
Основные структуры алгоритмов: сравнительный анализ и примеры их использования (Способы записи алгоритмов)
Содержание:

Введение
Одним из базовых понятий информатики, программирования, вычислительной техники является понятие алгоритма, как некоторого правила преобразования информации. Умение составлять алгоритмы и программы решения различных практических задач является элементом алгоритмической культуры современного специалиста в области информационных технологий.
Алгоритм и его свойства являются основами теоретической информатики, вводящей в обширные практические разделы алгоритмизации.
Разработка алгоритма является одним из основных решений задач на электро-вычислительной машине. От правильного составления последствий действия алгоритма зависит точность получения результата.
Целью курсовой работы является изучение структуры алгоритмов, а также их видов и примеры использования.
1.Понятие алгоритма
Алгоритмом является четко описание последовательности действий, которые необходимо выполнить для получения результата.
Основные свойства алгоритмов:
- дискретность - алгоритм должен представлять процесс решения задачи как последовательное исполнение простых (или ранее определенных) шагов (этапов);
- определенность - каждое правило алгоритма должно быть четким, однозначным и не оставлять места для произвола. Данное свойство обеспечивает выполнение алгоритма механически не требует никаких дополнительных указаний или сведений о решаемой задаче;
- результативность (конечность) - алгоритм должен приводить к решению задачи за конечное число шагов;
- массовость - алгоритм решения задачи производится в общем виде, т. е. его можно будет применять для некоторого класса задач, различающихся лишь исходными данными. При этом исходные данные могут выбираться из определенной области, которая называется областью применимости алгоритма /1, с.6/.
1.1 Свойства алгоритмов
Алгоритмы обладают целым рядом свойств: понятностью, дискретностью, точностью, результативностью, массовостью.
Свойства алгоритма – это набор свойств, отличающих алгоритм от любых предписаний и обеспечивающих автоматическое исполнение алгоритма.
Понятность для исполнителя – содержание предписания о выполнении только определенных действий, входящих в систему команд исполнителя, т. е. алгоритм должен быть задан с помощью указаний, которые исполнитель (персональный компьютер, промышленный компьютер, контроллер и др.) может воспринимать и выполнять по ним требуемые действия, которые называются операции.
Дискретность (прерывность, раздельность) – выполнение последовательных команд алгоритма, с точной фиксацией моментов окончания выполнения одной команды и начала выполнения следующей, т. е. алгоритм должен содержать последовательность указаний или команд, каждое из которых приводит к выполнению в исполнителе одного шага (действия).
Определенность – каждое правило алгоритма должно быть четким, однозначным. Благодаря этому свойству выполнение алгоритма носит механический характер и не требует никаких дополнительных указаний или сведений о решаемой задаче.
Результативность – это завершение решения задачи после выполнения алгоритма, либо вывод о невозможности продолжения решения по какой-либо причине, т. е. алгоритм должен обеспечивать возможность получения результата после конечного числа шагов.
Массовость – означает, что алгоритм решения задачи разрабатывается в общем виде, т.е. алгоритм должен быть применим для некоторого класса задач, различающихся лишь исходными данными. При этом исходные данные могут выбираться из некоторой области, которая называется областью применимости алгоритма /2, с.8-9/.
1.2 Основные характеристики алгоритмов
Для решения одной и той же задачи как правило можно использовать разные по классификации алгоритмы. В связи с этим, возникает необходимость сравнивать их между собой, и для этого нужны определенные критерии качества алгоритмов.
Временные характеристики алгоритма определяют длительность решения или временную сложность.
Длительность решения часто выражается в единицах времени, но в большинстве случаев ее следует выражать через количество операций, так как количество операций не зависит от быстродействия конкретной машины.
Временная сложностью алгоритма - зависимость времени счета, затрачиваемого на получение результатов от объема исходных данных.
Временная сложность позволяет определить наибольший размер задачи, которую можно решить с помощью данного алгоритма на персональном компьютере. Каждый алгоритм можно характеризовать функцией f(n), выражающей скорость роста объема вычислений при увеличении размерности задачи – n. Если данная зависимость имеет линейный или полиномиальный характер, то алгоритм считается ″хорошим″, если экспоненциальный – ″плохим″.
Для сложных задач эта характеристика имеет большое значение, так как ее изменение значительно сильнее влияет на время решения, чем изменение быстродействия персонального компьютера. Например, при зависимости f(n) = 2n увеличение производительности в 10 раз увеличивает размерность задачи, решаемой за то же время, всего на 15%.
Объемные характеристики алгоритма определяют его информационную сложность. Информационная сложность связана со сложностью описания, накопления и хранения исходных, промежуточных и результирующих данных при решении определенной задачи.
Объем текста алгоритма (программы) определяется количеством операторов, использованных для записи алгоритма.
Объем внутренней и внешней памяти необходимой для хранения данных и программ при использовании данного алгоритма определяется на основании расчетов или опытным путем. При недостатке памяти носителей информации используется сегментация программ.
Сложность структуры алгоритма определяется количеством маршрутов, по которым может реализовываться процесс вычислений и сложностью каждого маршрута.
Очевидно, что при выборе алгоритмов нужно учитывать не только их характеристики качества, но и способ реализации алгоритма.
К примеру, многие итерационные алгоритмы удобны для персонального компьютера, но слишком трудоемки для человека. Тип используемый персональным компьютером также может влиять на выбор алгоритма (иногда имеет место и обратный вариант, когда сначала определяется алгоритм и лишь затем способ реализации) /2, с.9-10/
1.3 Способы записи алгоритмов
1) Словесный способ – запись алгоритмов представляет собой последовательное описание основных этапов обработки данных и задается в произвольном изложении на естественном языке.
Данный способ не представляет трудностей с точки зрения написания, так как он основан на использование общепринятых средств общения между людьми. Этот способ удобно использовать на начальном этапе алгоритмизации задачи.
К недостаткам словесного способа записи алгоритмов можно отнести следующее:
А) полное подробное словесное описание алгоритма получается слишком большим;
Б) естественный язык допускает неоднозначность толкования отдельных инструкций;
В) при переходе к этапу программирования требуется дополнительная работа по формализации алгоритма, так как словесное описание может быть понятно человеку, но не может быть понятно персональному компьютеру /2, с.10-11/.
2) Графический способ (блок-схема) – запись алгоритмов производится с помощью блоков, которые представляют собой геометрические фигуры.
Каждая фигура представляет собой какую-либо операцию или действие, а также процесс решения задачи.
Фигура называется блоком. Порядок выполнения этапов показывается стрелками, которые соединяют блоки.
Блоки размещаются сверху вниз или слева направо в зависимости от порядка их выполнения.
Обозначение блоков и их выполняемые функции «см. Приложение 1» /3, с.10/.
3) псевдокоды – полуформализованные описание алгоритмов на некотором условном алгоритмическом уровне, включает в себя язык программирования, общепринятые фразы и математические символы /1, с.6/.
1.4 Правила построения алгоритмов на языке блок-схем
1. Блок-схема всегда строится сверху вниз.
2. В любой блок-схеме всегда должен присутствовать один элемент, который будет соответствовать началу, и один элемент, соответствовать концу.
3. В блок-схеме должен быть хотя бы один путь из начала блок-схемы к любому элементу.
4. Должен быть хотя бы один путь от каждого элемента блок-схемы в конец блок-схемы.
в) Операторный способ (алгоритмический язык). Алгоритм – это задание для исполнителя. Исполнитель выполняет алгоритм, т. е. делает то, что написано в алгоритме. Если исполнитель точно выполнит то, что написано в алгоритме, то он получит результат.
Человек, автоматическое устройство, компьютер являются разными исполнителями алгоритмов.
Для того чтобы компьютер мог выполнить алгоритм, его надо написать на понятном компьютеру языке.
Компьютер понимает машинный язык. Например, равенство 5*2=5+5 на машинном языке имеет вид: 00011110000011100001101100101010000110110000111000011100001011010001111000001110000110110010101100011110.
Человеку трудно писать и читать алгоритмы на машинном языке. Человек легко может писать и читать на естественном языке. Но нельзя научить компьютер понимать естественный язык потому, что в естественном языке много слов и нет строгих правил записи предложений.
Для того чтобы человек и компьютер понимали друг друга, разработаны специальные языки для записи алгоритмов – алгоритмические языки. Самые известные алгоритмические языки – это Бейсик (Basic), Паскаль (Pascal), Фортран (Fortran).
В отличие от машинного языка, алгоритмический язык состоит из слов и символов, как естественный язык. Алгоритмический язык отличается от естественного языка тем, что в нем мало основных слов (обычно 30-40) и очень строгие правила составления предложений.
Служебные слова – основные слова алгоритмического языка.
В алгоритмических языках используют слова английского алфавита. Алгоритмический язык легко понимает и человек и компьютер.
Алгоритм, который записан на алгоритмическом языке, – это программа для компьютера.
Оператором называется каждое предложение в программе.
Например, можно написать программу решения квадратного уравнения ax 2 +bx+c=0 на компьютере. На алгоритмическом языке Бейсик эта программа будет выглядеть так:
REM РЕШЕНИЕ КВАДРАТНОГО УРАВНЕНИЯ
INPUT “введите а,b,c“; А,B,C
D=B-2 - 4*A*C
IF D<0 THEN “РЕШЕНИЙ НЕТ”
Y1=(-B+SQR(D))/(2*A):Y2=(-B-SQR(D))/(2*A)
PRINT “КОРНИ УРАВНЕНИЯ”;Y1,Y2 /3, с.11-12/.
1.5 Классификация алгоритмов
В зависимости от используемого вычислительного процесса различают следующие алгоритмы:
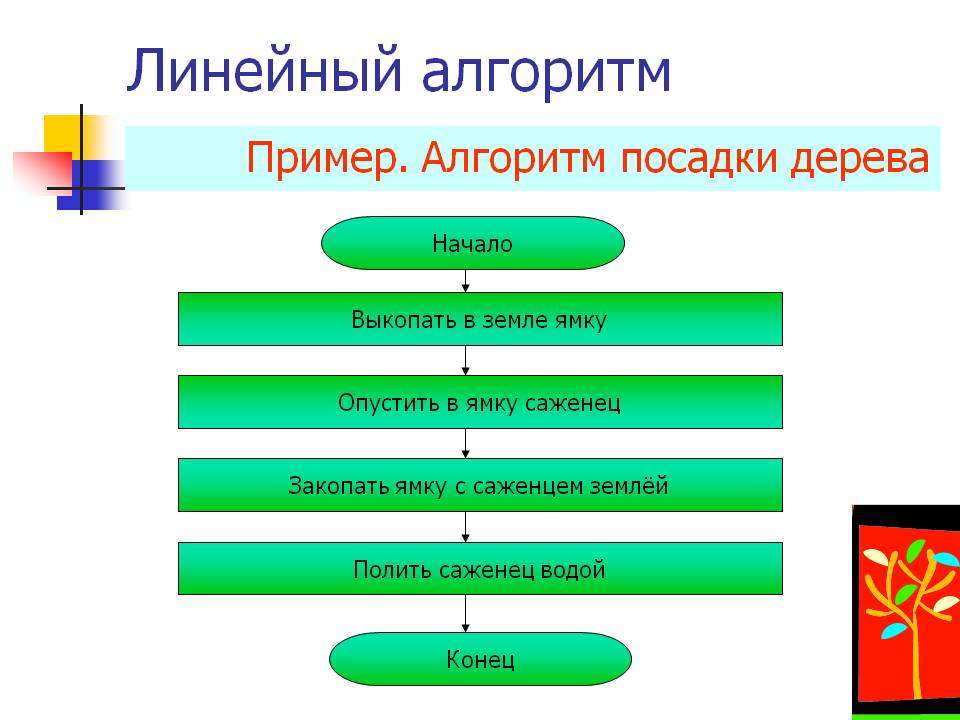
1) линейные алгоритмы – описывают линейный вычислительный процесс, этапы которого выполняются однократно и последовательно один за другим «см. Приложение 2»;
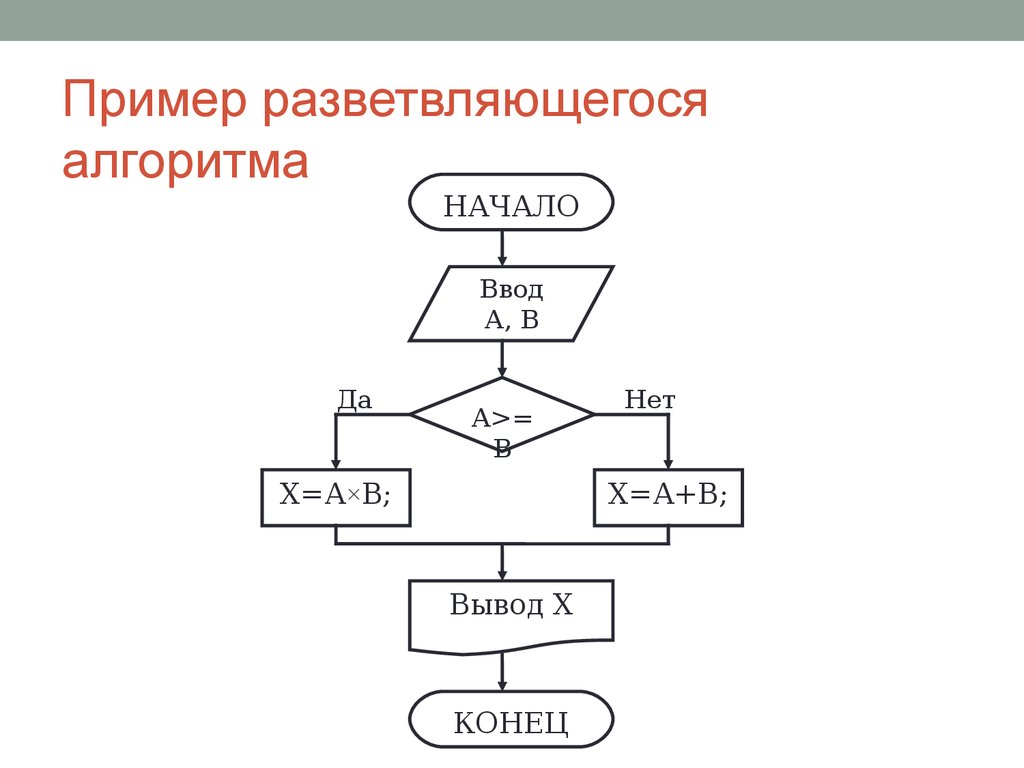
2) разветвляющийся алгоритм – реализация вычислительного процесса происходит по одному из нескольких заранее предусмотренных направлений. Направления, по которым может следовать вычислительный процесс, называются ветвями. Выбор конкретной ветви вычисления зависит от результатов проверки выполнения некоторого логического условия. Результатами данной проверки, если условие выполняется, является «истина» (да), при невыполнении условия «ложь» (нет) «см. Приложение 3»;
3) циклический алгоритм – этапы вычислительного процесса повторяются многократно. В зависимости от ограничения числа повторений выделяют циклы с известным числом повторений и циклы, число повторений которых заранее неизвестно /4, с.5-6/.
Выполняется циклический алгоритм так: сначала проверяется условие, если условие верно (истина), то выполняется тело цикла (действия или группа операторов) и, далее, изменяются значения параметра цикла и снова проверяется условие и т. д. На каком-то шаге условие не выполнится (ложь) и тогда происходит выход из цикла и продолжается выполнение программы /3, с.15/.
1.6 Циклы с известным числом повторений
При организации циклов с известным числом повторений присутствуют стандартные элементы, сопровождающие любой цикл:
- подготовка первого выполнения цикла;
- тела цикла, которое образуют блоки, выполняемые многократно;
- изменение значения счетчика циклов и сравнение его с конечным значением.
Блок-схемы циклических алгоритмов существенно отличаются структурами повторения “повторять ДО” (повторять до выполнения условия окончания цикла) или “повторять ПОКА” (повторять пока выполняются условия продолжения циклического процесса). В первом варианте проверка условий окончания циклических вычислений осуществляется в конце цикла, а во втором – в начале цикла /4, с.6-7/.
1.7 Циклы с неизвестным числом повторений
В циклах с неизвестным числом повторений, процесс решения задачи происходит путем последовательного приближения к исконному результату. Из-за этого процесс является циклическим, поскольку заключается в многократных вычислениях. Начальное приближение Y0 может выбираться заранее, либо задаваться по определенным правилам. Заканчивается вычисление, если выполнено следующее условие:
Yi – Yi-1 ≤ d, где d является допустимой ошибкой вычисления /4, с.8/.
1.8 Сложные циклы
Если вычислительные процессы, содержат два и более включенных друг в друга циклов, то такие процессы называются сложными циклическими процессами или по-другому алгоритмами.
Если цикл содержит внутри себя другой цикл, такие циклы называются внешними, а в противоположность внутреннему (вложенному).
Так же необходимо учитывать, что за одно исполнение внешнего цикла, внутренний цикл повторяется многократно /4, с.10/.
В настоящее время алгоритм является неотъемлемой частью в сфере программирования. С помощью правильного построения алгоритмической схемы работают программы, персональные компьютеры и электронно-вычислительные машины.
При помощи алгоритмов решаются задачи не только в сфере программирования, но и на производстве.
2 Обзор алгоритмов сортировки
Сортировка является процессом перестановки объектов данного множества в определённом порядке.
У сортировки всего лишь одна цель – это облегчить последующий поиск элементов в отсортированном множестве. Поэтому элементы сортировки присутствуют во многих задачах прикладного программирования.
Алгоритм сортировки - алгоритм для упорядочения элементов в списке.
Существуют множество методов сортировки, которые имеют, как плюсы, так и минусы.
Алгоритмы сортировки — это достаточно глубоко исследованная область информатики, которая используется в информационно-поисковых системах, в банках и в военкомате.
Важными показателями в быстродействие алгоритмов различных методов сортировки являются:
- Память. Некоторые алгоритмы требуют дополнительного выделения памяти под временное хранение данных (например, на хранение кода программы).
- Устойчивость. При устойчивой сортировки взаимное расположение равных элементов не меняется. Это может быть полезным, если они состоят из нескольких полей, а сортировка происходит только по одному из них.
- Естественность поведения. От естественного поведения зависит эффективность работы метода при обработке уже отсортированных или частично отсортированных данных /5, с.71-72/.
2.1 Алгоритм сортировки вставками
В алгоритме сортировке вставками решается задача сортировки списка имен в алфавитном порядке. Но необходимо отсортировать список путем перестановки его элементов, не перемещая весь список в другое место.
Подобное ограничение типично для компьютерных приложений, которые стремятся наиболее эффективно использовать весь доступный объем памяти.
Для их сортировки должны повторяться следующие действия:
1. Поднять карточку с именем, первую в неотсортированной части списка;
2. Сдвинуть вниз карточки с именами, которые находятся ниже по алфавиту, чем имя на взятой карточке;
3. Поместить эту карточку на освободившееся место в списке.
Текст программы сортировки на языке псевдокода выглядит так:
procedure Сортировка () assign N the value 2;
while (значение N не превышает )
do (Выбрать N-й элемент списка в качестве опорного; Переместить этот элемент во временное хранилище, оставив в списке пустое место;
while (над пустым местом есть имя, которое по алфавиту размещается ниже, чем опорный элемент)
do (переместить имя, находящееся над пустым местом вниз, оставив в прежней позиции пустое место); Поместить опорный элемент на пустое место в списке assign N the value N+1
где N - счетчик, параметр - количество элементов в списке.
После чего программа сортирует данный список, многократно повторяя следующие действия: «Элемент извлекается из списка, а затем вставляется на надлежащее ему место».
Каждое выполнение тела внешнего цикла приводит к тому, что внутренний цикл инициализируется и выполняется до тех пор, пока не будет выполнено условие его окончания. Условие окончания внешнего цикла будет выполнено, когда значение счетчика N превысит длину сортируемого списка.
Управление внутренним циклом инициализируется, когда опорный элемент извлекается из списка и в нем образуется пустое место.
Операция модификации включает перемещение расположенных выше элементов на пустое место вниз, в результате чего свободное место перемещается вверх по списку. Условие окончания выполняется тогда, когда пустое место будет находится непосредственно под именем, которое по алфавиту размещается выше опорного значения или же достигает верхней позиции списка /6, с.46-47/.
2.2 Пузырьковая сортировка
Основной принцип пузырьковой сортировки состоит в том, что происходит выталкивание маленьких значений на вершину списка, в то время, когда большие значения опускаются вниз.
Алгоритм пузырьковой сортировки совершает несколько проходов по списку. При выполнение каждого прохода происходит сравнение соседних элементов друг с другом.
Если порядок соседних элементов будет неправильный, то они поменяются местами. При этом каждый проход начинается с начала списка.
Сначала сравниваются первый и второй элементы, потом третий и четвертый и так далее. Элементы, в которых неправильный порядок в паре, переставляются.
Если на первом проходе обнаружен наибольший элемент списка, то он будет переставляться со всеми последующими элементами пока не дойдет до конца списка. Отсюда следует, что при втором проходе нет необходимости производить сравнение с последним элементом.
Так же при втором проходе второй по величине элемент списка опустится во вторую позицию с конца. Когда будет происходить продолжение процесса, то на каждом проходе по крайне мере одно из следующих по величине значений встает на свое место. При этом меньшие значения тоже собираются на верху.
Если при каком-то проходе не произошло ни одной перестановки элементов, то все они стоят в нужном порядке и исполнение алгоритма можно прекратить.
Стоит обратить внимание, что при каждом проходе ближе к своему месту продвигается сразу несколько элементов, хотя гарантировано лишь один элемент занимает окончательное положение.
Рассмотрим алгоритм, который реализует данный вариант пузырьковой сортировки:
BubbleSort(list,N)
list сортируемый список элементов
N – число элементов в списке
numberOfPairs=N
swappedElements=true
while swappedElements do
numberOfPairs=numberOfPairs-l
swappedElements=false
for i=l to numberdfPairs do
if list[i] > list[i+l] then
Swap(list[i], list[i+l] then
swappedElements=true
end if
end for
end while
На данном примере рассмотрим наилучший случай, чтобы предупредить неверную интерпретацию флага swappedElements.
Стоит заметить, что при первом проходе цикл for должен быть выполнен полностью, так как алгоритму потребуется по меньшей мере хотя бы N – 1 сравнение.
Рассмотрим возможности, когда при первом переходе была одна перестановка и когда перестановок не было.
Первый случай: первая перестановка приводит к изменению флага swappedElements на true. Это значит, что цикл while будет выполнен повторно, что потребует еще как минимум N – 2 сравнений.
Второй случай: флаг swappedElements сохранит значение false и выполнение данного алгоритма прекратиться.
Отсюда следует, что в лучшем случае будет выполнено N – 1 сравнений, что происходит при отсутствие перестановок при первом проходе. Наилучший набор данных будет представлять собой список элементов, которые уже идут в требуемом порядке.
И если в наилучшем возможном списке элементы идут в требуемом порядке, то стоит посмотреть, не дает ли обратный порядок элементов наихудший случай.
Если в списке наибольший элемент стоит первым, то он будет переставляться со всеми остальными элементами до самого конца списка.
Перед первым проходом второй по величине элемент будет занимать вторую позицию, однако в результате первого сравнения и первой перестановки он переставляется на первое место.
В начале второго прохода на первой позиции уже находится второй по величине элемент, и он переставляется со всеми остальными элементами вплоть до предпоследнего. Этот процесс повторяется для всех остальных элементов, поэтому цикл for будет повторен N—1 раз.
Поэтому обратный порядок входных данных приводит к наихудшему случаю.
Если даже в наихудшем случае цикл for будет повторяться N — 1 раз, то можно уже предполагать, что появление прохода без перестановки элементов равновероятно в любой из этих моментов /6, с.77-79/.
2.3 Сортировка Шелла
Сортировка Шелла была придумана Дональдом Л. Шелл. Данной особенность сортировки состоит в том, что она рассматривает весь список как совокупность перемешанных подсписков.
На первом шаге сортировки подсписки представляют собой просто пары элементов.
На втором шаге в каждой группе по четыре элемента.
Если процесс повторяется, то число элементов в каждом подсписке увеличивается, а число подсписков соответственно будет падать. На рисунке 1 изображены подсписки, которые можно использовать при сортировке списков из 16 элементов.
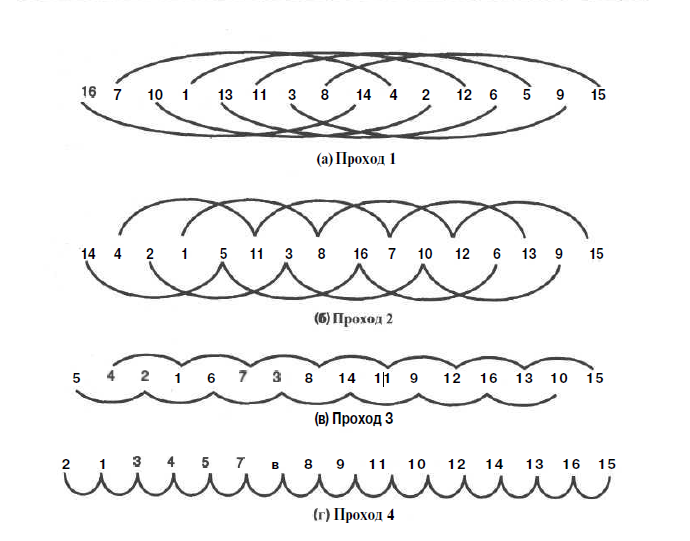
Рисунок 1 Четыре прохода сортировки Шелла
На рисунке 1 (а) изображены восемь подсписков, которые содержат в себе по два элемента в каждом. Первый подсписок содержит первый и девятый элементы, второй подсписок — второй и десятый элементы, и так далее.
На рисунке 1 (б) изображены четыре подсписка по четыре элемента в каждом. В этом проходе первый подсписок содержит в первый, пятый, девятый и тринадцатый элементы. Второй подсписок будет состоять из второго, шестого, десятого и четырнадцатого элементов.
На рисунке 1 (в) у нас показаны два подсписка, которые состоя из элементов с нечетными и четным номерами соответственно.
На рисунке 1 (г) мы вновь приходим к одному списку.
Сортировка подсписков будет выполняться путем однократного применения сортировки вставками, откуда мы и получаем следующий алгоритм:
Shellsort(list.N)
N число элементов в списке
passes = [log_2 N]
while (passes>=l) do
increment=2"passes-1
for start=l to increment do
InsertionSort(list,N,start,increment)
end for
passes=passes-l
end while
I
В данном алгоритме переменная increment содержит величину шага между номерами элементов подсписка. Мы видим, что на рисунке 1 шаг принимает значения 8, 4, 2 и 1.
В алгоритме мы начинаем с шага, на один меньшего наибольшей степени двойки, меньшей, чем длина элемента списка. Следует, что для списка из 1000 элементов первое значение шага равно 511. При этом значение шага также равно числу подсписков.
Элементы первого подсписка имеют номера 1 и 1+increment; первым элементом последнего подсписка служит элемент с номером increment.
Если при последнем исполнение цикла while значение переменной будет равно единице, то значит и при последнем вызове функции InsertionSort значение increment будет равно единице /6, с.82-84/.
2.4 Корневая сортировка
Корневая сортировка – это когда, упорядочивание списка происходит без непосредственного сравнения ключевых значений между собой.
При корневой сортировке создается набор «стопок», а элементы распределяются по стопкам в зависимости от значений ключей. После собирания всех значений обратно, и повторив, данную процедуру для последовательных частей ключа, в итоге получается отсортированный список. Для правильности работы процедуры распределения по стопкам и последующую сборку следует выполнять очень аккуратно.
Используется такая процедура при ручной сортировке карт. В докомпьютерные времена в большинстве библиотек, при выдаче книги заполнялась карта выдачи. Эти карты были занумерованы, а с боку на картах проделывался ряд выемок – в зависимости от номера карты.
Когда книга возвращалась, то карта выдачи удалялась и убиралась в стопку. После чего вся стопка прокалывалась длинной иглой на месте первой выемки, и иглу поднимали. Карты с удаленной выемкой оставались на столе, а остальные были наколоты на иглу. После чего две получившиеся стопки переставлялись таким образом, что карточки на игле шли за карточками с отверстиями. Затем игла втыкалась в месте второй выемки и весь процесс повторялся. Когда прокалывание происходило по всем позициям, карты оказывались в порядке возрастания номеров.
Вся эта процедура ручной обработки разделяет карты по значению младшего разряда номера на первом шаге и старшего разряда на последнем.
Компьютеризованный вариант этого алгоритма использует десять стопок:
RadixSort(List,N)
list сортируемый список элементов
N число элементов в списке
shift=l
for loop=l to keySize do
for entry=l to N do
bucketNumber=(list[entry].key/shift) mod 10
Append(bucket[bucketNumber], list[entry])
end for entry
list=CombineBuckets О
shift=shift*10
end for loop
При вычислении значения переменной bucketNumber из ключа вытаскивается одна цифра. При делении на shift ключевое значение сдвинется на несколько позиций вправо, а последующее применение операции mod оставляет лишь цифру единиц полученного числа.
При первом проходе с величиной сдвига 1 деление не меняет числа, а результатом операции mod будет служить цифра единиц ключа.
При втором проходе значение переменной shift будет уже равно 10, поэтому целочисленное деление и последующее применение операции mod дают цифру десятков. При очередном проходе будет получена следующая цифра числа.
Функция CombineBuckets вновь сводит все стопки от bucket [0] до bucket [9] в один список. Тем самым переформированный список будет служить основой для следующего прохода. Так как переформирование стопок идет в определенном порядке, а числа добавляются к концу каждой стопки, то ключевые значения постепенно оказываются отсортированными.
Исходный список
313 217 021 131 016 308 225 037 202 112 329 005 334 104 232 125
Номер стопки Содержимое
0 313 131 334 125
1 308 202 112 232
2 225 037 005 104
3 217 021 016 329
Первый проход, разряд единиц
Список, полученный в результате первого прохода
313 131 334 125 308 202 112 232 225 037 005 104 217 021 016 329
Номер стопки Содержимое
0 308 202 005 104
1 313 112 217 016
2 125 225 021 329
3 131 334 232 037
Второй проход, разряд десятков
Список полученный в результате второго прохода
308 202 005 104 313 112 217 016 125 225 021 329 131 334 232 037
Номер стопки Содержимое
0 005 016 021 037
1 104 112 125 131
2 202 217 225 232
3 308 313 329 334
Третий проход, разряд сотен
На данном примере показана три прохода на списке трехзначных чисел. Чтобы упростить пример в ключах, использовались числа, которые начинались от 0 до 3, поэтому достаточно было всего лишь четырех стопок.
Если посмотреть на данный пример, то сразу становится ясно, что если соберем стопки по порядку, то получим отсортированный список.
Способ реализации такого алгоритма существенно оказывает влияние на саму эффективность алгоритма, как по памяти, так и по времени. Но все же ключевым препятствием в реализации корневой сортировки служит ее неэффективность по памяти.
Для корневой сортировки дополнительной памяти нужно гораздо больше, чем для пузырьковой сортировки, сортировки вставкой и сортировки Шелла. В этих алгоритмах сортировки память нужна была только для обмена двух записей.
Если стопки пробовать организовывать массивами, то эти массивы должны быть чрезвычайно огромны. Потому что величина каждого из них должна совпадать с длиной всего списка. Если же использовать массивы, то потребуется время на копирование записей в стопки на этапе формирования самих стопок, а так же на обратное их копирование на этапе сборке списка. Значительное время потребуется, если такие записи будут длинными.
Так же можно применить и другой подход, который заключается в объединение записей со ссылками. При этом помещение записи в стопку, а так же ее возвращение в список требует всего лишь изменение ссылки. При всем этом дополнительная память остается значительной, поскольку на каждую ссылку для реализации уходит от двух до четырех байтов /6, с.87-91/.
2.5 Пирамидальная сортировка
Пирамидальная сортировка – специальный тип бинарного дерева, который называется пирамидой; значение корня в любом поддереве такого дерева больше, чем значение каждого из его потомков.
Левый непосредственный потомок иногда оказывается больше правого, а иногда и наоборот, это связано с тем, что непосредственные потомки каждого узла не упорядочены.
Сама пирамида представляет собой дерево, в котором заполнение нового уровня начинается только тогда, когда предыдущий уровень будет заполнен целиком, а все узлы на одном уровне заполнятся слева направо.
Пирамидальная сортировка начинается сначала с построения пирамиды. На этом уровне максимальный элемент списка оказывается на вершине дерева, так как потомки вершины всегда должны быть меньше. Корень записывается последним элементом списка. Пирамида переформировывается, если максимальный элемент удален.
Результатом оказывается то, что в корне оказывается по второй величине элемент, который копируется в список, а сама процедура повторяется пока все элементы не окажутся возвращенными в список.
Алгоритм пирамидальной сортировки будет выглядеть следующим образом:
сконструировать пирамиду
for i=l to N do
скопировать корень пирамиды в список
переформировать пирамиду
end for
На рисунке 2 изображена пирамида и ее списочное представление.
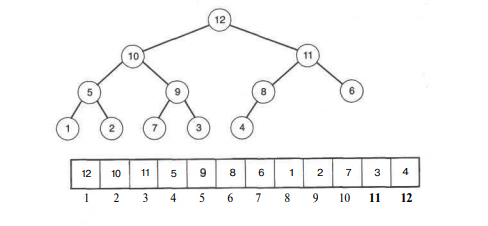
Рисунок 2 Пирамида и ее списочное представление
Переформирование пирамиды.
При переформировании пирамиды, она должна остаться насколько возможно близкой к дереву. Переформирование начинается с самого правого элемента на ее нижнем уровне. В результате чего, узлы с нижней части дерева будут убираться равномерно.
Если за этим не следить, то все большие значения оказываются в одной части пирамиды и пирамида разбалансируется, при этом эффективность алгоритма упадет. В итоге получаем следующий алгоритм:
FixHeap(list,root,key,bound)
list сортируемый список/пирамида
root номер корня пирамиды
key ключевое значение, вставляемое в пирамиду
bound правая граница (номер) в пирамиде
vacant = root
while 2*vacant <= bound do
larger-Child = 2*vacant
// поиск наибольшего из двух непосредственных потомков
if (largerChild<bound) and (list[largerChild+l]>
list[largerChild+l]) then
largerChild=largerChild+l
end if
// находится ли ключ выше текущего потомка?
if key>list[largerChild] then
// да, цикл завершается
break
else
// нет, большего непосредственного потомка
//следует поднять
list[vacant]=list[largerChild]
vacant=largerChild
end if e
nd while
list[vacant]=key
В данном алгоритме, корень пирамиды всегда должен быть первым элементом /6, с.92-95/.
2.6 Сортировка слиянием
В основе сортировки слиянием лежит замечание, согласно которому слияние двух отсортированных списков выполняется быстро. Так как список одного элемента отсортирован, то сортировка слиянием разбивает список на одноэлементные куски, а затем постепенно сливает их. Именно поэтому вся деятельность данной сортировки заключается в слияние двух списков.
Сортировку слиянием можно записать в виде рекурсивного алгоритма, который выполняет работу двигаясь вверх по рекурсии. При взгляде не нижеследующий алгоритм можно увидеть, что он разбивает список пополам до тех пор, пока номер первого элемента куска меньше номера последнего элемента в нем.
После возврата из двух вызовов процедуры MergeSort со списками длиной один вызывается процедура MergeLists, которая сливает эти два списка, в результате чего получается отсортированный список длины два. При возврате на следующий уровень два списка длины два сливаются в один отсортированный список длины четыре. Сам процесс будет продолжаться, пока две отсортированные половины списка сливаются в общий отсортированный список. Процедура MergeSort разбивает список пополам при движении рекурсии вниз, после чего на обратном пути сливает отсортированные половинки списка. Вышеизложенный алгоритм будет выглядеть следующим образом:
MergeSort(list,first,last)
list сортируемый список элементов
first номер первого элемента в сортируемой части списка
last номер последнего элемента в сортируемой части списка
if first < last then
middle=(first+last)/2
MergeSort(list.first.middle)
MergeSort(list,middle+l,last)
MergeLists(list.first.middle,middle+l,last)
End if
Отсюда видно, что основную работу в алгоритме проделывает функция MergeLists /6, с.98-99/.
2.7 Быстрая сортировка
Быстрая сортировка является рекурсивным алгоритмом сортировки. Как и сортировка слиянием, быстрая сортировка, выбрав элемент делит с его помощью список на две части.
В первую часть попадают все элементы, которые меньше выбранного, а во вторую часть – большие элементы. В среднем быстрая сортировка эффективна, однако в наихудшем случае у нее такая же эффективность, как у пузырьковой сортировки и сортировки вставками.
Быстрая сортировка выбирает элемент списка, который называется осевым, а затем переупорядочивает список таким образом, что все элементы, меньшие осевого, оказываются перед ним, а большие оказываются за ним. В каждой из частей списка элементы не упорядочиваются.
Если г – окончательное положение осевого элемента, то все значения в позициях с первой по г -1 меньше осевого, а значения с номерами г + 1 до N больше осевого. После чего алгоритм Quicksort вызывается рекурсивно на каждой из двух частей. Когда происходит вызов процедуры Quicksort на списке, который состоит из одного элемента, то он ничего не делает, так ка одноэлементный список уже отсортирован.
Процедура в алгоритме Quicksort должна проследить за границами обеих частей, потому что основная работа алгоритма заключается в определение осевого элемента и последующей перестановки элементов. Вся работа по сортировке выполняется при возвращении по рекурсии, так как перемещение ключей происходит в процессе разделения списка на две части.
Ниже показан алгоритм быстрой сортировки:
Quicksort(list,first.last)
list упорядочиваемый список элементов
first номер первого элемента в сортируемой части списка
last номер последнего элемента в сортируемой части списка
if first < last then
pivot=PivotList(list,first,last)
Quicksort(list,first,pivot-1)
Quicksort(list,pivot+l,last)
end if
В данном алгоритме функция PivotList берет в качестве осевого элемента первый элемент списка и устанавливает указатель pivot начало списка. После чего функция проходит по списку, сравнивая осевой элемент со всеми элементами списка. Если функция обнаруживает элемент, который меньше осевого, то она увеличивает указатель PivotPoint и переставляет элемент с новым номером PivotPoint во вновь найденный элемент.
После того, как произведено сравнения части списка с осевым элементом, то список оказывается разбит на четыре части:
первая часть – состоит из первого осевого элемента списка;
вторая часть – начинается с положения first + 1, а кончается в положении PivotPoint, состоящих из всех просмотренных элементов, которые оказались меньше осевого;
третья часть – начинается в положении PivotPoint + 1 и заканчивается указателем параметра цикла index;
четвертая часть – состоит из еще не просмотренных значений.
Пример алгоритма PivotList:
PivotListdist , first .last)
list обрабатываемый список
first номер первого элемента
last номер последнего элемента
PivotValue=list [first]
PivotPoint=first
for index=f irst+1 to last do
if list [index] < Pivot Value then\
PivotPoint=PivotPoint+l
Swap(list [PivotPoint] , list [index] )
end if
end for
// перенос осевого значения на нужное место
Swap (list [first] , list [PivotPoint])
return PivotPoint /6, с.105-107/.
2.8 Внешняя многофазная сортировка слиянием
Бывает, что сортируемый список оказывается велик, что он не помещается целиком в память компьютера. Большая часть алгоритмов связана с упорядочивание ключей, а эти ключи связаны с целыми записями. И во многих случаях длина записи значительно превышает длину ключа. Когда длина записи очень велика и перестановка двух записей занимает много времени, что анализ эффективности алгоритма должен учитывать, как число сравнений, так и число обменов.
Иногда допустимо объявить массив, так как его размер доступен для размещения всех требуемых данных, хотя размеры этого массива значительно превышают объемы доступные компьютерной памяти. Тогда операционной системе приходится пользоваться виртуальной памятью, так же следует учитывать эффективность ее использования. Хотя даже в этом случае обмен между дисками и оперативной памятью может быть значительным.
Даже в эффективных алгоритмах сортировки на подобие QuickSort разбиение и длина блока логической памяти может привести к большому числу переписывания блоков. Эту проблему тяжело заметить, пока программа не будет реализована на компьютере, при этом ее скорость будет настолько маленькой, что приходится применять средства технического анализа для выяснения узких мест. Только даже в таком случае анализ может оказаться безрезультатным, если операционная система компьютера не имеет инструментов отслеживания обменов в виртуальной памяти.
Так как, объем работы по чтения или записи на диск блоков виртуальной памяти может во много раз превышать трудоемкость арифметических и логических операций, то эту работу выполняет сама операционная система компьютера.
Для того, чтобы уменьшить размер используемой логической памяти и уменьшить неконтролируемую нагрузку на виртуальную память, можно воспользоваться файлами с прямым доступом и заменить непосредственные обращения к массиву операциями поиска в файле для выхода в нужную позицию с последующим чтением блока.
В результате алгоритмы сортировки на больших объемах данных оказываются непрактичными.
Допустим есть четыре файла и инструмент их слияния. Для начала стоит оценить число записей, которые можно хранить в оперативной памяти компьютера одновременной. Далее объявим массив S, длина которого равна этой величине, данный массив будет использоваться на двух этапах сортировки.
Первый этап: прочитать S записей и отсортировать их с помощью подходящей внутренней сортировки. Отсортированный набор записей перепишем в файл A. Далее S записей прочитывается еще раз и сортируется с дальнейшем переписывание в файл B. При этом отсортированные блоки пишутся попеременно в файл A и файл B. Снизу показан алгоритм, который реализует первый этап:
CreateRuns(S)
S размер создаваемых отрезков
CurrentFile=A
while конец входного файла не достигнут do
read S записей из входного файла
sort S записей
if CurrentFile=A then
CurrentFile=B else
CurrrentFile=A
end if
end while
Теперь данный файл разбит на отсортированные отрезки.
Второй этап (слияние данных отрезков): процесс слияния аналогичен функции MergeLists, только вместо того, чтобы записи переписывать в новый массив они будут записаны в новый файл. Для начала начнем читать половинки первых отрезков из фалов A и B. Чтение производится строго по половине отрезков, так как в памяти может находится только одновременно S записей, а требуются файлы из обоих файлов. Далее половинки отрезков сливаются в один отрезок файла C. После того, как одна половинка закончится, то следует прочесть вторую половинку из этого же файла. По окончанию обработки одного из отрезков, конец второго отрезка будет переписан в файл C.
После завершения слияния двух отрезков из файла A и B, следующие два отрезка сливаются в файл D. Процесс слияния отрезков продолжается с попеременной записью слитых отрезков в файлы C и D.
По завершению сортировки мы получаем два файла, которые разбиты на отсортированные отрезки длины 2S. После чего процесс повторяется, при этом отрезки читаются из файлов C и D, а слитые отрезки 4S запишутся в файл A и B. В конце отрезки сольются в один отсортированный список в одном из файлов. Снизу показан алгоритм показан алгоритм, который реализует второй этап:
PolyPhaseMerge(S)
S размер исходных отрезков
Size=S
Input1=A
Input2=B
Current Output=C
while not done do
while отрезки не кончились do
слить отрезок длины Size из файла Input1
с отрезком длины Size из файла Input2
записав результат в CurrentOutput
if (CurrentOutput=A) then
CurrentOutput=B
elsif (CurrentOutput=B) then
CurrrentOutput=A
elsif (CurrentOutput=C) then
Currrent Output=D
elsif (CurrentOutput=D) then
CurrrentOutput=C
end if
end while
Size=Size*2
if (Input1=A) then
Input1=C
Input2=D
Current Output=A
else
Input1=A
Input2=B
CurrentOutput=C
end if
end while /6, с.112-115/.
Исходя из вышеизложенного стоит отметить, что алгоритмы сортировки делятся на разные виды. Каждый из которых занимает свое определенное место в программировании.
Стоит отметить и то, что у всех алгоритмов сортировки есть свои преимущества и недостатки. Поэтому перед началом сортировки лучше всего выбрать тот алгоритм, который будет более ориентирован на быстрое выполнение сортировки и удовлетворять заранее установленные критерии.
Заключение
По данной курсовой работе можно сделать выводы, что алгоритм - это точно определенная инструкция, благодаря которой мы можем решить поставленную нам задачу.
Как правило, алгоритм служит не для решения какой-то конкретной задачи, а для решения определенного класса задач.
Алгоритм может быть изображен схематически, а также записан словами, которые понятны исполнителю: к примеру машинный код, который состоит из нулей и единиц.
Для каждой задачи существует множество алгоритмов, приводящих к цели. Пример этого служит курсовая работа, в которой описаны алгоритмы сортировки.
В курсовой работе были описаны алгоритмы сортировки, которые разделяются на: сортировка вставками, пузырьковая сортировка, сортировка Шелла, корневая сортировка, пирамидальная сортировка, сортировка слиянием, быстрая сортировка и многофазная сортировка слиянием.
Список использованной литературы и источников
- Кадырова, Г. Р. Основы алгоритмизации и программирования : учебное пособие / Г. Р. Кадырова. – Ульяновск : УлГТУ, 2014. – 95 с.
- Белов М. П. Основы алгоритмизации в информационных системах: Учеб. пособие. - СПб.: СЗТУ, 2003. - 85 с.
- Основы алгоритмизации и программирования: учеб. пособие / Т.А. Жданова, Ю.С. Бузыкова. – Хабаровск : Изд-во Тихоокеан. гос.ун-та, 2011. – 56 с.
- Макаров В.Л. Программирование и основы алгоритмизации: учебное пособие – СПб. СЗТУ, 2003 – 110 с.
- Дж. Макконнелл Основы современных алгоритмов. 2-е дополненное издание Москва: Техносфера, 2004. - 368с.
- Основы алгоритмизации и программирования. Курс лекций. URL:http://lib.ssga.ru/fulltext/UMKисходные%20для%20Кацко/заменить%20полностью/Информатика/лекции/13%20Основы%20алгоритмизации%20и%20программирования.pdf
Приложения
Приложение 1.

Источник: http://900igr.net/datas/informatika/Formy-predstavlenija-algoritma/0052-022-Blok-skhema-nazyvajut-graficheskoe-predstavlenie-algoritma-v-kotorom.jpg
Приложение 2.
Источник: http://900igr.net/up/datas/180017/014.jpg
Приложение 3.
Источник: https://cf.pptonline.org/files/slide/1/1SgDJ4RljkWzYbwXKy95ZU2VLrvmHA3C0Fqh7s/slide-10.jpg

- Понятие правонарушения ( Понятие и признаки правонарушения)
- ПОНЯТИЕ ГОСУДАРСТВА (Теории происхождения государства )
- Понятие и признаки государств (Понятие государства)
- Системный подход при анализе потенциала организации ( Теоретическое обоснование системного подхода при анализе потенциала организации)
- Психологические основы бизнес - тренинга как метода профессионального обучения
- Понятие и границы суверенитета государства ( Понятие и признаки суверенитета государства)
- Анализ внешней и внутренней среды
- Корпоративная культура в организации (Сущность, функции, принципы корпоративной культуры организации)
- Формы и системы оплаты труда на предприятии (Система оплаты труда)
- Бизнес-планирование
- Дидактическая игра как средство активизации познавательной̆ деятельности младших школьников (Психолого-педагогическое образование)
- Управление конфликтами в организации (Способы урегулирования конфликтов)