
Обзор методов и средств анализа сетевого трафика и поиска аномалий трафика (Классификация средств мониторинга и анализа)
Содержание:

ВВЕДЕНИЕ
Стремительная популяризация и, соответственно, развитие сетей значительно усложнили вычислительные системы и сделали их связанными относительно друг друга, следовательно, менее защищенными от вредоносной деятельности. Рост уровня автоматизации процессов обработки, хранения и передачи информации также сказывается на возникновении проблем по обеспечению безопасности, а расходы на покрытие убытков от деятельности злоумышленников постоянно увеличиваются [10].
Стоит отметить, что складывается устойчивая тенденция к увеличению количества атак на вычислительные системы и сети [5]: способы и методики удаленного воздействия постоянно совершенствуются, а существующие системы защиты не позволяют своевременно реагировать на изменения в этой сфере, потому что сначала нужно обнаружить, а затем и изучить сетевую атаку. Из-за этого нет возможности полностью исключить вредоносный трафик. Эти обстоятельства придают большое значение вопросам выработки эффективных методик обнаружения несанкционированного трафика и разработки актуальных средств защиты информации.
Актуальность выбранной темы обусловлена тем, что на текущий момент активно разрабатываются и применяются различные методы по обнаружению и предотвращению вторжений, но они не всегда являются эффективными на практике. Вследствие этого все технологии защиты постоянно изучаются и улучшаются.
Существующие системы объединяет общая черта – защита локальной сети от злоумышленного воздействия извне. В моей работе рассматривается построение аналитики внутреннего трафика таким образом, чтобы на основе нее администратор мог принять решение о принятии своевременных действий и тем самым защитить внешнюю сеть от воздействия из локальной сети. Если распространить такую схему в работе большинства подсетей, то обеспечение безопасности сетевой инфраструктуры выйдет на новый уровень.
В связи с этим целью курсовой работы является разработка прототипа системы сбора сетевого трафика для анализа и выявления несанкционированной активности.
В рамках работы будут решены следующие задачи:
- изучение проблемы обеспечения безопасности сети и исследование современных методик анализа сетевого трафика;
- разработка оптимальной архитектуры системы;
- создание алгоритмов статистической обработки полученных данных;
- реализация прототипа программной системы обнаружения вредоносного трафика на основе разработанной архитектуры и алгоритмов.
Глава 1. Исследование существующих систем мониторинга и анализа сетевого трафика
1.1 Классификация средств мониторинга и анализа
В процессе обработки и хранения информации неизбежно возникает необходимость в обмене данными между участниками этого процесса. С конца 70-х годов началось бурное развитие компьютерных сетей и сопутствующего сетевого оборудования. Локальные и глобальные сети продолжают развиваться, возникают новые протоколы передачи данных, расширяются аппаратные возможности сетевого оборудования, растет число подключенных абонентов и суммарный объем трафика.
Такое интенсивное развитие области влечет за собой ряд проблем. Одна из них заключается в том, что при растущем числе потребителей информационных услуг увеличиваются требования к сетевому и серверному оборудованию, которое используется для поддержания надлежащего уровня качества обслуживания. Вторая основывается на необходимости защиты информации, которая циркулирует внутри сети [6].
Для решения этих проблем используют мониторинг и анализ трафика, помогающие эффективно диагностировать и решать проблемы при их возникновении, не позволяя сетевому оборудованию простаивать долго [1]. Так как информация по сети передается почти непрерывно, то становится понятно, что прекращение работы оборудования или иные причины отказа в обслуживания приводят к убыткам организаций или компаний предоставляющих услуги. В связи с этим администраторам необходимо следить за движением сетевого трафика и производительностью всей сети, а также проверять ее на бреши в политике безопасности.
Инструменты, которые предлагают для мониторинга и анализа вычислительных сетей, можно разделить на несколько групп [12]:
Системы управления сетью (Network Management Systems) - централизованные программные системы, которые собирают данные о состоянии сетевых устройств и информацию о трафике в сети. Функционал данных программ не ограничен мониторингом и анализом сети. Дополнительно, в полуавтоматическом или автоматическом (в зависимости от реализации) режиме, осуществляются действия по управлению сетью: настройка и изменение адресных таблиц коммутаторов и прочего оборудования, включение и отключение портов устройств. К системам в этой категории относятся HPOpenView, SunNetManager, IBMNetView.
Встроенные системы диагностики и управления (Embedded systems). Системы данного типа выполнены в виде программно-аппаратных модулей, которые устанавливаются в коммуникационное оборудование, либо – в операционную систему в виде программных модулей. Они позволяют управлять и диагностировать только тем устройством, на котором находятся. Примером таких систем является модуль управления концентратором Distributed 5000, который выполняет функции автосегментации портов после обнаружения неисправностей, приписывания портов внутренним сегментам концентратора и некоторые другие. Обычно, встроенные модули управления также выполняют роль SNMP-агентов, передавая данные о состоянии устройства в систему управления.
Средства управления системой (System Management). Инструменты из этой группы выполняют функции, аналогичные функциям систем управления, но по отношению к другим объектам. В первом случае объектом управления является программное и аппаратное обеспечение компьютеров сети, а во втором - коммуникационное оборудование. При этом часть функций этих двух видов систем могут дублироваться (например, средства управления системой могут проводить простейший анализ трафика).
Анализаторы протоколов (Protocol analyzers) – это программные или аппаратно-программные системы, используемые только для мониторинга и анализа трафика в сетях. Хорошим анализатором считается тот, который может захватывать и декодировать пакеты большого количества протоколов, применяемых в сетях - примерно нескольких десятков. Эта группа систем может устанавливать некоторые логические условия для захвата отдельных пакетов и выполнять полное декодирование пакетов, то есть отображать в удобной для пользователя форме вложенность пакетов протоколов разных уровней с расшифровкой содержания каждого полей пакета.
Когда начинают проектировать или модернизировать сеть, часто возникает потребность в количественном измерении характеристик сети: например, возникающие на различных этапах задержки, частота возникновения выборочных событий, интенсивность потоков данных по линиям связи, время реакции на запросы.
Оборудование для диагностики и сертификации кабельных систем. Из названия становится ясно предназначение этой группы. Условно можно выделить четыре подтипа подобного оборудования: кабельные сканеры, сетевые мониторы, мультиметры и приборы для сертификации кабельных систем.
Экспертные системы соединяют человеческие знания о выявлении причин аномальной работы сетей и возможных способах возвращения сети в рабочее состояние. Чаще всего они представлены в виде отдельных подсистем других средств мониторинга и анализа сетей, рассмотренных ранее.
К простому варианту экспертной системы относится контекстно- зависимая help-система, а более сложные представляют собой так называемые базы знаний, которые обладают элементами искусственного интеллекта. Примером данной группы является система, встроенная в систему управления Spectrum компании Cabletron.
Многофункциональные устройства анализа и диагностики. Из-за широкого распространения локальных сетей появилась потребность в разработке недорогих портативных приборов с функционалом нескольких устройств: кабельных сканеров, программ сетевого управления и анализаторов протоколов. В качестве примера можно привести Compas компании MicrotestInc или 675 LANMeter компании FlukeCorp.
Также стоит отметить еще два способа мониторинга сети. Первый – это маршрутизаторо-ориентированный. Он представляет собой мониторинг, встроенный непосредственно в маршрутизатор и не требующий дополнительной установки другого обеспечения. Второй способ, соответственно, – это не ориентированный на маршрутизаторы, то есть это подобранное самим специалистом необходимое аппаратное и программное обеспечение для текущих нужд.
Системы обнаружения и предотвращения вторжений
Внедрение подобных систем для защиты информации является необходимостью для всех серьезных сетевых инфраструктур, так как существуют программы, которые постоянно выискивают уязвимости в любом оборудовании, подключенном к глобальной сети. К примеру, поисковый движок Shodan [17] в автоматическом режиме собирает информацию о подключенных устройствах, которые не имеют какой-либо части системы безопасности. Пользователи Shodan находят системы управления крематорием, газовой станцией и тому подобное, которые не имеют реквизитов доступа, либо они настроены по умолчанию. Следовательно, к ним можно легко проникнуть и уменьшить работоспособность.
Против такого воздействия и направлены системы обнаружения и предотвращения вторжений, поэтому они являются часто используемым инструментом в политике безопасности [2].
Система обнаружения вторжений (СОВ) (англ. Intrusion Detection System (IDS)) – программное или аппаратное средство, предназначенное для выявления фактов неавторизованного доступа (вторжения или сетевой атаки) в компьютерную систему или сеть.
Система предотвращения вторжений (СПВ) (англ. Intrusion Prevention System (IPS)) – программное или аппаратное средство, осуществляющее мониторинг сети или системы в реальном времени с целью выявления, предотвращения или блокировки вредоносной активности.
Системы предотвращения вторжений можно считать расширением систем обнаружения вторжений, так как задача отслеживания атак остается одинаковой. Но СПВ должна отслеживать вторжения в реальном времени и сразу осуществлять действия по предотвращению атак. Для этого они используют: сброс соединений, блокировку потоков трафика в сети, выдачу сигналов оператору. Помимо этого такие системы могут дефрагментировать пакеты, изменять порядок TCP пакетов для защиты от пакетов с измененными SEQ и ACK номерами и тому подобное [3].
Данные системы используются для автоматизации процесса контроля над событиями, которые протекают в компьютерной системе или сети, и анализа этих событий с целью поиска признаков проблем безопасности. Так как количество различных способов и видов организации несанкционированных вторжений в сети за последнее время значительно увеличилось, то системы обнаружения вторжений стали обязательной частью инфраструктуры безопасности для большинства организаций. Этому способствуют как большое количество литературы по данному вопросу, которую потенциальные злоумышленники внимательно изучают, так и все более изощренные подходы к обнаружению попыток проникновения в информационные системы.
Современные системы обнаружения вторжений имеют различную архитектуру, основными из которых являются: сетевая и локальная. Сетевые системы устанавливают на выделенных для этих целей компьютерах так, чтобы они могли анализировать трафик, протекающий по локальной вычислительной сети. Локальные же системы размещаются на тех компьютерах, которые нуждаются в защите, и изучают определенные события (программные вызовы или действия пользователя).
Кроме архитектуры СОВ также могут различать по методике обнаружения: часть систем ищет аномальное поведения, другая – злоумышленное [7].
Методики обнаружения аномального и злоумышленного поведения пользователей
Системы обнаружения аномального поведения (от англ. anomaly detection) основаны на том, что СОВ известны признаки, характеризующие правильное или допустимое поведение объекта наблюдения. Под «нормальным» или «правильным» поведением понимаются действия, выполняемые объектом и не противоречащие политике безопасности [3].
Системы обнаружения злоумышленного поведения (misuse detection) основаны на том, что заранее известны признаки, характеризующие поведение злоумышленника. Наиболее распространенной реализацией технологии обнаружения злоумышленного поведения являются экспертные системы (например, системы Snort, RealSecure IDS, Enterasys Advanced Dragon IDS).
Рассмотрим более подробно технологии, используемые в данных системах (рисунок 1) [11].

Рисунок 1 – Существующие технологии СОВ
Технологии обнаружения аномальной деятельности
Датчики-сенсоры аномалий идентифицируют необычное поведение, так называемые аномалии, в функционировании отдельного объекта. Поэтому главная трудность в применении их на практике связана с нестабильностью самих защищаемых объектов, а также и взаимодействующих с ними внешних объектов. В качестве объекта наблюдения может выступать сеть в целом, отдельный компьютер, сетевая служба (например, файловый сервер FTP), пользователь и так далее Датчики срабатывают при условии, что нападения отличаются от «обычной» (законной) деятельности. Тут стоить отметить, что в разных реализациях свое определение допустимого отклонения для наблюдаемого поведения от разрешенного и свое определение для «порога срабатывания» сенсора наблюдения.
Меры и методы, обычно используемые в обнаружении аномалии, включают в себя следующие [11]:
- пороговые значения: наблюдения за объектом выражаются в виде числовых интервалов. Выход за пределы этих интервалов считается аномальным поведением. В качестве наблюдаемых параметров могут быть, например: количество файлов, к которым обращается пользователь в данный период времени, число неудачных попыток входа в систему, загрузка центрального процессора и тому подобное. Пороги могут быть статическими и динамическими (то есть изменяться, подстраиваясь под конкретную систему);
- параметрические: для выявления атак строится специальный «профиль нормальной системы» на основе шаблонов (то есть некоторой политики, которой обычно должен придерживаться данный объект);
- непараметрические: профиль строится на основе наблюдения за объектом в период обучения;
- статистические меры: решение о наличии атаки делается по большому количеству собранных данных путем их статистической предобработки;
- меры на основе правил (сигнатур): они очень похожи на непараметрические статистические меры. В период обучения составляется представление о нормальном поведении объекта, которое записывается в виде специальных «правил». Получаются сигнатуры «хорошего» поведения объекта;
- другие меры: нейронные сети, генетические алгоритмы, позволяющие классифицировать некоторый набор видимых сенсору-датчику признаков.
В современных системах обнаружения аномалий в основном используют первые два метода. Следует заметить, что существуют две крайности при использовании данной технологии:
- обнаружение аномального поведения, которое не является атакой, и отнесение его к классу атак (ошибка второго рода);
- пропуск атаки, которая не подпадает под определение аномального поведения (ошибка первого рода). Этот случай гораздо более опасен, чем ложное причисление аномального поведения к классу атак.
Поэтому при установки и эксплуатации систем такой категории обычные пользователи и специалисты сталкиваются с двумя довольно нетривиальными задачами:
- определение граничных значений характеристик поведения субъекта для снижения вероятности появления одного из двух вышеописанных крайних случаев;
- построение профиля объекта – это трудно формализуемая и затратная по времени задача, требующая от специалиста безопасности большой предварительной работы, высокой квалификации и опыта.
Как правило, системы обнаружения аномальной активности используют журналы регистрации и текущую деятельность пользователя в качестве источника данных для анализа. К достоинствам систем обнаружения атак на основе технологии выявления аномального поведения можно отнести то, что они:
- не нуждаются в обновлении сигнатур и правил обнаружения атак;
- способны обнаруживать новые типы атак, сигнатуры для которых еще не разработаны;
- генерируют информацию, которая может быть использована в системах обнаружения злоумышленного поведения.
Недостатками этих систем является следующее:
- генерируют много ошибок второго рода;
- требуют длительного и качественного обучения;
- обычно слишком медленны в работе и требуют большого количества вычислительных ресурсов.
Статистический анализ компьютерных атак
Применение методов статистического анализа является наиболее распространенным видом реализации технологии обнаружения аномального поведения. Статистические датчики собирают различную информацию о типичном поведении объекта и формируют ее в виде профиля. Профиль в данном случае – это набор параметров характеризующих типичное поведение объекта. Он формируется на основе статистики наблюдаемого объекта, с применением методов математической статистики (например, метода скользящих окон и метода взвешенных сумм).
Сначала проходит период начального формирования профиля, после этого действия объекта сравниваются с соответствующими параметрами и при обнаружении существенных отклонений подается сигнал о начале атаки. Параметры профиля можно систематизировать по распространенным группам:
- категориальные параметры (имена файлов, команды пользователя, открытые порты и так далее);
- числовые параметры (количество переданных данных по различным протоколам, загрузка центрального процессора, число файлов, к которым осуществлялся доступ и тому подобное);
- не вписывающиеся в классификацию наравне с предыдущими типами параметров.
Также профили имеют механизмы динамического изменения, для того чтобы более полно описывать изменяющееся поведение объекта. Системы, применяющие статистические методы, обладают целым рядом достоинств:
- не требуют постоянного обновления базы сигнатур атак (это значительно облегчает задачу сопровождения данных систем);
- могут адаптироваться к изменению поведения пользователя и поэтому являются более чувствительными к попыткам вторжения, чем люди;
- могут обнаруживать неизвестные атаки, сигнатуры для которых еще не написаны и, следовательно, являться своеобразным сдерживающим буфером до тех пор, пока не будет разработан соответствующий шаблон для экспертных систем;
- позволяют обнаруживать более сложные атаки, чем другие методы, например, распределенные во времени или по объектам нападения.
Среди недостатков систем обнаружения вторжений можно отметить следующие:
- в статистических методах вероятность получения ложных сообщений об атаке является гораздо более высокой, чем при других методах;
- трудность задания порогового значения (выбор этих значений – очень нетривиальная задача, которая требует глубоких знаний контролируемой системы);
- статистические методы не очень корректно обрабатывают изменения в деятельности пользователя (например, когда менеджер исполняет обязанности подчиненного в критической ситуации). Этот недостаток может представлять большую проблему в организациях, где изменения являются частыми. В результате могут появиться как ложные сообщения об опасности, так и отрицательные ложные сообщения (пропущенные атаки);
- система может воспринимать деятельность, соответствующую атаке, в качестве нормальной из-за своей адаптации к новому поведению, если изменения режима работы были постепенными;
- статистические методы не способны обнаружить атаки со стороны субъектов, для которых невозможно описать шаблон типичного поведения;
- статистические методы должны быть предварительно настроены (заданы пороговые значения для каждого параметра, для каждого пользователя);
- системы, построенные исключительно на статистических методах, не справляются с обнаружением атак со стороны субъектов, которые с самого начала выполняют несанкционированные действия, так как шаблон обычного поведения для них будет включать только атаки;
- статистические методы на основе профиля нечувствительны к порядку следования событий.
Тем не менее, существуют пути решения данных проблем, и их практическая реализация является лишь вопросом времени. Очевидно, что статистический метод является чистой реализацией технологии аномального поведения. Статистический метод наследует у технологии обнаружения аномалий все так необходимые на практике достоинства [9].
Анализ недостатков современных систем обнаружения вторжений
С учетом сказанного выше, все системы обнаружения вторжений можно разделить на системы, ориентированные на поиск:
- сигнатур всех узнаваемых атак;
- аномалий взаимодействия контролируемых объектов;
- искажения эталонной профильной информации.
В настоящее время почти отсутствуют системы гибридного типа, а также системы, использующие информацию распределенного во времени и пространстве характера. В ходе работы подавляющего большинства современных систем используется только сигнатурный метод распознавания атакующих воздействий или только поиск аномалий в поведении контролируемой сети.
Также у почти всех известных систем отсутствует имитатор атак или любое другое средство для проверки корректности развернутой и эксплуатируемой СОА, которое обеспечивало бы простое и надежное средство тестирования конфигурационных параметров, использованных в каждой конкретной компьютерной сети.
Данное средство, по логическим соображениям, должно позволять имитировать деятельность программного обеспечения вирусного типа (например, СodeRed, NetSky, Bagle, MSBlast), атак на отказ в обслуживании (например, SYN-шторм или атаку типа fraggle), атак с целью повышения привилегий учетной записи (как пример, можно привести уязвимости в сетевых службах MS SQL Server 2000, MS Internet Information Service 5.0), атаку с целью перенаправления трафика и навязывания ложных данных (подмена ARP и навязывание DNS службы). Желательно, чтобы при всем этом программное средство имело возможность генерировать атаки распределенного характера.
Например, архитектура некоторых типов имитаторов СОА состоит из набора агентов различных типов, специализированных для решения подзадач обнаружения вторжений. Агенты размещаются на отдельных компьютерах системы. В этой архитектуре в явном виде отсутствует «центр управления» семейством агентов, потому что в зависимости от ситуации ведущим может становиться любой из агентов, который инициирует функции кооперации и управления. В случае необходимости они могут скопироваться в сетевой и локальной среде, либо прекратить свое функционирование. В зависимости от ситуации (вида и количества атак на компьютерные сети, наличия вычислительных ресурсов для выполнения функций защиты), может потребоваться генерация нескольких экземпляров агентов каждого класса. Предполагается, что архитектура системы может адаптироваться к реконфигурации сети, изменению трафика и новым видам атак, используя накопленный опыт.
Многоагентные системы являются интересной разработкой, но в отечественных работах нет указаний на используемые или разработанные алгоритмы обнаружения атак. А также текущие версии известных имитаторов не функционируют в реальном режиме времени (поскольку этого не позволяет делать выбранный базовый инструментарий).
В общем, отсутствие имитаторов атак для оценки эффективности СОА не является основной проблемой данного направления. Реальными недостатками существующих систем обнаружения является примитивность простого сигнатурного поиска, низкая эффективность при обнаружении распределенных по времени и месту сложных атак, недостаточная интеграция информации на уровне хоста и сети для обнаружения комбинированных атак и несанкционированных проникновений.
В качестве эксплуатационных недостатков можно отметить большое количество вычислительных операций для простого деления принадлежности события на «свой-чужой» и невозможность обработки всей поступающей информации в реальном режиме времени на обычных персональных компьютерах, так как скорость обработки сетевого или иного трафика событий зачастую медленнее реального времени в 1.5-2 раза. Поэтому в некоторых системах анализ происходит в отложенном режиме. Это означает, что реализация атаки на защищаемые информационные и вычислительные ресурсы не будет замечена вовремя и уж тем более не будет отражена с помощью имеющихся средств защиты. В данном режиме средства обнаружения атак могут быть использованы в лучшем случае как средство журналирования всех этапов атаки для последующей экспертизы.
Большинство современных СОА изначально не разрабатываются для работы на различных операционных систем и произвольных аппаратно- вычислительных платформах. Поэтому работа на нескольких операционных системах для большинства продуктов (как западных, так и отечественных) является невозможной. Эти системы не используют преимущества разработки и оптимизации кода для выбранных операционных систем и аппаратных платформ, что является их одним из самых существенных недостатков.
Также ни в одной программной или аппаратно-программной системе не предусмотрен режим «горячей замены», позволяющий в случае выведения из строя основного комплекса оперативно ввести в работу комплекс резервирования и восстановить уничтоженный рубеж обороны сетевого периметра.
Несмотря на это, есть положительный момент в развитии систем обнаружения аномалий – это стремление разработчиков интегрировать свои системы с существующими средствами защиты (межсетевыми экранами, блокираторами каналов, QoS-диспетчерами).
В первой главе обоснована актуальность проблемы анализа сетевого трафика для защиты от несанкционированного воздействия и рассмотрены существующие способы решения данной проблемы.
В последнее время в области систем управления наблюдаются две достаточно четко выраженные тенденции:
- интеграция в одном продукте функций управления сетями и системами;
- распределенность системы управления, при которой существует несколько консолей, собирающих информацию о состоянии устройств и подсистем, а затем выдающих управляющие действия.
Это связано с тем, что большинство представленных систем узкоспециализированы и направлены на хорошее выполнение своего функционала. Соответственно специалистам приходится использовать связку из нескольких продуктов, чтобы полностью покрыть все возможные уязвимости сети: системы мониторинга и учета трафика проверяют работоспособность оборудования и сети, выявляют оптимальность текущей аппаратно-программной конфигурации; системы обнаружения и предотвращения вторжений – позволяют выявить угрозу внутри и снаружи сети.
Современный подход к построению систем обнаружения сетевых вторжений и выявления признаков компьютерных атак на информационные системы полон недостатков и уязвимостей, позволяющих, к сожалению, злонамеренным воздействиям успешно преодолевать рубежи защиты информации.
На рынке представлено около десятка систем предотвращения и обнаружения вторжений [13], но все они имеют один важный недостаток: так как их работа построена на отработке правил и шаблонов, не все случаи вторжений улавливаются; кроме того они слабо справляются с
«мимикрирующим» вредоносным трафиком.
Помимо этого стоит отметить, что продуктов отечественных производителей на данном рынке представлено мало. Также, описанные ранее методики не всегда доступны, так как являются коммерческой тайной [14]. Поэтому возникает необходимость в разработке новой системы, которую можно применять в комплексе сетевых инструментов.
По итогу первой главы была выполнена первая задача работы – изучить проблемы обеспечения безопасности сети и исследовать современные методики анализа сетевого трафика.
Глава 2. Проектирование системы
2.1. Задача перехвата трафика
Система анализа должна обеспечивать захват 100% трафика и предоставлять эффективные методы анализа с навигацией по результатам.
Если говорить о комплексном решении задачи анализа сетевого трафика, то в первую очередь следует разделить ее на три в достаточной степени независимые подзадачи (рисунок 2): перехват трафика, его хранение и анализ [8].

Рисунок 2 – Подзадачи системы анализа сетевого трафика
Захват трафика осуществляется посредством снифферов. В общем случае, сниффер (англ. «sniffer» - дословно переводится как «нюхач» или «вынюхиватель») – это программа или программно-аппаратное устройство, предназначенное для перехвата трафика. В рамках конкретных продуктов могут быть реализованы дополнительные возможности, например, разбор заголовков сетевых протоколов, фильтрация по заданным критериям, восстановление сессий. Перехват сетевого трафика может осуществляться:
- с помощью «прослушивания» сетевого интерфейса;
- подключением сниффера в разрыв канала;
- ответвлением («зеркалированием») трафика и направления его копии на сниффер (пример: Network tap);
- посредством анализа побочных электромагнитных излучений;
- через атаку на канальном или сетевом уровне, приводящую к перенаправлению трафика жертвы на сниффер.
Различают два вида снифферов по их месторасположению:
-
- на маршрутизатор (шлюзе);
- на оконечном узле сети.
В первом случае будет перехватываться весь трафик, проходящий через интерфейсы устройства, во втором – либо только трафик узла сети, если сетевая карта работает в нормальном режиме, либо пакеты всех устройств этого сегмента сети (для этого у сетевой карты выставляется режим «promiscuous» - неразборчивый).
Создаются такие программы, основываясь на свободно распространяемой библиотеке Pcap (англ. «packet capture»). Она предназначена для использования совместно с языками C/C++, а для работы с библиотекой на других языках, таких как Java, .NET, используют обертки. Для Unix-подобных систем это библиотека libpcap, а для Microsoft Windows – WinPcap.
Программное обеспечение сетевого мониторинга может использовать libpcap или WinPcap, чтобы захватить пакеты в сети, для передачи пакетов в сети. Кроме того поддерживается сохранение захваченных пакетов в файл и чтение файлов, содержащих сохранённые пакеты.
Так как разрабатываемая нами система подключается к выходному маршрутизатору, связывающего сеть провайдера и сеть Интернет, соответственно, чтобы не создавать задержки в работе оборудования при таком объеме обрабатываемого трафика, разумно использовать метод «зеркалирования» трафика, то есть дублировать его на другой сетевой интерфейс (рисунок 3).
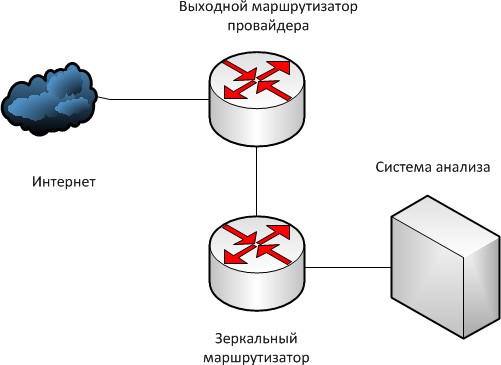
Рисунок 3 – Схема установки системы сбора информации
Что касается задачи анализа, то предпочтение тому или иному инструменту отдается исходя из специфики подзадач, которые необходимо решить [9]. Большинство существующих инструментов, как правило, проводит разбор заголовков сетевых протоколов, а также восстанавливает сессии (базовый анализ). В то же время существуют достаточно специфические задачи, для которых может не оказаться готового инструмента, например:
- анализ туннелированных протоколов произвольной глубины;
- анализ сессий на уровне приложений (выделение связей между потоками данных, передаваемых по сети);
- выполнение определенных сценариев (скриптов) в случае обнаружения в трафике предварительно заданных сигнатур.
Выделяют два режима работы анализаторов:
- в реальном времени;
- по предварительно сохраненному трафику.
Анализ в реальном времени требует поддержки работы инструмента в непрерывном режиме с производительностью, достаточной для разбора трафика, поступающего на вход. При этом должна быть обеспечена возможность обработки потенциально бесконечного входного потока данных.
В случае отложенного анализа инструмент получает входные данные из файла, что позволяет проводить более детальный анализ сетевой трассы по сравнению с анализом в режиме реального времени на аналогичном трафике.
Для примерной оценки работы и тестирования прототипа системы нам был предоставлен трафик Сибирского федерального университета (СФУ) с шириной канала по официальным данным – 1,5 Гбит/с. Если смотреть данные статистики по загруженности на 09 июня 2016 года (рисунок 4, таблица 1), то в сумме его средняя нагрузка выходит 591 Мбит/с. Соответственно такой поток трудно обрабатывать в реальном времени, эффективнее будет сохранять его дамп и работать уже с ним. Отсюда следует необходимость решения задачи хранения трафика.
Таблица 1 – Статистика трафика за сутки
|
Канал |
Максимальная загруженность канала (Мбит/с) |
Средняя загруженность (Мбит/с) |
Текущая загруженность (Мбит/с) |
|
Входящий |
810.0 |
478.7 |
526.8 |
|
Исходящий |
206.7 |
112.3 |
150.2 |
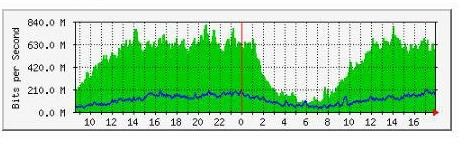
Рисунок 4 – Загруженность внешнего Интернет-канала СФУ
Предоставленная часть трафика СФУ занимает 110 Гб для 28,190358 секунд реального времени передачи информации; можно предположить, что для провайдера эти цифры будут увеличены в разы. Из полученных сведений следует необходимость обработки и преобразования дампа с целью уменьшения занимаемого пространства и оптимизации выборки данных. Для достижения этого хорошо подходят базы данных.
Во-первых, это дает нам возможность быстро находить среди всего дампа подходящие условиям пакеты, потому что каждый из них хранится отдельной записью в таблице. Кроме этого для ускорения выборок большого количества данных применяется индексирование.
Индекс – объект базы данных, создаваемый из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы. Соответственно ускорение работы достигается в первую очередь за счёт того, что индекс имеет структуру, оптимизированную под поиск.
Существует два типа индексов: кластерные и некластерные. При наличии кластерного индекса строки таблицы упорядочиваются по значению ключа этого индекса.
Если в таблице нет кластерного индекса, таблица называется кучей, и индекс, созданный для такой таблицы, содержит только указатели на записи. Это второй тип индексов. Кластерный индекс может быть только одним для каждой таблицы, но каждая таблица может иметь несколько различных некластерных индексов, каждый из которых определяет свой собственный порядок следования записей.
Индексы могут быть реализованы различными структурами, часто применяемыми являются B*-деревья, B+-деревья, B-деревья и хеши.
Для оптимальной производительности запросов индексы обычно создаются на тех столбцах таблицы, которые больше используются в запросах. То есть для одной таблицы может быть создано несколько индексов. Однако увеличение числа индексов замедляет операции добавления, обновления, удаления строк таблицы, так как при этом приходится обновлять сами индексы. А поскольку они занимают дополнительный объем памяти, перед их созданием следует убедиться, что планируемый выигрыш в производительности запросов превысит дополнительную затрату ресурсов компьютера на сопровождение индекса.
Во-вторых, применение баз данных должно обеспечить уменьшение размера занимаемого пространства, так как в продуманной архитектуре на хранение останутся только прописанные данные.
В разработанном прототипе трафик СФУ размером 110 Гб был преобразован и записан в базу данных; размер новых данных составил 73,9 Гб, что иллюстрирует сжатие в 1,49 раз. Количество записанных пакетов – 138 миллионов.
Таким образом, перед введением системы в эксплуатацию нужно провести исследование: какие базы данных лучше всего подходят для этой цели.
Во второй главе была разработана архитектура прототипа и описаны следующие модули системы:
- модуль захвата трафика;
- модуль хранения пакетов;
- модуль анализа полученных данных.
Также были выявлены важные критерии для некоторых модулей. Например, мы установили, что при перехвате трафика нужно использовать метод «зеркалирования», преобразовывать дамп и сохранять его базе данных.
По итогу второй главы решена следующая задача работы – разработка оптимальной архитектуры системы.
Глава 3. Разработка прототипа системы анализа сетевого трафика
3.1 Модуль преобразования дампа сетевого трафика
Во второй главе работы спроектирована архитектура системы анализа, ее развернутую схему можно увидеть на рисунке 5.
Трафик с выходящего маршрутизатора дублируется в систему в виде фиксированных по объему файлов, которые затем попадают на чтение и преобразование программе-снифферу. Из пакетов мы собираем и записываем в базу данных следующую информацию:
- длину пакета;
- время получения;
- о протоколах сетевого и транспортного уровня;
- ip-адреса источники и получателя;
- флаги SYN, ACK, FIN протокола TCP;
- значения портов протокола UDP.
Получая запрос от пользователя, web-сервер загружает из базы необходимые данные, анализирует их в запрошенном виде и отображает.
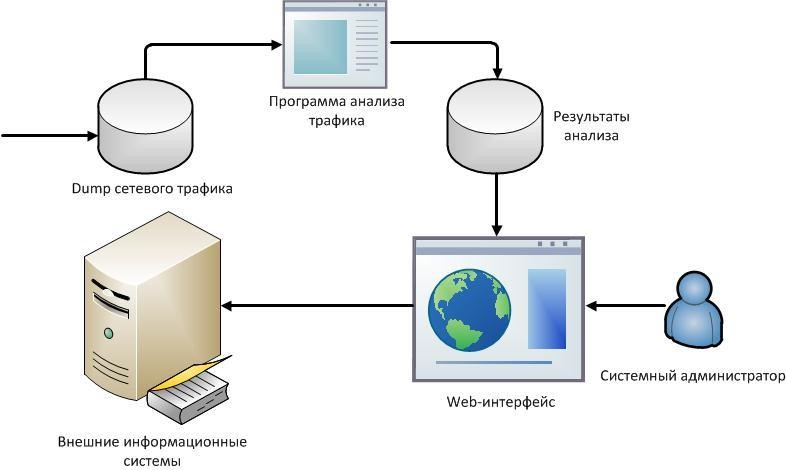
Рисунок 5 – Структурная схема системы анализа сетевого трафика
Данный модуль предназначен для чтения и преобразования в другой формат сохраненных данных. Он постоянно мониторит состояние файловой системы сервера: как только появляется новый файл дампа, сразу отправляем его на обработку.
На текущий момент идет разбор пакетов исключительно на сетевом и транспортном уровне, так как для прототипа это тот максимум информации, который нужен в дальнейшем анализе [18]. Этот функционал системы легко расширяем по мере надобности.
С сетевого уровня сохраняем информацию о:
- длине пакета;
- времени поступления пакета (секунды, миллисекунды и строку с датой и временем);
- протоколе сетевого уровня (идентификатор и название);
- протоколе транспортного уровня (идентификатор и название). С транспортного уровня сохраняем информацию о:
- ip-адрес и порт источника;
- ip-адрес и порт получателя.
Модуль реализован на языке С++ с использованием библиотеки WinPcap
- для правильной обработки дампа трафика и драйвером для базы данных.
3.2 Обоснование выбора программных средств
C++ — компилируемый, статически типизированный язык программирования общего назначения. Являясь чрезвычайно мощным языком, он содержит средства создания эффективных программ почти любого назначения: от низкоуровневых утилит и драйверов до сложных программных комплексов. В частности:
-
- поддерживает разные технологии программирования: традиционное директивное программирование, метапрограммирование (шаблоны, макросы), ООП, обобщённое программирование;
- позволяет пользовательским функциям-операторам кратко и емко записывать выражения над пользовательскими типами в естественной алгебраической форме;
- автоматически вызывает деструкторы объектов при их уничтожении в порядке обратном вызову конструкторов, что упрощает создание кода, делает более надёжным освобождение ресурсов (таких как память, семафоры, файлы и т. п.) и позволяет гарантированно выполнить любые переходы состояний программы, даже не обязательно связанные с освобождением ресурсов (к примеру, запись в журнал);
- выполняет программы предсказуемо, что является важным для построения систем реального времени. Генерируемый компилятором код для реализации языковых возможностей (например, при преобразовании переменной к другому типу) описан в стандарте, в котором также строго определены места, где этот код выполняется. Такое поведение дает возможность измерять время реакции программы на внешнее событие;
- поддерживает понятия логической (mutable) и физической (const) константности, что увеличивает надежность программы, так как позволяет компилятору диагностировать ошибочные попытки изменения значения переменной. Объявление константности предоставляет программисту, который читает текст программы, дополнительное представление о правильном использовании классов и функций, что, в свою очередь, может являться подсказкой для оптимизации. Перегрузка функций-членов по признаку константности дает возможность определить внутри объекта цели вызова метода (константный – для чтения, неконстантный – для изменения). Чтобы сохранить логическую константность при использовании кэшей и ленивых вычислений используют объявление mutable;
- может создавать встроенные предметно-ориентированные языки программирования. Для иллюстрации этого пункта можно привести библиотеку Boost.Spirit, которая позволяет задавать EBNF-грамматику парсеров прямо в коде C++;
- использует шаблоны с целью создания обобщённых контейнеров и алгоритмов для различных типов данных, а также специализации и вычисления на этапе компиляции;
- с помощью шаблонов и множественного наследования может имитировать классы-примеси и комбинаторную параметризацию библиотек. Пример такого использования языка существует в библиотеке Loki, где класс SmartPrt позволяет, управляя всего несколькими параметрами времени компиляции, сгенерировать примерно 300 видов «умных указателей» для управления ресурсами;
- может имитировать расширения языка для поддержки парадигм, которые не поддерживаются компиляторами напрямую: к примеру, библиотека Boost.Bind позволяет связывать аргументы функций;
- кроссплатформенен: стандарт языка накладывает минимальные требования на вычислительное устройство для запуска скомпилированных программ. В стандартной библиотеке есть возможности для определения реальных свойств системы выполнения. Стоит отметить, что компиляторы этого языка доступны для большого количества платформ;
- высоко совместим с языком Си; это позволяет использовать весь существующий Си-код: код на Си может быть с минимальными переделками скомпилирован компилятором C++; библиотеки, написанные на Си, могут вызываться из C++ без каких-либо дополнительных затрат, в том числе и на уровне функций обратного вызова, позволяя библиотекам, написанным на Си, вызывать код, написанный на С++.
- эффективен при использовании, благодаря тому, что язык спроектирован так, чтобы дать программисту максимальный контроль над всеми аспектами структуры и порядка исполнения программы. Для обеспечения максимальной производительности позволяет отключить все языковых возможностей, которые приводят к дополнительным накладным расходам, потому что они не являются обязательными для использования;
- имеет инструменты для работы на низком уровне с памятью и адресами.
Хотя у С++ существуют и недостатки, в нашем случае они не столь важны, потому что скоростная эффективность от использования этого языка превышает неудобства при разработке.
3.3 Модуль хранения сетевого трафика
Через драйвер программа-сниффер заполняет базу данных записями о полученных пакетах (одна запись – один пакет). Назначение данного модуля по мимо хранения информации – это уменьшить объем занимаемый дампом и ускорить выборку данных при запросе пользователя.
Для нашей системы сниффер записывает только определенные части пакетов, которые на текущем этапе интересны нам для анализа. В таблице 2 отображена схема записи об одном пакете.
Таблица 2 – Схема данных, хранящихся в базе данных
|
Поле |
Тип |
Описание |
|
|
id |
ObjectId |
Идентификатор записи в документе |
|
|
time |
Object |
Сборное поле для времени получения пакета |
|
|
seconds |
Int32 |
Время в секундах |
|
|
useconds |
Int32 |
Время в миллисекундах |
|
|
data |
String |
Дата и время получения пакета |
|
|
internetLayer |
Object |
Данные о протоколе сетевого уровня |
|
|
number |
Int32 |
Идентификатор |
|
|
name |
String |
Название |
|
|
transportLayer |
Object |
Данные о протоколе транспортного уровня |
|
|
number |
Int32 |
Идентификатор |
|
|
name |
String |
Название |
|
|
length |
Int32 |
Длина пакета в октетах, включая заголовок и данные |
|
|
source |
Object |
Данные об отправителе пакета |
|
|
ip |
String |
IP-адрес |
|
|
port |
Int32 |
Порт |
|
|
destination |
Object |
Данные о получателе пакета |
|
|
ip |
String |
IP-адрес |
|
|
port |
Int32 |
Порт |
|
3.4 Обоснование выбора программных средств
Для прототипа была взята MongoDB – документо-ориентированная база данных с открытым исходным кодом, не требующая описания схемы таблиц.
Основные возможности:
-
- документо-ориентированное хранение (JSON-подобная схема данных);
- использование Javascript в качестве языка для формирования запросов;
- широкий набор атомарных операций над данными (условный поиск, сложная вставка/обновление и тому подобное);
- разные типы данных (в том числе поддержка массивов);
- поддержка индексов (B-Tree);
- профилирование запросов;
- журналирование операций, изменяющих данные в базе данных;
- поддержка отказоустойчивости и масштабируемости: асинхронная репликация, набор реплик и распределения базы данных на узлы;
- эффективное хранение больших объектов, административный интерфейс, серверные функции, Map/Reduce и другое;
- полнотекстовый поиск, в том числе на русском языке, с поддержкой морфологии.
В отличие от реляционных баз данных MongoDB предлагает документо- ориентированную модель данных, благодаря чему она работает быстрее, обладает лучшей масштабируемостью, ее легче использовать.
Но, даже учитывая все недостатки традиционных баз данных и достоинства MongoDB, важно понимать, что задачи бывают разные и методы их решения бывают разные. В какой-то ситуации MongoDB действительно улучшит производительность вашего приложения, например, если надо хранить сложные по структуре данные. В другой же ситуации лучше будет использовать традиционные реляционные базы данных. Кроме того, можно использовать смешенный подход: хранить один тип данных в MongoDB, а другой тип данных - в традиционных БД.
Вся система MongoDB может представлять не только одну базу данных, находящуюся на одном физическом сервере. Функциональность MongoDB позволяет расположить несколько баз данных на нескольких физических серверах, и эти базы данных смогут легко обмениваться данными и сохранять целостность.
Рассмотрим несколько свойств этой базы данных:
- Формат данных в MongoDB.
Одним из популярных стандартов обмена данными и их хранения является JSON (JavaScript Object Notation). JSON эффективно описывает сложные по структуре данные. Способ хранения данных в MongoDB в этом плане похож на JSON, хотя формально JSON не используется. Для хранения в MongoDB применяется формат, который называется BSON или сокращение от binary JSON.
BSON позволяет работать с данными быстрее: быстрее выполняется поиск и обработка. Хотя надо отметить, что BSON в отличие от хранения данных в формате JSON имеет небольшой недостаток: в целом данные в JSON- формате занимают меньше места, чем в формате BSON, с другой стороны, данный недостаток с лихвой окупается скоростью.
- Кроссплатформенность.
MongoDB написана на C++, поэтому ее легко портировать на самые разные платформы. MongoDB может быть развернута на платформах Windows, Linux, MacOS, Solaris. Можно также загрузить исходный код и самому скомпилировать MongoDB, но рекомендуется использовать библиотеки с официального сайта.
- Коллекции.
Если в традиционном мире SQL есть таблицы, то в мире MongoDB есть коллекции. И если в реляционных БД таблицы хранят однотипные жестко структурированные объекты, то в коллекции могут содержать самые разные объекты, имеющие различную структуру и различный набор свойств.
- Репликация.
Система хранения данных в MongoDB представляет набор реплик. В этом наборе есть основной узел, а также может быть набор вторичных узлов. Все вторичные узлы сохраняют целостность и автоматически обновляются вместе с обновлением главного узла. И если основной узел по каким-то причинам выходит из строя, то один из вторичных узлов становится главным.
- Простота в использовании.
Отсутствие жесткой схемы базы данных и в связи с этим потребности при малейшем изменении концепции хранения данных пересоздавать эту схему значительно облегчают работу с базами данных MongoDB и дальнейшим их масштабированием. Кроме того, экономится время разработчиков. Им больше не надо думать о пересоздании базы данных и тратить время на построение сложных запросов.
- GridFS.
Одной из проблем при работе с любыми системами баз данных является сохранение данных большого размера. Можно сохранять данные в файлах, используя различные языки программирования. Некоторые СУБД предлагают специальные типы данных для хранения бинарных данных в БД (например, BLOB в MySQL).
В отличие от реляционных СУБД MongoDB позволяет сохранять различные документы с различным набором данных, однако при этом размер документа ограничивается 16 Мб. Но MongoDB предлагает решение - специальную технологию GridFS, которая позволяет хранить данные по размеру больше, чем 16 Мб.
Система GridFS состоит из двух коллекций. В первой коллекции, которая называется files, хранятся имена файлов, а также их метаданные, например, размер. А в другой коллекции, которая называется chunks, в виде небольших сегментов хранятся данные файлов, обычно сегментами по 256 Кб.
3.5 Модуль анализа и отображения
К заполненной базе подключается web-сервер, который берет на себя функционал:
- разграничения доступа к информации – взаимодействие разрешено только провайдеру (рисунок 6);
- проведения заданной аналитики;
- отображение данных и графиков;
- обеспечение запросов на сторонние ресурсы – получение данных об автономных системах, которым принадлежат IP-адреса, на которые идут запросы.
Рисунок 6 – Аутентификация пользователя
3.6Аналитика сетевого трафика
С заданного временного промежутка выбираются пакеты, которые отправляются из локальной сети во внешнюю, измеряется временной промежуток между соседними по записи пакетами, а затем подсчитывается количество пакетов, попавших в заданный временной интервал. То есть, к примеру, если пакет пришел с интервалом 10 от предыдущего, то он записывается в промежуток от 0 до 10.
Для демонстрации работы был установлен промежуток в 200 миллисекунд, это значит, что подсчитывались пакеты, попадающие в интервал с шагом 200. Также было установлено ограничение на вывод полученных результатов: отображаются первые 50 (рисунок 7).
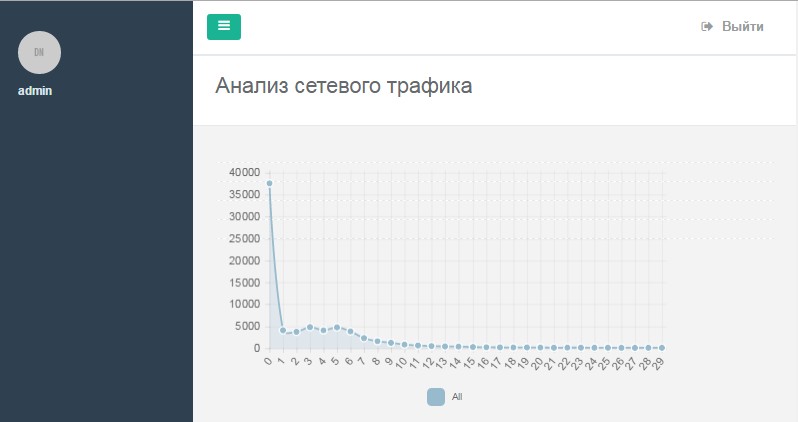
Рисунок 7 – Отображение графика временных интервалов между
отправленными пакетами с шагом в 200 миллисекунд
Кроме этого имеет фильтр, позволяющий получать временную статистику для всех типов сетевых пакетов, так и для отдельных протоколов.
Например, на рисунках 8-10 выводятся графики временных интервалов для пакетов, устанавливающих сессию в протоколе TCP, для пакетов протокола UDP.

Рисунок 8 – График временных интервалов между отправленными
пакетами с установкой сессии

Рисунок 9 – График временных интервалов между отправленными
пакетами протокола UDP
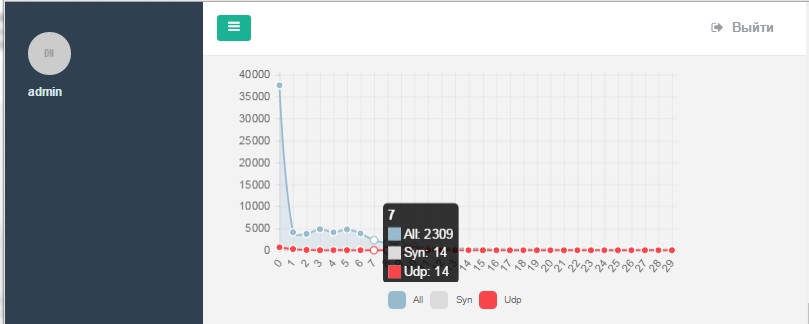
Рисунок 10 – График временных интервалов для сравнения аналитики по различным протоколам
3.7 Анализ частоты запросов по ip-адресам
Следующий частью аналитики является вывод статистики частоты запросов на различные ip-адреса (рисунок 11). Для демонстрации вывод был ограничен до 30 часто запрашиваемых ресурсов.
Таким образом, можно определять популярные ресурсы, и в случае появления нового адреса в списке быстро проверить доступную информацию о его автономной системе.
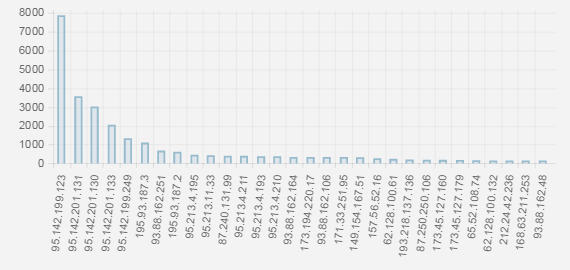
Рисунок 11 – График частоты запросов на ip-адреса
3.8 Обоснование выбора программных средств
Сервер реализован на кроссплатформенном стеке технологий MEAN (рисунок 12):
-
- MongoDB — база данных;
- Express.js — каркас веб-приложений, работающий поверх Node.js;
- Angular.js — MVC-фреймворк для фронтенда, интерфейсной части веб-приложения, работающей в браузере;
- Node.js — JavaScript платформа для серверной разработк
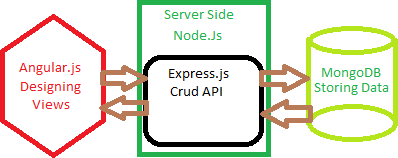
Рисунок 12 – Стек технологий MEAN
Использование Node.js позволяет включить автоматически в состав проекта уже готовый веб-сервер. В результате процесс развертывания значительно упрощается, так как требуемая версия веб-сервера явно определена вместе с остальными зависимостями времени выполнения.
Express позволяет управлять и маршрутизацией / генерацией страниц на стороне сервера, но с помощью AngularJS — упор делается на представления на стороне клиента. Кроме того AngularJS одинаково хорошо работает на настольных компьютерах и ноутбуках, смартфонах и планшетах.
Стоит отметить, что клиентская часть собирается с помощью потокового сборщика проектов – gulp. Это позволяет автоматизировать сборку и минификацию CSS и JS-файлов, запуск тестов и прочее, тем самым ускоряя и оптимизируя процесс веб-разработки.
Связь с базой данной происходит через инструмент Mongoose, который связывает базу данных с концепциями объектно-ориентированных языков программирования. Это ускоряет разработку, потому что избавляет программиста от написания большого количества однообразного кода и позволяет представлять и взаимодействовать с данными из базы как с набором объектов.
Реализован прототип системы анализа сетевого трафика. Система состоит из трех модулей: модуля преобразования дампа трафика, модуля хранения и модуля анализа и вывода. Каждый из них решает свою задачу.
Модуль захвата преобразования дампа трафика считывает и преобразует дамп трафика в BSON структуру, которая затем записывается в базу данных.
Модуль хранения данных отвечает за быстрый доступ к данным.
Модуль анализа и вывода предназначен для проведения заданной пользователем аналитики и отображения ее результатов.
По итогу третьей главы решены оставшиеся задачи – создать алгоритмы обработки полученных данных и разработать прототип системы анализа сетевого трафика.
ЗАКЛЮЧЕНИЕ
Изучение современных методик анализа сетевого трафика показало, что статистическое исследование трафика провайдера, исходящего из локальной сети во внешнюю сеть на текущий момент активно не используется в системах защиты. Основное направление подобных систем – это мониторинг работоспособности оборудования, нагрузки на каналы; а для локальных сетей – это защита от угроз приходящих из внешней сети.
Разработанная архитектура показала себя достойно в рамках прототипа, но для дальнейшей разработки необходимо исследовать другие базы данных, чтобы подобрать самую оптимальную из них для работы в заданных условиях, и продумать архитектуру хранящихся в ней данных.
Созданные алгоритмы статистической обработки являются первым приближением для серьезной аналитики. В будущем следует учесть, что получаемые данные имеют большой объем, добавить оптимизацию, а также проконсультироваться с предполагаемыми пользователями системы, чтобы реализовать актуальные для их нужд алгоритмы исследования трафика.
В рамках курсовой работы был разработан прототип системы анализа трафика, который решает следующие задачи:
-
- обрабатывает дамп трафика;
- преобразует и сохраняет сетевые пакеты в базу данных;
- отображает разработанную нами аналитику.
Предполагаемый эффект, в случае применения подобных систем у большого числа провайдеров, выглядит перспективным. Стоит учитывать, что назначение системы не защита трафика, а анализ большого потока и выявление возможных статистически некорректных случаев, на основе которых провайдер может принять решение о выполнении каких-нибудь противоборствующих действий.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ И ЛИТЕРАТУРЫ
- Cecil Alisha. A Summary of Network Traffic Monitoring and Analysis Techniques [Электронный ресурс] : статья / Alisha Cecil // сайт Вашингтонского университета в Сент-Луисе. – Режим доступа: http://www.cse.wustl.edu/~jain/cse567-06/ftp/net_monitoring/index.html
- IDS/IPS — Системы обнаружения и предотвращения вторжений [Электронный ресурс]: статья. Режим доступа: http://netconfig.ru/server/ids-ips/.
- IDS/IPS - системы обнаружения и предотвращения вторжений и хакерских атак [Электронный ресурс]: статья // сайт компании «АльтЭль». – Режим доступа: http://www.altell.ru/solutions/by_technologies/ids/.
- WinPcap Documentation [Электронный ресурс]: документация. – Режим доступа: http://www.winpcap.org/docs/docs_412/html/main.html
- Анализ угроз сетевой безопасности [Электронный ресурс]: статья // Лаборатория Сетевой Безопасности. – 2019. – Режим доступа: http://ypn.ru/138/analysis-of-threats-to-network-security/.
- Басараб, М. А. Анализ сетевого трафика корпоративной сети университета методами нелинейной динамики [Электронный ресурс]: статья / М. А. Басараб, А. В. Колесников, И. П. Иванов // Наука и образование: научное издание / МГТУ им. Н. Э. Баумана. – 2013. – Режим доступа: http://technomag.bmstu.ru/doc/587054.html.
- Лукацкий, А. Предотвращение сетевых атак: технологии и решения [Электронный ресурс]: статья / А. Лукацкий // IT-портал. – 2006. – Режим доступа: http://citforum.ru/security/articles/ips/.
- Маркин, Ю. В. Обзор современных инструментов анализа сетевого трафика [Электронный ресурс]: статья / Ю. В. Маркин, А. С Санаров // сборники трудов Института системного программирования Роcсийской академии наук. – 2014. – Режим доступа: http://www.ispras.ru/preprints/docs/prep_27_2014.pdf.
- Михеев, А. В. Исследование методов сбора статистических данных о трафике в ip-сетях передачи данных [Электронный ресурс]: статья / А. В.
Михеев // электронный научный архив Уральского федерального университета им. Б. Н. Ельцина. – 2016. – Режим доступа: http://elar.urfu.ru/bitstream/10995/36237/1/ittsm-2016-16.pdf.
- Мустафаев, А. Г. Нейросетевая система обнаружения компьютерных атак на основе анализа сетевого трафика [Электронный ресурс]: статья / А. Г, Мустафаев. – 2016. – Режим доступа: http://e-notabene.ru/nb/article_18834.html.
- Новый подход к защите информации – системы обнаружения компьютерных угроз [Электронный ресурс]: статья // Jet Info : ежемесячное деловое ИТ издание. – Инфосистемы Джет ; Москва, 2007. – № 4. – Режим доступа: http://www.jetinfo.ru/jetinfo_arhiv/novyj-podkhod-k-zaschite-informatsii- sistemy-obnaruzheniya-kompyuternykh-ugroz/2007.
- Олифер, Н. А. Средства анализа и оптимизации локальных сетей [Электронный ресурс]: статья / Н. А. Олифер, В. Г. Олифер. // IT-портал. – 1998.
– Режим доступа: http://citforum.ru/nets/optimize/locnop_07.shtml.
- Парфентьев, А. Обзор корпоративных IPS-решений на российском рынке [Электронный ресурс]: статья / А. Парфентьев // аналитический центр
«Anti-Malware.ru». – 2013. – Режим доступа: https://www.anti-malware.ru
/IPS_russian_market_review _2013.
- Спецификация: Система мониторинга, анализа и ответной реакции Cisco MARS [Электронный ресурс]: спецификация продукта // сайт компании
«Cisco». – Режим доступа: http://www.cisco.com/web/RU/products/ps6241
/products_data_sheet0900aecd80272e64.html
- Столлингс, В. Современные компьютерные сети : пер. с англ. / В. Столлингс. – Санкт-Петербург : Питер, 2003. – 783 с.
- Таненбаум, Э. Компьютерные сети : пер. с англ. / Э. Таненбаум. – Санкт-Петербург : Питер, 2003. – 992 c.
- Чивчалов, А. Shodan – самый страшный поисковик Интернета [Электронный ресурс]: статья / А. Чивчалов // IT-ресурс «Хабрахабр» – 2013. – Режим доступа: https://habrahabr.ru/post/178501/.
- Шакуалкызы, Ш. Ш. Моделирование трафика мультисервисной сети: дис. магистра техники и технологии : 6М071900 / Шакуалкызы Шакуал Шырын
– Алматы, 2014. – С. 58.
ПРИЛОЖЕНИЕ 1
Исходный программный код сниффера-анализатора
#include "stdafx.h" #include <pcap.h> #include <string> #include <stdio.h> #include <cstdlib> #include <iostream> #include <WinSock2.h> #include <Windows.h>
#include "mongo/client/dbclient.h" #include <string.h>
#pragma comment(lib, "WS2_32.lib") using namespace std;
using std::string;
using mongo::BSONObj;
using mongo::BSONObjBuilder;
//Ethernet Header
typedef struct ethernet_header
{
UCHAR dest[6]; UCHAR source[6]; USHORT type;
} ethernet_header;
typedef struct ethernet_header_VLAN
{
UCHAR dest[6]; UCHAR source[6];
UCHAR tag[4];
USHORT type;
} ethernet_header_VLAN;
/* 4 bytes IP address */ typedef struct ip_address{
u_char byte1; u_char byte2; u_char byte3; u_char byte4;}ip_address;
/* IPv4 header */
typedef struct ip_header{
u_char ver_ihl; // Version (4 bits) + Internet header length (4 bits) u_char tos; // Type of service
u_short tlen; // Total length u_short identification; // Identification
u_short flags_fo; // Flags (3 bits) + Fragment offset (13 bits) u_char ttl; // Time to live
u_char proto; // Protocol
u_short crc; // Header checksum
u_int saddr; // Source address
u_int daddr; // Destination address u_int op_pad; // Option + Padding
}ip_header;
/* UDP header*/
typedef struct udp_header{
u_short sport; // Source port
u_short dport; // Destination port u_short len; // Datagram length u_short crc; // Checksum
}udp_header;
/* TCP header */
typedef struct tcp_header{
u_short source_port; // source port u_short dest_port; // destination port
u_int sequence; // sequence number - 32 bits
u_int acknowledge; // acknowledgement number - 32 bits
u_char ns :1; //Nonce Sum Flag Added in RFC 3540. u_char reserved_part1:3; //according to rfc
u_char data_offset:4; /*The number of 32-bit words in the TCP header. This indicates where the data begins.
The length of the TCP header is always a multiple of 32 bits.*/
u_char fin :1; //Finish Flag u_char syn :1; //Synchronise Flag u_char rst :1; //Reset Flag
u_char psh :1; //Push Flag
u_char ack :1; //Acknowledgement Flag u_char urg :1; //Urgent Flag
u_char ecn :1; //ECN-Echo Flag
u_char cwr :1; //Congestion Window Reduced Flag
//////////////////////////////// u_short window; // window
u_short checksum; // checksum
u_short urgent_pointer; // urgent pointer
}tcp_header;
int _tmain(int argc, _TCHAR* argv[])
{
mongo::DBClientConnection c; mongo::client::initialize();
try { c.connect("localhost");
std::cout << "connected ok" << std::endl;
} catch( const mongo::DBException &e ) { std::cout << "caught " << e.what() << std::endl;
return 0;
}
ethernet_header *eh; ethernet_header_VLAN *ehvlan; ip_header *ih;
udp_header *uh; tcp_header *th; u_int ip_len; u_short sport,dport;
struct sockaddr_in source,dest;
char buffer[100];
int num, inum, i = 0;
pcap_if_t* alldevs; // network device pcap_t* adhandle; // session handle struct bpf_program fcode;
bpf_u_int32 net; // the ipof our filtering device bpf_u_int32 mask; // the netmask of filtering device char* dev;
time_t seconds; struct tm tbreak;
char errbuff[PCAP_ERRBUF_SIZE];
// Create a header object:
struct pcap_pkthdr *header;
// Create a character array using a u_char const u_char *data;
dev = pcap_lookupdev(errbuff);
if(pcap_lookupnet(dev, &net, &mask, errbuff) == -1)
{
fprintf(stderr, "Can't get netmask for device %s\n", dev); net = 0;
mask = 0;
}
u_int packetCount = 0; char iStr[4];
for (int i = 119; i >= 0; i--)
{
itoa(i, iStr, 10);
string number = string(iStr); while (number.length() < 3)
{
number = '0' + number;
}
string filename = file + number;
pcap_t * pcap = pcap_open_offline(filename.c_str(), errbuff);
while (int returnValue = pcap_next_ex(pcap, &header, &data) >= 0)
{
++packetCount;
// Show a warning if the length captured is different if (header->len != header->caplen)
printf("Warning! Capture size different than packet size:
%ld bytes\n", header->len);
BSONObjBuilder b; BSONObjBuilder internetLayer; BSONObjBuilder transportLayer; BSONObjBuilder sourceObj; BSONObjBuilder destinationObj;
seconds = header->ts.tv_sec; localtime_s( &tbreak , &seconds);
strftime (buffer , 80 , "%d-%b-%Y %I:%M:%S %p" , &tbreak );
//print pkt timestamp and pkt len
b.append("time", BSON("seconds" << header->ts.tv_sec <<
"useconds" << header->ts.tv_usec << "data" << buffer));
b.append("length", header->len);
/* retireve the position of the ip header */
//Ip packets
eh = (ethernet_header *) data; u_short proto = eh->type;
int headerLen = sizeof(ethernet_header);
if (ntohs(eh->type) == 0x8100)
{
headerLen = sizeof(ethernet_header_VLAN); ehvlan = (ethernet_header_VLAN *) data; proto = ehvlan->type;
}
internetLayer.append("number", proto);
//Ip packets
if (ntohs(proto) == 0x0800)
{
ethernet header
internetLayer.append("name", "IPv4");
ih = (ip_header *) (data + headerLen); //length of
transportLayer.append("number", ih->proto);
/* print ip addresses*/ memset(&source, 0, sizeof(source)); source.sin_addr.s_addr = ih->saddr;
memset(&dest, 0, sizeof(dest)); dest.sin_addr.s_addr = ih->daddr;
sourceObj.append("ip", inet_ntoa(source.sin_addr)); destinationObj.append("ip", inet_ntoa(dest.sin_addr)); ip_len = (ih->ver_ihl & 0xf) * 4;
switch (ih->proto)
{
case 6: // TCP protocol transportLayer.append("name", "TCP"); th = (tcp_header *)((u_char*)ih + ip_len);
sourceObj.append("port", ntohs(th->source_port)); destinationObj.append("port", ntohs(th->dest_port));
signed int)th->syn <<
transportLayer.append("flags", BSON("syn" << (un-
"ack" << (unsigned int)th->ack << "fin" << (unsigned int)th->fin));
break;
case 17: // UDP protocol transportLayer.append("name", "UDP"); uh = (udp_header *)((u_char*)ih + ip_len);
sourceObj.append("port", ntohs(uh->sport)); destinationObj.append("port", ntohs(uh->dport)); break;
}
}
b.append("internetLayer", internetLayer.obj()); b.append("transportLayer", transportLayer.obj()); b.append("source", sourceObj.obj()); b.append("destination", destinationObj.obj()); c.insert("network.packages", b.obj());
}
std::cout << "File number: " << number << "\tPacket # " << packetCount
<< std::endl;
}
printf("End\n"); getchar(); return 0;
}
Исходный программный код отображения аналитики
<div class="wrapper wrapper-content">
<div class="row">
<div class="col-lg-12">
<div class="ibox float-e-margins">
<div class="col-sm-10">
<canvas id="all" class="chart chart-line" chart-data="all.data"
chart-labels="all.labels" chart-legend="true" chart-series="all.series">
</canvas>
</div>
<div class="hr-line-dashed"></div>
<div class="col-sm-10">
<canvas id="syn" class="chart chart-line" chart-legend="true" chart- series="syn.series"
chart-data="syn.data" chart-labels="syn.labels">
</canvas>
</div>
<div class="hr-line-dashed"></div>
<div class="col-sm-10">
<canvas id="udp" class="chart chart-line" chart-legend="true" chart- series="udp.series"
chart-data="udp.data" chart-labels="udp.labels">
</canvas>
</div>
<div class="hr-line-dashed"></div>
<div class="col-sm-10">
<canvas id="together" class="chart chart-line" chart-legend="true" chart- series="together.series"
chart-data="together.data" chart-labels="together.labels">
</canvas>
</div>
<div class="hr-line-dashed"></div>
<div class="col-sm-10">
<canvas id="ip" class="chart chart-bar" chart-series="ip.series" chart-data="ip.data" chart-labels="ip.labels">
</canvas>
</div>
<div class="hr-line-dashed"></div>
</div>
</div>
</div>
</div>
((angular) => { angular
.module('graph')
.component('graphView', {
templateUrl: '/components/graphView/graphView.view.html', controller: GraphViewController
});
function GraphViewController($scope, Data, toastr) {
let ctrl = this; ctrl.$onInit = () => {
Data.bar().$promise.then((data) => {
$scope.all = data.all;
$scope.syn = data.syn;
$scope.udp = data.udp;
$scope.together = {
labels: data.all.labels,
series: [data.all.series[0], data.syn.series[0], data.udp.series[0]],
data: [data.all.data[0], data.syn.data[0], data.udp.data[0]]
};
});
Data.ipSource().$promise.then((data) => {$scope.ip = data;});
};
}
})(window.angular);

- Процедуры несостоятельности (банкротства)
- Статус нотариуса(Цели, задачи и принципы)
- Нотариат и его роль в защите гражданских прав и законных интересов
- Определение, основные задачи, функции бухгалтерского учета(История возникновения и развития бухгалтерского учета)
- Виды и состав угроз информационной безопасности
- «ЗАЩИТА ПРАВА СОБСТВЕННОСТИ.»(Понятие, содержание и особенности гражданско-правовой защиты права собственности на недвижимое имущество )
- Основы управления конфликтами в организации
- Организационная культура АО «Жилстрой»
- Основные теории мотивации труда
- Разработка регламента выполнения процесса «Расчет заработной платы»
- Управление финансовыми ресурсами на предприятии
- Бухгалтерский учет и его место в рыночной экономике