
Алгоритмизация как обязательный этап разработки программы (Преобразование Фурье)
Содержание:

Введение
В наше время мы живем в большом потоке информации, новые информационные технологии занимают очень важное место во всех сферах жизни. Компьютеры применяются в медицине, бизнесе, перевозках, торговле, учебе и во многих других сферах деятельности человека.
Компьютерные технологии очень удобны для выполнения разнообразных операций, но в разных сферах применения эти операции разные. Потому, каждая отдельная отрасль, которая использует специфические технические средства, нуждается в своих собственных программах, которые обеспечивают работу компьютеров.
В нашей повседневной жизни нас окружают алгоритмы, любой человек выполняет свои действия по порядку, не раздумывая, правильно ли он поступает. В любой сфере деятельности, в которой есть базы данных, используются алгоритмы сортировки. Алгоритм представляет собой последовательность шагов, которая позволяет решить определённую задачу.
Алгоритм должен обладать тремя важными характеристиками, чтобы иметь право так называться:
Он должен работать за конечное количество времени. Если ваш алгоритм не может разобраться с проблемой, для которой он был создан, за конечное количество времени, то он бесполезен.
Он должен иметь чётко определённые инструкции. Каждый шаг алгоритма должен быть точно определён. Инструкции должны быть однозначны для каждого случая.
Он должен быть пригодным к использованию. Алгоритм должен решать проблему, для решения которой он был написан.
Далее мы рассмотрим, что такое алгоритмизация и опишем несколько видов основных алгоритмов сортировки данных.
Алгоритмизация – это метод описания систем или процессов путем составления алгоритмов их функционирования. Алгоритмом называется точное предписание, определяющее вычислительный процесс, ведущий от варьируемых начальных данных к искомому результату
Алгоритм решения задачи имеет ряд обязательных свойств:
— дискретность — разбиение процесса обработки информации на более простые этапы (шаги выполнения), выполнение которых компьютером или человеком не вызывает затруднений;
— определенность алгоритма — однозначность выполнения каждого отдельного шага преобразования информации;
— выполнимость — конечность действий алгоритма решения задач, позволяющая получить желаемый результат при допустимых исходных данных за конечное число шагов;
— массовость — пригодность алгоритма для решения определенного класса задач.
В алгоритме отражаются логика и способ формирования результатов решения с указанием необходимых расчетных формул, логических условий, соотношений для контроля достоверности выходных результатов. В алгоритме обязательно должны быть предусмотрены все ситуации, которые могут возникнуть в процессе решения комплекса задач.
Алгоритм решения комплекса задач и его программная реализация тесно взаимосвязаны. Специфика применяемых средств проектирования алгоритмов и используемых при этом инструментальных средств разработки программ может повлиять на форму представления и содержание алгоритма обработки данных.
Из известных основных способов представления алгоритмов:
словесный;
структурно-стилизованный (псевдокод);
графический;
программный.
Графическая форма, в виде блок-схем наиболее удобна. Блок-схемой называется графическое изображение структуры алгоритма, в которой каждый этап процесса обработки данных представляется в виде графических символов (блоков)- геометрических фигур, в контуры которых вписано содержание операции. Фигура, представленная в виде блочного символа (блока) называется символом действия.
Алгоритмизация, как процесс преобразования исходной информации к алгоритмическому виду, включает в себя:
выделение актуальных (задействованных в операциях) объектов;
идентификация выделенных объектов;
выделение операций, понятных исполнителю и не допускающих неоднозначных интерпретаций;
указание порядка выполнения операций.
Исполнителем результатов алгоритмизации могут быть: человек, компьютер, автоматизированное устройство. Порядок операций в разработанном алгоритме может быть: линейный, с разветвлениями, с циклами, смешанный. Линейный порядок предусматривает пошаговое выполнение операций в последовательности: начиная с первой и заканчивая последней операцией без каких-либо отклонений и вариантов изменения этой последовательности.
Ветвление в алгоритме предполагает возможность изменения последовательности выполнения операций в зависимости от условия, выявленного в результате выполнения предшествующей или нескольких предшествующих операций. Однако ветвление не предполагает переход к какой-либо из предшествующих (предыдущих) операций.
Цикл от ветвления отличается тем, что он предусматривает возможность перехода (возвращения) к одной из предыдущих операций.
Смешанный порядок в алгоритме предполагает наличие участков с неодинаковым типом последовательностей операций. Смешанный порядок выполнения операций всегда присутствует в сложных алгоритмах и программах. Даже в "примере с задвижками" часто приходится менять порядок действий в зависимости от складывающейся походу дела ситуации и обстановки. Например, менять порядок открытия задвижек из-за неисправности одной из них (ветвление) или повторно включать подремонтированный насос, повторяя порядок открытия-закрытия задвижек (цикл), и т.п.
Программирование (programming) — теоретическая и практическая деятельность, связанная с созданием программ.
Программирование является собирательным понятием и может рассматриваться и как наука и как искусство, на этом основан научно-практический подход к разработке программ. Программа — результат интеллектуального труда, для которого характерно творчество, а оно, как известно, не имеет четких границ. В любой программе присутствует индивидуальность ее разработчика, программа отражает определенную степень искусства программиста. Вместе с тем программирование предполагает и рутинные работы, которые могут и должны иметь строгий регламент выполнения и соответствовать стандартам.
Язык программирования — формальная знаковая система, предназначенная для описания алгоритмов в форме, которая удобна для исполнителя (например, компьютера). Язык программирования определяет набор лексических, синтаксических и семантических правил, используемых при составлении компьютерной программы. Он позволяет программисту точно определить то, на какие события будет реагировать компьютер, как будут храниться и передаваться данные, а также какие именно действия следует выполнять над этими данными при различных обстоятельствах.
Каждый язык программирования может быть представлен в виде набора формальных спецификаций, определяющих его синтаксис и семантику
Эти спецификации обычно включают в себя описание:
Типов и структур данных;
Операционную семантику (алгоритм вычисления конструкций языка);
Семантические конструкции языка;
Библиотеки примитивов (например, инструкции ввода-вывода);
Философии, назначения и возможностей языка.
Последовательное выполнение операторов в языке программирования означает, что они выполняются в том порядке, как записаны в программе. Условное выполнение означает, что при определенных условиях должны выполняться одни операторы, а при других условиях — другие. Для организации такого порядка служат условные операторы. Условное выполнение также часто называют ветвлением.
При повторяющемся выполнении некоторые операторы выполняются несколько раз, несмотря на то, что в программе они записаны один раз. Такой рациональный способ записи и выполнения обеспечивается операторами цикла.
1. АЛГОРИТМЫ СОРТИРОВКИ
Алгоритм сортировки — это алгоритм для упорядочения элементов в списке. В случае, когда элемент списка имеет несколько полей, поле по которому производится сортировка, называется ключом сортировки. На практике, в качестве ключа часто выступает число, а в остальных полях хранятся какие-либо данные, никак не влияющие на работу алгоритма.
Для оценки алгоритмов рассмотрим параметры, по которым мы будем оценивать алгоритмы:
Время сортировки — основной параметр, характеризующий быстродействие алгоритма. Называется также вычислительной сложностью. Для сортировки важны худшее, среднее и лучшее поведения алгоритма в терминах размера списка (n). Для типичного алгоритма хорошее поведение — это O(n log n) и плохое поведение — это Ω(n²). Идеальное поведение для сортировки — O(n). Алгоритмы сортировки, которые используют только абстрактную операцию сравнения ключей, всегда нуждаются, по меньшей мере, в Ω(n log n) сравнениях в среднем;
Память — ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы.
Устойчивость — устойчивая сортировка не меняет взаимного расположения равных элементов. Такое свойство может быть очень полезным, если они состоят из нескольких полей, а сортировка происходит по одному из них.
Естественность поведения — эффективность метода при обработке уже отсортированных, или частично отсортированных данных. Алгоритм ведёт себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Ещё одним важным свойством алгоритма является его сфера применения. Здесь основных типов сортировки два:
- Внутренняя сортировка оперирует с массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно сортируются на том же месте, без дополнительных затрат.
- Внешняя сортировка оперирует с запоминающими устройствами большого объёма, но с доступом не произвольным, а последовательным (сортировка файлов), т.е. в данный момент мы «видим» только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики. Это накладывает некоторые дополнительные ограничения на алгоритм и приводит к специальным методам сортировки, обычно использующим дополнительное дисковое пространство. Кроме того, доступ к данным на носителе производится намного медленнее, чем операции с оперативной памятью. Доступ к носителю осуществляется последовательным образом: в каждый момент времени можно считать или записать только элемент, следующий за текущим. Объём данных не позволяет им разместиться в ОЗУ.
Сортировка пузырьком — это самый простой алгоритм сортировки. Он проходит по массиву несколько раз, на каждом этапе перемещая самое большое значение из неотсортированных в конец массива.
Например, у нас есть массив целых чисел:
|
3 |
7 |
4 |
4 |
6 |
5 |
8 |
При первом проходе по массиву мы сравниваем значения 3 и 7. Поскольку 7 больше 3, мы оставляем их как есть. После чего сравниваем 7 и 4. 4 меньше 7, поэтому мы меняем их местами, перемещая семерку на одну позицию ближе к концу массива. Теперь он выглядит так:
|
3 |
4 |
7 |
4 |
6 |
5 |
8 |
Этот процесс повторяется до тех пор, пока семерка не дойдет почти до конца массива. В конце она сравнивается с элементом 8, которое больше, а значит, обмена не происходит. После того, как мы обошли массив один раз, он выглядит так:
|
3 |
4 |
4 |
6 |
5 |
7 |
8 |
Поскольку был совершен по крайней мере один обмен значений, нам нужно пройти по массиву еще раз. В результате этого прохода мы перемещаем на место число 6.
И снова был произведен как минимум один обмен, а значит, проходим по массиву еще раз.
При следующем проходе обмена не производится, что означает, что наш массив отсортирован, и алгоритм закончил свою работу.
|
3 |
4 |
4 |
5 |
6 |
7 |
8 |
Пример пузырьковой сортировки:
|
1 public void Sort(T[] items) 2 { 3 bool swapped; 4 5 do 6 { 7 swapped = false; 8 for (int i = 1; i < items.Length; i++) { 9 if (items[i - 1].CompareTo(items[i]) > 0) 10 { 11 Swap(items, i - 1, i); 12 swapped = true; 13 } 14 } 15 } while (swapped != false); 16} |
Сортировка вставками работает, проходя по массиву и перемещая нужное значение в начало массива. После того, как обработана очередная позиция, мы знаем, что все позиции до нее отсортированы, а после нее — нет.
Важный момент: сортировка вставками обрабатывает элементы массива по порядку. Поскольку алгоритм проходит по элементам слева направо, мы знаем, что все, что слева от текущего индекса — уже отсортировано. На этом рисунке показано, как увеличивается отсортированная часть массива с каждым проходом:
|
? |
? |
? |
? |
? |
? |
? |
|
? |
? |
? |
? |
? |
? |
|
|
? |
? |
? |
? |
? |
||
|
? |
? |
? |
? |
Постепенно отсортированная часть массива растет, и, в конце концов, массив окажется упорядоченным.
Давайте взглянем на конкретный пример. Вот наш неотсортированный массив, который мы будем использовать:
|
3 |
7 |
4 |
4 |
6 |
5 |
8 |
Алгоритм начинает работу с индекса 0 и значения 3. Поскольку это первый индекс, массив до него включительно считается отсортированным.
Далее мы переходим к числу 7. Поскольку 7 больше, чем любое значение в отсортированной части, мы переходим к следующему элементу.
На этом этапе элементы с индексами 0..1 отсортированы, а про элементы с индексами 2..n ничего не известно.
Следующим проверяется значение 4. Так как оно меньше семи, мы должны перенести его на правильную позицию в отсортированную часть массива. Остается вопрос: как ее определить? Это осуществляется методом FindInsertionIndex. Он сравнивает переданное ему значение (4) с каждым значением в отсортированной части, пока не найдет место для вставки.
Итак, мы нашли индекс 1 (между значениями 3 и 7). Метод Insert осуществляет вставку, удаляя вставляемое значение из массива и сдвигая все значения, начиная с индекса для вставки, вправо. Теперь массив выглядит так:
|
3 |
4 |
4 |
7 |
6 |
5 |
8 |
Теперь часть массива, начиная от нулевого элемента и заканчивая элементом с индексом 2, отсортирована. Следующий проход начинается с индекса 3 и значения 4. По мере работы алгоритма мы продолжаем делать такие вставки.
|
3 |
4 |
4 |
5 |
6 |
7 |
8 |
Когда больше нет возможностей для вставок, массив считается полностью отсортированным, и работа алгоритма закончена.
Пример сортировки вставками:
|
public void Sort(T[] items) { int sortedRangeEndIndex = 1; while (sortedRangeEndIndex < items.Length) { if (items[sortedRangeEndIndex].CompareTo(items[sortedRangeEndIndex - 1]) < 0) { int insertIndex = FindInsertionIndex(items, items[sortedRangeEndIndex]); Insert(items, insertIndex, sortedRangeEndIndex); } sortedRangeEndIndex++; } } private int FindInsertionIndex(T[] items, T valueToInsert) { for (int index = 0; index < items.Length; index++) { if (items[index].CompareTo(valueToInsert) > 0) { return index; } } throw new InvalidOperationException("The insertion index was not found"); } private void Insert(T[] itemArray, int indexInsertingAt, int indexInsertingFrom) { // itemArray = 0 1 2 4 5 6 3 7 // insertingAt = 3 // insertingFrom = 6 // // Действия: // 1: Сохранить текущий индекс в temp // 2: Заменить indexInsertingAt на indexInsertingFrom // 3: Заменить indexInsertingAt на indexInsertingFrom в позиции +1 // Сдвинуть элементы влево на один. // 4: Записать temp на позицию в массиве + 1. // Шаг 1. T temp = itemArray[indexInsertingAt]; // Шаг 2. itemArray[indexInsertingAt] = itemArray[indexInsertingFrom]; // Шаг 3. for (int current = indexInsertingFrom; current > indexInsertingAt; current--) { itemArray[current] = itemArray[current - 1]; } // Шаг 4. itemArray[indexInsertingAt + 1] = temp; } |
Сортировка выбором — это некий гибрид между пузырьковой и сортировкой вставками. Как и сортировка пузырьком, этот алгоритм проходит по массиву раз за разом, перемещая одно значение на правильную позицию. Однако, в отличие от пузырьковой сортировки, он выбирает наименьшее неотсортированное значение вместо наибольшего. Как и при сортировке вставками, упорядоченная часть массива расположена в начале, в то время как в пузырьковой сортировке она находится в конце.
Давайте посмотрим на работу сортировки выбором на нашем неотсортированном массиве.
|
3 |
4 |
7 |
4 |
6 |
5 |
8 |
При первом проходе алгоритм с помощью метода FindIndexOfSmallestFromIndex пытается найти наименьшее значение в массиве и переместить его в начало.
Имея такой маленький массив, мы сразу можем сказать, что наименьшее значение — 3, и оно уже находится на правильной позиции. На этом этапе мы знаем, что на первой позиции в массиве (индекс 0) находится самое маленькое значение, следовательно, начало массива уже отсортировано. Поэтому мы начинаем второй проход — на этот раз по индексам от 1 до n – 1.
На втором проходе мы определяем, что наименьшее значение — 4. Мы меняем его местами со вторым элементом, семеркой, после чего 4 встает на свою правильную позицию.
|
3 |
4 |
4 |
7 |
6 |
5 |
8 |
Теперь неотсортированная часть массива начинается с индекса 2. Она растет на один элемент при каждом проходе алгоритма. Если на каком-либо проходе мы не сделали ни одного обмена, это означает, что массив отсортирован.
После еще двух проходов алгоритм завершает свою работу:
|
3 |
4 |
4 |
5 |
6 |
7 |
8 |
Пример сортировки выбором:
|
public void Sort(T[] items) { int sortedRangeEnd = 0; while (sortedRangeEnd < items.Length) { int nextIndex = FindIndexOfSmallestFromIndex(items, sortedRangeEnd); Swap(items, sortedRangeEnd, nextIndex); sortedRangeEnd++; } } private int FindIndexOfSmallestFromIndex(T[] items, int sortedRangeEnd) { T currentSmallest = items[sortedRangeEnd]; int currentSmallestIndex = sortedRangeEnd; for (int i = sortedRangeEnd + 1; i < items.Length; i++) { if (currentSmallest.CompareTo(items[i]) > 0) { currentSmallest = items[i]; currentSmallestIndex = i; } } return currentSmallestIndex; } |
До сих пор мы рассматривали линейные алгоритмы. Они используют мало дополнительной памяти, но имеют квадратичную сложность. На примере сортировки слиянием мы посмотрим на алгоритм типа «разделяй и властвуй» (divide and conquer).
Алгоритмы этого типа работают, разделяя крупную задачу на более мелкие, решаемые проще. Мы пользуемся ими каждый день. К примеру, поиск в телефонной книге — один из примеров такого алгоритма.
Если вы хотите найти человека по фамилии Петров, вы не станете искать, начиная с буквы А и переворачивая по одной странице. Вы, скорее всего, откроете книгу где-то посередине. Если попадете на букву Т, перелистнете несколько страниц назад, возможно, слишком много — до буквы О. Тогда вы пойдете вперед. Таким образом, перелистывая туда и обратно все меньшее количество страниц, вы, в конце концов, найдете нужную.
Предположим, что в телефонной книге 1000 страниц. Если вы открываете ее на середине, вы отбрасываете 500 страниц, в которых нет искомого человека. Если вы не попали на нужную страницу, вы выбираете правую или левую сторону и снова оставляете половину доступных вариантов. Теперь вам надо просмотреть 250 страниц. Таким образом мы делим нашу задачу пополам снова и снова и можем найти человека в телефонной книге всего за 10 просмотров. Это составляет 1% от всего количества страниц, которые нам пришлось бы просмотреть при линейном поиске.
При сортировке слиянием мы разделяем массив пополам до тех пор, пока каждый участок не станет длиной в один элемент. Затем эти участки возвращаются на место (сливаются) в правильном порядке.
Давайте посмотрим на такой массив:
|
3 |
8 |
2 |
1 |
5 |
4 |
6 |
7 |
Разделим его пополам:
|
3 |
8 |
2 |
1 |
5 |
4 |
6 |
7 |
И далее будем делить пополам, пока не останутся части с одним элементом.
|
3 |
8 |
2 |
1 |
5 |
4 |
6 |
7 |
|
3 |
8 |
2 |
1 |
5 |
4 |
6 |
7 |
Теперь, когда мы разделили массив на максимально короткие участки, мы сливаем их в правильном порядке.
|
3 |
8 |
1 |
2 |
4 |
5 |
6 |
7 |
Сначала мы получаем группы по два отсортированных элемента, потом «собираем» их в группы по четыре элемента.
|
1 |
2 |
3 |
8 |
4 |
5 |
6 |
7 |
В конце собираем все вместе в отсортированный массив.
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
Для работы алгоритма мы должны реализовать следующие операции:
Операцию для рекурсивного разделения массива на группы (метод Sort).
Слияние в правильном порядке (метод Merge).
Стоит отметить, что в отличие от линейных алгоритмов сортировки, сортировка слиянием будет делить и склеивать массив вне зависимости от того, был он отсортирован изначально или нет. Поэтому, несмотря на то, что в худшем случае он отработает быстрее, чем линейный, в лучшем случае его производительность будет ниже, чем у линейного. Поэтому сортировка слиянием — не самое лучшее решение, когда надо отсортировать частично упорядоченный массив.
Пример сортировки слиянием:
|
public void Sort(T[] items) { if (items.Length <= 1) { return; } int leftSize = items.Length / 2; int rightSize = items.Length - leftSize; T[] left = new T[leftSize]; T[] right = new T[rightSize]; Array.Copy(items, 0, left, 0, leftSize); Array.Copy(items, leftSize, right, 0, rightSize); Sort(left); Sort(right); Merge(items, left, right); } private void Merge(T[] items, T[] left, T[] right) { int leftIndex = 0; int rightIndex = 0; int targetIndex = 0; int remaining = left.Length + right.Length; while(remaining > 0) { if (leftIndex >= left.Length) { items[targetIndex] = right[rightIndex++]; } else if (rightIndex >= right.Length) { items[targetIndex] = left[leftIndex++]; } else if (left[leftIndex].CompareTo(right[rightIndex]) < 0) { items[targetIndex] = left[leftIndex++]; } else { items[targetIndex] = right[rightIndex++]; } targetIndex++; remaining--; } } |
Быстрая сортировка — это еще один алгоритм типа «разделяй и властвуй». Он работает, рекурсивно повторяя следующие шаги:
Выбрать ключевой индекс и разделить по нему массив на две части. Это можно делать разными способами, но в данной статье мы используем случайное число.
Переместить все элементы больше ключевого в правую часть массива, а все элементы меньше ключевого — в левую. Теперь ключевой элемент находится в правильной позиции — он больше любого элемента слева и меньше любого элемента справа.
Повторяем первые два шага, пока массив не будет полностью отсортирован.
Давайте посмотрим на работу алгоритма на следующем массиве:
|
3 |
7 |
4 |
4 |
6 |
5 |
8 |
Сначала мы случайным образом выбираем ключевой элемент:
int pivotIndex = _pivotRng.Next(left, right);
|
3 |
7 |
4 |
4 |
6 |
5 |
8 |
Теперь, когда мы знаем ключевой индекс (4), мы берем значение, находящееся по этому индексу (6), и переносим значения в массиве так, чтобы все числа больше или равные ключевому были в правой части, а все числа меньше ключевого — в левой. Обратите внимание, что в процессе переноса значений индекс ключевого элемента может измениться (мы увидим это вскоре).
Перемещение значений осуществляется методом partition.
|
3 |
7 |
4 |
4 |
6 |
5 |
8 |
На этом этапе мы знаем, что значение 6 находится на правильной позиции. Теперь мы повторяем этот процесс для правой и левой частей массива.
Мы рекурсивно вызываем метод quicksort на каждой из частей. Ключевым элементом в левой части становится пятерка. При перемещении значений она изменит свой индекс. Главное — помнить, что нам важно именно ключевое значение, а не его индекс.
|
3 |
5 |
4 |
4 |
6 |
7 |
8 |
|
3 |
4 |
4 |
5 |
6 |
7 |
8 |
Снова применяем быструю сортировку:
|
3 |
4 |
4 |
5 |
6 |
7 |
8 |
|
3 |
4 |
4 |
5 |
6 |
7 |
8 |
И еще раз:
|
3 |
4 |
4 |
5 |
6 |
7 |
8 |
|
3 |
4 |
4 |
5 |
6 |
7 |
8 |
У нас осталось одно неотсортированное значение, а, поскольку мы знаем, что все остальное уже отсортировано, алгоритм завершает работу.
Пример быстрой сортировки:
|
Random _pivotRng = new Random(); public void Sort(T[] items) { quicksort(items, 0, items.Length - 1); } private void quicksort(T[] items, int left, int right) { if (left < right) { int pivotIndex = _pivotRng.Next(left, right); int newPivot = partition(items, left, right, pivotIndex); quicksort(items, left, newPivot - 1); quicksort(items, newPivot + 1, right); } } private int partition(T[] items, int left, int right, int pivotIndex) { T pivotValue = items[pivotIndex]; Swap(items, pivotIndex, right); int storeIndex = left; for (int i = left; i < right; i++) { if (items[i].CompareTo(pivotValue) < 0) { Swap(items, i, storeIndex); storeIndex += 1; } } Swap(items, storeIndex, right); return storeIndex; } |
2. Другие алгоритмы.
Алгоритмы используются не только в информатике, но и в математике. По факту, самые ранние математические алгоритмы — разложение на простые множители и извлечение квадратного корня — использовались вавилонянами уже в 1600 г. до н. э. Таким образом, мы имеем проблему, связанную с упомянутой ранее записью, которая рассматривает алгоритмы как компьютерные сущности. Далее рассмотрим такие алгоритмы, которые больше всего используются в мире.
Преобразование Фурье (символ ℱ) — операция, сопоставляющая одной функции вещественной переменной другую функцию вещественной переменной. Эта новая функция описывает коэффициенты («амплитуды») при разложении исходной функции на элементарные составляющие — гармонические колебания с разными частотами (подобно тому, как музыкальный аккорд может быть выражен в виде суммы музыкальных звуков, которые его составляют).
Весь цифровой мир использует эти простые, но по-настоящему мощные алгоритмы, которые преобразуют сигналы из временных интервалов в диапазоны частот и наоборот.
Интернет, Wi-Fi, смартфон, телефон, компьютер, маршрутизатор, спутники — почти всё, что имеет внутри себя электронно-вычислительное устройство, так или иначе использует эти алгоритмы для функционирования.
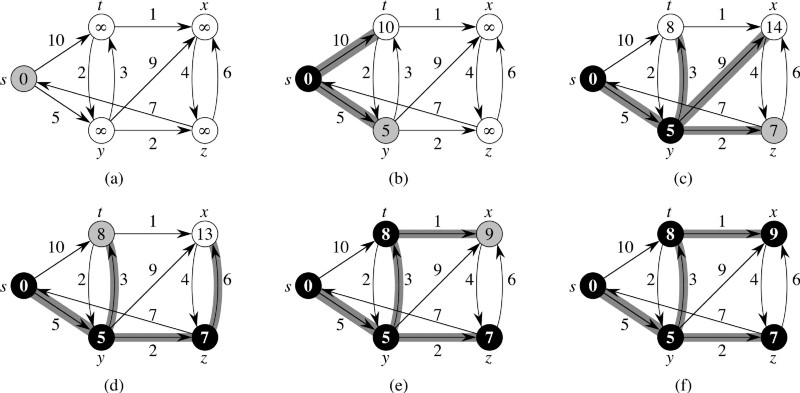
Алгори́тм Де́йкстры (англ. Dijkstra’s algorithm) — алгоритм на графах, изобретённый нидерландским учёным Эдсгером Дейкстрой в 1959 году. Находит кратчайшие пути от одной из вершин графа до всех остальных. Алгоритм работает только для графов без рёбер отрицательного веса. Алгоритм широко применяется в программировании и технологиях, например, его используют протоколы маршрутизации OSPF и IS-IS.
Как ни странно, интернет не смог бы работать эффективно без существования этого алгоритма. Он используется в задачах, где проблему можно представить в виде графа, для поиска кратчайшего пути между двумя узлами.
Сегодня, даже когда для поиска кратчайшего пути у нас есть решения получше, алгоритм Дейкстры используется в системах, требующих стабильности.
RSA (аббревиатура от фамилий Rivest, Shamir и Adleman) — криптографический алгоритм с открытым ключом, основывающийся на вычислительной сложности задачи факторизации больших целых чисел.
Криптосистема RSA стала первой системой, пригодной и для шифрования, и для цифровой подписи. Алгоритм используется в большом числе криптографических приложений, включая PGP, S/MIME, TLS/SSL, IPSEC/IKE и других.
Интернет не был бы так глубоко интегрирован в нашу жизнь, как в наше время, если бы не криптография и кибербезопасность. Из криптографии пришёл алгоритм, который остаётся одним из самых важных в мире, — алгоритм RSA. Разработанный основателями компании RSA, этот алгоритм сделал криптографию доступной для всех в мире и предопределил её будущее. Алгоритм RSA создан для простой задачи с неочевидным решением: как делиться открытыми ключами между независимыми платформами и конечными пользователями так, чтобы была возможность использовать шифрование.
Алгоритм безопасного хэширования.
Secure Hash Algorithm 1 — алгоритм криптографического хеширования. Описан в RFC 3174. Для входного сообщения произвольной длины алгоритм генерирует 160-битное (20 байт) хеш-значение, называемое также дайджестом сообщения, которое обычно отображается как шестнадцатиричное число, длиной в 40 цифр. Используется во многих криптографических приложениях и протоколах. Также рекомендован в качестве основного для государственных учреждений в США. Принципы, положенные в основу SHA-1, аналогичны тем, которые использовались Рональдом Ривестом при проектировании MD4.
Это не совсем алгоритм, а скорее семейство криптографических хэш-функций (SHA-1, SHA-2, и т.д.), разработанных Национальным институтом стандартов и технологий в США. Оно имеет основополагающее значение для функционирования всего мира. Магазины приложений, антивирусы, электронная почта, браузеры и т. д. — все они используют эти алгоритмы (на самом деле — хэш, который является результатом их работы), чтобы определить, загрузили ли вы то, что хотели, а также не стали ли вы жертвой атаки «человек посередине» или фишинга.
Алгоритм факторизации целых чисел.
Факторизацией натурального числа называется его разложение в произведение простых множителей. Существование и единственность (с точностью до порядка следования множителей) такого разложения следует из основной теоремы арифметики.
В отличие от задачи распознавания простоты числа, факторизация предположительно является вычислительно сложной задачей. В настоящее время неизвестно, существует ли эффективный не квантовый алгоритм факторизации целых чисел. Однако доказательства того, что не существует решения этой задачи за полиномиальное время, также нет.
Предположение о том, что для больших чисел задача факторизации является вычислительно сложной, лежит в основе широко используемых алгоритмов (например, RSA). Множество областей математики и информатики находят применение в решении этой задачи. Среди них: эллиптические кривые, алгебраическая теория чисел и квантовые вычисления.
Сложность, связанная с разложением числа на простые множители, широко используется в машинной области. Без неё криптография могла бы быть не такой безопасной, какой мы её знаем.
Многие криптографические протоколы — например, RSA — основаны на сложности факторизации больших составных целых чисел или на сходных проблемах. Алгоритм, который эффективно сможет разбивать на простые множители произвольное целое число, сделает криптографию с открытым ключом на основе RSA небезопасной.
3. Анализ связей.
Анализ связей или анализ ссылок (от англ. «link analysis») — это метод анализа данных, используемый в рамках сетевого анализа для оценки отношений (связей) между узлами (объектами/акторами). Отношения могут быть определены для различных типов узлов: людей, организаций, операций и т. д. Термин «link analysis» (один из вариантов перевода: «анализ взаимосвязей») обозначает процесс анализа совокупности взаимоотношений между разными объектами сети для выявления её характеристик.
В информационную эру взаимоотношения между различными субъектами имеют большое значение. От поисковых систем и социальных сетей до инструментов анализа рынка — каждый пытается найти реальную структуру интернета на все времена.
Алгоритм анализа связей за время своего существования оброс большим количеством мифов и заблуждений среди широкой публики. Проблема заключается в существовании различных способов анализа ссылок с различными характеристиками, что делает каждый алгоритм немного другим (и позволяет патентовать алгоритмы), хотя при этом их основания похожи.
Идея анализа связей проста: вы можете представить график в виде матрицы, что сводит задачу к проблеме собственной значимости каждого узла. Такой подход к структуре графа даёт нам возможность оценить относительную важность каждого объекта, включённого в систему. Алгоритм был разработан в 1976 году Габриэлем Пински и Фрэнсисом Нарином.
Где используется этот алгоритм? При ранжировании страниц во время поиска в Google, при генерации ленты новостей в Facebook (поэтому новостной канал Facebook — не алгоритм, а его результат), при составлении списка возможных друзей на Google+ и Facebook, при работе с контактами в LinkedIn и т. д. Каждый из вышеперечисленных сервисов работает с разными параметрами и объектами, но математика за каждым алгоритмом остаётся неизменной.
Кстати, видимо, Google является не первой компанией, начавшей работу с подобными типами алгоритмов. В 1996 году (за два года до основания Google) небольшая поисковая система под названием «RankDex», основанная Робином Ли, уже использовала эту идею для ранжирования страниц. Также, Массимо Марчиори, основатель «HyperSearch», использовал алгоритм ранжирования страниц, основанный на отношениях между отдельными страницами (эти два основателя упоминаются в патентах Google).
4. Алгоритмы сжатия данных.
Сжатие данных (англ. data compression) — алгоритмическое преобразование данных, производимое с целью уменьшения занимаемого ими объёма. Применяется для более рационального использования устройств хранения и передачи данных. Синонимы — упаковка данных, компрессия, сжимающее кодирование, кодирование источника. Обратная процедура называется восстановлением данных (распаковкой, декомпрессией).
Сжатие основано на устранении избыточности, содержащейся в исходных данных. Простейшим примером избыточности является повторение в тексте фрагментов (например, слов естественного или машинного языка). Подобная избыточность обычно устраняется заменой повторяющейся последовательности ссылкой на уже закодированный фрагмент с указанием его длины. Другой вид избыточности связан с тем, что некоторые значения в сжимаемых данных встречаются чаще других. Сокращение объёма данных достигается за счёт замены часто встречающихся данных короткими кодовыми словами, а редких — длинными (энтропийное кодирование). Сжатие данных, не обладающих свойством избыточности (например, случайный сигнал или белый шум, зашифрованные сообщения), принципиально невозможно без потерь.
Сжатие без потерь позволяет полностью восстановить исходное сообщение, так как не уменьшает в нем количество информации, несмотря на уменьшение длины. Такая возможность возникает только если распределение вероятностей на множестве сообщений не равномерное, например, часть теоретически возможных в прежней кодировке сообщений на практике не встречается.
Трудно решить, какой алгоритм сжатия является наиболее важным, поскольку в зависимости от задачи используемый алгоритм может изменяться от zip до mp3 и от JPEG до MPEG-2. Но всем известно, насколько важны эти алгоритмы почти во всех сферах деятельности.
Где может использоваться алгоритм сжатия помимо очевидного заархивированного документа? Например, эта веб-страница использует сжатие данных во время загрузки на ваш компьютер. Также эти алгоритмы используются в видеоиграх, видео, музыке, облачных вычислениях, базах данных и т. д. Можно сказать, что почти все используют алгоритмы сжатия данных, потому что они помогают сделать системы более дешёвыми и эффективными.
5. Алгоритм генерации случайных чисел.
Генератор псевдослучайных чисел (ГПСЧ, англ. pseudorandom number generator, PRNG) — алгоритм, порождающий последовательность чисел, элементы которой почти независимы друг от друга и подчиняются заданному распределению (обычно равномерному).
Заключение
Современная информатика широко использует псевдослучайные числа в самых разных приложениях — от метода Монте-Карло и имитационного моделирования до криптографии. При этом от качества используемых ГПСЧ напрямую зависит качество получаемых результатов.
Генераторы псевдослучайных чисел имеют большую вариативность использования: от разнообразных приложений, криптографии, алгоритмов хеширования, видеоигр и искусственного интеллекта до тестов при разработке программ и т. д.
Список используемой литературы
- Семакин И.Г., Шестаков А.П. Основы программирования: Учебник. - М.: Мастерство, 2001.
- Голицына О.Л., Попов И.И. Основы алгоритмизации и программирования: Учебное пособие. - М.: Форум: Инфра-М, 2004.
- Программирование на языке высокого уровня: Текст лекций/ Н.В. Ефимушкина, С.П. Орлов, В.М. Чухонцев; Самар. гос. техн. ун-т. - Самара, 2002. 182с.
- Экономическая информатика : В.П.Косарев/Л.В.Еремина, Москва, 2001.
- Фризен, И.Г. Основы алгоритмизации и программирования (среда PascalABC.Net): Учебное пособие / И.Г. Фризен. - М.: Форум, 2018. - 784 c.
- Серкова, Е.Г. Основы алгоритмизации и программирования (ОП.04): практикум / Е.Г. Серкова. - Рн/Д: Феникс, 2017. - 159 c.
- Семакин, И.Г. Основы алгоритмизации и программирования. Практикум: Учебное пособие / И.Г. Семакин. - М.: Academia, 2017. - 328 c.
- Колдаев, В.Д. Основы алгоритмизации и программирования: Учебное пособие / В.Д. Колдаев. - М.: Форум, 2015. - 352 c.
- Григорьев, А.А. Методы и алгоритмы обработки данных: Учебное пособие / А.А. Григорьев. - М.: Инфра-М, 2018. - 384 c.
- Труды ИСА РАН: Алгоритмы. Решения. Математическое моделирование. Управление рисками и безопасностью / Под ред. С.В. Емельянова. - М.: Ленанд, 2014. - 102 c.
- Свободная энциклопедия "Википедия". https://ru.wikipedia.org/wiki/
- Сайт https://tproger.ru/.

- Корпоративная культура в организации (Корпоративная культура АО «ОДК-Пермские моторы»)
- Производительность труда складских работников
- Американизмы в английском языке (Становление американского варианта английского языка)
- Проблема переводимости (Неологизмы в книге Дж. Роулинг как репрезентанты проблемы переводимости)
- Понятие и виды субъектов правоотношений (Общая характеристика правоотношений)
- Нотариат в Рф (Проверка дееспособности граждан)
- Теории происхождения права (Классификационные определения современного права )
- Оперативно-розыскная деятельность и права граждан (Пути решения проблем правового регулирования защиты прав граждан в оперативно-розыскной деятельности)
- Советские и постсоветские теории происхождения государства
- Распределенная технология обработки информации (Архитектурное построение систем распределенной обработки информации)
- Язык программирования (ЯП)
- Применение объектно- ориентированного подхода при проектировании информационной системы