
Методы кодирования данных (Определение и история появления методов кодирования данных)
Содержание:

Введение
Важным и главным элементом информатики как наука является публикация статьей «Теория информации» и «Теория кодирования» Клод Шеннона в 1948. Я не зря упомянул К. Шеннона, ведь, он начал развивать кодирование информации на ЭВМ, также он считается «отцом информационного века».
Тема «Методы кодирования данных» является актуальный по сей день, ведь, люди начиная изучать информатику без исключения в первую очередь столкнуться, с кодировкой информации, так как это способ «общения» с цифровыми устройствами, язык на котором «работают» цифровые устройство, «общаются между собой», сложный, но одновременно и легкий, ведь алфавит данного языка состоит из двух букв 1 и 0. Данная тема дает широкие возможности в проведение:
- интегрированных уроков совместно с историей, математикой и литературой
- нестандартных уроков с элементами тайной переписки
- магической игры с черным ящиком
- уроков в форме сюжетно-ролевой игры
- элементы проектной деятельности.
Целью данной курсовой работы является изучение методов кодирования данных. Некоторым может показаться что кодирование информации, оно присуще только для цифровых устройств, но это не так далее в курсовой работе это будет рассмотрено, ведь, кодированием еще пользовались в 5 век до н.э. только не путать шифрование и кодирование. Шифрование — это способ изменения сообщения или другого документа, обеспечивающее искажение (сокрытие) его содержимого. (Кодирование – это преобразование обычного, понятного, текста в код. При этом подразумевается, что существует взаимно однозначное соответствие между символами текста (данных, чисел, слов) и символьного кода – в этом принципиальное отличие кодирования от шифрования.
ГЛАВА 1.Определение и история появления методов кодирования данных.
Кодирование – способ представления информации в удобном для хранения и передачи виде. С развитием информационных технологий появляется кодирование данных и претендует на решение самых разных центральных задач программирования, таких как:
- представление данных произвольной структуры (числа, текст, графика) в памяти компьютера;
- обеспечение помехоустойчивости при передаче данных по каналам связи;
- сжатие информации в базах данных.
Теория кодирования и теория информации возникли в начале XX века. Начало развитию этих теорий как научных дисциплин положило появление в 1948 г. статей К. Шеннона, которые заложили фундамент для дальнейших исследований в этой области. Но до возникновения теории кодирования и до появления ЭВМ, телеграфов люди искали наиболее эффективные способы передачи информации.
- Оптический телеграф– семафор рисунок 1 – впервые использовали братья Шапп в 1792 г. На протяжении 225 км были устроены 22 станции, то есть башни с шестами и подвижными планками. Для передачи одного знака требовалось при этом 2 мин. Вскоре построены были и другие линии, и система братьев Шапп получила широкое распространение. От Парижа до Бреста депеша передавалась в 7 мин., от Берлина до Кёльна — в 10 мин. Три подвижные планки такой системы могли принимать 196 различных относительных положений и изображать таким образом столько же отдельных знаков, букв и слов, наблюдаемых при помощи зрительных труб. Несмотря на недостатки оптической телеграфии, заключающиеся главным образом в зависимости от погоды, её активно использовали почти до середины XIX века, в России — до начала 1860-х годов. Своими блестящими победами Наполеон I немало обязан оптическому телеграфу, с помощью которого он имел возможность быстро передавать свои распоряжения на большие расстояния.
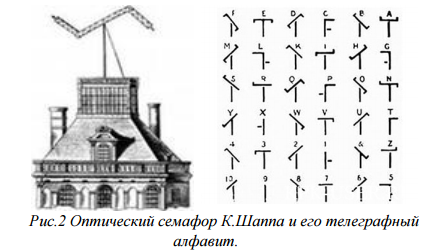
Рисунок 1. Оптический семафор братьев Шаппа и их телеграфный алфавит
- Движение электромагнитной стрелки в электромагнитных телеграфных аппаратах впервые применили русский физик П.Л. Шиллинг (1832) и профессора Гёттингенского университета Вебер и Гаусс (1833). 1 – источник тока, 2 – клавиатура, 3 – магнитные стрелки, 4 – провод обратной связи, 5 – вызывное устройство. Посредством 16 клавиш передаточного прибора можно было послать ток того или другого направления и таким образом стрелки мультипликаторов поворачивать вперёд то белым, то чёрным кружком, составляя этим путём условленные знаки. Впоследствии Шиллинг упростил свой приёмный прибор, оставив в нём только один мультипликатор вместо шести, причём условный алфавит был составлен из 36 различных отклонений магнитной стрелки.
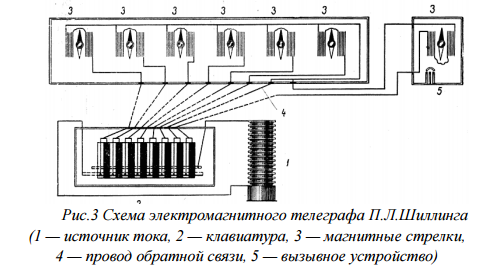
Рисунок 2. Схема электромагнитного телеграфа П.Л.Шилинга
- Азбука и телеграфный аппарат Самюэла Морзе (1837). Принцип кодирования азбуки Морзе исходит из того, что буквы, которые чаще употребляются в английском языке, кодируются более простыми сочетаниями точек и тире. Это делает освоение азбуки Морзе проще, а передачи — компактнее. Передача кодов Морзе производится при помощи телеграфного ключа различных конструкций: классического ключа Морзе, электронного ключа, механических полуавтоматов типа «виброплекс», а также при помощи клавиатурных датчиков кода Морзе (например, Р-010, Р-020) и электронных устройств, автоматически формирующих телеграфное сообщение.

Рисунок 3. Дерево кода Морзе - направо точки, налево тире.
В эпоху развития телеграфов, для передачи информации использовали азбуку Морзе, в которой буквы были закодированы точкой и тире, ведь, в телеграф передавал гальванический ток на приемник, на котором была установлена магнитная стрелка, которая дергалась при поступлении тока. Также создатели передатчиков обеспокоились тем что передаваемую информацию могут прочитать и понять третьи лица. Для предотвращения таких ситуаций информацию начали шифровать. Методов шифрования было куча, ведь, шифрование развивалось еще с 5 в.н.э., а может и еще раньше. Один из шифровщиков, который внес большой вклад в развитие и формирования модели шифровок — это Сэр Френсис Бэкон(1561-1626) автор двухлитерного кода, доказал в 1580 г., что для передачи информации достаточно двух знаков. Также Ф. Бэкон сформулировал требования к шифру:
1. Шифр должен быть несложен, прост в работе;
2. Шифр должен быть надежен, труден для дешифровки 10 посторонним;
3. Шифр должен быть скрытен, по возможности не должен вызывать подозрений.
Шифры Бэкона – сочетание шифрованного текста с дезинформацией в виде нулей. Таким образом, двузначные коды и шифры использовались задолго до появления ЭВМ. Новый толчок развитию теории кодирования дало создание в 1948 году Клодом Эльвудом Шенноном (1916 — 2001) теории информации. Идеи, изложенные Шенноном в статье «Математическая теория связи», легли в основу современных теорий и техник обработки, передачи и хранения информации. В основе теории информации лежит гипотеза о статистическом характере источника сообщений. Случайная последовательность знаков не несет информации, так же как и ключ кода. А расшифровать код можно, используя знания о статистических закономерностях сообщения и кода. Теория количества информации Шеннона основана на известной со времен Аристотеля альтернативе выбора одного из двух знаков между 0 и 1. В книге вводится логарифмическая функция как мера информации, и показывается её удобство: «Она удобна практически. Параметры, важные в инженерных приложениях — такие, как время, пропускная способность, число переключателей и так далее — обычно меняются линейно при логарифмическом изменении числа возможных вариантов. К примеру, добавление одного переключателя удваивает число возможных состояний их группы, увеличивая на единицу его логарифм по основанию 2. Увеличение в два раза времени приводит к квадратичному росту числа сообщений, или удвоению их логарифма, и так далее. Она близка к нашему интуитивному представлению о такой мере. Это тесно связано с предыдущим пунктом, так как мы интуитивно измеряем величины, линейно сравнивая их со стандартами. Так, нам кажется, что на двух перфокартах можно разместить в два раза больше информации, а по двум одинаковым каналам — передать её в два раза больше. Она удобна математически. Многие предельные переходы просты в логарифмах, в то время как в терминах числа вариантов они достаточно нетривиальны» - К. Шеннон. Также вводится понятие обобщённой системы связи, состоящей из источника информации, передатчика, канала, приемника и пункта назначения. Шеннон разделяет все системы на дискретные, непрерывные и смешанные. Результаты его научных исследований способствовали развитию помехоустойчивого кодирования и простых методов декодирования сообщений. Далее речь будет идти только о методах кодирования данных на цифровых устройствах как персональный компьютер.
2. Методы кодирования данных
2.1 Кодирование чисел
Для работы с числовой информацией мы пользуемся системой счисления, содержащей десять цифр: от 0 до 9. Эта система называется десятичной. Кроме цифр, в десятичной системе большое значение имеют разряды. Подсчитывая количество чего-нибудь и дойдя до самой большой из доступных нам цифр (до 9), мы вводим второй разряд и дальше каждое последующее число формируем из двух цифр. Дойдя до 99, мы вынуждены вводить третий разряд. В пределах трех разрядов мы можем досчитать уже до 999 и т.д. Таким образом, используя всего десять цифр и вводя дополнительные разряды, мы можем записывать и проводить математические операции с любыми, даже самыми большими числами. Компьютер ведет подсчет аналогичным образом, но имеет в своем распоряжении всего две цифры - логический ноль (отсутствие у бита какого-то свойства) и логическую единицу (наличие у бита этого свойства). Система счисления, использующая только две цифры, называется двоичной. При подсчете в двоичной системе добавлять каждый следующий разряд приходится гораздо чаще, чем в десятичной.
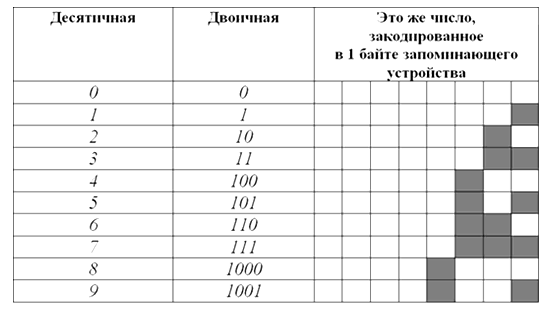
Рисунок 4. Первые десять чисел в каждой системе счисления
Как видите, в десятичной системе счисления для отображения любой из первых десяти цифр достаточно 1 разряда. В двоичной системе для тех же целей потребуется уже 4 разряда. Соответственно, для кодирования этой же информации в виде двоичного кода нужен носитель емкостью как минимум 4 бита (0,5 байта). Человеческий мозг, привыкший к десятичной системе счисления, плохо воспринимает систему двоичную. Хотя обе они построены на одинаковых принципах и отличаются лишь количеством используемых цифр. В двоичной системе точно так же можно осуществлять любые арифметические операции с любыми числами. Главный ее минус - необходимость иметь дело с большим количеством разрядов. Так, самое большое десятичное число, которое можно отобразить в 8 разрядах двоичной системы - 255, в 16 разрядах – 65535, в 24 разрядах – 16777215.
Компьютер, кодируя числа в двоичный код, основывается на двоичной системе счисления. Но, в зависимости от особенностей чисел, может использовать разные алгоритмы:
- Небольшие целые числа без знака. Для сохранения каждого такого числа на запоминающем устройстве, как правило, выделяется 1 байт (8 битов). Запись осуществляется в полной аналогии с двоичной системой счисления. Целые десятичные числа без знака, сохраненные на носителе в двоичном коде, будут выглядеть примерно так:
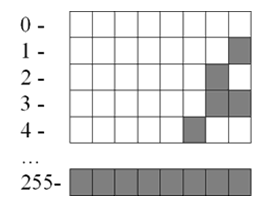
Рисунок 5. Число на носителе в двоичном коде
- Большие целые числа и числа со знаком. Для записи каждого такого числа на запоминающем устройстве, как правило, отводится 2-байтний блок (16 битов). Старший бит блока (тот, что крайний слева) отводится под запись знака числа и в кодировании самого числа не участвует. Если число со знаком "плюс", этот бит остается пустым, если со знаком "минус" – в него записывается логическая единица. Число же кодируется в оставшихся 15 битах. Например, алгоритм кодирования числа +2676 будет следующим:
- Перевести число 2676 из десятичной системы счисления в двоичную. В итоге получится 101001110100;
- Записать полученное двоичное число в первые 15 бит 16-битного блока (начиная с правого края). Последний, 16-й бит, должен остаться пустым, поскольку кодируемое число имеет знак +.
В итоге +2676 в двоичном коде на запоминающем устройстве будет выглядеть так:
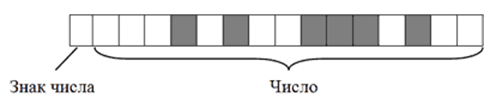
Рисунок 6. Закодированное число на носителе
Запись отрицательных чисел в инвертированной форме позволяет заменить все операции вычитания, в которых они участвуют, операциями сложения. Это необходимо для нормальной работы компьютерного процессора. Максимальным десятичным числом, которое можно закодировать в 15 битах запоминающего устройства, является 32767. Иногда для записи чисел по этому алгоритму выделяются 4-байтные блоки. В таком случае для кодирования каждого числа будет использоваться 31 бит плюс 1 бит для кодирования знака числа. Тогда максимальным десятичным числом, сохраняемым в каждую ячейку, будет 2147483647 (со знаком плюс или минус).
- Дробные числа со знаком. Дробные числа на запоминающем устройстве в двоичном коде кодируются в виде так называемых чисел с плавающей запятой (точкой). Алгоритм их кодирования сложнее, чем рассмотренные выше. Тем не менее, попытаемся разобраться. Для записи каждого числа с плавающей запятой компьютер чаще всего выделяет 4-байтную ячейку (32 бита):
- в старшем бите этой ячейки (тот, что крайний слева) записывается знак числа. Если число отрицательное, в этот бит записывается логическая единица, если оно со знаком "плюс" – бит остается пустым.
- во втором слева бите аналогичным образом записывается знак порядка (что такое порядок поймете позже);
- в следующих за ним 7 битах записывается значение порядка.
- в оставшихся 23 битах записывается так называемая мантисса числа.

Рисунок 7. 4 байтная ячейка
Чтобы стало понятно, что такое порядок, мантисса и зачем они нужны, переведем в двоичный код десятичное число 6,25. Порядок кодирования будет примерно следующим:
- Перевести десятичное число в двоичное (десятичное 6,25 равно двоичному 110,01);
- Определить мантиссу числа. Для этого в числе необходимо передвинуть запятую в нужном направлении, чтобы слева от нее не осталось ни одной единицы. В нашем случае запятую придется передвинуть на три знака влево. В итоге, получим мантиссу, 11001;
- Определить значение и знак порядка. Значение порядка – это количество символов, на которое была сдвинута запятая для получения мантиссы. В нашем случае оно равно 3 (или 11 в двоичной форме);
Знак порядка – это направление, в котором пришлось двигать запятую: влево – "плюс", вправо – "минус". В нашем примере запятая двигалась влево, поэтому знак порядка – "плюс". Таким образом, порядок двоичного числа 110,01 будет равен +11, а его мантисса, 11001. В результате в двоичном коде на запоминающем устройстве это число будет записано следующим образом

Рисунок 8. Число 6.25 закодированное на носитель
Обратите внимание, что мантисса в двоичном коде записывается, начиная с первого после запятой знака, а сама запятая упускается. Числа с плавающей запятой, кодируемые в 32 битах, называю числами одинарной точности. Когда для записи числа 32-битной ячейки недостаточно, компьютер может использовать ячейку из 64 битов. Число с плавающей запятой, закодированное в такой ячейке, называется числом двойной точности.
2.2 Кодирование теста
Текстовую информацию кодируют двоичным кодом через обозначение каждого символа алфавита определенным целым числом. С помощью восьми двоичных разрядов возможно закодировать 256 различных символов. Данного количества символов достаточно для выражения всех символов английского и русского алфавитов. В первые годы развития компьютерной техники трудности кодирования текстовой информации были вызваны отсутствием необходимых стандартов кодирования. В настоящее время, напротив, существующие трудности связаны с множеством одновременно действующих и зачастую противоречивых стандартов.
Для английского языка, который является неофициальным международным средством общения, эти трудности были решены. Институт стандартизации США выработал и ввел в обращение систему кодирования ASCII (American Standard Code for Information Interchange – стандартный код информационного обмена США). Для кодировки русского алфавита были разработаны несколько вариантов кодировок:
1) Windows-1251 – введена компанией Microsoft; с учетом широкого распространения операционных систем (ОС) и других программных продуктов этой компании в Российской Федерации она нашла широкое распространение;
2) КОИ-8 (Код Обмена Информацией, восьмизначный) – другая популярная кодировка российского алфавита, распространенная в компьютерных сетях на территории Российской Федерации и в российском секторе Интернет;
3) ISO (International Standard Organization – Международный институт стандартизации) – международный стандарт кодирования символов русского языка. На практике эта кодировка используется редко.
Ограниченный набор кодов (256) создает трудности для разработчиков единой системы кодирования текстовой информации. Вследствие этого было предложено кодировать символы не 8-разрядными двоичными числами, а числами с большим разрядом, что вызвало расширение диапазона возможных значений кодов. Система 16-разрядного кодирования символов называется универсальной – UNICODE. Шестнадцать разрядов позволяет обеспечить уникальные коды для 65 536 символов, что вполне достаточно для размещения в одной таблице символов большинства языков. Структура кодировки ASCII на таблице ниже.
Таблица 1. Структура кодировки ASCII
|
Порядковый номер |
Код |
Символ |
|
0 - 31 |
00000000 - 00011111 |
Символы с номерами от 0 до 31 принято называть управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п. |
|
32 - 127 |
00100000 - 01111111 |
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символ 32 - пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками |
|
128 - 255 |
10000000 - 11111111 |
Альтернативная часть таблицы (русская). Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер. Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. |
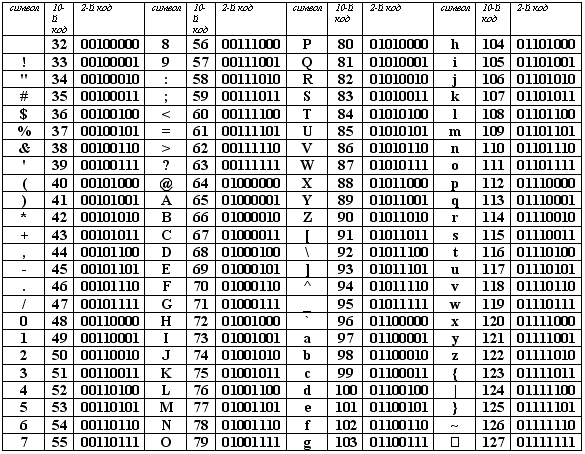
Рисунок 9. Первая часть таблицы ASCII
Обращаю ваше внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита. Для букв русского алфавита также соблюдается принцип последовательного кодирования.
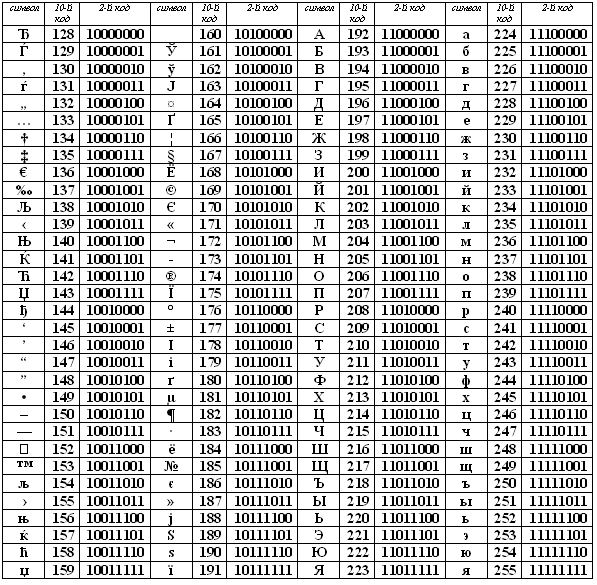
Рисунок 10. Вторая часть
К сожалению, в настоящее время существуют пять различных кодировок кириллицы (КОИ8-Р, Windows. MS-DOS, Macintosh и ISO). Из-за этого часто возникают проблемы с переносом русского текста с одного компьютера на другой, из одной программной системы в другую.
3. Кодирование графической информации
Графическая информация на экране монитора представляется в виде растрового изображения, которое формируется из определенного количества строк, которые в свою очередь содержат определенное количество точек (пикселей). Графический режим вывода изображения на экран монитора определяется величиной разрешающей способности и глубиной цвета. В современных персональных компьютерах обычно используются три основные разрешающие способности экрана: 1024 х 768, 1280 х 1024. Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого и синего. Такая цветовая модель называется RGB-моделью по первым буквам английских названий цветов (Red, Green, Вluе). Для получения богатой палитры цветов базовым цветам могут быть заданы различные интенсивности. Цветные изображения формируются в соответствии с двоичным кодом цвета каждой точки, хранящимся в видеопамяти. Цветные изображения могут иметь различную глубину цвета, которая задается количеством битов, используемым для кодирования цвета точки. Наиболее распространенными значениями глубины цвета являются 8, 16, 24 или 32 бита. Каждый цвет можно рассматривать как возможное состояние точки, тогда количество цветов, отображаемых на экране монитора, может быть вычислено по формуле: N = 2i, где i - глубина цвета:
Таблица 2. Глубина цвета и количество отображаемых цветов
|
Глубина цвета (I)
|
Количество отображаемых цветов (N)
|
|
8 |
28 = 256 |
|
16(НighСоlоr) |
216 = 65536 |
|
24 (Тruе Соlоr) |
224= 16777216 |
|
32 (Тruе Соlоr) |
232 = 4 294 967 296 |
Для того чтобы на экране монитора формировалось изображение, информация о каждой его точке (код цвета точки) должна храниться в видеопамяти компьютера.
3.1 Кодирование звука
Для того чтобы компьютер мог обрабатывать звук, непрерывный звуковой сигнал должен быть превращен в последовательность электрических импульсов (двоичных нулей и единиц). В процессе кодирования непрерывного звукового сигнала производится его временная дискретизация. Непрерывная звуковая волна разбивается на отдельные маленькие временные участки, причем для каждого такого участка устанавливается определенная величина амплитуды.
Т.е. при двоичном кодировании непрерывного звукового сигнала он заменяется последовательностью дискретных уровней сигнала.
Таким образом, непрерывная зависимость амплитуды сигнала от времени А(t) заменяется на дискретную последовательность уровней громкости. На рисунке 11 это выглядит как замена гладкой кривой на последовательность «ступенек»:
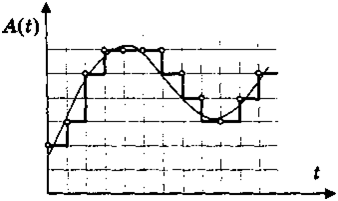
Рисунок 11. временная дискретизация звука
Каждой «ступеньке» присваивается значение уровня громкости звука, его код (1, 2, 3 и так далее). Уровни громкости звука можно рассматривать как набор возможных состояний, соответственно, чем большее количество уровней громкости будет выделено в процессе кодирования, тем большее количество информации будет нести значение каждого уровня и тем более качественным будет звучание.
Рисунок 12. Устройство звуковой платы
Преобразование аналоговой формы представления звука в дискретную происходит в процессе аналогово-цифрового преобразования (АЦП). Преобразование дискретной формы представления звука в аналоговую происходит в процессе цифро-аналогового преобразования (ЦАП)
Качество кодирования звуковой информации зависит от:
1) частотой дискретизации, т.е. количества измерений уровня сигнала в единицу времени. Чем большее количество измерений производится за 1 секунду (чем больше частота дискретизации), тем точнее процедура двоичного кодирования.
2) глубиной кодирования, т.е. количества уровней сигнала.
Современные звуковые карты обеспечивают 16-битную глубину кодирования звука. Количество различных уровней сигнала (состояний при данном кодировании) можно рассчитать по формуле: N = 2i = 216 = 65536, где i — глубина звука.
Таким образом, современные звуковые карты могут обеспечить кодирование 65536 уровней сигнала. Каждому значению амплитуды звукового сигнала присваивается 16-битный код. Количество измерений в секунду может лежать в диапазоне от 8000 до 48 000, то есть частота дискретизации аналогового звукового сигнала может принимать значения от 8 до 48 кГц. При частоте 8 кГц качество дискретизированного звукового сигнала соответствует качеству радиотрансляции, а при частоте 48 кГц — качеству звучания аудио-СD. Следует также учитывать, что возможны как моно-, так и стерео-режимы.
Заключение
В данной курсовой работе описаны базовые знания кодирования информации. В курсовой были описаны только «верхушка айсберга» методов кодирования, я планирую развивать данную тему в своей будущей ВКР.
Список литературы
- Босова Л.Л Информатика и ИКТ 6 класс [Текст]: Учебник/ Босова Л.Л .- М.: Изд-во "БИНОМ. Лаборатория знаний", 2012. - 208 с.;
- Босова Л.Л Информатика и ИКТ 7 класс [Текст]: Учебник/ Босова Л.Л..- М.: Изд-во "БИНОМ. Лаборатория знаний", 2010. - 229 с.;
- Семакин И.Г. Информатика и ИКТ для 8-9 классов [Текст]: Учеб. по базовому курсу / Семакин И.Г., Залогова Л.А, Русаков С.В., Шестакова Л.В.. М.: Изд-во "БИНОМ. Лаборатория знаний", 2009. - 320 с.;
- Угринович Н.Д «Информатика и ИКТ» Базовый курс. 9 класс [Текст]: Учебник/ Угринович Н.Д.- М.: Изд-во "БИНОМ. Лаборатория знаний", 2011. 295 с.;
- Могилев А.В. Информатика [Текст]: Учеб. для студентов пед. вузов/ Могилев А.В., Пак Н.И., Хённер Е.К. М.: Академия, 2004. -- 848 с.
- Якушкин П.А., Лещинер В.Р., Кириенко Д.П. ЕГЭ 2011. Информатика. Типовые тестовые задания [Текст] / Якушкин П.А. -- М.: Экзамен, 2011.
- Электронные ресурсы spravochnick.ru, studfiles.net, pandia.ru, www.e-reading.club, school497.ru, informatika.edusite.ru

- Разработка регламента выполнения процесса «Расчет заработной платы."
- Защита права собственности
- Принципы и основания наследования
- Понятие и классификация функций государства
- Виды налогов. Классификация налогов. Налоговая система. Налоговая политика
- Классификация правовых норм
- Разработка сайта кинотеатра «Дружба» (Цель разработки)
- «Автоматизация бронирования и продажи билетов в музей»
- ПРЕДМЕТ, МЕТОД ПРЕДПРИНИМАТЕЛЬСКОГО ПРАВА И ПРИНЦИПЫ ПРЕДПРИНИМАТЕЛЬСКОГО ПРАВА
- МУНИЦИПАЛЬНЫЕ ПРЕДПРИЯТИЯ»
- Тенденции развития международного кредитного рынка (Проблемы мировых кредитных рынков)
- Налоговый учет по налогу на имущество (на примере ООО ИРАС «Астрахань. Дельта Сити»)