
перации, производимые с данными (Процессы обработки данных)
Содержание:

ВВЕДЕНИЕ
В современном мире данные играют значимую роль абсолютно в любых процессах и явлениях. Без данных невозможно правильно осознать и понять явления реальной действительности.
С позиции информационных технологий управления информация является связанными между собой сведениями, данными, понятиями, которые изменяют наше представление о явлении либо об объекте окружающего мира. Вместе с тезисом информацией довольно часто в литературе употребляется понятие данные.
Актуальность темы исследования связана с повсеместностью использования данных, необходимостью ежедневной обработки и хранению данных. Данные рассматриваются в качестве признаков или записанных наблюдений, которые по различным причинам не используются, а исключительно хранятся. При условии, что появляется возможность использования этих данных для уменьшения какой-либо неопределенности, данные трансформируются в информацию. В связи с этим можно утверждать, что информация представлена используемыми данными.
Объектом исследования являются данные, информация.
Предметом работы является совокупность процессов, явлений, отношений, закономерностей, связей, присущих исследуемому объекту и представляющих интерес с точки зрения цели исследования.
Цель данной курсовой работы: провести анализ протекания процессов обработки информации и иных операций с данными.
Для достижения этой цели необходимо решить следующие задачи:
- рассмотреть понятие, сущность данных;
- рассмотреть этапы обработки данных,
- охарактеризовать носителей данных,
- рассмотреть особенности кодирования данных,
- охарактеризовать процессы, производимые с данными;
- подвести итог исследования.
Теоретической основой написания курсовой работы выступают труды отечественных авторов, изучающих вопросы современных информационных технологий.
В процессе исследования применялись методы экспертных оценок, системного подхода, логического анализа, ретроспективного анализа, моделирования.
Структура работы также определена ее темой: введение, основная часть (2 главы), заключение и список использованных источников.
1. СУЩНОСТЬ И НОСИТЕЛИ ДАННЫХ
1.1 Информация и этапы ее обработки
Информация является отображением реального мира посредством различных сведений. Кроме термина «информация» в информатике принято также использовать такое понятие, как «данные».
Понятие «данные» характеризуется отрывочными, не связанными между собой сведениями [11, с. 13].
Технологический процесс обработки данных состоит из четырех последовательных этапов:
1. Первый этап представлен формированием первичных данных, которые могут заключаться в первичных сообщениях о финансовых и хозяйственных операциях, документах, содержащих нормативные правовые акты и иные юридические акты, результатах экспериментов, к примеру, параметрах вновь созданной конструкторской модели автомобиля, квадрокоптера и иных данных о происходящих событиях.
2. Второй этап представлен накоплением и систематизацией данных, т.е. процессом организации определенного размещения данных, обеспечивающим быстроту поиска и отбора необходимых сведений, методического обновления данных, установление защиты информации от различных искажений и т.д.
3. Третий этап представлен обработкой данных, то есть процессами, которые позволяют сформировать новые виды данных, основываясь на ранее накопленных данных. Такие процессы могут быть:
- обобщающими процессами,
- аналитическими процессами,
- рекомендательными процессами,
- прогнозными процессами и пр.
Такие данные вторичной обработки можно подвергать последующей обработке, которая позволяет получить углубленные, более точные обобщения данных [1, с. 108].
4. Четвертый этап представлен отображением данных - представлением данных в форме, которая является удобной для человека. Таким отображением является вывод данных на печать, представление графического изображения (иллюстраций, графиков, диаграмм и пр.), звука и пр.
Сообщения, которые формируются на первом этапе, могут быть представлены в различном виде: в виде обычного бумажного документа, звука, видео, числовых данных на определенном носителе. В большинстве случаев носители первичной информации являются физическими носителями и представлены бумагой, пластинками, кассетами, видеокассетами, характеризующиеся своей недолговечностью [1, с. 109].
Благодаря компьютерным технологиям разработан принципиально новый подход, представленный цифровым (дискретным) представлением информации с помощью магнитных, а также лазерных носителей.
Технические и программные средства электронно - вычислительных машин преобразуют первичные данные в машинный код.
Основной проблемой, которая связана с документацией данных в компьютере является установление точности и корректности четырех различных видов данных.
Точность является способностью выполнить задачи без каких-либо погрешностей либо ошибок. Данная характеристика может быть изложена следующим образом: точность является степенью соответствия меры к некому стандарту [3, с. 144].
Корректность является мерой частоты появления в данных ошибок. Возникновение ошибок возможно, как при сборе данных, так и во время наблюдений либо же измерении.
Точность определяется степенью детализации. В качестве примера можно представить количество десятичных знаков в процессе измерения определенной величины. Вес тела, который выражен как 89.12 кг, обладает большей точностью, чем вес, который выражен как 89.1 кг.
Данные являются диалектической составной частью информации. Они являются зарегистрированными сигналами. При этом можно использовать любой физический метод регистрации данных:
- с помощью механического перемещения физических тел, изменения их формы либо качественных параметров поверхности, изменения магнитных, электрических, оптических характеристик, изменения химического состава тел либо характера химических связей в общей цепи, изменения состояния электронной системы и пр. [8, с. 140].
Согласно методу регистрации данные хранение и транспортировка данных возможна с использованием носителей различных видов.
Самый распространенный носитель данных представлен бумагой, при этом данный носитель не является самым экономичным. Регистрация данных на бумаге производится посредством изменения оптических характеристик бумажной поверхности.
Необходимо отметить, что изменения в оптических свойствах (в определенном диапазоне длин волн изменения коэффициента отражения поверхности) также используется в устройствах, которые осуществляют запись на пластмассовых носителях, имеющих отражающее покрытие, лазерным лучом ( CDROM ).
Носители, использующие изменения магнитных свойств, представлены магнитными лентами и дисками. В фотографии широко используется регистрация данных с помощью изменения химического состава в поверхностных веществах носителя. В живой природе накопление и передача данных происходит на биохимическом уровне [9, с. 74].
Носители данных в разрезе исследования интересны тем, что свойства информации весьма обладают тесной связью со свойствами ее носителей. Каждый носитель может быть охарактеризован с помощью параметра разрешающего способности (таким как: количество данных, которые записаны в единице измерения, принятой для носителя) и динамического диапазона (логарифмическое отношение интенсивности амплитуд минимального и максимального регистрируемого сигналов). Данные свойства носителя зачастую определяют свойства информации, представленные полнотой, доступностью и достоверностью.
Так, к примеру, в базе данных, которая размещена на компакт-диске, в большей степени обеспечена полнота информации, в отличие от аналогичной базы данных, которая размещена на гибком магнитном диске, так как в первом случае на единице длины дорожки плотность записи данных значительно выше.
Доступность информации в книге для обычного потребителя существенно выше, чем этой же информации, записанной на компакт-диске, так как не для всех потребителей доступно необходимые оборудование. Также необходимо отметить, что визуальный эффект, полученный в результате просмотра слайдов на проекторе, значительно больше, чем эффект, полученный в результате просмотра этой же иллюстрации, которая напечатана на бумажном носителе [8, с. 141].
Задача преобразования данных посредством замены носителя является одной из наиболее важных задач информатики. В структуру стоимости вычислительных систем устройства, необходимых для ввода и вывода данных, которые работают с носителями информации, входит около половины стоимости аппаратных средств.
Замечательное запоминающее устройство и носитель данных представлен человеческим мозгом, содержащим примерно (10—15)–109 нейронов — ячеек, которые совмещают функции памяти, а также логической обработки информации.
В среднем объём мозга составляет 1,5м3, масса -1,2 кг, при этом потребляемая мощность составляет приблизительно 2,5 Вт. Лучшими современными электронными запоминающими устройствами при такой же ёмкости занимается объём в несколько м3 с учетом массы в десятки и сотни кг, и потребляемой мощности достигающей несколько кВт [2, с. 75].
Согласно научно обоснованным прогнозам совершенствование электронной техники, а также применение в сочетании новейших высокоэффективных накопительных сред и широкое использование методов бионики при решении проблем, которые связаны с синтезом запоминающих устройств, смогут позволить получить запоминающее устройство, близкое по параметрам человеческой памяти.
1.2 Операции с данными
Данные характеризуются своим типом и множеством операций над ними. Условно данные в компьютере можно разделить на два вида:
- простые данные,
- сложные данные.
В качестве примера простых данных, обрабатываемых компьютером, можно представить данные таблицы 1:
Таблица 1
Типы данных, обрабатываемых компьютером
|
№ |
Типы данных |
Операции |
|
1 |
Числа (числовые данные) |
Все арифметические операции |
|
2 |
Тексты(символьные данные) |
Замещение, вставка, удаление символов, сравнение, конкатенация строк |
|
3 |
Логические(бинарные) данные |
Все логические операции (конъюнкция, дизъюнкция, отрицание и др.) |
|
4 |
Изображения:рисунки, графика,анимация (графические данные) |
Операции над пикселями, из которых состоит изображение: яркость, цвет, контрастность |
|
5 |
Видео данные |
Удаление фрагмента, вставка фрагмента, работа с кадрами |
|
6 |
Аудио данные |
Усиление, уменьшение, удаление фрагмента, вставка фрагмента |
Сложные данные представлены массивами и списками (однотипными), структурами, записями, таблицами (разнотипными).
При течение информационного процесса происходит преобразование данных из одного вида в другой посредством различных методов. В процесс обработки данных входит множество разных операций [8, с. 143].
Развитие научно-технического прогресса и общее усложнение связей в человеческом обществе неуклонно влекут повышение трудозатрат на обработку данных. Как правило, это связано с тем, что постоянно усложняются условия управления обществом и производством. Вторым фактором, который также вызывает увеличение объема обрабатываемых данных, также неукоснительно связан с научно-техническим прогрессом, им являются быстрые темпы создания и внедрения новых носителей данных, различных средств хранения, а также доставки данных [4, с. 96].
Основными операциями в структуре возможных операций с данными представлены:
- сбором данных, то есть накоплением информации для того, чтобы была обеспечена достаточная полнота для принятия решений;
- формализацией данных, то есть приведением данных, которые поступают из различных источников, к одной форме, для установления их сопоставимости между собой, то есть повышается уровень их доступности;
- фильтрацией данных, то есть отсеиванием «лишних» данных, которые не требуются для того, чтобы принять решения; при этом уменьшается уровень «шума», а также возрастает степень достоверности и адекватности данных;
- сортировкой данных, то есть упорядочением данных по заданному признаку для повышения удобства их использования; повышается доступность информации;
- архивацией данных, то есть организацией хранения данных в легкодоступной и удобной форме; необходимо для того, чтобы снизить экономические затраты по хранению данных и повысить в целом общую надежность информационного процесса;
- защитой данных, представленной комплексом мер, которые направлены на предотвращение утраты, воспроизведение и модификацию данных;
- транспортировкой данных, то есть приемом и передачей (доставкой и поставкой) данных среди удаленных участников информационного процесса; при этом в информатике источник данных принято именовать сервером, а потребителя принято именовать клиентом;
- преобразованием данных, то есть переводом данных из одной формы в другую либо переводом из одной структуры данных в другую. Зачастую преобразование данных связывается с изменением типа носителя, к примеру, хранение книг возможно в обычной бумажной форме, но также возможно и использование для хранения электронной формы, и микрофотопленки [8, с. 145].
Таким образом, многократное преобразование данных также необходимо в случае транспортировки данных, в частности, если транспортировка осуществляется средствами, которые не предназначены для транспортировки этого вида данных. К примеру, для транспортировки по каналам телефонных сетей цифровых потоков данных требуется преобразовать цифровые данные в определенное подобие звуковых сигналов, чем и занимаются специальные устройства, именуемые телефонными модемами.
2. ПРОЦЕССЫ ОБРАБОТКИ ДАННЫХ
2.1 Кодирование данных двоичным кодом
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления. Для этого обычно используется прием кодирования, то есть выражение данных одного типа через данные другого типа. Естественные человеческие языки — это не что иное, как системы кодирования понятий для выражения мыслей посредством речи. К языкам близко примыкают азбуки (системы кодирования компонентов языка с помощью графических символов) [8, с. 149].
История знает интересные, хотя и безуспешные попытки создания «универсальных» языков и азбук. По-видимому, безуспешность попыток их внедрения связана с тем, что национальные и социальные образования естественным образом понимают, что изменение системы кодирования общественных данных непременно приводит к изменению общественных методов (то есть норм права и морали), а это может быть связано с социальными потрясениями.
Та же проблема универсального средства кодирования достаточно успешно реализуется в отдельных отраслях техники, науки и культуры. В качестве примеров можно привести систему записи математических выражений, телеграфную азбуку, морскую флажковую азбуку, систему Брайля для слепых и многое другое [5, с. 83].
Своя система существует и в вычислительной технике — она называется двоичным кодированием и основана на представлении данных последовательностью всего двух знаков: 0 и 1. Эти знаки называются двоичными цифрами, по-английски — binary digit или сокращенно bit (бит). 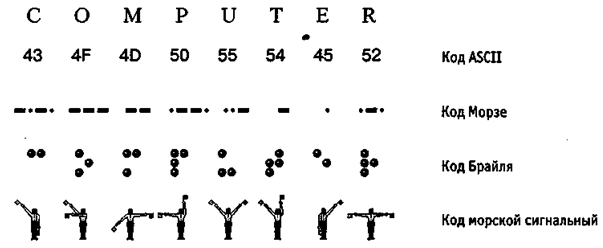
Рисунок 1- Примеры различных систем кодирования
Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т. п.). Если количество битов увеличить до двух, то уже можно выразить четыре различных понятия:
00 01 10 11 данные обработка носитель кодирование
Тремя битами можно закодировать восемь различных значений: 000 001 010 011 100 101 ПО 111
Увеличивая на единицу количество разрядов в системе двоичного кодирования, мы увеличиваем в два раза количество значений, которое может быть выражено в данной системе, то есть общая формула имеет вид:
N=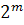
где N является количеством независимых кодируемых значений;
m — разрядностью двоичного кодирования, которая принята в данной системе [8, с. 151].
2.2 Кодирование целых и действительных чисел
Целые числа кодируются двоичным кодом довольно просто — достаточно взять целое число и делить его пополам до тех пор, пока частное не будет равно единице. Совокупность остатков от каждого деления, записанная справа налево вместе с последним частным, и образует двоичный аналог десятичного числа.
19:2 = 9 + 1
9:2=4+1
4 : 2 = 2 +-0
2:2=1+0
Таким образом, 1910= 100112.
Для кодирования целых чисел от 0 до 255 достаточно иметь 8 разрядов двоичного кода (8 бит). Шестнадцать бит позволяют закодировать целые числа от 0 до 65 535, а 24 бита — уже более 16,5 миллионов разных значений.
Для кодирования действительных чисел используют 80-разрядное кодирование. При этом число предварительно преобразуется в нормализованную форму:
3,1415926 = 0,31415926 • 101 300 000 = 0,3 • 106
123 456 789 - 0,123456789 • 1010
Первая часть числа называется мантиссой, а вторая — характеристикой. Большую часть из 80 бит отводят для хранения мантиссы (вместе со знаком) и некоторое фиксированное количество разрядов отводят для хранения характеристики (тоже со знаком) [5, с. 86].
2.3 Кодирование текстовых данных
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов.
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности [6, с. 59].
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII приведена в таблице 2.
Таблица 2
Базовая таблица кодировки ASCII
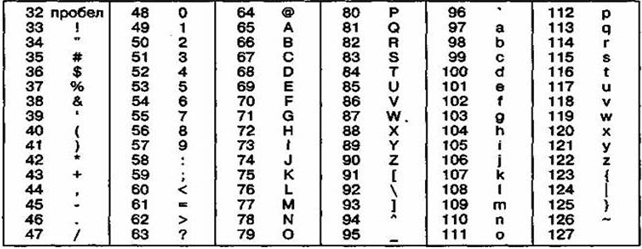
Так, например, кодировка символов русского языка, известная как кодировка Windows-1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 3).
Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
Таблица 3
Кодировка Windows 1251
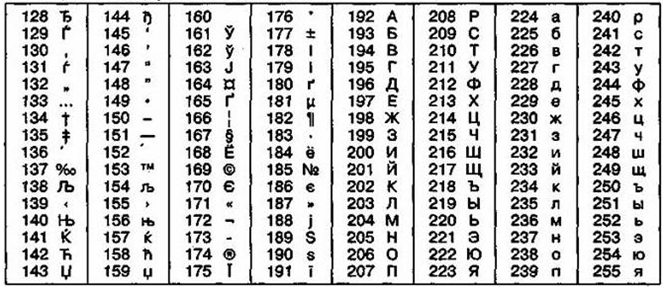
Другая распространенная кодировка носит название КОИ-8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица4). Сегодня кодировка КОИ-8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернет.
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки /50 (International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко (таблица 5).
Таблица 4
Кодировка КОИ-8
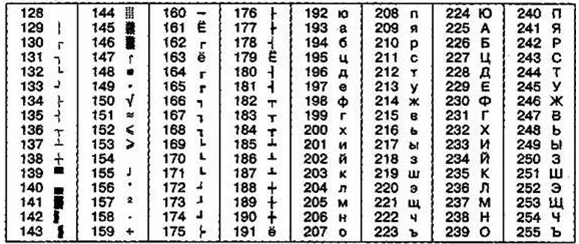
Таблица 5
Кодировка ISO
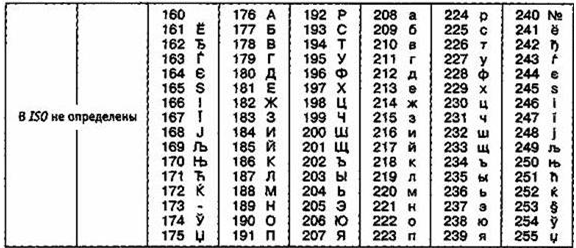
Таблица 6
ГОСТ-альтернативная кодировка
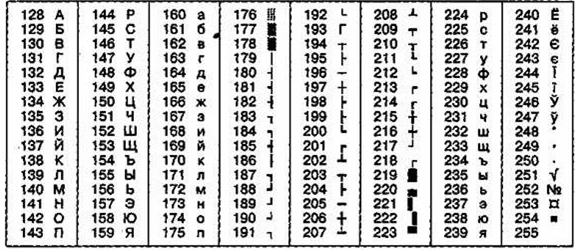
На компьютерах, работающих в операционных системах MS-DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (см. таблицу 6).
В связи с изобилием систем кодирования текстовых данных, действующих в России, возникает задача межсистемного преобразования данных — это одна из распространенных задач информатики.
2.4 Универсальная система кодирования текстовых данных
Если проанализировать организационные трудности, связанные с созданием единой системы кодирования текстовых данных, то можно прийти к выводу, что они вызваны ограниченным набором кодов (256). В то же время очевидно, что если, например, кодировать символы не восьмиразрядными двоичными числами, а числами с большим количеством разрядов, то и диапазон возможных значений кодов станет намного больше [12, с. 176].
Такая система, основанная на 16-разрядном кодировании символов, получила название универсальной — UNICODE. Unicode (Юникод или Уникод, англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Юникод имеет несколько форм представления: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. В MicrosoftWindows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX-подобных операционных системах GNU/Linux, BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти.
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium), объединяющей крупнейшие IT-корпорации.
Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита и кириллицы, при этом становятся ненужными кодовые страницы [5, с. 89].
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы — это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают в себя следующие группы:
буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов; цифры; знаки пунктуации; специальные знаки (математические, технические, идеограммы и пр.); разделители.
Юникод является системой для линейного представления текста. Символы, которые имеют дополнительные над- или подстрочные элементы, можно отобразить как построенную по определённым правилам последовательность кодов (составной вариант, composite character) либо как единый симвоа (монолитный вариант, precomposed character) [1, с. 113].
Графические символы в Юникоде подразделяются на протяжённые и непротяжённые (бесширинные). Непротяжённые символы при отображении не занимают места в строке. К ним относятся, в частности, знаки ударения и прочие диакритические знаки.
Особый тип модифицирующих символов — селекторы варианта начертания (variation selectors). Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов письма Phags-Pa.
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определённому стандартному виду.
В стандарте Юникода определены 4 формы нормализации текста:
- Форма нормализации D (NFD) — каноническая декомпозиция. В процессе приведения текста в эту форму все составные символы рекурсивно заменяются на несколько составных, в соответствии с таблицами декомпозиции.
- Форма нормализации C (NFC) — каноническая декомпозиция с последующей канонической композицией. Сначала текст приводится к форме D, после чего выполняется каноническая композиция — текст обрабатывается от начала к концу и выполняются следующие правила:
Символ S является начальным, если он имеет нулевой класс модификации в базе символов Юникода.
В любой последовательности символов, стартующей с начального символа S символ C блокируется от S если и только если между S и C есть какой-либо символ B, который или является начальным, или имеет одинаковый или больший класс модификации, чем C. Это правило распространяется только на строки прошедшие каноническую декомпозицию [11, с. 15].
Первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода.
Символ X может быть первично совмещен с символом Y если и только если существует первичный композит Z, канонически эквивалентный последовательности <X, Y>.
Если очередной символ C не блокируется последним встреченным начальным базовым символом L, и он может быть успешно первично совмещен с ним, то L заменяется на композит L-C, а C удаляется.
- Форма нормализации KD (NFKD) — совместимая декомпозиция. При приведении в эту форму все составные символы заменяются используя как канонические карты декомпозиции Юникода, так и совместимые карты декомпозиции, после чего результат ставится в каноническом порядке.
- Форма нормализации KC (NFKC) — совместимая декомпозиция с последующей канонической композицией [10, с. 68].
Термины «композиция» и «декомпозиция» понимают под собой соответственно соединение или разложение символов на составные части.
2.5 Кодирование графических данных и звуковой информации
Если рассмотреть с помощью увеличительного стекла черно-белое графическое изображение, напечатанное в газете или книге, то можно увидеть, что оно состоит из мельчайших точек, образующих характерный узор, называемый растром. Растровое изображение представлено на рисунке 2.
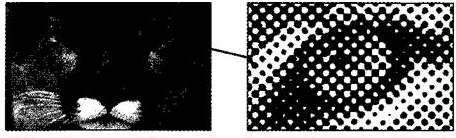
Рисунок 2-Растровое изображение
Растр является методом кодирования графической информации (точечная структура графического изображения).
Поскольку линейные координаты и индивидуальные свойства каждой точки (яркость) можно выразить с помощью целых чисел, то можно сказать, что растровое кодирование позволяет использовать двоичный код для представления графических данных.
Общепринятым на сегодняшний день считается представление черно-белых иллюстраций в виде комбинации точек с 256 градациями серого цвета, и, таким образом, для кодирования яркости любой точки обычно достаточно восьмиразрядного двоичного числа [7, с. 130].
Для кодирования цветных графических изображений применяется принцип декомпозиции произвольного цвета на основные составляющие. В качестве таких составляющих используют три основных цвета:
- красный (Red, R);
- зеленый (Green, G);
- синий (Blue, В).
На практике считается, что любой цвет, видимый человеческим глазом, можно получить путем механического смешения этих трех основных цветов. Такая система кодирования называется системой RGB (по первым буквам названий основных цветов).
Если для кодирования яркости каждой из основных составляющих использовать по 256 значений (восемь двоичных разрядов), как это принято для полутоновых черно-белых изображений, то на кодирование цвета одной точки надо затратить 24 разряда. При этом система кодирования обеспечивает однозначное определение 16,5 млн. различных цветов, что на самом деле близко к чувствительности человеческого глаза. Режим представления цветной графики с использованием 24 двоичных разрядов называется полноцветным (True Color) [5, с. 95].
Каждому из основных цветов можно поставить в соответствие дополнительный цвет, то есть цвет, дополняющий основной цвет до белого. Нетрудно заметить, что для любого из основных цветов дополнительным будет цвет, образованный суммой пары остальных основных цветов. Следовательно, дополнительные цвета представлены:
-
- голубым (Cyan, С);
- пурпурным (Magenta., М);
- желтым (yellow, Y).
Принцип декомпозиции произвольного цвета на составляющие компоненты можно применять не только для основных цветов, но и для дополнительных, то есть любой цвет можно представить в виде суммы голубой, пурпурной и желтой составляющей. Такой метод кодирования цвета принят в полиграфии, но в полиграфии используется еще и четвертая краска — черная (Black, К). Поэтому данная система кодирования обозначается четырьмя буквами CMYK (черный цвет обозначается буквой К, потому, что буква В уже занята синим цветом), и для представления цветной графики в этой системе надо иметь 32 двоичных разряда. Такой режим тоже называется полноцветным (True Color).
Если уменьшить количество двоичных разрядов, используемых для кодирования цвета каждой точки, то можно сократить объем данных, но при этом диапазон кодируемых цветов заметно сокращается. Кодирование цветной графики 16-разрядными двоичными числами называется режимом High Color.
Приемы и методы работы со звуковой информацией пришли в вычислительную технику позднее. К тому же, в отличие от числовых, текстовых и графических данных, у звукозаписей не было столь же длительной и проверенной истории кодирования. В итоге методы кодирования звуковой информации двоичным кодом далеки от стандартизации. Множество отдельных компаний разработали свои корпоративные стандарты, но если говорить обобщенно, то можно выделить два основных направления.
- Метод FM (Frequency Modulation) основан на том, что теоретически любой сложный звук можно разложить на последовательность простейших гармонических сигналов разных частот, каждый из которых представляет собой правильную синусоиду, а следовательно, может быть описан числовыми параметрами, то есть кодом. В природе звуковые сигналы имеют непрерывный спектр, то есть являются аналоговыми. Их разложение в гармонические ряды и представление в виде дискретных цифровых сигналов выполняют специальные устройства — аналогово-цифровые преобразователи (АЦП). Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки.
- Метод таблично-волнового ( Wave-Table) синтеза лучше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них) [7, с. 136].
В технике такие образцы называют сэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука.
Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
ЗАКЛЮЧЕНИЕ
В заключение настоящего исследования необходимо отметить, что цель и задачи, поставленные в работе, достигнуты в полном объеме. Целесообразно подчеркнуть основные выводы исследования:
Информация является отображением реального мира посредством различных сведений. Кроме термина «информация» в информатике принято также использовать такое понятие, как «данные».
Понятие «данные» характеризуется отрывочными, не связанными между собой сведениями.
Технологический процесс обработки данных состоит из четырех последовательных этапов:
1. Первый этап представлен формированием первичных данных, которые могут заключаться в первичных сообщениях о финансовых и хозяйственных операциях, документах, содержащих нормативные правовые акты и иные юридические акты, результатах экспериментов, к примеру, параметрах вновь созданной конструкторской модели автомобиля, квадрокоптера и иных данных о происходящих событиях.
2. Второй этап представлен накоплением и систематизацией данных, т.е. процессом организации определенного размещения данных, обеспечивающим быстроту поиска и отбора необходимых сведений, методического обновления данных, установление защиты информации от различных искажений и т.д.
3. Третий этап представлен обработкой данных, то есть процессами, которые позволяют сформировать новые виды данных, основываясь на ранее накопленных данных. Такие процессы могут быть:
- обобщающими процессами,
- аналитическими процессами,
- рекомендательными процессами,
- прогнозными процессами и пр.
Такие данные вторичной обработки можно подвергать последующей обработке, которая позволяет получить углубленные, более точные обобщения данных.
4. Четвертый этап представлен отображением данных - представлением данных в форме, которая является удобной для человека. Таким отображением является вывод данных на печать, представление графического изображения (иллюстраций, графиков, диаграмм и пр.), звука и пр.
Сообщения, которые формируются на первом этапе, могут быть представлены в различном виде: в виде обычного бумажного документа, звука, видео, числовых данных на определенном носителе. В большинстве случаев носители первичной информации являются физическими носителями и представлены бумагой, пластинками, кассетами, видеокассетами, характеризующиеся своей недолговечностью.
Самый распространенный носитель данных представлен бумагой, при этом данный носитель не является самым экономичным. Регистрация данных на бумаге производится посредством изменения оптических характеристик бумажной поверхности.
Необходимо отметить, что изменения в оптических свойствах (в определенном диапазоне длин волн изменения коэффициента отражения поверхности) также используется в устройствах, которые осуществляют запись на пластмассовых носителях, имеющих отражающее покрытие, лазерным лучом ( CDROM ).
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления. Для этого обычно используется прием кодирования, то есть выражение данных одного типа через данные другого типа. Естественные человеческие языки — это не что иное, как системы кодирования понятий для выражения мыслей посредством речи. К языкам близко примыкают азбуки (системы кодирования компонентов языка с помощью графических символов).
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
- Воройский Ф. С. Информатика. Энциклопедия словарь справочник: введение в современные информационные и телекоммуникационные технологии в терминах и фактах. – М.: ФИЗМАТЛИТ, 2011. – 768 с.
- Гаврилов, М.В. Информатика и информационные технологии [Текст] / В.А. Климов. – М.: Юрайт, 2012. - 350 с.
- Гвоздева, В.А. Информатика, автоматизированные информационные технологии и системы [Текст]. – М.: Форум, 2011. - 544 с.
- Гохберг, Г.С. Информационные технологии [Текст] / А.В. Зафиевский, А.А. Короткин. – М.: Академия, 2013. - 208 с.
- Исаев, Г.Н. Информационные технологии [Текст]. - М.: Омега-Л, 2012. – 464 с.
- Крапивенко, А.В.Технологии мультимедиа и восприятие ощущений [Текст]. - М.: Бином. Лаборатория знаний, 2012. - 272 с.
- Попов, В.Б. Основы информационных и телекоммуникационных технологий. Мультимедиа [Текст]. – М.: Финансы и статистика, 2012. - 336 с.
- Проектирование информационных систем (на примере методов структурного системного анализа): учебное пособие / О.Г. Инюшкина, Екатеринбург: «Форт-Диалог Исеть», 2014. 240 с.
- Советов, Б.Я. Информационные технологии [Текст] / В.В. Цехановский. – М.: Юрайт, 2011. - 272 с.
- Трайнев, В.А. Новые информационные коммуникационные технологии в образовании [Текст] / В.Ю. Теплышев, И.В. Трайнев. – М.: Дашков и Ко, 2012. – 320 с.
- Чернобай, Е.В. Технология подготовки урока в современной информационной образовательной среде [Текст]. – М.: Просвещение, 2012. – 56
- Чепмен, Н. Цифровые технологии мультимедиа [Текст]. - М.: Вильямс, 2011. – 624 с.

- Разработка регламента выполнения процесса «Анализ и изучение конкуренции» ( Разработка регламента выполнения процесса «Анализ и изучение конкуренции» в ОАО «АвтоСанс»)
- Перспективы диверсификации торговли Беларуси
- Анализ структуры движения денежных средств на основе предприятия
- Противозаконное налоговое планирование
- Субъекты банкротства, их права, обязанности и ответственность (Анализ финансовой состоятельности Частного торгового унитарного предприятия «Ювентабелстрой»)
- Принципы и основания наследования (Основы наследования в законодательстве)
- Гражданское право (Виды вещных прав)
- Понятие и виды наследования (общественные отношения, связанные с переходом (наследованием) после смерти гражданина)
- Корпоративная культура в организации (Анализ российской и зарубежной практики управления организацией на основе изменения корпоративной культуры)
- Анкетирование как метод маркетингового исследования (Оценка удовлетворенности потребителя ОАО «Белшина»)
- Методы онлайн маркетинга
- Распределенная технология обработки информации(Архитектурное построение и свойства систем распределённой обработки информации )