Массивы полезны при создании отсортированных и неотсортированных списков данных, при сохранении таблиц данных и для выполнения многих других задач. С понятием «массив» приходится работать и при решении научно-технических и экономических задач, связанных с обработкой совокупностей большого количества значений.
Цель работы: изучить принципы поиска слова в массивах.
Для выполнения цели необходимо выполнить ряд задач:
- рассмотреть понятие массива;
- рассмотреть понятие поиска слова;
- рассмотреть примеры использования.
Глава 1. Рассмотрение понятия «массив»
Переменная позволяет хранить одно значение за раз. Например, нам необходимо сохранить номер броска ста студентов. Для этой задачи необходимо объявить 100 переменных, а затем присвоить значения каждой из них. Но если студентов 10000 или больше, объявлять столько переменных плохое решение. В такой ситуации, лучший способ – это массивы.
Массив – это коллекция из одного или нескольких значений одного типа. Каждое значение называется элементом массива. Элементы массива имеют одно и то же имя переменной, но каждый элемент имеет свой собственный уникальный номер индекса (также известный как индекс). Массив может быть любого типа, например: int, float, и charт.д. Если массив имеет тип , intто это элементы должны быть типа intтолько.
Массивы и их представление приведены ниже на рисунке 1.
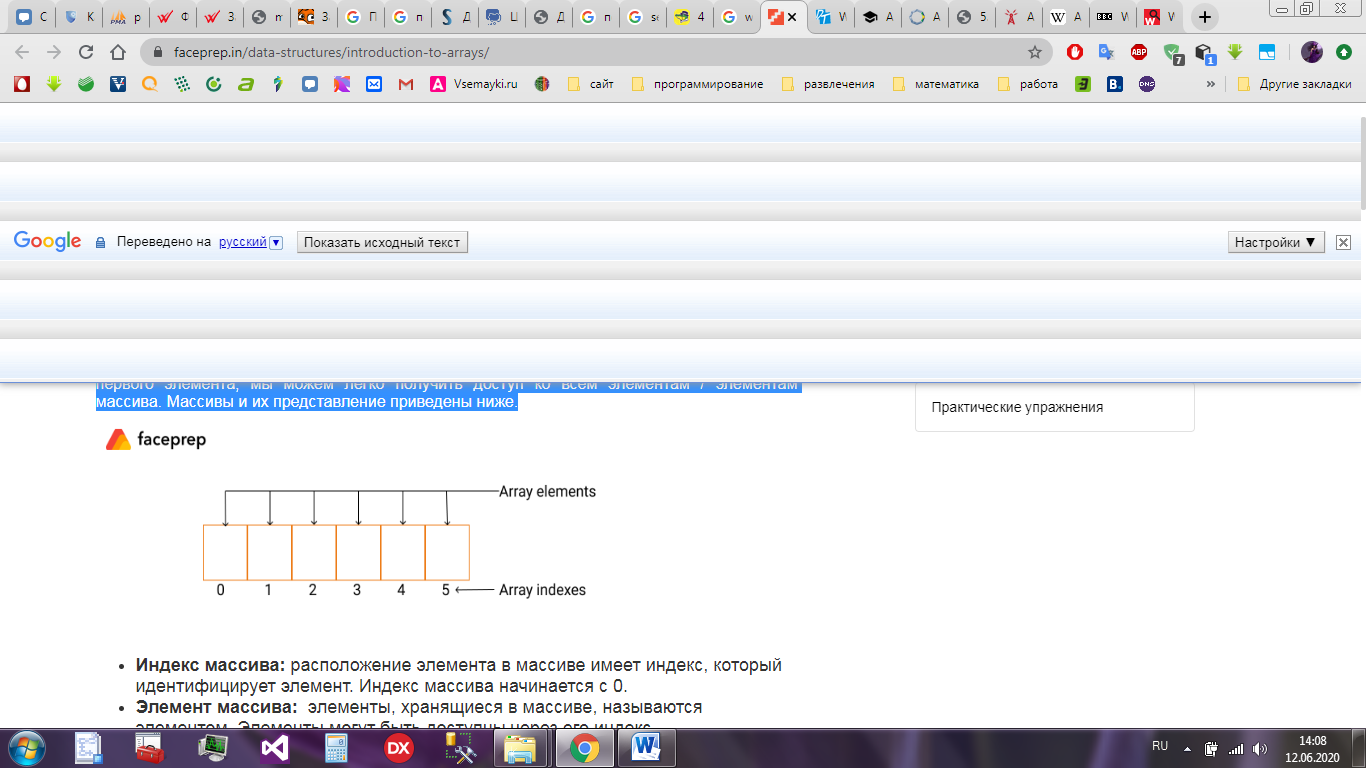
Рисунок 1 – Представление массива
Индекс массива: расположение элемента в массиве имеет индекс, который идентифицирует элемент. Индекс массива начинается с 0.
Элемент массива: элементы, хранящиеся в массиве, называются элементом. Элементы могут быть доступны через его индекс.
Длина массива: длина массива определяется на основе количества элементов, которые массив может хранить. В приведенном выше примере длина массива равна 6, что означает, что он может хранить 6 элементов.
Когда объявляется массив размера и типа, компилятор выделяет достаточно памяти для хранения всех элементов данных.
Переменные стандартного типа можно изобразить отдельными маленькими ячейками. То же самое относится и к переменным перечисляемого и интервального типов – рисунок 2.
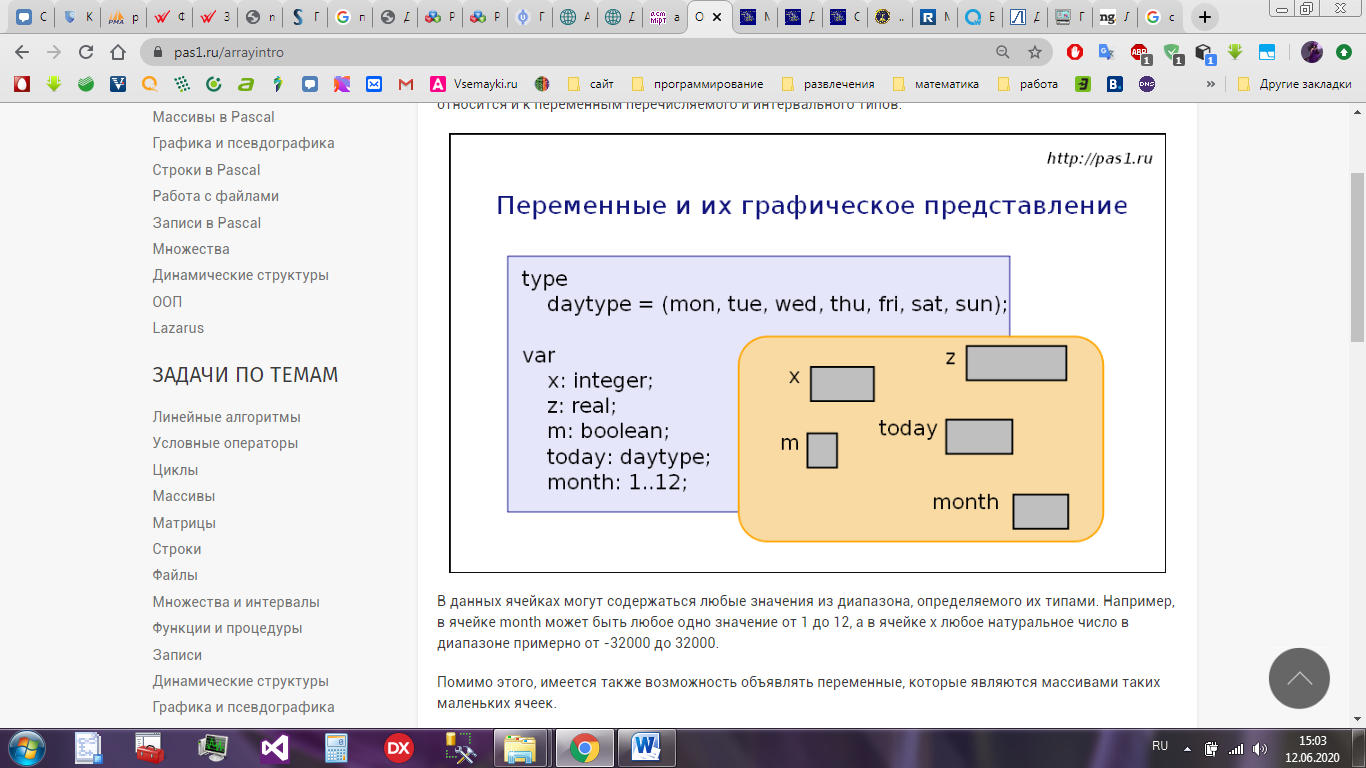
Рисунок 2 – Графическое представление переменной
В данных ячейках могут содержаться любые значения из диапазона, определяемого их типами.
Базовый тип массива – это тип элементов, из которых составлен массив (в каждом массиве все компоненты одного типа) – рисунок 3. Элементы можно обрабатывать так же, как переменные базового типа. Однако такое использование элементов массива в качестве обычных переменных не дает никакой выгоды.
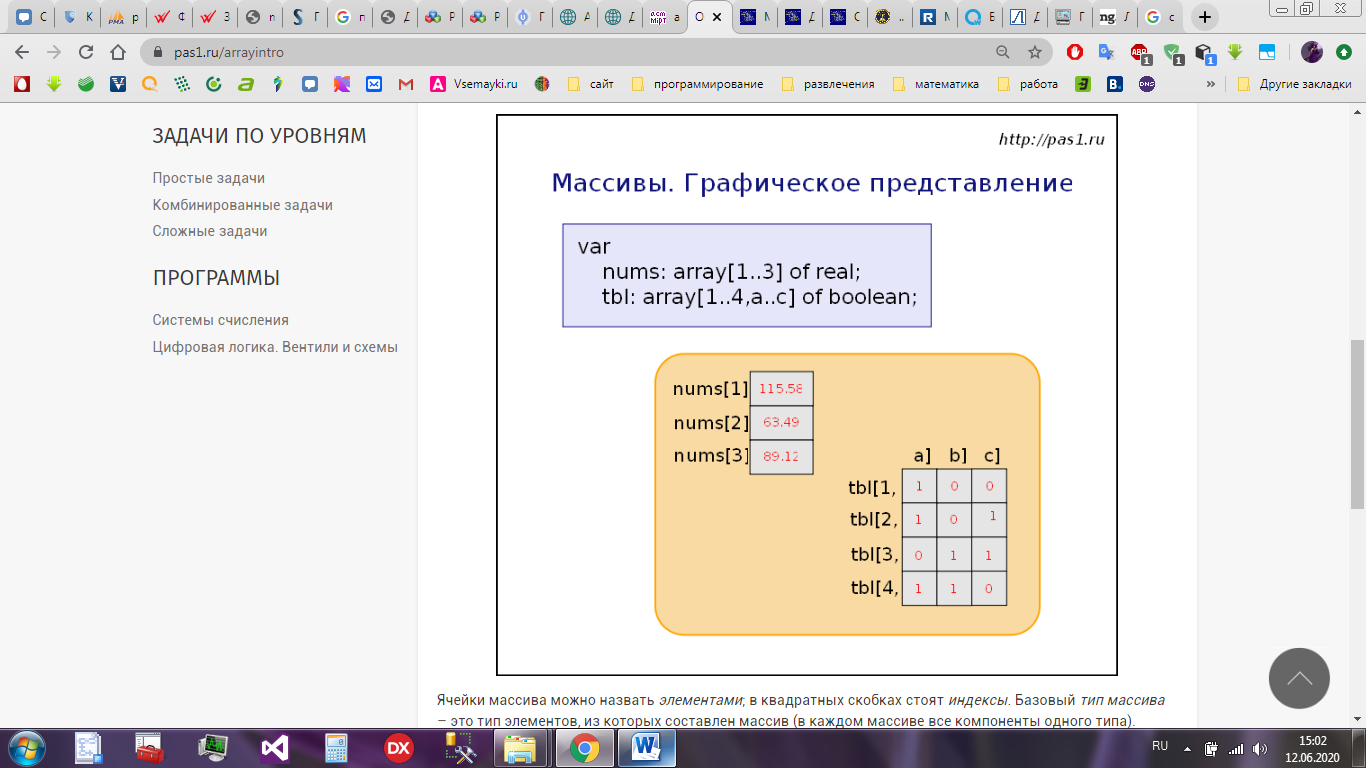
Рисунок 3 – Графическое представление массива
1.1 Одномерные массивы
Предположим, что программа работает с большим количеством однотипных данных. Например, около ста разных целых чисел нужно обработать, выполнив над ними те или иные вычисления. 100 переменных в программе и для каждой переменной написать одно и тоже выражение вычисления значения – очень неэффективно.
Есть более простое решение. Это использование такой структуры (типа) данных как массив. Массив представляет собой последовательность ячеек памяти, в которых хранятся однотипные данные. При этом существует всего одно имя переменной связанной с массивом, а обращение к конкретной ячейке происходит по ее индексу (номеру) в массиве.
Индекс ячейки массива не является ее содержимым. Содержимым являются хранимые в ячейках данные, а индексы только указывают на них. Действия в программе над массивом осуществляются путем использования имени переменной, связанной с областью данных, отведенной под массив. Порядковый номер элемента массива называется индексом этого элемента.
Все элементы определенного массива имеют один и тот же тип. У разных массивов типы данных могут различаться. Например, один массив может состоять из чисел типа integer, а другой – из чисел типа real.
Массив можно создать несколькими способами – рисунок 3.
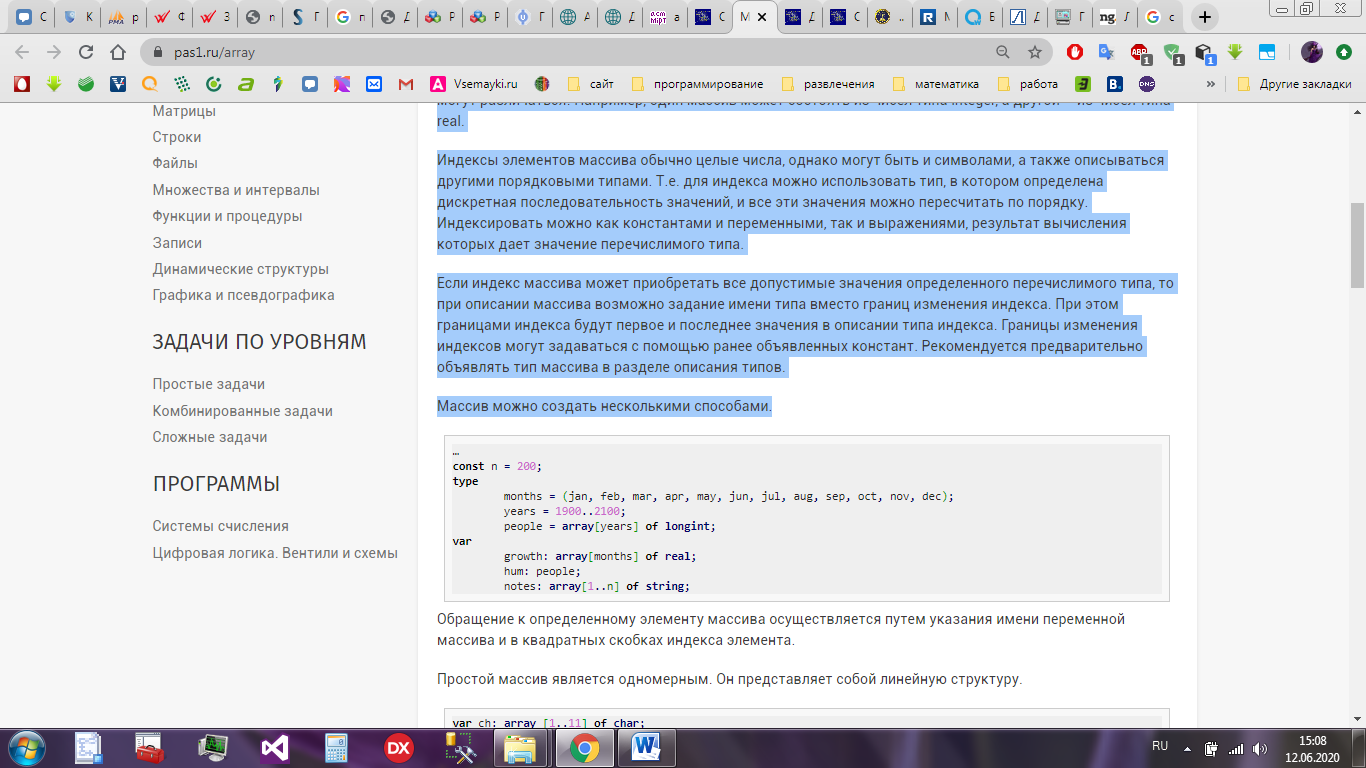
Рисунок 3 – Пример создания массива на языке программирования Pascal
Обращение к определенному элементу массива осуществляется путем указания имени переменной массива и в квадратных скобках индекса элемента.
Простой массив является одномерным. Он представляет собой линейную структуру – рисунок 4.
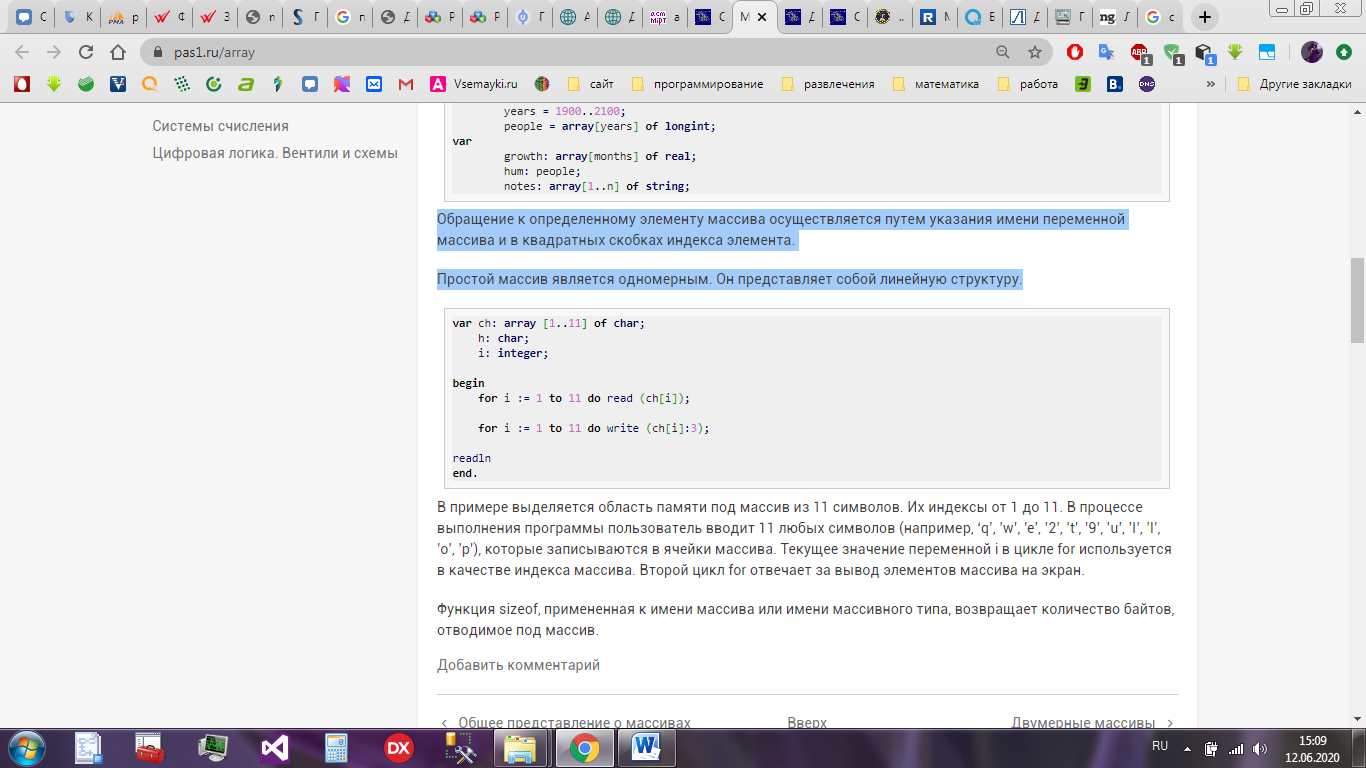
Рисунок 4 – Пример обращения к массиву на языке программирования Pascal
Общие правила объявления одномерного массива:
- переменная массива должна быть объявлена перед использованием в программе;
- объявление должно иметь тип данных (int, float, char, double и т. Д.), Имя переменной и индекс;
- индекс представляет размер массива. Если размер объявлен как 10, программисты могут хранить 10 элементов;
- индекс массива всегда начинается с 0. Например, если переменная массива объявлена как s [10], то она колеблется от 0 до 9;
- каждый элемент массива хранится в отдельной ячейке памяти.
1.2 Двумерные массивы
Одномерный массив можно представить как линейную структуру, в которой элементы следуют друг за другом. Однако бывают более сложные структуры данных. Например, двумерные массивы, которые можно описать как таблицу, в ячейках которой располагаются значения. Для обращения к данным массива указывается номера их строк и столбцов. Часто табличные массивы называют матрицами.
Одномерный массив представляет информацию в линейном порядке, одномерным списком. Однако данные, связанные с определенными системами (цифровое изображение, настольная игра и т. д.), «живут» в двух измерениях. Чтобы визуализировать эти данные, нужна многомерная структура данных, то есть многомерный массив. Двумерный массив – это не что иное, как массив массивов.
В качестве массива можно представить ужин. Можно иметь одномерный список всего, что едите: салат, помидоры, стейк, картофельное пюре, торт, мороженое.
А можно получить двумерный список из трех блюд, каждый из которых содержит две вещи, которые едите: (салат, помидоры) и (стейк, пюре) и (торт, мороженое).
В первом случае одномерный массив выглядит так:
int [] myArray = {0,1,2,3};
А двумерный массив выглядит так:
int [] [] myArray = {{0,1,2,3}, {3,2,1,0}, {3,5,6,1}, {3,8,3,4}};
Лучше рассматривать двумерный массив как матрицу. Матрица может рассматриваться как сетка чисел, расположенных в строках и столбцах.
Обычно двумерные массивы на языке программирования Pascal описываются так – рисунок 5, однако можно их описывать и по-другому – рисунок 6:
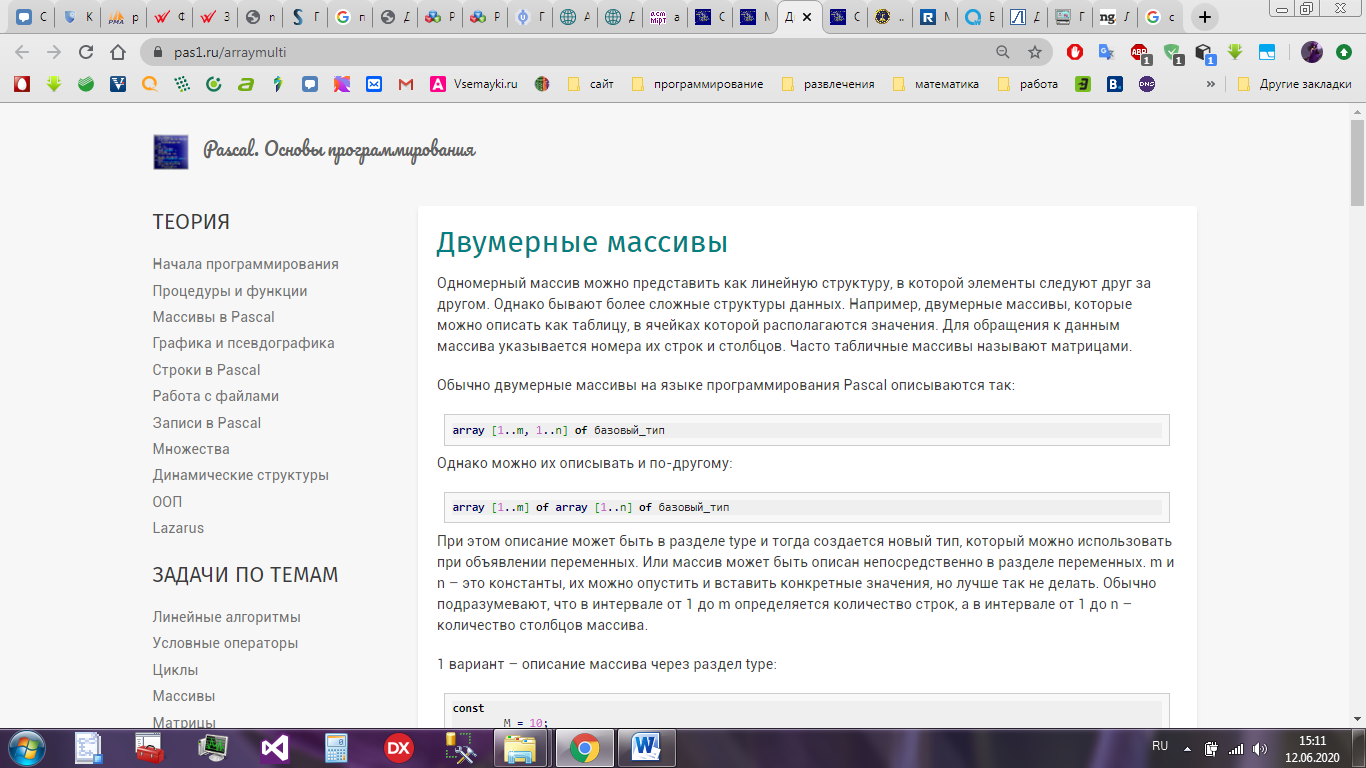
Рисунок 5 – Описание массива 1
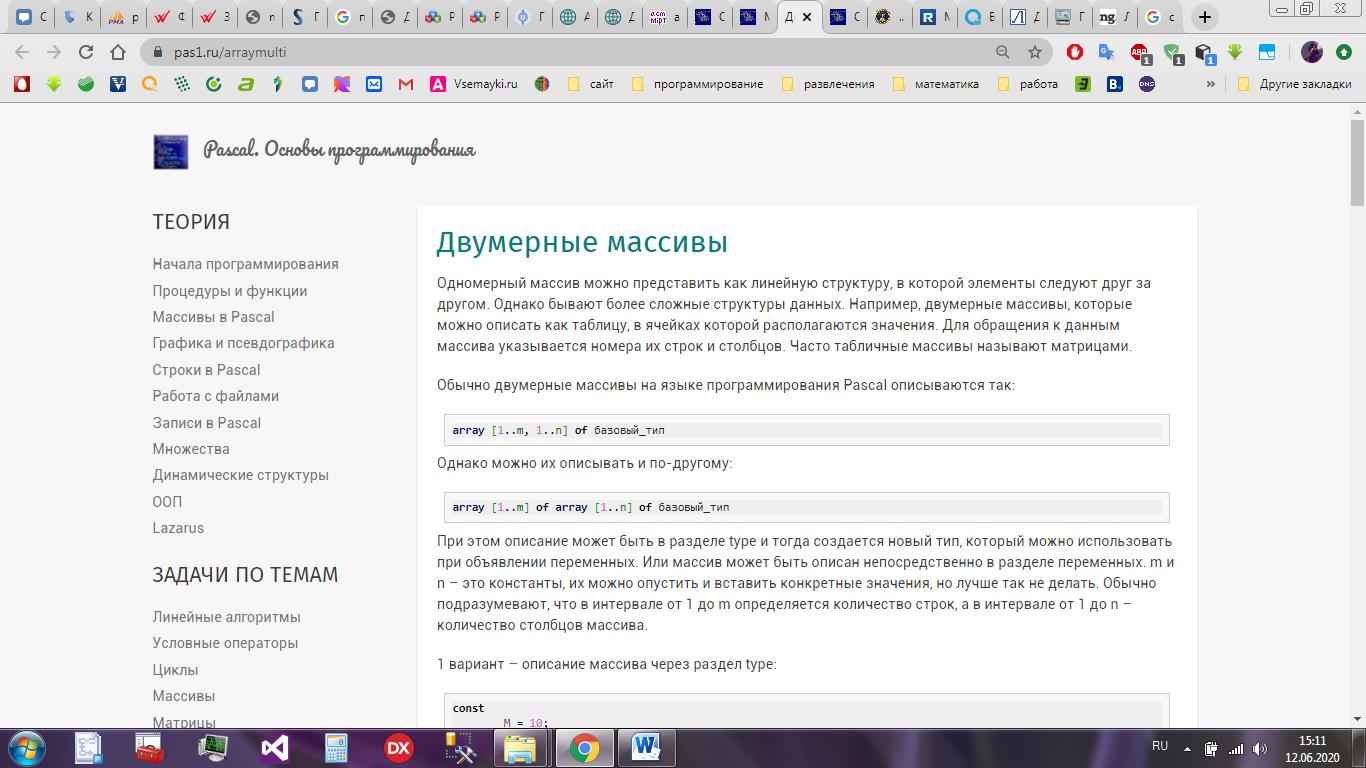
Рисунок 6 – Описание массива 2
При этом описание может быть в разделе type и тогда создается новый тип, который можно использовать при объявлении переменных. Или массив может быть описан непосредственно в разделе переменных. m и n – это константы, их можно опустить и вставить конкретные значения, но лучше так не делать. Обычно подразумевают, что в интервале от 1 до m определяется количество строк, а в интервале от 1 до n – количество столбцов массива.
Для обращения к элементу двухмерного массива необходимо указать имя массива и в квадратных скобках через запятую – значения двух индексов (первый указывает номер строки, а второй – номер столбца), на пересечение которых стоит элемент (например, a[i,2]:=6). В языке программирования Pascal допустимо разделение индексов с помощью квадратных скобок (например, a[i][5]:= 7).
Если описывается двумерный массив как типизированная константа, то при задании значений его элементов он рассматривается как массив массивов. При этом в общих круглых скобках через запятую перечисляются заключенные в круглые скобки значения элементов строк (каждая строка в своих скобках) – рисунок 7.
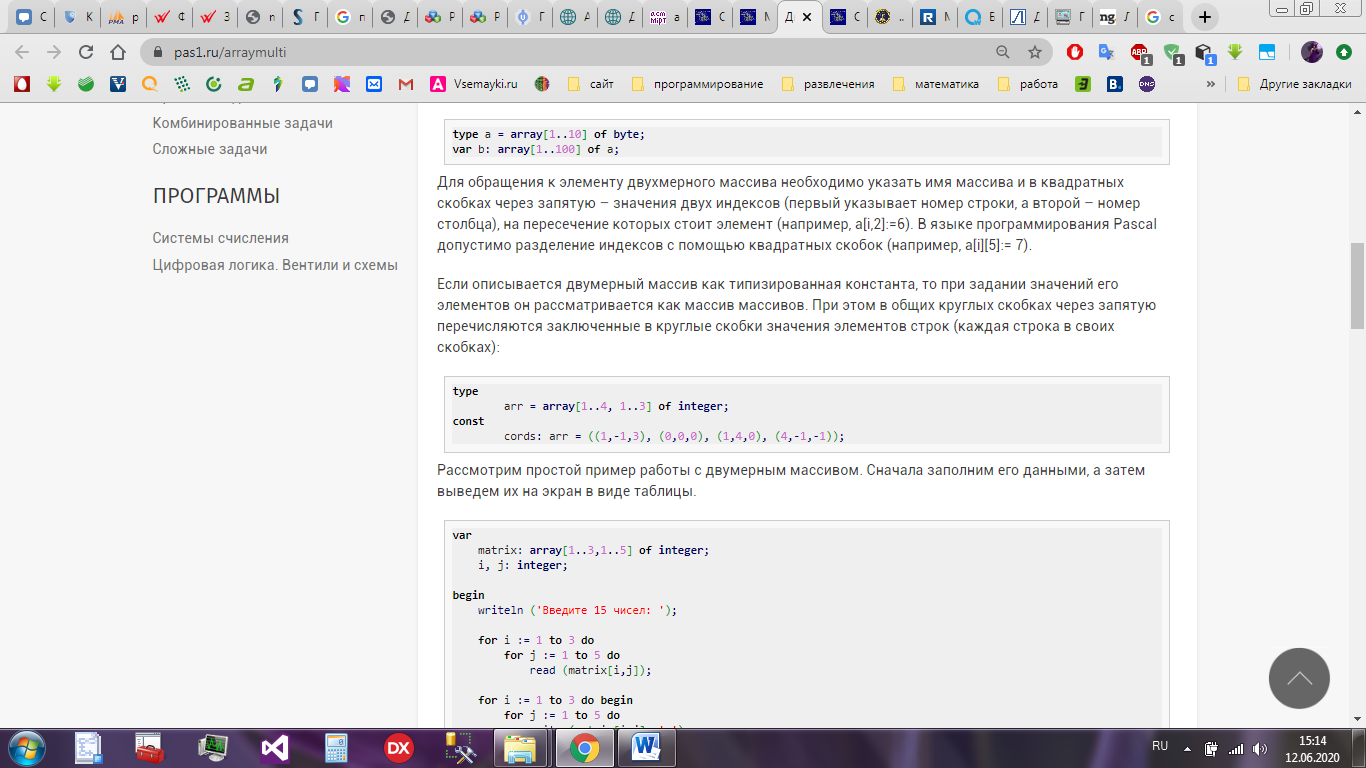
Рисунок 7 -Константа
Размерность массива (т.е. количество содержащихся в нем значений) определяется произведением количества строк на количество столбцов. В примере в массив помещается 15 значений – рисунок 8.
Когда пользователь вводит очередное число, то процедура read считывает его и помещает в ячейку с текущими индексами i и j. Когда i равна единице, значение j меняется пять раз, и, значит, заполняется первая строка таблицы. Когда i равна двум, значение j снова меняется пять раз и заполняется вторая строка таблицы. Аналогично заполняется третья строка таблицы. Внутренний цикл for в общей сложности совершает 15 итераций, внешний только 3.
Как пользователь вводит значения – не важно. Он может их разделять либо пробелом, либо переходом на новую строку.
Вывод значений двумерного массива организован в виде таблицы. Выводятся 3 строки по 5 чисел в каждой. Внутри строк числа разделяются пробелом.
В программе следует использовать константы. В случае чего их значения можно поменять всего лишь в одном месте.
При описании открытого массива необходимо указать тип элементов, из которых он состоит, но не указывать границы индексов. Таким образом можно сформировать «безразмерный» массив. Размер такого массива можнт задаваться и изменяться при выполнении программы – динамическое распределение памяти. Переменные этих массивов - указатели на динамически выделяемую область памяти. Это означает, что в этих переменных будут содержаться адреса начала массива, а не сам массив. Пример программы представлен на Рисунке 9.
Обычно открытые массивы используются для передачи в подпрограмму массивов переменных размеров. Это позволяет с помощью одной и той же подпрограммы обрабатывать массивы произвольной длины.
Двумерный массив также можно использовать для хранения объектов, что особенно удобно при программировании эскизов, в которых используются некие «сетки» или «доски».
Например, можно написать программу, использующую двумерный массив для рисования изображения в градациях серого.
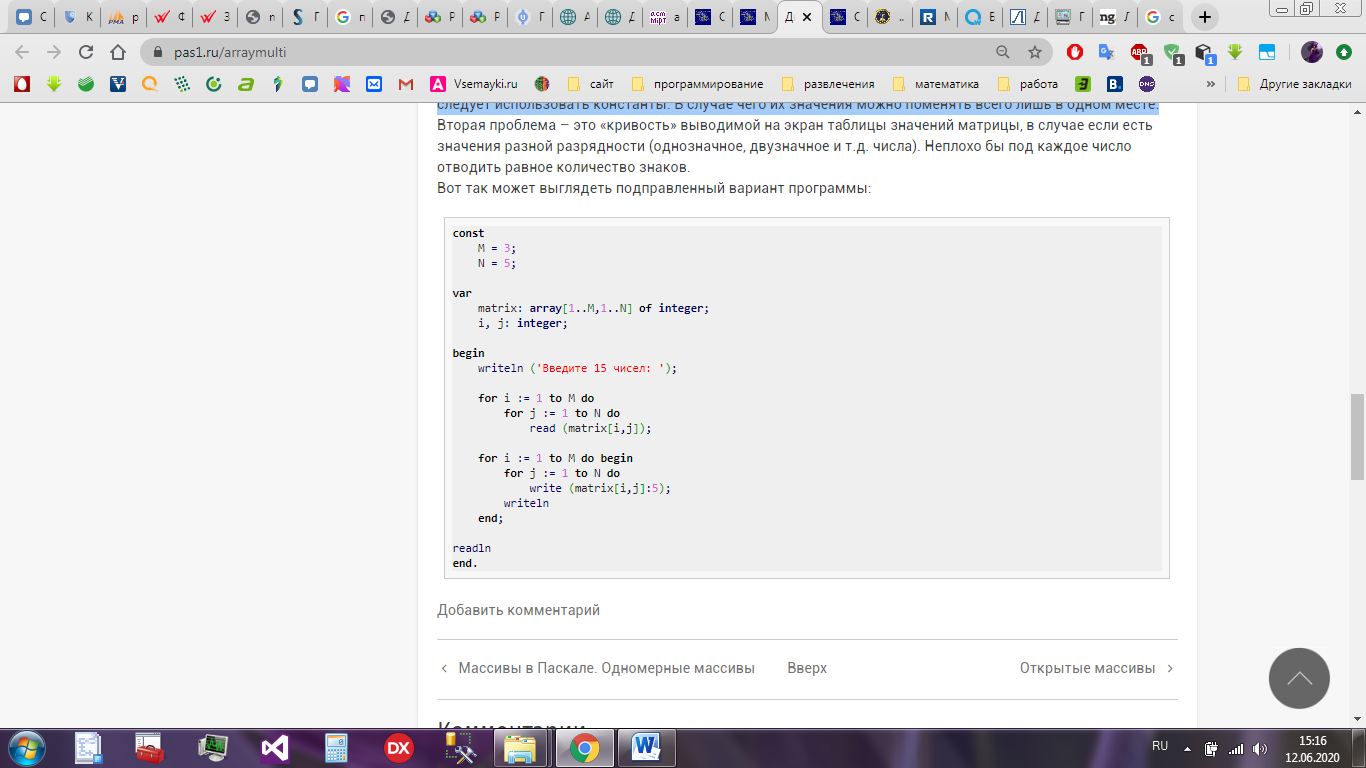
Рисунок 8 – Пример работы с массивом
Основные операции над массивами:
- траверс – печать всех элементов массива один за другим;
- вставка – добавляет элемент по указанному индексу;
- удаление – удаляет элемент по указанному индексу;
- поиск – поиск элемента в массиве по заданному индексу или значению;
- обновить – обновляет элемент по указанному индексу.
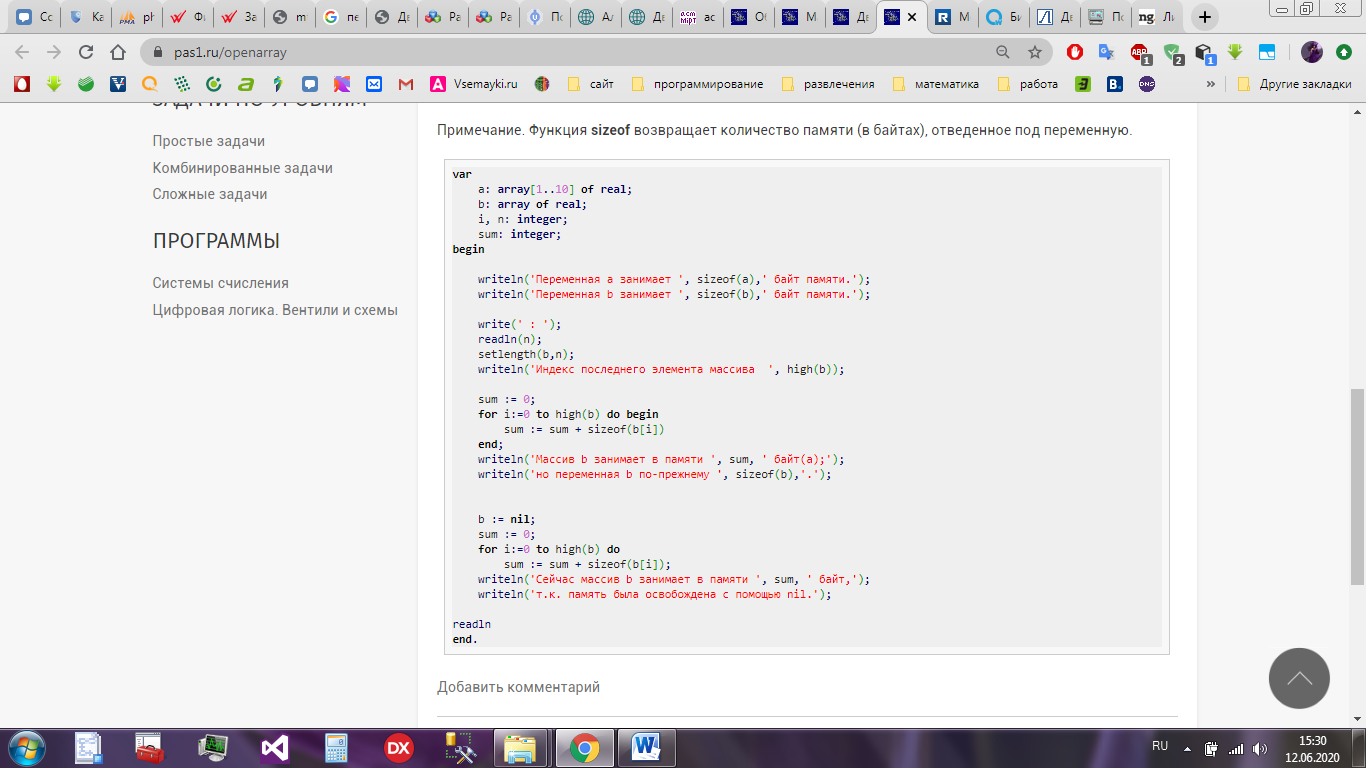
Рисунок 9 – Пример программы с массивом на языке Pascal
В следующей главе будут рассмотрены методы поиска в массивах.
Глава 2. Рассмотрение понятия «поиск» в массиве
Переменная содержит один элемент данных. Может возникнуть ситуация, когда для хранения похожих и связанных данных требуется много переменных. В этой ситуации использование массива может упростить программу, храня все связанные данные под одним именем. Это означает, что программа может быть написана для поиска по массиву данных гораздо быстрее, чем необходимость писать новую строку кода для каждой переменной. Это уменьшает сложность и длину программы, что облегчает поиск и устранение ошибок.
Необходимость в массивах возникает всякий раз, когда при решении задачи приходится иметь дело с большим, но конечным количеством однотипных упорядоченных данных.
Задача поиска слова – это очень часто встречающаяся задача. Например, словарь и поиск слова в нём. Словарь – это упорядоченный массив данных (текстовый).
2.1 Линейный поиск
Линейный или последовательный поиск – самый простой из алгоритмов поиска элемента в массиве.
Алгоритм заключается в обходе всех элементов массива, как правило, слева на право, и сравнения их с искомым значением. Если значения элемента и ключа совпадают, то поиск возвращает индекс элемента.
Поскольку, линейный алгоритм, обходит массив последовательно, он очень медленный.
Тем не менее, этот метод используется для поиска:
- на небольших массивах данных;
- в потоковой обработке данных;
- минимального и максимального значения массива;
- на одиночных неупорядоченных больших массивах.
Он работает как с неотсортированными массивами, так и отсортированными, но для вторых существуют алгоритмы эффективнее линейного поиска (см. 2.2).
То, что данный алгоритм неэффективен при работе с большими массивами, может компенсировать его простота. Его можно применять к неупорядоченным последовательностям, что является плюсом.
В ходе такого поиска выбирается ключ – некая величина, которая сравнивается по очереди со всеми элементами массива.
Алгоритм недаром называют «последовательным», это название означает, что все элементы просматриваются последовательно – от первого к последнему. Если текущий элемент равен ключу, то поиск считается завершённым. Если все элементы пройдены и никакой из них не равен ключу - выдаётся результат о том, что искомый элемент не найден.
В хорошей ситуации, искомый элемент – ключ, будет первым или в первых рядах. В плохой ситуации – он окажется последнем или вообще не будет найден. Тогда придётся выполнить N сравнений (N равно количеству элементов массива).
Такой принцип работы используют не часто. Этот алгоритм оправдывает себя на небольших и/или неотсортированных последовательностях.
Но если последовательность большая или поиск необходимо выполнять много раз подряд, то предпочтительнее сначала выполнить сортировку последовательности, а затем, применить другой алгоритм поиска, например, двоичный (бинарный).
Пример программы линейного поиска – рисунок 10.
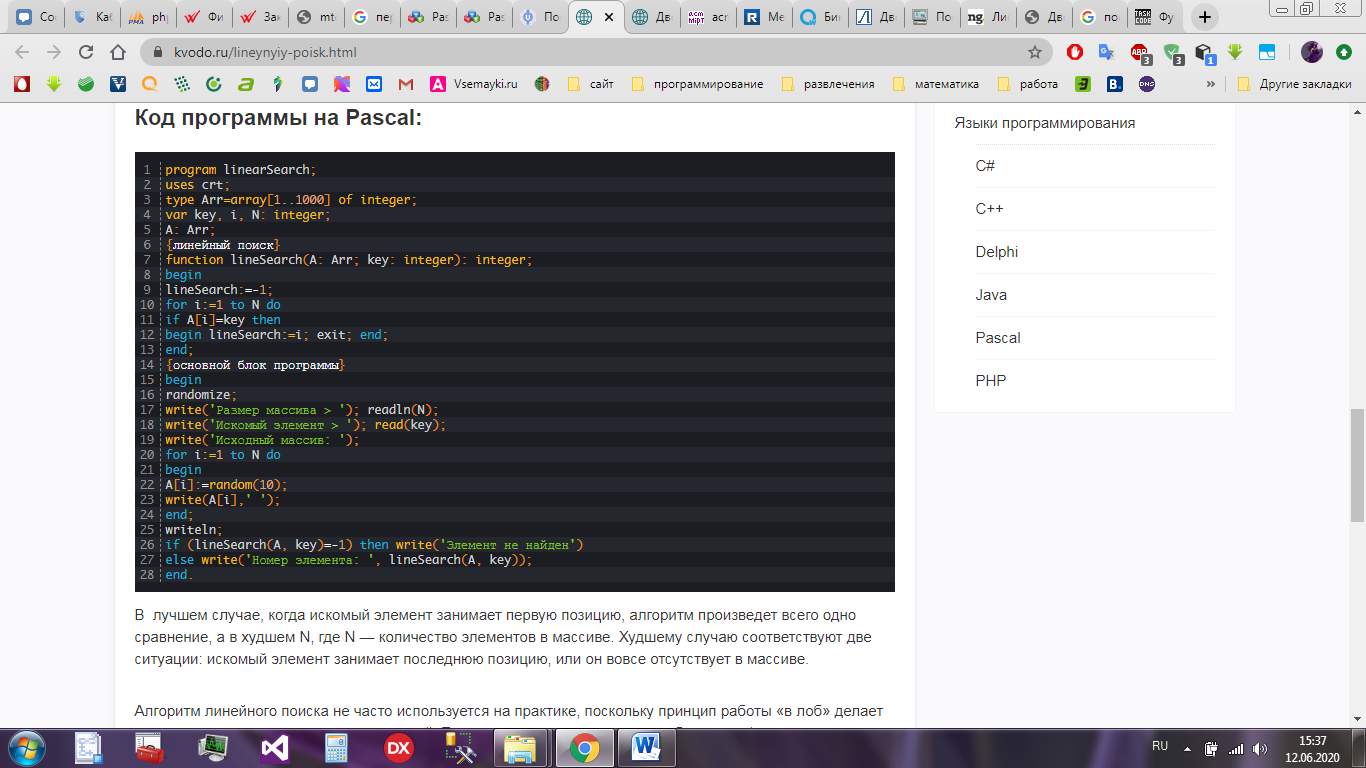
Рисунок 10 – Линейный поиск Pascal
2.2 Бинарный поиск
В практической деятельности часто приходится работать с упорядоченной по некоторому критерию информацией.
На практике часто приходится иметь дело с информацией, которая упорядочена по некоторому критерию. Например, список фамилий, как правило, упорядочен по алфавиту, массив метеорологических данных – по датам наблюдений. Если информация была изначально упорядочена, то можно сделать предположение, в какой части списка может находится искомое слово (в начале или конце). Например, фамилия Якимова будет в конце списка, а Белов в начале.
В данном случае оптимально применение алгоритма двоичного (бинарного) поиска.
Суть метода: последовательность делится пополам на равные части. Поиск выполняется в одной из частей, которая в дальнейшем так же делится пополам и так до получения результата.
Найдя средний элемент (сделать это, зная число элементов массива, не составит труда), и, сравнив его значение с искомым, можно уверено сказать, где относительно среднего элемента находится искомый элемент.
Поскольку в каждом бинарном поиске сравнения используется половина пространства поиска, мы можем утверждать и легко доказать, что бинарный поиск никогда не будет использовать больше, чем (в большой записи) O (log N ) сравнений, чтобы найти целевое значение.
Логарифм – ужасно медленно растущая функция. Если вы не знаете, насколько эффективен бинарный поиск, попробуйте найти имя в телефонной книге, содержащей миллион имен. Бинарный поиск позволяет систематически находить любое имя, используя не более 21 сравнения. Если бы было необходимо управлять списком, содержащим всех людей в мире, отсортированных по имени, можно было бы найти любого человека менее чем за 35 шагов.
Такой поиск предполагает, что у нас есть произвольный доступ к последовательности. Попытка использовать двоичный поиск в контейнере, таком как связанный список, не имеет смысла, и вместо этого лучше использовать простой линейный поиск.
Бинарный поиск также можно использовать для монотонных функций, домен которых представляет собой набор действительных чисел. Реализовать бинарный поиск по реальным числам обычно проще, чем по целым, потому что тогда не нужно следить за границами.
Например, есть задача: ряд работников должны изучить ряд картотек. Шкафы не все одинакового размера, и известно для каждого шкафа, сколько папок он содержит. Необходимо найти такое назначение, чтобы каждый работник получал последовательную серию шкафов для просмотра и сводил к минимуму максимальное количество папок, которые работник должен был бы просмотреть.
После ознакомления с проблемой требуется творческий подход. Допустим, что в распоряжении неограниченное количество работников. Важное замечание заключается в том, что для некоторого числа MAX можно рассчитать минимальное количество работников, необходимое для того, чтобы каждому работнику приходилось проверять не более MAX папок (если это возможно).
Решение: некоторому работнику нужно проверить первый шкаф, поэтому выбирается любой работник. Но, поскольку шкафы должны быть назначены в последовательном порядке (рабочий не может изучить шкафы 1 и 3 без проверки 2), всегда оптимально назначать его ко второму шкафу, если это не приведет к превышению предела, который был введен (MAX). Если это число выходит за предел, делается вывод, что его работа выполнена, и назначается новый работник во второй кабинет. Действуем аналогичным образом, пока все кабинеты не будут назначены, и утверждаем, что мы использовали минимально возможное количество работников с введенным нами искусственным ограничением. Количество работников обратно пропорционально MAX: чем выше устанавливается лимит, тем меньше работников понадобится.
Теперь, если вы вернуться назад и внимательно изучить проблему, можно увидеть, что действительно просили наименьшее MAX, чтобы число требуемых работников было меньше или равно числу доступных работников. Таким образом, очевидно, что задача почти решена. Осталось лишь соединить точки и посмотреть, как все это вписывается в решение проблем с помощью бинарного поиска.
Теперь, когда проблема перефразирована, чтобы лучше соответствовать потребностям, необходимо исследовать предикат. Установим, как распределить рабочую нагрузку так, чтобы каждому работнику приходилось проверять не более x папок при ограниченном количестве рабочих. Можно использовать описанный жадный алгоритм, чтобы эффективно оценить этот предикат для любого x.
На этом завершается первая часть построения решения для бинарного поиска. Осталось доказать, что условие в основной теореме выполнено. Увеличение x фактически ослабляет ограничение на максимальную рабочую нагрузку, поэтому может потребоваться только такое же количество рабочих или меньше, а не больше. Таким образом, если предикат говорит «да» для некоторого x, он также скажет «да» для всех больших x.
Очень важно правильно выбрать нижнюю и верхнюю границы. Можно заменить верхнюю границу любым достаточно большим целым числом, но нижняя граница не должна быть меньше, чем самый большой шкаф, чтобы избежать ситуации, когда один шкаф будет слишком большим для любого работника, случай, который не будет правильно обрабатываться предикатом. Альтернативой было бы установить нижнюю границу равной нулю, а затем обрабатывать слишком малые x как особый случай в предикате.
Общая сложность решения составляет O ( n log SIZE ), где SIZE - размер пространства поиска. Это очень быстро.
При работе с таким поиском важно учесть:
- необходимость разработки предиката, который можно эффективно оценить, чтобы можно было применять бинарный поиск;
- необходимость определения того, что ищется, и обеспечить факт его наличия в пространстве поиска;
- если область поиска состоит только из целых чисел, протестировать алгоритм на двухэлементном наборе, чтобы убедиться, что он не блокируется;
- убедиться, что нижняя и верхняя границы не слишком ограничены: обычно лучше их ослаблять, если они не нарушают предикат.
Алгоритм представлен на рисунке 11.
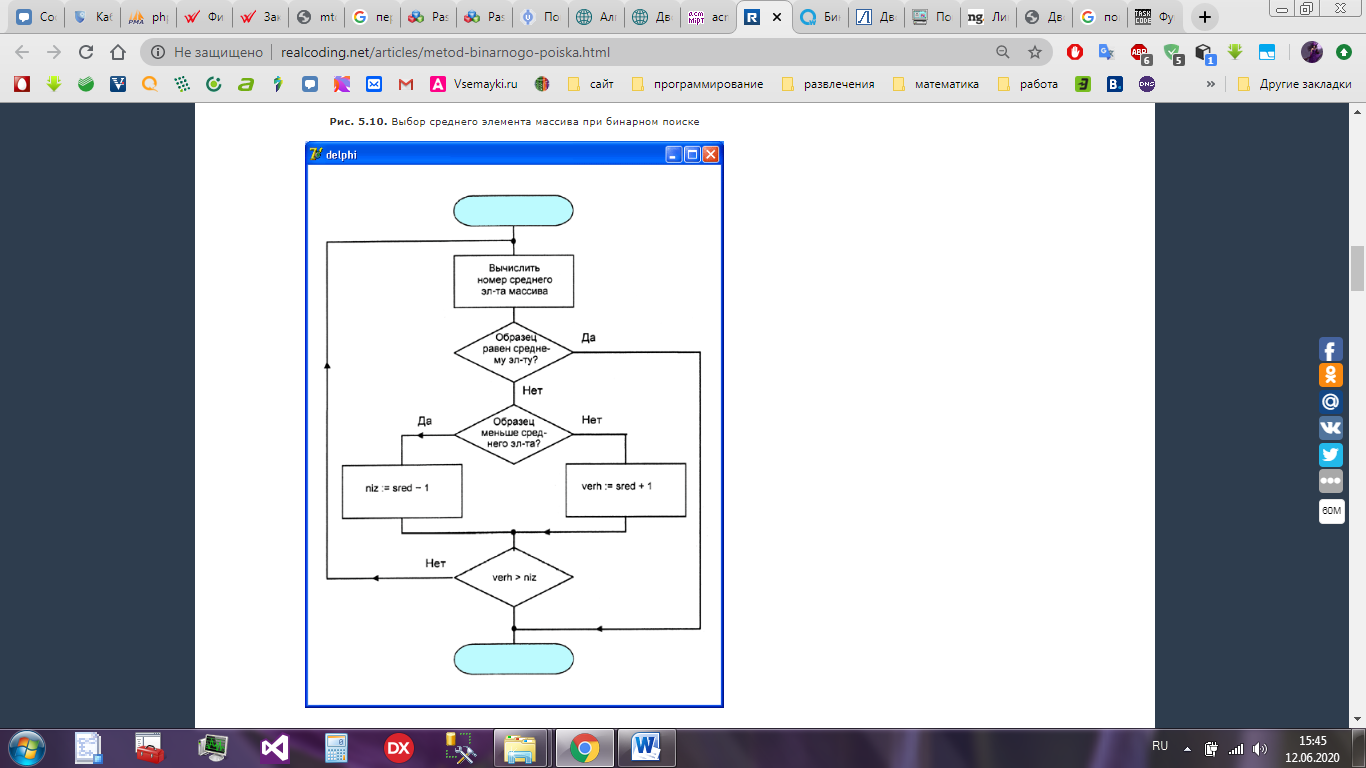
Рисунок 11 – Алгоритм поиска
На рисунке ниже – рисунок 12, представлен конкретный целочисленный массив, и пошаговое выполнение алгоритма бинарного поиска применительно к его элементам. Для экономии места в таблице left, right и mid заменены на a, b и c.
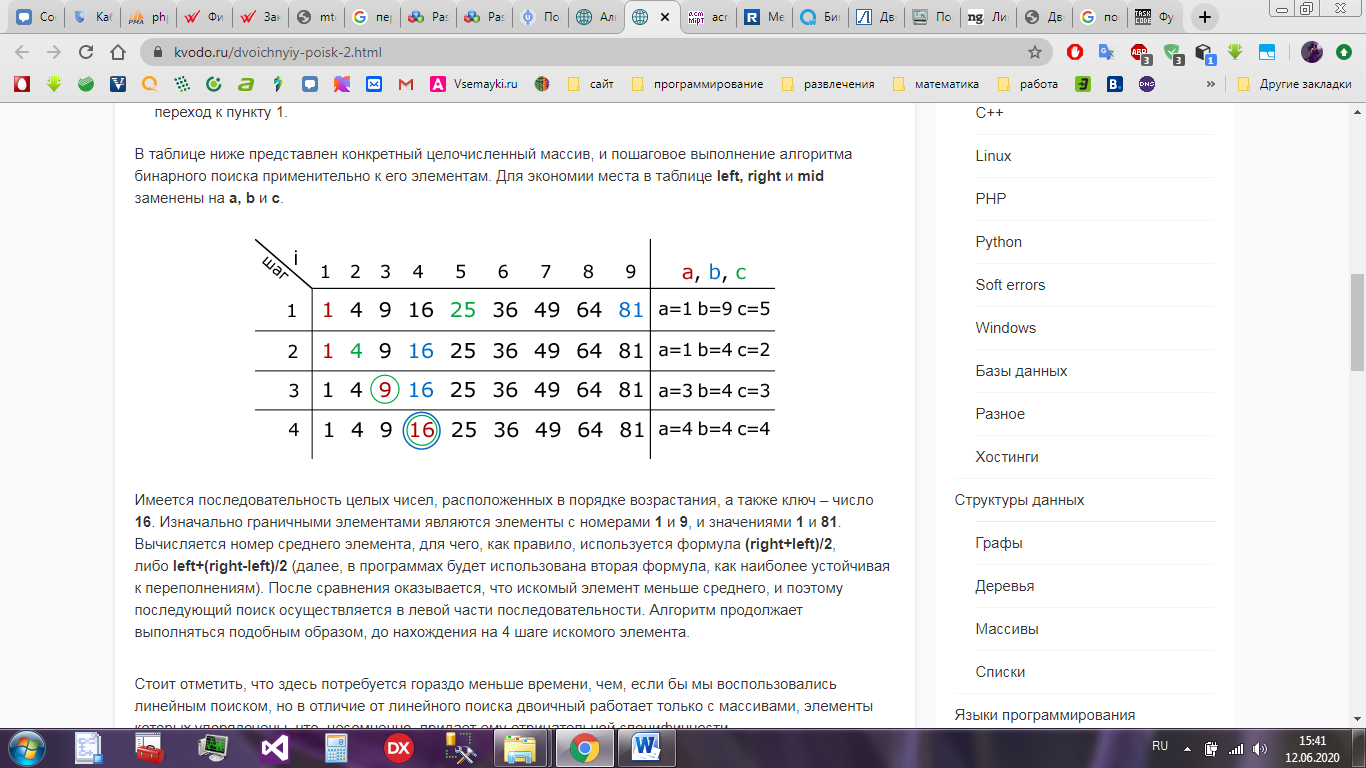
Рисунок 12 – Пример выполнения алгоритма поиска
На данном рисунке изображена последовательность целых чисел, расположенных в порядке возрастания. В качестве ключа выбрано число 16.
Изначально граничными элементами являются элементы с номерами 1 и 9, и значениями 1 и 81.
Вычисляется номер среднего элемента, для чего, как правило, используется формула (right+left)/2, либо left+(right-left)/2 (вторая формула наиболее устойчивая к переполнениям).
После сравнения оказывается, что искомый элемент меньше среднего, и поэтому последующий поиск осуществляется в левой части последовательности.
Алгоритм продолжает выполняться подобным образом, до нахождения на 4 шаге искомого элемента.
Код программы представлен на рисунке 13.
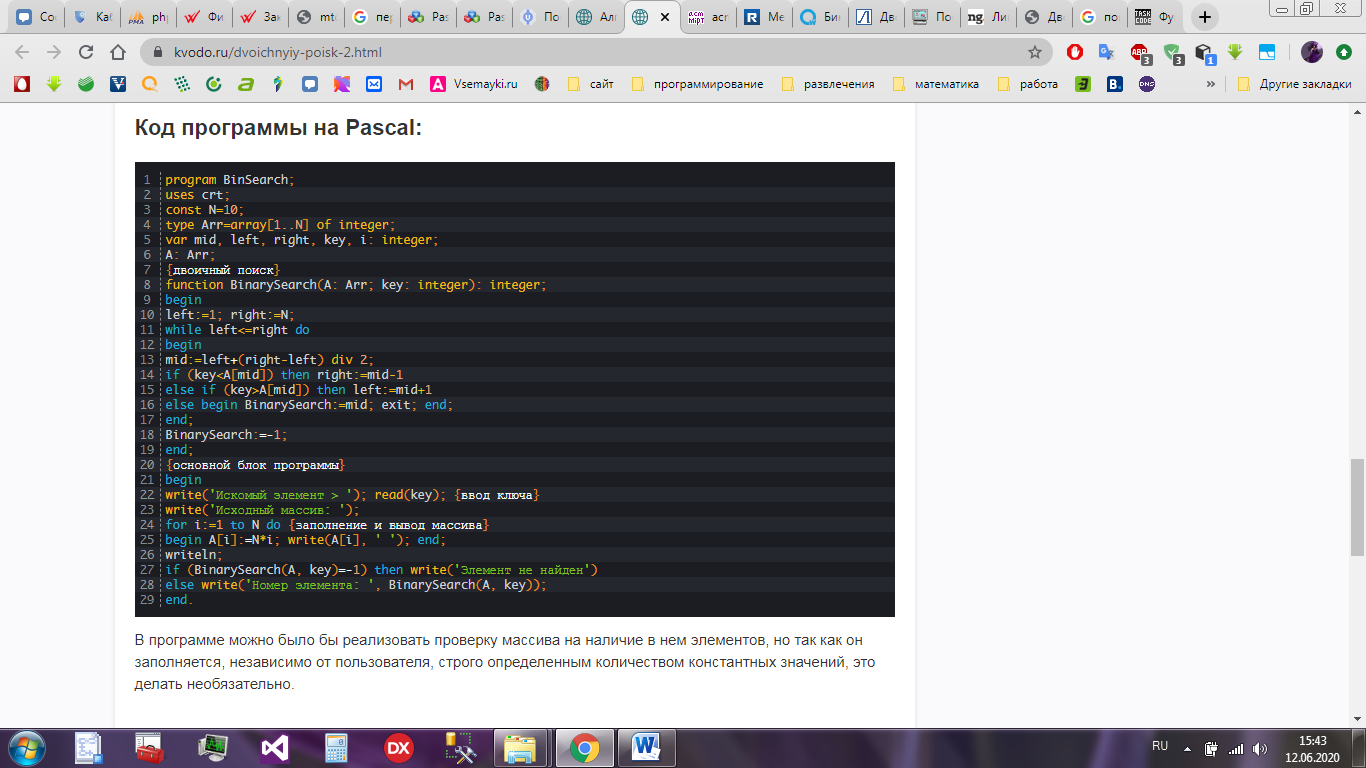
Рисунок 13 – Код бинарного поиска на Pascal
В случае, когда первое значение mid совпадает с ключом, тогда считается, что алгоритм выполнился за свое лучшее время O(1). В среднем и худшем случае время работы алгоритма составляет O(logn), что значительно быстрее, чем у линейного поиска, требующего линейного времени.
ЗАКЛЮЧЕНИЕ
Массив одна из самых популярных структур данных и в тоже время, самых старых. С их помощью можно решать многие задачи связанный с хранением, поиском, удалением и добавлением данных.
Упорядоченный массив, представляет собой массив, в котором его элементы расположены в упорядоченном виде (по возрастанию/убыванию). Такие массивы используются в тех случаях, если при работе с ним, количество операций поиска элемента массива много больше операций вставок и удаления.
Двоичный, или бинарный, поиск значения в списке или массиве используется только для упорядоченных последовательностей, то есть отсортированных по возрастанию или убыванию. Заключается в определении, содержит ли массив искомое значение, а также в определение места его нахождения.
В отличии от линейного, алгоритм двоичного поиска эффективен только в упорядоченном массиве, однако скорость выполнения не так сильно зависит от размера массива. Даже можно сказать, что алгоритм двоичного поиска создан для поиска в массивах больших размеров.
Данная курсовая работа состоит из введения, 2 глав, заключения, списка используемых источников.
В ведение была рассмотрена актуальность выбранной темы, определена цель и составлены задачи для её достижения.
В первой главе было рассмотрено понятие «массив», описаны виды массивов.
Во второй главе было рассмотрено понятие «поиск в массиве», описаны виды поиска, способы применения.
В заключении описаны основные выводы по работе.
Задачи курсовой работы выполнены, цель достигнута.
СПИСОК ИСПОЛЬЗУЕМЫХ ИСТОЧНИКОВ
- Аубакиров Г.Д., Языки программирования Pascal, Delphi, «Астана»2019. – 208 с.
- Белецкий Я.Н., Турбо Паскаль с графикой для персональных компьютеров, 2018. – 411 с.
- Вирт Н. Алгоритмы и структуры данных. M.: ДМК Пресс, 2018. – 350 с.
- Грызлов В. И., Грызлова Т. П., Турбо Паскаль 7.0. Учебный курс, «Питер», 2018. – 416 стр.
- Дрейер М., C# для школьников: Учебное пособие – М.: БИНОМ. Лаборатория знаний, 2019. – 128 с.
- Дузелбаев С.Т., Основы алгоритмизации и программирования, «Астана», 2018. – 255 с.
- Кораблев В.А., Турбо Паскаль 7.0. Самоучитель, 16-е издание, «Питер», 2017. – 480 стр.
- Левитин А.В., Метод декомпозиции. – М.: «Вильямс», 2017. – 174 с.
- Львовский М.Б., Методическое пособие «BOOK» по информатике. – М.: «Вильямс», 2017. – 179 с.
- Немнюгин С.А., Turbo Pascal. Учебник для вузов, 1-е издание, «Питер», 2018. – 544 с.
- Немнюгин С.А., Turbo Pascal: Практикум, 2-е издание, «Питер», 2019. – 272 с.
- Павловская Т.А., Паскаль. Программирование на языке высокого уровня: Учебник для вузов, «Питер», 2018. – 400 стр.
- Плискин М., Эволюция языков программирования, 2017. – 189 с.
- Сергиевский М.В., ШалашовА. В., Турбо Паскаль 7.0. М. 2018. – 256 с.
- Фаронов В.В., Turbo Pascal в подлиннике, «BHV-Санкт-Петербург», 2017. – 1056 с.

- Предпринимательская деятельность в сфере физической культуры и спорта
- Организация кассовой работы в банке (Роль банков в организации денежного обращения)
- Понятие потребительской кооперации и основы анализа производственной деятельности кооператива
- Нормативные документы, регулирующие порядок ведения кассовых операций (Сущность и нормативно-правовое регулирование порядка ведения кассовых операций)
- Как организовать банк в современных условиях (Коммерческие банки – основное звено банковской системы)
- Теоретические аспекты принятия управленческих решений
- Правовое регулирование при оказании различных услуг (Теоретические основы правового регулирования)
- Менеджмент человеческих ресурсов (Теоретические аспекты изучения человеческих ресурсов организации)
- Мотивация и ее теория
- Понятия и виды наследования (Наследование: сущность, содержание понятия, виды)
- Индивидуальное предпринимательство (Статус индивидуального предпринимателя по законодательству российской федерации)
- Несостоятельность (банкротство) индивидуального предпринимателя (Итоги и последствия признания индивидуального предпринимателя банкротом)