
Методы кодирования данных (Методы кодирования текстовой и числовой информации)
Содержание:

Введение
Люди используют шифрование (кодирование) текста с момента, когда появилась первая секретная информация. Существуют несколько приёмов кодирования текстовой информации, которые были изобретены на различных этапах развития человеческой цивилизации:
- криптография – это тайнопись, система изменения текстового сообщения с целью сделать его непонятным для третьих лиц;
- азбука Морзе или неравномерный телеграфный код, в котором каждая буква и знак представлены своей комбинацией коротких элементарных посылок электрического тока (точек) и элементарных посылок утроенной продолжительности (тире);
- сурдожесты – язык жестов, используемый людьми с нарушенным слухом.
Один из самых первых известных методов шифрования текстовой информации носит имя римского императора Юлия Цезаря. Этот метод основан на замене каждого символа шифруемого сообщения, на другой, путем смещения в алфавите от исходного символа на фиксированное количество символов, причем алфавит читается по кругу (циклически), то есть после буквы я рассматривается а. Для расшифровки сообщения необходимо заменять символы зашифрованного сообщения на символы алфавита, сдвинутые относительно данного на тоже самое количество букв в обратную сторону.
Современные электронно-вычислительные машины (ЭВМ) умеют обрабатывать различные виды информации– числовую, текстовую, звуковую, графическую. В связи с тем, что ЭВМ работает на основе электрических импульсов, алфавит, которым она оперирует, состоит всего из двух символов: 0 и 1, обозначающих присутствие и отсутствие импульса. В связи с этим были разработаны методы кодирования различных типов информации для ее удобной обработки на ЭВМ.
ГЛАВА 1. Цели кодирования
Рассмотрим ряд определений, которые мы будем использовать далее:
Код- правило, которое описывает соответствие знаков и их сочетаний одного алфавита знакам или их сочетаниям из другого алфавита.
Под кодированием понимают процесс преобразования информации из одной формы представления (алфавита) в другую.
Декодирование – это процесс обратный кодированию, т.е. восстановление
информации в первичном алфавите по полученной последовательности кодов.
Операции кодирования и декодирования называются обратимыми, если их последовательное применение обеспечивает возврат к исходной информации без каких-либо ее потерь.
Языки представления информации делятся на два типа:
• Естественные, например:
1. Английский
2. Французский
3. Русский
• Формальные, например:
1. Математический
2. Языки программирования
3. Ноты
Для каждого типа языка существуют различные методы преобразования (кодирования) информации на исходном языке в форму, которая может храниться и обрабатываться на компьютере. Они в свою очередь различаются по целям:
• Засекречивание информации. Для получения шифротекстов используют
специально разработанные алгоритмы криптографии
• Ускорение записи или сжатие информации. Используют специально
созданные алгоритмы, преобразующие информацию определенного
размера в более короткое ее представление, которое не изменяет меру
взаимной информации у исходных и полученных данных и может быть
однозначно декодировано
• Для передачи по техническим каналам связи. Например, код Морзе для
передачи телеграфных сообщений, протокол Ethernet (для передачи
информации по сети интернет)
• Для выполнения математических вычислений. Например, человек привык проводить вычисления в десятичной системе, а компьютеры- в двоичной Начиная с конца 60-х годов, компьютеры все больше стали использоваться для обработки текстовой информации, и в настоящее время основная доля персональных компьютеров в мире (и большая часть времени) занята обработкой именно текстовой информации. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1). Наиболее значимым для развития техники оказался способ представления информации с помощью кода, состоящего всего из двух символов: 0 и 1. Для удобства использования такого алфавита договорились называть любой из его знаков «бит» (от английского «binary digit» -двоичный знак). Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т.п.). Двоичные числа очень удобно хранить и передавать с помощью электронных устройств. Например, 1 и 0 могут соответствовать намагниченным и ненамагниченным участкам диска; нулевому и ненулевому напряжению; наличию и отсутствию тока в цепи и т.п. Поэтому данные в компьютере на физическом уровне хранятся, обрабатываются и передаются именно в двоичном коде.
Последовательностью битов можно закодировать текст, изображение, звук или какую-либо другую информацию. Такой метод представления информации называется двоичным кодированием. Таким образом, двоичный код является универсальным средством кодирования информации. Наиболее важными видами информации являются:
• Текстовая
• Графическая
• Аудио
• Видео
1.1 Шифрование
Наука, которая занимается изучением методов шифрования информации, является криптография, но у нее есть также и другие объекты изучения: Методы обеспечения конфиденциальности, целосности данных, аутентификации и невозможности отказа от авторства.
Рассмотрим следующие определения, которые используются в криптографии:
- Открытый (исходный) текст — данные, которые передаются без использования криптографии.
- Шифротекст, шифрованный (закрытый) текст — данные, полученные после применения шифра с некоторым ключом.
- Шифр, криптосистема — семейство обратимых преобразований открытого текста в шифротекст.
- Ключ — параметр шифра, который определяет конкретное преобразование открытого текста. По принципу Керкгоффса, в шифрах криптографическая стойкость шифра целиком определяется секретностью ключа.
- Шифрование — процесс нормального применения криптографического преобразования открытого текста на основе алгоритма и ключа, в результате которого возникает шифрованный текст.
- Расшифровывание — процесс нормального применения криптографического преобразования шифрованного текста в открытый.
- Открытый ключ — тот из двух ключей асимметричной системы, который свободно распространяется. Шифрующий для секретной переписки и расшифровывающий — для электронной подписи.
- Секретный ключ, закрытый ключ — тот из двух ключей асимметричной системы, который хранится в секрете.
- Криптоанализ — наука, которая изучает математические методы нарушения конфиденциальности и целостности информации и уязвимости шифров
- Криптоаналитик — человек, создающий и применяющий методы криптоанализа.
- Криптографическая атака — попытка криптоаналитика вызвать отклонения в атакуемой защищённой системе обмена информацией. Успешную криптографическую атаку называют взлом или вскрытие.
- Дешифрование — процесс извлечения открытого текста без знания криптографического ключа на основе известного шифрованного. Термин дешифрование обычно применяют по отношению к процессу криптоанализа шифротекста (криптоанализ сам по себе, вообще говоря, может заключаться и в анализе криптосистемы, а не только зашифрованного ею открытого сообщения).
- Криптографическая стойкость — способность криптографического алгоритма противостоять криптоанализу.
- Имитозащита — защита от навязывания ложной информации. Другими словами, текст остаётся открытым, но появляется возможность проверить, что его не изменяли ни случайно, ни намеренно. Имитозащита достигается обычно за счет включения в пакет передаваемых данных имитовставки.
- Имитовставка — блок информации, применяемый для имитозащиты, зависящий от ключа и данных.
- Электронная цифровая подпись, или электронная подпись — асимметричная имитовставка (ключ защиты отличается от ключа проверки). Другими словами, такая имитовставка, которую проверяющий не может подделать.
- Хеш-функция — функция, которая преобразует сообщение произвольной длины в целое число фиксированной длины, зависящей от алгоритма.
В современной криптографии чаще всего используются открытые алгоритмы шифрования. Существует множество проверенных открытых алгоритмов шифрования, которые являются достаточно криптографически стойкими при использовании ключа достаточной длины. Самые распространённые из них:
- Симметричные:
1. DES
2. AES
3. ГОСТ 28147-89
4. BlowFish
5. RC4
- Асимметричные:
1. RSA
2. Эль-Гамаль
Для построения криптографически стойких систем необходимо неоднократно использовать простые преобразования, так называемые криптографические примитивы. На системе криптографических алгоритмов основываются криптографические протоколы. В его основе лежит набор правил, определяющих использование криптографических примитивов. Примеры криптографических протоколов:
- Протокол Диффи-Хелмана
- MtProto – протокол обмена сообщениями в Telegram
- Протокол конфиденциального вычисления
1.2 Архивация
Архивация (сжатие) информации — это такое преобразование информации, при котором объем файла уменьшается, а количество информации, содержащейся в архиве, остается прежним. Процесс записи файла в архивный файл называется архивирование (упаковкой, сжатием), а извлечение файла из архива — разархивированием(распаковкой). Упакованный (сжатый) файл называется архивом.
Степень сжатия информации зависит от содержимого файла и формата файла, а также от выбранного метода архивации. Степень (качество) сжатия файлов характеризуется коэффициентом сжатия K, определяемым как отношение объема исходного файла K V = к объему V V сжатого файла V: Чем больше величина K, тем выше степень сжатия информации. Заметим, что в некоторых литературных источниках встречается определение коэффициента сжатия, обратное приведенному отношению.
Все существующие методы сжатия информации можно разделить на два класса: сжатие без потерь информации (обратимый алгоритм) и сжатие с потерей информации (необратимый алгоритм). В первом случае исходную информацию можно точно восстановить по имеющейся упакованной информации. Во втором случае распакованное сообщение будет отличаться от исходного сообщения.
В настоящее время разработано много алгоритмов архивации без потерь. Однако все они используют две простые идеи. Первая идея, основанная на учете частот появления символов в тексте, была разработана Хаффманом (D.A. Huffman) в 1952 г. Она базируется на том факте, что в обычном тексте частоты появления различных символов неодинаковые. При кодировании символов в ЭВМ используют кодовые таблицы. При этом каждый символ кодируется либо одним байтом (CP-1251, КОИ-8), либо двумя байтами (Unicode). Кодовые таблицы стандартизируют процедуру кодирования. Однако для передачи информации по каналу связи (или для долговременного хранения) можно использовать более сложную процедуру кодирования, которая обеспечит уменьшение размера файла при полном сохранении исходной информации. При архивации не используются стандартные кодовые таблицы, а создаются собственные. При этом вид кодовой таблицы каждый раз изменяется и зависит от содержания архивируемого документа. При упаковке по методу Хаффмана часто встречающиеся символы кодируются (заменяются) короткими последовательностями битов, а более редкие символы — длинными последовательностями. К каждому сжатому архиву прикладывается таблица соответствия имеющихся символов и кодов (чисел), заменяющих эти символы. Архивы как бы отменяют стандартные кодовые таблицы.
Все способы сжатия можно разделить на две категории: обратимое и необратимое сжатие. Необратимое сжатие - такое преобразование входного потока информации, при котором выходной поток, основанный на определенном формате информации, представляет собой объект, достаточно похожий по внешним характеристикам на входной поток, однако отличается от него объемом. Степень сходства входного и выходного потоков определяется степенью соответствия некоторых свойств объекта (до сжатия и после), представляемого данным потоком информации. Такие подходы и алгоритмы используются для сжатия информации растровых графических файлов, видео и звука. При таком подходе используется свойство структуры данного формата файла и возможность представить информацию приблизительно схожую по качеству для восприятия человеком. Поэтому, кроме степени или величины сжатия, в таких алгоритмах возникает понятие качества, т.к. исходная информация в процессе сжатия изменяется. Под качеством можно понимать степень соответствия исходной и результирующей информации, оцениваемое субъективно, исходя из формата информации. Для графических файлов такое соответствие определяется визуально, хотя имеются и соответствующие интеллектуальные алгоритмы и программы. Необратимое сжатие невозможно применять в областях, в которых необходимо иметь точное соответствие информационной структуры входного и выходного потоков. Данный подход реализован в популярных форматах представления фотоинформации - JPEG, TIFF, GIF, PNG и др., аудио информации - MP3, видео информации - MPEG-4.
Обратимое сжатие всегда приводит к снижению объема выходного потока информации без изменения его информативности, т.е. без потери информационной структуры. Из выходного потока, при помощи восстанавливающего или декомпрессирующего алгоритма, можно получить входной, а процесс восстановления называется декомпрессией или распаковкой и только после процесса распаковки информация пригодна для использования в соответствии с их внутренним форматом.
ГЛАВА 2. Методы кодирования текстовой и числовой информации
2.1 Кодирование целых и действительных чисел
Для представления информации в памяти ЭВМ (как числовой, так и не числовой) используется двоичный способ кодирования. Элементарная ячейка памяти процессора имеет длину 8 бит или 1байт. Каждый байт имеет свой порядковый номер, который называют его адресом. Наибольшую последовательность бит, которую ЭВМ может обрабатывать как единое целое, называют машинным словом. Длина машинного слова зависит от разрядности процессора и может быть равной 16, 32, 64 битам. Для графических карт возможны длины слов 256 и 512 бит, что ускоряет работу процессора при вычислениях.
2.1.1 Двоично-десятичное кодирование
В некоторых ситуациях при представлении чисел в памяти ЭВМ используется комбинированная двоично-десятичная "система счисления", в которой для обработки каждого десятичного знака нужен полубайт (4 бита) и десятичные цифры от 0 до 9 представляются соответствующими двоичными представлениями чисел от 0000 до 1001. Например, упакованный десятичный формат, предназначенный для хранения целых чисел с 18-ю значащими цифрами и занимающий в памяти байт (старший из которых знаковый), использует именно этот вариант.
2.1.2 Представление целых чисел в дополнительном коде
Иным методом представления целых чисел в ЭВМ является дополнительный код. Спектр значений величин зависит от количества бит (байт) памяти, которые отведены для работы с ними. К примеру, величины типа short лежат в диапазоне от -32768 (−) до 32767 ( − 1) и для их хранения отводится 2 байта (16 бит); типа int — в диапазоне от − до − 1 и помещаются в 4 байтах (32 бита); типа char —в диапазоне от 0 до 65535 (используют 2 байта – 16 бит) и т.д.
Как было показано в примерах, существуют типы чисел как со знаком так и без него (signed, unsigned). В случае представления величины со знаком самый высокий (старший) разряд показывает на неотрицательное число, если содержит нуль, и на отрицательное, если — единицу. Вообще, разряды нумеруются справа налево, начиная с 0. Ниже показана нумерация бит в двухбайтовом машинном слове.
|
15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
Дополнительный код положительных чисел совпадает с их прямым кодом. Прямой код целого числа может быть получен следующим образом: число переводится в двоичную систему счисления, а затем к его двоичное представление слева приписывают такое количеством незначащих нулей, сколько требует тип данных, к которому принадлежит число.
Например, если число 37(в десятичной с.с.) = 0b100101 объявлено величиной типа short (шестнадцати битовое со знаком), то его прямым кодом будет 0b0000000000100101, а если величиной типа int (тридцати двух битовое со знаком), то его прямой код будет 0b00000000000000000000000000100101. Для более компактной записи чаще используют шестнадцатеричное представление кода. Полученные коды можно переписать соответственно, как 0x0025 и 0x00000025.
Дополнительный код целого отрицательного числа может быть получен по следующему алгоритму:
1. записываем прямой код модуля числа;
2. инвертировать его (заменить единицы нулями, нули — единицами);
3. прибавляем к инвертированному коду единицу.
2.1.3 Кодирование вещественных чисел
Несколько иной способ применяется для представления в памяти персонального компьютера действительных чисел. Рассмотрим представление величин с плавающей точкой. Любое действительное число можно записать в стандартном виде M × 10, где 1 <= M < , p — целое. Например, 120100000 = 1,201 × . Поскольку каждая позиция десятичного числа отличается от соседней на степень числа 10, умножение на 10 эквивалентно сдвигу десятичной запятой на одну позицию вправо. Аналогично деление на 10 сдвигает десятичную запятую на позицию влево. Поэтому приведенный выше пример можно продолжить: 120100000 =1,201 × = 0,1201 × = 12,01 × . Десятичная запятая "плавает" в числе и больше не помечает абсолютное место между целой и дробной частями. В приведенной выше записи M называют мантиссой числа, а p — его порядком. Для того чтобы сохранить максимальную точность, вычислительные машины почти всегда хранят мантиссу в нормализованном виде, что означает, что мантисса в данном случае есть число, лежащее между 1(10) и 2(10) (1 <= M <2). Основание системы счисления здесь, как уже отмечалось выше, — число 2.
Способ хранения мантиссы с плавающей точкой подразумевает, что двоичная запятая находится на фиксированном месте. Фактически подразумевается, что двоичная запятая следует после первой двоичной цифры, т.е. нормализация мантиссы делает единичным первый бит, помещая тем самым значение между единицей и двойкой. Место, отводимое для числа с плавающей точкой, делится на два поля. Одно поле содержит знак и значение мантиссы, а другое содержит знак и значение порядка.
Современный персональный компьютер позволяет работать со следующими действительными типами (диапазон значений указан по абсолютной величине; в некоторых случаях перечень типов данных может быть расширен):
|
Тип |
Диапазон |
Мантисса |
Байты |
|
Real |
2,9×10-39..1,7×1038 |
11-12 |
6 |
|
Single |
1,5×10-45..3,4×1038 |
7-8 |
4 |
|
Double |
5,0×10-324..1,7×10308 |
15-16 |
8 |
|
Extended |
3,4×10-4932..1,1×104932 |
19-20 |
10 |
Покажем преобразование действительного числа для представления его в памяти ЭВМ на примере величины типа Double. Как видно из таблицы, величина это типа занимает в памяти 8 байт. На рисунке ниже показано, как здесь представлены поля мантиссы и порядка (нумерация битов осуществляется справа налево):
|
S |
Смещенный порядок |
Мантисса |
|
63 |
62..52 |
51..0 |
Можно заметить, что старший бит, отведенный под мантиссу, имеет номер 51, т.е. мантисса занимает младшие 52 бита из 64. Черта указывает здесь на положение двоичной запятой. Перед запятой обязан стоять бит целой части мантиссы, но поскольку она всегда равна 1, здесь данный бит не требуется и соответствующий разряд отсутствует в памяти (но он подразумевается). Значение порядка хранится здесь как целое число, представленное в дополнительном коде. Для упрощения вычислений и сравнения вещественных чисел значение порядка в ЭВМ хранится в виде смещенного числа, т.е. к настоящему значению порядка перед записью его в память прибавляется смещение. Смещение выбирается так, чтобы минимальному значению порядка соответствовал нуль. Например, для типа Double порядок занимает 11 бит и имеет диапазон от - до , поэтому смещение равно 1023(10) = 1111111111(2). Наконец, бит с номером 63 указывает на знак числа. Таким образом, из вышесказанного вытекает следующий алгоритм для получения представления действительного числа в памяти ЭВМ:
1. перевести модуль заданного числа в двоичную систему счисления;
2. нормализовать полученное двоичное число, т.е. записать в виде M × , где M — мантисса (ее целая часть равна 1(2)) и p — порядок, записанный в десятичной системе счисления;
3. прибавить к порядку смещение и перевести смещенный порядок в двоичную систему счисления;
4. учесть знак заданного числа (0 — положительное; 1 — отрицательное), и выписать его представление в памяти процессора.
2.2 Кодирование текстовой информации
С точки зрения ЭВМ текст состоит из отдельных символов. К числу символов принадлежат не только буквы алфавита (заглавные или строчные, латинские или русские), но и другие символы - цифры, знаки препинания, специальные знаки типа "=", "(", "&" и т.п. и даже пробелы, знаки табуляции. Тексты вводятся в память ЭВМ с помощью клавиатуры и других устройств ввода. На клавишах написаны привычные нам буквы, цифры, знаки препинания и другие символы. В оперативную память они попадают в двоичном виде. Это значит, что каждый символ представляется 8-разрядным двоичным кодом.
Традиционно для кодирования одного знака используется количество информации, равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных вариантов событий К и количество информации I, можно вычислить сколько отличных символов можно закодировать, т. е. для представления (считая, что символы текстовой - информации это возможные можно события)использовать : К = 2^алфавит = 2^8 =256 мощностью 256 символов. Такое количество символов вполне достаточно для представления текстовой информации, включая прописные и строчные буквы русского и латинского алфавита, цифры, знаки, графические символы и пр.
Кодирование заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичное число от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду. Удобство побайтового кодирования символов очевидно, поскольку байт - наименьшая адресуемая часть памяти и, следовательно, процессор ЭВМ может обратиться к каждому символу отдельно, выполняя обработку текста. С другой стороны, 256 символов – это вполне достаточное количество для представления самой разнообразной текстовой информации.
Для вывода знака символа на экран пк делается обратный процесс — декодирование, то есть преобразование кода символа в его изображение. Важно, что присвоение символу конкретного кода — это вопрос соглашения, которое фиксируется в кодовой таблице. Теперь возникает вопрос, какой именно восьмиразрядный двоичный код поставить в соответствие каждому символу. Понятно, что это дело условное, можно придумать множество способов кодировки.
Все символы компьютерного алфавита пронумерованы от 0 до 255. Каждому номеру соответствует восьмиразрядный двоичный код от 00000000 до 11111111. Этот код просто порядковый номер символа в двоичной системе счисления.
2.2.1 Кодировка ASCII
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, именуется таблицей кодировки. Для различных типов ЭВМ используются разные таблицы кодировки.
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange - Американский стандартный код для информационного обмена), кодирующая первую половину символов с числовыми кодами от 0 до 127 (коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII делится на две части. Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0(00000000), до 127 (01111111).
Изначально в 1963 году кодировка ASCII была разработана для кодирования символов, коды которых помещались в 7 бит (128 символов; =128); при этом старший 7-й бит (нумерация с нуля) использовался для контроля ошибок, возникающих при передаче данных. Со временем — кодировка была расширена до 256 символов (=256); коды первых 128 символов не изменились. ASCII стала восприниматься как половина 8-битной кодировки, а «расширенной ASCII» называли ASCII с задействованным 8-м битом (например, КОИ-8).
С помощью знака Backspace (\b) (возврат на один символ) на устройстве вывода можно печатать один символ поверх предыдущего. В ASCII таким же способом можно добавить к буквам диакритические знаки, например:
- a \b ' → á
- a \b ` → à
- a \b ^ → â
- o \b / → ø
- c \b , → ç
- n \b ~ → ñ
Если в одной позиции дважды напечатать одинаковый символ — получится жирный символ; если в одной позиции напечатать символ, а затем подчёркивание «_» — получится подчёркнутый символ:
- a BS a → a
- a BS _ → a
Эта техника до сих пор используется в различных программах, например, в справочной системе man.
Структура таблицы кодировки ASCII
|
Порядковый номер символа |
Код символа |
Символ |
|
0-31 |
00000000 - 00011111 |
Управляющие символы (позволяют управлять процессом вывода текста на экран или печать, разметка текста и т.д.) |
|
32-127 |
01000000 - 01111111 |
Стандартная часть таблицы кодировки – содержит буквы латинского алфавита, десятичные цифры, знаки препинания, скобки и другие символы |
|
128-255 |
10000000 - 11111111 |
Альтернативная половина таблицы В ней размещаются национальные алфавиты, отличные от латинского. В русских вариациях ASCII(КОИ-8, CP1251 и др.)размещаются символы русского языка (кириллица). |
2.2.2 Кодировка Unicode
В 1991 году некоммерческой организацией «Консорциум Юникода» был предложен новый стандарт кодирования символов - Unicode, который включает в себя почти все письменности языков мира. На данный момент этот стандарт является доминирующим по использованию в интернете. Использование этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом становится ненужным переключение кодовых страниц. Стандарт состоит из двух главных частей: универсального набора символов и семейства кодировок (англ. Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые в стандарте Юникод символы и присваивает каждому код в виде неотрицательного целого числа, которое записывается обычно в шестнадцатеричной форме с префиксом U+, например, U+040F. Семейство кодировок определяет способы преобразования кодов символов для передачи в потоке или в файле.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.
Юникод имеет несколько форм представления (англ. Unicode transformation format, UTF): UTF-8, UTF-16 и UTF-32.
Формат UTF-8 был изобретен в 1992 году Кеном Томпсоном и Робом Пайком и официально закреплен в документах RFC 3629 и ISO/IEC 10646 Annex D. Данный формат является представлением Юникода, которое обеспечивает наибольшую компактность и обратную совместимость с 7- битной системой ASCII. текст, состоящий только из символов с номерами меньше 128, при записи в UTF-8 превращается в обычный текст ASCII и может быть отображён любой программой, работающей с ASCII; и наоборот, текст, закодированный 7-битной ASCII может быть отображён программой, предназначенной для работы с UTF-8. Остальные символы Юникода изображаются последовательностями длиной от 2 до 4 байт, в которых первый байт всегда имеет маску 11xxxxxx, а остальные — 10xxxxxx. В UTF-8 не используются суррогатные пары.
UTF-16 — кодировка, позволяющая записывать символы Юникода в диапазонах U+0000...U+D7FF и U+E000...U+10FFFF (общим количеством 1 112 064). При этом каждый символ записывается одним или двумя словами (2 байта) (суррогатная пара). Кодировка UTF-16 описана в приложении Q к международному стандарту ISO/IEC 10646, а также ей посвящён документ IETF RFC 2781 под названием «UTF-16, an encoding of ISO 10646».
UTF-32 — способ представления Юникода, при котором каждый знак занимает ровно 4 байта. Главное преимущество UTF-32 перед кодировками переменной длины заключается в том, что символы Юникод в ней непосредственно индексируемы, поэтому найти символ по номеру его позиции в файле можно чрезвычайно быстро, и получение любого символа n-й позиции при этом является операцией, занимающей всегда константное время, не зависящее от позиции символа в тексте. Это также делает замену символов в строках UTF-32 проще остальных вариаций кодировки юникод. Напротив, кодировки с переменной длиной требуют последовательного доступа к символу n-й позиции, что может быть очень затратной по времени операцией. Главный недостаток UTF-32 — это неэффективное использование дискового пространства и оперативной памяти, так как для хранения любого символа используется четыре байта. Символы, лежащие за пределами нулевой (базовой) плоскости кодового пространства, редко используются в большинстве текстов. Поэтому удвоение, в сравнении с UTF-16, занимаемого строками в UTF-32 пространства, зачастую не оправдано.
ГЛАВА 3. Методы кодирования графической, аудио и видео информации
3.1 Кодирование графической информации
В середине 50-х годов для больших ЭВМ, которые применялись в научных и военных исследованиях, впервые в графическом виде было реализовано представление данных. В настоящее время широко используются технологии обработки графической информации с помощью ПК. Графический интерфейс пользователя стал стандартом "де-факто" для ПО разных классов, начиная с операционных систем. Вероятно, это связано со свойством человеческой психики: наглядность способствует более быстрому пониманию. Широкое применение получила специальная область информатики, которая изучает методы и средства создания и обработки изображений с помощью программно-аппаратных вычислительных комплексов, - компьютерная графика. Без нее сложно представить уже не только компьютерный, но и окружающий мир, так как визуализация данных употребляется в различных сферах человеческой деятельности. В качестве примера можно привести опытно-конструкторские разработки, медицину (компьютерная томография), научные исследования и прочее. Особенно интенсивно технология обработки графической информации с помощью компьютера начала развиваться в 80-х годах.
Графическую информацию можно представлять в двух формах: дискретной или аналоговой. Живописное полотно, цвет которого изменяется непрерывно - пример аналогового представления, а изображение, напечатанное при помощи струйного принтера и состоящее из отдельных точек разного цвета – это дискретное представление. Путем разбиения графического изображения (дискретизации) происходит преобразование графической информации из аналоговой формы в дискретную. При этом производится кодирование - присвоение каждому элементу конкретного значения в форме кода. При кодировании изображения происходит его пространственная дискретизация. Ее можно сравнить с построением изображения из большого количества маленьких цветных фрагментов (метод мозаики). Все изображение разбивается на отдельные точки, каждому элементу ставится в соответствие код его цвета. При этом качество кодирования будет зависеть от следующих параметров: размера точки и количества используемых цветов. Чем меньше размер точки, а, значит, изображение составляется из большего количества точек, тем выше качество кодирования. Чем большее количество цветов используется (т. е. точка изображения может принимать больше возможных состояний), тем больше информации несет каждая точка, а, значит, увеличивается качество кодирования.
Создание и хранение графических объектов возможно в нескольких видах – в виде растрового, векторного или фрактального изображения. Отдельным предметом считается 3D (трехмерная) графика, в которой сочетаются векторный и растровый способы формирования изображения. Она изучает методы и приемы построения объемных графических моделей объектов в виртуальном пространстве. Для каждого вида изображений используется свой способ кодирования графической информации.
3.1.1 Растровое изображение.
При помощи увеличительного стекла можно увидеть, что черно-белое графическое изображение, например из газеты, состоит из мельчайших точек, составляющих определенный узор - растр. Во Франции в 19 веке возникло новое направление в живописи - пуантилизм. Его техника заключалась в том, что на холст рисунок наносился кистью в виде разноцветных точек. Также этот метод издавна применяется в полиграфии для кодирования графической информации. Точность передачи рисунка зависит от количества точек и их размера. После разбиения рисунка на точки, начиная с левого угла, двигаясь по строкам слева направо, можно кодировать цвет каждой точки. Далее одну такую точку будем называть пикселем (происхождение этого слова (pixel) связано с английской аббревиатурой "picture element" - элемент рисунка). Объем растрового изображения определяется умножением количества пикселей (на информационный объем одной точки, который зависит от количества возможных цветов. Качество изображения определяется разрешающей способностью зрительного устройства(монитора). Чем она выше, то есть больше количество строк растра и точек в строке, тем выше качество изображения. Так как яркость каждой точки и ее линейные координаты можно выразить с помощью целых чисел, то можно сказать, что этот метод кодирования позволяет использовать двоичный код для того, чтобы обрабатывать и хранить графические данные. Если говорить о черно-белых иллюстрациях, то, если не использовать полутона, то пиксель будет принимать одно из двух состояний: светится (белый) и не светится (черный). А так как информация о цвете пикселя называется кодом пикселя, то для его кодирования достаточно одного бита памяти: 0 - черный, 1 - белый. Если же рассматриваются иллюстрации в виде комбинации точек с 256 градациями серого цвета (а именно такие в настоящее время общеприняты), то достаточно восьмиразрядного двоичного числа для того чтобы закодировать яркость любой точки. В компьютерной графике чрезвычайно важен цвет. Он выступает как средство усиления зрительного впечатления и повышения информационной насыщенности изображения. Как формируется ощущение цвета человеческим мозгом? Это происходит в результате анализа светового потока, попадающего на сетчатку глаза от отражающих или излучающих объектов. Принято считать, что цветовые рецепторы человека, которые еще называют колбочками, подразделяются на три группы, причем каждая может воспринимать всего один цвет - красный, или зеленый, или синий.
Самой известной системой кодирования растровых изображений является RGB модель. В данной модели используются всего три цвета – красный, зеленый и синий. Рассмотрим как в ней получаются различные цвета
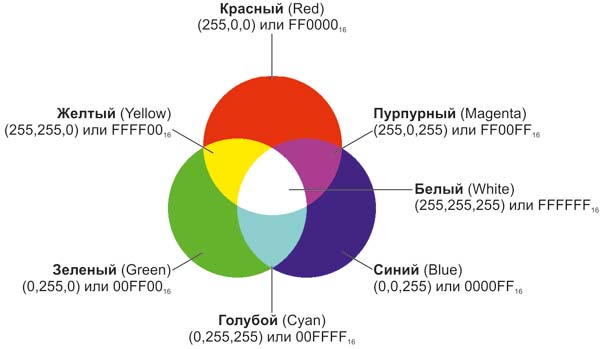
Числовое представление цвета в данной модели может отличаться по размеру- бывает 16-битное представление (5 бит на красный, 6 бит на зеленый и 5 бит на синий), 24-битное (по 8 бит на каждый цвет) и 32 битное (HDR, в нем один бит используется для корректировки яркости и для различной фильтрации).
Растровые изображения могут храниться на жестком диско в одном из форматов (кодировок). Рассмотрим самые популярные форматы:
- JPEG. Файлы с изображениями в данном формате имеют различные расширения (.jpg, .jfif, .jpe или .jpeg). Mime-тип данных изображений – image/jpeg. Алгоритм JPEG позволяет сжимать изображение как с потерями, так и без потерь (режим сжатия lossless JPEG). Поддерживаются изображения с линейным размером не более 65535 × 65535 пикселей. Алгоритм JPEG в наибольшей степени пригоден для сжатия фотографий и картин, содержащих реалистичные сцены с плавными переходами яркости и цвета. Наибольшее распространение JPEG получил в цифровой фотографии и для хранения и передачи изображений с использованием сети Интернет. Формат JPEG в режиме сжатия с потерями малопригоден для сжатия чертежей, текстовой и знаковой графики, где резкий контраст между соседними пикселями приводит к появлению заметных артефактов. Такие изображения целесообразно сохранять в форматах без потерь
- PNG. Это растровый формат хранения графической информации, использующий сжатие без потерь по алгоритму Deflate. Он был создан как свободный формат для замены GIF, поэтому в Интернете появился рекурсивный акроним «PNG is Not GIF». PNG поддерживает три основных типа растровых изображений: Полутоновое изображение (с глубиной цвета 16 бит), Цветное индексированное изображение (палитра 8 бит для цвета глубиной 24 бит), Полноцветное изображение (с глубиной цвета 48 бит). Формат PNG хранит графическую информацию в сжатом виде. Причём это сжатие производится без потерь.
3.1.2 Векторное и фрактальное изображения
Векторное изображение- графический объект, состоящий из элементарных отрезков и дуг. Базовым элементом изображения является линия. Как и любой объект, она обладает свойствами: формой (прямая, кривая), толщиной., цветом, начертанием (пунктирная, сплошная). Замкнутые линии имеют свойство заполнения (или другими объектами, или выбранным цветом). Все прочие объекты векторной графики составляются из линий. Так как линия описывается математически как единый объект, то и объем данных для отображения объекта средствами векторной графики значительно меньше, чем в растровой графике.
Информация о векторном изображении кодируется как обычная буквенно-цифровая и обрабатывается специальными программами. К программным средствам создания и обработки векторной графики относятся следующие ГР: CorelDraw, Adobe Illustrator, а также векторизаторы (трассировщики) - специализированные пакеты преобразования растровых изображений в векторные.
Фрактальная графика основывается на математических вычислениях, как и векторная. Но в отличии от векторной ее базовым элементом является сама математическая формула. Это приводит к тому, что в памяти компьютера не хранится никаких объектов и изображение строится только по уравнениям. При помощи этого способа можно строить простейшие регулярные структуры, а также сложные иллюстрации, которые имитируют ландшафты.
3.2 Кодирование аудио информации
В основе кодирования звука с использованием ПК лежит процесс преобразования колебаний воздуха в колебания электрического тока и последующая дискретизация аналогового электрического сигнала. Кодирование и воспроизведение звуковой информации осуществляется с помощью специальных программ (редактор звукозаписи). Качество воспроизведения закодированного звука зависит от частоты дискретизации и её разрешения (глубины кодирования звука — количество уровней).
Цифровой звук — это аналоговый звуковой сигнал, представленный посредством дискретных численных значений его амплитуды.
Оцифровка звука — технология поделенным временным шагом и последующей записи полученных значений в численном виде. Другое название оцифровки звука — аналогово-цифровое преобразование звука.
Оцифровка звука включает в себя два процесса:
- процесс дискретизации (осуществление выборки) сигнала по времени
- процесс квантования по амплитуде.
3.2.1 Кодирование оцифрованного звука
Для хранения цифрового звука существует множество различных способов. Оцифрованный звук являет собой спектр значений амплитуды сигнала, взятых через определенные промежутки времени.
Блок оцифрованной аудио информации можно записать в файл без изменений, то есть последовательностью чисел - значений амплитуды. В этом случае существуют два способа хранения информации. Первый - PCM (Pulse Code Modulation - импульсно-кодовая модуляция) - способ цифрового кодирования сигнала при помощи записи абсолютных значений амплитуд. (В данном виде записаны данные на всех аудио CD.) Второй - ADPCM (Adaptive Delta PCM - адаптивная относительная импульсно-кодовая модуляция) – запись значений сигнала не в абсолютных, а в относительных изменениях амплитуд (приращениях). Можно сжать данные так, чтобы они занимали меньший объем памяти, нежели в исходном состоянии. Тут тоже имеется два способа. Кодирование данных без потерь (lossless coding) - способ кодирования аудио, который позволяет производить стопроцентное восстановление данных из сжатого потока. К нему прибегают в тех случаях, когда сохранение оригинального качества данных особо значимо. Существующие сегодня алгоритмы кодирования без потерь (например, Monkeys Audio) позволяют уменьшить занимаемый данными объем на 20-50%, но при этом обеспечить стопроцентное восстановление оригинальных данных из полученных после сжатия.
Кодирование данных с потерями (lossy coding). Здесь цель – добиться схожести звучания восстановленного сигнала с оригиналом при как можно меньшем размере сжатого файла. Это достигается с помощью использования алгоритмов, «упрощающих» оригинальный сигнал (удаляющих из него «несущественные», неразличимые на слух детали). Это ведет к тому, что декодированный сигнал перестает быть идентичным оригиналу, а представляет собой лишь «похоже звучащим». Методов сжатия, а также программ, реализующих эти методы, имеется множество. Наиболее известными выступают MPEG-1 Layer I,II,III (последним является всем известный MP3), MPEG-2 AAC (advanced audio coding), Ogg Vorbis, Windows Media Audio (WMA), TwinVQ (VQF), MPEGPlus, TAC, и прочие. В среднем, коэффициент сжатия, обеспечиваемый такими кодерами, находится в пределах 10-14 (раз). В основе всех lossy-кодеров лежит использование так называемой психоакустической модели. Она занимается этим самым «упрощением» оригинального сигнала. Степень сжатия оригинального сигнала зависит от степени его «упрощения» - сильное сжатие достигается путём «воинственного упрощения» (когда кодером игнорируются множественные нюансы). Такое сжатие приводит к сильной потере качества, поскольку удалению могут подлежать не только незаметные, но и значимые детали звучания.
3.3 Кодирование видео-информации
Видеоинформация – наиболее сложный вид для хранения, обработки и воспроизведения. В начале движущиеся изображения сохранялись на кинематографической пленке в виде большого количества отдельных кадров видео потока, заснятых через небольшие промежутки времени (24 кадра в секунду). Позднее на ту же пленку стала записываться и звуковая дорожка (в последующем несколько дорожек для многоканального (стерео) звука). Далее возникло телевидение с аналоговой записью движущегося изображения на магнитные ленты (системы телевидения PAL и SECAM используют 25 кадров в секунду, система NTSC – 29,97 кадров в секунду). С появлением компьютеров широкое распространение получили цифровые способы записи и кодирования видеоинформации, которые постоянно совершенствуются.
Качество видеоизображения в цифровых методах постоянно улучшается. Широкое распространение цифрового видео было связано с появление сначала CD-дисков, далее DVD, далее Blu-Ray дисков, на которых, в основном, и распространялись кинофильмы, и емкостью которых ограничивались качественные возможности.
Алгоритмы кодирования видео очень сложны, их описания можно выяснить в специальной литературе или на сайте http://www.mpeg.org.
Все форматы сжатия семейства MPEG (MPEG-1, MPEG-2, MPEG-4, MPEG-7) используют высокую избыточность информации в изображениях, разделенных малым интервалом времени.
Алгоритмы MPEG сжимают только опорные кадры – I-кадры (Intra frame – внутренний кадр). В промежутки между ними включаются кадры, содержащие только изменения между двумя соседними I-кадрами – P-кадры (Predicted frame – прогнозируемый кадр). MPEG-4 использует технологию фрактального сжатия изображений. Фрактальное (контурно-основанное) сжатие подразумевает выделение из изображения контуров и текстур объектов. Контуры представляются в виде сплайнов (полиномиальных функций) и кодируются опорными точками. Текстуры могут быть представлены в качестве коэффициентов пространственного частотного преобразования (к примеру, дискретного косинусного или вейвлет-преобразования). Считается, что за 10-15 кадров картинка изменится настолько, что необходим новый исходный кадр. В результате при использовании MPEG можно добиться уменьшения объема информации более чем в 200 раз, хотя это и приводит к некоторой потере качества. В настоящее время наиболее используемым является алгоритм сжатия MPEG-1, разработанный для хранения видео на компакт-дисках с качеством VHS, MPEG-2, используемый в цифровом, спутниковом телевидении и DVD, а также алгоритм MPEG-4, разработанный для передачи информации по компьютерным сетям и широко используемый в цифровых видеокамерах и для домашнего хранения видеофильмов.
Форматы файлов AVI и MKV – контейнеры, предназначенные для хранения видеоинформации, синхронизованной с аудиоинформацией. AVI может содержать в себе потоки 4 типов – Video, Audio, MIDI, Text. Причем видеопоток может быть только один, тогда как аудио – несколько.
Не смотря на различные форматы файлов в них могут использоваться одинаковые кодеки для видео и аудио, различаются лишь их представление в выходном файле, хранящемся на жестком диске. Рассмотрим различные варианты кодеков:
- DivX - видеокодек, различные версии которого соответствуют стандартам MPEG-4 part 2, MPEG-4 part 10 (MPEG-4 AVC, H.264), HEVC (H.265). Изначально был создан как патч к видеокодеку MPEG-4 от Microsoft. Позже стал платным и на его замену пришел бесплатный аналого Xvid
- H.264 или AVC (Advanced Video Coding) — лицензируемый стандарт сжатия видео, предназначенный для достижения высокой степени сжатия видеопотока при сохранении высокого качества. Данный стандарт имеет различные профили, которые обеспечивают различные степени зжатия видеопотока в зависимости от требования к итоговому видео. Так, например базовый профиль отличается тем, что выходной поток видео информации устойчив к потерям и шумам, основной профиль применяется в цифровом телевещании стандартной четкости, высокий профиль является основным для видео на оптических носителях и для цифрового телевидения высокой четкости.
- Xvid является заменой кодеку DivX, полностью открытый исходный код, распространяемый по лицензии GNU. Видео файлы с использованием данного кодека могут быть без проблем проиграны на плеере, поддерживающем кодек DivX, потому что в видео файле отличаются лишь 4 управляющих байта.
- FFmpeg – набор свободных библиотек с открытым исходным кодом, позволяющие упростить работу с видео. В его состав входит набор кодеков libavcodec, которые были написаны с помощью обратного программирования (реверс инжиниринг). Данные набор кодеков поддерживает все самые популярные кодеки, такие как- mjpeg, mpeg4, h263 и другие.
Заключение
В первой главе курсовой работы были рассмотрены общие положения в теории кодирования и хранении информации в компьютере. В ходе проведенного анализа были затронуты темы оптимального хранения информации и защищенной передачи информации – шифрование. Эти аспекты в теории информации выполняют огромную задачу – защищают пользовательские данные и позволяют предотвратить несанкционированный доступ к ним.
Вопрос кодирования информации является очень важным в процессе работы с различной информацией, так как неоптимальный выбор метода кодирования может привести к уменьшению производительности при ее обработке или хранении.
Способы кодирования разнообразны и зависят от поставленной цели. Формы представления данных определяются типами (форматами) данных. Таким образом, поставленная цель работы, а именно рассмотреть методы кодирования информации в компьютере достигнута.
Были рассмотрены следующие задачи:
- Изучены цели кодирования, такие как эффективное хранение данных и защита данных.
- Рассмотрены методы кодирования различных типов информации – числовой, текстовой, аудио, графической и видео информации.
Используемая литература
- Бабаш А. В. Криптографические методы защиты информации: учебник для вузов, 2016. — 189с ISBN 978-5-406-04766-8
- Amdahl G. M., Blaauw G. A., Brooks F. P., Jr. «Architecture of the IBM system/360». 1964
- Агеев В.М. Теория информации и кодирования: дискретизация и кодирование измерительной информации. — МАИ, 1977.
- Кузьмин И.В., Кедрус В.А. Основы теории информации и кодирования. — Киев, Вища школа, 1986.
- Простейшие методы шифрования текста/ Д.М. Златопольский. – М.: Чистые пруды, 2007 – 32 с.
- Гольденберг Л. М. и др. Цифровая обработка сигналов. Учебное пособие для вузов. — М.: Радио и связь, 1990. — 256 с.
- Блейхут Р. Быстрые алгоритмы цифровой обработки сигналов. — М.: Мир, 1989. — 448 с.
- Савельев А. Я. Основы информатики: Учебник для вузов. Оникс 2001.
- Ф.Дж.Мак-Вильямс, Н.Дж.А.Слоэн, Теория кодов, исправляющих ошибки, Москва, Связь, 1979.
- Э.Берлекэмп, Алгебраическая теория кодирования, Москва, Мир, 1971.
- Т.Касами, Н.Токура, Е.Ивадари, Я.Инагаки, Теория кодирования, Москва, Мир, 1978.
- Стандарт Unicode https://www.unicode.org/standard/standard.html

- Налоги с физических лиц и их экономическое значение (Теоретические и законодательные основы налогообложения физических лиц)
- Теория государства и права. Возникновение права
- Процессы принятия решений в организации (Организация исполнения управленческих решений)
- Понятия «затраты», «расходы», «издержки» (Теоретические аспекты управления затратами и себестоимостью)
- Сущность и значение бухгалтерского учета оплаты
- Порядок составления бухгалтерской отчетности организации
- Основные функции в системе менеджмента (О ТЕОРЕТИЧЕСКИХ АСПЕКТАХ ОСНОВНЫХ ФУНКЦИЙ В СИСТЕМЕ МЕНЕДЖМЕНТА СОВРЕМЕННОЙ ОРГАНИЗАЦИИ)
- Выработка практических навыков использования методов , принципов, технологии и инструментов маркетинга при анализе, оценке и решении конкретных рыночных проблем
- Понятие и виды государственных пенсий (Понятие и роль государственного суверенитета)
- Понятие и условия назначения пособия по безработице (Понятие и признаки статуса безработного)
- Основы работы с операционной системой Windows 7 (Дальнейшие перспективы Windows 7)
- Изучение роли игры как метода воспитания.