
Анализ поисковых систем в сети Интернет
Содержание:

Введение
Современный мир характеризуется использованием новых информационных технологий во всех сферах жизнедеятельности человека. Информация становится определяющим фактором развития общества. Все информационное пространство, в котором человек существует, все больше углубляется в Internet. С появлением глобальной информационной компьютерной сети появилась возможность оперативно получать информацию из любой точки земного шара. Самым распространенным средством информационных компьютерных технологий являются поисковые системы. Первые поисковые системы появились в сети Интернет более двадцати лет назад. В то время они реализовывали лишь функцию – поиска ссылок к недавно созданным страницам. На начальном этапе появления интернета, число пользователей сети было ограниченным, а количество информации относительно небольшим. Сегодня же поисковые системы превратились в многофункциональный сервис со своими службами. Они позволяют пользователям искать в сети Интернет самую разнообразную информацию, благодаря чему пользуются колоссальным спросом.
Проблема поиска информации существенно усложняется при использовании виртуальных источников. Здесь используется технология онлайновых каталогов, впоследствии использования которой, пользователь имеет право выполнять поиск в каталогах сразу двух или более библиотек, Тем самым, еще больше усложняет себе задачу, но, с другой стороны, увеличивает вероятность ее решения.
Иными словами, в современном мире невозможно представить жизнь без Интернета, с его помощью мы приобретаем разнообразные продукты пользования, общаемся, работаем, проводим с пользой свободное время. Возможности Всемирной Паутины безграничны, роль надежных гидов в виртуальных лабиринтах играют поисковые системы. Нет ничего проще, чем написать в строке поисковика нужный запрос, и поисковая система выдаст огромное количество предложений по внесенным словам или фразе. Еще сравнительно недавно, о чем-то подобном даже не догадывались.
Таким образом, актуальность проблемы обусловливается противоречием между большими потоками информации, циркулирующими в современном мире и неумением быстрого и качественного ее поиска в сети Интернет.
Актуальность определила тему курсовой работы – «Анализ поисковых систем в сети Интернет».
Объект исследования –процесс поиска информации в современных поисковых системах сети Internet.
Цель исследования –определить сущность и значимость информационно-поисковых систем в современном обществе и выявить наиболее совершенную с точки зрения интерфейса и алгоритма поиска систему для пользователя.
В соответствии с поставленной целью были определены следующие задачи исследования:
- рассмотреть теоретические основы автоматизированного информационного поиска;
- описать классификации и разновидности современных поисковых систем;
- выявить преимущества и недостатки поисковых систем;
- провести сравнительный анализ современных поисковых систем.
Глава 1. Характеристика информационно-поисковых систем
Поиск информации - задача, которую человечество решает уже многие столетия. По мере роста объема информации, потенциально доступных одному человеку (например, посетителю библиотеки), создавались более совершенные поисковые средства и приемы, позволяющие найти необходимый документ. Одним из таких средств является информационно-поисковая система.
Информационно-поисковая система (ИПС) - система, обеспечивающая поиск и отбор необходимых данных в специальной базе с описаниями источников информации (индексе) на основе информационно-поискового языка и соответствующих правил поиска[1].
Главной задачей любой информационно-поисковой системы является поиск информации соответствующей информационным потребностям пользователя. Очень важно в результате проведенного поиска ничего не потерять, то есть найти все документы, относящиеся к запросу (полнота поиска), и не найти ничего лишнего (точность поиска). Поэтому устанавливается качественная характеристика процедуры поиска - релевантность.
Релевантность - соответствие результатов поиска сформулированному запросу[2].
В неавтоматизированных информационно-поисковых системах описание источников информации проводится персоналом ИПС, то есть людьми, которые составляют краткую аннотацию на каждый ресурс. Затем, как правило, проводится сортировка описанных ресурсов по темам (составление тематического каталога). Конечно, описание, составленное человеком, будет адекватно источнику. Правда, в этом случае процедура индексирования занимает значительный период времени, поэтому формируемый индекс имеет, как правило, ограниченный объем. Зато поиск в подобной системе можно будет проводить так же легко, как в тематических каталогах библиотек.
В ИПС другого типа процедура описания информационных ресурсов автоматизирована. Для этого разрабатывается специальная программа-робот, которая по определенной технологии обходит ресурсы, описывает их (проводит индексирование) и анализирует ссылки с текущей страницы для расширения области поиска. Чаще всего для описания документа просто составляется список слов, которые встречаются в тексте и других частях документа, при этом учитывается частота повторения и местоположение слова, то есть, слову приписывается своеобразный весовой коэффициент в зависимости от его значимости. Таким образом, следующей задачей для ИПС второго типа является разработка робота - индексировщика.
Для поиска в системах автоматизированного типа пользователю необходимо научиться составлять запросы, в простейшем случае состоящие из нескольких слов. Тогда ИПС будет искать в своем индексе документы, в описаниях которых встречаются слова из запроса. Для проведения более качественного поиска необходимо разрабатывать специальный язык запросов для пользователя. В зависимости от особенностей построения модели индекса и поддерживаемого языка запросов разрабатываются механизм поиска и алгоритм сортировки результатов.
Поскольку индекс имеет значительный объем, количество найденных документов может оказаться достаточно большим. Следовательно, чрезвычайно важно, как поисковая машина проведет поиск и отсортирует его результаты.
Существенное значение имеет внешний вид поисковой системы, предстающий перед пользователем, поэтому одной из задач является разработка удобного и красивого интерфейса.
Наконец, исключительно важна форма представления результатов поиска, поскольку пользователю необходимо узнать как можно больше о найденном источнике информации, чтобы принять правильное решение о необходимости его посещения.
Информационно-поисковый язык (ИПЯ) – формализованный искусственный язык, предназначенный для индексирования документов, информационных запросов и описания фактов с целью последующего хранения и поиска. Информационно-поисковый язык, знаковая система, предназначенная для описания (путём индексирования) основного смыслового содержания текстов (документов) или их частей, а также для выражения смыслового содержания информационных запросов с целью реализации информационного поиска[3].
Любой абстрактный ИПЯ состоит из алфавита (списка элементарных символов), правил образования и правил интерпретации. Правила образования устанавливают, какие комбинации элементарных символов допускаются при построении слов и выражений, а правила интерпретации – как надлежит понимать эти слова и выражения.
ИПЯ должен располагать лексико-грамматическими средствами, необходимыми для выражения основного смыслового содержания любого текста и смысла любого информационного запроса по данной отрасли или предмету, быть недвусмысленным (допускать одно истолкование каждой записи), удобным для алгоритмического сопоставления и отождествления (полного или частичного) записей основного смыслового содержания текстов и смыслового содержания информационных запросов. При разработке конкретного ИПЯ учитываются специфика отрасли или предмета, для которой этот язык создаётся, особенности текстов, образующих поисковый массив, характер информационных потребностей, для удовлетворения которых создается данная информационно-поисковая система.
В большинстве ИПЯ основной словарный состав (лексика) задаётся его перечислением и представляет собой фрагмент лексики того или иного естественного языка. Отобранные из естественного языка слова и словосочетания, в совокупности образующие основной словарный состав, служат как бы алфавитом данного ИПЯ. Правила образования в таких ИПЯ выполняют функцию синтаксиса. В некоторых ИПЯ основной словарный состав задаётся (полностью или частично) методом порождения, который заключается в том, что для таких ИПЯ правила образования устанавливают, как из данного алфавита строить слова ИПЯ, а из этих слов – выражения (фразы) и какие из них будут правильно построенными. ИПЯ отличается от информационного языка и от машинного языка.
Современные поисковые системы просты и удобны в использовании, чем не могли похвастаться их предшественники. С помощью самых первых поисковых систем найти необходимую информацию было крайне сложно, они требовали огромных, по тем временам, сетевых ресурсов, выводя из строя веб-сервера.
Сегодня поисковая система –один из самых широко используемых методов навигации в киберпространстве. Современная автоматизированная информационно-поисковая система определяется как веб-сайт, предоставляющий возможность поиска информации в Интернете. Основной частью веб-сайта является поисковая машина, или поисковый движок – комплекс программ, обеспечивающий функциональность поисковой системы.
Иными словами поисковая система - это сумма следующих компонентов:
Webserver (веб-сервер) – сервер поисковой машины, который осуществляет взаимодействие между пользователем и остальными компонентами системы.
Spider (паук)- программа, написанная по принципу браузера, предназначена для скачивания веб-страниц. Браузер предназначен для визуального использования страниц, а паук работает с HTML кодом напрямую. Чтобы посмотреть «сырой» исходник нажмите в меню браузера: Вид- Просмотр HTML кода.
Crawler («путешествующий» паук) – программа, которая автоматически уходит по всем внешним ссылкам страницы. Ее задача - поиск не известных (или измененных) документов и в расстановке приоритетов, куда дальше должен идти Spider.
Indexer (индексатор) - программа-анализатор скаченных пауками веб-страниц. Она «разбирает» на части скачанную страницу и анализирует ее элементы, такие как текст, служебные html-теги, заголовки, особенности стилистики и структурные формы.
Database (база данных) – хранилище для скачанных и обработанных страниц - общая база данных поисковой машины.
Searchengineresultsengine (система выдачи результатов) – извлекает результаты поиска из базы данных поисковой системы. Именно она решает, какие страницы более соответствуют запросу пользователя, и отсортировывает их в нужном порядке. Модуль работает согласно заданным поисковой системой алгоритмам ранжирования[4].
Далее мы будем, рассматривать ИПС для всемирной паутины (WorldWideWeb). «Для начала рассмотрим динамику развития сетиInternet, изучив историю ее возникновения, мы сможем понять, для чего изначально создавались поисковые системы. Данная сеть была создана в связи с возникшей необходимостью совместного использования информационных ресурсов, распределенных между различными компьютерными системами. Большинство первых приложений, включая FTP и электронную почту, были разработаны исключительно для обмена данными междухост - компьютерами Internet»[5].
Другие приложения, такие как Telnet, создавались для того, чтобы пользователь получил возможность доступа не только к информации, но и к рабочим ресурсам удаленной системы. «По мере развития Internet (увеличения пользователей и хост-компьютеров) прежние методы обмена данными перестали отвечать возросшим потребностям пользователей. Возникла необходимость разработки новых способов поиска сетевых ресурсов и доступа к ним, которые позволяли бы использовать информацию независимо от ее формата и расположения»[6].
«Для удовлетворения таких потребностей сначала были созданы поисковая система Archie, решающая задачу локализации ресурсов на FTP-сервере, и система Gopher, упрощающая доступ к различным сетевым ресурсам. Затем были разработаны сетевые информационные системы World Wide Web и WAIS, предлагающие абсолютно новые методы получения информации. Принципы работы этих систем позволяют легко ориентироваться в огромном количестве информационных ресурсов без необходимости предоставления механизмов работы самой сети Internet. Такой подход позволяет говорить уже не просто о ресурсах взаимосвязанных компьютерных систем, а об особых информационных пространствах сети»[7].
Система Archieпредставляет собой комплекс программных средств, работающих со специальными базами данных. В этих базах данных содержится постоянно пополняющаяся информация о файлах, к которым можно получить доступ через сервис FTP. Пользуясь услугами системы Archie, можно осуществить поиск файла по шаблону его имени. При этом пользователь получит список файлов с точным указанием места их хранения в сети, а также с информацией о типе, времени создания и размере файлов. Доступ к информационно-поисковой системе Archie может осуществляться различными путями, начиная от запросов по электронной почте и с помощью сервиса Telnet и заканчивая использованием графических Archie-клиентов.
Система Gopher была разработана для упрощения процесса локализации FTP-ресурсов Internet и для более удобного представления сведений о содержании хранящихся на FTP-серверах файлов. «Система Gopher дает возможность в удобной форме (в виде меню) представлять пользователям информацию об имеющихся файлах и их содержании. Меню Gopher-серверов могут содержать ссылки на другие Gopher- и FTP-серверы. Таким образом, пользователь получает возможность «путешествовать» по Internet, не обращая внимания на местонахождение интересующих его ресурсов, и получать доступ к этим ресурсам»[8].
Система Veronica используется для поиска информации в Gopher-пространстве по заголовкам пунктов меню. После ввода ключевого слова, система Veronica выясняет, встречается ли оно в меню на каком-либо Gopher-сервере, и в качестве результатов поиска выдает список заголовков пунктов меню, содержащих ключевое слово. «Поскольку система Veronica не является автономной поисковой программой, а тесно связана с системой Gopher, она обладает тем же, что и система Gopher, недостатком: далеко не всегда по заголовку можно сказать, что собой представляет тот или иной информационный ресурс. Достоинства системы заключается в том, что нет необходимости узнавать, где расположена найденная информация, достаточно выбрать требуемую запись из списка»[9].
Таким образом, основными показателями ИПС для всемирной паутины являются пространственный масштаб и специализация.
По пространственному масштабу ИПС можно разделить на локальные, региональные и глобальные.
Локальные поисковые системы могут быть разработаны для быстрого поиска страниц в масштабе отдельного сервера.
Региональные ИПС описывают информационные ресурсы определенного региона, например, русскоязычные страницы в Интернете.
Глобальные поисковые системы в отличие от локальных стремятся объять необъятное - по возможности наиболее полно описать ресурсы всего информационного пространства сети Интернет
По тематике ИПС можно разделить на универсальные и специализированные.
Универсальные — ищут информацию по любой теме (могут быть как локальными, так и глобальными).
Специализированные — ищут информацию по определенному профилю или тематике (преимущественно локальные).
Далее нам будут интересны лишь универсальные ИПС, потому что поисковые системы данного вида более востребованы и популярны среди пользователей. Как было уже сказано, главным достоинством информационно-поисковой системы является быстрый поиск нужной информации, который во многом зависит от структуры ИПС.
«В основу построения структуры ИПС легло её функциональное назначение, область применения и особенности описываемой ею предметной области.
Функционально ИПС предназначена для быстрого и удобного поиска и выборки данных из больших массивов информации по шаговым двигателям как для внутренней работы с данными, так и для подготовки их для различных САПР. Это накладывает определённые требования на построение пользовательского интерфейса и на форму предоставления информации. При построении структуры ИПС учитывается также потребность потенциального пользователя в доступе к системе контекстно-зависимой подсказке»[10].
«Реализация вышеперечисленных требований возложена на следующий ряд структурных компонентов, так называемых блоков:
- проверки БД на целостность;
- просмотра;
- редактирования;
- защиты паролем;
- поиска;
- вывода результата;
- хранения параметров поиска;
- помощи.
В основе выбора именно такой структуры информационно-поисковой системы по шаговым двигателям лежит очень простая логика - любой блок системы должен получать данные, обрабатывать их и выдавать пользователю в определенном порядке, обеспечивая логику процесса»[11].
Рассмотрим каждый блок более подробно (рис. 1)[12]:
Блок проверки БД на целостность осуществляет проверку всех составных частей базы данных.
Блок просмотра позволяет начать работу в системе с просмотра БД и далее выбрать другой режим работы.
Блок редактирования производит редактирование только числовых полей БД и позволяет изменять характеристики, вводить новые и удалять старые записи в таблицы БД. Здесь также можно произвести смену режима работы.
Блок защиты паролем осуществляет блокировку доступа к редактированию данных путем ввода шестизначного пароля.
Блок поиска предназначен для осуществления поиска по введенному техническому заданию (ТЗ) и перехода к другим режимам работы.
Блок вывода результатов поиска выводит на экран в определенном порядке все найденные шаговые двигатели и их характеристики в соответствии с ТЗ поиска. Блок хранения параметров поиска записывает и хранит информацию до следующего этапа поиска.
Блок помощи выполняет роль подсказки в различных режимах работы системы.
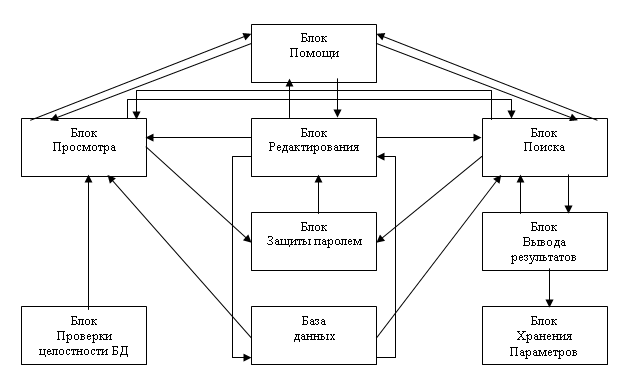
Рисунок 1. Структура ИПС
Следующим компонентом в основе построения структуры ИПС является ее область применения.
«Область применения ИПС, как было указано выше, - это внутренняя работа с информацией и обработка информации для использования её в работе САПР, включающей в свой состав ИПС как один из модулей. Из этого вытекают очень высокие требования к надёжности функционирования системы, поскольку любая САПР - это достаточно сложное построение с заданными параметрами надежности, и каждая структура, включаемая в такое построение, должна обладать надежностью, по крайней мере, не меньшей, чем вся система в целом. Обеспечение нужных показателей надежности, в свою очередь, во многом определяется структурой построения системы.
Для организации БД ИПС необходимо полное исследование предметной области. В данной ИПС предметной областью является широкий класс шаговых двигателей»[13]. Информационно-поисковые системы (ИПС) Интернет, при всем их внешнем разнообразии, также попадают в один из этих классов. Поэтому, прежде чем знакомиться с ИПС Интернет, рассмотрим абстрактные алфавитные (словарные), систематические и предметные ИПС.
В классификационных ИПС используется иерархическая (древовидная) организация информации, которая называется классификатором. Разделы классификатора называются рубриками. Библиотечный аналог классификационной ИПС - систематический каталог. Классификатор разрабатывается и совершенствуется коллективом авторов. Затем его использует другой коллектив специалистов, называемых систематизаторами. «Систематизаторы, зная классификатор, читают документы и приписывают им классификационные индексы, указывающие, каким разделам классификатора эти документы соответствуют»[14].
Предметная ИПС с точки зрения пользователя устроена наиболее просто. Ищи название нужного предмета своего интереса (предметом может быть и нечто невещественное, например, индийская музыка), а с названием связаны списки соответствующих ресурсов Интернет. Это было бы особенно удобно, если полный перечень предметов невелик.
Словарные ИПС с обобщенным англоязычным названием searchengines. были созданы в результате возникновения культурных проблем, связанных с использованием классификационных ИПС.
«Основная идея словарной ИПС - создать словарь из слов, встречающихся в документах Интернет, в котором при каждом слове будет храниться список документов, из которых взято данное слово»[15].
Теория информационного поиска предполагает два основных алгоритма работы словарных ИПС: с использованием ключевых слов и с использованием дескрипторов. В первом случае, для оценки содержимого документа используются только те слова, которые в нем встречаются, и по запросу ИПС сопоставляет слова из запроса со словами документа, определяя по количеству, расположению, весу слов из запроса в документе его релевантность. Все работающие ИПС по историческим причинам используют этот алгоритм, в различных модификациях[16].
При работе с дескрипторами индексируемые документы переводятся на некоторый дескрипторный информационный язык. Дескрипторный информационный язык, как и любой другой язык, состоит из алфавита (символов), слов, средств выражения парадигматических и синтагматических отношений между словами. «Парадигматика предусматривает выявление скрытых в естественном языке лексико- семантических отношений между понятиями»[17]. В рамках парадигматических отношений можно рассматривать, например, синонимию, омонимию. Синтагматика исследует такие отношения между словами, которые позволяют объединять их в словосочетания и предложения. Синтагматика включает правила построения слов из элементов алфавита (кодирование лексических единиц), правила построения предложений (текстов) из лексических единиц (грамматика)[18].
То есть, запрос пользователя переводится в дескрипторы и обрабатывается ИПС уже в этой форме. Такой подход более затратен по вычислительным ресурсам, но и потенциально более продуктивен, так как позволяет отказаться от критерия релевантности и работать непосредственно с пертинентностью документов.
«Словарные ИПС способны выдавать списки документов, содержащие миллионы ссылок. Даже просто просмотреть такие списки невозможно, да и не нужно. Было бы удобно иметь возможность задать формальные критерии (хотя бы относительной) важности (с точки зрения пертинентности) документов с тем, чтобы наиболее важные документы попадали бы в начало списка. Все ИПС в настоящее время уделяют основное внимание именно алгоритму ранжирования полученных ссылок»[19].
Наиболее часто используемыми критериями при ранжировании в ИПС являются наличие слов из запроса в документе, их количество, близость к началу документа, близость друг к другу;
«Наличие слов из запроса в заголовках и подзаголовках документов (заголовки должны быть специально отформатированы);
Количество ссылок на данный документ с других документов; «респектабельность» ссылающихся документов»[20].
Почти все современные популярные информационные поисковые системы предоставляют возможность поиска информации разными способами. Это обеспечивается интеграцией в современную поисковую систему перечисленных выше поисковых систем. Таким образом, можно сделать вывод, что алфавитные (словарные), систематические и предметные ИПС являются подсистемами ИПС Интернет. По большей части это «склеивание» направленно на удовлетворение «прихотей» пользователя.
Глава 2. Обзор популярных мировых и российских информационно-поисковых систем
2.1 Сферы использования современных ИПС
Современные ИПС характерны для так называемой информационной индустрии — новейшей области экономики и социальной сферы, занятой обработкой, систематизацией, накоплением и распространением информации. Бурное развитие ИПС связано с успехами информатики (Информатика). Предметами запроса в ИПС могут быть библиографические данные, управленческая и фактографическая информация, экспертные оценки, ретроспективный опыт, результаты исследования моделей и т.д. Такой широкий круг задач обусловливает большое разнообразие типов ИПС. Они различаются своими целями, объемом содержащихся сведений, видами информации, способами доведения ее до потребителя[21]. Наряду с локальными ИПС, действующими в рамках одного учреждения (например, поликлиники или больницы), существуют национальные и интернациональные центры информационного обслуживания (например, в области охраны окружающей среды). Широкое распространение получили библиографические ИПС (например, содержащие библиографию по всем областям медицины и медико-биологических наук). Массовое производство персональных ЭВМ, развитие средств коммуникаций, возможность объединения ЭВМ в информационные сети и обращения со своего рабочего места к сведениям, находящимся в памяти других ЭВМ, существенно расширили диапазон применения информации, широту и глубину ее поиска. Качественно новый этап развития ИПС связан с формированием баз данных на машиночитаемых носителях. Такие базы данных позволяют обращаться к ним дистанционно, одновременно по многим запросам, получая результаты поиска оперативно и в удобном виде[22].
Медицина и здравоохранение являются чрезвычайно специфической областью внедрения ИПС. Это связано со сложной структурой и многообразием форм медико-санитарной информации, которая включает трудно формализуемые понятия и категории, а также значительные массивы подлежащих учету данных. Особенностью медицинской информации является и то, что результаты единичных клинических или экспериментальных наблюдений по мере накопления и обобщения становятся основой для осуществления крупных здравоохранительных и социальных мероприятий. Медико-санитарная информация является базой принятия управленческих решений — от выбора наиболее важных направлений научно-исследовательской работы до проведения экстренных санитарно-профилактических мероприятий. В массивы информации, на основании анализа которой осуществляется управление здравоохранением, входят статистика (демографическая и популяционная, статистика кадров, данные о заболеваемости и смертности и пр.), обобщенные данные о состоянии и достижениях медицинской и ряда смежных научных дисциплин, опыт предшествующих лет. Именно комплексный характер сведений послужил причиной разработки единой концепции ИПС. Она включает поэтапное создание отдельных подсистем, объединение которых достигается как на уровне обмена базами данных, так и (или) с помощью средств коммуникаций[23].
Процесс разработки и интеграции подсистем в ИПС может осуществляться по вертикали и по горизонтали по мере их создания. Подсистемы, являющиеся вспомогательными (например, учет и движение кадров, планирование и финансирование), могут создаваться независимо от других. На нижнем уровне учреждения здравоохранения (больницы, клиники, НИИ) пользуются ИПС для ведения историй болезни, контроля эффективности лечебных мероприятий, сбора и обработки первичных статистических данных, а также для решения управленческих задач своего уровня компетенции (использование коечного фонда и лабораторно-диагностического оборудования, лекарственное обеспечение и др.). Осуществляя оперативные функции, эти ИПС одновременно накапливают, а затем передают необходимую информацию на более высокий уровень (городской, областной). Отдельно создаются подсистемы справочно-информационного обслуживания (в области библиографии и научных исследований, нормативных материалов, стандартов). В рамках общей ИПС могут разрабатываться подсистемы для поддержки и развития отдельных служб (например, психиатрической, онкологической) или целевых программ (например, побочное действие лекарственных препаратов)[24].
2.2 Популярные поисковые системы
Рейтинг мировых и российских информационно-поисковых систем, поможет нам выявить наиболее популярные поисковые системы, которые в дальнейшем мы будем рассматривать. Обратимся к данным рейтинга мировых поисковых систем, показанных на рисунке 2.
Google первая по популярности поисковая машина в мире обрабатывающая более 40 миллиардов запросов в месяц (доля рынка 70,4 %), и индексирует более 8 миллиардов веб-страниц. Google может находить информацию на 191 языке[25]. Второе место (с большим отрывом) у поисковой системы Baidu.com – 17% рынка. Третье место занимает поисковик Yahoo– 7% рынка[26]. Уверенные позиции последнего связаны с тем, что на территории Китая заблокированы и Google, и Yahoo. Четвертое место занимает Bing(MSN), она является относительно молодой поисковой системой от Microsoft, её успех главным образом определяется огромным массивом статистических данных, который накопился у компании за годы существования браузера Internet Explorer, который в дальнейшем позволил ее инженерам создать поисковой алгоритм, дающий пользователям релевантную выдачу.[27]
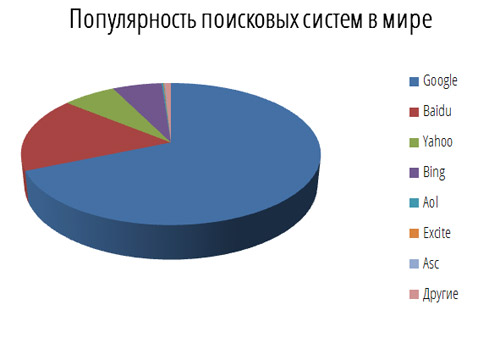
Рисунок 2. Рейтинг мировых поисковых систем
Лидер поисковых машин Интернета, Google занимает более 70% мирового рынка, а значит, семь из десяти находящихся в сети людей обращаются к его странице в поисках информации в Интернете. Сейчас регистрирует ежедневно около 50 миллионов поисковых запросов и индексирует более 8 миллиардов веб-страниц[28].
Информационно-поисковая система Google была разработана в 1998 году выпускниками Стэндфордского университета Сергеем Брином и Лари Пейджем, которые применили для ранжирования документов технологию PageRank, где одним из ключевых моментов является определение «авторитетности» конкретного документа на основе информации о документах, ссылающихся на него. Говоря общими словами, чем больше документов ссылается на данный документ, и чем они авторитетнее, тем авторитетнее становится данный документ. Количественное значение авторитетности документа (другими словами, взвешенное количество ссылок или Page Rank) относится к так называемым статическим факторам (т.е. независящим от конкретного запроса) и учитывается при определении релевантности документа конкретному запросу как весовой коэффициент. Наряду с этим Google применил для определения релевантности документа не только текст самого документа, но и текст ссылок на него. Эта технология позволила ему обеспечить выдачу довольно релевантных результатов на фоне других поисковиков. Довольно быстро Google стал лидировать в различных опросах по такому показателю, как удовлетворенность пользователей результатами поиска. Google осуществляет поиск по документам на более чем 35 языках, в том числе русском. В настоящее время многие порталы и специализированные сайты предоставляют услуги поиска информации в Интернете на базе Google, что делает задачу успешного позиционирования сайтов в Google еще более важной. Google проводит переиндексацию своей поисковой базы примерно раз в четыре недели. Во время этого усовершенствования, неофициально называемого Googledance, происходит обновление базы на основе информации, собранной роботами за время, прошедшее с предыдущего усовершенствования, и перерасчет значений PageRank документов[29].
Также существует определенное количество документов с достаточно большим значением Page Rank, информация о которых в поисковой базе обновляется ежедневно, однако значение Page Rank пересчитывается только во время Google dance. Нормированное значение Page Rank для конкретного документа, загруженного в браузер, можно узнать, скачав и установив GoogleToolBar - специальную панель инструментов для работы с этим поисковиком. Не смотря на то, что в поисковике имеется форма для бесплатного добавления страницы в базу, Google предпочитает сам находить новые документы по ссылкам с уже известных страниц, и не будет индексировать добавленную через форму страницу, если в его базе не найдется ни одной страницы, ссылающейся на нее.
Так же на страницах результатов поиска Google отображаются платные (payperclick) рекламные объявления конкурирующих компаний, которые основывают рекламные объявления на брендах. «В то время как сервис мог бы помочь увеличить трафик, некоторые пользователи «сливаются», так как Google использует известность брендов для продажи рекламных объявлений, как правило, конкурирующим компаниям». Чтобы сгладить этот конфликт Google предложил отключать эту возможность для желающих компаний.
22 сентября 2010 года компания запустила голосовой поиск в России. Чтобы осуществить поиск, необходимо нажать в телефоне кнопку рядом со строкой поиска и произнести свой запрос, телефон отправит ваш голос на сервер и браузер, будет выдавать строку с распознанным вашим запросом и результатами поиска по нему.
По случаю праздника или круглой даты какой-нибудь широко известной личности, стандартный логотип Google у региональных доменов может меняться на праздничный, имеющий определённую тематику, смысл.
Baidu – лидер среди китайских поисковых систем. По количеству обрабатываемых запросов поисковый сайт Байду стоит на 2 месте в мире (с долей в глобальном поиске 7 %). Уже в конце 2019 года в Китае свыше 250 млн. пользователей займутся поиском информации в Интернете. Аналитик J.P. Морган Дик Вей исходит в своем актуальном анализе из того, что это число вырастет в течение следующих трех, четырех лет до 400 млн. пользователей. Гигантский рынок с высокими доходами для Baidu, сравнивают только прибыль, которую Google достигает в США с очень похожей бизнес-моделью[30].
Поисковая система Yahoo —одна из самых первых (создана Дэвидом Фило и Джерри Янгом в апреле 1994 года) по сей день остается и самой популярной из них, традиционно сочетая поиск, как по ключевым словам, так и с помощью иерархического дерева разделов[31] [6].
Нынешнее развитие Yahoo можно определить как движение в онлайн, интерактивность. Yahoo быстро осваивает эту область Интернет-услуг, но возникает одна проблема: ядро Yahoo! не было на это рассчитано. Не была в 1994 году заложено в него «онлайновая» составляющая, ее «приклеил» Тим Кугл несколькими годами позже. Естественно возникает угроза хакерских атак через эту незащищенную область.
Одно из новшеств поисковой системы Yahoo - панель задач для браузера Firefox, Этот инструмент помогает пользоваться поиском Yahoo, не заходя на официальный сайт, а лишь используя функциональные кнопки панели.
1 сентября 2005 года поисковик Yahoo, которому принадлежит более 200 миллионов адресов электронной почты по всему миру, анонсировал запуск новой системы поиска текстов, фотографий и других документов, содержащихся в письмах.
Необходимость такого нововведения возникла вслед за увеличением объёма хранимых данных, ведь некоторые пользователи создают целые почтовые архивы. Подгоняемый конкурентом Google и его почтовым сервисом Gmail, Yahoo для хранения почты предлагает отныне 1 гигабайт бесплатного места, или 2 гигабайта по годовому абонементу. «Как только вы получаете возможность хранить больше информации, вам необходимы и расширенные поисковые возможности», – объясняет Эрик Петерсон, аналитик компании JupiterResearch.
Пользователи поисковой системы Yahoo, в свою очередь, смогут теперь использовать возможности детализированного поиска слов в названии или непосредственно в тексте письма, а также в присоединенных документах, не открывая их. Результат поиска отражается в трёх строках с указанием всех атрибутов. На панели справа отображаются все похожие документы. Найденные фотографии выводятся на экран в уменьшенном виде, что значительно облегчает поиск. Система также учитывает орфографические ошибки, позволяя искать слова лишь по первым буквам.
Yahoo планирует предложить новую систему небольшому числу американских пользователей, а затем распространить её по всему миру. Со стороны клиентов это не потребует никаких дополнительных усилий. «Когда услуга станет, доступна, в левом верхнем углу страницы вашего почтового ящика появится соответствующий баннер», – обещает компания Yahoo.
Теперь опишем наиболее популярные поисковые системы российского рынка информационных ресурсов.
Большинство «русскоязычных» поисковых систем индексируют и ищут тексты на многих языках — украинском, белорусском, английском и др. Отличаются же они от «всеязычных» систем, индексирующих все документы подряд, тем, что в основном индексируют ресурсы, расположенные в доменных зонах, где доминирует русский язык или другими способами ограничивают своих роботов русскоязычными сайтами. По данным LiveInternet, лучшей поисковой системой Рунета является все-таки Яндекс.
- Яндекс – 53,9% российского рынка поисковых услуг.
- Google – 35,1% российского рынка поисковых услуг.
- Mail – 8,3%.
- Rambler – 0,9%.
- Bing – 0,6%.
Рейтинг российских поисковых систем показан на Рисунке 3.
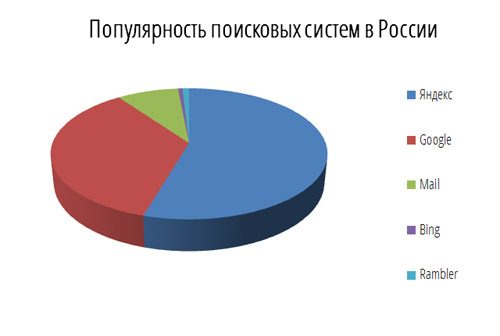
Рисунок 3. Рейтинг российских поисковых систем
Основное отличие русскоязычных поисковых систем от иностранных одно – то, что глобальные поисковые системы, поддерживающие поиск на русском языке, не поддерживают русскую морфологию. В русскоязычной части сети Интернет работают около двух десятков поисковых систем, но подавляющие большинство пользователей работает лишь с несколькими, подробно остановимся на самых крупных.
Яндекс – на сегодня наиболее популярная русскоязычная поисковая система, ежемесячно к ней обращаются более 35 миллионов пользователей сети Internet. Начала свою работу во второй половине 1997 года учитывая морфологию русского языка. История компании «Яндекс» началась в 1990 году с разработки поискового программного обеспечения в компании «Аркадия». За два года работ были созданы две информационно-поисковые системы – Международная Классификация Изобретений, 4 и 5 редакция, а также Классификатор Товаров и Услуг. Обе системы работали локально под DOS и позволяли проводить поиск, выбирая слова из заданного словаря, с использованием стандартных логических операторов. В1993 году «Аркадия» стала подразделением компании CompTek. В 1993-1994 годы программные технологии были существенно усовершенствованы благодаря сотрудничеству с лабораторией Ю. Д. Апресяна (Институт Проблем Передачи Информации РАН). В частности, словарь, обеспечивающий поиск с учетом морфологии русского языка, занимал всего 300Кб, то есть целиком грузился в оперативную память и работал очень быстро. С этого момента пользователь мог задавать в запросе любые формы слов[32].
Помимо поисковой системы, сегодня Яндекс – огромный портал с целым набором широко используемых сервисов, такими как каталог, Яндекс. деньги, и другие. Официально поисковая машина Yandex.Ru была анонсирована 23 сентября 1997 года на выставке Softool. Основными отличительными чертами Yandex.Ru на тот момент были проверка уникальности документов (исключение копий в разных кодировках), а также ключевые свойства поискового ядра Яндекс, а именно: учет морфологии русского языка (в том числе и поиск по точной словоформе), поиск с учетом расстояния (в том числе в пределах абзаца, точное словосочетание), и тщательно разработанный алгоритм оценки релевантности (соответствия ответа запросу), учитывающий не только количество слов запроса, найденных в тексте, но и «контрастность» слова (его относительную частоту для данного документа), расстояние между словами, и положение слова в документе[33].
Гибкий язык запросов, позволяет производить поиск по самым различным критериям. Так, например, для операции исключения можно указать область действия: запрос A ~~ B найдёт документы (страницы), в которых присутствует А, но не присутствует В, а запрос А ~ Б - документы, где слово Б не присутствует со словом А в одном предложении. Аналогично, оператор & ищет сочетания ключевых слов в предложении, а && - во всём документе.
По умолчанию Яндекс выводит по 10 ссылок на каждой странице выдачи результатов, в настройках результатов поиска можно увеличить размер страницы до 20, 30 или 50 найденных документов. Иногда порядок сайтов на этих страницах может отличаться, так как обновление баз для этих результатов происходит не одновременно.
Время от времени алгоритмы Яндекса, отвечающие за релевантность выдачи, меняются, что приводит к изменениям в результатах поисковых запросов. В частности, эти изменения направлены против поискового спама, приводящего к нерелевантным результатам по некоторым запросам (реже - по целым семействам запросов).
Rambler – одна из первых российских ИПС, открыта в 1996 году. В конце 2002 года была произведена коренная модернизация, после которой Rambler вновь вошел в группу лидеров сетевого поиска. В настоящее время объем индекса составляет порядка 150 миллионов документов. Для составления сложных запросов рекомендуется использовать режим «Детальный запрос», который предоставляет широкие возможности для составления поискового предписания с помощью пунктов меню.
По результатам тестов Rambler занимает 2-ое место после Yandex. Производительность поискового робота декларируется в объеме 6,9 млн. страниц в сутки. В системе также усовершенствован поиск по новостям: робот посылается на ведущие новостные сайты России каждые 2 часа.
Mail (русскоязычный интерфейс) - бесплатный почтовый сервис с неограниченным размером ящика, защитой от спама и вирусов. Социальная сеть, фото- и видеохостинги, поисковая система и другие коммуникационные и развлекательные сервисы.
Поиск@Mail.Ru — поисковая система от компании Mail.Ru. По данным на октябрь 2018 года на рынке Рунета он занимает долю около 2,9 % (третье место в рейтинге поисковых систем на российском рынке)[34].
Система начала работать в 2007 году. Объем индексного файла весной 2009 г. составлял более 1,5 миллиарда страниц, расположенных на русскоязычных серверах. Помимо разыскания текстов, системой осуществляется поиск иллюстраций и видеофрагментов, размещенных на специализированных «самонаполняемых» российских серверах: Фото@Mail.Ru, Flamber.Ru, 35Photo.ru, PhotoForum.ru, Видео@Mail.Ru, RuTube, Loadup, Rambler Vision и им подобных. Gogo.ru позволяет ограничивать область поиска сайтами коммерческой направленности, информационными сайтами, а также форумами и блогами. Форма “Расширенного поиска” также дает возможность ограничить разыскания определенными типами файлов (PDF, DOC, XLS, PPT), местом положения искомых слов в документе или определенным доменом. В ноябре 2013 в Google Play появилась новая версия поискового приложения от компании Mail.Ru, позволяющего переходить с главного экрана в любые социальные сети и содержащего быстрый доступ к поиску по картинам, видео и новостям.
Таким образом, на данный момент Яндекс задает моду в отечественном поиске. Разница в аудитории тоже есть. Если Google пользуется в основном молодежь, Яндекс предпочитают те, кому за 30.
Кроме того, в Google чаще заходят с мобильных устройств. Это обусловлено в первую очередь тем, что на платформе Android по умолчанию установлен именно поиск в Google.
В данной главе были рассмотрены мировые и русскоязычные поисковые системы. По результатам рейтинговых данных были выявлены наиболее популярные системы поиска. Таковыми являются Google, среди мировых ИПС, и Яндекс, среди русскоязычных систем. Критериями выбора именно этих систем являются удобство поиска информации, а именно: высокое качество алгоритма сортировки результатов, гибкий язык запросов, релевантность. Кроме этого были рассмотрены свойства большинства систем, и были определены некоторые особенности каждой из них. Таким образом, удалось выявить, что каждая система по-своему удовлетворяет критериям поиска и вполне может конкурировать с другими поисковыми системами.
Глава 3. Сравнительный анализ современных информационно-поисковых систем
Теперь обратимся к положительным и отрицательным сторонам ранее рассмотренных наиболее популярных поисковых систем, тем самым продемонстрировав особенности, которыми должна обладать наиболее удобная система поиска. Данные представим в таблице 1.
Таблица 1
Преимущества и недостатки современных поисковых систем
|
Поисковая система |
Преимущества |
Недостатки |
|
Яндекс |
1) Непрерывное развитие системы. 2) Качество выдачи растет, все больше удобных сервисов предлагает компания: каталог, карты, новости, прогноз погоды, почта. 3) глубокий морфологический анализ обрабатываемых терминов. 4) обладает хорошим механизмом распознавания одного документа в нескольких кодировках или на зеркальных серверах. 5) оригинально сконструированный механизм выдачи результатов. 6) огромная индексная база. |
1) Разница в выдаче при наборе слова с большой (маленькой) буквы (иногда выдача меняется, иногда нет). 2) Частое выпадение секторов поисковой базы - когда исчезают части сайтов из выдачи и восстанавливаются через 2-5 дней. 3) Обновление индексов поисковой базы происходит недостаточно часто и регулярно. |
|
Rambler |
1) Система работает с большой скоростью поиска. 2) Обновление поискового индекса происходит несколько раз в день. 3) Поисковик всегда находит самые свежие документы и последние новости. 4) Обладает близким к оптимальному выводом результатов поиска. 5) производит ранжирование результатов в зависимости от частоты употребления и местоположения искомых терминов. 6) Один и тот же документ в различных кодировках показывается только один раз, а его конкретные адреса. суммируются в списке, идущим за резюме. |
1) На величину индекса релевантности влияет время существования сайта в сети. Эта особенность позволяет пользователям находить ресурсы, которые давно существуют, успешно развиваются, а не сайты-однодневки. Но такой подход значительно затрудняет попадание в выдачу новых сайтов, информация на которых подчас оказывается актуальной и, возможно, более важной для пользователя. 2) невозможность осуществления поиска по целой фразе указывая в запросах предельное расстояние искомых терминов друг от друга. |
|
|
1) Очень мощная поисковая система, которая находится в постоянном развитии. 2) База индексов этой системы обновляется раз в два дня, качество выдачи очень высокое, найти необходимый документ или информацию довольно легко. 3) Система ориентирована в основном на ссылки, причем учитываются как входящие, так и исходящие ссылки с ресурса. 4) Способна выдавать результаты на запросы по семантике языка программирования (исходный код поиска). |
1) Нередко встречаются ссылки на сайты с уже устаревшей информацией. 2) Случается, что ссылки, которые находятся в результатах поиска, ведут на сайт, находящийся в стадии разработки. 3) На запрос «фильм» и «фильмы» результаты поиска будут отличаться. 4) отсутствие возможности указать конкретную грамматическую форму слова, либо ударение также значительно усложняет процесс поиска информации. |
|
Yahoo! |
1) Содержит ссылки, которые наиболее полно отвечают указанной в запросе тематике. 2) Имеются интеллектуальные средства «отсечения» пустых, находящихся в разработке или чисто рекламных сайтов, далеких от искомой тематики. 3) всегда легко определить, в каком разделе находится нужная информация. 4) В случае если на Yahoo нет результатов, сразу выводятся результаты с AltaVista. |
1) Возможна проблема с отсутствующими страницами, поскольку веб-мастера обычно забывают удалить свои сайты с поисковых систем, а на Yahoo нет механизма автоматического обновления. 2) Чисто русские ресурсы не добавляются, потому что их просто некому смотреть и оценивать содержимое. 3) Ищет слова, заданные в критерии поиска только в названии и описании страницы |
|
Baidu |
К концу 2017 года количество китайских сайтов, индексируемых Baidu, было на 50% больше, чем у любого конкурента. |
Число заблокированных результатов поиска у Baidu на 30% больше, чем у Google Google оставила Baidu далеко позади, поскольку предлагает рекламодателям выход на международные рынки. |
Главный недостаток современных поисковых систем – это их централизация. А централизация означает, что вся информация хранится в одном месте, все работы и расчёты производятся в одном месте, все решения (результаты выдачи) принимаются в одном месте.
Итак, почему это недостаток, здесь несколько причин:
1) Полная централизация требует колоссальных ресурсов – это огромные базы данных, множество компьютеров и т.д. Учитывая темпы роста Интернета в ближайшем будущем придется применять просто невероятные мощности.
2) Только при управлении в одном центре можно достичь полной конфиденциальности. А так как по нашей концепции поисковая система должна быть открытой, то и необходимость в централизации отпадает полностью.
3) Поисковая система не всегда может правильно оценить конкретный ресурс. Правильнее самому обладателю сайта поручить выполнение ранжирования документов внутри сайта. И теперь, самое главное как уйти от централизации и устранить все эти минусы - это внедрение в каждый сайт своей мини-поисковой системы. Эта мини-поисковая система будет индексировать содержимое сайта по правилам самого обладателя сайта. Только вебмастер будет решать, какие страницы его сайта по каким запросам более релевантные. А потом свои индексы уже будет отправлять на сервер поисковой системы.
Ещё одной из основных проблем при создании новой поисковой системы является учет мнения пользователей.
Попытка непосредственного выявления представлений пользователей об идеальной поисковой системе обычно не приводит к нужному результату: пользователи перечисляют все, что когда-либо видели или использовали в существующих системах. Не стоит ждать от пользователей навыков проектирования – они вряд ли смогут быстро описать, как должна выглядеть идеальная поисковая система.
Более продуктивным подходом к решению этой проблемы является анализ идеальной модели поисковой системы, которой оперируют пользователи. Идеальная модель – это совокупность представлений пользователя о целях, функциях, структуре, способах контроля и управления, возможных действиях с системой, которые определяют его деятельность. Такой подход – от анализа представлений пользователей и построения идеальной модели к проектированию интерфейсов продукта - снижает риск того, что продукт не понравится пользователям, не будет принят и востребован ими.
В идеальной модели должны присутствовать следующие компоненты:
Primarynouns (электронное письмо, товар в Интернет-магазине, картинка, доступная для просмотра в Интернете) – это основные элементы, с которыми пользователь производит действия или манипуляции при работе с системой.
Сценарий использования - это описание представлений пользователей о взаимодействии с системой, разбитое на элементарные шаги. Сценарий использования иллюстрирует поведение пользователя при решении определенной задачи с помощью поисковой системы.
Диаграмма задач является графическим отображением представлений пользователей о перечне решаемых в системе задач.
Диаграмма навигации демонстрирует представления пользователей о порядке смены экранов, с которыми они сталкиваются при работе с системой, и содержании этих экранов. Диаграмма построена на основе сценариев использования системы и используется в процессе проектирования интерфейсов.
На данный момент, как видно из приведенных в предыдущей главе данных рейтингов, самые популярные поисковики – это Google и Яндекс.
Две компании заняли прочные позиции в русскоязычном сегменте интернета. Отсюда и вытекает давний спор о том, «Гугл» или «Яндекс» что лучше. Ответить на этот вопрос довольно сложно, каждый имеет свои несомненные плюсы, а также недостатки. В большей степени использование каждого поисковика обусловлено привычкой. Сегодня Яндекс охватывает 58% пользователей, остальное делят между собой Гугл и остальные малоизвестные поисковые системы. Для того чтобы хоть как-то сравнить эти компании проведём обзор поисковых систем и часто используемых сопутствующих программ и сервисов:
Яндекс отличается более наполненным и разнообразным интерфейсом, тогда как Гугл склонен к минимализму;
С точки зрения веб-разработки, Гугл считается более стабильным, поэтому ему отдаётся больше предпочтений;
Яндекс – русская компания, Гугл – американская; Yandex имеет значительно больше полезных разработок, чем его оппонент;
Google предлагает пользователям отличные поисковые подсказки;
Считается что релевантность результатов поиска у Гугла выше, тем не менее, не стоит забывать, что Яндекс был разработан именно для русскоязычного сегмента интернета и в нём он превосходит конкурента[35].
А также сравним скорость индексации и количество проиндексированных страниц (табл. 2).
Таблица 2
Сравнительные характеристики Yandex и Google
|
№ п/п |
Критерии сравнения |
Yandex |
|
|
1 |
Количество проиндексированных страниц |
2 миллиарда |
8 миллиардов |
|
2 |
Скорость индексации страниц |
Несколько дней |
В течение суток |
В данном случае приоритет на стороне Google[36].
Заключение
Пользователи сети Internet имеют широкие возможности для получения экономической, социальной, научной, технологической и разнообразной текущей информации.
В соответствии с поставленной целью в теоретической части курсовой роботы были рассмотрены основные элементы и понятия информационного поиска, показана структура, работа и компоненты информационно-поисковых систем. Также были определены основные показатели оценки работы поисковых систем.
Очень часто приходится искать информацию в сети, незная даже приблизительно адрес страницы, на которой она может располагаться. В таких случаях на помощь приходит поисковая машина.
Поисковые машины – это роботизированные системы. Специальная программа-робот, которую называют паук или ползун, постоянно обходит Сеть в поисках новой информации, которую она вносит в базу данных.
При поиске в Интернете важны две составляющие – полнота (ничего не потеряно) и точность (не найдено ничего лишнего). Обычно это все называют одним словом – релевантность, то есть соответствие ответа вопросу. Важными показателями являются охват и глубина поисковой машины, скоростью обхода и актуальностью ссылок (скорость обновления информации в этой базе данных), качеством поиска (чем ближе к началу списка оказывается нужный вам документ, тем лучше работает релевантность).
При решении практической задачи части исследовательской курсовой был проведен сравнительный анализ самых популярных поисковых систем на мировом и российском рынке информационных ресурсов. Были выявлены их преимущества и недостатки.
На данный момент самые популярные поисковые системы в России – это Google и Яндекс. Две компании заняли прочные позиции в русскоязычном сегменте интернета.
Список использованной литературы
1. Ашманов, И. С. Продвижение сайта в поисковых системах / И. С. Ашманов. - М.: «Вильямс», 2010. - 304 с.
2. Байков, В. Д. Интернет. Поиск информации. Продвижение сайтов / В. Д. Байков. - СПб: БХВ - Петербург, 2010. — 288 с.
3. Блог WebMilk.ru. - [Электронный ресурс]. URL:http://webmilk.ru/2008/01/24/yandeks-voshel-v-top-10-poiskovyih-mashin - Режим доступа: (дата обращения: 08.02.2019);
4.Гаврилов, А. В. Локальные сети ЭВМ / А. В. Гаврилов.- М. : «Мир», 1990.- 154 с.
5. Гайдамакин, Н. А. Автоматизированные информационные системы, базы и банки данных / Н. А. Гайдамакин.- М. : «Гелиос», 2012.- 280 с.
6. ГОСТ 7.74-96 «СИБИД. Информационно-поисковые языки. Термины и определения - [Электронный ресурс]. URL: http://www.standartov.ru/norma_doc/33/33984/index.htm- Режим доступа: (дата обращения: 08. 02. 2019);
7. Информатика. Базовый курс: учебник / под ред. С. В. Симоновича. - СПб: «Питер», 2007.- 110 с.
8. Информационные поисковые системы - [Электронный ресурс]. URL: http://oka2o1o.narod.ru/ips.htm - Режим доступа: (дата обращения: 01.02.2019).
9. Итоги года - Sostav.ru. - [Электронный ресурс]. URL: http://www.sostav.ru/itogi/s/2009/6 - Режим доступа: (дата обращения: 08.02.2019);
10. Кадеев, Д. Н. Информационные технологии и электронные коммуникации / Д. Н. Кадеев.- М.: «Электро», 2011.- 250 с.
27. Как все начиналось - Google, Yahoo, Яндекс, Mail.ru, Rambler. TvoiExpert.
11. Колисниченко, Д. Н. Поисковые системы и продвижение сайтов в Интернете / Д. Н. Колисниченко. - М.: «Диалектика», 2007. – 272 с.
12. Ландэ, Д. В. Поиск знаний в Internet / Д. В. Ландэ. - М. : «Диалектика», 2005. — 272 с.
13. Маннинг, К. Введение в информационный поиск / К. Маннинг. – М.: «Вильямс», 2011.- 200 с.
14.Описание поисковой системы Bing. - [Электронный ресурс]. URL: http://anokalintik.ru/opisanie-poiskovoj-sistemy-bing.html - Режим доступа: (дата обращения: 10.02.2019)
15.Поисковаясистема Google- история компании Bbcont.ru. - [Электронный ресурс].URL:http://bbcont.ru/business/poiskovaya_sistema_google_istoriya_kompanii.html- Режим доступа: (дата обращения: 12.02.2019);
16. Путеводители в лабиринте Интернета. - [Электронный ресурс]. URL:http://rutracker.org/forum/viewtopic.php?t=1117865 - Режим доступа: (дата обращения: 08.02.2019);
17. Поисковая система Yahoo! - [Электронный ресурс]. URL: http://www.egonika.ru/forum/poiskovye_sistemy/poiskovaya_sistema_yahoo - Режим доступа: (дата обращения: 08.02.2019);
18. Поисковая система Байду. ЦИТ-Форум - журнал о поисковых системах. - [Электронный ресурс]. URL:http://www.cit-forum.com/baidu/poiskovaja-sistema-bajdu.html - Режим доступа: (дата обращения: 14.02.2019);
19. Поисковая машина Yandex.Ru. - [Электронный ресурс]. URL:http://spravki.se-ua.net/yandex - Режим доступа: (дата обращения: 08.02.2019);
20. Поисковая оптимизация веб страниц SEO. - [Электронный ресурс]. URL: http://creng.ru/seo/seo-poiskovaya-optimizaciya-veb-stranic - Режим доступа: (дата обращения: 08.02.2019);
21. Просвещение W3. Google. - [Электронный ресурс]. URL: http://w3pro.ru/tematika/google - Режим доступа: (дата обращения: 08.02.2019);
23. Сахарова, Е. В. Информатика. Методические указания / Е. В. Сахарова.- Ставрополь: СТИС, 2011.- 200 с.
24. Схемы и рисунки ИПС - [Электронный ресурс]. URL: http://ssofta.narod.ru/bd/ets2.htm - Режим доступа: (дата обращения: 10.02.2019).
25. Структура и классификация автоматизированных информационных систем - [Электронный ресурс]. URL: http://do.rksi.ru/library/courses/opais/tema1_3.dbk - Режим доступа: (дата обращения: 08.02.2019).
26. Терехов, И. В. Автоматизированные информационные системы в образовании и науке [Электронный ресурс]: семинар / И. В. Терехов: М.-2009. http://ou.tsu.ru/seminars/sem13/tezis/section6.htm - Режим доступа: (дата обращения: 08.02.2019).
27. Чурсин, Н. А. Популярная информатика / Н. А. Чурсин.- М.: «Вильямс», 2011.- 300 с.
28. Якубайтис, Э. А. Информатика – электроника- сети / Э. А. Якубайтис.- М.: «Финансы и статистика», 2010.- 300 с.
Интернет-ресурсы
29. «Гугл» или «Яндекс», что лучше? Сравнение ведущих конкурентов Всемирной сети – https://strana-it.ru/gugl-ili-yandeks-chto-luchshe/
30. Англоязычные поисковые системы – https://w512.ru/articles/Search_eng.htm
31. Как правильно искать информацию в Интернете – http://ccinet.info/kak-pravilno-iskat-informaciyu-v-internete/
32. Поиск@Mail.Ru – Википедия – https://ru.wikipedia.org/wiki/Поиск@Mail.Ru
33. Поисковые системы – https://studfiles.net/preview/5882109/page:2/
34. Современные поисковые системы – https://studfiles.net/preview/5788402/page:8/
-
Структура и классификация автоматизированных информационных систем - [Электронный ресурс]. URL: http://do.rksi.ru/library/courses/opais/tema1_3.dbk - Режим доступа: (дата обращения: 08.02.2019) ↑
-
Информационные поисковые системы - [Электронный ресурс]. URL: http://oka2o1o.narod.ru/ips.htm - Режим доступа: (дата обращения: 09.02.2019). ↑
-
ГОСТ 7.74-96 «СИБИД. Информационно-поисковые языки. Термины и определения - [Электронный ресурс]. URL: http://www.standartov.ru/norma_doc/33/33984/index.htm- Режим доступа: (дата обращения: 08.02. 2019) ↑
-
Поисковая оптимизация веб страниц SEO. - [Электронный ресурс]. URL: http://creng.ru/seo/seo-poiskovaya-optimizaciya-veb-stranic - Режим доступа: (дата обращения: 08.02.2019) ↑
-
Ашманов, И. С. Продвижение сайта в поисковых системах / И. С. Ашманов. - М.: «Вильямс», 2010. - с.3. ↑
-
Ландэ, Д. В. Поиск знаний в Internet / Д. В. Ландэ. - М. : «Диалектика», 2005. — с.10. ↑
-
Ашманов, И. С. Продвижение сайта в поисковых системах / И. С. Ашманов. - М.: «Вильямс», 2010. - с.4. ↑
-
Поисковая оптимизация веб страниц SEO. - [Электронный ресурс]. URL: http://creng.ru/seo/seo-poiskovaya-optimizaciya-veb-stranic - Режим доступа: (дата обращения: 08.02.2019) ↑
-
Поисковая оптимизация веб страниц SEO. - [Электронный ресурс]. URL: http://creng.ru/seo/seo-poiskovaya-optimizaciya-veb-stranic - Режим доступа: (дата обращения: 08.02.2019) ↑
-
Гайдамакин, Н. А. Автоматизированные информационные системы, базы и банки данных / Н. А. Гайдамакин.- М. : «Гелиос», 2012.- с.23. ↑
-
Гайдамакин, Н. А. Автоматизированные информационные системы, базы и банки данных / Н. А. Гайдамакин.- М. : «Гелиос», 2012.- с.25. ↑
-
Чурсин, Н. А. Популярная информатика / Н. А. Чурсин.- М.: «Вильямс», 2011.- с.121 ↑
-
Гайдамакин, Н. А. Автоматизированные информационные системы, базы и банки данных / Н. А. Гайдамакин.- М. : «Гелиос», 2012.- с.26. ↑
-
Байков, В. Д. Интернет. Поиск информации. Продвижение сайтов / В. Д. Байков. - СПб: БХВ - Петербург, 2010. — с.121. ↑
-
Кадеев, Д. Н. Информационные технологии и электронные коммуникации / Д. Н. Кадеев.- М.: «Электро», 2011.- с.42. ↑
-
Байков, В. Д. Интернет. Поиск информации. Продвижение сайтов / В. Д. Байков. - СПб: БХВ - Петербург, 2010. — с.121. ↑
-
Колисниченко, Д. Н. Поисковые системы и продвижение сайтов в Интернете / Д. Н. Колисниченко. - М.: «Диалектика», 2007. – с.44 ↑
-
Путеводители в лабиринте Интернета. - [Электронный ресурс]. URL:http://rutracker.org/forum/viewtopic.php?t=1117865 - Режим доступа: (дата обращения: 08.02.2019); ↑
-
Кадеев, Д. Н. Информационные технологии и электронные коммуникации / Д. Н. Кадеев.- М.: «Электро», 2011.- с.122 ↑
-
Маннинг, К. Введение в информационный поиск / К. Маннинг. – М.: «Вильямс», 2011.- с.168 ↑
-
Байков, В. Д. Интернет. Поиск информации. Продвижение сайтов / В. Д. Байков. - СПб.: БХВ- Петербург, 2000. —с.14. ↑
-
Байков, В. Д. Интернет. Поиск информации. Продвижение сайтов / В. Д. Байков. - СПб.: БХВ- Петербург, 2000. —с.14. ↑
-
Чурсин, Н. А. Популярная информатика / Н. А. Чурсин.- М.: «Вильямс», 2007.- с.50. ↑
-
Ашманов, И. С. Продвижение сайта в поисковых системах / И. С. Ашманов. - М. : «Вильямс», 2007. - с.60. ↑
-
Поисковаясистема Google- история компании Bbcont.ru. - [Электронный ресурс].URL:http://bbcont.ru/business/poiskovaya_sistema_google_istoriya_kompanii.html- Режим доступа: (дата обращения: 12.02.2019); ↑
-
Поисковая система Yahoo! - [Электронный ресурс]. URL: http://www.egonika.ru/forum/poiskovye_sistemy/poiskovaya_sistema_yahoo - Режим доступа: (дата обращения: 8.02.2019) ↑
-
Чурсин, Н. А. Популярная информатика / Н. А. Чурсин.- М.: «Вильямс», 2011.- 300 с ↑
-
Якубайтис, Э. А. Информатика – электроника- сети / Э. А. Якубайтис.- М.: «Финансы и статистика», 2010.- 300 с. ↑
-
Поисковая система Google- история компании Bbcont.ru. - [Электронный ресурс].URL:http://bbcont.ru/business/poiskovaya_sistema_google_istoriya_kompanii.html- Режим доступа: (дата обращения: 12.02.2019) ↑
-
Поисковая система Байду. ЦИТ-Форум - журнал о поисковых системах. - [Электронный ресурс]. URL:http://www.cit-forum.com/baidu/poiskovaja-sistema-bajdu.html - Режим доступа: (дата обращения: 14.02.2019) ↑
-
Поисковая система Yahoo! - [Электронный ресурс]. URL: http://www.egonika.ru/forum/poiskovye_sistemy/poiskovaya_sistema_yahoo - Режим доступа: (дата обращения: 08.02.2019) ↑
-
Поисковая машина Yandex.Ru. - [Электронный ресурс]. URL:http://spravki.se-ua.net/yandex - Режим доступа: (дата обращения: 08.02.2019) ↑
-
Поисковая машина Yandex.Ru. - [Электронный ресурс]. URL:http://spravki.se-ua.net/yandex - Режим доступа: (дата обращения: 08.02.2019) ↑
-
Поисковые системы – https://studfiles.net/preview/5882109/page:2/ ↑
-
«Гугл» или «Яндекс», что лучше? Сравнение ведущих конкурентов Всемирной сети – https://strana-it.ru/gugl-ili-yandeks-chto-luchshe/ ↑
-
Поисковые системы – https://studfiles.net/preview/5882109/page:2/ ↑

- Средства товарной информации о товарах фанера клееная (ОКП 551000)
- Кадровое планирование и его значение
- Договоры и их виды, как одна из форм коммерческой деятельности по работе с контрагентами (на примере конкретной организации)
- Анализ внешней и внутренней среды организации (ОК «Прометей»)
- Интернет-маркетинговые решения для кондитерской
- PR в системе Интегрированных коммуникаций (Особенности маркетинговой деятельности в сети интернет )
- Муниципальные предприятия
- Информационные технологии и платформы разработки информационных систем
- Моделирование предметной области «Кадровое делопроизводство» с помощью UML
- Управление поведением в конфликтных ситуациях
- Использование типологии трудовой мотивации менеджеров и сотрудников по В. Герчикову в современной организации
- Виды договоров (подробно)