
Методы кодирования данных (Кодирование чисел)
Содержание:

ВВЕДЕНИЕ
Кодирование информации — это процесс формирования определенного представления информации. При кодировании информация представляется в виде дискретных данных. Декодирование является обратным к кодированию процессом. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки. Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (например, звуки, изображения, показания приборов и т. д.) для обработки на компьютере должна быть преобразована в числовую форму. С помощью программ для компьютера можно выполнить обратные преобразования полученной информации.
Актуальность темы в том, что вычислительная техника первоначально возникла как средство автоматизации вычислений. Следующим видом обрабатываемой информации стала текстовая. Сначала тексты просто поясняли труднообозримые столбики цифр, но затем машины все более существенным образом стали преобразовывать текстовую информацию. Оформление текстов достаточно быстро вызвали у людей стремление дополнить их графиками и рисунками. Делались попытки частично решить эти проблемы в рамках символьного подхода: вводились специальные символы для рисования таблиц и диаграммам. Но практические потребности людей в графике делали ее появление среди видов компьютерной информации неизбежной. Числа, тексты и графика образовали некоторый относительно замкнутый набор, которого было достаточно для многих решаемых на компьютере задачи. Постоянный рост быстродействия вычислительной техники создал широкие технические возможности для обработки звуковой информации, а также для быстро сменяющихся изображений. Все это обусловило и развитие способов представления и кодирования различных видов информации в компьютере.
Для автоматизации работы с данными, относящимися к различным типам, очень важно унифицировать их форму представления. Для этого используется прием кодирования, то есть выражение данных одного типа через данные другого типа.
В вычислительной технике применяется система кодирования двоичным кодом. Она основана на представлении данных последовательностью всего двух знаков 0 и 1. Эти знаки называются двоичными цифрами, каждая из которых представляет 1 бит. Одним битом могут быть выражены два понятия: 0 или 1 (да или нет, черное или белое, истина или ложь и т. и.). Двумя битами можно выразить четыре различных понятия: 00, 01, 10, 11. Тремя битами можно закодировать 8 различных значений: 000, 001, 010, 011, 100, 101, 110, 111. При увеличении количества разрядов в системе двоичного кодирования на единицу количество кодируемых значений увеличивается в два раза. Общая формула расчета имеет вид: N = 2т, где N - количество независимых кодируемых значений; т - количество разрядов двоичного кодирования.
Кроме системы двоичного кодирования в программировании используются системы восьмеричного и шестнадцатеричного кодирования, а вообще-то в качестве основания системы счисления, используемой для кодирования, может выступать любое число.
1. КОДИРОВАНИЕ ЧИСЕЛ
Числовую информацию компьютер обрабатывает в двоичной системе счисления. Таким образом, числа в компьютере представлены последовательностью цифр 0 и 1, называемых битами (бит – один разряд двоичного числа). В начале 1980-х гг. процессоры для персональных компьютеров были 8-разрядными, и за один такт работы процессора компьютер мог обработать 8 бит, т.е. максимально обрабатываемое десятичное число нс могло превышать 111111112 (или 25510). Последовательность из восьми бит называют байтом, т.е. 1 байт = 8 бит. Затем разрядность процессоров росла, появились 16-, 32- и, наконец, 64-разрядные процессоры для персональных компьютеров, соответственно возросла и величина максимального числа, обрабатываемого за один такт.
Использование двоичной системы для кодирования целых и действительных чисел позволяет с помощью 8 разрядов кодировать целые числа от 0 до 255, 16 бит дает возможность закодировать более 65 тыс. значений.
В ЭВМ применяются две формы представления чисел:
• естественная форма, или форма с фиксированной запятой. В этой форме числа изображаются в виде последовательности цифр с постоянным для всех чисел положением запятой, отделяющей целую часть от дробной, например, +00456,78800; +00000,00786; -0786,34287. Эта форма неудобна для вычислений и применяется только как вспомогательная для целых чисел;
• нормальная форма, или форма с плавающей точкой. В этой форме число выражается с помощью мантиссы и порядка как N = ±Μ • Р±r, где Μ – мантисса числа (|M| < 1), r – порядок числа (целое число), Р – основание системы счисления. Приведенные выше числа в нормальной форме будут представлены как +0,456788 • 103, +0,786 • 102, -0,3078634287 • 105.
Нормальная форма представления обеспечивает большой диапазон отображения чисел и является основной в современных ЭВМ. Все числа с плавающей запятой хранятся в ЭВМ в нормализованном виде. Нормализованным называют такое число, старший разряд мантиссы которого больше нуля.
Разрядная сетка для чисел с плавающей запятой имеет следующую структуру:
• нулевой разряд – это знак числа;
• с 1-го по 7-й разряд – записывается порядок в двоичном коде;
• с 8-го по 31-й – указывается мантисса.
2. КОДИРОВАНИЕ ТЕКСТОВЫХ ДАННЫХ
Если каждому символу алфавита сопоставить определенное целое число (например, порядковый номер), то с помощью двоичного кода можно кодировать и текстовую информацию. Восьми двоичных разрядов достаточно для кодирования 256 различных символов. Этого хватит, чтобы выразить различными комбинациями восьми битов все символы английского и русского языков, как строчные, так и прописные, а также знаки препинания, символы основных арифметических действий и некоторые общепринятые специальные символы, например, символ «§».
Технически это выглядит очень просто, однако всегда существовали достаточно веские организационные сложности. В первые годы развития вычислительной техники они были связаны с отсутствием необходимых стандартов, а в настоящее время вызваны, наоборот, изобилием одновременно действующих и противоречивых стандартов. Для того чтобы весь мир одинаково кодировал текстовые данные, нужны единые таблицы кодирования, а это пока невозможно из-за противоречий между символами национальных алфавитов, а также противоречий корпоративного характера.
Для английского языка, захватившего де-факто нишу международного средства общения, противоречия уже сняты. Институт стандартизации США (ANSI — American National Standard Institute) ввел в действие систему кодирования ASCII (American Standard Code for Information Interchange — стандартный код информационного обмена США). В системе ASCII закреплены две таблицы кодирования — базовая и расширенная. Базовая таблица закрепляет значения кодов от 0 до 127, а расширенная относится к символам с номерами от 128 до 255.
Первые 32 кода базовой таблицы, начиная с нулевого, отданы производителям аппаратных средств (в первую очередь производителям компьютеров и печатающих устройств). В этой области размещаются так называемые управляющие коды, которым не соответствуют никакие символы языков, и, соответственно, эти коды не выводятся ни на экран, ни на устройства печати, но ими можно управлять тем, как производится вывод прочих данных.
Начиная с кода 32 по код 127 размещены коды символов английского алфавита, знаков препинания, цифр, арифметических действий и некоторых вспомогательных символов. Базовая таблица кодировки ASCII приведена в таблице 1.1.
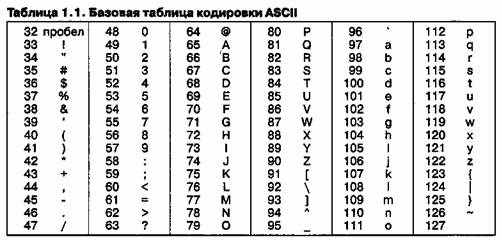
Аналогичные системы кодирования текстовых данных были разработаны и в других странах. Так, например, в СССР в этой области действовала система кодирования КОИ7 (код обмена информацией, семизначный). Однако поддержка производителей оборудования и программ вывела американский код ASCII на уровень международного стандарта, и национальным системам кодирования пришлось «отступить» во вторую, расширенную часть системы кодирования, определяющую значения кодов со 128 по 255. Отсутствие единого стандарта в этой области привело к множественности одновременно действующих кодировок. Только в России можно указать три действующих стандарта кодировки и еще два устаревших.
Так, например, кодировка символов русского языка, известная как кодировка Windows 1251, была введена «извне» — компанией Microsoft, но, учитывая широкое распространение операционных систем и других продуктов этой компании в России, она глубоко закрепилась и нашла широкое распространение (таблица 1.2). Эта кодировка используется на большинстве локальных компьютеров, работающих на платформе Windows.
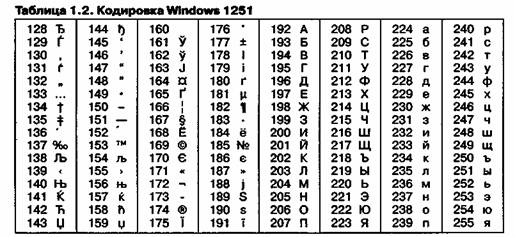
Другая распространенная кодировка носит название КОИ8 (код обмена информацией, восьмизначный) — ее происхождение относится ко временам действия Совета Экономической Взаимопомощи государств Восточной Европы (таблица1.3). Сегодня кодировка КОИ8 имеет широкое распространение в компьютерных сетях на территории России и в российском секторе Интернета.
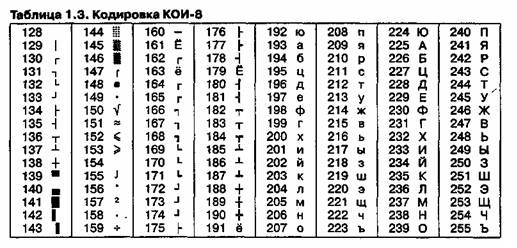
Международный стандарт, в котором предусмотрена кодировка символов русского алфавита, носит название кодировки ISO ( International Standard Organization — Международный институт стандартизации). На практике данная кодировка используется редко (таблица 1.4).
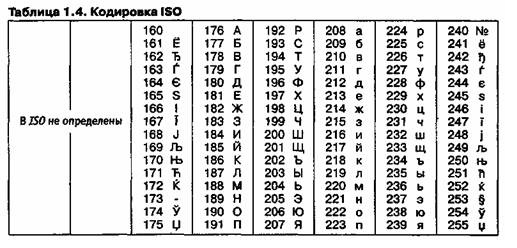
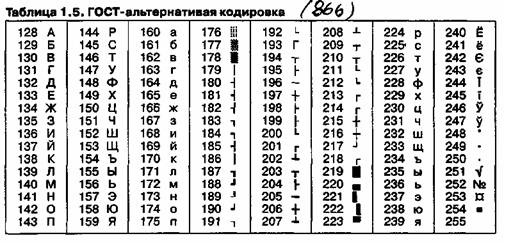
На компьютерах, работающих в операционных системах MS-DOS, могут действовать еще две кодировки (кодировка ГОСТ и кодировка ГОСТ-альтернативная). Первая из них считалась устаревшей даже в первые годы появления персональной вычислительной техники, но вторая используется и по сей день (см. таблицу 1.5).
Unicode (Юникод, или Уникод) — стандарт кодирования символов, позволяющий представить знаки практически всех письменных языков. Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium), объединяющей крупнейшие IT-корпорации. Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита и кириллицы, при этом становятся ненужными кодовые страницы. Коды в стандарте Unicode разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены коды от U+0400 до U+052F. Большинство современных операционных систем в той или иной степени обеспечивают поддержку Юникода. В операционных системах семейства Windows NT для внутреннего представления имён файлов и других системных строк используется двухбайтовая кодировка UTF-16LE. Системные вызовы, принимающие строковые параметры, существуют в однобайтном и двухбайтном вариантах. UNIX-образные операционные системы, в том числе, Linux, BSD, Mac OS X, используют для представления Юникода кодировку UTF-8. Большинство программ могут работать с UTF-8 как с традиционными однобайтными кодировками, не обращая внимания на то, что символ представляется как несколько последовательных байт. Для работы с отдельными символами строки обычно перекодируются в UCS-4, так что каждому символу соответствует машинное слово. Одной из первых успешных коммерческих реализаций Юникода стала среда программирования Java. В ней принципиально отказались от 8-битного представления символов в пользу 16-битного. Сейчас большинство языков программирования поддерживают строки Юникода, хотя их представление может различаться в зависимости от реализации.
3. КОДИРОВАНИЕ ГРАФИЧЕСКОЙ ИНФОРМАЦИИ
В середине 50-х годов для больших ЭВМ, которые применялись в научных и военных исследованиях, впервые в графическом виде было реализовано представление данных. В настоящее время широко используются технологии обработки графической информации с помощью ПК. Графический интерфейс пользователя стал стандартом "де-факто" для ПО разных классов, начиная с операционных систем. Вероятно, это связано со свойством человеческой психики: наглядность способствует более быстрому пониманию. Широкое применение получила специальная область информатики, которая изучает методы и средства создания и обработки изображений с помощью программно-аппаратных вычислительных комплексов, - компьютерная графика. Без нее трудно представить уже не только компьютерный, но и вполне материальный мир, так как визуализация данных применяется во многих сферах человеческой деятельности. В качестве примера можно привести опытно-конструкторские разработки, медицину (компьютерная томография), научные исследования и др.
Особенно интенсивно технология обработки графической информации с помощью компьютера стала развиваться в 80-х годах. Графическую информацию можно представлять в двух формах: аналоговой или дискретной. Живописное полотно, цвет которого изменяется непрерывно - это пример аналогового представления, а изображение, напечатанное при помощи струйного принтера и состоящее из отдельных точек разного цвета - это дискретное представление. Путем разбиения графического изображения (дискретизации) происходит преобразование графической информации из аналоговой формы в дискретную. При этом производится кодирование - присвоение каждому элементу конкретного значения в форме кода. При кодировании изображения происходит его пространственная дискретизация. Ее можно сравнить с построением изображения из большого количества маленьких цветных фрагментов (метод мозаики). Все изображение разбивается на отдельные точки, каждому элементу ставится в соответствие код его цвета. При этом качество кодирования будет зависеть от следующих параметров: размера точки и количества используемых цветов. Чем меньше размер точки, а, значит, изображение составляется из большего количества точек, тем выше качество кодирования. Чем большее количество цветов используется (т. е. точка изображения может принимать больше возможных состояний), тем больше информации несет каждая точка, а, значит, увеличивается качество кодирования. Создание и хранение графических объектов возможно в нескольких видах - в виде векторного, фрактального или растрового изображения. Отдельным предметом считается 3D (трехмерная) графика, в которой сочетаются векторный и растровый способы формирования изображений. Она изучает методы и приемы построения объемных моделей объектов в виртуальном пространстве. Для каждого вида используется свой способ кодирования графической информации.
3.1. Растровое изображение
При помощи увеличительного стекла можно увидеть, что черно-белое графическое изображение, например, из газеты, состоит из мельчайших точек, составляющих определенный узор - растр. Во Франции в 19 веке возникло новое направление в живописи - пуантилизм. Его техника заключалась в том, что на холст рисунок наносился кистью в виде разноцветных точек. Также этот метод издавна применяется в полиграфии для кодирования графической информации. Точность передачи рисунка зависит от количества точек и их размера. После разбиения рисунка на точки, начиная с левого угла, двигаясь по строкам слева направо, можно кодировать цвет каждой точки. Далее одну такую точку будем называть пикселем (происхождение этого слова связано с английской аббревиатурой "picture element" - элемент рисунка). Объем растрового изображения определяется умножением количества пикселей (на информационный объем одной точки, который зависит от количества возможных цветов. Качество изображения определяется разрешающей способностью монитора. Чем она выше, то есть больше количество строк растра и точек в строке, тем выше качество изображения. В современных ПК в основном используют следующие разрешающие способности экрана: 640 на 480, 800 на 600, 1024 на 768 и 1280 на 1024 точки. Так как яркость каждой точки и ее линейные координаты можно выразить с помощью целых чисел, то можно сказать, что этот метод кодирования позволяет использовать двоичный код для того чтобы обрабатывать графические данные.
Если говорить о черно-белых иллюстрациях, то, если не использовать полутона, то пиксель будет принимать одно из двух состояний: светится (белый) и не светится (черный). А так как информация о цвете пикселя называется кодом пикселя, то для его кодирования достаточно одного бита памяти: 0 - черный, 1 - белый. Если же рассматриваются иллюстрации в виде комбинации точек с 256 градациями серого цвета (а именно такие в настоящее время общеприняты), то достаточно восьмиразрядного двоичного числа для того, чтобы закодировать яркость любой точки. В компьютерной графике чрезвычайно важен цвет. Он выступает как средство усиления зрительного впечатления и повышения информационной насыщенности изображения. Как формируется ощущение цвета человеческим мозгом? Это происходит в результате анализа светового потока, попадающего на сетчатку глаза от отражающих или излучающих объектов. Принято считать, что цветовые рецепторы человека, которые еще называют колбочками, подразделяются на три группы, причем каждая может воспринимать всего один цвет - красный, или зеленый, или синий.
3.2. Цветовые модели
Если говорить о кодировании цветных графических изображений, то нужно рассмотреть принцип декомпозиции произвольного цвета на основные составляющие. Применяют несколько систем кодирования: HSB, RGB и CMYK. Первая цветовая модель проста и интуитивно понятна, т. е. удобна для человека, вторая наиболее удобна для компьютера, а последняя модель CMYK-для типографий. Использование этих цветовых моделей связано с тем, что световой поток может формироваться излучениями, представляющими собой комбинацию " чистых" спектральных цветов: красного, зеленого, синего или их производных. Различают аддитивное цветовоспроизведение (характерно для излучающих объектов) и субтрактивное цветовоспроизведение (характерно для отражающих объектов). В качестве примера объекта первого типа можно привести электронно-лучевую трубку монитора, второго типа - полиграфический отпечаток.
1) Модель HSB характеризуется тремя компонентами: оттенок цвета (Hue), насыщенность цвета (Saturation) и яркость цвета (Brightness). Можно получить большое количество произвольных цветов, регулируя эти компоненты. Эту цветовую модель лучше применять в тех графических редакторах, в которых изображения создают сами, а не обрабатывают уже готовые. Затем созданное свое произведение можно преобразовать в цветовую модель RGB, если ее планируется использовать в качестве экранной иллюстрации, или CMYK, если в качестве печатной, Значение цвета выбирается как вектор, выходящий из центра окружности. Направление вектора задается в угловых градусах и определяет цветовой оттенок. Насыщенность цвета определяется длиной вектора, а яркость цвета задается на отдельной оси, нулевая точка которой имеет черный цвет. Точка в центре соответствует белому (нейтральному) цвету, а точки по периметру - чистым цветам.
2) Принцип метода RGB заключается в следующем: известно, что любой цвет можно представить в виде комбинации трех цветов: красного (Red, R), зеленого (Green, G), синего (Blue, B). Другие цвета и их оттенки получаются за счет наличия или отсутствия этих составляющих. По первым буквам основных цветов система и получила свое название - RGB. Данная цветовая модель является аддитивной, то есть любой цвет можно получить сочетание основных цветов в различных пропорциях. При наложении одного компонента основного цвета на другой яркость суммарного излучения увеличивается. Если совместить все три компоненты, то получим ахроматический серый цвет, при увеличении яркости которого происходит приближение к белому цвету.
При 256 градациях тона (каждая точка кодируется 3 байтами) минимальные значения RGB (0,0,0) соответствуют черному цвету, а белому - максимальные с координатами (255, 255, 255). Чем больше значение байта цветовой составляющей, тем этот цвет ярче. Например, темно-синий кодируется тремя байтами ( 0, 0, 128), а ярко-синий (0, 0, 255).
3) Принцип метода CMYK. Эта цветовая модель используется при подготовке публикаций к печати. Каждому из основных цветов ставится в соответствие дополнительный цвет (дополняющий основной до белого). Получают дополнительный цвет за счет суммирования пары остальных основных цветов. Значит, дополнительными цветами для красного является голубой (Cyan,C) = зеленый + синий = белый - красный, для зеленого - пурпурный (Magenta, M) = красный + синий = белый - зеленый, для синего - желтый (Yellow, Y) = красный + зеленый = белый - синий. Причем принцип декомпозиции произвольного цвета на составляющие можно применять как для основных, так и для дополнительных, то есть любой цвет можно представить или в виде суммы красной, зеленой, синей составляющей или же в виде суммы голубой, пурупурной, желтой составляющей. В основном такой метод принят в полиграфии. Но там еще используют черный цвет (BlacК, так как буква В уже занята синим цветом, то обозначают буквой K). Это связано с тем, что наложение друг на друга дополнительных цветов не дает чистого черного цвета.
Различают несколько режимов представления цветной графики:
а) полноцветный (True Color);
б) High Color;
в) индексный.
При полноцветном режиме для кодирования яркости каждой из составляющих используют по 256 значений (восемь двоичных разрядов), то есть на кодирование цвета одного пикселя (в системе RGB) надо затратить 8*3=24 разряда. Это позволяет однозначно определять 16,5 млн цветов. Это довольно близко к чувствительности человеческого глаза. При кодировании с помощью системы CMYK для представления цветной графики надо иметь 8*4=32 двоичных разряда. Режим High Color — это кодирование при помощи 16-разрядных двоичных чисел, то есть уменьшается количество двоичных разрядов при кодировании каждой точки. Но при этом значительно уменьшается диапазон кодируемых цветов. При индексном кодировании цвета можно передать всего лишь 256 цветовых оттенков. Каждый цвет кодируется при помощи восьми бит данных. Но так как 256 значений не передают весь диапазон цветов, доступный человеческому глазу, то подразумевается, что к графическим данным прилагается палитра (справочная таблица), без которой воспроизведение будет неадекватным: море может получиться красным, а листья - синими. Сам код точки растра в данном случае означает не сам по себе цвет, а только его номер (индекс) в палитре. Отсюда и название режима - индексный.
Соответствие между количеством отображаемых цветов (К) и количеством бит для их кодировки (а) находиться по формуле: К = 2а.
|
А |
К |
Достаточно для… |
|
4 |
24=16 |
|
|
8 |
28=256 |
Рисованных изображений типа тех, что видим в мультфильмах, но недостаточно для изображений живой природы |
|
16(High Color) |
216=65536 |
Изображений, которые на картинках в журналах и на фотографиях |
|
24(True Color) |
224=16777216 |
Обработки и передачи изображений, не уступающих по качеству наблюдаемым в живой природе |
Двоичный код изображения, выводимого на экран, хранится в видеопамяти. Видеопамять — это электронное энергозависимое запоминающее устройство. Размер видеопамяти зависит от разрешающей способности дисплея и количества цветов. Но ее минимальный объем определяется так, чтобы поместился один кадр (одна страница) изображения, т.е. как результат произведения разрешающей способности на размер кода пикселя.
Vmin = M * N * a.
Двоичный код восьмицветной палитры
|
Цвет |
Составляющие |
||
|
К |
З |
С |
|
|
Красный |
1 |
0 |
0 |
|
Зеленый |
0 |
1 |
0 |
|
Синий |
0 |
0 |
1 |
|
Голубой |
0 |
1 |
1 |
|
Пурпурный |
1 |
0 |
1 |
|
Желтый |
1 |
1 |
0 |
|
Белый |
1 |
1 |
1 |
|
Черный |
0 |
0 |
0 |
Шестнадцатицветная палитра позволяет увеличить количество используемых цветов. Здесь будет использоваться 4-разрядная кодировка пикселя: 3 бита основных цветов + 1 бит интенсивности. Последний управляет яркостью трех базовых цветов одновременно (интенсивностью трех электронных пучков).
Двоичный код шестнадцатицветной палитры
|
Цвет |
Составляющие |
|||
|
К |
З |
С |
Интенс |
|
|
Красный |
1 |
0 |
0 |
0 |
|
Зеленый |
0 |
1 |
0 |
0 |
|
Синний |
0 |
0 |
1 |
0 |
|
Голубой |
0 |
1 |
1 |
0 |
|
Пурпурный |
1 |
0 |
1 |
1 |
|
Ярко-желтый |
1 |
1 |
0 |
1 |
|
Серый(белый) |
1 |
1 |
1 |
0 |
|
Темно-серый |
0 |
0 |
0 |
1 |
|
Ярко-голубой |
0 |
1 |
1 |
1 |
|
Ярко-синий |
0 |
0 |
1 |
0 |
|
… |
||||
|
Ярко-белый |
1 |
1 |
1 |
1 |
|
Черный |
0 |
0 |
0 |
0 |
При раздельном управлении интенсивностью основных цветов количество получаемых цветов увеличивается. Так для получения палитры при глубине цвета в 24 бита на каждый цвет выделяется по 8 бит, то есть возможны 256 уровней интенсивности (К = 28).
Двоичный код 256-цветной палитры
|
Цвет |
Состовляющие |
||
|
К |
З |
С |
|
|
Красный |
11111111 |
00000000 |
00000000 |
|
Зеленый |
00000000 |
11111111 |
00000000 |
|
Синий |
00000000 |
00000000 |
11111111 |
|
Голубой |
00000000 |
11111111 |
11111111 |
|
Пурпурный |
11111111 |
00000000 |
11111111 |
|
Желтый |
11111111 |
11111111 |
00000000 |
|
Белый |
11111111 |
11111111 |
11111111 |
|
Черный |
00000000 |
00000000 |
00000000 |
3.3. Векторное и фрактальное изображения
Векторное изображение — это графический объект, состоящий из элементарных отрезков и дуг. Базовым элементом изображения является линия. Как и любой объект, она обладает свойствами: формой (прямая, кривая), толщиной., цветом, начертанием (пунктирная, сплошная). Замкнутые линии имеют свойство заполнения (или другими объектами, или выбранным цветом). Все прочие объекты векторной графики составляются из линий. Так как линия описывается математически как единый объект, то и объем данных для отображения объекта средствами векторной графики значительно меньше, чем в растровой графике. Информация о векторном изображении кодируется как обычная буквенно-цифровая и обрабатывается специальными программами.
К программным средствам создания и обработки векторной графики относятся следующие ГР: CorelDraw, Adobe Illustrator, а также векторизаторы (трассировщики) - специализированные пакеты преобразования растровых изображений в векторные.
Фрактальная графика основывается на математических вычислениях, как и векторная. Но в отличии от векторной, ее базовым элементом является сама математическая формула. Это приводит к тому, что в памяти компьютера не хранится никаких объектов и изображение строится только по уравнениям. При помощи этого способа можно строить простейшие регулярные структуры, а также сложные иллюстрации, которые имитируют ландшафты.
4. КОДИРОВАНИЕ ЗВУКОВОЙ И ВИДЕОИНФОРМАЦИИ
Стандартов на кодирование звуковой информации двоичным кодом нет. Существуют отдельные корпоративные стандарты. Способы работы со звуком и видео получили название мультимедийных технологий.
Имеется два основных метода кодирования звука.
Метод FM (Frequency Modulation) – метод частотной модуляции. В нем используется разложение сложного звука на последовательность простейших гармонических сигналов разной частоты. Гармонический сигнал представляет собой правильную синусоиду, которую можно описать набором числовых параметров – амплитуды, фазы и частоты.
Преобразование звука в цифровую форму или оцифровывание звука происходит следующим образом. В природе звуковые сигналы являются аналоговыми, т. е. непрерывными. В компьютере непрерывный звуковой сигнал заменяется дискретным и значение параметров, определяющих звуковые характеристики, определяются только в некоторые фиксированные моменты времени. Количество отсчетов сигнала в единицу времени называется частотой дискретизации, которую принимают равной 8, 11, 22 и 44 кГц. Например, частота дискретизации в 22 килогерца означает, что одна секунда непрерывного звучания заменяется набором из двадцати двух тысяч отдельных отсчетов сигнала. Чем выше частота дискретизации, тем лучше качество оцифрованного звука.
Качество преобразования звука в цифровую форму определяется также количеством битов памяти, используемых для записи амплитуды, фазы и частоты для одного дискретного значения времени. Этот параметр принято называть разрядностью преобразования. В настоящее время используется разрядность 8 бит 16 или 24 бит.
Аналогово-цифровые преобразователи (АЦП) выполняют разложение аналоговых сигналов в гармонические ряды, которые кодируются в виде дискретных цифровых сигналов. Обратное преобразование для воспроизведения звука, закодированного числовым кодом, выполняют цифро-аналоговые преобразователи (ЦАП). При таких преобразованиях неизбежны потери информации, связанные с методом кодирования, поэтому качество звукозаписи обычно получается не вполне удовлетворительным и соответствует качеству звучания простейших электромузыкальных инструментов с окрасом, характерным для электронной музыки. В то же время данный метод кодирования обеспечивает весьма компактный код, и потому он нашел применение еще в те годы, когда ресурсы средств вычислительной техники были явно недостаточны.
Метод таблично-волнового (Wave-Table) синтеза лучше соответствует современному уровню развития техники. Если говорить упрощенно, то можно сказать, что где-то в заранее подготовленных таблицах хранятся образцы звуков для множества различных музыкальных инструментов (хотя не только для них). В технике такие образцы называютсэмплами. Числовые коды выражают тип инструмента, номер его модели, высоту тона, продолжительность и интенсивность звука, динамику его изменения, некоторые параметры среды, в которой происходит звучание, а также прочие параметры, характеризующие особенности звука. Поскольку в качестве образцов используются «реальные» звуки, то качество звука, полученного в результате синтеза, получается очень высоким и приближается к качеству звучания реальных музыкальных инструментов.
Используются следующие форматы кодирования звука.
Формат WAV (от WAVeform-audio — волновая форма аудио) кодирования звука. Получить запись звука в этом формате можно от подключаемых к компьютеру микрофона, проигрывателя, магнитофона, телевизора и других стандартно используемых устройств работы со звуком. Однако формат WAV требует очень много памяти. Так, при записи стереофонического звука с частотой дискретизации 44 килогерца и разрядностью 16 бит — параметрами, дающими хорошее качество звучания, — на одну минуту записи требуется около десяти миллионов байтов памяти.
Широко применяется также формат с названием MIDI (Musical Instruments Digital Interface — цифровой интерфейс музыкальных инструментов). Фактически этот формат представляет собой набор инструкций, команд так называемого музыкального синтезатора — устройства, которое имитирует звучание реальных музыкальных инструментов. Команды синтезатора фактически являются указаниями на высоту ноты, длительность ее звучания, тип имитируемого музыкального инструмента и т. д. Таким образом, последовательность команд синтезатора представляет собой нечто вроде нотной записи музыкальной мелодии. Получить запись звука в формате MIDI можно только от специальных электромузыкальных инструментов, которые поддерживают интерфейс MIDI. Формат MIDI обеспечивает высокое качество звука и требует значительно меньше памяти, чем формат WAV.
Есть и другие, чисто компьютерные, форматы записи музыки. Среди них – формат MP3, позволяющий с очень большим качеством и степенью сжатия кодировать музыку, при этом вместо 18–20 музыкальных композиций на стандартном компакт-диске (CDROM) помещается около 200. Одна песня занимает, примерно, 3,5 Mбайт, что позволяет пользователям сети Интернет легко обмениваться музыкальными композициями.
Особое внимание также уделяют кодированию видеоинформации. Чтобы хранить и обрабатывать видео на компьютере, необходимо закодировать его особым образом.
Изображение в видео состоит из отдельных кадров, которые меняются с определенной частотой. Кадр кодируется как обычное растровое изображение, то есть разбивается на множество пикселей. Закодировав отдельные кадры и собрав их вместе, мы сможем описать все видео.
Отметим то, что видеоданные характеризуются частотой кадров и экранным разрешением. Скорость воспроизведения видеосигнала составляет 30 или 25 кадров в секунду, в зависимости от телевизионного стандарта. Наиболее известными из таких стандартов являются: SECAM, принятый в России и Франции, PAL, используемый в Европе, и NTSC, распространенный в Северной Америке и Японии [4].
Разрешение для стандарта NTSC составляет 768 на 484 точек, а для PAL и SECAM – 768 на 576 точек. Но не все пиксели используются для хранения видеоинформации. Так, при стандартном разрешении 768 на 576 пикселей, на экране телевизора отображается всего 704 на 540 пикселей. Поэтому для хранения видеоинформации в компьютере или цифровой видеокамере, размер кадра может отличаться от телевизионного. Например, в формате Digital Video или, как его еще называют DV, размер кадра составляет 720 на 576 пикселей. Такое же разрешение имеет кадр стандарта DVD Video. Размер кадра формата Video-CD составляет 352 на 288 пикселей [5].
Если представить каждый кадр изображения как отдельный рисунок, то видеоизображение будет занимать очень большой объем, например, одна секунда записи в системе PAL будет занимать 25 Мбайт, а одна минута – уже 1,5 Гбайт. Поэтому на практике используются различные алгоритмы сжатия для уменьшения скорости и объема потока видеоинформации [3, с.109].
Если использовать сжатие без потерь, то самые эффективные алгоритмы позволяют уменьшить поток информации не более чем в два раза. Для более существенного снижения объемов видеоинформации используют сжатие с потерями.
Среди алгоритмов с потерями одним из наиболее известных является MotionJPEG или MJPEG. Приставка Motion говорит, что алгоритм JPEG используется для сжатия не одного, а нескольких кадров. При кодировании видео принято, что качеству VHS соответствует кодирование MJPEG с потоком около 2 Мбит/с, S-VHS – 4 Мбит/с.
Еще одним методом сжатия видеосигнала является MPEG. Поскольку видеосигнал транслируется в реальном времени, то нет возможности обработать все кадры одновременно. В алгоритме MPEG запоминается несколько кадров. Основной принцип состоит в предположении того, что соседние кадры мало отличаются друг от друга. Поэтому можно сохранить один кадр, который называют исходным, а затем сохраняются только изменения от исходного кадра, называемые предсказуемыми кадрами [3, с.113].
Считается, что за 10-15 кадров картинка изменится настолько, что необходим новый исходный кадр. В результате при использовании MPEG можно добиться уменьшения объема информации более чем в двести раз, хотя это и приводит к некоторой потере качества. В настоящее время используются алгоритм сжатия MPEG-1, разработанный для хранения видео на компакт-дисках с качеством VHS, MPEG-2, используемый в цифровом, спутниковом телевидении и DVD, а также алгоритм MPEG-4, разработанный для передачи информации по компьютерным сетям и широко используемый в цифровых видеокамерах и для домашнего хранения видеофильмов [3, с.115].
ЗАКЛЮЧЕНИЕ
Наиболее удобной для построения ЭВМ оказалась двоичная система счисления, т.е. система счисления, в которой используются только две цифры: 0 и 1, т.к. с технической точки зрения создать устройство с двумя состояниями проще, также упрощается различение этих состояний.
Для представления этих состояний в цифровых системах достаточно иметь электронные схемы, которые могут принимать два состояния, четко различающиеся значением какой-либо электрической величины - потенциала или тока. Одному из значений этой величины соответствует цифра 0, другому - 1. Относительная простота создания электронных схем с двумя электрическими состояниями и привела к тому, что двоичное представление чисел доминирует в современной цифровой технике. При этом 0 обычно представляется низким уровнем потенциала, а 1 - высоким уровнем. Такой способ представления называется положительной логикой.
Кодирование информации — это процесс формирования определенного представления информации. В более узком смысле под термином «кодирование» часто понимают переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.
Компьютер может обрабатывать только информацию, представленную в числовой форме. Вся другая информация (звуки, изображения, показания приборов и т.д.) для обработки на компьютере должна быть преобразована в числовую форму. Например, чтобы перевести в числовую форму музыкальный звук, можно через небольшие промежутки времени измерять интенсивность звука на определенных частотах, представляя результаты каждого измерения в числовой форме. С помощью компьютерных программ можно преобразовывать полученную информацию, например, «наложить» друг на друга звуки от разных источников.
Аналогично на компьютере можно обрабатывать текстовую информацию. При вводе в компьютер каждая буква кодируется определенным числом, а при выводе на внешние устройства (экран или печать) для восприятия человеком по этим числам строятся изображения букв. Соответствие между набором букв и числами называется кодировкой символов.
Как правило, все числа в компьютере представляются с помощью нулей и единиц (а не десяти цифр, как это привычно для людей). Иными словами, компьютеры обычно работают в двоичной системе счисления, поскольку при этом устройства для их обработки получаются значительно более простыми.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1. Акулов О.А., Медведев Н.В. Информатика. Базовый курс: учебник для студентов вузов, бакалавров, магистров, обучающихся по направлению «Информатика и вычислительная техника». 6-е изд. М.: Омега-Л, 2009. 574 с.
2. Алехина Г.В. и др., Информатика. Базовый курс – М.: Маркет ДС, 2010. – 736 с.
3. Вальциферов Ю.В., Тихомиров В.П. Информатика, часть 1, Системы счисления. Элементы математической логики, Учебно-практическое пособие, М.: МЭСИ, 1996. - 101 стр.
4. Гуда А.Н., Бутакова М.А., Нечитайло Н.М. Информатика. Общий курс: учебник. – М.: Издательско-торговая корпорация «Дашков и К»; Ростов н/Д: Наука-Пресс, 2007. – 400с.
5. Жукова Е.Л., Бурда Е.Г. Информатика: учебное пособие. 2-е изд. М.: Дашков и К°, 2009. 272 с.
6. Информатика: учебное пособие для вузов / А. В. Могилев, Н. И. Пак, Е. К. Хеннер. - 7-е изд., стереотип. - Москва: ИЦ Академия, 2009. - 848 с.
7. Информатика / учебник / В. А. Острейковский - М.: Высшая школа, 2000. - 511 с.
8. Информатика: учебник / Б.В. Соболь [и др.] -Изд. 3-е, дополн. и перераб. — Ростов н/Д: Феникс, 2007. — 446 с.
9. Информатика. Базовый курс / Под ред. С.В. Симоновича. — СПб.: Питер, 2005. — 640 с.
10. Панин В.В., Основы теории информации. Учебное пособие для ВУЗов. Бином, 2009.
11. Степанов А.Н. Информатика: учебник для вузов. – 4-е издание. – СПб.: Питер, 2006. – 684с.
12. Хлебников А.А. Информатика: учебник. Ростов н/Д: Феникс, 2007. 571 с.

- Разработка регламента выполнения процесса «Управление документооборотом» (Описание предметной области: постановка задачи)
- Шекспиризмы вчера и сегодня (История вхождения наследия Шекспира в российскую словесность)
- Россия на международном валютно-финансовом рынке»
- "Понятие, признаки и правовое регулирование банкротства"
- Виды Юридических лиц (Понятие и признаки юридического лица. Правовая природа юридического лица)
- Корпоративная культура: понятие и сущность
- Государственная социальная помощь (Понятие и цели государственной социальной помощи)
- Технология обслуживания и стандарты сервиса в гостиничном и ресторанном бизнесе(«Вега Измайлово»)
- Менеджмент как организационно-целевое управление(АО «Роспечать»)
- Технология и организация клубного сервиса (Понятие и особенности клубного отдыха на современном этапе)
- Роль мотивации в поведении организации(ООО «Bao Mochi» )
- Методы кодирования данных (Метод кодирования Хаффмана)