
Методы кодирования данных (Основные принципы кодирования данных)
Содержание:

Введение
Потребность кодировать информацию, т.е. преобразовывать ее для каких-то специфических целей, люди испытывали и в докомпьютерную эпоху. Письменность есть ни что иное, как способ кодировать сообщения для долговременного хранения, публикации или отправки адресату. То же можно сказать о цифрах, применяемых для вычислений, записи дат. Музыка уже несколько веков записывается с помощью нот.
Со временем появились специальные системы кодирования для передачи информации с помощью радиосигналов (азбука Морзе), для людей с ограниченными возможностями (азбука Брайля для незрячих, азбука жестов для глухонемых). По мере развития науки и техники были внедрены знаковые системы для отдельных отраслей человеческой деятельности. Химики пользуются особыми формулами для записи структуры молекул, астрономы - для обозначения интенсивности блеска и цвета небесных тел, инженеры, создавая чертежи и схемы, применяют стандартизированные условные обозначения. В каждой отрасли человеческой деятельности есть свои особенности общения между специалистами, свой сленг, свои символы.
С появлением компьютеров кодирование информации унифицировалось: все традиционные знаковые системы были оцифрованы, т. е. приведенными к виду, пригодному для использования в компьютерных системах. Кодирование для них производится посредством электрических импульсов, для которых характерны: полярность; время активности; фаза; частота.
Сегодня кодирование – это трансляция информационных данных из одного формата обозначений, в иной системный формат, иными словами, - преобразование текста из обычного, понятного людям, формата, в форму записи посредством кодов. Кодовое обозначение - это знак или несколько знаков, которые обозначают данный объект согласно некоторым законам, предписанным кодовой системой.
Актуальность выбранной темы обусловлена тем, что в связи с широким распространением персональных компьютеров не только как средств обработки информации, но также как оперативных средств коммуникации (электронная, телефаксная почта), возникают проблемы, связанные с обеспечением защиты информации от преднамеренных или случайных искажений. Поэтому необходимость кодирования информации имеет большое значение в решении этой проблемы и остаётся актуальной и на сегодняшний день.
Целью данной работы является изучение существующих методов кодирования данных.
Для достижения поставленной цели необходимо решить ряд задач:
- Изучить основные принципы кодирования данных,
- Рассмотреть основные методы кодирования текстовой и числовой информации,
- Изучить особенности кодирования графической информации.
Объектом исследования в данной работе является информационный процесс обработки данных.
Предмет исследования – способы и методы кодирования данных.
В структуру данной работы входит введение, основная часть, состоящая из трех глав, заключение и список использованной литературы.
1. Основные принципы кодирования данных
Под кодированием понимается преобразование информации в другой (альтернативный) формат. По существу, системы кодирования являются аналогом шифру поимённой подмены, когда каждый единичный модуль информационных данных, подлежащих кодировке, заменяется соответствующим ему шифром[1]. Однако есть и отличие, и оно состоит в наличии у операции шифрования так называемой изменяемой части (ключа). Эта изменяемая часть для одного и того же передаваемого сообщения и при неизменном алгоритме, способна выдать различные тексты шифровки. При использовании кодировки вместо шифрования, такой изменяемой составляющей просто нет. Именно из-за этого одно и тоже передаваемое сообщение при многократном кодировании не меняет свой вид, а всегда имеет одинаковый формат.
Ещё одним отличием кодирования можно считать использование кодовых заменителей для целых слов и даже предложений или набора цифр. Подмена частей информации, подлежащей кодированию, кодовыми символами выполняется на базе специальных таблиц (аналогичных таблицам шифровальных замен) или определяется с помощью алгоритмов или функций для кодировок.
Кодирование в общем понимании — это процесс преобразования данных в формат, необходимый для удовлетворения потребностей в обработке информации, в том числе[2]:
- Компиляция и исполнение программы.
- Передача данных, хранение и сжатие (декомпрессия).
- Обработка данных приложений, таких как преобразование файлов.
Все виды кодов могут иметь два значения:
- В компьютерной технологии кодирование представляет собой процесс применения определенного кода, такого как буквы, символы и цифры, к данным для преобразования в эквивалентный шифр.
- В электронике кодирование относится к аналого-цифровому преобразованию.
Компонентами информации, подлежащими кодированию, могут быть[3]:
- Предложения (фразы) разговорной речи, отдельные слова или буквы.
- Разные символьные обозначения, к примеру, операции логики и арифметики, знаки препинания, операторы сравнения (больше, меньше, равно) и тому подобное. Надо заметить, что сами знаки операций и операторы сравнения относятся к кодовым обозначениям.
- Цифры (числа).
- Аудио и визуальные объекты (образы).
- Различные явления и ситуации.
- Информация, переданная по наследству.
Кодовыми обозначениями могут выступать:
- Комбинации букв разговорного языка и непосредственно буквы.
- Различные цифры (числа).
- Обозначения в виде графических изображений.
- Звуковые и световые команды (сигналы)
- Электрические и электромагнитные импульсы.
- Комбинация различных химических молекул.
Основными задачами (целями) кодирования информации являются:
- Создать дополнительные преимущества для сохранения, анализа и пересылки данных (практически всегда информация в виде кодов занимает меньше места в памяти и более приспособлена для работы с ней и пересылки автоматизированными программными и техническими средствами).
- Обеспечить удобный обмен информацией между объектами.
- Сделать наглядным отображение.
- Выполнить идентификацию субъектов и объектов.
- Скрыть доступ к секретной информации.
Существует одноуровневое кодирование информации и многоуровневое. Например, световые сигналы светофора (красный, жёлтый, зелёный) - это одно уровневое кодирование. Многоуровневым кодированием является визуальный образ фотографии, сохранённый как отдельный файл. Сначала фотография расчленяется на отдельные мелкие модули (пиксели), то есть все мелкие составляющие части изображения кодируются элементарными модулями (элементами). Каждый элемент может быть представлен как набор составляющих основных цветов: красного, зелёного и синего каждый с требуемой амплитудой (интенсивностью), выраженной в форме числа. В дальнейшем числовые наборы переформатируются (перекодируются) для того, чтобы сделать информацию более компактной (к примеру, форматы jpeg, png и так далее). В итоге, полученные числовые значения преобразуются (перекодируются) в электромагнитные импульсы и передаются по специальным каналам для коммутации или зонам на информационных носителях[4]. Необходимо также отметить, что конкретные числовые значения при работе программы, представлены согласно правилам используемой системы кодировки чисел.
Существуют обратимые и необратимые способы кодирования информационных данных:
- Если используется обратимое кодирование, то закодированная информация всегда может быть восстановлена без потери данных. К таким типам кодирования можно отнести, к примеру, азбуку Морзе или штрих-кодирование.
- При применении необратимого кодирования нет возможности достоверно восстановить исходную информацию. Примерами могут служить коды аудио и визуальной информации (в форматах jpg, mp3 или avi), а также хеширование.
Существуют системы кодирования с общим доступом и засекреченные системы. Первый тип применяется для улучшения качества обмена информацией, второй тип для обеспечения скрытности данных от несанкционированного доступа.
Таким образом, можно говорить о том, что кодированием информации называют преобразование данных в вид, удобный для обработки и передачи. То есть, по сути, это превращение одной информационной формы в другую. А собственно код — это комбинация символов для обозначения общепринятых и общеизвестных понятий.
Как правило, определённые образы при кодировке (можно сказать шифровании) могут быть выражены определёнными знаками. Набор различных знаков образует некое множество с ограниченным набором элементов. Электронные вычислительные машины способны работать только с информационными данными, заданными в формате чисел[5]. Поэтому информационные данные других видов (к примеру, речь, различные звуки, изображения и так далее) для использования и преобразования компьютерными программами необходимо представить в числовом формате.
В качестве примера можно рассмотреть преобразование в формат набора чисел музыкальных звуков. Для этого необходимо через определённые временные интервалы определять амплитуду звуковых колебаний на некотором наборе частот, выражая в виде числа итоги этих замеров. Далее, используя специальное программное обеспечение, возможно сделать практически любую обработку этих данных. К примеру, соединить звуковую информацию от различных источников.
Аналогично этому, возможно преобразовывать и любые данные, представленные в виде текста. При наборе текста, например, с клавиатуры компьютера, любой символ заменяется некоторым числовым значением, а при выводе сформированного текстового файла на дисплей или принтер, выполняется обратная процедура. То есть набор чисел преобразуется в понятные людям визуальные образы букв.
Выстроенную связь между числовыми значениями и соответствующими им буквами, можно назвать кодировкой символов. В компьютерной технике принято использовать не десятичную, а более легко реализуемую электроникой, двоичную систему счисления. То есть, применяются всего две цифры ноль и единица, что соответствует двум устойчивым состояниям базового элемента электроники, триггера[6]. Но ввод и вывод числовой информации осуществляется в привычной обычному человеку десятичной системе счисления, что обеспечивает соответствующее программное обеспечение.
Одни и те же информационные данные можно выразить (кодировать) в различных форматах. С созданием электронных вычислительных машин появилась потребность кодировать практически все типы информационных данных, с которыми связаны конкретные люди и всё мировое сообщество в целом. Но заниматься проблемой шифрования (кодирования) информации люди начали ещё до изобретения электронных вычислительных машин. Великие изобретения людей, какими являются письменность и математика (и её подраздел, арифметика), по сути и есть методы кодирования человеческой речи и числовых данных.
В абсолютно чистом виде информацию мы нигде не встретим, в любом случае она будет как-то выражена (закодирована). Самым распространённым методом выражения информации является система двоичных кодов. В электронных вычислительных машинах, в роботизированных комплексах, в устройствах числового программного управления (УЧПУ) металлорежущими и другими станками, информационные данные, с которыми оперирует оборудование, представлены в виде набора двоичных чисел.
2. Методы кодирования текстовой (символьной) и числовой информации
Любой текст может состоять из различных символов:
- букв (латинского и национального алфавитов);
- цифр (чаще всего т.н. арабских);
- иероглифов (китайских, японских, корейских и т.д.);
- знаков препинания и типографских символов;
- специальных знаков (математических, физических, таких, как знак градуса Цельсия);
- прочих символов, как, к примеру, недавно появившиеся знаки «эмодзи».
Общее количество символов, употребляемых человечеством измеряется сотнями, а возможно и тысячами, причем в будущем, по мере появления новых знаний, этот перечень, скорее всего, будет расширен.
Оптимальный способ представить символ в памяти компьютера - присвоить ему порядковый номер. Однако длина двоичного числа для каждого такого номера должна быть постоянной, иначе придется хранить о ней дополнительную информацию, что осложнит обработку. Стандартным решением этой проблемы является кодировка Unicode, где каждому знаку соответствует 16-битная последовательность. Всего таких различных последовательностей может быть 65536, поэтому Unicode способен не только вместить в себя все существующие на сегодняшний день системы письменности, но и содержит достаточно свободного пространства для будущего применения[7].
Главная процедура, выполняемая над каждым элементом текстовых данных, это сопоставление символов. В процедуре сравнения символов основным моментом выступает неповторимость шифра (кода) любого символа и размер данного шифра (кода), а собственно метод кодировки фактически не важен. Чтобы закодировать какой-либо текст, применяются разнообразные таблицы перекодирования. Главное, чтобы для кодирования и последующего декодирования применялись одни и те же таблицы. Таблица перекодирования должна включать в свой состав формализованный определённым порядком список символов для кодирования, согласно которому выполняется перевод символа в двоичный код, а также обратная процедура. Наиболее распространёнными формами таблиц являются ДКОИ-8, ASCII, CP1251 и Unicode.

Рисунок 1. Фрагмент таблицы Unicode с «эмодзи»
Длина кода представления символа уже давно сформировалась как 8 бит (1 байт). И именно по этой причине один текстовый символ занимает один байт памяти компьютера. Соответственно, число вариантов (комбинаций) набора нулей и единиц при размере кода 8 бит будет два в восьмой степени, то есть 256. Это означает, одна таблица для перекодирования позволяет кодировать максимум 256 символов. Но если использовать код длиною в два байта, то это число соответственно возрастёт до 65536 символов.
У кодирования чисел и текста есть один общий момент, для возможности сравнения данных такого вида, различные числа (как и в случае символов) обязаны иметь разные коды. Главной отличительной особенностью числовой информации от символьной, является то, что числа кроме процедуры сравнения, подвергаются ещё самым разным арифметическим операциям (вычитание и сложение, умножение и так далее). Для выполнения этих действий в электронных вычислительных машинах служит двоичная позиционная система счисления[8].
При кодировании текстовой информации каждый символ имеет своё двоичное число (код) от 00000000 до 11111111, что в десятичной системе соответствует числам от 0 до 255. Следует учитывать, что для кодирования букв русского алфавита существует пять разных кодовых таблиц (КОИ - 8, СР1251, СР866, Мас, ISO), при этом, если текст вводился с применением одной из таблиц, то он будет неправильно декодироваться при использовании другой таблицы.
Целые положительные числа представляются в виде двоичных (битовых, бинарных) последовательностей. Длина этих последовательностей зависит от величины числа. Например, для записи чисел он 0 до 255 достаточно 8 бит. Такую "порцию" информации принято называть байтом (byte). Для более длинных чисел выделяют по 16 (word), 32 (int), 64 (long) бита. Более длинные последовательности используются редко, поскольку с помощью 64 бит можно закодировать большинство чисел, используемых в человеческой практике[9] (264=18446744073709551616).
Для представления отрицательных чисел задействуют отдельный (обычно старший) бит. Для представления действительных (дробных) чисел используется форма записи с плавающей точкой.
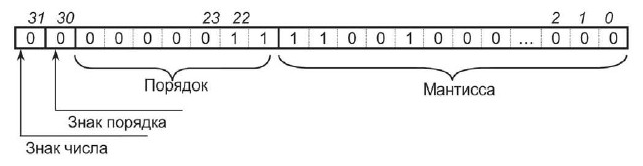
Рисунок 2. Представление дробного числа в виде байтовой последовательности
Методы кодирования, которые имеют статус самостоятельных, называются регистрационными методами кодирования. Методы, основанные на первоначальной классификации объектов, называются классификационными методами кодирования. В свою очередь, регистрационное кодирование делится на два типа:
- Порядковый тип.
- Серийно-порядковый тип.
Порядковый метод использует для кодирования наборы натуральных чисел. При этом все объекты множества получают свой порядковый номер. Данный метод кодировки имеет небольшую избыточность информации, даёт значительную долговечность классификатора и при этом очень прост, применяет самые короткие кодовые комбинации и позволяет обеспечить однозначное определение каждого классифицируемого объекта[10]. Плюс ко всему, достаточно просто присвоить коды вновь появившемся при классификации объектам.
Главным недостатком порядкового способа кодирования можно считать то, что в нём нет данных, описывающей свойства объекта, и достаточно сложно выполнить автоматизированную работу с данными при формировании результатов по элементам одной группы и с совпадающими описаниями. Порядковый метод кодирования не имеет возможности размещать новые объекты, которые надо классифицировать, в требуемом месте классификатора, потому что зарезервированные коды находятся в самом конце. Поэтому, порядковый метод создания классификатора почти никогда не используется самостоятельно, а только вместе с другими способами.
Серийно – порядковый метод кодирования основывается на применении в качестве кодов натуральных чисел, но с резервированием некоторых наборов таких чисел (фрагментам натурального ряда) для объектов классификации с совпадающими признаками. Во всех сериях чисел, кроме кодирования уже существующих объектов классификации, фиксируется некоторое число резервных кодов. Резервные коды могут быть расположены в середине или в окончании кодового набора. По этой причине, лучше использовать серийно-порядковый метод кодирования, чем просто порядковый. Он имеет все преимущества и недостатки порядкового метода кодировки. Но чаще всего он применяется совместно с классификационными методами кодирования, которые также делятся на два типа:
- Последовательное кодирование.
- Параллельное кодирование.
Последовательное кодирование основано на формировании кодов группировки или объекта с использованием кодов, идущих друг за другом, зависимых группировок, образованных иерархическим методом кодировки. Его главным достоинством можно считать логичность формирования кодов и значительную ёмкость. Но при этом, у него есть все недостатки, которыми обладает иерархический метод классификации, и у него ограничена возможность идентификации объекта.
При параллельном методе кодирования коды классификационной группировки или классифицируемого объекта формируются с применением свободных группировок, которые получены с помощью фасетного метода классификации.
В локальных сетях процедура логического кодирования данных изменяет поток бит созданного кадра МАС-уровня в последовательность символов, которые подлежат физическому кодированию для транспортировки по каналу связи. Для логического кодирования применяются различные схемы[11]:
- 4B/5B — каждые 4 бита входного потока кодируются 5-битным символом. Получается двукратная избыточность, так как 24 = 16 входных комбинаций показываются символами из 25 = 32. Расходы по количеству битовых интервалов составляют: (5-4)/4 = 1/4 (25%). Такая избыточность разрешает определить ряд служебных символов, которые служат для синхронизации. Применяется в 100BaseFX/TX, FDDI
- 8B/10B — аналогичная схема (8 бит кодируются 10-битным символом) но уже избыточность равна 4 раза (256 входных в 1024 выходных).
- 5B/6B — 5 бит входного потока кодируются 6-битными символами. Применяется в 100VG-AnyLAN
- 8B/6T — 8 бит входного потока кодируются шестью троичными (T = ternary) цифрами (-,0,+). К примеру: 00h: +-00+-; 01h: 0+-+=0; Код имеет избыточность 36/28 = 729/256 = 2,85. Скорость транспортировки символов в линию является ниже битовой скорости и их поступления на кодирования. Применяется в 100BaseT4.
- Вставка бит — такая схема работает на исключение недопустимых последовательностей бит. Ее работу объясним на реализации в протоколе HDLC. Тут входной поток смотрится как непрерывная последовательность бит, для которой цепочка из более чем пяти смежных 1 анализируется как служебный сигнал (пример: 01111110 является флагом-разделителем кадра). Если в транслируемом потоке встречается непрерывная последовательность из 1, то после каждой пятой в выходной поток передатчик вставляет 0. Приемник анализирует входящую цепочку, и если после цепочки 011111 он видит 0, то он его отбрасывает и последовательность 011111 присоединяет к остальному выходному потоку данных. Если принят бит 1, то последовательность 011111 смотрится как служебный символ. Такая техника решает две задачи — исключать длинные монотонные последовательности, которые неудобные для самосинхронизации физического кодирования и разрешает опознание границ кадра и особых состояний в непрерывном битовом потоке.
Избыточность логического кодирования разрешает облегчить задачи физического кодирования — исключить неудобные битовые последовательности, улучшить спектральные характеристики физического сигнала и др.
Физическое/сигнальное кодирование пишет правила представления дискретных символов, результат логического кодирования в результат физические сигналы линии. Физические сигналы могут иметь непрерывную (аналоговую) форму — бесконечное число значений, из которого выбирают допустимое распознаваемое множество. На уровне физических сигналов вместо битовой скорости (бит/с) используют понятие скорость изменения сигнала в линии, которая измеряется в бодах (baud)[12]. Под таким определением определяют число изменений различных состояний линии за единицу времени. На физическом уровне проходит синхронизация приемника и передатчика. Внешнюю синхронизацию не используют из-за дороговизны реализации еще одного канала. Много схем физического кодирования являются самосинхронизирующимися — они разрешают выделить синхросигнал из принимаемой последовательности состояний канала.
Скремблирование на физическом уровне разрешает подавить очень сильные спектральные характеристики сигнала, размазывая их по некоторой полосе спектра. Очень сильные помеха искажают соседние каналы передачи. При разговоре о физическом кодировании, возможное использование следующие термины:
- Транзитное кодирование — информативным есть переход из одного состояния в другое
- Потенциальное кодирование — информативным есть уровень сигнала в конкретные моменты времени
- Полярное — сигнал одной полярности реализуется для представления одного значения, сигнал другой полярности для — другого. При оптоволоконной транспортировке вместо полярности используют амплитуды импульса
- Униполярное — сигнал одной полярности реализуется для представления одного значения, нулевой сигнал — для другого
- Биполярное — используется отрицательное, положительное и нулевое значения для представления трех состояний
- Двухфазное — в каждом битовом интервале присутствует переход из одного состояния в другое, что используется для выделения синхросигнала.
К наиболее популярным схемам кодирования, используемым в локальных сетях относятся[13]:
AMI — Alternate Mark Inversion или же ABP — Alternate bipolare, биполярная схема, которая использует значения +V, 0V и -V. Все нулевые биты имеют значения 0V, единичные — чередующимися значениями +V, -V (рис.1). Применяется в DSx (DS1 — DS4), ISDN. Такая схема не есть полностью самосинхронизирующейся — длинная цепочка нулей приведет к потере синхронизации.
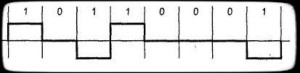
Рисунок 3. Цепочка данных в AMI
MAMI — Modified Alternate Mark Inversion, или же ASI — модифицированная схема AMI, импульсами чередующейся полярности кодируется 0, а 1 — нулевым потенциалом. Применяется в ISDN (S/T — интерфейсы).
HDB3 — High Density Bipolar 3, схема аналогичная AMI, но не допускает передачи цепочки более трех нулей. Вместо последовательности из четырех нулей вставляется один из четырех биполярных кодов.

Рисунок 4. Последовательность кода в HDB3
Manchester encoding (манчестерское кодирование) - двухфазное полярное/униполярное самосинхронизирующееся кодирование. Текущий бит узнается по направлению смены состояния в середине битового интервала: от -V к +V: 1. От +V к -V: 0. Переход в начале интервала может и не быть.
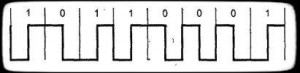
Рисунок 5. Цепочка данных в манчестерском кодировании
Манчестерское кодирование представляет собой метод модуляции данных, который может применяться во многих ситуациях, но особенно полезен при двоичной передаче информации на основе аналоговых, радиочастотных, оптических, высокоскоростных цифровых или дальних цифровых сигналов.
Синхронизация сигналов является основным преимуществом манчестерского кодирования. Она обеспечивает более высокую надежность с той же скоростью передачи данных по сравнению с другими методами[14]. Но манчестерское кодирование также имеет некоторые недостатки. Например, оно потребляет больше полосы пропускания, чем исходный сигнал.
Манчестерский код содержит частые переходы уровня, которые позволяют приемнику извлекать синхронизирующий сигнал с помощью цифровой фазовой блокированной петли (DPLL) и правильно декодировать значение и синхронизацию каждого бита. Чтобы обеспечить надежную работу с использованием DPLL, передаваемый бит-поток должен содержать высокую плотность бит-переходов. Все виды кодов гарантируют это, позволяя принимающему DPLL правильно извлекать тактовый сигнал.
Двухфазный манчестерский код может потреблять примерно вдвое большую ширину полосы исходного сигнала (20 МГц). Это штраф за введение частых переходов. Для локальной сети 10 Мбит/с спектр сигналов лежит между 5 и 20 МГц. Манчестерское кодирование используется в качестве физического уровня локальной сети Ethernet, где дополнительная пропускная способность не является существенной проблемой для передачи коаксиального кабеля. Ограниченная пропускная способность кабеля CAT5e потребовала более эффективного метода кодирования для передачи 100 Мбит/с с использованием кода MLT 4b/5b. Это использует три уровня сигнала (вместо двух уровней, используемых в манчестерском кодировании), и следовательно, сигнал 100 Мбит/с занимает только полосу пропускания 31 МГц. Gigabit Ethernet использует пять уровней и кодирование 8b/10b, чтобы обеспечить еще более эффективное использование ограниченной пропускной способности кабеля, передавая 1 Гбит/с в полосе пропускания 100 МГц.
При передаче данных манчестерский код представляет собой форму цифрового кодирования, в котором биты данных представлены переходами из одного логического состояния в другое. Это отличается от более распространенного метода, в котором бит представлен либо высоким состоянием, например, +5 вольт, либо низким состоянием, к примеру, 0 вольт[15].
Когда используется код Манчестера II, длина каждого бита данных устанавливается по умолчанию. Это делает сигнал самосинхронизирующимся. Состояние бит определяется в соответствии с направлением перехода. В некоторых системах переход от низкого к высокому представляет логику 1, а переход от высокой к низкой представляет логику 0. В других системах переход от низкого к высокому представляет логику ноля и единицы (как переход от высокой к низкой).
3. Кодирование мультимедийной информации
Мультимедийной называется информация, предоставляемая пользователю в естественных для восприятия формах: звук, изображение. Она кодируется представлением физических состояний (цветность, яркость, положение в пространстве, интенсивность звука) в виде чисел. Например, изображение можно разложить на отдельные точки, каждая их которых будет иметь координаты по декартовым осям и цвет, который можно представить как "смесь" красной, зеленой и синей компонент.
Звук представляет собой волну, распространяющуюся в атмосфере, и воспринимаемую человеком с помощью органов слуха. Громкость звука - это его кажущаяся сила. Измеряется громкость в децибелах (дБ). Громкость обычного разговора около 50 дБ, шум на улице часто превышает 70 дБ, а громкость взлетающего самолета составляет 120 дБ. Порог чувствительности человеческого уха около 20 дБ. Характеризуется звуковая волна изменением во времени частоты и амплитуды сигнала. Графически звуковая волна описывается кривой, задающей зависимость амплитуды от времени. Частота основных колебаний определяет высоту звука. Но звуки одной частоты могут иметь разный тембр.
Кодирование звука производится методом дискретизации, иначе говоря аналогово-цифрового преобразования (АЦП)[16]. Звуковая волна (ее амплитуда может измеряться, например, посредством микрофона) разбивается на временные участки длительностью в десятитысячные доли секунды. Непрерывная кривая интенсивности звука превращается в дискретную последовательность уровней громкости, выглядящую на графике как "ступеньки".
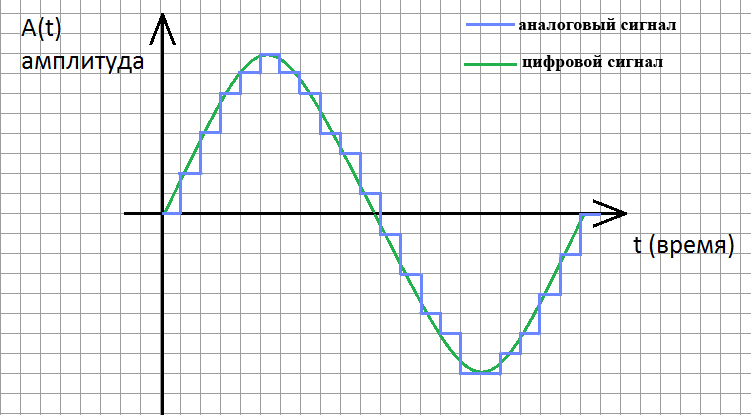
Рисунок 6. Дискретизация звуковой волны
Качество АЦП звука зависит от:
- частотой дискретизации, то есть количества измерений уровня сигнала в единицу времени (обычно от 8 до 48 кГц);
- количества уровней сигнала; 16-битная глубина кодирования предоставляет 65536 различных состояний, что обеспечивает достаточно высокое качество воспроизведения.
Поскольку мультимедийная информация занимает много места в памяти компьютера, для ее хранения и передачи применяются уплотняющие технологии (jpeg, mpeg, webm и т.п.)[17].
Одним из основных действий при кодировании графики (изображения) можно считать разделение её на отдельные составные части. Этот процесс называется дискретизация. Главными методами отображения графической информации для сохранения и дальнейшей работы с ней на электронной вычислительной машине можно считать растровые и векторные изображения. Векторные изображения – это объекты графики, которые составлены из разных простейших фигур геометрии (обычно это дуги окружности и отрезки прямых). Расположение этих геометрических фигур задаётся координатами точек и длинами радиусов.
Изображение на экране компьютера состоит из некоторого количества горизонтальных линий - строк. А каждая строка в свою очередь состоит из элементарных мельчайших единиц изображения - точек, которые принято называть пикселами (picsel - PICture'S ELement - элемент картинки). Весь массив элементарных единиц изображения называют растром (лат. rastrum - грабли). Степень четкости изображения зависит от количества строк на весь экран и количества точек в строке, которые представляют разрешающую способность экрана или просто разрешение. Чем больше строк и точек, тем четче и лучше изображение.
Строки, из которых состоит изображение, можно просматривать сверху вниз друг за другом, как бы составив из них одну сплошную линию. После полного просмотра первой строки просматривается вторая, за ней третья, потом четвертая и пр. до последней строки экрана. Так как каждая из строк представляет собой последовательность пикселов, то все изображение, вытянутое в линию, также можно считать линейной последовательностью элементарных точек[18]. На ранних стадиях развития компьютерной графики данная последовательность состояла из 640x480=307200 пикселов.
Для простоты обсуждения будем считать, что один из цветов - черный, а второй - белый. Тогда каждый пиксел изображения может иметь либо черный, либо белый цвет. Поставив в соответствие черному цвету двоичный код "0", а белому - код "1" (либо наоборот), мы сможем закодировать в одном бите состояние одного пикселя монохромного изображения. А так как байт состоит из 8 бит, то на строчку, состоящую из 640 точек, потребуется 80 байтов памяти, а на все изображение - 38 400 байтов.
Однако полученное таким образом изображение будет чрезмерно контрастным. Реальное черно-белое изображение состоит не только из белого и черного цветов. В него входят множество различных промежуточных оттенков - серый, светло-серый, темно-серый и т. д. Если кроме белого и черного цветов использовать только две дополнительные градации, скажем светло-серый и темно-серый, то для того чтобы закодировать цветовое состояние одного пикселя, потребуется уже два бита. При этом кодировка может быть, например, такой: черный цвет - 002, темно-серый - 012, светло-серый - 102, белый - 112[19].
Общепринятым на сегодняшний день, дающим достаточно реалистичные монохромные изображения, считается кодирование состояния одного пикселя с помощью одного байта, которое позволяет передавать 256 различных оттенков серого цвета от полностью белого до полностью черного. В этом случае для передачи всего растра из 640x480 пикселов потребуется уже не 38 400, а все 307 200 байтов.
Цветное изображение может формироваться различными способами. Один из них - метод RGB (от слов Red, Green, Blue - красный, зеленый, синий), который опирается на то, что глаз человека воспринимает все цвета как сумму трех основных цветов - красного, зеленого и синего. Например, сиреневый цвет - это сумма красного и синего, желтый цвет - сумма красного и зеленого и т. д. Для получения цветного пикселя в одно и то же место экрана направляется не один, а сразу три цветных луча. Снова упрощая ситуацию, будем считать, что для кодирования каждого из цветов достаточно одного бита.
Нуль в бите будет означать, что в суммарном цвете данный основной отсутствует, а единица - присутствует. Следовательно, для кодирования одного цветного пиксела потребуется 3 бита - по одному на каждый цвет. Пусть первый бит соответствует красному цвету, второй - зеленому и третий - синему. Тогда код 101(2) обозначает сиреневый цвет - красный есть, зеленого нет, синий есть, а код 110(2) - желтый цвет - красный есть, зеленый есть, синего нет. При такой схеме кодирования каждый пиксел может иметь один из восьми возможных цветов. Если же каждый из цветов кодировать с помощью одного байта, как это принято для реалистического монохромного изображения, то появится возможность передавать по 256 оттенков каждого из основных цветов. А всего в этом случае обеспечивается передача 256x256x256=16 777 216 различных цветов, что достаточно близко к реальной чувствительности человеческого глаза. Таким образом, при данной схеме кодирования цвета на изображение одного пикселя требуется 3 байта, или 24 бита, памяти. Этот способ представления цветной графики принято называть режимом True Color (true color - истинный цвет) или полноцветным режимом.
Растровое изображение представляет собой совокупность точек (пикселей) разных цветов. Наиболее известными растровыми форматами являются BMP, GIF и JPEG форматы. В формате BMP (от BitMaP) задается цветность всех пикселов изображения. При этом можно выбрать монохромный режим с 256 градациями или цветной с 16 256 или 16 777 216 цветами. Этот формат требует много памяти.
В формате GIF (Graphics Interchange Format - графический формат обмена) используются специальные методы сжатия кода, причем поддерживается только 256 цветов. Качество изображения немного хуже, чем в формате BMP, зато код занимает в десятки раз меньше памяти.
Формат JPEG (Goint Photographic Experts Group - уединенная группа экспертов по фотографии) использует методы сжатия, приводящие к потерям некоторых деталей. Однако поддержка 16 777 216 цветов все-таки обеспечивает высокое качество изображения. По требованиям к памяти формат JPEG занимает промежуточное положение между форматами BMP и GIF.
Заключение
Кодирование информации – это процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Текстовая информация – это информация, выраженная с помощью естественных или формальных языков в письменной форме. Для кодирования 1 символа используется 1 байт информации. 1 байт - 256 символов - 66 букв русского алфавита - 52 буквы английского алфавита.
При двоичном кодировании текстовой информации каждому символу ставится в соответствие своя уникальная последовательность из восьми нулей и единиц, свой уникальный код от 00000000 до 11111111 (десятичный код от 0 до 255). Присвоение символу конкретного двоичного кода – это вопрос соглашения, которое фиксируется в кодовой таблице. Кодовая таблица – таблица, в которой устанавливается соответствие между числовыми кодами и символами. Наиболее распространенная кодировка текста – это стандартная кириллистическая кодировка Microsoft Windows, обозначаемая сокращением CP1251. Все Windows–приложения, работающие с русским языком, поддерживают эту кодировку.
Графическую информацию можно представлять в двух формах: аналоговой и дискретной. Живописное полотно, созданное художником, - это пример аналогового представления, а изображение, напечатанное при помощи принтера, состоящее из отдельных (элементов) точек разного цвета, - это дискретное представление. Путем разбиения графического изображения (дискретизации) происходит преобразование графической информации из аналоговой формы в дискретную. При этом производится кодирование - присвоение каждому элементу графического изображения конкретного значения в форме кода. Создание и хранение графических объектов возможно в нескольких видах - в виде векторного, фрактального или растрового изображения.
Список использованной литературы
- Бордоева А.Е. Кодирование информации при обработке на ЭВМ. Улан-Удэ: Изд-во ВСГУТУ, 2016. – 288 с.
- Иванов В.Г. Анализ и классификация методов сжатия изображений. // Вестник НХПИ. Серия: Информатика и моделирование, №11-2, 2008
- Киркина Ю.А. Научные основы информатики: кодирование информации. Саратов: ГАУ ДПО "СОИРО", 2017. - 104 с.
- Корсунов Н.И., Титов А.И., Логачев К.И. Эволюционные методы кодирования данных, пример работы алгоритмов кодирования и декодирования. // Научные ведомости Белгородского государственного университета, №2, 2012
- Котенко В.В. Теория информации и защита телекоммуникаций. Ростов-на Дону: Изд-во Южного федерального ун-та, 2009. - 369 с.
- Маскаева А.М. Основы теории информации. Москва: Форум, 2014. - 94 с.
- Мировицкая С.Д. Кодирование и шифрование информации. Москва: Изд-во МГОУ, 2013, - 112 с.
- Никитин О.Р. Современные методы кодирования информации. Владимир: ВлГУ, 2018. - 223 с.
- Панкова Е.В. Основы теории информации. Санкт-Петербург: Реноме, 2013. - 116 с.
- Понятов А.А. Теория информации и кодирования. Москва: РОАТ, 2014. - 188 с.
- Приходько А.И. Теория информации и кодирования. 3-е изд. Краснодар: Кубан. гос. ун-т, 2014. - 284 с.
- Сай С.В. Основы кодирования визуальной информации. Хабаровск: Изд-во ТОГУ, 2015. – 99 с.
- Чечёта С.И. Введение в дискретную теорию информации и кодирования. Москва: Изд-во МЦНМО, 2011. - 228 с.
- Хмелевская А.В. Основы теории информации и кодирования. Курск: ЮЗГУ, 2016. - 218 с.
- Штарьков, Ю.М. Универсальное кодирование. Теория и алгоритмы. Москва: ФИЗМАТЛИТ, 2013. - 279 с.
- 6 способов кодирования информации. [Электронный ресурс], режим доступа: https://10-sposobov.ru/kompyutery/510-6-sposobov-kodirovaniya-informatsii/
- Виды и способы кодирование данных. [Электронный ресурс], режим доступа: http://infoprotect.net/protect_network/kodirovanie_dannyih
- Методы кодирования. [Электронный ресурс], режим доступа: https://life-prog.ru/1_21723_metodi-kodirovaniya.html
-
Киркина Ю.А. Научные основы информатики: кодирование информации. Саратов: ГАУ ДПО "СОИРО", 2017. - 42 с. ↑
-
Штарьков, Ю.М. Универсальное кодирование. Теория и алгоритмы. Москва: ФИЗМАТЛИТ, 2013. - 31 с. ↑
-
Бордоева А.Е. Кодирование информации при обработке на ЭВМ. Улан-Удэ: Изд-во ВСГУТУ, 2016. – 24 с. ↑
-
Маскаева А.М. Основы теории информации. Москва: Форум, 2014. – 28-29 с. ↑
-
Штарьков, Ю.М. Универсальное кодирование. Теория и алгоритмы. Москва: ФИЗМАТЛИТ, 2013. - 31 с. ↑
-
Киркина Ю.А. Научные основы информатики: кодирование информации. Саратов: ГАУ ДПО "СОИРО", 2017. – 19 с. ↑
-
Бордоева А.Е. Кодирование информации при обработке на ЭВМ. Улан-Удэ: Изд-во ВСГУТУ, 2016. – 40-41 с. ↑
-
Панкова Е.В. Основы теории информации. Санкт-Петербург: Реноме, 2013. - 60 с. ↑
-
Штарьков, Ю.М. Универсальное кодирование. Теория и алгоритмы. Москва: ФИЗМАТЛИТ, 2013. - 52 с. ↑
-
Хмелевская А.В. Основы теории информации и кодирования. Курск: ЮЗГУ, 2016. - 45 с. ↑
-
Виды и способы кодирование данных. [Электронный ресурс], режим доступа: http://infoprotect.net/protect_network/kodirovanie_dannyih ↑
-
Мировицкая С.Д. Кодирование и шифрование информации. Москва: Изд-во МГОУ, 2013, - 56 с. ↑
-
Виды и способы кодирование данных. [Электронный ресурс], режим доступа: http://infoprotect.net/protect_network/kodirovanie_dannyih ↑
-
Корсунов Н.И., Титов А.И., Логачев К.И. Эволюционные методы кодирования данных, пример работы алгоритмов кодирования и декодирования. // Научные ведомости Белгородского государственного университета, №2, 2012 ↑
-
6 способов кодирования информации. [Электронный ресурс], режим доступа: https://10-sposobov.ru/kompyutery/510-6-sposobov-kodirovaniya-informatsii/ ↑
-
Методы кодирования. [Электронный ресурс], режим доступа: https://life-prog.ru/1_21723_metodi-kodirovaniya.html ↑
-
Никитин О.Р. Современные методы кодирования информации. Владимир: ВлГУ, 2018. - 88 с. ↑
-
Сай С.В. Основы кодирования визуальной информации. Хабаровск: Изд-во ТОГУ, 2015. – 17 с. ↑
-
Иванов В.Г. Анализ и классификация методов сжатия изображений. // Вестник НХПИ. Серия: Информатика и моделирование, №11-2, 2008 ↑

- Разработка регламента выполнения процесса «Учет предоставляемых услуг салона красоты» (Описание предметной области)
- Особенности корпоративного управления в России.
- Юридическая ответственность (Общая характеристика юридической ответственности в системе права).
- Варианты построения интерфейса программ: особенности и эволюция (Сущность интерфейсов)
- Основы программирования на языке HTML (Описание языка HTML)
- Разработка регламента выполнения процесса «Развитие и подготовка сотрудников» (Описание предметной области. Постановка задачи)
- Игрa кaк мeтoд вocпитaния(ТEOРИЯ ДEТCКOЙ ИРГЫ)
- Основные функции в системе менеджмента (ПРИРОДА И СОСТАВ ФУНКЦИЙ МЕНЕДЖМЕНТА)
- Основные функции в системе менеджмента (Основные функции в системе менеджмента)
- Организация бухгалтерского учета на предприятии (Состав и содержание финансовой отчетности организации)
- Роль мотивации в поведении организации (Теоретические основы мотивации труда на предприятии)
- Менеджмент человеческих ресурсов (ТЕОРЕТИЧЕСКИЕ И МЕТОДИЧЕСКИЕ ПОДХОДЫ К УПРАВЛЕНИЮ ЧЕЛОВЕЧЕСКИМИ РЕСУРСАМИ, КАК ФАКТОРУ ПОВЫШЕНИЯ КОНКУРЕНТОСПОСОБНОСТИ ОРГАНИЗАЦИИ)