
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ РАЗРАБОТКИ И ИСПОЛЬЗОВАНИЯ АВТОМАТИЗИРОВАННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ
Содержание:

ВВЕДЕНИЕ
Актуальность выбранной темы курсовой работы связана с тем, что любое предприятие, относящееся к любой области коммерческой деятельности, использует различное программное обеспечение, так как в настоящее время подавляющее количество данных передается, обрабатывается и хранится в цифровой форме.
Применение цифровых данных позволяет значительно оптимизировать работу предприятия, затрачивая меньше энергии в виде трудовых или стоимостных затрат на одну единицу результатной деятельности компании.
В настоящее время уже трудно найти какую-либо организацию, которая не использует в своей деятельности средства информатизации. Внедрение средств вычислительной техники, доступность информации, объем и скорость её обработки становятся решающими факторами развития производственных сил государства, науки, культуры, общественных институтов и всех сфер жизнедеятельности человека. Информация и данные все чаще рассматриваются как жизненно важные ресурсы, которые должны быть организованы таким образом, чтобы ими можно было легко пользоваться.
Основные идеи современной информационной технологии базируются на концепции, согласно которой данные должны быть организованы в базы данных, с целью адекватного отображения изменяющегося реального мира и удовлетворения информационных потребностей пользователей.
Любая информационная система представляет собой программный комплекс, функции которого состоят в поддержке надежного хранения информации в памяти компьютера, выполнении специфических для данного приложения преобразований информации и вычислений, предоставлении пользователям удобного и легко осваиваемого интерфейса.
Цель курсовой: изучение распределенной обработки информации.
Задачи работы:
1) Рассмотреть основные теоретические аспекты разработки и использования АИС;
2) Рассмотреть основные аспекты организации АРМ учета бизнес-процессов;
3) рассмотреть основные технологии распределенной обработки информации
4) спроектировать клиент-серверное приложение для автоматизации деятельности менеджера автосалона.
Под жизненным циклом информационной системы понимается непрерывно происходящий процесс, начинающийся с решения о разработке информационной системы и заканчивающийся выводом ее из эксплуатации.
Основными стадиями в процессе являются:
- Разработка требований к информационной системе;
- Разработка описательной концепции;
- Разработка подробного технического задания;
- Описание проекта информационной системы в соответствии с техническим заданием;
- Разработка технической документации;
- Описание порядка внедрения системы в деятельность предприятия (рисунок 1.1).

Рисунок 1.1 – Основные стадии создания ИС
Сегодня чаще всего используют следующую модель жизненного цикла:
1) Каскадная модель (рисунок 1.2) предполагает последовательное выполнение всех обозначенных этапов в строго порядке. Переход на следующий этап показывает полностью выполненные работы на предыдущих.

Рисунок 1.2 - Каскадная модель ЖЦ ИС
2) Поэтапная модель с промежуточным контролем (рисунок 4).
Проектирование И разработка информационной системы осуществляется путем выполнения операций с осуществлением контроля выполнения каждой. Исправления на этапе разработки дают возможность своевременно учитывать возникающие проблемы и их устранять.

Рисунок 1.3 - Поэтапная модель с промежуточным контролем
3) Спиральная модель (рисунок 1.4). На каждом цикле выполняется создание очередной версии продукта, уточняются требования проекта, определяется его качество, планируются работы следующего цикла.

Рисунок 1.4 - Спиральная модель ЖЦ ИС
Особое внимание всегда уделяется начальным этапам разработки – проектированию и анализу, где все технические решения проверяются и обосновываются посредством разработки прототипов.
Стандартная каскадная модель, несмотря на частные негативные отзывы за последнее время, исправно помогала специалистам по программному инжинирингу много лет. Понимание ее сильных и слабых сторон только улучшает оценочный анализ других, чаще более эффективных моделей ЖЦ, которые также основаны на данной модели.
Сама каскадная модель имеет множество преимуществ, но только при условии использования ее в проекте, приемлемом для нее. Ниже представлены ее преимущества:
• хорошо известна потребителям, не имеющим никакого отношения к созданию и эксплуатации программ, а также конечным пользователям (часто используется другими компаниями для отслеживания проектов, которые не связана с разработкой ПО);
• лучше справляется с трудностями и отлично срабатывает в тех проектах, где все достаточно понятно, но трудноразрешимо;
• легко доступна для понимания, так как нацелена на выполнение необходимых действий;
• проста и удобно в использовании, т.к. процесс разработки идет поэтапно.
Но в случае, если каскадная модель используется в проекте, не предназначенном для нее, проявляются следующие ее недостатки:
• Основа модели – линейная последовательная структура, и в результате попытки вернуться назад на одну-две фазы для исправления проблемы или недостатка теряется много времени, увеличиваются затраты и срывается график работы;
• не может предотвращать итерацию между фазами, которые очень часто встречаются при создании ПО, поскольку сама модель строится согласно стандартному циклу аппаратного инжиниринга;
• не показывает главное свойство разработки ПО, которое направлено на решение задачи. Отдельные фазы связаны определенными действиями, что часто отличается от привычной работы коллектива или персонала;
• создает ошибочное впечатление о работе с проектом. Указание, что «45% выполнено» обычно не имеет какого-то смысла и не служит показателем для менеджера проектов.
Исходя из недостатков каскадной модели, ее применение нужно ограничивать ситуациями, в которых все требования для их разработки очень точны и понятны.
Спиральная модель несет в себе преимущества каскадной модели. При этом она включает в себя анализ рисков, умеет ими управлять, а также содержит процессы поддержки и менеджмента. Еще в ней заложена разработка ПО, то при использовании методов прототипирования или быстрой разработки программ при помощи языков программирования и средств разработки 4-го поколения и выше.
Особые свойства спиральной модели:
– отказ от закрепления требований и установки приоритетов пользовательским требованиям;
- создание последовательных прототипов, начиная с наиболее высшего;
- определение и анализ риска на каждом шаге;
- оценка результата по итогам каждой итерации и планирование проведения следующей итерации.
Преимущества спиральной модели:
• Быстрая разработка (получение более раннего результата за счет прототипа);
• Постоянное присутствие заказчика с процессе разработки;
• Разбиение большого проекта на малые части;
• Снижение рисков (более предсказуемое поведение системы).
Для настоящего проекта больше всего подойдет каскадная модель для создания приложения, т.к. она имеет возможность контроля промежуточных фаз, да и сам проект не слишком большой, что не даст возможности проявиться недостаткам данной модели.
Затем производится выбор плана внедрения созданной системы. Сегодня выделяют 4 стратегии внедрения ИС:
1) Параллельная стратегия, которая подразумевает замену старой на новую;
2) Скачок – подразумевается резкий переход с одной системы сразу на другую;
3) Опытное использование пилотного проекта – та же тактика скачка, только к некоторому количеству изделий, при этом очень успешна на малом участке деятельности;
4) Узкое место – при внедрении «узкого места», план выполняется только для него самого, а также для сотрудников, которые там работают.
В итоге, исходя из описаний и условий деятельности фирмы, а также из характеристик создаваемой системы, в качестве стратегии выбирается «опытное использование пилотного проекта», что позволяет начать использовать всю систему сразу же после ее подготовки. При этом прекращается использование ручного учета данных, что позволяет значительно увеличивать скорость работы сотрудников фирмы прямо с первого дня использования системы, и в таком случае само внедрение пройдет безболезненно.
К базовым технологиям АИС можно отнести:
• объектно-ориентированный подход;
• функционально-модульный или структурный подход.
Структурный (функционально-модульный) подход выражается принципом алгоритмического разделения. В соответствии с этим принципом реализуется декомпозиция функций ИС на отдельные модули по функциональной принадлежности, и каждый подобный модуль воспроизводит один из этапов целого процесса[18].
Функционально-модульный подход в процессе создания ИС, который также называется «модель водопада», включает в себя строго последовательный порядок действий.
Главным достоинством функциональных моделей становится реализация структурного подхода к созданию информационных систем по схеме "сверху-вниз", когда любой функциональный блок может быть разделен на множество подфункций и т.д., таким образом, реализуя модульное проектирование ИС. Для функциональных моделей зачастую характерной чертой является строгость разделения ИС и наглядность представления[19].
В процессе функционального подхода объектные модели данных в виде ER-диаграмм "объект — свойство — связь" создаются отдельно. Чтобы проверить правильность проектирования предметной области между объектными и функциональными моделями выделяются взаимно однозначные связи.
Основной недостаток такого подхода объясняется движением данных в одном направлении. При наличии какой-либо сложности в ходе разработки в соответствии с таким стандартом она может решиться только на данной стадии и никак не может быть связана с другими стадиями разработки [20].
Получается, что помимо функционального разделения, имеет место быть также структура данных, которая всегда располагается на втором плане[21].
В объектно-ориентированном подходе (ООП) главной категорией объектной модели является класс, который включает в себя на элементарном уровне, как данные, так и операции, которые над ними реализуются (методы). Именно с такой позиции все изменения, относящиеся к переходу от структурного к ООП, становятся максимально заметными. Разделение процессов и данных устранено, но существует еще вопрос по минимизации сложности системы, который решается методом применения механизма компонентов[22].
Основным достоинством объектно-ориентированного программирования является наличие неизменной части системы в виде ее классов. Следовательно, в так м случае сама система с большей легкостью может быть подвержена изменениями, надстройкам и так далее, что позволяет система развиваться без значительной ее переработки даже в случае внесения каких-либо глобальных изменений.
Можно выделить также ряд преимуществ ООП:
1) Объектная декомпозиция позволяет разрабатывать программные системы более компактного размера при помощи общих механизмов, которые дают необходимую экономию выразительных средств. Применение объектного подхода значительно увеличивает уровень оптимизации разработки и пригодность для последующих применений не только программ, но и проектов, что позволяет создать среду разработки и перейти к сборочному созданию ПО. Системы практически всегда получаются более компактными, чем их структурные эквиваленты, что показывает не только уменьшение объема кода программы, но и уменьшение затрат на проект за счет применения итогов предыдущих разработок[23];
2) Объектная декомпозиция минимизирует риск разработки сложных систем ПО, основывается на эволюционном пути развития системы на базе небольших внутренних подсистем. Процесс объединения системы проходит на протяжении всего времени разработки и не становится единовременным событием;
3) Объектная модель очень естественна, поскольку изначально ориентирована на человеческое восприятие мира, а не IT-реализацию;
4) Объектная модель дает возможность максимально использовать выразительные способности объектных и объектно-ориентированных средств программирования.
К недостаткам ООП относят небольшое снижение эффективности функционирования ПО и повышенные начальные затраты.
Объектная декомпозиция значительно отличается от функционального подхода, именно поэтому переход на новую технологию связан как с решением вопроса психологических трудностей, так и дополнительными материальными вложениями[24].
Конечно, объектно-ориентированная модель более правильно отражает реальный мир, который представляет собой совокупность взаимодействующих (при помощи обмена сообщениями) объектов. Но в реальности даже в настоящий момент не останавливается формирование стандарта языка объектно-ориентированного моделирования UML, и количество различных CASE-средств, которые поддерживают ООП, очень мало в сравнении с поддерживающими структурный подход.
Помимо этого, диаграммы, передающие специфику объектного подхода (диаграммы классов и т.п.), не так наглядны и менее понятны непрофессионалам. Именно поэтому основополагающая цель продвижения CASE-технологии, а именно обеспечение всех участников проекта, а также самого заказчика, единым языком для понимания происходящего, может быть реализована на сегодняшний день только при помощи структурных методов.
При смене структурного подхода на объектный, как при случае смены любой другой технологии, нужно вкладывать деньги в покупку новых инструментальных средств. В таком случае следует обращать внимание на расходы на обучение (понимание метода, инструментальных средств и языка программирования). Для многих компаний подобные обстоятельства могут стать значительными препятствиями[25].
ООП не гарантирует немедленной отдачи. Эффект от его применения проявляется после создания нескольких проектов и появления повторно используемых компонентов, которые могут отражать проектные решения в данной области. Переход компании на объектно-ориентированную технологию определяется сменой мировоззрения, а не просто изучением инновационных CASE-средств и новых языков программирования.
В процессе применения ООП может меняться и принцип проектирования информационных систем. Сначала отражаются классы объектов, а уже потом, в зависимости от возможных состояний объектов (их жизненного цикла) выбираются методы обработки, т.н. функциональные процедуры, что в совокупности позволяет обеспечить лучший вариант реализации динамического поведения конкретной ИС.
Для ООП созданы графические методы построения предметной области, собранные воедино в языке унифицированного моделирования UML. Но если говорить о наглядности проекта для самого заказчика, то объектно-ориентированные модели безусловно уступают функциональным моделям.
В процессе выбора варианта моделирования предметной области зачастую используется степень его динамичности.
В нашем проекте предпочтительнее будет функциональный метод, поскольку проект не будет слишком большим, чтобы применять объектно-ориентированного метода[26].
По итогу, путь от разработки до внедрения ИС с компании состоит из нескольких этапов:
1) Изучение описанных требований и вникание в БП компании;
2) Подготовка ТЗ;
3) Процесс создания системы;
4) Подготовка документов по системе;
5) Проведение тестирования;
6) Установка и начало использования системы.
Выделим основные варианты перехода на ИС для упрощения процесса продаж [29]:
1) Покупка готового продукта
Плюсы такого решения в том, что оно уже отлажено, имеет мало недочетов, и требуется немного времени на настройку и развертывание системы. Часто такая система включает богатый пакет документов и уже проверена на многих компаниях с похожей структурой и принципами работы. Но в нашей фирме имеются уникальные бизнес-процессы, которые не позволяют найти уже готовое решение.
В рамках изучения подобных ПО для автоматизации складского учета так и не было найдено решение, которое бы на 100% могло соответствовать описанным требованиям.
2) Разработка система на заказ
Такой вариант получения ИС позволяет иметь систему, которая почти идеально соответствует требованию заказчика. Но всегда есть и сторонние риски: время разработки ПО может сильно затянутся, цена вырастет в несколько раз, само ПО будет с неявными дефектами, проявляемыми только по факту начала использования. Также, подобный вариант получения ПО так или иначе требует передачи неких конфиденциальных данных фирме-разработчику [10];
3) Покупка и модификация
Подобное решение помогает улучшить готовое решение для полного соответствия функциональным требованиям, предъявляемым к системе. Такое решение имеет в себе плюсы и минусы вариантов «Покупка готового ПО» и «Реализация ПО на заказ».
Полученное решение не сможет на 100% соответствовать требованиям фирмы. Часть модулей ПО будет протестирована идеально, вторая будет написана с нуля и вполне сможет иметь внутри разные дефекты.
Время на модернизацию уйдет не так много в сравнении с созданием ПО с нуля, в цена – чуть больше, нежели приобретение коробочного решения, но меньше, чем стоимость полноценного создания. Но модификация системы, созданной сторонней фирмой, часто вызывает значительные сложности, связанные с отсутствием или минимальным набором тех документов и проблемами в рамках реализации система-аналога.
По итогу данный вариант реализации несет в себе некоторые риски: неявная несовместимость отдельных элементов системы, скрытые ошибки в ПО [11];4) Собственное создание с нуля. Такой вариант позволяет реализовать систему, полностью соответствующую потребностям предприятия.
Плюсы данного варианта заключаются в последующей модернизации системы; минимизации рисков получения решения, не соответствующего требованиям компании; максимальная совместимость абсолютно компонентов системы; прямое взаимодействие с имеющимися ИС личной разработки; сохранение всех конфиденциальных данных в стенах компании [12].
Развитие современных информационных технологий, основанных на методах сетевой распределенной обработки данных, выдвигает задачу определения показателей эффективности информационной деятельности в разряд наиболее актуальных и пристально изучаемых проблем.
Необходимость углубления исследований, проводимых в этой области, продиктована не только неуклонным нарастанием объемов отечественных и мировых информационных ресурсов, но также и появлением на рынке информационных услуг качественно новой формы офисных систем [1] - организаций информационного профиля (ОИП), построение которых имеет изначально распределенный тип и основано на применении электронных форм документооборота, современного программно-технологического оснащения, а также сетевых технологий обработки данных. Отличительной чертой таких организаций является наличие принципиальной возможности перенесения их деятельности в среду виртуального пространства сети без значительных функциональных изменений.
Разделенная обработка информации подразумевает работу распределенной системы, где любой технологический или функциональный узел системы способен самостоятельно анализировать локальные данные и выполнять ряд решений. При реализации некоторых процессов узлы подобной системы могут обмениваться данными посредством каналов связи для их анализа и определения итоговых вариантов, которые представляют их взаимные интересы [11].
Разделенная система анализа данных помогает:
• Улучшить показатели методом распределения данных и вариантов анализа между машинами, которые могут отлично управлять ими;
• Привнести новые возможности, характерные для роста эффективности;
• Повысить общий уровень удобства. Юзер не будет сам разбираться в разных системах и производить транспорт файлов [12].
Технология распределенной обработки данных – технология, при которой обработка данных проводится в разных узлах сети, при этом с точки зрения пользователей выглядит так, как будто все данные обрабатываются в одном месте [44].
По способу организации корпоративные информационные системы подразделяются на системы, построенные на основе:
1) архитектуры файл-сервер;
2) архитектуры клиент-сервер;
3) многоуровневой архитектуры;
4) Интернет - технологий.
В информационной системе можно выделить следующие типовые функциональные компоненты (таблица 3).
Таблица 2.1 - Типовые функциональные компоненты ИС
|
Обозначение |
Наименование |
Характеристика |
|
PS |
Presentation Services |
Обслуживает пользовательский ввод и отображает то, что сообщает ему компонент логики представления (PL), с использованием соответствующей программной поддержки |
|
PL |
Presentation Logic |
Управляет взаимодействием между пользователем и ЭВМ. Обрабатывает действия пользователя при выборе команды в меню, щелчке на кнопке или выборе пункта в списке |
|
BL |
Business Logic |
Набор правил для принятия решений, вычислений и операций, которое должно выполнить приложение |
|
DL |
Data Logic |
Операции с БД (реализуемые SQL-операторами), которые нужно выполнить для реализации прикладной логики управления данными |
|
DS |
Data Services |
Действия СУБД, реализующие логику управления данными, такие как манипулирование данными, определение данных, фиксация или откат и т. п. СУБД обычно компилирует SQL-предложения |
|
FS |
File Services |
Дисковые операции чтения и записи данных для СУБД и других компонентов. Обычно являются функциями ОС |
Технология файл-сервер – это технология обработки данных, при которой база данных располагается в виде файлов на винчестерском диске одного из компьютеров сети. Серверы, разделяемым ресурсом которых является дисковая память (или, говоря иначе, файлы, хранящиеся на винчестерском диске), называются файл-серверами.
Архитектура "файл-сервер" предусматривает концентрацию обработки на рабочих станциях (рисунок 2.1).

Рисунок 2.1 - Архитектура "файл-сервер"
Файловый сервер служит для реализации структурного хранения данных пользователей с учетом политик информационной безопасности и доступа.
Определяющими моментами при создании подобной системы являются в данной ситуации количество пользователей и объем хранимых данных.
В качестве сервера выступает выделенный персональный компьютер, на котором установлена серверная операционная система и быстрая дисковая подсистема.
Помимо хранения документов и доступа к ним, файловый сервер также решает задачу разграничения прав пользователей относительно доступа к данным. Любой сотрудник может просматривать и вносить изменения только в те документы, на которые он имеет соответствующие права.
Достоинства технологии файл-сервер:
- Простота реализации и дешевизна;
- независимость компьютера от сети;
- высокая защита от несанкционированного доступа.
Недостатки технологии файл-сервер:
- не оперативное обновление данных на нескольких компьютерах;
- высокая стоимость компьютеров для работы в такой системе;
- сложность изменения структуры данных.
Технология клиент-сервер – вычислительная или сетевая архитектура, в которой задания или сетевая нагрузка распределены между поставщиками услуг [6], называемыми серверами, и заказчиками услуг, называемыми клиентами (рисунок 82.2).

Рисунок 2.2 - Технология клиент-сервер
Один из основных принципов технологии «клиент-сервер», заключается в разделении операций обработки данных на три группы, имеющие различную природу [9]:
- Ввод и отображение данных [8];
- Прикладные операции обработки данных, характерные для решения задач данной предметной области;
- Операции хранения и управления данными (базами данных или файловыми системами).
Исходя из данной классификации, любой техпроцесс включает ПО 3 видов:
• ПО представления, передающее операции 1 группы;
• ПО, помогающее операциям 2 группы;
• ПО для доступа к информационным ресурсам, выполняющее операции 3 группы
Исход из этого, выделим 3 модели реализации клиент-серверной технологии [45]:
1) Доступ к удаленной информации (Remote Data Access — RDA);
2) Сервер БД (DateBase Server — DBS);
3) Сервер приложений (Application Server — AS).
Плюсы клиент-серверной технологии:
• Удобная синхронизация информации;
• Минимальная цена аппаратного комплекса (производительный тут только сервер);
• Гибкая корректировка структуры данных;
Плюсы клиент-серверной технологии:
• Плохая защита от НСД;
• Работа только в КС;
• Ценник.
Сетевое многопользовательское приложение создано на базе файл-серверной архитектуры. Информация в виде файлов или файла помещается на файловом сервере [46].
Данный сервер принимает запросы, идущие от клиентов в сети, и передает им желаемые данные. Но вся обработка происходит на ПК-клиентах. Каждый компьютер запускает полновесную копия ПО для анализа данных. Каждая копия по-своему управляет файлами БД, включающими данные. Есть лишь одна связь между данными независимыми работами – файл блокировок, создаваемый в обязательном порядке для любого файла БД [47]. При этом любая копия производит корректировку индексов, работу внутренними таблицами и остальные функции, которые есть в возможностях СУБД.
В архитектуре клиент-сервер головная часть БД поддерживает не только доступ к данным, но и отвечает за их обработку. Клиент передает на сервер запросы на чтение или корректировку данных, созданные в рамках SQL-языка. Сервер сам реализует требуемые выборки или корректировки, отслеживая по факту каждой операции целостность и согласованность данных, а финальное значение кода возврата или набора записей передает на ПК клиента.
Минусы файлового сервера очевидны и определяется главным образом тем, что данные существуют в одном месте, а обрабатываются в другом.
При этом их нужно передавать по сети, что часто приводит к повышенным нагрузкам на сеть и, как следствие, понижению производительности ПО при увеличении числа работающих одновременно пользователей. Еще одним важным недостатком подобной архитектуры является децентрализованное решение возникающих проблем согласованности и целостности данных, а также доступа к данным. Подобное решение значительно уменьшает надежность приложения.
Архитектура "клиент-сервер" устраняет все указанные недостатки. Также она дает возможность лучшим образом распределить всю нагрузку между клиентом и сервером, что влияет на многие параметры системы: поддержку, производительность и стоимость.
Архитектура «клиент-сервер» может быть как двухуровневой, так и трехуровневой [18].
В двухуровневой архитектуре присутствуют два звена: это клиентская ЭВМ и сервер СУБД (рисунок 2.3).

Рисунок 2.3 - Двухуровневая архитектура «клиент-сервер»
В свою очередь, двухуровневая архитектура может быть устроена по-разному [7]:
- По принципу «тонкий сервер» - «толстый клиент» (Рисунок 2.4);
- По принципу «толстый сервер» - «тонкий клиент» (Рисунок 2.5).

Рисунок 2.4 - Двухуровневая архитектура «тонкий сервер»- «толстый клиент»
Архитектура «толстый сервер» - «тонкий клиент» является наиболее предпочтительной по ряду причин[13]:
- большее быстродействие и производительность системы за счет того, что все операции манипулирования и выбора данных происходят на сервере, а клиенту передается только результат запроса;
- не происходит блокировок информации на период изменения её одним из клиентов;
- каналы передачи данных не перегружаются из-за необходимости передачи всего объема данных для модификации на клиенте[14];
- логику функционирования системы можно изменить на сервере без перекомпиляции клиентского ПО, что особенно актуально в условиях территориальной удаленности рабочих мест [15].

Рисунок 2.5 - Двухуровневая архитектура «толстый сервер»- «тонкий клиент»
Наиболее яркой отличительной особенностью архитектуры, состоящей их трех звеньев, является разделение функций хранения, обработки и представления данных пользователю между данными звеньями [7].
Пример построения такой архитектуры приведен на рисунке 2.5. Доступ к данными организован таким образом, что используется промежуточное звено, а именно сервер приложений, который принимает, обрабатывает и передаёт информацию между другими звеньями системы. Использование такого сервера оправдывается тем преимуществом, что данное звено позволяет оптимизировать потоки данных, несмотря на необходимость использования дополнительного программного обеспечения.
Кроме того, построение системы по такому принципу позволяет значительно увеличить ее надежность, обеспечить работу с необходимым уровнем качества при большом количестве клиентов и при использовании распределённой архитектуры. К положительным чертам такой архитектуры также относится возможность переноса базы данных из одной СУБД на другую при минимальных временных и стоимостных затратах без необходимости переделки всего программного обеспечения.
Сервер приложений, кроме выполнения предметных задач, еще и значительно уменьшает нагрузку на сервер базы данных

Рисунок 2.6 - Трехуровневая архитектура «клиент-сервер»
Наиболее целесообразной для решения выбранной задачи является выбор двухуровневой архитектуры «тонкий клиент» - «толстый сервер», так как преимущества трехзвенной архитектуры не являются ценными для текущей задачи, а стоимость и сложность организации трехзвенной архитектуры существенно выше, чем двухуровневой. К тому же, существующая информационная инфраструктура отлично подходит именно для двухуровневой архитектуры [23].
Интернет сегодня становится самым большим и популярным межсетевым объединением во всем мире — оно объединяет миллиарды пользователей. Сети разных конфигураций соединяют ПК множества типов, имеющих самое разное ПО. Но пользователи Интернет обычно на данные различия не обращают внимания [16].
Интернет и его поддерживающие технологии становятся неотъемлемым атрибутом информационного общества и его главной основной. Эти технологии, которые были не известны еще в XX веке, сегодня применяются почти во всех областях человеческой деятельности. Интернет соединяет множество компьютерных сетей (локальных, федеральных, мировых) сетей на всей планете.
Сам термин Интернет подразумевает [17]:
• Обобщенное число случайно объединяемых мировых сетей, применяющихся для обмена данными;
• Ряд технологий, которые поддерживают обмен инфомрацией в рамках применения протоколов TCP/IP (Transmission Control Protocol/Internet Protocol), которые также называют технологиями Интернет.
Базовые технологии WWW [18]:
• Гипертекстовые страницы (Hyper Text Markup Language — HTML);
• Механизм обмена гипертекстовыми страницами (Hyper Text Transfer Protocol — HTTP);
• Адресация внутри самой сети (Universal Resource Identifier: URI, Universal Resource Locator: URL);
• Доменные имена (Domain Name System);
• Шлюзовой интерфейс (Common Gateway Interface — CGI), который был внедрен позднее специалистами Центра Суперкомпьютерного ПО (National Center for Supercomputing Applications — NCSA), одобренный Сообществом Всемирной паутины.
HTML-язык впервые был создан для применения редактора TeX и аппаратно-программных независимых методов визуализации текста в электронном виде (Standard Generalized Markup Language — SGML, ISO 8879). Суть гипертекста состояла в наличии внутри ASCII-текста для форматирования ссылок и полей как внутри документа, таки на остальных документах. Такой способ помогает смотреть документы в таком порядке, какой нужен, а не в последовательном виде, как в книге. БД гипертекста выступает составляющей файловой системы, включающей файлы с текстом в формате HTML и совокупные графические и медиа ресурсы [19].
Формат XML стал использоваться позже, и зачастую предназначался для описания систем сохранения структурных данных. Целью реализации XML - поддержка совместимости при отправке разложенных данных между аналитическими системами, особенно в рамках передачи данных посредством Internet, а также реализации в рамках этого языка некой разметки, именуемой словарями. Словари, базирующиеся на XML, описаны формально, но позволяют на программном уровне корректировать и проверять документы на базе данных словарей, без знания семантики, без учета смыслового значения элементов. Важным нюансом XML также выступает применение неких пространств имён (Name Space) [40].
Для приема файла из Интернет браузеру важно понять, где файл находится и как обращаться к ПК, где этот файл лежит. Клиентское ПО WWW отправляет имя требуемого файла, его координаты положения (хост) и вариант доступа (зачастую HTTP или FTP). Совокупность данных элементов составляет URI. URI в свою очередь отражает способ записи адресов разных ресурсов данных. В базе URI имеется идея о расширяемости, читаемости и плотности. Применение URI для WWW выступает вариантов адресации в сети (URL). И выглядит URL: <протокол://узел/путь/файл /метка>.
Интернет выступает совокупностью результативным методик коммуникации (в рамках новейших протоколов связи) и обработки данных, хранящихся на распределенных носителях. Помимо самих функций по транзиту данных различных вариаций, Интернет поддерживает множество разнообразных инфо-услуг, которые реализуются при помощи:
• Механизма получения и отправки почты (E-mail);
• Механизма гипертекстовой среды (WWW);
• Механизма транспорта данных (File Transfer Protocol — FTP);
• Механизма удаленного доступа к ПК (TERminal NETwork — Telnet);
• Службы доменных имен (Domain Name System);
• Механизма телеконференций (Users Network — Usenet)
Интрасеть — это некое обособленное пространство компании, реализуемое либо в ЛВС, либо в масштабе глобальной сети WAN (Wide Area Network) и имеющее все возможности Интернет.
Интрасеть — хорошая платформа для работы с данными внутри компании. Много программ создано в рамках открытых систем и отлично работают в ней. Web-технология могут наращивать мощности и могут применяться в любых вычислительных сетях. Методики создания ПО в совокупных прикладных программах для ПК клиентов упрощают реализацию HTML-страниц для Web-сервера.
Большой объем данных, обрабатываемых менеджером автосалона, вынуждает затрачивать соответствующее количество времени и трудовых ресурсов на обработку, исполнение и контроль документов. Поэтому необходимо, с применением разрабатываемой ИС, уменьшить затрачиваемые ресурсы в целях оптимизации деятельности всей компании.
Программа будет использоваться для обеспечения учета единиц автомобилей в автосалоне, проведения необходимых работ, осуществления предпродажной подготовки, ведения учета склада запчастей, выдачи и их использования.
- Сотрудники – таблица-справочник со списком сотрудников автосалона.
Указывается ФИО сотрудника, пол, возраст, должность, телефон.
- Марки и модели – таблица-справочник с марками и моделями автомобилей.
- Автомобили – таблице со списком автомобилей.
Указывается марка, модель, год выпуска, заводской номер, стоимость.
- Работы – таблица с данными о проведенных работах в автосалоне.
Указывается № автомобиля, ответственный за работы, дата начала работ, дата окончания работ, стоимость работ.
- Запчасти – таблица со списком запчастей для автомобилей.
Указывается тип запчасти, название, единица измерения, стоимость.
- Работы – таблица со списком выполняемых в автосалоне работ.
Указывается название, единица измерения, стоимость.
- Склад – таблица с информацией о количестве запчастей для автомобилей на складе.
Указывается № запчасти, количество запчастей.
- ЗапчастиРаботы – таблица с данными об использованных запчастях при проведении работ с конкретным автомобилем.
Указывается № работы, № запчасти, кол-во использованных запчастей.
- СкладДокументы – таблица с информацией о приходе запчастей на склад и списании запчастей со склада при проведении работ с автомобилем.
Указывается тип документа (приход/расход), дата документа, № запчасти, количество запчастей.
АИС состоит из следующих модулей:
- Модуль «Справочники».
- Модуль «Склад».
- Модуль «Работы».
- Модуль «Отчеты».
Каждый модуль АИС будет выполнять соотв. функции.
В представленных модулях будут в наличии следующие функции:
- Модуль «Справочники»:
- Добавление, редактирование и удаление данных в справочнике «Сотрудники»;
- Добавление, редактирование и удаление данных в справочнике «Марки и модели»;
- Добавление, редактирование и удаление данных в справочнике «Работы»;
- Добавление, редактирование и удаление данных в справочнике «Запчасти»;
- Добавление, редактирование и удаление данных в справочнике «Автомобили».
- Модуль «Склад»:
- Ведение остатков запчастей для автомобилей на складе;
- Ввод, редактирование и удаление данных о приходе запчастей на склад;
- Ввод, редактирование и удаление данных о выдаче запчастей со склада;
- Возможность формирования карточки по каждой запчасти с данными о приходе, перемещении и списании.
- Модуль «Работы»:
- Ввод, редактирование и удаление данных о проводимых работах с автомобилями ;
- Ввод, редактирование и удаление данных о выдаче запчастей со склада для проведения данных работ;
- Контроль состояния работ и ввода данных об окончании работ.
- Модуль «Отчеты»:
- Выдача отчета за период о проведенных работах в разрезе автомобилей.
- Выдача отчета за период о проведенных работах в разрезе видов работ.
- Выдача отчета за период об использованных запчастях для выполнения работ.
Структура приложения показана на рисунке 3.1.

Рисунок 3.1 Структура приложения
Сервер приложений разработан при помощи технологии C++ XE2 DataSnap. Передача данных между клиентом и сервером осуществляется через протокол TCP.
Сервер приложений взаимодействует с базой данных через СУБД Microsoft Access. Подключение к базе данных выполняется через технологию ADO.
В структуре сервера можно выделить две основные части: Модуль управления сервером (TdmServer) и модуль предоставления данных (TdssmRemoteData). Описание модулей приведено ниже.
Таблица 3.1 Структура сервера приложений
|
№ |
Название модуля |
Описание |
Функции |
|
1 |
TdmServer |
Содержит компоненты для подключения к системе управления базами данных (через ADO) и компоненты для организации сервера приложений (передача данных выполняется через протокол TCP). |
Подключение к СУБД. Управление сервером приложений (установка соединений с клиентскими приложениями, аутентификация пользователей, передача данных клиентам). |
|
2 |
TdssmRemoteData |
Модуль системы, который определяет доступные клиенту данные и функциональность системы. Экземпляр данного модуля создается для каждого подключенного клиента. |
Авторизация. Предоставление данных; Предоставление функциональности; |
Модуль управления сервером
При инициализации данного модуля автоматически выполняется инициализация соединения с базой данных. Параметры соединения содержаться в файле Settings.ini. Если соединение с базой данных по каким-то причинам не удалось установить, то сервер выдаст сообщение о невозможности дальнейшей работы, т.е. успешное подключение к базе данных обязательное условии запуска сервера.
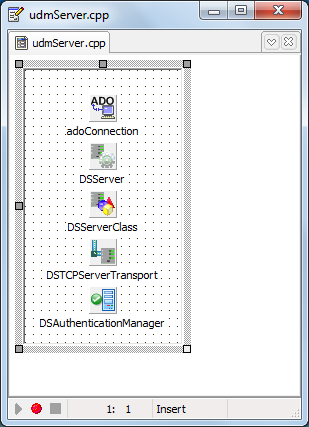
Рисунок 3.2 Состав модуля TdmServer
Как уже отмечалось ранее, сервер передает данные по протоколу TCP (за это отвечает компонент DSTCPServerTransport). Потому, для сервера должен быть задан порт прослушивания. В нашем случае он имеет значение 6000.
При подключении, на сервере создается отдельный поток. Клиент в обязательном порядке передает данные для выполнения аутентификации (логин и пароль), проверку которых выполняет компонент DSAuthenticationManager. В случае успешного прохождения процедуры аутентификации, для передачи данных между сервером и клиентом, DSServer создаст интерфейс взаимодействия. Этим интерфейсом является экземпляр класса TdssmRemoteData.
В случае ошибки аутентификации сервер вызывает исключение и уничтожает поток, который был создан для данного подключения.
Таблица 3.2 Описание класса «TdmServer»
|
Field Summary |
|
|
public TADOConnection |
adoConnection |
|
public TDSAuthenticationManager |
DSAuthenticationManager |
|
public TDSServer |
DSServer |
|
public TDSServerClass |
DSServerClass |
|
public TDSTCPServerTransport |
DSTCPServerTransport |
|
internal TIniFile |
FSettings |
|
Property Summary |
|
|
public TIniFile |
Settings |
|
Method Summary |
|
|
public Sub |
DataModuleCreate(Sender: TObject) |
|
public Sub |
DSAuthenticationManagerUserAuthenticate(Sender: TObject; Protocol: string; Context: string; User: string; Password: string; valid: Boolean; UserRoles: TStrings) |
|
public Sub |
DSServerClassGetClass(DSServerClass: TDSServerClass; PersistentClass: TPersistentClass) |
|
public Sub |
DSTCPServerTransportConnect(Event: TDSTCPConnectEventObject) |
|
public Sub |
DSTCPServerTransportDisconnect(Event: TDSTCPDisconnectEventObject) |
|
public function Integer |
ExecQuery(SQL: String) |
|
public function TADOQuery |
GetQuery(SQL: String) |
|
public function TADOTable |
GetTable(TableName: String) |
|
public function Integer |
GetUserKey(Login: String; Password: String; Blocked: Boolean; UserType: Integer) |
Интерфейс взаимодействия
Как было сказано выше, экземпляр класса TdssmRemoteData создается после успешной аутентификации и служит для предоставления клиентскому приложению определенных данных и функциональности сервера.

Рисунок 3.3 Состав модуля TdssmRemoteData
Цепочка передачи данных между клиентом и сервером выглядит так:
- Компонент подключения к БД (TADOConnection);
- Набор данных (TADOTable или TADOQuery);
- Провайдер набора данных (TDataSetProvider);
- Компонент клиентского соединения (TSQLConnection);
- Клиентский компонент соединения с провайдером данных (TDSProviderConnection);
- Клиентский набор данных (TClientDataSet).
Пункты 1, 2, 3 – выполняются на стороне сервера, а пункты 4, 5, 6 – на стороне клиента. Компоненты класса TDataSetProvider служат для определения прав доступа и настройки параметров передачи данных клиенту. В его настройках можно указать такие параметры как: доступность набора данных для клиента, режим «только чтение», запрет редактирования, запрет вставки, запрет удаления и т.д.
Таблица 3.3 Структура клиентского приложения
|
№ |
Название модуля |
Описание |
Функции |
|
1 |
TdmData |
Основа клиентского приложение. |
Подключение к серверу приложений. Подключение клиентских наборов данных. Управление пользовательскими наборами данных. Передача изменений, сделанных пользователем в данных, на сервер. |
|
2 |
TdmReport |
Модуль отчетов. |
Развертывание генератора отчетов FastReport. Подключение наборов данных к генератору отчетов. Вычисление отчетов. Экспорт вычисленных отчетов в различные форматы. |
Основой клиентской части является модуль TdmData. Модуль выполняет следующие функции: соединение с сервером; управление предоставленными сервером наборами данных; получение доступа к функциональности сервера (создание проекции интерфейса взаимодействия «TdssmRemoteData»).
Для подключения к серверу используется компонент SQLConnection. В качестве параметров подключения мы указываем: тип подключения (DataSnap); IP-адрес сервера; порт подключения (6000); протокол взаимодействия (в нашем случае TCP); логин и пароль пользователя.
Для доступа к функциональности и данным сервера используется специальный компонент DSProviderConnection, который необходим для подключения клиентского набора данных (TClientDataSet) к провайдеру набора данных (TDataSetDrovider).
После успешного подключения к серверу выполняется активация доступных наборов данных (открытие набора данных).
После открытия набора пользователь может редактировать набор данных через визуальные компоненты (такие как TDBGrid, TDBEdit, TDBMemo, TDBImage, TDBNavigator и т.д.), разработанные специально для работы с базами данных. Но визуальные компоненты подключаются не напрямую к клиентскому набору данных, а используют специальный «посредник» (объект класса TDataSource) который призваны унифицировать использование визуальных компонентов с различными типами наборов данных.
Клиент также получает доступ к интерфейсу взаимодействия сервера TdssmRemoteData. На стороне клиента, через компонент DSProviderConnection, создается «проекция» класса TdssmRemoteData, в которую входят все методы серверного класса со спецификатором public. Класс «проекция» инициализируется сразу после подключения клиента к серверу.
Все отчеты системы сконцентрированы в модуле TdmReport и формируются при помощи генератора отчетов «FastReports». Простота в использовании, высокая производительность и надежность генератора отчетов делают его непревзойденным лидером в своей области. Концентрация всех отчетов в одном модуле, а также использование компонента TActionManager позволяет с легкостью вызывать отчеты из различных модулей интерфейса системы. Ядро Fast Reports позволяет экспортировать созданные отчеты в различные форматы: PDF, XLS, ODT, RTF и т.д.
ЗАКЛЮЧЕНИЕ
Архитектура информационной системы — это, по своей сути, концепция, определяющая модель, структуру, выполняемые функции и взаимосвязь компонентов информационной системы. При разработке архитектуры системы реализуются следующие компоненты: спецификации требований к проектируемой системе; конструирование концептуальной модели предметной области; спецификации обработки данных в проектируемой системе; спецификации пользовательского интерфейса системы; спецификации деятельности в предметной области с учетом внедрения системы.
В рамках разработки или разделения ИС часто возникают проблемы, которые связаны с математическим и алгоритмическим описанием представленных задач. От уровня формализации зачастую зависит производительность работы системы и процесс автоматизации, отражаемый частотой участия человека в рамках выбора решения на основе полученных данных. И чем конкретнее математическое описание задачи, тем больше шанс компьютерного анализа и ниже роль человека в самом процессе решения. Это и показывает уровень автоматизации задачи.
ИС, применяемые в рамках решения частично распределённых задач, делятся на 2 вида: генерирующие управленческие отчеты и направленные на анализ данных (нахождение, группировку, агрегацию, фильтр).
ИС, реализующие управленческие отчеты, поддерживают данными самого пользователя, т. е. дают доступ к БД и ее информации, а также ее частичную обработку. Процедуры работы с данными в ИС должны включать некие возможности: сочетание комбинаций данных, принимаемых из разных источников; оперативное добавление или вычитание какого-то источника данных и мгновенное направление источников в режиме поиска; контроль данными с применением средств СУБД; зависимость данных этого типа на логическом уровне с другими БД, включенными в подсистему ИО; постоянный контроль потока данных для пополнения БД.
Процедуры перемещения данных в ИС должна давать такие возможности: сочетание комбинаций данных, принимаемых из разных источников; оперативное добавление или вычитание какого-то источника данных и мгновенное направление источников в режиме поиска; контроль данными с применением средств СУБД; зависимость данных этого типа на логическом уровне с другими БД, включенными в подсистему ИО; постоянный контроль потока данных для пополнения БД.
Спроектированная в данной курсовой работе информационная система позволит менеджеру компании более внятно представлять предстоящий объем задач, выполняемых монтажными бригадами и соответственно более оперативно и правильно распределять его между бригадами, учитывая их загруженность, в удобном виде получать отчётность по их работе.
Следовательно, цель курсовой работы следует полагать достигнутой.
СПИСОК ЛИТЕРАТУРЫ
- Баклин Д. Профессиональное программирование приложений для iPhone и iPad / Джин Баклин ; [пер. с англ. ООО "Айдиономикс"].
- Алистер Коберн, Современные методы описания функциональных требований к системам, М. , Лори, 2017 г., 288 с.
- Баодин Лю, Теория и практика неопределенного программирования, М., Бином. Лаборатория знаний, 2017 г, 416 с.
- Барт Бэзинс, Эйми Бэкил, Зеппе Ванден Бруке, Java для начинающих. Объектноориентированный подход, М., Питер, 2018 г, 688 с.
- Березин С.А., Березин Б.А., Начальный курс С и С++, М., ДиалогМИФИ, 2017 г., 288 с.
- Брайан У. Керниган, Деннис М. Ритчи, Язык программирования C, М., Вильямс, 2017 г, 288 с.
- Брайан У. Керниган, Роб Пайк, Практика программирования, М., Вильямс, 2017 г., 288 с.
- Бунаков П.А., Лопатин А. В, Практикум по решению задач на ЭВМ в среде Delphi. Учебное пособие, М., ИнфраМ, 2018 г, 304 с.
- Васильев Р.А, Калянов Г.А., Левочкина Г.А., Стратегическое управление информационными системами, М, Интернетуниверситет информационных технологий, Бином. Лаборатория знаний, 2017 г, 512 с.
- Вон Вернон, Реализация методов предметноориентированного проектирования, М, Вильямс, 2017 г, 688 с.
- Габасов Р.А., Кириллова Ф.А., Методы линейного программирования. Часть 1. Общие задачи, М., Либроком, 2018 г, 176 с.
- Габасов Р.А., Кириллова Ф.А., Методы линейного программирования. Часть 3. Специальные задачи, М., Либроком, 2018 г, 368 с.
- Головин И. Г., Захаров В. Б., Мостяев А. И. Влияние тенденций современного общества на процесс создания, распространения и поддержки программ для мобильных устройств // Научный взгляд в будущее. 2016. Т. 4, № 2. С. 4151.
- Гольштейн Е.А., Юдин Д.А., Специальные направления в линейном программировании, М, Красанд, Editorial URSS, 2018 г, 526 с.
- Грацианова Т.А., Программирование в примерах и задачах, М., Лаборатория знаний, 2018 г, 368 с.
- Данилин А.А., Слюсаренко А. В., Архитектура и стратегия. "Инь" и "янь" информационных технологий, М, Интернетуниверситет информационных технологий, 2017 г, 506 с.
- Джеффри Рихтер, CLR via C#. Программирование на платформе Microsoft.NET Framework 4.5 на языке C#, М., Питер, 2017 г, 896 с.
- Джон Скит, C# для профессионалов. Тонкости программирования, М., Вильямс, 2017 г, 608 с.
- Джоэл Грас, Data Science. Наука о данных с нуля, М, БХВПетербург, 2018, 336 с.
- Дональд Эрвин Кнут, Искусство программирования. Том 2. Получисленные алгоритмы, М., Вильямс, 2017 г, 832 с.
- Дональд Эрвин Кнут, Искусство программирования. Том 3. Сортировка и поиск, М., Вильямс, 2017 г., 824 с.
- Дронов В.А., Laravel. Быстрая разработка современных динамических Webсайтов на PHP, MySQL, HTML и CSS, Спб, БХВПетербург, 2018 г, 768 с.
- Иванова Г.А., Технология программирования, М, КноРус, 2018 г, 336 с.
- Исаев Г.А, Теоретикометодологические основы качества информационных систем, М. ИнфраМ, 2018 г. 258 с.
- Кузнецов А. С., Ченцов С. В, Многоэтапный анализ архитектурной надежности и синтез отказоустойчивого программного обеспечения сложных систем, М, ИнфраМ, 2018 г, 144 с.
- Ли Атчисон, Масштабирование приложений. Выращивание сложных систем, М, Питер, 2018 г, 256 с.
- М. Тим Джонс, Программирование искусственного интеллекта в приложениях, М., ДМК Пресс, 2018 с., 312 с.
- Макаровских Т.А., Панюков А. С., Языки и методы программирования. Создание простых GUIприложений с помощью Visual С++, М., Ленанд, 2018 г, 144 с.
- Мартин Фаулер, Предметноориентированные языки программирования, М., Вильямс, 2017 г, 576 с.
- Окулов С.А., Пестов О.Г, Динамическое программирование, М., Бином. Лаборатория знаний, 2017 г, 296 с.
- Панюкова Т.А. Панюков А.С., Языки и методы программирования. Путеводитель по языку С++, М., Ленанд, 2018 г, 216 с.
- Подбельский В.А, Курс программирования на языке Си, М., ДМК Пресс, 2018 г, 384 с.
- Поль М. Дюваль, Стивен Матиас, Эндрю Гловер, Непрерывная интеграция. Улучшение качества программного обеспечения и снижение риска, М., Вильямс, 2017 г, 240 с.
- Стенли Б. Липпман, Жози Лажойе, Барбара Э. Му, Язык программирования C++. Базовый курс, М, Вильямс, 2017 г, 1120 с.
- Стивен Прата, Язык программирования C++. Лекции и упражнения, М., Вильямс, 2017 г, 1248 с.
- Стивен С. Скиена, Алгоритмы. Руководство по разработке, Спб, БХВПетербург, 2018 г, 720 с.
- Фредерик Брукс, Проектирование процесса проектирования. Записки компьютерного эксперта, М., Вильямс, 2017 г, 464 с.
- Царев Ю.Р, Мультиверсионное программное обеспечение. Алгоритмы голосования и оценка надёжности: Монография, М, ИнфраМ, 2018 г, 118 с.
- Эрик Эванс, Предметно-ориентированное проектирование (DDD). Структуризация сложных программных систем, М. , Вильямс, 2017 г, 448 с.
- Выбор языка программирования // Центр разработки для Windows [Официальный вебсайт]. [Электронный ресурс]URL: https://docs.microsoft.com/ruru/windows/uwp/porting/getting startedchoosingaprogramminglanguage.( дата обращения 01.01.2019)

- Разработка конфигурации «Обеспечение послепродажного обслуживания» в среде 1С: Предприятие 8.3
- Применение автоматизированных информационных систем
- Разработка регламента выполнения процесса «Разработка стратегии охраны окружающей среды»
- Источники предпринимательского права .
- Интернет банкинг, дистанционное обслуживание клиентов банка
- Процесс построения модели управленческого решения на примере ООО «Калинка»
- Законность и правопорядок
- Интеллектуальная собственность и ее место в гражданском праве
- Бизнес-планирование в индустрии спорта (Бизнес-план и его функции)
- Преимущества и недостатки инструментов интегрированных коммуникаций (ИНТЕГРИРОВАННЫЕ КОММУНИКАЦИИ: PR, HR, МАРКЕТИНГ PR и HR)
- Интернет-маркетинговые решения для салона красоты (Эффективный маркетинг салона красоты)
- Административная и уголовная ответственность авторских и смежных прав