
Методы кодирования данных (Сущность и общие особенности представления данных)
Содержание:

Введение
Актуальность темы курсовой работы обусловлена тем, что в настоящее время во многих приложениях активно используются разнообразные методы кодирования данных. Им посвящено большое количество литературы, в частности. Методы кодирования данных можно разделить на две категории:
- методы кодирования данных без потерь;
- методы кодирования данных с потерями.
Методы кодирования данных без потерь позволяют полностью восстановить кодированную информацию, в то время как методы кодирования данных с потерями позволяют достичь значительно лучшего кодирования за счет вносимых искажений. Соответственно методы кодирования данных с потерями имеют более узкую область применения и используются там, где некоторые искажения допустимы – например, для кодирования мультимедиа-информации.
Методы кодирования данных с потерями более универсальны. Их можно подразделить на методы статистического кодирования данных и словарные методы кодирования данных.
Методы оптимального кодирования данных применяются в тех случаях, когда символы алфавита встречаются в сообщениях с различной вероятностью. В этом случае применение оптимальных кодов позволяет минимизировать избыточность кода, а, следовательно, сократить время передачи сообщений. Код Шеннона-Фано и код Хаффмана относятся к множеству оптимальных кодов.
Алгоритм Шеннона-Фано ‒ один из первых алгоритмов кодирования, который впервые сформулировали американские учёные Шеннон и Фано. Данный метод кодирования имеет большое сходство с алгоритмом Хаффмана, который появился на несколько лет позже. Алгоритм использует коды переменной длины: символы, имеющие большую вероятность появления, кодируется кодом меньшей длины, символы с малой вероятностью появления ‒ кодом большей длины.
Несмотря на кажущуюся разработанность данной темы, решение проблемы поиска оптимальных методов кодирования данных является открытой в прикладном плане.
Исходя из факторов актуальности данного исследования, рационально сформулировать его объект, предмет и цель.
Объект исследования курсовой работы - кодирование данных.
Предмет исследования – методы кодирования данных.
Цель исследования курсовой работы – выявить сущность и описать оптимальные методы кодирования данных.
Исходя из данной цели, требуется решить следующие задачи:
1. Дать определение представления данных
2. Провести анализ сущности кодирования данных
3. Исследовать основные методы кодирования данных
4. Провести сравнение методов оптимального кодирования
В соответствии с целью и задачами исследования были использованы следующие методы:
- теоретический анализ и синтез литературы по теме исследования,
- изучение и обобщение отечественной и зарубежной практики,
- сравнение,
- абстрагирование,
- конкретизация и идеализация,
- индукция и дедукция,
- аналогия,
- классификация,
- обработка и обобщение полученных данных.
1. Сущность и общие особенности представления данных
1.1 Определение представления данных
Информация может быть заключена множеством символов (букв, цифр, знаков препинания и т. д.). Последовательности символов представляют слова языка[1].
В вычислительных машинах символы не могут храниться иначе, как в виде последовательностей бит (как и числа). Для передачи символа и его корректного отображения ему должна соответствовать уникальная последовательность нулей и единиц. Для этого были разработаны таблицы кодировок.
Количество символов, которые можно задать последовательностью бит длины n, задается простой формулой 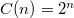 . Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
. Таким образом, от нужного количества символов напрямую зависит количество используемой памяти.
При записи числа в прямом коде (англ. Signed magnitude representation) старший разряд является знаковым разрядом. Если его значение равно нулю, то представлено положительное число или положительный ноль, если единице, то представлено отрицательное число или отрицательный ноль. В остальных разрядах (которые называются цифровыми) записывается двоичное представление модуля числа. Например, число 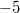 в восьмибитном типе данных, использующем прямой код, будет выглядеть так:
в восьмибитном типе данных, использующем прямой код, будет выглядеть так: 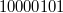 [2].
[2].
Таким способом в 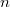 -битовом типе данных можно представить диапазон чисел
-битовом типе данных можно представить диапазон чисел ![[-2^{n-1} + 1; 2^{n-1} - 1]](/evkovaupload/job/95177/5.png) .
.
Достоинства представления чисел с помощью прямого кода
- Получить прямой код числа достаточно просто.
- Из-за того, что
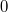 обозначает
обозначает 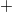 , коды положительных чисел относительно беззнакового кодирования остаются неизменными.
, коды положительных чисел относительно беззнакового кодирования остаются неизменными. - Количество положительных чисел равно количеству отрицательных.
Недостатки представления чисел с помощью прямого кода
- Выполнение арифметических операций с отрицательными числами требует усложнения архитектуры центрального процессора (например, для вычитания невозможно использовать сумматор, необходима отдельная схема для этого).
- Существуют два нуля:
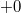
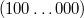 и
и 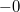
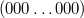 , из-за чего усложняется арифметическое сравнение.
, из-за чего усложняется арифметическое сравнение.
Из-за весьма существенных недостатков прямой код используется очень редко.
Код со сдвигом. Как видно, двоичное представление зациклено по модулю 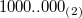 (
(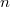 нулей)
нулей)
При использовании кода со сдвигом (англ. Offset binary) целочисленный отрезок от нуля до 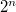 (
(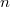 — количество бит) сдвигается влево на
— количество бит) сдвигается влево на 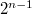 , а затем получившиеся на этом отрезке числа последовательно кодируются в порядке возрастания кодами от
, а затем получившиеся на этом отрезке числа последовательно кодируются в порядке возрастания кодами от  до
до 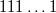 . Например, число
. Например, число 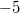 в восьмибитном типе данных, использующем код со сдвигом, превратится в
в восьмибитном типе данных, использующем код со сдвигом, превратится в 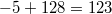 , то есть будет выглядеть так:
, то есть будет выглядеть так: 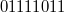 .
.
По сути, при таком кодировании:
- к кодируемому числу прибавляют
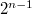 ;
; - переводят получившееся число в двоичную систему исчисления.
Можно получить диапазон значений ![[-2^{n-1}; 2^{n-1} - 1]](/evkovaupload/job/95177/23.png) .
.
Достоинства представления чисел с помощью кода со сдвигом
- Не требуется усложнение архитектуры процессора.
- Нет проблемы двух нулей.
Недостатки представления чисел с помощью кода со сдвигом
- При арифметических операциях нужно учитывать смещение, то есть проделывать на одно действие больше (например, после «обычного» сложения двух чисел у результата будет двойное смещение, одно из которых необходимо вычесть).
- Ряд положительных и отрицательных чисел несимметричен.
Из-за необходимости усложнять арифметические операции код со сдвигом для представления целых чисел используется не часто, но зато применяется для хранения порядка вещественного числа.
Дополнительный код (дополнение до единицы)
Нумерация двоичных чисел в представлении c дополнением до единицы. В отличии от кода со сдвигом, нулю соответствуют коды и
В качестве альтернативы представления целых чисел может использоваться код с дополнением до единицы (англ. Ones' complement).
Алгоритм получения кода числа:
- если число положительное, то в старший разряд (который является знаковым) записывается ноль, а далее записывается само число;
- если число отрицательное, то код получается инвертированием представления модуля числа (получается обратный код);
- если число является нулем, то его можно представить двумя способами:
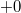
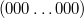 или
или 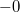
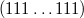 .
.
Пример: переведём число 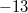 в двоичный восьмибитный код. Прямой код модуля
в двоичный восьмибитный код. Прямой код модуля 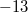 :
: 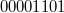 , инвертируем и получаем
, инвертируем и получаем 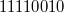 . Для получения из дополнительного кода самого числа достаточно инвертировать все разряды кода.
. Для получения из дополнительного кода самого числа достаточно инвертировать все разряды кода.
Таким способом можно получить диапазон значений ![[-2^{n-1}+1; 2^{n-1} - 1]](/evkovaupload/job/95177/32.png) [3].
[3].
Достоинства представления чисел с помощью кода с дополнением до единицы
- Простое получение кода отрицательных чисел.
- Из-за того, что
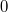 обозначает
обозначает 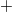 , коды положительных чисел относительно беззнакового кодирования остаются неизменными.
, коды положительных чисел относительно беззнакового кодирования остаются неизменными. - Количество положительных чисел равно количеству отрицательных.
Недостатки представления чисел с помощью кода с дополнением до единицы
- Выполнение арифметических операций с отрицательными числами требует усложнения архитектуры центрального процессора.
- Существуют два нуля:
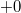 и
и 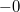 .
.
В качестве примера переведём число 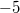 в дополнительный восьмибитный код. Прямой код модуля
в дополнительный восьмибитный код. Прямой код модуля 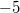 :
: 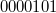 , обратный —
, обратный — 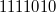 , прибавляем
, прибавляем 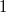 , получаем
, получаем 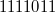 , приписываем
, приписываем 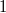 в качестве знакового разряда, в результате получаем
в качестве знакового разряда, в результате получаем 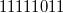 .
.
Дополнительный код также удобно использовать для вычислений в длинной арифметике, особенно для операций сложения и вычитания. Это операции удобно выполнять с числами одинаковой длины, поэтому в старшие разряды меньшего числа нужно поместить нули (если число положительно) или единицы (если число отрицательно). Тогда числа будут выглядеть следующим образом: в старших разрядах бесконечное число нулей (единиц), а в младших разрядах уже встречаются и нули, и единицы, которые кодируют само число, а не знак[4].
Удобство заключается в том, что нам не обязательно проделывать операции сложения с каждой парой бит, если мы знаем, что на этом отрезке в числах стоят либо единицы, либо нули. Таким образом, на этом отрезке в получившемся числе тоже будут либо только единицы, либо только нули. Операцию сложения можно выполнить только один раз для старших бит, таким образом мы узнаем знак получившегося числа. Вычитание тоже выполняется просто: инвертируем число, прибавляем один и получаем это число с минусом, затем просто делаем сложение. Однако умножение с числами, представленными дополнительным кодом, выполнять не всегда оптимально: алгоритм либо слишком медленный (наивный алгоритм работает за 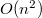 ), либо слишком сложный. Лучше для умножения использовать прямой код (бит под знак). Тогда можно числа перевести в десятичную систему счисления, выполнить быстрое преобразование Фурье за
), либо слишком сложный. Лучше для умножения использовать прямой код (бит под знак). Тогда можно числа перевести в десятичную систему счисления, выполнить быстрое преобразование Фурье за 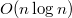 , затем перевести их обратно в двоичную. Обычно такой алгоритм работает быстрее, чем выполнение операции напрямую с двоичными числами. Для деления обычно тоже лучше использовать прямой код[5].
, затем перевести их обратно в двоичную. Обычно такой алгоритм работает быстрее, чем выполнение операции напрямую с двоичными числами. Для деления обычно тоже лучше использовать прямой код[5].
1.2 Анализ сущности кодирования данных
На заре компьютерной эры на каждый символ было отведено по пять бит. Это было связано с малым количеством оперативной памяти на компьютерах тех лет. В эти 64 символа входили только управляющие символы и строчные буквы английского алфавита.
С ростом производительности компьютеров стали появляться таблицы кодировок с большим количеством символов. Первой семибитной кодировкой стала ASCII7. В нее уже вошли прописные буквы английского алфавита, арабские цифры, знаки препинания. Затем на ее базе была разработана ASCII8, в которым уже стало возможным хранение 256 символов: 128 основных и еще столько же расширенных. Первая часть таблицы осталась без изменений, а вторая может иметь различные варианты (каждый имеет свой номер). Эта часть таблицы стала заполняться символами национальных алфавитов.
Но для многих языков (например, арабского, японского, китайского) 256 символов недостаточно, поэтому развитие кодировок продолжалось, что привело к появлению UNICODE[6].
Стоит отметить, что одна из важных практических задач — как поместить в компьютер как можно больше информации. Для этих нужд применяются механизмы кодирования.
Кодирование информации (англ. information coding) — отображение данных на кодовые слова. Обычно в процессе кодирования информация преобразуется из формы, удобной для непосредственного использования, в форму, удобную для передачи, хранения или автоматической обработки. В более узком смысле кодированием информации называют представление информации в виде кода. Средством кодирования служит таблица соответствия знаковых систем, которая устанавливает взаимно однозначное соответствие между знаками или группами знаков двух различных знаковых систем[7].
Пусть 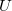 — множество исходных символов,
— множество исходных символов, 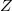 — кодовый алфавит,
— кодовый алфавит, 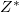 — множество всех строк конечной длины из
— множество всех строк конечной длины из 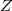 .
.
Код (англ. code) — отображение 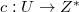 и
и 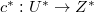 так, что
так, что 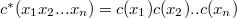 [8]
[8]
Существуют такие виды кодов:
1) Код фиксированной длины (англ. fixed-length code) — кодирование каждого символа производится с помощью строк одинаковой длины. Также он называется равномерным или блоковым кодом.
2) Код переменной длины (англ. variable-length code) — кодирование производится с помощью строк переменной длины. Также называется неравномерным кодом.
Префиксный код — код, в котором, никакое кодовое слово не является началом другого. Аналогично, можно определить постфиксный код — это код, в котором никакое кодовое слово не является концом другого. Предпочтение префиксным кодам отдается из-за того, что они упрощают декодирование. Поскольку никакое кодовое слово не выступает в роли префикса другого, кодовое слово, с которого начинается файл, определяется однозначно, как и все последующие кодовые слова[9].
Преимущества префиксных кодов
- Однозначно декодируемый и разделимый
- Удается получить более короткие коды, чем с помощью кода фиксированной длины.
- Возможности декодировки сообщения, не получая его целиком, а по мере его поступления.
Недостатки префиксных кодов
- При появлении ошибок в кодовой комбинации, при определенных обстоятельствах, может привести к неправильному декодированию не только данной, но и последующей кодовой комбинации, в отличии от равномерных кодов, где ошибка в кодовой комбинации приводит к неправильному декодированию только ее[10].
Все вышеперечисленные коды являются однозначно декодируемыми — для такого кода любое слово, составленное из кодовых слов, можно декодировать только единственным способом.
Таким образом, можно констатировать, что решение проблемы кодирования данных представляет не только научный, но и прикладной интерес и возможно с помощью оптимальных методов.
2. Основные методы кодирования данных
2.1 Метод Шеннона-Фано
Метод Шеннона-Фано (Shannon–Fano coding) является одним из первых методов кодирования информации. Впервые он был предложен независимо друг от друга Клодом Шенноном[11] и Робертом Фано. Метод основан на представлении информации с помощью кода переменной длины, в котором символы, встречающиеся с большей частотой, кодируются кодом меньшей длины, а встречающиеся с большей частотой – кодом большей длины, используя таким образом избыточность сообщений, заключающуюся в неравномерном распределении частот символов, для кодирования. Причем такой код префиксный, то есть никакое кодовое слово не является началом (префиксом) какого-либо другого кодового слова. Свойство это влечет однозначную декодируемость такого кода.
Опишем теперь этот метод.
Кодированный текст будем полагать состоящим из символов некоторого алфавита (в двоичном случае, символ может представлять собой, например, один байт, тогда мощность алфавита равна 256). Сначала вычисляются частоты символов в тексте. Далее производится построение префиксного кода с помощью дерева. Его построение начинается с корня, которому ставится в соответствие весь алфавит. Он разбивается на два подмножества, суммарные частоты символов которых примерно одинаковы. Этим подмножествам ставятся в соответствие две вершины дерева второго яруса, являющиеся детьми корня.
Затем каждое из этих подмножеств опять разбивается аналогичным образом и полученным подмножествам ставятся в соответствие вершины третьего яруса. При этом, если подмножество включает единственный элемент, то ему соответствует лист кодового дерева и дальнейшему разбиению такое подмножество не подлежит. Аналогично действуем до тех пор, пока не получим все листья. Построенное дерево следует разметить, т.е. его ребра пометить символами 1 и 0. Коды символов формируются из меток ребер на пути от соответствующего символу листа к корню.
Заметим, что разбиение множества элементов в некоторых случаях может быть произведено различными способами. При этом неудачный выбор разбиения может привести к неоптимальности кода. Из-за этого код Шеннона-Фано не является оптимальным в общем случае, хотя может быть оптимальным в частных случаях.
Структурируем алгоритм оптимального кодирования Шеннона-Фано:
- Все символы алфавита[12] упорядочиваются в порядке убывания вероятности их появления.
- Кодируемые символы делятся на две равновероятные или приблизительно равновероятные подгруппы.
- Каждому символу из верхней подгруппы присваивается код «0», а каждому символу из нижней подгруппы ‒ код «1».
- Каждая из подгрупп снова делится на две равновероятные или приблизительно равновероятные подгруппы. При этом каждому символу из верхней подгруппы присваивается код «0», а из нижней ‒ «1».
- Деление на подгруппы проводится до тех пор, пока в подгруппе не останется по одному символу.
- Результирующие кодовые слова записываются слева направо по кодам подгрупп, соответствующих кодируемому символу.
Пример оптимального кодирования по методу Шеннона-Фано приведен в таблице 2.1.
Таблица 2.1 ‒ Кодирование по методу Шеннона-Фано
|
Символ алфавита
|
Вероятность
|
Шаги алгоритма |
Количество элементарных символов
|
Кодовое слово |
||||
|
1 |
2 |
3 |
4 |
5 |
||||
|
|
0,30 |
0 0,55 |
0 0,3 |
2 |
00 |
|||
|
|
0,25 |
0 |
1 0,25 |
2 |
01 |
|||
|
|
0,15 |
1 |
0 0,25 |
0 0,15 |
3 |
100 |
||
|
|
0,1 |
1 |
0 |
1 0,1 |
3 |
101 |
||
|
|
0,1 |
1 0,45 |
1 0,2 |
0 0,1 |
3 |
110 |
||
|
|
0,05 |
1 |
1 |
1 0,1 |
0 0,05 |
4 |
1110 |
|
|
|
0,04 |
1 |
1 |
1 |
1 0,05 |
0 0,04 |
5 |
11110 |
|
|
0,01 |
1 |
1 |
1 |
1 |
1 0,01 |
5 |
11111 |











При использовании данного метода кодирования применяются вероятности появления символов алфавита в тексте сообщения. Вероятность появления символов считается исходной информацией и может быть вычислена любим способом. Далее вероятности сортируются по убыванию и записываются в столбец.
В коде Шеннона-Фано метод решения основывается на делении столбика вероятностей на две части, так чтобы сумма вероятностей сверху и снизу была примерно одинакова. Для полученных частей ставятся коды 0 и 1. Далее деление каждой полученной части повторяется. И так далее до того момента, когда образуются неделимые части. В таблице 2.2 представлена схема построения равномерного двоичного кода, в таблице 2.3 - схема Шеннона-Фано.
Таблица 2.2 – Схема построения равномерного двоичного кода
|
Символ |
Вероятность |
Код |
|
XI |
0.125 |
000 |
|
Х2 |
0.125 |
001 |
|
ХЗ |
0.125 |
010 |
|
Х4 |
0.125 |
011 |
|
Х5 |
0.125 |
100 |
|
Х6 |
0.125 |
101 |
|
Х7 |
0.125 |
ПО |
|
Х8 |
0.125 |
111 |
Среднее количество бит на символ:
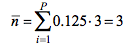
Таблица 2.3 – Схема построения двоичного кода Шеннона-Фано[13]
|
Символ |
Вероятность |
Код |
Схема кодирования |
|||
|
XI |
0.25 |
00 |
0 |
0 |
||
|
Х2 |
0.25 |
01 |
1 |
|||
|
ХЗ |
0.125 |
100 |
1 |
0 |
0 |
|
|
Х4 |
0.125 |
101 |
1 |
|||
|
Х5 |
0.0625 |
1100 |
1 |
0 |
0 |
|
|
Х6 |
0.0625 |
1101 |
1 |
|||
|
Х7 |
0.0625 |
1110 |
1 |
0 |
||
|
Х8 |
0.0625 |
1111 |
1 |
|||
Среднее количество бит на символ:
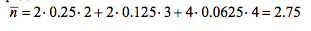
Код составляется из полученных, по горизонтали, в схеме кодирования нолей и единиц.
Отметим, что рассмотренная методика построения оптимального кода имеет некоторую неоднозначность для случаев, когда невозможно разбить символы алфавита на подгруппы с равными вероятностями. В таких случаях для одного и того же распределения вероятностей появления символов алфавита могут быть получены коды различной длины. Этой неоднозначности можно избежать, если для построения эффективного кода использовать алгоритм кодирования Хаффмана.
На сегодняшний день, метод Шеннона-Фано практически не используется и представляет лишь исторический интерес. Подмножеством кодов Шеннона-Фано являются коды Хаффмана.
2.2 Метод Хаффмена
Метод Хаффмана был впервые предложен в 1952 г[14]. Этот метод похож на метод Шеннона-Фано.
Будем полагать, что текст состоит из символов некоторого алфавита. Сначала вычисляются частоты символов в тексте. Далее исходя из этих частот строится дерево кодирования Хаффмана. При этом используется вспомогательный список свободных вершин. Построение дерева происходит следующим образом.
1. Для каждого символа строится по листу дерева. Каждому листу ставится в соответствие вес равный частоте этого символа. Все листья добавляются в список свободных вершин.
2. Из списка свободных вершин выбираются две вершины с наименьшими весами. Они удаляются из этого списка. Создается вершина дерева, являющаяся отцом двух этих вершин и имеющая вес, равный сумме их весов. Она добавляется в список свободных вершин.
3. Одно ребро инцидентное отцовской вершине помечается двоичной цифрой «0», а другое – двоичной цифрой «1».
4. Повторять шаги начиная с шага 2 до тех пор, пока в списке свободных вершин не останется ровно одна вершина. Она станет корнем дерева.
Кодом символа является последовательность меток ребер на пути от корня к листу, соответствующему этому символу.
Структурируем метод Хаффмана.
Алгоритм оптимального кодирования Хаффмана:
- Все символы алфавита упорядочиваются в порядке убывания их вероятностей появления.
- Проводится «укрупнение» символов. Для этого два последних символа «укрупняются» в некоторый вспомогательный символ с вероятностью, которая равняется сумме вероятностей символов, которые были «укрупнены».
- Образовавшаяся новая последовательность вновь сортируется в порядку убывания вероятностей с учетом вновь образованного за счет «укрупнения» символа.
- Процедура повторяется до тех пор, пока не получится один «укрупненный» символ, вероятность которого равна 1.
На практике не используют многократное выписывание символов алфавита и их упорядочивание. Обходятся построением кодового дерева так как это показано в таблице 2.4. Верхние ветви кодового дерева кодируются как 0, нижние ‒ 1. Кодирование каждой буквы проводится путем считывания значений (0 или 1) ответвлений, которые находятся на пути от корня кодового дерева (точки с вероятностью 1), до вершин, соответствующих каждому символу алфавита.
Таблица 2.4 ‒ Кодирование по методу Хаффмана
|
Символ алфавита
|
Вероятность
|
Кодовое дерево |
Количество элементарных символов
|
Кодовое слово |
||||||
|
|
0,30 |
0 |
F (0,55) |
2 |
00 |
|||||
|
|
0,25 |
1 |
0 |
G (1) |
2 |
01 |
||||
|
|
0,15 |
0 |
D (0,25) |
0 |
1 |
3 |
100 |
|||
|
|
0,1 |
1 |
C (0,2) |
E (0,45) |
3 |
101 |
||||
|
|
0,1 |
0 0 |
1 |
1 |
3 |
110 |
||||
|
|
0,05 |
0 |
1 |
B (0,1) |
4 |
1110 |
||||
|
|
0,04 |
A (0,05) |
5 |
11110 |
||||||
|
|
0,01 |
1 |
5 |
11111 |
||||||











Код Дэвида Хаффмана основан на построении дерева вероятностей. В столбце сортированных вероятностей складываются два последних значения. Полученный результат помещается в этот же столбец с учётом сортировки, а также записывается код прежней позиции слагаемых. Так продолжается до получения единственного элемента в столбце. Схема построения кода Хаффмана представлена на рисунке 2.1.
Код Хаффмана по схеме на рисунке 2.1 составляется из элементов кода при движении по веткам до номера позиции символа, код которого требуется построить.
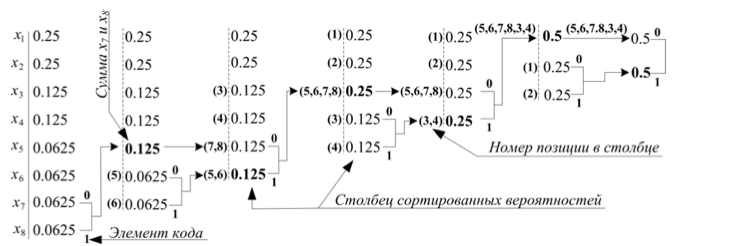
Рис. 2.1 – Код Хаффмана
Таблица 2.5 – Метод Хаффмана для сообщения 8 символов
|
Символ |
Вероятность |
Код |
|
XI |
0.25 |
10 |
|
Х2 |
0.25 |
11 |
|
ХЗ |
0.125 |
010 |
|
Х4 |
0.125 |
011 |
|
Х5 |
0.0625 |
0010 |
|
Х6 |
0.0625 |
0011 |
|
Х7 |
0.0625 |
0000 |
|
Х8 |
0.0625 |
0001 |
Метод Хаффмана находит широкое применение как при кодировании фотографий (в составе стандарта JPEG), видео (в составе стандартов MPEG), так и в архиваторах (например, в PKZIP). Хотя в качестве самостоятельного алгоритма кодирования метод применяется редко, чаще он используется в комплексе с другими алгоритмами кодирования.
2.3. Сравнение методов оптимального кодирования
Методика Шеннона–Фано не всегда приводит к однозначному построению кода.
Ведь при разбиении на подгруппы на 1-й итерации можно сделать большей по вероятности как верхнюю, так и нижнюю подгруппу. В результате среднее число символов на букву окажется другим.
Таким образом, построенный код может оказаться не самым лучшим.
От указанного недостатка свободна методика Хаффмана. Она гарантирует однозначное построение кода с наименьшим для данного распределения вероятностей средним числом символов на букву.
Метод Хаффмана производит идеальное кодирование (то есть, кодирует данные до их энтропии), если вероятности символов точно равны отрицательным степеням числа 2. Результаты эффективного кодирования по методу Хаффмана всегда лучше результатов кодирования по методу Шеннона-Фано.
Предложенный Хаффманом алгоритм построения оптимальных неравномерных кодов – одно из самых важных достижений теории информации, как с теоретической, так и с прикладной точек зрения. Этот весьма популярный алгоритм служит основой многих компьютерных программ кодирования текстовой и графической информации. Некоторые из них используют непосредственно алгоритм Хаффмана, а другие берут его в качестве одной из ступеней многоуровневого процесса кодирования.
Этот алгоритм был придуман в 1952 г. студентом Дэвидом Хаффманом в процессе выполнения домашнего задания.
Кодирование методом Хаффмана называют двухпроходным, так как его реализация распадается на два этапа[15]:
- на первом этапе реализуется алгоритм Хаффмана,
- а на втором этапе строится дерево Хаффмана.
Дальнейшим развитием идеи, лежащей в основе метода Хаффмана, является арифметическое кодирование.
Отличие этого алгоритма в том, что он работает с непрерывным отрезком, который мы будем называть рабочим отрезком. Вначале объявим рабочим отрезком единичный отрезок. Расположим на нем точки таким образом, что отношения длин образованных подотрезков к длине всего рабочего отрезка будут равны частотам символов, а каждый такой подотрезок будет соответствовать одному символу.
Теперь возьмем очередной символ кодируемого текста, выберем соответствующий ему отрезок среди только что сформированных и объявим его рабочим. Разобьем и его вышеприведенным образом и т.д. Отрезок будет постоянно уменьшаться. После того, как мы таким образом обработаем все символы кодируемого текста, возьмем любое число, принадлежащее рабочему отрезку. Оно и будет закодированным сообщением.
Метод арифметического кодирования позволяет достичь высокого коэффициента кодирования.
Метод PPM (prediction by partial matching) представляет собой метод контекстнозависимого моделирования ограниченного порядка. Он основан на оценке вероятности символа в зависимости от контекста, т.е. от символов, стоящих перед ним. Если для этой оценки используется контекст длины n, то говорят об использовании контекстноограниченной модели порядка n.
В рамках модели порядка n, при n > 0 , оценка вероятности символа c равна отношению количества раз, которое встретилась конкатенация данного контекста с символом c к количеству раз, которое встретился данный контекст. При использовании модели нулевого порядка, оценка вероятности равна частоте, с которой данный символ встретился в тексте. При использовании модели порядка –1, вероятность каждого символа оценивается как , где A – алфавит.
Например, пусть следует закодировать строку 121123123122123 над алфавитом {1,2,3}. Оценим вероятность последнего символа.
В модели порядка 2 вероятность символа «3» оценивается как 2/4, поскольку контекст длины 2 встретился в строке 4 раза, причем 2 раза в этом контексте имел место символ «3». Модель первого порядка оценивает вероятность символа «3» как 2/5. Для модели порядка 0 эта вероятность оценивается как 1/5, а для модели порядка –1 – как 1/3.
Рассматриваемый алгоритм работает следующим образом. К алфавиту кодируемой последовательности добавляется специальный символ – код ухода «ESC». Вводится понятие вероятности ухода, т.е. вероятности, которую имеют еще не появлявшиеся символы. При этом любая модель должна выдавать отличную от нуля оценку вероятности ухода.
Пусть задан максимальный порядок m. Для кодирования очередного символа рассматривается модель порядка m. Если она выдает ненулевую оценку вероятности этого символа, то эта вероятность и используется в качестве исходных данных для его кодирования. Если же модель не может произвести оценку вероятности данного символа, либо эта оценка равна нулю, выдается код ухода и производится следующая попытка оценки вероятности этого символа с помощью модели порядка m – 1.
Если и эта модель не может произвести такую оценку, то применяется модель порядка m – 2 и т.д. Так продолжается до тех пор, пока не будет получена ненулевая оценка вероятности. Получение такой оценки гарантируется моделью порядка –1. В результате, каждый символ может предваряться несколькими символами ухода. При этом символы кодируются, например, с помощью кода Хаффмана, используя вместо частоты символа, полученную оценку вероятности.
Метод PPM демонстрирует один из самых высоких коэффициентов кодирования, прежде всего, для текстов на естественном языке, что обуславливает весьма широкое его применение. Мы также можем предложить его использовать для кодирования текстов на естественном языке перед кодированием с помощью различных криптоалгоритмов, например, предложенных в работах. Недостатком метода PPM является медленное декодирование[16].
Заключение
Для достижения цели курсовой работы были решены следующие задачи:
1. Дано определение представления данных
Решение данной задачи позволило сформулировать следующие выводы:
Было установлено, что представление данных — это характеристика, которая выражает правила кодирования элементов и формирования конструкций данных на конкретном уровне рассмотрения в вычислительной системе.
Было также отмечено, что единицей измерения информации служит бит: один ответ на вопрос типа «да-нет».
2. Проведен анализ кодирования данных
Решение данной задачи позволило сформулировать следующие выводы:
В ходе реализации данной задачи было установлено, что возможность для кодирования файла заключается в оптимизации двоичного кодирования его алфавита.
Можно констатировать, что двоичная сложность вопроса об индивидуализации произвольного элемента n-элементного множества не меньше чем log2 n.
Решение проблемы кодирования данных представляет не только научный, но и прикладной интерес и возможно с помощью оптимальных методов.
3. Исследованы основные методы кодирования данных
Решение данной задачи позволило сформулировать следующие выводы:
Рассмотренный метод Шеннона-Фано основан на представлении информации с помощью кода переменной длины, в котором символы, встречающиеся с большей частотой, кодируются кодом меньшей длины, а встречающиеся с большей частотой – кодом большей длины, используя таким образом избыточность сообщений, заключающуюся в неравномерном распределении частот символов, для кодирования. Было отмечено, что на сегодняшний день метод Шеннона-Фано практически не используется и представляет лишь исторический интерес.
Рассмотренный метод кодирования Хаффмана основан на построении дерева вероятностей. В столбце сортированных вероятностей складываются два последних значения. Полученный результат помещается в этот же столбец с учётом сортировки, а также записывается код прежней позиции слагаемых. Так продолжается до получения единственного элемента в столбце.
4. Проведено сравнение методов оптимального кодирования и изучено их развитие
Решение данной задачи позволило сформулировать следующие выводы:
Было отмечено, что методика Шеннона–Фано не всегда приводит к однозначному построению кода, т.к. построенный код может оказаться не самым лучшим. Методика Хаффмана гарантирует однозначное построение кода с наименьшим для данного распределения вероятностей средним числом символов на букву.
Метод PPM (prediction by partial matching) представляет собой метод контекстнозависимого моделирования ограниченного порядка. Он основан на оценке вероятности символа в зависимости от контекста, т.е. от символов, стоящих перед ним. Если для этой оценки используется контекст длины n, то говорят об использовании контекстноограниченной модели порядка n.
Метод PPM демонстрирует один из самых высоких коэффициентов кодирования, прежде всего, для текстов на естественном языке, что обуславливает весьма широкое его применение. Мы также можем предложить его использовать для кодирования текстов на естественном языке перед кодированием с помощью различных криптоалгоритмов, например, предложенных в работах. Недостатком метода PPM является медленное декодирование.
Список литературы
- Верещагин Н.К., Щепин Е.В. Информация, кодирование и предсказание. — М.: ФМОП, 2012. — 236 с.
- Дидовский В.В. Теория информации. ‒ М.: Спутник+, 2014. - 308 с.
- Ключарев П.Г. Блочные шифры, основанные на обобщённых клеточных автоматах // Наука и образование. Электронное научно-техническое издание. - 2012. - No 12. – C. 78-81
- Костров Б.В. Основы цифровой передачи и кодирования информации. - ТехБук, 2007. - 192 с.
- Кудряшов Б.Д. Основы теории кодирования. - СПб.: БХВ-Петербург, 2016. - 400 с.
- Кудряшов Б.Д. Теория информации. ‒ СПб.: Питер, 2013. - 244 с.
- Литвинская О.С., Чернышев Н.И. Основы теории передачи информации. – М.: КНОРУС, 2014. – 164 с.
- Мазурков М.И. Основы теории передачи информации. ‒ Одесса: Наука и техника, 2015. ‒ 168 с.
- Матвеев Б.В. Основы корректирующего кодирования. - М.: Лань, 2014. - 192 с.
- Панин В.В. Основы теории информации. - М.: Бином. Лаборатория знаний, 2014. - 440 с.
- Сэломон Д. Кодирование данных, изображений и звука. — М. : Техносфера, 2006. — 365 с.
- Хохлов Г.И. Основы теории информации. - М.: Academia, 2008. - 176 с.
- - М.: МЦНМО, 2011. - 224 с.
- Huffman D.A. A method for the construction of minimum redundancy codes // proc. IRE. 1952. Т. 40. No 9. — C. 1098-1101
- Shennon K., Weaver W. A mathematical theory of communication // Bell System Tehn. J. 1948. Т. 3. — C. 623-637
-
Хохлов Г.И. Основы теории информации. - М.: Academia, 2008. - 176 с. ↑
-
Матвеев Б.В. Основы корректирующего кодирования. - М.: Лань, 2014. - 192 с. ↑
-
Литвинская О.С., Чернышев Н.И. Основы теории передачи информации. – М.: КНОРУС, 2014. – 164 с. ↑
-
Верещагин Н.К., Щепин Е.В. Информация, кодирование и предсказание. — М.: ФМОП, 2012. — 236 с. ↑
-
Сэломон Д. Кодирование данных, изображений и звука. — М. : Техносфера, 2006. — 365 с. ↑
-
Мазурков М.И. Основы теории передачи информации. ‒ Одесса: Наука и техника, 2015. ‒ 168 с. ↑
-
Кудряшов Б.Д. Теория информации. ‒ СПб.: Питер, 2013. - 244 с. ↑
-
Дидовский В.В. Теория информации. ‒ М.: Спутник+, 2014. - 308 с. ↑
-
Чечёта С.И. Введение в дискретную теорию информации и кодирования. - М.: МЦНМО, 2011. - 224 с. ↑
-
Панин В.В. Основы теории информации. - М.: Бином. Лаборатория знаний, 2014. - 440 с. ↑
-
Shennon K., Weaver W. A mathematical theory of communication // Bell System Tehn. J. 1948. Т. 3. — C. 623-637 ↑
-
Суммарная вероятность появления символов алфавита должна равняться 1 ↑
-
Кудряшов Б.Д. Основы теории кодирования. - СПб.: БХВ-Петербург, 2016. - 400 с. ↑
-
Huffman D.A. A method for the construction of minimum redundancy codes // proc. IRE. 1952. Т. 40. No 9. — C. 1098-1101 ↑
-
Костров Б.В. Основы цифровой передачи и кодирования информации. - ТехБук, 2007. - 192 с. ↑
-
Ключарев П.Г. Блочные шифры, основанные на обобщённых клеточных автоматах // Наука и образование. Электронное научно-техническое издание. - 2012. - No 12. – C. 78-81 ↑

- Методы кодирования данных (Физическое кодирование данных)
- Основные технологии проектирования информационных систем
- Общение как взаимодействие (ТЕОРЕТИЧЕСКОЕ ИЗУЧЕНИЕ ОСОБЕННОСТЕЙ ОБЩЕНИЯ ДЕТЕЙ СТАРШЕГО ДОШКОЛЬНОГО ВОЗРАСТА)
- Понятие “ноу хау” и договоры о его передаче (Правовая охрана секрета производства (ноу-хау))
- ОБЪЕКТЫ И СУБЪЕКТЫ АВТОРСКОГО ПРАВА
- ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ВНЕШНЕЙ И ВНУТРЕННЕЙ СРЕДЫ
- Жизненный цикл организации и управление организацией (Организация как носитель жизненного цикла)
- Жизненный цикл организации и управление организацией (Теоретические основы изучения жизненного цикла организации жизненного цикла)
- Особенности учета и анализа состава, структуры, технического состояния основных средств
- Формирование портфеля инновационных проектов. Методы оценки эффективности нововведений. Использование информационных технологий в инновационном менеджменте.
- Проектирование организации (Главные цели и задачи организационного проектирования)
- Цель, задачи, объект, предмет и этапы эмпирического исследования