
Методы сортировки данных и ее эволюции
Содержание:

ВВЕДЕНИЕ
Сортировка данных в массиве является одной из наиболее распространенных задач в информатике. Но повышение эффективности алгоритмов сортировки очень важно не только по этой причине. Неослабевающий интерес к их оптимизации объясняется тем, что объемы информационных массивов непрерывно и стремительно растут, соответственно возрастают и требования к скорости сортировки.
К концу XX века человечество осуществило переход к новому типу построения общества – общество стало информационным, основой его стала информация. В связи с растущими объемами и потоками информации потребовались новые технологии хранения, обработки и передачи информации. Базы данных совместили в себе функции хранения и обработки. Объемы хранимой информации бывают таковы, что в некоторых случаях база данных превышает несколько терабайт. Одним из ключевых элементов обработки информации является поиск необходимой ее части в общем объеме, а в больших базах данных этот вопрос является особенно актуальным и требует быстрых методов поиска.
Существует много методов поиска, каждый из которых показывает лучшие результаты по сравнению с другими в определенных условиях. Каждый из них рассматривать в данной работе не целесообразно, поэтому остановимся на 2-х основных: линейный (последовательный) поиск и бинарный поиск.
Алгоритм сортировки - это алгоритм для упорядочения элементов в списке. В случае, когда элемент списка имеет несколько полей, поле по которому производится сортировка, называется ключом сортировки. На практике, в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.
Пожалуй, никакая другая проблема не породила такого количества разнообразнейших решений, как задача сортировки. Существует ли некий «универсальный», наилучший алгоритм? Вообще говоря, нет. Однако, имея приблизительные характеристики входных данных, можно подобрать метод, работающий оптимальным образом. Вышесказанное определяет актуальность темы работы.
Целью курсовой работы является изучение методов сортировки данных и ее эволюции.
Объектом в работе является методы сортировки данных.
Предметом сравнение методов сортировки данных.
Задачи работы:
Рассмотрет эволюцию сортировки данных;
Изучить методы сортировки данных;
Провести сравнение алгоритмов сортировки.
В процессе исследований были использованы основные положения теории информации, теории кодирования дискретных источников сообщений, комбинаторики, дискретной математики, теории чисел, методы динамического программирования, математического анализа и теории асимптотических функций.
ГЛАВА 1. ИСТОРИЯ И ХАРАКТЕРИСТИКА СОРТИРОВКИ ДАННЫХ
1.1.Эволюция сортировки данных
Важное практическое значение проблема сортировки данных в больших массивах впервые приобрела в США в середине XIX века. В 1840 году там был создан центральный офис переписи населения, куда стекались первичные данные из всех штатов. В ходе переписи было опрошено 17 069 453 человек, каждая анкета состояла из 13 вопросов. Объем полученных данных был столь велик, что их обработка традиционным ручным способом потребовала непомерных затрат труда и времени. Ситуация усугублялось необходимостью проведения постоянных сверок и пересчетов из-за допускаемых при ручной сортировке данных ошибок. С каждой новой переписью, которая проводилась раз в десять лет, объем обрабатываемой информации, а вместе с ним стоимость и длительность обработки данных возрастали. Так, ручная обработка данных переписи населения 1880 года (50 189 209 человек) потребовала привлечения сотен служащих и длилась семь с половиной лет [1].
Перед переписью 1890 года для решения проблемы сортировки данных в очень больших массивах информации по инициативе бюро переписи был проведен конкурс на лучшее электромеханическое сортировочное оборудование, которое сделало бы сортировку данных более эффективной — более быстрой, точной и дешевой. Конкурс выиграл американский инженер и изобретатель немецкого происхождения Герман Холлерит (Herman Hollerith), разработавший оборудование для работы с перфокартами — электрическую табулирующую систему, ставшую известной как Hollerith Electric Tabulating System. Использование этого оборудования при переписях населения США в 1890 и 1900 годах было признано очень успешным. Вот как были описаны преимущества машины Холлерита в русском журнале «Вестник Опытной Физики и Элементарной Математики» в 1895 году: «Преимущества машины Голлерита заключаются: а) в значительном ускорении и удешевлении работы. При ручном способе можно разложить и подсчитать за час не более 400 карточек. [4]
Таким образом, обработка данных с помощью машины Холлерита потребовала в три раза меньше времени, чем вручную, причем точность сводных таблиц значительно возросла. Таким образом, в конце XIX века на смену ручной сортировке данных в массивах пришла сортировка с помощью статистических табуляторов. При этом использовался алгоритм поразрядной сортировки. Следующий этап развития способов и алгоритмов сортировки начался в начале 1940-х годов с появлением первых электронных вычислительных машин. Фантастическое по тем временам быстродействие ЭВМ вызвало рост интереса к новым, приспособленным для машинной обработки алгоритмам сортировки.
В 1946 году вышла первая статья об алгоритмах сортировки данных, автором которой был Джон Уильям Мочли (John William Mauchly) — американский физик и инженер, один из создателей первого в мире электронного цифрового компьютера общего назначения ENIAC. В статье рассматривался целый ряд новых алгоритмов сортировки, в том числе метод бинарных вставок. До середины 1950-х годов наиболее распространенными были модификации сортировки слиянием и вставками сложности O (n log n) для п элементов. Еще одним следствием перехода к сортировке данных с помощью ЭВМ стало разделение сортировки на два типа — внешнюю и внутреннюю, то есть на использующую и не использующую данные, расположенные на периферийных устройствах. В середине 1950-х годов с разработкой ЭВМ второго поколения началось активное развитие алгоритмов сортировки [3].
Итоги этого этапа активного развития алгоритмов сортировки подвел в 1973 году Дональд Эрвин Кнут (Donald Ervin Knuth) в третьем томе своей фундаментальной монографии «Искусство программирования» («The Art of Computer Programming»). К началу 1970-х годов использовались следующие виды алгоритмов внутренней сортировки: сортировка посредством подсчета; сортировка путем вставок; обменная сортировка; сортировка посредством выбора; сортировка методом слияния; сортировка методом распределения. Наибольшее количество разработанных к тому времени методов относилось к сортировке путем вставок (метод простых вставок, бинарные и двухпутевые вставки, метод Шелла, вставка в список, сортировка с вычислением адреса и др.), обменной сортировке (метод пузырька и его модификации, параллельная сортировка Бэтчера, быстрая сортировка, обменная поразрядная сортировка, асимптотические методы) и сортировке посредством выбора (выбор из дерева, пирамидальная сортировка, метод исключения наибольшего из включенных, метод связанного представления приоритетных очередей). [11]
Не менее активно разрабатывались и методы внешней сортировки, в том числе методы многопутевого слияния и выбора с замещением, многофазного слияния, каскадного слияния, осциллирующей сортировки, внешней поразрядной сортировки и т. д. [4]. Очередной всплеск интереса к алгоритмам сортировки произошел в середине 1970-х годов, когда элементной базой компьютеров стали большие интегральные схемы и появилась возможность объединения мощности вычислительных машин путем создания единых вычислительных центров, позволяющих работать с разделением времени. В период с середины 1970-х до 1990-х годов были достигнуты значительные успехи в увеличении скорости сортировки за счет повышения эффективности уже известных к тому времени алгоритмов путем их доработки или комбинирования. К примеру, нидерландский учёный Эдсгер Вибе Дейкстра (Edsger Wybe Dijkstra) в 1981 году предложил алгоритм плавной сортировки (Smoothsort), который является развитием пирамидальной сортировки (Heapsort). Вторым направлением совершенствования алгоритмов сортировки стал поиск оптимальных входных последовательностей для разных методов сортировки, что позволяло значительно сократить ее время. Третьим направлением, наиболее интенсивно развивающимся, было решение задачи сортировки в классе параллельных алгоритмов, для чего не только обобщались ранее известные парадигмы, но и разрабатывались принципиально новые алгоритмы. Развитие данного направления стимулировалось и все более широким использованием сортирующих сетей, а также многомерных вычислительных решеток.
Таким образом, исследовав эволюцию способов и алгоритмов машинной сортировки данных в массивах, можно выделить следующие пять этапов. Первый этап начался в 1870 году и длился до начала 1940-х годов. Его ознаменовал переход от ручной сортировки к сортировке с помощью статистических табуляторов. При этом использовался алгоритм поразрядной сортировки. Второй этап — с начала 1940-х годов до середины 1950-х. На смену счетно-перфорационным машинам пришли ЭВМ первого поколения, для которых был разработан ряд новых алгоритмов сортировки. [15]
Наибольшее количество разработанных к тому времени методов относилось к сортировке путем вставок, обменной сортировке и сортировке посредством выбора. Четвертый этап продолжался с середины 1970-х до середины 1990-х годов. Появление вычислительных центров, объединяющих мощности отдельных вычислительных машин и позволяющих работать с разделением времени потребовало разработки новых алгоритмов сортировки и модификации существующих.
Началось исследование задач сортировки в классе параллельных алгоритмов, были достигнуты значительные успехи в увеличении скорости сортировки за счет повышения эффективности уже известных к тому времени алгоритмов путем их доработки или комбинирования. Одновременно происходил поиск оптимальных входных последовательностей для разных методов сортировки, что позволяло значительно сократить ее время. Пятый этап начался с середины 1990-х годов и продолжается по настоящее время. Особую актуальность получило исследование задач сортировки на частично упорядоченных множествах: задач распознавания частично упорядоченного множества М; задач сортировки частично упорядоченного множества М с использованием результатов попарных сравнений элементов, а также задач определения порядка на множестве М без априорной информации. Актуальность этих задач объясняется появлением и широким распространением компьютеров на сверхсложных микропроцессорах с параллельно-векторной структурой, а также высокоэффективных сетевых компьютерных систем.
1.2 Методы сортировки данных
Статьи ниже являются частями одной большой, так что в последующих может использоваться информация из предыдущих. В программах используются переопределения:
typedef double real;
typedef unsigned long ulong;
typedef unsigned short ushort;
typedef unsigned char uchar;
Сортировка выбором
Идея метода состоит в том, чтобы создавать отсортированную последовательность путем присоединения к ней одного элемента за другим в правильном порядке. [2]
Будем строить готовую последовательность, начиная с левого конца массива. Алгоритм состоит из n последовательных шагов, начиная от нулевого и заканчивая (n-1)-м.
На i-м шаге выбираем наименьший из элементов a[i] ... a[n] и меняем его местами с a[i]. Последовательность шагов при n=5 изображена на рисунке ниже.
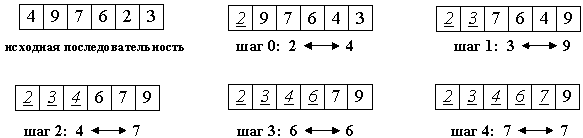
Вне зависимости от номера текущего шага i, последовательность a[0]...a[i] (выделена курсивом) является упорядоченной. Таким образом, на (n-1)-м шаге вся последовательность, кроме a[n] оказывается отсортированной, а a[n] стоит на последнем месте по праву: все меньшие элементы уже ушли влево.
Сортировка пузырьком
Расположим массив сверху вниз, от нулевого элемента - к последнему.
Идея метода: шаг сортировки состоит в проходе снизу вверх по массиву. По пути просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то меняем их местами.
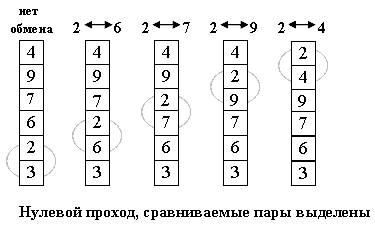
После нулевого прохода по массиву "вверху" оказывается самый "легкий" элемент - отсюда аналогия с пузырьком. Следующий проход делается до второго сверху элемента, таким образом второй по величине элемент поднимается на правильную позицию...
Делаем проходы по все уменьшающейся нижней части массива до тех пор, пока в ней не останется только один элемент. На этом сортировка заканчивается, так как последовательность упорядочена по возрастанию.
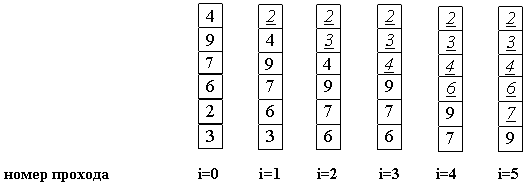
Среднее число сравнений и обменов имеют квадратичный порядок роста: Theta(n2), отсюда можно заключить, что алгоритм пузырька очень медленен и малоэффективен.
Тем не менее, у него есть громадный плюс: он прост и его можно по-всякому улучшать. Чем мы сейчас и займемся. [14]
Во-первых, рассмотрим ситуацию, когда на каком-либо из проходов не произошло ни одного обмена. Что это значит ?
Это значит, что все пары расположены в правильном порядке, так что массив уже отсортирован. И продолжать процесс не имеет смысла(особенно, если массив был отсортирован с самого начала !).
Итак, первое улучшение алгоритма заключается в запоминании, производился ли на данном проходе какой-либо обмен. Если нет - алгоритм заканчивает работу.
Процесс улучшения можно продолжить, если запоминать не только сам факт обмена, но и индекс последнего обмена k. Действительно: все пары соседих элементов с индексами, меньшими k, уже расположены в нужном порядке. Дальнейшие проходы можно заканчивать на индексе k, вместо того чтобы двигаться до установленной заранее верхней границы i.
Качественно другое улучшение алгоритма можно получить из следующего наблюдения. Хотя легкий пузырек снизу поднимется наверх за один проход, тяжелые пузырьки опускаются со минимальной скоростью: один шаг за итерацию. Так что массив 2 3 4 5 6 1 будет отсортирован за 1 проход, а сортировка последовательности 6 1 2 3 4 5 потребует 5 проходов.
Чтобы избежать подобного эффекта, можно менять направление следующих один за другим проходов. Получившийся алгоритм иногда называют "шейкер-сортировкой".
Насколько описанные изменения повлияли на эффективность метода ? Среднее количество сравнений, хоть и уменьшилось, но остается O(n2), в то время как число обменов не поменялось вообще никак. Среднее(оно же худшее) количество операций остается квадратичным. [3]
Для нахождения наименьшего элемента из n+1 рассматримаемых алгоритм совершает n сравнений. С учетом того, что количество рассматриваемых на очередном шаге элементов уменьшается на единицу, общее количество операций:
n + (n-1) + (n-2) + (n-3) + ... + 1 = 1/2 * ( n2+n ) = Theta(n2).
Таким образом, так как число обменов всегда будет меньше числа сравнений, время сортировки растет квадратично относительно количества элементов.
Алгоритм не использует дополнительной памяти: все операции происходят "на месте".
Устойчив ли этот метод ? Прежде, чем читать далее, попробуйте получить ответ самостоятельно.
Сортировка вставками
Сортировка простыми вставками в чем-то похожа на вышеизложенные методы.
Аналогичным образом делаются проходы по части массива, и аналогичным же образом в его начале "вырастает" отсортированная последовательность...
Однако в сортировке пузырьком или выбором можно было четко заявить, что на i-м шаге элементы a[0]...a[i] стоят на правильных местах и никуда более не переместятся. Здесь же подобное утверждение будет более слабым: последовательность a[0]...a[i] упорядочена. При этом по ходу алгоритма в нее будут вставляться (см. название метода) все новые элементы.
Будем разбирать алгоритм, рассматривая его действия на i-м шаге. Как говорилось выше, последовательность к этому моменту разделена на две части: готовую a[0]...a[i] и неупорядоченную a[i+1]...a[n]. [13]
На следующем, (i+1)-м каждом шаге алгоритма берем a[i+1] и вставляем на нужное место в готовую часть массива.
Поиск подходящего места для очередного элемента входной последовательности осуществляется путем последовательных сравнений с элементом, стоящим перед ним.
В зависимости от результата сравнения элемент либо остается на текущем месте(вставка завершена), либо они меняются местами и процесс повторяется.
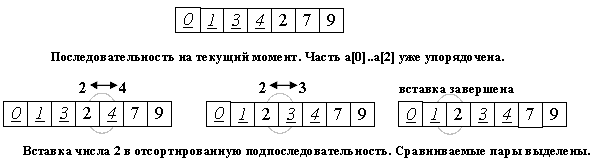
Таким образом, в процессе вставки мы "просеиваем" элемент x к началу массива, останавливаясь в случае, когда
Hайден элемент, меньший x или
Аналогично сортировке выбором, среднее, а также худшее число сравнений и пересылок оцениваются как Theta(n2), дополнительная память при этом не используется.
Хорошим показателем сортировки является весьма естественное поведение: почти отсортированный массив будет досортирован очень быстро. Это, вкупе с устойчивостью алгоритма, делает метод хорошим выбором в соответствующих ситуациях.
Алгоритм можно слегка улучшить. Заметим, что на каждом шаге внутреннего цикла проверяются 2 условия. Можно объединить из в одно, поставив в начало массива специальный сторожевой элемент. Он должен быть заведомо меньше всех остальных элементов массива.
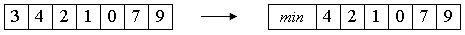
Тогда при j=0 будет заведомо верно a[0] <= x. Цикл остановится на нулевом элементе, что и было целью условия j>=0.
Таким образом, сортировка будет происходить правильным образом, а во внутреннем цикле станет на одно сравнение меньше. С учетом того, что оно производилось Theta(n2) раз, это - реальное преимущество. Однако, отсортированный массив будет не полон, так как из него исчезло первое число. Для окончания сортировки это число следует вернуть назад, а затем вставить в отсортированную последовательность a[1]...a[n].
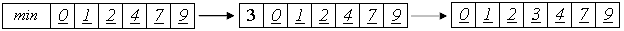
// сортировка вставками со сторожевым элементом
Функция setmin(T& x) должна быть создана пользователем. Она заменяет x на элемент, заведомо меньший(меньший или равный, если говорить точнее) всех элементов массива. [4]
Сортировка Шелла
Сортировка Шелла является довольно интересной модификацией алгоритма сортировки простыми вставками.
Рассмотрим следующий алгоритм сортировки массива a[0].. a[15].
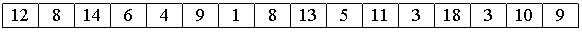
1. Вначале сортируем простыми вставками каждые 8 групп из 2-х элементов (a[0], a[8[), (a[1], a[9]), ... , (a[7], a[15]).

2. Потом сортируем каждую из четырех групп по 4 элемента (a[0], a[4], a[8], a[12]), ..., (a[3], a[7], a[11], a[15]).
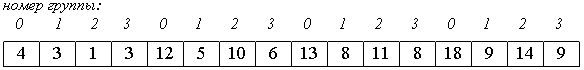
В нулевой группе будут элементы 4, 12, 13, 18, в первой - 3, 5, 8, 9 и т.п.
3. Далее сортируем 2 группы по 8 элементов, начиная с (a[0], a[2], a[4], a[6], a[8], a[10], a[12], a[14]).

4. В конце сортируем вставками все 16 элементов.
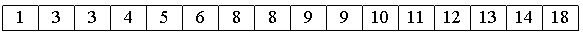
Очевидно, лишь последняя сортировка необходима, чтобы расположить все элементы по своим местам. Так зачем нужны остальные ?
Hа самом деле они продвигают элементы максимально близко к соответствующим позициям, так что в последней стадии число перемещений будет весьма невелико. [12]
Единственной характеристикой сортировки Шелла является приращение - расстояние между сортируемыми элементами, в зависимости от прохода. В конце приращение всегда равно единице - метод завершается обычной сортировкой вставками, но именно последовательность приращений определяет рост эффективности.
Использованный в примере набор ..., 8, 4, 2, 1 - неплохой выбор, особенно, когда количество элементов - степень двойки. Однако гораздо лучший вариант предложил Р.Седжвик. Его последовательность имеет вид
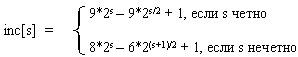
При использовании таких приращений среднее количество операций: O(n7/6), в худшем случае - порядка O(n4/3).
Обратим внимание на то, что последовательность вычисляется в порядке, противоположном используемому: inc[0] = 1, inc[1] = 5, ... Формула дает сначала меньшие числа, затем все большие и большие, в то время как расстояние между сортируемыми элементами, наоборот, должно уменьшаться. Поэтому массив приращений inc вычисляется перед запуском собственно сортировки до максимального расстояния между элементами, которое будет первым шагом в сортировке Шелла. Потом его значения используются в обратном порядке.
Часто вместо вычисления последовательности во время каждого запуска процедуры, ее значения рассчитывают заранее и записывают в таблицу, которой пользуются, выбирая начальное приращение по тому же правилу: начинаем с inc[s-1], если 3*inc[s] > size
ГЛАВА 2. СРАВНИТЕЛЬНЫЙ АНАЛИЗ АЛГОРИТМОВ СОРТИРОВКИ
2.1 Практика сортировки данных в Excel
Сортировка в Excel — это встроенная функция анализа данных. С помощью нее можно выставить фамилии в алфавитном порядке, отсортировать средний балл абитуриентов по возрастанию или убыванию, задать порядок строк в зависимости от цвета или значка и т.д. Также с помощью этой функции можно быстро придать таблице удобный вид, что позволит пользователю быстрее находить необходимую информацию, анализировать ее и принимать решения. [5]
Существует два способа открыть меню сортировки:
Щелкнуть правой кнопкой мыши по таблице. Выбрать «Сортировку» и способ.
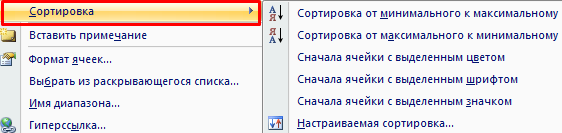
Открыть вкладку «Данные» - диалоговое окно «Сортировка».
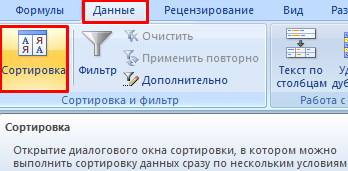
Часто используемые методы сортировки представлены одной кнопкой на панели задач:
Сортировка таблицы по отдельному столбцу:
Чтобы программа правильно выполнила задачу, выделяем нужный столбец в диапазоне данных.
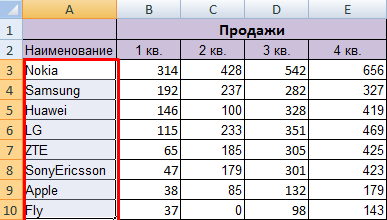
Далее действуем в зависимости от поставленной задачи. Если нужно выполнить простую сортировку по возрастанию/убыванию (алфавиту или обратно), то достаточно нажать соответствующую кнопку на панели задач. Когда диапазон содержит более одного столбца, то Excel открывает диалоговое окно вида: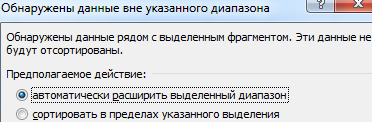 Чтобы сохранилось соответствие значений в строках, выбираем действие «автоматически расширить выделенный диапазон». В противном случае отсортируется только выделенный столбец – структура таблицы нарушится.
Чтобы сохранилось соответствие значений в строках, выбираем действие «автоматически расширить выделенный диапазон». В противном случае отсортируется только выделенный столбец – структура таблицы нарушится.
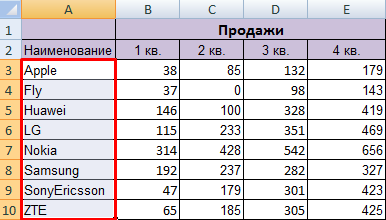
Если выделить всю таблицу и выполнить сортировку, то отсортируется первый столбец. Данные в строках станут в соответствии с положением значений в первом столбце. [11]
СОРТИРОВКА ПО ЦВЕТУ ЯЧЕЙКИ И ПО ШРИФТУ
Программа Excel предоставляет пользователю богатые возможности форматирования. Следовательно, можно оперировать разными форматами.
Сделаем в учебной таблице столбец «Итог» и «зальем» ячейки со значениями разными оттенками. Выполним сортировку по цвету:
Выделяем столбец – правая кнопка мыши – «Сортировка».
Из предложенного списка выбираем «Сначала ячейки с выделенным цветом».
Соглашаемся «автоматически расширить диапазон».
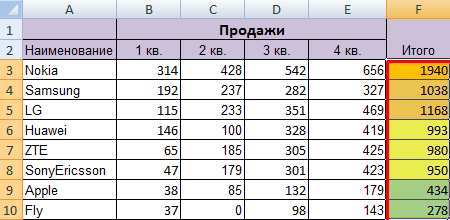
Программа отсортировала ячейки по акцентам. Пользователь может самостоятельно выбрать порядок сортировки цвета. Для этого в списке возможностей инструмента выбираем «Настраиваемую сортировку».
В открывшемся окне вводим необходимые параметры:
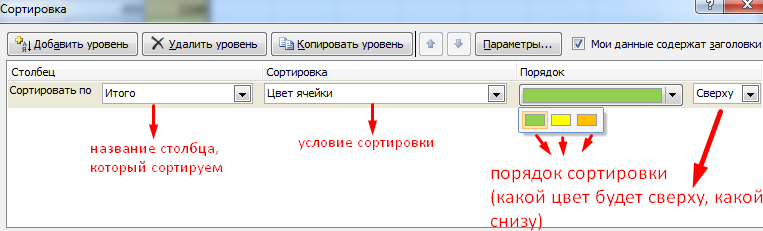
Здесь можно выбрать порядок представления разных по цвету ячеек.
По такому же принципу сортируются данные по шрифту.
СОРТИРОВКА В EXCEL ПО НЕСКОЛЬКИМ СТОЛБЦАМ
Как задать порядок вторичной сортировки в Excel? Для решения этой задачи нужно задать несколько условий сортировки.
Открываем меню «Настраиваемая сортировка». Назначаем первый критерий.

Нажимаем кнопку «Добавить уровень».
Появляются окошки для введения данных следующего условия сортировки. Заполняем их.

Программа позволяет добавить сразу несколько критериев чтобы выполнить сортировку в особом порядке.
СОРТИРОВКА СТРОК В EXCEL
По умолчанию сортируются данные по столбцам. Как осуществить сортировку по строкам в Excel:
В диалоговом окне «Настраиваемой сортировки» нажать кнопку «Параметры».

В открывшемся меню выбрать «Столбцы диапазона».
Нажать ОК. В окне «Сортировки» появятся поля для заполнения условий по строкам.
Таким образом выполняется сортировка таблицы в Excel по нескольким параметрам. [6]
СЛУЧАЙНАЯ СОРТИРОВКА В EXCEL
Встроенные параметры сортировки не позволяют расположить данные в столбце случайным образом. С этой задачей справится функция СЛЧИС.
Например, нужно расположить в случайном порядке набор неких чисел.
Ставим курсор в соседнюю ячейку (слева-справа, не важно). В строку формул вводим СЛЧИС(). Жмем Enter. Копируем формулу на весь столбец – получаем набор случайных чисел.
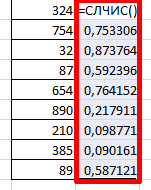
Теперь отсортируем полученный столбец по возрастанию /убыванию – значения в исходном диапазоне автоматически расположатся в случайном порядке.
ДИНАМИЧЕСКАЯ СОРТИРОВКА ТАБЛИЦЫ В MS EXCEL
Если применить к таблице стандартную сортировку, то при изменении данных она не будет актуальной. Нужно сделать так, чтобы значения сортировались автоматически. Используем формулы.
Есть набор простых чисел, которые нужно отсортировать по возрастанию.
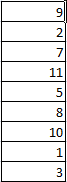
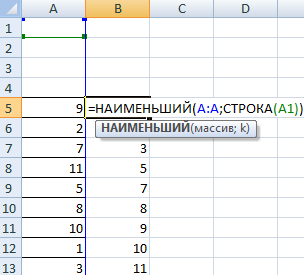
Ставим курсор в соседнюю ячейку и вводим формулу: =НАИМЕНЬШИЙ(A:A;СТРОКА(A1)). Именно так. В качестве диапазона указываем весь столбец. А в качестве коэффициента – функцию СТРОКА со ссылкой на первую ячейку.
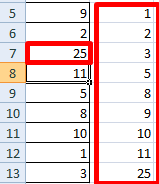
Изменим в исходном диапазоне цифру 7 на 25 – «сортировка» по возрастанию тоже изменится.
Если необходимо сделать динамическую сортировку по убыванию, используем функцию НАИБОЛЬШИЙ.
Для динамической сортировки текстовых значений понадобятся формулы массива.
Исходные данные – перечень неких названий в произвольном порядке. В нашем примере – список фруктов.

Выделяем столбец и даем ему имя «Фрукты». Для этого в поле имен, что находится возле строки формул вводим нужное нам имя для присвоения его к выделенному диапазону ячеек. [10]
В соседней ячейке (в примере – в В5) пишем формулу:  Так как перед нами формула массива, нажимаем сочетание Ctrl + Shift + Enter. Размножаем формулу на весь столбец.
Так как перед нами формула массива, нажимаем сочетание Ctrl + Shift + Enter. Размножаем формулу на весь столбец.

Если в исходный столбец будут добавляться строки, то вводим чуть модифицированную формулу:  Добавим в диапазон "фрукты" еще одно значение "помело" и проверим:
Добавим в диапазон "фрукты" еще одно значение "помело" и проверим:
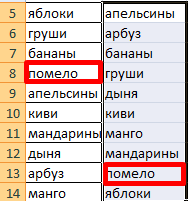
Впоследствии при добавлении данных в таблицу процесс сортирования будет выполняться автоматически.
2.2 Сравнение алгоритмов сортировки
Алгоритмы сортировок очень широко применяются в программировании, но иногда программисты даже не задумываются какой алгоритм работает лучше всех (под понятием «лучше всех» имеется ввиду сочетание быстродействия и сложности как написания, так и выполнения).
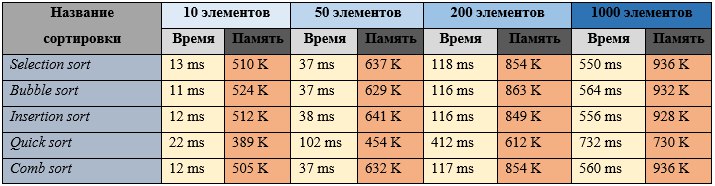
Для обеспечения наилучших результатов все представленные алгоритмы будут сортировать целочисленный массив из 200 элементов. Компьютер, на котором будет проводится тестирование имеет следующие характеристики: процессор AMD A6-3400M 4x1.4 GHz, оперативная память 8 GB, операционная система Windows 10 x64 build 10586.36. [9]
Для проведения исследования были выбраны следующие алгоритмы сортировки:
Selection sort (сортировка выбором) – суть алгоритма заключается в проходе по массиву от начала до конца в поиске минимального элемента массива и перемещении его в начало. Сложность такого алгоритма O(n2).
Bubble sort (сортировка пузырьком) – данный алгоритм меняет местами два соседних элемента, если первый элемент массива больше второго. Так происходит до тех пор, пока алгоритм не обменяет местами все неотсортированные элементы. Сложность данного алгоритма сортировки равна O(n^2).
Insertion sort (сортировка вставками) – алгоритм сортирует массив по мере прохождения по его элементам. На каждой итерации берется элемент и сравнивается с каждым элементом в уже отсортированной части массива, таким образом находя «свое место», после чего элемент вставляется на свою позицию. Так происходит до тех пор, пока алгоритм не пройдет по всему массиву. На выходе получим отсортированный массив. Сложность данного алгоритма равна O(n^2).
Quick sort (быстрая сортировка) – суть алгоритма заключается в разделении массива на два под-массива, средней линией считается элемент, который находится в самом центре массива. В ходе работы алгоритма элементы, меньшие чем средний будут перемещены в лево, а большие в право. Такое же действие будет происходить рекурсивно и с под-массива, они будут разделяться на еще два под-массива до тех пор, пока не будет чего разделать (останется один элемент). На выходе получим отсортированный массив. Сложность алгоритма зависит от входных данных и в лучшем случае будет равняться O(n×2log2n). В худшем случае O(n^2). Существует также среднее значение, это O(n×log2n). [7]
Comb sort (сортировка расческой) – идея работы алгоритма крайне похожа на сортировку обменом, но главным отличием является то, что сравниваются не два соседних элемента, а элементы на промежутке, к примеру, в пять элементов. Это обеспечивает от избавления мелких значений в конце, что способствует ускорению сортировки в крупных массивах. Первая итерация совершается с шагом, рассчитанным по формуле (размер массива)/(фактор уменьшения), где фактор уменьшения равен приблизительно 1,247330950103979, или округлено до 1,3. Вторая и последующие итерации будут проходить с шагом (текущий шаг)/(фактор уменьшения) и будут происходить до тех пор, пока шаг не будет равен единице. Практически в любом случае сложность алгоритма равняется O(n×log2n).
Для проведения тестирования будет произведено по 5 запусков каждого алгоритма и выбрано наилучшее время. Наилучшее время и используемая при этом память будут занесены в таблицу. Также будет проведено тестирование скорости сортировки массива размером в 10, 50, 200 и 1000 элементов чтобы определить для каких задач предназначен конкретный алгоритм.
Полностью неотсортированный массив:
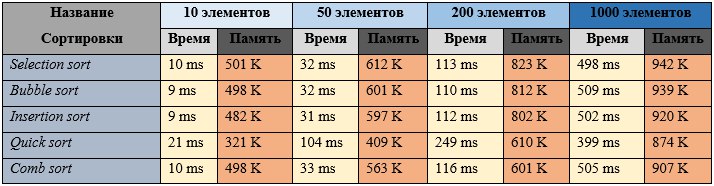
Частично отсортированный массив (половина элементов упорядочена):
Результаты, предоставленные в графиках:
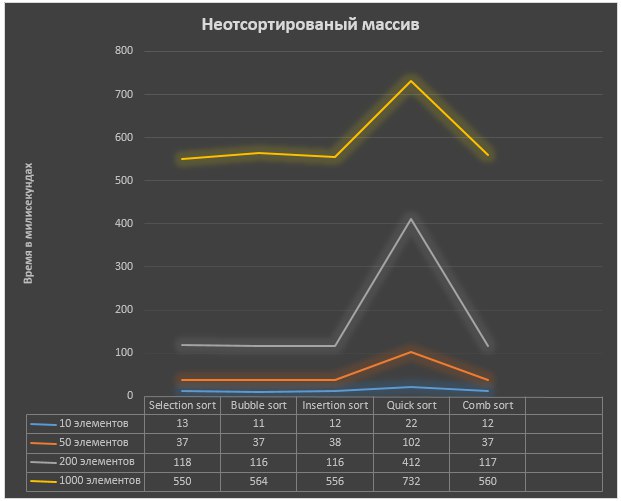
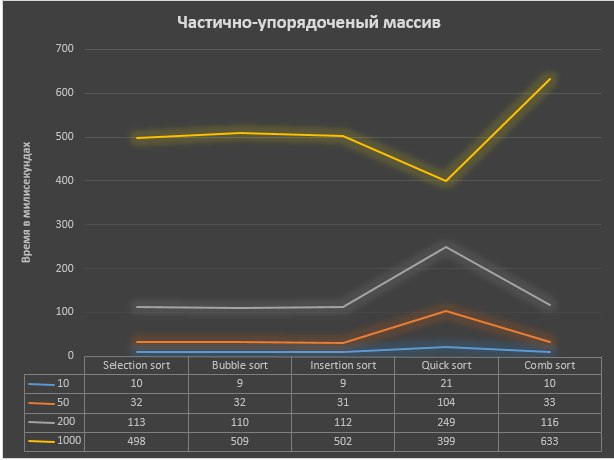
В результате проведенного исследования и полученных данных, для сортировки неотсортированного массива, наиболее оптимальным из представленных алгоритмов для сортировки массива является быстрая сортировка. Несмотря на более длительное время выполнения алгоритм потребляет меньше памяти, что может быть важным в крупных проектах. Однако такие алгоритмы как сортировка выбором, обменом и вставками могут лучше подойти для научных целей, например, в обучении, где не нужно обрабатывать огромное количество данных. При частично отсортированном массиве результаты не сильно отличаются, все алгоритмы сортировки показывают время примерно на 2-3 миллисекунды меньше. Однако при сортировке частично отсортированного массива быстрая сортировка срабатывает намного быстрее и потребляет меньшее количество памяти.
ЗАКЛЮЧЕНИЕ
Описанные методы сортировки имеют четкую логическую структуру и легко программируются различными средствами разработки программного обеспечения, что и позволяет применять их в автоматизированных средствах обработки информации. Все перечисленные методы реализованы с помощью языка программирования Delphi.
Сегодня проблема быстрой сортировки и быстрого поиска необходимой информации в больших объемах данных решается двумя методами: усовершенствованием методов сортировки и поиска и увеличением быстродействия ЭВМ. И хотя усовершенствование ЭВМ идет большими темпами, и уже достигло значительных результатов, все же прекращать усовершенствование методов сортировки и поиска не стоит, ведь еще часто работа ведется на ЭВМ с недостаточным быстродействием, да и кто знает, может быть скоро усовершенствование ЭВМ приостановиться, достигнув предела нынешних технологий.
С целью улучшения временных характеристик сортировки данных методом вычисления адреса (хеширования) вместо линейных односвязных списков предлагается использовать двусвязные линейные списки, дополнительно создать массив указателей на последние элементы линейных двусвязных списков и применить интерполяционный поиск для поиска места вставки элемента в данный список. Наиболее эффективными методами сортировок массивов данных являются сортировки, использующие методы вставок : простая сортировка вставками, сортировка двоичными вставками, сортировка Шелла, сортировка с вычислением адреса (хеширования). Одна их самых быстрых сортировок этой группы – метод хеширования. Известный способ реализации этой сортировки – использование одномерного массива указателей на линейные односвязные списки. К каждому ключу применяется некоторая функция f (функция, сохраняющая порядок) для вычисления индекса в одномерном массиве указателей. Затем элемент включается в соответствующий линейный односвязный упорядоченный список Одним из основных недостатков данного алгоритма сортировки является проход наибольшего элемента по всему линейному списку, что делает данный алгоритм медленным для случая сортировки по возрастанию значений элементов.
Таким образом, худшим случаем для данной реализации сортировки с вычислением адреса являетсясортировка упорядоченной по возрастанию последовательности, а лучшим случаем – сортировка упорядоченной по убыванию последовательности, так как элементы вставляются в начало линейного односвязного списка. Для решения данной проблемы были разработаны следующие пути улучшения алгоритма сортировки с вычислением адреса: – использование линейных двусвязных списков вместо линейных односвязных списков; – создание одномерного массива указателей на последние элементы линейных двусвязных списков; – применение интерполяционного поиска, позволяющего предсказать положение включаемого элемента в список, и тем самым найти короткий путь прохождения его через данный список (от начала или от конца). Линейные двусвязные списки в данном улучшении позволяют добавлять сразу не только наименьший элемент в начало, но и наибольший элемент в конец списка. Помимо этого, можно проходить по списку не только в направлении от начала к концу, но и от конца к началу для быстрого нахождения места включаемого элемента
СПИСОК ИСПОЛЬЗОВАННОЙ ЛИТЕРАТУРЫ
- А.В. Левитин. Глава 4. Метод декомпозиции: Быстрая сортировка // Алгоритмы: введение в разработку и анализ. - М.: «Вильямс», 2006. - С. 174-179.
- Вирт Н. Алгоритмы и структуры данных. — М.: ДМК Пресс, 2012. — 272 с.
- Горбунова О.В., Иванова О.А. // Алгоритм работы учителя // Школьные технологии. 2015. № 3. С. 124-142
- Г. В. Электрическая машина Голлерита для подсчета статистических данных//В. О. Ф.Э.М. -1895. -№ 225. -С. 193-201.
- Дупленко А. Г. Сравнительный анализ алгоритмов сортировки данных в массивах//Молодой ученый. -2013. -№ 8. -С. 50-53.
- Кнут Д. Э. Искусство программирования, т.3. Сортировка и поиск. -М.: Издательский дом «Вильямс», 2010.
- Никитин Ю. Б. Сложность алгоритмов сортировки на частично упорядочен-ных множествах: автореферат дис. … канд. физ.-мат. наук: 01.01.09/Никитин Юрий Бо-рисович. -Москва, 2001. -80 с.
- Кнут Дональд. Искусство программирования, том 3. Сортировка и поиск. 2-ое изд.-М.: Вильямс, 2007. -824 с.
- Кормен Томас, Лейзерсон Чарльз, Ривест Рональд, Штайн Клиффорд. Алгоритмы: построение и анализ. 2-ое изд.-М.: Вильямс, 2006. 1296 с.
- Седжвик Роберт. Фундаментальные алгоритмы на C.-С-Пб.: ДиаСофтЮП, 2003. -672 с.
- Музычкин П.А., Романова Ю.Д. // Информационная система // Плехановский научный бюллетень. 2015. № 1 (7). С. 135-178.
- Стивенс Р. Delphi. Готовые алгоритмы. — СПб.: Питер, 2010. — 384 с.
- Чередник А.В. // основы концепции создания учебных электронных изданий // Вестник МГУП имени Ивана Федорова. 2013. № 5. С. 101-108
- Сортировка массива. http://edunow.su/site/content/algorithms/sortirovka_massiva (доступ 14.06.2016). \
- Кузнецов С.Д. Методы сортировки и поиска. http://citforum.ru/programming/theory/sorting/sorting1.shtml (доступ 14.06.2016).

- Нотариальные действия (Понятие наследства и его нотариальное оформление)
- Общая характеристика оперативно-розыскных мероприятий (Общие условия проведения оперативно-розыскных мероприятий)
- Система источников предпринимательского права (Понятие и виды источников предпринимательского права)
- Построение организационных структур (Цели и задачи)
- Финансовый контроль (Содержание финансового контроля, его значение и функции в условиях рыночной экономики)
- Природа и сущность денег
- Лицензирование отдельных видов предпринимательской̆ деятельности
- Проблемы правового статуса нотариуса
- Распределение и использование прибыли как источник экономического роста предприятий (Экономическое значение и функции прибыли как источника экономического роста предприятия)
- Пенсионный фонд РФ (Современный механизм функционирования Пенсионного фонда РФ)
- Монометаллизм и его разновидности.
- Выбор стиля руководства в организации (Ситуационная модель руководства Митчела – Хауса «Путь-цель»)