
"Методы поиска данных: их эволюция, сравнительный анализ и примеры использования"
Содержание:

Введение
Одними из важнейших процедур обработки структурированной информации является поиск. Задача поиска привлекала большое внимание ученых (программистов) еще на заре компьютерной эры. С 50-х годов началось решение проблемы поиска элементов, обладающих определенным свойством в заданном множестве. Алгоритмам поиска посвятили свои труды J. von Neumann, K. E. Batcher, J. W. J. Williams, R. W. Floyd, R. Sedgewick, E. J. Isaac, C. A. R. Hoare, D. E. Knuth, R. C. Singleton, D. L. Shell и другие. Исследования алгоритмов поиска ведутся и в настоящее время.
У каждого алгоритма есть свои преимущества и недостатки. Поэтому важно выбрать тот алгоритм, который лучше всего подходит для решения конкретной задачи.
Целью работы является сравнительный анализ методов поиска данных.
Поиск – обработка некоторого множества данных с целью выявления подмножества данных, соответствующего критериям поиска.
Все алгоритмы поиска делятся на
- поиск в неупорядоченном множестве данных;
- поиск в упорядоченном множестве данных.
Упорядоченность – наличие отсортированного ключевого поля.
Сортировка – упорядочение (перестановка) элементов в подмножестве данных по какому-либо критерию. Чаще всего в качестве критерия используется некоторое числовое поле, называемое ключевым. Упорядочение элементов по ключевому полю предполагает, что ключевое поле каждого следующего элемента не больше предыдущего (сортировка по убыванию). Если ключевое поле каждого последующего элемента не меньше предыдущего, то говорят о сортировке по возрастанию.
Цель сортировки – облегчить последующий поиск элементов в отсортированном множестве при обработке данных.
Задачу поиска можно сформулировать так: найти один или несколько элементов в множестве, причем искомые элементы должны обладать определенным свойством. Это свойство может быть абсолютным или относительным. Относительное свойство характеризует элемент по отношению к другим элементам: например, минимальный элемент в множестве чисел. Пример задачи поиска элемента с абсолютным свойством: найти в конечном множестве занумерованных элементов элемент с номером 13, если такой существует.
Таким образом, в задаче поиска имеются следующие шаги [2]:
1) вычисление свойства элемента; часто это - просто получение «значения» элемента, ключа элемента и т. д.;
2) сравнение свойства элемента с эталонным свойством (для абсолютных свойств) или сравнение свойств двух элементов (для относительных свойств);
3) перебор элементов множества, т. е. прохождение по элементам множества.
Первые два шага относительно просты. Вся суть различных методов поиска сосредоточена в методах перебора, в стратегии поиска и здесь возникает ряд вопросов [2]:
- Как сделать так, чтобы проверять не все элементы?
- Если же задача требует неоднократного прохода по всем элементам множества, то как уменьшить количество проходов?
Ответы на эти вопросы зависят от структуры данных, в которой хранится множество элементов. Накладывая незначительные ограничения на структуру исходных данных, можно получить множество разнообразных стратегий поиска различной степени эффективности.
Сравнительный анализ методов поиска данных
Последовательный поиск
Поиск нужной записи в неотсортированном списке сводится к просмотру всего списка до того, как запись будет найдена. "Начать с начала и продолжать, пока не будет найден искомый ключ, затем остановиться" [1] -это простейший из алгоритмов поиска. Этот алгоритм не очень эффективен, однако он работает на произвольном списке.
Перед алгоритмом поиска стоит важная задача определения местонахождения ключа, поэтому он возвращает индекс записи, содержащей нужный ключ. Если поиск завершился неудачей (ключевое значение не найдено), то алгоритм поиска обычно возвращает значение индекса, превышающее верхнюю границу массива.
Здесь и далее предполагается, что массив А состоит из записей, и его описание и задание произведено вне процедуры (массив является глобальным по отношению к процедуре). Единственное, что требуется знать о типе записей – это то, что в состав записи входит поле key - ключ, по которому и производится поиск. Записи идут в массиве последовательно и между ними нет промежутков. Номера записей идут от 1 до n - полного числа записей. Это позволит нам возвращать 0 в случае, если целевой элемент отсутствует в списке. Для простоты мы предполагаем, что ключевые значения не повторяются.
Процедура SequentialSearch выполняет последовательный поиск элемента z в массиве A[1..n].
SequentialSearch(A, z, n)
(1) for i ←1 to n
(2) do if z = A[i].key
(3) then return i
(4) return 0
Анализ наихудшего случая. У алгоритма последовательного поиска два наихудших случая. В первом случае целевой элемент стоит в списке последним. Во втором его вовсе нет в списке. В обоих случаях алгоритм выполнит n сравнений, где n - число элементов в списке.
Анализ среднего случая. Целевое значение может занимать одно из n возможных положений. Будем предполагать, что все эти положения равновероятны, т. е. вероятность встретить каждое из них равна 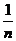 . Следовательно, для нахождения i‑го элемента A[i] требуется i сравнений. В результате для сложности в среднем случае мы получаем равенство
. Следовательно, для нахождения i‑го элемента A[i] требуется i сравнений. В результате для сложности в среднем случае мы получаем равенство
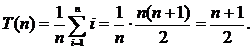
Если целевое значение может не оказаться в списке, то количество возможностей возрастает до n + 1. при отсутствии элемента в списке его поиск требует n сравнений. Если предположить, что все n + 1 возможностей равновероятны, то получим
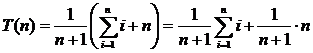
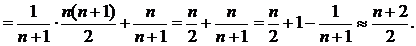
Получается, что возможность отсутствия элемента в списке увеличивает сложность среднего случая на 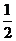 , но по сравнению с длиной списка, которая может быть очень велика, эта величина пренебрежимо мала.
, но по сравнению с длиной списка, которая может быть очень велика, эта величина пренебрежимо мала.
Рассмотрим общий случай, когда вероятность встретить искомый элемент в списке равна pi , где pi ≥ 0 и 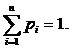 В этом случае средняя сложность (математическое ожидание) поиска элемента будет равна
В этом случае средняя сложность (математическое ожидание) поиска элемента будет равна 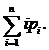 Хорошим приближением распределения частот к действительности является закон Зипфа:
Хорошим приближением распределения частот к действительности является закон Зипфа: 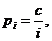 для i = 1, 2, ..., n. [n‑е наиболее употребительное в тексте на естественном языке слово встречается с частотой, приблизительно обратно пропорциональной n.] Нормирующая константа выбирается так, что
для i = 1, 2, ..., n. [n‑е наиболее употребительное в тексте на естественном языке слово встречается с частотой, приблизительно обратно пропорциональной n.] Нормирующая константа выбирается так, что 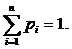 Пусть элементы массива A упорядочены согласно указанным частотам, тогда
Пусть элементы массива A упорядочены согласно указанным частотам, тогда 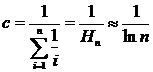 и среднее время успешного поиска составит
и среднее время успешного поиска составит
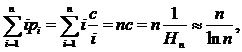 что намного меньше
что намного меньше 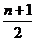 . Это говорит о том, что даже простой последовательный поиск требует выбора разумной структуры данных множества, который бы повышал эффективность работы алгоритма.
. Это говорит о том, что даже простой последовательный поиск требует выбора разумной структуры данных множества, который бы повышал эффективность работы алгоритма.
Алгоритм последовательного поиска данных одинаково эффективно выполня-ется при размещении множества a1, a2,..., anна смежной или связной памяти. Сложность алгоритма линейна - O(n).
Логарифмический поиск
Пусть упорядоченный массив x(1:n) содержит, например, элементы 5, 7, 11, 18, 26, 32, 44, 57, 81, 90, 94, 97, 107, 116, 129, 147, 179 и пусть задан аргумент поиска key, равный, например, 129.
Идея алгоритма бинарного поиска такова:
- сравнить аргумент поиска key со значением среднего элемента x(mid) массива x, где mid = [n/2], а [c] – целая часть числа c;
- если они равны, то поиск завершен, иначе, если key < x(mid), выполнить аналогичным образом поиск в позициях массива x, предшествующих позиции mid, в противном случае, если key ≥ x(mid), выполнить аналогичным образом поиск в позициях массива x, следующих за позицией mid.
Исключить из дальнейшего рассмотрения часть массива позволяет тот факт, что массив упорядочен.
Логарифмический (бинарный или метод делением пополам) поиск данных применим к сортированному множеству элементов a1 < a2 < ... < an, размещение которого выполнено на смежной памяти. Суть данного метода заключается в следующем: поиск начинается со среднего элемента. При сравнении целевого значения со средним элементом отсортированного списка возможен один из трех результатов: значения равны, целевое значение меньше элемента списка, либо целевое значение больше элемента списка. В первом, и наилучшем, случае поиск завершен. В остальных двух случаях мы можем отбросить половину списка. Действительно, когда целевое значение меньше среднего элемента, мы знаем, что если оно имеется в списке, то находится перед этим средним элементом. Если целевое значение больше среднего элемента, мы знаем, что если оно имеется в списке, то находится после этого среднего элемента. Этого достаточно, чтобы мы могли одним сравнением отбросить половину списка.
Итак, результат сравнения позволяет определить, в какой половине списка продолжить поиск, применяя к ней ту же процедуру.
Количество шагов поиска определится как
log2n↑, где n-количество элементов, ↑ - округление в большую сторону до ближайшего целого числа.
Процедура BinarySearch выполняет бинарный поиск элемента z в отсортированном массиве A[1..n].
BinarySearch(A, z, n)
(1) p←1
(2) r←n
(3) while p ≤ r do
(4) q← [(p+r)/2]
(5) if A[q].key = z
(6) then return q
(7) else if A[q].key < z
(8) then p←q+1
(9) else r←q-1
(10) return 0
Анализ наихудшего случая. Поскольку алгоритм всякий раз делит список пополам, будем предполагать при анализе, что n = 2k ‑ 1 для некоторого k. Ясно, что на некотором проходе цикл имеет дело со списком из 2j ‑ 1 элементов. Последняя итерация цикла производится, когда размер оставшейся части становится равным 1, а это происходит при j = 1 (так как 21 ‑ 1 = 1). Это означает, что при n = 2k ‑ 1 число проходов не превышает k. Следовательно, в наихудшем случае число проходов равно k = log2(n+1).
Анализ среднего случая. Рассмотрим два случая. В первом случае целевое значение наверняка содержится в списке, а во втором его может там и не быть. В первом случае у целевого значения n возможных положений. Будем считать, что все они равновероятны. Представим данные a1 < a2 < ... < an в виде бинарного дерева сравнений, которое отвечает бинарному поиску. Бинарное дерево называется деревом сравнений, если для любой его вершины выполняется условие:
{Вершины левого поддерева} < {Вершина корня} < {Вершины правого поддерева}
Если рассматривать бинарное дерево сравнений, то для элементов в узлах уровня i требуется i сравнений. Так как на уровне i имеется 2i‑1 узел, и при n = 2k ‑ 1 в дереве k уровней, то полное число сравнений для всех возможных случаев можно подсчитать, просумми-ровав произведение числа узлов на каждом уровне на число сравнений на этом уровне.
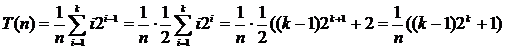
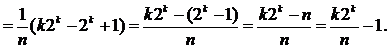
Подставляя 2k = n + 1, получим
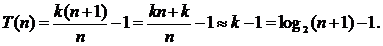
Во втором случае число возможных положений элемента в списке по-прежнему равно n, однако на этот раз есть еще n + 1 возможностей для целевого значения не из списка. Число возможностей равно n + 1, поскольку целевое значение может быть меньше первого элемента в списке, больше первого, но меньше второго, больше второго, но меньше третьего, и так далее, вплоть до возможности того, что целевое значение больше n‑го элемента. В каждом из этих случаев отсутствие элемента в списке обнаруживается после k сравнений. Всего в вычислении участвует 2n + 1 возможностей.
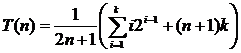 .
.
Аналогично получаем, что
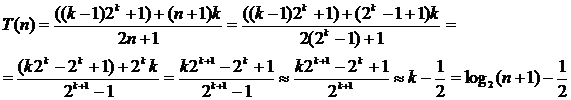
Значит, сложность поиска является логарифмической O(log2n).
Рассмотренный метод бинарного поиска предназначен главным образом для сортированных элементов a1 < a2 < ... < anна смежной памяти фиксированного размера. Если же размерность вектора динамически меняется, то экономия от использования бинарного поиска не покроет затрат на поддержание упорядо-ченного расположения a1 < a2 < ... < an.
Для индексно-последовательного поиска в дополнение к отсортированной таблице заводится вспомогательная таблица, называемая индексной. Каждый элемент индексной таблицы состоит из ключа и указателя на запись в основной таблице, соответствующей этому ключу. Элементы в индексной таблице, как элементы в основной таблице, должны быть отсортированы по этому ключу. Если индекс имеет размер, составляющий 1/8 от размера основной таблицы, то каждая восьмая запись основной таблицы будет представлена в индексной таблице.
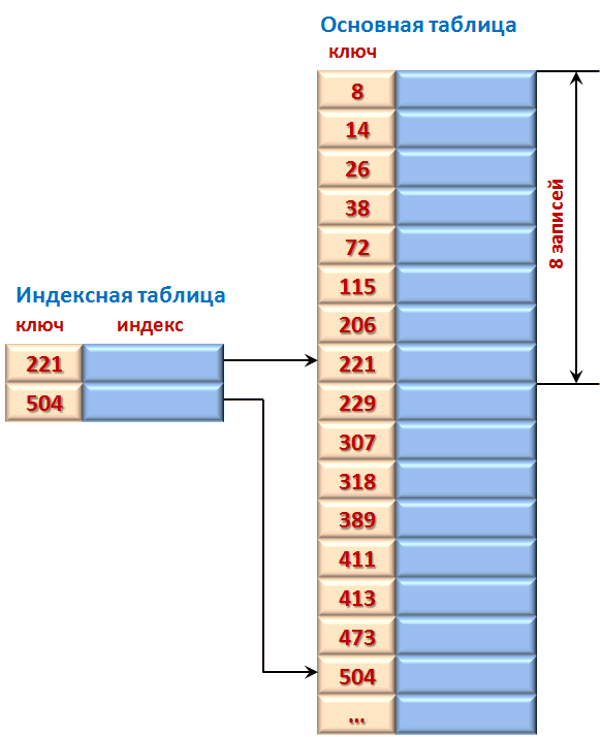
Если размер основной таблицы — n, то размер индексной таблицы — ind_size = n/8.
Достоинство алгоритма – сокращается время поиска, так как последовательный поиск первоначально ведется в индексной таблице, имеющей меньший размер, чем основная таблица. Когда найден правильный индекс, второй последовательный поиск выполняется по небольшой части записей основной таблицы.
Примеры использования методов поиска данных
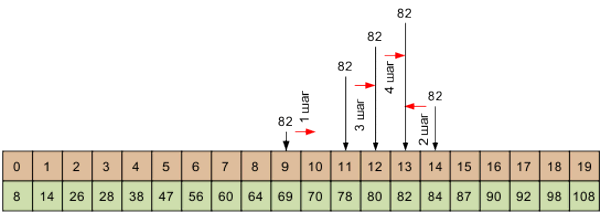
Проиллюстрируем процесс бинарного поиска. Число элементов массива n = 17, тогда [n/2] = 8. Поэтому первоначально выполняется сравнение key с x8 = 57. Так как key > x8, то зона поиска на следующем шаге ограничивается участком от 9-го элемента до 17-го. Этот участок состоит из девяти элементов и его серединой является элемент x13 = 107 ([(9 + 17)/2] = 13). Поскольку key > x13, то зона поиска ограничивается участком от 14-го до 17-го элемента. Его серединой является элемент x15. На этом процесс поиска завершен, так как x15 = key. Всего для завершения поиска потребовалось 3 итерации.
Отобразим на рис. 1 процесс поиска элемента key = 129, выделяя посредством подчеркивания на каждом шаге зоны поиска.
|
Итерация 0 |
5 7 11 18 26 32 44 57 81 90 94 97 107 116 129 147 179 |
|
Итерация 1 |
5 7 11 18 26 32 44 57 81 90 94 97 107 116 129 147 179 |
|
Итерация 2 |
5 7 11 18 26 32 44 57 81 90 94 97 107 116 129 147 179 |
|
Итерация 3 |
5 7 11 18 26 32 44 57 81 90 94 97 107 116 129 147 179 |
Рис. 1. Пример дихотомии
Каждое сравнение уменьшает число возможных кандидатов в два раза. Максимальное число шагов поиска будет в том случае, когда искомый элемент находится в начале или в конце массива. Для завершения поиска потребуется не более log2n + 1 итераций. Действительно, если число элементов в массиве равно n = 2m, то элемент будет найден через m шагов. В свою очередь, при заданном n имеем m = log2n. После анализа последнего элемента получаем общее число итераций log2n + 1. Поэтому вычислительная сложность бинарного поиска составляет O(log2n). Вычислительная сложность последовательного поиска равна O(n).
Однако приведенный алгоритм не позволяет в общем случае точно решить задачу поиска, когда файл или массив содержат повторяющиеся значения ключей. Рассмотрим, например, массив 5 7 11 18 26 32 44 57 81 90 94 97 107 129 129 147 179, в котором элемент (ключ) 129 содержится два раза. Тогда, если аргумент поиска равен 129, поиск по приведенному алгоритму завершится на элементе с номером 15, то есть будет найдено не первое, а второе значение ключа 129 (первое значение ключа расположено в позиции 14). В ряде случаев эта неточность принципиальна, впрочем, она легко устраняется.
Последовательный поиск предполагает последовательный просмотр всех записей множества, организованного как массив.
Пример: Найти в массиве элемент со значением, равным 3.
#include <stdio.h>
#include <stdlib.h>
int search(int *k, int n, int key) {
int index = -1;
for(int i=0; i<n; i++) {
if(k[i] == key) {
index = i;
break;
}
}
return(index);
}
int main() {
int i, k[8];
int point;
system("chcp 1251");
system("cls");
for(i=0;i<8;i++) {
printf("Введите k[%d]: ",i);
scanf("%d",&k[i]);
}
point = search(k,8,3);
if(point == -1)
printf("Элементов равных 3 в массиве нет!\n");
else
printf("Элемент с индексом %d равен 3", point);
getchar(); getchar();
return 0;
}
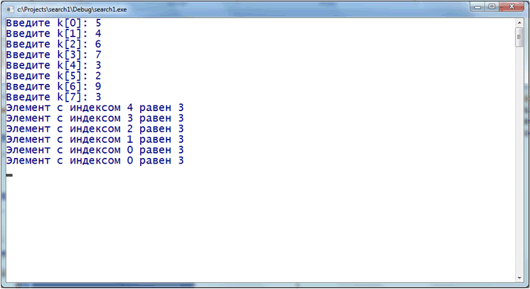
Метод транспозиции
Улучшением рассмотренного метода является метод транспозиции: каждый запрос к записи сопровождается сменой мест этой и предшествующий записи; в итоге наиболее часто используемые записи постепенно перемещаются в начало таблицы; и при последующем обращении к ней запись будет находиться почти сразу.
int search(int *k, int n, int key) {
int index = -1;
int temp;
for(int i=0; i<n;i++) {
if(k[i] == key) {
index = i;
if(index==0)
break;
temp = k[i];
k[i] = k[i-1];
k[i-1] = temp;
break;
}
}
return(index);
}
int main() {
int i, k[8];
int point;
system("chcp 1251");
system("cls");
for(i=0;i<8;i++) {
printf("Введите k[%d]: ",i);
scanf("%d",&k[i]);
}
for(i=0; i<6; i++) {
point = search(k,8,3);
if(point == -1)
printf("Элементов равных 3 в массиве нет!\n");
else
printf("Элемент с индексом %d равен 3", point);
}
getchar(); getchar();
return 0;
}
Результат выполнения
Метод перемещения в начало
Каждый запрос к записи сопровождается её перемещением в начало таблицы; в итоге в начале таблицы оказывается запись, используемая в последний раз.
int search(int *k, int n, int key) {
int index = -1;
int temp;
for(int i=0; i<n;i++) {
if(k[i] == key) {
index = i;
temp = k[i];
k[i] = k[0];
k[0] = temp;
break;
}
}
return(index);
}
Реализация индексно-последовательного поиска
#include <stdio.h>
#include <stdlib.h>
int main() {
int k[20]; // массив ключей
int r[20]; // массив записей
int i, j, ind_size;
int key;
int kindex[3]; // массив ключей индексной таблицы
int pindex[3]; // массив индексов индексной таблицы
system("chcp 1251");
system("cls");
// Инициализация ключевых полей упорядоченными значениями
k[0] = 8;
k[1] = 14;
k[2] = 26;
k[3] = 28;
k[4] = 38;
k[5] = 47;
k[6] = 56;
k[7] = 60;
k[8] = 64;
k[9] = 69;
k[10] = 70;
k[11] = 78;
k[12] = 80;
k[13] = 82;
k[14] = 84;
k[15] = 87;
k[16] = 90;
k[17] = 92;
k[18] = 98;
k[19] = 108;
// Ввод записей
for(i=0;i<20;i++) {
printf("%d. k[%d]= %d: r[%d]=",i,i,k[i],i);
scanf("%d",&r[i]);
}
// Формирование индексной таблицы
for(i=0, j=0;i<20;i=i+8) {
kindex[j] = k[i];
pindex[j] = i;
j++;
}
ind_size = j;
pindex[j] = 20;
// Поиск
printf("Введите key: ");
scanf("%d",&key);
for(j=0; j<ind_size; j++) {
if(key < kindex[j])
break;
}
if(j==0) i=0;
else i = pindex[j-1];
for(i; i<pindex[j];i++) {
if(k[i]==key)
printf("%d. key= %d. r[%d]=%d",i,k[i],i,r[i]);
}
getchar(); getchar();
return 0;
}
Результат выполнения
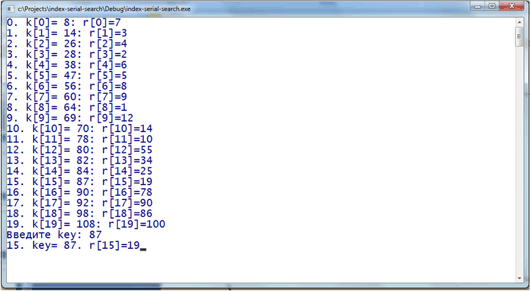
Реализация бинарного поиска
#include <stdio.h>
#include <stdlib.h>
int main() {
int k[20];
int r[20];
int key, i;
system("chcp 1251");
system("cls");
k[0] = 8;
k[1] = 14;
k[2] = 26;
k[3] = 28;
...
k[19] = 108;
for(i=0;i<20;i++) {
r[i] = i+1;
printf("%d. k[%d]= %d: r[%d]=%d\n",i,i,k[i],i,r[i]);
}
printf("Введите key: ");
scanf("%d",&key);
int low = 0;
int high = 19;
int search = -1;
while (low<=high) {
int mid=(low+high)/2;
if (key==k[mid]) {
search=mid;
break;
}
if (key<k[mid])
high=mid-1;
else
low=mid+1;
}
if(search==-1)
printf("Элемент не найден!\n");
else
printf("%d. key= %d. r[%d]=%d",search,k[search],search,r[search])
getchar(); getchar();
return 0;
}
Результат выполнения
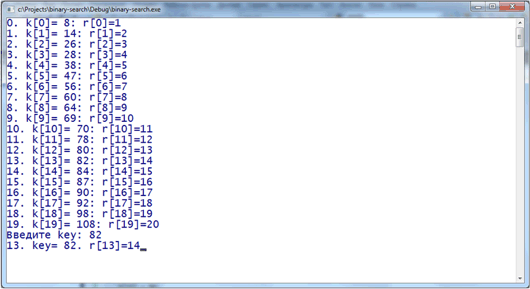
Заключение
В результате выполнения работы сравним алгоритмы последовательного и бинарного поиска.
Пусть файл, в котором выполняется поиск, отсортирован и содержит 1024 (210) элемента. В случае последовательного поиска наибольшее число итераций будет равно 1024, а бинарного – 11. То есть разница в два порядка.
Сравним теперь временные затраты на поиск в случае неотсортированного файла. При последовательном поиске максимальное число итераций, разумеется, сохраняется. Бинарный поиск неприменим. Выполним, однако, быструю сортировку файла. В среднем для этого потребуется 1024*log21024 = 10240 итераций. Далее выполним бинарный поиск, на который будет затрачено не более 11 итераций.
Приведенные цифры позволяют сделать вывод: если файл неотсортирован и в процессе вычислений задача поиска в файле возникает сравнительно редко (в нашем примере не более 10 раз), то можно применять последовательный поиск, в противном случае более целесообразно прежде отсортировать файл и при вычислениях применять бинарный поиск.
По очевидным причинам сортировка файла заменяется его индексированием. Записи каждого созданного индекса упорядочены по значениям индексного выражения в возрастающем или убывающем порядке.
Список использованной литературы
- Автоматизированные информационные технологии в экономике: Учебник / Под ред. проф. Г.А. Титоренко. – М.: ЮНИТИ, 2004. – 399 с.
- Гарольд Э., Минс С. XML. Справочник. – СПб: Символ-Плюс, 2002. – 576 с.
- Кокорева Л. В., Малашинин И. И. Проектирование банков данных. – М.: Наука, 1984.
- Мартин Дж. Организация баз данных в вычислительных системах. – М.: Мир, 1978.
- Мишенин А.И. Теория экономических информационных систем: Учебник. − М.: Финансы и статистика, 2002. – 240 с.
- Мишенин А.И., Салмин С.П. Теория экономических информационных систем. Практикум: Учебное пособие. – М.: Финансы и статистика, 2005. – 192 с.
- Олле Т. В. Предложения КОДАСИЛ по управлению базами данных. – М.: Финансы и статистика, 1981.
- Скляров В. А. Язык С++ и объектно-ориентированное программирование. – Минск: Высш. шк., 1997. – 478 с.
- Справочник по автоматизации. – М.: Изд. от. "Русская редакция" ТОО Channel Trading Ltd., 1998. – 440 с.

- Теоретические основы прокурорского надзора за органами, осуществляющими оперативно-розыскную деятельность
- Роль мотивации в поведении организации.
- Роль мотивации в поведении организации.(Теоретические основы мотивации в системе менеджмента)
- Фонд социального страхования Российской Федерации, его формирование
- "Местное самоуправление в Российской Федерации: тенденции и перспективы развития»
- Современные языки программирования.
- Индивидуальное предпринимательство
- НАСЛЕДОВАНИЕ ПО ЗАВЕЩАНИЮ
- Стратегический анализ конкурентов ООО «Бизнес-Софт»
- Юридическая ответственность
- Характеристика управленческих решений
- Разработка проекта системы мониторинга информационных ресурсов сети Интернет»