
МЕТОДЫ КОДИРОВАНИЯ ИФОРМАЦИИ
Содержание:

Введение
Кодирование информации - проблема, которая имеет достаточно давнюю историю, которая появилась задолго до изобретения и распространения средств вычислительной техники. С помощью алгоритмов кодирования проводится обработка входных потоков информации, наименьшим квантом которой является бит. Области использования кодирования информации в настоящее время довольно обширны – от идентификации товаров на складах или в супермаркетах до шифрования каналов передачи данных, а также конфиденциальной информации. Технологии кодирования и шифрования информации используются при работе с электронной подписью, в системах электронного документооборота, которые получают широкое развитие в настоящее время.
Целью данной работы является анализ технологий кодирования информации.
Задачи работы:
- анализ и классификация технологий кодирования информации;
- анализ технологий штрихового кодирования;
- анализ криптографических алгоритмов;
- анализ математических моделей шифрования и кодирования информации.
Объект исследования: информационные технологии.
Предмет исследования: технологии кодирования информации.
1. Теоретические основы кодирования информации
1.1 Основы и основные понятия кодирования информации
В рамках данной работы рассмотрены теоретические аспекты технологии кодирования информации. Проведем анализ терминологии, связанной с кодированием информации. В процессе передачи в коммуникационные каналы проводится преобразование сообщений в сигналы. Символы, посредством которых проводится создание сообщений, образуют первичный алфавит, при этом каждому символу сопоставляется вероятность его появления в сообщениях. Каждому сообщению однозначно сопоставляется сигнал, который представляет собой определенную последовательность элементарных дискретных символов, являющихся кодовыми комбинациями.
Алфавит представляет собой множество возможных кодовых элементов, т.е. элементарных символов (кодировки)X = {xi}, где i = 1, 2,..., m. Число кодовых элементов (m) представляет собой его основание. Для двоичных кодов xi = {0, 1} и m = 2. Конечные последовательности символов данного алфавита представляют собой кодовые комбинации (кодовые слова). Количество элементов в кодовых комбинациях - n представляет собой значимость кода (длину комбинации). Количество различных кодовых комбинаций (N = mn) называется объемом или мощностью кода.
Целями кодирования являются [2]:
1) Повышение эффективности процесса передачи данных, за счет повышения скорости передачи данных.
2) Повышение уровня защиты от помех при передаче данных.
В соответствии с данными целями развитие теории кодирования происходит в следующих направлениях:
1. Экономичное (эффективное, оптимальное) кодирование, заключающееся в поиске кодов, позволяющих в каналах без помех повышать эффективность передачи данных вследствие устранения избыточности в источниках и оптимальности согласования скорости трафика и пропускной способности канала связи.
2. Помехоустойчивое кодирование предполагает осуществление поиска кодов, позволяющих повышать уровень достоверности передачи данных в каналах с учетом наличия помех.
Описание теоретических основ технологий кодирования было проведено Шенноном К. , проводившим исследование процессов передачи информации по техническим каналам связи (теория связи, теория кодирования). Указанный подход к кодированию предполагает: осуществление перехода от представления данных в одной символьной системе к представлению в другой символьной системе. Подобное преобразование производится при кодировании письменного русского текста в символы азбуки Морзе для передачи его с помощью телеграфной связи или радиосвязи. Данное кодирование связано с наличием потребности приспособление кода к используемым техническим средствам работы с данными.
Процесс декодирования предполагает обратное преобразование кода к формату исходного алфавита, т.е. приведение к исходному сообщению. Например, декодированием является преобразование последовательности символов азбуки Морзе к письменному тексту на русском языке.
Таким образом, декодирование предполагает восстановление содержания закодированных сообщений. Данный подход к процессу записи текста с использованием символов русского алфавита предполагает возможность кодирования, обратная операция декодирования.
Методы кодирования одних и тех же сообщений могут быть различными. Например, русский текст записывается с использованием символов русского алфавита. При определенных условиях русский текст можно записывать и символами латинского алфавита.
Существуют и иные способы кодирования информации. Например, стенография является быстрым способом записи устной речи. Приемами стенографии владеют лишь специалисты с достаточной для этого квалификацией. Стенографисты проводят запись текста в синхронном режиме с речью говорящего человека. В стенограммах одному значку сопоставляются слова или словосочетания целиком. Расшифровка (декодирование) стенограммы может проводиться только стенографистом.
Указанные примеры позволяют увидеть следующую важную закономерность: при кодировании одних и тех же данных возможно использование разных способов; их выбор определяется рядом обстоятельств, включающих: цели кодирования, условия, имеющиеся средства. При необходимости записи текста в темпе речи используется стенография; если необходимо провести передачу текста за границу — используется английский алфавит; если необходимо представить текст в форме, понятной для грамотного русскоязычного читателя - проводится запись текстов соответствии с правилами грамматики русского языка.
Выбор метода кодирования информации осуществляется предполагаемым методом ее обработки. Например, если предполагается обработка числовой информации с использованием математических преобразований, то текст записывается с помощью цифр, если математических действий не предполагается, то запись числа возможно с помощью символов алфавита.
Если необходимо сохранение числовой информации без искажения, то её лучше записывать в форме текста. Например, в финансовых документах числовые суммы сопровождаются суммами в текстовой форме: «пятьсот шестьдесят три руб.» вместо «563 руб.». При записи в цифровой форме искажение или добавление одной цифры изменяет все значение. В случае использования текстовой формы даже наличие грамматических ошибок могут не приведет к изменению смысла.
В некоторых случаях могут возникнуть задачи, связанные с засекречиванием текстовой информации, либо документов, для того чтобы ограничить круг тех, кто имеет доступ к ним. Данный вод защиты представляет собой защиту от несанкционированного доступа. В данном случае проводится шифрование секретного текста. Шифрование предполагает превращение открытых текстов в зашифрованные, обратный процессимеет название дешифрованияи предполагает восстановление исходного текста. Шифрование также является кодированием, но с использованием засекреченного метода, который известен только источнику и адресату. Технологии шифрования представляют собой область науки криптографии.
1.2 Классификация назначения и способы представления кодов
Классификация кодов проводится с помощью следующих признаков [12]:
1. Кодирование по основанию (числу символов в алфавите): бинарное (двоичные m=2) и не бинарное кодирование (m > 2).
2. Классификация по длине кодовых комбинаций (слов): равномерное, при одинаковой длине кодовых комбинаций и неравномерное кодирование в случаях, когда длина кодовых комбинаций непостоянна.
3. Классификация по методам передачи: последовательное и параллельное; блочное (в данном случае данные помещаются в буфер, и далее передаются в канал) и бинарное непрерывное кодирование.
4. По уровню устойчивости к воздействию помех: простое (примитивное, полное) - для передачи данных используется набор всех возможных кодовых комбинаций (без избыточности); корректирующее (помехозащищенное) - для передачи сообщений используются не все, а только часть (разрешенных) кодовых комбинаций.
5. В зависимости от области использования условно можно определить следующие виды кодирования [3]:
Внутреннее кодирование, использующее коды, генерируемые устройствами. Это машинное кодирование, а также кодирование, использующее позиционные системы счисления (двоичные, десятичные, двоично-десятичные, восьмеричные, шестнадцатеричные и др.). Одним из наиболее распространенных кодов в ЭВМ является двоичный код, позволяющий проводить реализацию аппаратных устройств, осуществляющих хранение, обработку и передачу данных в двоичном коде. Такие устройства обеспечивают высокую надежность и простоту выполнения операций с данными с использованием двоичного кода. Двоичные данные, объединяемые в группы по 4 разряда, образуют шестнадцатеричные коды, совместимые с архитектурой компьютеров, работающих с данными кратными байту (8 бит).
Кодирование для обмена данными и их передачи по каналам связи. Широкое распространение в компьютерной технике получил код ASCII, представляющий собой7-битный код, содержащий буквенно-цифровые и другие символы. Так как ЭВМ работают с байтами, то 8-й разряд используется в целях синхронизации или проверки на четность, или расширения кода.
В процессе кодирования информации для передачи по каналам связи, в том числе внутри аппаратных трактов, применяются коды, которые обеспечивают максимальную скорость передачи данных, за счет их сжатия и устранения избыточности (данные алгоритмы используются в кодах Хаффмана и Шеннона-Фано), и коды, служащие для обеспечения достоверности передачи данных, за счет ввода избыточности в передаваемую информацию (данная функция реализована в групповых кодах, кодах Хэмминга, циклических алгоритмах и их разновидностях).
Кодирование для специальных применений используются для решения специальных задач, связанных с передачей и обработкой данных. в качестве примера таких кодов можно рассматривать циклический код Грея, широко используемый в АЦП угловых и линейных перемещений. Использование кодов Фибоначчи эффективно при построении быстродействующих и помехоустойчивых АЦП.
В зависимости от используемых способов кодирования, используются различные математические модели кодирования, при этом наиболее часто применяются представления кодов в формах, включающих: кодовые матрицы; кодовые деревья; многочлены; геометрические фигуры и т.д. Рассмотрим основные методы представления кодов.
Представление кодов в форме матрицы. Используется для представления равномерных n - значных кодов. Для примитивного (полного и равномерного) кода матрица содержит n - столбцов и 2n - строк, т.е. код использует все сочетания. Для помехоустойчивых (корректирующих, обнаруживающих и исправляющих ошибки) матрица содержит n - столбцов (n = k+m, где k-число информационных, а m - число проверочных разрядов) и 2k - строк (где 2k - число разрешенных кодовых комбинаций). При больших значениях n и k матрица будет слишком громоздкой, при этом код записывается в сокращенном виде. Матричное представление кодов используется, например, в линейных групповых кодах, кодах Хэмминга и т.д.
Представление кодов в форме кодовых деревьев. Кодовое дерево является связным графом, не содержащим циклы. Связные графы - графы, в которых любой паре вершин сопоставляется путь, который соединят данные вершины. Граф включает узлы (вершины) и ребра (ветви), соединяющие узлы, которые располагаются на различных уровнях. При построении дерева равномерного двоичного кода выбирается вершина, называемая корнем дерева (истоком), из которой проводят ребра в следующуюпару вершин и т.д.
1.3 Метод кодирования Хаффмана
Способ кодирования или сжатия данных с использованием двоичных кодирующих деревьев был разработан Д.А. Хаффманом. Данный алгоритм кодирования обладает высокой эффективностью, вследствие чего он до настоящего времени лежит в основе технологий шифрования. Код Хаффмана редко применяется отдельно, чаще работая совместно с другими алгоритмами шифрования. Метод Хаффмана представляет собой пример построения кодов, обладающих переменной длиной, имеющих наименьшую среднюю длину. Данный метод производит идеальное сжатие, то есть проводит сжатие данных до их энтропии, если вероятности символов точно равны отрицательным степеням числа 2.
Алгоритм данного метода кодирования включает этапы[10]:
- Строится оптимальное кодовое дерево;
- Строится отображение код - символа соответственно построенному дереву.
Алгоритм базируется на том, что повторяемость некоторых символов из стандартного 256-символьного набора в произвольных текстовдля некоторых символов выше, для некоторых ниже. Таким образом, если для записи распространенных символов используются короткие последовательности бит, имеющие длину менее 8, а для записи редких символов - длинные, то суммарный размер файла сокращается. В результате система приводитсяк форме дерева (двоичного дерева).
Пусть A={a1,a2,...,an} – алфавит, содержащий n различных символов, W={w1,w2,...,wn} - соответствующий ему набор положительных целых весов. Тогда набор бинарных кодов C={c1,c2,...,cn}, имеет следующие свойства [8]:
- ci не является префиксом для cj, при i=j;минимальна (|ci| - длина кода ci)выступает в качестве минимально-избыточного префиксного кодаили иначе кода Хаффмана.
Бинарное дерево представляет собой ориентированное дерево, полустепень исхода для любой из вершин которого не более двух.
Корень бинарного дерева - вершина, полустепень захода которой принимает нулевое значение. В остальных вершинах дерева полустепень захода принимает значение единицы.
Пусть Т- бинарное дерево, А=(0,1)- двоичный алфавит для каждого ребра Т-дерева прописан один из символов алфавита таким образом, что все ребра, выходящие из одной вершины, отмечены различными буквами. Тогда для любого листа Т-дерева прописывается уникальный кодовый идентификатор, образованный из букв, которыми отмечены ребра, которые встречаются при движении от корня к соответствующему листу. Особенностью описанного метода кодирования является то, что полученные коды являются префиксными.
Стоимость хранения данных, закодированных с помощью Т-деревьев, соответствует сумме длин путей от корня до каждого листа дерева, взвешенного частотой соответствующего кодового слова или длиной взвешенных путей:  , где
, где  - частота кодового слова длины
- частота кодового слова длины  во входном потоке.
во входном потоке.
В классическом алгоритме Хаффмана на входе генерируется таблица частот повторяемости символов в сообщении. Далее на основании данной таблицы проводится построение дерева кодирования Хаффмана (Н-дерева).
1. Из символов входного алфавита образуется список свободных узлов. Каждому листу сопоставляется вес, который соответствует либо вероятности, либо числу вхождений данного символа в сжимаемое сообщение;
2. Проводится выбор двух свободных узлов дерева с минимальными весами.
Проводится создание их родителя с весом, соответствующим их суммарному весу;
Проводится добавление родителя в перечень свободных узлов, удаление двух его потомков из указанного списка;
Одной дуге, которая выходит из родительского узла, сопоставляется бит 1, другой - бит 0;
Начиная со второй итерации проводится повторение алгоритма до тех пор, пока в списке свободных узлов не останется только один свободный узел, который выбирается в качестве корня дерева.
Допустим, имеется следующая таблица частот.
|
14 |
6 |
5 |
5 |
4 |
|
А |
Б |
В |
Г |
Д |
На первой итерации проводится выбор листьев, имеющих минимальные веса. (в данном случае Г и Д). Проводится их присоединение к новому узлу- родителю, которому устанавливается вес 4+5= 9. Далее проводится удаление узлов Г и Д из перечня свободных. Узлу Г сопоставляется ветвь 0 родителя, узлу Д- ветвь 1.
На следующем итерации то же производится с узлами Б и В, так как теперь данная пара обладает самым меньшим весом в дереве. Проводится создание нового узла с весом 11, удаление узлов Б и В из списка свободных.
Далее «наилегчайшими» парами выступают узлы Б/В и Г/Д.
Для них еще раз проводится создание родителя, теперь уже с весом 20. Узел Б/В соответствует нулевой ветви родителя, Г/Д - ветви 1.
На последней итерации в списке свободных находится только 2 узла - это узел А и узел Б (Б/В)/(Г/Д). Проводится создание родителя с весом 34, и бывшие свободные узлы присоединяются к различным его ветвям.
Так как свободным является только один узел, то построение дерева кодирования Хаффмана заканчивается.
Каждому символу, входящему в сообщение, сопоставляется конкатенация нулей и единиц, соответствующих ребрам дерева Хаффмана, на пути от корня к соответствующему листу.
Для данной таблицы символов коды Хаффмана принимают следующий вид:
|
А |
01 |
|
Б |
100 |
|
В |
101 |
|
Г |
110 |
|
Д |
111 |
Наиболее часто используемый символ сообщения А закодирован минимальным числом бит, а наиболее редкий символ Д - максимальным. Величина стоимости хранения кодированного потока, определяемая через сумму длин взвешенных путей, рассчитывается выражением 14*1+6*3+5*3+5*3+4*3=74, что значительно ниже стоимости хранения входного потока (312).
Поскольку ни один из полученных кодов не является префиксом другого, они могут быть однозначно декодированы при чтении их из потока.
Порядок декодирования предполагает просмотр потоков битов и синхронное перемещение от корня вниз по дереву Хаффмана в соответствии со считанным значением до тех пор, пока не будет достигнут лист, то есть декодировано очередное кодовое слово, после чего распознавание следующего слова вновь начинается с вершины дерева[4].
Для классического алгоритма Хаффмана характерен один существенный недостаток. Для возможности восстановления содержимого сжатых сообщений в декодере должна храниться таблицу частот, которая использовалась кодером. Следовательно, длина сжатого сообщения увеличивается на длину таблицы частот, которая должна посылаться впереди данных, что может свести на нет все усилия по сжатию сообщения. Кроме того, необходимость наличия полной частотной статистики перед началом собственно кодирования требует двух проходов по сообщению: одного для построения модели сообщения (таблицы частот и дерева Хаффмана), другого для кодирования.
2. Использование систем кодирования информации в технологиях информационной безопасности
2.1. Штриховое кодирование
Одним из способов кодирования информации является штриховое кодирование. Данный метод кодирования используется в областях, где необходимо проводить идентификацию объекта с использованием специализированных считывателей. Кодирование информации проводится посредством преобразования информации в графическое представление (например, чередования полос различной ширины или двумерное изображение).
Штриховой код может являться одним из средств систем автоматической идентификации объекта, наряду со средствами цифровой, магнитной, радиочастотной, звуковой и визуальной идентификации (магнитная карточка, радиочастотная бирка и т. д.). Его главным преимуществом перед другими средствами автоматической идентификации является возможность оперативной передачи данных о товаре по системе электронным каналам, таким образом штриховой представляет собой эффективное средство телекоммуникационных систем.
К основным функциям штрихового кода относятся [2]:
- оперативная идентификация объекта и производителя;
- проведение торговых сделок в безбумажной форме: с помощью штрихового кода сокращаются издержки, связанные с делопроизводством с 15% до 0,5-0,3% от стоимости товара;
- автоматизация учета и контроля товарных запасов;
- обеспечение оперативности управления процессами движения товаров: отгрузкой, транспортировкой и складированием (производительность труда по обеспечению товародвижения повышается на 30%, в некоторых случаях – на 80%);
- информационное обеспечение маркетинговых исследований [4, с. 146].
Штрих (полоса) – темная зона изображения на однотонном светлом фоне, ограниченная прямыми параллельными линиями или концентрическими окружностями. Нанесение элементов штрихового кодирования проводится на поверхность носителя, который имеет определенные светотехнические параметры. При этом штрихи, которые наносятся с использованием красителей, либо других средств, обладают способностью поглощения света на определенных частотах, а фоновая поверхность обладает хорошей отражательной способностью, что используется при оптическом считывании.
Пробел – пространство между штрихами. Вбольшинстве кодов кодируемая информация заключается в ширине пробела, в некоторых кодах пробел представляет собой вспомогательную частью изображения и выступает в роли элемента-разделителя. Кодирование информации может также производиться через высоту и ширину штрихов (пробелов), размеры изображения, выраженные в единицах измерения (миллиметрах, долях дюйма)или в безразмерных единицах (модулях) [7, c.3].
Ширина самого узкого элемента (штриха или пробела) принимается в качестве основного размера –модуля. Ширина любого элемента должна быть либо кратна модулю (например, в символике «Код 128» допустимы элементы шириной 1, 2, 3 или 4 модуля), либо должна выдерживаться постоянность отношения между широкими и узкими элементами (например, в символике «Код 39» элементы двух размеров – с заданным отношением ширины широких элементов к узким).
С помощью определенных комбинаций штрихов и пробелов можно образовать набор знаков штриховых кодов. Так, в символике «Код 39» для каждому знаку штрихового кода сопоставляется девять элементов (из которых три широких и шесть узких) и должен быть представлен в пяти и четырех пробелах. Каждой комбинацией штрихов и пробелов – знаку штрихового кода сопоставляется, как правило, знак данных или специальный символ.
Последовательность расположенных слева направо знаков штриховых кодов, кодирующих данные, начинаются знаком «Старт» и заканчивается знаком «Стоп» с примыкающими к данным знакам свободными полями, называется символом штрихового кода. Символ штрихового кода является законченным графическим объектом, подлежащим считыванию с применением специального аппаратного обеспечения.
Код двуцветный – код, в изображении которого закодирована информация на определенных частотах в виде темных и светлых штрихов. Код контролируемый – код, в изображении знаков и кодовых слов которого заложена избыточная информация, обеспечивающая обнаружение ошибок считывания.
Таким образом, основными областями использования технологий штрихового кодирования являются:
- идентификация товаров в технологии продаж;
- складской учет;
- инвентаризация;
- идентификация документов (некоторые государственные документы в настоящее время также используют технологии штрихового кодирования – например, государственный сертификат на материнский капитал).
Основное назначение технологии штрихового кодирования – упрощение идентификации товара. При этом данная технология не обладает защитой от копирования и не может служить степенью защиты его подлинности.
В настоящее время существует большое количество видов штрихкодов ,содержащих как цифровые, символьные, а также графические символы. Проведем анализ наиболее распространенных технологий штрихового кодирования.
Штрих-коды типа EAN / UPC. Данная технология штрихового кодирования предполагает генерацию уникального сочетания из 13 цифровых символов. Первые 7 символов кода соответствуют производителям (или фирмам, проводящим упаковку товаров). Для кодировки малогабаритных товаров используются аналогичные коды, включающие из 8 цифровых символов. Данные символики широко используются для маркировки потребительских товаров.
Штрих-коды типа Interleaved 2 of 5 (ITF). Для указанного типа штрихового кодирования характерна высокая плотность, при этом длина кода может быть различной. Символика данной системы находит широкое применение при перевозке или хранении товара на складах предприятий оптовой торговли, то есть в тех областях, где необходимо обеспечить уникальность маркировки упаковок с использованием многосимвольных идентификаторов. Так же данный тип штрихового кодирования используется для хранения на складах обувной продукции.
Первый и последний символы кода имеют наименование соответственно, «стартовых» и стоповых. Расположенные между ними символы, находящиеся на нечетных позициях (то есть, первые, третьи, пятые и т.д. символы) кодируются через последовательности, включающие два широких и три узких штриха. Символы, находящиеся на четных позициях (то есть, вторые,
четвертые, шестые и т.д.) кодируются через последовательность из просветов с разной шириной.
Штриховой кодирование типа Codabar .Данный тип маркировки считается одним из самых безопасных. Данные коды часто используются на объектах, где критичным является обеспечение уникальности идентификатора маркированного объекта (например, в медицине).
Стартовым и стоповым символом в данной системе являются первые четыре символа латинского алфавита. Это позволяет проводить разбивку необходимой информации на группы и категории. Основными символами являются односимвольные цифры, а также набор, включающий специальные символы (знаки препинания, символы валют и др.). Указанные символы закодированы с использованием четырех линий, имеющих различную ширину и три просвета.
Штриховой кодирование типа Code 39.Указанная символика является одной из первых, получивших широкое распространение в розничных торговых организациях. Для кодирования используются 44 различных символа (цифровых и буквенных). Для кодирования каждого из символов применяются девять позиций, включающих пять линий и четыре просвета. Для этого используется две широкие черные линии и один широкий просвет. Таким образом, на девять позиций приходится три широких.
Пример генерации штрихкода в системе «1С: Предприятие» показан на рисунке 1.
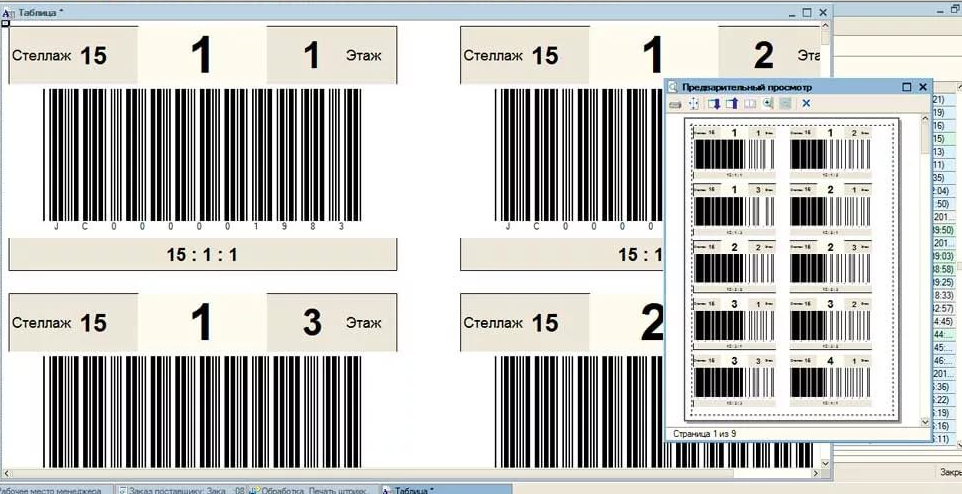
Рисунок 1 – Режим генерации штрихкода в системе «1С: Предприятие»
Штриховой кодирование типа Code 128.Указанный тип символики является высокоплотным, для кодирования используется комплект символов, входящий в набор 128ASCII. Для кодирования применяется три варианта комплектации, которые обозначаются символами А, В и С. Так, в комплекте С используется исключительно цифровых символов, в данном случае код получается очень компактным, что позволяет использовать его в малогабаритных изделиях.
Двухразмерное 2d-кодирование. Целью создания кодов данного типа является повышение объёмов закодированной информации при использовании минимальной площади. Двуразмерные коды позволяют размещать в 100 раз больше данных в сравнении с одноразмерными.
Технологии штрихового кодирования предполагает наличие следующих компонент:
- генераторы штрихового кода (программные средства);
- принтеры для печати штрих-кодов (либо обычные принтеры, либо принтеры для печати наклеек);
- считыватели штрих-кодов;
- программное обеспечение для идентификации считанных штрих-кодов.
Технологии генерации штриховых кодов в настоящее время реализованы в программных продуктах, где реализована автоматизация функционала процессов, требующих проведения маркировки продукции (например, 1С: Предприятие, либо необходимые компоненты во внешних подключаемых модулях в средствах разработки).
2.2. Общая характеристика криптографических методов защиты информации
Для обеспечения безопасности данных при их передаче с использованием использовании информационно-телекоммуникационных сетей применяются сертифицированные средства криптографической защиты.
Особенность криптографической защиты информации в том, что ее реализация предполагает выполнение ряда серьезных организационных мероприятий в области защиты информации, по сути представляя собой технологические решения. особенность технологии криптографической защиты информации состоит в том, что данная методика представляет собой как возможность шифрования данных, что делает возможным получение информации только лицами, располагающими ключами шифрования данной криптографической системы, так и ряд методов, позволяющих аутентифицировать автора электронного документа, а также методы подтверждения целостности документов.
Защита данных в информационных системах с использованием средств шифрования является одним из наиболее надежных методов решения проблемы безопасности..
Изучение технологических аспектов кодирования и шифрования данных входит в компетенцию науки -криптологии, включающей криптографические технологии и криптоанализ.
Предметом изучения криптографии являются методы и алгоритмы кодирования и шифрования информации (алгоритмы, используемые для построения шифров и работы с ними), направленные на то, чтобы перехваченная информация была нечитаемой.
Методы криптографии также могут находить применение при подтверждении подлинности источников данных и контроле целостности данных. Криптография является обязательной компонентой архитектуры безопасности информационных систем. Особое значение криптографические методы получили с развитием сетей с распределенной архитектурой, в которых невозможно обеспечение физической защиты каналов связи.
Криптоанализ - это наука, предметом которой является раскрытие исходного текста зашифрованных сообщений без доступа к ключам.
Различие кодирования и шифрования связано с тем, что коды работают с лингвистическими элементами, разделяют закрываемый текст на блоки, содержащие смысловые элементы, включающие слова и слоги. В шифрах имеется различение двух элементов: алгоритмов и ключей. Алгоритмы позволяют использовать сравнительно короткие ключи для шифрования текстов с неопределенной длиной.
В соответствии с ГОСТ 28147-89 шифр представляет собой совокупность обратимых преобразований множества открытых данных на множество зашифрованных данных, которые задаются посредством ключей и алгоритмов криптографических преобразований.
Ключ - это определенное (секретное или открытое) состояние некоторых параметров алгоритмов криптографических преобразований данных, которые обеспечивают выбор единственного варианта из всех возможных для алгоритма шифрования.
Основная характеристика шифра – это его криптостойкость, определяющая его стойкость к раскрытию посредством методов криптоанализа. Как правило, данная характеристика определяется промежутком времени, который необходим для раскрытия шифра.
Гаммирование представляет собой технологию наложения в соответствии с определенными правилами шифровых гамм на открытые данные. Шифровые гаммы являются псевдослучайными двоичными последовательностями, вырабатываемыми в соответствии с определенными алгоритмами, позволяющими проводить шифрование открытых данных и расшифровку зашифрованных данных.
Имитозащита представляет собой защиту системы шифрованных каналов связи от вставок ложных блоков.
Имитовставки - это блоки, включающие m бит, вырабатываемые в соответствии с определенными правилами из открытых источников с использованием ключей, которые добавляются к зашифрованным данным для обеспечения их имитозащиты.
К шифрам, которые используются для криптографической защиты информации, предъявляются следующие требования:
- достаточный уровень криптостойкости (надежности закрытия данных);
- простота алгоритмов шифрования и расшифровки;
- незначительный уровень избыточности данных, обусловленный шифрованием;
- отсутствие чувствительности к наличию ошибок шифрования и др.
Таким образом, особенности криптографической защиты информации в отличие от остальных методов состоят в следующем [12]:
- возможность шифрования документов;
- подтверждение аутентичности электронного документа;
- подтверждение целостности электронного документа.
Например, парольная защита может использоваться только для авторизации пользователя в автоматизированной системе, для юридически значимых действий в программных комплексах одного пароля недостаточно.
Криптографические методы, в силу своей специфики применяются в системах электронных платежей, сдачи отчетности в государственные органы, системах электронных торгов, а также других системах, связанных с электронным документооборотом. Наличие электронно-цифровой подписи делает электронный документ юридически значимым. В силу этого, к работе с криптографическими системами предъявляется ряд требований организационного обеспечения по сохранности электронных ключей, защите от их компрометации. компрометация ключа электронной подписи может привести к прямым финансовым потерям, утечкам информации, что может угрожать существованию предприятия – владельца ЭЦП.
Традиционные криптографические методы и алгоритмы подразделяются на:
- симметричные (использующие секретные ключи),
- асимметричные (использующие открытые ключи).
Симметричные методы для шифрования и расшифровки используют одни и те же секретные ключи.
Наиболее распространенным стандартом симметричного шифрования с закрытым ключом является стандарт DES (DataEncryptionStandard). Коммерческие варианты алгоритма DES используют ключ длиной 56 бит, что требует при атаке на него проведения перебора 721012 вариантов ключевых комбинаций. Более криптостойкие (но уступающие по быстродействию) версии алгоритма DES - Triple DES (тройной DES) позволяют работать с ключами длиной 112 бит.
Другим популярным алгоритмом шифрования является IDEA (InternationalDataEncryptionAlgorithm), отличающийся применением ключа длиной 128 бит. Он является более стойким, чем DES. Российский стандарт шифрования данных - ГОСТ 28147-89 определяет технологию симметричного шифрования с использованием ключа длиной до 256 бит.
3. Обзор алгоритмов кодирования и шифрования
3.1. Симметрическая (классическая) криптография
Традиционные криптографические методы и алгоритмы подразделяются на:
- симметричные (использующие секретные ключи),
- асимметричные (использующие открытые ключи).
Симметричные методы для шифрования и расшифровки используют одни и те же секретные ключи.
Наиболее распространенным стандартом симметричного шифрования с закрытым ключом является стандарт DES (DataEncryptionStandard). Коммерческие варианты алгоритма DES используют ключ длиной 56 бит, что требует при атаке на него проведения перебора 721012 вариантов ключевых комбинаций. Более криптостойкие (но уступающие по быстродействию) версии алгоритма DES - Triple DES (тройной DES) позволяют работать с ключами длиной 112 бит.
Другим популярным алгоритмом шифрования является IDEA (InternationalDataEncryptionAlgorithm), отличающийся применением ключа длиной 128 бит. Он является более стойким, чем DES. Российский стандарт шифрования данных - ГОСТ 28147-89 определяет технологию симметричного шифрования с использованием ключа длиной до 256 бит.
Схема алгоритма метода симметричного шифрования показана на рисунке 2.
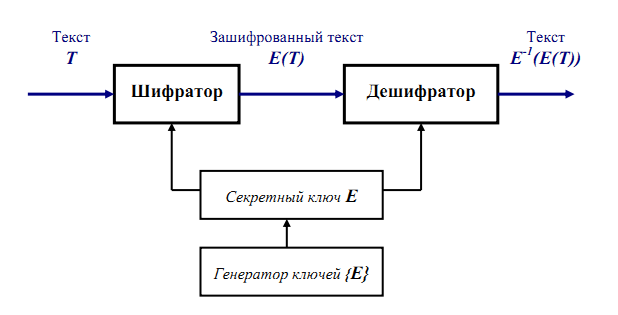
Рисунок - Схема метода симметричного шифрования
Шифрование заменой (подстановкой) заключается в том, что символы шифруемого текста заменяются символами того же самого (простая замена), также одно или нескольких других алфавитов (сложная замена) в соответствии с заранее обусловленной схемой замены.
Система шифрования Цезаря - частный случай шифра простой замены. Метод основан на замене каждой буквы сообщения на другую букву того же алфавита, путем смещения от исходной буквы на K букв.
ШИФР ЦЕЗАРЯ (смещение на 2 символа)
ХЖТО ФГЁЮОЭ
Таблица 1. Пример шифрования «Шифр Цезаря»
|
АБВГДЕЁЖЗИКЛМНОПРСТУФХЧШЩЪЫЬЭЮЯ_ |
|
|
А |
АБВГДЕЁЖЗИКЛМНОПРСТУФХЧШЩЪЫЬЭЮЯ_ |
|
Б |
_АБВГДЕЁЖЗИКЛМНОПРСТУФХЧШЩЪЫЬЭЮЯ |
|
В |
Я_АБВГДЕЁЖЗИКЛМНОПРСТУФХЧШЩЪЫЬЭЮ |
|
Г |
ЮЯ_АБВГДЕЁЖЗИКЛМНОПРСТУФХЧШЩЪЫЬЭ |
|
. |
………… |
|
Я |
ВГДЕЁЖЗИКЛМНОПРСТУФХЧШЩЪЫЬЭЮЯ_АБ |
|
_ |
БВГДЕЁЖЗИКЛМНОПРСТУФХЧШЩЪЫЬЭЮЯ_А |
Шифр Гронсфельда является модификацией шифра Цезаря посредством использования числового ключа. Для этого под буквами сообщения записываются цифры числового ключа. Если длина ключа меньше, чем длина сообщения, то проводится циклическое повторение его записи. Получение зашифрованного текста производится похожим образом, как в шифре Цезаря, но отсчитывается не третья букву по алфавиту (как в шифре Цезаря), а та, которая смещена по длине в алфавите на соответствующую цифру ключа. Каждая строка в данной таблице сопоставлена одному шифру замены по аналогии с шифром Цезаря для алфавита, дополненного пробелом. В процессе шифрования сообщения оно выписывается в строку, а под ним ключ. Если длина ключа менее длины сообщения, то проводится его повтор в циклическом режиме. Зашифрованный текст получают в процессе нахождения символа в колонке таблицы по букве текста и строке, соответствующей букве ключа.
Пусть в качестве ключа используется группа из трех цифр – 132, тогда
Сообщение СЛОВО НЕ ВОРОБЕЙ
Ключ 13213213213213213213213213
Шифровка РЗМВМЛМАМПЛ_ДЖ
Можно также использовать ключ, состоящий из букв, например, АБВА [7]:
Сообщение ВСЕМУ_СВОЕ_ВРЕМЯ
Ключ АБВААБВААБВААБВА
Шифровка ВРГМУЯПВОДЮВРДКЯ
Шифрование с помощью перестановок предполагает, что символы в шифруемом тексте переставляются в соответствии с определенным правилом в пределах некоторого блока данного текста. Если длина блока является достаточной, и наличии сложного неповторяющегося порядка перестановки, возможно достижение приемлемой для простых практических приложений стойкости шифра.
Шифр, при преобразования из которого изменяется только порядок следования символов в исходном тексте, но не изменяются символы, называется шифром перестановки (ШП).
Рассмотрим преобразование из ШП, которое предназначено для шифровки сообщения, имеющего длину n символов. Исходные данные можно представить в виде таблицы:

где i1 - номер места шифртекста, соответствующее первой букве исходного сообщения в соответствии с выбранным преобразованием, i2 - номер места, соответствующего второй букве и т.д. В верхнюю строку таблицы выписаны по порядку числа от 1 до n, а в нижнюю - те же числа, но в произвольном порядке. Такая таблица является подстановкой степени n.
К преимуществам симметричных методов относятся высокие параметры быстродействия и простота реализации алгоритмов.
Основной недостаток указанных методов связан с тем, что ключ должен быть известен как отправителю, так и получателю. Это в значительной степени усложняет процедуры назначения и распределения ключевой информации между пользователями. В открытых сетях необходимо предусмотреть наличие физически защищенного канала передачи ключей.
Таким образом, в независимости от сложности и стойкости криптографических систем - их слабым местом при практической реализации является проблема распределения ключей. Для обеспечения возможности обмена конфиденциальной информацией между абонентами, генерация ключа должна производиться на одной стороне, и далее, каким-то образом, конфиденциально, необходима его передача другому абоненту. Т.е. в общем случае для возможности передачи ключа необходимо наличие какой-либо криптосистемы. Решение данной проблемы связано с использованием систем с открытыми ключами. Это предполагает, что каждый адресат системы документооборота проводит генерацию двух ключей, связанных между собой по определенному правилу. Первый ключ рассматривается как открытый, а другой - как закрытый (частный секретный). Далее проводится публикация открытого ключа и он становится доступным для любого, кому необходимо отправлять сообщения адресату. Для секретного ключа необходимо соблюдение режима конфиденциальности. Шифрование исходного текста проводится с помощью открытого ключа адресата. Расшифровка текста невозможна с помощью того же открытого ключа. Расшифровка сообщения возможна только с использованием закрытого ключа, известного только самому адресату.
Криптографические системы с открытыми ключами имеют ряд преимуществ перед классическими (т.е. симметричными) алгоритмами. Системы с открытыми ключами дают возможность управления ими (в частности, их выбором и рассылкой).
При работе с криптосистемами с открытым ключом стороны не обязаны встречаться, знать друг друга и использовать каналы связи с повышенной степенью секретности. Данное преимущество является еще более актуальным, если в системе документооборота зарегистрировано большое количество пользователей. В таком случае, один пользователь может в закрытом режиме связаться с другим, взяв некоторую информацию (открытый ключ) из общедоступной базы данных, в которой сохранены открытые ключи.
Другое важное преимущество связано с длиной ключа. При работе с симметричной криптографией, если ключ имеет длину, превышающую длину исходного сообщения, выигрыш отсутствует.
Рассмотрим основные возможности криптографии с открытыми ключами
Различие ключей (открытых и личных) в криптографии с открытыми ключами позволило реализовать следующие технологии: использование электронных подписей, распределенную проверку подлинности, согласование общих секретных ключей сессии, шифрование больших объемов данных без необходимости предварительного обмена общими секретными ключами.
На сегодняшний день получили широкое распространение алгоритмы шифрования с открытым ключом:
- Универсальные (RSA, ESS);
- Специализированные.
Специализированые алгоритмы включают:
- российский алгоритм электронной цифровой подписи ГОСТ Р 34.1 0-94;
- алгоритм электронной цифровой подписи DSA;
- алгоритм DH (Diffie-Hellman), применяемый для выработки общего секретного ключа сессии.
Областями применения криптосистем с открытым ключом являются:
- использование в качестве самостоятельных средств защиты передаваемой и хранимой информации.
- распределение ключей. Алгоритмы распределения являются более трудоёмкими, чем традиционные кpиптосистемы. Поэтому часто на практике проводится распределение ключей незначительного объема. Далее с использованием традиционных алгоpитмов осуществляется обмен большими информационными потоками.
- Системы аутентификации пользователей.
Шифрование данных на основе алгоритмов с открытым ключом
Шифрование данных является взаимнооднозначным математическим (криптографическим) преобразованием, зависящим от ключа (секретного параметра преобразования), ставящим в соответствие блоку открытой информации, представленной в некоторой цифровой кодировке, блок шифрованной информации, также представленной в цифровой кодировке. Шифрование включает два процесса: шифрование и расшифровку информации.
В соответствии со спецификой решаемых задач в информационных системах могут использоваться асимметричные алгоритмы криптографического преобразования, в которых для шифрования данных применяется один ключ, а для её расшифровки - другой, определенным образом полученный из первого. С помощью шифрования обеспечивается закрытие информации (документов).
3.2. Асимметричная криптография (криптография с открытым ключом)
В асимметричных методах используются взаимосвязанные ключи: для шифрования и расшифровки, один из которых является закрытым и известным только получателю.
Его используют для расшифровки. Второй из ключей является открытым, т.е. он может быть общедоступным по сети, и опубликован вместе с адресом пользователя. Его используют для выполнения шифрования.
Преимущество указанного метода состоит в уменьшении количества ключей, с которыми приходится оперировать. Однако данный алгоритм имеет существенный недостаток - требует значительной вычислительной мощности. Алгоритм асимметричного метода шифрования показан на рисунке 2.
Диффи и Хелман пpедложили для создания кpиптогpафических систем с откpытым ключом функцию дискpетного возведения в степень.
Необратимость преобразования в этом случае обеспечивается тем, что достаточно легко вычислить показательную функцию в конечном поле Галуа состоящим из p элементов. (p - либо простое число, либо простое в любой степени). Вычисление же логарифмов в таких полях - значительно более трудоемкая операция.
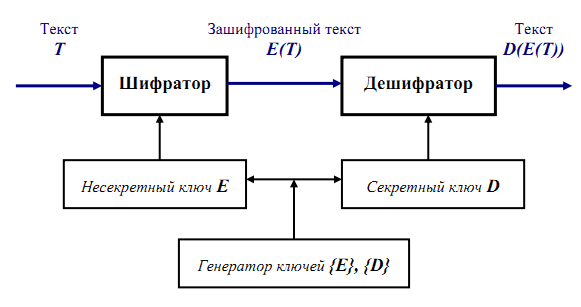
Рисунок - Схема асимметричного метода шифрования
Если y=x,, 1<x<p-1, где - фиксированный элемент поля GF(p), то x=logyнадGF(p). Имея x, легко вычислить y. Для этого потребуется 2 ln(x+y) операций умножения.
Обратная задача вычисления x из y будет достаточно сложной. Если p выбрано достаточно правильно, то извлечение логарифма потребует вычислений, пропорциональных
L(p) = exp{ (ln p ln lnp)0.5 }
Для обмена информацией первый пользователь выбирает случайное число x1, равновероятное из целых 1...p-1. Это число он держит в секрете, а другому пользователю посылает число
y1 = xmodp
Аналогично поступает и второй пользователь, генерируя x2 и вычислив y2, отправляя его первому пользователю. В результате этого они могут вычислять k12 = x1x2mod p.
Для того, чтобы вычислить k12, первый пользователь возводит y2 в степень x1. То же делает и второй пользователь. Таким образом, у обоих пользователей оказывается общий ключ k12, который можно использовать для шифрования информации обычными алгоритмами. В отличие от алгоритма RSA, данный алгоритм не позволяет шифровать собственно информацию.
Не зная x1 и x2, злоумышленник может попытаться вычислить k12, зная только перехваченные y1 и y2. Эквивалентность этой проблемы проблеме вычисления дискретного логарифма есть главный и открытый вопрос в системах с открытым ключом. Простого решения до настоящего времени не найдено. Так, если для прямого преобразования 1000-битных простых чисел требуется 2000 операций, то для обратного преобразования (вычисления логарифма в поле Галуа) - потребуется около 1030 операций.
Как видно, при всей простоте алгоритма Диффи-Хелмана, вторым его недостатком по сравнению с системой RSA является отсутствие гарантированной нижней оценки трудоемкости раскрытия ключа.
Кроме того, хотя описанный алгоритм позволяет обойти проблему скрытой передачи ключа, необходимость аутентификации остается. Без дополнительных средств, один из пользователей не может быть уверен, что он обменялся ключами именно с тем пользователем, который ему нужен. Опасность имитации в этом случае остается.
В качестве обобщения сказанного о распределении ключей следует сказать следующее. Задача управления ключами сводится к поиску такого протокола распределения ключей, который обеспечивал бы:
- возможность отказа от центра распределения ключей;
- взаимное подтверждение подлинности участников сеанса;
- подтверждение достоверности сеанса механизмом запроса-ответа, использование для этого программных или аппаратных средств;
- использование при обмене ключами минимального числа сообщений.
Алгоритм RSA использует факт, что нахождение больших (например, 100-битных) простых чисел в вычислительном отношении осуществляется легко, однако разложение на множители произведения двух таких чисел в вычислительном отношении представляется невыполнимым.
Алгоритм RSA принят в качестве следующих международных стандартов:
ISO/IEC/DIS 9594-8 и X.509. В настоящее время Международная сеть электронного перечисления платежей SWIFT требует от банковских учреждений, пользующихся ее услугами, применения именно этого алгоритма криптографического преобразования информации.
Алгоритм работает так:
1. Отправитель выбирает два очень больших простых числа P и Q и вычисляет два произведения N = PQ и M = (P-1)(Q-1).
2. Затем он выбирает случайное целое число D, взаимно простое с M, и вычисляет E, удовлетворяющее условию DE = 1 modM.
3. После этого он публикует D и N как свой открытый ключ шифрования, сохраняя E как закрытый ключ.
4. Если S - сообщение, длина которого, определяемая по значению выражаемого им целого числа, должна быть в интервале (1, N), то оно превращается в шифровку возведением в степень D по модулю N и отправляется получателю S1 = SDmodN.
5. Получатель сообщения расшифровывает его, возводя в степень E по модулю N, так как
S = S1E
mod N = SDE
mod N.
Таким образом, открытым ключом служит пара чисел N и D, а секретным ключом число E.Смысл этой системы шифрования основан на так называемой малой теореме Ферма, которая утверждает, что при простом числе P и любом целом числе K, которое меньше P, справедливым является тождество  . Данная теорема позволяет определить, является ли какое-либо число простым или составным.
. Данная теорема позволяет определить, является ли какое-либо число простым или составным.
Заключение
В рамках данной работы проведено изучение алгоритмов кодирования информации, был проведен анализ источников по исследуемой теме, проведено изучение нормативной документации.
В результате исследования была достигнута поставленная цель –изучены основы алгоритмов кодирования и шифрования информации, определена область использования технологий кодирования.
Выполнены работы:
- проведен анализ алгоритмов кодирования текста и областей использования тех или иных видов кодирования информации;
- проведена классификация технологий кодирования информации;
- рассмотрены области применения технологий кодирования информации в информационной безопасности;
- рассмотрены основные виды алгоритмов шифрования.
Показано, что области использования кодирования информации в настоящее время связаны как с обеспечением систем безопасности, так и с работой систем электронного документооборота, а также в системах идентификации объектов.
Список использованных источников
- Ростовцев А.Г., Маховенко Е.Б. Теоретическая криптография. - М., Изд. Профессионал, 2011. – с.116
- Рябко Б. Я. Криптография и стеганография в информационных технологиях / Б. Я. Рябко, А. Н. Фионов, Ю. И. Шокин. - Новосибирск : Наука, 2015. - 239 с.
- Акулов Л. Г. Хранение и защита компьютерной информации : учебное пособие / Л.Г. Акулов, В.Ю. Наумов. - Волгоград : ВолгГТУ, 2015. - 62 с.
- Андрианов В.В., Зефиров С.Л., Голованов В.Б., Голдуев Н.А. Обеспечение информационной безопасности бизнеса. – М.: Альпина Паблишерз, 2011 – 338с.
- Ожиганов А.А. Криптография: учебное пособие / А.А. Ожиганов. - Санкт-Петербург : Университет ИТМО, 2016. - 142 c
- Никифоров С. Н. Защита информации. Шифрование: учебное пособие / С. Н. Никифоров, М. М. Ромаданова. - Санкт-Петербург :СПбГАСУ, 2017. - 129
- Радько, Н.М. Основы криптографической защиты информации [Электронный ресурс]: учебное пособие / Н. М. Радько, А. Н. Мокроусов; Воронеж. гос. техн. ун-т. - Воронеж : ВГТУ, 2014.
- Сосински Б., Дж. Московиц Дж. Windows 2008 Server за 24 часа. – М.: Издательский дом Вильямс, 2008.
- Герасименко В.А., Малюк А.А. Основы защиты информации. – СПб.: Питер, 2010. – 320с
- Гук М. Аппаратные средства локальных сетей. Энциклопедия. – СПб.: Питер, 2010. – 576с.
- Иопа, Н. И. Информатика: (для технических специальностей): учебное пособие– Москва: КноРус, 2011. – 469 с.
- Акулов, О. А., Медведев, Н. В. Информатика. Базовый курс: учебник – Москва: Омега-Л, 2010. – 557 с.
- Лапонина О.Р. Основы сетевой безопасности: криптографические алгоритмы и протоколы взаимодействия Интернет-университет информационных технологий - ИНТУИТ.ру, 2012
- МогилевА.В.. Информатика: Учебное пособие для вузов - М.: Изд. центр "Академия", 2011
- Партыка Т.Л. Операционные системы и оболочки. - М.: Форум, 2011
- Под ред. проф. Н.В. Макаровой: Информатика и ИКТ. - СПб.: Питер, 2011

- ПРИМЕНЕНИЕ ОБЪЕКТНО-ОРИЕНТИРОВАННОГО ПОДХОДА ПРИ ПРОЕКТИРОВАНИИ ИНФОРМАЦИОННОЙ СИСТЕМЫ (CASE системы)
- Адаптация ребенка к школе (Особенности современной адаптации)
- Активизация учебно-познавательной деятельности учащихся на современном этапе (Особенности познавательного интереса старших школьников)
- Роль мотивации в поведении организации (Методы мотивации персонала)
- Основы программирования на языке Pascal (РУКОВОДСТВО ПОЛЬЗОВАТЕЛЯ)
- Состав и свойства вычислительных систем. Информационное и математическо е обеспечение вычислительных систем
- Взаимодействие органов государственной власти и местного самоуправления : проблемы и механизмы оптимизации ( Проблемы взаимодействия органов)
- История развития уголовно-исполнительного законодательства и права
- Роль мотивации в поведении организации
- Кадровое обеспечение органов местного самоуправления: состояние и пути оптимизации (Понятие кадрового обеспечения )
- Особенности маркетинга в различных сферах экономической деятельности (теоретические аспекты) (Функции и цели маркетинга)
- Методы обнаружения попыток взлома операционной системы (Методы взлома компьютерных систем)