
ТЕХНОЛОГИЯ ПОСТРОЕНИЯ РАСПРЕДЕЛЕННЫХ ИНФОРМАЦИОННЫХ СИСТЕМ В РФ
Содержание:

Введение
Актуальность темы использования распределенных информационных систем связана с наличием тенденций к централизации организационных структур в крупных и средних компаниях, что приводит к необходимости использования консолидированных информационных ресурсов. Посредством распределенных информационных систем обеспечивается работа с данными, хранящимися на разных серверах, различных аппаратных и программных платформах, представленных в различных форматах. Распределенные информационные системы являются легко расширяемыми, использующими открытые стандарты и протоколы, обеспечивающими возможности интеграции своих ресурсов с другими информационными системами, предоставляющими для пользователей интерфейсы, необходимые для выполнения своих обязанностей.
В данной работе проведено рассмотрение основных сведений о распределенных информационных системах: описываются предпосылки их развития, проанализирован функционал средств для работы с информационными ресурсами, рассмотрены типы и основные принципы функционирования распределенных информационных систем.
Цель работы: изучение теоретических аспектов использования распределенных информационных и основных принципов их функционирования.
Задачи работы:
- описание областей использования распределенных информационных систем;
- классификация распределенных информационных систем;
- анализ программной и аппаратной реализации распределенных информационных систем.
Объект исследования: распределенные информационные системы.
Предмет исследования: анализ программной и аппаратной реализации распределенных информационных систем.
1. Теоретические аспекты использования распределенных информационных систем
1.1. Общая характеристика задач, решаемых с использованием распределенных информационных систем
Как правило, распределенной считаются такие системы, в которых используется более одного сервера баз данных. Такая архитектура используется для сокращения нагрузки на вычислительные мощности серверов и обеспечения эффективной работы территориально удаленных филиалов компаний. Различный уровень сложности работ по созданию, модификации, сопровождению, интеграции позволяют проводить разделение информационных систем на малые, средние и крупные распределенные системы. Малые информационные системы обладают небольшим жизненным циклом (ЖЦ), ориентированы на массовое использование, имеют невысокую стоимость, проведение для модификации требуется привлечение разработчиков. Также информационные системы данного класса используют, в основном, настольные системы управления базами данных (СУБД), однородные аппаратно-программные решения, в которых отсутствуют средства по обеспечению безопасности. Для крупных корпоративных информационных систем характерна высокая продолжительность жизненного цикла, миграция унаследованных систем, возможность использования разнообразных аппаратных и программных средств, масштабность и высокий уровень сложности решаемых задач, пересечение множества прикладных областей, использование систем аналитической обработки данных, территориальная распределенность компонент [6].
К функциям информационных систем подобного класса относят: возможность использования данных, имеющих распределенную структуру, расположенных на различных физических серверах, использующих разные аппаратные и программные платформы, хранение которых производится в различных внутренних форматах. В данном случае система должна предоставлять полные данные о себе и используемых ресурсах, иметь возможность расширяемости, основываться на открытых стандартах и протоколах, обеспечивать возможности интеграции своих ресурсов с ресурсами других ИС. Для пользователей системы должны обеспечивать различные уровни пользовательского доступа, для которых устанавливаются собственные интерфейсы.
Данные из распределенных систем, как правило, объединяются в логические группы, к которым проводится отправка запросов. Использование абстрактной системы запросов предполагает, что система работает не с определенным синтаксисом запросов, а их логической структурой с использованием абстрактных атрибутов.
В процессе построения распределенных ИС обычно используются следующие базовые архитектуры: Клиент/серверная, а также использующая Интернет-технологии.
В корпоративных информационных системах, построенных в соответствии с клиент-серверной архитектурой, для клиентов предоставляется значительные спектр приложений и средств разработки, ориентированных на максимально эффективное использование вычислительных мощностей на уровне клиентской части. Использование серверных ресурсов предполагает хранение и обмен документацией, а также возможности обращения к внешней среде. Указанная архитектура позволяет обеспечить защищённость серверной части приложений, при этом, предоставляя возможности для приложений либо непосредственно обращаться к другим серверным приложениям, либо управлять маршрутизацией запросов к ним. Однако, при частых обращениях клиентов к серверам снижается производительность работы сетевых ресурсов. Также необходимо обеспечивать безопасность работы с сетевыми ресурсами, так как приложения и данные распределяются между различными клиентами. Распределенный характер архитектуры системы предполагает сложность при ее настройке и сопровождении.
В основу распределенных информационных систем нс архитектурой Интернет/Интранет положены принципы "открытой архитектуры". Программное обеспечение в данном случае реализуется в форме аплетов или сервлетов или в форме cgi модулей (программ на Perl или С). Информационные системы с данной архитектурой включают Web-yinh & bsol, реализованные посредством технологий CORBA Enterprise JavaBeans, ActiveX 1X'ОМ, многоуровневых приложений на основе Java и XML, .Net-концепции с XML, в которой обмен между различными серверами (хранилищами данных, бизнес-приложениями, серверами для мобильных клиентов и другое) производится при помощи нейтрального к любой архитектуре формата XML.
Распределенные информационные базы работают с неограниченным количеством баз данных, которые могут быть дистанционно отдалены друг от друга и имеют множество общих характеристик:
- функционирование по единым правилам, которые определены централизованно для всех баз данных, входящих в распределенную информационную базу;
- обмен данными осуществляется по правилам, также определенным централизованно.
Организация распределенной базы необходима для компаний, осуществляющих различные виды деятельности, если в их повседневной работе возникает потребность решения следующих задач:
- необходимость оперативного получения информации из баз данных дистанционно отдаленных подразделений (или филиалов);
-необходимость консолидации в единой базе данных информации из баз данных юридических лиц, входящих в структуру компании, для последующего анализа данных и получения отчетности из одной базы, как по компании в целом, так и по каждому юридическому лицу в отдельности;
Таким образом, распределенные информационные системы представляют собой совокупность баз данных, дистанционно удаленных друг от друга и имеющих множество общих параметров. Их функционирование строится в соответствии с общими правилами, определенными централизованно одновременно для всей группы баз данных, которые включены в распределенную информационную систему. Операции обмена данными производятся в соответствии с правилами, которые определяются также централизованно.
Организацию распределенных информационных систем необходимо производить в условии компаний различного профиля деятельности, при возникновении потребностей в оперативном получении данных из дистанционно удаленных подразделений. Возникновение потребности во внедрении таких систем возможно, когда необходимо проводить консолидацию информации, содержащейся в базах данных юридических лиц, входящих в структуру организации. Это осуществляется в целях проведения анализа данных с возможностью формирования отчетности по всей базе, как по компании в целом, так и по ее филиалам и структурным подразделениям.
Реализация подобных информационных систем возможна в случаях, когда проводится централизация организационной структуры компании и технологические процессы предполагают необходимость работы с консолидированными данными. При этом в единой информационной базе устанавливается разграничение доступа, соответствующее функциональным обязанностям сотрудников.
Также внедрение распределенных информационных систем осуществляется в случае необходимости контроля над модификацией данных в дистанционно удаленных структурных подразделениях компании.
Организация распределенных информационных систем включает несколько этапов. На первом этапе проводятся подготовительные работы: определение структуры данных информационной системы, определяются правила миграции данных между информационными базами, входящими в распределенную информационную систему, а также правила ограничения на модификацию данных.
На втором этапе проводится подготовка распределенной информационной системы. На данном этапе выбирается оптимально подходящее программное обеспечение, посредством которого будет проводиться организация распределенной информационной базы, работающей по правилам, определенным в результате проведения подготовительных работ. Также на данном этапе осуществляется конфигурирование выбранного программного продукта в целях организации и обеспечения эффективности управления распределенными информационными системами.
1.2. Обзор средства работы с распределенными данными
При выборе распределенных ИС необходимо обращать внимание на перечень поддерживаемых операционных систем и сетевых. Также необходим анализ методов работы с распределенными информационными ресурсами.
Проведем обзор основных методов работы с распределенными информационными системами.
1) Методы фрагментации и дублирования
Один из методов распределенного хранения таблиц - это фрагментация, при использовании которого таблицы могут быть расщеплены на части, помещаемые в различные узлы. Другой метод распределения данных - это дублирование (репликация). Возможно создание дублей всей базы или ее сегментов с последующим их размещением в узлах. Данные методы позволяют осуществлять хранение данных именно в тех узлах, где они предполагается наиболее частое их использование. Это позволяет минимизировать затраты, связанные с передачей данных по сети и сокращает нагрузку на процессоры и прочие ресурсы остальных узлов. При использовании такой архитектуры БД приложения передача данных по сети производится достаточно редко.
2) Словари данных и директории
После того, проведения распределения информации по различным сетевым узлам, необходимо обеспечить эффективное использование этих данных. Для поиска данных и преобразования их в необходимый формат, необходимо использование глобальных словарей данных и директорий. В словарях хранятся данные о структуре каталогов, их использовании, пользовательских ролях и соответствующих им уровнях доступа, а также о приложениях. Каталоги данных используются для определения адреса хранения данных и методов их извлечения. Словари и директории могут быть глобальными и локальными
3) Метод двухфазной фиксации изменений
Методы распределения данных являются очень важными, однако центральным звеном современных распределенных СУБД являются протоколы двухфазной фиксации изменений. Данные протоколы позволяют управлять транзакциями, изменяющими данные на нескольких узлах. Основной идеей двухфазной фиксации является следующее: недопустимы ситуации, при которых транзакции, изменяющие данные в нескольких узлах, выполняются в одних узлах и не выполняются в других. Транзакции должны либо быть успешно выполненными на всех узлах, либо не выполняться ни в одном из них.
4) Методы обеспечения целостности
Важная характеристика распределенных ИС связана с обеспечением поддержки ссылочной целостности данных таблицы-мастера и данных связанных с ней таблиц. Рассмотрим пример обеспечения ссылочной целостности. Пусть в распределенной БД хранятся следующие таблицы:
- таблица с данными о детях сотрудников;
- таблица с данными о зарплатах сотрудников за год;
- таблица с данными о темах, выполненных сотрудником.
В данных таблицах содержится столбец "ФИО сотрудника". Правила обеспечения ссылочной целостности требуют, чтобы при изменении значений столбца "ФИО сотрудника" в одной таблице, автоматически выполнялась корректировка значений данного столбца в других таблицах. Для обеспечения ссылочной целостности используются 2 различных метода - триггеры и декларативные ограничения целостности стандарта ANSI [7].
1.3 Основные подходы к реализации распределенных баз данных
Распределённые базы данных (РБД) — совокупность логически взаимосвязанных баз данных, распределённых в компьютерной сети.
РБД включают наборы узлов, связанных посредством коммуникационных сетей, в которых [2]:
- На каждом узле развернута отдельная СУБД;
- Взаимодействие узлов построено таким образом, что пользователи каждого из них имеют возможность получения доступа к любым данным в сети таким образом, как будто они развернуты на его собственном узле.
Каждый узел выступает в качестве системы базы данных. Любому пользователю доступно выполнение операций с данными на своих локальных узлах аналогично отсутствию распределённой системы. Распределённая система баз данных может рассматриваться как партнёрство отдельных локальных СУБД на отдельных локальных узлах.
Фундаментальное правило реализации распределённых баз данных («правило 0»): «Для пользователей распределённые системы должны выглядеть аналогично нераспределённым системам».
Цели создания распределенных систем:
1. Обеспечение локальной независимости. Узлы в распределённых системах должны быть автономными. Локальная независимость предполагает возможность контроля всех операций на узле данным узлом.
2. Отсутствие необходимости в опоре на центральный узел. Локальная независимость предполагает, что все узлы в распределённых системах должны быть равными, что предполагает отсутствие приоритета какого-либо из узлов.
3.Непрерывность функционирования. Распределённые системы должны предоставлять более высокий уровень по характеристикам надёжности и доступности.
4. Обеспечение независимости от расположения. Пользователи не должны знать, где именно данные хранятся физически и должны работать с ними так, как если бы хранение всех ресурсов осуществлялось на их собственных локальных узлах.
5. Независимость от фрагментации. Система поддерживает независимость от фрагментации, если данная переменная-отношение может быть разделена на части или фрагменты при организации её физического хранения. В этом случае данные могут храниться в том месте, где они чаще всего используются, что позволяет достичь локализации большинства операций и уменьшения сетевого трафика.
6. Независимость от репликации. Система поддерживает репликацию данных, если данная хранимая переменная-отношение — или в общем случае данный фрагмент данной хранимой переменной-отношения — может быть представлена несколькими отдельными копиями или репликами, которые хранятся на нескольких отдельных узлах.
7. Возможность обработки запросов, представленных в распределенной форме. Суть в том, что для обработки запросов возможно обращение к нескольким сетевым узлам. В данной системе возможно множество возможных методов пересылки данных, которые позволяют выполнять рассматриваемые запросы.
8. Возможность управления распределёнными транзакциями. Существуют следующие аспекты управления транзакциями: управление системами восстановления и управление системами параллельности обработки. Управление восстановлением обеспечивает атомарность транзакций в распределённых средах, в системе должно гарантироваться, что все множество относящихся к данным транзакциям агентов (агенты — процессы, выполняемые для определенных транзакций на отдельных узлах) или зафиксировало свои результаты, или выполнило откат. Что касается управления параллельностью, то оно в большинстве распределённых систем базируется на механизме блокирования, точно так, как и в нераспределённых системах.
9.Обеспечение аппаратной независимости. Необходимо иметь возможности запуска одних и тех же СУБД на разных аппаратных платформах и, более того, добиться, чтобы различные машины были задействованы в работе распределённых систем в качестве равноправных партнёров.
10. Обеспечение независимости от операционных систем, что обеспечивает возможности функционирования СУБД под различными программными платформами.
11. Обеспечение независимости от систем передачи данных. Возможность поддержки множества принципиально разных узлов, которые отличаются оборудованием и операционными системами, а также рядом типов различных коммуникационных сетей.
12. Обеспечение независимости от типа СУБД. Необходимо, чтобы экземпляры СУБД на различных узлах все вместе поддерживали один и тот же интерфейс, и совсем необязательно, чтобы это были копии одной и той же версии СУБД [6].
Основной задачей систем управления распределенными базами данных является обеспечение средств интеграции локальных баз данных, которые располагаются в определенных узлах вычислительных сетей, с тем, чтобы пользователи, работающие в любом сегменте сети, имели возможность доступа ко всем этим базам данных как к единой базе данных.
Возможна реализация однородных и неоднородных распределенных базы данных. В однородных базах данных управление каждой локальной базой данных осуществляется посредством одной и той же СУБД. В неоднородных системах локальные базы данных могут относиться даже к разным моделям данных.
Кроме вышеназванных видов распределенных баз данных существуют также следующие [10]:
- Мультибазы данных, имеющие глобальную схему. Системы Мультибаз данных являются распределёнными системами, выступающими в качестве внешних интерфейсов для доступа к нескольким локальным СУБД.
- Федеративные базы данных, не располагающие глобальной схемой, к которой производится обращение всех приложений. Вместо этого реализована поддержка локальных схем импорта-экспорта данных. На всех узлах поддерживаются частичные глобальные схемы, описывающие информацию по тем удалённым источникам, данные из которых необходимы для обеспечения их работы.
- Мультибазы с общим языком доступа являются распределёнными средами управления на основе клиент-серверной технологии
- Интероперабельные системы - это системы, в которых сами приложения, исполняемые в среде той или иной СУБД, ответственны за интерфейсы между различными средами приложения, в независимости от того, являются они однородными или неоднородными. Системы ориентированы главным образом на операции обмена данными. Дальнейшим развитием данных систем являются объектно-ориентированные базы данных.
1.4. Принцип действия распределенных баз данных
В головном офисе проводится создание начальных образов базы (для каждого подразделения - собственный образ) с дальнейшей передачей данных для загрузки. При этом необходимо определить настройки обмена, в соответствии с которыми будет производиться синхронизация между периферийными (подчиненными) базами с главной базой.
Структура компании может быть такова, что у удаленных подразделений, подчиненных главному офису, могут существовать собственные удаленные подразделения. В таком случае проводится процедура, аналогичная той, которая производилась при настройке филиалов, подчиненных напрямую главной базе [5].
Таким образом, можно подытожить, что в распределенных базах проводится формирование древообразных связей. Например, когда в компании главному офису подчиняется два филиала, при этом у первого филиала имеется два удаленных подразделения, а у второго - три подразделения. В таком случае основной базе подчиняется две периферийных базы. Первой периферийной базе, в свою очередь, подчинено еще две базы, а второй периферийной - три. Схема связей в такой распределенной базе показана на рисунке 1.
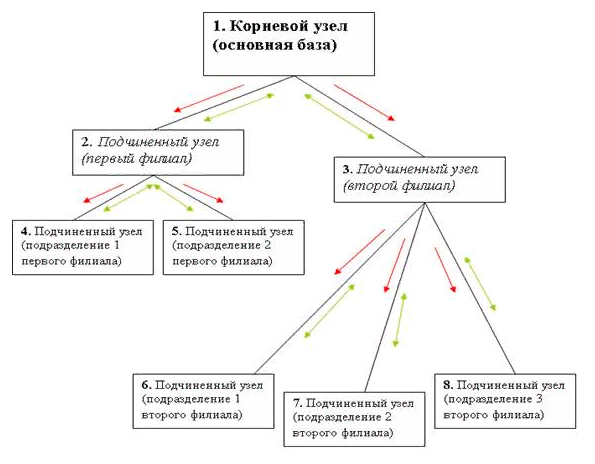
Рис. – Схема распределенной базы данных
Узел 1 является корневым для всей распределенной базы и главным узлом для подчиненных ему второму и третьему. Второй узел является главным узлом для подчиненных ему четвертому и пятому. Третий узел будет главным для подчиненных ему шестому, седьмому и восьмому.
Любой узел распределенной базы данных (УРБД) связан только с соседними узлами, с которыми проводятся операции обмена данными.
Внесение изменений в данные информационной базы возможно в любом узле УРБД, причем изменения данных передаются между любыми связанными узлами. На схеме направления, по которым передаются изменения данных, обозначены зелеными стрелочками (по ним из любого узла УРБД за определенное количество шагов можно попасть в любой другой узел, отсюда следует, что при внесении изменений в данные любого узла эти изменения постепенно перенесутся во все остальные).
Внесение изменений в конфигурацию информационной базы возможно только в одном (корневом) узле УРБД, причем изменения конфигурации передаются от главного узла к подчиненным. На схеме направления, по которым передаются изменения конфигурации, обозначены красными стрелочками [9].
Теперь рассмотрим, каким образом осуществляется обмен данными между узлами УРБД. При внесении изменений в данные информационной базы программа запоминает, что было изменено и каким образом. Для любого узла раз в определенный промежуток времени запускается обработка (вручную либо автоматически), которая формирует специальные сообщения, в каких в формате XML отображена информация о том, были ли изменения (если были, то какие), и отправляет их в определенные каталоги по локальной сети либо по FTP, или же на определенные адреса электронной почты. Также обработка проверяет, появились ли в этом каталоге либо электронном ящике аналогичные сообщения от других узлов, связанных напрямую с этим узлом, адресованные ему. Если появились, то загрузит сообщения, а следовательно и изменения в данных. Инфраструктура сообщений поддерживает нумерацию сообщений, и позволяет получать подтверждения от узла-получателя о приеме сообщений. Такое подтверждение содержится в каждом сообщении, приходящем от узла-получателя в виде номера последнего принятого сообщения.
Если узел-приемник еще не успел загрузить сообщение из каталога обмена , узел-источник не будет выкладывать, а тем более формировать файл сообщений в каталог обмена по этому узлу. Подразумевается, что после успешной загрузки, файл удаляется из каталога обмена. Это позволяет не осуществлять лишние операции при обмене и не загружать канал лишний раз.
При изменении конфигурации базы информация об изменениях распространяется в сообщениях обмена вместе с изменениями данных.
Алгоритм обмена данными между базами [12]:
- В базе-источнике система проводит определение списка изменённых объектов за время, прошедшее с предыдущего этапа выгрузки данных.
- По данному списку система формирует XML-пакет, который передается в базу-приемник.
- Для возможности формирования пакета система проводит обращение к модифицированным объектам базы данных. При обращении система проводит блокировку данных объектов.
- передача XML-пакета в базу-приемник.
- Развертывание XML-пакета базе-приемнике, запись проведенных изменений в основную базу.
- Запись всех изменений в рамках одной транзакции, блокировка измененных объектов.
2.Аппаратная реализация распределенных вычислений
2.1 Преимущество кластерных вычисления в HPC
Построение кластерных компьютеров не является самоцелью, а средством достижения большей эффективности и продуктивности научной работы. Существует определенный тип задач, которые требуют более высоких характеристик производительности, нежели можно получить, посредством использования обычных компьютеров. В указанных случаях из нескольких мощных систем создаются HPC (High Perfomance Computing) кластеры, позволяющие разносить вычисления не только на разные процессоры (если применяются многопроцессорные SMP-системы), но и на разные компьютеры. Для задач, которые поддерживают приемлемые характеристики распараллеливания и не предъявляют высоких требований для взаимодействия параллельных потоков, зачастую принимается решение о реализации HPC кластеров из большого числа однопроцессорных систем небольшой мощности. Часто использование решений подобного типа, при наличии низких стоимостных характеристик, позволяют достигать гораздо больших параметров производительности, чем аналогичные характеристики суперкомпьютеров.
При этом, реализация кластерной системы подобного типа требует необходимых компетенций знаний и усилий, а использование его предполагает необходимость кардинальной смены используемых парадигм в области программирования, что зачастую представляет собой сложную задачу. Можно быть компетентным специалистом в области разработки последовательного программного обеспечения, но это также предполагает необходимость изучения технологий параллельного программирования с самых основ.
Тезис о том, что прирост производительности возможен только при использовании суперкомпьютеров, является ошибочным. Если поставленные задачи не имеют внутреннего параллелизма и не адаптированы соответствующим образом, максимальным эффектом от использования кластерных систем будет возможность одновременного запуска нескольких экземпляров программы, которые работают с разными начальными данными. Использование кластера в данном случае не ускорит процесс выполнения одного конкретного ПО, но позволит сэкономить значительное количество времени, при необходимости расчета множества вариантов состояния системы за ограниченный промежуток времени. Для кластеров можно привести следующую аналогию: если для одного корабля время хода на нужное расстояние составляет 7 дней, то семь кораблей не пройдут также же расстояние за один день. При этом семь кораблей могут перевести большее количество груза. При высоких объемах вычислений по поставленной задаче, то длительность одного прогона на одной рабочей станции может составлять сутки, недели и месяцы, отсюда очевидно, что необходимо приложение усилий, направленных на адаптацию алгоритма. Следует проводить разделение задачи на несколько (по количеству процессоров) небольших подзадач, расчет которых может производиться в независимом режиме, а в тех областях, где независимость выполнения обеспечить невозможно, необходим явный вызов процедур синхронизации, путем обмена информацией через сеть. Так, при обработке большого массива данных, необходимо будет провести разделение задачи на области и распределение их по процессорам через обеспечение равномерной загрузки всего кластера.
Таким образом, прежде чем начать практическую реализацию кластерных технологий необходимо осуществить решение нескольких принципиальных проблем.
Первая из них формулируется таким образом: "Необходимо ли для решения поставленных задач использовать кластеры и технологии параллельных вычислений?" Для ответа на данный вопрос необходимо проводить детальный анализ поставленных задач. Параллельные вычисления являются достаточно специфичной областью математики и далеко не во всех областях использование параллельных вычислений даст необходимые характеристики мощности. Кластерные вычисления использовать неэффективно в случаях [8]:
- Используются специализированные программные пакеты, не адаптированные для параллельных вычислений в средах MPI и PVM или которые не предназначены для работы в системах на основе UNIX. В данном случае невозможно использование более чем одного процессора.
- Программы, разработанные для решения поставленных задач, требуют не более, чем несколько часов процессорного времени на существующем оборудовании. Такая схема использования приведет к тому, что время, потраченное на проведение распараллеливания и отладки разработанной задачи будет выше, чем прирост в быстродействии, которое дает многопроцессорная обработка.
- Время использования разработанной программы сравнимо со временем, затраченным на ее создание с помощью параллельного варианта. К основным особенностям технологии параллельного программирования можно отнести высокую эффективность программ, использование специализированных приемов программирования что, как следствие, предполагает более высокую трудоемкость процесса разработки ПО. Не имеют смысла затраты времени на проведение распараллеливания программы, вычисление данных по которой будет проведено единожды.
Одной из проблем, которую необходимо решить, является наличие принципиальной возможности "распараллеливания" поставленной задачи. Для некоторых численные схем в силу специфики реализации алгоритма невозможна постановка задачи эффективной параллелезиции. перед постановкой задачи на применение кластеров решения поставленной задачи, необходимо убедиться в возможности использования паралельных алгоритмов.
Приложения в параллельной архитектуре должны создаваться с расчетом на эффективность использования ресурсов данной архитектуры. Это означает, что программа должна быть разделена на части, которые способны выполняться параллельно на нескольких процессорах, и разделены эффективно, чтобы отдельно исполняемые компоненты программы оказывали минимальное влияние на выполнение остальных частей.
Пусть в программе доля операций, которые необходимо исполнять последовательно, равна f, где  (при этом доля определяется не по статическому количеству строк кода, а количеством операций в процессе исполнения). Крайними случаями в значениях параметра f являются состояние полной параллельности (f=0) и полной последовательности (f=1) исполняемым программам. Таким образом, для оценки прироста производительности S может быть получено на компьютере, на котором установлено p процессоров при известном значении f, можно использовать законом Амдала:
(при этом доля определяется не по статическому количеству строк кода, а количеством операций в процессе исполнения). Крайними случаями в значениях параметра f являются состояние полной параллельности (f=0) и полной последовательности (f=1) исполняемым программам. Таким образом, для оценки прироста производительности S может быть получено на компьютере, на котором установлено p процессоров при известном значении f, можно использовать законом Амдала:

Предположим, что в разработанной программе лишь 10% приходится на последовательные операции, т.е. f=0.1 . Тогда согласно указанному закону вне зависимости от количества установленных процессоров максимальное ускорение составит только 10 раз.
Таким образом, при проектировании программной архитектуры, необходимо учитывать, насколько применимы в нем кластерные вычисления, каков максимальный прирост производительности за счет их использования.
2.2 Классификация кластерных вычислений
Далее рассмотрим задачи, к решению которых оптимально подходят алгоритмы кластерных вычислений.
Диаграмма классификации кластерных вычислений приведена на рисунке 2.
Рис. 2 - Классификация кластерных вычислений
1. Обработка одномерных массивов
Задачи данного класса встречаются довольно часто. Если значения элементов массива можно определять с помощью довольно сложных выражений, а проводить вычисление необходимо многократно, то применение технологий распараллеливания цикла для проведения вычислений элементов массивов может оказаться очень эффективной методикой. Также к данному типу задач можно отнести численное решение систем дифференциальных уравнений, что также представляет собой обработку массивов функций, производных и т.д. Также эффективное применение кластерных вычислений возможно при вычислении сверток, суммировании, вычислении значений функций от каждого из элементов массива и т.п. При этом не имеет смысла распараллеливание действий над массивами с небольшим количеством элементов кроме тех случаев, когда проведение вычислений для каждого элемента занимает длительное время.
2. Обработка двумерных массивов
При выполнении алгоритмов с вложенными циклами, как правило, возможно эффективно распараллелить самые внешние циклы. Однако практически для всех действий с матрицами (операции сложения, умножения, умножения на вектор, прямого произведения) может быть реализован алгоритм с использованием кластеров. Для многих алгоритмов линейной алгебры (но не всех) может быть применено распараллеливания. Некоторые из библиотек подпрограмм (например, LAPACK) также реализованы для кластерных машин. Совершенно неэффективным является использование кластеров для работы с матрицами, имеющими низкую размерность (к примеру, 3x3). Есть возможность переработки алгоритма для реализации возможности по одновременной обработке нескольких (к примеру, 5000) матриц для проведения операций обращения, поиска собственных чисел и т.д. При росте размера матриц возрастает эффективность работы программы, при этом растут требования к памяти, используемой для хранения матриц.
3.Клеточные автоматы
Для многих областей знания характерны задачи, сводимые к расчетам параметров эволюции объектов, располагаемых в дискретных точках и взаимодействующих с соседствующими объектами. Простейшая и, наверно, наиболее широко распространенная задача подобного типа - игра "Жизнь". К задачам подобного типа также можно так же отнести модели магнетиков Изинга, представляющие собой наборы спинов (элементарных магнитов), которые располагаются в узлах кристаллической решетки и взаимодействующие только с ближайшими из соседей. Порядок построения модели эволюции Изинговских магнетиков является идентичным алгоритму игры "Жизнь".
4. Системы дифференциальных уравнений
Численные решения систем дифференциальных уравнений характерны для многих типов инженерных и научных задач. Для большинства случаев алгоритмы решения задач подобного типа можно эффективно использовать параллельные алгоритмы при обработке в кластерных системах. В качестве примеров можно также привести задачи молекулярного моделирования сплошных сред из статистической физики, проведение инженерных расчетов распределения нагрузок в сложных конструктивных элементах, моделей N тел (например расчетов движения космических аппаратов, динамики звездного диска Галактики), газодинамики сплошных сред (особенно, если проводится исследование многокомпонентных среда), задачах электродинамики и др.
Также очевидно, что класс задач, решаемых с помощью параллельных алгоритмов является довольно широким. Однако необходимо учитывать, что параллельность задачи определяется не только ее физической природой, но и выбранным методом решения. Так, для всем известного метода прогонки практически невозможно реализовать алгоритм распараллеливания. Если единственным или предпочтительным методом решения вашей задачи является метод прогонки, то необходимо отказаться от использования кластерных вычислений. С другой стороны, методы семейства Монте-Карло идеально подходят для кластерных компьютеров. Причем, с ростом числа процессоров кластере, растёт эффективность решения задачи. Практически все алгоритмы использования явных разностных схем при решении дифференциальных уравнений могут быть использованы при параллельных вычислениях.
Также кластеры могут классифицироваться по:
- стандартности комплектующих;
- по однородности узлов;
- по типу узловых процессоров.
На рисунке 3 показана схема классификации кластерных вычислений по типу узловых процессоров.
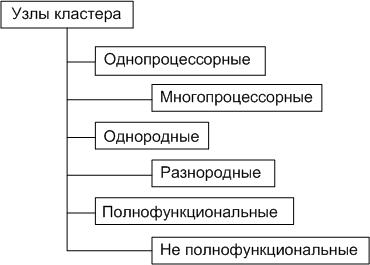
Рис. 3 - Классификации кластерных вычислений по типу узловых процессоров
При использовании в качестве узлов вычислительных кластеров используются персональных компьютеров или рабочих станций, то типичной является ситуация, когда в процессе решения задачи с помощью параллельных алгоритмов на узлах данного кластера продолжают исполняться последовательные пользовательские задания. В результате параметры относительной производительности узлов кластера меняются случайным образом и в значительных пределах. В качестве решения данной проблемы необходима разработка самоадаптирующегося пользовательского ПО. Однако, эффективность решения данной задачи представляется весьма проблематичной. Ситуация может усугубляться, если среди узловых компьютеров вычислительных кластеров имеются файловые серверы. При этом в процессе решения задачи на кластере в широком диапазоне может изменяться загрузка коммуникационной среды, что делает непредсказуемыми параметры коммуникационных расходов задачи.
На рисунке 4 показана система классификации кластеров по другим классификационным признакам.
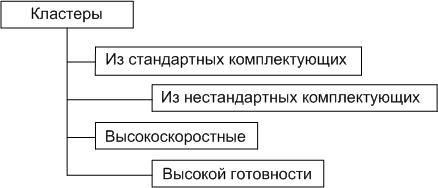
Рис. 4 - Система классификации кластеров по другим классификационным признакам
С позиции стандартности комплектующих можно определить следующие классы кластерных систем:
- вычислительные кластеры, построенные в целом из стандартных комплектующих;
- вычислительные кластеры, построенные из эксклюзивных или нешироко распространенных комплектующих.
Вычислительные кластеры первого класса имеют низкую стоимость и просты в обслуживании. Широкое распространение кластерных технологий получило как средство реализации именно относительно недорогих систем суперкомпьютеров, включающих составные части массового производства.
Кластерные системы второго класса позволяют получать очень высокие параметры производительности, но обладают, как правило, более высокой стоимостью.
Реализация кластеров контейнеров возможна с помощью настроек размещения в компоненте, который отвечает за работу контейнера и проводить задание их размеров.
Процесс создания кластера контейнеров предполагает:
- подготовку, при которой необходимо убедиться во включении кластеров в поддерживаемом развертывании;
- проверку наличия необходимых прав.
При настройке кластеров в компоненте контейнеров автоматически производится подготовка указанного числа контейнеров. Далее проводится равномерное распределение запросов между всеми контейнерами в кластере.
Можно изменять размер кластера таким образом, чтобы было возможно добавление или удаление какого-либо из подготовленных контейнеров или приложений в данном кластере. В процессе изменения размера кластера в среде исполнения необходимо учитывать работу всех связанных фильтров и правил размещения.
Open Source-система Kubernetes, служащая для решения задач по управлению контейнерными кластерами появилась в результате разработок, накопленных Google в течение 10 лет эксплуатации Borg — технологии по изоляции процессов в виртуальной среде.
Технология Kubernetes в настоящее время считается «идеальной платформой» для оркестрации контейнеров. Она позволяет управлять кластерами виртуальных машин и Linux-контейнерами как единым целым, является лидером систем, рекомендуемых для внедрения для средних и крупных предприятий.
Назначение Kubernetes состоит в выстраивании эффективной системы распределения контейнеров по узлам кластеров в зависимости от параметров текущей нагрузки и существующих потребностей при работе сервисов. Система Kubernetes способна обслуживать одновременно большое количество хостов, запускать на них большое количество контейнеров Docker или Rocket, проводить отслеживание их состояния, осуществлять контроль совместной работы и репликаций, проводить масштабирование и балансировку параметров нагрузки.
Для платформы Kubernetes налажен трехмесячный цикл обновлений. Новые улучшения делаются в основном в направлении развития системы защиты, наращивания объемов используемых данных и масштабируемости.
Вторым крупным игроком на рынке систем по оркестрации контейнеров — является система Docker Swarm. Данное решение, разработанное в 2013 г., значительно упростило процесс развертывания полноценных виртуальных систем. По сути с данного момента стало возможным осуществлять объединять вместе большого количества вычислительных мощностей, осуществлять запуск тысяч изолированных друг от друга приложений, быстро выстраивая необходимую конфигурацию из виртуализованных прикладных систем
Технология контейнерной кластеризации Docker Swarm появилась немного позже и стала частью платформы Docker. С его помощью решаются задачи объединения Docker-хостов в общий виртуальный хост.
Docker Swarm является REST API-интерфейсом, совместимым с Docker API. Поэтому всем пользователями, ране активно использовавшим Docker-инструменты, стали доступны возможности работы с контейнерными кластерами под управлением Docker Swarm, даже посредством одновременного управления большим количеством Docker-контейнеров.
Технология Swarm интересна в первую очередь представителям малых и средних предприятий, объем запуска задач в которых не более 60 тыс. контейнеров и до 1500 нод. Благодаря автоматической совместимости с Docker использование Swarm интересно разработчикам как развитие данной бизнес-модели по наращиванию своего облачного присутствия. Большую помощь в развитии этого направления оказывает Microsoft Azure, которая предлагает поддержку Swarm.
Несмотря на то, что за Docker Swarm пока занимает более скромные позиции на рынке, чем Kubernetes, его поддержка со стороны корпоративного рынка достаточно весома. Для многих Swarm уже стал главным механизмом для выстраивания будущей облачной стратегии развития.
Третьим основным игроком на рынке кластеризации контейнеров является система Apache Mesos. Данная система является централизованной отказоустойчивой для управления кластерами, позволяющей объединять в группы отдельные узлы (Mesos Slaves) в соответствии с выставленными требованиями, позволяющая в дальнейшем обеспечивать им изоляцию от остальных ИТ-ресурсов и управление.
Суть работы системы Mesos является в определенной степени противоположной модели виртуализации. При традиционном подходе, который предусматривает дробление вычислительных сред, состоящих из множества физических машин, на их виртуальные аналоги с предоставлением для каждой своей квоты общих ресурсов ЦОДа, Mesos, наоборот, проводит объединение существующих объектов в единый виртуальный ресурс с формированием крупных кластеров и эффективной системы управления инфраструктурой серверов с выделением для каждого кластера индивидуального пула ресурсов.
Подходы Mesos позволяют значительно упрощать процедуры по развертыванию и управлению, проводить перемещение приложений, запущенных в контейнерах, с одного места на другое, быстро переходить в публичное облако.
2.3 Типы технологии контейнеров (Семейство решений)
Разработчиками Windows до недавнего времени предлагались следующие технологии виртуализации: виртуальные машины и виртуальные приложения Server App-V. Каждая из них имеет свою нишу использования, свои достоинства и недостатки. В настоящее время ассортимент расширился — в Windows Server 2016 включены контейнеры (Windows Server Containers). Главным отличием является то, что в системе предложены следующие виды контейнеров: контейнеры Windows и контейнеры Hyper-V. В TP3 были доступны только первые.
Контейнеры семейства Hyper-V обеспечивают дополнительные уровни изоляции с использованием Hyper-V. Для каждого из контейнеров выделяется собственное ядро и ресурсы памяти, изоляция осуществляется не ядром ОС, а гипервизором Hyper-V. В результате возможно достижение такого же уровня изоляции, как у виртуальных машин, при меньших затратах по сравнению с VM, но большей, по сравнению с контейнерами Windows. Для возможности использования такого типа контейнеров необходима установка на хосте роли Hyper-V. Контейнеры Windows по большей части подходят для применения в доверенных средах, например когда на серверах производится запуск приложений от одной организации. Когда сервер используется множеством компаний и необходимо обеспечивать больший уровень изоляции, использование контейнеров Hyper-V, вероятнее, будут более рациональным решением.
Важной особенностью контейнеров в Win 2016 является то, что выбор типа проводится не в момент создания, а в моменты деплоя. То есть запуск любого контейнера может производиться как Windows, и как Hyper-V.
В ОС Win 2016 за контейнеры отвечают абстракции Contаiner Management stack, реализующие все необходимые функции. При хранении применяется формат образа жесткого диска типа VHDX. Сохранение контейнеров, производится в образы в репозитории. Причем сохранение осуществляется не для полного набора данных, а только для отличий создаваемого образа от эталонного, и в момент запуска производится проецирование всех нужных данных в память. При управлении сетевым трафиком между контейнерами и физической сетью используется Virtual Switch.
В качестве ОС в контейнерах может использоваться Server Core или Nano Server. С помощью Server Core обеспечивается необходимый уровень совместимости с имеющимися приложениями. Nano Server представляет собой еще более урезанную версию для работы без мониторов, позволяющую проводить запуск сервера в минимально возможной конфигурации для работы с Hyper-V, ресурсами файлового сервера (SOFS) и облачными службами.
Докер — это открытая платформа для разработки, доставки и эксплуатации приложений. Docker разработан для более быстрого выкладывания ваших приложений. С помощью docker вы можете отделить ваше приложение от вашей инфраструктуры и обращаться с инфраструктурой как управляемым приложением. Docker помогает выкладывать ваш код быстрее, быстрее тестировать, быстрее выкладывать приложения и уменьшить время между написанием кода и запуска кода. Docker делает это с помощью легковесной платформы контейнерной виртуализации, используя процессы и утилиты, которые помогают управлять и выкладывать ваши приложения.
В своем ядре docker позволяет запускать практически любое приложение, безопасно изолированное в контейнере. Безопасная изоляция позволяет вам запускать на одном хосте много контейнеров одновременно. Легковесная природа контейнера, который запускается без дополнительной нагрузки гипервизора, позволяет вам добиваться больше от вашего железа.
Платформа и средства контейнерной виртуализации могут быть полезны в следующих случаях:
- упаковка приложения (а также используемых компонент) в docker контейнеры;
- раздача и доставка этих контейнеров командам для проведения разработки и тестирования;
- выкладывание данных контейнеров на продакшены, как в Data-центры так и в облака
Docker является системой управления контейнерами. Данная система позволяет проводить «упаковку» приложений или веб-сайтов со всем их окружением и зависимостями в контейнеры, которыми далее можно управлять, выполняя задачи: перенос на другой сервер, масштабирование, обновление.
Разработка системы Docker была проведена с помощью языка программирования Go. Система была выпущена в 2013 году. Первоначально Docker работал только с Linux-системами, однако в настоящий момент выпущены его версии для Windows и MacOS. Несмотря на то, что данное решение является относительно новым, оно уже широко применяется многими специалистами.
Одной из важных составляющих экосистемы Docker является Docker Hub, представляющий собой открытый репозиторий образов контейнеров, в котором можно найти большое количество ПО от официальных разработчиков. Для запуска WordPress с помощью Docker достаточно выполнить следующие команды:
docker run --name wp-mysql -e MYSQL_ROOT_PASSWORD=wpmsqlpsswd -d mysql:5.7
<вывод пропущен>
docker run --name my-wordpress --link wp-mysql:mysql -d -p 80:80 wordpress
Docker являются оптимальным решением для организации технологии разработки. Docker позволяет разработчикам использовать локальные контейнеры с приложениями и сервисами. Что в последствии позволяет интегрироваться с процессом постоянной интеграции и выкладывания (continuous integration and deployment workflow).
Например, если разработчики пишут код локально и делятся своим стеком разработки (набором docker образов) с коллегами. Когда они готовы, отравляют код и контейнеры на тестовую площадку и проводят запуск любых необходимых тестов. С тестовой площадки они могут оправить код и образы на продакшен.
Docker состоит из двух главных компонент:
- Docker: платформа виртуализации с открытым кодом;
- Docker Hub: наша платформа-как-сервис для распространения и управления docker контейнерами.
Docker использует клиент-серверную архитектуру. Docker клиенты общаются с агентом Docker, на который возлагается нагрузка по созданию, запуску, распределению контейнеров. Оба, клиент и сервер могут работать на одной системе, вы можете подключить клиент к удаленному демону docker. Клиент и сервер общаются посредством сокета или технологию RESTful API.
Docker-образ — это read-only шаблон. Например, образ может содержать операционку Ubuntu c Apache и приложением на ней. Образы используются для создания контейнеров. Docker позволяет легко создавать новые образы, обновлять существующие, или вы можете скачать образы созданные другими людьми. Образы — это компонента сборки docker-а.
Основная технология работы Docker включает [6]:
- скачивание образа ubuntu: docker проводит проверку наличия образа ubuntu на локальной машине, и от отсутствует, то проводится его скачивание с Docker Hub. Если образ присутствует, то система использует его для создания контейнера;
- создание контейнера: когда образ получен, docker использует его для создания контейнера;
- инициализация файловой системы и монтирование read-only уровня: контейнер создается в файловой системе и read-only уровень добавляется в образ;
- инициализация сети/моста: создается сетевой интерфейс, позволяющего docker-у общаться с хост машиной;
- Установка IP адреса: нахождение и задание адреса;
- Запуск указанного процесса: запуск приложения;
- Обработка и выдача выходных данных загруженного приложения: подключение и протоколирование стандартного входа, вывод и поток ошибок приложения, что бы было возможно отслеживание работы приложения.
Заключение
В настоящее время актуальным становится вопрос оптимизации вычислений, а также рационального распределения мощностей вычислительных ресурсов. С развитием телекоммуникационных систем появляются возможности создания распределенных вычислительных сетей, позволяющих максимально рационально распределять нагрузку между аппаратными ресурсами. Внедрение технологий распределенных информационных систем позволяет провести создание консолидированных информационных систем, каждая из компонент которой может быть представлена в различных форматах.
Реализовать данные задачи можно посредством перераспределения имеющихся аппаратных систем через использование виртуальных сред. Оптимизации вычислений можно достичь несколькими способами - через кластерные вычисления, использование контейнеров, а также систем виртуализации.
Рассмотрев технологии по оптимизации вычислительных ресурсов, можно сделать вывод о возможности рационального использования вычислительных систем через создания кластеров, посредством которых достигаются оптимальные характеристики по вычислительным мощностям. Использование виртуальных сред позволяет достичь максимальной независимости от аппаратной вычислительной среды, предоставляет возможности моделирования различных аппаратных систем, а также позволяет работать с программными средствами, которые не функционируют в условиях реальной аппаратной среды.
Использование контейнеров также позволяет распределять вычислительную нагрузку, оптимизировать работу с виртуальными средами.
Список использованных источников
- Ежова, Е.В. Контейнерная виртуализация в различных средах/ Ежова Е.Н. . - Москва: Мир, 2010. - 370 c.
- Лэнгоун, Джейсон Виртуализация настольных компьютеров с помощью VMware View 5: моногр. / Джейсон Лэнгоун , Андрэ Лейбовичи. - М.: ДМК Пресс, 2013. - 280 c.
- Багдасарян Е.А., Королев В.С., Черненький М.В. Архитектура системы управления рабочим процессом // Инженерный вестник: электронный научно-технический журнал МГТУ им. Н.Э. Баумана . 2013. № 10. С. 519 - 526.
- Виноградова М.В., Белоусова В.И., Мельник В.Н. Концепции разработки и организации системы прозрачного доступа к файлам больших объемов и raid -массивам в распределенной разнородной среде // Инженерный вестник : электронный научно-технический журнал МГТУ им. Н.Э. Баумана . 2013. № 9. С. 549 - 560.
- Черненький В.М., Гапанюк Ю.Е. Кластеризация аппаратных ресурсов. // Инженерный журнал: наука и инновации. / Электронное научно-техническое издание. 2012. № 3(3). С. 30 – 39.
- Виноградов В.И., Мазнев В.Г. Технологии использования контейнеров в средах виртуализации // Инженерный журнал: наука и инновации/ Электронное научно-техническое издание. 2012. № 3 (3). С. 13 - 19. Режим доступа
- Постников В.М., Спиридонов С.Б. Подход к расчету весовых коэффициентов ранговых оценок экспертов при выборе варианта развития информационной системы // Наука и образование: электронное научно-техническое издание МГТУ им. Н.Э. Баумана. 2013. № 8. С. 395 - 412.
- Галкин В.А., Осипов А.В. Оценка параметров системы мониторинга рабочих станций в локальной вычислительной сети // Инженерный вестник : электронный научно-технический журнал МГТУ им. Н.Э. Баумана . 2014. № 10. С. 528 – 539
- Бабиева Н. А., Раскин Л. И. Проектирование информационных систем : учебно-методическое пособие / Н. А. Бабиева, Л. И. Раскин. - Казань : Медицина, 2014. – 200с.
- Баранников Н. И., Яскевич О. Г. Современные проблемы проектирования корпоративных информационных систем / Н. И. Баранников, О. Г. Яскевич; ФГБОУ ВПО "Воронежский гос. технический ун-т". - Воронеж: Воронежский государственный технический университет, 2014. - 237 с.
- Аврунев О. Е., Стасышин В. М. Модели баз данных : учебное пособие : / О. Е. Аврунев, В. М. Стасышин. - Новосибирск : Изд-во НГТУ, 2018. – 121с.
- Баранчиков А. И. Синтез информационных структур хранения данных на основе анализа предметных областей: А. И. Баранчиков. - Рязань: РГУ, 2014. - 229 с.
- Васильков, А.В. Информационные системы и их безопасность: Учебное пособие / А.В. Васильков, А.А. Васильков, И.А. Васильков. - М.: Форум, 2013. - 528 c.
- Венделева, М.А. Управленческие информационные системы/ М.А. Венделева, Ю.В. Вертакова. - М.: Юрайт, 2013. - 462 c.
- Гагарин А. Г., Костикова А. В. Проектирование информационных систем : учебное пособие / А. Г. Гагарин, А. В. Костикова. - Волгоград : ВолГТУ, 2015. – 57 с.
- Windows Server 2012 R2. Полное руководство. Том 2. Дистанционное администрирование, установка среды с несколькими доменами, виртуализация, мониторинг и обслуживание сервера. - М.: Диалектика, 2015. - 864 c

- СОСТАВ И СВОЙСТВА ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ. ИНФОРМАЦИОННОЕ И МАТЕМАТИЧЕСКОЕ ОБЕСПЕЧЕНИЕ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ.(Состав технических средств вычислительных систем)
- РАЗРАБОТКА РЕГЛАМЕНТА ПРОЦЕССА «УПРАВЛЕНИЕ ДОКУМЕНТООБОРОТОМ»
- «Цель и задачи налогового учета» .
- Финансы акционерных обществ ЛУКОЙЛ
- Организация работы кофейни на 70 мест (Современное состояние общественного питания)
- Создание ресторанного бренда .»
- Процессы принятия решений разной сложности в организациях
- Международные финансы
- Мотивация и ее роль в поведении организаций
- Учетные регистры, их классификация и способы записи
- Общие принципы и правила формирования отчетности в РФ
- «Пояснительная записка к годовой бухгалтерской отчетности, ее назначение и содержание»(Бухгалтерская отчетность)