
История развития нейронных сетей
Содержание:

Введение
Сегодня в условиях стремительно развивающихся информационных технологий нейронные сети становятся очень актуальным инструментом решения самых разных задач. Из за широких возможностей настройки и обучения нейронных сетей, а так-же возможностей создания все новых топологий и методов обучения, нейронные сети завоевывают свое место во многих сферах жизни. Самый разный подход к обработке информации и спектр решаемых задач, а так-же все более и более доступные в современном мире внушительные вычислительные мощности современных электронных устройств, делают нейронные сети доступным и эффективным способом решения возникающих перед человеком проблем.
Изучение нейронных сетей в современном мире весьма актуально, по скольку с увеличением доступности аппаратных средств , нейронные сети могут быть применены в повседневных задачах широкими слоями общества. Это делает нейронные сети перспективной отраслью развития искусственного интеллекта.
Основой для получения информации при написании работы послужили книги С. Хайкина «Нейронные сети: полный курс» [25] и Яхъяевой «Нечеткие множества и нейронные сети.» [26]. А также статья Федора ван Вина «Зоопарк нейронных сетей» [27]. Данные источники обладают наиболее емкой информацией по теме на мой взгляд.
Целью работы служит анализ принципов построения и функционирования нейронных систем, а также применение инструментов нечеткой логики.
На протяжении работы будут разобраны темы истории нейронных сетей, аналогий с биологическим мозгом, понятия искусственного нейрона, виды искусственных нейронных сетей, способы их обучения, а также приведен пример применения нечеткой логики.
Предметом курсовой работы являются нейронные сети и нечеткая логика.
Глава 1. История развития нейронных сетей.
Развитие нейронных систем в современном понимании началось с новаторской работы двух ученых, довольно далеких друг от друга по профилю. Психиатр и нейроанатом Уоррен Мак-Каллок и талантливый математик Уолтер Питтс в 1943 году опубликовали статью «Логическое исчисление идей, относящихся к нервной активности» [1]. В статье описывались результаты, полученные группой специалистов по нейромоделированию из университета Чикаго, возглавляемой Рашевским (Rashevsky), в течении пяти лет. Мак-Каллок и Питтс описали логику вычислений в нейронных сетях на основе результатов нейрофизиологии и математической логики. Ученые показывали что сеть, составленная из большого количества формализованных нейронов, соответствующих принципу «все или ничего», соединенных правильно сконфигурированными и синхронно работающими синаптическими связями теоретически способна выполнять любые вычисления. Это послужило причиной зарождения современных направлений в науке, таких как искусственный интеллект и нейронные сети.
В 1949 году Дональд Хебб опубликовал книгу под названием «Организация поведения» [2], в которой вывел правило обучения для синаптической модификации, суть которого состоит в том что по мере процесса обучения связи в мозге постоянно изменяются, формируя при этом ансамбли нейронов. Постулат обучения Хебба гласит: эффективность переменного синапса между нейронами повышается при многократной активации этих нейронов через данный синапс. К сожалению, книга Хебба оказала большее влияние на развитие психологии, нежели направления искусственного интеллекта. При создании вычислительных моделей обучаемых и адаптивных систем, в результате компьютерного моделирования было четко показано, что для полноты теории к ней следует добавить торможение.
В 1954 году Деннис Габор предложил идею нелинейного адаптивного фильтра в работе «Communication theory and cybernetics» [3] и создал с командой единомышленников машину, обучающуюся на примере стохастического процесса.
Отдельной задачей в деле нейронных сетей было создание надежных сетей из нейронов, которые сами по себе надежными компонентами не считаются. В 1956 году фон Нейман решил эту задачу, применив идею избыточности [4]. Распределенное избыточное представление показывало, как большая группа элементов может в совокупности представлять одно понятие при соответствующем повышением робостности и степени параллелизма.
В 1958 году Фрэнк Розенблатт предложил новый подход к задаче распознавания образов, основанный на использовании персептрона, и нового метода обучения с учителем в работе «The Perceptron: A probabilistic model for information storage and organization in the brain»[5], в ней Розенблатт вывел теорему сходимости персептрона, доказал которую в 1960 году.
В 1960-е годы был описан алгоритм наименьших квадратов LMS (least mean-square algorithm), который применялся для построения адаптивных линейных элементов Adaline, Видроу вместе со своими студентами в работе «Generalization and information storage in networks of adaline ”neurons”» [6] предложил одну из первых обучаемых многослойных нейронных сетей, содержащей многочисленные адаптивные элементы, так же был подробно описан процесс линейной разделимости образов. Однако в вышедшей в 1969 году книге Минского и Пайперта «Perceptrons» [7] были выведены фундаментальные ограничения однослойного персептрона и высказано предположение, что ограничения скорее всего не удастся преодолеть в многослойных версиях. Эта работа оттолкнула ученых от дальнейших исследований в данном направлении, а так же затруднила финансирование этих исследований из - за кажущейся бесперспективности дальнейшего развития. Отсутствие интереса к направлению спровоцировало застой в развитии нейронных сетей на десятилетие.
В 1980-х годах развитие направления продолжилось. Новый принцип самоорганизации названный теорией адаптивного резонанса открыт Гроссбергом в 1980 году.
В 1982 году Хопфилд в работе «Neural networks and physical systems with emergent collective computational abilities» [8] установил изоморфизм между рекурентной сетью и изинговской моделью, используемой в статистичесткой физике, что позволило использовать результаты физической теории, а также привлечь ученых физиков в нейронное моделирование.
В 1983 году выведен в работе «Absolute stability of global pattern formation and parallel memory storage by competitive neural networks» [9] выведен общий принцип устойчивости ассоциативной памяти. Тогда же была описана процедура моделирования отжига, в работе «Optimization by simulated annealing» [10] открывающая возможность решения задач комбинаторной оптимизации. Позже с использованием имитации отжига была создана первая успешная многослойная нейронная сеть получившая название «машина Больцмана». Хоть алгоритм обучения машины Больцмана и не был так эффективен как алгоритм обратного распространения но все же доказывал, что выводы Минского и Пайперта были неверны.
Принцип целенаправленного самоорганизующегося управления был обоснован в 1984 году в работе «Vehicles: Experiments in Synthetic Psychology» [11] он гласит, что понимания сложного процесса легче достичь путем синтеза элементарных механизмов, а не анализа «сверху вниз».
В 1986 году Дэвид Румельхарт разработал алгоритм обратного распространения ошибок и описал его в своем труде «Learning representations of back-propagation errors» [12]. Этот алгоритм стал самым популярным алгоритмом обучения многослойных персептронов. Тогда же алгоритм обратного распространения получили и другие ученые в работах «Une procedure d'aprentissage pour reseau a seuil assymetrique» [13] и «Learning-logic: Casting the cortex of the human brain in silicon» [14]. В 1988 году Линскер описал новый принцип самоорганизации в перцепционной сети в работе «Self-organization in perceptual network» [15] основанный на теории информации, созданной Шенноном в 1948 году. На основе теории информации он сформулировал принцип максимума взаимной информации Infomax, что открыло двери применению теории информации в нейронных сетях. В том же году Брумхед и Лове описали альтернативу многослойному персептрону — процедуру построения многослойной сети прямого распространения на базе радиальных базисных функций в работе «Multivariable dunctional interpolation and adaptive networks»[16], которая позже получила развитие путем применения к ней теории регуляризации Тихонова.
В начале 1990-х Вапник вместе с коллегами выделили мощный с вычислительной точки зрения класс сетей, обучаемых с учителем, названный машины опорных векторов. Такие сети позволяют решать задачи распознавания образов, регрессии и оценки плотности.
Со времен публикации статьи Мак-Каллока и Питтца нейронные сети прошли внушительный путь эволюционного развития от юного направления на стыке математики и биологии до междисциплинарной отрасли науки тесно связанной с математикой, физикой, биологией, психологией. Современные технические средства позволили исследователям воплотить идеи самообучаемых систем, результаты работы которых сегодня можно встретить в большинстве сфер жизни, связанных с обработкой информации от развлечений до серьезных исследований, помогающих спасать и сохранять человеческие жизни. Искусственный интеллект сегодня развивается бурно, проникая во все новые сферы применения, помогая человечеству подниматься все дальше по ступеням прогресса.
Глава 2. Аналогия нейронных сетей с мозгом
и биологическим нейроном
Строение нейронных сетей определяется аналогией с человеческим мозгом, который является ярким примером того, что отказоустойчивые параллельные вычисления не только физически реализуемы, но и являются быстрым и мощным инструментом решения задач.
Мозг представляет собой сложную, нелинейную, параллельную систему обработки информации. Основной составной единицей человеческого мозга являются специфические клетки называемые нейронами. В коре головного мозга имеется около 1011 нейронов каждый из которых имеет множество связей с нейронами по всему мозгу через синаптические отростки длинной до одного метра. В целом мозг человека имеет приблизительно от 1014 до 1015 взаимосвязей. В процессе своей работы нейроны способны накапливать опыт предыдущих действий и применять его к последующим.
Аналогично мозгу человека в искусственных нейронных сетях работа проводится с искусственными нейронами которые являют собой основную составную часть нейронной сети. В общем случае нейронная сеть представляет собой машину моделирующую способ обработки мозгом конкретной задачи. Для того чтобы добиться высокой производительности, нейронные сети используют множество взаимосвязей между элементарными ячейками вычислений — нейронами. Таким образом можно дать следующее определение нейронной сети.
Нейронная сеть — это огромный распределенный параллельный процессор, состоящий из элементарных единиц обработки информации, накапливающих экспериментальные знания и предоставляющих из для последующей обработки. Нейронная сеть сходна с мозгом в двух аспектах:
Задания поступают в нейронную сеть из окружающей среды и используются в процессе обучения.
Для накапливания знаний применяются связи между нейронами, называемые синаптическими весами.
Процедура, используемая для обучения нейронных сетей называется алгоритмом обучения. Подобно человеческому мозгу который способен настраивать нервную систему в соответствии с окружающими условиями, алгоритм обучения выстраивает в определенном порядке синаптические веса нейронной сети для обеспечения необходимой структуры взаимосвязей нейронов.
Из выше сказанного можно сделать вывод, что несмотря на сходства нейронных сетей с биологической структурой мозга, искусственные нейросети способны моделировать лишь основные принципы работы мозга. Так в компьютерных моделях нейроны сильно упрощены относительно своих биологических аналогов, сети создаваемые искусственно сильно уступают биологическим в масштабах, и не способны обеспечить гибкость биологических структур по перестройке собственных структур.
Глава 3. Понятие искусственного нейрона
Нейрон представляет собой единицу обработки информации в нейронной сети. Искусственный нейрон в примитивном виде имитирует работу биологического нейрона. На вход нейрона приходит несколько сигналов, которые в свою очередь исходят из выходов нейронов расположенных раньше в нейронной сети — этот механизм представляет собой аналог биологического синапса. Сигнал каждого синапса умножается на свой синаптический вес который определяет силу каждого входа, после этого все полученные произведения суммируются, определяя уровень активации нейрона. На рис.1 изображена модель нейрона.
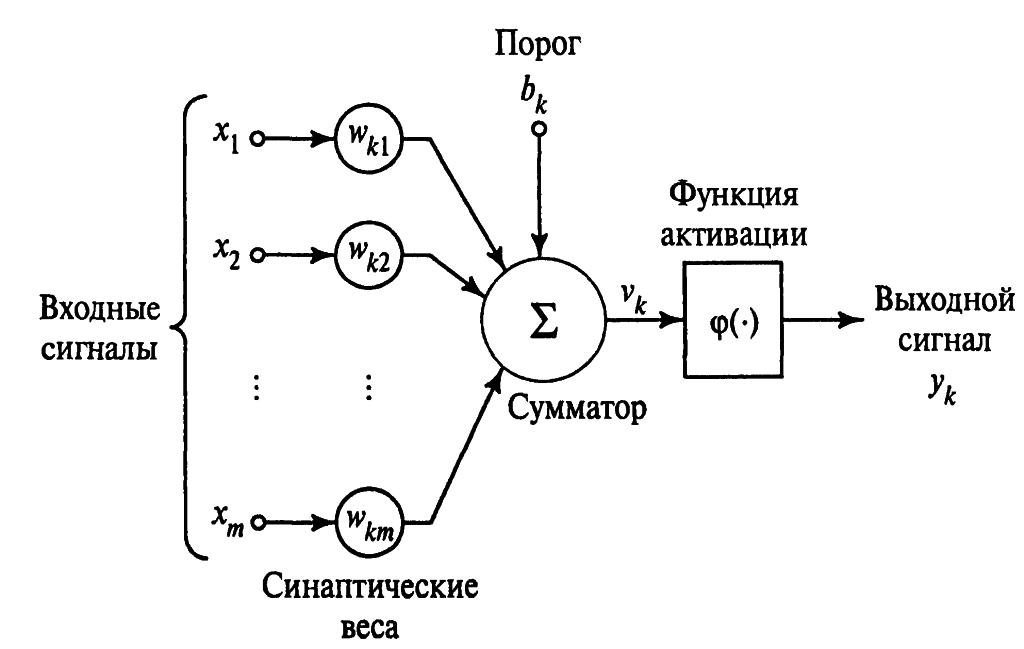 Рис 1.Модель нейрона
Рис 1.Модель нейрона
Множество входных сигналов других нейронов обозначенные x1, x2 … xj приходят на вход нейрона. Каждый поступивший сигнал умножается на соответствующий ему вес wk1, wk2 … wkj, и поступает на сумматор (или суммирующий блок). Индексы синаптического веса wkj указаны в следующем порядке: первый индекс относится к данному нейрону, а второй ко входному окончанию синапса, с которым связан данный вес. В нейронных сетях в отличие от синапсов мозга, веса синапсов могут иметь как положительные, так и отрицательные значения. Далее сумматор складывает полученные после взвешивания входные сигналы. После этого сигнал преобразуется функцией активации которая ограничивает амплитуду выходного сигнала нейрона, которая обычно лежит в интервале [0,1] или [-1,1]. В модель нейрона показанную на рис.1 включен также пороговый элемент обозначенный символом bk, который отражает изменение входного сигнала, подаваемого на функцию активации.
Математически работу нейрона можно выразить через следующие уравнения:
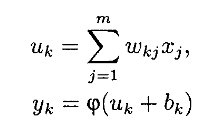
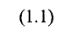 где x1,x2,...,xm – выходные сигналы; wk1,wk2,..., wkm – синаптические веса нейрона k; uk – линейная комбинация входных воздействий; bk – порог; φ() - функция активации; yk – выходной сигнал нейрона. Порог bk используется для достижения эффекта афинного преобразования выхода линейного сумматора uk. В нашей модели нейрона постсинаптический потенциал находится по следующей формуле:
где x1,x2,...,xm – выходные сигналы; wk1,wk2,..., wkm – синаптические веса нейрона k; uk – линейная комбинация входных воздействий; bk – порог; φ() - функция активации; yk – выходной сигнал нейрона. Порог bk используется для достижения эффекта афинного преобразования выхода линейного сумматора uk. В нашей модели нейрона постсинаптический потенциал находится по следующей формуле:
vk = uk + bk. (1.2)
Здесь в зависимости от значений порога bk индуцированное локальное поле или потенциал активации vk нейрона k изменяется как продемонстрировано на рис.2. В результате афинного преобразования график vk не проходит через начало координат как график uk.
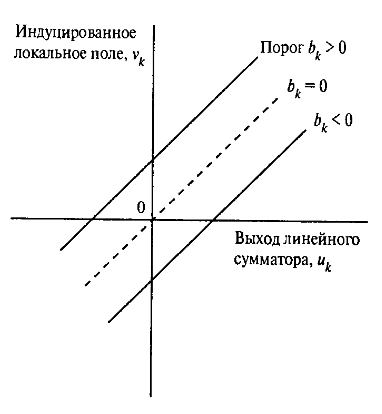
Рис 2. Афинное преобразование,
вызванное наличием порога.
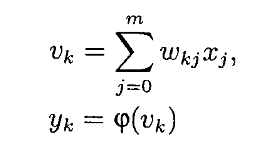 Исходя из (1.2) формулы (1.1) можно преобразовать к следующему виду:
Исходя из (1.2) формулы (1.1) можно преобразовать к следующему виду:
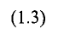 В выражении (1.3) добавляется новый синапс выходной сигнал которого равен:
В выражении (1.3) добавляется новый синапс выходной сигнал которого равен:
x0 = +1,
а вес:
wk0 = bk.
Это позволяет трансформировать модель нейрона из рис. 1 к новому математически эквивалентному виду рис. 3
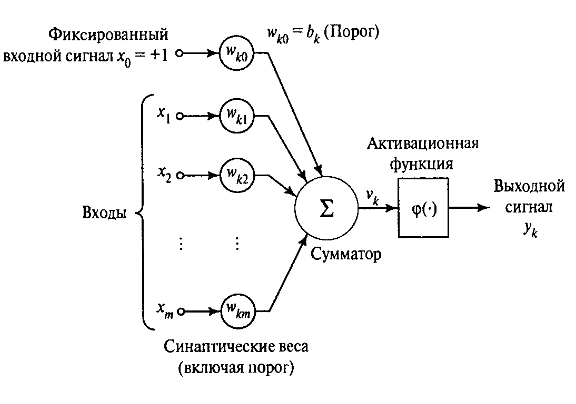 Рис. 3 Модель нейрона после
Рис. 3 Модель нейрона после
афинного преобразования
В новой модели нейрона в результате проведенных преобразований добавляется новый синапс с фиксированной величиной +1 и синаптическим весом равным порогу bk.
Искусственный нейрон на сегодняшний день не в состоянии в полной мере повторить свой биологический прототип, однако он представляет собой логическую схему, работающую по математическим формулам, которая обеспечивает реализацию основной идеи нейронных взаимодействий. Принимая сигналы с предшествующих нейронов, он преобразует сигналы исходя из заданных параметров обучения для достижения необходимых результатов в поставленных задачах.
Глава 4. Виды искусственных нейронных сетей.
За историю развития нейронных сетей было разработано большое количество вариаций отличающихся по нескольким критериям. В целом классификация нейронных сетей выгляди следующим образом рис. 4.
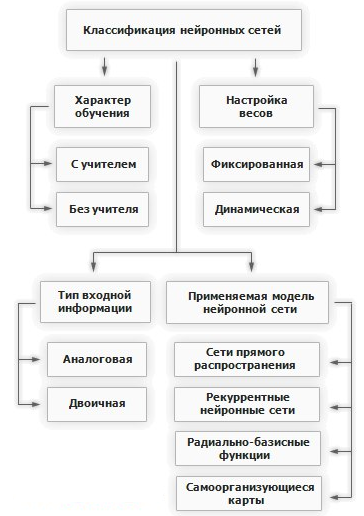 Рис. 4. Классификация нейронных сетей.
Рис. 4. Классификация нейронных сетей.
Как видно из схемы, нейронные сети классифицируются по следующим признакам:
По характеру обучения:
с учителем,
без учителя.
По настройке синаптических весов:
фиксированная,
динамическая.
По типу входной информации:
аналоговые,
двоичные.
По применяемой модели сети:
сети прямого распространения,
рекурентные нейронные сети,
радиально-базисные функции,
самоорганизующиеся карты.
Рассмотрим подробнее каждый критерий.
Характер обучения.
Обучение с учителем.
Обучение без учителя.
Настройка весов.
В сетях с фиксированными связями весовые коэффициенты нейронной сети задаются сразу, исходя из условия задачи.
В сетях с динамической настройкой веса настраиваются в процессе обучения сети.
Тип входной информации.
Входная информация может быть двоичной и аналоговой. В случае с аналоговой входные данные представляются в виде действительных чисел. Двоичная подразумевает представление всех вводных данных в виде нулей и единиц.
Применяемая модель нейронной сети.
Сети прямого распространения.[17]
 Рис.5. Сеть прямого распределения.
Рис.5. Сеть прямого распределения.
В сетях прямого распространения все связи направлены строго от входных нейронов к выходным, нейроны одного слоя не связаны между собой, каждый нейрон каждого слоя связан со всеми нейронами соседнего слоя. Простейший вариант такой сети будет состоять из двух входных нейронов и одного выходного (Рис. 6). Сети прямого распространения обычно обучаются методом обратного распространения ошибки. В работе чаще используют сети прямого распространения вместе с другими сетями нежели самостоятельно из за сопутствующих ограничений таких сетей.
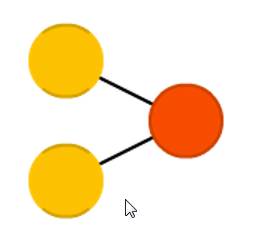 Рис. 6. Простейшая сеть
Рис. 6. Простейшая сеть
прямого распределения.
Радиально базисные функции.[18]
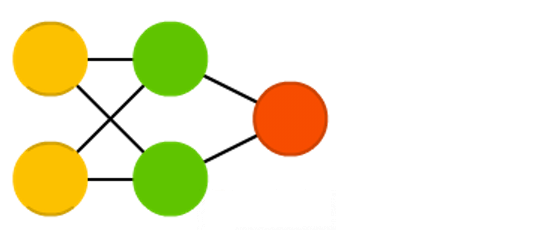 Рис. 7. Радиально базисная функция.
Рис. 7. Радиально базисная функция.
Отличие от сетей прямого распространения заключается в том, что нейроны скрытого слоя имеют нелинейную функцию активации, а синаптические веса входного и скрытого слоев равны единице. К преимуществам таких сетей можно отнести их компактность и высокую скорость обучения.
Реккурентные нейронные сети.[19]
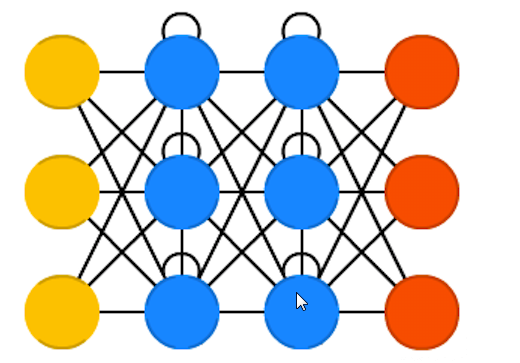 Рис. 8. Рекуррентная нейронная сеть.
Рис. 8. Рекуррентная нейронная сеть.
Отличие от сетей прямого распространения состоит в том что сигнал с выходных нейронов или нейронов скрытого слоя частично передается обратно на входы нейронов входного слоя. В рекуррентных сетях имеет значение порядок подачи информации при обучении так как результат для разных порядков будет отличатся.
Самоорганизующиеся карты или Сети Кохонена.[20]
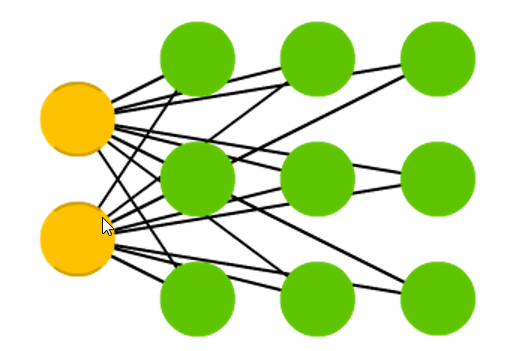 Рис. 9. Сеть Кохонена.
Рис. 9. Сеть Кохонена.
Сети этого типа способны выявлять новизну во входных данных: если после обучения сеть получит новый набор данных непохожий на уже изученные образцы, то она не сможет классифицировать этот набор, что будет свидетельствовать о его новизне.
На практике существует гораздо более богатое разнообразие нейронных сетей которые используют комбинации описанных моделей нейронных сетей. Каждая модель создаваемая инженерами служит для выполнения своей определенной задачи, и обладает своим набором достоинств и недостатков. Составить полный список всех топологий сетей не представляется возможным по скольку постоянно появляются новые. Выше мы вкратце разобрали основные архетипы топологий которые в том или ином виде служат кирпичиками для создания на их основе новых более сложных и продвинутых сетей для всех типов решаемых задач.
Глава 5. Обучение нейронных сетей.
Основным отличием нейронных сетей от других систем обработки информации является возможность обучения нейронной сети в результате которого сеть повышает свою производительность. Обучение происходит в результате корректировки синаптических весов и порогов в процессе многочисленных обучающий прогонов проходящий по определенным правилам.
У процесса обучения нет четкого определения по скольку с этим понятием связано большое количество видов деятельности и разных взглядов на само понятие обучения. Для нас возможно использовать следующее определение:
Обучение — это процесс, в котором свободные параметры нейронной сети настраиваются по средствам моделирования среды, в которую эта нейронная сеть встроена. Тип обучения определяется способом подстройки этих параметров.[21]
Это определение предполагает следующую последовательность событий:
- Поступление в нейронную сеть стимулов из внешней среды.
- Изменение свободных параметров сети.
- Изменения ответа сети на возбуждения после изменения внутренних параметров.
Вышеуказанные правила процесса обучения называются алгоритмом обучения. Существует большое количество алгоритмов обучения каждый из которых обладает своими преимуществам, недостатками и особенностями. Далее рассмотрим основные модели обучения нейронных сетей.
Обучение основанное на коррекции ошибок.
Для иллюстрации рассмотрим схему нейрона k — единственного вычислительного узла выходного слоя нейронной сети прямого распространения (рис. 10).
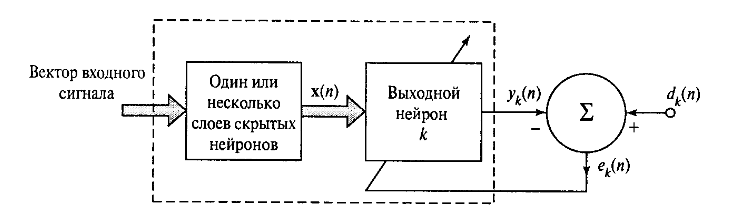 Рис. 10. Многослойная сеть
Рис. 10. Многослойная сеть
прямого распространения.
Как видно из изображения нейрон k работает под управлением вектора сигнала x(n), исходящего от одного или нескольких слоев скрытых нейронов, которые в свою очередь получают информацию от вектора входного сигнала. Под n подразумевается номер итерации процесса обучения сети, или, дискретное время. yk(n) – единственный выходной сигнал нейрона k, который будет сравниваться с dk(n) – желаемым выходом. В результате сравнения получаем сигнал ошибки ek(n). По определению ek(n) = dk(n) – yk(n).
Сигнал ошибки запускает процесс управления который применяет последовательность корректировок к синаптическим весам нейрона k с целью приближения выходного сигнала yk(n) к желаемому dk(n). Эта цель достигается путем минимизации индекса производительности E(n) который через сигнал ошибки выражается так:
E(n) = ½ e² k(n)
где E(n) — текущее значение энергии ошибки. Пошаговая корректировка синаптических весов нейрона k происходит до тех пор пока система не достигнет устойчивого состояния, после этого процесс обучения останавливается.
Функция стоимости E(n) минимизируется по правилу Видроу-Хоффа[22] Обозначим wkj(n) текущее значение синаптического веса wkj нейрона k, соответствующего элементу xj(n) вектора x(n), на шаге дискретизации n. По дельта правилу — изменение Δwkj(n) синаптического веса wkj на данном шаге, задается выражением
где Ƞ — положительная константа, определяющая скорость обучения при переходе от одного шага обучения к другому. Так-же константу Ƞ называют параметром скорости обучения. Определение дельта правила звучит так: Дельта — правило — это корректировка, применяемая к синаптическому весу нейрона, пропорциональна произведению сигнала ошибки на входной сигнал, его вызвавший. Параметр скорости обучения Ƞ является решающим в процессе обучения нейронной сети по скольку обеспечивает сходимость итеративного процесса, а так-же влияет на скорость обучения и другие параметры следовательно требуется тщательно подбирать этот параметр для оптимизации процесса обучения.
Обучение на основе памяти.
Обучение на основе памяти подразумевает накопление всего прошлого опыта в большое хранилище правильно классифицированных примеров вида вход-выход: где xi – входной вектор, di – соответствующий ему желаемый выходной сигнал. Для примера возьмем задачу классификации на два класса С1 и С2. В данной задаче отклик системы di, принимает значение 0 для С1 и +1 для С2. При необходимости классификации некоторого неизвестного вектора xtest, из хранилища подбирается подбирается выход наиболее близкий к xtest.
Для алгоритмов на основе памяти всегда будут существенны следующие компоненты:
Критерий определения окрестности xtest .
Правило обучения применяемое к примеру из xtest.
Разные обучения на основе памяти будут отличатся реализацией этих компонентов.
Обучение Хебба.
В основе обучения Хебба лежит наблюдение нейрофизиолога за биологическими процессами происходящими между нейронами в процессе работы мозга. Так Хебб заметил что если аксон одного нейрона находится достаточно близко к другому, и постоянно или периодически участвует в ее возбуждении, то сила возбуждения второго нейрона первым возрастает. Таким образом в основе данного метода обучения лежат 2 следующих правила:
- Если два нейрона по обе стороны синапса активизируются синхронно, то прочность этого соединения возрастает.[23]
- Если два нейрона по обе стороны синапса активизируются асинхронно, то такой синапс ослабляет или вообще отмирает[24].
Работающий по этим правилам синапс называется синапсом Хебба. Синапс Хебба обладает следующими основными свойствами:
1. Зависимость от времени возникновения постсинаптического и предсинаптического сигналов.
2. Локальность. Информационные сигналы в синапсе находятся в пространственно-временной близости. Эта информация используется синапсом Хебба для выполнения локальных синаптических модификаций, характерных для данного входного сигнала.
3. Интерактивность. Обучение синапса происходит в зависимости от взаимодействий обоих постсинаптического и предсинаптического сигналов.
- Корреляция. Подразумевается корреляция постсинаптического и предсинаптического сигналов во времени.
Конкурентное обучение.
В конкурентном обучении нейроны соревнуются между собой за право быть активизированными. В отличии от предыдущего метода в конкурентном методе одновременно может быть активен лишь один нейрон.
Правило конкурентного обучения составляют следующие элементы:
- Большое количество однотипных нейронов со синаптическими весами настроенными случайно, что приводит в различной реакции на одинаковые входные данные.
- Предельное значение силы для каждого нейрона.
- Механизм осуществляющий конкуренцию между нейронами, и позволяющий одному победившему нейрону откликаться на данное подмножество входных сигналов.
Таким образом, каждый отдельный нейрон сети соответствует группе близких образов. При этом нейроны становятся детекторами признаков различных классов входных образов.
В простейшем виде конкурентная сеть с конкурентным обучением содержит единственный слой выходных нейронов, каждый из которых соединен с входными узлами (Рис. 11). В таких сетях могут присутствовать обратные связи между нейронами которые обеспечивают латеральное торможение, когда каждый нейрон стремится затормозить связанный с ним нейроны.
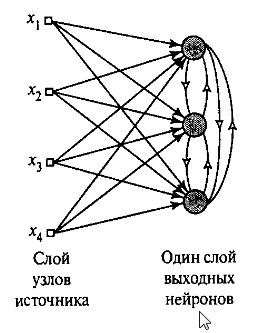 Рис. 11. Граф простой сети конкурентного обучения.
Рис. 11. Граф простой сети конкурентного обучения.
Для победы в конкурентной борьбе нейрону нужно чтобы его индуцированное локальное поле для заданного входного образа было максимальным среди всех нейронов сети. Тогда выходной сигнал нейрона-победителя принимается равным единице, а выходные сигналы остальных нейронов устанавливаются значение нуль, по принципу «победитель забирает все».
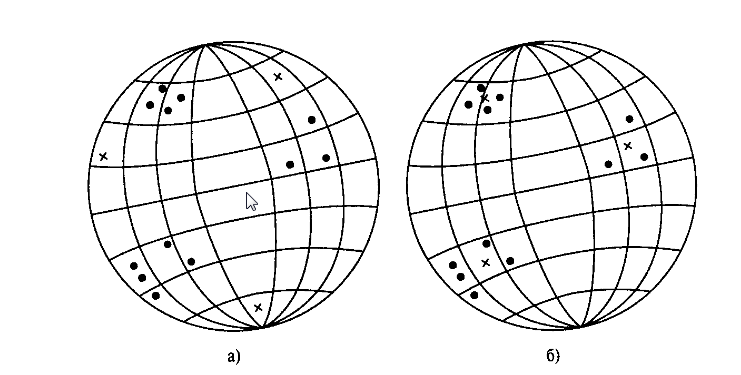 Для иллюстрации конкурентного обучения воспользуемся геометрической аналогией (Рис 12).
Для иллюстрации конкурентного обучения воспользуемся геометрической аналогией (Рис 12).
Рис. 12. Геометрическая интерпретация процесса конкурентного обучения.
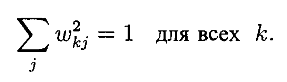 Исходят из того что все входные образы имеют некоторую постоянную Евклидову норму. Это позволяет изобразить их в виде точек на N - мерной единичной сфере, где N – количество входных узлов, а так-же размерность вектора входных синаптических весов wk. Если все узлы имеют одну и ту же Евклидову норму, то
Исходят из того что все входные образы имеют некоторую постоянную Евклидову норму. Это позволяет изобразить их в виде точек на N - мерной единичной сфере, где N – количество входных узлов, а так-же размерность вектора входных синаптических весов wk. Если все узлы имеют одну и ту же Евклидову норму, то
При правильно масштабированных синаптических весах, они формируют набор векторов, которые проецируются на ту же геометрическую сферу. На рис. 12 а можно наблюдать три естественные группы точек, представляющие входные векторы. Крестиками обозначено начальное состояние сети до обучения. На рис. 12 б) показано состояние сети прошедшей конкурентное обучение, в результате которого синаптические веса каждого выходного нейрона сместились к центрам каждой группы точек. Этот пример демонстрирует способность сети с конкурентным обучением решать задачи кластеризации. Однако для устойчивого решения подобной задачи входные образы должны формировать достаточно разрозненные группы векторов. Иначе сеть может потерять устойчивость, выдавая в ответ на очередной входной образ отклики от разных выходных нейронов.
Обучение Больцмана.
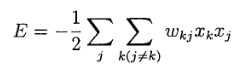 Нейронная сеть, созданная на основе обучения Больцмана, так же называется машиной Больцмана. В машине Больцмана все нейроны представляются рекуррентными структурами, работающими с бинарными сигналами. Это значит что они могут находится во включенном (значение +1) или выключенном (значение -1) состоянии. Машина Больцмана характеризуется функцией энергии Е, значение которой определяется конкретными состояниями отдельных составных нейронов. Это можно выразить следующим образом:
Нейронная сеть, созданная на основе обучения Больцмана, так же называется машиной Больцмана. В машине Больцмана все нейроны представляются рекуррентными структурами, работающими с бинарными сигналами. Это значит что они могут находится во включенном (значение +1) или выключенном (значение -1) состоянии. Машина Больцмана характеризуется функцией энергии Е, значение которой определяется конкретными состояниями отдельных составных нейронов. Это можно выразить следующим образом:
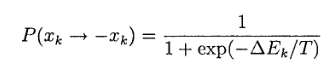 где xj — состояние нейрона j; wkj – синаптический вес связи нейронов j и k. В этой сети нейроны не имеют обратных связей с самими с собой, что обеспечено условием j ≠ k. Работа этой машины состоит в выборе случайного нейрона (например k-го) на определенном шаге процесса обучения и переводе его из состояния xk в состояние -xk при температуре Т с вероятностью
где xj — состояние нейрона j; wkj – синаптический вес связи нейронов j и k. В этой сети нейроны не имеют обратных связей с самими с собой, что обеспечено условием j ≠ k. Работа этой машины состоит в выборе случайного нейрона (например k-го) на определенном шаге процесса обучения и переводе его из состояния xk в состояние -xk при температуре Т с вероятностью
где ΔEk – изменение энергии машины, вызванное переходом состояний. При многократном применении этого правила машина Больцмана достигает термального равновесия.
Нейроны машины Больцмана подразделяются на две группы: видимые и скрытые. Видимые нейроны обеспечивают связь между сетью и средой ее функционирования, а скрытые работают независимо от внешней среды.
Помимо алгоритмов обучения нейронных сетей выделяют две основные парадигмы обучения.
Обучение с учителем.
Для нейронных сетей использующих обучение с учителем предполагается, что для каждого входного вектора существует целевой вектор, представляющий собой требуемый выход. Вместе эти вектора называются обучающей парой, таких пар обычно используется несколько для обучения сети. Предъявляется выходной вектор, вычисляется выход сети и сравнивается с соответствующим целевым вектором. Затем корректируются веса в соответствии с математическим алгоритмом который минимизирует ошибку. Таким образом последовательно предъявляя обучающие векторы и подстраивая веса для каждого вектора добиваются приемлемых показателей ошибки по всему обучающему вектору.
Процесс обучения без учителя гораздо ближе к идее имитации биологических процессов обучения нейронных сетей. В отличии от обучения с учителем здесь результат заранее неизвестен, а следовательно и нет эталонных результатов под которые надо подгонять результаты выхода сети. Вместо этого обучающий алгоритм выстраивает веса сети так чтобы при близких входных данных были одинаковые выходы. Это достигается выделением статистических свойств обучающего множества и группировкой сходных векторов в классы.
Из выше сказанного можно сделать вывод, что процесс машинного обучения нейронных сетей представляет из себя выведение математических закономерностей из представленных обучающих выборок, подобранных так чтобы в результате обучения в нейронной сети складывались шаблоны обработки типовых данных. Процесс обучения напоминает дрессировку животных, однако при правильной настройке всех параметров, можно добиться хороших результатов в обучении, и обеспечить выполнение нейронной сетью поставленных задач.
Глава 6. Применение нечеткой логики на практике
Задача на определение расхода воды на полив выполненная в программном комплексе MATLABFuzzyLogicToolbox.
Условие задачи:
В задаче требуется определить расход воды при поливе с/х угодий. Входные сигналы: а) количество с/ч культур (много культур, мало культур), б) температура воздуха летом (засушливое лето, нормальное лето, холодное лето). Выходной сигнал: расход воды на полив (большой расход, средний расход, маленький расход). Правила: 1. Если с/х культур много, лето засушливое, то расход воды большой. 2. Если с/х культур много, лето нормальное, то расход воды средний. 3. Если с/х культур мало, лето холодное, то расход воды маленький.
По условию задачи имеется два входных параметра — это температура воздуха летом и количество высаживаемых культур. От входных параметров будет вычисляться выходной параметр расхода воды на полив сельскохозяйственных угодий (Рис 13).
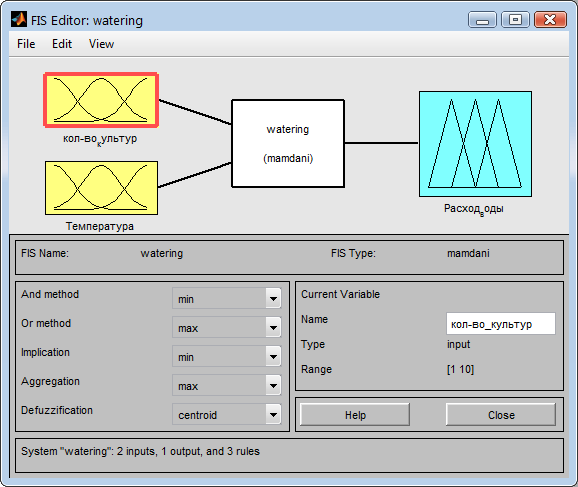
Рис. 13. Система с заданными выходами и входами в соответствии с условием задачи.
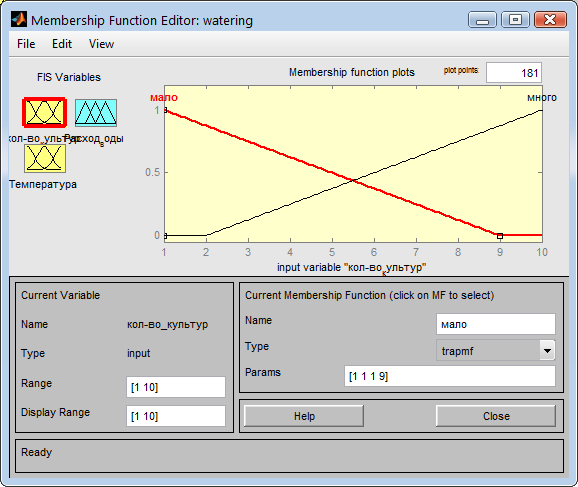 Далее задаем входу количества культур две функции которые согласно условию задачи будут отражать условия большого и маленького количества засеиваемых культур (Рис. 14).
Далее задаем входу количества культур две функции которые согласно условию задачи будут отражать условия большого и маленького количества засеиваемых культур (Рис. 14).
Рис. 14. Задание функций для входа количества культур.
Следующим шагом задаем функции для входа температур. В соответствие с условием задачи задаем три функции температуры: холодную, нормальную и засушливую (Рис. 15). Для холодной и засушливой температуры целесообразно будет выбрать функции trapmf по скольку наиболее сильное влияние на урожайность будут иметь именно экстремальные значения температур по краям температурного диапазона.
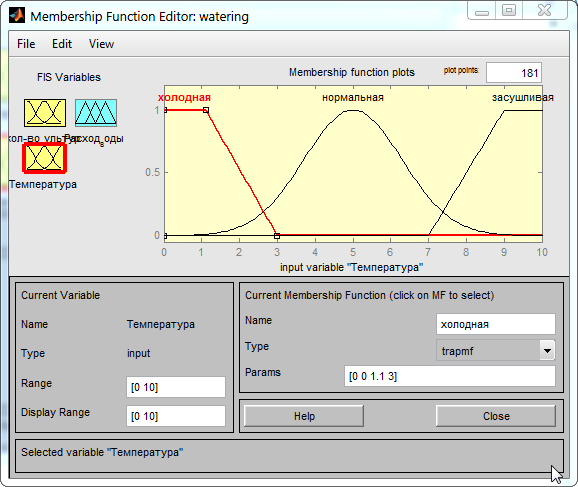 Рис. 15. Задание функций для входа «Температура».
Рис. 15. Задание функций для входа «Температура».
Затем для выхода «Расход воды» задаем функции соответствующие показателям большого, среднего и маленького расхода воды на полив в диапазоне от 0 до 30 (Рис. 16).
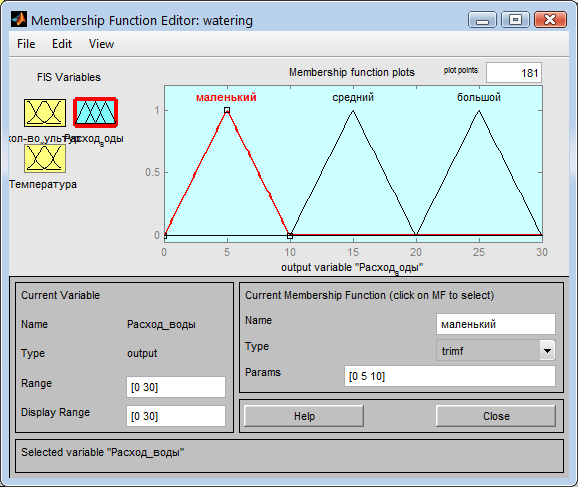 Рис. 16. Выход «Расход воды» с заданными функциями.
Рис. 16. Выход «Расход воды» с заданными функциями.
Согласно условию задачи расход воды будет зависеть от заданных условий входа по трем правилам:
-
-
- Если с/х культур много, лето засушливое, то расход воды большой.
- Если с/х культур много, лето нормальное, то расход воды средний.
- Если с/х культур мало, лето холодное, то расход воды маленький.
-
В редакторе правил задаем указанные правила согласно условию задачи (Рис. 17).
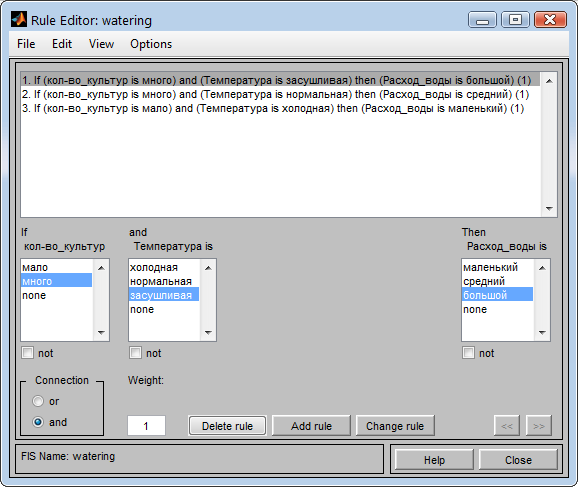 Рис. 17. Правила для определения расхода воды на полив.
Рис. 17. Правила для определения расхода воды на полив.
Результаты
После задания всех условий имеем возможность проверить результат работы фаззи-системы.
При средних температурных показателях и среднем количестве культур система назначает расход воды средним значением в 15 (Рис. 18).
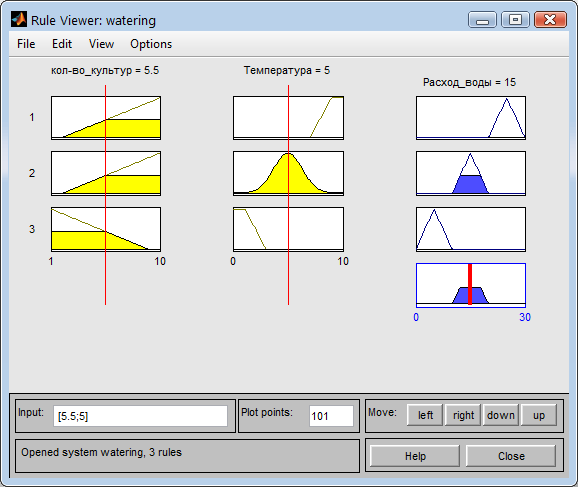 Рис. 18. Определение расхода воды для средних значений температур и кол-ва культур.
Рис. 18. Определение расхода воды для средних значений температур и кол-ва культур.
Если температура увеличивается то и расход воды растет (Рис. 19).
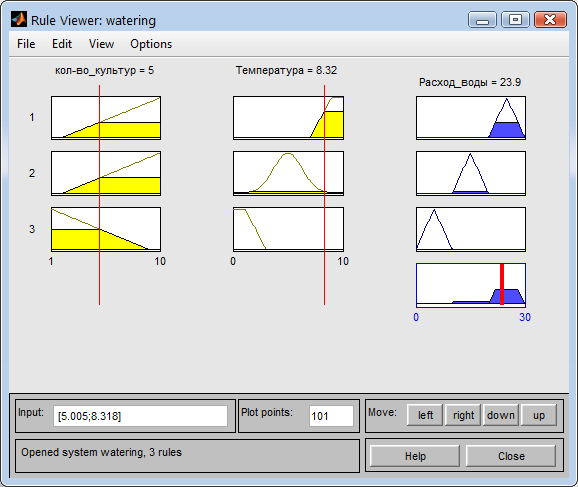 Рис. 19. Расход воды при высокой температуре.
Рис. 19. Расход воды при высокой температуре.
При маленьком количестве культур и низкой температуре, согласно условию задачи, расход воды будет небольшим (Рис. 20).
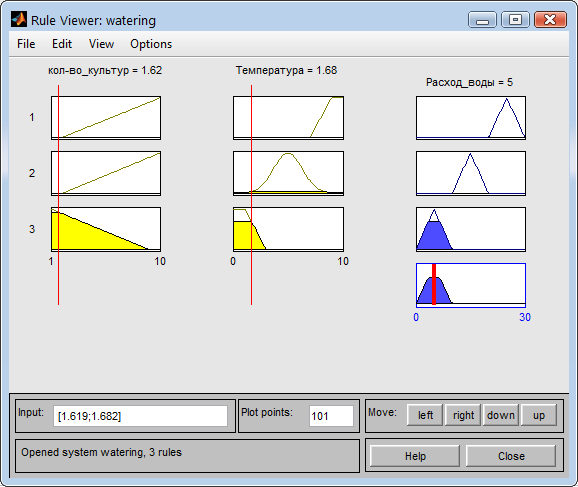 Рис. 20. Расход при низкой температуре и малом количестве культур.
Рис. 20. Расход при низкой температуре и малом количестве культур.
При небольшом количестве культур, но высокой сезонной температуре расход воды будет средним (Рис. 21)
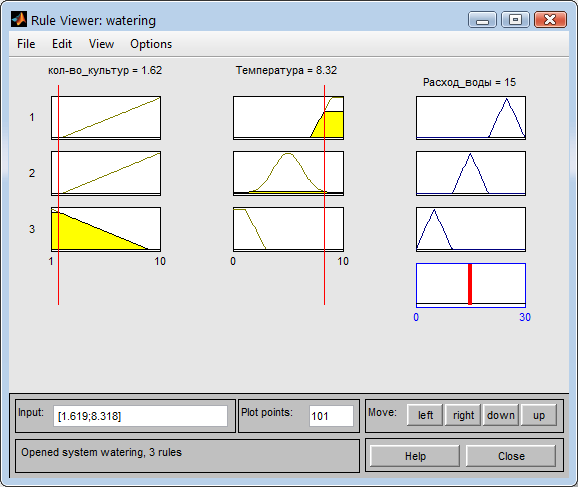 Рис. 21. Расход воды при высокой температуре и малом количестве культур.
Рис. 21. Расход воды при высокой температуре и малом количестве культур.
При большом количестве культур и засушливой температуре будет выполнятся правило 1 условия задачи и в соответствии с ним расход воды на полив будет высоким (Рис. 22).
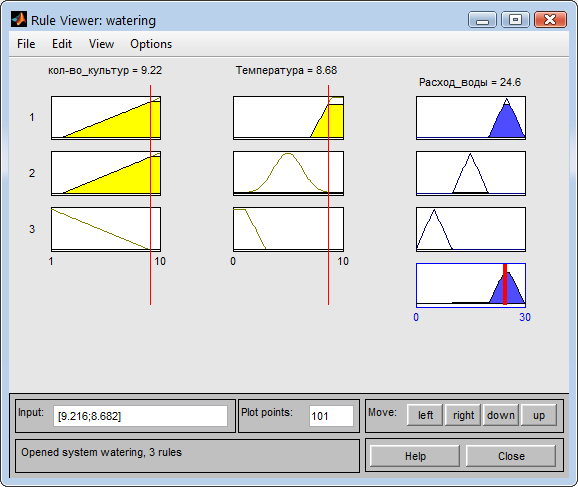 Рис. 22. Расход при большой температуре и большом количестве культур.
Рис. 22. Расход при большой температуре и большом количестве культур.
При большом количестве культур и небольшой температуре расход воды будет оставаться в средних значениях (Рис. 23).
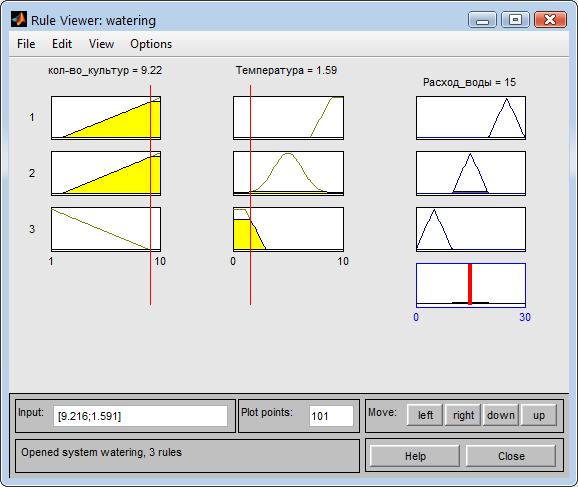 Рис. 23. Расход при большом количестве культур и маленькой температуре.
Рис. 23. Расход при большом количестве культур и маленькой температуре.
При нормальной температуре и большом количестве культур выполняется правило 2 и расход воды будет средним (Рис. 24).
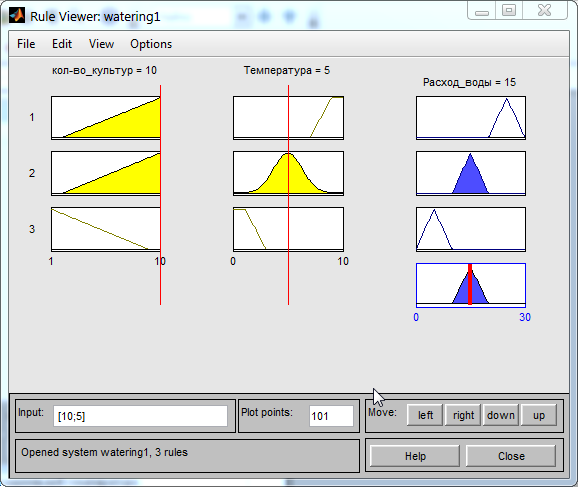 Рис. 24. Расход воды при нормальной температуре и большом количестве культур.
Рис. 24. Расход воды при нормальной температуре и большом количестве культур.
Программный комплекс MATLABFuzzyLogicToolbox дает возможность создавать наглядные визуальные модели решений задач нечеткой логики. Большое количество различных настроек и встроенных функций позволяет учесть все нюансы задачи при построении модели. При достаточном уровне владения программный комплекс может оказать большую помощь в моделировании деловых процессов.
Заключение
Нейронные сети прошли большой путь от теоретических предположений и математических теорий до рабочих инструментов, применяемых сегодня во многих сферах деятельности человека. В результате эволюции механизмов этого вида искусственного интеллекта нейронные сети обрели собственную логическую модель искусственного нейрона, подражающую процессам обучения мозга человека, и выносящую из этого сходства свои преимущества. Количество всевозможных топологий сегодня, исчисляясь десятками основных типов, позволяет подобрать наиболее подходящий для выполнения задачи вариант. А системы обучения позволяют добиться от сетей необходимой результативности при правильно выстроенном процессе обучения.
Также мы на примере посмотрели работу систем нечеткой логики в реальной сфере деятельности.
В целом сферу искусственного интеллекта ждет бурное развитие в ближайшее время судя по открывающимся для нейронных систем все новых областей применения.
Библиография
1. McCulloh W.S. And W. Pitts “A logical calculus of the ideas immanent in nervous activity” , Bulletin of Mathematical Biophysics, 1943
2. Donald O. Hebb "The Organization of Behavior" 1949
3. Gabor D. «Communication theory and cybernetics», IRE Transactions on Circuit Theory, 1954
4. Von Neumann J. “Probabilistic logics and the synthesis of reliable organisms from unreliable components” Princeton, NJ: Princeton University Press, 1956
5. Rosenblatt F. «The Perceptron: A probabilistic model for information storage and organization in the brain», Psychological Review, 1958
6. Widrow B, «Generalization and information storage in networks of adaline ”neurons”» in M.C Yovits, G.T. Jacobi and G.D., Goldstein eds., Self-Organizing Systems, Washington, DC: Spartan Books, 1962
7. Minsky M.L. And S.A. Papert, Perceptrons, Cambridge, MA: MIT Press, 1969
8. Hopfield J.J.«Neural networks and physical systems with emergent collective computational abilities», 1982
9. Cohen M.A. and S. Grossberg, «Absolute stability of global pattern formation and parallel memory storage by competitive neural networks», IEEE Transactions on systems, Man and Cybernetics, 1983
10. Kirkpatrick S., C.D. Gelatt, Jr. and M.P. Vecchi. «Optimization by simulated annealing», Science, 1983
11. Braitenberg V. «Vehicles: Experiments in Synthetic Psychology», Cambridge, MA: MIT Press, 1984
12. Rumelhart D.E., G.E. Hinton and R.J. Williams. «Learning representations of back-propagation errors», Nature (London), 1986
13. LeCun Y. «Une procedure d'aprentissage pour reseau a seuil assymetrique», Cognitiva, 1985
14. Parker D.B.,«Learning-logic: Casting the cortex of the human brain in silicon», Technical Report TR-47, Center for Computational Research in Economics and Management Science, Cambridge, MA: MIT Press, 1985
15. Linsker R. «Self-organization in perceptual network», Computer, 1988, vol 21, p.105-117.
16. Broomhead D.S. And D. Lowe. «Multivariable dunctional interpolation and adaptive networks», Complex Systems, 1988, vol. 2, p. 321-355.
17. Rosenblatt, Frank. “The perceptron: a probabilistic model for information storage and organization in the brain.” Psychological review 65.6 (1958): 386.
18. Broomhead, David S., and David Lowe. Radial basis functions, multi-variable functional interpolation and adaptive networks. No. RSRE-MEMO-4148. ROYAL SIGNALS AND RADAR ESTABLISHMENT MALVERN (UNITED KINGDOM), 1988.
19. Elman, Jeffrey L. “Finding structure in time.” Cognitive science 14.2 (1990): 179-211.
20. Kohonen, Teuvo. “Self-organized formation of topologically correct feature maps.” Biological cybernetics 43.1 (1982): 59-69.
21. Mendel J. M. and R. W. McLaren. “Reinforcement-learning control and pattern recognition systems”, in Adaptive, Learning and Pattern Recognition Systems: Theory and Aplications, vol.66 J.M. Mendel and K. S. Fu, eds., 1970, p. 287-318, New York: Academic Press.
22. Widrow B. and M.E. Hoff, Jr. “Adaptive switching circuits”, IRE WESCON Convention Record, 1960, p. 96-104.
23. Changeux J.P. And A. Danchin. “Selective stabilization of developing synapses as a mechanism for the specification of neural networks”, Nature, 1976, vol. 264, p. 705-712.
24. Stent G.S. “A physiological mechanism for Hebb's postulate of learning”, Proceedings of the National Academy of Sciences, USA, 1973, vol. 70, p. 997-1001.
25. Хайкин С. «Нейронные сети: полный курс», Издательский дом Вильямс, 2008.
26. Яхъяева Г.Э. «Нечеткие множества и нейронные сети.», Издательство Бином, 2006.
27. Fjodor van Veen “The Neural Network Zoo” URL: http://www.asimovinstitute.org/neural-network-zoo/ (Дата обращения: 14.02.2019).

- Проектирование диаграммы классов для сущности "Супермаркет"
- Основы объекно-ориентированного программирования
- Государственная служба в России: опыт, состояние и направления совершенствования
- Система управления всеми ресурсами и видами деятельности предприятия (на примере ОАО Мясокомбинат «Пятигорский»)
- Виртуальные предприятия
- Управление поведением при конфликтных ситуациях
- Менеджмент человеческих ресурсов
- Оперативное управление производством
- Проектирование нового продукта предприятия (новый продукт компании ООО «Паритет Инвест» и его особенности)
- «Классификация маркетинговых исследований»
- Курьерская доставка
- Достоинства и недостатки существующих подходов поддержки принятия решений